3.1. The Customized Naïve Associative Classifier
The Customized Naïve Associative Classifier (CNAC) is based on the NAC classifier [
38]. The main modification is to substitute the MIDSO operator of NAC with a customized similarity operator. By that, it preserved the nature of NAC, and it is making it more flexible and useful for specific problems.
Let x and y be two instances, described by a set of features . The set of attributes A may have an associated set of attribute weights . We define a similarity function between two instances as a function that receives two instances and an optional set of feature weights and returns a real number in a way such that more akin instances have high similarity values, and very different instances have small similarity values.
Several dissimilarities have been proposed to handle hybrid and incomplete data. Usually, a dissimilarity is converted into a similarity function as . By using instead of MIDSO as an algorithm parameter, we can customize the classifier by maintaining the NAC advantages.
The CNAC maintains the advantages of the NAC classifier: it is able to deal with hybrid, incomplete and multiclass data; it has tractable computational complexity ( for training and for classification), where is the number of instances in the dataset, and it is an explainable classifier. In addition, it solves the main disadvantage of NAC, which is the use of a predefined similarity function.
The pseudocode of the CNAC is shown in
Figure 1.
3.2. Datasets Used
We selected 22 datasets of such problems, including the clients’ responses to company offers, the employees’ probabilities of succeeding at work, and the people’s preferences towards clothes, among others. In the following, we briefly describe the selected datasets, which came from the Machine Learning Repository of the University of California at Irvine [
47], and from the Kaggle site [
48].
Table 1 present a summary of the description of the 22 used datasets, detailing the number of instances, numerical and categorical attributes, the presence of missing values (marked with an *), the number of classes, the imbalance ratio (IR) between the classes, and the size (in MB) of the corresponding dataset.
Regarding the size of the datasets, most of them are small (less than 2 MB), and the remaining are considered medium-sized (less than 5 MB). Of the selected datasets, 17 are imbalanced, with IR ranging from 1.80 to 10.74. The remaining five datasets are considered balanced, with IR from 1.11 to 1.38. As shown in
Table 1, five of the compared datasets are multiclass, having three to six classes.
In the following, we describe the classification tasks related to the datasets.
Success of Bank Telemarketing Data (alpha_bank). A bank company wants to know the potential success of telemarketing campaigns (whether or not the client will subscribe to a long-term deposit). To select profitable potential subscribers, the bank considers the age, job, marital status, education, credit, as well as home and personal loans, among others [
49].
Dress attributes (attribute_dataset). A shop needs to recommend dresses according to their characteristics, including style, price, rating, size, season, neckline, sleeve length, waistline, material, fabric type, decoration, and patterns, among others [
50].
HR Analytics: Job Change of Data Scientists (aug). A company that is active in Big Data and Data Science wants to hire data scientists among people who successfully passed some courses that were conducted by the company [
51].
Bank Marketing Campaign Subscriptions (bank_campaing). The dataset contains information about marketing campaigns that were conducted via phone calls from a Portuguese banking institution to their clients. The purpose of these campaigns is to prompt their clients to subscribe to a specific financial product of the bank (term deposit). After each call was conducted, the client had to inform the institution about their intention of either subscribing to the product (indicating a successful campaign) or not (unsuccessful campaign) [
52].
Marketing Series: Customer Churn (churn_modelling). The dataset contains the details of the customers in a company. The columns are about its estimated salary, age, sex, etc., aiming to provide all details about a client. This dataset contains details of a bank’s customers, and the target variable is a binary variable reflecting the fact whether the customer left the bank (closed his account) or he/she continues to be a customer [
53].
Predicting Profitable Customer Segments (targeting). Marketing is a key component of every modern business. Companies continuously re-invest large cuts of their profits for marketing purposes, trying to target groups of customers who have the potential to bring back the highest Return on Investment (ROI) for the company. The cost of marketing can be very high though, meaning that the decision about which customer group to target is of great financial importance. This dataset was made available by an online retail company that has collected historical data about such groups of customers, tracked the profitability of each group after the respective marketing campaign, and retrospectively assessed whether investing in marketing spending for that group was a good choice [
54].
Customer Behavior (behavior). The data represent details about 400 clients of a company, including the unique ID, the gender, the age of the customer, and the salary. Besides this, it has information regarding the buying decision—whether the customer decided to buy specific products or not [
55].
Customer Segmentation (segmentation). An automobile company has plans to enter new markets with their existing products (P1, P2, P3, P4, and P5). After intensive market research, they have deduced that the behavior of the new market is similar to their existing market. In their existing market, the sales team has classified all customers into four segments (A, B, C, and D). Then, they performed segmented outreach and communication for different segments of customers. This strategy has worked exceptionally well for them. They plan to use the same strategy in new markets and have identified 2627 new potential customers [
56].
Deposit Subscription—What Makes Consumers Buy? (deposit2020). This dataset corresponds to customers who will (and will not) subscribe to long-term deposits in 2020. The objective is to predict the decision of the targeted audience and to focus the campaigns on the clients who will probably subscribe to the company [
57].
Warranty Claims (df_clean). This dataset [
58] corresponds to clients who filled warranty claims, and the objective is to determine if such claims are fraudulent or not. This is cleaned data from the previous (Warranty Claims Data set), available at [
59].
HR Analysis Case Study (employee_promo). Every year, around 5% of the employees have been promoted in certain companies. This dataset includes the information to predict if an employee will be promoted or not [
60].
Employee Satisfaction Index Dataset (employee_satisf). This is a fictional dataset created to help the data analysts play around with the trends and insights on the employee job satisfaction index [
61].
In-vehicle coupon recommendation Data Set (in-vehicle-coupon). These data [
62] were collected via a survey on Amazon Mechanical Turk. The survey describes different driving scenarios, including the destination, current time, weather, passenger, etc., and then asks the person whether he will accept the coupon if he is the driver. For more information about the dataset, please refer to [
63].
Marketing Campaign (marketing_camp). The purpose of this dataset is to provide a significant boost to the efficiency of a marketing campaign by increasing responses or reducing expenses. The objective is to predict who will respond to an offer for a product or service [
64].
Marketing Series: Customer Churn (marketing_series). This dataset contains data from a telecom company. The objective is to predict which customers will stop being customers (churn) and those that will remain customers and then take action accordingly [
65].
Non-Verbal tourist (non-verbal-tourist). This dataset represents the non-verbal preferences of hotel guests in Jardines del Rey, Cuba. The objective is to predict the preferences of new guests and to classify them into one of the six groups of clients [
38].
Purchasing intentions (online_shoppers). The dataset [
66] consists of features belonging to 12,330 sessions. The dataset was formed so that each session would belong to a different user in one year to avoid any tendency to a specific campaign, special day, user profile, or period. The objective is to predict if the users will buy or not the products [
67].
Promotion response and target datasets (promoted). The context of this business problem is a new product introduction. The organization is interested in building a model to select the best customers for contacting from the pool of customers not contacted. The promoted dataset provides response information along with profiles of customers who are contacted [
68].
Customer Churn (telecom_churn). With the rapid development of the telecommunication industry, the service providers are inclined more towards the expansion of the subscriber base. To meet the need of surviving in the competitive environment, the retention of existing customers has become a huge challenge. It is stated that the cost of acquiring a new customer is far more than that of retaining the existing one. Therefore, the telecom industries must use advanced analytics to understand consumer behavior and, in turn, predict the association of the customers as to whether or not they will leave the company. This dataset contains customer-level information for a telecom company. Various attributes related to the services used are recorded for each customer [
69].
Client churn rate in Telecom sector (telecom_churnV2). Orange Telecom’s Churn Dataset, which consists of cleaned customer activity data (features), along with a churn label specifying whether a customer canceled the subscription, will be used to develop predictive models [
70].
Customer Classification (telecust). The dataset contains various information about their customers such as age and region, among others. It contains the information taken by a Telecommunication company. The objective is to predict the correct segment (type) of a customer [
71].
Term Deposit Prediction Data Set (term_deposit). Term deposits are a major source of income for a bank. A term deposit is a cash investment held at a financial institution. The money is invested for an agreed rate of interest over a fixed amount of time or term. The bank has various outreach plans to sell term deposits to their customers, such as email marketing, advertisements, telephonic marketing, and digital marketing. Telephonic marketing campaigns remain one of the most effective ways to reach out to people. However, banks require huge investments, as large call centers are hired to execute these campaigns. Hence, it is crucial to identify the customers most likely to convert beforehand so that they can be specifically targeted via call [
72].
3.3. Experimental Setup
First, we want to explore the influence of data complexity on the performance of the CNAC classifier. In particular, we aim to detect the conditions that made this classifier perform adequately and, therefore, establish rules to a priori known if it is convenient or not to apply this classifier to a certain problem.
Figure 2 shows the diagram of the experiments for this aim.
Our experimental configuration started with the division of the datasets into training and testing by means of a five-fold cross-validation procedure. After that, we computed data complexity measures over the training sets. In addition, we trained and tested the supervised classifiers and computed their performance. After that, we carried out a statistical analysis of the results, considering the performance of CNAC and the remaining supervised classifiers.
To obtain a meta-learner, we constructed a meta-dataset using as meta-features the values of the data complexity measures and, as class labels, the qualitative performance obtained by CNAC. We trained a C4.5 classifier over the meta dataset, and we obtained a set of rules defining the a priori expected performance of CNAC.
We divided the datasets using five-fold cross-validation due to the imbalanced nature of the data and averaged the results. Then, we applied five state-of-the-art classifiers (C4.5 [
39], Nearest Neighbor (NN) [
40], Repeated Incremental Pruning with Error Reduction (RIPPER) [
41], Multilayer Perceptron with Backpropagation (MLP) [
42], and Support Vector Machines (SVM) [
43]). Both the data partitioning and the classifier execution were made with the KEEL software [
73], except for the NN classifier, in which we used the EPIC software to be able to use the same dissimilarity function as CNAC. KEEL software automatically inputs missing data if needed by the classification algorithm, and its internal codification converts categorical data to numerical. With such procedures, algorithms such as SVM and MLP can be executed.
In addition, we applied the CNAC classifier, but with no feature weighting, to obtain a baseline performance. This was made by using the EPIC software [
74,
75], in which the CNAC classifier is available. EPIC software does not make any data preprocessing by defaults, and due to CNAC can handle missing and incomplete data, it was executed without any data preprocessing.
In the execution of the algorithms, we used the default parameter values provided by KEEL and EPIC, except for NN and CNAC in the non-verbal-tourist data, where we used the dissimilarity function suggested by the authors of the dataset [
38]. In addition, we set the dissimilarity for NN as the same as CNAC by using the EPIC software.
Table 2 shows the parameters of the classifiers
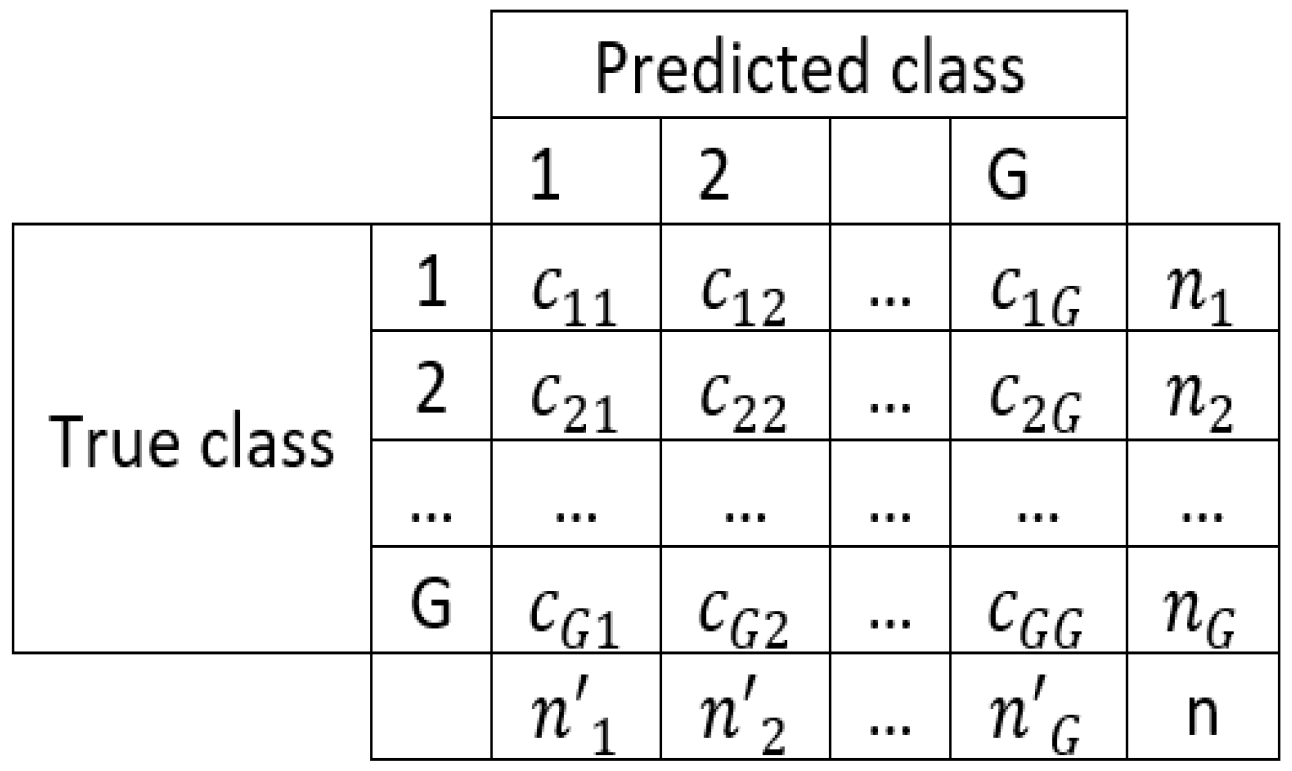
As a performance measure, we used the Non-Error Rate (NER), also known as averaged sensitivity [
76]. Given a confusion matrix of G classes (
Figure 3), the NER measure is computed as:
where
NER is suitable for multiclass data, and it is robust for imbalanced data. We computed the NER values for the state-of-the-art classifiers by using the result files (real and assigned labels) provided by KEEL; for CNAC and NN, we just used the NER values provided by the EPIC software.
Section 4.1 discusses the obtained results.
Then, we conducted the corresponding statistical analysis of performance (
Section 4.2), comparing the CNAC with respect to the state-of-the-art classifiers by using the Friedman [
77] and Holm [
78] tests. According to the results obtained, we established the CNAC performance as Good, Regular, or Bad for each of the compared datasets.
In parallel, we evaluated nine complexity measures, the F1, F2, F3, N1, N2, N3, N4, T1, and T2 measures [
31], which were computed using the KEEL software [
73]. We did not include the measures L1, L2, and L3 because we have five multiclass datasets, and the KEEL implementation does not allow multiclass data for such measures.
Section 4.3 discusses the results concerning data complexity.
Later, we created a new dataset for meta-learning purposes, having as condition attributes the complexity measures and as decision attribute the CNAC performance (Good, Regular, or Bad) for each of the compared datasets. Then, we trained a C4.5 decision tree to obtain the rules to a priori determine if the CNAC classifier is suitable for a certain classification problem. The corresponding results are in
Section 4.4.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}