
Deep Deterministic Policy Gradient-Based Active Disturbance Rejection Controller for Quad-Rotor UAVs



Abstract
:1. Introduction
- The classical controller design relies on understanding the physics of flight, and has difficulty to handling the coupling multiple loops design task. In other words, the classical one-loop-at-a-time design cannot guarantee success when more loops are added and coupled.
- Modern control techniques often require exact knowledge of models and are sensitive to parameter uncertainty and external disturbances [18]. However, different loads in each flight mission lead to uncertainty in system parameters. Meanwhile, parameters may be difficult to obtain, especially aerodynamic parameters. This sometimes leads to unstable behaviors, limiting the application of model-based controllers.
- For modern robust controllers [12], it is usually difficult to obtain the upper bounds of external disturbance and parameter uncertainty, which causes unsatisfactory performance.
- In the ADRC algorithm, the predefined bandwidth of the closed-loop system is unable to guarantee the tradeoff between robustness and transient tracking performance. Meanwhile, the estimation of parameters affects the ability of the controller to resist disturbances [14].
- A realistic and nonlinear model of quadrotors is established, considering parameter uncertainty and external disturbances.
- Online continuous adjustment of the bandwidth of the closed loop is realized by DDPG, and is beneficial for balancing the robustness and transient tracking performance.
- DDPG is adopted to achieve fast and accurate compensation for the total disturbance of the system, leading to the response speed and control accuracy being further improved.
2. Nonlinear Model of Quadrotors
2.1. Ideal Model of Quadrotors
2.2. Internal and External Disturbances
3. Construction of DDPG-Based ADRC
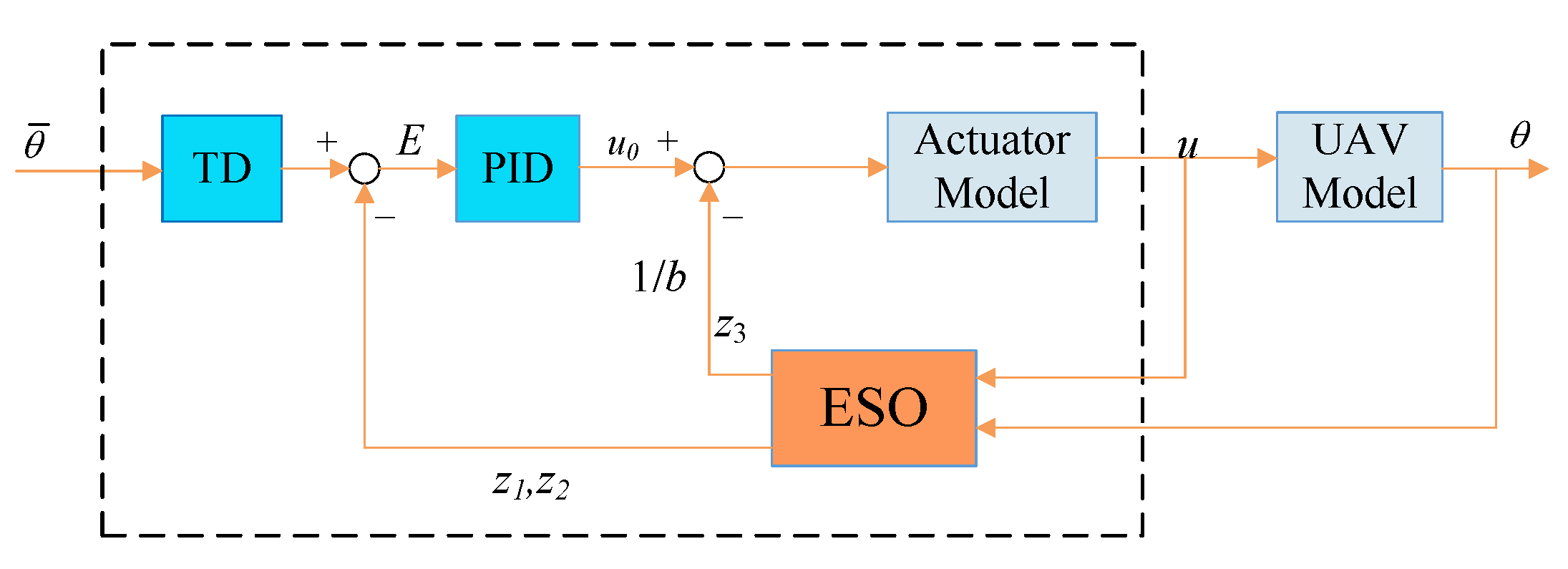
3.1. ADRC-Based Attitude Controller Design
3.2. Reinforcement Learning Theory
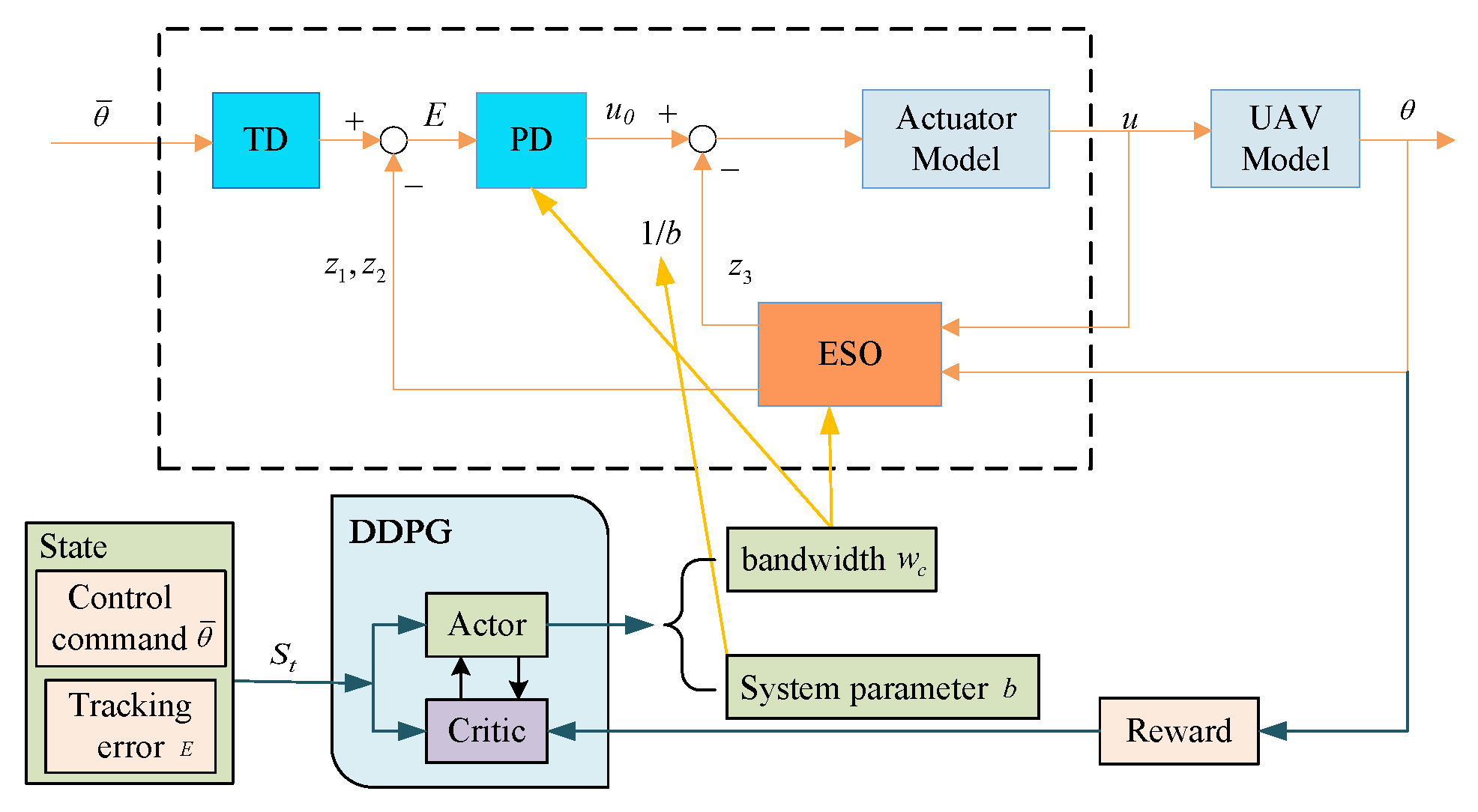
3.3. Structure of DDPG-Based ADRC
| Algorithm 1 DDPG-based ADRC controller |
|
4. Simulation and Results
4.1. Simulations in the Presence of Internal Disturbances
4.2. Simulations in the Presence of External Disturbances
4.3. Simulation under Sine Sweep
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | unmanned aerial vehicle |
| PID | proportion integration differentiation |
| PD | proportion differentiation |
| SMC | sliding mode control |
| ADRC | active disturbance rejection control |
| EMC | embedded model control |
| GA | genetic algorithm |
| PSO | particle swarm optimization |
| GWO | grey wolf optimization |
| RL | reinforcement learning |
| DDPG | deep deterministic policy gradient |
| ESO | extended state observer |
| TD | tracking differentiator |
| MDP | Markov decision process |
| DQN | deep Q network |
| ITAE | integrated time and absolute error |
| ITSE | integrated time and square error |
| IAE | integrated absolute error |
| MPC | model predictive control |
References
- Tian, B.; Liu, L.; Lu, H.; Zuo, Z.; Zong, Q.; Zhang, Y. Multivariable finite time attitude control for quadrotor UAV: Theory and experimentation. IEEE Trans. Ind. Electron. 2017, 65, 2567–2577. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, W.; Zuo, Z.; Zhong, Y. Robust control for quadrotors with multiple time-varying uncertainties and delays. IEEE Trans. Ind. Electron. 2016, 64, 1303–1312. [Google Scholar] [CrossRef]
- Hoffmann, G.M.; Huang, H.; Waslander, S.L.; Tomlin, C.J. Precision flight control for a multi-vehicle quadrotor helicopter testbed. Control Eng. Pract. 2011, 19, 1023–1036. [Google Scholar] [CrossRef]
- Mahony, R.; Kumar, V.; Corke, P. Multirotor aerial vehicles: Modeling, estimation, and control of quadrotor. IEEE Robot. Autom. Mag. 2012, 19, 20–32. [Google Scholar] [CrossRef]
- Pounds, P.; Mahony, R.; Corke, P. Modelling and control of a large quadrotor robot. Control Eng. Pract. 2010, 18, 691–699. [Google Scholar] [CrossRef] [Green Version]
- Tayebi, A.; McGilvray, S. Attitude stabilization of a VTOL quadrotor aircraft. IEEE Trans. Control Syst. Technol. 2006, 14, 562–571. [Google Scholar] [CrossRef] [Green Version]
- Cao, N.; Lynch, A.F. Inner–outer loop control for quadrotor UAVs with input and state constraints. IEEE Trans. Control Syst. Technol. 2015, 24, 1797–1804. [Google Scholar] [CrossRef]
- Zheng, E.H.; Xiong, J.J.; Luo, J.L. Second order sliding mode control for a quadrotor UAV. ISA Trans. 2014, 53, 1350–1356. [Google Scholar] [CrossRef]
- Xiong, J.J.; Zheng, E.H. Position and attitude tracking control for a quadrotor UAV. ISA Trans. 2014, 53, 725–731. [Google Scholar] [CrossRef] [PubMed]
- Zames, G.; Francis, B. Feedback, minimax sensitivity, and optimal robustness. IEEE Trans. Autom. Control 1983, 28, 585–601. [Google Scholar] [CrossRef]
- Babar, M.; Ali, S.; Shah, M.; Samar, R.; Bhatti, A.; Afzal, W. Robust control of UAVs using H∞ control paradigm. In Proceedings of the 2013 IEEE 9th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 9–10 December 2013; IEEE: New York, NY, USA, 2013; pp. 1–5. [Google Scholar]
- Liu, H.; Ma, T.; Lewis, F.L.; Wan, Y. Robust formation control for multiple quadrotors with nonlinearities and disturbances. IEEE Trans. Cybern. 2018, 50, 1362–1371. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Zhao, M.; Gao, K.; Su, J. Error Analysis of ADRC Linear Extended State Observer for the System with Measurement Noise. IFAC-PapersOnLine 2020, 53, 1306–1312. [Google Scholar] [CrossRef]
- Gao, Z. Scaling and bandwidth-parameterization based controller tuning. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; pp. 4989–4996. [Google Scholar]
- Niu, T.; Xiong, H.; Zhao, S. Based on ADRC UAV longitudinal pitching Angle control research. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016; IEEE: New York, NY, USA, 2016; pp. 21–25. [Google Scholar]
- Lotufo, M.A.; Colangelo, L.; Perez-Montenegro, C.; Canuto, E.; Novara, C. UAV quadrotor attitude control: An ADRC-EMC combined approach. Control Eng. Pract. 2019, 84, 13–22. [Google Scholar] [CrossRef]
- Zuo, Z.; Liu, C.; Han, Q.L.; Song, J. Unmanned aerial vehicles: Control methods and future challenges. IEEE/CAA J. Autom. Sin. 2022, 9, 601–614. [Google Scholar] [CrossRef]
- Wang, X.; Van Kampen, E.J.; Chu, Q.; Lu, P. Stability analysis for incremental nonlinear dynamic inversion control. J. Guid. Control Dyn. 2019, 42, 1116–1129. [Google Scholar] [CrossRef] [Green Version]
- Mudi, J.; Shiva, C.K.; Mukherjee, V. Multi-verse optimization algorithm for LFC of power system with imposed nonlinearities using three-degree-of-freedom PID controller. Iran. J. Sci. Technol. Trans. Electr. Eng. 2019, 43, 837–856. [Google Scholar] [CrossRef]
- Dubey, B.K.; Singh, N.; Bhambri, S. Optimization of PID controller parameters using PSO for two area load frequency control. IAES Int. J. Robot. Autom. 2019, 8, 256. [Google Scholar]
- Debnath, M.K.; Jena, T.; Sanyal, S.K. Frequency control analysis with PID-fuzzy-PID hybrid controller tuned by modified GWO technique. Int. Trans. Electr. Energy Syst. 2019, 29, e12074. [Google Scholar] [CrossRef]
- Bolandi, H.; Rezaei, M.; Mohsenipour, R.; Nemati, H.; Smailzadeh, S.M. Attitude control of a quadrotor with optimized PID controller. Intell. Control Autom. 2013, 4, 335–342. [Google Scholar]
- Koch, W.; Mancuso, R.; West, R.; Bestavros, A. Reinforcement learning for UAV attitude control. ACM Trans. Cyber-Phys. Syst. 2019, 3, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Lee, S.J.; Yim, S.C. Reinforcement learning-based adaptive PID controller for DPS. Ocean. Eng. 2020, 216, 108053. [Google Scholar] [CrossRef]
- Gheisarnejad, M.; Khooban, M.H. An intelligent non-integer PID controller-based deep reinforcement learning: Implementation and experimental results. IEEE Trans. Ind. Electron. 2020, 68, 3609–3618. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, H.; Wan, Y. Data-driven fault-tolerant formation control for nonlinear quadrotors under multiple simultaneous actuator faults. Syst. Control Lett. 2021, 158, 105063. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, Z.; Huang, Z.; Sun, M.; Sun, Q. Active disturbance rejection controller for multi-area interconnected power system based on reinforcement learning. Neurocomputing 2021, 425, 149–159. [Google Scholar] [CrossRef]
- Ma, J.; Peng, C. Adaptive model-free fault-tolerant control based on integral reinforcement learning for a highly flexible aircraft with actuator faults. Aerosp. Sci. Technol. 2021, 119, 107204. [Google Scholar] [CrossRef]
- Li, H.; Wu, Y.; Chen, M. Adaptive fault-tolerant tracking control for discrete-time multiagent systems via reinforcement learning algorithm. IEEE Trans. Cybern. 2020, 51, 1163–1174. [Google Scholar] [CrossRef] [PubMed]
- Gao, K.; Song, J.; Yang, E. Stability analysis of the high-order nonlinear extended state observers for a class of nonlinear control systems. Trans. Inst. Meas. Control 2019, 41, 4370–4379. [Google Scholar] [CrossRef] [Green Version]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Degrave, J.; Felici, F.; Buchli, J.; Neunert, M.; Tracey, B.; Carpanese, F.; Ewalds, T.; Hafner, R.; Abdolmaleki, A.; de Las Casas, D.; et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 2022, 602, 414–419. [Google Scholar] [CrossRef] [PubMed]
- Wada, D.; Araujo-Estrada, S.A.; Windsor, S. Unmanned aerial vehicle pitch control under delay using deep reinforcement learning with continuous action in wind tunnel test. Aerospace 2021, 8, 258. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Value | Measuring Unit |
|---|---|---|
| mass | kg | |
| acceleration of gravity | m/s2 | |
| moment of inertia and | kg·m2 | |
| radius of the quadrotor | m | |
| thrust coefficient | N/(rad/s) | |
| moment coefficient | N·m/(rad/s) | |
| moment of inertia of motor and propeller | kg·m2 |
| Parameter and Indicator | MPC | Traditional ADRC | DDPG ADRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| b | 12 | 13 | 14 | 15 | 12 | 13 | 14 | 15 | / |
| ITAE | 9.5016 | 13.047 | 10.629 | 14.049 | 9.4512 | 9.4512 | 9.4512 | 9.4512 | 9.357 |
| ITSE | 0.0664 | 0.2393 | 0.2504 | 0.2781 | 0.19384 | 0.19337 | 0.19293 | 0.19252 | 0.1848 |
| IAE | 13.895 | 22.555 | 20.976 | 24.614 | 18.868 | 18.868 | 18.868 | 18.868 | 18.273 |
| Rewards | 24,470 | 22,230 | 22,010 | 21,459 | 21,943 | 21,949 | 21,956 | 21,966 | 22,010 |
| Evaluation Indicator | Traditional ADRC | DDPG-ADRC |
|---|---|---|
| ITAE | 11.971 | 11.87 |
| ITSE | 0.2064 | 0.1848 |
| IAE | 20.73 | 20.131 |
| Total rewards | 21,829 | 21,904 |
| Parameter and Indicator | MPC | Traditional ADRC | DDPG ADRC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| b | 12 | 13 | 14 | 15 | 12 | 13 | 14 | 15 | / |
| ITAE | 375.85 | 361.27 | 351.32 | 344.28 | 288.38 | 288.62 | 288.89 | 289.18 | 286.3 |
| ITSE | 41.985 | 38.145 | 35.623 | 33.911 | 23.772 | 23.811 | 23.856 | 23.905 | 23.456 |
| IAE | 192.85 | 188.61 | 186.37 | 185.33 | 155.2 | 155.25 | 155.31 | 155.38 | 154.25 |
| Rewards | −19,203 | −18,821 | −18,513 | −18,267 | −16,996 | −17,027 | −17,071 | −17,104 | −16,946 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, K.; Song, J.; Hu, Y.; Xu, X.; Liu, Y. Deep Deterministic Policy Gradient-Based Active Disturbance Rejection Controller for Quad-Rotor UAVs. Mathematics 2022, 10, 2686. https://doi.org/10.3390/math10152686
Zhao K, Song J, Hu Y, Xu X, Liu Y. Deep Deterministic Policy Gradient-Based Active Disturbance Rejection Controller for Quad-Rotor UAVs. Mathematics. 2022; 10(15):2686. https://doi.org/10.3390/math10152686
Chicago/Turabian StyleZhao, Kai, Jia Song, Yunlong Hu, Xiaowei Xu, and Yang Liu. 2022. "Deep Deterministic Policy Gradient-Based Active Disturbance Rejection Controller for Quad-Rotor UAVs" Mathematics 10, no. 15: 2686. https://doi.org/10.3390/math10152686
APA StyleZhao, K., Song, J., Hu, Y., Xu, X., & Liu, Y. (2022). Deep Deterministic Policy Gradient-Based Active Disturbance Rejection Controller for Quad-Rotor UAVs. Mathematics, 10(15), 2686. https://doi.org/10.3390/math10152686