1. Introduction
Knowledge graphs are large-scale semantic network knowledge bases that utilise a graph-structured topology to integrate data [
1,
2]. They are widely used in multiform real-world applications. For instance, recommender systems can leverage knowledge graphs to establish semantic connections between items to improve the accuracy of recommendation [
3,
4]. Search engines can utilise knowledge graphs to establish user’s interest collection through a variety of relations to provide intelligent and personalised search results [
2,
5,
6]. To conveniently and efficiently utilise knowledge graph information, recent advances in this domain focus on learning effective representations of knowledge graphs, also known as knowledge representation learning (knowledge graph embedding) [
7,
8]. Knowledge graph representation learning can learn distributed representations of the knowledge graphs, which can significantly improve computing efficiency, effectively alleviate the data sparseness of knowledge graphs, etc. Thus, knowledge representation learning can further facilitate knowledge graphs in real applications, such as providing personalised recommendations and optimising intelligent search services.
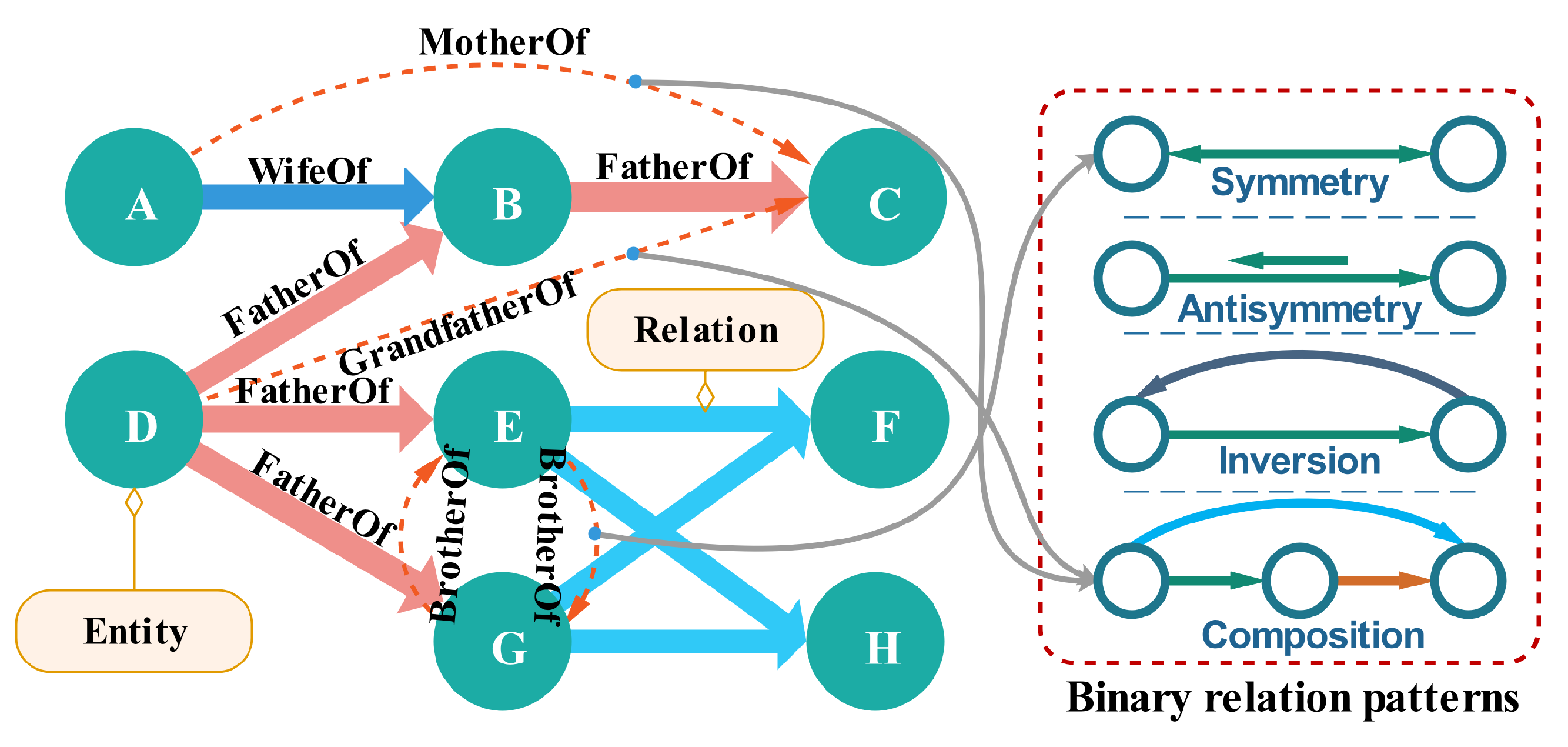
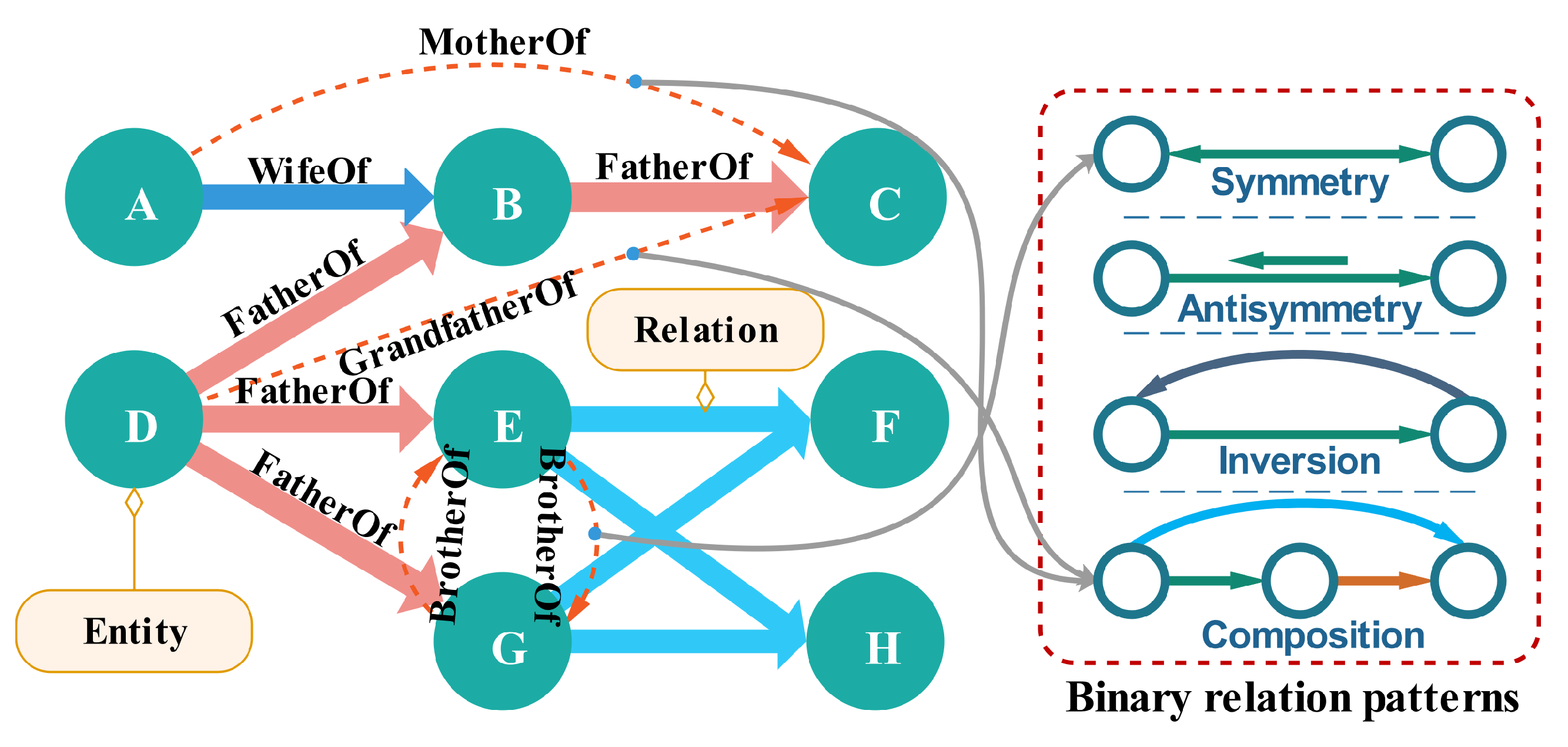
In knowledge graphs, various complex relations establish associations between entities, playing a major part in the expression of semantic information. These complex relations have rich relational structures [
9] and binary relational patterns [
10]. For instance, given triplets (D, FatherOf, B), (D, FatherOf, E), (D, FatherOf, G), (B, GrandfatherOf, C), the entity “D” has multiple relations to multiple entities. Moreover, a relation can have various binary relation patterns, for example the relation “GrandfatherOf” is the combination of two “FatherOf” relations. A simple illustration of complexity of relations is shown in
Figure 1. Thus, how to effectively model various complex relations to capture the rich semantic information in knowledge graphs is a challenging area of knowledge representation learning, which has attracted much attention from many researchers [
11,
12,
13,
14].
Recently, extensive and various solutions for modelling complex relations of knowledge graphs have been proposed [
15,
16,
17]. These solutions usually contain three steps: (1) defining a relation modelling strategy; (2) defining a score function that measures positive and negative triplets; (3) minimising the loss function based on the defined score function. For example, TransE [
18] is a promising natural-language-based model. It treats a relation between two entities as a translation process following the translational principle
and builds a two-way model to capture relations between entities. However, both entities and relations are embedded in a single space. Inspired by TransE, TransH [
9] and TransR [
19] embed entities and relations based on the translation process. They map entities and relations into different spaces; thus, they can preserve rich relational structures (multi-mapping relations), such as many-to-many (M2M), many-to-one (M2O), and one-to-many (O2M) relations. However, these methods lack the ability to address various types of binary relations [
20,
21,
22,
23], such as symmetric (e.g., brothers), antisymmetry (e.g., father), and inversion (e.g., hypernym). However, some knowledge representation learning methods are designed to solve this problem. For example, ComplEx [
24] can capture (anti)symmetry and inversion relations, but it maps relation and entity vectors into a single complex space. Specifically, RotatE [
10] has a similar translation strategy to TransE [
18]. It treats a relation as a rotation from source entities to target entities in a single complex space. These complex-number-based methods only map various complex relations into a single feature space. Thus, they cannot hold the various relational structures.
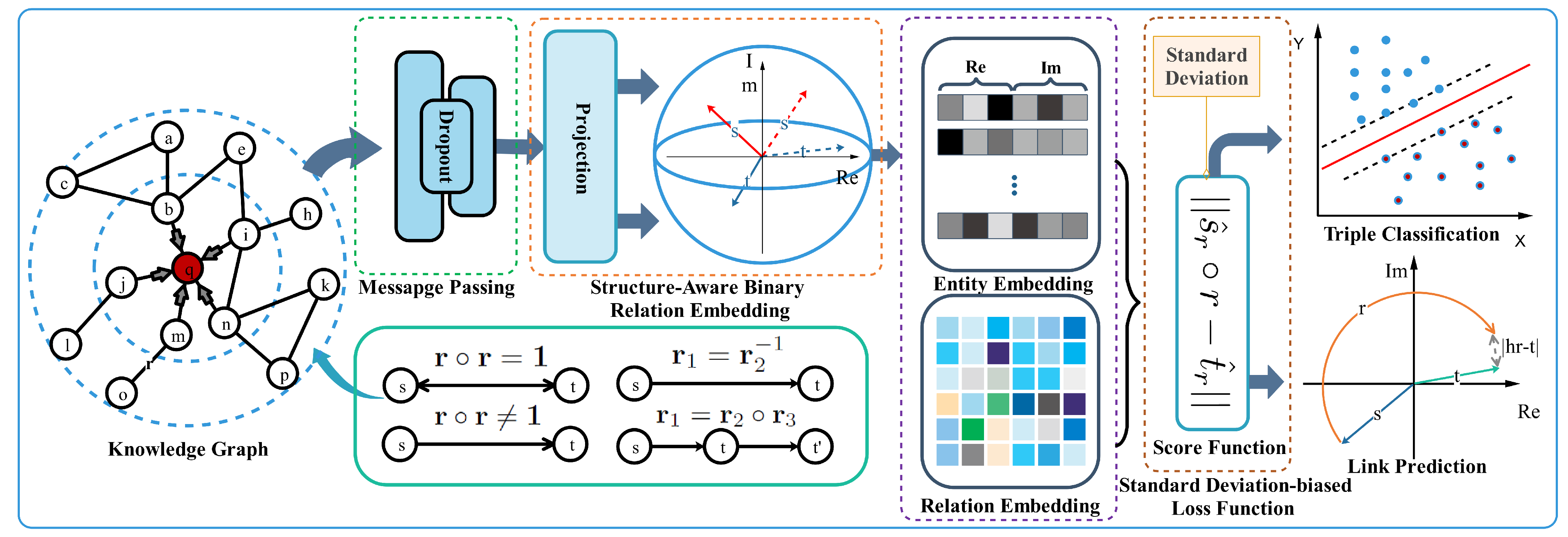
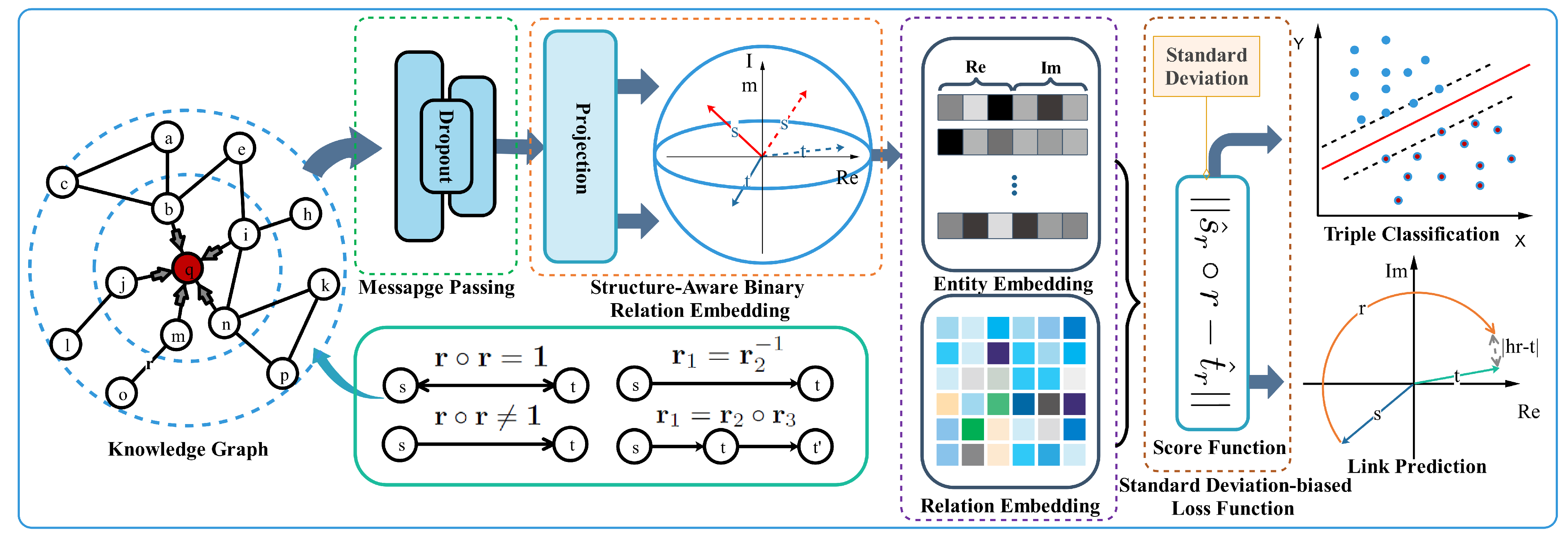
Due to the complexity of relations, previous solutions are not flexible enough to capture the various binary relation patterns and structural information simultaneously. Therefore, we deployed multiple complex spaces and propose a novel knowledge representation learning model, namely MARS, to explore complex relations to embed knowledge graphs. MARS takes advantage of RotatE [
10], which can fully preserve various binary relation patterns including (anti)symmetry, inversion, and composition. Furthermore, our proposed model maps embeddings of entities and relations into multiple feature spaces, thus leading to preserving rich relational structures, such as multi-mapping relations. To strengthen the assumption in the network representation learning, that is the connected nodes have similar representations, we utilised the message propagation mechanism [
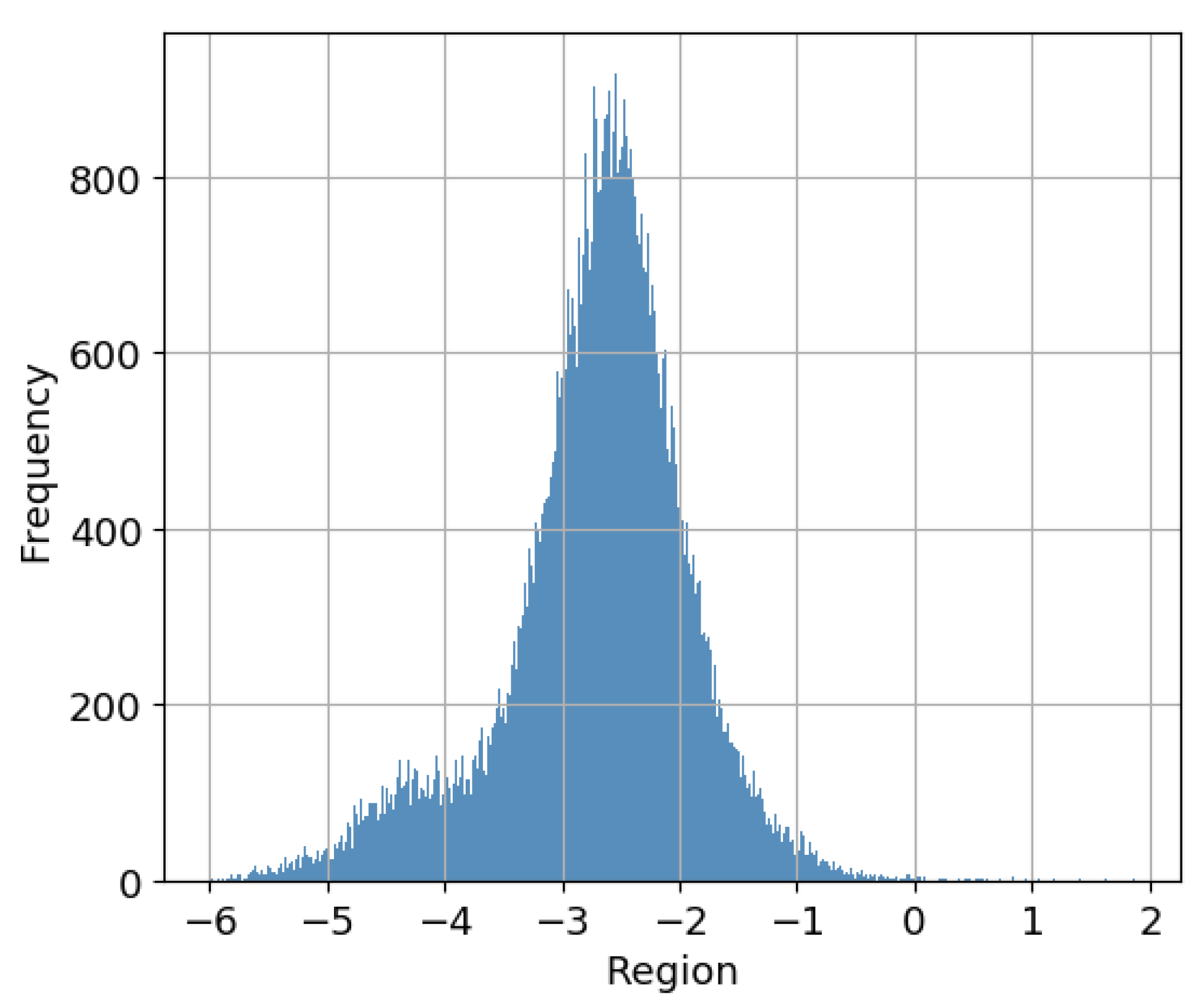
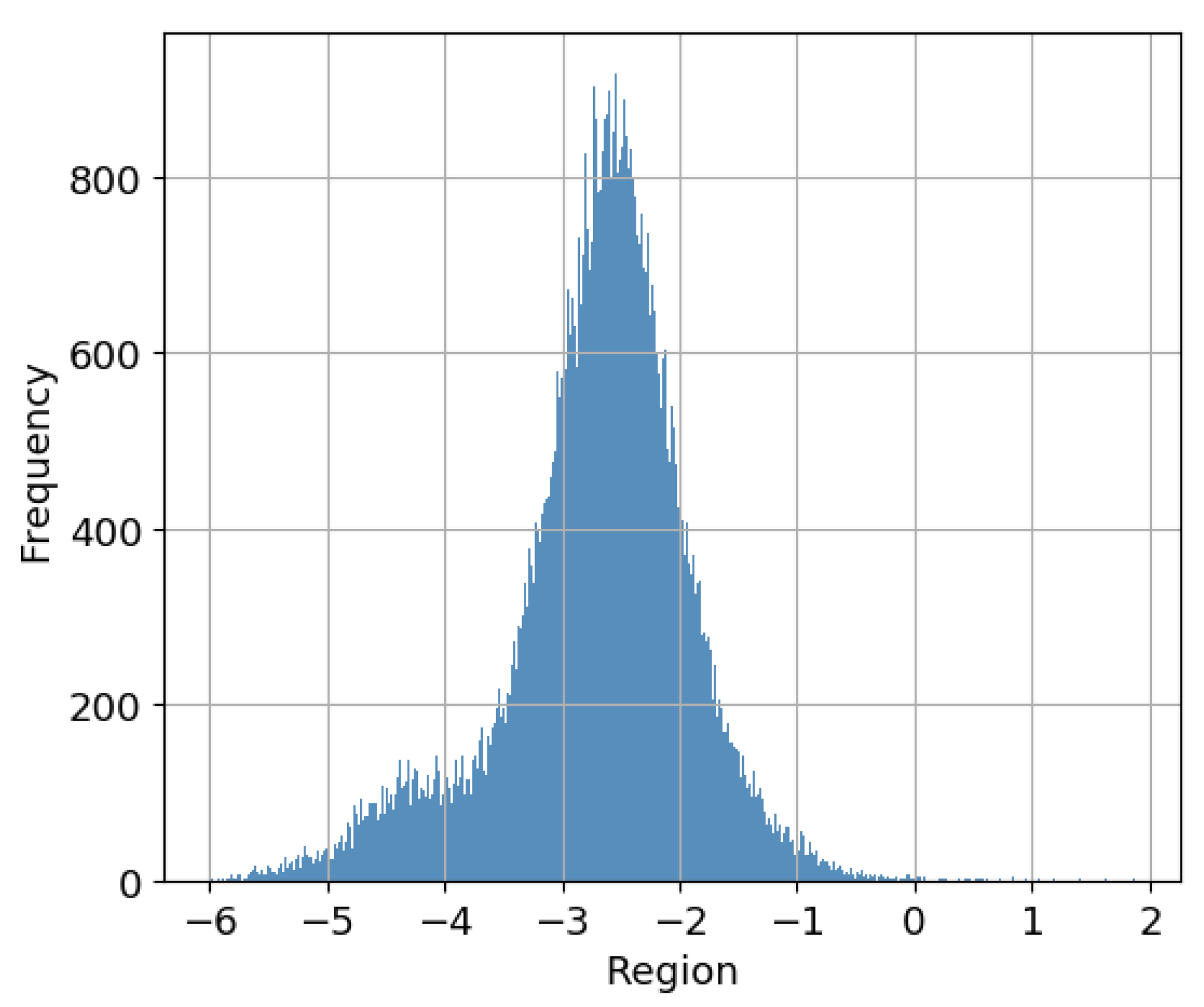
25] to restrict feature vectors of entities following the graph connectivity structure. This simple trick makes embeddings of entities able to well preserve local and global structural information. In addition, we found that the scores generated from the original score function approximate a Gaussian distribution. A simple illustration is shown in
Figure 2. The scores in the tail part cannot correctly represent the corresponding positive and negative samples. Thus, we involved the standard deviation approach in solving this problem to obtain more accurate embeddings of triplets. The main contributions of our work are summarised as follows:
We present a novel knowledge graph representation learning framework, namely MARS, to exploit complex relations for embedding knowledge graphs. MARS can effectively capture various binary relation patterns, as well as rich relational structures in knowledge graphs. Thus, our model can achieve more accurate embeddings.
We find that the scores of triplets that preserve rich relational structures and various binary relational patterns approximate a Gaussian distribution. The scores in the tail have negative influences on tasks. To overcome this weakness and optimise the accuracy of embedding triplets, we specifically involved the standard deviation approach to alleviate the deviation caused by the scores of the triplets located in the tail of the distribution, leading to better performance in triple classification and link prediction.
We conducted comprehensive experiments on several benchmark datasets. The experimental results of MARS consistently outperformed state-of-the-art models on the tasks of link prediction and triple classification. This demonstrates the effectiveness of our proposed model.
This paper is divided into six sections.
Section 2 deals with the previous relevant research related to our study.
Section 3 introduces some involved basic concepts and definitions.
Section 4 presents the details of our model. Towards the end of our study,
Section 5 provides a detailed experiment introduction and the related experimental results. Finally,
Section 6 summarises our contributions.
2. Related Work
As we know, knowledge bases store triplets in the form of one-hot vectors. With this representation, we need to design special graph algorithms to calculate the semantic and reasoning relations between entities. These one-hot-vector-based models have a high computational complexity and are hard to transfer to other datasets. Compared with these traditional models, knowledge representation learning can learn distributed representations of triplets in a low-dimensional continuous feature space; thus, it can efficiently calculate semantic similarity, leading to higher computing efficiency. In addition, the representations can effectively alleviate the problem of data sparsity and can effectively fuse the heterogeneous information of knowledge graphs. In recent years, numerous investigations have been conducted in this domain. We introduce several representative models, including classical models and the recent deep-learning-based models in the following.
The classical knowledge embedding methods, for instance TransE [
18], are derived from a natural language model [
26,
27]. TransE projects both entities and relations to feature vectors into a continual feature space. Let
r represent a relation and
s and
t represent a source and target entity accordingly; the feature vectors follow the translational distance constraint
. Given a triplet
, if it describes a plausible or credible fact (golden triplets),
r should be regarded as a translation from
s to
t. For example, given a triplet
, this should satisfy the equation
by a certain relation. Many subsequent models are proposed based on TransE with a more complex process of modelling relations. For instance, TransH [
9] involves a plain vector space and relational projection matrix. TransR [
19] involves two separate feature spaces for entity embedding and relation embedding. TransD [
28] involves two mapping matrices for projecting source entities and target entities. It is a more fine-grained model compared with TransR. There are bilinear models, such as DISTMULT [
29], ComplEx [
24], SME [
30], and ANALOGY [
31]. Specifically, ComplEx and RotatE embed triplets into a complex feature space. The embeddings can well preserve binary relation patterns.
At present, one of the most popular knowledge representation learning methods is based on deep learning, as it can construct high-level semantic features from lower-level features suitable for tasks [
15,
32,
33]. For instance, ConvE [
34] utilises 2D-convolution to join features of triplets and then feeds the outputs from the fully connected layer to the logistic classification layer. R-GCN [
35] is derived from graph convolutional networks (GCNs) [
36,
37,
38]. The embeddings of entities are aggregated utilising the GCN method based on structural information. SCAN [
39] benefits from both GCNs and ConvE [
34]. SCAN introduces attributes’ information into the embedding vectors. There are some other methods for specific knowledge graph embedding. For example, wRAN [
40] is based on an adversarial network. This method can be used for link prediction and relation extraction under low resource conditions. FSRL [
41] is a few-shot knowledge graph completion framework based on LSTM. Some representative approaches and their abilities to model relations are summarised in
Table 1.
Studies have shown the scalability and effectiveness of the above approaches. However, these approaches are still insufficient for modelling relations. Our proposed model (MARS) is a generalisation of RotatE in complex space, while we strengthen MARS’s ability to capture the structural information with the message-passing scheme [
25]. Thus, MARS is capable of preserving both rich relational structures and binary connectivity patterns in knowledge graphs. In addition, we formally discuss the distribution of scores, and we involved the standard deviation method to alleviate the inaccurate representation problem caused by the unbalanced score distributions.
5. Experiments
In this section, we thoroughly conduct experiments to verify the effectiveness of our model. This section is divided into five main subsections, an introduction to the used datasets and baselines, hyperparameter settings, evaluation protocols, and experiment results.
5.1. Datasets
FB15K. The FB15k dataset contains triplets extracted from entity pairs of the freebase dataset. The entities and relations of the dataset are uniquely encoded and stored in the form of text in different files. The triplet file has 592,213 triplets; the entity dictionary file has 14,951 unique entities; the relation dictionary file has 1345 unique relations.
FB15K-237. The FB15K-237 dataset is a subset of the Freebase knowledge base. It is extracted and purified from the FB15K dataset by removing the inverse relations from the original dataset. Here, “15K” means 15,000 keywords in the knowledge base and “237” means 237 relations in total. The training set contains 272,115 triplets; the validation set contains 17,535 triplets; the test set contains 20,466 triplets.
WN18. The WN18 dataset is a subset of WordNet, having 18 kinds of relations and roughly 41,000 kinds of entities scraped from the original dataset. The source of WN18 has training, validation, and test sets, resulting in 151,442 triplets.
The statistical information of the three benchmark datasets is shown in
Table 3.
5.2. Evaluation Protocols
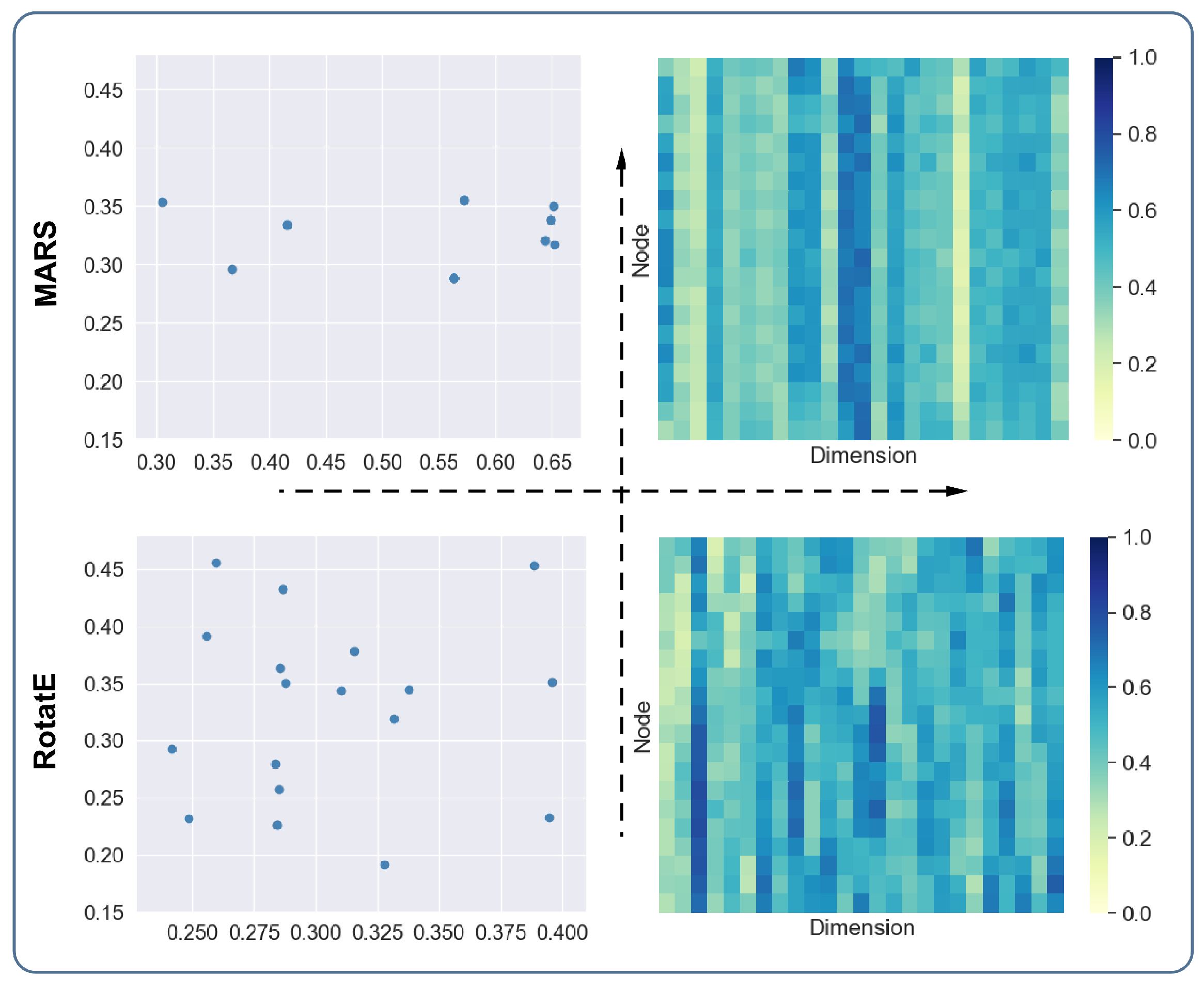
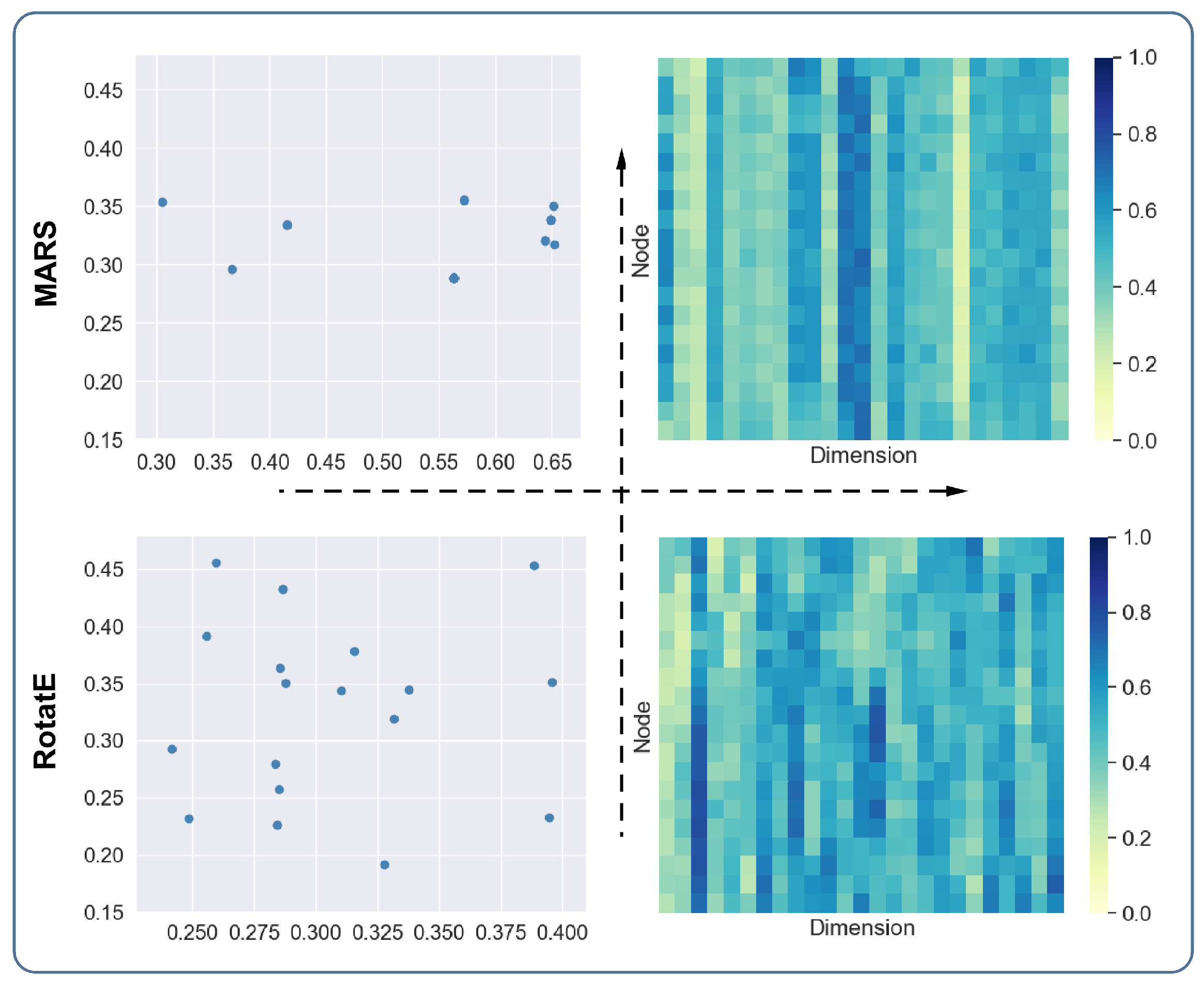
The purpose of the structural preserving experiment is to explore the intuitive influence of the message-passing schema on entity embeddings. RotatE was selected as the comparison method. A random walk with a fixed step length was used to obtain subgraphs from knowledge graphs. We utilised PCA to reduce the dimensions (128) of the original embedding vector to 2 and 25 dimensions. The 2-dimensional embedding vectors were used to draw scatter diagrams of entities, and the 25-dimensional embedding vectors were used to draw heat maps. By following the visualisation of the embedding vectors, we conducted a qualitative analysis of the embedding vectors of the two methods.
The task of (semi-)supervised triple classification is to verify the capacity of models to predict positive or negative triplets. To construct negative triplets, we adopted the self-adversarial negative sampling approach proposed by RotatE. This approach generates meaningful negative samples with the self-adversarial technique. We simply performed the task with the FB15K, FB15K-237, and WN18 datasets. The principle of triple classification is to compare the score of samples with a manually set threshold. If the score of a sample is higher than the threshold, the sample is classified as positive or negative. Thus, the classification experiment can be treated as a binary classification problem. We utilised four classification metrics, accuracy , precision , recall , and , to measure the accuracy of triple classification.
The link prediction task deals with predicting the target/source entity given a source/ target entity and a relation (i.e.,
). In other words, it assigns the most probable entity based on score function
. The evaluation protocols for the link prediction experiment adopt the mean reciprocal rank (MRR) and Hit@n measures. For the MRR evaluation protocol, the scores of triplets are calculated and sorted in ascending order. The rank of a positive triplet is the score of one sample. This whole procedure is applied to all the test samples, and the average rank of all test samples is the final performance of link prediction. Different from MRR, Hit@n just measures the rank of ground-truth triplets in Top-n. Obviously, a good model should obtain a lower ranking in Top-n. In addition, these negative samples constructed through replacing the head/tail entity may contain correct triplets. Hence, these correct triplets that exist in negative samples in knowledge graphs need to be filtered out before computing the scores. Following the raw and filtered settings of RotatE [
10], both filtered and raw MRR, and filtered Hits with
, the results are reported in this link prediction experiment.
5.3. Baselines
For the comparison in our experiment, we compared our model with the recent state-of-the-art baselines, which include five different knowledge embedding models. TransE [
18] is a kind of translational model for knowledge representation learning. It treats a relation as a translation in the feature space and optimises embeddings with the
strategy. As the second translational model, TransH [
9] can handle one-to-many, many-to-one, and many-to-many relations without increasing complexity. As the third translational model, TransR [
19] is derived from TranE, but it maps entities and relations into two different spaces, namely entity space and multiple relation spaces, while preserving various multi-mapping relations patterns. We further compared our model with ComplEx [
24], DISTMULT [
29], and RotatE [
10]. ComplEx can embed triplets in complex space as the previous description in
Section 2. The ComplEx algorithm belongs to a semantic matching model, which is an expansion of DISTMULT in complex space. Different from other models, RotatE treats a relation as a rotation in complex space according to Euler’s formula. It can preserve (anti)symmetry, composition, and inversion relation patterns.
5.4. Hyperparameter Settings
A series of hyperparameters of MARS need to be set in advance during training. These hyperparameters determine the performance of the model. We empirically set the learning rate sequence:
on the above different datasets during training. We accordingly set the batch size:
for the three datasets. We set the negative sampling rate to 1:64, the same as RotatE [
10], also known as 1 positive sample with 64 negative samples. We set the commonly used dimensions to 128 for both triple classification and link prediction. The message-passing layer for both tasks was empirically set to 2 layers. There is a dropout layer between the two message-passing layers. For different datasets, We empirically set the dropout rate sequence to
. In addition, we used 8 threads for sampling in each dataset. In our experiment, each dataset was divided into three subsets, which included the training, validation, and test subsets. The training and validation subsets were used to train the models. According to
Table 3, the ratios for training, validation, and testing for WN18, FB15K, and FB15K-237 were about
.
We implemented our model leveraging the OpenKE-PyTorch (
https://github.com/thunlp/OpenKE, accessed on 4 May 2022) and DGL (
https://github.com/dmlc/dgl/, accessed on 4 May 2022) libraries. OpenKE-PyTorch is an open-source library for knowledge representation learning. The DGL library is a universal Python package for graph learning. Because a GPU can effectively improve the training speed of deep learning models, we implemented our model leveraging the GPU version of Pytorch. The training of the model was performed on NVIDIA 2080TI Graphics Processing Units. The training process of the model adopted the adaptive moment (Adam) algorithm to optimise the parameters. We performed
training epochs on both triple classification and link prediction tasks on the benchmark datasets.
5.5. Experimental Results
The following gives the experimental results and analysis, including the models’ efficiency, structural preserving, triple classification, and link prediction tasks.
5.5.1. Structural Preserving Results and Analysis
According to the two scatter diagrams in the second and third quadrant in
Figure 4, we can see that the score distributions of the entities of RotatE are relatively scattered, while the distributions of the entities of MARS are relatively concentrated. We know that the connected entities tend to have similar representations. The visualisation can give an intuitive illustration that MARS has better performance in preserving the structural information of knowledge graphs. There are some overlapping entities in the scatter diagram due to the procedure of reducing high-dimensional vectors to low-dimensional vectors. According to the two heat maps in the first and fourth quadrant in
Figure 4, we can see that the entity vectors of MARS in each row have relatively similar values, and the transition between vectors from top to bottom is relatively smooth. However, the vector distributions of RotatE are relatively scattered. Thus, the distributions of vectors shown in the heat maps are consistent with the distributions of the scatter diagrams. This result further supports the above conclusion.
5.5.2. Triple Classification Results and Analysis
Table 4 summarises the triple classification results on FB15K, FB15K237, and WN18. We can see that DISTMULT achieved the best performance of triple classification among the baselines on the FB15K dataset. The prediction scores (also known as the F1-score, accuracy, precision, and recall) of DISTMULT were slightly higher than those of ComplEx, as well as higher than those of the translational models. The performances of TransR, TransH, and TransE are similar, and TransH slightly outperformed the other two translational models. On the WN18 dataset, DISTMULT still outperformed ComplEx and was the best among the baselines. The prediction scores of TransR were higher than those of TranH and TransE. On the FB15K237 dataset, the performances of complEx and RotatE were better than the translational models on this dataset. Our model outperformed the baselines on the FB15K and WN18 datasets. On the FB15K237 dataset, the
of triple classification of our model was slightly lower than the
of ComplEx. In summary, the embeddings of our model were effective in triple classification, and our model obtained improvements compared to the baselines on the benchmark datasets.
5.5.3. Link Prediction Results and Analysis
According to the link prediction results on the FB15K dataset in
Table 5, we can see that the scores of the filtered MRR were higher than those of the raw MRR. This was due to the setting of the raw MRR, for which some conflicting positive samples could influence the prediction results, and so were removed from the test set. Thus, the filtered MRR has the capacity to accurately measure the performance of link prediction. The performance of ComplEx and DISTMULT on FB15K was poorer than the other baselines. TransE and TransH had similar performances on this dataset. The scores on the MRR of TransE outperformed TransH. TransH performed better than TransE, when
on hit@n. The RotatE and TransR algorithms had similar performance, while RotatE had the best performance among the baselines, and its scores outperformed all the other baselines. The scores of MARS are presented in the last line. We can see that the scores were always higher than RotatE. Thus, our model had the best performance compared all baselines on the FB15K dataset.
According to the results on the WN18 dataset in
Table 6, the translational algorithms (also known as TransE, TransH, and TransR) had similar performance. These three algorithms had low scores for Hits@1, 0.089, 0.035, and 0.096, respectively. RotatE still achieved the best performance among all the baselines in link prediction on the WN18 dataset. Our model obtained slight improvements compared to RotatE on the WN18 dataset. However, our model still achieved the best performance among all the baselines.
According to the results of link prediction on the FB15K-237 dataset in
Table 7, we can see that the three translational algorithms had similar experimental results on the WN18 dataset. The scores of TransR were slightly higher than the other two translational algorithms. RotatE and ComplEx had similar experimental performances. RotatE outperformed ComplEx for MRR and His@1. Similar to the results on the above two datasets, MARS outperformed all the baselines and obtained significant improvements compared to the other two complex-number-based algorithms.
In addition, we can see that the scores for triplet classification were significantly higher than those for link predictions. That is because the models only have two categories of prediction results (positive and negative) in the former, while in the latter, the models need to predict the right entity from an entity candidate set, so the hit probability is lower than the former.
5.5.4. Efficiency Analysis
We tested the running speed and resource consumption of our proposed model on the FB15K dataset. We recorded the average time (second) of an epoch and the GPU memory and the CPU memory of models. The experimental results are shown in
Table 8.
According to the results in the table, we can see that TransE was the fastest and needed the least memory. The RotatE model was slightly slower than TransE. TransR was the slowest model, while it also needed the most memory among all the models. In order to capture the diversity of the relations in knowledge graphs, MARS has more parameters than most of the compared models, so it needs relatively more memory and is slightly slower than them. Anyway, from the results in the table, we can see that most GPU platforms could offer the computing resources necessary for our model. In addition, our model achieved better embedding accuracy while slightly sacrificing running efficiency.






{kind=link}
{kind=link}
{kind=link}
{kind=link}