
MST-RNN: A Multi-Dimension Spatiotemporal Recurrent Neural Networks for Recommending the Next Point of Interest



Abstract
:1. Introduction
- We propose a novel MST-RNN model to learn the rule of next-POI changes from spatial, temporal, and semantic dimensions.
- We consider the duration time of a user as a new indicator in next-POI recommendations, which can measure the user’s preference dimension.
- We add a tag regularization item for exploring the semantic dimension of POI changes, which presents a novel perspective on the next-POIs recommendation.
- We detail the specific learning process of the proposed models and present the tuning steps of the hyperparameter.
- Experiments conducted on real-world vehicle trajectory data show that the proposed MST-RNN is effective and clearly outperforms the state-of-the-art methods.
2. Related Works
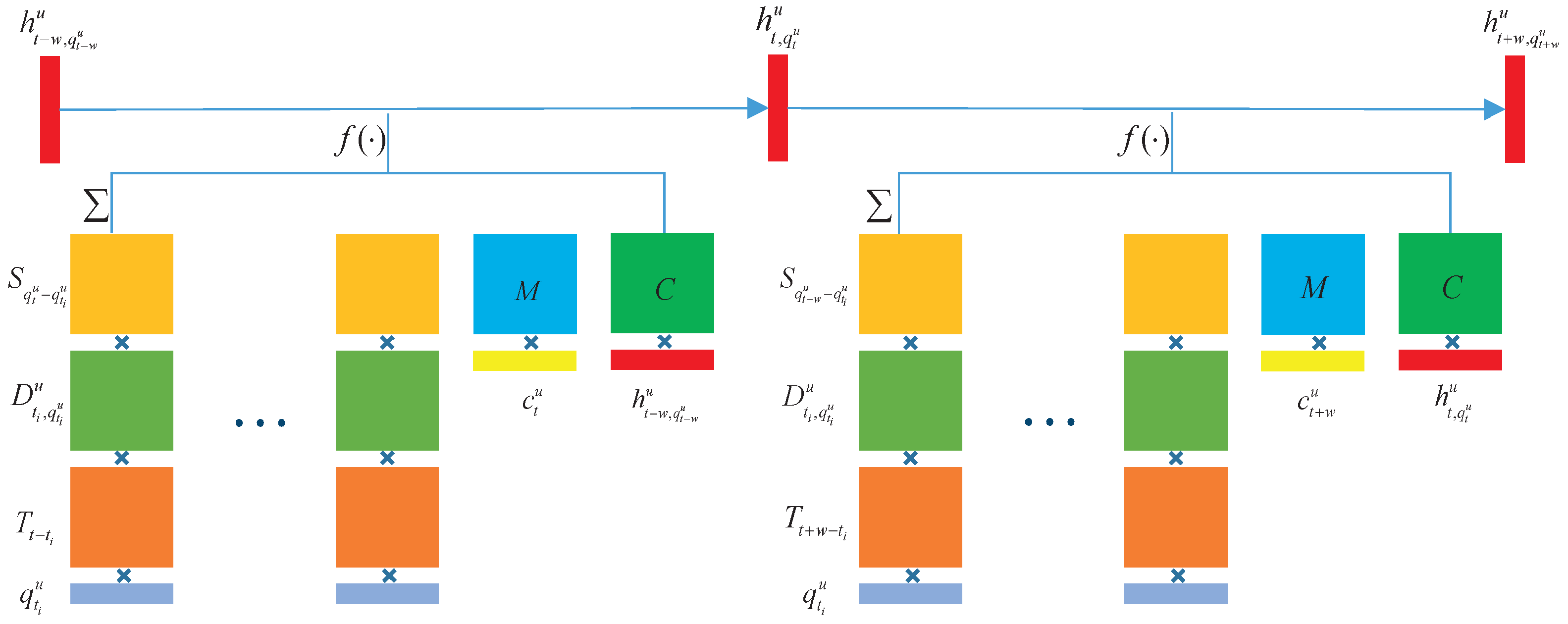
3. Model
3.1. Problem Definition
3.2. Baseline Model
3.3. Proposed Models
3.4. Generation of Transition Matrix
3.5. Parameter Inference
4. Experimental Results and Analysis
4.1. Vehicle Trajectory Dataset
4.2. Experimental Settings
- MF [13]: The MF model extends the traditional collaborative filtering recommendation and performs well on the user–item matrix.
- FPMC [8]: The Markov chain is a classical sequential model, which extends the Markov chain model by introducing a personalized transfer matrix.
- PRME [9]: This model embeds users’ information and the POI information into the user preference space and sequence transfer space, where it takes the spatial and temporal factors into consideration.
- RNN [10]: An RNN is an excellent model in the field of temporal prediction. It performs word embedding and ad-click prediction very well.
- ST-RNN [11]: This method models temporal and spatial factors and extends the basic RNN model.
- ST-LSTM [26]: Spatiotemporal-LSTM is a variant of an ST-RNN, which can capture the spatiotemporal relation from the two directions forward and backward.
4.3. Analysis of Experimental Results
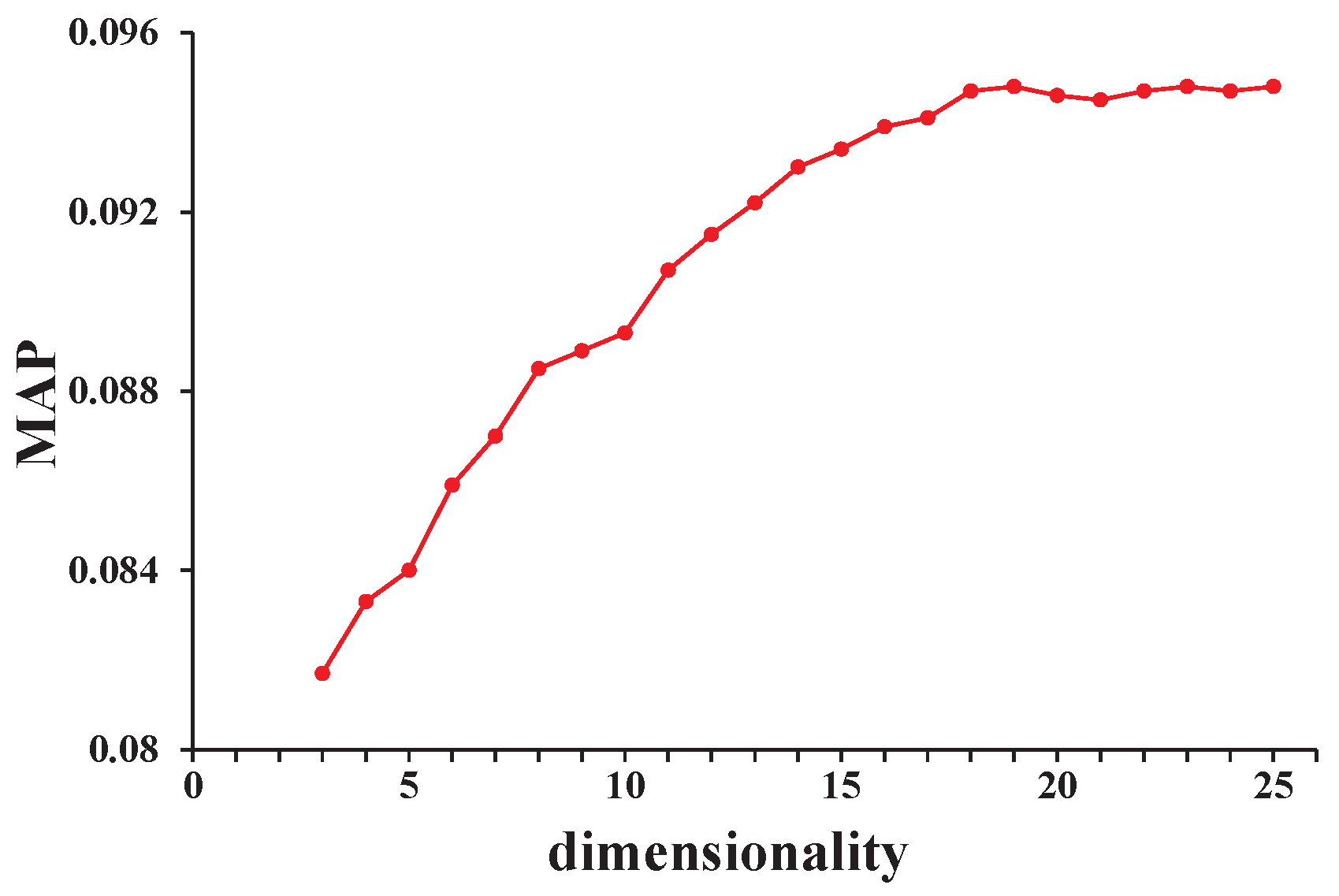
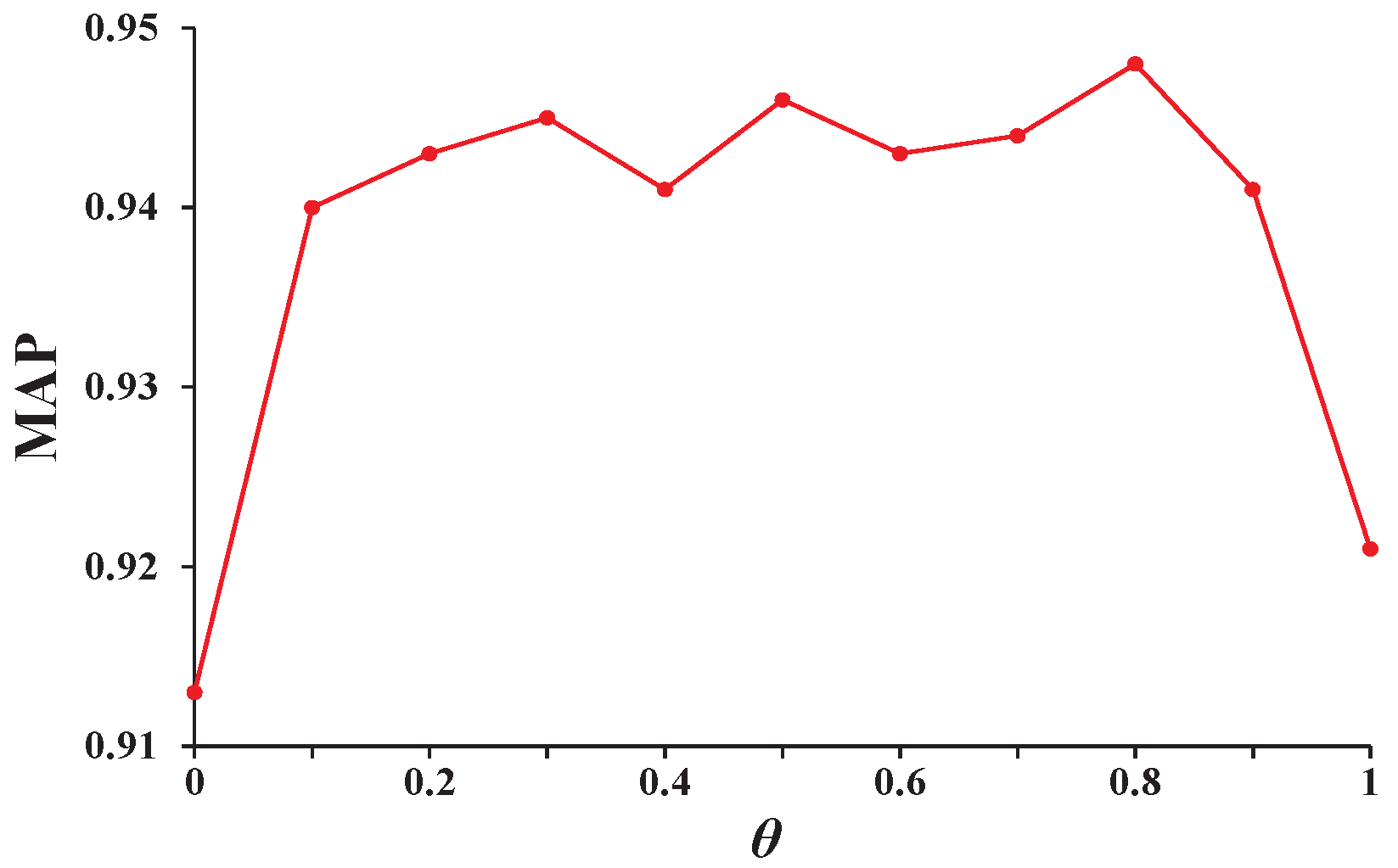
4.4. Analysis of Hyperparameters
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Ge, Y.; Hong, R.; Zhu, H. Point-of-interest recommendations: Learning potential check-ins from friends. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 975–984. [Google Scholar]
- Li, X.; Cong, G.; Li, X.L.; Pham, T.A.N.; Krishnaswamy, S. Rank-geofm: A ranking based geographical factorization method for point of interest recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 433–442. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on RESEARCH and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Cheng, C.; Yang, H.; King, I.; Lyu, M. Fused matrix factorization with geographical and social influence in location-based social networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 17–23. [Google Scholar]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on KNOWLEDGE Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2605–2611. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Feng, S.; Li, X.; Zeng, Y.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized ranking metric embedding for next new poi recommendation. In Proceedings of the IJCAI’15 Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2069–2075. [Google Scholar]
- Zhang, Y.; Dai, H.; Xu, C.; Feng, J.; Wang, T.; Bian, J.; Wang, B.; Liu, T.Y. Sequential click prediction for sponsored search with recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1369–1375. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Chen, X.; Zeng, Y.; Cong, G.; Qin, S.; Xiang, Y.; Dai, Y. On information coverage for location category based point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 37–43. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Xiong, L.; Chen, X.; Huang, T.K.; Schneider, J.; Carbonell, J.G. Temporal Collaborative Filtering with Bayesian Probabilistic Tensor Factorization. In Proceedings of the SIAM International Conference on Data Mining, Columbus, OH, USA, 29 April–1 May 2010; pp. 211–222. [Google Scholar]
- Zhao, S.; Zhao, T.; Yang, H.; Lyu, M.R.; King, I. STELLAR: Spatial-temporal latent ranking for successive point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 315–321. [Google Scholar]
- Li, X.; Han, D.; He, J.; Liao, L.; Wang, M. Next and next new POI recommendation via latent behavior pattern inference. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.S.; Huang, J.L. GLR: A graph-based latent representation model for successive POI recommendation. Future Gener. Comput. Syst. 2020, 102, 230–244. [Google Scholar] [CrossRef]
- Qiao, Y.; Luo, X.; Li, C.; Tian, H.; Ma, J. Heterogeneous graph-based joint representation learning for s and POIs in location-based social network. Inf. Process. Manag. 2020, 57, 102151. [Google Scholar] [CrossRef]
- Ying, H.; Wu, J.; Xu, G.; Liu, Y.; Liang, T.; Zhang, X.; Xiong, H. Time-aware metric embedding with asymmetric projection for successive POI recommendation. World Wide Web 2019, 22, 2209–2224. [Google Scholar] [CrossRef]
- Vinh Tran, L.; Tay, Y.; Zhang, S.; Cong, G.; Li, X. HyperML: A boosting metric learning approach in hyperbolic space for recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 609–617. [Google Scholar]
- Feng, S.; Tran, L.V.; Cong, G.; Chen, L.; Li, J.; Li, F. HME: A Hyperbolic Metric Embedding Approach for Next-POI Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event China, Xi’an, China, 25–30 July 2020; pp. 1429–1438. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Chamberlain, B.P.; Hardwick, S.R.; Wardrope, D.R.; Dzogang, F.; Daolio, F.; Vargas, S. Scalable hyperbolic recommender systems. arXiv 2019, arXiv:1902.08648. [Google Scholar]
- Altaf, B.; Yu, L.; Zhang, X. Spatio-temporal attention based recurrent neural network for next location prediction. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 937–942. [Google Scholar]
- Li, R.; Shen, Y.; Zhu, Y. Next point-of-interest recommendation with temporal and multi-level context attention. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1110–1115. [Google Scholar]
- Zhao, P.; Zhu, H.; Liu, Y.; Li, Z.; Xu, J.; Sheng, V.S. Where to go next: A spatio-temporal lstm model for next poi recommendation. arXiv 2018, arXiv:1806.06671. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback; UAI: Arlington, VA, USA, 2009; pp. 452–461. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Casillo, M.; Colace, F.; Pascale, F.; Lemma, S.; Lombardi, M. Context-aware computing for improving the touristic experience: A pervasive app for the Amalfi coast. In Proceedings of the 2017 IEEE International Workshop on Measurement and Networking, Naples, Italy, 27–29 September 2017; pp. 1–7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Recall@1 | Recall@5 | Recall@10 | F1-Score@1 | |
|---|---|---|---|---|
| MF | 0.0113 | 0.0365 | 0.0562 | 0.0113 |
| FPMC | 0.0176 | 0.0526 | 0.0783 | 0.0176 |
| PRME | 0.0206 | 0.0633 | 0.0867 | 0.0206 |
| RNN | 0.0267 | 0.0749 | 0.1021 | 0.0267 |
| ST-RNN | 0.0312 | 0.0887 | 0.1103 | 0.0312 |
| ST-LSTM | 0.0356 | 0.0937 | 0.1192 | 0.0356 |
| SD-RNN | 0.0304 | 0.0896 | 0.1082 | 0.0304 |
| SDT-RNN | 0.0359 | 0.0965 | 0.1231 | 0.0359 |
| MST-RNN | 0.0367 | 0.0984 | 0.1257 | 0.0367 |
| F1-Score@5 | F1-Score@10 | MAP | AUC | |
| MF | 0.0198 | 0.0177 | 0.0489 | 0.6379 |
| FPMC | 0.0247 | 0.0223 | 0.0623 | 0.6822 |
| PRME | 0.0351 | 0.0310 | 0.0755 | 0.7011 |
| RNN | 0.0425 | 0.0364 | 0.0842 | 0.7293 |
| ST-RNN | 0.0540 | 0.0477 | 0.0883 | 0.7319 |
| ST-LSTM | 0.0588 | 0.0519 | 0.0914 | 0.7493 |
| SD-RNN | 0.0533 | 0.0465 | 0.0879 | 0.7311 |
| SDT-RNN | 0.0601 | 0.0527 | 0.0927 | 0.7525 |
| MST-RNN | 0.0609 | 0.0536 | 0.0946 | 0.7611 |
| w | Recall@1 | Recall@5 | Recall@10 | MAP | AUC |
|---|---|---|---|---|---|
| 3 h | 0.0349 | 0.0932 | 0.1162 | 0.0891 | 0.7562 |
| 6 h | 0.0367 | 0.0984 | 0.1257 | 0.0946 | 0.7611 |
| 12 h | 0.0392 | 0.0961 | 0.1206 | 0.0914 | 0.7584 |
| 1 d | 0.0331 | 0.0956 | 0.1195 | 0.0906 | 0.7577 |
| 2 d | 0.0324 | 0.0953 | 0.1203 | 0.0911 | 0.7569 |
| 3 d | 0.0328 | 0.0955 | 0.1198 | 0.0907 | 0.7563 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Li, D.; Zhang, Z.; Chu, D. MST-RNN: A Multi-Dimension Spatiotemporal Recurrent Neural Networks for Recommending the Next Point of Interest. Mathematics 2022, 10, 1838. https://doi.org/10.3390/math10111838
Li C, Li D, Zhang Z, Chu D. MST-RNN: A Multi-Dimension Spatiotemporal Recurrent Neural Networks for Recommending the Next Point of Interest. Mathematics. 2022; 10(11):1838. https://doi.org/10.3390/math10111838
Chicago/Turabian StyleLi, Chunshan, Dongmei Li, Zhongya Zhang, and Dianhui Chu. 2022. "MST-RNN: A Multi-Dimension Spatiotemporal Recurrent Neural Networks for Recommending the Next Point of Interest" Mathematics 10, no. 11: 1838. https://doi.org/10.3390/math10111838
APA StyleLi, C., Li, D., Zhang, Z., & Chu, D. (2022). MST-RNN: A Multi-Dimension Spatiotemporal Recurrent Neural Networks for Recommending the Next Point of Interest. Mathematics, 10(11), 1838. https://doi.org/10.3390/math10111838