Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology: The CK-IBI


Abstract
1. Introduction
1.1. Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology
1.2. Conceptualization of CK
1.3. Assessment of CK
1.4. Hypotheses
- Teacher education program. Pre-service teachers choose between two secondary teacher education programs (both require the study of two teaching subjects) which provide a teaching certificate for schools qualifying their students for an academic (grade 5–12 [or 13]; academic track) or nonacademic career (grade 5–9 [or 10]; nonacademic track). There are strong indications that the type of teacher education program pre-service teachers attend influences their performance [37,58,59], partly due to associated variations in the number of subject-related courses they take [60]. Pre-service teachers of the academic track reportedly perform better in CK tests than their nonacademic colleagues [48,61,62]. Thus, we hypothesize that CK scores for participants of the academic track would be higher than those of their colleagues of the nonacademic track.
- Period of time spent in higher education. During their 3.5 to 5 years of higher education, pre-service teachers in Germany get lectures to develop professional knowledge, that is, CK, PCK, and pedagogical/psychological knowledge (PPK). Beyond that, they have instructional practice at schools, lasting up to five months in total [63]. Research confirms that pre-service teachers’ professional knowledge arise during the course of higher education [61,64]. As higher education in Germany is structured in semesters—the semester is one of the two periods of time that a year at university is divided into—we expect a positive correlation between CK scores and semester (Since there is no standard order of CK contents across universities in Germany, for the sake of simplicity this hypothesis assumes that pre-service teachers are best prepared in the end of higher education, although content thought in the first semester may have been forgotten in the end).
- Academic success. The high school grade point average (GPA) is one of the most important criteria for selecting higher education candidates in Germany [65]. There are varying opinions regarding what it measures, e.g., cognitive abilities [66,67] or academic achievement [68]. A meta-analysis by Baron-Boldt [69] showed that GPA is a valid predictor of academic success (finding a correlation between GPA and academic success in university with r = 0.46), and other authors regard GPA as one of the best available predictors of academic success [70,71]. Thus, unsurprisingly given the association between GPA and CK, several authors have found moderate correlations between GPA and measured CK of pre-service teachers of physics (e.g., [48]) and mathematics [72,73]. Therefore, we expected to find negative correlations between GPA and CK subscale scores.
- Cognitive abilities. Inferences about peoples’ cognitive abilities are commonly derived from their formal reasoning abilities. This construct—defined as the “basic intellectual processes of manipulating abstractions, rules, generalizations, and logical relationships” [74] (p. 583)—is a viable predictor of learning progress and performance according to various studies (e.g., [75]). Three sub-constructs of formal reasoning ability can be distinguished: verbal, nonverbal figural, and numerical reasoning (the abilities to solve text-based, geometric, and quantitative problems, respectively) [76]. As verbal abilities seem most relevant for a primarily language-based instrument, we expect CK scores to be positively related to verbal reasoning abilities, but not to the other subscales.
- Knowledge of the nature of science (NOS). Knowledge of NOS refers to individuals’ conceptions of the values and assumptions underlying scientific understanding and methodology: “an individual’s beliefs concerning whether or not scientific knowledge is amoral, tentative, empirically based, a product of human creativity, or parsimonious reflect [sic] that individual’s conception of the nature of science” [77] (p. 331). As knowledge of NOS is sometimes assumed to be an integral facet of CK [32], we expected to find a positive correlation between CK and knowledge of NOS scores.
- PCK. Research has shown that biology teachers’ CK and PCK are highly correlated but distinct domains of knowledge [78], in accordance with findings regarding the knowledge of teachers of various other subjects, physics, and mathematics for example [48,79,80]. We expect CK scores and PCK scores to be highly correlated, but CK and PCK to be empirically separable constructs.
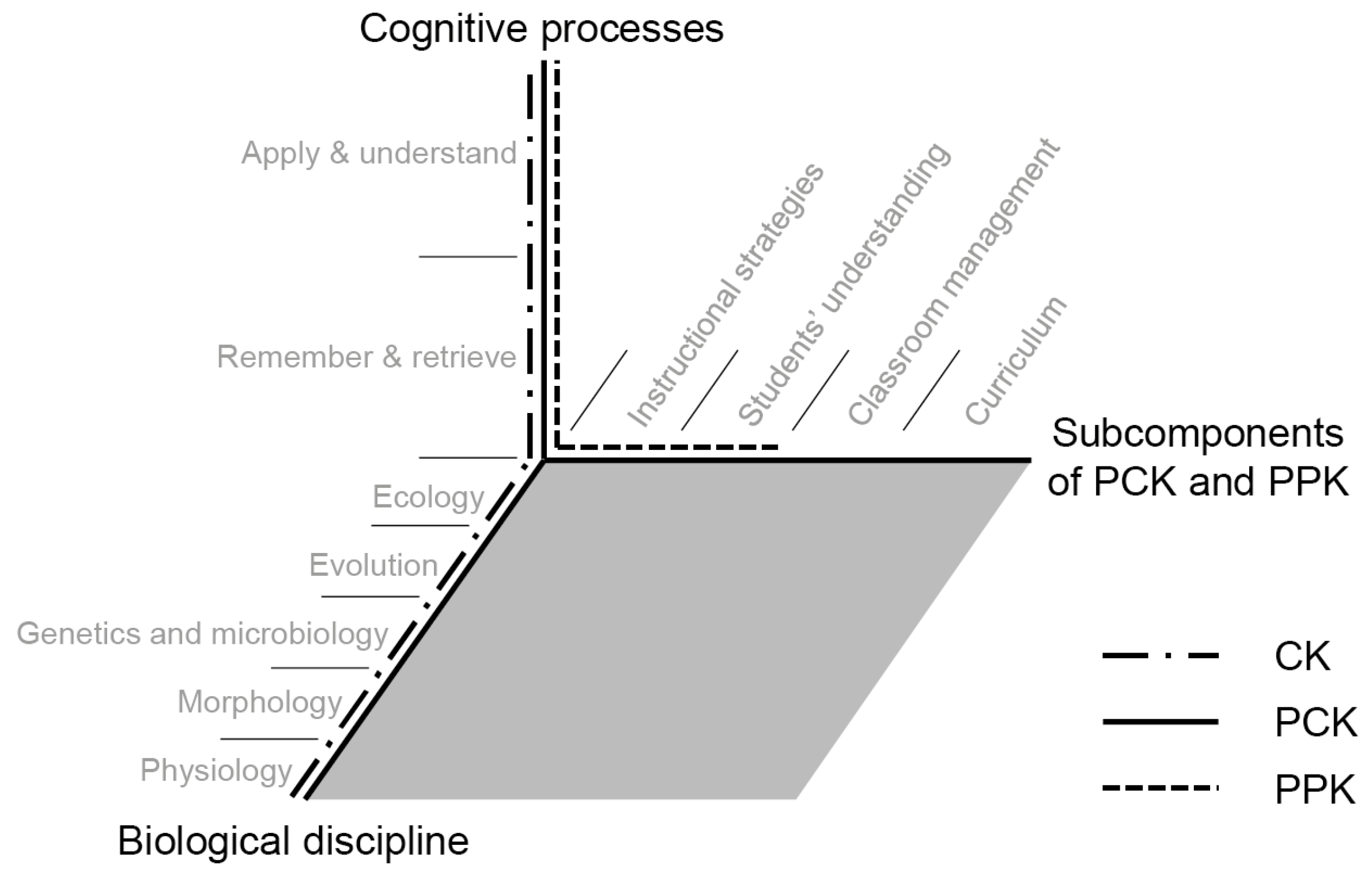
- PPK. Pedagogical knowledge was initially defined as knowledge of the “broad principles and strategies of classroom management and organization” [81] (p. 8), which is independent of the subject matter. Tamir [82] extended this definition by identifying four elements of pedagogical knowledge: knowledge of “instructional strategies for teaching”, “students’ understanding”, “classroom management”, and “assessment”. Voss [83] recently further extended the boundaries of pedagogical knowledge into PPK, by including psychological aspects related to the classroom and heterogeneity of individual students. Großschedl and colleagues [32] found that pre-service biology teachers’ CK and PPK are moderately correlated domains of knowledge, while other researchers have found a substantial correlation among a sample of pre-service physics teachers and a weak correlation among a sample of pre-service mathematics teachers [33]. We hypothesize that CK and PPK scores would be positively correlated, but expect CK and PPK to be empirically separable constructs.
- Opportunities to learn. It is well known that the curriculum of educational institutions as well as the intensity of CK, PCK, and PPK contents in teacher education influence students’ performance [3]. Thus, CK, PCK, and PPK contents considered in participants’ previous teacher education were captured as indicators of their opportunities to learn (in addition to type of teacher education program and number of semesters). Regarding the contents considered in previous teacher education as indicators of the realized curriculum, we expect to find a positive correlation between coverage of CK contents in previous teacher education and the participants’ CK scores. Given that PCK is defined as an “amalgam of content and pedagogy” [81], we also expect to detect positive (but weaker) correlations between their CK scores and the PCK/PPK contents considered, due to reciprocal effects between PCK and CK/PPK.
- Interest. Individual interest is defined as a relatively enduring preference for particular topics, subject areas, or activities [84]. Pohlmann and Möller [85] have shown that “subject-specific interest” is a positive predictor of pre-service teachers’ self-efficacy, working commitment, and task orientation (i.e., pursuit of increasing competence), all of which are positively related to academic performance [86,87,88,89,90]. Thus, there are positive correlations between interest and achievement, with published r values ranging between 0.05–0.26 according to a review by Fishman and Pasanella [91]. A meta-analysis by Schiefele et al. [92] corroborated these results, finding mean correlations between the two constructs of r = 0.31, averaged over various subject areas, and r = 0.16 in the subject area of biology. As interest is reportedly a highly content-specific motivational characteristic [84,93], we expect CK-IBI scores to be significantly related to interest in the subject, but not correlated, or even negatively correlated, to interest in pedagogy/psychology and interest in the pedagogy of subject matter.
- Self-concept. Shavelson [94] defined self-concept as “a person’s perception of himself” (p. 411), arising from his set of attitudes, beliefs, and knowledge about his personal characteristics and attributes [95,96]. The general self-concept can be subdivided into academic and non-academic self-concepts. A large body of research on academic self-concept has revealed positive relations between students’ academic self-concept and their performance (e.g., [97,98]). Recently, Paulick et al. [99] showed that pre-service teachers’ academic self-concept is empirically separable into CK-, PCK-, and PPK-related components. As self-concept and achievement have reciprocal effects [100,101], we expect to find a stronger positive correlation between CK scores and CK self-concept than correlations between CK scores and PCK/PPK self-concepts.
2. Evaluation 1
2.1. Materials and Methods
2.1.1. Sample and Procedure
2.1.2. Operationalization of CK as a Dependent Variable
2.1.3. Independent Variables
2.2. Results
2.2.1. Statistical Item Analyses
2.2.2. Criterion Validity
2.2.3. Construct Validity
3. Evaluation 2
3.1. Materials and Methods
3.1.1. Sample and Procedure
3.1.2. Operationalization of PCK as a Dependent Variable
3.1.3. Independent Variables
3.1.4. Statistical Analysis
3.2. Results
3.2.1. Statistical Item Analyses
3.2.2. Latent Structure of Professional Knowledge
3.2.3. Criterion Validity
3.2.4. Construct Validity
3.2.5. DIF
4. Discussion
4.1. Evaluation 1
4.2. Evaluation 2
4.3. Limitations
4.4. Implications
4.4.1. Implications for Further Research
4.4.2. Implications for Teacher Education
4.4.3. Implications for the Further Application of the CK-IBI
4.5. Applications
4.5.1. Application in Further Research
4.5.2. Application in University-Level Teacher Education
4.5.3. Application in School
4.6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Ball, S.J. Politics and Policy Making in Education: Explorations in Policy Sociology; Routledge: London, UK, 2012. [Google Scholar]
- Hashweh, M.Z. Effects of Subject-matter Knowledge in the Teaching of Biology and Physics. Teach. Teach. Educ. 1987, 3, 109–120. [Google Scholar] [CrossRef]
- Hattie, J. Visible Learning: A Synthesis of over 800 Meta-Analyses Relating to Achievement; Routledge: London, UK, 2009. [Google Scholar]
- Ferguson, P.; Womack, S.T. The Impact of Subject Matter and Education Coursework on Teaching Performance. J. Teach. Educ. 1993, 44, 55–63. [Google Scholar] [CrossRef]
- American Council on Education. Touching the Future: Final Report: Presidents’ Task Force on Teacher Education. Available online: https://www.acenet.edu/news-room/Documents/Touching-the-Future-Final-Report-2002.pdf (accessed on 1 May 2018).
- Secretariat of the Standing Conference of the Ministers of Education and Cultural Affairs of the Länder in the Federal Republic of Germany. Ländergemeinsame inhaltliche Anforderungen für die Fachwissenschaften und Fachdidaktiken in der Lehrerbildung. Available online: http://www.kmk.org/fileadmin/Dateien/veroeffentlichungen_beschluesse/2008/2008_10_16-Fachprofile-Lehrerbildung.pdf (accessed on 1 May 2018).
- Carlisle, J.F.; Correnti, R.; Phelps, G.; Zeng, J. Exploration of the Contribution of Teachers’ Knowledge about Reading to Their Students’ Improvement in Reading. Read. Writ. 2009, 22, 457–486. [Google Scholar] [CrossRef]
- Großschedl, J.; Welter, V.; Harms, U. A New Instrument for Measuring Pre-service Biology Teachers’ Pedagogical Content Knowledge: The PCK-IBI. J. Res. Sci. Teach. (accepted).
- Lange, K.; Ohle, A.; Kleickmann, T.; Kauertz, A.; Möller, K.; Fischer, H.E. Zur Bedeutung von Fachwissen und fachdidaktischem Wissen für Lernfortschritte von Grundschülerinnen und Grundschülern im naturwissenschaftlichen Sachunterricht. Zeitschrift für Grundschulforschung 2015, 8, 23–38. [Google Scholar]
- Sadler, P.M.; Sonnert, G.; Coyle, H.P.; Cook-Smith, N.; Miller, J.L. The Influence of Teachers’ Knowledge on Student Learning in Middle school Physical Science Classrooms. Am. Educ. Res. J. 2013, 50, 1020–1049. [Google Scholar] [CrossRef]
- Heller, J.I.; Daehler, K.R.; Wong, N.; Shinohara, M.; Miratrix, L. Differential Effects of Three Professional Development Models on Teacher Knowledge and Student Achievement in Elementary Science. J. Res. Sci. Teach. 2012, 49, 333–362. [Google Scholar] [CrossRef]
- Ohle, A.; Fischer, H.E.; Kauertz, A. Der Einfluss des physikalischen Fachwissens von Primarstufenlehrkräften auf Unterrichtsgestaltung und Schülerleistung [Primary School Teachers’ Content Knowledge in Physics and Its Impact on Teaching and Students’ Achievement]. ZfDN 2011, 17, 357–389. [Google Scholar]
- Byrne, C.J. Teacher Knowledge and Teacher Effectiveness: A Literature Review, Theoretical Analysis, and Discussion of Research Strategy. In Proceedings of the 14th Annual Convention of the Northeastern Educational Research Association, Ellenville, NY, USA, October 1983. [Google Scholar]
- Darling-Hammond, L. Teacher Quality and Student Achievement: A Review of State Policy Evidence. Educ. Policy Anal. Arch. 2000, 8, 1–44. [Google Scholar] [CrossRef]
- Leinhardt, G.; Smith, D.A. Expertise in Mathematics Instruction: Subject Matter Knowledge. J. Educ. Psychol. 1985, 77, 247–271. [Google Scholar] [CrossRef]
- Carlsen, W.S. Why Do You Ask? The Effects of Science Teacher Subject-matter Knowledge on Teacher Questioning and Classroom Discourse. In Proceedings of the Annual Meeting of the American Educational Research Association, Washington, DC, USA, 20–24 April 1987. [Google Scholar]
- Carlsen, W.S. Effects of New Biology Teachers’ Subject-matter Knowledge on Curricular Planning. Sci. Educ. 1991, 75, 631–647. [Google Scholar] [CrossRef]
- Dewey, J. The Sources of a Science of Education; Horace Liveright: New York, USA, 1929. [Google Scholar]
- Hill, H.C.; Rowan, B.; Ball, D.L. Effects of Teachers’ Mathematical Knowledge for Teaching on Student Achievement. Am. Educ. Res. J. 2005, 42, 371–406. [Google Scholar] [CrossRef]
- Großschedl, J.; Konnemann, C.; Basel, N. Pre-service Biology Teachers’ Acceptance of Evolutionary Theory and Their Preference for Its Teaching. Evol. Educ. Outreach 2014, 7, 1–16. [Google Scholar] [CrossRef]
- Riese, J.; Reinhold, P. Empirische Erkenntnisse zur Struktur professionelller Handlungskompetenz angehender Physiklehrkräfte [Empirical Findings Regarding the Structure of Future Physics Teachers’ Competence Regarding Professional Action]. ZfDN 2010, 16, 167–187. [Google Scholar]
- Bandura, A. Self-efficacy: Toward a Unifying Theory of Behavioral Change. Adv. Behav. Res. Ther. 1978, 1, 139–161. [Google Scholar] [CrossRef]
- Cousins, J.B.; Walker, C.A. Predictors of Educators’ Valuing of Systemic Inquiry in Schools. Available online: https://evaluationcanada.ca/system/files/cjpe-entries/15–0–025.pdf (accessed on 1 May 2018).
- Guskey, T. Teacher Efficacy, Self-concept, and Attitudes toward the Implementation of Instructional Innovation. Teach. Teach. Educ. 1988, 4, 63–69. [Google Scholar] [CrossRef]
- Bandura, A. Perceived Self-efficacy in Cognitive Development and Functioning. Educ. Psychol. 1993, 28, 117–148. [Google Scholar] [CrossRef]
- Muijs, D.; Reynolds, D. Effective Teaching: Research and Practice; Paul Chapman: London, UK, 2001. [Google Scholar]
- Tschannen-Moran, M.; Woolfok-Hoy, A.; Hoy, W.K. Teacher Efficacy: Its Meaning and Measure. Rev. Educ. Res. 1998, 68, 202–248. [Google Scholar] [CrossRef]
- Baumert, J.; Kunter, M.; Blum, W.; Brunner, M.; Voss, T.; Jordan, A.; Klusmann, U.; Krauss, S.; Neubrand, M.; Tsai, Y.-M. Teachers’ Mathematical Knowledge, Cognitive Activation in the Classroom, and Student Progress. Am. Educ. Res. J. 2010, 47, 133–180. [Google Scholar] [CrossRef]
- Shulman, L.S. Those Who Understand: Knowledge growth in Teaching. Educ. Res. 1986, 15, 4–14. [Google Scholar] [CrossRef]
- Ball, D.L.; Hill, H.C.; Bass, H. Knowing Mathematics for Teaching. Who Knows Mathematics Well Enough to Teach Third Grade, and How Can We Decide? Am. Educ. 2005, 29, 14–46. [Google Scholar]
- Ma, L. Knowing and Teaching Elementary Mathematics: Teachers’ Understanding of Fundamental Mathematics in China and the United States; Erlbaum: Hillsdale, NJ, USA, 1999. [Google Scholar]
- Großschedl, J.; Harms, U.; Kleickmann, T.; Glowinski, I. Preservice Biology Teachers’ Professional Knowledge: Structure and Learning Opportunities. J. Sci. Teach. Educ. 2015, 26, 291–318. [Google Scholar] [CrossRef]
- Buchholtz, N.; Kaiser, G.; Blömeke, S. Die Erhebung mathematikdidaktischen Wissens—Konzeptualisierung einer komplexen Domäne [Measuring Pedagogical Content Knowledge in Mathematics—Conceptualizing a Complex Domain]. J. Math. Didaktik 2013, 35, 101–128. [Google Scholar] [CrossRef]
- Jüttner, M.; Neuhaus, B.J. Validation of a Paper-and-pencil Test Instrument Measuring Biology Teachers’ Pedagogical Content Knowledge by Using Think-aloud Interviews. J. Educ. Train. Stud. 2013, 1, 113–125. [Google Scholar] [CrossRef]
- Kirschner, S.; Borowski, A.; Fischer, H.E. Das Professionswissen von Physiklehrkräften: Ergebnisse der Hauptstudie. In Konzepte fachdidaktischer Strukturierung für den Unterricht, Gesellschaft für Didaktik der Chemie und Physik. Jahrestagung in Oldenburg 2011; Bernhold, S., Ed.; Lit: Oldenburg, Germany; pp. 209–211.
- Schmelzing, S.; van Driel, J.H.; Jüttner, M.; Brandenbusch, S.; Sandmann, A.; Neuhaus, B.J. Development, Evaluation, and Validation of a Paper-and-pencil Test for Measuring Two Components of Biology Teachers’ Pedagogical Content Knowledge Concerning the “Cardiovascular System”. Int. J. Sci. Math. Educ. 2013, 11, 1369–1390. [Google Scholar] [CrossRef]
- Tatto, M.T.; Senk, S. The Mathematics Education of Future Primary and Secondary Teachers: Methods from the Teacher Education and Development Study in Mathematics. J. Teach. Educ. 2011, 62, 121–137. [Google Scholar] [CrossRef]
- Lupia, A.; Alter, G. Data Access and Research Transparency in the Quantitative Tradition. PS-Polit. Sci. Polit. 2013, 47, 54–59. [Google Scholar] [CrossRef]
- Lupia, A.; Elman, C. Openness in Political Science: Data Access and Research Transparency. PS-Polit. Sci. Polit. 2014, 47, 19–42. [Google Scholar] [CrossRef]
- Open Science Collaboration. Estimating the Reproducibility of Psychological Science. Science 2015, 349, 4716–4718. [Google Scholar] [CrossRef] [PubMed]
- Großschedl, J.; Harms, U.; Glowinski, I.; Waldmann, M. Erfassung des Professionswissens angehender Biologielehrkräfte: Das KiL-Projekt. MNU 2014, 67, 457–462. [Google Scholar]
- Mehrens, W.A.; Phillips, S.E. Sensitivity of Item Difficulties to Curricular Validity. J. Educ. Meas. 1987, 24, 357–370. [Google Scholar] [CrossRef]
- Cochran, K.F.; Jones, L.L. The Subject Matter Knowledge of Preservice Science Teachers. In International Handbook of Science Education; Fraser, B.J., Tobin, K.G., Eds.; Kluwer Academic Publishers: Dortrecht, The Netherlands, 1998; pp. 707–718. [Google Scholar]
- Arzi, H.; White, R. Change in Teachers’ Knowledge of Subject Matter: A 17-year Longitudinal Study. Sci. Educ. 2008, 92, 221–251. [Google Scholar] [CrossRef]
- Käpylä, M.; Heikkinen, J.-P.; Asunta, T. Influence of Content Knowledge on Pedagogical Content Knowledge: The Case of Teaching Photosynthesis and Plant Growth. Int. J. Sci. Educ. 2009, 31, 1395–1415. [Google Scholar] [CrossRef]
- Douvdevany, O.; Dreyfus, A.; Jungwirth, E. Diagnostic Instruments for Determining Junior High-school Science Teachers’ Understanding of Functional Relationships Within the ‘Living Cell’. Int. J. Sci. Educ. 1997, 19, 593–606. [Google Scholar] [CrossRef]
- Guyton, E.; Farokhi, E. Relationships among Academic Performance, Basic Skills, Subject Matter Knowledge, and Teaching Skills of Teacher Education Graduates. J. Teach. Educ. 1987, 38, 37–42. [Google Scholar] [CrossRef]
- Riese, J.; Reinhold, P. Die professionelle Kompetenz angehender Physiklehrkräfte in verschiedenen Ausbildungsformen—Empirische Hinweise für eine Verbesserung des Lehramtsstudiums [The Professional Competencies of Trainee Teachers in Physics in Different Educational Programs—Empirical Findings for the Improvement of Teacher Education Programs]. ZfE 2012, 15, 111–143. [Google Scholar]
- Akyol, G.; Tekkaya, C.; Sungur, S.; Traynor, A. Modeling the Interrelationships among Pre-service science Teachers’ Understanding and Acceptance of Evolution, Their Views on Nature of Science and Self-efficacy Beliefs Regarding Teaching Evolution. J. Sci. Teach. Educ. 2012, 23, 937–957. [Google Scholar] [CrossRef]
- Phelps, G.; Schilling, S. Developing Measures of Content Knowledge for Teaching Reading. Elem. Sch. J. 2004, 105, 31–48. [Google Scholar]
- Schoenfeld, A.H. The Complexities of Assessing Teacher knowledge. Meas. Interdisciplin. Res. Perspect. 2007, 5, 198–204. [Google Scholar] [CrossRef]
- Lipton, A.; Huxham, G.J. Comparison of Multiple-choice and Essay Testing in Preclinical Physiology. Br. J. Med. Educ. 1970, 4, 228–238. [Google Scholar] [CrossRef] [PubMed]
- Walstad, W.; Becker, W. Achievement Differences on Multiple-choice and Essay Tests in Economics. Am. Econ. Rev. 1994, 84, 193–196. [Google Scholar]
- Bacon, D.R. Assessing Learning Outcomes: A Comparison of Multiple-choice and Short Answer Questions in a Marketing Context. J. Mark. Educ. 2003, 25, 31–36. [Google Scholar] [CrossRef]
- Bridgeman, B.; Lewis, C. The Relationship of Essay and Multiple-choice Scores with Grades in College Courses. J. Educ. Meas. 1994, 31, 37–50. [Google Scholar] [CrossRef]
- Bennett, R.E.; Rock, D.A.; Wang, M. Equivalence of Free-response and Multiple-choice Items. J. Educ. Meas. 1991, 28, 77–92. [Google Scholar] [CrossRef]
- Wainer, H.; Thissen, D. Combining Multiple-choice and Constructed-response Test Scores: Toward a Marxist Theory of Test Construction. Appl. Psychol. Meas. 1993, 6, 103–118. [Google Scholar] [CrossRef]
- Blömeke, S.; Delaney, S. Assessment of Teacher Knowledge across Countries: A Review of the State of Research. ZDM-Math. Educ. 2012, 44, 223–247. [Google Scholar] [CrossRef]
- Wang, J.; Lin, E. Comparative Studies on US and Chinese Mathematics Learning and the Implications for Standards-based Mathematics Teaching Reform. Educ. Res. 2005, 34, 3–13. [Google Scholar] [CrossRef]
- Blömeke, S.; Kaiser, G.; Döhrmann, M.; Lehmann, R. Mathematisches und mathematikdidaktisches Wissen angehender Sekundarstufen-I-Lehrkräfte im internationalen Vergleich. In TEDS-M 2008: Professionelle Kompetenz und Lerngelegenheiten angehender Mathematiklehrkräfte für Die Sekundarstufe I im Internationalen Vergleich; Blömeke, S., Kaiser, G., Lehmann, R., Eds.; Waxmann: Münster, Germany, 2010; pp. 197–238. [Google Scholar]
- Kleickmann, T.; Richter, D.; Kunter, M.; Elsner, J.; Besser, M.; Krauss, S.; Baumert, J. Teachers’ Content Knowledge and Pedagogical Content Knowledge: The Role of Structural Differences in Teacher Education. J. Teach. Educ. 2013, 64, 90–106. [Google Scholar] [CrossRef]
- Schmidt, W.H.; Tatto, M.T.; Bankow, K.; Blömeke, S. The Preparation Gap: Teacher Education for Middle School Mathematics in Six Countries; MSU Center for Research in Mathematics and Science Education: East Lansing, MI, USA, 2007. [Google Scholar]
- Secretariat of the Standing Conference of the Ministers of Education and Cultural Affairs of the Länder in the Federal Republic of Germany. The Education System in the Federal Republic of Germany 2011/2012: A Description of the Responsibilities, Structures and Developments in Education Policy for the Exchange of Information in Europe. Available online: http://www.kmk.org/fileadmin/doc/Dokumentation/Bildungswesen_en_pdfs/teachers.pdf (accessed on 1 May 2018).
- Großschedl, J.; Neubrand, C.; Kirchner, A.; Oppermann, L.; Basel, N.; Gantner, S. Entwicklung und Validierung eines Testinstruments zur Erfassung des evolutionsbezogenen Professionswissens von Lehramtsstudierenden (ProWiE). ZfDN 2015, 21, 173–185. [Google Scholar] [CrossRef]
- Heine, C.; Briedis, K.; Didi, H.J.; Haase, K.; Trost, G. Bestandsaufnahme von Auswahl- und Eignungsfeststellungsverfahren beim Hochschulzugang in Deutschland und ausgewählten Ländern; HIS-Hochschul-Informations-System-GmbH: Hannover, Germany, 2006. [Google Scholar]
- Anderson, J.R.; Lebière, C. The Atomic Components of Thought; Erlbaum: Mahwah, NJ, USA, 1998. [Google Scholar]
- Rindermann, H.; Oubaid, V. Auswahl von Studienanfängern: Vorschläge für ein zuverlässiges Verfahren. Forschung und Lehre 1999, 41, 589–592. [Google Scholar]
- Rohde, T.E.; Thompson, L.A. Predicting Academic Achievement with Cognitive Ability. Intelligence 2007, 35, 83–92. [Google Scholar] [CrossRef]
- Baron-Boldt, J. Die Validität von Schulabschlussnoten für Die Prognose von Ausbildungs-und Studienerfolg; Peter Lang: Frankfurt, Germany, 1989. [Google Scholar]
- Moser, K. Alternativen zur Abiturnote? Sinn und Unsinn neuer eignungsdiagnostischer Verfahren. Forschung und Lehre 2007, 8, 474–476. [Google Scholar]
- Tarazona, M. Berechtigte Hoffnung auf bessere Studierende durch hochschuleigene Studierendenauswahl? Eine Analyse der Erfahrungen mit Auswahlverfahren in der Hochschulzulassung. Beiträge zur Hochschulforschung 2006, 28, 68–89. [Google Scholar]
- Blömeke, S.; Kaiser, G.; Lehmann, R. Professionelle Kompetenz Angehender Lehrerinnen und Lehrer: Wissen, Überzeugungen und Lerngelegenheiten Deutscher Mathematikstudierender und—Referendare: Erste Ergebnisse zur Wirksamkeit der Lehrerausbildung; Waxmann: Münster, Germany, 2008. [Google Scholar]
- Kleickmann, T.; Anders, Y. Learning at University. In Cognitive Activation in the Mathematics Classroom and Professional Competence of Teachers: Results from the COACTIV Project; Kunter, M., Baumert, J., Blum, W., Klusmann, U., Krauss, S., Neubrand, M., Eds.; Springer: New York, USA, 2013; pp. 321–332. [Google Scholar]
- Carrol, J.B. Human Cognitive Abilities: A Survey of Factor-analytic Studies; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Hattie, J.A.C.; Hansford, B.C. Self Measures and Achievement: Comparing a Traditional Review of Literature with Meta-analysis. Aust. J. Educ. 1982, 26, 71–75. [Google Scholar] [CrossRef]
- Heitmann, P.; Hecht, M.; Schwanewedel, J.; Schipolowski, S. Students’ Argumentative Writing Skills in Science and First-language Education: Commonalities and Differences. Int. J. Sci. Educ. 2014, 36, 3148–3170. [Google Scholar] [CrossRef]
- Ledermann, N.G. Students’ and Teachers’ Conceptions of the Nature of Science: A Review of the Research. J. Res. Sci. Teach. 1992, 29, 331–359. [Google Scholar] [CrossRef]
- Großschedl, J.; Mahler, D.; Kleickmann, T.; Harms, U. Content-related Knowledge of Biology Teachers from Secondary Schools: Structure and Learning Opportunities. Int. J. Sci. Educ. 2014, 36, 2335–2366. [Google Scholar] [CrossRef]
- Blömeke, S.; Suhl, U. Modeling Teacher Competencies: Using Different IRT-scales to Diagnose Strengths and Weaknesses of German Teacher Trainees in an International Comparison. Z. Erziehungswiss 2010, 13, 473–505. [Google Scholar] [CrossRef]
- Krauss, S.; Brunner, M.; Kunter, M.; Baumert, J.; Blum, W.; Neubrand, M.; Jordan, A. Pedagogical Content Knowledge and Content Knowledge of Secondary Mathematics Teacher. J. Educ. Psychol. 2008, 100, 716–725. [Google Scholar] [CrossRef]
- Shulman, L.S. Knowledge and Teaching: Foundations of the New Reform. Harv. Educ. Rev. 1987, 57, 1–22. [Google Scholar] [CrossRef]
- Tamir, P. Subject Matter and Related Pedagogical Knowledge in Teacher Education. Teach. Teach. Educ. 1988, 4, 99–110. [Google Scholar] [CrossRef]
- Voss, T.; Kunter, M.; Baumert, J. Assessing Teacher Candidates’ General Pedagogical/Psychological Knowledge: Test Construction and Validation. J. Educ. Psychol. 2011, 103, 952–969. [Google Scholar] [CrossRef]
- Schiefele, U. Interest, Learning, and Motivation. Educ. Psychol. 1991, 26, 299–323. [Google Scholar] [CrossRef]
- Pohlmann, B.; Möller, J. Fragebogen zur Erfassung der Motivation für die Wahl des Lehramtsstudiums (FEMOLA). Zeitschrift für Pädagogische Psychologie 2010, 24, 73–84. [Google Scholar] [CrossRef]
- Carrol, A.; Houghton, S.; Wood, R.; Unsworth, K.; Hattie, J.; Gordon, L.; Bower, J. Self-efficacy and Academic Achievement in Australian High School Students: The Mediating Effects of Academic Aspirations and Delinquency. J. Adolesc. 2009, 32, 797–817. [Google Scholar] [CrossRef] [PubMed]
- Multon, K.D.; Brown, S.D.; Lent, R.W. Relation of self-Efficacy Beliefs to Academic Outcomes: A Meta-analytic Investigation. J. Couns. Psychol. 1991, 38, 30–38. [Google Scholar] [CrossRef]
- Robbins, S.; Lauver, K.; Le, H.; Davis, D.; Langley, R.; Carlstrom, A. Do Psychosocial and Study Skill Factors Predict College Outcomes? A Meta-analysis. Psychol. Bull. 2004, 130, 261–288. [Google Scholar] [CrossRef] [PubMed]
- Sheard, M. Hardiness Commitment, Gender, and Age Differentiate University Academic Performance. Br. J. Educ. Psychol. 2009, 79, 189–204. [Google Scholar] [CrossRef] [PubMed]
- Sideridis, G.D. Goal Orientation, Academic Achievement, and Depression: Evidence in Favor of a Revised Goal Theory Framework. J. Educ. Psychol. 2005, 97, 366–375. [Google Scholar] [CrossRef]
- Fishman, J.A.; Pasanella, A.K. College Admission-selection Studies. Rev. Educ. Res. 1960, 30, 298–310. [Google Scholar] [CrossRef]
- Schiefele, U.; Krapp, A.; Winteler, A. Interest as a Predictor of Academic Achievement: A Meta-analysis of Research. In The Role of Interest in Learning and Development; Renniger, K.A., Hidi, S., Krapp, A., Eds.; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1992; pp. 183–212. [Google Scholar]
- Lowman, R.L. Interests. In Corsini Encyclopedia of Psychology; Wiley: Hobroken, NJ, USA, 2010. [Google Scholar]
- Shavelson, R.J.; Hubner, J.J.; Stanton, G.C. Self-concept: Validation of Construct Interpretations. Rev. Educ. Res. 1976, 46, 407–441. [Google Scholar] [CrossRef]
- Ghazvini, S.D. Relationships between Academic Self-concept and Academic Performance in High School Students. Procedia-Soc. Behav. Sci. 2011, 15, 1034–1039. [Google Scholar] [CrossRef]
- Purkey, W.W. Self-Concept and School Achievement; Prentice Hall: Englewood Cliffs, NJ, USA, 1970. [Google Scholar]
- Arens, A.K.; Yeung, A.S.; Craven, R.G.; Hasselhorn, M. The Twofold Multidimensionality of Academic Self-concept: Domain Specificity and Separation between Competence and Affect Components. J. Educ. Psychol. 2011, 103, 970–981. [Google Scholar] [CrossRef]
- Marsh, H.W.; Martin, A.J. Academic Self-concept and Academic Achievement: RELATIONS and Causal Ordering. Br. J. Educ. Psychol. 2011, 81, 59–77. [Google Scholar] [CrossRef] [PubMed]
- Paulick, I.; Großschedl, J.; Harms, U.; Möller, J. Preservice Teachers’ Professional Knowledge and Its Relation to Academic Self-concept. J. Teach. Educ. 2016, 67, 173–182. [Google Scholar] [CrossRef]
- Marsh, H.W.; Craven, R.G. Reciprocal Effects of Self-concept and Performance from a Multidimensional Perspective: Beyond Seductive Pleasure and Unidimensional Perspectives. Perspect. Psychol. Sci. 2006, 1, 133–163. [Google Scholar] [CrossRef] [PubMed]
- Retelsdorf, J.; Köller, O.; Möller, J. Reading Achievement and Reading Self-concept: Testing the Reciprocal Effects Model. Learn. Instr. 2014, 29, 21–30. [Google Scholar] [CrossRef]
- Ackerman, P.L.; Kanfer, R. Test Length and Cognitive Fatigue: An Empirical Examination of Effects on Performance and Test-taker Reactions. J. Exp. Psychol. Appl. 2009, 15, 163–181. [Google Scholar] [CrossRef] [PubMed]
- Ackerman, P.L.; Kanfer, R.; Shapiro, S.W.; Newton, S.; Beier, M.E. Cognitive Fatigue during Testing: An Examination of Trait, Time-on-task, and Strategy Influences. Hum. Perform. 2010, 23, 381–402. [Google Scholar] [CrossRef]
- Heller, K.A.; Perletz, C. Effects of Teachers’ Mathematical Knowledge for Teaching on Student Achievement; Beltz-Testgesellschaft: Göttingen, Germany, 2000. [Google Scholar]
- Liang, L.L.; Chen, S.; Chen, X.; Kaya, O.N.; Adams, A.D.; Macklin, M.; Ebenezer, J. Student Understanding of Science and Scientific Inquiry (SUSSI): Revision and Further Validation of an Assessment Instrument. In Proceedings of the Annual Conference of the National Association for Research in Science Teaching (NARST), San Francisco, CA, USA, 3–6 April 2006. [Google Scholar]
- Secretariat of the Standing Conference of the Ministers of Education and Cultural Affairs of the Länder in the Federal Republic of Germany. Standards für die Lehrerbildung: Bildungswissenschaften. Available online: http://www.kmk.org/fileadmin/veroeffentlichungen_beschluesse/2004/2004_12_16-Standards-Lehrerbildung.pdf (accessed on 17 January 2018).
- Krapp, A.; Schiefele, U.; Wild, K.P.; Winteler, A. The Study Interest Questionnaire (SIQ). Diagnostica 1993, 39, 335–351. [Google Scholar]
- Van Driel, J.H.; Berry, A. The Teacher Education Knowledge Base: Pedagogical Content Knowledge. In International Encyclopedia of Education, 3rd ed.; McGraw, B., Peterson, P.L., Baker, E., Eds.; Elsevier: Oxford, UK, 2010; pp. 656–661. [Google Scholar]
- Braun, E.; Gusy, B.; Leidner, B.; Hannover, B. The Berlin Evaluation Instrument for Self-evaluated Student Competences (BEvaKomp). Diagnostica 2008, 54, 30–42. [Google Scholar] [CrossRef]
- Hattie, J. Methodology review: Assessing Unidimensionality of Tests and Items. Appl. Psychol. Meas. 1985, 9, 139–164. [Google Scholar] [CrossRef]
- Segars, A. Assessing the Unidimensionality of Measurement: A Paradigm and Illustration within the Context of Information Systems Research. Omega 1997, 25, 107–121. [Google Scholar] [CrossRef]
- Hagell, P. Testing Rating Scale Unidimensionality Using the Principal Component Analysis (PCA)/t-Test Protocol with the Rasch Model: The Primacy of Theory over Statistics. Open J. Stat. 2014, 4, 456–465. [Google Scholar] [CrossRef]
- Tennant, A.; Pallant, J.F. Unidimensionality Matters! (A Tale of Two Smiths?). Rasch Meas. Trans. 2006, 20, 1048–1051. [Google Scholar]
- Wright, B.D.; Linacre, J.M. Observations are Always Ordinal; Measurements, However, Must be Interval. Arch. Phys. Med. Rehabil. 1989, 70, 857–860. [Google Scholar] [PubMed]
- Linacre, J.M. What Do Infit and Outfit, Mean-square and Standardized Mean? Rasch Meas. Trans. 2002, 3, 878. [Google Scholar]
- Wright, B.D.; Linacre, J.M. Reasonable Mean-square Fit Values. Rasch Meas. Trans. 1994, 8, 370–371. [Google Scholar]
- Wright, B.D.; Masters, G.N. Computation of OUTFIT and INFIT Statistics. Rasch Meas. Trans. 1990, 3, 84–85. [Google Scholar]
- Wu, M.L.; Adams, R.J.; Wilson, M.R.; Haldane, S.A. ACER ConQuest Version 2: Generalised Item Response Modelling Software; Australian Council for Educational Research: Camberwell, Australian, 2007. [Google Scholar]
- Masters, G.N. A Rasch Model for Partial Credit Scoring. Psychometrika 1982, 47, 149–174. [Google Scholar] [CrossRef]
- Wright, B.D.; Mok, M. Rasch Models Overview. J. Appl. Meas. 2000, 1, 83–106. [Google Scholar] [PubMed]
- Warm, T.A. Weighted Likelihood Estimation of Ability in Item Response Theory. Psychometrika 1989, 54, 427–450. [Google Scholar] [CrossRef]
- Bentler, P.M. Comparative Fit Indexes in Structural Models. Psychol. Bull. 1990, 107, 238–246. [Google Scholar] [CrossRef] [PubMed]
- Akaike, H. Likelihood of a Model and Information Criteria. J. Econ. 1981, 16, 3–14. [Google Scholar] [CrossRef]
- Wilson, M.; De Boeck, P.; Carstensen, C. Explanatory Item Response Models: A Brief Introduction. In Assessment of Competencies in Educational Contexts: State of the Art and Future Prospects; Hartig, J., Klieme, E., Leutner, D.E., Eds.; Hogrefe and Huber: Göttingen, Germany, 2008; pp. 91–120. [Google Scholar]
- Schermelleh-Engel, K.; Mossbrugger, H. Evaluating the Fit of Structural Equation Models: Tests of Significance and Descriptive Goodness-of-fit Measures. Meth. Psychol. Res. Online 2003, 8, 23–74. [Google Scholar]
- Rost, J. Lehrbuch Testtheorie—Testkonstruktion, 2nd ed.; Verlag Hans Huber: Bern, Switzerland, 2004. [Google Scholar]
- Little, T.D.; Cunningham, W.A.; Shahar, G.; Widaman, K.F. To Parcel or not to Parcel: Exploring the Question, Weighing the Merits. Struct. Equ. Model. 2002, 9, 151–173. [Google Scholar] [CrossRef]
- Muthén, L.K.; Muthén, B.O. Mplus User’s Guide, 6th ed.; Muthén and Muthén: Los Angeles, CA, USA, 2007. [Google Scholar]
- Penfield, R.D.; Lam, T.C.M. Assessing Differential Item Functioning in Performance Assessment: Review and Recommendation. Educ. Meas. 2000, 19, 5–15. [Google Scholar] [CrossRef]
- Penfield, R.D. An Approach for Categorizing DIF in Polytomous Items. Appl. Psychol. Meas. 2007, 20, 335–355. [Google Scholar] [CrossRef]
- Zumbo, B.D. A Handbook on the Theory and Methods of Differential Item Functioning (DIF): Logistic Regression Modeling as a Unitary Framework for Binary and LIKERT-Type (Ordinal) Item Scores; Directorate of Human Resources Research and Evaluation, Department of National Defense: Ottawa, ON, Canada, 1999.
- Wetzel, E.; Böhnke, J.R.; Carstensen, C.H.; Ziegler, M.; Ostendorf, F. Do Individual Response Styles Matter? Assessing Differential Item Functioning for Men and Women in the NEO-PI-R. J. Individ. Differ. 2013, 34, 69–81. [Google Scholar] [CrossRef]
- Zieky, M. Practical Questions in the Use of DIF Statistics in Test Development. In Differential Item Functioning, Holland; Paul, W., Wainer, H., Eds.; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1993; pp. 337–347. [Google Scholar]
- Linacre, J.M.; Wright, B.D. Mantel-Haenszel DIF and PROX are Equivalent. Rasch Meas. Trans. 1989, 3, 52–53. [Google Scholar]
- Smith, E.V. Metric Development and Score Reporting in Rasch Measurement. J. Appl. Meas. 2000, 1, 303–326. [Google Scholar] [PubMed]
- Schreiber, J.B.; Stage, F.K.; King, J.; Nora, A.; Barlow, E.A. Reporting Structural Equation Modeling and Confirmatory Factor Analysis Results: A Review. J. Educ. Res. 2006, 99, 323–337. [Google Scholar] [CrossRef]
- Hu, L.; Bentler, P.M. Evaluating Model Fit. In Structural Equation Modeling: Issues, Concepts, and Applications; Hoyle, R., Ed.; Sage: Newbury Park, CA, USA, 1995; pp. 76–99. [Google Scholar]
- Steiger, J.H. Structural Model Evaluation and Modification: An Interval Estimation Approach. Multivar. Behav. Res. 1990, 25, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Thorndike, E.L. Mental Fatigue. J. Educ. Psychol. 1911, 2, 61–80. [Google Scholar] [CrossRef]
- Grossman, P.L. The Making of a Teacher: Teacher Knowledge and Teacher Education; Teacher College Press: New York, NY, USA, 1990. [Google Scholar]
- Jüttner, M.; Boone, W.; Park, S.; Neuhaus, B.J. Development and Use of a Test Instrument to Measure Biology Teachers’ Content Knowledge (CK) and Pedagogical Content Knowledge (PCK). Educ. Assess. Eval. Account. 2013, 25, 45–67. [Google Scholar] [CrossRef]
- Magnusson, S.; Krajcik, J.; Borko, H. Nature, Sources, and Development of Pedagogical Content Knowledge for Science Teaching. In Examining Pedagogical Content Knowledge; Gess-Newsome, J., Lederman, N.G., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1999; pp. 95–132. [Google Scholar]
- Voss, T.; Kunter, M. Teachers’ General Pedagogical/Psychological Knowledge. In Cognitive Activation in the Mathematics Classroom and Professional Competence of Teachers. Results from the COACTIV Project; Kunter, M., Baumert, J., Blum, W., Klusmann, U., Krauss, S., Neubrand, M., Eds.; Springer: New York, NY, USA, 2013; pp. 207–228. [Google Scholar]
- Jüttner, M.; Neuhaus, B.J. Development of Items for a Pedagogical Content Knowledge-test Based on Empirical Analysis of Pupils’ Errors. Int. J. Sci. Educ. 2012, 34, 1125–1143. [Google Scholar] [CrossRef]
- Teclaw, R.; Price, M.C.; Osatuke, K. Demographic Question Placement: Effect on Item Response Rates and Means of a Veterans Health Administration Survey. J. Bus. Psychol. 2012, 27, 281–290. [Google Scholar] [CrossRef]
- Ihme, T.A.; Möller, J. “He Who Can, Does; He Who Cannot, Teaches?”: Stereotype Threat and Preservice Teachers. J. Educ. Psychol. 2015, 107, 300–308. [Google Scholar] [CrossRef]
- Neugebauer. Wer entscheidet sich für ein Lehramtsstudium - und warum? Eine empirische Überprüfung der These von der Negativselektion in den Lehrerberuf (Who Chooses to Study Education—and Why? An Empirical Examination of the Thesis of Negative Selection into the Teaching Profession). Z. Erziehungswiss 2013, 16, 157–184. [Google Scholar]
- Jordan, A.H.; Lovett, B.J. Stereotype Threat and Test Performance: A Primer for School Psychologists. J. Sch. Psychol. 2007, 45, 45–59. [Google Scholar] [CrossRef]
- Hansen, J. Spielt die Identifikation mit Stereotypen im Studium des Sekundarstufenlehramts Biologie eine Rolle? (Does Identification with Stereotypes in University Studies of Pre-Service Biology Teachers Matter?); Leibniz-Institut für die Pädagogik der Naturwissenschaften und Mathematik an der Christian-Albrechts-Universität zu Kiel: Kiel, Germany, 2017. [Google Scholar]



{kind=link}
{kind=link}
| Subject Matter | Teacher Education Program | Semester | Grade Point Average (GPA) | Verbal Reasoning | Nonverbal Figural Reasoning | Numerical Reasoning |
|---|---|---|---|---|---|---|
| Ecology (n = 89) | 0.35 *** | −0.06 | −0.23 * | 0.28 ** | −0.13 | −0.14 |
| Evolution (n = 85) | 0.43 *** | 0.16 | −0.38 *** | 0.27 * | 0.09 | 0.27 * |
| Genetics and microbiology (n = 85) | 0.32 ** | 0.27 * | −0.29 ** | 0.14 | −0.05 | 0.17 |
| Morphology (n = 89) | 0.16 | 0.11 | −0.21 * | 0.11 | 0.22 * | 0.12 |
| Physiology (n = 89) | 0.21 * | 0.13 | −0.11 | 0.26* | −0.10 | −0.06 |
| Predictor Variable | M | SD | CK | ||
|---|---|---|---|---|---|
| r | p | ||||
| Opportunities to learn | Track | -- | -- | 0.29 | <0.001 |
| Semester | 5.87 | 2.81 | 0.24 | <0.001 | |
| CK | 2.86 | 0.49 | 0.26 | <0.001 | |
| PCK | 2.69 | 0.75 | 0.11 | <0.05 | |
| PPK | 0.45 | 0.23 | 0.07 | 0.07 | |
| Performance | NOS | 3.65 | 0.42 | 0.31 | <0.001 |
| PCK | 27.51 | 7.52 | 0.61 | <0.001 | |
| PPK | 82.60 | 29.38 | 0.42 | <0.001 | |
| Interest | CK | 3.39 | 0.51 | 0.14 | <0.01 |
| PCK | 2.59 | 0.61 | −0.06 | 0.11 | |
| PPK | 2.43 | 0.73 | −0.17 | <0.001 | |
| Self-concept | CK | 2.85 | 0.46 | 0.28 | <0.001 |
| PCK | 2.58 | 0.57 | 0.12 | <0.01 | |
| PPK | 2.46 | 0.50 | −0.05 | 0.15 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Großschedl, J.; Mahler, D.; Harms, U. Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology: The CK-IBI. Educ. Sci. 2018, 8, 145. https://doi.org/10.3390/educsci8030145
Großschedl J, Mahler D, Harms U. Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology: The CK-IBI. Education Sciences. 2018; 8(3):145. https://doi.org/10.3390/educsci8030145
Chicago/Turabian StyleGroßschedl, Jörg, Daniela Mahler, and Ute Harms. 2018. "Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology: The CK-IBI" Education Sciences 8, no. 3: 145. https://doi.org/10.3390/educsci8030145
APA StyleGroßschedl, J., Mahler, D., & Harms, U. (2018). Construction and Evaluation of an Instrument to Measure Content Knowledge in Biology: The CK-IBI. Education Sciences, 8(3), 145. https://doi.org/10.3390/educsci8030145