
Nowcasting Unemployment Using Neural Networks and Multi-Dimensional Google Trends Data

 , , and
, , and
Abstract
1. Introduction
2. Background
2.1. Forecasting Unemployment Using Google Trends
2.2. Additional Keyword Opportunities
2.3. Nowcasting and Machine Learning
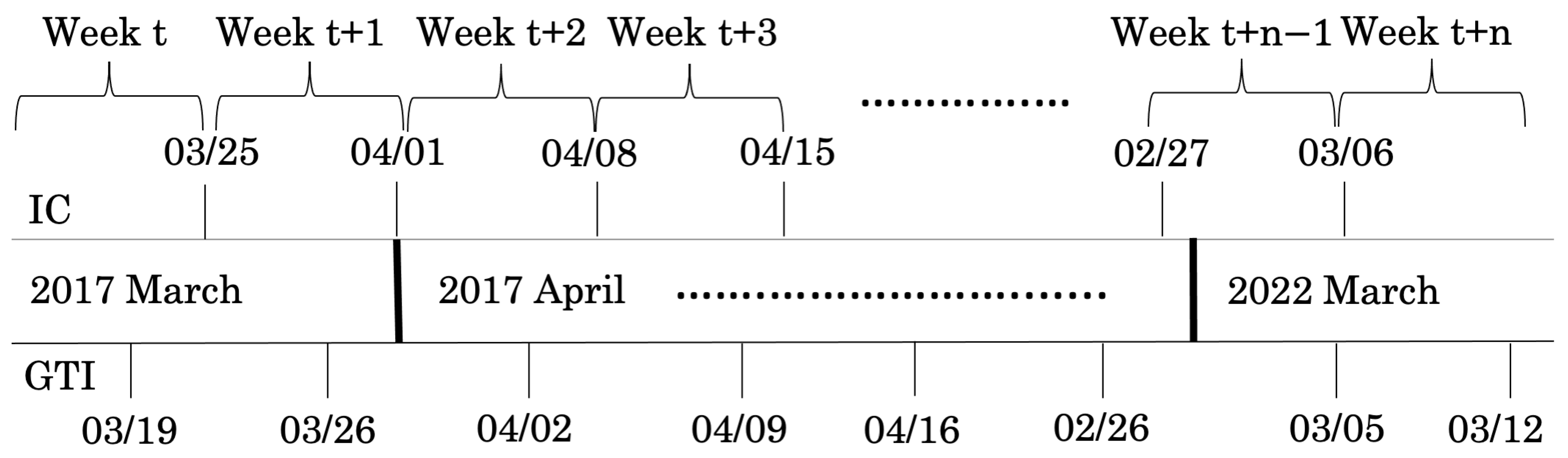
3. Data
- (a)
- Job search, benefits, and application (JSBA);
- (b)
- Mental health (MHK);
- (c)
- Violence and abuse (VA);
- (d)
- Leisure search (LA);
- (e)
- Consumption and lifestyle (CL);
- (f)
- Disasters, war, and viruses (DWV)
4. Methodology
4.1. Feature Selection and Dimension Reduction
4.2. The Nowcasting Model
5. Empirical Results
6. Conclusions
7. Policy Recommendations
8. Future Directions and Limitations
- (a)
- Consider gathering many keywords over multiple crises and extract the most indicative keywords that are prevalent in all crises and all periods;
- (b)
- Further explore keyword dimension reduction techniques to avoid omitting useful keywords that might have a high prediction impact on one crisis but not the other.
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | According to Speed (2011) and Edelmann et al. (2020), the Pearson correlation coefficient suffers from the drawback of only being able to identify the linear dependence while leaving non-linear patterns undetected (Speed 2011). Furthermore, Pearson requires a roughly normal distribution with no extreme outliers. These serious limitations may miss the dynamism that could exist among the dependent variable and Google Trends. |
| 2 | In this paper, the neural networks were compiled using the MSE loss functions. Thus, RMSE is a better-suited metric for accuracy evaluation than MAPE or MAE. Furthermore, optimization was not possible using MAPE due to differencing the data, which leads to infinite values because the original target values in certain cases come close to zero. |
| 3 | The full timeframe corresponds to the period of 2017/03/19 to 2021/01/16; the pre-pandemic timeframe corresponds to 2017/03/19 to 2020/02/01; and the pandemic timeframe corresponds to 2020/02/08 to 2021/01/16. |
References
- Aaronson, Daniel, Scott A. Brave, R. Andrew Butters, Michael Fogarty, Daniel W. Sacks, and Boyoung Seo. 2022. Forecasting unemployment insurance claims in realtime with Google Trends. International Journal of Forecasting 38: 567–81. [Google Scholar] [CrossRef]
- Aastveit, Knut Are, Tuva Marie Fastbø, Eleonora Granziera, Kenneth Sæterhagen Paulsen, and Kjersti Næss Torstensen. 2020. Nowcasting Norwegian Household Consumption with Debit Card Transaction Data. Norges Bank, Working Paper 17/2020. Available online: https://hdl.handle.net/11250/2722899 (accessed on 4 August 2022).
- Agarwal, Sumit, Tal Gross, and Bhashkar Mazumder. 2016. How Did the Great Recession Affect Payday Loans? Economic Perspective. Available online: https://fraser.stlouisfed.org/files/docs/historical/frbchi/economicperspectives/frbchi_econper_2016n2.pdf (accessed on 4 August 2022).
- Anderberg, Dan, Helmut Rainer, Jonathan Wadsworth, and Tanya Wilson. 2016. Unemployment and Domestic Violence: Theory and Evidence. Economic Journal, Royal Economic Society 126: 1947–79. [Google Scholar] [CrossRef]
- Antolini, Fabrizio, and Laura Grassini. 2018. Foreign arrivals nowcasting in Italy with Google Trends data. Quality & Quantity 53: 2385–401. [Google Scholar] [CrossRef]
- Anttonen, Jetro. 2018. Nowcasting the Unemployment Rate in the EU with Seasonal BVAR and Google Search Data. ETLA Working Papers, No. 62. Helsinki: The Research Institute of the Finnish Economy (ETLA). [Google Scholar]
- Askitas, Nikolaos, and Klaus F. Zimmermann. 2009. Google Econometrics and Unemployment Forecasting. IZA Discussion Paper. Bonn: Institute for the Study of Labor, p. 4201. [Google Scholar]
- Askitas, Nikolaos. 2015. Google Search Activity Data and Breaking Trends. IZA World of Labor. Bonn: Institute for the Study of Labor (IZA), p. 206. [Google Scholar] [CrossRef]
- Banbura, Marta, Domenico Giannone, and Lucrezia Reichlin. 2010. Nowcasting (November 30, 2010). ECB Working Paper No. 1275. Available online: https://ssrn.com/abstract=1717887 (accessed on 4 August 2022).
- Bańbura, Marta, Domenico Giannone, Michele Modugno, and Lucrezia Reichlin. 2013. Now-Casting and the Real-Time Data Flow. Working Paper Series. Available online: https://www.ecb.europa.eu/pub/pdf/scpwps/ecbwp1564.pdf (accessed on 4 August 2022).
- Barreira, Nuno, Pedro Godinho, and Paulo Melo. 2013. Nowcasting unemployment rate and new car sales in south-western Europe with Google Trends. NETNOMICS: Economic Research and Electronic Networking 14: 129–65. [Google Scholar] [CrossRef]
- Berniell, Inés, and Gabriel Facchini. 2021. COVID-19 lockdown and domestic violence: Evidence from internet-search behavior in 11 countries. European Economic Review 136: 103775. [Google Scholar] [CrossRef]
- Bhalotra, Sonia, Diogo G. C. Britto, Paolo Pinotti, and Breno Sampaio. 2021. Job Displacement, Unemployment Benefits and Domestic Violence. CEPR Discussion Paper No. DP16350. Available online: https://ssrn.com/abstract=3886839 (accessed on 4 August 2022).
- Borup, Daniel, David E. Rapach, and Erik Christian Montes Schütte. 2021. Mixed-Frequency Machine Learning: Now- and Backcasting Weekly Initial Claims with Daily Internet Search-Volume Data (July 28, 2021). Available online: https://ssrn.com/abstract=3690832 (accessed on 4 August 2022).
- Breuer, Christian. 2015. Unemployment and Suicide Mortality: Evidence from Regional Panel Data in Europe. Health Economics 24: 936–50. [Google Scholar] [CrossRef]
- Brownlee, Jason. 2018. Deep Learning for Time Series Forecasting. Machine Learning Mastery. Available online: https://machinelearningmastery.com/deep-learning-for-time-series-forecasting/ (accessed on 4 August 2022).
- Bruneckiene, Jurgita, Robertas Jucevicius, Ineta Zykiene, Jonas Rapsikevicius, and Mantas Lukauskas. 2021. Quantum Theory and Artificial Intelligence in the Analysis of the Development of Socio-Economic Systems: Theoretical Insights. In Developing Countries and Technology Inclusion in the 21st Century Information Society. Hershey: IGI Global. [Google Scholar]
- Butterworth, Peter, Liana S. Leach, Jane Pirkis, and Margaret Kelaher. 2012. Poor mental health influences risk and duration of unemployment: A prospective study. Social Psychiatry and Psychiatric Epidemiology 47: 1013–21. [Google Scholar] [CrossRef] [PubMed]
- Caperna, Giulio, Marco Colagrossi, Andrea Geraci, and Gianluca Mazzarella. 2020. Googling Unemployment During the Pandemic: Inference and Nowcast Using Search Data. JRC Working Papers in Economics and Finance. Brussels: Joint Research Centre, European Commission. [Google Scholar]
- Chadwick, Meltem Gülenay, and Gönül Sengul. 2012. Nowcasting Unemployment Rate in Turkey: Let’s Ask Google. Ankara: Central Bank of the Republic of Turkey. [Google Scholar]
- Chadi, Adrian, and Clemens Hetschko. 2017. Income or Leisure? On the Hidden Benefits of (Un-)employment. Available online: https://www.researchgate.net/publication/329152413_Income_or_Leisure_On_the_Hidden_Benefits_of_Un-employment (accessed on 4 June 2022).
- Chernis, Tony, and Rodrigo Sekkel. 2017. A dynamic factor model for nowcasting Canadian GDP growth. Empirical Economics 53: 217–34. [Google Scholar] [CrossRef]
- Chiaroni, Caroline, and Greg Kaplan. 2016. Do Households Substitute Among Luxury Goods? The Impact of the Great Recession on Fragrance Consumption. Available online: https://dataspace.princeton.edu/handle/88435/dsp01g732dc44x (accessed on 4 August 2022).
- Choi, Hyunyoung, and Hal Varian. 2009a. Predicting Initial Claims for Unemployment Benefits. Google Technical Report. Mountain View: Google Inc. [Google Scholar]
- Choi, Hyunyoung, and Hal Varian. 2009b. Predicting Present with Google Trends. Available online: https://static.googleusercontent.com/media/www.google.com/en//googleblogs/pdfs/google_predicting_the_present.pdf (accessed on 4 August 2022).
- Coble, David, and Pablo M. Pincheira. 2017. Now-Casting Building Permits with Google Trends (February 1, 2017). Available online: https://ssrn.com/abstract=2910165 (accessed on 5 August 2022). [CrossRef]
- D’Amuri, Francesco. 2009. Predicting Unemployment in Short Samples with Internet Job Search Query Data. MPRA Paper No: 18403. Boston: Statistical Association. [Google Scholar]
- D’Amuri, Francesco, and Juri Marcucci. 2017. The predictive power of Google searches in forecasting US unemployment. International Journal of Forecasting 33: 801–16. [Google Scholar] [CrossRef]
- Dávalos, María E., Hai Fang, and Michael T. French. 2011. Easing The Pain of An Economic Downturn: Macroeconomic Conditions And Excessive Alcohol Consumption. Health Economics 52: 1318–35. [Google Scholar] [CrossRef]
- Dilmaghani, Maryam. 2019. Workopolis or The Pirate Bay: What does Google Trends say about the unemployment rate? Journal of Economic Studies 46: 422–45. [Google Scholar] [CrossRef]
- Edelmann, Dominic, Tamás F. Móri, and Gábor J. Székely. 2020. On relationships between the Pearson and the distance correlation coefficients. Statistics & Probability Letters 169: 108960. [Google Scholar] [CrossRef]
- Ettredge, Michael, John Gerdes, and Gilbert Karuga. 2005. Using Web-based Search Data to Predict Macroeconomic statistics. Communications of the ACM 48: 87–92. [Google Scholar] [CrossRef]
- Fenga, Livio, and Semen Son-Turan. 2022. Forecasting youth unemployment in the aftermath of the COVID-19 pandemic: The Italian case. International Journal of Scientic and Management Research 5: 75–91. [Google Scholar] [CrossRef]
- Fondeur, Yannick, and Frédéric Karamé. 2013. Can Google data help predict French youth unemployment? Economic Modelling 30: 117–25. [Google Scholar] [CrossRef]
- Frangos, Christos C., Constantinos C. Frangos, and Ioannis Sotiropoulos. 2011. Cyberpsychology, Behavior, and Social Networking. Cyberpsykologi, Beteende och Sociala Nätverk 14: 51–58. [Google Scholar] [CrossRef]
- Gabrielyan, Gnel, and David R. Just. 2020. Economic shocks and lottery sales: An examination of Maine State lottery sales. Applied Economics 52: 3498–511. [Google Scholar] [CrossRef]
- Gamze, Gamze Bayın, and Seda Aydan. 2021. Association of COVID-19 with lifestyle behaviours and socio-economic variables in Turkey: An analysis of Google Trends. International Journal of Health Planning and Management 1: 20. [Google Scholar] [CrossRef]
- Giannone, Domenico, Lucrezia Reichlin, and David Small. 2008. Nowcasting: The real-time informational content of macroeconomic data. Journal of Monetary Economics 55: 665–76. [Google Scholar] [CrossRef]
- Ginsberg, Jeremy, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski, and Larry Brilliant. 2009. Detecting influenza epidemics using search engine query data. Nature 457: 1012–1014. [Google Scholar] [CrossRef]
- Giovannelli, Tommaso, Alessandro Giovannelli, Ottavio Ricchi, Ambra Citton, Christían Tegami, and Cristina Tinti. 2020. Nowcasting GDP and Its Components in a Data-Rich Environment: The Merits of the Indirect Approach (May 29, 2020). CEIS Working Paper No. 489. Available online: https://ssrn.com/abstract=3614110 (accessed on 4 August 2022).
- Goodman, William K., Ashley M. Geiger, and Jutta M. Wolf. 2016. Leisure Activities Are Linked to Mental Health Benefits by Providing Time Structure: Comparing Employed, Unemployed and Homemakers. Journal of Epidemiology and Community Health 71: 4–11. Available online: https://jech.bmj.com/content/71/1/4.short (accessed on 6 August 2022). [CrossRef] [PubMed]
- Havitz, Mark E., Peter A. Morden, and Diane M. Samdahl. 2004. The Diverse Worlds of Unemployed Adults: Consequences for Leisure, Lifestyle, and Well-Being. Waterloo: Wilfrid Laurier University Press. [Google Scholar]
- Hopp, Daniel. 2021. Economic Nowcasting with Long Short-Term Memory Artificial Neural Networks (LSTM). UNCTAD Research Paper No. 62. Genève: UNCTAD. [Google Scholar]
- Huang, Ni, Gordon Burtch, and Paul Pavlou. 2018. Local Economic Conditions and Worker Participation in the Online Gig Economy. Paper presented at the Thirty Ninth International Conference on Information Systems, San Francisco, CA, USA, December 13–16; Available online: http://metadataetc.org/gigontology/pdf/Huang%20et%20al.%20%20Local%20Economic%20Conditions%20and%20Worker%20Participation.pdf (accessed on 4 August 2022).
- Hyndman, Rob J., and George Athanasopoulos. 2018. Forecasting: Principles and Practice, 2nd ed. Melbourne: OTexts. Available online: OTexts.com/fpp2 (accessed on 6 August 2022).
- Jolliffe, Ian T. 2002. Principal Component Analysis. Springer Series in Statistics; New York: Springer. [Google Scholar]
- Khanthavit, Anya. 2021. A Causality Analysis of Lottery Gambling and Unemployment in Thailand. The Journal of Asian Finance, Economics and Business 8: 149–56. [Google Scholar]
- Kinney, Justin B., and Gurinder S. Atwal. 2014. Equitability, mutual information, and the maximal information coefficient. Proceedings of the National Academy of Sciences 111: 3354–59. [Google Scholar] [CrossRef]
- Laptev, Nikolay, Slawek Smyl, and Santhosh Shanmugam. 2017. Engineering Extreme Event Forecasting at Uber with Recurrent Neural Networks. Available online: https://eng.uber.com/neural-networks/ (accessed on 4 August 2022).
- Larson, William D., and Tara M. Sinclair. 2021. Nowcasting unemployment insurance claims in the time of COVID-19. International Journal of Forecasting 38: 635–47. [Google Scholar] [CrossRef]
- Lehdonvirta, Vili. 2013. A history of the digitalization of consumer culture. In Digital Virtual Consumption. Edited by Mike Molesworth and Janice Denegri-Knott. Abingdon-on-Thames: Routledge, pp. 18–35. [Google Scholar]
- Liu, Shuyan, Stephan Heinzel, Matthias N. Haucke, and Andreas Heinz. 2021. Increased Psychological Distress, Loneliness, and Unemployment in the Spread of COVID-19 over 6 Months in Germany. Medicina 57: 53. [Google Scholar] [CrossRef]
- Maas, Benedikt. 2019. Short-term forecasting of the US unemployment rate. Journal of Forecasting 39: 394–411. [Google Scholar] [CrossRef]
- Mallorquí-Bagué, Nuria, Fernando Fernández-Aranda, María Lozano-Madrid, Roser Granero, Gemma Mestre-Bach, Marta Baño, Amparo Del Pino-Gutiérrez, Mónica Gómez-Peña, Neus Aymam, José M. Menchón, and et al. 2017. Internet gaming disorder and online gambling disorder: Clinical and personality correlates. Journal of Behavioral Addictions 6: 669–77. [Google Scholar] [CrossRef]
- McKinsey & Company. 2020. How the Coronavirus Could Change US Personal Auto Insurance. Available online: http://dln.jaipuria.ac.in:8080/jspui/bitstream/123456789/1531/1/How-the-coronavirus-could-change-us-personal-auto-insurance.pdf (accessed on 4 August 2022).
- Mousteri, Victoria, Michael Daly, and Liam Delaney. 2018. The scarring effect of unemployment on psychological well-being across Europe. Social Science Research 72: 146–69. [Google Scholar] [CrossRef]
- Mulero, Rodrigo, and Alfredo García-Hiernaux. 2021. Forecasting Spanish unemployment with Google Trends and dimension reduction techniques. SERIEs 12: 329–49. [Google Scholar] [CrossRef]
- Naccarato, Alessia, Stefano Falorsi, Silvia Loriga, and Andrea Pierini. 2017. Combining official and Google Trends data to forecast the Italian youth unemployment rate. Technological Forecasting and Social Change 130: 114–22. [Google Scholar] [CrossRef]
- Nagao, Shintaro, Fumiko Takeda, and Riku Tanaka. 2019. Nowcasting of the U.S. unemployment rate using Google Trends. Finance Research Letters 30: 103–109. [Google Scholar] [CrossRef]
- Netmarketshare. 2022. Google Search Engine Total Market Share. Available online: https://netmarketshare.com/search-engine-market-share (accessed on 4 August 2022).
- Nymand-Andersen, Per, and Emmanouil Pantelidis. 2018. Google Econometrics: Nowcasting Euro Area Car Sales and Big Data Quality Requirements. ECB Statistics Paper, No. 30. Frankfurt a. M.: European Central Bank (ECB). ISBN 978-92-899-3359-9. [Google Scholar] [CrossRef]
- Pallesen, Ståle, Rune Aune Mentzoni, Arne Magnus Morken, Jonny Engebø, Puneet Kaur, and Eilin Kristine Erevik. 2021. Changes Over Time and Predictors of Online Gambling in Three Norwegian Population Studies 2013–2019. Frontiers in Psychiatry 12: 597615. [Google Scholar] [CrossRef] [PubMed]
- Palomeque Recio, Rocío. 2021. ‘I have bills to pay!’ Sugar dating in British higher education institutions. Journal of Gender and Education 34: 545–60. [Google Scholar] [CrossRef]
- Pavlicek, Jaroslav, and Ladislav Kristoufek. 2015. Nowcasting Unemployment Rates with Google Searches: Evidence from the Visegrad Group Countries. PLoS ONE 10: e0127084. [Google Scholar] [CrossRef]
- Reshef, David N., Yakir A. Reshef, Hilary K. Finucane, Sharon R. Grossman, Gilean McVean, Peter J. Turnbaugh, Eric S. Lander, Michael Mitzenmacher, and Pardis C. Sabeti. 2011. Detecting Novel Associations in Large Data Sets. Science 334: 1518–24. [Google Scholar] [CrossRef]
- Reyneke, Mignon, Alexandra Sorokáčová, and Leyland Pitt. 2012. Managing brands in times of economic downturn: How do luxury brands fare? Journal of Brand Management 19: 457–66. [Google Scholar] [CrossRef]
- Richardson, Adam, and Thomas Mulder. 2018. Nowcasting New Zealand GDP Using Machine Learning Algorithms. International Journal of Forecasting 37: 941–48. [Google Scholar] [CrossRef]
- Rusnák, Marek. 2016. Nowcasting Czech GDP in real time. Economic Modelling 54: 26–39. [Google Scholar] [CrossRef]
- Schiavoni, Caterina, Franz Palm, Stephan Smeekes, and Jan van den Brakel. 2021. A dynamic factor model approach to incorporate Big Data in state space models for official statistics. Journal of the Royal Statistical Society Series A-Statistics in Society 184: 324–53. [Google Scholar] [CrossRef]
- Schmidhuber, Jürgen, and Sepp Hochreiter. 1997. Long-short-term memory. Neural Computation 9: 1735–80. [Google Scholar]
- Simionescu, Mihaela. 2020. Improving unemployment rate forecasts at regional level in Romania using Google Trends. Technological Forecasting and Social Change 155: 120026. [Google Scholar] [CrossRef]
- Simionescua, Mihaela, and Javier Cifuentes-Faura. 2021. Can unemployment forecasts based on Google Trends help government design better policies? An investigation based on Spain and Portugal. Journal of Policy Modeling 44: 1–21. [Google Scholar] [CrossRef]
- Singhania, Rajshekhar, and Sourav Kundu. 2020. Forecasting the United States Unemployment Rate by Using Recurrent Neural Networks with Google Trends Data (June 18, 2020). International Journal of Trade, Economics and Finance 11. Available online: https://ssrn.com/abstract=3801209 (accessed on 6 August 2022).
- Smith, Paul. 2016. Google’s MIDAS Touch: Predicting UK Unemployment with Internet Search Data. Journal of Forecasting 35: 263–84. [Google Scholar] [CrossRef]
- Sotis, Chiara. 2021. How do Google searches for symptoms, news and unemployment interact during COVID-19? A Lotka–Volterra analysis of google trends data. Quality & Quantity 55: 2001–16. [Google Scholar] [CrossRef]
- Speed, Terry. 2011. A Correlation for the 21st Century. Science 334: 1502–503. [Google Scholar] [CrossRef] [PubMed]
- Uzieblo, Kasia, and David Prescott. 2020. Online pornography use during the COVID-19 pandemic: Should we worry? Part I. Sexual Abuse-Blogspot 40: 1080–1089. [Google Scholar] [CrossRef]
- Wanberg, Connie R., Edwin A. J. van Hooft, Karyn Dossinger, Annelies E. M. van Vianen, and Ute-Christine Klehe. 2019. How Strong Is My Safety Net? Perceived Unemployment Insurance Generosity and Implications for Job Search, Mental Health, and Reemployment. Journal of Applied Psychology 105: 209. [Google Scholar] [CrossRef]
- Yi, Dingdong, Shaoyang Ning, Chia-Jung Chang, and Supeng Kou. 2021. Forecasting Unemployment Using Internet Search Data via PRISM. Journal of the American Statistical Association 116: 1662–73. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Keywords Used |
|---|---|
| Choi and Varian (2009a) | “Jobs”, “Welfare & Unemployment” |
| D’Amuri (2009); Maas (2019); Larson and Sinclair (2021) | “jobs” |
| Askitas and Zimmermann (2009) | “unemployment office or agency”, “unemployment rate”, “Personnel Consultant”, and keywords that relate to the most popular job search engines in Germany. |
| Chadwick and Sengul (2012) | looking for a job”, “job announcements”, “CV”, and “career” |
| Fondeur and Karamé (2013) | “job”. |
| Simionescu (2020); Simionescua and Cifuentes-Faura (2021) | “unemployment” and “job offers”. |
| Pavlicek and Kristoufek (2015) | “work” or “jobs” |
| Nagao et al. (2019) | jobs” and “job offer”. |
| Barreira et al. (2013) | “unemployment” and “unemployment benefits” |
| Schiavoni et al. (2021) | 85 keywords that strongly relate to the job process (e.g., CV, cover letter, job vacancies). |
| Yi et al. (2021) | 25 work or job-related keywords |
| Caperna et al. (2020) | Many work related keywords. |
| Vanilla LSTM | ||||||||
| Optimized For Pandemic | ||||||||
| TF | Model 16 | Model (17a) | Model (17b) | Model (18a) | Model (18b) | Model (19) | Model (20) | Model (21) |
| Full | 38,577.35 | 40,065.89 | 37,825.99 | 59,880.21 | 42,081.86 | 50,979.00 | 99,616.56 | 196,009.32 |
| Pre-p. | 7548.92 | 7516.13 | 7562.90 | 7461.71 | 7705.44 | 8036.815 | 7837.147 | 159,54.240 |
| Pand. | 58,539.20 | 84,259.30 | 54,983.85 | 56,974.43 | 44,256.68 | 97,397.90 | 110,090.8 | 259,531.99 |
| Optimized For Full | ||||||||
| Full | 34,539.50 | 36,792.24 | 28,842.48 | |||||
| Pre-p. | 7780.78 | 7564.31 | 10,095.02 | |||||
| Pand. | 64,079.87 | 140,741 | 117,158.69 | |||||
| Optimized For Pre-Pandemic | ||||||||
| Full | 130,737.6 | 36,706.20 | 42,986.68 | |||||
| Pre-p. | 6768.696 | 6284.63 | 5456.54 | |||||
| Pand. | 95,662.77 | 85,302.66 | 142,165.29 | |||||
| Encoder–Decoder Style LSTM Layering | ||||||||
| Variables Used For Pandemic | ||||||||
| Full | 28,173.06 | 28,179.74 | 28,149.95 | 28,168.96 | 28,118.63 | 28,202.63 | 28,202.41 | 28,203.59 |
| Pre-p. | 7830.775 | 7828.18 | 7831.052 | 7830.53 | 7831.084 | 7830.88 | 7831.01 | 7830.82 |
| Pand. | 52,079.45 | 51,476.21 | 52,095.41 | 51,239.92 | 51,217.42 | 52,100.72 | 52,084.75 | 52,107.12 |
| Variables Used For Full | ||||||||
| Full | 28,158.31 | 28,202.03 | 28,126.43 | |||||
| Pre-p. | 7830.871 | 7830.54 | 7831.04 | |||||
| Pand. | 52,299.02 | 51,613.26 | 51,774.72 | |||||
| Variables Used For Pre-Pandemic | ||||||||
| Full | 28,154.71 | 28,174.80 | 28,114.49 | |||||
| Pre-p. | 7830.25 | 7830.618 | 7829.38 | |||||
| Pand. | 50,987.53 | 51,801.75 | 51,911.86 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grybauskas, A.; Pilinkienė, V.; Lukauskas, M.; Stundžienė, A.; Bruneckienė, J. Nowcasting Unemployment Using Neural Networks and Multi-Dimensional Google Trends Data. Economies 2023, 11, 130. https://doi.org/10.3390/economies11050130
Grybauskas A, Pilinkienė V, Lukauskas M, Stundžienė A, Bruneckienė J. Nowcasting Unemployment Using Neural Networks and Multi-Dimensional Google Trends Data. Economies. 2023; 11(5):130. https://doi.org/10.3390/economies11050130
Chicago/Turabian StyleGrybauskas, Andrius, Vaida Pilinkienė, Mantas Lukauskas, Alina Stundžienė, and Jurgita Bruneckienė. 2023. "Nowcasting Unemployment Using Neural Networks and Multi-Dimensional Google Trends Data" Economies 11, no. 5: 130. https://doi.org/10.3390/economies11050130
APA StyleGrybauskas, A., Pilinkienė, V., Lukauskas, M., Stundžienė, A., & Bruneckienė, J. (2023). Nowcasting Unemployment Using Neural Networks and Multi-Dimensional Google Trends Data. Economies, 11(5), 130. https://doi.org/10.3390/economies11050130