
Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem




Abstract
:1. Introduction
1.1. Data Classification Problem Analysis
1.2. Customer Experience and Associated Metrics
- Market surveys: The survey is performed typically in a random sample of the market population. This method has the advantage of measuring CX for all market competitors. Moreover, apart from the main CX metric the survey also measures the customer satisfaction for a number CX attributes, such as the product experience, the value perception, the touchpoint experience (call center, website, mobile app, shops, etc.), or key customer journeys (e.g., billing, product purchase);
- Customer feedback during or right after a transaction: this method is used so as to measure the customer satisfaction at different stages of a transaction (or more generally a customer journey) or to measure the CX of a specific touchpoint (e.g., shop, call center, website, mobile app, etc.) Such measurements capture only the feedback of own customers, however, they can reveal significant customer insights.
1.3. The CX Metric Classification Problem
2. Classification Algorithm Performance Analysis
2.1. Algorithm Performance for Binary Classification Problems
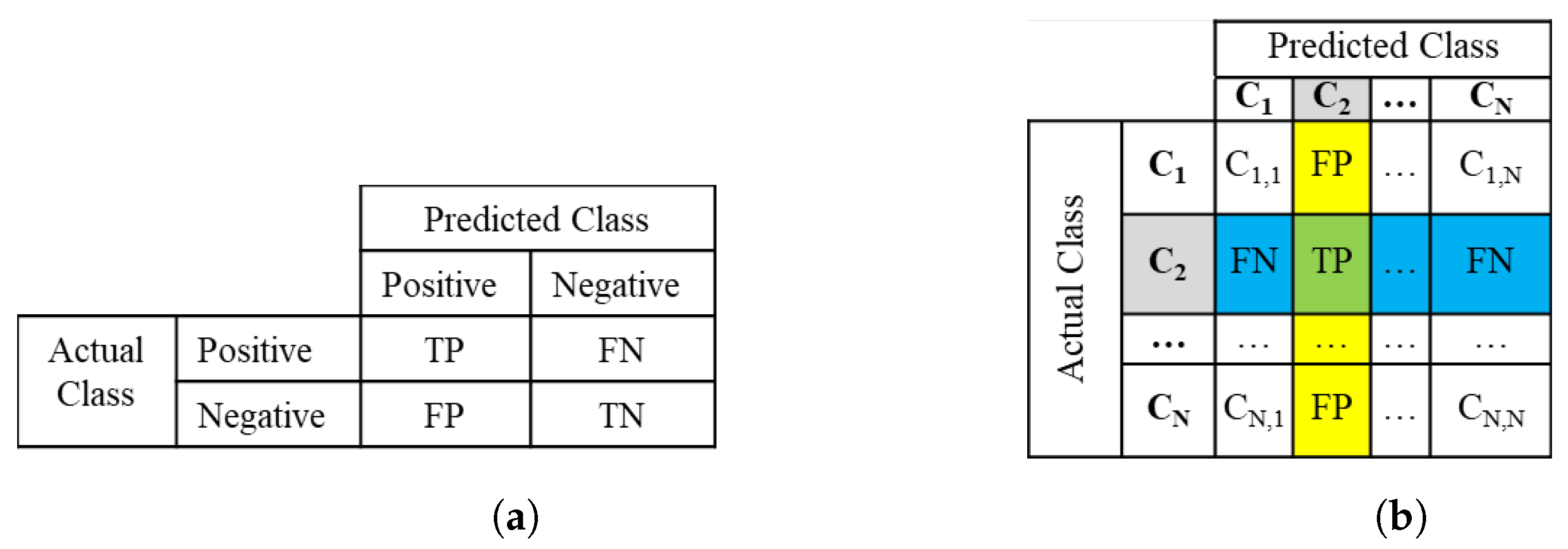
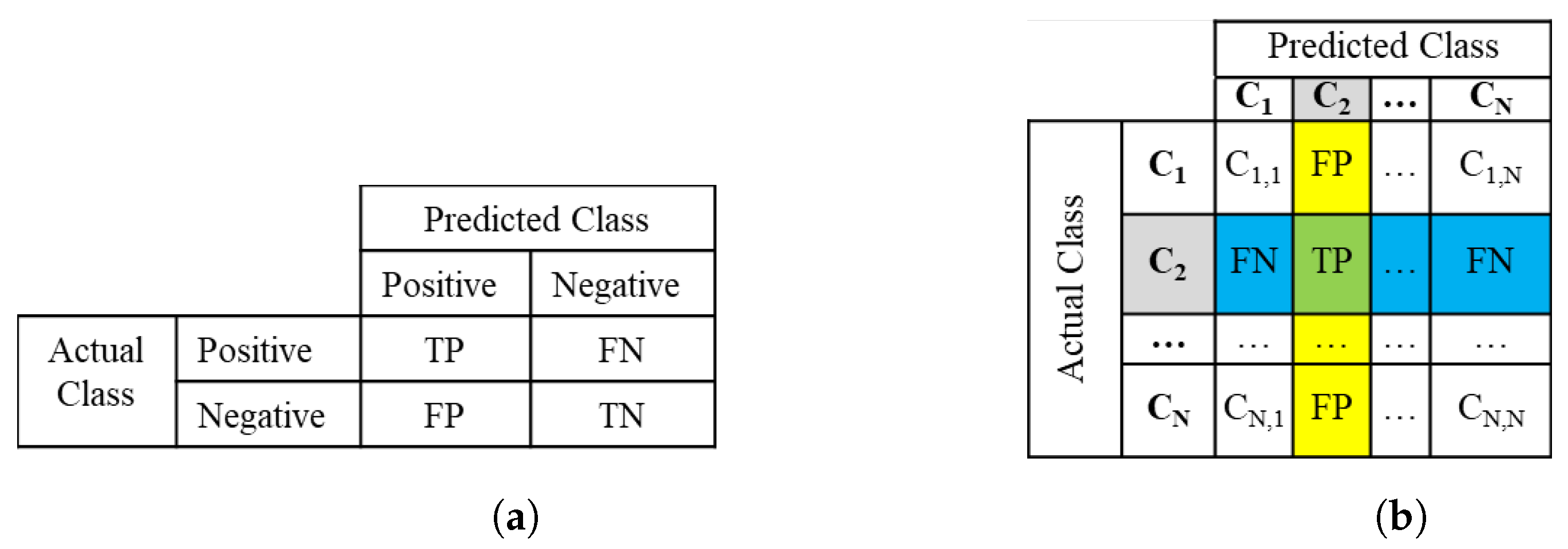
2.2. Multiclass Confusion Matrix and Metrics
3. Multiclass Confusion Matrix Reduction Methods
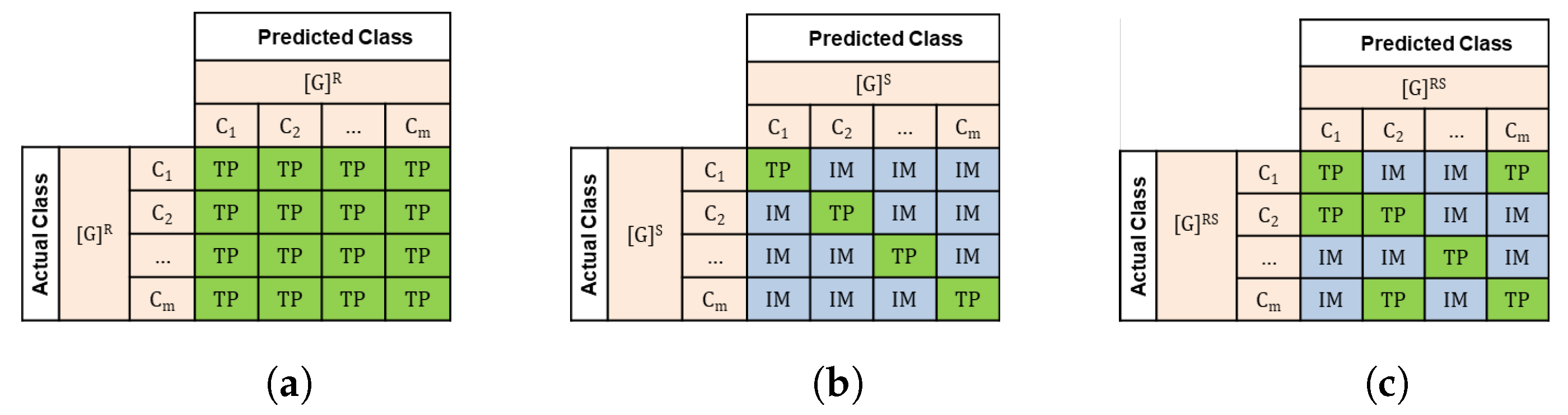
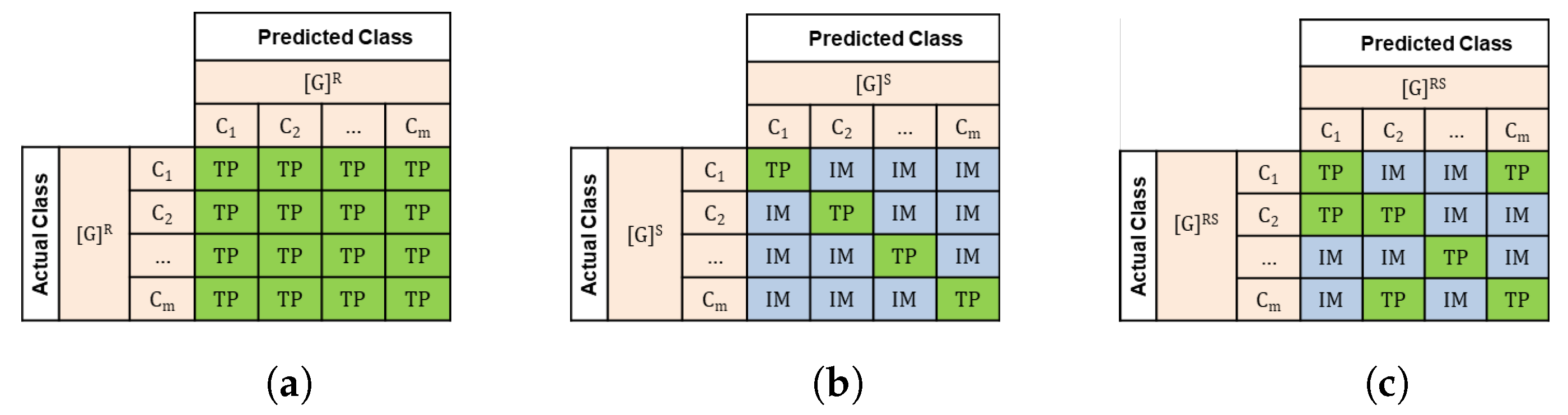
3.1. Class Grouping Options
- Relaxed Grouping of Classes: As shown in Figure 3a, in this case any prediction of a class with actual class is considered to be a true positive instance. In the example of NPS classification, assuming that we are interested in the group of detractors (score from 0 to 6) then a prediction of score 1 with an actual score 3 is considered to be true positive since both the predicted and the actual group is “detractor”;
- Strict Grouping of Classes: As shown in Figure 3b, in this case only the predictions which are identical to the actual class are considered to be true positive instances, i.e., only the instances with . For example, assuming the grouped class of detractors in NPS problem, if the predicted class is 3 then a TP instance occurs only if the actual class is 3;
- Hybrid-RS Grouping of Classes: As shown in Figure 3c, in this case apart from the instances where the predicted class is identical to the actual class, there is an additional set of combinations of predicted and actual classes which are considered to be a TP instance. For example, assuming the group of detractors in NPS problem, assume that we are interested in an algorithm that predicts the scores that are equal of better than the actual scores.
3.2. The Grouped Class Formal Definition
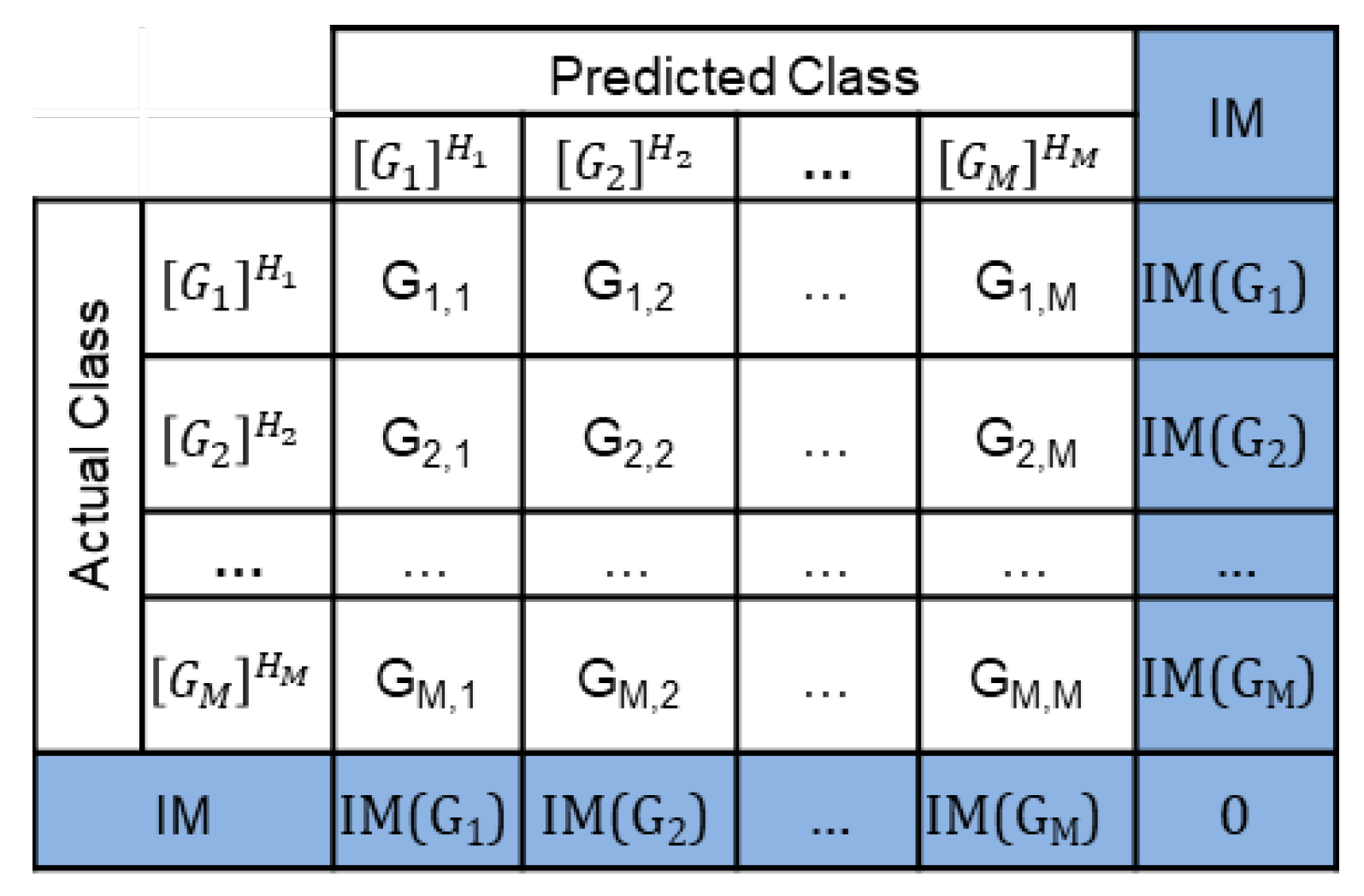
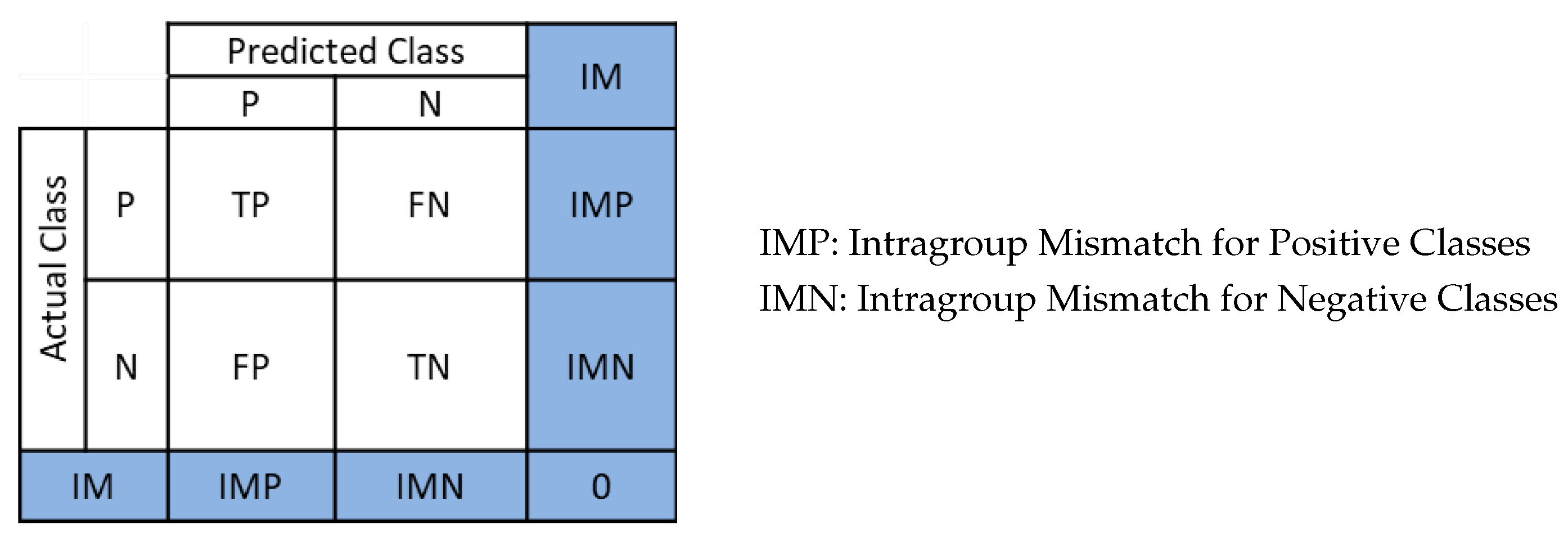
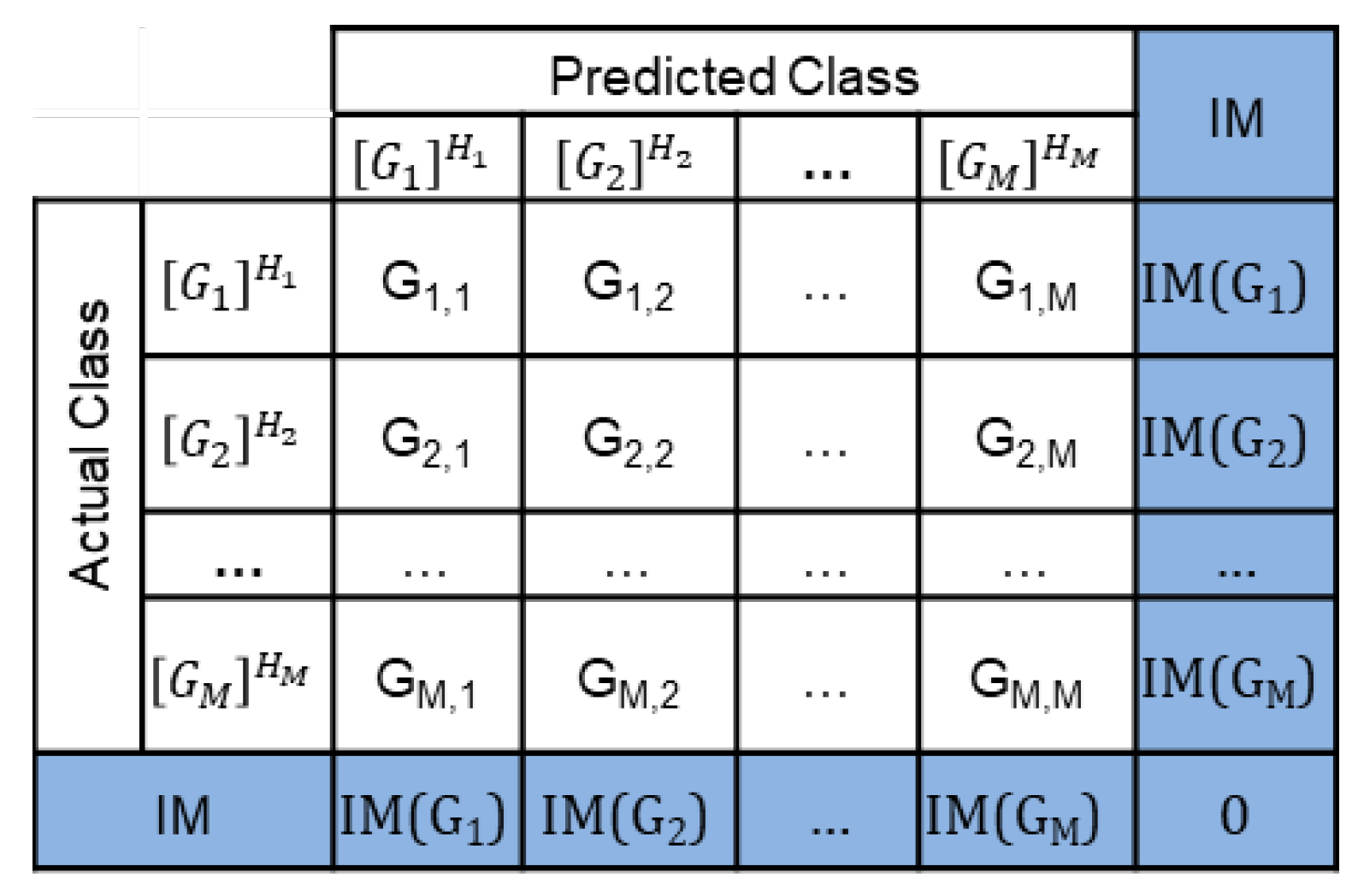
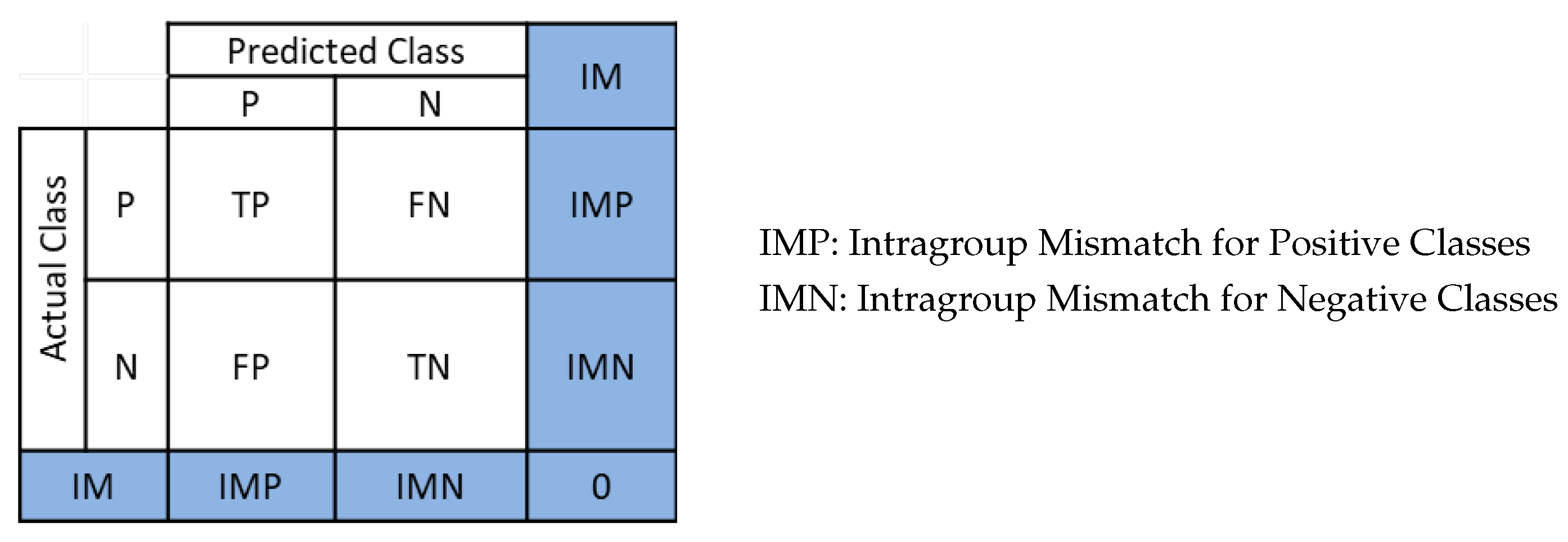
3.3. The Intragroup Mismatch Instances
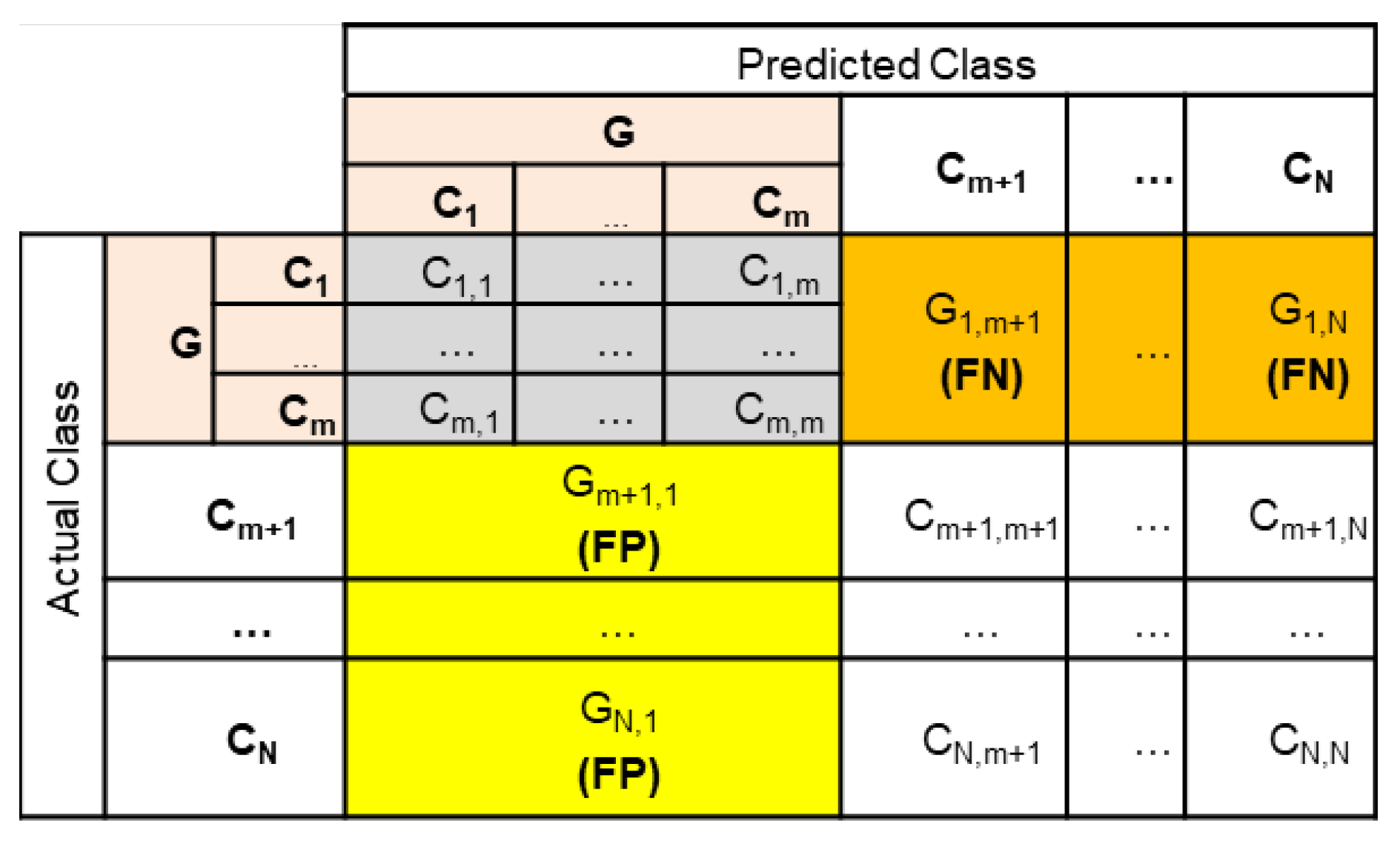
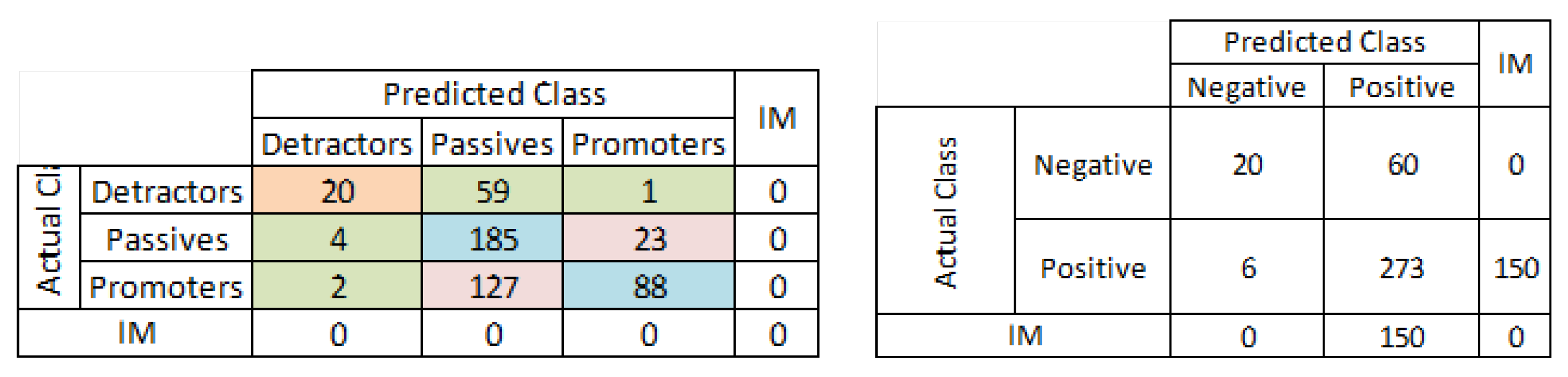
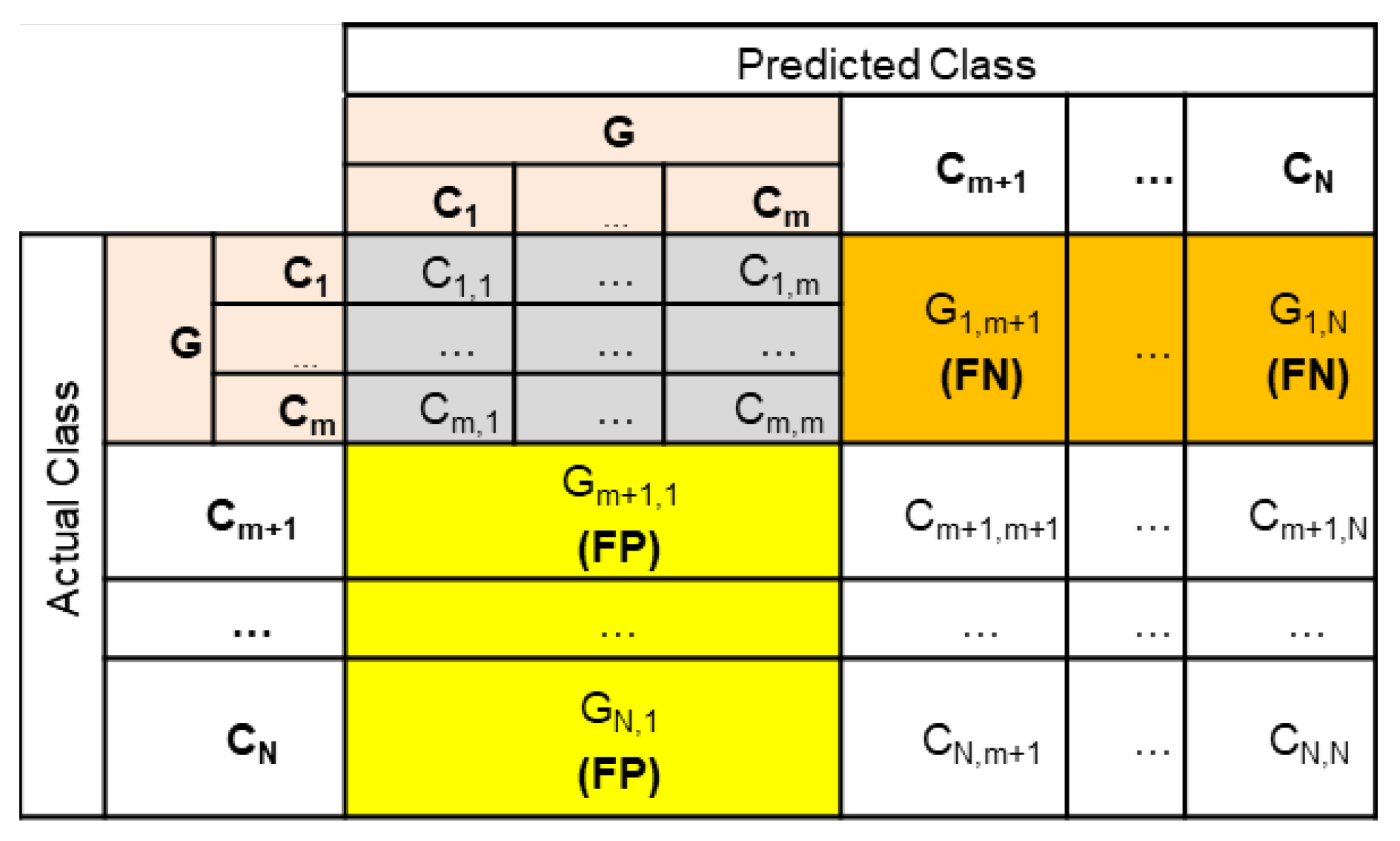
4. The Concept of the Reduced Confusion Matrix
4.1. Consecutive Confusion Matrix Reduction Steps
4.2. Performance Metrics for a Reduced Confusion Matrix
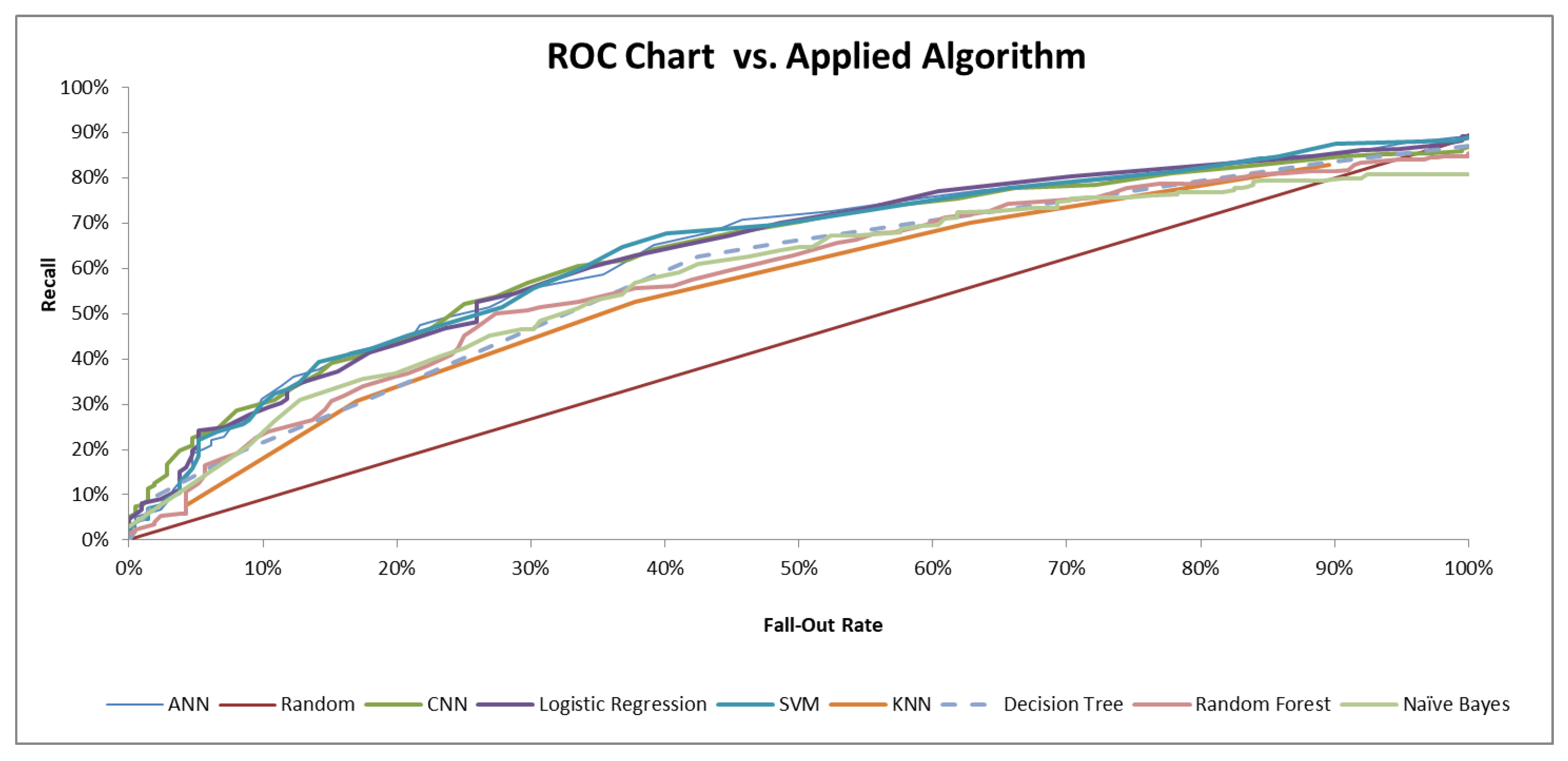
4.3. Receiver Operating Characteristic for a Reduced Confusion Matrix
- Step 1: As in the ordinary binary classification, the prediction of positive vs. negative grouped class is based on a threshold ;
- Step 2: The prediction of a specific class from the set of grouped positive or negative classes is based on maximum likelihood.
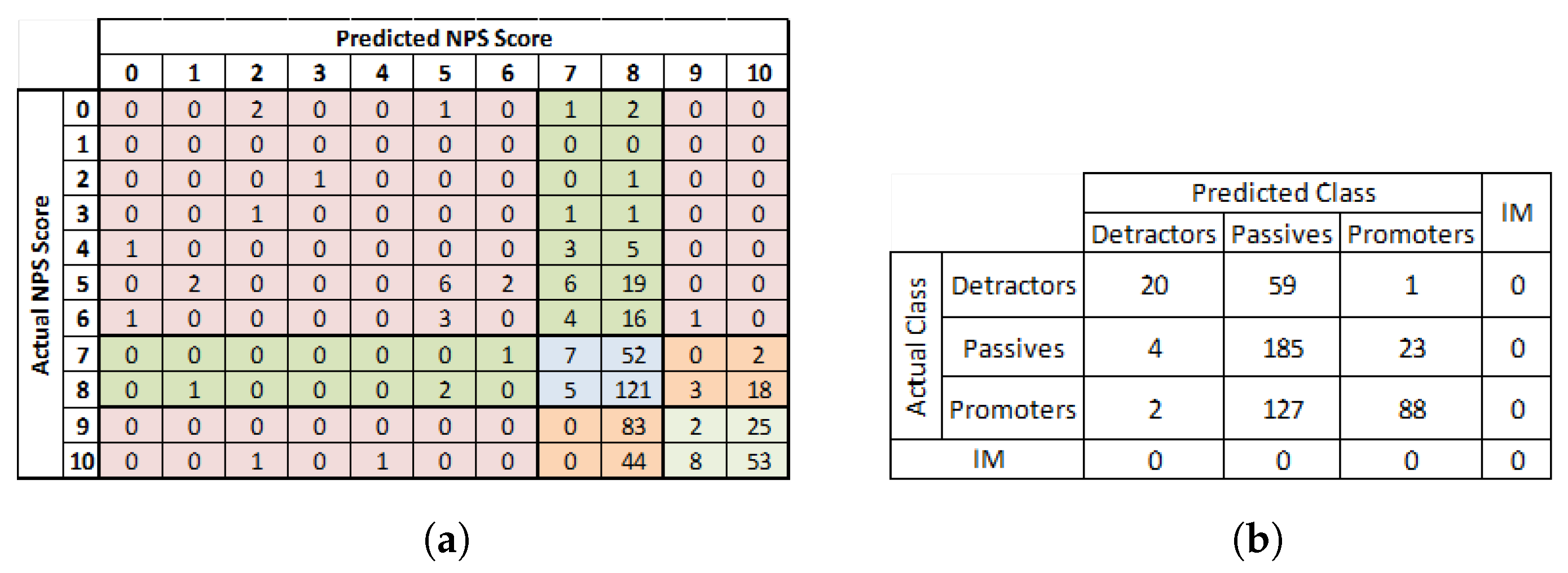
5. Confusion Matrix Reduction for NPS Classification
5.1. NPS Classification Dataset
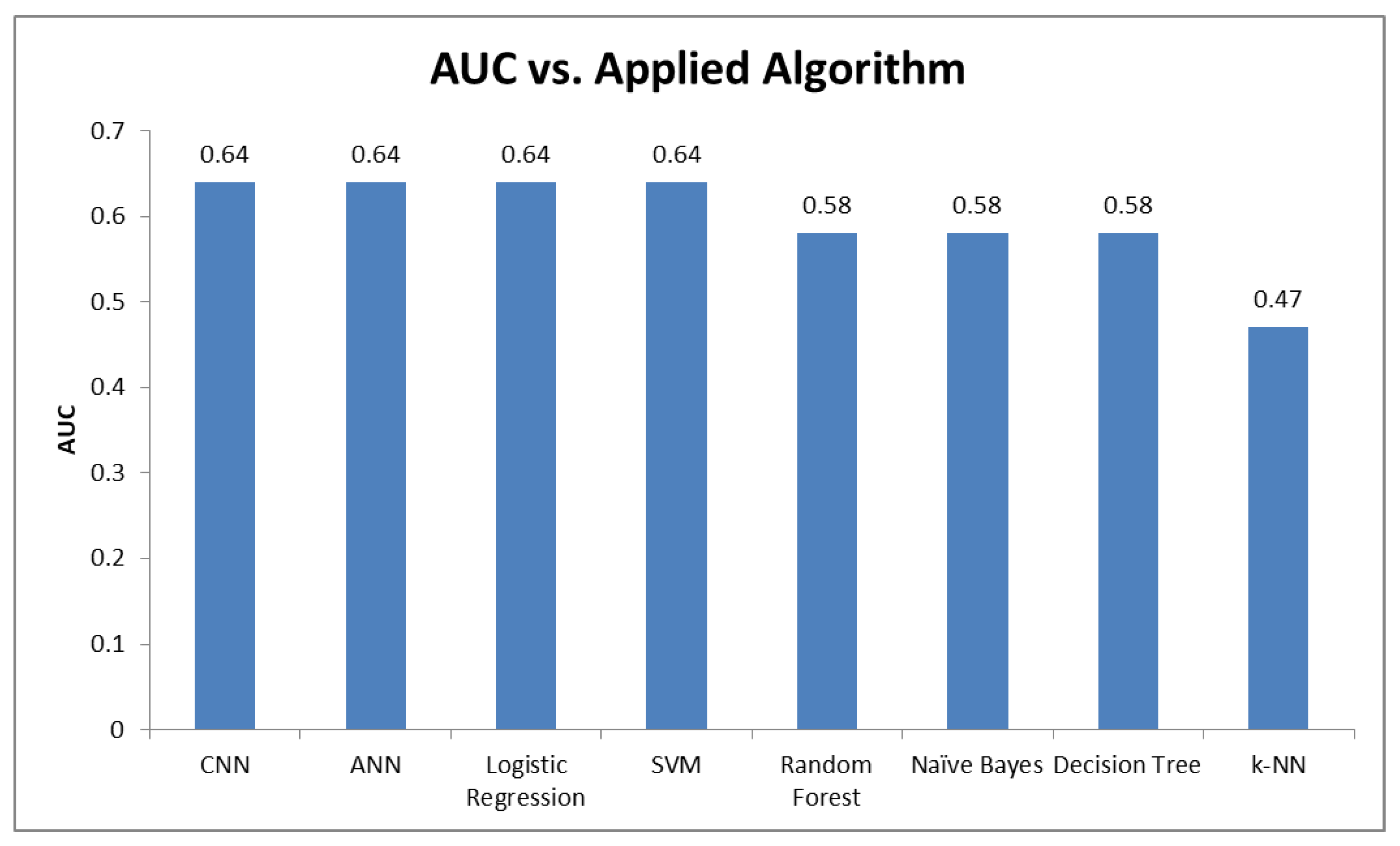
5.2. Machine Learning Algorithms for NPS Classification
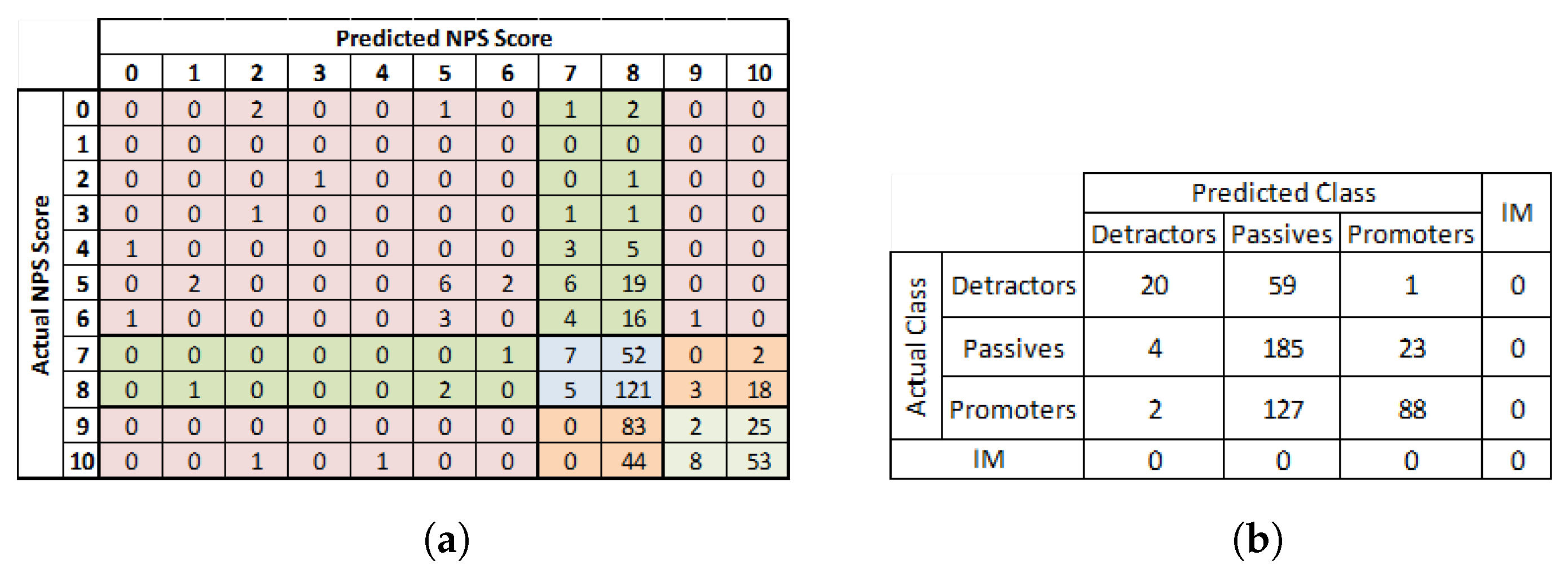
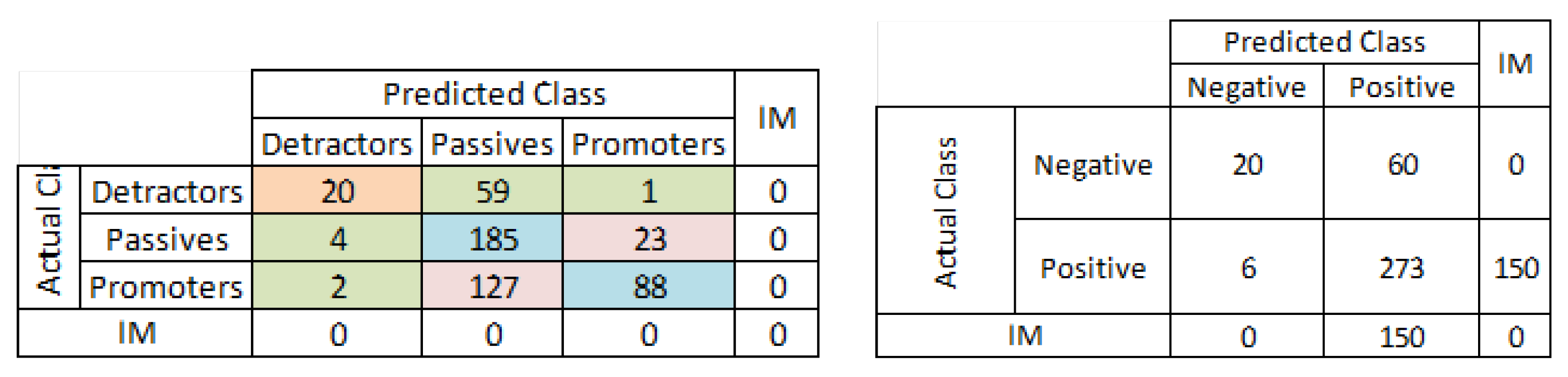
5.3. Confusion Matrix for the NPS Classification Problem
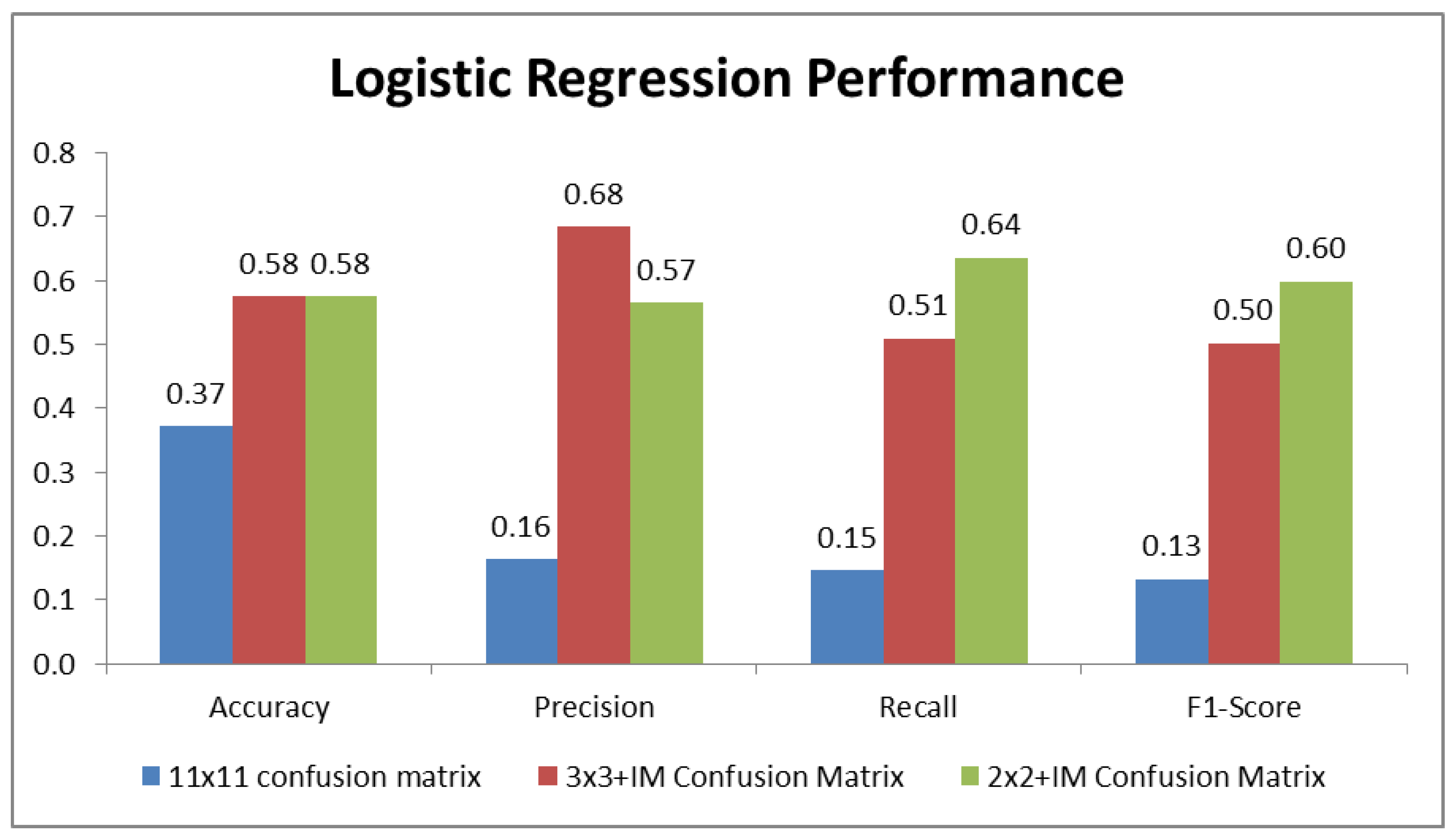
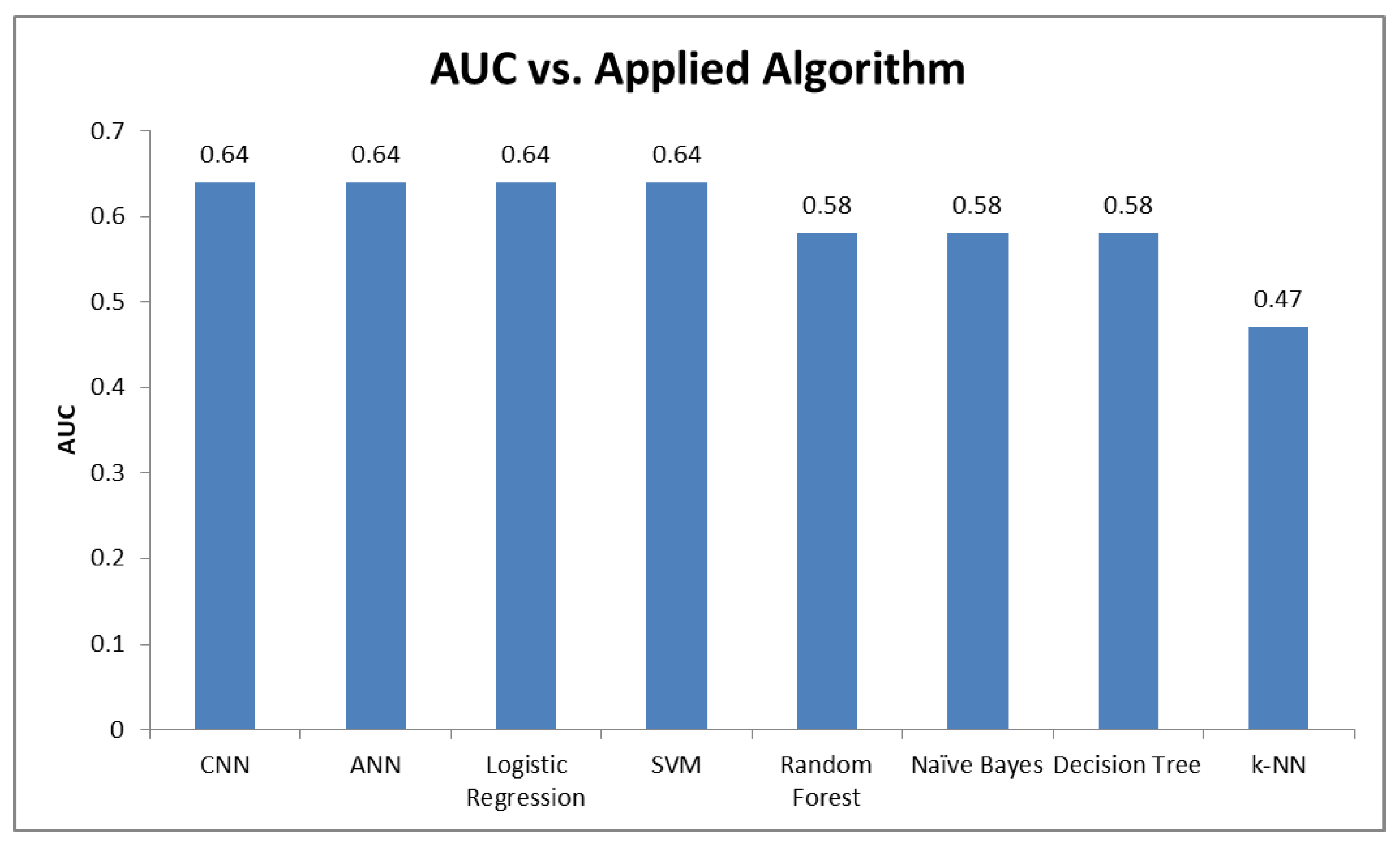
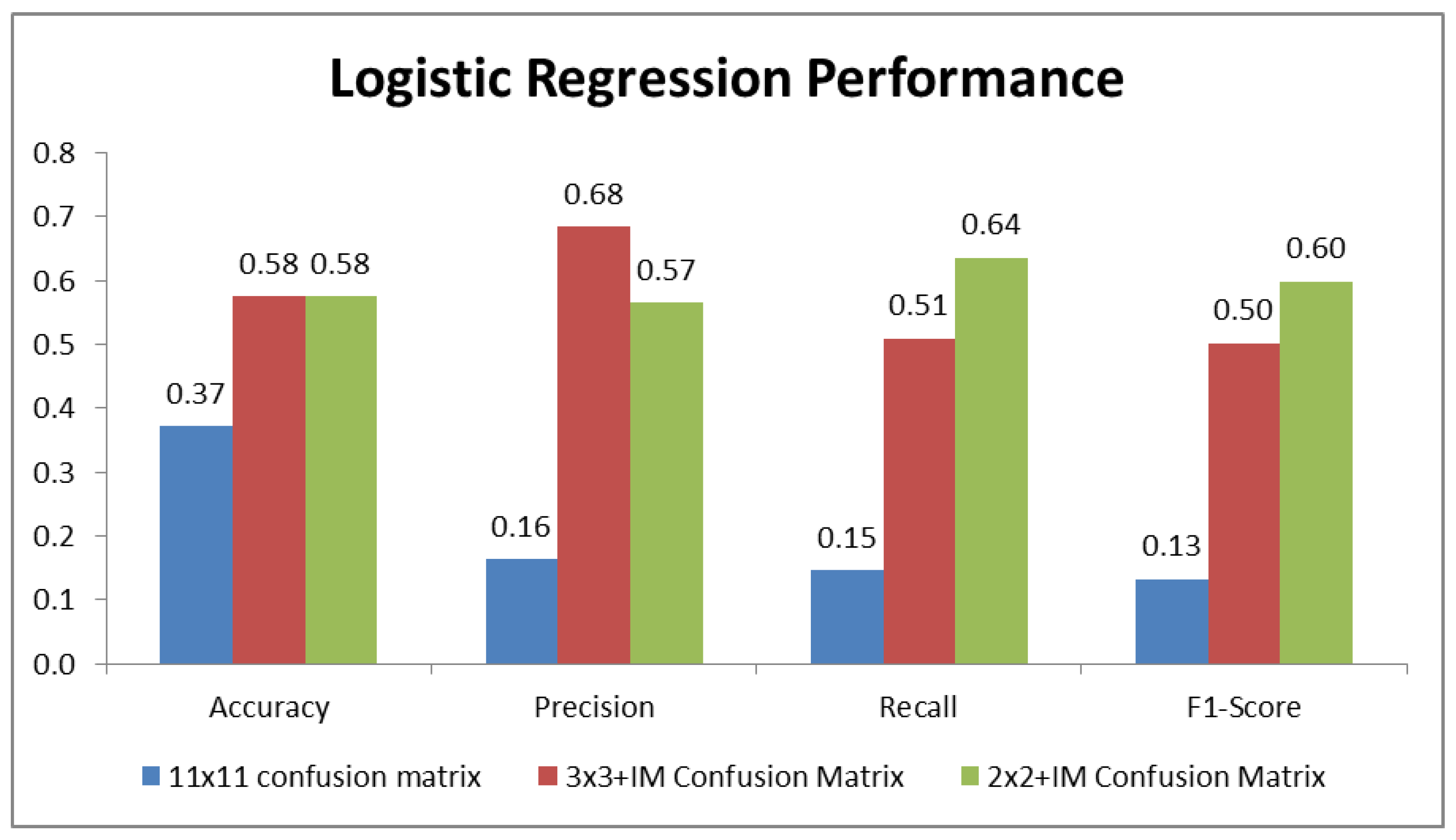
5.4. Performance Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Mathews Correlation Coefficient for Reduced Multiclass Confusion Matrix
Appendix B. The Applied Machine Learning Algorithms
Appendix B.1. Decision Trees

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| Function measuring quality of split | Entropy |
| Maximum depth of tree | 3 |
| Weights associated with classes | 1 |
Appendix B.2. k-Nearest Neighbors
| Parameter | Values |
|---|---|
| Number of neighbors | 5 |
| Distance metric | Minkowski |
| Weight function | uniform |
Appendix B.3. Support Vector Machines
| Parameter | Values |
|---|---|
| Kernel type | Linear |
| Degree of polynomial kernel function | 3 |
| Weights associated with classes | 1 |
Appendix B.4. Random Forest
| Parameter | Values |
|---|---|
| Number of trees | 100 |
| Measurements of quality of split | Gini index |
Appendix B.5. Artificial Neural Networks
| Parameter | Values |
|---|---|
| Number of hidden neurons | 6 |
| Activation function applied for the input and hidden layer | ReIU |
| Activation function applied for the output layer | Softmax |
| Optimizer network function | Adam |
| Calculated loss | Sparse categorical cross-entropy |
| Epochs used | 100 |
| Batch size | 10 |
Appendix B.6. Convolutional Neural Networks
| Parameter | Values |
|---|---|
| Model | Sequential (array of Keras Layers) |
| Kernel size | 3 |
| Pool size | 4 |
| Activation function applied | ReIU |
| Calculated loss | categorical cross-entropy |
| Epochs used | 100 |
| Batch size | 128 |
Appendix B.8. Logistic Regression
| Parameter | Values |
|---|---|
| Maximum number of iterations | 300 |
| Algorithm used in optimization | L-BFGS |
| Weights associated with classes | 1 |
References
- Alpaydin, E. Introduction to Machine Learning; The MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Matthews, B.W. Comparison of the Predicted and Observed Secondary Structure of T4 Phage Lysozyme. Biochim. Biophys. Acta-(Bba)-Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Mossman, D. Three-Way ROCs. Med Decis. Mak. 1999, 19, 78–89. [Google Scholar] [CrossRef]
- Bolton, R.N.; Drew, J.H. A Multistage Model of Customers’ Assessments of Service Quality and Value. J. Consum. Res. 1991, 17, 375–384. [Google Scholar] [CrossRef]
- Aksoy, L.; Buoye, A.; Aksoy, P.; Larivière, B.; Keiningham, T.L. A Cross-National Investigation of the Satisfaction and Loyalty Linkage for Mobile Telecommunications Services across Eight Countries. J. Interact. Mark. 2013, 27, 74–82. [Google Scholar] [CrossRef]
- Rageh Ismail, A.; Melewar, T.C.; Lim, L.; Woodside, A. Customer Experiences with Brands: Literature Review and Research Directions. Mark. Rev. 2011, 11, 205–225. [Google Scholar] [CrossRef] [Green Version]
- Gentile, C.; Spiller, N.; Noci, G. How to Sustain the Customer Experience:: An Overview of Experience Components That Co-Create Value With the Customer. Eur. Manag. J. 2007, 25, 395–410. [Google Scholar]
- Reichheld, F.F.; Covey, S.R. The Ultimate Question: Driving Good Profits and True Growth; Harvard Business School Press: Boston, MA, USA, 2006; Volume 211. [Google Scholar]
- Fornell, C.; Johnson, M.D.; Anderson, E.W.; Cha, J.; Bryant, B.E. The American Customer Satisfaction Index: Nature, Purpose, and Findings. J. Mark. 1996, 60, 7–18. [Google Scholar] [CrossRef] [Green Version]
- de Haan, E.; Verhoef, P.C.; Wiesel, T. The Predictive Ability of Different Customer Feedback Metrics for Retention. Int. J. Res. Mark. 2015, 32, 195–206. [Google Scholar] [CrossRef]
- Markoulidakis, I.; Rallis, I.; Georgoulas, I.; Kopsiaftis, G.; Doulamis, A.; Doulamis, N. A Machine Learning Based Classification Method for Customer Experience Survey Analysis. Technologies 2020, 8, 76. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote. Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Powers, D. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Doulamis, A.; Doulamis, N.; Kollias, S. On-Line Retrainable Neural Networks: Improving the Performance of Neural Networks in Image Analysis Problems. IEEE Trans. Neural Netw. 2020, 11, 137–155. [Google Scholar] [CrossRef]
- Doulamis, N.; Voulodimos, A. FAST-MDL: Fast Adaptive Supervised Training of Multi-Layered Deep Learning Models for Consistent Object Tracking and Classification. In Proceedings of the 2016 IEEE International Conference on Imaging Systems and Techniques (IST), Chania, Greece, 4–6 October 2016; pp. 318–323. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Rokach, L.; Maimon, O.Z. Data Mining with Decision Trees: Theory and Applications; World Scientific: Singapore, 2007. [Google Scholar]
- Bhatia, N. Survey of nearest neighbor techniques. arXiv 2010, arXiv:1007.0085. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Camarinopoulos, S.; Doulamis, N.; Miaoulis, G. Dance Pose Identification from Motion Capture Data: A Comparison of Classifiers. Technologies 2018, 6, 31. [Google Scholar] [CrossRef] [Green Version]
- Keller, J.M.; Gray, M.R.; Givens, J.A. A Fuzzy K-Nearest Neighbor Algorithm. IEEE Trans. Syst. Man Cybern. 1985, 580–585. [Google Scholar] [CrossRef]
- Abe, S. Support Vector Machines for Pattern Classification; Advances in Pattern Recognition; Springer: London, UK, 2010. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Kopsiaftis, G.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Mantoglou, A. Gaussian Process Regression Tuned by Bayesian Optimization for Seawater Intrusion Prediction. Comput. Intell. Neurosci. 2019, 2019, e2859429. [Google Scholar] [CrossRef]
- Pal, M. Random Forest Classifier for Remote Sensing Classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Hecht-Nielsen, R.; Drive, O.; Diego, S. Kolmogorov’s Mapping Neural Network Existence Theorem. In Proceedings of the International Conference on Neural Networks; IEEE Press: New York, NY, USA, 1987; Volume 3, pp. 11–14. [Google Scholar]
- Doulamis, N.; Doulamis, A.; Varvarigou, T. Adaptable Neural Networks for Modeling Recursive Non-Linear Systems. In Proceedings of the 2002 14th International Conference on Digital Signal Processing Proceedings. DSP 2002 (Cat. No.02TH8628), Santorini, Greece, 1–3 July 2002; Volume 2, pp. 1191–1194. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A. On the Impact of Labeled Sample Selection in Semisupervised Learning for Complex Visual Recognition Tasks. Complexity 2018, 2018, e6531203. [Google Scholar] [CrossRef]
- Doulamis, A.; Doulamis, N.; Protopapadakis, E.; Voulodimos, A. Combined Convolutional Neural Networks and Fuzzy Spectral Clustering for Real Time Crack Detection in Tunnels. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4153–4157. [Google Scholar] [CrossRef]
- Haouari, B.; Ben Amor, N.; Elouedi, Z.; Mellouli, K. Naïve Possibilistic Network Classifiers. Fuzzy Sets Syst. 2009, 160, 3224–3238. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]

| (a) The NPS customer catergorization | |
| NPS Response | NPS Label |
| 9–10 | Promoter |
| 7–8 | Passive |
| 0–6 | Detractor |
| (b) The CSAT customer catergorization | |
| CSAT Response | CSAT Label |
| 5 | Very Satisfied |
| 4 | Satisfied |
| 3 | Neutral |
| 2 | Dissatisfied |
| 1 | Very Dissatisfied |
| Metric | Formula |
|---|---|
| Accuracy | |
| True Positive Rate (Recall) | |
| True Negative Rate (Specificity) | |
| Positive Predictive Value (Precision) | |
| Negative Predictive Value | |
| -Score | |
| False Negative Rate (Miss Rate) | |
| False Positive Rate (Fall Out Rate) | |
| False Discovery Rate | |
| False Omission Rate | |
| Fowlkes-Mallows index | |
| Balanced Accuracy | |
| Mathews Correlation coefficient | |
| Prevalence Threshold | |
| Informedness | |
| Markedness | |
| Threat Score (Critical Success Index) |
| Metric | Formula |
|---|---|
| Accuracy | |
| Recall of Class | |
| Precision of Class | |
| -Score of Class | |
| Recall (macro average) | |
| Precision (macro average) | |
| -Score (macro average) | |
| Recall (micro average) | |
| Precision (micro average) | |
| -Score (micro average) |
| Metric | Formula |
|---|---|
| Accuracy of Reduced Confusion Matrix | |
| Recall of Group | |
| Precision of Group |
| Metric | Formula |
|---|---|
| Accuracy | |
| True Positive Rate (Recall) | |
| True Negative Rate (Specificity) | |
| Positive Predictive Value (Precision) | |
| Negative Predictive Value | |
| False Negative Rate (Miss Rate) | |
| False Positive Rate (Fall Out Rate) | |
| False Discovery Rate | |
| False Omission Rate |
| Logistic Regr. | SVM | k-NN | Decision Trees | Random Forest | Naïve Bayes | CNN | ANN | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.37 | 0.38 | 0.34 | 0.39 | 0.33 | 0.31 | 0.38 | 0.37 |
| Precision | 0.16 | 0.17 | 0.17 | 0.23 | 0.19 | 0.17 | 0.21 | 0.14 |
| Recall | 0.15 | 0.17 | 0.16 | 0.22 | 0.17 | 0.15 | 0.19 | 0.17 |
| F1-score | 0.13 | 0.14 | 0.16 | 0.21 | 0.18 | 0.15 | 0.19 | 0.15 |
| Logistic Regr. | SVM | k-NN | Decision Trees | Random Forest | Naïve Bayes | CNN | ANN | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.58 | 0.56 | 0.60 | 0.51 | 0.54 | 0.56 | 0.63 | 0.57 |
| Precision | 0.68 | 0.65 | 0.62 | 0.50 | 0.55 | 0.54 | 0.66 | 0.69 |
| Recall | 0.51 | 0.48 | 0.56 | 0.50 | 0.50 | 0.58 | 0.60 | 0.52 |
| F1-score | 0.50 | 0.53 | 0.58 | 0.50 | 0.51 | 0.57 | 0.62 | 0.51 |
| Logistic Regr. | SVM | k-NN | Decision Trees | Random Forest | Naïve Bayes | CNN | ANN | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.58 | 0.56 | 0.60 | 0.51 | 0.54 | 0.56 | 0.63 | 0.57 |
| Precision | 0.57 | 0.55 | 0.60 | 0.52 | 0.54 | 0.62 | 0.62 | 0.56 |
| Recall | 0.64 | 0.61 | 0.63 | 0.52 | 0.58 | 0.54 | 0.65 | 0.62 |
| F1-Score | 0.60 | 0.58 | 0.61 | 0.52 | 0.56 | 0.58 | 0.63 | 0.59 |
| Specificity | 0.09 | 0.07 | 0.16 | 0.15 | 0.11 | 0.27 | 0.19 | 0.10 |
| Miss Rate | 0.01 | 0.01 | 0.05 | 0.10 | 0.05 | 0.19 | 0.04 | 0.02 |
| Negative Predictive Value | 0.11 | 0.09 | 0.18 | 0.15 | 0.13 | 0.21 | 0.21 | 0.13 |
| Fall Out Rate | 0.14 | 0.10 | 0.10 | 0.10 | 0.12 | 0.06 | 0.09 | 0.13 |
| False Discovery Rate | 0.12 | 0.10 | 0.10 | 0.10 | 0.12 | 0.07 | 0.09 | 0.12 |
| False Omission Rate | 0.03 | 0.01 | 0.11 | 0.18 | 0.11 | 0.32 | 0.08 | 0.04 |
| Fowlkes-Mallows index | 0.60 | 0.58 | 0.61 | 0.52 | 0.56 | 0.58 | 0.63 | 0.59 |
| Mathews Correlation Coefficient | 0.33 | 0.37 | 0.35 | 0.37 | 0.36 | 0.34 | 0.38 | 0.36 |
| PIMR | 0.35 | 0.39 | 0.32 | 0.38 | 0.37 | 0.27 | 0.31 | 0.36 |
| PPIMR | 0.31 | 0.35 | 0.30 | 0.38 | 0.35 | 0.31 | 0.30 | 0.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Markoulidakis, I.; Rallis, I.; Georgoulas, I.; Kopsiaftis, G.; Doulamis, A.; Doulamis, N. Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem. Technologies 2021, 9, 81. https://doi.org/10.3390/technologies9040081
Markoulidakis I, Rallis I, Georgoulas I, Kopsiaftis G, Doulamis A, Doulamis N. Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem. Technologies. 2021; 9(4):81. https://doi.org/10.3390/technologies9040081
Chicago/Turabian StyleMarkoulidakis, Ioannis, Ioannis Rallis, Ioannis Georgoulas, George Kopsiaftis, Anastasios Doulamis, and Nikolaos Doulamis. 2021. "Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem" Technologies 9, no. 4: 81. https://doi.org/10.3390/technologies9040081
APA StyleMarkoulidakis, I., Rallis, I., Georgoulas, I., Kopsiaftis, G., Doulamis, A., & Doulamis, N. (2021). Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem. Technologies, 9(4), 81. https://doi.org/10.3390/technologies9040081