Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
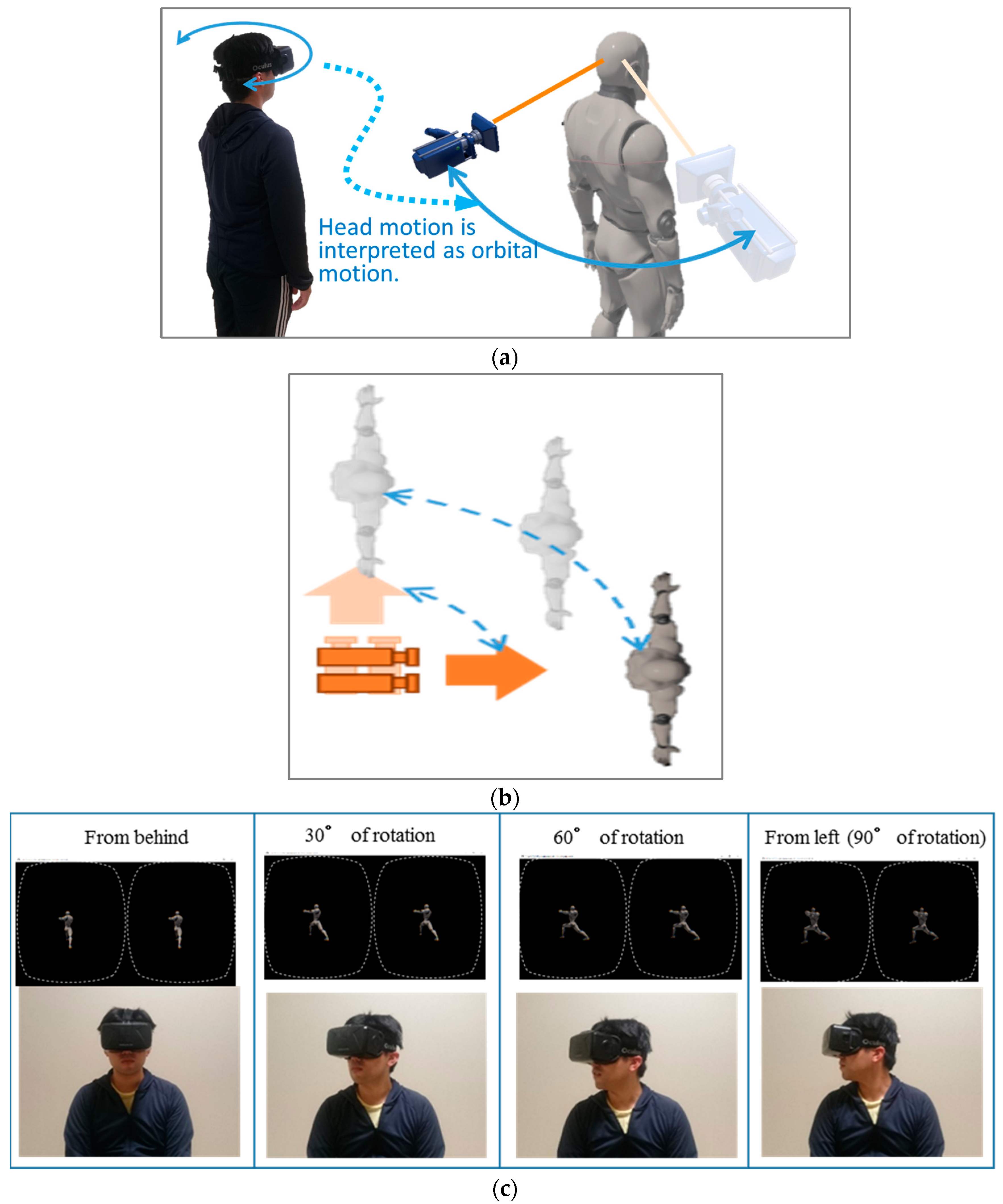
2. Proposal of Head Motion-Associated Virtual Stereo Rearview (HMAR)
2.1. System Configuration
- Avatar-centered perceptual mode (see Figure 1)
- Observer-centered perceptual mode (see Figure 1b)
2.2. Expected Effects
3. Pose-Recognition Experiment
3.1. Experimental Method
3.1.1. Experimental Conditions
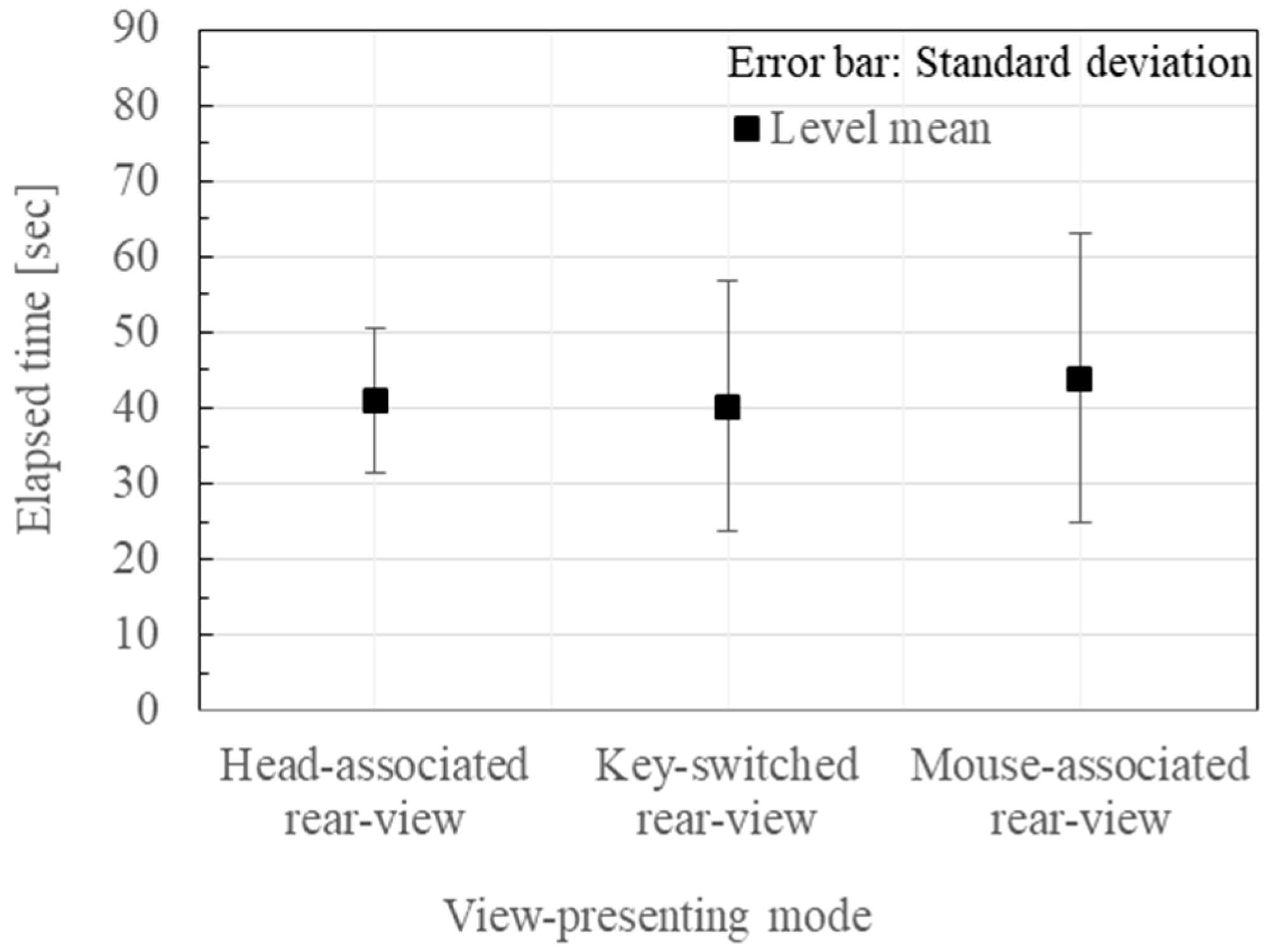
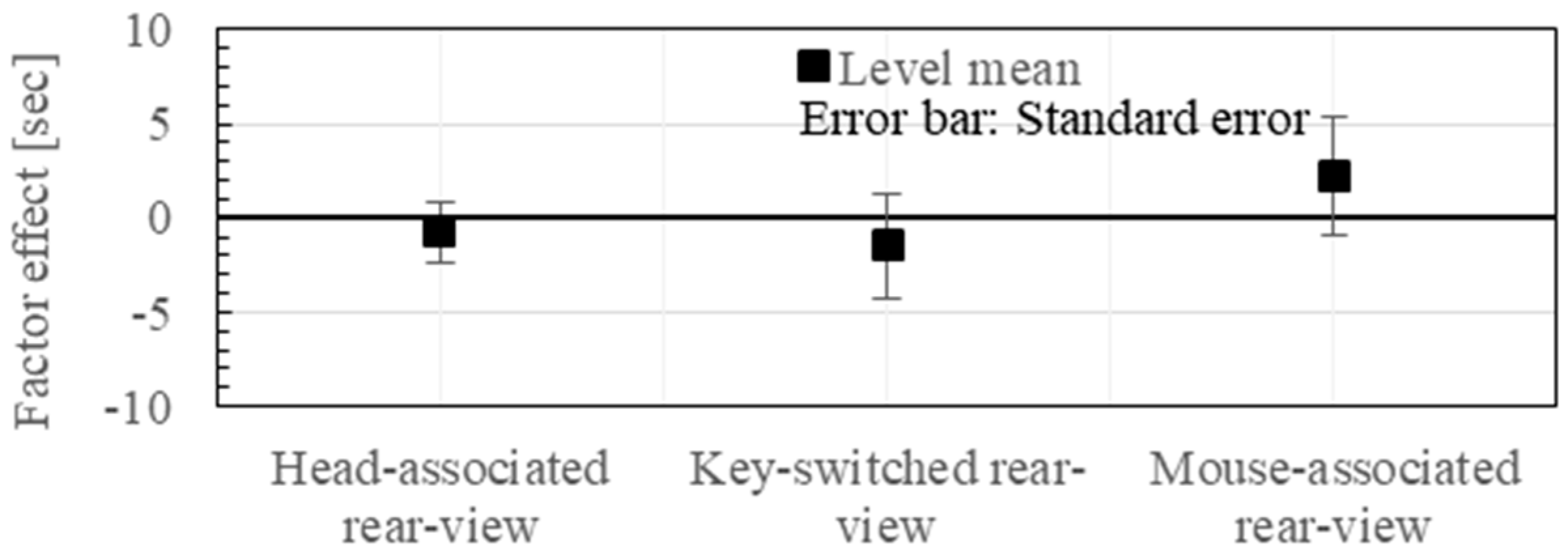
- Head Motion-Associated virtual stereo Rearview (HMAR) (see Section 2).
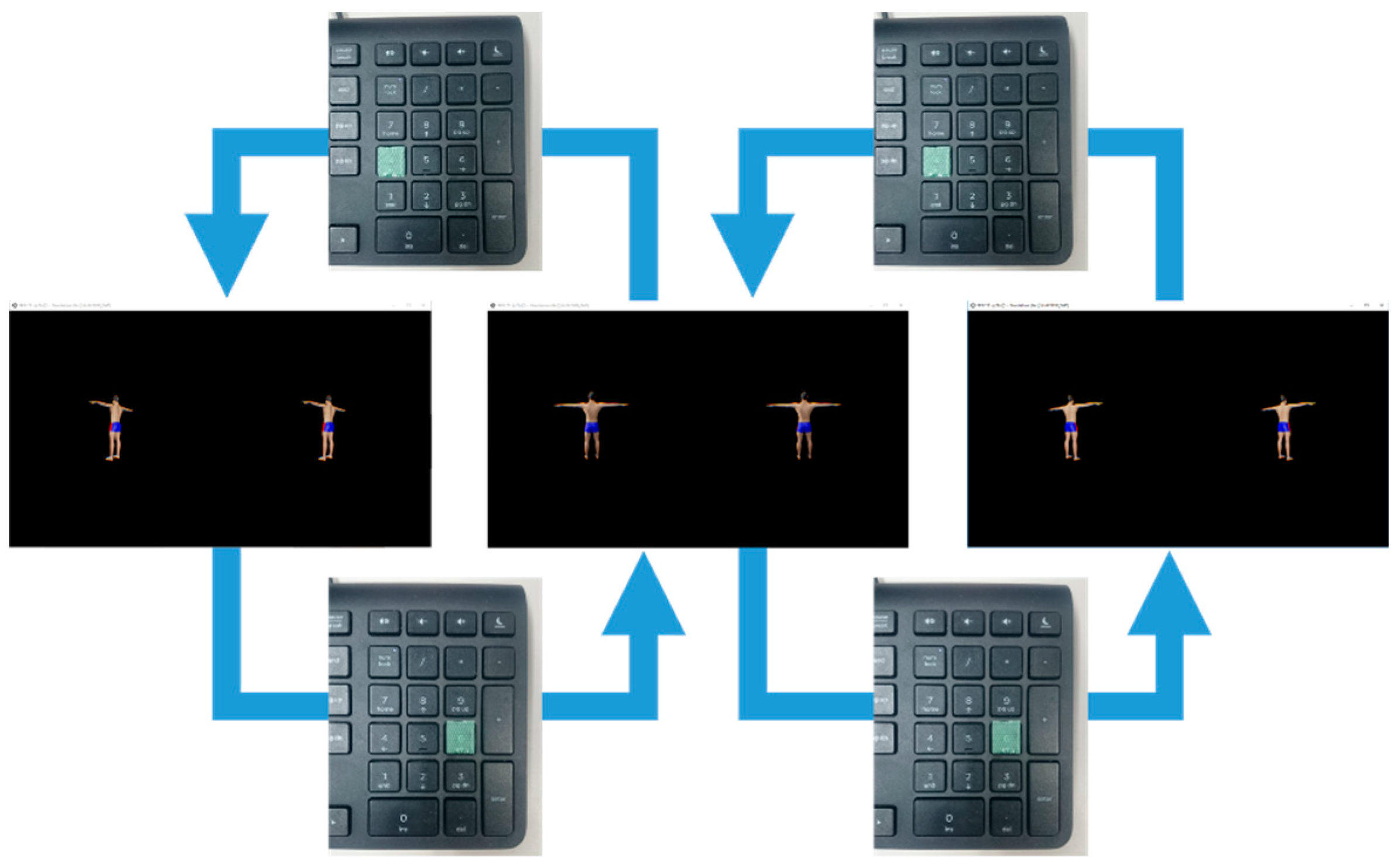
- Key-Switched virtual stereo Rearview (KSR): One of the eight discrete views that were taken from the eight viewpoints at 45° intervals in 360° around the target avatar and displayed in the HMD. It was switched on after the other upon a subject’s key-pressing operation, as shown in Figure 2. This instructional mode is regarded as the most representative ordinary method.
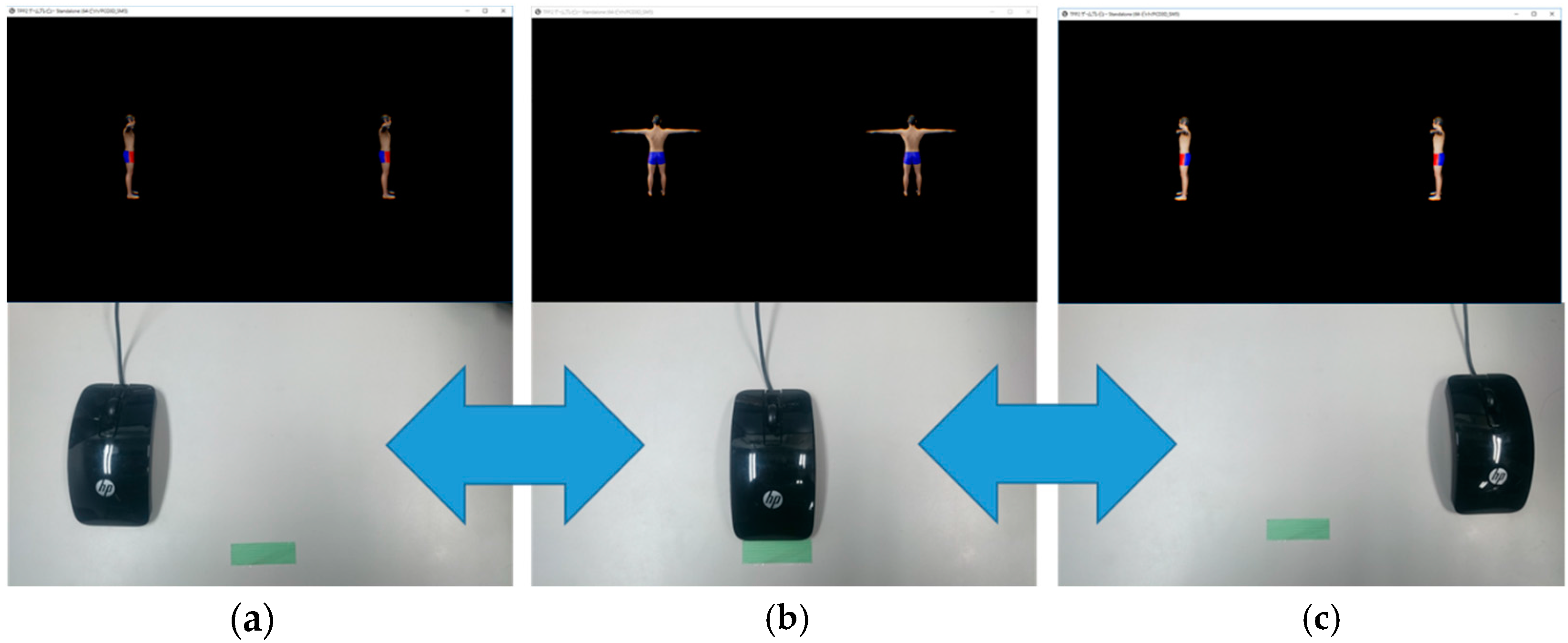
- Mouse-associated virtual stereo Rearview (MAR): The virtual stereo camera (VSC) is rotated around the reference avatar in accordance with the mouth-dragging operation by the observer. The stereo view that is assumed to be taken by the VSC is displayed in the HMD, as shown in Figure 3. This instructional method is regarded as an elaborated ordinary method.
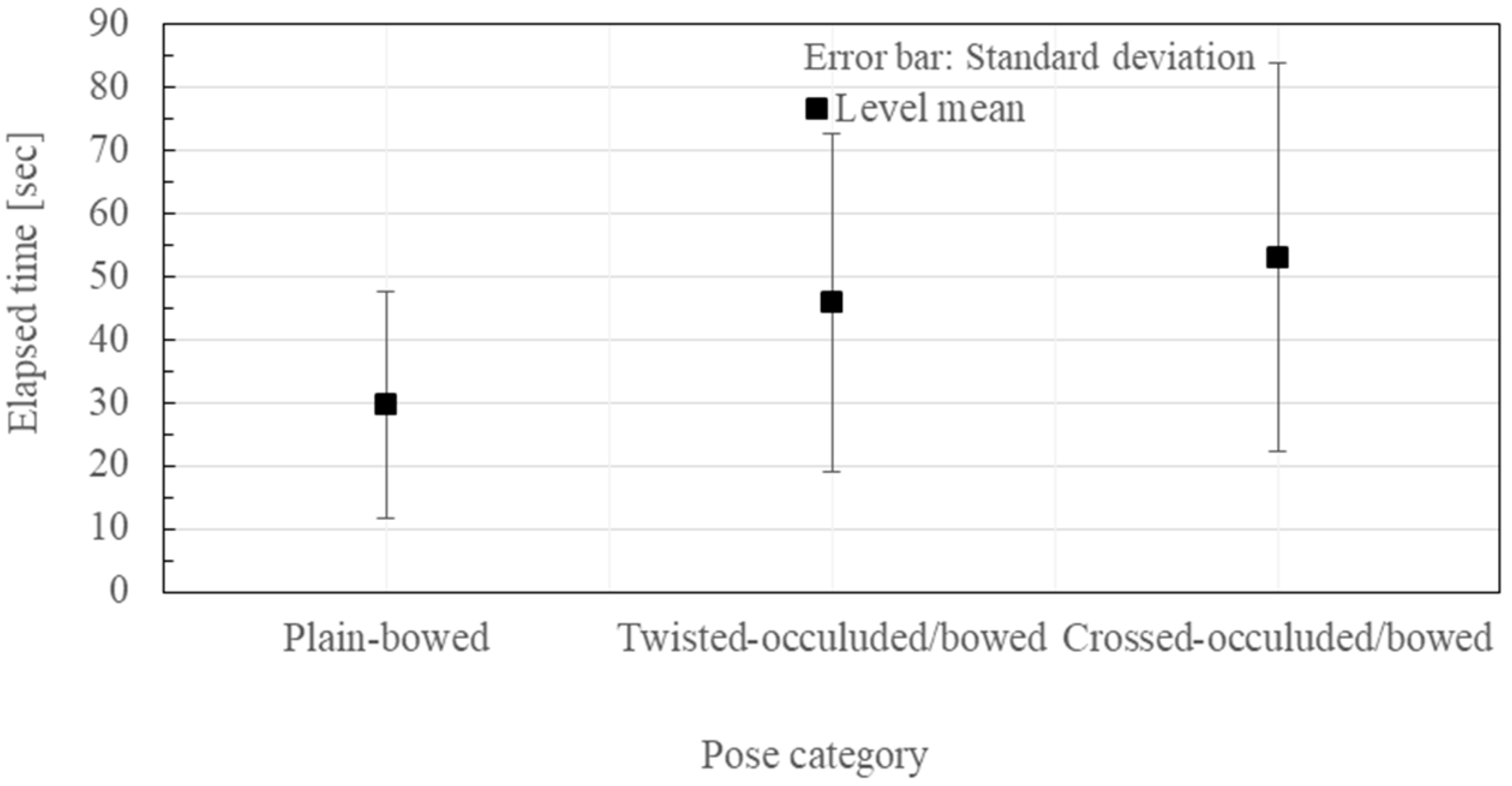
- Plain poses (see Figure 4): This category of pose is considered to be recognized only by one view.
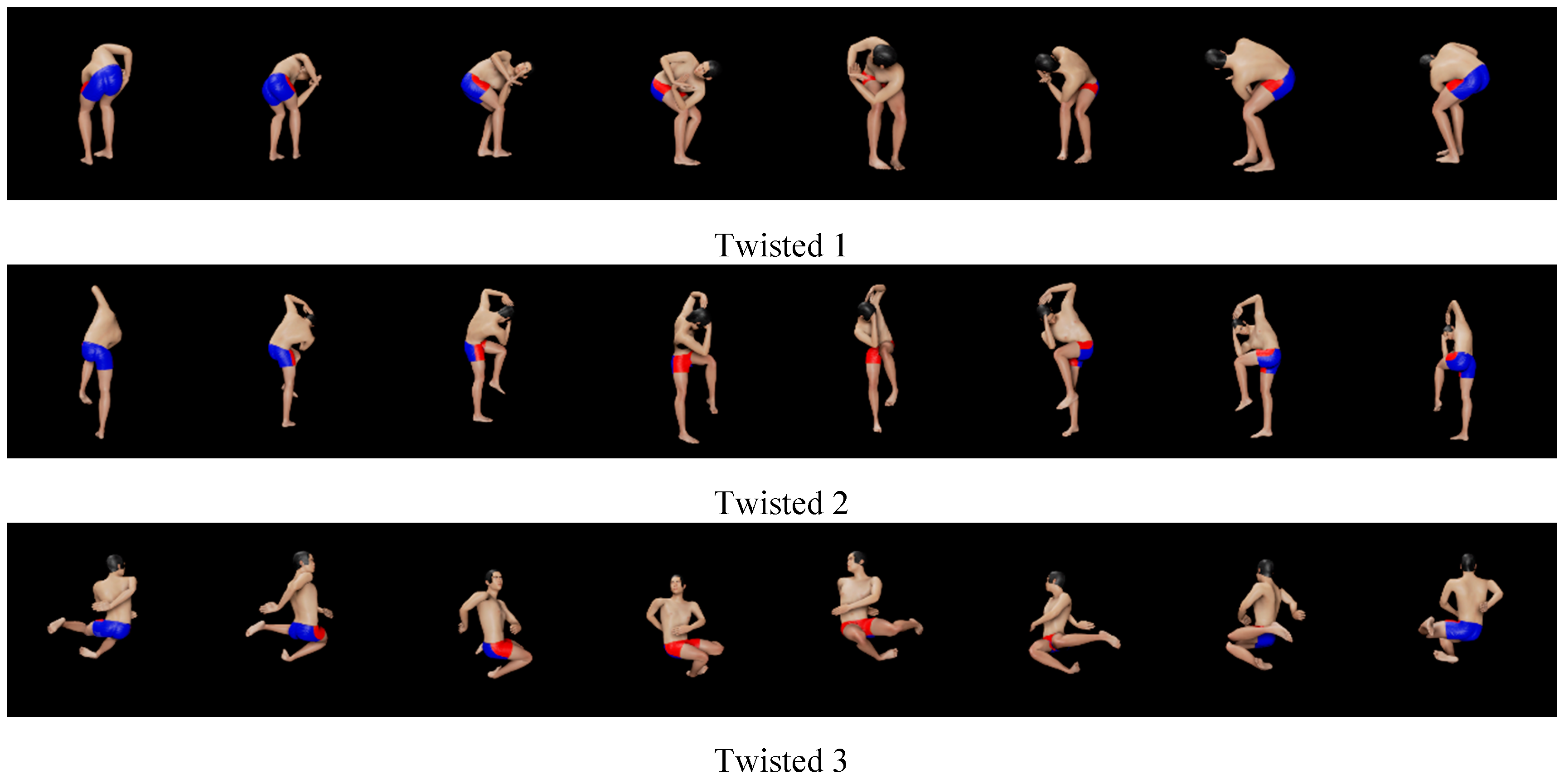
- Twisted poses (see Figure 5): Upper trunk is bent and/or twisted. It is considered to be necessary to look at the avatar from multiple directions in order to recognize the poses.
- Crossed poses (see Figure 6): Some of the avatar’s limbs are crossed. It is also considered to be necessary to look at the avatar from multiple directions in order to recognize the poses, as in the twisted poses. In addition, positional relationships between limbs should be studied further.
3.1.2. Experimental Procedure
- Sitting on a chair, the subject wore an HMD, and closed his eyes.
- Experimenter decided upon one of the above explained three view-presenting modes and an avatar pose. Then, the experimenter instructed the subject to perceive the avatar’s pose by using the instructed view-presenting mode.
- Triggered by the notice of the experimenter, the subject opened his eyes. Then, employing the instructed view-presentation mode, the subject made an effort to recognize and store the avatar’s whole pose in their memory as early as possible.
- Just after the subject finished the above process, they said “Yes”, instantly stood up, and reproduced the avatar’s pose by themself.
- The elapsed time was measured as the overall evaluation value of the pose recognition, storage, and reproduction performance. The shorter the elapsed time is, the more the subjects are assumed to get many pieces of information for pose-recognition effectively and to store them.
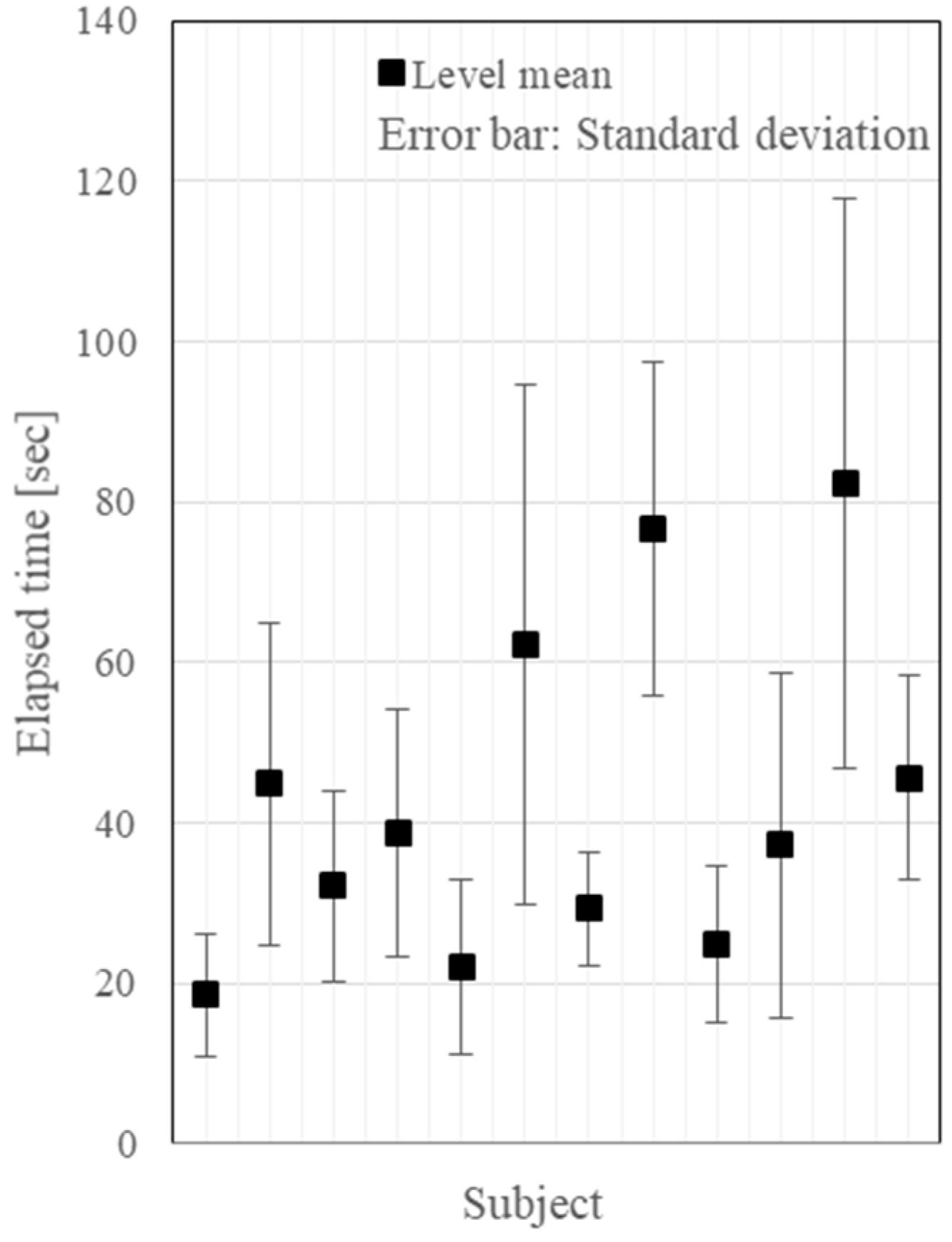
3.2. Experimental Results
3.3. Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bowman, D.A.; Datey, A.; Farooq, U.; Ryu, Y.; Vasnaik, O. Empirical Comparisons of Virtual Environment Displays. Available online: https://vtechworks.lib.vt.edu/bitstream/handle/10919/20060/TR1.pdf?sequence=3 (accessed on 30 November 2017).
- Lee, L.H.; Hui, P. Interaction Methods for Smart Glasses. arXiv, 2017; arXiv:1707.09728. [Google Scholar]
- Swan, J.E.; Jones, A.; Kolstad, E.; Livingston, M.A.; Smallman, H.S. Egocentric depth judgments in optical, see-through augmented reality. IEEE Trans. Vis. Comput. Graph. 2007, 13, 429–442. [Google Scholar] [CrossRef] [PubMed]
- Covaci, A.; Olivier, A.H.; Multon, F. Visual perspective and feedback guidance for VR free-throw training. IEEE Comput. Graph. Appl. 2015, 35, 55–65. [Google Scholar] [CrossRef] [PubMed]
- Salamin, P.; Tadi, T.; Blanke, O.; Vexo, F.; Thalmann, D. Quantifying effects of exposure to the third and first-person perspectives in virtual-reality-based training. IEEE Trans. Learn. Technol. 2010, 3, 272–276. [Google Scholar] [CrossRef]
- Salamin, P.; Thalmann, D.; Vexo, F. The benefits of third-person perspective in virtual and augmented reality? In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, Limassol, Cyprus, 1–3 November 2006; pp. 27–30. [Google Scholar]
- Pomés, A.; Slater, M. Drift and ownership toward a distant virtual body. Front. Hum. Neurosci. 2013, 7, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Hoover, A.E.; Harris, L.R. The role of the viewpoint on body ownership. Exp. Brain Res. 2015, 233, 1053–1060. [Google Scholar] [CrossRef] [PubMed]
- Sakamoto, R.; Yoshimura, Y.; Sugiura, T.; Nomura, Y. External skeleton type upper-limbs motion instruction system. In Proceedings of the JSME-IIP/ASME-ISPS Joint Conference on Micromechatronics for Information and Precision Equipment: IIP/ISPS joint MIPE, Tsukuba, Japan, 17–20 June 2009; pp. 59–60. [Google Scholar]
- Nomura, Y.; Fukuoka, H.; Sakamoto, R.; Sugiura, T. Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview. In Proceedings of the 10th International Conference on Pervasive Technologies Related to Assistive Environments, Island of Rhodes, Greece, 21–23 June 2017; pp. 56–58. [Google Scholar]
- Shepard, R.N.; Metzler, J. Mental rotation of three-dimensional objects. Science 1971, 171, 701–703. [Google Scholar] [CrossRef] [PubMed]
- Shenna, S.; Metzler, D. Mental rotation: Effects of dimensionality of objects and type of task. J. Exp. Psychol. Hum. Percept. Perform. 1988, 14, 3–11. [Google Scholar]
- Amorim, M.A.; Isableu, B.; Jarraya, M. Embodied spatial transformations: “Body analogy” for the mental rotation of objects. J. Exp. Psychol. Gen. 2006, 135, 327–347. [Google Scholar] [CrossRef] [PubMed]
- Rigal, R. Right-left orientation, mental rotation, and perspective-taking: When can children imagine what people see from their own viewpoint? Percept. Mot. Skills 1996, 83, 831–842. [Google Scholar] [CrossRef] [PubMed]
- Camporesi, C.; Kallmann, M. The Effects of Avatars, Stereo Vision and Display Size on Reaching and Motion Reproduction. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1592–1604. [Google Scholar] [CrossRef] [PubMed]
- Yu, A.B.; Zacks, J.M. How are bodies special? Effects of body features on spatial reasoning. J. Exp. Psychol. 2016, 69, 1210–1226. [Google Scholar] [CrossRef] [PubMed]
- Sharples, S.; Cobb, S.; Moody, A.; Wilson, J.R. Virtual reality induced symptoms and effects (VRISE): Comparison of head mounted display (HMD), desktop and projection display systems. Displays 2008, 29, 58–69. [Google Scholar] [CrossRef]
- Lo, W.T.; So, R.H. Cybersickness in the presence of scene rotational movements along different axes. Appl. Ergon. 2001, 32, 1–4. [Google Scholar] [CrossRef]
- Rebenitsch, L.; Owen, C. Review on cybersickness in applications and visual displays. Virtual Reality. 2016, 20, 101–125. [Google Scholar] [CrossRef]
- Tan, D.S.; Gergle, D.; Scupelli, P.; Pausch, R. Physically large displays improve performance on spatial tasks. ACM Trans. Comput. Hum. Interact. 2006, 13, 71–99. [Google Scholar] [CrossRef]
- Roosink, M.; Robitaille, N.; McFadyen, B.J.; Hébert, L.J.; Jackson, P.L.; Bouyer, L.J.; Mercier, C. Real-time modulation of visual feedback on human full-body movements in a virtual mirror: Development and proof-of-concept. J. Neuroeng. Rehabil. 2015, 12, 2. [Google Scholar] [CrossRef] [PubMed]
- Macauda, G.; Bertolini, G.; Palla, A.; Straumann, D.; Brugger, P.; Lenggenhager, B. Binding body and self in visuo-vestibular conflicts. Eur. J. Neurosci. 2015, 41, 810–817. [Google Scholar] [CrossRef] [PubMed]
- David, N.; Newen, A.; Vogeley, K. The “sense of agency” and its underlying cognitive and neural mechanisms. Conscious. Cognit. 2008, 17, 523–534. [Google Scholar] [CrossRef] [PubMed]
- Maselli, A.; Slater, M. The building blocks of the full body ownership illusion. Front. Hum. Neurosci. 2013, 7, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez-Franco, M.; Perez-Marcos, D.; Spanlang, B.; Slater, M. The contribution of real-time mirror reflections of motor actions on virtual body ownership in an immersive virtual environment. In Proceedings of the IEEE Virtual Reality Conference (VR), Waltham, MA, USA, 20–24 March 2010; pp. 111–114. [Google Scholar]
- Mohler, B.J.; Creem-Regehr, S.H.; Thompson, W.B.; Bülthoff, H.H. The effect of viewing a self-avatar on distance judgments in an HMD-based virtual environment. Presence Teleoper. Virtual Environ. 2010, 19, 230–242. [Google Scholar] [CrossRef]
- Available online: http://support.sas.com/techsup/technote/ts723_Designs.txt (accessed on 29 November 2017).













© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nomura, Y.; Fukuoka, H.; Sakamoto, R.; Sugiura, T. Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview. Technologies 2017, 5, 77. https://doi.org/10.3390/technologies5040077
Nomura Y, Fukuoka H, Sakamoto R, Sugiura T. Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview. Technologies. 2017; 5(4):77. https://doi.org/10.3390/technologies5040077
Chicago/Turabian StyleNomura, Yoshihiko, Hiroaki Fukuoka, Ryota Sakamoto, and Tokuhiro Sugiura. 2017. "Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview" Technologies 5, no. 4: 77. https://doi.org/10.3390/technologies5040077
APA StyleNomura, Y., Fukuoka, H., Sakamoto, R., & Sugiura, T. (2017). Motion Instruction Method Using Head Motion-Associated Virtual Stereo Rearview. Technologies, 5(4), 77. https://doi.org/10.3390/technologies5040077