
Review of Masked Face Recognition Based on Deep Learning

 ,
,  , and
, and
Abstract
1. Introduction
- We provide a unique taxonomy of MFR methods, organized by deep learning architecture types (CNN, GAN, Transformer), which is not explicitly presented in prior surveys.
- A comprehensive comparative table is included, summarizing state-of-the-art MFR models based on architecture, dataset, performance, and special characteristics.
- We offer a new visual framework of the review methodology, outlining the selection criteria, filtering stages, and thematic categorization of 167 papers from 2001 to 2024.
- This review highlights underexplored areas such as masked face recognition under real-world unconstrained conditions, and it provides forward-looking research directions.
- Unlike prior reviews, this study integrates both OFR and MFR methods, bridging two closely related but separately treated areas.
2. Study Scope and Relevant Research
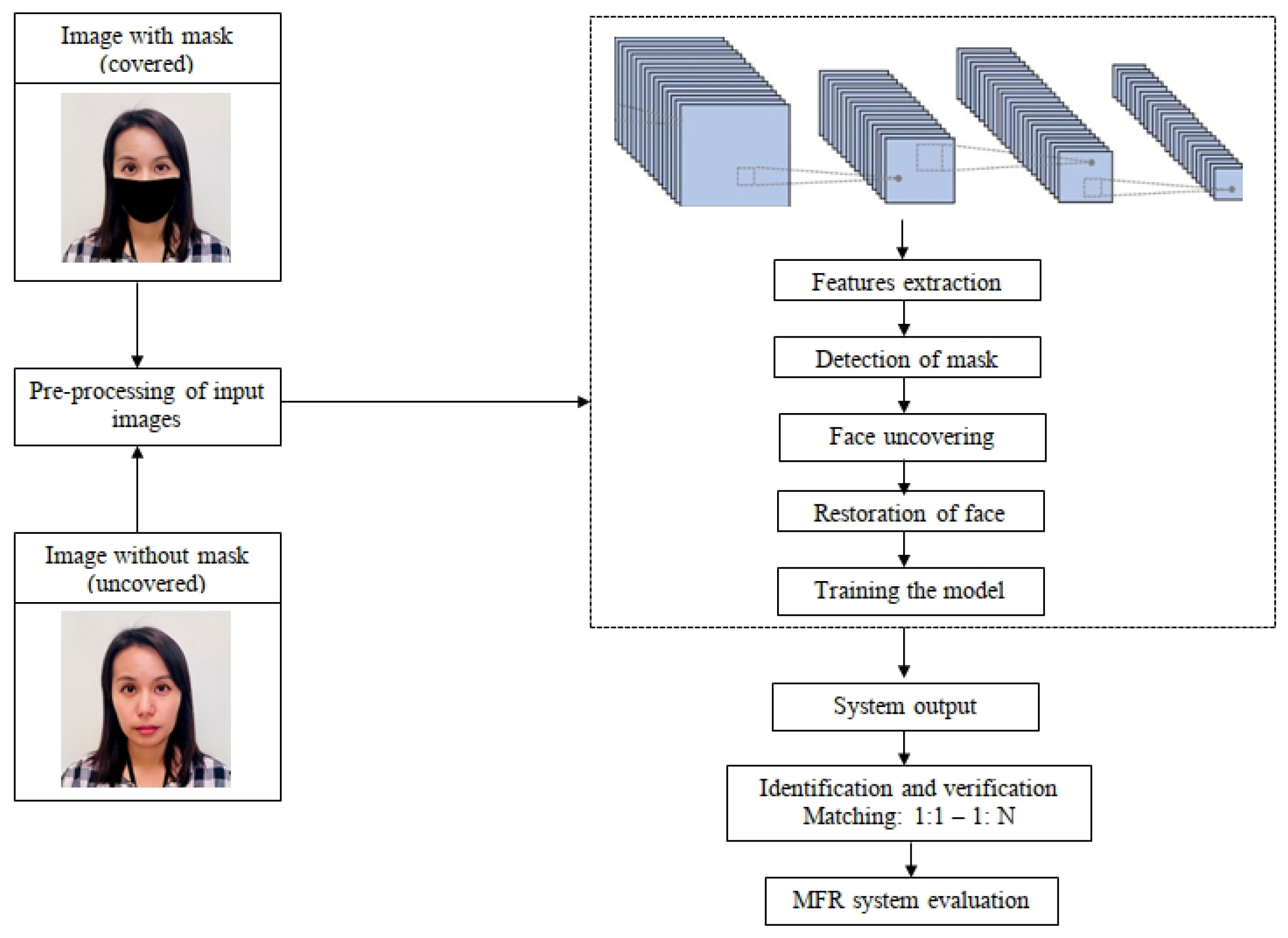
3. MFR Framework
3.1. Preprocessing of Images
3.2. Deep Learning Models
3.2.1. CNN
3.2.2. Autoencoders
- LSTM-autoencoders [69] capture temporal dependencies, which is useful in video-based MFR, enabling models to learn from sequences of partially occluded frames.
- DC-SSDA [70], or Double Channel Stacked Denoising Autoencoders, enhance feature robustness by learning from both clean and noisy inputs; useful for handling diverse mask types and positions.
- De-corrupt autoencoders [71] are tailored to restore occluded regions of the face, such as those covered by masks or hands, making them effective in recovering key facial features lost due to occlusion.
- 3D landmark-based VAEs [72] generate plausible 3D face structures from partial inputs, offering a path forward for reconstructing occluded geometry in MFR systems, particularly under varying head poses.
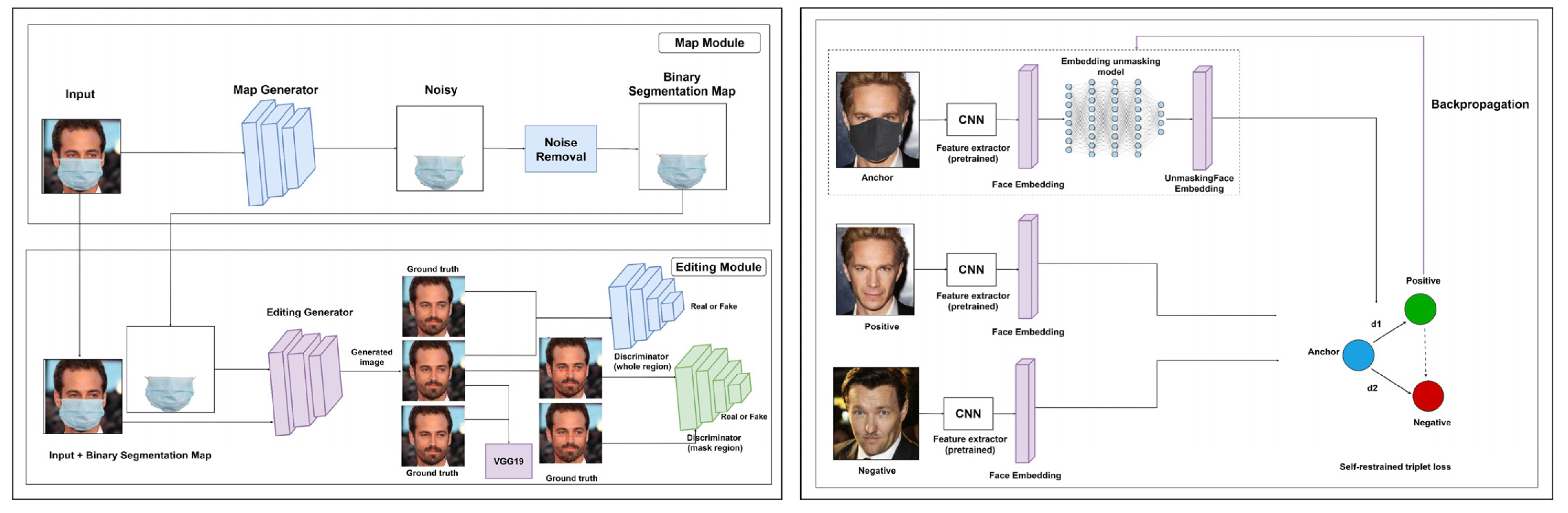
3.2.3. Generative Adversarial Networks
3.2.4. Deep Belief Network
3.3. Extraction of Features
4. Mask Detection
5. Face Unmasking
6. Review of Face Recognition Techniques
6.1. Face Recognition in the Presence of Occlusions
6.2. Reviewing Methods for MFR
7. Datasets
8. Performance Evaluation Metrics
9. Challenges and Future Research Directions
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition: A literature survey. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Infection Prevention and Control During Health Care When Coronavirus Disease (COVID-19) Is Suspected or Confirmed: Interim Guidance, 12 July 2021; WHO/2019-nCoV/IPC/2021.1; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Hsu, G.S.J.; Wu, H.Y.; Tsai, C.H.; Yanushkevich, S.; Gavrilova, M.L. Masked face recognition from synthesis to reality. IEEE Access 2022, 10, 37938–37952. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, B.; Wang, G.; Yi, P.; Jiang, K. Masked face recognition dataset and application. IEEE Trans. Biom. Behav. Identity Sci. 2023, 5, 298–304. [Google Scholar] [CrossRef]
- Kaur, P.; Krishan, K.; Sharma, S.K.; Kanchan, T. Facial-recognition algorithms: A literature review. Med. Sci. Law 2020, 60, 131–139. [Google Scholar] [CrossRef]
- Utegen, D.; Rakhmetov, B.Z. Facial recognition technology and ensuring security of biometric data: Comparative analysis of legal regulation models. J. Digit. Technol. Law 2023, 1, 825–844. [Google Scholar] [CrossRef]
- Ngan, M.L.; Grother, P.J.; Hanaoka, K.K. Ongoing Face Recognition Vendor Test (FRVT) Part 6B: Face Recognition Accuracy with Face Masks Using Post-COVID-19 Algorithms; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [Google Scholar]
- Talahua, J.S.; Buele, J.; Calvopiña, P.; Varela-Aldás, J. Facial recognition system for people with and without face mask in times of the COVID-19 pandemic. Sustainability 2021, 13, 6900. [Google Scholar] [CrossRef]
- Liu, F.; Chen, D.; Wang, F.; Li, Z.; Xu, F. Deep learning based single sample face recognition: A survey. Artif. Intell. Rev. 2023, 56, 2723–2748. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K.; Peer, P. Occluded thermal face recognition using BoCNN and radial derivative Gaussian feature descriptor. Image Vis. Comput. 2023, 132, 104646. [Google Scholar] [CrossRef]
- Peng, Y.; Wu, J.; Xu, B.; Cao, C.; Liu, X.; Sun, Z.; He, Z. Deep learning based occluded person re-identification: A survey. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 20, 1–27. [Google Scholar] [CrossRef]
- Fang, Z.; Lei, Y.; Yuan, G. Research advanced in occluded face recognition. In Proceedings of the Fifth International Conference on Computer Information Science and Artificial Intelligence (CISAI 2022), Chongqing, China, 16–18 September 2022; Volume 12566, pp. 624–633. [Google Scholar]
- Shree, M.; Dev, A.; Mohapatra, A.K. Review on facial recognition system: Past, present, and future. In Proceedings of the International Conference on Data Science and Applications: ICDSA 2022, Volume 1; Springer Nature: Singapore, 2023; pp. 807–829. [Google Scholar]
- Makrushin, A.; Uhl, A.; Dittmann, J. A survey on synthetic biometrics: Fingerprint, face, iris and vascular patterns. IEEE Access 2023, 11, 33887–33899. [Google Scholar] [CrossRef]
- Abdulrahman, S.A.; Alhayani, B. A comprehensive survey on the biometric systems based on physiological and behavioural characteristics. Mater. Today Proc. 2023, 80, 2642–2646. [Google Scholar] [CrossRef]
- Ramasundaram, B.A.; Gurusamy, R.; Jayakumar, D. Facial recognition technologies in human resources: Uses and challenges. J. Inf. Technol. Teachnol. Cases 2023, 13, 165–169. [Google Scholar] [CrossRef]
- Al-Nabulsi, J.; Turab, N.; Owida, H.A.; Al-Naami, B.; De Fazio, R.; Visconti, P. IoT solutions and AI-based frameworks for masked-face and face recognition to fight the COVID-19 pandemic. Sensors 2023, 23, 7193. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Verma, B.; Tjondronegoro, D.; Chandran, V. Facial expression analysis under partial occlusion: A survey. ACM Comput. Surv. 2018, 51, 1–49. [Google Scholar] [CrossRef]
- Lahasan, B.; Lutfi, S.L.; San-Segundo, R. A survey on techniques to handle face recognition challenges: Occlusion, single sample per subject and expression. Artif. Intell. Rev. 2019, 52, 949–979. [Google Scholar] [CrossRef]
- Zeng, D.; Veldhuis, R.; Spreeuwers, L. A survey of face recognition techniques under occlusion. IET Biom. 2021, 10, 581–606. [Google Scholar] [CrossRef]
- Hasan, M.R.; Guest, R.; Deravi, F. Presentation-level privacy protection techniques for automated face recognition—A survey. ACM Comput. Surv. 2023, 55, 1–27. [Google Scholar] [CrossRef]
- Sharma, R.; Ross, A. Periocular biometrics and its relevance to partially masked faces: A survey. Comput. Vis. Image Underst. 2023, 226, 103583. [Google Scholar] [CrossRef]
- Duong, H.T.; Nguyen-Thi, T.A. A review: Preprocessing techniques and data augmentation for sentiment analysis. Comput. Soc. Netw. 2021, 8, 1. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Liu, X.; Zou, Y.; Kuang, H.; Ma, X. Face image age estimation based on data augmentation and lightweight convolutional neural network. Symmetry 2020, 12, 146. [Google Scholar] [CrossRef]
- Charoqdouz, E.; Hassanpour, H. Feature extraction from several angular faces using a deep learning based fusion technique for face recognition. Int. J. Eng. Trans. B Appl. 2023, 36, 1548–1555. [Google Scholar] [CrossRef]
- Riaz, Z.; Mayer, C.; Beetz, M.; Radig, B. Model based analysis of face images for facial feature extraction. In Proceedings of the Computer Analysis of Images and Patterns: 13th International Conference, CAIP 2009, Münster, Germany, 2–4 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 99–106. [Google Scholar]
- Feihong, L.; Hang, C.; Kang, L.; Qiliang, D.; Jian, Z.; Kaipeng, Z.; Hong, H. Toward high-quality face-mask occluded restoration. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–23. [Google Scholar] [CrossRef]
- Shukla, R.K.; Tiwari, A.K. Masked face recognition using MobileNet V2 with transfer learning. Comput. Syst. Sci. Eng. 2023, 45, 293–309. [Google Scholar] [CrossRef]
- Fan, Y.; Guo, C.; Han, Y.; Qiao, W.; Xu, P.; Kuai, Y. Deep-learning-based image preprocessing for particle image velocimetry. Appl. Ocean Res. 2023, 130, 103406. [Google Scholar] [CrossRef]
- Zhang, Y.; Safdar, M.; Xie, J.; Li, J.; Sage, M.; Zhao, Y.F. A systematic review on data of additive manufacturing for machine learning applications: The data quality, type, preprocessing, and management. J. Intell. Manuf. 2023, 34, 3305–3340. [Google Scholar] [CrossRef]
- Hayashi, T.; Cimr, D.; Fujita, H.; Cimler, R. Image entropy equalization: A novel preprocessing technique for image recognition tasks. Inf. Sci. 2023, 647, 119539. [Google Scholar] [CrossRef]
- Murcia-Gomez, D.; Rojas-Valenzuela, I.; Valenzuela, O. Impact of Image Preprocessing Methods and Deep Learning Models for Classifying Histopathological Breast Cancer Images. Appl. Sci. 2022, 12, 11375. [Google Scholar] [CrossRef]
- Nazarbakhsh, B.; Manaf, A.A. Image pre-processing techniques for enhancing the performance of real-time face recognition system using PCA. In Bio-Inspiring Cyber Security and Cloud Services: Trends and Innovations; Springer: Berlin/Heidelberg, Germany, 2014; pp. 383–422. [Google Scholar]
- Abbas, A.; Khalil, M.I.; Abdel-Hay, S.; Fahmy, H.M. Expression and illumination invariant preprocessing technique for face recognition. In Proceedings of the 2008 International Conference on Computer Engineering & Systems, Cairo, Egypt, 25–27 November 2008; pp. 59–64. [Google Scholar]
- Mohammed Ali, F.A.; Al-Tamimi, M.S. Face mask detection methods and techniques: A review. Int. J. Nonlinear Anal. Appl. 2022, 13, 3811–3823. [Google Scholar]
- Nowrin, A.; Afroz, S.; Rahman, M.S.; Mahmud, I.; Cho, Y.Z. Comprehensive review on facemask detection techniques in the context of COVID-19. IEEE Access 2021, 9, 106839–106864. [Google Scholar] [CrossRef]
- Anwar, A.; Raychowdhury, A. Masked face recognition for secure authentication. arXiv 2020, arXiv:2008.11104. [Google Scholar]
- Cabani, A.; Hammoudi, K.; Benhabiles, H.; Melkemi, M. MaskedFace-Net–A dataset of correctly/incorrectly masked face images in the context of COVID-19. Smart Health 2021, 19, 100144. [Google Scholar] [CrossRef] [PubMed]
- Hooge, K.D.O.; Baragchizadeh, A.; Karnowski, T.P.; Bolme, D.S.; Ferrell, R.; Jesudasen, P.R.; O’toole, A.J. Evaluating automated face identity-masking methods with human perception and a deep convolutional neural network. ACM Trans. Appl. Percept. 2020, 18, 1–20. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Geng, M.; Peng, P.; Huang, Y.; Tian, Y. Masked face recognition with generative data augmentation and domain constrained ranking. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2246–2254. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Hong, J.H.; Kim, H.; Kim, M.; Nam, G.P.; Cho, J.; Ko, H.S.; Kim, I.J. A 3D model-based approach for fitting masks to faces in the wild. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 235–239. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Geng, C.; Jiang, X. Face recognition using SIFT features. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3313–3316. [Google Scholar]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced Fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar]
- Yi, Z. Researches advanced in image recognition based on deep learning. Highlights Sci. Eng. Technol. 2023, 39, 1309–1316. [Google Scholar] [CrossRef]
- Sharifani, K.; Amini, M. Machine Learning and Deep Learning: A Review of Methods and Applications. World Inf. Technol. Eng. J. 2023, 10, 3897–3904. [Google Scholar]
- Krichen, M. Convolutional neural networks: A survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Murphy, J. An Overview of Convolutional Neural Network Architectures for Deep Learning; Microway Inc.: Plymouth, MA, USA, 2016; pp. 1–22. [Google Scholar]
- Shah, A.; Shah, M.; Pandya, A.; Sushra, R.; Sushra, R.; Mehta, M.; Patel, K. A comprehensive study on skin cancer detection using artificial neural network (ANN) and convolutional neural network (CNN). Clin. eHealth 2023, 6, 76–84. [Google Scholar] [CrossRef]
- Salehi, A.W.; Khan, S.; Gupta, G.; Alabduallah, B.I.; Almjally, A.; Alsolai, H.; Mellit, A. A Study of CNN and Transfer Learning in Medical Imaging: Advantages, Challenges, Future Scope. Sustainability 2023, 15, 5930. [Google Scholar] [CrossRef]
- Indira, D.N.V.S.L.S.; Goddu, J.; Indraja, B.; Challa, V.M.L.; Manasa, B. A review on fruit recognition and feature evaluation using CNN. Mater. Today Proc. 2023, 80, 3438–3443. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Fei-Fei, L. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Academic Press: London, UK, 2020; pp. 193–208. [Google Scholar]
- Sewak, M.; Sahay, S.K.; Rathore, H. An overview of deep learning architecture of deep neural networks and autoencoders. J. Comput. Theor. Nanosci. 2020, 17, 182–188. [Google Scholar] [CrossRef]
- Bajaj, K.; Singh, D.K.; Ansari, M.A. Autoencoders based deep learner for image denoising. Procedia Comput. Sci. 2020, 171, 1535–1541. [Google Scholar] [CrossRef]
- Chen, S.; Guo, W. Auto-Encoders in Deep Learning-A Review with New Perspectives. Mathematics 2023, 11, 1777. [Google Scholar] [CrossRef]
- Sebai, D.; Shah, A.U. Semantic-oriented learning-based image compression by Only-Train-Once quantized autoencoders. Signal Image Video Process. 2023, 17, 285–293. [Google Scholar] [CrossRef]
- Zhao, F.; Feng, J.; Zhao, J.; Yang, W.; Yan, S. Robust LSTM-autoencoders for face de-occlusion in the wild. IEEE Trans. Image Process. 2017, 27, 778–790. [Google Scholar] [CrossRef]
- Cheng, L.; Wang, J.; Gong, Y.; Hou, Q. Robust deep auto-encoder for occluded face recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1099–1102. [Google Scholar]
- Zhang, J.; Kan, M.; Shan, S.; Chen, X. Occlusion-free face alignment: Deep regression networks coupled with de-corrupt autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3428–3437. [Google Scholar]
- Sharma, S.; Kumar, V. 3D landmark-based face restoration for recognition using variational autoencoder and triplet loss. IET Biom. 2021, 10, 87–98. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Chen, C.; Kurnosov, I.; Ma, G.; Weichen, Y.; Ablameyko, S. Masked Face Recognition Using Generative Adversarial Networks by Restoring the Face Closed Part. Opt. Mem. Neural Netw. 2023, 32, 1–13. [Google Scholar] [CrossRef]
- Mahmoud, M.; Kang, H.S. Ganmasker: A two-stage generative adversarial network for high-quality face mask removal. Sensors 2023, 23, 7094. [Google Scholar] [CrossRef] [PubMed]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A novel GAN-based network for unmasking of masked face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Li, X.; Shao, C.; Zhou, Y.; Huang, L. Face mask removal based on generative adversarial network and texture network. In Proceedings of the 2021 4th International Conference on Robotics, Control and Automation Engineering (RCAE), Wuhan, China, 4–6 November 2021; pp. 86–89. [Google Scholar]
- Hua, Y.; Guo, J.; Zhao, H. Deep belief networks and deep learning. In Proceedings of the 2015 International Conference on Intelligent Computing and Internet of Things, Harbin, China, 17–18 January 2015; pp. 1–4. [Google Scholar]
- Zhang, N.; Ding, S.; Zhang, J.; Xue, Y. An overview on restricted Boltzmann machines. Neurocomputing 2018, 275, 1186–1199. [Google Scholar] [CrossRef]
- Chu, J.L.; Krzyźak, A. The recognition of partially occluded objects with support vector machines, convolutional neural networks and deep belief networks. J. Artif. Intell. Soft Comput. Res. 2014, 4, 5–19. [Google Scholar] [CrossRef]
- Naskath, J.; Sivakamasundari, G.; Begum, A.A.S. A study on different deep learning algorithms used in deep neural nets: MLP, SOM and DBN. Wirel. Pers. Commun. 2023, 128, 2913–2936. [Google Scholar] [CrossRef]
- Kong, X.; Zhang, X. Understanding masked image modeling via learning occlusion invariant feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6241–6251. [Google Scholar]
- Alzu’bi, A.; Albalas, F.; Al-Hadhrami, T.; Younis, L.B.; Bashayreh, A. Masked face recognition using deep learning: A review. Electronics 2021, 10, 2666. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature extraction for hyperspectral imagery: The evolution from shallow to deep: Overview and toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Mita, T.; Kaneko, T.; Hori, O. Joint haar-like features for face detection. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Washington, DC, USA, 17–20 October 2005; Volume 2, pp. 1619–1626. [Google Scholar]
- Babu, K.N.; Manne, S. An Automatic Student Attendance Monitoring System Using an Integrated HAAR Cascade with CNN for Face Recognition with Mask. Trait. Signal 2023, 40, 743. [Google Scholar] [CrossRef]
- Oztel, I.; Yolcu Oztel, G.; Akgun, D. A hybrid LBP-DCNN based feature extraction method in YOLO: An application for masked face and social distance detection. Multimed. Tools Appl. 2023, 82, 1565–1583. [Google Scholar] [CrossRef] [PubMed]
- Chong, W.J.L.; Chong, S.C.; Ong, T.S. Masked Face Recognition Using Histogram-Based Recurrent Neural Network. J. Imaging 2023, 9, 38. [Google Scholar] [CrossRef] [PubMed]
- Şengür, A.; Akhtar, Z.; Akbulut, Y.; Ekici, S.; Budak, Ü. Deep feature extraction for face liveness detection. In Proceedings of the 2018 International Conference on Artificial Intelligence and Data Processing (IDAP), Malatya, Turkey, 28–30 September 2018; pp. 1–4. [Google Scholar]
- Lin, C.H.; Wang, Z.H.; Jong, G.J. A de-identification face recognition using extracted thermal features based on deep learning. IEEE Sens. J. 2020, 20, 9510–9517. [Google Scholar] [CrossRef]
- Li, X.; Niu, H. Feature extraction based on deep-convolutional neural network for face recognition. Concurr. Comput. Pract. Exp. 2020, 32, 1. [Google Scholar] [CrossRef]
- Wang, H.; Hu, J.; Deng, W. Face feature extraction: A complete review. IEEE Access 2017, 6, 6001–6039. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Jin, X.; Lai, Z.; Jin, Z. Learning dynamic relationships for facial expression recognition based on graph convolutional network. IEEE Trans. Image Process. 2021, 30, 7143–7155. [Google Scholar] [CrossRef]
- Balaji, S.; Balamurugan, B.; Kumar, T.A.; Rajmohan, R.; Kumar, P.P. A brief survey on AI-based face mask detection system for public places. Ir. Interdiscip. J. Sci. Res. 2021, 5, 108–117. [Google Scholar]
- Chu, P.; Li, Z.; Lammers, K.; Lu, R.; Liu, X. Deep learning-based apple detection using a suppression mask R-CNN. Pattern Recognit. Lett. 2021, 147, 206–211. [Google Scholar] [CrossRef]
- Qin, B.; Li, D. Identifying facemask-wearing condition using image super-resolution with classification network to prevent COVID-19. Sensors 2020, 20, 5236. [Google Scholar] [CrossRef]
- Tomás, J.; Rego, A.; Viciano-Tudela, S.; Lloret, J. Incorrect facemask-wearing detection using convolutional neural networks with transfer learning. Healthcare 2021, 9, 1050. [Google Scholar] [CrossRef] [PubMed]
- Ristea, N.C.; Ionescu, R.T. Are you wearing a mask? Improving mask detection from speech using augmentation by cycle-consistent GANs. arXiv 2020, arXiv:2006.10147. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef]
- Suganthalakshmi, R.; Hafeeza, A.; Abinaya, P.; Devi, A.G. COVID-19 facemask detection with deep learning and computer vision. Int. J. Eng. Res. Technol. 2021, 9, 73–75. [Google Scholar]
- Hussain, A.; Hosseinimanesh, G.; Naeimabadi, S.; Al Kayed, N.; Alam, R. WearMask in COVID-19: Identification of Wearing Facemask Based on Using CNN Model and Pre-trained CNN Models. In Intelligent Systems and Applications: Proceedings of the 2021 Intelligent Systems Conference (IntelliSys) Volume 3; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 588–601. [Google Scholar]
- Inamdar, M.; Mehendale, N. Real-time face mask identification using facemasknet deep learning network. SSRN 2020, 3663305. [Google Scholar] [CrossRef]
- Farman, H.; Khan, T.; Khan, Z.; Habib, S.; Islam, M.; Ammar, A. Real-time face mask detection to ensure COVID-19 precautionary measures in the developing countries. Appl. Sci. 2022, 12, 3879. [Google Scholar] [CrossRef]
- Sheikh, B.U.H.; Zafar, A. RRFMDS: Rapid Real-Time Face Mask Detection System for Effective COVID-19 Monitoring. SN Comput. Sci. 2023, 4, 288. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Zhang, J.; Han, F.; Chun, Y.; Chen, W. A novel detection framework about conditions of wearing face mask for helping control the spread of COVID-19. IEEE Access 2021, 9, 42975–42984. [Google Scholar] [CrossRef] [PubMed]
- Luo, F.; Zhang, Y.; Xu, L.; Zhang, Z.; Li, M.; Zhang, W. Mask wearing detection algorithm based on improved YOLOv7. Meas. Control 2024, 57, 751–762. [Google Scholar] [CrossRef]
- Samreen, S.; Arpana, C.; Spandana, D.; Sheetal, D.; Sandhya, D. Real-Time Face Mask Detection System for COVID-19 Applicants. Turk. J. Comput. Math. Educ. 2023, 14, 1–14. [Google Scholar]
- Rahman, M.H.; Jannat, M.K.A.; Islam, M.S.; Grossi, G.; Bursic, S.; Aktaruzzaman, M. Real-time face mask position recognition system based on MobileNet model. Smart Health 2023, 28, 100382. [Google Scholar] [CrossRef]
- Cao, R.; Mo, W.; Zhang, W. MFMDet: Multi-scale face mask detection using improved Cascade R-CNN. J. Supercomput. 2024, 80, 4914–4942. [Google Scholar] [CrossRef]
- Shetty, R.R.; Fritz, M.; Schiele, B. Adversarial scene editing: Automatic object removal from weak supervision. Adv. Neural Inf. Process. Syst. 2018, 31, 7717–7727. [Google Scholar]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.H. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3911–3919. [Google Scholar]
- Khan, M.K.J.; Ud Din, N.; Bae, S.; Yi, J. Interactive removal of microphone object in facial images. Electronics 2019, 8, 1115. [Google Scholar] [CrossRef]
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Self-restrained triplet loss for accurate masked face recognition. Pattern Recognit. 2022, 124, 108473. [Google Scholar] [CrossRef]
- Zhu, J.; Guo, Q.; Juefei-Xu, F.; Huang, Y.; Liu, Y.; Pu, G. Masked faces with face masks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 360–377. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. Effective removal of user-selected foreground object from facial images using a novel GAN-based network. IEEE Access 2020, 8, 109648–109661. [Google Scholar] [CrossRef]
- Afzal, H.R.; Luo, S.; Afzal, M.K.; Chaudhary, G.; Khari, M.; Kumar, S.A. 3D face reconstruction from single 2D image using distinctive features. IEEE Access 2020, 8, 180681–180689. [Google Scholar] [CrossRef]
- Qiu, H.; Gong, D.; Li, Z.; Liu, W.; Tao, D. End2end occluded face recognition by masking corrupted features. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6939–6952. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Guo, G. DSA-Face: Diverse and sparse attentions for face recognition robust to pose variation and occlusion. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4534–4543. [Google Scholar] [CrossRef]
- Biswas, R.; González-Castro, V.; Fidalgo, E.; Alegre, E. A new perceptual hashing method for verification and identity classification of occluded faces. Image Vis. Comput. 2021, 113, 104245. [Google Scholar] [CrossRef]
- Neto, P.C.; Pinto, J.R.; Boutros, F.; Damer, N.; Sequeira, A.F.; Cardoso, J.S. Beyond masks: On the generalization of masked face recognition models to occluded face recognition. IEEE Access 2022, 10, 86222–86233. [Google Scholar] [CrossRef]
- Alsaedi, N.H.; Jaha, E.S. Dynamic Feature Subset Selection for Occluded Face Recognition. Intell. Autom. Soft Comput. 2022, 31, 407. [Google Scholar] [CrossRef]
- Albalas, F.; Alzu’bi, A.; Alguzo, A.; Al-Hadhrami, T.; Othman, A. Learning discriminant spatial features with deep graph-based convolutions for occluded face detection. IEEE Access 2022, 10, 35162–35171. [Google Scholar] [CrossRef]
- Lokku, G.; Reddy, G.H.; Prasad, M.G. OPFaceNet: OPtimized Face Recognition Network for noise and occlusion affected face images using hyperparameters tuned Convolutional Neural Network. Appl. Soft Comput. 2022, 117, 108365. [Google Scholar] [CrossRef]
- Georgescu, M.I.; Duţǎ, G.E.; Ionescu, R.T. Teacher-student training and triplet loss to reduce the effect of drastic face occlusion: Application to emotion recognition, gender identification and age estimation. Mach. Vis. Appl. 2022, 33, 12. [Google Scholar] [CrossRef]
- Polisetty, N.K.; Sivaprakasam, T.; Sreeram, I. An efficient deep learning framework for occlusion face prediction system. Knowl. Inf. Syst. 2023, 65, 5043–5063. [Google Scholar] [CrossRef]
- Wang, D.; Li, R. Enhancing accuracy of face recognition in occluded scenarios with OAM-Net. IEEE Access 2023, 11, 117297–117307. [Google Scholar] [CrossRef]
- Li, Y.; Liu, H.; Liang, J.; Jiang, D. Occlusion-Robust Facial Expression Recognition Based on Multi-Angle Feature Extraction. Appl. Sci. 2025, 15, 5139. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Y.; Wang, W.; Zhang, S.; Zhang, S. Recovery-Based Occluded Face Recognition by Identity-Guided Inpainting. Sensors 2024, 24, 394. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Han, S.; Liu, D.; Ming, D. Focus and imagine: Occlusion suppression and repairing transformer for occluded person re-identification. Neurocomputing 2024, 127442. [Google Scholar] [CrossRef]
- Maharani, D.A.; Machbub, C.; Rusmin, P.H.; Yulianti, L. Improving the capability of real-time face masked recognition using cosine distance. In Proceedings of the 2020 6th International Conference on Interactive Digital Media (ICIDM), Virtual, 14–15 December 2020; pp. 1–6. [Google Scholar]
- Golwalkar, R.; Mehendale, N. Masked-face recognition using deep metric learning and FaceMaskNet-21. Appl. Intell. 2022, 52, 13268–13279. [Google Scholar] [CrossRef]
- Li, C.; Ge, S.; Zhang, D.; Li, J. Look through masks: Towards masked face recognition with de-occlusion distillation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3016–3024. [Google Scholar]
- Ding, F.; Peng, P.; Huang, Y.; Geng, M.; Tian, Y. Masked face recognition with latent part detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2281–2289. [Google Scholar]
- Hong, Q.; Wang, Z.; He, Z.; Wang, N.; Tian, X.; Lu, T. Masked face recognition with identification association. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 731–735. [Google Scholar]
- Montero, D.; Nieto, M.; Leskovsky, P.; Aginako, N. Boosting masked face recognition with multi-task arcface. In Proceedings of the 2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Dijon, France, 19–21 October 2022; pp. 184–189. [Google Scholar]
- Hariri, W. Efficient masked face recognition method during the COVID-19 pandemic. Signal Image Video Process. 2022, 16, 605–612. [Google Scholar] [CrossRef] [PubMed]
- Mandal, B.; Okeukwu, A.; Theis, Y. Masked face recognition using ResNet-50. arXiv 2021, arXiv:2104.08997. [Google Scholar]
- Du, H.; Shi, H.; Liu, Y.; Zeng, D.; Mei, T. Towards NIR-VIS masked face recognition. IEEE Signal Process. Lett. 2021, 28, 768–772. [Google Scholar] [CrossRef]
- Wu, G. Masked face recognition algorithm for a contactless distribution cabinet. Math. Probl. Eng. 2021, 2021, 5591020. [Google Scholar] [CrossRef]
- Deng, H.; Feng, Z.; Qian, G.; Lv, X.; Li, H.; Li, G. MFCosface: A masked-face recognition algorithm based on large margin cosine loss. Appl. Sci. 2021, 11, 7310. [Google Scholar] [CrossRef]
- Li, Y.; Guo, K.; Lu, Y.; Liu, L. Cropping and attention based approach for masked face recognition. Appl. Intell. 2021, 51, 3012–3025. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Liu, R.; Deguchi, D.; Murase, H. Masked face recognition with mask transfer and self-attention under the COVID-19 pandemic. IEEE Access 2022, 10, 20527–20538. [Google Scholar] [CrossRef]
- Ullah, N.; Javed, A.; Ghazanfar, M.A.; Alsufyani, A.; Bourouis, S. A novel DeepMaskNet model for face mask detection and masked facial recognition. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 9905–9914. [Google Scholar] [CrossRef] [PubMed]
- Vu, H.N.; Nguyen, M.H.; Pham, C. Masked face recognition with convolutional neural networks and local binary patterns. Appl. Intell. 2022, 52, 5497–5512. [Google Scholar] [CrossRef]
- Kocacinar, B.; Tas, B.; Akbulut, F.P.; Catal, C.; Mishra, D. A real-time CNN-based lightweight mobile masked face recognition system. IEEE Access 2022, 10, 63496–63507. [Google Scholar] [CrossRef]
- Pann, V.; Lee, H.J. Effective attention-based mechanism for masked face recognition. Appl. Sci. 2022, 12, 5590. [Google Scholar] [CrossRef]
- Huang, B.; Wang, Z.; Wang, G.; Jiang, K.; Han, Z.; Lu, T.; Liang, C. PLFace: Progressive learning for face recognition with mask bias. Pattern Recognit. 2023, 135, 109142. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Li, Y.; Zou, H. Masked face recognition system based on attention mechanism. Information 2023, 14, 87. [Google Scholar] [CrossRef]
- Huang, B.; Wang, Z.; Wang, G.; Han, Z.; Jiang, K. Local eyebrow feature attention network for masked face recognition. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–19. [Google Scholar] [CrossRef]
- Mishra, N.K.; Kumar, S.; Singh, S.K. MmLwThV framework: A masked face periocular recognition system using thermo-visible fusion. Appl. Intell. 2023, 53, 2471–2487. [Google Scholar] [CrossRef]
- Zhong, M.; Xiong, W.; Li, D.; Chen, K.; Zhang, L. MaskDUF: Data uncertainty learning in masked face recognition with mask uncertainty fluctuation. Expert Syst. Appl. 2024, 238, 121995. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. Agedb: The first manually collected, in-the-wild age database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 51–59. [Google Scholar]
- Sengupta, S.; Chen, J.C.; Castillo, C.; Patel, V.M.; Chellappa, R.; Jacobs, D.W. Frontal to profile face verification in the wild. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-Celeb-1M: A dataset and benchmark for large-scale face recognition. In Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part III 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 87–102. [Google Scholar]
- Damer, N.; Grebe, J.H.; Chen, C.; Boutros, F.; Kirchbuchner, F.; Kuijper, A. The effect of wearing a mask on face recognition performance: An exploratory study. In Proceedings of the 2020 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 16–18 September 2020; pp. 1–6. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D.J. From few to many: Illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008; pp. 1–9. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Model | Summary | Trainable Parameters | Convolutional Layers |
|---|---|---|---|
| AlexNet | Introduced in 2012, one of the pioneering deep convolutional neural networks for image classification. Consists of eight layers, including five convolutional layers and three fully connected layers. Employed techniques like ReLU activation, dropout, and local response normalization. Won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012, sparking the resurgence of interest in DL. | 62 million | 5 |
| VGGNet | Developed by the Visual Geometry Group (VGG) at the University of Oxford. Known for its simplicity, comprising multiple convolutional layers with 3 × 3 filters and max-pooling layers. Offers different configurations (e.g., VGG16, VGG19) with varying depths and number of parameters. Achieves strong performance on image classification tasks but is computationally expensive due to its large number of parameters. | 138 million–143 million | 13–16 |
| ResNet | Introduced the concept of residual connections to address the vanishing gradient problem in very deep networks. Enables training of extremely deep networks with hundreds of layers by allowing the model to learn residual mappings. Significantly improves accuracy and convergence speed by mitigating degradation issues in deeper networks. Offers various configurations, including ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152, with increasing depths. | 25 million–44 million | 48–99 |
| GoogLeNet | Developed by Google researchers, GoogLeNet introduced the inception module with parallel convolutional pathways of different filter sizes. Enables efficient capture of features at multiple scales while reducing computational complexity. Achieves high accuracy on image classification tasks with fewer parameters compared to traditional architectures. Utilizes global average pooling and auxiliary classifiers to encourage convergence and regularization during training. | 4.2 million | 28 |
| MobileNet | Designed specifically for mobile and embedded devices with limited computational resources. Utilizes depthwise separable convolutions to reduce model size and computational complexity while preserving performance. Offers different model sizes and complexities to balance between accuracy and efficiency, making it suitable for mobile applications. Well-suited for tasks like image classification, object detection, and semantic segmentation on resource-constrained devices. | 13 million–3.5 million | 28 |
| Xception | An extension of the Inception architecture that replaces standard convolutional layers with depthwise separable convolutions. Aims to improve computational efficiency and model performance by decoupling spatial and channel-wise convolutions. Achieves state-of-the-art performance on image classification tasks with significantly fewer parameters compared to previous architectures. Well-suited for applications where computational resources are limited or efficiency is crucial. | 7 million–56 million | 22 |
| DenseNet | Densely connected convolutional network where each layer receives inputs from all preceding layers; promotes feature reuse and efficient learning | 7.98 M (DenseNet-121) | 121 |
| Ref. | Method/Model | Core Techniques | Dataset/Type | Accuracy/Performance | Remarks |
|---|---|---|---|---|---|
| [137] | Haar + MobileNet | Haar-cascade, cosine distance, transfer learning | Custom | 100%, 82.20%; 4–22 FPS | Real-time, high accuracy |
| [138] | FaceMaskNet-21 | Deep metric learning | Custom (real-time CCTV) | 88.92%, <10 ms | Real-time public surveillance |
| [139] | De-Occlusion Distillation | GAN, knowledge distillation | Not specified | – | Face completion + distillation |
| [140] | LPD | Latent part detection, data augmentation | MFV, MFI (real + synthetic) | – | High generalization performance |
| [141] | Re-ID Association | Person Re-ID + face quality ranking | Surveillance-like scenes | – | Matches masked to unmasked appearances |
| [142] | MTArcFace | ArcFace + multitask mask detection | Augmented ArcFace | 99.78% (mask detection) | Joint FR and mask classification |
| [143] | CNN + MLP | VGG16, AlexNet, ResNet50, BoF | Eyes/forehead focus | – | Occlusion removal and pooling |
| [144] | ResNet-50 | DL training with masked faces | Not specified | – | Practical for security systems |
| [145] | Semi-Siamese + 3D | Mutual info maximization, 3D synthesis | NIR images | – | Domain-invariant feature learning |
| [146] | Attention + Dictionary | Dictionary learning, dilated conv, attention | RMFRD, SMFRD | – | Preserves resolution, boosts accuracy |
| [147] | MFCosface | Large margin cosine loss, Att-Inception | Synthetic masked faces | – | Focuses on unmasked areas |
| [148] | Cropping + CBAM | Attention to eye regions, cropping | Custom | – | Cross-condition learning (mask/no mask) |
| [149] | AMaskNet | Mask transfer, attention-aware model | Augmented data | – | End-to-end + mask-aware inference |
| [150] | DeepMaskNet | Face mask detection + MFR | MDMFR | – | Unified benchmark dataset and model |
| [151] | RetinaFace + LBP | LBP + DL feature fusion | COMASK20, Essex | 87% (COMASK), 98% (Essex) | Hybrid handcrafted + DL method |
| [152] | Ensemble MobileNet | Lightweight CNN, mobile deployment | 1849 samples, 12 subjects | 90.4% | Real-time FR mobile app |
| [153] | CBAM + ArcFace | Attention module + ArcFace loss | LFW, AgeDB-30, CFP-FP, MFR2 | – | High precision on eye-region features |
| [30] | MobileNetV2 + TL | VGG16/19, ResNet variants, TL | Custom datasets | Up to 99.82% | Transfer learning performance analysis |
| [154] | PLFace | Progressive training, margin loss | ArcFace-based | – | Adaptive masked/unmasked training |
| [155] | ConvNeXt-T + Attention | Lightweight attention backbones | Custom masked dataset | 99.76% (masked), 99.48% (combined) | Robust to lighting variation |
| [156] | Eyebrow GCN | Eyebrow pooling, GCN fusion | RMFRD, SMFRD | – | Leverages symmetry and component hierarchy |
| [157] | MmLwThV | Thermo-visible fusion, ensemble classifier | Visible + IR data | – | Mobile-ready, dual-modal input |
| [158] | MaskDUF | Uncertainty modeling, H-KLD, MUF | Custom + standard datasets | +1.33–13.28% over baselines | Learns sample recognizability distribution |
| Dataset Name | Type | Size | Masking Type | Notes/Significance |
|---|---|---|---|---|
| Synthetic CelebA [77] | Synthetic | 10,000 images | 50 mask types | Based on CelebA, mask types vary by size, shape, and color |
| Synthetic Face-Occluded [122] | Synthetic | – | Occlusions (hands, masks, etc.) | Based on CelebA-HQ; includes 5 object types with 40+ variations |
| MFSR [43] | Real-world | 21,357 images | Real | Segmentation + recognition; 1004 identities; manual mask annotations |
| MFDD [5] | Real-world | 24,771 images | Real | Focused on face detection with masks |
| RMFRD [5] | Real-world | 95,000 images | Real | 5000 masked + 90,000 unmasked of 525 individuals |
| SMFRD [5] | Synthetic | 500,000 images | Synthetic | 10,000 individuals; improves training diversity |
| EMFR [164] | Real-world | 4320 images | Real | Captured in sessions over days; includes reference and probe sets |
| AgeDB [160] | Real-world | 16,488 images | No mask | Faces at different ages; shows impact of aging on recognition |
| CFP [161] | Real-world | 7000 pairs | No mask | Frontal/profile views; evaluates pose variation |
| MS1MV2 [162]/MS1MV2-Masked [119] | Real/synthetic | 58 M images | Synthetic masked version exists | Widely used large-scale FR dataset; synthetic masking adds robustness |
| WebFace [165] | Real-world | 500,000 images | No mask | Faces from IMDb; identity-level diversity |
| Extended Yela B [166] | Real-world | 16,128 images | No mask | Pose + illumination variations |
| LFW [167]/LFW-SM [39] | Real/synthetic | 50,000/13,233 images | Simulated masks | Classical dataset; LFW-SM adds mask simulation |
| VGGFace2/VGGFace2_m [147] | Real/synthetic | 3.3 M+ images | Simulated masks | High intra-class variation; VGGFace2_m masks for MFR |
| CASIA-FaceV5_m [147] | Real/synthetic | 2500 images | Simulated masks | Asian faces; upgraded with masking |
| MFV/MFI [140] | Real-world | 400 pairs/4916 images | Real | Designed specifically for MFR verification and identification |
| 3D Landmark MFR dataset [123] | Real/synthetic | 200 images | Real/simulated | Based on 3D Morphable Model; useful for 3D MFR evaluation |
| Masked Face Database (MFD) | Real-world | 990 images | Real | 45 individuals, gender balanced |
| Masked Faces in the Wild (MFW) [39] | Real-world | 3000 images | Real | 300 people with 5 masked + 5 unmasked images each |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saoud, B.; Mohamed, A.H.H.M.; Shayea, I.; El-Saleh, A.A.; Alashbi, A. Review of Masked Face Recognition Based on Deep Learning. Technologies 2025, 13, 310. https://doi.org/10.3390/technologies13070310
Saoud B, Mohamed AHHM, Shayea I, El-Saleh AA, Alashbi A. Review of Masked Face Recognition Based on Deep Learning. Technologies. 2025; 13(7):310. https://doi.org/10.3390/technologies13070310
Chicago/Turabian StyleSaoud, Bilal, Abdul Hakim H. M. Mohamed, Ibraheem Shayea, Ayman A. El-Saleh, and Abdulaziz Alashbi. 2025. "Review of Masked Face Recognition Based on Deep Learning" Technologies 13, no. 7: 310. https://doi.org/10.3390/technologies13070310
APA StyleSaoud, B., Mohamed, A. H. H. M., Shayea, I., El-Saleh, A. A., & Alashbi, A. (2025). Review of Masked Face Recognition Based on Deep Learning. Technologies, 13(7), 310. https://doi.org/10.3390/technologies13070310