1. Introduction
The development of generative models opens up new possibilities in entertainment, media, and content creation and helps with our daily lives. However, the advancement of generative models has led to remarkable progress in creating photorealistic images, also significantly lowering the expertise and effort needed to produce fake images. This capability extends beyond static images to include videos, audio, and even text. The ease of producing such realistic fakes also raises significant ethical and security concerns, as it becomes increasingly difficult to detect manipulated content. This evolution necessitates advancements in detection technologies and regulatory measures to mitigate potential misuse while harnessing the creative potential of these powerful tools.
Diffusion-based generation models usually focus on low-level details of the generation image. Therefore, even though the resolution, texture, and detail of AI-generated images continuously improve, there is no semantic-level supervision or guidance in modern generative models, leading to a common issue that the generative images violate world knowledge and common sense. As shown in
Figure 1b, the AI-generated images contain penguins walking in the desert, zebras with horns, and persons with shirts on snow mountains. The current AI-generated image detection methods lack the ability to capture such semantic-level issues. Specifically, artifact-feature-based methods [
1,
2] train deep learning networks as binary classifiers on both real and AI-generated images. Spectrum-feature-based methods [
3] transform images into a spectrum domain using Fourier transform before performing recognition. Those methods are more adept at identifying detailed flaws and inconsistencies in the frequency domain while having no reasoning ability to understand high-structured information, such as the relation between objects, events, and causality for semantic error detection.
In this work, we propose reasoning AI-generated image detection, a new task focusing on identifying semantic fakes in generative images that violate world knowledge and common sense. This task pioneers a new perspective on detecting AI-generated images, complementing traditional methods by uncovering semantic-level fakes in generative images. To accomplish this task, the detection models are supposed to locate the semantic-fake regions and generate corresponding explanations in natural language, thereby potentially helping to improve the quality of generative images with the text feedback.
To tackle this new task, we introduce RADAR: a reasoning AI-generated image detection assistor, to detect semantic fakes in AI-generated images. Specifically, we conduct instruction tuning of a multimodal LLM to generate boxes of semantic fakes and corresponding text descriptions. To improve the generalization ability over novel semantic fakes, we incorporate ChatGPT-3.5 as a general AI assistor, which detects unrealistic components in the grounded descriptions given by the multimodal LLM. Finally, the results are obtained by combining the box–text responses from both the multimodal LLM and ChatGPT assistor.
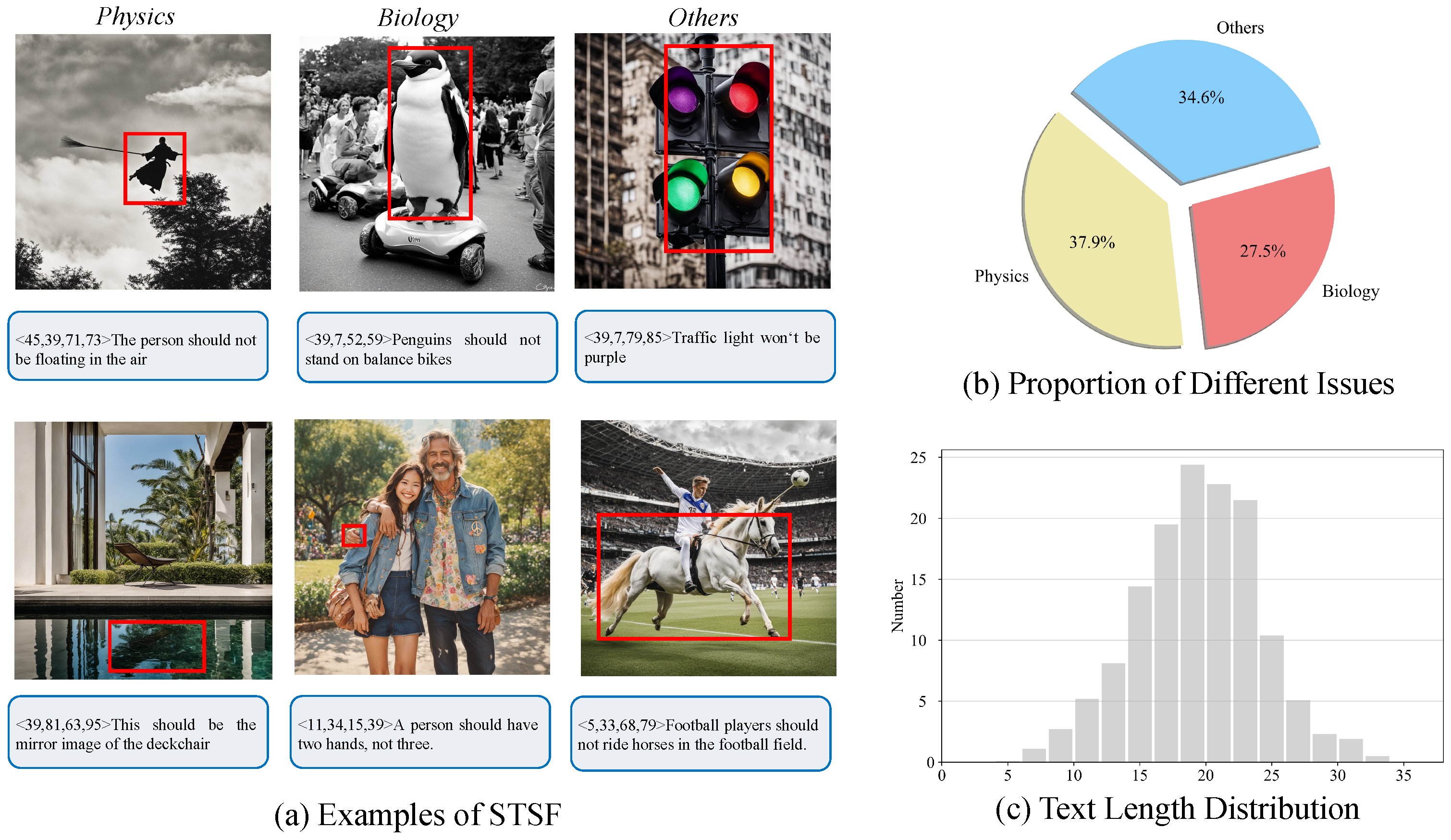
To benchmark reasoning AI-generated image detection, we assemble a dataset STSF, Spot the Semantic Fake, which contains 358 images with clear semantic-level issues. Specifically, we use three modern generative models and tools, SDXL [
4], SDXL-Turbo [
5], and Stable-Diffusion-3 [
6] to generate more than 20,00 initial images. We then manually select 358 images that violate world knowledge and common sense, annotate the fake regions with bounding boxes, and provide corresponding text descriptions, as shown in
Figure 1b. Compared with general AI-generated image detection datasets [
7,
8,
9], the STSF dataset focuses on semantic-level fakes in the generative images. We also provide detailed regional and textual information instead of solo binary signals, enhancing the interpretability of the recognition and regional detection, and promoting the development of generative models as a consequence. Experimentally, RADAR shows a promising ability to detect semantic errors in our collected STSF dataset.
To sum up, our contributions are as follows:
We propose a new task, reasoning AI-generated image detection, which focuses on identifying semantic fakes in generative images that contradict world knowledge and common sense.
We collect a new dataset STSF that contains AI-generated images with clear semantic fakes to be a proper testbed for reasoning AI-generated image detection.
We introduce RADAR: a reasoning AI-generated image detection assistor, a specialized multimodal LLM to detect semantic errors in AI-generated images with ChatGPT assistor. Experiments on STSF show that RADAR could detect semantic fakes in generative images, which is an extensive complement to traditional AI-generated image detection methods focusing on low-level details.
2. Related Work
Recent advancements in generative models, especially diffusion models, have revolutionized the field of image generation, facilitating the production of realistic and superior-quality images and videos. Diffusion models (DMs) [
10,
11], generating samples by gradually denoising images corrupted by Gaussian noise, have demonstrated their superior performance in various image synthesis, such as text-to-image (T2I) generation in Stable Diffusion [
12], GLIDE [
13], DALLE-2 [
14], and Imagen [
15], speech synthesis [
16,
17], and super-resolution in SR3 [
18] and IDM [
19]. Moreover, DMs have been applied to text-to-3D synthesis in DreamFusion [
20] and subsequent research [
21,
22,
23,
24,
25], video synthesis [
26,
27,
28,
29,
30], text-to-motion generation [
31], etc. On the other hand, DiT [
32] provides better potential for diffusion models based on vision transformers. Pixart [
33], Stable-Diffusion-3 [
6], Hunyuan-DiT [
34], and Lumina-T2X [
35] further enhance the stability and scalability of DiT, expanding its applicability across various complex visual tasks.
Recent research has witnessed a surge of interest in multimodal large language models (MLLMs). Benefiting from the strong reasoning capabilities of large language models (LLMs), MLLMs exhibit promising performance in multimodal generation tasks, such as image captioning and Visual Question Answering (VQA). Collaborative models, such as Visual ChatGPT [
36], MM-REACT [
37], and HuggingGPT [
38], often use pretrained tools to translate visual information into text inputs of LLMs. End-to-end trained models including BLIP series [
39,
40], LLaVA series [
41], and MiniGPT-4 [
42] enable the LLMs to comprehend the visual inputs by training projection layers to map the image contents to the text space of LLMs.
Early works primarily centered around face forgery detection, which usually focuses on capturing the low-level artifacts [
43,
44,
45] and frequency domain inconsistencies [
46,
47,
48]. Similar strategies have also been applied to general fake image detection [
1,
3,
49,
50,
51]. More recently, DIRE [
52] utilizes the reconstruction error between the input and its reconstruction counterpart by a diffusion model to train the detector. RIGID [
53] proposes a training-free method by comparing the representation similarity of the real and fake images. In general, these methods concentrate on capturing the artifacts of image features (e.g., image stitching and cropping), ignoring specific semantic-level fakes (e.g., logical or physical errors). In contrast, our RADAR leverages the inference ability of an LLM to not only locate semantic forgery in generated images but also provide semantic level explanations.
To benchmark AI-generated image detection, many works use advanced generative models to collect synthetic datasets. Early datasets [
54,
55] are primarily constructed using manipulated facial images. For general datasets, CNNSpot [
1] introduces ProGAN [
56] to obtain synthetic data. DeepArt [
57], DE-FAKE [
58], and CiFAKE [
59] employ advanced diffusion models to produce more realistic images. Nonetheless, these datasets only have simple classification labels, indicating whether the given images are real or fake. In contrast, our collected STSF is specially collected with distinct semantic-level issues, complete with annotations in the form of bounding boxes and textual explanations.
3. Method
3.1. Task Setup
Given a set
containing AI-generated and real images, traditional AI-generated image detection aims to distinguish AI-generated images from real images. In other words, a binary classifier
is required to recognize real images
and AI-generated images
. Given the binary labels, the classifiers are usually trained end-to-end with neural networks [
43,
44,
45,
48]. Therefore, the models tend to learn shortcuts that recognize specific artifacts from certain generative models that may not even be visible to the naked eye.
We claim that a common issue of current generative models is the lack of reasoning ability. In other words, the generative models have no awareness of world knowledge and common sense. As a result, the generative images may possess semantic-level fakes.
Figure 2 shows cases, a man features three hands and a person is floating in the air, which are unlikely to happen in the real world. In this work, we propose reasoning AI-generated image detection, which aims to locate those semantic unrealistic regions in given images, and also provide corresponding text explanations:
where
is the bounding boxes of the target regions, and
is the corresponding text explanations of each box.
is a binary score to indicate the confidence of the box–text response, which could be aggregated and used for binary classification as in traditional methods.
To sum up, traditional AI-generated image detection aims to recognize generative images with binary classifiers, without the requirements of interpretability, while reasoning AI-generated image detection focuses on detecting regions with semantic fakes in generative images, which could benefit the generative models to produce more realistic images given the feedback of the semantic fakes.
We design three sub-tasks for reasoning AI-generated image detection. (a) Binary Classification aims to identify generative images from real images, the same as the traditional AI-generated image detection. We utilize AUC and AP as the evaluation metrics, following existing work [
53]. (b) Regional Semantic Fake Detection aims to locate the regions with semantic issues in given images. We adopt average precision (AP) and average recall (AR) as the evaluation metrics. (c) Text Generation aims to output reasonable text descriptions for semantic fakes. As for the evaluation, we adopt LAVE (LLM-Assisted VQA Evaluation) [
60] to score the similarity of generated text and ground truth text with the help of large language models.
3.2. STSF Dataset
3.2.1. Collection and Annotation
To benchmark reasoning AI-generated image detection, we establish a dataset named STSF (Spot the Semantic Fake), which contains real images and generative images with semantic errors. Specifically, we start with collecting 2000 text prompts from widely used image caption datasets, COCOCaption [
61] and LLaVA-Instruct-158K [
41], as the inputs of generative models. Then we obtain corresponding generative images given text inputs with three modern diffusion-based models SDXL [
4], SDXL-Turbo [
5], and Stable-Diffusion-3 [
6]. Some of the generative images have no obvious semantic fakes, which is not the objective of this work. Therefore, we manually select generative images with obvious semantic fakes that violate world knowledge and common sense, and remove the rest as a consequence, forming a collection of 358 generative images with obvious semantic fakes. The resolution is set to
. To provide detailed information for the semantic fakes, we thoroughly annotate the bounding boxes of the fake regions as well as the text descriptions, which increases the interpretability compared with traditional AI-generated image detection datasets. We further randomly sample 968 real images from MS-COCO [
62] to serve as negative samples in binary classification task.
3.2.2. Dataset Statistics
Specifically, the length of the text descriptions varies from 4 to 34 words. We group all data into several commonly seen issues, as shown in
Figure 2. (i) Physics: events, interactions, and states violate laws of physics, such as a person floating in the air, and a mirror showing different objects; (ii) Biology: organisms have unreal structures or are in the wrong habitats, such as a person with three hands, and a penguin on a balance bike. (iii) Others: images violate all other common senses, such as a traffic light having 4 different colors, and a man riding a horse in the football field.
Compared to traditional AI-generated image detection benchmarks, such as LSUN-BEDROOM [
7], Genimage [
8], and Wildfake [
9], we provide multimodal annotations rather than binary labels to intuitively explain unrealistic parts, which could benefit the generative models as a consequence with the feedback from the semantic fakes. For training and evaluation purposes, STSF is split into a train set and a validation set, which contain 843 and 1157 images, respectively.
3.3. RADAR
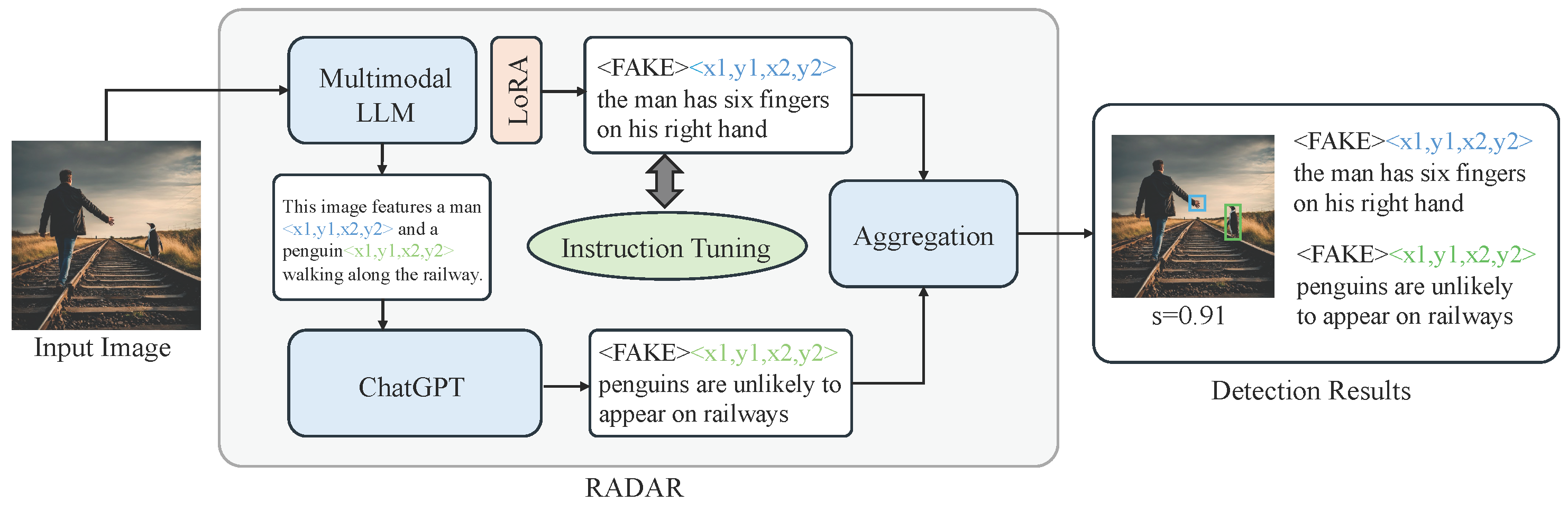
After constructing the STSF dataset, we here present RADAR, a reasoning AI-generated image detection assistor, to detect the semantic fakes in generative images, as shown in
Figure 3. Specifically, we conduct instruction tuning of a pretrained multimodal LLM (MLLM) on the STSF dataset. Then the finetuned MLLM is enabled to generate bounding boxes and text descriptions of semantic fakes in given images. To improve the generalization ability on novel semantic fakes, we propose to incorporate ChatGPT as an AI assistor to detect general unrealistic components in grounded image descriptions given by MLLM.
3.3.1. Instruction Tuning of MLLM
To detect semantic fakes in AI-generated images, knowledge awareness and reasoning ability are required. Inspired by the achievements of recent large language models, we adopt an instruction tuning scheme over a pretrained MLLM to accomplish reasoning AI-generated image detection. We start with building a visual-to-text (V2T) mapping to align the visual inputs with text inputs. Specifically, an EVA [
63] model is adopted as the visual backbone to extract visual features from the input images. Then a trainable linear projection layer is used to project visual features into text domains. The projected features are then concatenated with the text prompts as the inputs to a pretrained LLaMA2-chat(7B) [
64]. We follow the LLaMA-2 conversation template design and adapt it for the reasoning AI-generated image detection template. The template is shown as follows:
USER: <Img> <ImgFeature> </Img> Please locate the regions that look unreal (violate world knowledge and common sense), and explain why.
RADAR: <flag ><x1, y1, x2, y2 ><reason>.
In this template,
USER refers to the human role, and
RADAR refers to assistor role.
<flag> identifies if the image is AI-generated. For AI-generated images,
<flag> is set to
<FAKE>, while for real images,
<flag> is set to
<REAL>.
<FAKE> and
<REAL> are two special tokens; we conduct softmax over logits of those two tokens to obtain the classification score
s of this box–text response:
<x1, y1, x2, y2> represents the coordinate top-left corner and bottom-right corner of the semantic-fake regions. The coordinates are encoded by integers normalized in range [0, 100]. The <reason> is the text description of the semantic fake. As for real images or images without semantic level issues, we set <x1, y1, x2, y2> and <reason> to be empty.
Based on the designed template, we conduct the instruction tuning on the STSF training set. Specifically, we use the pretrained MiniGPT-v2 [
65] after stage 2 training as the starting point of instruction tuning. During the instruction tuning, we combine STSF and datasets used in the MiniGPT-v2 stage 3 for joint training to maintain the general ability of the MLLM, such as grounding and conversation.
3.3.2. ChatGPT Assistor
Reasoning AI-generated image detection is a completely new task for the MLLM, and there are not enough training samples to cover all kinds of semantic fakes during the instruction tuning process. Moreover, the original reasoning ability of the LLM is harmed during the alignment with the visual domain in the multimodal LLM, which makes it challenging to generalize to unseen semantic issues requiring complex knowledge reasoning ability. To improve the generalization ability of RADAR on various semantic fakes, we introduce ChatGPT as a zero-shot assistor to help locate complex semantic issues. The process is shown in
Figure 4. As a general LLM, such as ChatGPT, cannot take images as input, we first ask the multimodal LLM to provide detailed and grounded descriptions in text. After obtaining the grounded description of the images, the LLM assistor could understand the details of objects and events in the given images and find illogical components with only text as inputs.
Result Aggregation Finally, the outputs of the ChatGPT assistor are aggregated with the original outputs from the MLLM. Specifically, NMS (Non-Maximum Suppression) is applied to remove duplicated boxes. Then we utilize ChatGPT to refine the text generated by the MLLM. The final image classification score is obtained by averaging the classification score s of all valid box–text responses. By combining the results from the MLLM and ChatGPT assistor, RADAR could locate more complex semantic fakes requiring comprehensive knowledge reasoning, performing robust generalization ability over unseen semantic fakes.
4. Experiments
4.1. Implementation Details
Following MiniGPT-v2 [
65], RADAR adopts LLaMA2-7B [
64] as the LLM and a ViT vision encoder to extract visual tokens. We initialize RADAR with the parameters of pretrained MiniGPT-v2 after stage two. During the entire training process, the visual backbone remains frozen. We finetune the LLM with LoRA [
66] on our collected STSF dataset, in which the rank
r is set to 64. The images are resized to
during the training. We use AdamW [
67] optimizer with a cosine learning rate scheduler to train RADAR. The learning rate is set to
. We train on 8 × A100 GPUs for 50,000 iterations with a global batch size of 48 for the STSF dataset. As for the results aggregation, we generate five responses from the MLLM and utilize all results from ChatGPT. Then NMS is conducted to remove duplicated boxes. The NMS threshold is set to 0.5. During training, the datasets used in MiniGPT-v2, such as LLaVA-Instruction [
41], Flicker 30k [
68], and RefCOCO [
69], are combined with the STSF dataset for joint training to maintain the general ability of the MLLM, such as text generation and grounded image caption. As for regional semantic fake detection evaluation, the threshold of IoU between predicted boxes and ground truth boxes is fixed to a small value of 0.3, as we focus on rough semantic fake regions.
4.2. Results on STSF Datasets
We conduct extensive experiments on the STSF dataset, see
Table 1. In terms of binary classification, two existing AI-generated image detection methods, DIRE [
52] and RIGID [
53], achieve 71.2/73.1 and 78.4/77.6 on the STSF validation set, while RADAR achieves 81.4/82.0, outperforming GIRE and RIGID by 10.2/8.9 and 3.0/4.4. Moreover, the existing AI-generated image detection methods can only generate a binary classification signal, without the ability to detect the semantic fake regions and generate corresponding text descriptions. RADAR outperforms traditional object detection methods Faster-RCNN [
70] and DETR [
71] by over 20 AP/AR in terms of detection performance. The reason is that object detection methods lack general knowledge reasoning ability, and thus suffer from poor generalization ability when novel issues occur. Some visualizations of RADAR are shown in
Figure 5. For instance, in the last image of the first row, RADAR outputs “The turtle looks unreal”. The bounding box precisely locates the turtle’s head, revealed to be a lion’s head, which is the specific attribute inconsistency that RADAR identified. This localization helps to pinpoint the visual evidence for the detected implausibility.
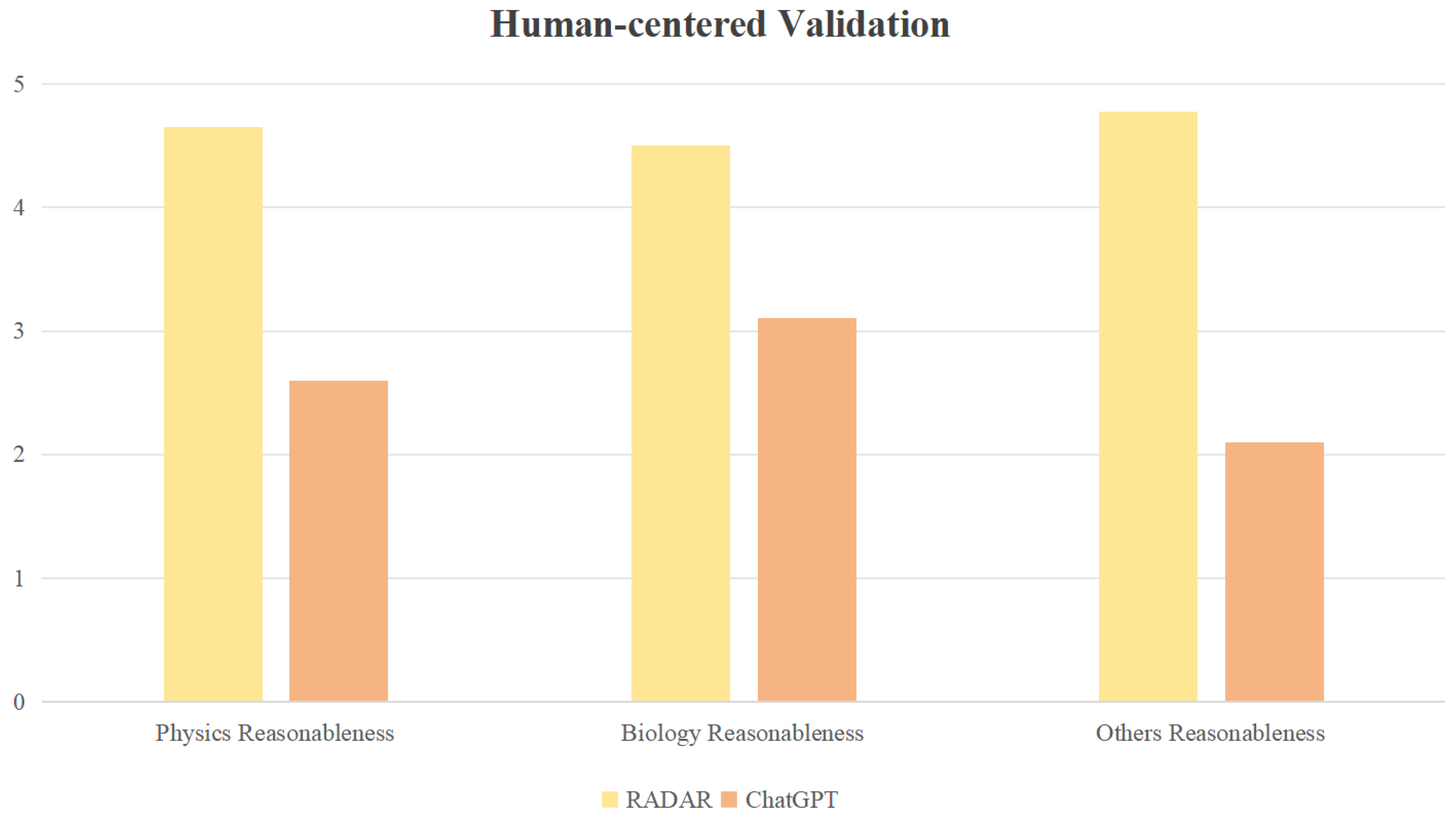
To further demonstrate the rationality of the proposed RADAR, we conduct a small-scale survey, inviting 50 participants to independently rate the reasonableness of the outputs from RADAR and ChatGPT on a scale of 0 to 5 (where 0 indicates completely unreasonable and 5 indicates completely reasonable). As shown in the following
Figure 6, compared to vision GPT, RADAR achieves superior results and its performance is close to the gold standard of human judgment. This indicates that the proposed RADAR can accurately reflect the semantic-level fakes of AI-generated images.
4.3. Ablation Studies
w/o ChatGPT Assistor As shown in
Table 1, with the ChatGPT assistor, RADAR achieves more than a 10 percent improvement in terms of detection AP/AR and text similarity. We claim that the pretrained multimodal large language models, such as LLaVA [
41], focus on visual–language alignment and have poor text generation ability. The raw text generation and reasoning ability of large language models are harmed during the visual–language joint training. As shown in the first row of
Figure 7, without the ChatGPT assistor, RADAR tends to generate simple text descriptions with the same pattern in the training set, while the detected boxes tend to be commonly seen issues such as extra hands and legs. With the help of the ChatGPT assistor, RADAR is enabled to generate reasonable text descriptions and locate novel mistakes without seeing any similar fakes during the training. However, the ChatGPT assistor fails to detect fake regions that will not appear in the grounded captions. For example, as for the cases in
Figure 7, the MLLM will generate grounded captions like: “A black man wearing a yellow T-shirt is playing tennis”, while the extra legs/arms are not included. Therefore, the ChatGPT assistor has no ability to locate such issues. To sum up, the combination of MLLM and ChatGPT will help to locate both detailed and high-level semantic fakes.
Cross-validation We show the experiment results of RADAR and MLLM (without the ChatGPT assistor) with different training and evaluation groups in
Table 2. As shown, without the ChatGPT Assistor, the MLLM trained on certain groups of training sets has serious overfitting, and cannot generalize to the rest of the groups. By utilizing the general knowledge reasoning ability of the ChatGPT assistor, RADAR is enabled to detect general semantic fakes given grounded text descriptions. As a result, RADAR achieves relatively stable performance in different validation groups.
4.4. Limitation
The main goal of RADAR is to locate and explain the semantic fakes in AI-generated images, thus helping generate more realistic images that conform to world knowledge and common sense. As shown in the third row of
Figure 5, the AI-generated images may not have semantic-level fakes. In this case, RADAR has no ability to distinguish AI-generated images from real images. As a result, for traditional deepfake detection, RADAR could only serve as a complement to existing binary classification methods to detect semantic-level issues.
5. Conclusions
In this work, we propose a new task, reasoning AI-generated image detection, which focuses on identifying semantic fakes in generative images that violate world knowledge and common sense. To benchmark reasoning AI-generated image detection, we collect a dataset, STSF, short for Spot the Semantic Fake. STSF contains 358 images with clear semantic errors generated by three different modern diffusion models and provides bounding boxes as well as text annotations to locate the fake regions. We propose RADAR, a reasoning AI-generated image detection assistor, to locate semantic fakes in the generated images and offer corresponding text explanations. Extensive experiment results on STSF show that RADAR has promising abilities to locate and explain semantic fakes in AI-generated images, which could help to improve the quality of the generative images.
6. Discussion
While RADAR demonstrates promising capabilities in detecting semantic fakes, several considerations and avenues for future research are important for advancing the field. A critical aspect for practical deployment is robustness against adversarial fakes, i.e., subtle manipulations designed to deceive detection methods. Future work should investigate the resilience of VLM-based approaches like RADAR to such attacks and develop mitigation strategies to ensure reliability. Furthermore, enhancing how semantic errors are represented in datasets warrants exploration. While the STSF dataset utilizes bounding boxes, adopting more flexible annotation methods such as segmentation masks could provide more precise localization of errors, and graph-based representations could explicitly model complex incorrect relationships between multiple entities. These richer annotation schemes could lead to models with a deeper understanding of intricate semantic fakes and improve the explainability of their results.
Future Work: Building upon the foundation of RADAR and the STSF dataset, further advancements in semantic fake detection can be achieved by enhancing dataset scale, diversity, and the granularity of semantic error representation. One such direction involves exploring novel generation and annotation paradigms. Specifically, leveraging dynamically generated sequences where visual content exhibits progressively increasing semantic implausibility holds considerable potential. This method could streamline annotation processes, as annotators could more readily identify the onset and nature of semantic errors by comparing distorted elements against a consistent baseline within the sequence. Such an approach might not only facilitate the efficient collection of diverse semantic fakes but also enable the creation of datasets with fine-grained labels capturing the severity or specific type of semantic deviation.
Ethical Impacts: While RADAR aims to address the challenge of detecting semantic fakes in AI-generated images, it is crucial to acknowledge its inherent limitations and potential ethical implications. The method, like any AI tool, cannot entirely avoid misidentification, leading to false positives or false negatives, which could discredit creators or allow misleading content to proliferate. This risk is compounded by the subjective nature of “common sense” and the continuous evolution of generative models. Furthermore, there is a potential for misuse of the technology, such as selective censorship or weaponizing of fake labels, if not deployed responsibly. A core component of RADAR involves large language models (LLMs), which are known to be prone to hallucinations and biases. Such hallucinations could result in inaccurate textual explanations, while inherent biases in LLM training data might skew RADAR’s performance across different cultural contexts or image types. Consequently, the explanations provided by RADAR should be critically evaluated, and the tool itself is best utilized as an assistor requiring human oversight in critical applications, rather than a definitive arbiter of semantic truth. The generalizability of RADAR is also dependent on the diversity of its training data, and its performance may vary on novel types of semantic fakes or generative models not represented in the current STSF dataset.
Author Contributions
Conceptualization and writing, H.W. and Z.L.; methodology and data curation, X.L.; software, C.Y.; validation, X.J. and C.Y.; review and editing, R.W.; project administration and funding acquisition, E.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded by the European Union (ERC, EVA, 950086).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
We declare that this study does not involve humans.
Data Availability Statement
Conflicts of Interest
Xiaolong Jiang was employed by Xiaohongshu. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 8695–8704. [Google Scholar]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN generated images easy to detect? A critical analysis of the state-of-the-art. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Sinitsa, S.; Fried, O. Deep image fingerprint: Towards low budget synthetic image detection and model lineage analysis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2024; pp. 4067–4076. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar]
- Sauer, A.; Lorenz, D.; Blattmann, A.; Rombach, R. Adversarial diffusion distillation. arXiv 2023, arXiv:2311.17042. [Google Scholar]
- Esser, P.; Kulal, S.; Blattmann, A.; Entezari, R.; Müller, J.; Saini, H.; Levi, Y.; Lorenz, D.; Sauer, A.; Boesel, F.; et al. Scaling rectified flow transformers for high-resolution image synthesis. In Proceedings of the Forty-first International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Zhu, M.; Chen, H.; Yan, Q.; Huang, X.; Lin, G.; Li, W.; Tu, Z.; Hu, H.; Hu, J.; Wang, Y. Genimage: A million-scale benchmark for detecting ai-generated image. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024; Volume 36. [Google Scholar]
- Hong, Y.; Zhang, J. Wildfake: A large-scale challenging dataset for ai-generated images detection. arXiv 2024, arXiv:2402.11843. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the NeurIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Vahdat, A.; Kreis, K.; Kautz, J. Score-based generative modeling in latent space. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Kong, Z.; Ping, W.; Huang, J.; Zhao, K.; Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv 2020, arXiv:2009.09761. [Google Scholar]
- Liu, J.; Li, C.; Ren, Y.; Chen, F.; Zhao, Z. Diffsinger: Singing voice synthesis via shallow diffusion mechanism. In Proceedings of the AAAI, Vancouver, BC, Canada, 22 February–1 March 2022. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Gao, S.; Liu, X.; Zeng, B.; Xu, S.; Li, Y.; Luo, X.; Liu, J.; Zhen, X.; Zhang, B. Implicit diffusion models for continuous super-resolution. In Proceedings of the CVPR, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Poole, B.; Jain, A.; Barron, J.T.; Mildenhall, B. Dreamfusion: Text-to-3d using 2d diffusion. arXiv 2022, arXiv:2209.14988. [Google Scholar]
- Lin, C.H.; Gao, J.; Tang, L.; Takikawa, T.; Zeng, X.; Huang, X.; Kreis, K.; Fidler, S.; Liu, M.Y.; Lin, T.Y. Magic3D: High-Resolution Text-to-3D Content Creation. arXiv 2022, arXiv:2211.10440. [Google Scholar]
- Wang, H.; Du, X.; Li, J.; Yeh, R.A.; Shakhnarovich, G. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Proceedings of the ICCV, Paris, France, 2–6 October 2023. [Google Scholar]
- Tang, J.; Wang, T.; Zhang, B.; Zhang, T.; Yi, R.; Ma, L.; Chen, D. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. arXiv 2023, arXiv:2303.14184. [Google Scholar]
- Wang, Z.; Lu, C.; Wang, Y.; Bao, F.; Li, C.; Su, H.; Zhu, J. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. arXiv 2023, arXiv:2305.16213. [Google Scholar]
- Zhu, J.; Zhuang, P. HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance. arXiv 2023, arXiv:2305.18766. [Google Scholar]
- Ho, J.; Salimans, T.; Gritsenko, A.; Chan, W.; Norouzi, M.; Fleet, D.J. Video diffusion models. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Ho, J.; Chan, W.; Saharia, C.; Whang, J.; Gao, R.; Gritsenko, A.; Kingma, D.P.; Poole, B.; Norouzi, M.; Fleet, D.J.; et al. Imagen video: High definition video generation with diffusion models. arXiv 2022, arXiv:2210.02303. [Google Scholar]
- Yu, S.; Sohn, K.; Kim, S.; Shin, J. Video probabilistic diffusion models in projected latent space. In Proceedings of the CVPR, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Blattmann, A.; Rombach, R.; Ling, H.; Dockhorn, T.; Kim, S.W.; Fidler, S.; Kreis, K. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the CVPR, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Wu, J.Z.; Ge, Y.; Wang, X.; Lei, S.W.; Gu, Y.; Shi, Y.; Hsu, W.; Shan, Y.; Qie, X.; Shou, M.Z. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the ICCV, Paris, France, 2–6 October 2023. [Google Scholar]
- Tevet, G.; Raab, S.; Gordon, B.; Shafir, Y.; Cohen-Or, D.; Bermano, A.H. Human motion diffusion model. In Proceedings of the ICLR, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Peebles, W.; Xie, S. Scalable Diffusion Models with Transformers. arXiv 2022, arXiv:2212.09748. [Google Scholar]
- Chen, J.; Yu, J.; Ge, C.; Yao, L.; Xie, E.; Wu, Y.; Wang, Z.; Kwok, J.; Luo, P.; Lu, H.; et al. Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv 2023, arXiv:2310.00426. [Google Scholar]
- Li, Z.; Zhang, J.; Lin, Q.; Xiong, J.; Long, Y.; Deng, X.; Zhang, Y.; Liu, X.; Huang, M.; Xiao, Z.; et al. Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding. arXiv 2024, arXiv:2405.08748. [Google Scholar]
- Gao, P.; Zhuo, L.; Lin, Z.; Liu, C.; Chen, J.; Du, R.; Xie, E.; Luo, X.; Qiu, L.; Zhang, Y.; et al. Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers. arXiv 2024, arXiv:2405.05945. [Google Scholar]
- Wu, C.; Yin, S.; Qi, W.; Wang, X.; Tang, Z.; Duan, N. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv 2023, arXiv:2303.04671. [Google Scholar]
- Yang, Z.; Li, L.; Wang, J.; Lin, K.; Azarnasab, E.; Ahmed, F.; Liu, Z.; Liu, C.; Zeng, M.; Wang, L. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv 2023, arXiv:2303.11381. [Google Scholar]
- Shen, Y.; Song, K.; Tan, X.; Li, D.; Lu, W.; Zhuang, Y. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024; Volume 36. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024; Volume 36. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 25–27 June 2016; pp. 5–10. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7890–7899. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 86–103. [Google Scholar]
- Li, J.; Xie, H.; Li, J.; Wang, Z.; Zhang, Y. Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6458–6467. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S.F. Detecting and simulating artifacts in gan fake images. In Proceedings of the 2019 IEEE international workshop on information forensics and security (WIFS), Delft, The Netherlands, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Dzanic, T.; Shah, K.; Witherden, F. Fourier spectrum discrepancies in deep network generated images. Adv. Neural Inf. Process. Syst. 2020, 33, 3022–3032. [Google Scholar]
- Chandrasegaran, K.; Tran, N.T.; Cheung, N.M. A closer look at fourier spectrum discrepancies for cnn-generated images detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7200–7209. [Google Scholar]
- Wang, Z.; Bao, J.; Zhou, W.; Wang, W.; Hu, H.; Chen, H.; Li, H. Dire for diffusion-generated image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 22445–22455. [Google Scholar]
- He, Z.; Chen, P.Y.; Ho, T.Y. RIGID: A Training-free and Model-Agnostic Framework for Robust AI-Generated Image Detection. arXiv 2024, arXiv:2405.20112. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Wang, Y.; Huang, Z.; Hong, X. Benchmarking deepart detection. arXiv 2023, arXiv:2302.14475. [Google Scholar]
- Sha, Z.; Li, Z.; Yu, N.; Zhang, Y. De-fake: Detection and attribution of fake images generated by text-to-image generation models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2023; pp. 3418–3432. [Google Scholar]
- Bird, J.J.; Lotfi, A. Cifake: Image classification and explainable identification of ai-generated synthetic images. IEEE Access 2024, 12, 15642–15650. [Google Scholar] [CrossRef]
- Mañas, O.; Krojer, B.; Agrawal, A. Improving automatic vqa evaluation using large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4171–4179. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Fang, Y.; Wang, W.; Xie, B.; Sun, Q.; Wu, L.; Wang, X.; Huang, T.; Wang, X.; Cao, Y. Eva: Exploring the limits of masked visual representation learning at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 19358–19369. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Chen, J.; Zhu, D.; Shen, X.; Li, X.; Liu, Z.; Zhang, P.; Krishnamoorthi, R.; Chandra, V.; Xiong, Y.; Elhoseiny, M. Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning. arXiv 2023, arXiv:2310.09478. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in adam. arXiv 2018, arXiv:1711.05101. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Yu, L.; Poirson, P.; Yang, S.; Berg, A.C.; Berg, T.L. Modeling context in referring expressions. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–85. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}