
Methods of Deployment and Evaluation of FPGA as a Service Under Conditions of Changing Requirements and Environments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- 1.
- to analyze the history of product changes of the leading vendors and manufacturers of programmable logic devices;
- 2.
- to conduct a comparative analysis of modern development FPGA boards and accelerator cards;
- 3.
- to analyze the dynamics of changes in the functionality of integrated environments for FPGA-based systems considering the existing requirements and restrictions of different versions of software and hardware platforms and components;
- 4.
- to propose the techniques for the creation and optimization of high-performance systems based on FPGA that are tolerant to project requirement changes;
- 5.
- to analyze the delays in communications between the host computer and FPGA kernels;
- 6.
- to propose the technique for evaluation and reduce the response time delay for FPGA as a Service, depending on the number of involved resources (FPGA cards).
2. Analysis of Technology Stack for the Creation of FPGA as a Service
2.1. Evolution and Competitive Landscape of PLD Manufactures
2.2. Analysis of Capabilities of Modern FPGA Silicon Chips and Cards
2.3. Analysis of Software Platforms and Designing Tools
3. Method of Deployment of FPGA as a Service
3.1. Steps for FPGA Project Development Within FPGA as a Service Flow
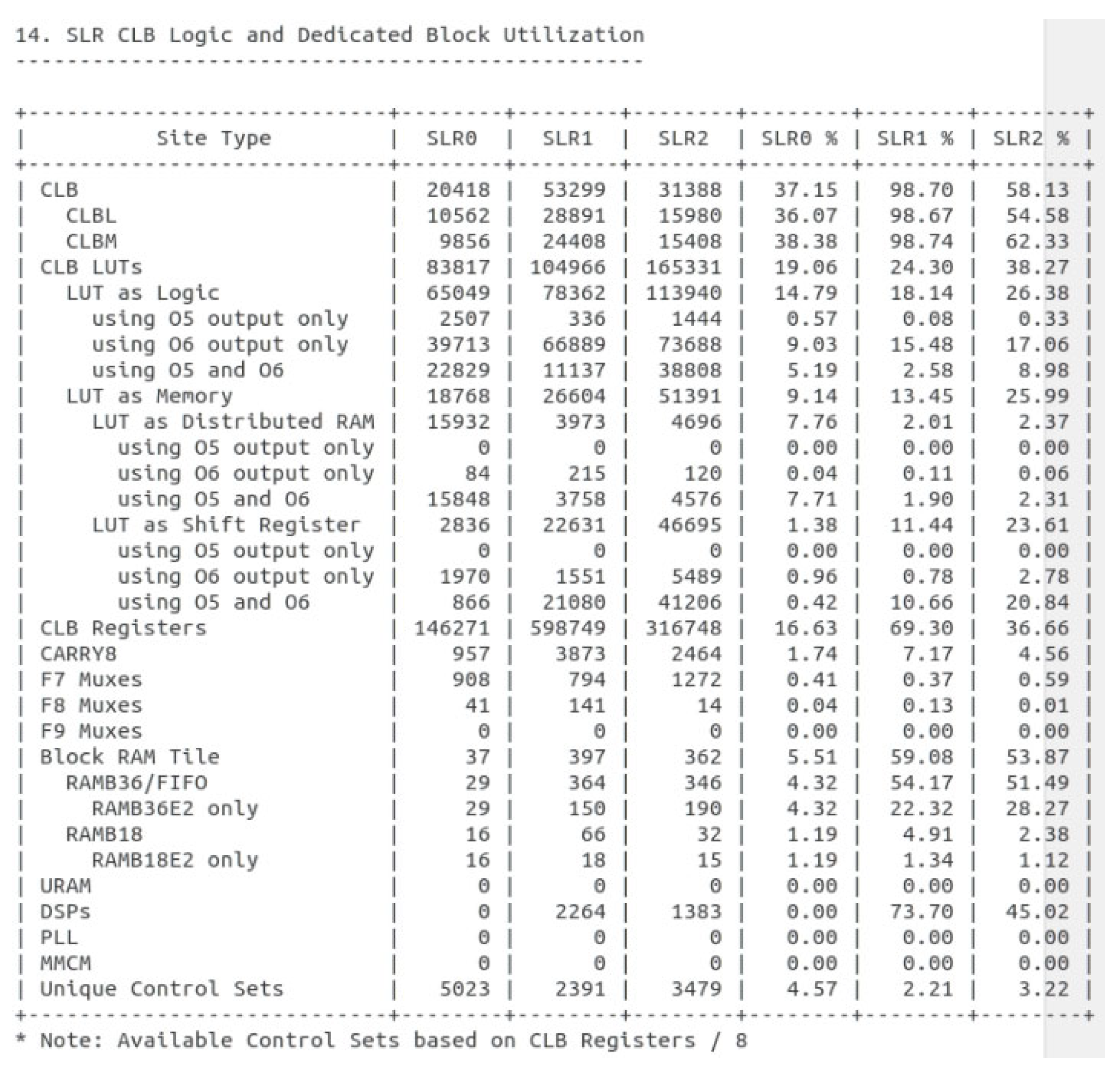
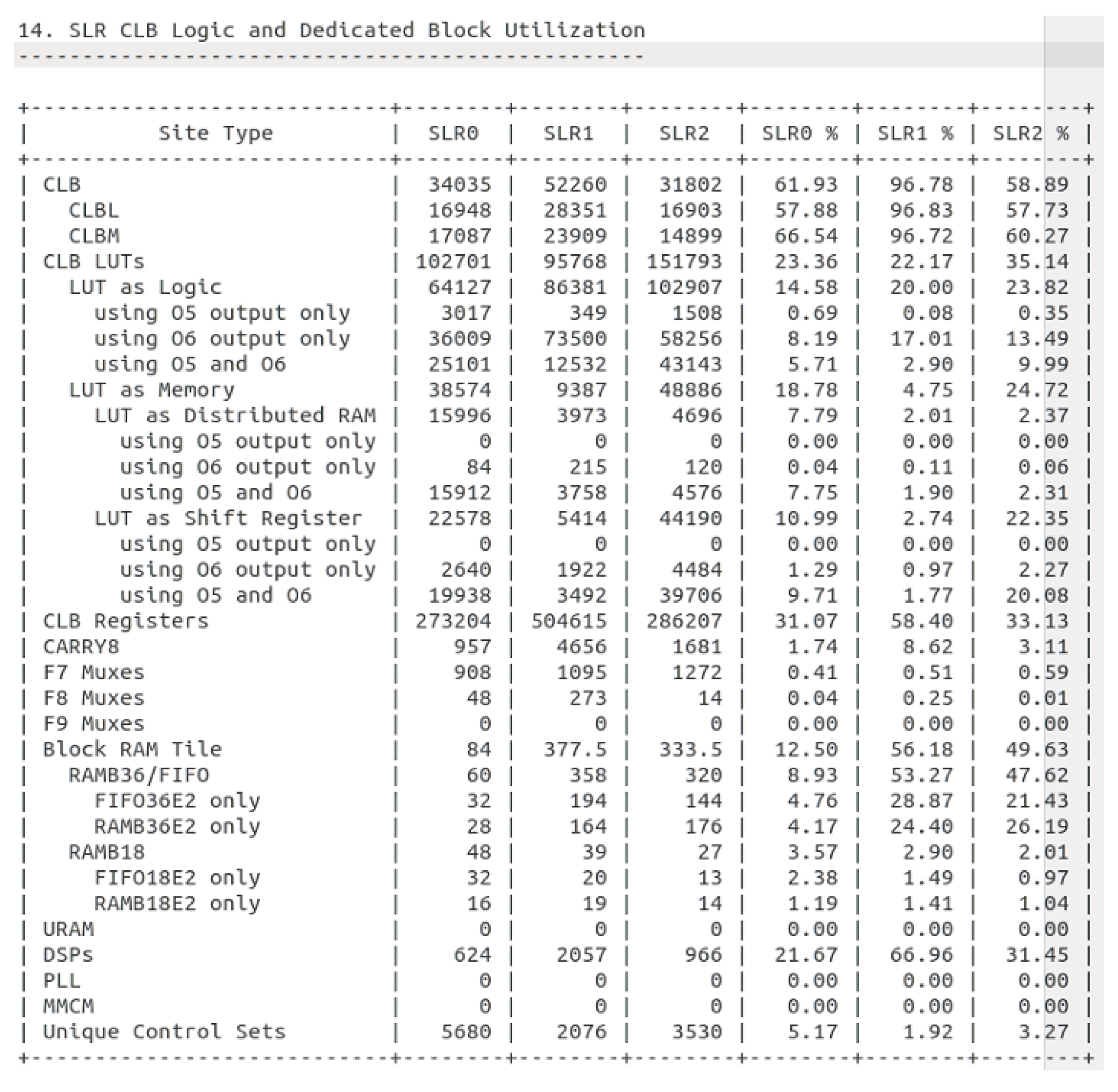
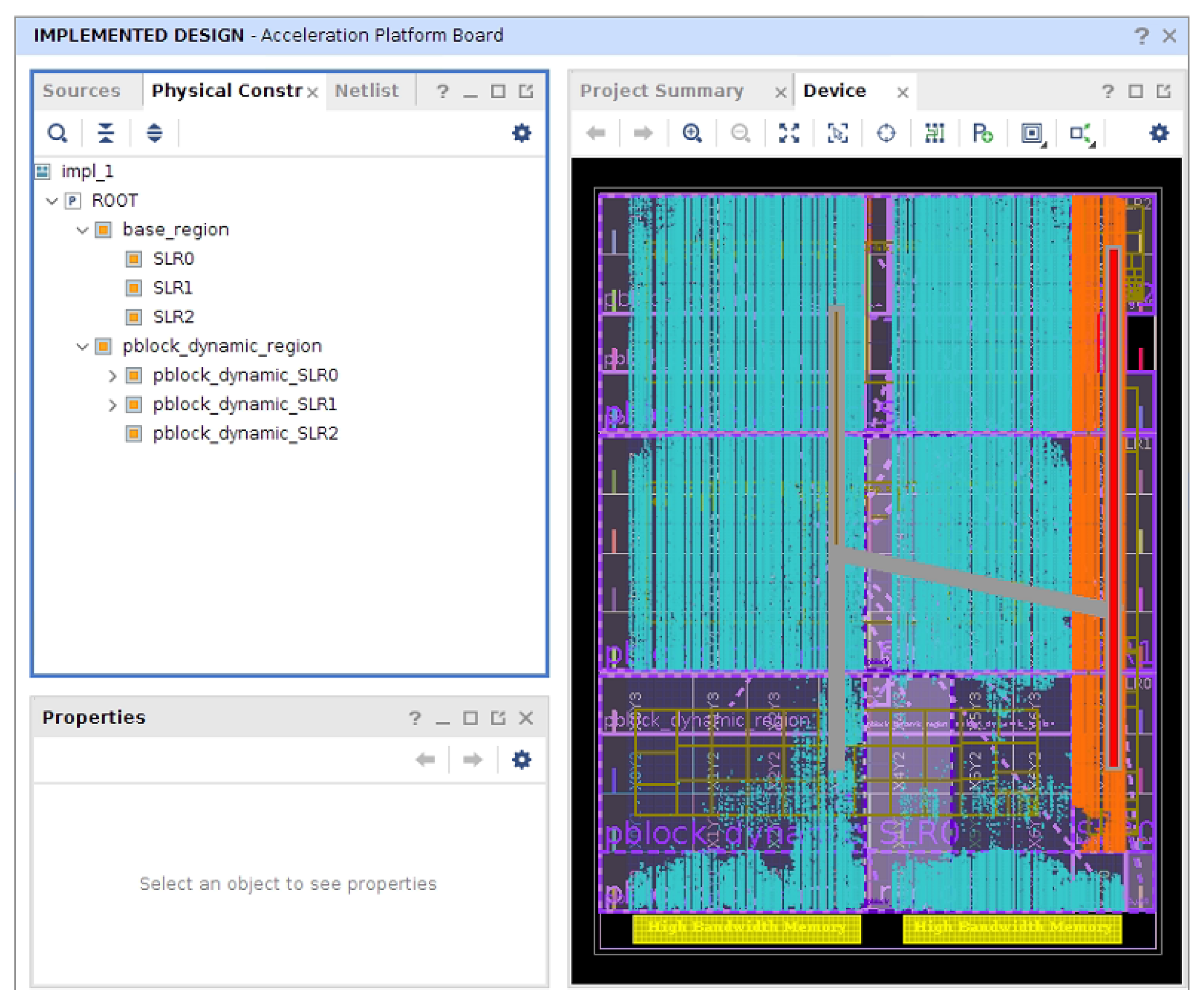
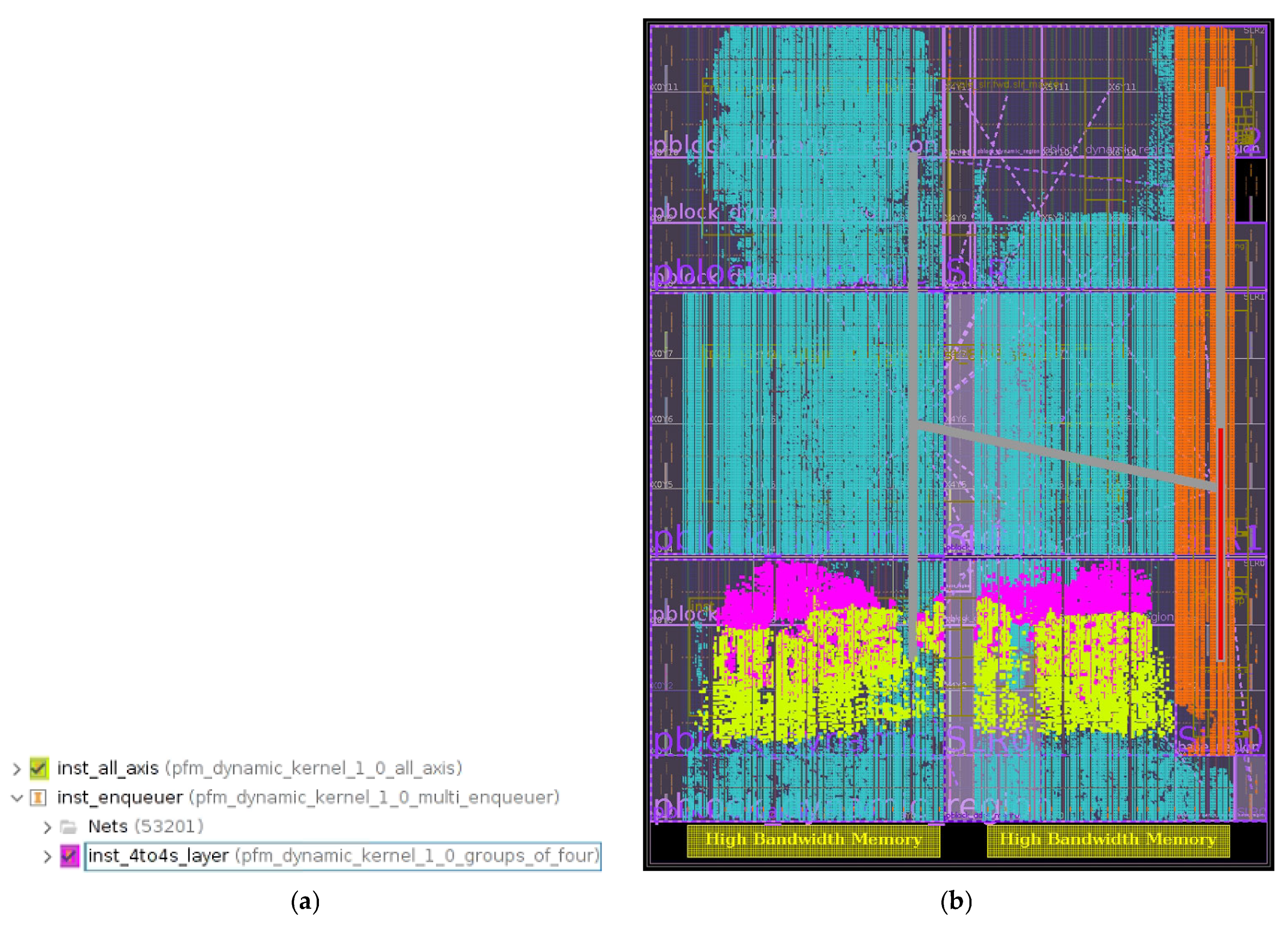
3.2. SLR Placement Optimization Strategy
3.3. Application of Proposed Techniques for FPGA as a Service
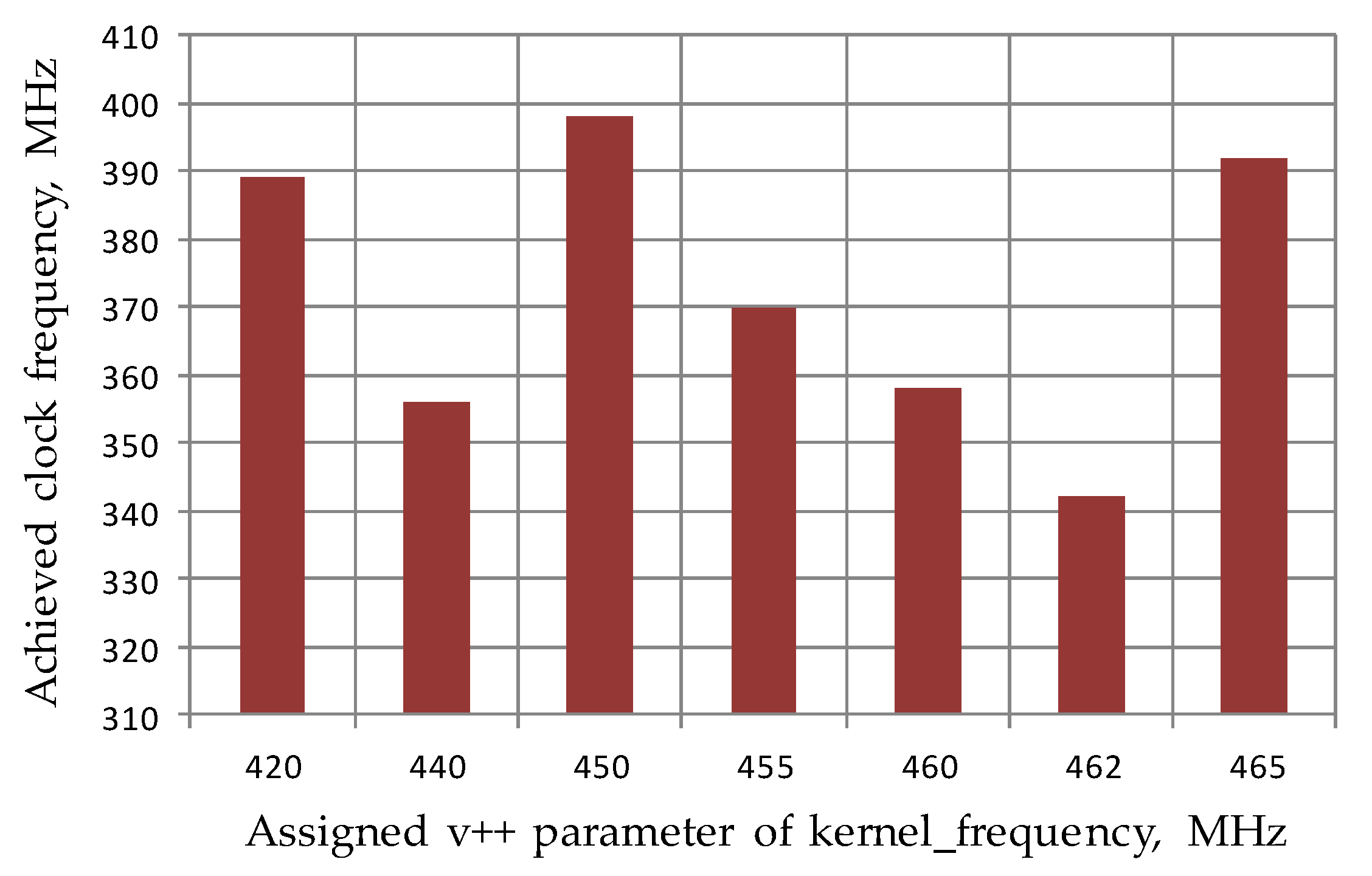
| Listing 1. An example of v++ parameters for the improvement of the final clock frequency of XRT-managed kernels in the Vitis design flow. The --kernel_frequency 0:250|1:100 parameter indicates that two clock domains are specified: the first is 250 MHz for the AXI kernel interface and the second is 100 MHz for part of the internal logic inside the kernel. These values are chosen as the reasonable parameters to obtain near the higher possible final frequencies of the AXI kernel bus in new versions of Vitis and the balance of high-throughput requirements of HBM interfaces (which benefit from higher frequencies) with lower power and thermal constraints for processing logic (implemented in parallel with pipelining to ensure the same computations with lower frequencies). |
 |
| Listing 2. Commands in the TCL file for the Vitis design flow in the new format for the mapping of two groups of modules with names inst_all_axis and inst_4to4s_layer to SLR0. |
 |
4. Method of Evaluation of FPGA as a Service
4.1. Model of Quality of Service of FPGA as a Service
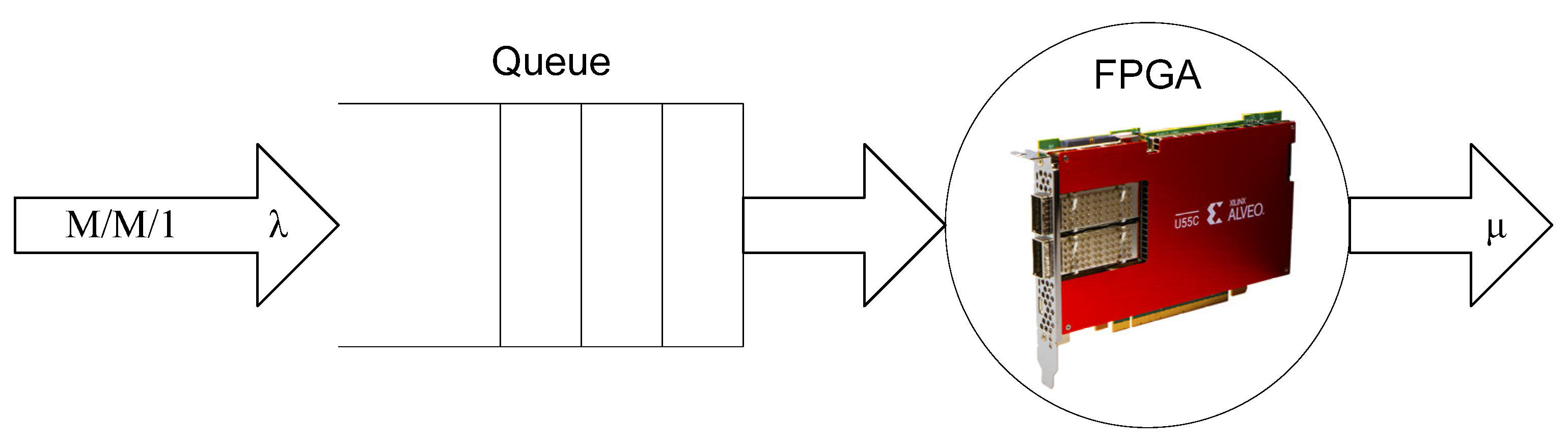
4.1.1. Applying a Queueing Theory for the Modeling of FPGA as a Service
4.1.2. Building of FPGA as a Service Model
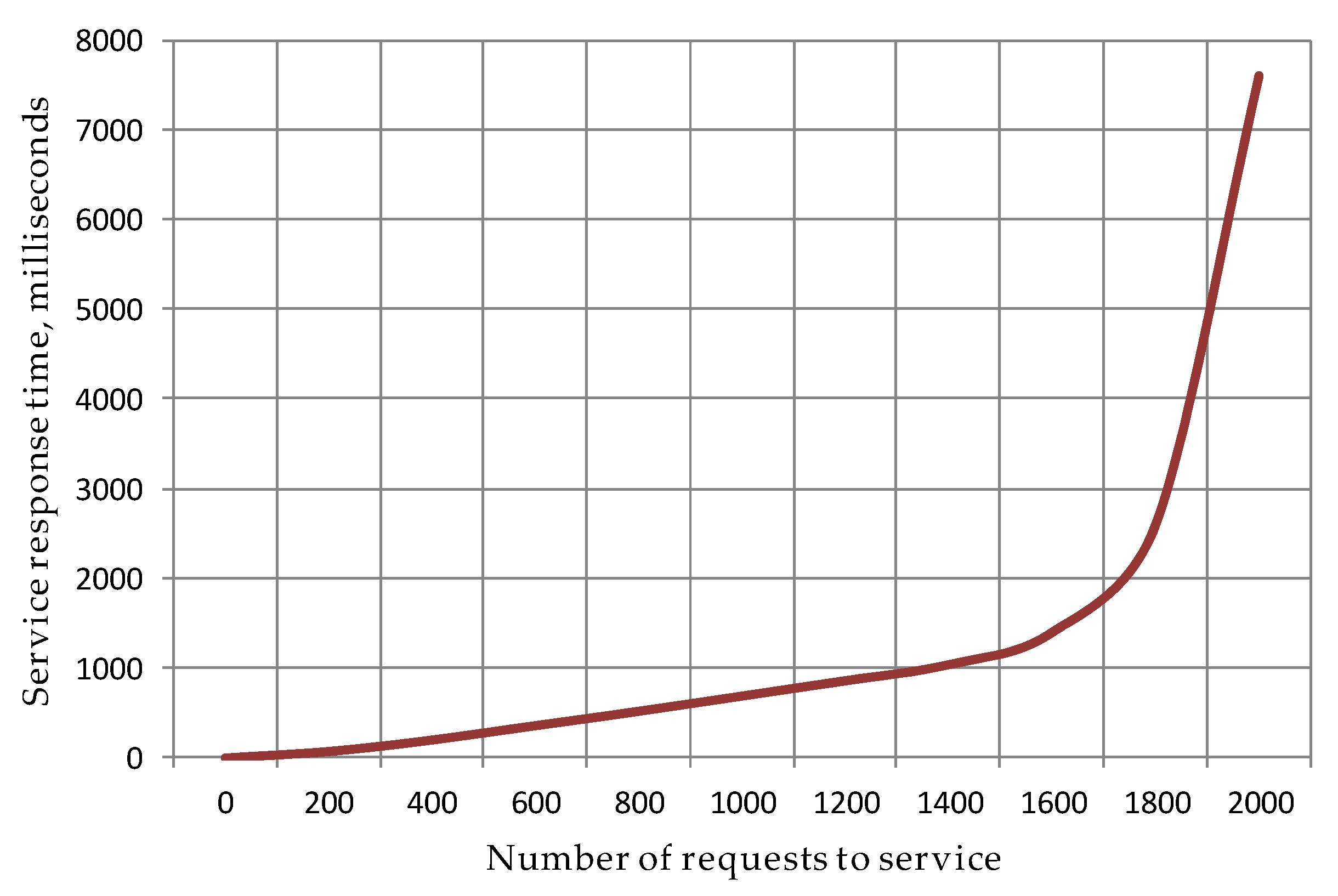
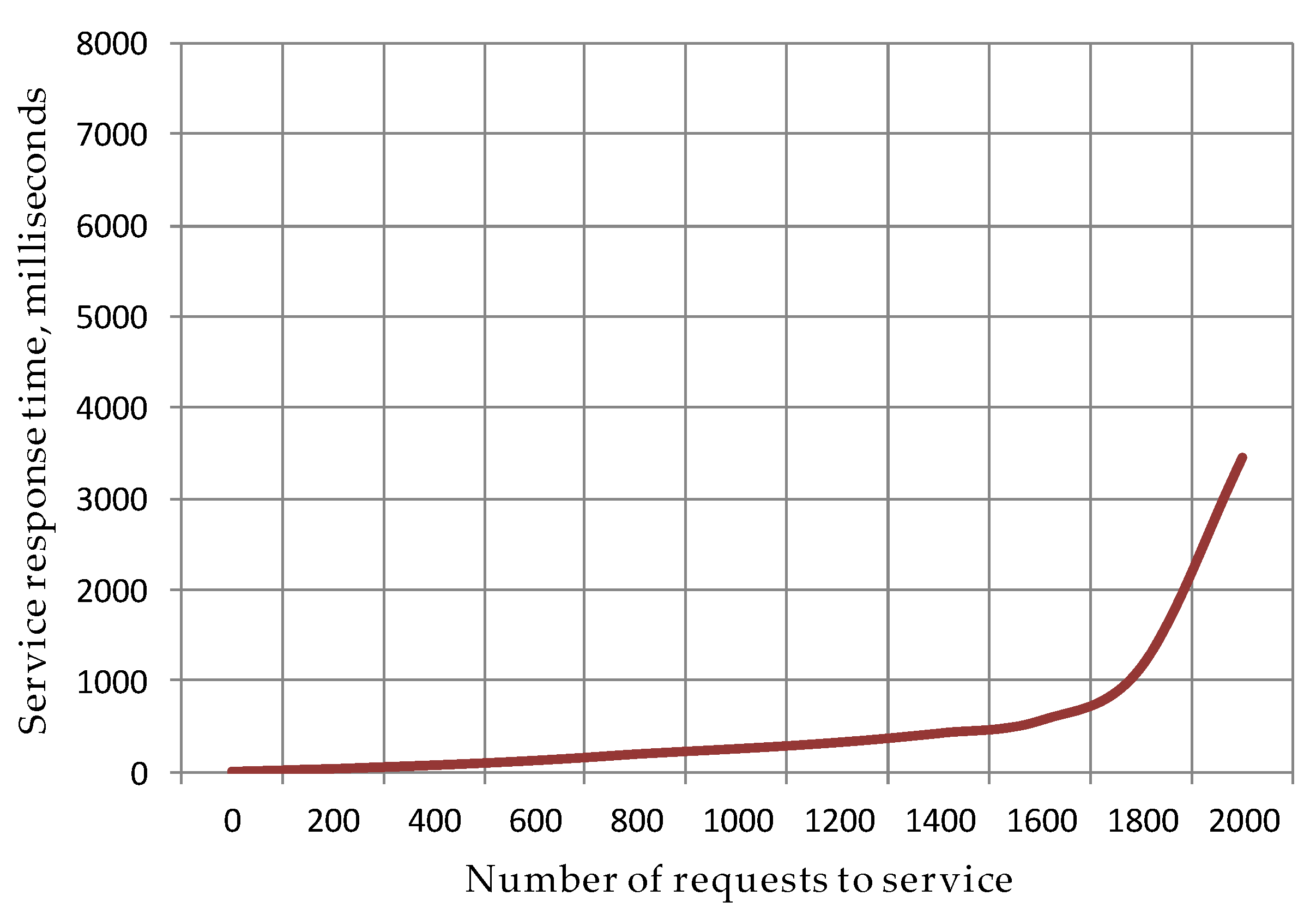
4.1.3. Evaluation of Response Time of FPGA as a Service
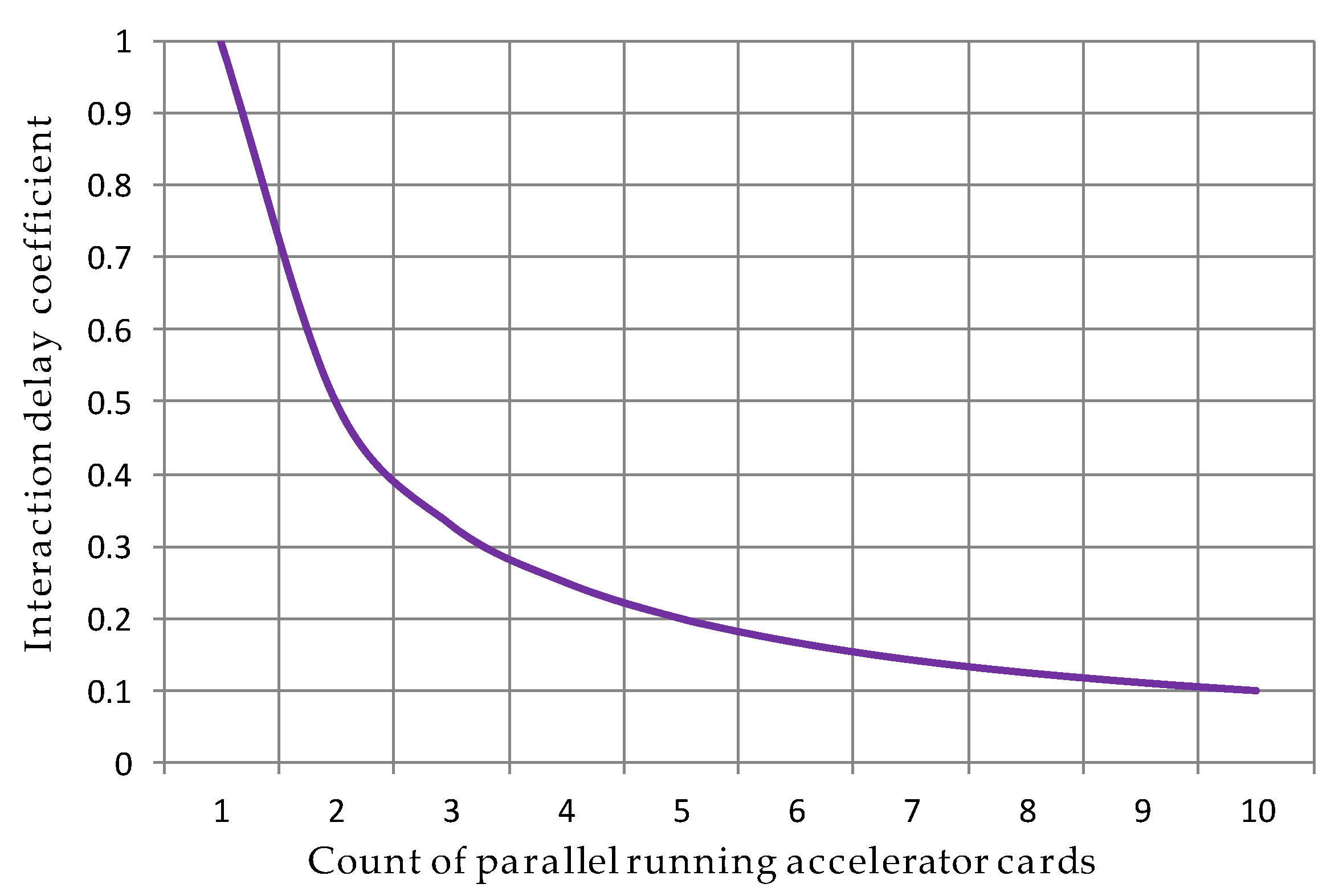
4.2. Model of Delays of FPGA as a Service
4.3. Evaluation of Memory Throughput of FPGA as a Service
4.4. Steps for Reducing Delays of FPGA as a Service Built on the Xilinx Platform
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, K.; Kim, M.; Choi, J.R. Memory-Tree Based Design of Optical Character Recognition in FPGA. Electronics 2023, 12, 754. [Google Scholar] [CrossRef]
- Perepelitsyn, A. Methodology of deployment of dependable FPGA based Artificial Intelligence as a Service. Radioelectron. Comput. Syst. 2024, 3, 156–165. [Google Scholar] [CrossRef]
- Mao, N.; Yang, H.; Huang, Z. An Instruction-Driven Batch-Based High-Performance Resource-Efficient LSTM Accelerator on FPGA. Electronics 2023, 12, 1731. [Google Scholar] [CrossRef]
- Faizan, M.; Intzes, I.; Cretu, I.; Meng, H. Implementation of Deep Learning Models on an SoC-FPGA Device for Real-Time Music Genre Classification. Technologies 2023, 11, 91. [Google Scholar] [CrossRef]
- Lattice Unveils First FPGAs on FD-SOI. Available online: https://www.eetimes.com/lattice-unveils-first-fpgas-on-fd-soi/ (accessed on 30 October 2024).
- Barkalov, A.; Titarenko, L.; Krzywicki, K.; Saburova, S. Improving Characteristics of FPGA-Based FSMs Representing Sequential Blocks of Cyber-Physical Systems. Appl. Sci. 2023, 13, 10200. [Google Scholar] [CrossRef]
- FinFET FPGA Market Size, Growth and Forecast from 2023–2030. Available online: https://www.linkedin.com/pulse/finfet-fpga-market-size-growth-forecast-from-2023-2030-1i3ve (accessed on 30 October 2024).
- Tetskyi, A. Penetration testing of FPGA as a Service components for ensuring cybersecurity. Aerosp. Tech. Technol. 2023, 6, 95–101. [Google Scholar] [CrossRef]
- Song, X.; Lu, R.; Guo, Z. High-Performance Reconfigurable Pipeline Implementation for FPGA-Based SmartNIC. Micromachines 2024, 15, 449. [Google Scholar] [CrossRef]
- Goz, D.; Ieronymakis, G.; Papaefstathiou, V.; Dimou, N.; Bertocco, S.; Simula, F.; Ragagnin, A.; Tornatore, L.; Coretti, I.; Taffoni, G. Performance and Energy Footprint Assessment of FPGAs and GPUs on HPC Systems Using Astrophysics Application. Computation 2020, 8, 34. [Google Scholar] [CrossRef]
- Kolasiński, P.; Poźniak, K.T.; Wojeński, A.; Linczuk, P.; Kasprowicz, G.; Chernyshova, M.; Mazon, D.; Czarski, T.; Colnel, J.; Malinowski, K.; et al. High-Performance FPGA Streaming Data Concentrator for GEM Electronic Measurement System for WEST Tokamak. Electronics 2023, 12, 3649. [Google Scholar] [CrossRef]
- Kulanov, V.; Perepelitsyn, A. Method of creation and deployment of FPGA projects resistant to change of requirements and development environments for cloud infrastructures. Aerosp. Tech. Technol. 2023, 5, 87–97. [Google Scholar] [CrossRef]
- Vivado Design Suite Reference Guide, Model-Based DSP Design Using System Generator, UG958 (v2020.2). 18 November 2020. Available online: https://docs.amd.com/r/en-US/ug958-vivado-sysgen-ref (accessed on 29 October 2024).
- UltraScale Architecture Memory Resources User Guide, UG573 (v1.13). 24 September 2021. Available online: https://docs.amd.com/v/u/en-US/ug573-ultrascale-memory-resources (accessed on 29 October 2024).
- Vivado Design Suite Properties Reference Guide, UG912 (v2022.1). 8 June 2022. Available online: https://www.xilinx.com/support/documents/sw_manuals/xilinx2022_1/ug912-vivado-properties.pdf (accessed on 29 October 2024).
- Vitis High-Level Synthesis User Guide, UG1399 (v2024.1). 3 July 2024. Available online: https://docs.amd.com/r/en-US/ug1399-vitis-hls (accessed on 29 October 2024).
- Choi, S.; Yoo, H. Approaches to Extend FPGA Reverse-Engineering Technology from ISE to Vivado. Electronics 2024, 13, 1100. [Google Scholar] [CrossRef]
- Taj, I.; Farooq, U. Towards Machine Learning-Based FPGA Backend Flow: Challenges and Opportunities. Electronics 2023, 12, 935. [Google Scholar] [CrossRef]
- Alveo U280es1: How to Update SC Version on System Shell? Adaptive SoC & FPGA Support. Available online: https://adaptivesupport.amd.com/s/question/0D52E00006hpFyRSAU/alveo-u280es1-how-to-update-sc-version-on-system-shell (accessed on 29 October 2024).
- Perepelitsyn, A.; Kulanov, V.; Zarizenko, I. Method of QoS evaluation of FPGA as a Service. Radioelectron. Comput. Syst. 2022, 4, 153–160. [Google Scholar] [CrossRef]
- Alveo U50 Data Center Accelerator Card Data Sheet, DS965 (v1.8). 23 June 2023. Available online: https://docs.amd.com/r/en-US/ds965-u50 (accessed on 29 October 2024).
- Perepelitsyn, A.; Fesenko, H.; Kasapien, Y.; Kharchenko, V. Technological Stack for Implementation of AI as a Service based on Hardware Accelerators. In Proceedings of the 2022 IEEE 12th International Conference on Dependable Systems, Services and Technologies DESSERT, Athens, Greece, 9–11 December 2022; 5p. [Google Scholar] [CrossRef]
- Perepelitsyn, A.; Kulanov, V. Technologies of FPGA-based projects Development Under Ever-changing Conditions, Platform Constraints, and Time-to-Market Pressure. In Proceedings of the 2022 12th International Conference on Dependable Systems, Services and Technologies DESSERT, Athens, Greece, 9–11 December 2022; 5p. [Google Scholar] [CrossRef]
- AMD. Versal AI Core Series Product Selection Guide, XMP452 (v1.15). Available online: https://docs.amd.com/v/u/en-US/versal-ai-core-product-selection-guide. (accessed on 24 April 2025).
- Di Mauro, M.; Liotta, A.; Longo, M.; Postiglione, F. Statistical Characterization of Containerized IP Multimedia Subsystem through Queueing Networks. In Proceedings of the 2020 6th IEEE Conference on Network Softwarization, NetSoft, Ghent, Belgium, 29 June–3 July 2020; pp. 100–105. [Google Scholar] [CrossRef]
- Pilz, S.; Porrmann, F.; Kaiser, M.; Hagemeyer, J.; Hogan, J.M.; Rückert, U. Accelerating Binary String Comparisons with a Scalable, Streaming-Based System Architecture Based on FPGAs. Algorithms 2020, 13, 47. [Google Scholar] [CrossRef]
- Regoršek, Ž.; Gorkič, A.; Trost, A. Parallel Lossless Compression of Raw Bayer Images on FPGA-Based High-Speed Camera. Sensors 2024, 24, 6632. [Google Scholar] [CrossRef]
- Alveo U280 Data Center Accelerator Card, UG1314 (v1.1). 15 June 2023. Available online: https://docs.amd.com/r/en-US/ug1314-alveo-u280-reconfig-accel (accessed on 29 October 2024).
- AMD. AMD Alveo™ U55C Data Center Accelerator Card. Available online: https://www.amd.com/en/products/accelerators/alveo/u55c.html (accessed on 29 October 2024).
- AMD. VHK158 Evaluation Board User Guide, UG1611 (v1.0). Available online: https://docs.xilinx.com/r/en-US/ug1611-vhk158-eval-bd (accessed on 28 October 2024).
- AMD. Alveo UL3524 Ultra Low Latency Trading Data Sheet, DS1009 (v1.1). Available online: https://docs.xilinx.com/r/en-US/ds1009-ul3524 (accessed on 29 October 2024).
- AMD. Alveo Portfolio Product Selection Guide, XMP451 (v2.1). Available online: https://docs.amd.com/v/u/en-US/alveo-product-selection-guide (accessed on 29 October 2024).
- Xilinx. SDAccel Environment User Guide, UG1023 (v2019.1). Available online: https://www.xilinx.com/support/documents/sw_manuals/xilinx2019_1/ug1023-sdaccel-user-guide.pdf (accessed on 29 October 2024).
- Xilinx. XRT Controlled Kernel Execution Models. Available online: https://xilinx.github.io/XRT/master/html/xrt_kernel_executions.html (accessed on 29 October 2024).
- Xilinx. UltraFast Design Methodology Guide for the Vivado Design Siute, UG949 (v2019.2). Available online: https://docs.xilinx.com/v/u/2019.2-English/ug949-vivado-design-methodology. (accessed on 29 October 2024).
- Xilinx. Vitis Unified Software Platform Documentation: Application Acceleration Development, UG1393 (v2019.2). Available online: https://docs.xilinx.com/r/en-US/ug1393-vitis-application-acceleration. (accessed on 28 February 2020).
- Xilin. Xilinx_Base_Runtime Release Notes. Available online: https://github.com/Xilinx/Xilinx_Base_Runtime (accessed on 29 October 2024).
- Xilinx. List of Corresponding Versions of XRT and Supported Board Shell Versions for Alveo FPGA Cards. Available online: https://github.com/Xilinx/Xilinx_Base_Runtime/blob/master/conf/spec.txt (accessed on 29 October 2024).
- Goswami, P.; Bhatia, D. Congestion Prediction in FPGA Using Regression Based Learning Methods. Electronics 2021, 10, 1995. [Google Scholar] [CrossRef]
- Gabrielli, A.; Alfonsi, F.; Annovi, A.; Camplani, A.; Cerri, A. Hardware Implementation Study of Particle Tracking Algorithm on FPGAs. Electronics 2021, 10, 2546. [Google Scholar] [CrossRef]
- Containerizing Alveo Accelerated Applications with Docker. Available online: https://xilinx.com/developer/articles/containerizing-alveo-accelerated-application-with-docker.html (accessed on 27 January 2020).
- Tsimashenka, I.; Knottenbelt, W.J. Reduction of Subtask Dispersion in Fork-Join Systems. In Computer Performance Engineering. EPEW 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8168, pp. 325–336. [Google Scholar] [CrossRef]
- Gorbunova, A.V.; Zaryadov, I.S.; Samouylov, K.E. A Survey on Queuing Systems with Parallel Serving of Customers. Part II. Discret. Contin. Models Appl. Comput. Sci. 2018, 26, 13–27. [Google Scholar] [CrossRef]
- Gaidamaka, Y.; Sopin, E.; Talanova, M. A Simplified model for performance analysis of cloud computing systems with dynamic scaling. In Distributed Computer and Communication Networks: Control, Computation, Communications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 75–86. [Google Scholar]
- Kothandaraman, D.; Kandaiyan, I. Analysis of a Heterogeneous Queuing Model with Intermittently Obtainable Servers under a Hybrid Vacation Schedule. Symmetry 2023, 15, 1304. [Google Scholar] [CrossRef]
- Gad-Elrab, A.A.A.; Alzohairy, T.A.; Raslan, K.R.; Emara, F.A. Genetic-Based Task Scheduling Algorithm with Dynamic Virtual Machine Generation in Cloud Computing. Int. J. Comput. 2021, 20, 165–174. [Google Scholar] [CrossRef]
- Sai Sowjanya, T.; Praveen, D.; Satish, K.; Rahiman, A. The queueing theory in cloud computing to reduce the waiting time. Int. J. Comput. Sci. Eng. Technol. 2011, 1, 110–112. [Google Scholar]
- AMD. What is XRT/AMD Runtime Library? Vitis Tutorials: Getting Started, XD098 (v2025.1). Available online: https://docs.amd.com/r/en-US/Vitis-Tutorials-Getting-Started/What-is-XRT/AMD-Runtime-Library (accessed on 26 March 2025).

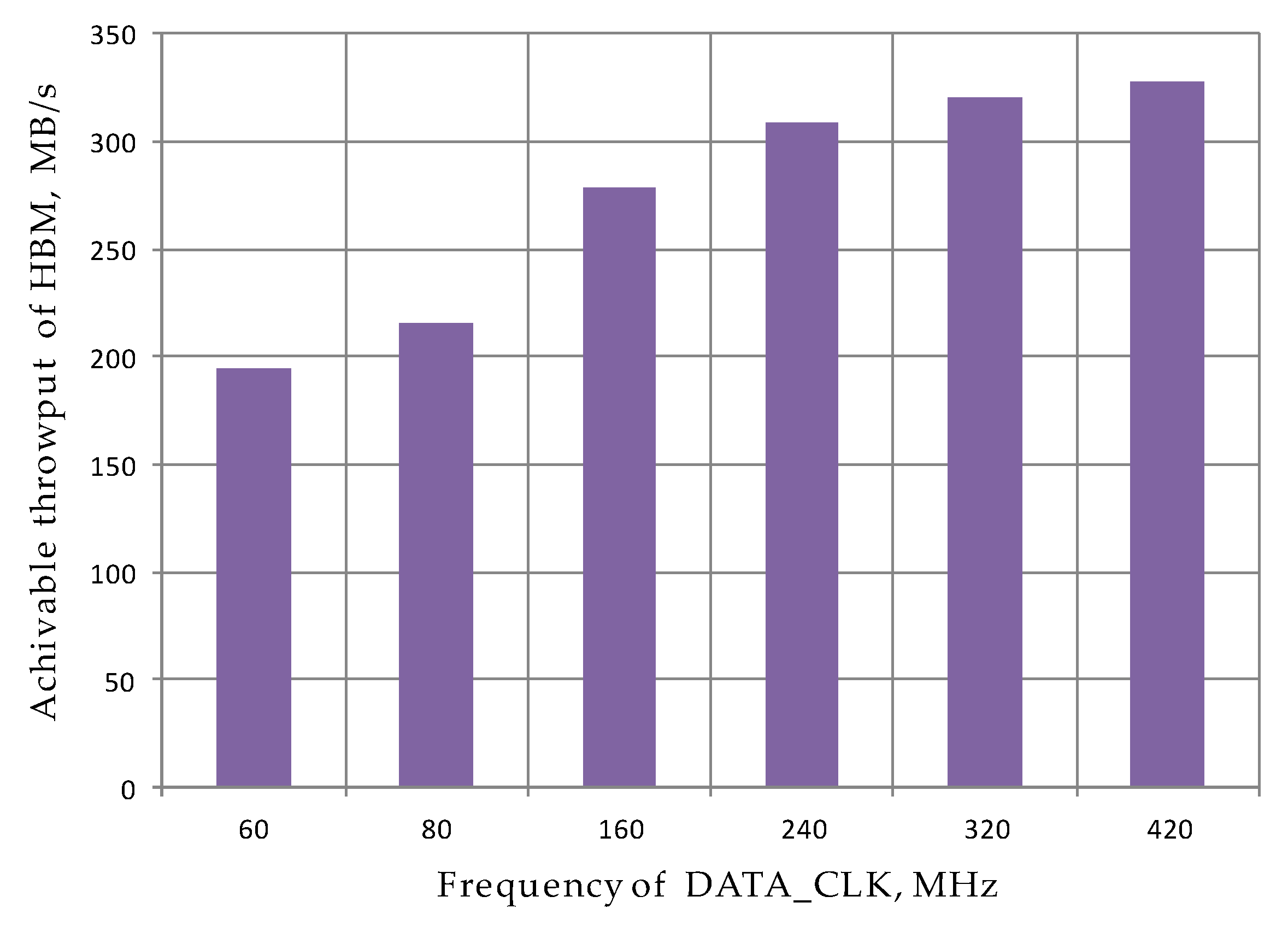
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perepelitsyn, A.; Kulanov, V. Methods of Deployment and Evaluation of FPGA as a Service Under Conditions of Changing Requirements and Environments. Technologies 2025, 13, 266. https://doi.org/10.3390/technologies13070266
Perepelitsyn A, Kulanov V. Methods of Deployment and Evaluation of FPGA as a Service Under Conditions of Changing Requirements and Environments. Technologies. 2025; 13(7):266. https://doi.org/10.3390/technologies13070266
Chicago/Turabian StylePerepelitsyn, Artem, and Vitaliy Kulanov. 2025. "Methods of Deployment and Evaluation of FPGA as a Service Under Conditions of Changing Requirements and Environments" Technologies 13, no. 7: 266. https://doi.org/10.3390/technologies13070266
APA StylePerepelitsyn, A., & Kulanov, V. (2025). Methods of Deployment and Evaluation of FPGA as a Service Under Conditions of Changing Requirements and Environments. Technologies, 13(7), 266. https://doi.org/10.3390/technologies13070266