1. Introduction
The Judd–Ofelt (JO) theory has received a great deal of interest due to its wide range of applications in materials science and chemistry, along with their numerous academic issues. Such uses include solid-state lasers [
1,
2] thermal sensors [
3,
4], optical amplifiers, upconversion [
5], and diverse biological contexts [
6,
7]. One of the main uses of the JO theory in this application, as in many others, is to provide a description of the optical properties of materials [
8]. These properties may include characteristics such as transition probability, branching ratio, and emission cross-section.
The JO theory provides significant insights into the structure of glass and the environment of the rare earth (RE), since the values of the parameters Ω
t (
t = 2, 4, and 6) are sensitive to variations of the RE site symmetry and of the RE-O covalency. The Ω
2 parameter describes the ligand field asymmetry of the local RE environment [
9,
10,
11] and/or is proportional to the degree of bond covalency for RE-O [
12]. In contrast, the JO intensity parameters Ω
4 and Ω
6 display the viscosity and dielectric properties of the glass matrix [
13,
14].
Although the JO theory exhibits mathematical elegance and physical utility, it presents a challenging framework not only in its understanding but also in its use. Similar to numerous theories in this field, it requires a sufficient depth of knowledge of solid-state physics and quantum mechanics. Additionally, the glass matrix under consideration for the calculation of the JO intensity parameters and its subsequent characterizations are highly specialized. Consequently, the combination of restrictions on the materials’ preparation, the measurement methods, the subsequent calculations, and the final interpretation makes JO theory elegant but frequently unapproachable. In this respect, given the breadth of applications that have emerged even despite the many limitations, it stands to reason that a more accessible method for obtaining the same or similar information would have very important implications for many scientific actions: for instance, how the three JO parameters could be predicted in the absence of spectral measurements and their corresponding mathematical calculations.
Predicting the relationship between composition and properties plays a crucial role in the developing of novel compositions. The developing physics-based models for predicting the properties in glasses remain a significant challenge that need to be addressed. An alternative method to address these challenges is to employ data-based modeling methods including machine learning [
9,
10,
15]. These techniques rely on accessible data to develop models that capture the hidden trends in the relationships between input and output. In the field of material informatics, ML is employed for various applications, including the development of interatomic potentials [
11,
16,
17], the predicting of novel materials and composites [
18,
19], the prediction of the composition–property relationship [
10,
15,
20,
21], and the development of the energy landscape [
22]. Specifically, ML has been successfully used in oxide glasses for predicting a wide range of equilibrium and nonequilibrium composition–property relationships, including the liquidus temperature [
9], solubility [
20], glass transition temperature [
15], stiffness [
23], and dissolution kinetics [
10].
This research leverages powerful machine learning models including XGBoost, LightGBM, GWO-XGBoost, and GWO-LightGBM to estimate the JO parameters in Er
3+-doped tellurite glasses. Er
3+-doped tellurite glass has received a great deal of interest in recent years because of its optical and chemical properties [
24]. Their high linear and nonlinear refractive indices, relatively low-phonon energy spectra, a low bonding strength of Te-O, chemical durability, and low glass transitions make them good candidates for fiber laser and 1.5 μm broadband optical amplifier applications [
24].
The experimental oscillator strengths (
) of the f-f induced electric dipole transitions of the various absorption bands are determined by measuring the integral area of the corresponding absorption transitions using the Judd–Ofelt theory [
13,
14] and the following equation:
where
and
are the electron mass and electron charge, respectively;
is the light velocity;
is the Avogadro’s number; and ν is the transition energy (in cm
−1). The oscillator strengths (
) for each absorption transition of the rare-earth ions within the 4f configuration were calculated through the following equation:
where
n is the refractive index;
J is the total angular momentum of the ground state;
(
= 2, 4, and 6) are the Judd–Ofelt intensity parameters, which are used to characterize the metal–ligand band in the host matrix; and
is the square reduced matrix elements of the unit tensor operator. The square reduced matrix elements
for this present work were obtained from the reported literature [
10].
The JO intensity parameters are host-dependent and play a vital role in investigating the glass structure and transition rates of the RE ion energy levels. The Ω
2 JO parameter is related to the covalency and symmetry of the ligand field around the rare-earth ions [
15]. The Ω
4 and Ω
6 parameters explore bulk properties like viscosity, the dielectric constant, and the vibronic transitions around the rare-earth ions [
9].
Traditional physics-based models, such as those derived from the Judd–Ofelt theory, have been extensively used to predict the optical parameters of rare-earth-doped glasses. These models rely heavily on detailed knowledge of the material’s atomic structure and the interactions between the rare-earth ions and the glass matrix. While they provide valuable insights into the optical properties of the materials, the process often involves complex calculations and assumptions that may not capture the full range of material behaviors, particularly in heterogeneous or poorly characterized systems.
In contrast, ML models, such as DeepBoost, XGBoost, and CatBoost, offer the advantage of data-driven predictions that can account for complex, nonlinear relationships in the data without relying on predefined physical models. These models excel at handling large, multi-dimensional datasets, which may be difficult to interpret using traditional physics-based approaches. Our study demonstrates that ML models, particularly DeepBoost, outperform conventional methods in terms of predictive accuracy and computational efficiency, making them a promising alternative for predicting the optical parameters in materials science. Moreover, ML approaches require fewer domain-specific assumptions, making them applicable to a broader range of materials and conditions where conventional models may not be easily adapted. While traditional models remain invaluable for understanding fundamental principles, ML methods complement them by providing more flexible, scalable, and efficient solutions for predicting material properties.
4. Data Presentation
This research investigates a substantial segment of the scientific literature concerning the experimental determination of the three JO parameters (Ω
2, Ω
4, and Ω
6) in RE-doped tellurite glasses. The concluding review encompassed scholarly articles [
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50], which related to 70 unique varieties of Er
3+-doped tellurite glasses. The relevant JO parameters and the percentage of oxide compositions for each glass were established using stoichiometry.
The dataset used in this study includes a comprehensive set of input and output parameters relevant to the analysis of chemical compositions and their effects on the output indices (Ω
2, Ω
4, and Ω
6).
Table 1 provides a detailed summary of the descriptive statistics for all the parameters involved. For each parameter, the key statistical metrics are reported, including the mean, median, standard deviation, and minimum and maximum values. Among the input parameters, the oxide compositions (e.g., TeO
2, SrO, P
2O
5, CaO, and CaF
2) and other chemical compounds (e.g., K
2O, Bi
2O
3, and TiO
2) show considerable variability, reflecting the diverse chemical nature of the dataset. For example, TeO
2 exhibits a wide range of values, with a mean of 46.483 and a standard deviation of 23.523, indicating significant variation across the samples. Similarly, other components, such as SrO and P
2O
5, have skewed distributions, as evidenced by their median values being notably different from the mean. The maximum values of certain parameters, such as P
2O
5 (35) and B
2O
3 (79.5), demonstrate that some samples contain extraordinarily high concentrations of specific compounds, which may influence the output indices significantly. The output parameters (Ω
2, Ω
4, and Ω
6) represent specific indices calculated based on the input compositions. These indices display unique statistical characteristics. For instance, Ω
2 has a mean of 5.937 and a standard deviation of 2.457, suggesting moderate variability. In contrast, Ω
4 and Ω
6 show lower mean values of 1.847 and 1.590, respectively, with relatively smaller standard deviations. These indices provide a quantitative measure of the system’s behavior, which is further analyzed in the correlation matrix (
Figure 1). The descriptive statistics serve as a foundation for the subsequent correlation and modeling analysis. By understanding the variability and distribution of the input and output parameters, researchers can better assess the relationships and interactions within the dataset, ultimately enhancing the interpretability of the findings.
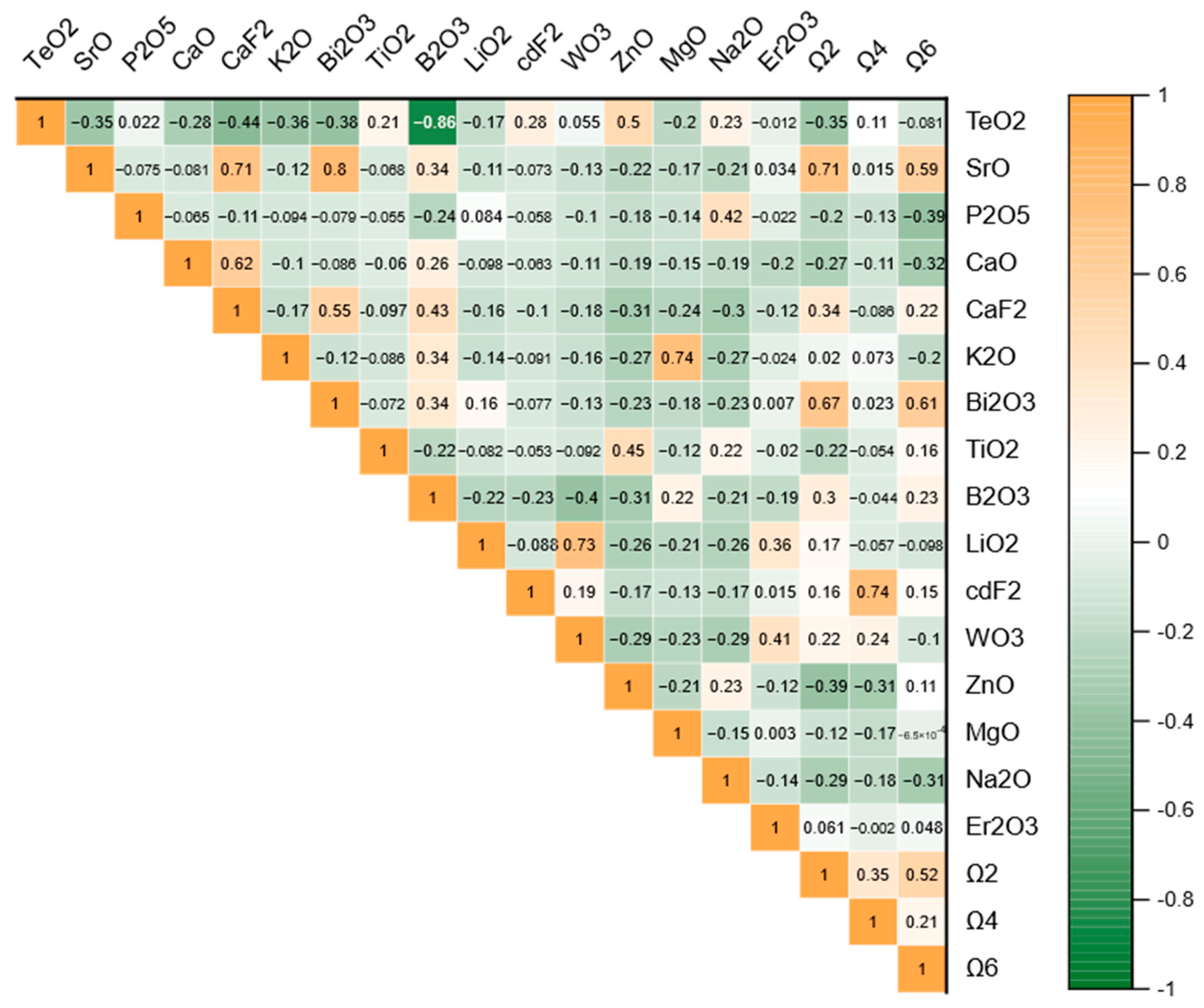
The correlation matrix depicted in
Figure 1 illustrates the relationships between the input parameters and the output indices (Ω
2, Ω
4, and Ω
6). The matrix displays the Pearson correlation coefficients, which quantify the linear relationship between pairs of variables. Values closer to 1 or −1 indicate stronger positive or negative correlations, respectively, while values near zero suggest weak or no correlations. Several key patterns can be observed from the matrix. The parameter TeO
2 shows moderate negative correlations with output indices such as Ω
2 (−0.353) and Ω
6 (−0.081), indicating that higher concentrations of TeO
2 might slightly reduce these indices. In contrast, SrO exhibits a strong positive correlation with Ω
2 (0.711) and a moderate positive correlation with Ω
6 (0.591), suggesting its significant influence on these outputs. Interestingly, Bi
2O
3 is also strongly correlated with Ω
2 (0.674) and Ω
6 (0.605), highlighting its potential role in determining the system’s characteristics. Some input parameters demonstrate notable interdependence. For example, CaF
2 and SrO are strongly positively correlated (0.709), as are MgO and K
2O (0.743). These relationships may indicate underlying chemical or physical interactions between these compounds. Additionally, the weak or negative correlations observed between some parameters, such as B
2O
3 and ZnO (−0.307), suggest minimal interaction or opposing trends. The output indices Ω
2, Ω
4, and Ω
6 exhibit distinct correlations with the input parameters. Ω
2 shows significant positive relationships with several variables, including SrO, Bi
2O
3, and CaF
2, while Ω
4 demonstrates strong positive correlations with CdF
2 and moderate negative correlations with MgO and ZnO. Ω
6, on the other hand, is positively influenced by Bi
2O
3 and SrO but shows weaker interactions with many other parameters.
Figure 1 is critical for identifying the dominant factors influencing the output indices and serves as a guide for further modeling and analysis. The insights derived from the correlation matrix provide a valuable foundation for predictive modeling, enabling the identification of the most impactful parameters and their interactions.
6. Model Evaluation
Model evaluation is a critical step in the development and implementation of predictive models, as it provides a comprehensive assessment of their performance and reliability. The primary objective of this process is to determine the model’s ability to generalize effectively to unseen data while ensuring that it meets the desired accuracy and robustness criteria. Evaluating models is essential to identify the most suitable algorithm for a specific problem, especially in complex predictive tasks where multiple models, such as MLP, CatBoost, XGBoost, RF, and DeepBoost, are employed.
In this study, the evaluation process involved the calculation of several performance metrics for each model during both the training and testing phases. Metrics such as the Coefficient of Determination (R
2); Variance Accounted For (VAF); a-20 index, Performance Index (PI), and accuracy were employed to evaluate the models based on the literature’s suggestions [
59,
60,
61,
62,
63,
64]. Each metric provides unique insights into the models’ performance. For instance, R
2 measures the proportion of variance explained by the model, while VAF indicates the degree to which the predicted values align with the observed values. The a-20 index evaluates the percentage of predictions falling within an acceptable range of deviation, and PI combines multiple aspects of prediction accuracy into a single measure. Lastly, accuracy reflects the overall correctness of the predictions.
By evaluating the models across these diverse metrics, this study aims to identify the optimal predictive algorithm for forecasting the Ω
2, Ω
4, and Ω
6 parameters. Such a comprehensive evaluation is not only essential for selecting the best-performing model but also for understanding the strengths and weaknesses of each algorithm, thereby enabling informed decisions in future applications. This rigorous approach ensures that the selected model provides reliable and accurate predictions, which are crucial for addressing the underlying research objectives effectively. The used statistical indices in this study can be formulated as follows [
60,
62,
63,
64,
65,
66,
67,
68,
69,
70,
71,
72]:
where
m signifies the number of data points; and
,
, and
are, respectively, the measured, anticipated, and average of the real
values [
67,
69,
70,
73].
Underpinning the success of this evaluation is the preprocessing step of data normalization, which plays a fundamental role in ensuring the models’ reliability and comparability. Normalization adjusts the scale of input features to prevent variables with larger ranges from disproportionately influencing the learning process. This step is particularly critical given the diversity of input features utilized for predicting Ω2, Ω4, and Ω6.
In this study, the min–max normalization technique was employed, which scales each feature to a range of [0, 1] using the following formula:
Here, xi represents the original data point, while xmin and xmax denote the minimum and maximum values of the respective feature. This transformation ensures that all features contribute equally to the training process, enhancing the models’ convergence rates and reducing computational inefficiencies.
The normalization process is particularly vital for models such as MLP and DeepBoost, where the scale of inputs significantly impacts the optimization of weights. Moreover, while tree-based models like CatBoost, XGBoost, and RF are less sensitive to feature scaling, normalization was applied uniformly across all the models to ensure consistency and fairness in the evaluation process.
By incorporating normalization, this study guarantees that the comparative analysis of model performance remains unbiased and that the chosen model delivers robust and accurate predictions of Ω2, Ω4, and Ω6. This preprocessing step further underscores the rigor and methodological soundness of the evaluation framework.
To ensure a robust evaluation of the predictive models, the dataset was partitioned into two distinct subsets: a training set and a testing set. This division is a fundamental practice in machine learning to assess the model’s performance on unseen data and to avoid overfitting, where the model performs well on training data but poorly on new data.
In this study, 80% of the available data, corresponding to 56 samples, was allocated to the training set. The training set is used to fit the models, allowing them to learn the underlying patterns and relationships in the data. The remaining 20%, consisting of 14 samples, was designated as the testing set. The testing set serves as an independent dataset to evaluate the model’s generalization ability, providing an unbiased estimate of its predictive performance. Although the data can be partitioned according to various schemes (e.g., 60/40, 70/30, 80/20, and 90/10), in this study the chosen partitioning ratio was selected based on the researcher’s recommendation [
74,
75,
76,
77,
78,
79,
80].
The data partitioning was carried out using a random sampling method to ensure that both subsets represent the overall distribution of the dataset. This approach minimizes the risk of introducing selection bias, which could compromise the reliability of the evaluation. Additionally, care was taken to maintain the integrity of the dataset by ensuring that no overlap occurred between the training and testing sets.
By adopting this partitioning strategy, this study guarantees that the models are rigorously evaluated under realistic conditions. The separate evaluation on the testing set provides critical insights into each model’s ability to predict the Ω2, Ω4, and Ω6 parameters accurately and consistently, further reinforcing the validity of the performance comparison.
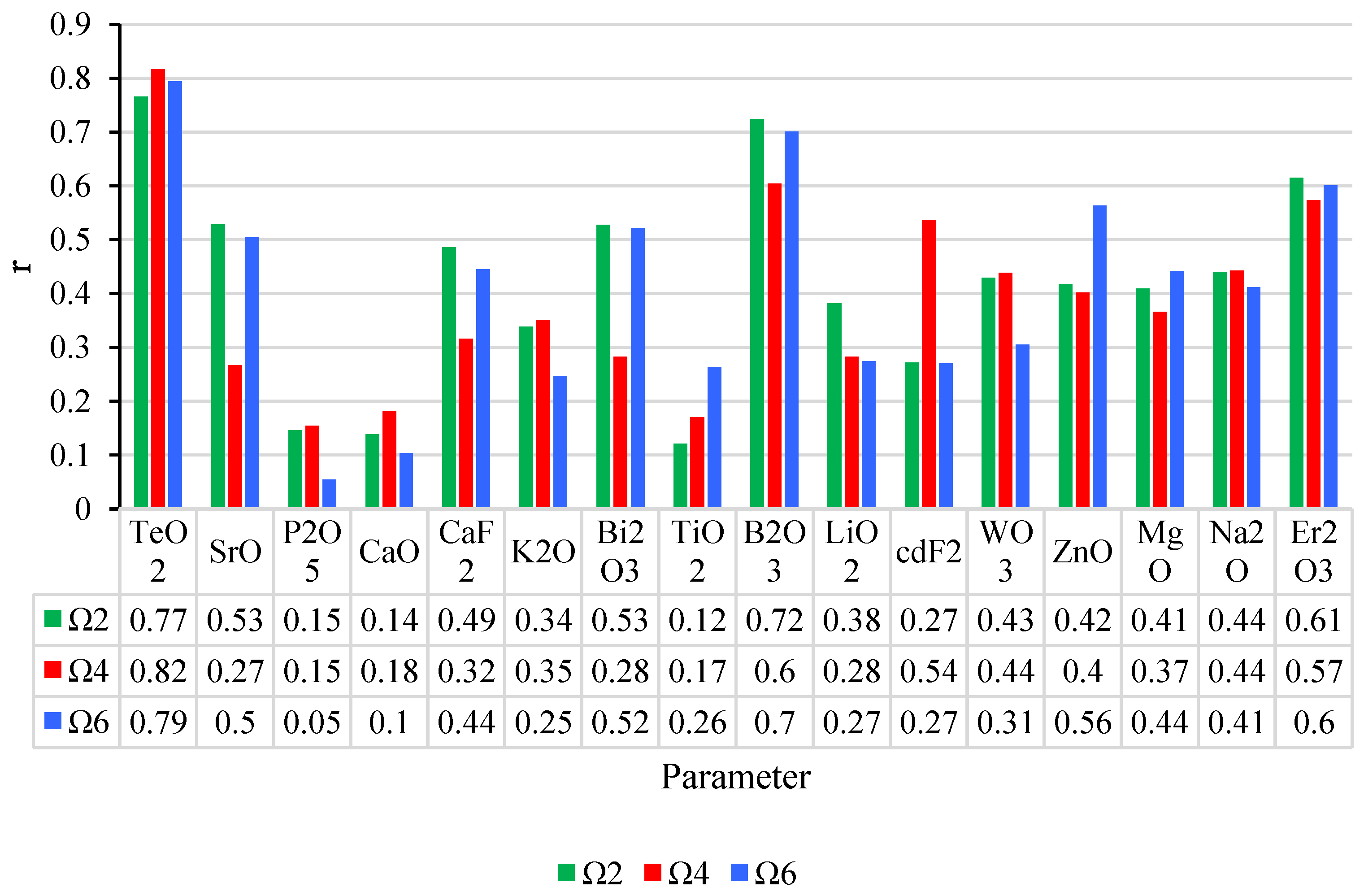
To gain a deeper understanding of the relationships between the input parameters and the optical properties (Ω
2, Ω
4, and Ω
6), a sensitivity analysis was conducted using the Cosine Amplitude Method (CAM). This method quantifies the strength of the relationship between pairs of effective parameters and their influence on the output variables (Ω
t). The CAM employs the following equation:
in which
rij is the intensity impact between
xi (input) and
xj (output).
The sensitivity analysis conducted using the Cosine Amplitude Method (CAM) provides valuable insights into the relative importance of the input parameters in influencing the output optical properties, specifically Ω
2, Ω
4, and Ω
6. As shown in
Figure 2, the results indicate that certain parameters have a stronger effect on the prediction of these optical properties. For instance, TeO
2 demonstrates a strong influence on Ω
2, with a higher sensitivity value indicating that changes in the TeO
2 concentration have a notable impact on the optical behavior of the material. Similarly, parameters like B
2O
3 and CaF
2 are shown to significantly affect Ω
4 and Ω
6, with their contributions being more pronounced in predicting these parameters. Other parameters, such as ZnO and Na
2O, while still influential, have a relatively weaker effect on the outputs.
7. Results and Discussion
The statistical performance of the models for predicting Ω
2 is detailed in
Table 2 and
Table 3. These tables reveal distinct trends in the accuracy and reliability of each model during the training and testing phases.
During the training phase, DeepBoost emerged as the most effective model, achieving the highest R2 value of 0.974, indicating that it explains 97.4% of the variance in the training data. This was corroborated by its VAF score of 96.704, further emphasizing its robust fitting ability. DeepBoost’s Performance Index (PI) of 1.297 and accuracy of 99.895 demonstrate its ability to make precise predictions. Additionally, the a-20 index, which reflects the proportion of predictions falling within 20% of the observed values, was the highest for DeepBoost (0.944), showcasing its reliability in practical scenarios.
Other models, while competitive, lagged behind DeepBoost. XGBoost achieved the second-highest R2 (0.931) and VAF (92.344), but its PI (1.142) and accuracy (99.889) were slightly lower. Similarly, CatBoost and RF had R2 values of 0.920 and 0.920, respectively, but their a-20 indices (0.907 for CatBoost and 0.889 for RF) were lower than that of DeepBoost. MLP, while showing decent performance (R2 = 0.907), had the lowest PI (1.055) and accuracy (99.877), indicating relatively less precise predictions.
The testing phase results reveal that DeepBoost maintained its superior performance. It achieved an R2 value of 0.971, VAF of 96.282, and PI of 1.108, all significantly higher than those of the other models. Its accuracy of 99.902 and a-20 index of 0.929 further underscored its strong generalization ability.
In contrast, other models displayed varying degrees of decline in their performance. XGBoost demonstrated relatively strong results, with an R2 of 0.929 and a PI of 0.722, but its accuracy (99.870) and a-20 index (0.786) were notably lower than those of DeepBoost. CatBoost performed moderately well, achieving an R2 of 0.887 and a PI of 0.605. MLP and RF showed the weakest generalization ability, with R2 values of 0.869 and 0.905, respectively, and lower a-20 indices of 0.786.
As shown in
Table 3, DeepBoost ranked first across both the training and testing phases, achieving the best total rate of 49. The consistent performance of DeepBoost reflects its ability to balance accuracy and reliability. In contrast, MLP ranked last with a total rate of 12, suggesting its limited effectiveness for predicting Ω
2.
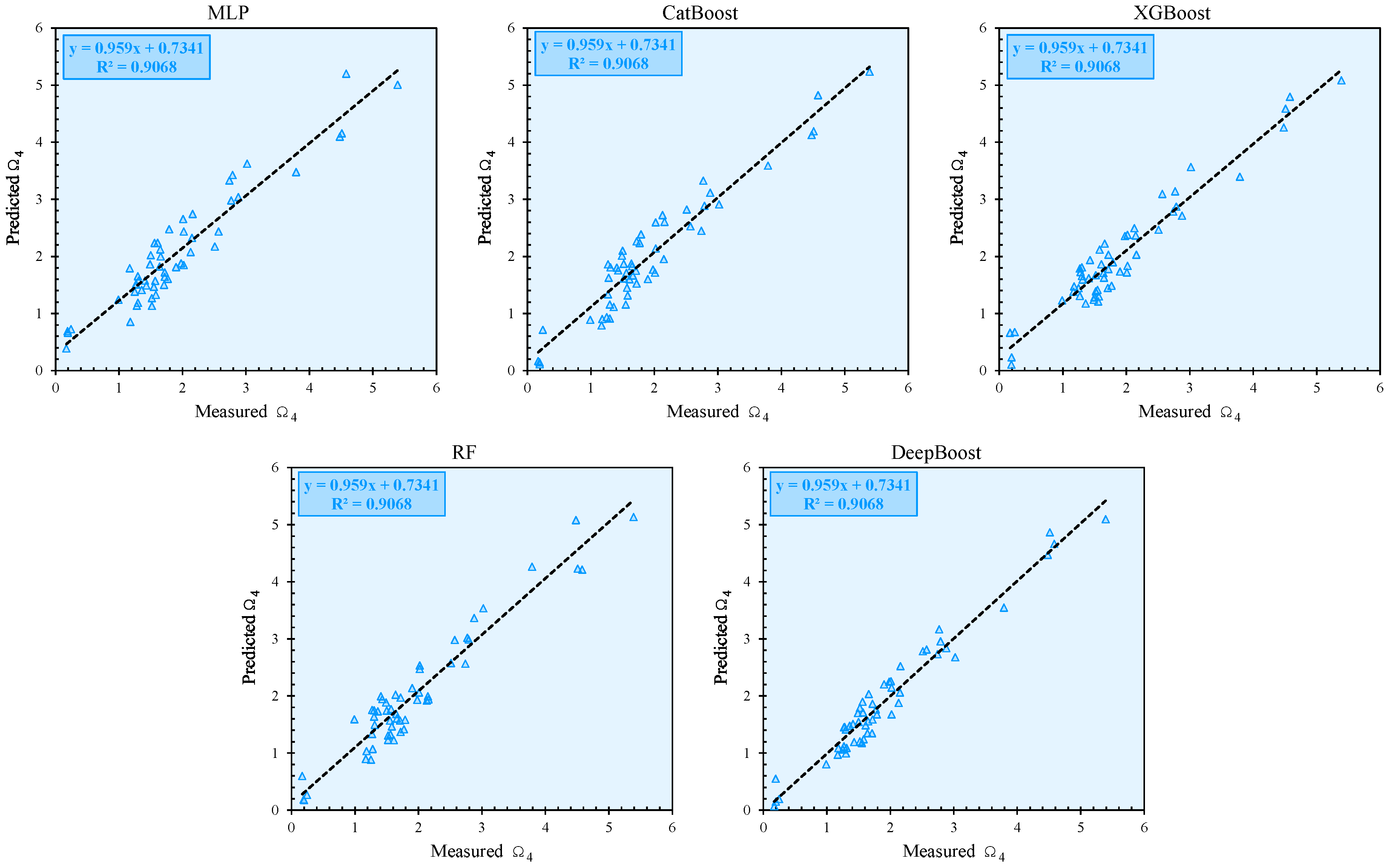
Table 4 highlights the strong performance of DeepBoost in predicting Ω
4. It achieved the highest R
2 (0.955), VAF (95.171), and PI (1.674) during the training phase, indicating its exceptional ability to model the data. Its accuracy of 99.846 and
a-20 index of 0.741 reinforce its reliability.
Other models, while competitive, demonstrated weaker performances. XGBoost (R2 = 0.929, VAF = 92.857) and RF (R2 = 0.919, VAF = 91.429) followed DeepBoost, but their PI values (1.555 and 1.512, respectively) were notably lower. CatBoost achieved moderate results (R2 = 0.910, VAF = 90.786), while MLP ranked lowest, with an R2 of 0.899 and a PI of 1.427.
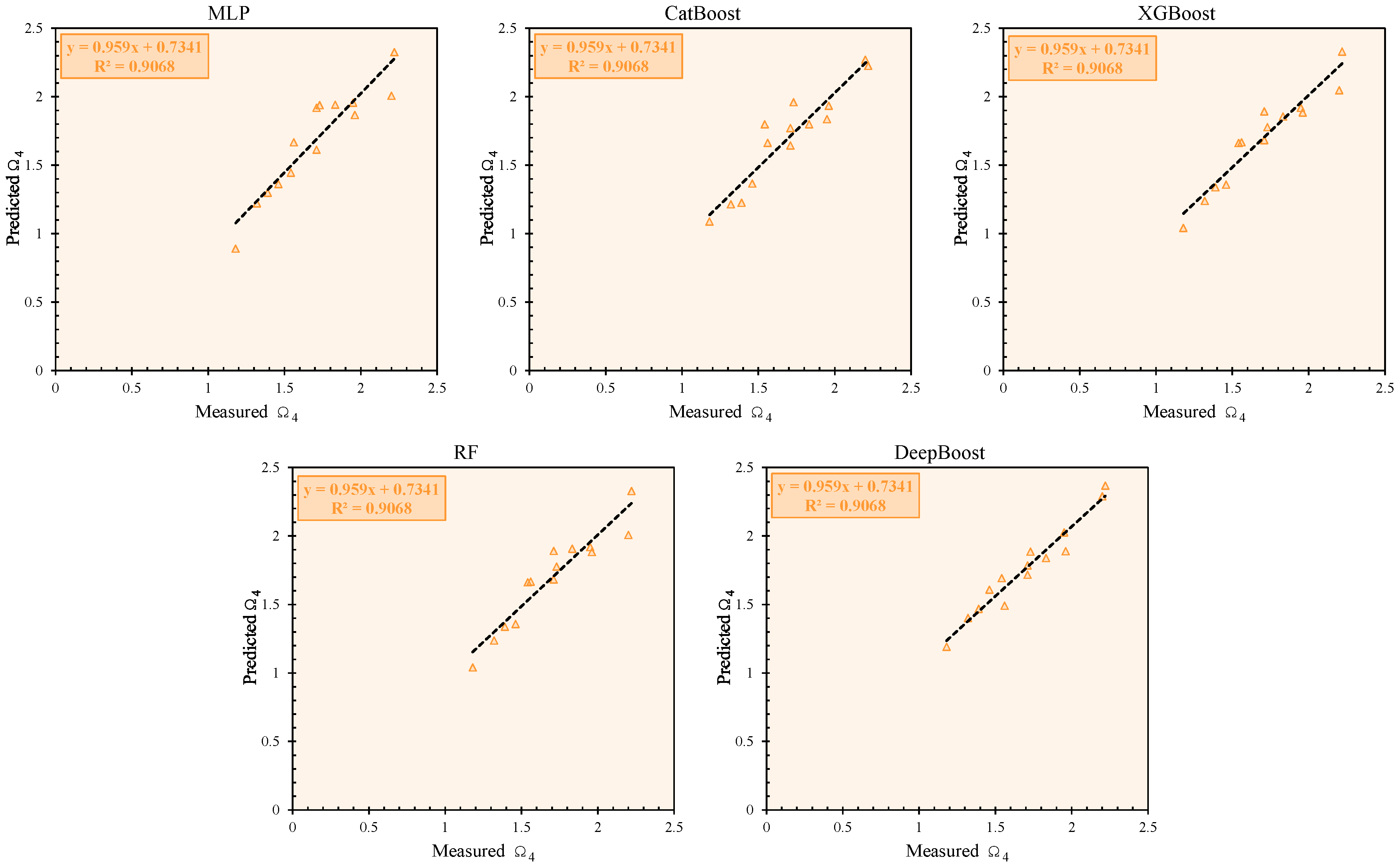
In the testing phase, DeepBoost continued to dominate, achieving an R2 of 0.945, VAF of 93.992, and PI of 1.787. Its accuracy of 99.951 and a-20 index of 1.000 signify its excellent generalization performance.
Other models showed varying levels of success. XGBoost and RF achieved relatively high R2 values (0.911 and 0.897, respectively) and competitive accuracy scores (99.945 and 99.941). However, their PI and a-20 indices were lower than those of DeepBoost. CatBoost displayed moderate performance, while MLP again showed the weakest results, with an R2 of 0.867 and a PI of 1.495.
As shown in
Table 5, DeepBoost ranked first with a total rate of 46, significantly outperforming other models. MLP ranked last with a total rate of 11, reinforcing its limited capability in predicting Ω
4.
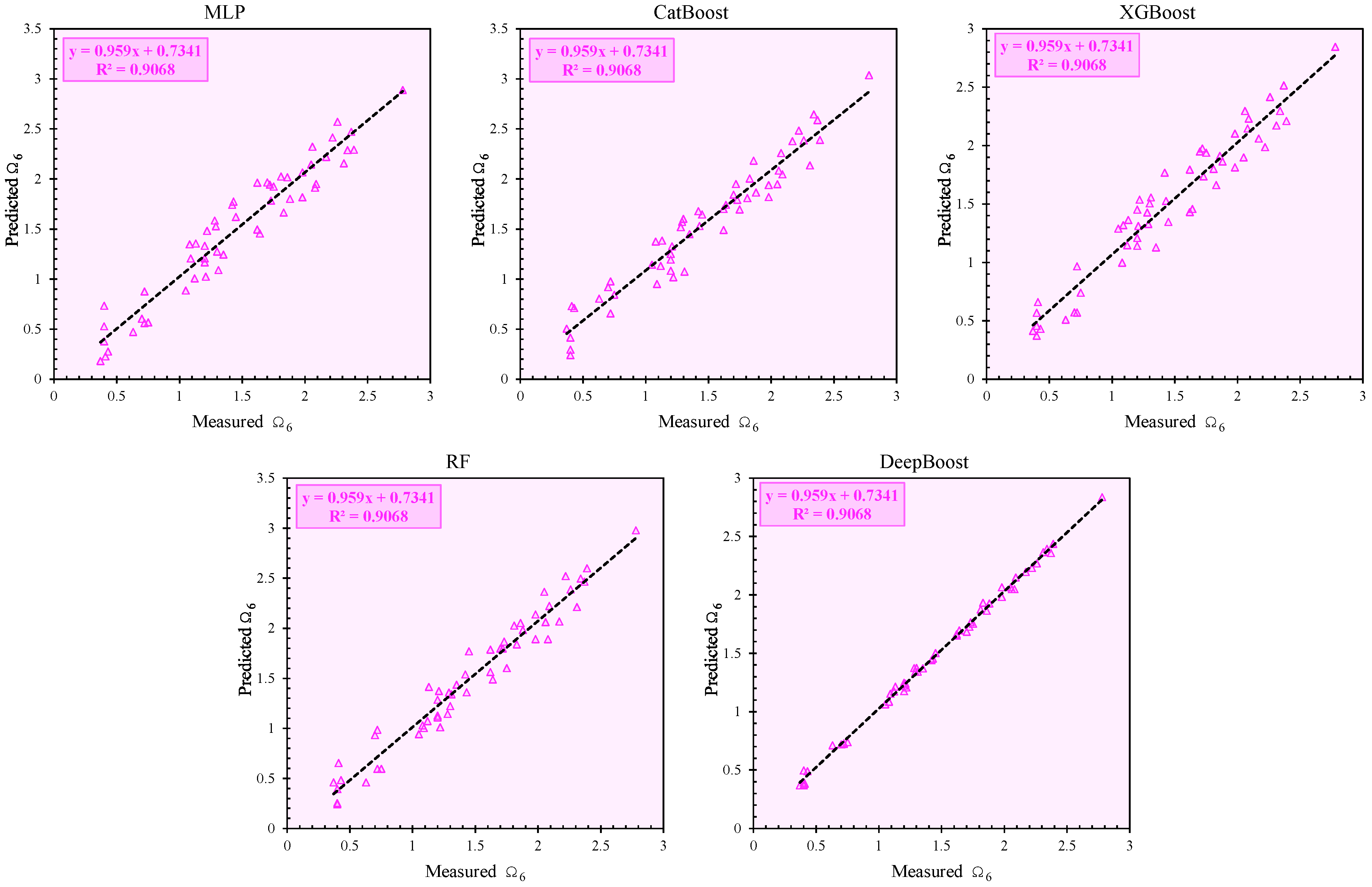
The training phase results for the Ω
6 predictions, shown in
Table 6, reveal that DeepBoost excelled with near-perfect values for all the indicators. It achieved an R
2 of 0.997, VAF of 99.681, and PI of 1.948, alongside an accuracy of 99.968 and an
a-20 index of 1.000. These metrics highlight its ability to capture the underlying relationships in the data.
Other models displayed good but less impressive performances. RF followed with an R2 of 0.953 and a VAF of 94.049, but its PI (1.738) and a-20 index (0.815) were notably lower. XGBoost and CatBoost achieved similar R2 values (0.934 and 0.939, respectively), but their lower PI values (1.701 and 1.695) and a-20 indices (0.870 and 0.815) limited their competitiveness. MLP showed the weakest results, with an R2 of 0.927 and a PI of 1.654.
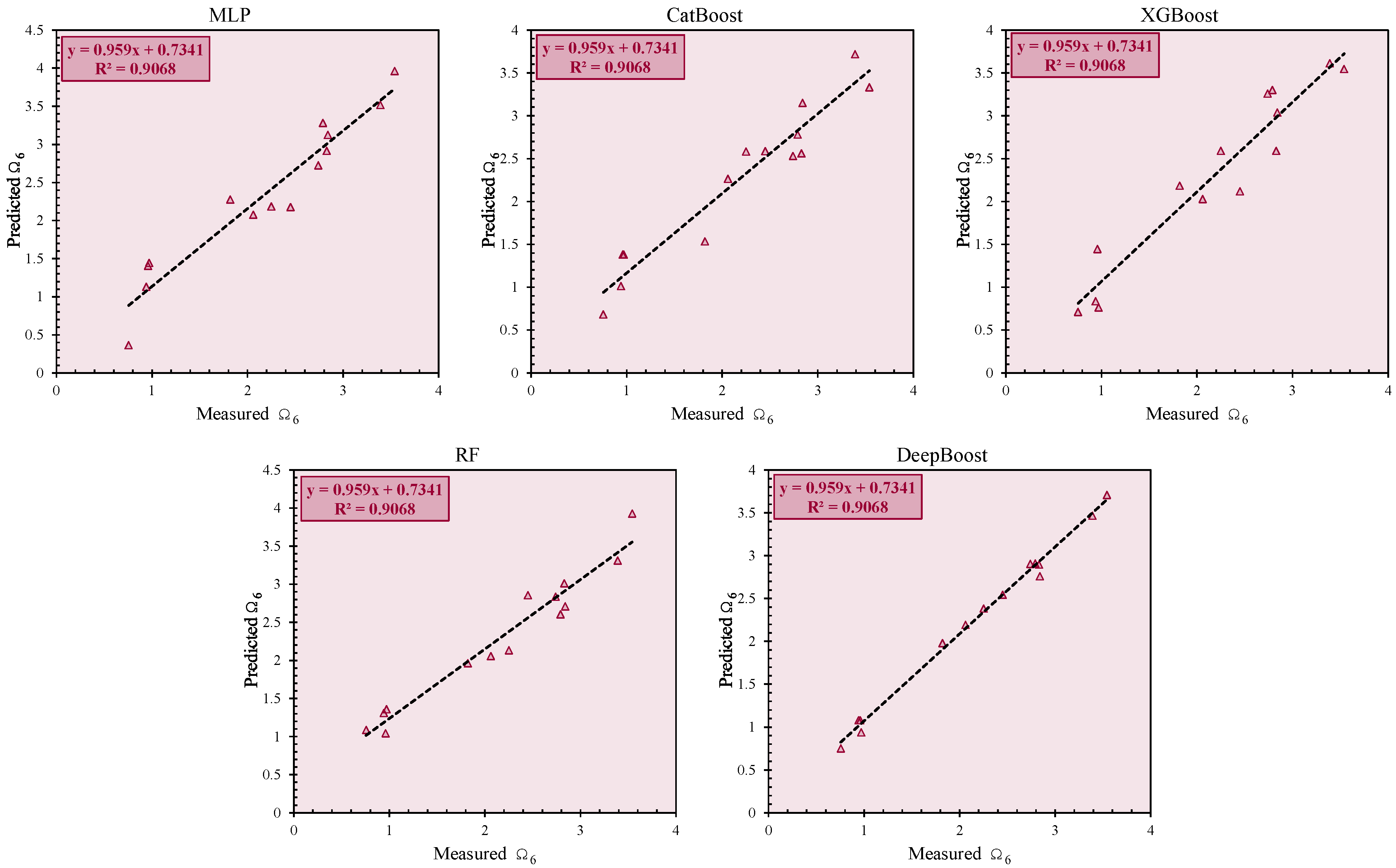
In the testing phase, DeepBoost maintained its superiority, achieving an R2 of 0.994, VAF of 99.323, and PI of 1.870. Its accuracy of 99.946 and a-20 index of 1.000 confirmed its exceptional generalization ability.
Other models showed declines in performance compared to the training phase. RF (R2 = 0.949) and XGBoost (R2 = 0.920) followed DeepBoost, but their PI and a-20 indices were lower. CatBoost and MLP exhibited moderate results, with R2 values of 0.924 and 0.919, respectively.
Table 7 confirms that DeepBoost achieved the top rank with a total rate of 50. MLP, despite its reasonable accuracy, ranked last with a total rate of 13, highlighting its comparatively weaker predictive performance.
The analyses across Ω2, Ω4, and Ω6 consistently identify DeepBoost as the most effective model. Its exceptional performance in both the training and testing phases underscores its ability to handle complex datasets and provide reliable predictions. Conversely, MLP ranked lowest for all the targets, demonstrating limited utility in this context.
The findings validate the evaluation framework and highlight the importance of model selection in predictive tasks, offering significant implications for similar studies and practical applications.
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8 illustrate the correlation between the measured and predicted values of the target parameters (Ω
2, Ω
4, and Ω
6) for both the training and testing phases. These plots provide a visual assessment of the predictive accuracy of the developed models. In
Figure 3 and
Figure 4, the measured versus predicted values for Ω
2 during the training and testing phases are shown. The data points cluster tightly around the 45-degree line, indicating a strong correlation and minimal deviation between the observed and predicted values. This highlights the models’ reliability in predicting Ω
2.
Figure 5 and
Figure 6 depict the correlation for Ω
4 during the training and testing phases, respectively. While the alignment of data points with the 45-degree line remains strong, there is a slight increase in the dispersion of points in the testing phase, reflecting the inherent challenges of generalization to unseen data. Similarly,
Figure 7 and
Figure 8 display the correlation for Ω
6 in the training and testing phases. The near-perfect alignment of the data points with the diagonal line, particularly for the DeepBoost model, confirms its exceptional predictive capability. The consistency across the training and testing phases further validates the robustness of the developed models. These figures collectively emphasize the effectiveness of the proposed methodologies in capturing the complex relationships between the input variables and the target parameters, making them suitable for practical applications. It should be mentioned that the dashed line in these figures represents the linear regression fit between predicted and measured values.
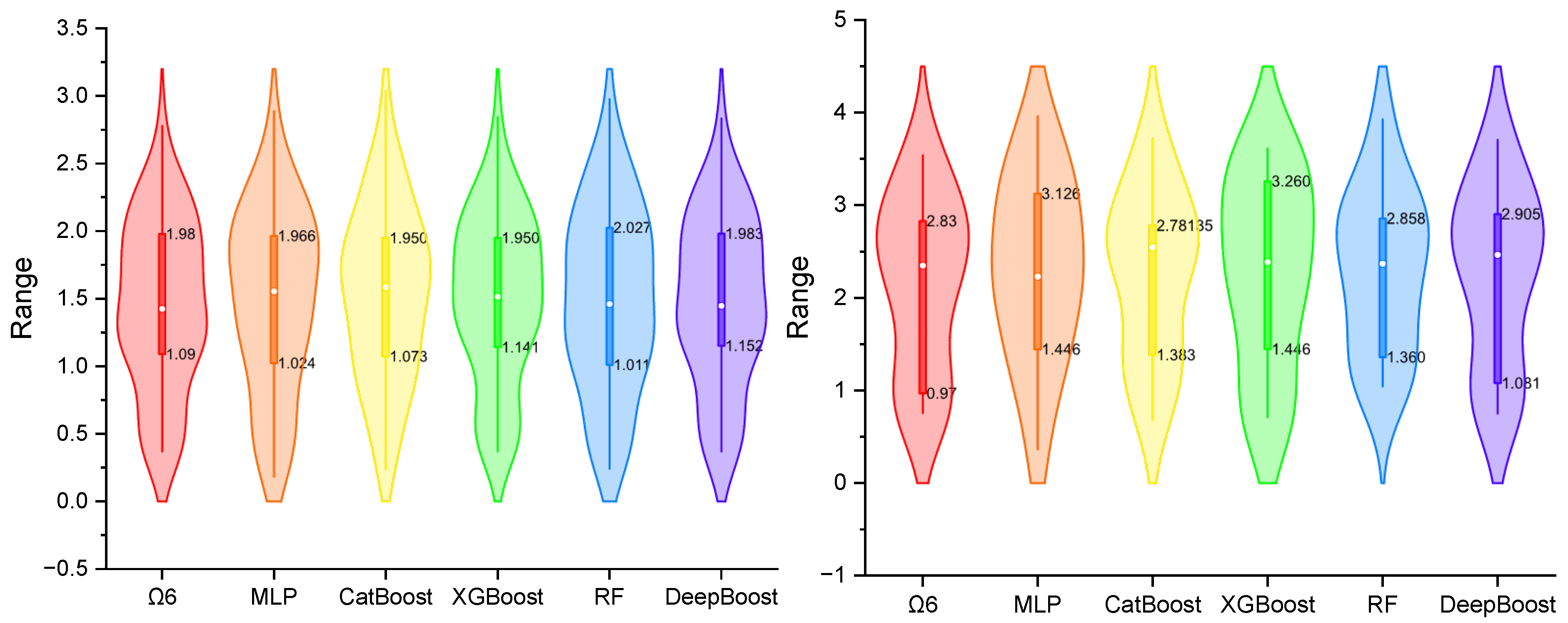
Violin plots are a robust visualization tool that combines the features of a box plot and a kernel density plot. They provide a comprehensive representation of the distribution of a dataset by showing both the central tendencies and the variability of the data. The plot displays a mirrored density curve, highlighting the data’s distribution shape, while an internal box plot indicates key statistical metrics such as the median and interquartile range (IQR). This visualization is particularly useful for comparing multiple models, as it allows for a detailed assessment of the spread, skewness, and potential outliers within the predictions. By evaluating the width and shape of the violin plot, one can infer the consistency and reliability of each model’s performance.
Figure 9,
Figure 10 and
Figure 11 illustrate violin plots of the developed models for predicting Ω
2, Ω
4, and Ω
6, respectively, in both the training (left) and testing (right) phases. These plots provide a comparative analysis of the distribution and variability of the predictions across the different models, offering insights into their consistency and robustness.
As detailed in
Table 8, we employed the Kruskal–Wallis H test—a distribution-free analogue of one-way ANOVA—to determine whether DeepBoost’s lower error metrics represent genuine improvements over competing models for each target variable (Ω
2, Ω
4, and Ω
6) on both the training (
n = 56) and test (
n = 14) splits. Every “omnibus” comparison produced a
p-value below the 0.05 threshold (Ω
2: H
train = 1.77,
p = 0.0078 and H
test = 8.94,
p = 0.0063; Ω
4: H
train = 9.06,
p = 0.0069 and H
test = 4.03,
p = 0.0043; and Ω
6: H
train = 79.55,
p = 0.0217 and H
test = 9.31,
p = 0.0342), confirming that at least one model’s error distribution differs significantly across the methods in every scenario. In all six cases, DeepBoost attained both the smallest median absolute deviation—Ω
2: 0.52 (training), 0.62 (test); Ω
4: 0.19, 0.08; and Ω
6: 0.03, 0.12—and the lowest RMSE—Ω
2: 0.61, 0.83; Ω
4: 0.23, 0.10; and Ω
6: 0.05, 0.12—demonstrating not only numerical superiority but statistical distinctness from its peers. The particularly large H statistic for the Ω
6 training underscores an especially pronounced effect, while the significant yet more moderate H values on the test splits highlight DeepBoost’s consistent advantage even with smaller sample sizes.
While the predictive performance of the models, particularly DeepBoost, has been thoroughly evaluated in this study, it is equally important to consider the trade-off between model accuracy and computational cost. In real-world applications, the choice of model often depends not only on its predictive power but also on its computational efficiency, especially when dealing with large datasets or time-sensitive tasks.
DeepBoost, for instance, achieved the highest accuracy across all the parameters, but its computational cost was higher compared to simpler models such as the Random Forest (RF) and a multilayer perceptron (MLP). Although DeepBoost demonstrated superior performance, its training time and resource requirements may limit its use in scenarios where rapid predictions are essential or computational resources are constrained.
On the other hand, models like XGBoost and RF, while slightly less accurate than DeepBoost, offer a better trade-off in terms of computational efficiency, making them suitable for real-time applications or situations with limited computational resources. These models require less training time and can be deployed more easily in industrial settings where quick predictions are needed.
Therefore, the selection of an appropriate model should take into account not only its accuracy but also its computational cost. In practice, if time and resource constraints are critical, simpler models with faster training times and less computational demand may be preferred, even if this results in a slight decrease in predictive accuracy. Conversely, when prediction accuracy is paramount and computational resources are available, more complex models like DeepBoost may be the best choice.
While this study emphasizes the computational efficiency and predictive performance of the advanced machine learning models used (e.g., DeepBoost, XGBoost, and CatBoost), we recognize that incorporating domain knowledge, such as ab initio data, into the modeling process has become a key trend in recent research. Recent studies, such as Zhang et al. [
81], have demonstrated the potential of hybrid neural networks that combine machine learning techniques with physics-based insights, such as NN potentials, to predict material properties more accurately and efficiently. These models integrate first-principles data with machine learning algorithms, enabling a deeper understanding of material behavior and improving predictive performance.
In addition to the application of machine learning in materials science, recent studies have shown the potential of hybrid models in image processing. For example, in a study conducted by Zhang et al. [
82], a hybrid neural network approach was used to efficiently predict key parameters such as pore pressure and temperature in fire-loaded concrete structures by leveraging a combination of autoencoders and fully connected neural networks. This work demonstrates the value of using images to represent complex material behaviors and to extract the key features for predictive modeling. Similarly, this study discusses the integration of image data with neural networks to enhance the analysis and prediction of concrete properties under extreme conditions, providing valuable parallels to the image-based data representations used in our study.
In comparison, our approach relies purely on data-driven machine learning models, without integrating domain-specific knowledge, which may limit the accuracy and interpretability of the results in complex systems like tellurite glasses. While our models perform well in terms of predictive accuracy and computational efficiency, integrating domain knowledge from the physical properties of materials could further enhance their performance. Future work could explore hybrid ML approaches, incorporating ab initio simulations or first-principles data, to improve the generalization capability of our models for complex material systems.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}