
Artificial Vision Systems for Mobility Impairment Detection: Integrating Synthetic Data, Ethical Considerations, and Real-World Applications


Abstract
1. Introduction
2. Background and Key Concepts
2.1. Artificial Vision and Deep Learning in Assistive Technology
Transformer-Based Object Detection in Assistive Vision and Rare Object Scenarios
2.2. Synthetic Data and Dataset Limitations
2.3. Ethical and Privacy Considerations
3. Threats and Challenges
3.1. Data Limitations and Real-World Generalization
3.2. Ethical Implications and Privacy Concerns
3.3. Technical Constraints and Interoperability
- Europe—GDPR (General Data Protection Regulation):Under GDPR, any personal identifiable information (PII) obtained from visual data (including biometric patterns or disability indicators) must be processed lawfully and transparently. Data controllers are required to obtain explicit consent from users, implement privacy-by-design principles, and adhere to data minimization standards that limit the scope and duration of data retention. Violations can lead to substantial legal and financial penalties, emphasizing the need for robust protective measures [10,11].
- United States—HIPAA (Health Insurance Portability and Accountability Act):In healthcare settings, visual data that may be linked to a person’s medical condition could be treated as Protected Health Information (PHI) under HIPAA. This mandates strict safeguards—both technical and administrative—to ensure data confidentiality and integrity. Any system integrating vision-based detection with health records or clinical monitoring must comply with HIPAA’s privacy and security rules, potentially complicating research and commercial deployments that share data across multiple platforms.
- Brazil—LGPD (Lei Geral de Proteção de Dados):Brazil’s LGPD requires clear disclosure of data processing purposes, the scope of data collection, and mechanisms for users to revoke consent or request deletion of personal data. Organizations must also appoint a Data Protection Officer (DPO) and establish transparent practices for handling incidents like data breaches. As in GDPR, non-compliance with LGPD can result in significant fines, thus urging researchers and developers to adopt comprehensive privacy governance frameworks [7,15].
- Inclusive Dataset Curation: Ensuring that training datasets encompass a representative spectrum of ages, ethnicities, and assistive device types.
- Fairness-Constrained Learning: Implementing fairness constraints during training, such as parity in false positive/negative rates across groups [27].
- Algorithmic Debiasing: Utilizing adversarial debiasing or reweighting methods (e.g., AI Fairness 360 toolkit) to decouple model outputs from sensitive attributes.
- Synthetic Augmentation: Introducing rare or underrepresented classes via generative models, including diffusion-based techniques, to improve generalization across edge-case scenarios [27].
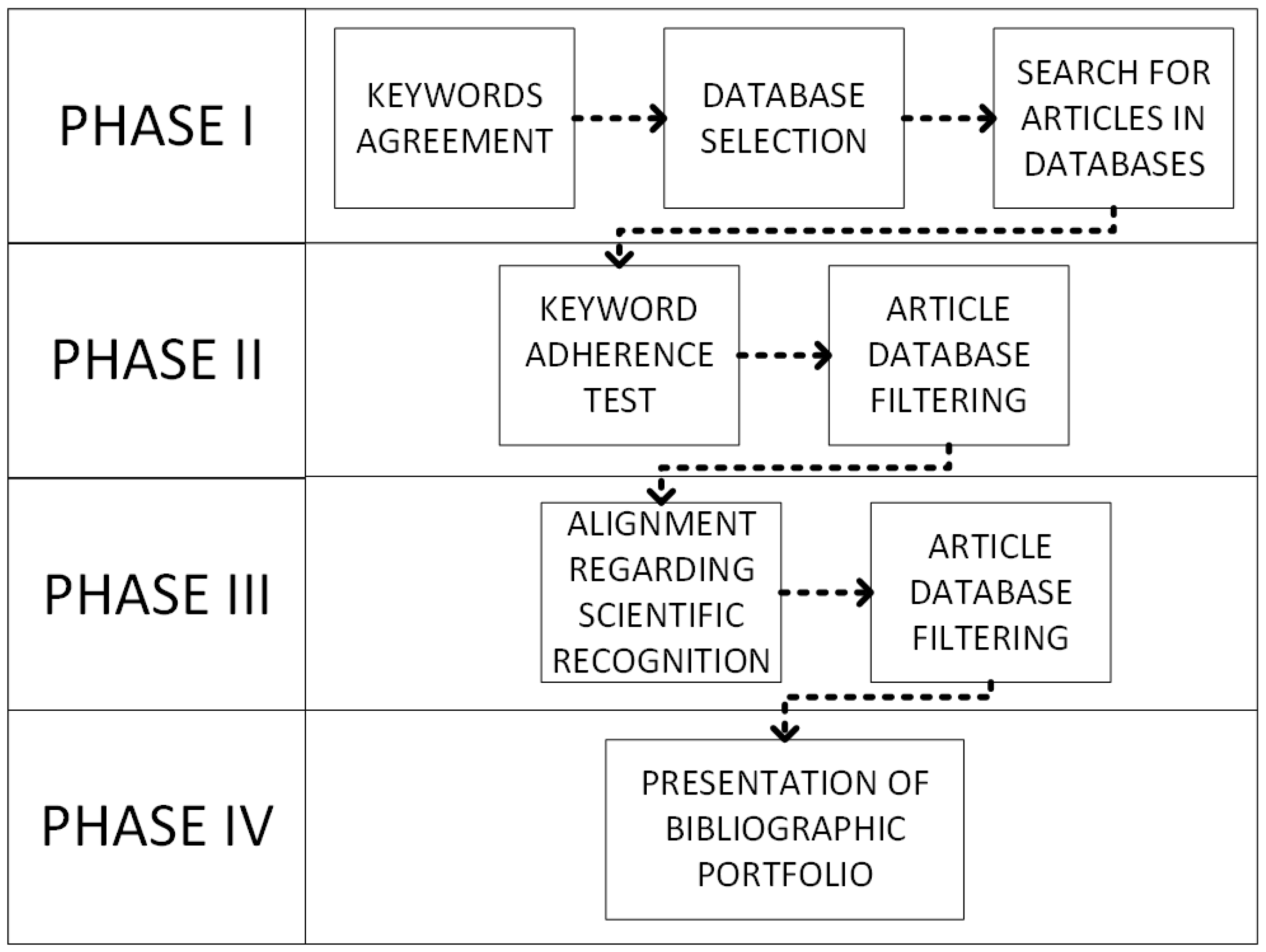
4. Literature Search and Article Selection
4.1. Definition and Combination of Keywords
- Theory: “Computer Vision”, “Deep Learning”, and “Image”.
- Techniques: “Object Detection”, “Segmentation”, and “Tracking”.
- Application: “Mobility Aids”, “Wheelchair”, “Walking Stick”, “Injured”, “Fall Detection”, and “Early Fall Detection”.
4.2. Database Selection and Search Period
4.3. Screening, Filtering, and Final Selection
- 1.
- Duplicate Removal:
- 2.
- Preliminary Screening (Topic Relevance):
- 3.
- Relevance and Methodological Quality Assessment:
4.4. Integration of Selected Articles
Object Detection Frameworks and Comparative Performance
Dataset Diversity and Synthetic Data
- Indoor vs. Outdoor Generalization.
- Synthetic Data Generation [21].
Fall Detection and Temporal Analysis
- Ethical and Privacy Frameworks.
Overall Effectiveness and Real-World Readiness
- Most Effective Methods.
- Key Gaps.
5. Key Enabling Technologies
5.1. Advanced Object Detection Models
5.2. Synthetic Data Generation and Simulation Environments
5.2.1. Integrating Synthetic and Real Data: CycleGAN, Domain Randomization, Style Transfer, Fine-Tuning
5.2.2. Diffusion Models for Synthetic Image and Mask Generation in Accessibility and Segmentation
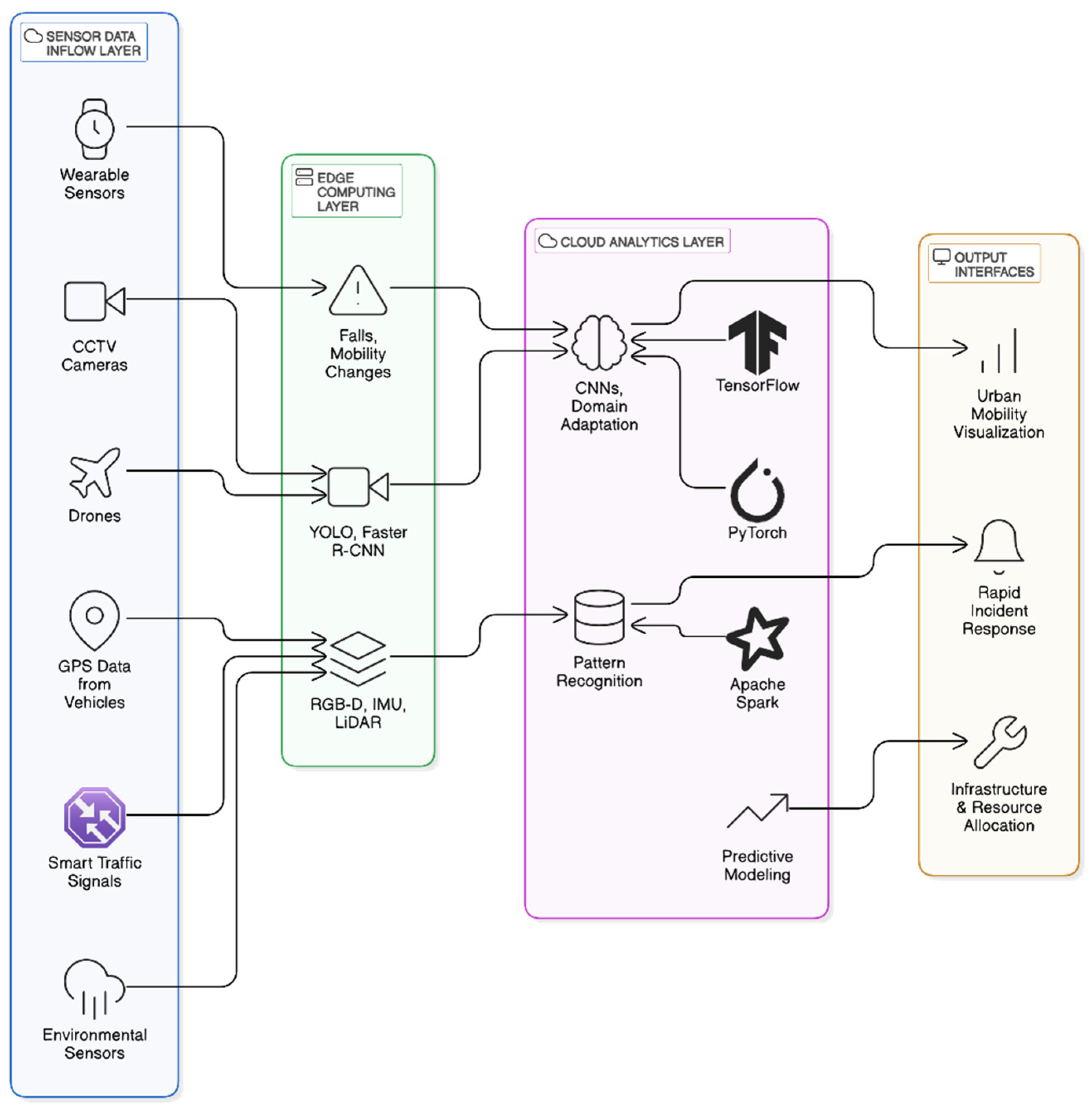
5.3. Sensor Fusion and Robotics Integration
6. Applications and Use Cases
6.1. Urban Surveillance and Public Safety
6.2. Assistive Robotics in Indoor Environments
6.3. Augmenting Accessibility in Public and Private Sectors
7. Proposed Conceptual Framework and Research Agenda
- Pilot Studies: Initiate small-scale deployments in controlled urban environments (e.g., bus terminals, public squares) to evaluate the performance of the integrated system under varying conditions.
- Experimental Designs: Develop experiments that compare the efficacy of different sensor fusion techniques and edge-cloud computing strategies, with a focus on latency, accuracy, and scalability.
- Interdisciplinary Collaborations: Form consortia with experts in computer vision, urban planning, robotics, and data ethics. This collaboration should focus on refining the architecture, addressing privacy concerns, and ensuring regulatory compliance across diverse jurisdictions.
8. Discussion and Future Directions
- 1.
- Bridging Data Gaps and Advancing Real-World Validation.
- Cross-institutional data sharing, ensuring broader geographical and demographic representation.
- Domain adaptation techniques (e.g., style transfer, adversarial learning) that mitigate the gap between synthetic simulations and live footage [73].
- 2.
- Vision-Based Mobility Impairment Detection in an Uncontrolled Urban Environment.
- 3.
- Reinforcing Ethical and Privacy Frameworks.
- 4.
- Technical Innovations for Scalable Deployment.
- 5.
- Toward Inclusive and Interdisciplinary Assistive Technologies.
- 6.
- Future Research Directions.
- Multi-sensor integration for robust, all-condition recognition, particularly in extreme lighting or weather.
- Longitudinal datasets to capture changes in user mobility status over time, enabling early intervention for progressive conditions.
- 7.
- Real-World Validation and Transnational Collaboration.
- 8.
- Real-World Implementation and Economic Feasibility.
- 9.
- Economic Feasibility and Industrial Adoption.
- 1.
- Cost–Benefit Analysis.
- Hardware and Sensor Costs: While deep learning frameworks (e.g., YOLOv5 [13], Faster R-CNN [12]) can run on standard GPUs, complex real-time applications often require dedicated accelerators or specialized edge devices. This raises initial capital expenses. Nonetheless, declining hardware prices and the scalability of cloud-based solutions can offset these outlays, making large-scale deployments increasingly feasible [49,111].
- Operational Savings: Automated detection of mobility impairments can reduce manual oversight in clinical or assisted-living settings, freeing healthcare professionals to focus on higher-level care tasks. Proactive fall detection or remote patient monitoring may decrease hospital readmissions, lowering long-term costs for healthcare systems [6,94].
- Return on Investment (ROI): For industrial stakeholders—ranging from robotics manufacturers to telehealth providers—ROI hinges on user acceptance, regulatory compliance, and evidence that these systems reduce care burdens or enhance patient satisfaction. Pilot studies and cost-modeling analyses in real-world environments can substantiate economic benefits, thereby attracting further investment and fostering market growth [11].
- 2.
- Pathways to Industrial Adoption.
- Collaborations with Established Players: Partnerships between AI-focused startups and larger medical device or robotics firms can expedite technology transfer, integrating mobility-detection modules into existing product lines (e.g., automated wheelchairs, clinical monitoring systems) [94].
- Subscription and Licensing Models: Some startups adopt a software-as-a-service (SaaS) paradigm, offering monthly or usage-based fees for AI-driven detection systems. This approach can lower upfront costs for care facilities while providing a recurring revenue stream for developers, facilitating continuous updates and iterative improvements [73].
9. Study Limitations
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Technical Configurations from Referenced Studies

{kind=link}
{kind=link}
{kind=link}
| Ref. | Neural Network Type Used | Learning Rate | Batch Size | GPU Model | Framework |
|---|---|---|---|---|---|
| [20] | Darknet-based CNN (YOLOv3 or similar) | 0.001 | 32 | NVIDIA GTX 1060 | Darknet/PyTorch |
| [21] | ResNet-50 + Mask R-CNN | 0.0001 | 16 | NVIDIA V100 | PyTorch |
| [14] | Faster R-CNN with RPN over 3D point clouds | 0.0003 | 8 | NVIDIA GTX 1080 Ti | TensorFlow |
| [26] | CNN for spatiotemporal key-frame selection | 0.001 | 32 | No GPU/CPU only | OpenCV + custom |
| [62] | CNN (PoseNet) + LSTM | 0.001 | 64 | NVIDIA Jetson Nano | TensorFlow Lite |
| [71] | VGG-16 + Attention-guided LSTM | 0.0001 | 16 | NVIDIA GTX 1080 | TensorFlow |
| [11] | 2-stream CNN + LSTM for multiview data | 0.0005 | 32 | NVIDIA RTX 2080 Ti | Keras/TensorFlow |
| [10] | YOLOv1 + DEEP-SEE pipeline (reported) | 0.1 | 64 | NVIDIA GTX 1050 Ti | Caffe |
| [13] | YOLOv5 for indoor detection | 0.01 | 32 | NVIDIA RTX 3090 | PyTorch |
References
- Bickenbach, J. The World Report on Disability. Disabil. Soc. 2011, 26, 655–658. [Google Scholar] [CrossRef]
- Brault, M.W. Americans with Disabilities: 2010; US Department of Commerce, Economics and Statistics Administration: Washington, DC, USA, 2012. [Google Scholar]
- Brasil, I. Censo Demográfico; Instituto Brasileiro de geografia e Estatística: Brasília, Brazil, 2010; p. 11. [Google Scholar]
- Yanushevskaya, I.; Bunčić, D. Russian. J. Int. Phon. Assoc. 2015, 45, 221–228. [Google Scholar] [CrossRef]
- Sumita, M. Communiqué of the National Bureau of Statistics of People’s Republic of China on major figures of the 2010 population census (No. 1). China Popul. Today 2011, 6, 19–23. [Google Scholar]
- Gupta, S.; Wittich, W.; Sukhai, M.; Robbins, C. Employment profile of adults with seeing disability in Canada: An analysis of the Canadian Survey on Disability 2017. Invest. Ophthalmol. Vis. Sci. 2021, 62, 3608. [Google Scholar]
- Mitra, S.; Posarac, A.; Vick, B. Disability and poverty in developing countries: A multidimensional study. World Dev. 2013, 41, 1–18. [Google Scholar] [CrossRef]
- Sabariego, C.; Oberhauser, C.; Posarac, A.; Bickenbach, J.; Kostanjsek, N.; Chatterji, S.; Officer, A.; Coenen, M.; Chhan, L.; Cieza, A. Measuring disability: Comparing the impact of two data collection approaches on disability rates. Int. J. Environ. Res. Public Health 2015, 12, 10329–10351. [Google Scholar] [CrossRef]
- Madans, J.H.; Loeb, M.E.; Altman, B.M. Measuring disability and monitoring the UN Convention on the Rights of Persons with Disabilities: The work of the Washington Group on Disability Statistics. BMC Public Health 2011, 11, S4. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance. arXiv 2017, arXiv:170609747. [Google Scholar] [CrossRef]
- Hsueh, Y.-L.; Lie, W.-N.; Guo, G.-Y. Human behavior recognition from multiview videos. Multimed. Tools Appl. 2020, 79, 11981–12000. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–30 June 2016; pp. 7794–7802. [Google Scholar]
- Kailash, A.S.; Sneha, B.; Authiselvi, M.; Dhiviya, M.; Karthika, R.; Prabhu, E. Deep Learning based Detection of Mobility Aids using YOLOv5. In Proceedings of the 2023 IEEE 3rd International conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; pp. 1–4. [Google Scholar]
- Kollmitz, M.; Eitel, A.; Vasquez, A.; Burgard, W. Deep 3D perception of people and their mobility aids. Robot. Auton. Syst. 2019, 114, 29–40. [Google Scholar] [CrossRef]
- Guleria, A.; Varshney, K.G.; Jindal, S. A systematic review: Object detection. AI Soc. 2025, 28, 1–18. [Google Scholar] [CrossRef]
- Ikram, S.; Sarwar Bajwa, I.; Gyawali, S.; Ikram, A.; Alsubaie, N. Enhancing Object Detection in Assistive Technology for the Visually Impaired: A DETR-Based Approach. IEEE Access 2025, 13, 71647–71661. [Google Scholar] [CrossRef]
- Song, H.; Bang, J. Prompt-guided DETR with RoI-pruned masked attention for open-vocabulary object detection. Pattern Recognit. 2024, 155, 110648. [Google Scholar] [CrossRef]
- Burges, M.; Dias, P.A.; Woody, C.; Walters, S.; Lunga, D. Interactive Rotated Object Detection for Novel Class Detection in Remotely Sensed Imagery. In Proceedings of the Winter Conference on Applications of Computer Vision, Tucson, AZ, USA, 28 February–4 March 2025; pp. 1219–1227. [Google Scholar]
- Wu, W.; Zhao, Y.; Shou, M.Z.; Zhou, H.; Shen, C. DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 1206–1217. [Google Scholar]
- Mukhtar, A. Vision Based System for Detecting and Counting Mobility Aids in Surveillance Videos. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 2022. [Google Scholar]
- Zhang, J.; Zheng, M.; Boyd, M.; Ohn-Bar, E. X-World: Accessibility, Vision, and Autonomy Meet. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9742–9751. [Google Scholar]
- Shifa, A.; Imtiaz, M.B.; Asghar, M.N.; Fleury, M. Skin detection and lightweight encryption for privacy protection in real-time surveillance applications. Image Vis. Comput. 2020, 94, 103859. [Google Scholar] [CrossRef]
- Liu, J.; Tang, Z.; Sun, N.; Han, G.; Kwong, S. Visual privacy-preserving level evaluation for multilayer compressed sensing model using contrast and salient structural features. Signal Process. Image Commun. 2020, 82, 115796. [Google Scholar] [CrossRef]
- Brščič, D.; Evans, R.W.; Rehm, M.; Kanda, T. Using a rotating 3d lidar on a mobile robot for estimation of person’s body angle and gender. In Proceedings of the 2020 15th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Cambridge, UK, 23–26 March 2020; pp. 325–333. [Google Scholar]
- Seijdel, N.; Scholte, H.S.; de Haan, E.H.F. Visual features drive the category-specific impairments on categorization tasks in a patient with object agnosia. Neuropsychologia 2021, 161, 108017. [Google Scholar] [CrossRef]
- Fang, J.; Qian, W.; Zhao, Z.; Yao, Y.; Wen, Z. Adaptively feature learning for effective power defense. J. Vis. Commun. Image Represent. 2019, 60, 33–37. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, Y.; Qian, Z.; Sha, J.; Xie, M.; Wan, Y.; Liu, P. Enhancing Rare Object Detection on Roadways Through Conditional Diffusion Models for Data Augmentation. IEEE Trans. Intell. Transp. Syst. 2024, 25, 19018–19029. [Google Scholar] [CrossRef]
- Casaburo, D. EDPB’s Opinion 28/2024 on Certain Data Protection Aspects Related to the Processing of Personal Data in the Context of AI Models: A Missed Chance? Eur. Data Prot. Law Rev. 2025, 11, 70–75. [Google Scholar] [CrossRef]
- Kazim, E.; Koshiyama, A. The interrelation between data and AI ethics in the context of impact assessments. AI Ethics 2021, 1, 219–225. [Google Scholar] [CrossRef]
- ISO 23894:2023; Artificial Intelligence—Guidance on Risk Management. International Organization for Standardization: Geneva, Switzerland, 2023.
- ISO/IEC 42001:2023; Artificial Intelligence—Management System. International Organization for Standardization/International Electrotechnical Commission: Geneva, Switzerland, 2023.
- Ensslin, L.; Ramos, V.A.; Raupp, F.R.; Reichert, F.M. ProKnow-C, Knowledge Development Process—Construtivist. Processus 2010, 17, 1–10. [Google Scholar]
- Vilela, J.A.; Ensslin, L.; Raupp, F.R. Systematic literature review on the use of knowledge management in SMEs: A ProKnow-C approach. J. Small Bus. Manag. 2014, 52, 767–787. [Google Scholar]
- Isasi, J.M.; Ensslin, L.; Raupp, F.R. Bibliometric analysis of risk management research in construction: A ProKnow-C approach. J. Constr. Eng. Manag. 2015, 141, 4015078. [Google Scholar]
- Afonso, J.A.; Ensslin, L.; Raupp, F.R. Systematic literature review of risk management in construction projects: A ProKnow-C approach. J. Constr. Eng. Manag. 2012, 138, 1006–1015. [Google Scholar]
- Castro, J.L.; Delgado, M.; Medina, J.; Ruiz-Lozano, M.D. An expert fuzzy system for predicting object collisions. Its application for avoiding pedestrian accidents. Expert. Syst. Appl. 2011, 38, 486–494. [Google Scholar] [CrossRef]
- Kmieć, M.; Glowacz, A. Object detection in security applications using dominant edge directions. Pattern Recognit. Lett. 2015, 52, 72–79. [Google Scholar] [CrossRef]
- Adán, A.; Quintana, B.; Vázquez, A.S.; Olivares, A.; Parra, E.; Prieto, S. Towards the automatic scanning of indoors with robots. Create simple three-dimensional indoor models with mobile robots. Sensors 2015, 15, 11551–11574. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Li, F. WiGeR: WiFi-Based Gesture Recognition System. ISPRS Int. J. Geo-Inf. 2016, 5, 92. [Google Scholar] [CrossRef]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. DeepGait: A learning deep convolutional representation for view-invariant gait recognition using joint Bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Garduño-Ramón, M.A.; Terol-Villalobos, I.R.; Osornio-Rios, R.A.; Morales-Hernandez, L.A. A new method for inpainting of depth maps from time-of-flight sensors based on a modified closing by reconstruction algorithm. J. Vis. Commun. Image Represent. 2017, 47, 36–47. [Google Scholar] [CrossRef]
- Fang, W.; Zhong, B.; Zhao, N.; Love, P.E.; Luo, H.; Xue, J.; Xu, S. A deep learning-based approach for mitigating falls from height with computer vision: Convolutional neural network. Adv. Eng. Inform. 2019, 39, 170–177. [Google Scholar] [CrossRef]
- Abobakr, A.; Nahavandi, D.; Hossny, M.; Iskander, J.; Attia, M.; Nahavandi, S.; Smets, M. RGB-D ergonomic assessment system of adopted working postures. Appl. Ergon. 2019, 80, 75–88. [Google Scholar] [CrossRef] [PubMed]
- Zoetgnande, Y.W.K.; Cormier, G.; Fougeres, A.J.; Dillenseger, J.L. Sub-pixel matching method for low-resolution thermal stereo images. Infrared Phys. Technol. 2020, 105, 103161. [Google Scholar] [CrossRef]
- Wang, X.; Liu, B.; Dong, Y.; Pang, S.; Tao, X. Anthropometric landmarks extraction and dimensions measurement based on ResNet. Symmetry 2020, 12, 1997. [Google Scholar] [CrossRef]
- Chu, J.; Dong, L.; Liu, H.; Lü, P.; Ma, H.; Peng, Q.; Ren, G.; Liu, Y.; Tan, Y. High-resolution measurement based on the combination of multi-vision system and synthetic aperture imaging. To improve the measurement of small-scale of longer-range objects. Opt. Lasers Eng. 2020, 133, 106116. [Google Scholar] [CrossRef]
- Wu, R.; Xu, Z.; Zhang, J.; Zhang, L. Robust Global Motion Estimation for Video Stabilization Based on Improved K-Means Clustering and Superpixel. Robust and simple method to implement global motion estimation. Sensors 2021, 21, 2505. [Google Scholar] [CrossRef]
- Yan, Y.; Yao, S.; Wang, H.; Gao, M. Index selection for NoSQL database with deep reinforcement learning. J. Syst. Archit. 2021, 123, 102070. [Google Scholar] [CrossRef]
- Espinosa, R.; Ponce, H.; Ortiz-Medina, J. A 3D orthogonal vision-based band-gap prediction using deep learning: A proof of concept. Comput. Mater. Sci. 2022, 202, 110967. [Google Scholar] [CrossRef]
- Jin, Y.; Ye, J.; Shen, L.; Xiong, Y.; Fan, L.; Zang, Q. Hierarchical Attention Neural Network for Event Types to Improve Event Detection. Sensors 2022, 22, 4202. [Google Scholar] [CrossRef]
- Ruiz-Lozano, M.D.; Medina, J.; Delgado, M.; Castro, J. An expert fuzzy system to detect dangerous circumstances due to children in the traffic areas from the video content analysis. Eng. Appl. Artif. Intell. 2012, 25, 1436–1449. [Google Scholar] [CrossRef]
- Ge, S.; Fan, G. Articulated non-rigid point set registration for human pose estimation from 3D sensors. Sensors 2015, 15, 15218–15245. [Google Scholar] [CrossRef] [PubMed]
- Gronskyte, R.; Clemmensen, L.H.; Hviid, M.S.; Kulahci, M. Monitoring pig movement at the slaughterhouse using optical flow and modified angular histograms. Biosyst. Eng. 2016, 141, 19–30. [Google Scholar] [CrossRef]
- Ijjina, E.P.; Chalavadi, K.M. Human action recognition in RGB-D videos using motion sequence information and deep learning. J. Ambient Intell. Humaniz. Comput. 2017, 8, 629–640. [Google Scholar] [CrossRef]
- Plantard, P.; Muller, A.; Pontonnier, C.; Dumont, G.; Shum, H.P.; Multon, F. Inverse dynamics based on occlusion-resistant Kinect data: Is it usable for ergonomics? The reliability of an inverse dynamics method based on corrected skeleton data and its potential use to estimate joint torques and forces in such cluttered environments. Int. J. Ind. Ergon. 2017, 61, 71–80. [Google Scholar] [CrossRef]
- Montero Quispe, K.G.; Sousa Lima, W.; Macêdo Batista, D.; Souto, E. MBOSS: A symbolic representation of human activity recognition using mobile sensors. In Proceedings of the 2018 IEEE/ACS 15th International Conference on Computer Systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–6. [Google Scholar]
- Wang, M.; Zhang, Y.D.; Cui, G. Human motion recognition exploiting radar with stacked recurrent neural network. Digit. Signal Process. 2019, 87, 125–131. [Google Scholar] [CrossRef]
- Lee, H.; Ahn, C.R.; Choi, N.; Kim, T.; Lee, H. The effects of housing environments on the performance of activity-recognition systems using Wi-Fi channel state information: An exploratory study. Sensors 2019, 19, 983. [Google Scholar] [CrossRef]
- Qamar, N.; Siddiqui, N.; Ehatisham-ul-Haq, M.; Azam, M.A.; Naeem, U. An approach towards position-independent human activity recognition model based on wearable accelerometer sensor. Appl. Soft. Comput. 2020, 93, 106345. [Google Scholar] [CrossRef]
- Zhao, P.; Lu, C.X.; Wang, J.; Chen, C.; Wang, W.; Trigoni, N.; Markham, A. Human tracking and identification through a millimeter wave radar. Ad Hoc Netw. 2021, 11, 102475. [Google Scholar] [CrossRef]
- Dursun, A.A.; Tuncer, T.E. Estimation of partially occluded 2D human joints with a Bayesian approach. Digit. Signal Process. 2021, 114, 103056. [Google Scholar] [CrossRef]
- Mamchur, N.; Shakhovska, N. Person Fall Detection System Based on Video Stream Analysis. Procedia Comput. Sci. 2022, 198, 676–681. [Google Scholar] [CrossRef]
- Elbouz, M.; Alfalou, A.; Brosseau, C.; Yahia, N.B.H.; Alam, M. Assessing the performance of a motion tracking system based on optical joint transform correlation. Opt. Commun. 2015, 349, 65–82. [Google Scholar] [CrossRef]
- Ding, W.; Liu, K.; Cheng, F.; Zhang, J. STFC: Spatio-temporal feature chain for skeleton-based human action recognition. Action recognition with 3D joints positions. J. Vis. Commun. Image Represent. 2015, 26, 329–337. [Google Scholar] [CrossRef]
- Batchuluun, G.; Kim, Y.G.; Kim, J.H.; Gil Hong, H.; Park, K.R. Robust behavior recognition in intelligent surveillance environments. Sensors 2016, 16, 1010. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Liu, H. Depth context: A new descriptor for human activity recognition by using sole depth sequences. Human actions recognition with depth sequences. Neurocomputing 2016, 175, 747–758. [Google Scholar] [CrossRef]
- Batchuluun, G.; Kim, J.H.; Hong, H.G.; Kang, J.K.; Park, K.R. Fuzzy system based human behavior recognition by combining behavior prediction and recognition. Expert Syst. Appl. 2016, 81, 108–133. [Google Scholar] [CrossRef]
- Wang, G.; Li, Q.; Wang, L.; Wang, W.; Wu, M.; Liu, T. Impact of sliding window length in indoor human motion modes and pose pattern recognition based on smartphone sensors. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 906–915. [Google Scholar]
- Zhang, X.; Li, X. Dynamic gesture recognition based on MEMP network. Future Internet 2019, 11, 91. [Google Scholar] [CrossRef]
- Demiröz, B.E.; Altınel, İ.K.; Akarun, L. Rectangle blanket problem: Binary integer linear programming formulation and solution algorithms. Eur. J. Oper. Res. 2019, 27, 62–83. [Google Scholar] [CrossRef]
- Feng, Q.; Gao, C.; Wang, L.; Zhao, Y.; Song, T.; Li, Q. Spatio-temporal fall event detection in complex scenes using attention guided LSTM. Pattern Recognit. Lett. 2020, 130, 242–249. [Google Scholar] [CrossRef]
- Yao, L.; Yang, W.; Huang, W. A data augmentation method for human action recognition using dense joint motion images. Appl. Soft Comput. 2020, 97, 106713. [Google Scholar] [CrossRef]
- Hossain, T.; Ahad, M.; Rahman, A.; Inoue, S. A method for sensor-based activity recognition in missing data scenario. Sensors 2020, 20, 3811. [Google Scholar] [CrossRef]
- Anitha, U.; Narmadha, R.; Sumanth, D.R.; Kumar, D.N. Robust human action recognition system via image processing. Procedia Comput. Sci. 2020, 167, 870–877. [Google Scholar] [CrossRef]
- Cui, W.; Li, B.; Zhang, L.; Chen, Z. Device-free single-user activity recognition using diversified deep ensemble learning. Appl. Soft Comput. 2021, 102, 107066. [Google Scholar] [CrossRef]
- Waheed, M.; Afzal, H.; Mehmood, K. NT-FDS—A Noise Tolerant Fall Detection System Using Deep Learning on Wearable Devices. Sensors 2021, 21, 2006. [Google Scholar] [CrossRef]
- Li, J.; Yin, K.; Tang, C. SlideAugment: A Simple Data Processing Method to Enhance Human Activity Recognition Accuracy Based on WiFi. Sensors 2021, 21, 2181. [Google Scholar] [CrossRef]
- Liu, R.; Zhang, B.; Yu, Z.; Han, Z.; Wu, J.; Wang, T. Vibration-based terrain classification recognition using a six-axis accelerometer. Sensors 2021, 21, 4645. [Google Scholar] [CrossRef]
- Sikder, N.; Nahid, A.A. KU-HAR: An open dataset for heterogeneous human activity recognition. Data Brief 2021, 36, 107020. [Google Scholar] [CrossRef]
- Mankodiya, H.; Jadav, D.; Gupta, R.; Tanwar, S.; Alharbi, A.; Tolba, A.; Neagu, B.-C.; Raboaca, M.S. XAI-Fall: Explainable AI for Fall Detection on Wearable Devices Using Sequence Models and XAI Techniques. Mathematics 2022, 10, 1990. [Google Scholar] [CrossRef]
- Ramirez De La Pinta, J.; Maestre Torreblanca, J.M.; Jurado, I.; Reyes De Cozar, S. Off the shelf cloud robotics for the smart home: Empowering a wireless robot through cloud computing. Sensors 2017, 17, 525. [Google Scholar] [CrossRef]
- Liu, X.; Cao, J.; Yang, Y.; Jiang, S. CPS-based smart warehouse for industry 4.0: A survey of the underlying technologies. Computers 2018, 7, 13. [Google Scholar] [CrossRef]
- Chen, F.; Deng, J.; Pang, Z.; Nejad, M.B.; Yang, H.; Yang, G. Finger angle-based hand gesture recognition for smart infrastructure using wearable wrist-worn camera. Appl. Sci. 2018, 8, 369. [Google Scholar] [CrossRef]
- Zhou, B.; Yang, J.; Li, Q. Smartphone-based activity recognition for indoor localization using a convolutional neural network. Sensors 2019, 19, 621. [Google Scholar] [CrossRef] [PubMed]
- Mohamadi, S.; Lattanzi, D. Life-Cycle Modeling of Structural Defects via Computational Geometry and Time-Series Forecasting. Sensors 2019, 19, 4571. [Google Scholar] [CrossRef] [PubMed]
- Sirmacek, B.; Riveiro, M. Occupancy prediction using low-cost and low-resolution heat sensors for smart offices. Sensors 2020, 20, 5497. [Google Scholar] [CrossRef] [PubMed]
- Zerkouk, M.; Chikhaoui, B. Spatio-temporal abnormal behavior prediction in elderly persons using deep learning models. Sensors 2020, 20, 2359. [Google Scholar] [CrossRef] [PubMed]
- Vu, V.H.; Nguyen, Q.P.; Shin, J.C.; Ock, C.Y. UPC: An Open Word-Sense Annotated Parallel Corpora for Machine Translation Study. J. Inf. Sci. Theory Pract. 2020, 8, 14–26. [Google Scholar] [CrossRef]
- Mandischer, N.; Huhn, T.; Hüsing, M.; Corves, B. Efficient and Consumer-Centered Item Detection and Classification with a Multicamera Network at High Ranges. Sensors 2021, 21, 4818. [Google Scholar] [CrossRef]
- Lagartinho-Oliveira, C.; Moutinho, F.; Gomes, L. Towards Digital Twin in the Context of Power Wheelchairs Provision and Support. In Proceedings of the Technological Innovation for Digitalization and Virtualization: 13th IFIP WG 5.5/SOCOLNET Doctoral Conference on Computing, Electrical and Industrial Systems, DoCEIS 2022, Caparica, Portugal, 29 June–1 July 2022; pp. 95–102. [Google Scholar]
- Manjari, K.; Verma, M.; Singal, G. A smart hand for VI: Resource-constrained assistive technology for visually impaired. In IoT-Based Data Analytics for the Healthcare Industry; Academic Press: Cambridge, MA, USA, 2021; pp. 225–235. [Google Scholar]
- Lalik, K.; Flaga, S. A Real-Time Distance Measurement System for a Digital Twin Using Mixed Reality Goggles. Sensors 2021, 21, 7870. [Google Scholar] [CrossRef]
- Odeh, N.; Toma, A.; Mohammed, F.; Dama, Y.; Oshaibi, F.; Shaar, M. An Efficient System for Automatic Blood Type Determination Based on Image Matching Techniques. Appl. Sci. 2021, 11, 5225. [Google Scholar] [CrossRef]
- Mostofa, N.; Feltner, C.; Fullin, K.; Guilbe, J.; Zehtabian, S.; Bacanlı, S.S.; Bölöni, L.; Turgut, D. A Smart Walker for People with Both Visual and Mobility Impairment. Sensors 2021, 21, 3488. [Google Scholar] [CrossRef]
- Luzi, G.; Espín-López, P.F.; Mira Pérez, F.; Monserrat, O.; Crosetto, M. A Low-Cost Active Reflector for Interferometric Monitoring Based on Sentinel-1 SAR Images. Sensors 2021, 21, 2008. [Google Scholar] [CrossRef]
- Shenoy, S.; Sanap, G.; Paul, D.; Desai, N.; Tambe, V.; Kalyane, D.; Tekade, R.K. Artificial intelligence in preventive and managed healthcare. In Biopharmaceutics and Pharmacokinetics Considerations; Elsevier: Amsterdam, The Netherlands, 2021; pp. 675–697. [Google Scholar]
- Stringari, C.E.; Power, H. Picoastal: A low-cost coastal video monitoring system. Environ. Model. Softw. 2022, 144, 105036. [Google Scholar] [CrossRef]
- Mishra, P.; Kumar, S.; Chaube, M.K.; Shrawankar, U. ChartVi: Charts summarizer for visually impaired. J. Comput. Lang. 2022, 69, 101107. [Google Scholar] [CrossRef]
- Ning, H.; Li, Z.; Wang, C.; Hodgson, M.E.; Huang, X.; Li, X. Converting street view images to land cover maps for metric mapping: A case study on sidewalk network extraction for the wheelchair users. Comput. Environ. Urban Syst. 2022, 95, 101808. [Google Scholar] [CrossRef]
- Santoyo-Ram’on, J.A.; Casilari, E.; Cano-Garc’a, J.M. A study of the influence of the sensor sampling frequency on the performance of wearable fall detectors. Sensors 2022, 22, 579. [Google Scholar] [CrossRef]
- Luna, J.C.; Rocha, J.M.; Monacelli, E.; Foggea, G.; Hirata, Y.; Delaplace, S. WISP, Wearable Inertial Sensor for Online Wheelchair Propulsion Detection. Sensors 2022, 22, 4221. [Google Scholar] [CrossRef]
- Figueira, A.; Vaz, B. Survey on Synthetic Data Generation, Evaluation Methods and GANs. Mathematics 2022, 10, 2733. [Google Scholar] [CrossRef]
- Acharya, D.; Tatli, C.J.; Khoshelham, K. Synthetic-real image domain adaptation for indoor camera pose regression using a 3D model. ISPRS J. Photogramm. Remote Sens. 2023, 202, 405–421. [Google Scholar] [CrossRef]
- Muratore, F.; Ramos, F.; Turk, G.; Yu, W.; Gienger, M.; Peters, J. Robot Learning From Randomized Simulations: A Review. Front. Robot. AI 2022, 9, 799893. [Google Scholar] [CrossRef]
- Rosskamp, J.; Weller, R.; Zachmann, G. Effects of Markers in Training Datasets on the Accuracy of 6D Pose Estimation. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 4445–4454. [Google Scholar]
- Dewil, V.; Barral, A.; Facciolo, G.; Arias, P. Self-supervision versus synthetic datasets: Which is the lesser evil in the context of video denoising? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 8–24 June 2022; pp. 4900–4910. [Google Scholar]
- Usman Akbar, M.; Larsson, M.; Blystad, I.; Eklund, A. Brain tumor segmentation using synthetic MR images—A comparison of GANs and diffusion models. Sci. Data 2024, 11, 259. [Google Scholar] [CrossRef]
- Jalab, H.A.; Al-Shamayleh, A.S.; Abualhaj, M.M.; Shambour, Q.Y.; Omer, H.K. Machine learning classification method for wheelchair detection using bag-of-visual-words technique. Disabil. Rehabil. Assist. Technol. 2025, 20, 1–11. [Google Scholar] [CrossRef]
- Alruwaili, M.; Siddiqi, M.H.; Atta, M.N.; Arif, M. Deep learning and ubiquitous systems for disabled people detection using YOLO models. Comput. Human Behav. 2024, 154, 108150. [Google Scholar] [CrossRef]
- Alruwaili, M.; Atta, M.N.; Siddiqi, M.H.; Khan, A.; Khan, A.; Alhwaiti, Y.; Alanazi, S. Deep Learning-Based YOLO Models for the Detection of People With Disabilities. IEEE Access 2024, 12, 2543–2566. [Google Scholar] [CrossRef]
- Cao, L.; Huo, T.; Li, S.; Zhang, X.; Chen, Y.; Lin, G.; Wu, F.; Ling, Y.; Zhou, Y.; Xie, Q. Cost optimization in edge computing: A survey. Artif. Intell. Rev. 2024, 57, 312. [Google Scholar] [CrossRef]

| Category | Reference | Year | Methodology/ Technique | Key Findings/ Recommendations |
|---|---|---|---|---|
| Computer Vision and Object Recognition | [36] | 2011 | Fuzzy logic-based prediction system | Demonstrated potential for preventing collisions and enhancing pedestrian safety. |
| [37] | 2015 | Edge direction analysis technique | Effective detection of knife objects; the approach may be extended to detect mobility aids in complex environments. | |
| [38] | 2015 | Robotic scanning combined with image processing | Established feasibility for automated indoor mapping; applicable for controlled detection of mobility aids. | |
| [39] | 2016 | WiFi signal processing for gesture recognition | Enabled recognition of gestures via WiFi; indirectly relevant for assessing mobility. | |
| [40] | 2017 | Deep CNN with joint Bayesian inference | Achieved view-invariant gait recognition; useful for assessing mobility impairments. | |
| [41] | 2017 | Depth map inpainting via reconstruction algorithm | Improved quality of depth maps; supports more accurate detection in 3D scenarios. | |
| [10] | 2017 | Integrated CNN-based tracking and object detection | Enhanced detection in dynamic environments with occlusions; promising for navigational assistance. | |
| [42] | 2019 | CNN-based fall mitigation approach | Demonstrated potential in fall detection with high accuracy in controlled settings. | |
| [43] | 2019 | RGB-D imaging and posture analysis | Assessed ergonomic postures; findings have implications for mobility aid evaluation. | |
| [44] | 2020 | Sub-pixel image matching technique | Improved resolution in thermal imaging; useful for surveillance and mobility detection in low-resolution scenarios. | |
| [45] | 2020 | Deep learning with ResNet for landmark extraction | Provided accurate anthropometric measurements; potential for classifying mobility aids. | |
| [22] | 2020 | Skin detection algorithms combined with encryption | Balanced real-time surveillance with enhanced privacy protection; relevant for ethical data handling. | |
| [46] | 2020 | Multi-vision integration with synthetic aperture imaging | Enhanced measurement resolution; supports detailed analysis of mobility aids. | |
| [23] | 2020 | Compressed sensing with privacy-preserving evaluation | Advanced privacy preservation techniques; crucial for the ethical deployment of surveillance systems. | |
| [24] | 2020 | Three-dimensional lidar integration on the mobile robot platform | Provided robust body angle and gender estimation; indirectly aids mobility analysis. | |
| [25] | 2021 | Clinical case study analyzing visual feature impact | Highlighted challenges in visual categorization; informs understanding of impairments in object recognition. | |
| [47] | 2021 | Motion estimation via clustering and superpixel segmentation | Enhanced video stabilization; supports improved tracking in dynamic environments. | |
| [48] | 2021 | Deep reinforcement learning for index selection | Optimized database performance is indirectly applicable to managing large-scale assistive data. | |
| [49] | 2022 | Deep learning for 3D vision-based prediction | Provided a proof of concept for band-gap prediction; demonstrates potential for 3D analysis techniques. | |
| [13] | 2023 | YOLOv5 deep learning model for object detection | Achieved 91% accuracy in controlled settings; recommends further evaluation under diverse conditions. | |
| [50] | 2022 | Hierarchical attention mechanisms in neural networks | Improved event detection accuracy; potential to detect dynamic mobility-related events. | |
| Person Recognition and Tracking | [51] | 2012 | Fuzzy system applied to video content analysis | Identified risk scenarios in traffic that are applicable to enhancing pedestrian safety. |
| [52] | 2015 | Non-rigid point set registration algorithm | Enhanced human pose estimation accuracy; beneficial for tracking mobility impairments. | |
| [53] | 2016 | Optical flow analysis with histogram methods | Successfully monitored movement under challenging conditions; method adaptable for human activity tracking. | |
| [54] | 2017 | Deep learning applied to RGB-D motion sequences | Achieved reliable action recognition; supports continuous tracking of mobility impairments. | |
| [55] | 2017 | Inverse dynamics estimation using Kinect data | Addressed occlusion challenges; indicated potential for ergonomic assessments. | |
| [56] | 2018 | Symbolic representation for activity recognition | Provided a lightweight method for recognizing activities; useful for mobile sensor integration. | |
| [57] | 2019 | Radar sensing combined with stacked RNNs | Demonstrated high accuracy in motion recognition; valuable for non-visual tracking scenarios. | |
| [58] | 2019 | Wi-Fi CSI analysis for activity recognition | Showed environmental factors significantly impact recognition; emphasizes the need for contextual data. | |
| [59] | 2020 | Wearable accelerometer-based activity recognition | Achieved position-independent recognition, promising for continuous mobility monitoring. | |
| [60] | 2021 | Millimeter wave radar technology | Provided robust identification in challenging scenarios; useful for urban non-visual tracking. | |
| [61] | 2021 | Bayesian estimation for occluded joint detection | Improved estimation accuracy of occluded joints; beneficial for precise motion tracking. | |
| [62] | 2022 | Video stream analysis for fall detection | Achieved reliable fall detection, critical for enhancing assistive safety applications. | |
| Human Action Detection and Recognition | [63] | 2015 | Optical joint transform correlation method | Accurately tracked motion; demonstrated high performance in controlled experiments. |
| [64] | 2015 | Spatio-temporal feature extraction from skeleton data | Enhanced recognition accuracy for human actions; validated under laboratory conditions. | |
| [65] | 2016 | Deep learning-based behavior recognition | Displayed robust performance in varied surveillance contexts; potential for real-time monitoring. | |
| [66] | 2016 | Depth sequence analysis for activity recognition | Introduced novel depth-based descriptors; improved recognition in low-visibility scenarios. | |
| [67] | 2017 | Fuzzy logic combines prediction and recognition | Achieved improved performance by integrating prediction; applicable for real-time behavior monitoring. | |
| [68] | 2018 | Sliding window analysis on smartphone sensor data | Identified optimal window lengths for accurate recognition; provides recommendations for sensor-based applications. | |
| [26] | 2019 | Adaptive feature learning techniques | Enhanced recognition of power defense actions; method adaptable to various settings. | |
| [69] | 2019 | MEMP network for dynamic gesture recognition | Achieved high accuracy in dynamic gesture recognition; promising for interactive applications. | |
| [70] | 2019 | Optimization algorithms for spatial segmentation | Offered effective solutions for spatial optimization that are applicable to image segmentation tasks. | |
| [14] | 2019 | Deep 3D convolutional networks for perception | Achieved high precision in 3D perception; recommended for enhancing spatial awareness in assistive systems. | |
| [20] | 2022 | Integrated detection and tracking system | Demonstrated promising accuracy in real-world surveillance; suggests further optimization is needed. | |
| [71] | 2020 | Attention-guided LSTM for temporal analysis | Achieved around 90% accuracy in fall detection; highlights the importance of temporal cues in dynamic environments. | |
| [72] | 2020 | Data augmentation via dense joint motion imaging | Improved training data diversity and enhanced recognition accuracy. | |
| [73] | 2020 | Sensor fusion and imputation techniques | Addressed missing data challenges while maintaining recognition performance. | |
| [11] | 2020 | Multi-view video analysis | Enhanced accuracy by integrating multiple perspectives; recommended for complex environments. | |
| [74] | 2020 | Robust image processing techniques | Displayed high reliability in recognizing actions; potential for deployment in surveillance systems. | |
| [75] | 2021 | Ensemble learning without device dependency | Provided robust single-user activity recognition; useful for non-intrusive monitoring. | |
| [76] | 2021 | Deep learning with noise-tolerant techniques | Achieved reliable fall detection in wearable settings; addressed challenges of noisy data. | |
| [77] | 2021 | WiFi signal processing with efficient data processing | Improved recognition accuracy with computational efficiency. | |
| [78] | 2021 | Vibration analysis using accelerometer data | Effectively classified terrain types; has implications for activity recognition in varied environments. | |
| [79] | 2021 | Dataset creation and benchmark evaluation | Provided a comprehensive dataset; encourages standardization in activity recognition research. | |
| [80] | 2022 | Sequence models combined with explainable AI techniques | Enhanced fall detection with improved interpretability; recommended for safety-critical applications. | |
| Assistive and Accessibility Applications | [81] | 2017 | Integration of commercial cloud robotics | Demonstrated feasibility for using off-the-shelf robotics for home assistance; supports smart home accessibility. |
| [82] | 2018 | Survey of Cyber-Physical Systems technologies | Provided an overview of smart warehouse solutions relevant to industrial assistive technology applications. | |
| [83] | 2018 | Hand gesture recognition via wearable cameras | Achieved high accuracy in recognizing hand gestures; potential for controlling assistive devices in smart environments. | |
| [84] | 2019 | CNN-based activity recognition from smartphone data | Enabled accurate indoor localization; enhances accessibility in smart environments. | |
| [85] | 2019 | Computational geometry and time-series forecasting | Advanced modeling of structural defects is indirectly applicable for monitoring infrastructure impacting accessibility. | |
| [86] | 2020 | Heat sensor data analysis | Demonstrated occupancy prediction with low-cost sensors; valuable for optimizing resources in smart buildings. | |
| [87] | 2020 | Deep learning for spatio-temporal behavior prediction | Provided early warnings of abnormal behavior, critical for elder care and mobility support. | |
| [88] | 2020 | Corpus creation and annotation | Developed an annotated corpus for machine translation; supports multimodal data integration. | |
| [89] | 2021 | Multicamera network analysis | Improved detection of items in wide-range scenarios; applicable for urban surveillance in smart cities. | |
| [90] | 2022 | Digital twin technology integration | Demonstrated potential of digital twins in enhancing wheelchair services; provides technical and economic insights for smart city deployments. | |
| [21] | 2021 | Synthetic data simulation environment development | Addressed data scarcity; supports advanced research on assistive autonomous systems. | |
| [91] | 2021 | Resource-constrained hardware design | Developed an affordable smart hand for visually impaired users; enhances independence and accessibility. | |
| [92] | 2021 | Mixed reality and digital twin integration | Enabled real-time measurements; supports dynamic adjustments in assistive systems. | |
| [93] | 2021 | Image matching algorithms | Offered accurate blood type determination; illustrates potential for rapid diagnostic applications in healthcare. | |
| [94] | 2021 | Smart walker design with integrated sensors | Provided a prototype for a smart walker; promotes improved mobility and safety for users with dual impairments. | |
| [95] | 2021 | Interferometric monitoring using SAR images | Demonstrated cost-effective monitoring; potential applications in infrastructure and accessibility evaluations. | |
| [96] | 2021 | Review and integration of AI in healthcare | Reviewed AI applications in healthcare; provides insights into preventive measures benefiting mobility-impaired populations. | |
| [97] | 2022 | Low-cost video monitoring system | Enabled efficient coastal monitoring, which is indirectly relevant for urban surveillance and safety. | |
| [98] | 2022 | Automated chart summarization using AI | Enhanced accessibility of visual data for visually impaired users; improves information accessibility. | |
| [99] | 2022 | Image-to-map conversion and extraction algorithms | Provided an innovative method for extracting sidewalk networks; supports urban planning for accessibility. | |
| [100] | 2022 | Sensor sampling frequency analysis | Identified optimal sampling rates for fall detection, critical for improving wearable device performance. | |
| [101] | 2022 | Inertial sensor data analysis | Enabled real-time detection of wheelchair propulsion; supports continuous monitoring of mobility aid usage. |
| Title | Method | Dataset | Available | Disabilities Detected | Accuracy | Criteria | Environment | Recommendations |
|---|---|---|---|---|---|---|---|---|
| [20] | Darknet | Surveillance videos | No | wheelchairs, canes, walkers | 95% | Size, shape, color | Outdoor | Develop a prototype of the system and test it on a larger dataset of surveillance videos in a variety of environments. |
| [21] | ResNet-50 | Synthetic Data | Yes | City objects, People, cars, wheelchairs, canes, walkers | 90% | Size, shape, location | Outdoor | Develop the X-World platform and test it with people with disabilities. |
| [14] | Faster R-CNN with Region Proposal Network | 3D point clouds | Yess | wheelchairs, canes, walkers | 95% | Size, shape, location | Indoor | Develop a prototype system based on the approach and test it on a larger dataset of 3D point clouds and in a variety of different environments. |
| [26] | Gaussian mixture model | Video streams | No | Power attacks | 98% | Features of power attacks | Outdoor | Develop a prototype system based on the method and test it on a larger dataset of power attacks and in a variety of different environments. |
| [62] | Deep convolutional neural network (CNN) | Video streams | No | Falls | 92% | Features of falls | Indoor | Develop a prototype system based on the method and test it on a larger dataset of video streams and in a variety of different environments. |
| [71] | Yolo, LSTM, SVM | Fall events in complex environments | No | Falls | 90% | Spatio-temporal features of falls | Indoor | Develop a prototype system based on the method and test it on a larger dataset of fall events in complex environments. |
| [11] | Autoencoder | Multiview videos | No | Human behaviors (e.g., walking, running, sitting) | 95% | Features of human behaviors | Indoor | Develop a prototype system based on the method and test it on a larger dataset of multiview videos. |
| [10] | CNNs | 3D point clouds | No | Objects (e.g., cars, people, buildings) | 90% | Size, shape, location | Outdoor | Develop a prototype system based on DEEP-SEE and test it in a real-world setting. |
| [13] | YOLOv5 | Specific indoor imagery | Yes | wheelchairs, canes, walkers | 91% | Size, shape, location | Indoor | Future studies should test the model outdoors and with varied datasets to confirm its robustness and adaptability |
| Aspect | Cloud-Only Architecture | Hybrid Architecture |
|---|---|---|
| Initial Infrastructure Cost | Low (USD 0–USD 10 thousand start-up; uses existing cloud services) | High (USD 50–USD 100 thousand for edge devices + servers) |
| Latency (round-trip) | 50–100 ms network + 20–50 ms processing | 5–10 ms edge inference + 20–50 ms occasional cloud |
| Data Volume (upload/day) | ~40 GB (continuous high-res video streams) | ~7 GB (only summarized/anonymized events) |
| Scalability | Excellent (elastic cloud resources) | Good (limited by the number/capacity of edge nodes) |
| Reliability / Resilience | Medium (single-site failure or network outage disrupts service) | High (local edge fallback when cloud is unreachable) |
| Operational Cost | USD 300–USD 600/month (cloud compute + bandwidth) | USD 500–USD 800/month (edge maintenance + reduced bandwidth) |
| Return on Investment (ROI) | Lower upfront; longer payback (~24–36 months) due to performance penalties | Higher upfront; shorter payback (~12–18 months) from reduced latency and operational savings |
| Energy Consumption | Low local (camera idle); high network energy per GB | Moderate local (edge CPU/GPU ~5–20 W); low network load |
| Maintenance Overhead | Minimal on-site (cloud patches managed by provider) | Higher on-site (hardware upkeep, firmware updates) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luna-Romero, S.F.; Abreu de Souza, M.; Serpa Andrade, L. Artificial Vision Systems for Mobility Impairment Detection: Integrating Synthetic Data, Ethical Considerations, and Real-World Applications. Technologies 2025, 13, 198. https://doi.org/10.3390/technologies13050198
Luna-Romero SF, Abreu de Souza M, Serpa Andrade L. Artificial Vision Systems for Mobility Impairment Detection: Integrating Synthetic Data, Ethical Considerations, and Real-World Applications. Technologies. 2025; 13(5):198. https://doi.org/10.3390/technologies13050198
Chicago/Turabian StyleLuna-Romero, Santiago Felipe, Mauren Abreu de Souza, and Luis Serpa Andrade. 2025. "Artificial Vision Systems for Mobility Impairment Detection: Integrating Synthetic Data, Ethical Considerations, and Real-World Applications" Technologies 13, no. 5: 198. https://doi.org/10.3390/technologies13050198
APA StyleLuna-Romero, S. F., Abreu de Souza, M., & Serpa Andrade, L. (2025). Artificial Vision Systems for Mobility Impairment Detection: Integrating Synthetic Data, Ethical Considerations, and Real-World Applications. Technologies, 13(5), 198. https://doi.org/10.3390/technologies13050198