
Enhancing Computational Efficiency of Network Reliability with a New Prime Shortest Path Algorithm


Abstract
1. Introduction
2. Modified Network and MP
2.1. Network Assumptions and Terminology
2.2. Scenario of Modified Network
2.3. Minimal Paths
2.4. Principle of Separation
2.5. Existing Algorithms
3. Proposed Novel Prime Shortest Path
3.1. Concept of PSP
3.2. PSP Pseudo Code
| Algorithm 1: Find the PSP from node α to node β in a network G(V, E). | |
| Input: | A connected graph G(V, E) with a set of nodes V and a set of arcs E. |
| Output: | The PSP from node α to node β. |
| STEP 0: | Initialization: Assign a distinct prime number ni > 2 to each arc ei ∈ E, ensuring that ni ≠ nj for i ≠ j. |
| STEP 1: | Setup: For all nodes v in V except α, set W(v) = L(v) = Prec(v) = ∞. For node α, set W(α) = L(α) = 0, and let u = α. |
| STEP 2: | Relaxation: For each arc euv ∈ E with L(v) > 0, update W(v) = W(u) × W(euv) and Prec(v) = u if W(u) × W(euv) < W(v). |
| STEP 3: | Selection: Find a node u such that W(u) ≤ W(v) for all v ∈ V, and set L(u) = 0. |
| STEP 4: | Termination: If u = β, terminate the algorithm; otherwise, return to STEP 2. |
3.3. Example
4. The Proposed Algorithm and Example
4.1. The Pseudocode of the Proposed PSP-Based Self-Test MP Algorithm
| Algorithm 2: The Pseudocode of the Proposed PSP-Based Self-Test MP Algorithm | |
| STEP 0: | Initialize Ωs,x, Ωy,t, Ωs,y, and Ωx,t as empty sets. Set i = 1, and assign a distinct prime number ni > 2 to each arc ei ∈ E, ensuring ni ≠ nj for i ≠ j. |
| STEP 1: | Check if the MP pi is in Px,y, Py,x, Px/y, or Py/x. Based on this, set α and β accordingly to determine πα,t(pi) and πs,β(pi). If none of these conditions are met, proceed to STEP 4. |
| STEP 2: | If πα,t(pi) is equal to pi, update Ωs,α by adding πs,α(pi). |
| STEP 3: | If πs,β(pi) is equal to pi, update Ωβ,t by adding πβ,t(pi). |
| STEP 4: | If i is less than the total number of MPs (N), increment i by 1 and return to STEP 1. |
| STEP 5: | Combine the sets {Ωs,x⊗bx,y⊗Ωy,t} and {Ωs,y⊗by,x⊗Ωx,t} to form the set of all new MPs in the modified network. |
4.2. Example
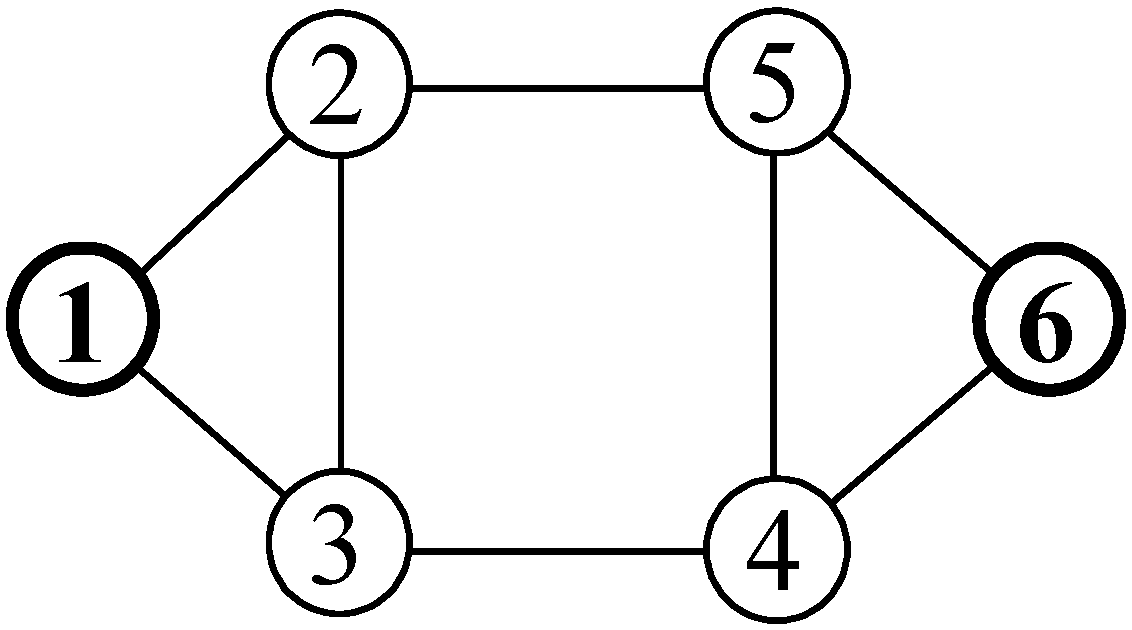
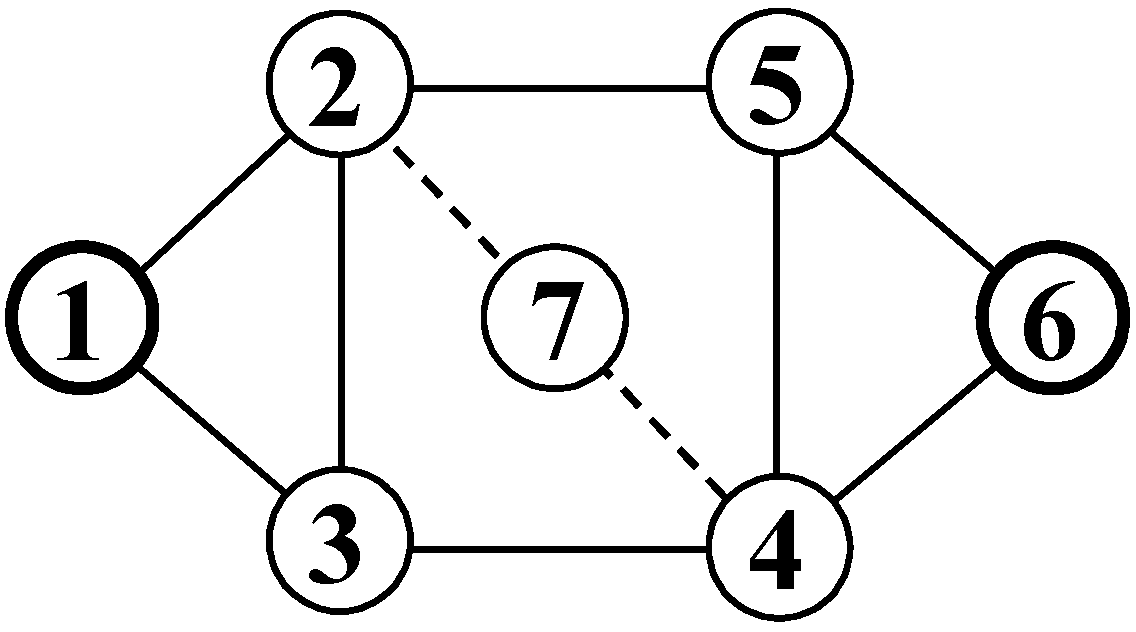
| Solution: An illustration of the proposed algorithm by a medium-sized benchmark network shown in Figure 1. |
| STEP 0. Let Ω1,2 = Ω4,6 = Ω1,4 = Ω2,6 = Ø and i = 1. STEP 1. Because pi = p1 = {e1,2, e2,5, e5,6}∈P2/4, let α = β = 2. STEP 2. Because πα,t(pi) = π2,6(p1) = {e2,5, e5,6} = (p1), let Ωs,β = Ω1,2∪{{e1,2}} = {{e1,2}}. STEP 3. Because πs,β(pi) = π1,2(p1) = {e1,2} = (p1), let Ωα,t = Ω2,6∪{{e2,5, e5,6}} = {{e2,5, e5,6}}. STEP 4. Because i = 1 < (the number of MPs) = 8, let i = i + 1 = 2 and go to STEP 1. STEP 1. Because pi = p2 = {e1,2, e2,5, e5,4, e4,6}∈P2,4 and π2,4(p2) = {e2,5, e5,4} = (p2), let α = 2 and β = 4. STEP 2. Because πα,t(pi) = π2,6(p2) = {e2,5, e4,5, e4,6} ≠ (p2), go to STEP 3. STEP 3. Because πs,β(pi) = π1,4(p2) = {e1,2, e2,5, e5,4} ≠ (p2), go to STEP 4. STEP 4. Because i = 2 < (the number of MPs) = 8, let i = i + 1 = 3 and go to STEP 1. STEP 1. Because pi = p3 = {e1,2, e2,3, e3,4, e4,6}∈P2,4 and π2,4(p3) = {e23, e34} ≠ (p3), go to STEP 4. STEP 4. Because i = 3 < (the number of MPs) = 8, let i = i + 1 = 4 and go to STEP 1. STEP 1. Because pi = p4 = {e1,2, e2,3, e3,4, e4,5, e5,6}∈P2,4 and π2,4(p4) = {e2,3, e3,4} = (p4), let α = 2 and β = 4. STEP 2. Because πα,t(pi) = π2,6(p4) = {e2,3, e3,4, e4,5, e5,6} ≠ (p4), go to STEP 3. STEP 3. Because πs,β(pi) = π1,4(p4) = {e1,2, e2,3, e3,4} ≠ (p4), go to STEP 4. STEP 4. Because i = 4 < (the number of MPs) = 8, let i = i + 1 = 5 and go to STEP 1. STEP 1. Because pi = p5 = {e1,3, e3,4, e4,6}∈P4/2, let α = β = 4. STEP 2. Because πα,t(pi) = π4,6(p5) = {e4,6} = (p5), let Ωs,β = Ω1,4∪{{e1,3, e3,4}} = {{e1,3, e3,4}}. STEP 3. Because πs,β(pi) = π1,4(p5) = {e1,3, e3,4} = (p5), let Ωα,t = Ω4,6∪{{e4,6}} = {{e4,6}}. STEP 4. Because i = 5 < (the number of MPs) = 8, let i = i + 1 = 6 and go to STEP 1. STEP 1. Because pi = p6 = {e1,3, e3,4, e4,5, e5,6}∈P4/2, let α = β = 4. STEP 2. Because πα,t(pi) = π4,6(p6) = {e4,5, e5,6} ≠ (p6), go to STEP 3. STEP 3. Because πs,β(pi) = π1,4(p6) = {e1,3, e3,4} = (p6), let Ωα,t = Ω4,6∪{{e4,5, e5,6}} = {{e4,5, e5,6}, {e4,6}}. STEP 4. Because i = 6 < (the number of MPs) = 8, let i = i + 1 = 7 and go to STEP 1. STEP 1. Because pi = p7 = {e1,3, e3,2, e2,5, e5,6}∈P2/4, let α = β = 2. STEP 2. Because πα,t(pi) = π2,6(p7) = {e2,5, e5,6} = (p7), let Ωs,β = Ω1,2∪{{e1,3, e3,2}} = {{e1,2}, {e1,3, e3,2}}. STEP 3. Because πs,β(pi) = π1,2(p7) = {e1,3, e3,2} ≠ (p1), go to STEP 4. STEP 4. Because i = 7 < (the number of MPs) = 8, let i = i + 1 = 8 and go to STEP 1. STEP 1. Because pi = p8 = {e1,3, e3,2, e2,5, e5,4, e4,6}∈P2,4 and π2,4(p8) = {e2,5, e5,4} = (p8), let α = 2 and β = 4. STEP 2. Because πα,t(pi) = π2,6(p8) = {e2,5, e5,4, e4,6} ≠ (p8), go to STEP 3. STEP 3. Because πs,β(pi) = π1,4(p8) = {e1,3, e3,2, e2,5, e5,4} ≠ (p9), go to STEP 4. STEP 4. Because i = |P| = 8, go to STEP 5. STEP 5. [Ω1,2⊗{{e2,7, e7,4}}⊗Ω4,6]∪[Ω1,4⊗{{e4,7, e7,2}}⊗Ω2,6] = [{{e1,2}, {e1,3, e3,2}}⊗{{e2,7, e7,4}}⊗{{e4,5, e5,6},{e4,6}}]∪ {{e1,3, e3,4}}⊗{{e4,7, e7,2}}⊗{{e2,5, e5,6}} = {{e1,2, e2,7, e7,4 e4,5, e5,6}, {e1,2, e2,7, e7,4 e4,6}, {e1,3, e3,2, e2,7, e7,4 e4,5, e5,6}, {e1,3, e3,2, e2,7, e7,4 e4,6}}∪{{e1,3, e3,4, e4,7, e7,2, e2,5, e5,6}}. |
4.3. Computational Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohammadi, M.B.; Hooshmand, R.A.; Fesharaki, F.H. A New Approach for Optimal Placement of PMUs and Their Required Communication Infrastructure in Order to Minimize the Cost of the WAMS. IEEE Trans. Smart Grid 2016, 7, 84–93. [Google Scholar] [CrossRef]
- Theodorakatos, N.P. A nonlinear well-determined model for power system observability using interior-point methods. Measurement 2019, 152, 107305. [Google Scholar] [CrossRef]
- Bhonsle, J.S.; Junghare, A.S. An optimal PMU-PDC placement technique in wide area measurement system. In Proceedings of the 2015 International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Avadi, India, 6–8 May 2015; pp. 401–405. [Google Scholar]
- Mahapatra, R.; Bhattacharyya, S.; Nag, A. Intelligent Communication Networks: Research and Applications; CRC Press: Boca Raton, FL, USA, 2024. [Google Scholar]
- Yeh, W.C.; Zhu, W. Forecasting by combining chaotic PSO and automated LSSVR. Technologies 2023, 11, 50. [Google Scholar] [CrossRef]
- Yeh, W.C.; Chuang, M.C.; Lee, W.C. Uniform parallel machine scheduling with resource consumption constraint. Appl. Math. Model. 2015, 39, 2131–2138. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Du, K.L. Distribution Path Optimization by an Improved Genetic Algorithm Combined with a Divide-and-Conquer Strategy. Technologies 2022, 10, 81. [Google Scholar] [CrossRef]
- Agyemang, J.O.; Kponyo, J.J.; Gadze, J.D.; Nunoo-Mensah, H.; Yu, D. A Lightweight Messaging Protocol for Internet of Things Devices. Technologies 2022, 10, 21. [Google Scholar] [CrossRef]
- Zhu, W.; Liu, N.; Zhu, Z.; Li, H. Ash Content Detection in Coal Slime Flotation Tailings Based on Neural Architecture Search. In Proceedings of the 2023 5th International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Hangzhou, China, 15–17 December 2023. [Google Scholar] [CrossRef]
- Yeh, W.C. Search for minimal paths in modified networks. Reliab. Eng. Syst. Saf. 2002, 75, 389–395. [Google Scholar] [CrossRef]
- Yeh, W.C. A simple heuristic algorithm for generating all minimal paths. IEEE Trans. Reliab. 2007, 56, 488–494. [Google Scholar] [CrossRef]
- Nahman, J.M. Enumeration of MPs of modified networks. Microelectron. Reliab. 1994, 34, 475–484. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Weight | s = 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| STEP | |||||||
| 0 | 00 | ∞ | ∞ | ∞ | ∞ | ∞ | |
| 1 | 31 | 11 | ∞ | ∞ | ∞ | ||
| 2 | 111 | ∞ | 15 | ∞ | |||
| 3 | 143 | 152 | ∞ | ||||
| 4 | 1433 | 285 | |||||
| 5 | 2854 | ||||||
| p | π1,2(p) | π2,4(p) | π4,6(p) | π1,4(p) | π2,6(p) | Remark |
|---|---|---|---|---|---|---|
| p1∈P2/4 | {e1,2}* | {e2,5, e5,6}* | Ω1,2 = {{e1,2}} Ω2,6 = {{e2,5, e5,6}} | |||
| p2∈P2,4 | {e1,2} | {e2,5, e5,4}* | {e4,6} | {e1,2, e2,5, e5,4} | {e2,5, e5,4, e4,6} | |
| p3∈P2,4 | {e1,2} | {e2,3, e3,4} | {e4,6} | |||
| p4∈P2,4 | {e1,2} | {e2,3, e3,4}* | {e4,5, e5,6} | {e1,2, e2,3, e3,4} | {e2,3, e3,4, e4,5, e5,6} | |
| p5∈P4/2 | {e4,6}* | {e1,3, e3,4}* | Ω1,4 = {{e1,3, e3,4}} Ω4,6 = {{e4,6}} | |||
| p6∈P4/2 | {e4,5, e4,6} | {e1,3, e3,4}* | Ω4,6 = {{e4,6},{e4,5,e4,6}} | |||
| p7∈P2/4 | {e1,3, e3,2} | {e2,5, e5,6}* | Ω1,2 = {{e1,2},{e1,3,e3,2}} | |||
| p8∈P2,4 | {e1,3, e3,2} | {e2,5, e5,4} | {e4,6} | {e1,3, e3,2, e2,5, e5,4} | {e2,5, e5,4, e4,6} |
| K = |V| | |Ek| | |Pk| | Tk | |
|---|---|---|---|---|
| 5 | 15 | 61.04 | 0.0101 | 0.0908 |
| 10 | 30 | 1845.60 | 0.0436 | 0.0799 |
| 15 | 45 | 65,545.67 | 0.3054 | 1.1198 |
| 20 | 60 | 5,625,891.49 | 4.0845 | 4.2153 |
| 25 | 75 | 97,745,622.73 | 16.5051 | 34.8428 |
| 30 | 90 | 1,198,096,571.07 | 66.3704 | 267.7001 |
| 35 | 105 | 15,678,565,410.66 | 270.0127 | 2934.3659 |
| 40 | 120 | 133,915,691,581.97 | 1191.0334 | 12,342.3152 |
| 45 | 135 | 2,743,769,009,302.40 | 5120.5834 | 165,360.2595 |
| 50 | 150 | 15,049,530,474,939.80 | 22,804.5198 | 1,206,765.7107 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, W.-C.; Jiang, Y.; Huang, C.-L. Enhancing Computational Efficiency of Network Reliability with a New Prime Shortest Path Algorithm. Technologies 2025, 13, 109. https://doi.org/10.3390/technologies13030109
Yeh W-C, Jiang Y, Huang C-L. Enhancing Computational Efficiency of Network Reliability with a New Prime Shortest Path Algorithm. Technologies. 2025; 13(3):109. https://doi.org/10.3390/technologies13030109
Chicago/Turabian StyleYeh, Wei-Chang, Yunzhi Jiang, and Chia-Ling Huang. 2025. "Enhancing Computational Efficiency of Network Reliability with a New Prime Shortest Path Algorithm" Technologies 13, no. 3: 109. https://doi.org/10.3390/technologies13030109
APA StyleYeh, W.-C., Jiang, Y., & Huang, C.-L. (2025). Enhancing Computational Efficiency of Network Reliability with a New Prime Shortest Path Algorithm. Technologies, 13(3), 109. https://doi.org/10.3390/technologies13030109