Abstract
Quantum-enhanced machine learning, encompassing both quantum algorithms and quantum-inspired classical methods such as tensor networks, offers promising tools for extracting structure from complex, high-dimensional data. In this work, we study the training dynamics of Matrix Product State (MPS) classifiers applied to three-class problems, using both fashion MNIST and hyperspectral satellite imagery as representative datasets. We investigate the phenomenon of grokking, where generalization emerges suddenly after memorization, by tracking entanglement entropy, local magnetization, and model performance across training sweeps. Additionally, we employ information-theory tools to gain deeper insights: transfer entropy is used to reveal causal dependencies between label-specific quantum masks, while O-information captures the shift from synergistic to redundant correlations among class outputs. Our results show that grokking in the fashion MNIST task coincides with a sharp entanglement transition and a peak in redundant information, whereas the overfitted hyperspectral model retains synergistic, disordered behavior. These findings highlight the relevance of high-order information dynamics in quantum-inspired learning and emphasize the distinct learning behaviors that emerge in multi-class classification, offering a principled framework to interpret generalization in quantum machine learning architectures.
1. Introduction
The convergence of quantum physics, machine learning, and computer science is giving rise to a new computational paradigm with the potential to reshape how information is processed and learned. Quantum machine learning (QML) stands at the forefront of this development, with the aim of exploiting the unique properties of quantum mechanics to improve learning algorithms by encoding data into quantum states and elaborating them through quantum circuits [1,2,3,4,5,6,7,8,9,10,11,12,13,14]. However, current quantum hardware is still facing issues such as noise, decoherence, and limited circuit depth, which impose serious constraints on the scalability and reliability of purely quantum models [15,16,17].
To address these limitations, hybrid quantum-classical approaches have gained prominence. These strategies incorporate quantum components within a predominantly classical framework, or emulate quantum-like behaviors using classical algorithms. Among the most successful tools in this direction are tensor network methods, which originate from condensed matter physics and quantum many-body theory. Specifically, Matrix Product States (MPSs) have proven highly effective for data-driven tasks: they provide an efficient way to represent high-dimensional data with limited entanglement and allow for tracking learning mechanism via local observables, making them well suited for scalable quantum-inspired machine learning [18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36].
One central challenge in remote sensing tasks, such as land cover classification by means of hyperspectral images, lies in managing the high-dimensional feature space while preserving relevant spectral correlations [37]. In such settings, tensor network models like MPSs allow us to control the expressivity and entanglement of the model, navigating the trade-off between overfitting and generalization [23,24,25,26,27,28,29,30,31,32,33,34,35]. Moreover, the phenomenon of grokking, a delayed yet sudden improvement in generalization performance after the model fits the training data, is particularly relevant in over-parameterized regimes [35,38,39,40,41,42,43]: a competition arises between fast, memorizing modes and slower, generalizing dynamics [42,43,44,45], which can lead to transitions in the information structure of the learned representation in both quantum and classical models [35,46,47].
To quantitatively analyze these transitions, we adopt an information-theoretic perspective [48] rooted in two complementary tools. First, we apply transfer entropy [49,50], a directional and time-resolved measure of information flow, to track causal relationships between different components (e.g., label-specific quantum masks) of the trained MPSs during learning. This approach reveals asymmetric causal dependencies and the emergence of hierarchical information channels during training. Second, we leverage the O-information [51], a high-order generalization of mutual information, to quantify whether the interaction among multiple outputs is dominated by redundancy (shared, overlapping information) or synergy (complementary, distributed information). Positive O-information indicates redundant correlations, while negative values highlight synergistic structure.
These tools provide a refined lens through which to observe learning phase transitions in quantum machine learning models. In particular, we show how a transition in entanglement entropy correlates with changes in information structure, as encoded by O-information and transfer entropy, across different tasks. While this framework has broad applicability, we focus on two representative datasets: the widely used fashion MNIST (Modified National Institute of Standards and Technology) dataset and a challenging hyperspectral satellite image dataset for land cover classification. The former exhibits clear signs of grokking, including a transition from synergistic to redundant inter-label information and the emergence of causal mask interactions. The latter remains trapped in a regime dominated by synergy and weak causal structure, consistent with overfitting and poor generalization. Among the three fashion MNIST classes, i.e., dress, sneaker, and bag, the last acts as a confounding class, introducing controlled difficulty in feature separation. In contrast, the PRISMA (PRecursore IperSpettrale della Missione Applicativa) dataset, with labels such as grapevine, olive tree, and cropland, presents intrinsic noise and label uncertainty, often resulting in limited generalization. This dual setting enables a comparative study of grokking under both learnable and noisy conditions, and it supports the analysis of emergent causal and high-order information structures.
Our decision to focus on three-class classification problems is motivated by both theoretical and practical considerations related to the study of emergent correlations and learning dynamics in quantum-inspired models. In particular, the use of O-information requires at least three interacting variables to be meaningfully defined. Applying O-information to the output classification scores allows us to probe how information is distributed across the three label subspaces, capturing collective behaviors that are invisible in binary settings. Moreover, the presence of three classes enables the emergence of non-trivial causal relationships among the corresponding MPS masks, whose magnetizations evolve during training. By computing pairwise transfer entropies between these masks, we can track how the activation of one class may temporally influence others, uncovering latent structure in the learning process. This is particularly important for understanding grokking transitions, where generalization is not only a matter of performance but also of reorganization in the causal and informational architecture of the model. Therefore, the three-class setup provides a minimal yet sufficient setting to jointly analyze higher-order correlations and directional interactions, offering deeper insights into the internal dynamics of tensor network learning.
In summary, this study provides a detailed account of the learning dynamics in quantum-inspired MPS models for fashion MNIST and satellite image classification, revealing how causal and high-order information-theoretic indicators serve as robust probes of generalization, structure, and phase transitions in quantum machine learning. In this work, we focus on three-class classification problems, presented in Section 2, as a natural extension beyond the well-studied binary case. Although two-class quantum classification has been thoroughly analyzed, particularly in the context of tensor network models, as discussed in [35], the multi-class setting introduces richer structure, more complex decision boundaries, and novel information-theory behaviors that are described in Section 3. A comprehensive discussion of the observed learning dynamics for the targeted classification tasks is presented in Section 4.
2. Materials and Methods
The characterizing workflow of this study is represented in Figure 1, which presents a comparative approach outlining the data preprocessing and learning pipeline for two distinct three-class classification tasks: one based on hyperspectral satellite imagery for land cover classification, and the other using fashion MNIST images as a structured vision benchmark. The PRISMA hyperspectral images are partitioned in super-pixels in order to sample single pixels beyond a typical correlation length. These 3D image cubes consist of hundreds of contiguous spectral bands. From this spectral stack, Boruta feature selection is applied to identify the most relevant spectral features for distinguishing the land cover classes: grapevine, olive tree, and cropland. This selected feature set endowed with 43 elements is then used to train MPS quantum masks. Fashion MNIST images are coarse-grained to a lower resolution of pixels to match a manageable input size of the tensor network model. The three considered classes are dress, sneaker, and bag. These low-resolution inputs are also fed into the MPS quantum mask training pipeline. During training the system undergoes entanglement transitions, characterized by changes in the entanglement entropy along the qubit chain. These transitions are analyzed using two complementary information-theory tools: transfer entropy—quantifying directional, pairwise causal information flow between spins—and O-information—capturing high-order information structure, revealing synergy or redundancy in the collective score dynamics. For the land cover problem, the trained system exhibits a synchronized magnetization across labels and a dominance of synergistic interactions among the three output scores. For the fashion MNIST task, the system shows delayed magnetization transitions (with one label magnetizing before the others) and a stronger presence of redundant score information, especially corresponding to grokking.
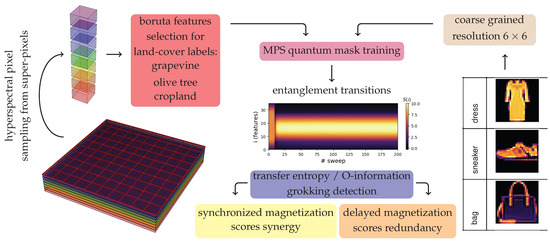
Figure 1.
Workflow representation for the considered multi-class classification problems pair, hyperspectral images for land cover, and the benchmark fashion MNIST dataset.
2.1. PRISMA Hyperspectral Dataset
For the land cover classification task, we employ hyperspectral imagery acquired by the PRISMA (PRecursore IperSpettrale della Missione Applicativa) satellite, an Earth observation mission developed by the Italian Space Agency (ASI). The area of interest is primarily located in the province of Barletta-Andria-Trani, in the Apulia region of southern Italy. This region features a heterogeneous agricultural landscape, including grapevines, olive trees, and cropland, making it a suitable testbed for remote sensing-based land cover analysis. PRISMA provides high-resolution hyperspectral data across two spectral ranges: the Visible and Near-Infrared (VNIR) domain, covering wavelengths from 400 to 1010 nm with a spectral resolution of approximately nm, and the Short-Wave Infrared (SWIR) domain, spanning 920 to 2505 nm with a resolution of around 10 nm, yielding over 240 contiguous channels.
Our analysis is based on Level 0 PRISMA data, which are raw satellite acquisitions subsequently processed to align with high-quality land cover annotations. A key step in our workflow involves resolution enhancement, where the native 30 m × 30 m spatial resolution of the hyperspectral data is upsampled to 10 m × 10 m. The upsampled images are then co-registered with land cover labels provided by AGEA (Agenzia per le Erogazioni in Agricoltura), ensuring accurate spatial correspondence between spectral data and class annotations. This integration supports supervised learning and evaluation of classification models under real-world conditions typical of satellite-based agricultural monitoring.
2.2. Fashion MNIST Dataset
The fashion MNIST dataset serves as a well-established benchmark in the machine learning community, often used to assess the performance of classification algorithms under realistic yet manageable conditions. It comprises 60,000 grayscale images of clothing items, each having a resolution of pixels, uniformly distributed across 10 distinct classes: T-shirt/top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, and ankle boot. In order to construct a dataset with a controlled cardinality and to mitigate potential confounding effects on grokking dynamics, particularly those arising from dataset size, we extracted a stratified random sample corresponding to of the original data. This subset was subsequently split evenly into training and test sets, ensuring both class balance and statistical robustness.
To further simplify the problem while retaining its essential structure, we focused on a reduced three-class classification task involving the categories dress, sneaker, and bag. This specific selection was motivated both by visual distinguishability at low resolution and by computational constraints, as detailed in Figure 1. To make the simulations tractable, all images were downsampled to a compact pixel format using an appropriate interpolation method that preserves global shape information. Despite this aggressive compression, key visual features remain identifiable, particularly for the sneaker class, which is characterized by high-contrast pixel patterns in the first and last rows, enabling relatively robust recognition even in the low-dimensional regime.
For subsequent modeling, each image was linearized into a one-dimensional sequence by flattening the pixel matrix row-wise, from top to bottom. This transformation allowed us to interpret the data as configurations on a one-dimensional lattice, a setup providing a controlled yet nontrivial environment for studying emergent learning phenomena like grokking.
2.3. Tensor Network
Tensor network machine learning capitalizes on the ability of tensor networks to compactly represent high-dimensional data. These techniques originate from quantum many-body physics and quantum information theory, where they have proven essential for analyzing both the equilibrium and dynamical properties of complex quantum systems [52,53,54]. Among the most widely adopted architectures for machine learning are Matrix Product States (MPSs), known in applied mathematics as tensor trains [55,56,57,58]. MPSs provide an efficient decomposition of large, multi-dimensional tensors into a sequential chain of low-rank tensors, dramatically reducing the number of parameters while preserving expressive power.
A key advantage of MPSs lies in their controllable approximation: by tuning the bond dimension , i.e., the number of singular values or Schmidt components as described in Appendix A, one can balance the trade-off between computational cost and model expressiveness. This scalability, combined with their transparency and interpretability, makes MPSs an ideal candidate for integrating quantum-inspired representations into classical machine learning pipelines.
We leverage a quantum-inspired representation to train a variational object, referred to as a quantum mask W, capable of performing multi-class classification on classical input data. Each input array is mapped to a quantum state in the exponentially large Hilbert space , using a local feature encoding scheme:
where each sample is embedded into a single-qubit state given by and depicted diagrammatically in Figure 2a [23,24]. This encoding partially preserves the geometric structure of the input while allowing quantum-inspired models to act linearly in Hilbert space but nonlinearly in input space, thus enhancing their expressive power.
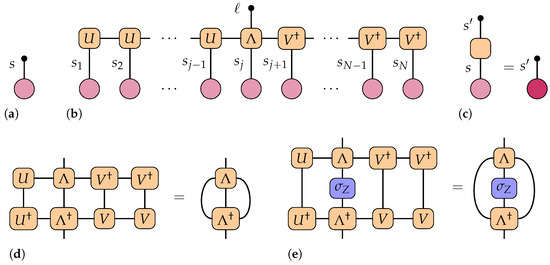
Figure 2.
Diagrammatic illustration of monitored quantities. The qubit encoding introduced in Equation (1) is presented in panel (a). The predictor defined in Equation (3) is shown in panel (b), where the variational tensor W is expressed as a Matrix Product State (MPS) in the mixed-canonical form, as introduced in Equation (2) [54]. In panel (c) the action of a general matrix on the encoded qubit is depicted. The inclusion of an orthogonality center enables efficient tensor contractions over repeated indices , for the pictorial purpose of a lattice; (d) the reduced density matrix in label space, and (e) the local magnetization at each site.
To enable efficient learning and scalability, we represent the quantum mask W using a MPS ansatz, which efficiently parameterizes high-dimensional tensors by factorizing them into a sequence of low-rank matrices, with controllable expressive capacity governed by the bond dimension . The construction relies on a truncated singular value decomposition (SVD) at each bipartition of the one-dimensional system as described in Appendix A, where we consider the top singular values to limit the growth of entanglement and computational cost [54].
The MPS decomposition of the mask W takes the following form [54]:
where the tensor , located at site j, acts as the orthogonality center. This structure, shown schematically in Figure 2b, allows for efficient contraction and differentiation, even in high-dimensional input spaces [59,60].
For a classification task involving classes labeled by ℓ, the MPS defines a predictive model that acts on the encoded product state:
where is the single-qubit encoding of the j-th feature and denotes the MPS tensor network associated with class ℓ. During training, the parameters of W are optimized to minimize the mean squared error cost function:
where is the number of training samples , and for the considered three-class problems if sample belongs to class 0, for class 1, and otherwise. The predicted label is determined by the component showing the highest absolute value [34]. Operationally, we convert the kets shown in Equation (4) and subsequent equations below to vectors that match the dimensions of when minimizing the cost function, similar to [23,24], whose formalism we closely follow. Notably, the authors of [23,24] define their feature maps in terms of vectors while we use ket notation as shown in Equation (1). Additionally, it should be noted that in the definition of the cost function there exists a difference between Refs. [23,24,34], namely the use of normalized amplitude scores as opposed to Born rule conditional class probabilities. A more detailed investigation of these discrepancies is required in future research.
The learning process is driven by the minimization of the task-specific cost function in Equation (4), typically designed to penalize misclassification. To update the MPS parameters, we employ a two-site gradient descent scheme, which enables the optimization of adjacent tensors simultaneously, contracted as , while preserving the canonical form of the MPS
 referring to a single right step, which leads to a sweep when back at the initial sites pair. The update rule requires the introduction of the following quantity, where we exploit the diagrammatic notation in Figure 2c for the action of left- and right-normalized matrices on the encoded qubits
referring to a single right step, which leads to a sweep when back at the initial sites pair. The update rule requires the introduction of the following quantity, where we exploit the diagrammatic notation in Figure 2c for the action of left- and right-normalized matrices on the encoded qubits
 equivalently expressed in the predictor
such that
equivalently expressed in the predictor
such that
At each step of the training process, the variational tensor is updated via a gradient descent rule governed by the learning rate , as follows:
Given that the evolution induced by gradient descent is inherently non-unitary, we must renormalize the updated quantum state to maintain physical interpretability and numerical stability. This is accomplished by compressing to the prescribed bond dimension through a truncated singular value decomposition (SVD), followed by a global rescaling. Effectively, this post-selection protocol implements a projective operation onto the dominant subspace spanned by the retained singular vectors, analogous to a measurement collapsing the state onto its most significant modes [61]. The conservation of unit norm and probability ensures an appropriate definition of entropy-related quantities. By contrast, when probability conservation is broken, as in non-Hermitian systems, such quantities must be generalized, for example by working with non-normalized density matrices, in order to retain information about the total probability flow between the system and its environment [62,63].
To monitor the learning dynamics and interpret the internal structure of the quantum mask W, we evaluate a set of physically meaningful observables:
- (i)
- Reduced density matrix in the label space, extracted using the contraction scheme shown in Figure 2d. This quantity encodes the coherence and distinguishability between label states during training.
- (ii)
- Local magnetization , computed separately for each label and feature index , as depicted in Figure 2e. These expectation values reveal the contribution of individual input features to the classification decision, serving as a form of interpretable attribution.
Following each tensor update, we perform a two-site SVD:
where contains the singular values . Depending on the direction of the optimization sweep, the updated orthogonality center is obtained by contracting with U (leftward) or (rightward). The singular value spectrum encodes entanglement information across the bond between sites i and , allowing us to compute the von Neumann entanglement entropy:
This quantity measures the degree of quantum correlation (or representational complexity) between the subsystems to the left and right of the bond, serving as an informative diagnostic of model capacity and learning phase transitions.
Furthermore, to analyze how class-specific information is distributed across the network, we perform independent SVDs on the updated tensors and , corresponding to the label-resolved components of the quantum mask. This enables the computation of label-specific entanglement entropies and , providing a nuanced view of how each class utilizes correlations across the lattice, a key indicator of information localization.
2.4. Transfer Entropy
Causal relations among quantum masks during training sweeps are monitored by means of transfer entropy [49] adopting joint and conditional probability densities of local magnetization expectation values
where with t and integer labels that identify the training sweep and delay, respectively. For our numerical purposes, it is useful to express the transfer entropy in terms of conditional entropies between processes yielding the sequences of expectation values , particularly in the entropy difference form exploited by the Kraskov–Stögbauer–Grassberger nearest-neighbor method [48,64,65] described in Appendix B
—that is, the reduction in uncertainty of the future of due to knowledge of past , beyond what is already known from past . In the following we will considered averaged transfer entropy over spin pairs .
For a given spin pair and masks pair , we have a time series of expectation values with length equal to the number of training sweeps. Corresponding to each training step we build and we determine the distance to the k-th nearest neighbor with respect to the maximum norm. Then we switch to the marginals , , and in order to determine for each case the number of points with distance strictly less than , denoted by , and [50,65]:
where is the digamma function and denotes the average over all time steps. We choose to adopt the number of nearest neighbors .
2.5. O-Information
The O-information is a high-order information theory quantity designed to quantify the dominant mode of interaction among multiple variables in a system. It was introduced as “information about organizational structure”, and it coincides with interaction information for three variables [51]. As an extension of mutual information beyond pairwise relationships, it distinguishes whether a group of variables primarily shares redundant or synergistic information. A positive O-information indicates that variables tend to be redundant, meaning their dependencies are largely shared or overlapping—often pointing to coordinated, predictable behavior. Conversely, a negative O-information signals synergy, where information is distributed across variables in a way that cannot be fully captured by subsets, thus implying more complex, complementary interactions. This makes O-information particularly well-suited for analyzing emergent dependencies in learning systems, such as in quantum or classical neural networks, where one seeks to track the transition from disordered, synergistic regimes to structured, redundant ones.
We consider the three processes associated with predicted labels in output, namely with . At each training step these scores are sampled from the aforementioned processes , such that we express the O-information, or equivalently, the interaction information:
where the result is invariant under any swap in the variables order. These terms are separately evaluated [64]:
where are the number of points within the k-th nearest neighbor distance for each marginal and T is the total number of training steps.
3. Results
3.1. Classification Performances
The performance of the MPS classifier on the two multi-class problems is resumed in the top panels of Figure 3. Each task involves three classes as introduced in Section 2:
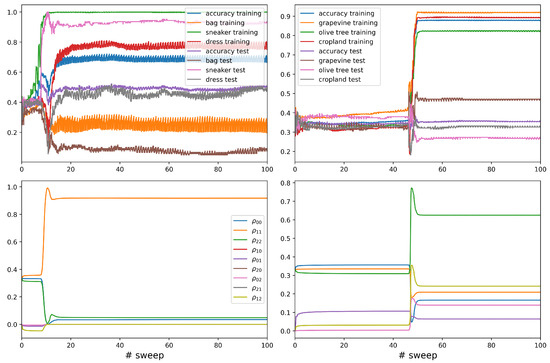
Figure 3.
Performance analysis of two quantum MPS classifiers on three-class problems: fashion MNIST (left) and hyperspectral land cover classification (right). (Top) panels show overall and per-class training/test accuracies. (Bottom) panels display the evolution of the reduced density matrix elements in the label subspace.
- (i)
- Fashion MNIST: dress, sneaker, bag;
- (ii)
- Hyperspectral land cover: cropland, olive tree, grapevine.
The top panels display evaluation metrics, while the bottom panels show the evolution of the reduced density matrix in the label subspace for each case. This provides insight into how the quantum classifier organizes information in the output space.
In the top left panel the performance on fashion MNIST is characterized in terms of the overall training and test accuracy, plotted alongside the per-class performance. The sneaker class achieves the highest performance, with the test accuracy stabilizing around . The dress class follows with a slightly lower performance.These patterns yield a grokking transition based on an effective feature extraction useful for unseen data. The bag class performs poorly as a confounding case, having training accuracy around , with oscillations, and test performance reaching a value even smaller than .
The general training accuracy increases steadily and saturates near , but the test accuracy is limited by the poor generalization of the bag class. Oscillations and performance disparities suggest insufficient data quality for certain classes imposed by image rescaling. The MPS classifier handles sneakers and dresses well, likely due to distinguishable features consisting in horizontally and vertically elongated shapes in rescaled pixel space. However, bags are harder to distinguish.
In the top right panel, the performance on hyperspectral land cover classification is shown. There is a sharp transition in accuracy around sweep 45, indicating a shift in the overfitting regime, since the test performances are low. Grapevine achieves the highest training accuracy (around ) and test accuracy around . Olive tree performs moderately, with almost training and test accuracy. Cropland performs the worst, having the lowest test accuracy at around . The generalization gap is more pronounced than in the fashion MNIST task.
In bottom panels the reduced density matrix in the label subspace is characterized. On the left, for fashion MNIST, the evolution of the reduced density matrix shows diagonal elements () representing class populations: corresponding to sneaker saturates around 0.95, while and are much lower. Off-diagonal elements (e.g., ) decrease and stabilize near zero, so the model reaches a nearly classically separable form in the label subspace. Off-diagonal suppression indicates vanishing label entanglement, meaning that the model makes confident, distinct predictions for each input. On the right, for land cover classification, a sudden jump near sweep 45 aligns with the accuracy jump. After this transition the diagonal elements stabilize to less balanced values (e.g., around , others ), while off-diagonal elements (e.g., ) remain significant, some up to . Unlike the fashion MNIST task, the land cover model retains quantum coherence in the label subspace. This suggests that the classifier operates in a superposed decision space, potentially due to the overlap in spectral features between the vegetation types.
3.2. Magnetization Pattern Extraction
The evolution of the local magnetization along the Z direction is represented in Figure 4 for each site i (feature index) and for each of the three label-targeted quantum masks () across training sweeps (horizontal axis). The left column refers to the fashion MNIST classification task, while the right column corresponds to the hyperspectral land cover classification.
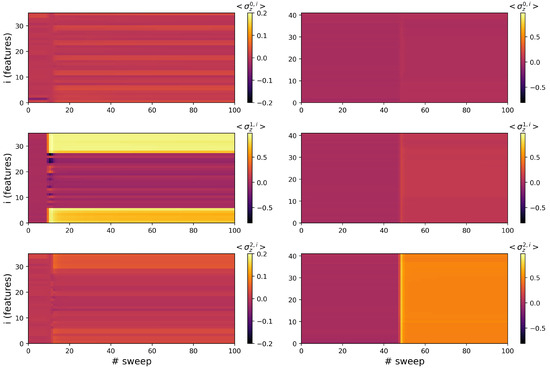
Figure 4.
Local Z-magnetization of the trained quantum masks for the three class labels (rows) in fashion MNIST (left) and hyperspectral land cover classification (right). Each row corresponds to the following label: first row refers to dress/cropland, second row to sneaker/olive tree, and third row to bag/grapevine.
Each row represents one of the three class-specific quantum masks:
- (i)
- Top row: label 0—dress/cropland;
- (ii)
- Middle row: label 1—sneaker/olive tree;
- (iii)
- Bottom row: label 2—bag/grapevine.
The three quantum masks for the fashion MNIST dataset show distinct, label-specific magnetization patterns across features. Each mask develops structure early during training (around sweep 10), where specific feature regions acquire non-trivial magnetization values. Label 1 (middle panel) shows the earliest and most pronounced activation, with magnetizations saturating near on subsets of features. This aligns with the high classification performance of the sneaker class. Label 0 (top panel) follows shortly after, with a visible delay of a few sweeps relative to label 1. Its final magnetization values are smaller in magnitude and less structured. Label 2 (bottom panel) develops more slowly and remains less polarized, consistent with the weaker classification performance for the bag class.
The masks for fashion MNIST evolve asynchronously and specialize at different times. The slight temporal offset between the activation of label 1 (sneaker) and label 0 (dress) reflects the model’s ease in learning separable features for sneakers earlier than for dresses. Bag features remain harder to encode, with less magnetization contrast.
The right column refers to the land cover classification, where all three quantum masks undergo a sharp and synchronized transition in their local magnetizations at approximately sweep 50. This transition is abrupt and coherent across the three labels, resulting in simultaneous polarization across many features. Before sweep 50, magnetizations are close to zero for all classes, indicating the model is in an unstructured or pre-learning phase. After sweep 50, all masks acquire relatively uniform and structured magnetization patterns, though with subtle differences in magnitude.
Unlike the fashion MNIST task, the masks for land cover classification display collective behavior, with a global learning transition likely triggered by a structural modification in the training process. The absence of delay between label activations suggests that the model required a global capacity boost to start encoding meaningful class distinctions, reflecting the presence of an overfitting regime, as shown in Figure 3.
Figure 5 illustrates the evolution of the entanglement entropy along the MPS chain during training sweeps. The vertical axis corresponds to the site index i (i.e., feature index) and each panel shows the local bipartite von Neumann entropy, capturing the degree of entanglement across a cut in the MPS at the edge between site i and .
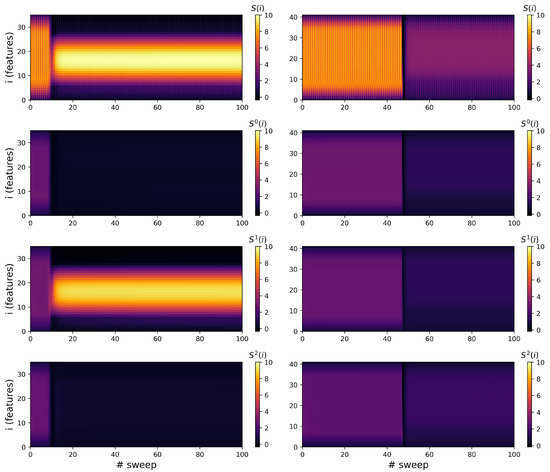
Figure 5.
Entanglement entropy along the MPS chain during training for fashion MNIST (left) and land cover classification (right). The top row shows total entropy, while rows 2–4 display label-resolved components: label 0 for dress/cropland, label 1 for sneaker/olive tree, label 2 for bag/grapevine.
The left column refers to the fashion MNIST task, while the right column refers to the hyperspectral land cover classification. The top row describes total entanglement entropy for the full output state. From the second to the fourth row we have label-specific contributions , ordered as follows: dress/cropland, sneaker/olive tree, bag/grapevine.
In both tasks, the top row clearly displays a transition from a high-entropy, volume law regime at early sweeps to a lower-entropy, sub-volume law regime as training progresses [35]. This is typical of MPS initialization with random parameters, where entanglement is initially extensive across the chain. As training optimizes the tensor network, the system moves toward a more structured state that requires less entanglement, indicating emergent efficient interactions among features required to minimize the cost function.
Initially, for fashion MNIST all positions exhibit high entanglement, consistent with a volume law state. As training progresses (especially by around sweep 10), entanglement becomes highly localized. The third row, corresponding to label 1 (sneaker), dominates the entropy dynamics. It maintains high entropy centered along the chain, indicating non-trivial internal correlations within the label-1 subspace. After the transition, two regions with high local magnetization become weakly entangled, consistent with effective feature segmentation. The other labels (0 = dress, 2 = bag) show negligible entropy after early sweeps, indicating that those subspaces become effectively decoupled from the evolving state. The MPS optimization concentrates most of the entanglement in the subspace associated with label 1 (sneaker), suggesting that this class is the dominant attractor in the learned representation.
The initial state for land cover classification exhibits a broad, uniform volume law entanglement across the MPS chain as well. At around sweep 50, a sharp drop in entropy is observed, consistent with a collective transition already seen in the magnetization and accuracy plots. After the transition, all the labels exhibit low entanglement across the chain, with no particular label dominating the entropy budget. The near-flat, low-entropy pattern reflects the model’s attempt to suppress complexity and extract spatially coarse features. Unlike fashion MNIST, the learning here leads to an overall reduction in entanglement across all class subspaces, consistent with overfitted data representations.
3.3. Causal Information Transfer Between Quantum Masks
The proposed detection of grokking in the presence of an entanglement transition is based on the determination of causal relations between quantum masks during the training dynamics. Classical transfer entropy is a measure of information flow originally framed for time series. Figure 6 presents this quantity between each quantum mask pair as a function of time delay (in training sweeps, ranging from 1 to 10) for the two previously discussed classification tasks: fashion MNIST (blue) and hyperspectral land cover (orange). Each subplot represents the directional transfer entropy from one label-specific quantum mask to another, averaged over all pairs of spins Z expectation values between the source and target masks. Shaded regions determine one standard deviation around the mean.
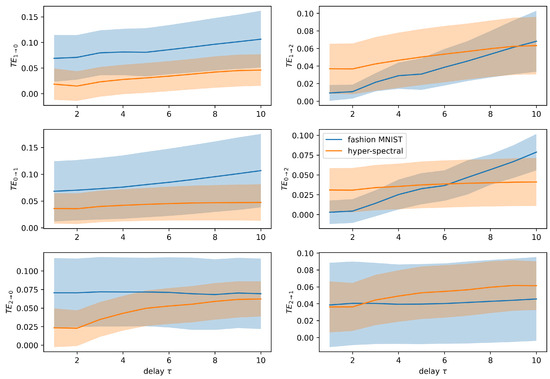
Figure 6.
Transfer entropy between pairs of quantum masks as a function of training delay , comparing fashion MNIST (blue) and hyperspectral (orange) classification tasks. Each panel shows the directional TE from one label-specific mask to another, averaged over spin pairs. Solid lines are referred to the mean value, while shaded regions determine one standard deviation.
In the top-left panel the information transfer from label 1 (sneaker/olive) to label 0 (dress/cropland) is endowed with a clear and persistent separation between the fashion MNIST and hyperspectral cases. The blue and orange curves are separated by more than one standard deviation, indicating statistically significant causal influence from mask 1 to mask 0 in fashion MNIST. The separation peaks around suggest that the influence of the sneaker mask on the dress mask in the MPS is strongest at short delays during training. This is corroborated by the z-scores for in the Table 1, i.e., with and with . The first value further increases to 2.783 when averaging is restricted to strongly magnetized spins, i.e., spins encoding the most relevant features.

Table 1.
Z-scores collected from comparisons of quantum masks’ transfer entropy mean and standard deviation in Figure 6.
The remaining directions for information transfer could be signaled by , showing moderate differences between tasks, but the statistical separation significantly weakens with increasing delay. This is reflected in the decreasing z-scores, e.g., drops from 1.3 to nearly 0 by . , , and show overlapping shaded regions, with low z-scores and weak directional dependencies. These directions appear less informative in distinguishing dynamics between the two tasks. For the hyperspectral case, transfer entropy values remain consistently lower and flatter, suggesting that information flow between masks is weaker and less temporally structured.
In the fashion MNIST, the strong signal implies that the learning dynamics of the sneaker mask (label 1) drive or condition those of the dress mask (label 0). This supports earlier observations that label 1 dominates both magnetization and entropy dynamics. The asymmetry of transfer entropy confirms a causal hierarchy: the sneaker mask organizes meaningful features early, and this structure propagates to influence other masks. In the hyperspectral classification, the flat transfer entropy curves point to a more synchronized or globally entangled evolution, with no single mask strongly conditioning the others.
This analysis demonstrates that transfer entropy between quantum masks can reveal asymmetric causal dependencies in the learning process. For fashion MNIST, label 1 (sneaker) emerges as a dynamical driver, with being the most statistically robust and interpretable signature. In contrast, the hyperspectral task exhibits a more balanced and collective mask interaction, lacking clear causal dominance. These findings provide a dynamical fingerprint of how quantum models internally organize information during training, potentially guiding task-specific architecture adjustments or mask pruning strategies.
3.4. Score Redundancy Peak at Grokking
A proper characterization of quantum masks dynamics in targeted multi-class classification tasks resides in evaluating O-information among probabilistic output scores. Figure 7 shows the evolution of the O-information averaged during training, over the available order permutations of the variables in Equation (13), for the two different tasks: fashion MNIST (top panel) and hyperspectral land cover classification (bottom panel). The O-information is a high-order information-theoretic quantity that captures whether the correlations among variables are redundant (positive values) or synergistic (negative values).
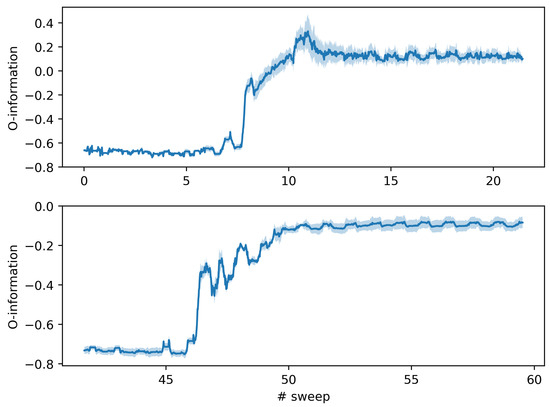
Figure 7.
O-information among the output scores of the three label-specific quantum masks during training for fashion MNIST (top) and hyperspectral (bottom) classification tasks. Both panels focus on sweeps hosting the entanglement transition, potentially related with grokking. Solid lines and shaded regions are referred to mean and standard deviation of the six permutations available for variables order in Equation (13).
The initial regime is driven by the random MPS in both tasks: the training begins with strongly negative O-information, indicating a regime where synergy dominates the interactions among the label scores. This is expected from the randomly initialized MPS, where the output probabilities for each class are not yet structured and exhibit complex, non-redundant joint behavior. This is characteristic of a random classifier where different class predictions are not yet disentangled.
Corresponding to the entanglement transition, leading to grokking in the fashion MNIST task (top panel), a sharp transition occurs around sweep 8–9. The O-information jumps into the positive regime, peaking significantly before stabilizing. This transition coincides with earlier observations of improved accuracy, magnetization structure, and entanglement collapse. The shift to positive O-information reflects a regime dominated by redundancy. In contrast, the hyperspectral task (bottom panel) shows a more gradual transition around sweep 46, without reaching positive values. The O-information remains negative even after the transition, suggesting that the learned representations maintain synergistic, entangled relationships more typical of a random or overfitted classifier. This aligns with previous observations of weak causal mask interactions, low label-specific magnetization polarization, and flat transfer entropy curves. In both cases it is possible to identify a moderate peak forecasting the transition jump during the previous MPS sweep.
The O-information offers a compact global measure of the nature of inter-dependencies in the model output: a positive O-information (redundancy) is provided by predictive outputs highly coordinated and mutually informative, a signature of successful learning, while a negative O-information (synergy) among predictive outputs expresses complementary, distributed information. The clear divergence between the two tasks highlights the qualitative difference in learning behavior: fashion MNIST exhibits a grokking transition, with outputs reorganizing toward redundancy and predictability; the hyperspectral model, even after fitting, retains features of a disordered system, with score synergy, indicating limited generalization.
This analysis of O-information complements earlier metrics (accuracy, entropy, magnetization, transfer entropy), revealing that fashion MNIST undergoes a coherent learning transition to redundancy-dominated dynamics, while hyperspectral classification remains trapped in a synergistic, less interpretable regime. The O-information thus acts as a powerful high-order probe for emergent structure and model interpretability in QML.
4. Discussion
Our study investigates the training dynamics of MPS-based quantum machine learning models in the context of three-class classification problems, extending previous analyses that focused on binary tasks such as those presented in [35]. By comparing the fashion MNIST and hyperspectral satellite imagery datasets, we reveal qualitatively distinct behaviors in how these models generalize, organize internal correlations, and evolve information structure throughout training.
A key finding is the identification of a grokking-like phase transition in the three-class fashion MNIST task, marked by a sharp improvement in test accuracy, an abrupt drop in entanglement entropy from the initial volume law regime, and a peak in O-information, signaling the onset of redundancy-driven learning. This aligns with theoretical models of grokking in classical deep learning, where generalization follows a delay after fitting, driven by the reorganization of internal representations [38,39,40,41,42,43,46,47]. In contrast, the hyperspectral task, despite overfitting training data, fails to exhibit this transition. It maintains persistent synergistic correlations and weak directional information flow between class-specific quantum masks, resembling the behavior of a random classifier.
The selection of the PRISMA hyperspectral dataset and the fashion MNIST image dataset reflects a deliberate choice to investigate learning dynamics across two qualitatively distinct scenarios. Fashion MNIST serves as a structured benchmark in which class-defining features, such as shape, are spatially coherent and separable. However, among the three selected classes, i.e., dress, sneaker, and bag, the last functions as a confounding class, sharing visual features with both of the others and thereby introducing ambiguity into the classification task. This setup allows us to explore how the model resolves feature competition and reorganizes its internal representations across training. A comparison of tensor network machine learning with the state-of-the-art deep learning methods is targeted in [31] regarding the full multi-class fashion MNIST classification problem with 10 labels. Promising performances were identified for hybrid schemes, combining both conventional and tensor network algorithms. In contrast, the PRISMA dataset represents a significantly more complex and noisy regime. Its hyperspectral data are high-dimensional, with subtle spectral differences between land cover types, i.e., grapevine, olive tree, and cropland, and potential ambiguities due to mixed pixels and acquisition noise. These factors hinder generalization and trap the model in overfitting learning phases. By juxtaposing these two datasets, we can contrast structured learning with non-learning behavior and interpret emergent information-theory signatures, such as redundancy, synergy, and causal flow, across fundamentally different data regimes.
The methodological choice in our study was the focus on three-class classification problems, which serves as the minimal setting for exploring both high-order statistical dependencies and causal interactions within the learning dynamics. Unlike binary classification, which limits the scope of interaction analysis to pairwise relations [35], the three-class scenario allows us to investigate how multiple output channels co-evolve and influence each other during training. In particular, this structure enables the application of O-information distinguishing between redundancy, where variables share overlapping information, and synergy, where the whole carries more information than the sum of its parts. By applying this formalism to the classification scores associated with the three output classes, we gain insight into how the network restructures its internal representations across the grokking transition. Moreover, having three label-specific MPS masks makes it possible to examine directional dependencies in the form of transfer entropy, offering a window into the causal relationships that emerge as different subspaces magnetize.
The application of transfer entropy to monitor causal interactions between masks and the use of O-information to distinguish synergy from redundancy offer new diagnostic tools for probing the internal structure of quantum-inspired learners. This richer structure, unavailable in simpler binary setups, proves essential for revealing the interplay between information organization, learning dynamics, and entanglement restructuring in quantum-inspired models. These methods go beyond accuracy metrics, providing interpretable signatures of training phases and class-specific dynamics, and may be particularly valuable for understanding overfitting and generalization in high-dimensional regimes.
Our results underscore the importance of task complexity and input structure. Despite pixel rescaling, the fashion MNIST data allows the MPS model to develop a clear causal hierarchy among masks (e.g., the sneaker class driving the dress one), while the spectral noise of hyperspectral imagery appears to suppress such organization. This suggests that data structure, not model architecture alone, governs the emergence of interpretable learning dynamics.
Looking forward, these findings motivate several directions. First, refining the role of redundancy and synergy in multi-class classification may guide architecture design, such as adaptive bond dimensions or class-specific entanglement constraints. Second, the integration of classical and quantum representations (e.g., through hybrid or shallow quantum circuits) could leverage the observed causal flows to reduce training overhead or compress information flow. Finally, the application of this framework to other structured datasets, such as time-series, geospatial patterns, or biological signals, may further test the generality of grokking and provide deeper insight into the informational geometry of learning in quantum systems. These use cases will allow us to test promising scaling properties for higher dimensional feature spaces, as already verified in [34] for generative purposes of full resolution MNIST images.
5. Conclusions
In this work, we explored the training dynamics of quantum-inspired MPS classifiers in three-class learning tasks, focusing on fashion MNIST and hyperspectral land cover classification. By combining conventional performance metrics with high-order information-theory tools, namely transfer entropy and O-information, we uncovered distinct learning behaviors between the two tasks. Fashion MNIST exhibited a clear grokking transition characterized by redundancy, entanglement compression, and directional information flow among class-specific quantum masks. In contrast, the hyperspectral model remained in a synergistic regime, indicative of overfitting and weak internal structure. These results demonstrate the utility of causal and high-order information measures for diagnosing learning phases and generalization in quantum machine learning, paving the way for more interpretable and task-adaptive quantum models.
Author Contributions
Conceptualization: D.P., R.C. and N.A.; software: D.P. and R.C.; data curation: D.P. and R.C.; methodology: D.P., R.C., M.O.O. and N.A.; formal analysis and investigation: D.P.; visualization: D.P.; funding acquisition: R.B. and S.S.; resources: D.P., A.M. and N.A.; supervision: D.P., R.C. and N.A.; writing—original draft preparation: D.P.; writing—review and editing: D.P., R.C., L.B., M.L.R., T.M., G.M., A.M., M.O.O., E.P., S.T., S.S., R.B. and N.A. All authors have read and agreed to the published version of the manuscript.
Funding
D.P. acknowledges the support by PNRR MUR project CN00000041-“National Center for Gene Therapy and Drugs based on RNA Technology”. S.S. was supported by the project “Higher-order complex systems modeling for personalized medicine,” Italian Ministry of University and Research (funded by MUR, PRIN 2022-PNRR, code P2022JAYMH, CUP: H53D23009130001). The authors were supported by the Italian funding within the “Budget MIUR-Dipartimenti di Eccellenza 2023–2027” (Law 232, 11 December 2016)—Quantum Sensing and Modelling for One-Health (QuaSiModO), CUP:H97G23000100001. The authors want to thank the project “Genoma mEdiciNa pERsonalizzatA–GENERA”, local project code T3-AN-04–CUP H93C22000500001, financed under the Health Development and Cohesion Plan 2014–2020, Trajectory 3 “Regenerative, predictive and personalized medicine”—Action line 3.1 “Creation of a precision medicine program for the mapping of the human genome on a national scale”, referred to in the Notice of the Ministry of Health published in the Official Journal no. 46 of 24 February 2021. The authors want to thank the Funder: Project funded under the National Recovery and Resilience Plan (NRRP), Mission 4 Component 2 Investment 1.4—Call for tender No. 3138 of 16 December 2021 of Italian Ministry of University and Research funded by the European Union—NextGenerationEU (award number/project code: CN00000013), and Concession Decree No. 1031 of 17 February 2022 adopted by the Italian Ministry of University and Research (CUP: D93C22000430001), Project title: “National Centre for HPC, Big Data and Quantum Computing”. This work was also funded by the Italian Ministry of Enterprises and Made in ITaly (MIMIT) with the ‘‘Project CALLIOPE-Casa dell’Innovazione per il One Health’’ (FSC 2014–2020, CUP: E53C22002800001) and with the WADIT project (Water Digital Twin) co-funded by the Italian Ministry of Enterprises and Made in ITaly (MIMIT), “Decreto n. Accordi per l’innovazione di cui al D.M. 31 December 2021 e D.D. 18 March 2022” project n. F/310272/01-05/X56.
Data Availability Statement
The fashion MNIST and PRISMA datasets that support the findings of this study are openly available in Kaggle at https://www.kaggle.com/datasets/zalando-research/fashionmnist (accessed on 27 September 2025) and through authentication https://www.asi.it/en/earth-science/prisma/ (accessed on 27 September 2025), respectively.
Acknowledgments
Computational resources were provided by ReCaS Bari [66].
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| QML | quantum machine learning |
| MPS | Matrix Product State |
| MNIST | Modified National Institute of Standards and Technology |
| PRISMA | PRecursore IperSpettrale della Missione Applicativa |
| SVD | singular value decomposition |
Appendix A
The most basic setting for introducing tensor network methods is that of one-dimensional lattices. In such a lattice , each site s hosts a spin, so that the global quantum state is . However, describing this state becomes exponentially difficult as the number of spins N increases, since the dimension of the total Hilbert space grows exponentially according to .
To cope with the rapidly growing demand for computational resources, it is essential to reduce the number of degrees of freedom by retaining only those that carry the most relevant information. The density matrix renormalization group achieves this by introducing an efficient cut-off in the Schmidt decomposition, discarding components whose coefficients fall below a given threshold. This idea is generalized within the Matrix Product State (MPS) framework [54], where the reduction is implemented through an iterative reshaping of coefficient tensors combined with singular value decomposition (SVD).
In general a SVD corresponds to the Schmidt decomposition for a properly reshaped array of state coefficients
depending on the chosen bipartition of the lattice, uniquely determined in the one-dimensional case
where is a diagonal matrix containing Schmidt coefficients (or singular values) . Physical indices collected within parentheses, , are generally associated with the matrix unfolding of tensors [57]. By adopting the standard MPS notation used in Figure A1, one can then obtain the Schmidt decomposition
with , . We can consider Equation (A3) as a first iterative step by imposing and reshaping
with left-normalized matrix because of left-eigenvectors contained in such that .
The iteration of the reshaping and SVD sequence up to a new generic site yields
further elaborated by adopting the reshaping
with right-normalized matrices defined according to . A mixed-canonical MPS is obtained by iterations
according to the diagrammatic scheme in Figure A1b.

Appendix B
The Kraskov-Stögbauer-Grassberger nearest-neighbor method is based on the definition of Shannon entropy of a continuous random variable X, in a metric space endowed with distance , as an average of the “surprise” with respect to the related probability measure [48], such that we can build the estimator
with random sample of T realizations of X. For each point we aim to determine the probability that there is one point within distance , such that there are points at smaller distances and at larger distances. Since we will estimate such probabilities locally, the condition has to be satisfied. The targeted density imposes a mass centered at , such that the probability of getting successful detection of the k-th nearest neighbor exploits the trinomial coefficient as follows
with normalization ensured by iteratively integrating by parts to obtain . The expectation value of is evaluated over the remaining points with respect to according to [64]
where is the digamma function.
Under the assumption of constant in the neighborhood of and according to the choice of maximum norm presented in Section 2, it is possible to deduce the estimator by exploiting , where d is the dimension of x. In this way we obtain the final expression for Equation (A8)
The estimation of the mutual information takes into account the joint random variable . We consider for each , , the distance to the k-th nearest neighbor, endowed with a probability . The dimension of w is , such that
In order to estimate marginal entropies, we have that Equation (A11) holds true for any k and it has not to be fixed. If there are points within the distance around , chosen such that the -th neighbor lies at , we can express
as well as for with respectively. The mutual information then reads [64]
The last quantity exploited in our analysis is the conditional mutual information
where by keeping into account that the dimension of is , we obtain [65]
References
- Arrazola, J.M.; Bergholm, V.; Brádler, K.; Bromley, T.R.; Collins, M.J.; Dhand, I.; Fumagalli, A.; Gerrits, T.; Goussev, A.; Helt, L.G.; et al. Quantum circuits with many photons on a programmable nanophotonic chip. Nature 2021, 591, 54–60. [Google Scholar] [CrossRef]
- Banchi, L.; Fingerhuth, M.; Babej, T.; Ing, C.; Arrazola, J.M. Molecular docking with Gaussian Boson Sampling. Sci. Adv. 2020, 6, 23. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Zhong, Z.-P.; Fang, Y.; Patel, R.B.; Li, Q.-P.; Liu, W.; Li, Z.; Xu, L.; Sagona-Stophel, S.; Mer, E.; et al. A universal programmable Gaussian boson sampler for drug discovery. Nat. Comput. Sci. 2023, 3, 839–848. [Google Scholar] [CrossRef]
- Vakili, M.G.; Gorgulla, C.; Nigam, A.K.; Bezrukov, D.; Varoli, D.; Aliper, A.; Polykovsky, D.; Krishna, M.; Das, P.; Snider, J.; et al. Quantum Computing-Enhanced Algorithm Unveils Novel Inhibitors for KRAS. Nat. Biotechnol. 2025. [Google Scholar] [CrossRef]
- Benedetti, M.; Garcia-Pintos, D.; Perdomo, O.; Leyton-Ortega, V.; Nam, Y.; Perdomo-Ortiz, A. A generative modeling approach for benchmarking and training shallow quantum circuits. npj Quantum Inf. 2019, 1, 45. [Google Scholar] [CrossRef]
- Hibat-Allah, M.; Mauri, M.; Carrasquilla, J.; Perdomo-Ortiz, A. A framework for demonstrating practical quantum advantage: Comparing quantum against classical generative models. Commun. Phys. 2024, 7, 1. [Google Scholar] [CrossRef]
- Gili, K.; Hibat-Allah, M.; Mauri, M.; Ballance, C.; Perdomo-Ortiz, A. Do quantum circuit Born machines generalize? Quantum Sci. Technol. 2023, 8, 035021. [Google Scholar] [CrossRef]
- Caro, M.C.; Huang, H.Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef]
- Gibbs, J.; Holmes, Z.; Caro, M.C.; Ezzell, N.; Huang, H.-Y.; Cincio, L.; Sornborger, A.T.; Coles, P.J. Dynamical simulation via quantum machine learning with provable generalization. Phys. Rev. Res. 2024, 1, 013241. [Google Scholar]
- Peters, E.; Schuld, M. Generalization despite overfitting in quantum machine learning models. Quantum 2023, 7, 1210. [Google Scholar] [CrossRef]
- Bowles, J.; Wright, V.J.; Farkas, M.; Killoran, N.; Schuld, M. Contextuality and inductive bias in quantum machine learning. arXiv 2023, arXiv:2302.01365. [Google Scholar] [CrossRef]
- Gil-Fuster, E.; Eisert, J.; Bravo-Prieto, C. Understanding quantum machine learning also requires rethinking generalization. Nat. Commun. 2024, 15, 2277. [Google Scholar] [CrossRef]
- Pomarico, D.; Monaco, A.; Amoroso, N.; Bellantuono, L.; Lacalamita, A.; La Rocca, M.; Maggipinto, T.; Pantaleo, E.; Tangaro, S.; Stramaglia, S.; et al. Emerging generalization advantage of quantum-inspired machine learning in the diagnosis of hepatocellular carcinoma. Discov. Appl. Sci. 2025, 7, 205. [Google Scholar] [CrossRef]
- Pomarico, D.; Fanizzi, A.; Amoroso, N.; Bellotti, R.; Biafora, A.; Bove, S.; Didonna, V.; La Forgia, D.; Pastena, M.I.; Tamborra, P.; et al. A Proposal of Quantum-Inspired Machine Learning for Medical Purposes: An Application Case. Mathematics 2021, 9, 410. [Google Scholar] [CrossRef]
- Nahum, A.; Roy, S.; Skinner, B.; Ruhman, J. Measurement and Entanglement Phase Transitions in All-To-All Quantum Circuits, on Quantum Trees, and in Landau-Ginsburg Theory. PRX Quantum 2021, 1, 010352. [Google Scholar]
- Pomarico, D.; Cosmai, L.; Facchi, P.; Lupo, C.; Pascazio, S.; Pepe, F.V. Dynamical Quantum Phase Transitions of the Schwinger Model: Real-Time Dynamics on IBM Quantum. Entropy 2023, 25, 4. [Google Scholar] [CrossRef] [PubMed]
- Pomarico, D.; Pandey, M.; Cioli, R.; Dell’Anna, F.; Pascazio, S.; Pepe, F.V.; Facchi, P.; Ercolessi, E. Quantum Error Mitigation in Optimized Circuits for Particle-Density Correlations in Real-Time Dynamics of the Schwinger Model. Entropy 2025, 27, 427. [Google Scholar] [CrossRef]
- Ran, S.-J. Encoding of matrix product states into quantum circuits of one- and two-qubit gates. Phys. Rev. A 2020, 3, 032310. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Chen, J.; Miller, J.; Acharya, A.; Perdomo-Ortiz, A. Decomposition of matrix product states into shallow quantum circuits. Quantum Sci. Technol. 2023, 9, 015012. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Miller, J.; Motlagh, D.; Chen, J.; Acharya, A.; Perdomo-Ortiz, A. Synergistic pretraining of parametrized quantum circuits via tensor networks. Nat. Commun. 2023, 14, 8367. [Google Scholar] [CrossRef]
- Schuhmacher, J.; Ballarin, M.; Baiardi, A.; Magnifico, G.; Tacchino, F.; Montangero, S.; Tavernelli, I. Hybrid Tree Tensor Networks for Quantum Simulation. PRX Quantum 2025, 1, 010320. [Google Scholar] [CrossRef]
- Khosrojerdi, M.; Pereira, J.L.; Cuccoli, A.; Banchi, L. Learning to classify quantum phases of matter with a few measurements. Quantum Sci. Technol. 2025, 10, 025006. [Google Scholar] [CrossRef]
- Stoudenmire, E.M.; Schwab, D.J. Supervised Learning with Quantum-Inspired Tensor Networks. arXiv 2017, arXiv:1605.05775. [Google Scholar] [CrossRef]
- Stoudenmire, E.M.; Schwab, D.J. Supervised Learning with Tensor Networks. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Huggins, W.; Patil, P.; Mitchell, B.; Whaley, B.; Stoudenmire, E.M. Towards quantum machine learning with tensor networks. Quantum Sci. Technol. 2019, 4, 024001. [Google Scholar] [CrossRef]
- Felser, T.; Trenti, M.; Sestini, L.; Gianelle, A.; Zuliani, D.; Lucchesi, D.; Montangero, S. Quantum-inspired machine learning on high-energy physics data. npj Quantum Inf. 2021, 7, 111. [Google Scholar] [CrossRef]
- Dborin, J.; Barratt, F.; Wimalaweera, V.; Wright, L.; Green, A.G. Matrix product state pre-training for quantum machine learning. Quantum Sci. Technol. 2022, 7, 035014. [Google Scholar] [CrossRef]
- Ballarin, M.; Mangini, S.; Montangero, S.; Macchiavello, C.; Mengoni, R. Entanglement entropy production in Quantum Neural Networks. Quantum 2023, 7, 1023. [Google Scholar] [CrossRef]
- Collura, M.; Dell’Anna, L.; Felser, T.; Montangero, S. On the descriptive power of Neural-Networks as constrained Tensor Networks with exponentially large bond dimension. SciPost 2021, 4, 1. [Google Scholar] [CrossRef]
- Glasser, I.; Pancotti, N.; August, M.; Rodriguez, I.D.; Cirac, J.I. Neural-Network Quantum States, String-Bond States, and Chiral Topological States. Phys. Rev. X 2018, 8, 011006. [Google Scholar] [CrossRef]
- Glasser, I.; Pancotti, N.; Cirac, J.I. From Probabilistic Graphical Models to Generalized Tensor Networks for Supervised Learning. IEEE Access 2020, 8, 68169–68182. [Google Scholar] [CrossRef]
- Gallego, A.J.; Orús, R. From Language Design as Information Renormalization. Springer Nat. Comput. Sci. 2022, 3, 140. [Google Scholar]
- Cheng, S.; Wang, L.; Xiang, T.; Zhang, P. Tree tensor networks for generative modeling. Phys. Rev. B 2019, 99, 155131. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, L.; Xiang, T.; Zhang, P. Machine learning with tree tensor networks, CP rank constraints, and tensor dropout. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7825–7832. [Google Scholar] [CrossRef]
- Pomarico, D.; Monaco, A.; Magnifico, G.; Lacalamita, A.; Pantaleo, E.; Bellantuono, L.; Tangaro, S.; Maggipinto, T.; La Rocca, M.; Picardi, E.; et al. Grokking as an entanglement transition in tensor network machine learning. arXiv 2025, arXiv:2503.10483. [Google Scholar] [CrossRef]
- Larrarte, O.S.; Aizpurua, B.; Dastbasteh, R.; Otxoa, R.M.; Martinez, J.E. Tensor Network based Gene Regulatory Network Inference for Single-Cell Transcriptomic Data. arXiv 2025, arXiv:2509.06891. [Google Scholar] [CrossRef]
- Venkatesh, S.M.; Macaluso, A.; Nuske, M.; Klusch, M.; Dengel, A. Q-Seg: Quantum Annealing-Based Unsupervised Image Segmentation. IEEE Comput. Graph. Appl. 2024, 44, 27–39. [Google Scholar] [CrossRef]
- Power, A.; Burda, Y.; Edwards, H.; Babuschkin, I.; Misra, V. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. arXiv 2022, arXiv:2201.02177. [Google Scholar] [CrossRef]
- Liu, Z.; Kitouni, O.; Nolte, N.; Michaud, E.J.; Tegmark, M.; Williams, M. Towards Understanding Grokking: An Effective Theory of Representation Learning. arXiv 2022, arXiv:2205.10343. [Google Scholar] [CrossRef]
- Liu, Z.; Zhong, Z.; Tegmark, M. Grokking as Compression: A Nonlinear Complexity Perspective. arXiv 2023, arXiv:2310.05918. [Google Scholar] [CrossRef]
- Miller, J.; O’Neill, C.; Bui, T. Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity. arXiv 2024, arXiv:2310.17247. [Google Scholar] [CrossRef]
- Varma, V.; Shah, R.; Kenton, Z.; Kramár, J.; Kumar, R. Explaining grokking through circuit efficiency. arXiv 2023, arXiv:2309.02390. [Google Scholar] [CrossRef]
- Huang, Y.; Hu, S.; Han, X.; Liu, Z.; Sun, M. Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition. arXiv 2024, arXiv:2402.15175. [Google Scholar] [CrossRef]
- Mei, S.; Montanari, A.; Nguyen, P.-M. A mean field view of the landscape of two-layer neural networks. Proc. Natl. Acad. Sci. USA 2018, 115, E7665–E7671. [Google Scholar] [CrossRef]
- Seroussi, I.; Naveh, G.; Ringel, Z. Separation of scales and a thermodynamic description of feature learning in some CNNs. Nat. Commun. 2023, 14, 908. [Google Scholar] [CrossRef]
- Rubin, N.; Seroussi, I.; Ringel, Z. Grokking as a First Order Phase Transition in Two Layer Networks. arXiv 2024, arXiv:2310.03789. [Google Scholar]
- Clauw, K.; Stramaglia, S.; Marinazzo, D. Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition. arXiv 2024, arXiv:2408.08944. [Google Scholar] [CrossRef]
- Varley, T.F. Information Theory for Complex Systems Scientists: What, Why, & How? arXiv 2023, arXiv:2304.12482. [Google Scholar]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef]
- Faes, L.; Kugiumtzis, D.; Nollo, G.; Jurysta, F.; Marinazzo, D. Estimating the decomposition of predictive information in multivariate systems. Phys. Rev. E 2015, 91, 032904. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.M.; Gastpar, M.; Jensen, H.J. Quantifying high-order interdependencies via multivariate extensions of the mutual information. Phys. Rev. E 2019, 100, 032305. [Google Scholar] [CrossRef]
- White, S.R. Density matrix formulation for quantum renormalization groups. Phys. Rev. Lett. 1992, 69, 2863–2866. [Google Scholar] [CrossRef]
- Schollwöck, U. The density-matrix renormalization group. Rev. Mod. Phys. 2005, 77, 259–315. [Google Scholar] [CrossRef]
- Schollwöck, U. The density-matrix renormalization group in the age of matrix product states. Ann. Phys. 2011, 326, 96–192. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef]
- Hackbusch, W. Tensor Spaces and Numerical Tensor Calculus; Springer Series in Computational Mathematics: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A Multilinear Singular Value Decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Oseledets, I.V. Tensor-Train Decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Zaletel, M.P.; Pollmann, F. Isometric Tensor Network States in Two Dimensions. Phys. Rev. Lett. 2020, 124, 037201. [Google Scholar] [CrossRef]
- Evenbly, G. A Practical Guide to the Numerical Implementation of Tensor Networks I: Contractions, Decompositions, and Gauge Freedom. Front. Appl. Math. Stat. 2022, 8, 806549. [Google Scholar] [CrossRef]
- Wiersema, R.; Zhou, C.; Carrasquilla, J.F.; Kim, Y.B. Measurement-induced entanglement phase transitions in variational quantum circuits. SciPost Phys. 2023, 14, 147. [Google Scholar] [CrossRef]
- Li, D.; Zheng, C. Non-Hermitian Generalization of Rényi Entropy. Entropy 2022, 24, 1563. [Google Scholar] [CrossRef]
- Liu, Z.; Zheng, C. Non-Hermitian Quantum Rényi Entropy Dynamics in Anyonic-PT Symmetric Systems. Symmetry 2024, 16, 584. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Frenzel, S.; Pompe, B. Partial Mutual Information for Coupling Analysis of Multivariate Time Series. Phys. Rev. Lett. 2007, 99, 204101. [Google Scholar] [CrossRef]
- ReCaS Bari. Available online: https://www.recas-bari.it/index.php/en/ (accessed on 27 September 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).