1. Introduction
The problem of data classification in the field of supervised machine learning refers to the capability of an algorithm to predict the class label of a sample consisting of a set of parameters called features or explanatory variables. Data classification is an instance of pattern recognition [
1], and its solution includes two phases: (a) a training phase where the exploited machine learning algorithm is trained based on a set of training data, i.e., data for which both the features and the corresponding class label are known, and (b) the application of the trained machine learning algorithm to datasets with known feature values and unknown class labels leading to a prediction of the class labels.
Depending on the number of class labels, a classification problem can be characterized as binary classification (the class label can take only two values), multiclass classification (the class label can take more than two different values) or multi-label classification (each observation is associated with multiple classes). Different machine learning algorithms are employed to address classification problems [
1], such as Linear Regression, logistic regression (LogReg), Naïve Bayes (NB), Support Vector Machines (SVMs), decision trees (DTs), random forest (RF), k-nearest neighbors, Convolutional Neural Networks (CNNs), Artificial Neural Networks (ANNs), etc. [
2,
3]. The performance of classification algorithms is expressed via specific metrics like accuracy, precision, recall, F1-score [
4]. Such metrics are calculated based on the derivation of the confusion matrix (CM) [
5,
6] which represents the way that predicted labels are confused with the actual class labels.
During the training phase, an algorithm is optimized based on the available training dataset (fitting process). To assess the generalized performance [
7] of the trained algorithm typically some cross-validation method is applied (e.g., exhaustive, non-exhaustive, hold-out cross-validation) [
8,
9]. In all of these methods the trained algorithm is applied to one or more datasets called test or validation sets with known class labels providing thus the opportunity to assess its performance for samples not seen during the training process.
Probabilistic versions of the confusion matrix have been proposed in the literature [
10,
11,
12,
13,
14,
15,
16,
17]. In [
10], a probabilistic confusion matrix was developed as a method for cross-entropy/loss minimization, and in [
11], the concept of a fuzzy confusion matrix was proposed aiming at the improvement of multi-label classification problem. In [
12], the authors consider the true and the empirical version of the confusion matrix and they use a norm of the confusion matrix as a loss function in order to optimize the classification algorithm performance. In [
13,
14], the authors define a probabilistic confusion matrix version which relies on the actual class labels and the class probabilities and provide an analysis of the relevant performance metrics. In [
15], multiple classification algorithms are exploited for document classification, and a probabilistic confusion matrix is proposed, which, for each class, sums up the class probabilities produced by each one of the applied algorithms in order to select the class with the maximum sum of class probabilities. In [
16], the authors use the concept of the entropy confusion matrix developed in [
10] in order to assess probabilistic classification models. Finally, in [
17], the authors exploit a probabilistic confusion matrix for a binary classification problem analysis (presence–absence problem). The probabilistic confusion matrix used is based on the same definition as the one used in [
13,
14], i.e., based on the actual class labels and the class probabilities.
The current paper develops a novel concept based on a probabilistic definition of the confusion matrix using the predicted class and the associated class probabilities estimated by the applied algorithm. The proposed concept is called Actual Label Probabilistic confusion matrix (ALP CM) since the actual labels corresponding to a set of input samples are approximated by the relevant class probabilities. This is a different version compared to [
13,
14,
17], where the probabilistic confusion matrix is based on the actual class labels and the class probabilities. Moreover, the ALP CM is based on a different definition compared to [
10] as it becomes evident from the equations provided in
Section 3.
The theoretical analysis indicates that the properties of the ALP confusion matrix under certain convergence conditions lead to a good estimation of the algorithm performance. Further theoretical results provide useful insights related to the class probabilities and the algorithm performance metrics. The theoretical analysis is then tested based on a set of real-world classification problems and a set of state-of-the-art classification algorithms. The results confirm the theoretical analysis and provide additional insights related to the observed pattern under the presence of overfitting and generalization error. The derived conclusions are exploited so as to develop a method for exploiting the proposed confusion matrix concept for improving the training phase of a classification problem as well as for predicting the trained algorithm performance when applied to a real-world set of input samples.
The paper is organized as follows:
Section 2 provides modelling of state-of-the-art machine learning classification algorithms.
Section 3 develops the probabilistic confusion matrix concept and provides the associated theoretical framework of the algorithm performance.
Section 4 provides the analysis of real-world classification problems so as to verify the theoretical analysis.
Section 5 provides the exploitation use cases of the probabilistic confusion matrix, and
Section 6 summarizes the paper conclusions and discusses potential next research steps.
3. The Actual Label Probabilistic Confusion Matrix Concept
The current paper considers the definition of a different version of the confusion matrix, which is estimated based on the class probabilities produced by the applied classification algorithm. In particular, the confusion matrix defined in this paper is called Actual Label Probabilistic (ALP) confusion matrix and is developed based on the following assumptions:
- (a)
The selected classification algorithm f is trained based on a training dataset (i.e., a set of input samples with known actual class labels ). The pair is assumed to be a set of samples from the problem space (SX, SY).
- (b)
The trained classification algorithm is then applied to a set of input samples . It is assumed that the pair of input samples and the corresponding actual labels are also a set of samples from the problem space (SX, SY). Note that depending on the use case, the set of actual labels can be either known (e.g., a test set so to validate the trained algorithm performance) or unknown (e.g., an application set so as to exploit the trained algorithm to predict the class labels).
- (c)
When the trained classification algorithm
f is applied to the input set
, it produces the predicted class probabilities (see Equation (13)), and it uses Equation (17) as the decision rule for the selection of the predicted class labels based on the estimated class probabilities. From this assumption, it is clear that the proposed concept applies to classification algorithms like logistic regression, decision trees, etc. On the other hand, the proposed concept is not applicable to algorithms like k-nearest neighbors (KNN) where the estimation of the predicted label of an input sample is based on a plurality vote of the k nearest neighbors [
21].
- (d)
When the trained classification algorithm f is applied to the input set , the Actual Label Probabilistic confusion matrix (ALP CM) can be calculated based on: (i) the predicted class labels (as in the case of the regular confusion matrix) and (ii) the fractional approximation of the actual class labels, which is estimated based on the predicted class probabilities of each input sample instance. The concept behind this approach is the fact that the classification algorithm has been trained so as to approximate the distribution of actual class labels corresponding to the set of input samples through the produced class label probabilities.
Applying the process described in point (d) to Equation (10) by replacing the actual labels array
with the estimated class probabilities array
, we obtain the following equations for the ALP CM:
where
is a real number with the property 0 ≤
≤
N. The ALP CM of a trained algorithm can be calculated even for datasets for which the actual class labels
are unknown as in the case of a real-world application dataset. The ALP CM has the following properties:
where
is the number of instances for which the actual class label is
, and
is the number of input sample instances for which the predicted class label is
Lk. It should be noted that the property expressed in Equation (22) stems from Equation (16). Moreover, it is interesting to note that the above properties also apply to the regular CM.
3.1. Actual Label Probabilistic vs. the Regular Confusion Matrix
In this section we prove the following theorem which provides the relation between the ALP CM and the regular CM:
Theorem 1. Let us consider an algorithm f that properly fits the training dataset (i.e., there is no presence of overfitting or underfitting) and produces estimated class probabilities with a good level of accuracy. Let us also consider an input dataset (X,Y) with a substantially large size N that follows the same distribution of samples as the one of the training set. Then, the elements of the ALP CM approximate the values of the elements of the regular CM corresponding to the same input dataset: Proof of Theorem 1. It is evident that in the case of an algorithm that suffers from overfitting or underfitting, it will also suffer from generalization error issues. Therefore, for such an algorithm it is not possible to derive performance metrics that form a reliable prediction of the algorithm when applied to any input set of samples .
It is also evident that in the case that the applied algorithm produces predicted class probabilities of limited accuracy, then the estimation of the ALP CM elements will also be characterized by limited accuracy. For example, it is known from the literature [
19] that certain types of algorithms like Naïve Bayes or Boosted Trees have an issue of bias in the estimated class probabilities while algorithms like neural networks have a much better behavior.
Assuming that the applied algorithm does not suffer from overfitting or underfitting and the produced estimated class probabilities are of good accuracy, we have (from Equation (8)):
where from the input set of samples
, we select the sub-set of sample instances
with indexes
i =
a1,
a2, …,
an for which the predicted label is
and therefore
= 1. The number of sample instances in this sub-set is
n and is equal to the number of samples in
for which the predicted label is
:
We can now use
to express the probability of the actual label
y being
Lm given that the predicted label
is
Lk:
Accordingly, the ALP CM elements can be expressed as follows:
Taking into account that
expresses the predicted class probability for class
and the above sum aggregates the class probabilities for all input sample instances for which the predicted class label is
, we obtain for a substantially large sample size:
Combining Equations (26), (27) and (29), we obtain Equation (24), which proves Theorem 1. □
It is now evident that the following property applies: under the conditions for which the above theorem holds, the performance metrics of the CM are the same as the performance metrics of the ALP CM of any input dataset (
X,
Y) that follows the distribution of the training dataset:
Therefore, the above property applies for all types of input datasets (training, test/validation, and real application sets).
3.2. The Algorithm Performance Metrics vs. the Maximum Estimated Class Probabilities
In this section we provide an analysis that reveals the relation of the maximum estimated class probabilities and the algorithm performance metrics. We start from the estimation of
of the ALP CM as a function of the maximum class probability. Assuming that Equation (17) is applied to the selection of the predicted class, and taking into account Equation (20), we obtain:
We can split the input set of samples into the following two sub-sets:
- (a)
Sub-set with samples for which , i.e., is the maximum estimated class probability;
- (b)
Sub-set with samples where is not the maximum estimated class probability.
Apparently, the size of sub-set is since according to Equation (17), if the estimated class probability is the maximum one for sample , then the predicted class for the specific sample is .
Based on the above split of set
, the estimation of
becomes:
Let us define
as the average value of the predicted class probability for class
k in the sub-set
(i.e., when
is the maximum class probability for sample
):
Equation (32) can now be expressed as follows:
Based on Equation (34), it is possible to estimate basic performance metrics like accuracy, precision, recall, F1-score as a function of the maximum class probabilities as produced by an algorithm
f when applied over a set
of
N samples:
where
is the average value of the maximum estimated class probability in the entire set of results produced by the algorithm
f when applied over the input set of samples
.
The precision score can be defined as a function of the maximum estimated class probability as follows (considering the generic multiclass classification and macro average definition of precision):
The precision score for a binary classification problem (assuming two classes with
P for Positive and
N for Negative) is:
Note that in binary classification, (where TP: True Positives, FP: False Positives).
The recall score can similarly be defined as a function of the maximum estimated class probability as follows (considering the generic multiclass classification case and macro average definition of recall):
The recall metric for a binary classification problem is:
Note that in binary classification, (where FN: False Negatives).
Finally, the F1-score can be estimated as follows assuming a multiclass classification problem and the macro average definition of the F1-score:
Taking into account Equation (34), we obtain:
and for a binary classification problem, we obtain:
From the above analysis, we may obtain some insights regarding the performance of classification algorithms:
Based on Theorem 1 and Equation (30), we may conclude that if the conditions of Theorem 1 apply, then the equations provided for the performance metrics of the ALP CM approximate the regular CM performance metrics.
The above set of equations indicates that the performance metrics of a classification algorithm are related to the maximum classification probabilities produced by the algorithm when applied over a set of input samples. This is an expected result based on the fact that the maximum class probability provides an indication of the confidence of the prediction provided by the classification algorithm.
It is feasible to use the above equations so as to estimate the ALP CM performance metrics even without the need to first calculate the ALP CM. Note, that in the case of input sets with unknown actual class labels (e.g., real application sets) the number of actual class labels appearing in some of the equations can be estimated based on the produced class probabilities according to Equation (22).
Let us assume that two different trained algorithms f1, f2 when applied over the same set of input samples lead to the same number of predicted class labels, i.e., common for all classes k = 1, 2, …, M. We also assume that the conditions of Theorem 1 apply for both algorithms. Then, if algorithm f1 produces higher average class probabilities than algorithm f2 for all classes k = 1, 2, …, M, then algorithm f1 outperforms algorithm f2 in accuracy, precision, recall, and F1-score metrics.
Let us assume that a trained algorithm f when applied over an input set of samples produces the same average class probabilities for all classes k = 1, 2, …, M. Then, the ALP CM-based accuracy and the precision score are equal: . If the conditions of Theorem 1 apply, then the same property applies for the regular CM accuracy and precision metrics.
Let us assume that a trained algorithm f when applied over an input set of samples leads to the same number of predicted classes as the actual number of classes, i.e., for k = 1, 2, …, M. Then, the ALP CM-based precision score is equal to the relevant recall score and equal to the F1-score: . If the conditions of Theorem 1 apply, then the same property applies for the metrics of the regular CM.
4. Actual Label Probabilistic Confusion Matrix in Real Classification Problems
In order to verify the theoretical framework provided in the previous section for the ALP CM, we considered a set of known classification problems from the UCI machine learning repository [
22] listed in
Table 1. Moreover, the following set of state-of-the-art machine learning algorithms were exploited in this study: logistic regression (LogReg), Support Vector Machines (SVMs), decision trees (DTs), random forest (RF), Naïve Bayes (NB), eXtreme Gradient Boosting (XGB), Convolutional Neural Networks (CNN), and Artificial Neural Network (ANNs).
Appendix A provides the necessary details on the applied machine learning algorithms.
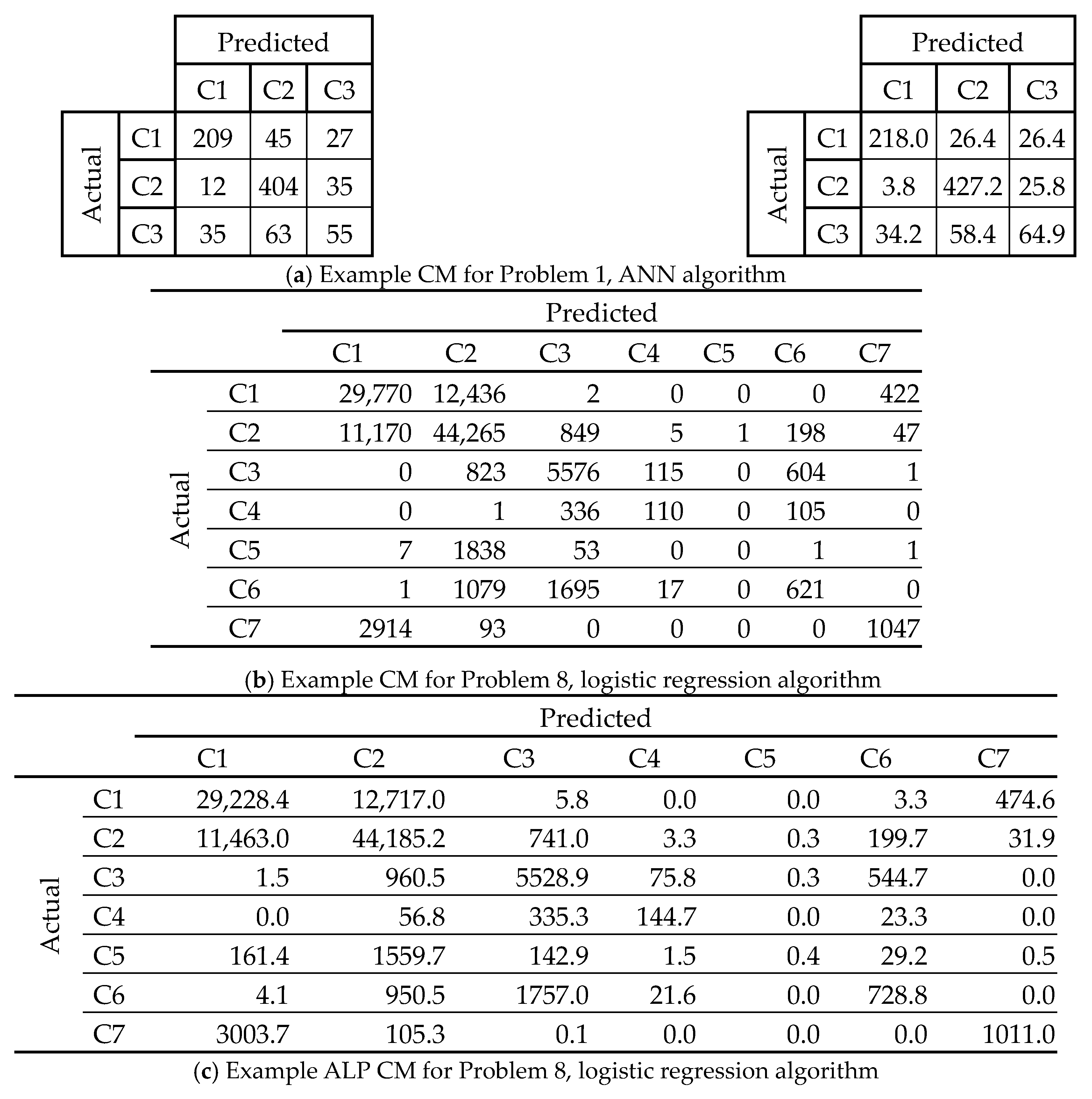
Figure 1 provides examples of a regular CM and an ALP CM for Problems 1 (students’ dropout rate) and 8 (cover type) for LogReg and ANN algorithms, accordingly. As it can be observed, the values of the CM ALP elements are relatively close to their respective CM ones as expected from the theoretical analysis.
4.1. Algorithm Performance: ALP CM vs. Regular CM Metrics
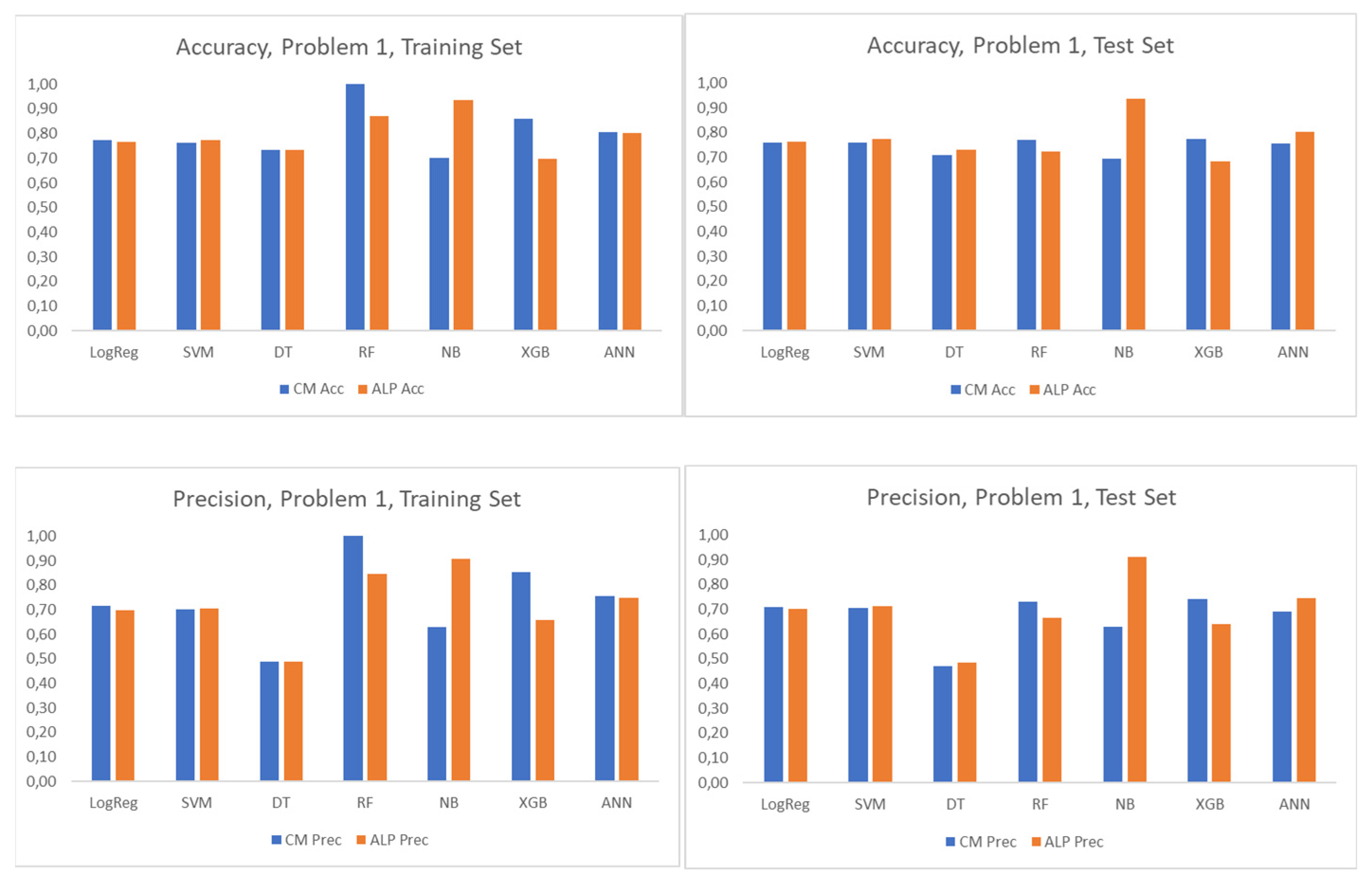
Figure 2 provides an overview of the performance metrics (accuracy, precision, recall and F1-score) occurring from the CM and ALP CM analysis for all applied algorithms on Problem 1 (students’ dropout rate) dataset. The metrics refer to the training and the test set, which were defined based on a random 80–20% split of the problem dataset. As it can be observed, there was a good agreement in the estimated metrics based on the CM and ALP CM for LogReg, SVM, DT, and ANN. This fact indicates that the conditions of Theorem 1 were probably satisfied for these algorithms as the performance metrics converged. For NB, the ALP CM metrics were significantly higher than the CM metrics. For RF and XGB, the CM metrics were higher than the ALP CM metrics in the training set and at a closer distance for the test set. Probably, for these algorithms, the conditions of Theorem 1 were not fully satisfied, leading to a discrepancy in the relevant ALM CM and CM performance metrics.
The metrics of ALP CM provided in
Figure 2 were calculated based on two different methods: (a) a calculation of the ALP CM and then an estimation of the relevant performance metrics (accuracy, precision, recall, F1-score) and (b) based on Equations (35)–(39), (41), and (42). The same methodology was applied to the rest of the problems provided in
Table 1. In all cases, the resulting metrics for ALP CM were identical, as expected, thus verifying the provided theoretical analysis.
Table 2 provides an overview of the accuracy metric per problem and per applied algorithm as resulting from the CM and the ALP CM analysis. The training and test sets were produced based on a random split of 80–20% of the overall dataset of each problem. The results presented in
Table 2 confirm that the accuracy defined based on the ALP CM was quite close to the one defined based on the CM for most of the applied algorithms. As observed in
Figure 2, the results of
Table 2 confirm that for the NB algorithm, there was a lack of agreement between the accuracy based on the ALP CM and CM. This finding was possibly related to the known fact that the estimation of class probabilities may have an issue for algorithms like NB. There were also some spotted differences between the CM and ALP CM accuracy metrics for the CNN and XGB algorithms indicating the need for further investigation. These discrepancies probably indicate cases where the conditions of Theorem 1 were not satisfied.
4.2. Algorithm Learning Curve Analysis
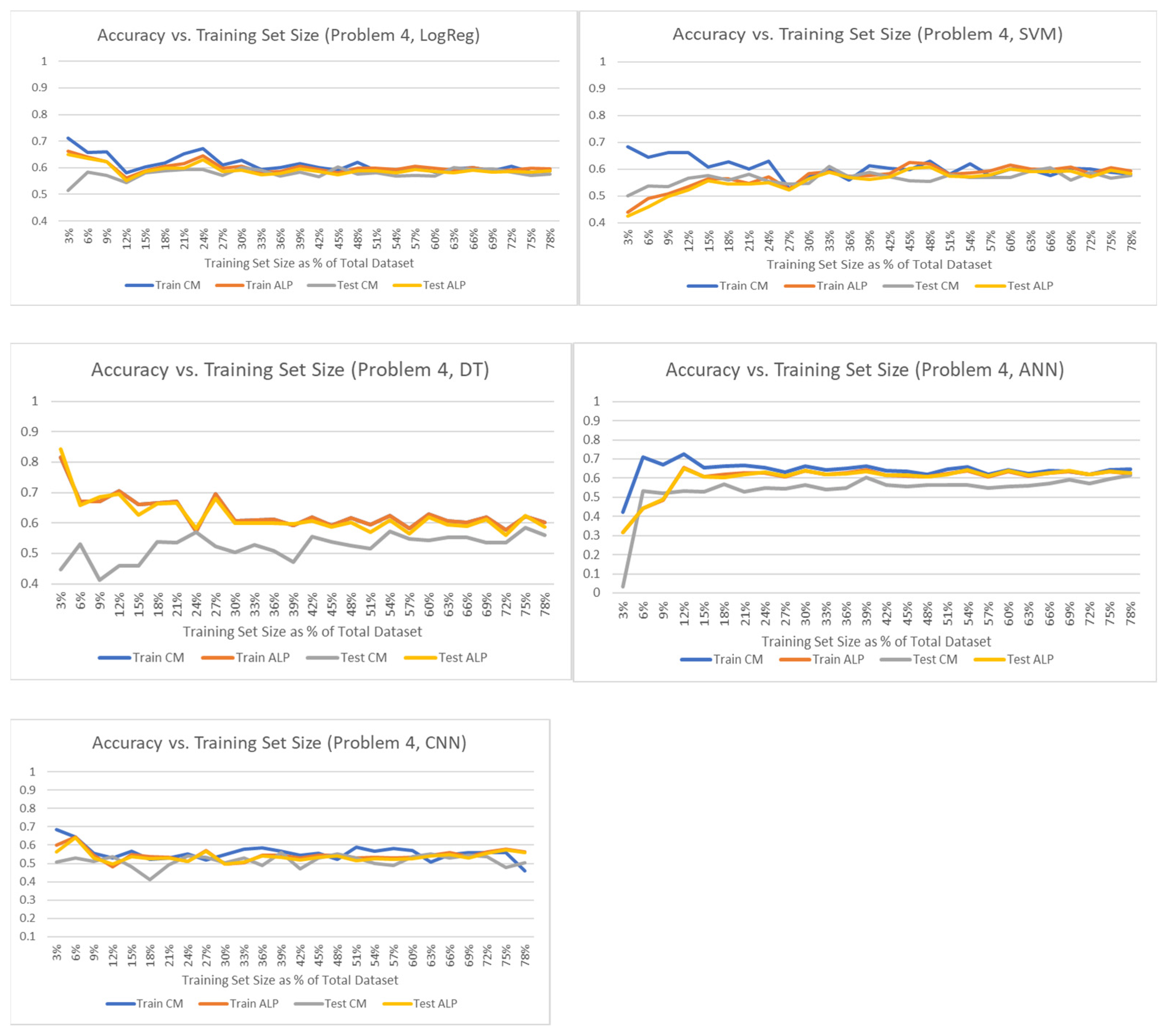
Figure 3,
Figure 4 and
Figure 5 provide an example of the algorithm learning curve based on the accuracy vs. the training set size for Problem 4 (red wine quality) and for all the applied algorithms. The training set was selected randomly from the problem input dataset with a size expressed in the figure as a percentage of the overall input dataset ranging from 3% to 78%. After selecting the training set, a test set was also selected randomly from the remaining input dataset with a size equal to 20% of the total dataset.
As shown in
Figure 3, the LogReg, SVM, DT, ANN, and CNN algorithms were characterized by a similar pattern in the CM accuracy curves. For a small training set size, we observed an overfitting pattern with the training set CM accuracy being higher than the test set CM accuracy (generalization error). As the training set size increased, the CM accuracy converged to a rather stable level similar for both training and test sets. This was a clear pattern of overfitting which faded out as the training set size increased.
From the same figure, we may observe that the ALP CM accuracy for the training set was clearly lower than the corresponding CM accuracy in the small training set size region and effectively converged to the CM accuracy as the training set size increased. Moreover, the ALP CM accuracy values for the training and the test sets were very close for these algorithms especially in the range of a large training set size. The DT algorithm was an exception, where it appeared that the ALP CM accuracy of both training and test sets almost coincided with the CM accuracy of the training set. Based on these results, we may assume that for Problem 4, the set of algorithms presented in
Figure 3 satisfied both conditions of Theorem 1 for a substantially large size of the training set, thus leading to a converged performance of the ALP CM and regular CM.
As shown in
Figure 4, for the RF and XGB algorithms, across the entire range of training set size, the performance for the training set was very high while there was a clear evidence of generalization error, i.e., the test set CM performance was substantially lower. Moreover, the ALP CM accuracy was very close to the actual CM accuracy of the test set. In that case, we had a pattern of overfitting which was not related to the training set size but to the configuration of the applied algorithm. Therefore, for these algorithms, the conditions of Theorem 1 were not satisfied leading to a discrepancy between the ALP CM and the CM performance metrics (accuracy in this case).
There are methods to mitigate this type of overfitting for both RF and XGB algorithms. In this study, we set the maximum tree depth limit of the RF algorithm to two, and the learning rate parameter of the XGB algorithm to 0.01. The results are presented in
Figure 4 with the adjusted algorithms marked as RF’ and XGB’, accordingly. The adjusted RF algorithm (RF’) led to a converged level of both training and test set CM accuracy even for small training set size. The corresponding ALP CM accuracy was common for training and test sets and close to the CM ones. For the adjusted XGB algorithm (XGB’), we observed an overfitting pattern in the range of a small training set size which faded out as the sample size increased. However, even in the area of convergence, the ALP CM accuracy values for both training and test sets were substantially lower than the CM ones. This was an indication of a potential issue with the quality of the estimated class probabilities. To further investigate this issue, we applied probability calibration (based on Platt’s method) [
19,
30,
31]. The results shown in
Figure 4 with the algorithm named XBG” indicate that probability calibration indeed resolved the issue of discrepancy between the ALP CM and CM accuracy. The results presented in
Figure 4 indicate that for algorithms for which a discrepancy between ALP CM and CM metrics is observed, the conditions of Theorem 1 should be investigated, i.e., overfitting and class probability estimation quality. As soon as these issues were resolved (based on state-of-the-art methods), Theorem 1’s prediction applied (i.e., the ALP CM and CM metrics converged).
Observing the learning curves of the NB algorithm in
Figure 5, it appears that the discrepancy between the CM and ALP CM metrics observed in
Table 2 is evident here too. The ALP CM accuracy is very high compared to the CM metrics for both train and test sets. As already mentioned, this discrepancy is related to the quality of the class probabilities produced by NB algorithm. As in the case of XGB algorithm, we applied probability calibration to further investigate this observation. The resulting performance is presented in
Figure 5 in the chart with the NB’ algorithm. As it can be seen, the probability calibration process improved the convergence of the algorithm performance (accuracy in this case) for both the training and the test sets. Moreover, the ALP CM accuracy was in full agreement with CM accuracy for both training and test sets.
The results presented in this section provide solid evidence of the predictions of Theorem 1 both in terms of the required conditions related to appropriate algorithm fitting and the good quality of class probabilities and in terms of the observed converged ALP CM and regular CM performance metrics. Moreover, the presented results highlight the fact that in order to exploit the ALP CM concept, it may be required to apply state-of-the art methods like techniques for the mitigation of overfitting or class probability calibration.
4.3. Distribution of Algorithm Performance Metrics
The performance of a trained algorithm over an application input set of samples (i.e., a set for which the class labels are unknown) is considered to be in line with the performance of the algorithm observed during the training phase (i.e., the algorithm performance on test/validation sets). This is valid under the following two basic assumptions: (a) the application set of samples originates from the same space of solutions (SX,SY) as the training and the test/validation sets and (b) the distribution of samples in the application set is similar to the one of the training and test/validation sets.
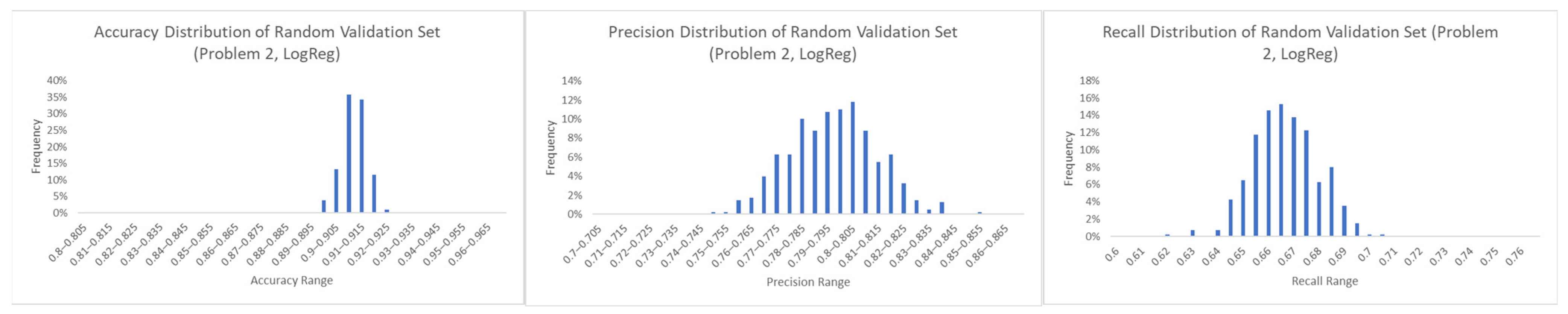
Let us now consider the distribution of the algorithm performance over a set of randomly selected validation sets. We considered the Problem 2 dataset and applied a split of 60% for the training, 20% for the testing, and 20% for the validation analysis. The LogReg algorithm was then trained using the training and test sets leading to a prediction of the algorithm performance. Then, through a randomized process we produced 400 validation sets of size 10% of the overall input dataset selected from the reserved 20% of samples for validation purposes.
Figure 6 presents the results of this analysis. As it can be seen, the accuracy metric was distributed quite closely to the predicted performance from the training analysis. On the other hand, the precision and recall metrics had a wider distribution around the predicted performance.
As already mentioned, the ALP CM has the advantage that it can be calculated based on the knowledge of the predicted labels and the class probabilities produced by the applied machine learning algorithm. This allows us to calculate the ALP CM for application datasets for which the actual labels are unknown. Based on this property, we investigated the option of using the ALP CM as a means to estimate the algorithm performance when applied to a specific application set.
Using the analysis performed to produce
Figure 6 (Problem 2, LogReg algorithm, 400 randomly generated validation sets with size 10% of the overall input dataset), we assessed the capability of the ALP CM to predict the algorithm performance. As shown in
Figure 7, the ALP CM metrics were quite close to the actual CM metrics of the randomly selected validation sets. However, it appeared that there was low correlation between ALP CM and CM metrics.
Table 3 provides the Mean Squared Error (MSE) of the predicted metrics (ALP CM based) vs. the actual ones (CM based) for Problem 2 and all of the applied algorithms based on the observed performance on validation sets generated according to the method described above. Combining the results presented in
Figure 7 and
Table 3, we may conclude that the ALP CM metrics can be used to predict the performance of a trained algorithm over a real-world application sample, at a reasonable level of approximation.
5. ALP CM Exploitation Methodology
Taking into account the results presented in the previous section, it is feasible to derive a methodology for exploiting the ALP CM and its properties for handling classification problems.
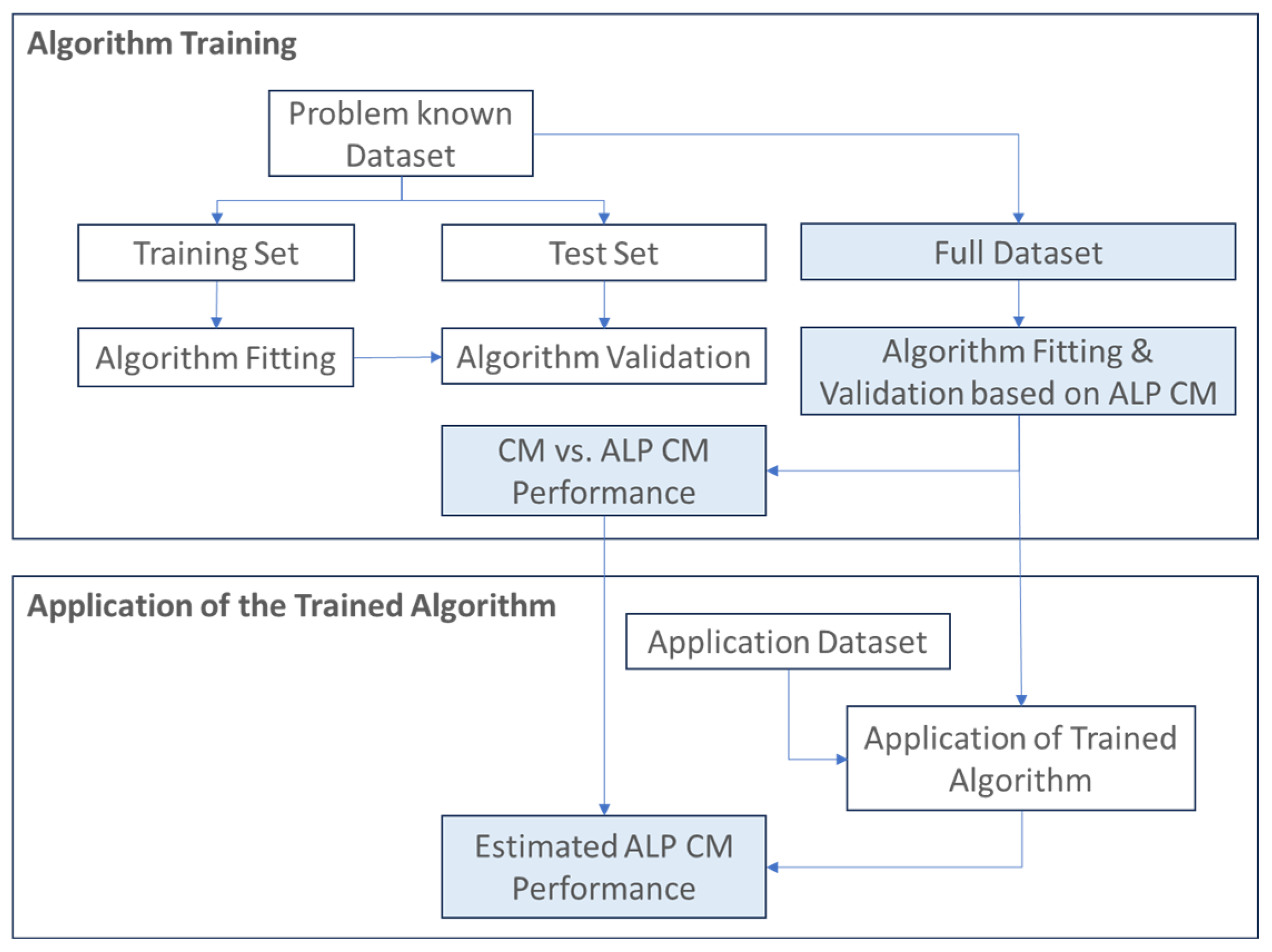
Figure 8 presents the proposed methodology with special highlights on the steps related to ALP CM capabilities. The provided steps are explained later in this section.
During the algorithm training phase, the originally available known dataset is split into training and test sets, e.g., an 80–20% sample split. The typical state-of-the-art cross-validation methods eventually lead to algorithm training based on only a portion of the available dataset (e.g., 80% of the available samples with a known solution).
Taking advantage of the observed learning curve patterns presented in the previous section, it is feasible to use ALP CM as a validation method and proceed with an additional step of algorithm training and validation. In this additional step, the algorithm is trained based on the entire available input dataset, and the ALP CM analysis is exploited to support a validation analysis. It should be noted here that as shown in
Section 3, before proceeding to the full exploitation of the ALP CM analysis, state-of-the-art techniques may have to be applied so as to handle possible issues of the algorithm related to overfitting as well as class probability calibration techniques so as to handle issues related to the quality of the produced class probabilities of the selected algorithm.
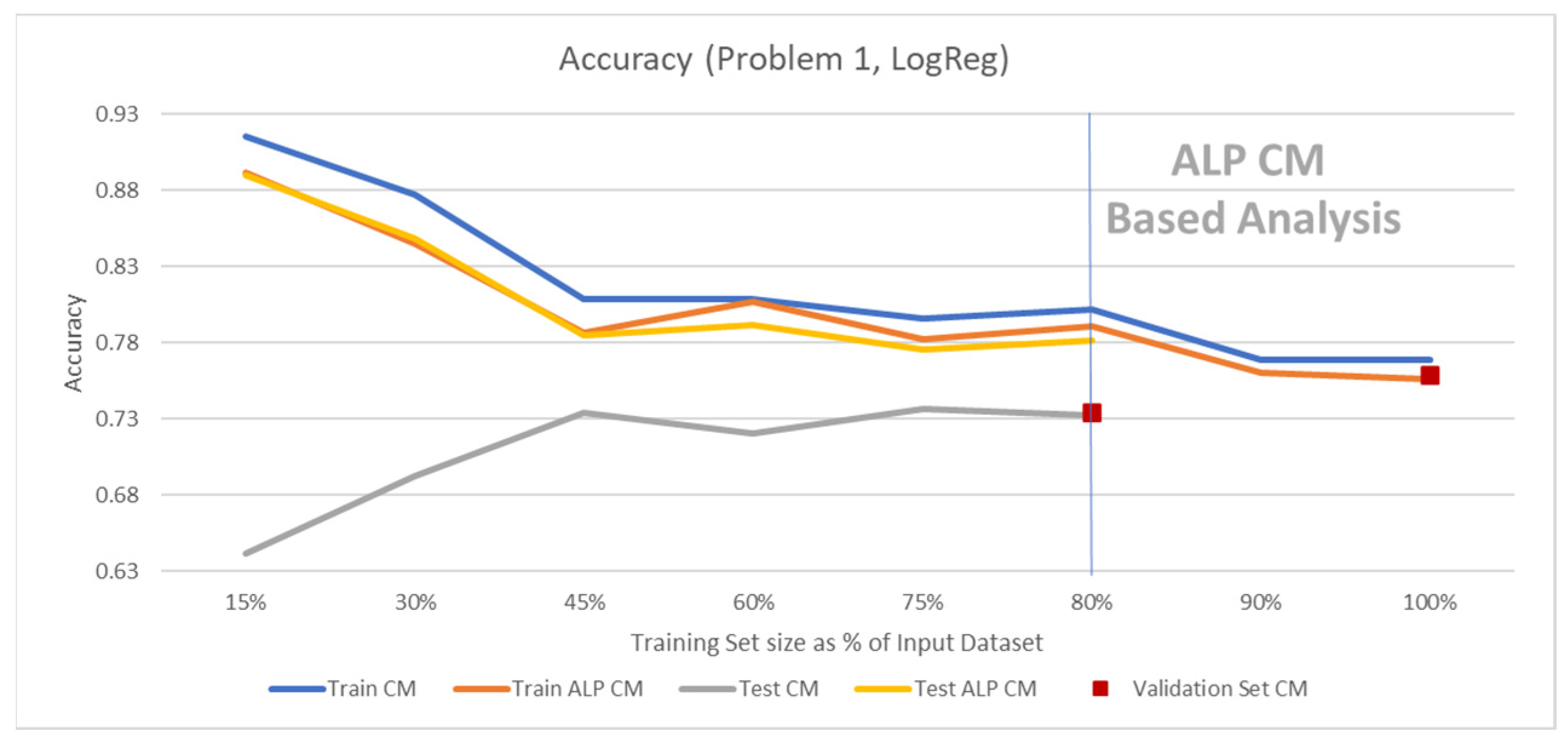
To demonstrate the potential of this method, we used Problem 1 (students’ dropout rate). Our study was based on an input dataset with known solutions of size N = 1194 samples which were generated based on a random selection of samples from the overall problem dataset (i.e., selected from a total of 4424 samples). The input set was randomly split into 80% of samples for forming the training set and 20% for forming a test set. Based on the method described above, we considered two phases of algorithm training: (a) algorithm training using the training set and verification of its performance based on the test set, and (b) based on the proposed method, the training and test sets were united to a single training set and based on ALP CM analysis, we continued the algorithm training for 100% of the input dataset.
Figure 9 shows the resulting learning curve for the specific case study. The figure presents the above two training phases:
- (a)
In the range of training set size equal to 15–80% of the input dataset, we obtained a pattern of overfitting which was confirmed by the presence of a generalization error (i.e., the test set accuracy was substantially lower than the training set accuracy) and the lower ALP CM accuracy.
- (b)
In the range of training set size of 80–100% of the input set, we observed that the ALP CM accuracy converged to the training set CM accuracy. This was an indication that training the algorithm with 100% of the input dataset led to better algorithm performance.
To simulate the performance of the algorithm in a real-world application set of input samples we randomly selected a validation set of 300 samples from the remaining pool of problem samples (i.e., 4424–1194 = 3230 samples). The validation set was then analyzed based on the trained algorithm based on the two phases described before (i.e., based on 80% and 100% of the input dataset).
Figure 9 shows the achieved accuracy performance, and
Table 4 summarizes the achieved performance metrics. This example illustrates that the ALP CM can improve the training process of an algorithm.
It should be noted here that this example as designed to demonstrate the value of the ALP CM method. Therefore, although the proposed method did not lead to an improvement under any condition, the presented case study highlighted the fact that in practice, depending on the nature of the problem and the availability of known input data, the proposed method may prove valuable.
To further assess the potential of using the ALP CM in order to estimate the algorithm performance for real-world application sets, we applied a similar approach to the one followed in the previous section. A number of 200 validation sets with a size of 300 samples were generated by a random selection of samples from the pool of Problem 2 samples which were not used in the training and testing phase (i.e., 4.424–1.194 = 3.230 samples). The comparison of the ALP CM metrics with the CM metrics led to the following MSE levels: accuracy MSE: 5.48 × 10−3, precision MSE: 4.62 × 10−2, recall MSE: 4.83 × 10−3. The results confirmed the fact the ALP CM metrics provide a good approximation of the application set performance metrics.
6. Conclusions and Next Research Steps
The current paper addressed the topic of classification problem analysis based on supervised machine learning and introduced a novel concept of Actual Label Probabilistic confusion matrix, which was calculated based on the predicted class labels and the relevant class probabilities. The theoretical analysis suggested that for algorithms not suffering from overfitting or underfitting and for a substantially large training dataset size, the performance metrics of the ALP CM would converge to the ones of the regular CM. In addition, the theoretical framework developed in this paper indicated that the performance metrics of an algorithm could be estimated from the ALP CM metrics as a function of the average of the maximum class probability.
The theoretical predictions were tested using a wide variety of real-world problems and machine learning algorithms. In this process, it was observed that the theoretical analysis results were applicable for all problems and for almost all of the applied algorithms, except for algorithms like random forest, Naïve Bayes, and XGBoost. The adoption of methods for mitigating overfitting and class probability calibration eventually led to agreement with the theoretical analysis for all algorithms.
Based on the above results, this paper provided two specific use cases where the ALP CM could be exploited to improve the analysis of a classification problem:
- (a)
During the training phase of a classification algorithm, the ALP CM provides the ability to use 100% of the input dataset for algorithm training. In this case, the ALP CM provided the means to validate the algorithm performance (assess the expected generalization error) as opposed to state-of-the-art methods where a portion of the available dataset is reserved for cross-validation purposes. This method may prove essential for cases where the available input dataset size is limited compared to the required sample size for achieving convergence in the performance of the algorithm.
- (b)
During the implementation of the trained algorithm over a real-world application set, the ALP CM can still be calculated despite the fact that the actual class labels are unknown. In this case, the ALP CM metrics provide a good approximation of the actual algorithm performance.
The next research steps in the area of probabilistic confusion matrix indicatively include the following:
A potential link of the probabilistic confusion matrix with the conditions which ensure that a machine learning algorithm generalizes [
32].
The capability to employ nested methods based on the probabilistic confusion matrix so as to apply hyperparameter optimization [
33].
The ability to combine the probabilistic confusion matrix use cases with the reduced confusion matrix methodology developed in [
34].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}