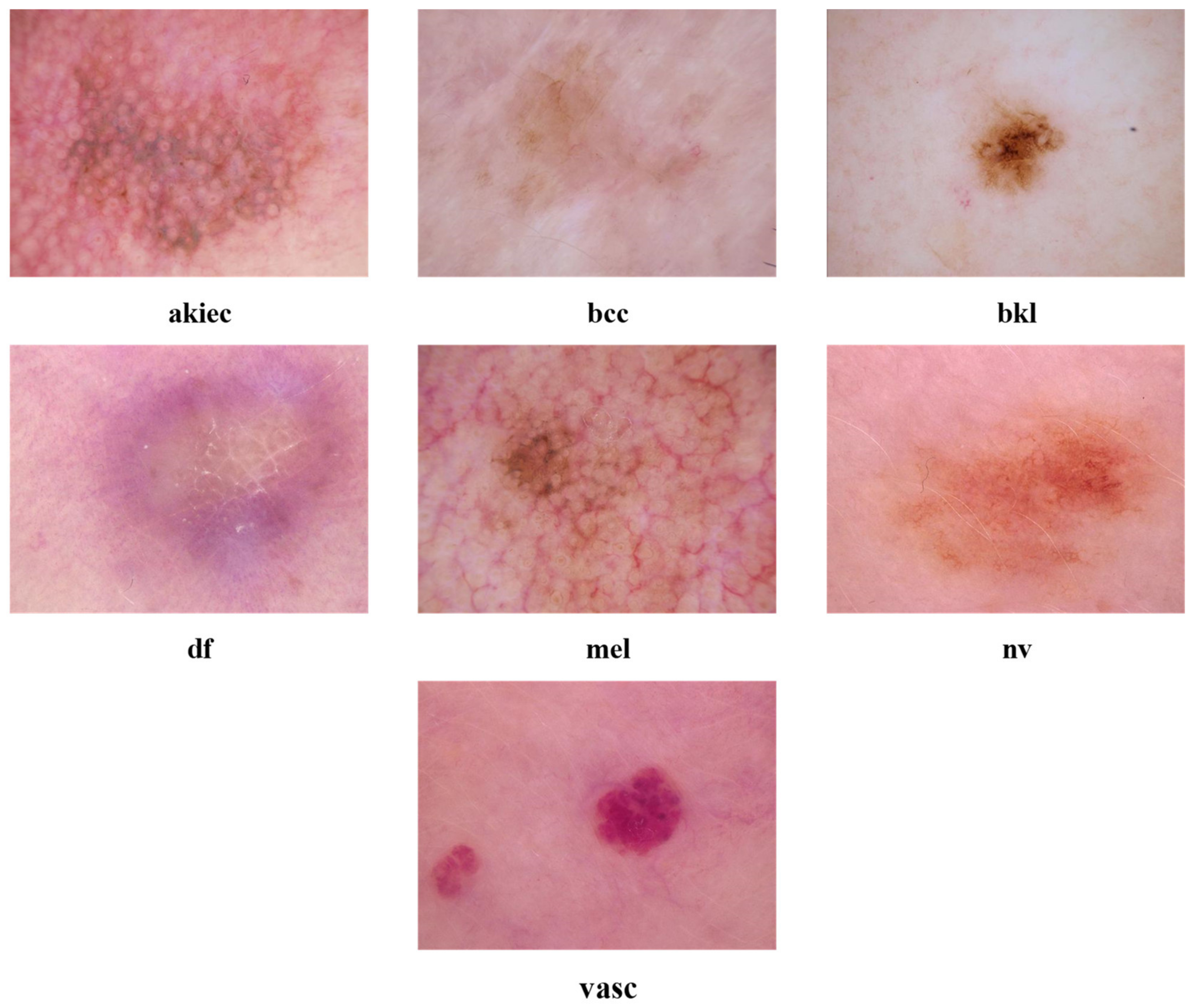
1. Introduction
Skin cancer is widely recognised as one of the most prevalent and substantial types of cancer worldwide, with its incidence steadily increasing in recent times. By the year 2023, the United States is projected to have a total of 97,610 individuals who will be diagnosed with skin cancer [
1]. There are various types of skin cancer; melanoma is the most fatal [
2]. This particular form of cancer is responsible for 75% of fatalities, despite only comprising 7% of the overall number of cases [
3]. Fortunately, the likelihood of survival is significantly high when the disease is detected, and appropriate treatment is given to patients during the early stages [
4]. Without treatment, the condition will progressively spread to various parts of the body, significantly reducing the likelihood of successful treatment [
5,
6]. Therefore, early detection is crucial.
The traditional approach for detecting skin cancer involves conducting a physical examination and performing a biopsy. Although biopsies are an effective strategy for identifying skin cancer, the procedure is time-consuming and uncertain. Dermoscopic skin imaging has emerged as the predominant non-invasive technique utilised by dermatologists for the identification of skin lesions [
7]. Nevertheless, the main drawbacks of dermoscopy are the requirement for the extensive training of dermatologists, subjectivity, and the insufficient number of experienced dermatologists. Furthermore, different types of skin cancer have similar characteristics, leading to misdiagnosis [
8].
Advancements in digital image processing and artificial intelligence involving machine learning and deep learning have led to the development of several Computer-Aided Diagnosis (CAD) systems in the last twenty years for diagnosing several diseases [
9,
10,
11,
12,
13,
14]. Conventional machine learning techniques require substantial prior knowledge and time-consuming preparation phases. On the other hand, deep learning-based CAD systems do not need these preprocessing and handcrafted feature extraction processes. Multiple deep learning schemes have been developed for the purposes of classification, segmentation, and detection [
15,
16,
17,
18]. Of these methods, convolutional neural networks (CNNs) are particularly significant well-known approaches for image recognition and classification [
19,
20,
21]. CNN-based CAD systems can accurately identify skin cancer, surpassing dermatologists in this aspect.
Colour plays a crucial role in identifying malignant lesions. The presence of different shades in a skin lesion can indicate irregularities, which can be helpful in identifying skin cancer [
4,
5]. Timely detection of alterations in the hue of a lesion is a crucial element for prompt diagnosis and efficient treatment [
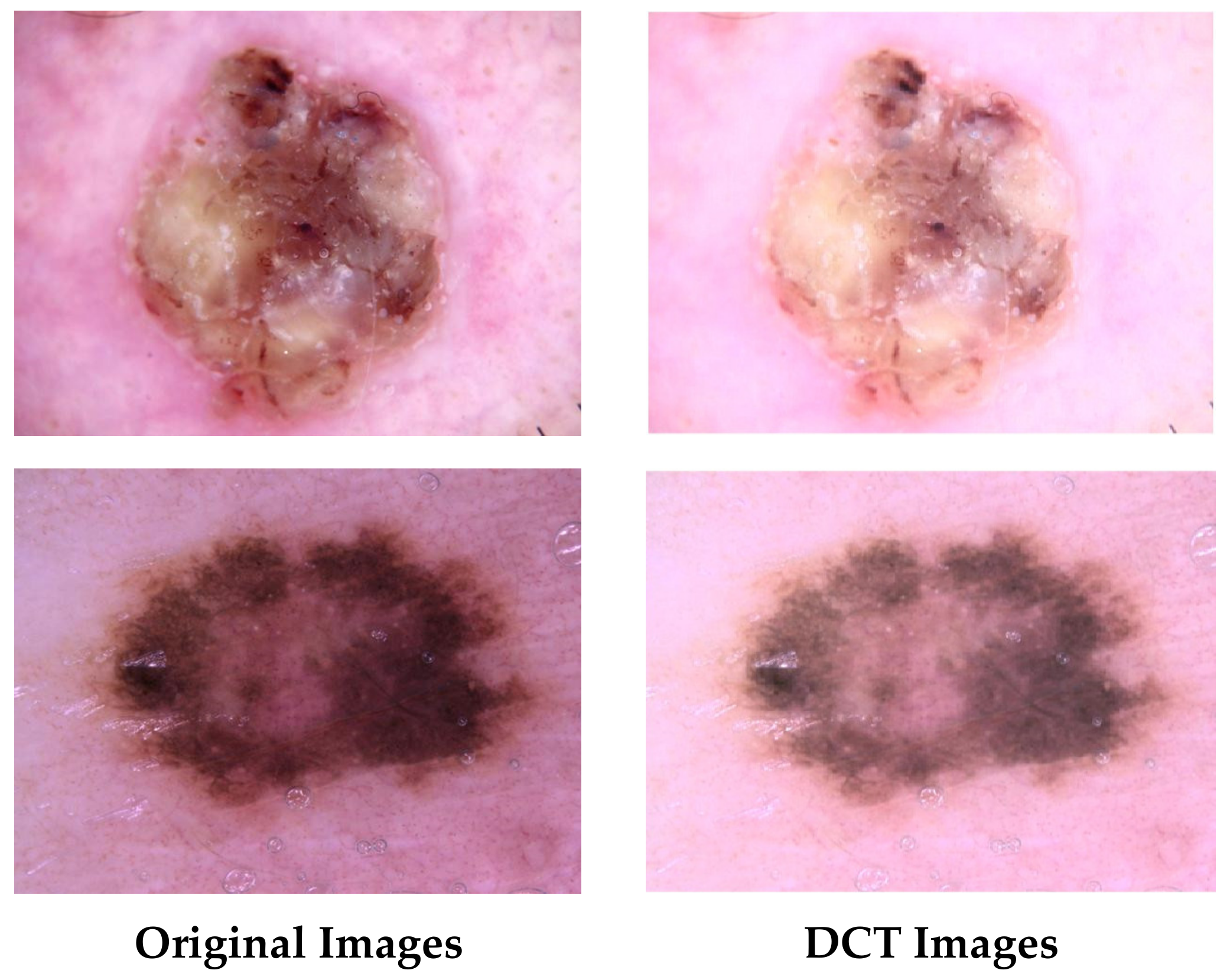
6]. The quality of the photos is an important aspect when constructing deep neural network models and necessitates appropriate handling. However, most previous studies did not consider this issue when building their models. The application of Discrete Cosine Transform (DCT) to dermoscopic images allows for the improvement of image quality and the correction of colour distortions. This correction results in a more precise depiction of skin features. Moreover, combining attributes derived from CNNs that have been trained on both enhanced and original images can greatly enhance diagnostic accuracy. This approach exploits the collaborative information offered by diverse image representations, thereby capturing minor image attributes that could be missed when relying solely on a single image method.
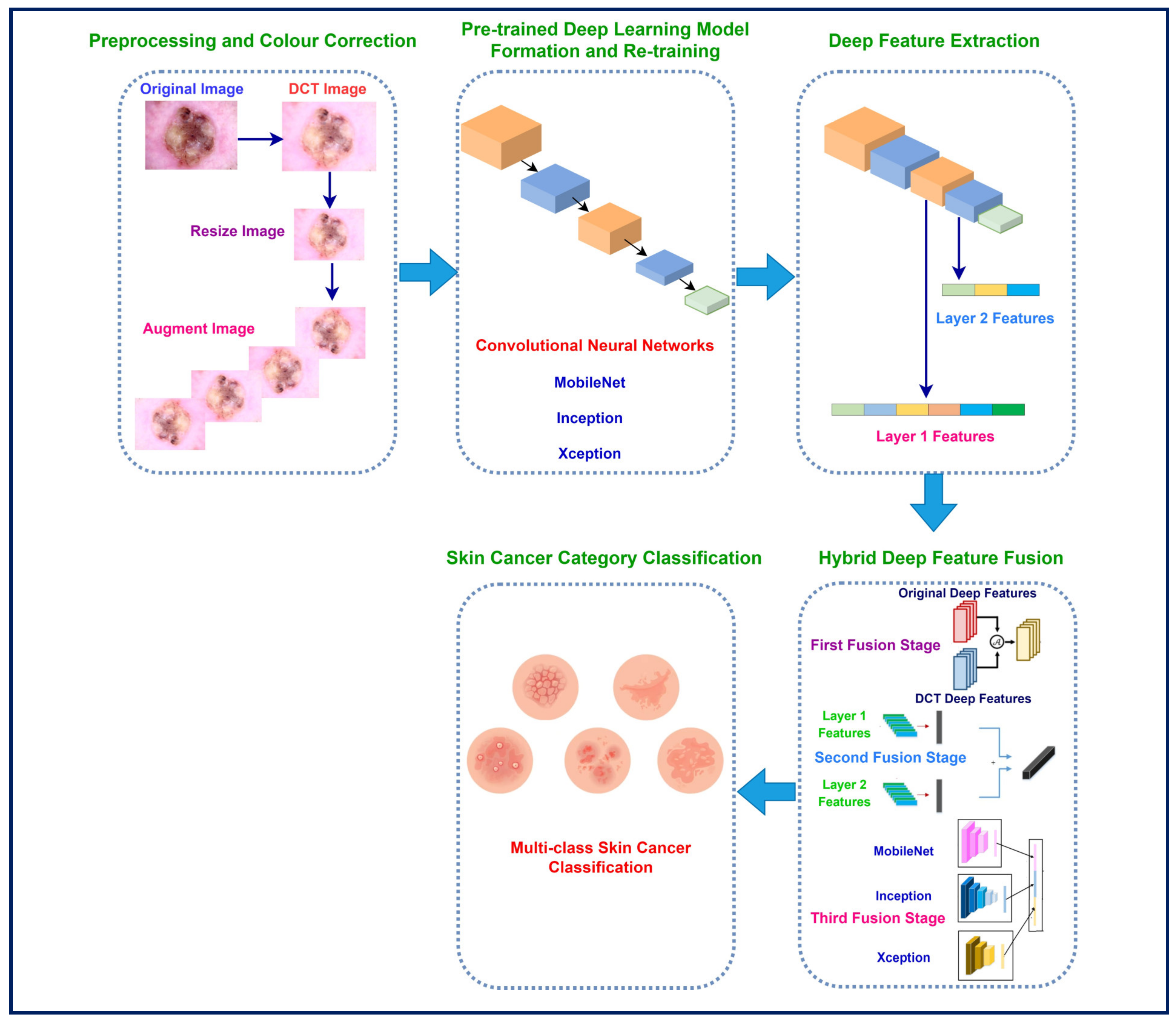
This study proposes a framework based on DCT to enhance images and correct colour distortions in dermoscopic images, taking into account the significance of precise diagnosis and the difficulties caused by variations in lighting and colour. The framework examines the influence of utilising both original and improved dermoscopic photographs on the diagnostic efficacy of skin cancer. This framework is built upon three CNNs with different architectures. The CNNs are initially provided with the original images of skin cancer. Subsequently, the same CNNs undergo training using the DCT-enhanced images. Afterwards, features are derived out of two layers of each deep learning model and then combined. This study investigates whether combining attributes gathered out of these dual layers of each network can enhance performance. Additionally, the bi-layer deep features of the three CNNs trained with the original and DCT-enhanced images are merged to explore whether the attributes’ incorporation retrieved from the deep learning networks fed with the original images and DCT-enhanced images can enhance the accuracy of classification. The novelty and contributions of this study are as follows:
Utilising a diverse set of deep networks with varying configurations, in contrast to existing deep learning-based frameworks for skin cancer classification that depend on an individual deep network.
As opposed to counting solely on the features of an individual deep layer, the approach involves extracting attributes out of dual distinctive layers (namely, layer 1 and layer 2) of a CNN.
Merging information obtained from the original dermoscopic images with DCT images by extracting deep features from CNN trained with both images.
Fusing layer 1 features of each CNN (trained with original and DCT images) having high dimensionality using discrete wavelet transform (DWT) to reduce their size and provide time–frequency representations to improve performance.
Concatenating layer 2 features for each CNN (trained with original and DCT images) and then integrating them with fused layer 1 deep features to further improve classification accuracy.
Integrating both deep layers features of the three CNNs to merge the benefits of each CNN architecture which usually achieves greater results.
2. Related Works
Several studies have demonstrated that CAD systems have the capacity to enhance the diagnostic rates for skin cancer. The literature offers a wide range of machine learning-based automated methods to address this challenge. The methods are classified into two categories: classic and deep learning-based automated skin cancer diagnosis. The former approaches require extensive preprocessing and processing steps such as segmentation and handcrafted feature extraction, which are prone to error. On the other hand, deep learning-based approaches do not require these steps and can automatically extract features from the input and produce a decision. Deep learning approaches, particularly pre-trained CNN models, show potential for improving the accuracy as well as effectiveness of skin cancer detection, segmentation, and classification. This section will focus on examining previous studies that have utilised methods of deep learning, specifically CNNs, to classify skin cancer. Some research was conducted for binary skin cancer classification. For example, the paper [
22] presented a web-based CAD model that accurately identified skin cancer as benign and malignant. The CAD utilised several CNNs to identify malignant melanoma. With ResNet-50, the study showed that the new model for identifying skin cancer achieved an accuracy level of 94%, which is the highest among all models tested. Additionally, it achieved an F1-score of 93.9%. On the other hand, the study [
23] introduced a new and efficient convolutional neural network (CNN) named TurkerNet. TurkerNet consists of four key components: the input block, residual bottleneck block, efficient block, and output block. The TurkerNet system demonstrated an impressive performance of 92.12% accuracy in classifying binary skin cancer.
Other research was carried out for multi-class skin cancer classification. For instance, the authors of [
24] created a CAD system for the early-stage multi-class categorisation of skin cancer carcinoma using the HAM10000 dataset. They employed a hair removal image processing algorithm and an Ensemble Visual Geometry Group-16 (EVGG-16) CNN. The primary concept was to assign distinct initialisations to the VGG-16 model on three separate scenarios, followed by combining the outcomes through an ensemble method. The experimental results demonstrate that the VGG-16 model reached an average accuracy of 87% and an F1 score of 86%. The EVGG-16 model achieved an average accuracy of 88% and an F1-score of 88% without using the hair removal image processing approach. However, when the hair removal image processing technique was applied, the exact model attained an average accuracy of 89% and an F1-score of 88%. While the authors of reference [
1] employed median filtering and random sampling to enhance images and increase the amount of images, these images were then fed into a Gated Recurrent Unit Network (GRU) optimised by the Orca Predation algorithm (OPA). The results achieved are sensitivity (0.95), specificity (0.97), and accuracy (0.98). The study [
25] provided a CAD framework that employed a customised CNN design along with a variant of a GAN network for preprocessing. The effectiveness of the model is greatly enhanced by employing preprocessing techniques, as demonstrated by its exceptional accuracy (exceeding 98%) when applied to the HAM10000 dataset.
The authors of reference [
26] applied traditional image enhancement techniques and various CNN structures, resulting in a maximum performance of 92.08 percent accuracy via ResNet-50. The authors of reference [
27] tackled the issue of data imbalance by using augmentation techniques. They employed three different CNN models, namely InceptionV3, AlexNet, and RegNetY-320. Among these models, RegNetY-320 showed better performance. Also, the researchers in [
28] employed a combination of image filtering, segmentation, and CNN-based classification techniques. They operated ResNet-50 and DenseNet-169 models for this purpose. The utilisation of wavelet transform was introduced by [
29] to obtain features from skin cancer photographs, subsequently followed by classification employing a deep residual neural network (R-CNN) and Extreme Learning Machine. The F1-Score and accuracy reached were 93.44% and 95.73%. Other research [
30] integrated feature pyramid network (FPN) and Mask R-CNN techniques for segmentation, along with CNN for classification, resulting in an accuracy rate of 86.5%. Khan et al. [
31] employed Mask R-CNN and DenseNet to derive features and used a support vector machine (SVM) for classification, achieving an accuracy of 88.5%. In [
32], DenseNet and EfficientNet were used for skin cancer classification. EfficientNet achieved an outstanding accuracy of 85.8%.
In addition, in the study [
33], Inception-Resnet-v2 was investigated, resulting in an enhanced accuracy rate of 95.09% using the HAM10000 dataset. In [
34], a novel approach for enhancing contrast was introduced, along with numerous CNN topologies. Additionally, feature integration methods were employed using serial–harmonic mean and marine predator optimisation. The study attained accuracy rates of 85.4% and 98.80% on the two versions of the ISIC dataset, respectively. In reference [
35], a CAD system was introduced that used a CNN model and feature selection. The researchers exploited transfer learning, genetic algorithms for hyperparameter optimisation, and feature combination strategies. The suggested technique demonstrated remarkable accuracies of 96.1% and 99.9% on the ISIC2018 and ISIC2019 datasets, respectively. The study [
36] combined deep features extracted from three CNNs with handcrafted features to recognise skin lesion subcategories. In another paper [
37], three CNNs were employed to obtain multiple deep features and they were then fused and a feature selection approach was performed to select among these features reaching an accuracy of 0.965. In study [
38], a CAD system was constructed based on multi-directional CNNs trained with Gabor wavelets images reaching an accuracy of 91.70% on the HAM10000 dataset.
The results of these investigations emphasise the significance of image preprocessing, feature extraction, and reliable classification models for the precise identification of skin cancer. Nevertheless, there is still potential for enhancement in terms of managing various image conditions, improving feature representation, and investigating innovative fusion approaches. Reviewing the literature makes it abundantly evident that even with many diagnostic and classification systems for skin cancer, several gaps still need attention. For example, many CAD systems available in the scientific literature generate acceptable outcomes in clearly differentiating benign from malignant skin lesions. Nonetheless, this exception does not hold true when recognising different types of skin cancer. Additionally, it is noteworthy that the majority of the research investigations have concentrated on obtaining deep attributes from a solitary deep layer. The latest studies showed that various layers of a CNN may collect various forms of information [
39,
40,
41]. The CNN layers gradually develop more complex characteristics. The lower layers of the structure gather fundamental characteristics such as borderlines and textures, whereas the deeper layers acquire more intricate patterns that are disease-specific. The proposed hybrid model employs a detailed data pyramid to improve comprehension of skin diseases by integrating attributes from multiple layers. Prior investigations have shown that combining data from several layers often produces improved classification accuracy when as opposed to using information from one layer [
39,
40,
41]. This is so because every layer catches a different aspect of the image and when the outcomes are merged, the classification task finds a more consistent interpretation. One can improve performance by adding deep features obtained from several layers. Moreover, former CAD systems usually rely on individual CNNs for classification. Nevertheless, it is possible to improve the accuracy of diagnoses by combining more intricate characteristics from various CNNs with distinct structures. Furthermore, the majority of current CAD systems have not taken into account the correction of colour distortion during the construction of their models. This consideration could potentially improve the identification procedure of deep networks. Furthermore, the majority of existing CADs exclusively utilise spatial information data for constructing their models. However, incorporating time–frequency information alongside spatial data has the potential to enhance performance.
This study presents a framework that exploits DCT to improve the quality of images and resolve colour distortions in dermoscopic images. The framework takes into consideration the importance of accurate diagnosis and the challenges posed by variations in lighting and colour. The framework assesses the impact of using both original and enhanced dermoscopic photographs on the diagnostic effectiveness of skin cancer. This framework is constructed using three CNNs with distinct architectures. The CNNs are initially presented with the original images of skin cancer. Afterwards, the identical CNNs are trained using the DCT-enhanced images. After that, attributes are taken out of both substantial layers of every CNN and then put together. The research investigates whether merging features from each CNN’s two layers can enhance performance. In addition, the bi-layer deep features of three CNNs trained on both the original and DCT-enhanced images are combined. This is carried out to investigate whether merging the deep features obtained from CNNs trained on the original images and DCT-enhanced images can improve the accuracy of classification.
4. Experimental Setting and Evaluation Metrics
This section presents the metrics of efficacy applied to evaluate the ability of the proposed hybrid model, along with the refined hyper-parameter configurations. Each CNN has undergone numerous alterations to its hyperparameter settings. The values of these hyper-parameters are shown in
Table 5. For instance, the mini-match size is 10 and the maximum number of epochs is 40. Whereas the learning rate is 0.001 and the validation frequency is 701. The remainder of the parameters are preserved in their initial state. The optimisation method employed for learning the networks is SGDM, an abbreviation for stochastic gradient descent with momentum.
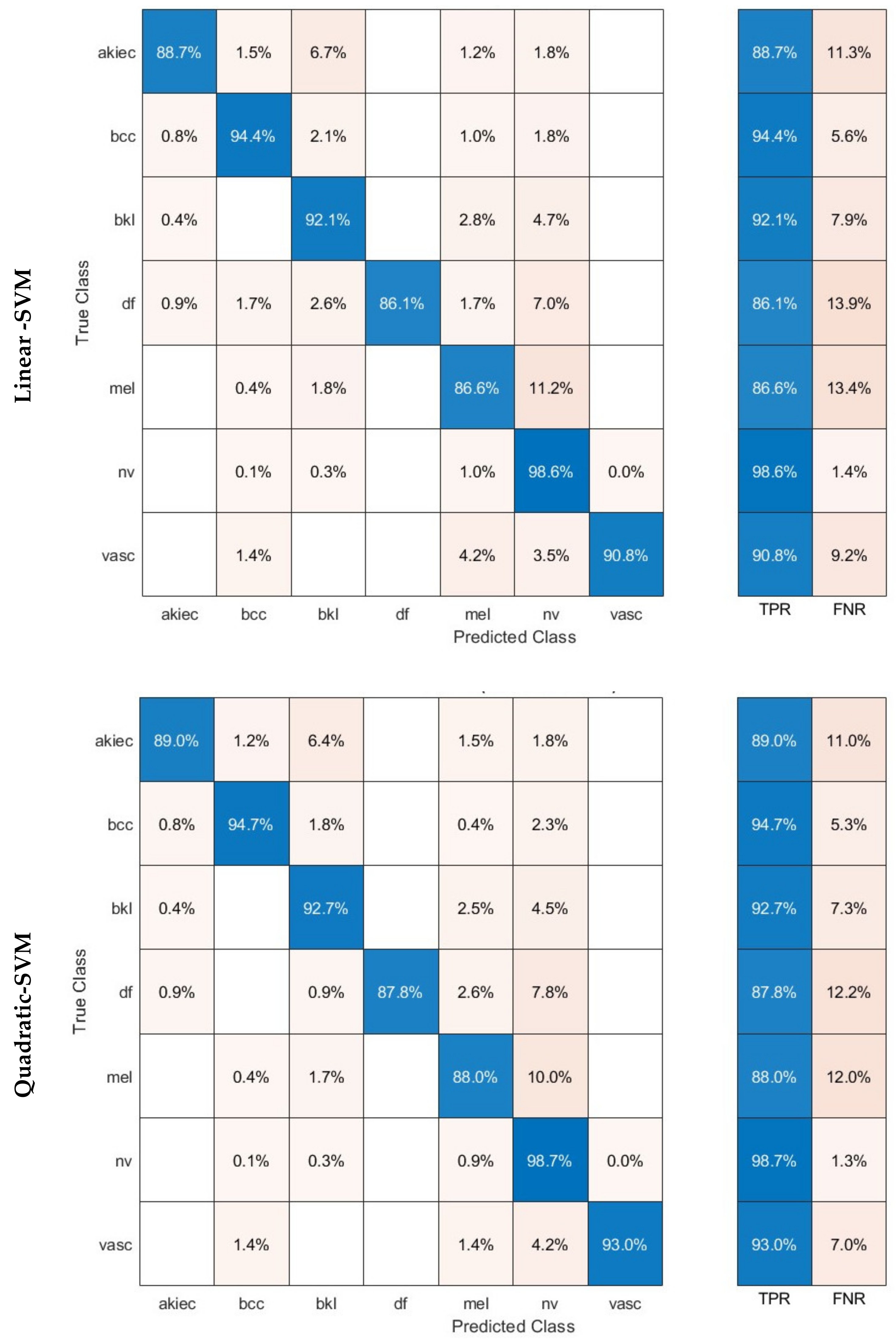
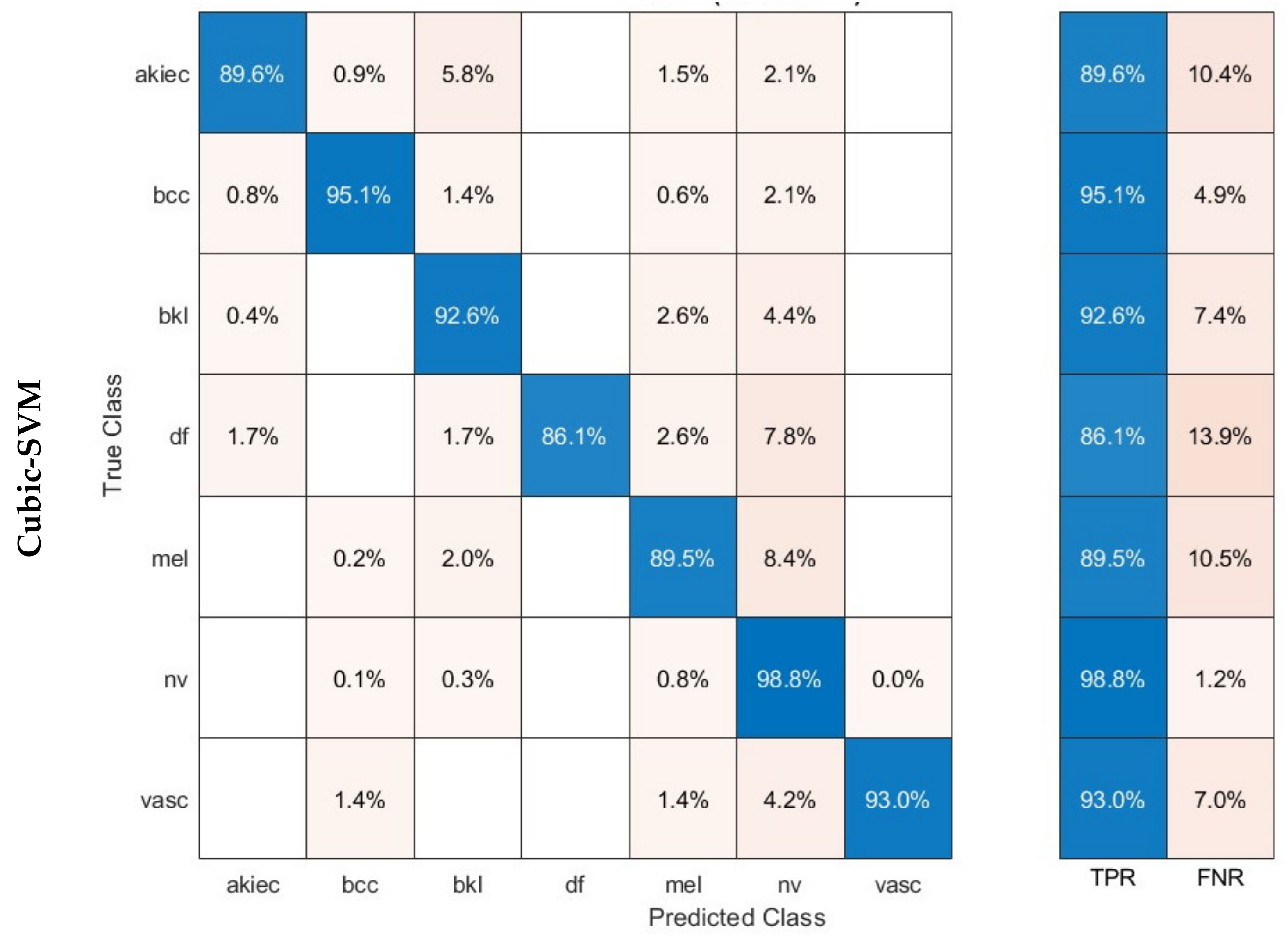
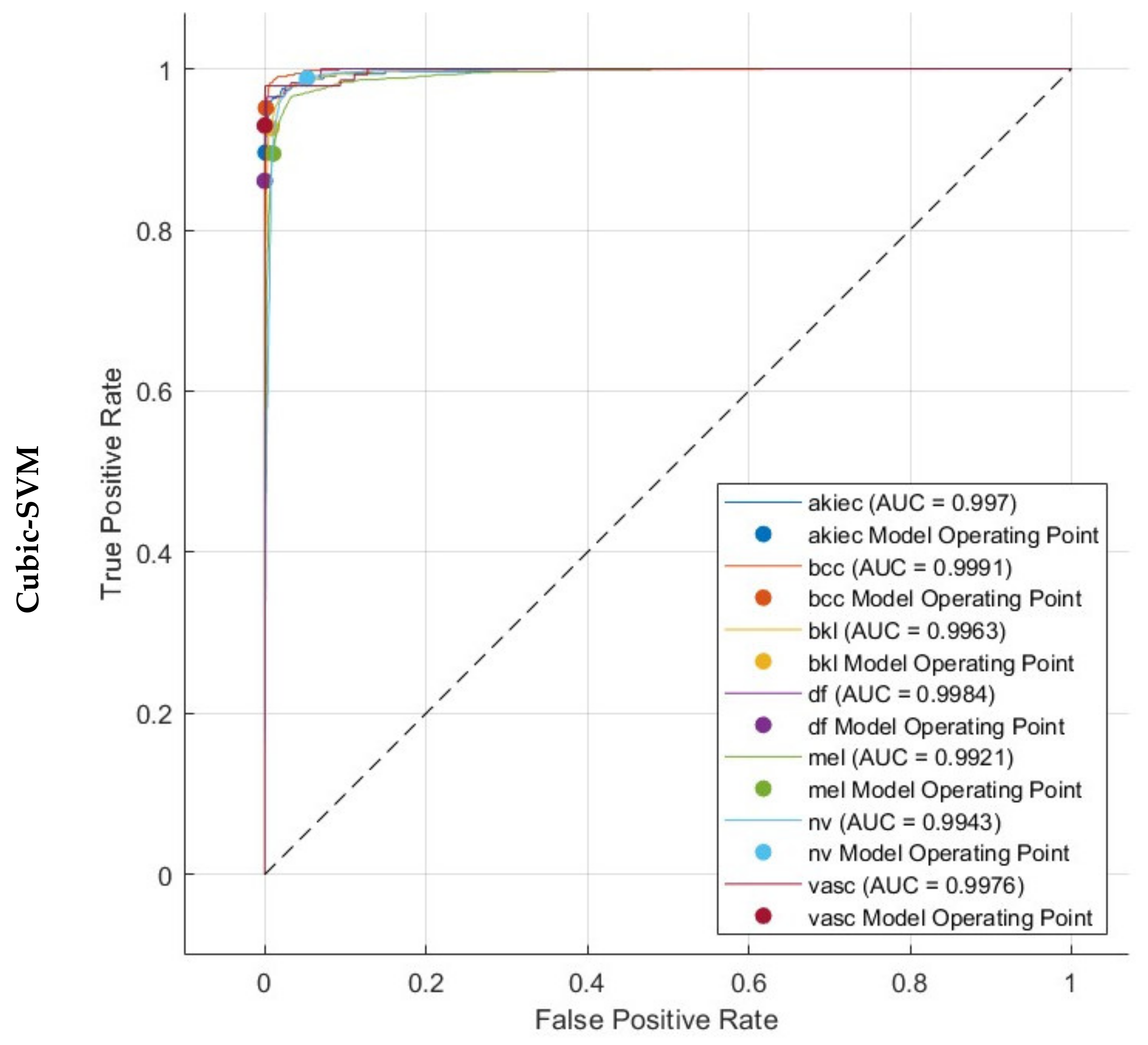
Evaluation measures are essential for evaluating the effectiveness of deep learning methods, providing useful information on how well they perform. The main indicators employed to assess networks are accuracy, precision, sensitivity, specificity, Mathew correlation coefficient (MCC), F1-score, receiving characteristics curve (ROC), and the area under this curve (AUC). Accuracy is a metric that quantifies the proportion of accurate predictions out of the overall number of predictions, offering a comprehensive assessment of the efficacy of a given model. Precision measures how accurate the model is in properly recognising positive cases, whereas sensitivity, also known as the true positive rate (TPR), evaluates how well it can obtain all positive examples. The F1-score provides a comprehensive measure of the model’s efficiency by taking into account both precision and recall. These metrics are essential for identifying overfitting, fine-tuning model settings, and guaranteeing reliable performance. Specificity, or the true negative rate (TNR), is the percentage of correctly categorised negative examples out of the overall number of negative observations. It is additionally referred to as the opposite of sensitivity. In the classification of multiple classes, the specificity is determined by calculating the specificity for each individual category followed by finding the mean among these specificities. The AUC measure, which is frequently employed in binary classification purposes, may additionally be expanded to encompass multiple class cases. It is a metric used to assess the effectiveness of a model in ranking examples of various categories in multiclass classification. The MCC metric quantifies the degree of correlation among the predicted and the actual classification labels. In the case of multi-class classification, it is determined by computing a one-vs.-rest MCC for every category and subsequently averaging the outcomes. These metrics are calculated using the Formulas (1)–(7).
TP represents the count of cases that have been accurately estimated as positive (P). TN signifies the count of incidences that are reliably estimated as negative (N). FP represents the count of cases that are mistakenly identified as positive. FN denotes the count of occurrences that are inaccurately categorised as negative.
6. Discussion
The present research introduces a hybrid model that employs DCT to enhance image quality and address colour defects in dermoscopic images. It acknowledges the significance of precise diagnosis and the difficulties presented by fluctuations in illumination and hue. The model evaluates the influence of deploying both the actual and improved dermoscopic images on the diagnostic efficacy of skin cancer. This hybrid model was built by employing three CNNs that have various layouts. The CNNs were first provided with the actual photographs of skin cancer. Subsequently, the same CNNs were trained with the DCT-enhanced photos. Afterwards, features were gathered from two deep layers of each CNN and then combined. In addition, the doubled layered features generated by the three CNNs learned using the original and DCT-enhanced images were merged. The purpose of this investigation was to determine if combining the deep features extracted from CNNs trained on the original images with those obtained from DCT-enhanced images may increase the accuracy of classification. The research also investigated the potential for enhancing performance by integrating features from both layers of each CNN.
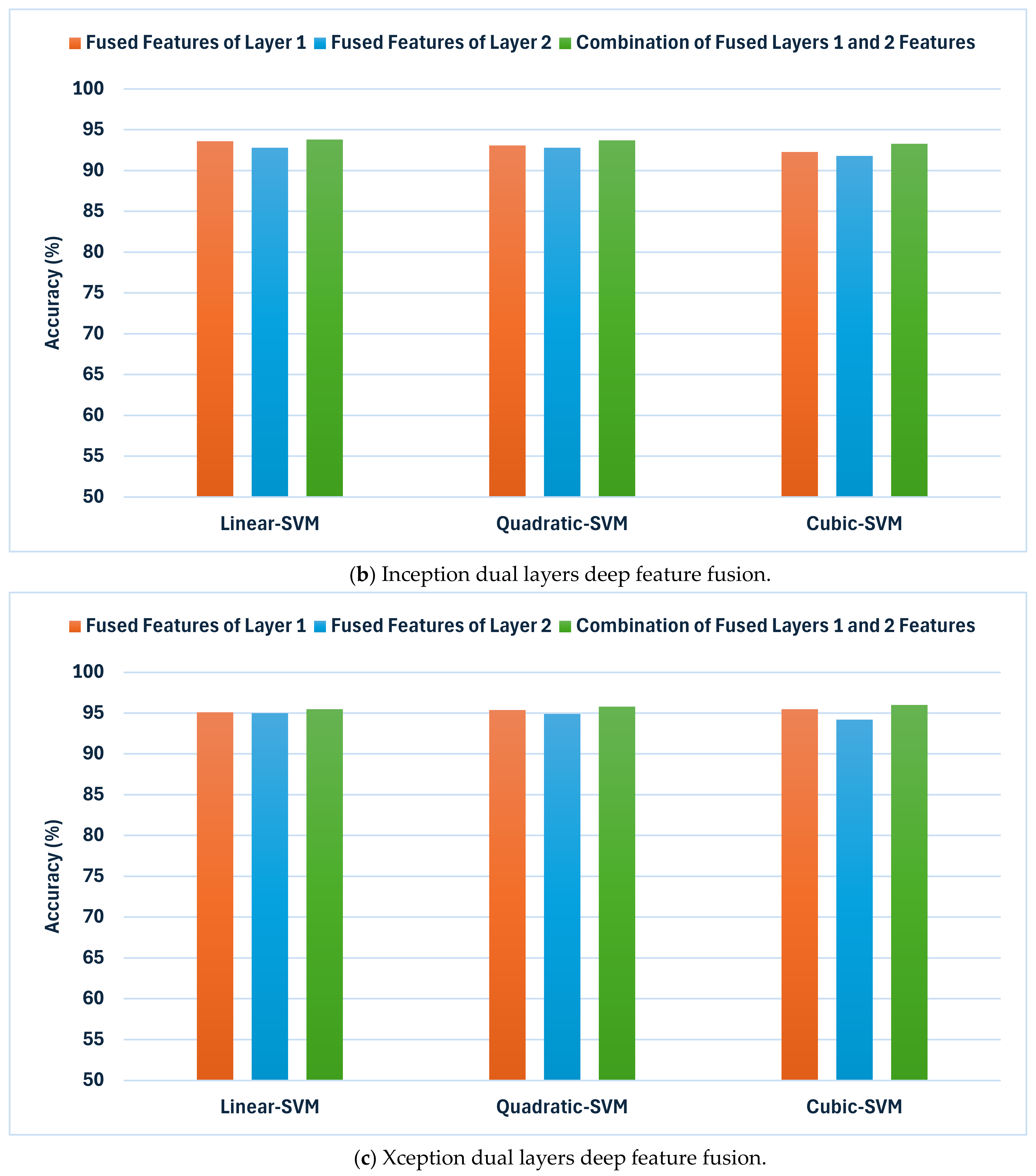
To achieve the above goals, the hybrid model accomplishes three hybrid deep feature fusion stages. Each CNN’s first layer’s high-dimensional variables from DCT-enhanced images and dermoscopic images are combined using DWT in the preliminary stage to reduce their dimensions and give time–frequency representation, improving their ability to distinguish skin cancer types. The deep features of deep layer 2 are concatenated for each CNN developed autonomously using DCT-enhanced pictures and dermoscopic photos in the first fusion stage. The second stage of deep feature fusion merges layer 1 features from each CNN with layer 2 fused features to create a highly efficient feature vector. In the third stage of deep feature fusion, the fused bi-layer features from the three CNNs trained separately using DCT-enhanced and dermoscopic images are combined.
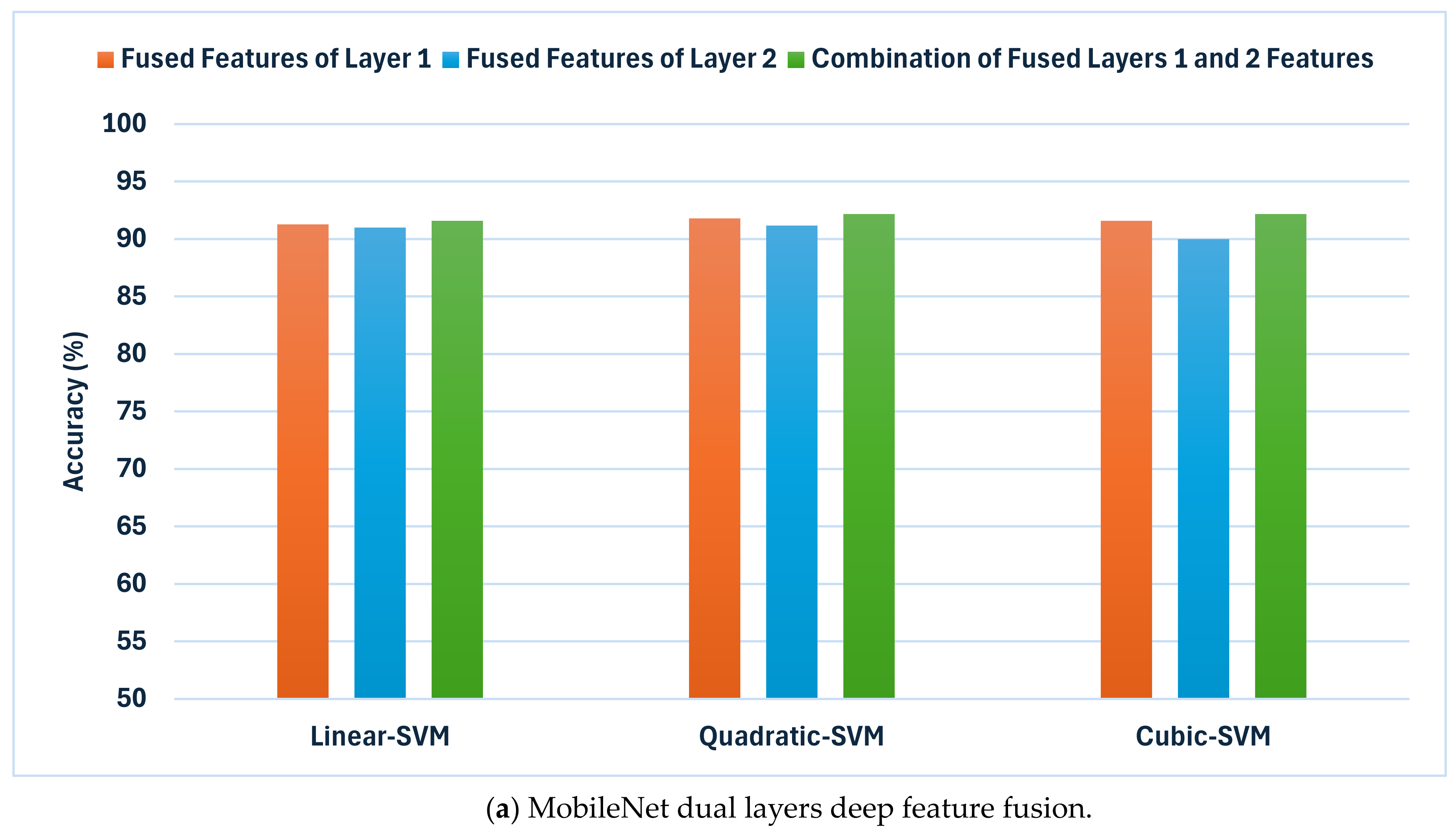
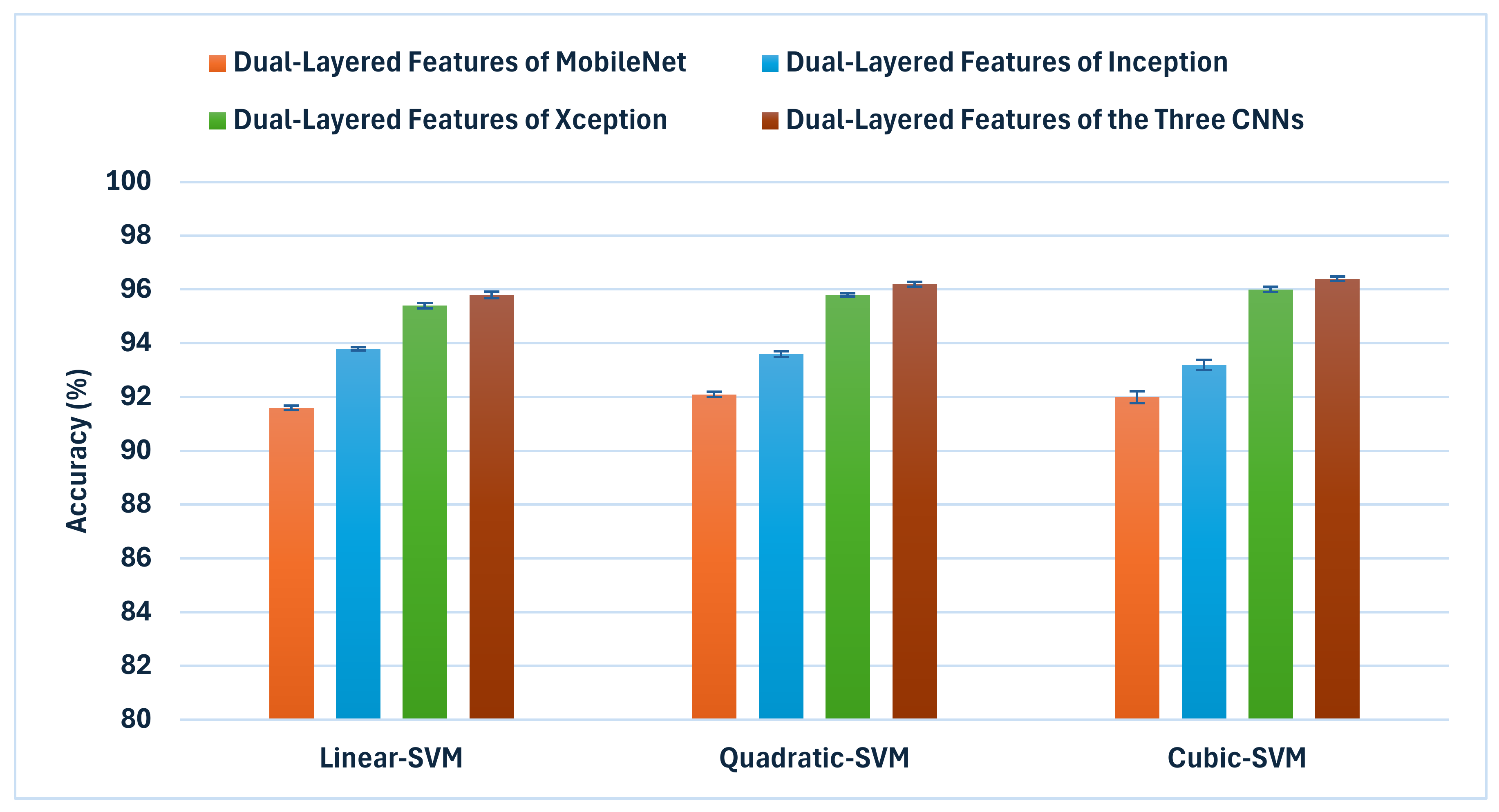
Figure 8 shows and compares the superior accuracy reached in every fusion stage. As can be seen in
Figure 8, each of the fusion stages has enhanced the accuracy of the hybrid model. These findings prove that merging the deep features captured from the DCT-enhanced images with that of the actual dermoscopic images could boost performance. Additionally, integrating spatial and time–frequency information provides better representations of the input and improves classification performance. Additionally, relying on deep features gathered from multiple deep layers is superior to employing one deep layer. Finally, integrating deep features from several CNNs having different structures is capable of further improving the accuracy of skin cancer classification.
6.1. Cutting-Edge CAD Comparisons
Table 10 displays a thorough examination of the suggested hybrid model in comparison to various cutting-edge methods for categorising skin lesions on the HAM10000 dataset. The results indicate a substantial enhancement in performance attained by the proposed hybrid model in all of the metrics of assessment. The success of the proposed model depends significantly on the DCT approach. DCT reduces noise by efficiently separating the image into many frequency components, so enabling selective enhancement of salient features. This procedure is especially helpful for dermoscopic images, where diagnosis depends critically on minute colour and texture changes. Improving these aspects gives the CNNs clearer, more diagnostically relevant input, which directly helps to raise classification accuracy. Moreover, the proposed hybrid model makes advantage of three different CNN architectures: MobileNet, Inception, and Xception. Every one of these networks is different: Inception uses parallel convolutional filters of different sizes, allowing it to capture features at many scales concurrently; Xception uses depthwise separable convolutions, which are particularly effective at learning cross-channel correlations and spatial correlation independently; MobileNet excels in efficient feature extraction with less parameters, capturing general features effectively. Combining these architectures allows the hybrid model to capture, at different levels of abstraction and scales, a more complete set of features than any one model might neglect.
Furthermore, the proposed hybrid model extracts features from two layers of every CNN. This method captures low-level attributes (such as edges, and textures) as well as high-level semantic features (such as complicated structures unique to particular lesion types). These multi-level attributes taken together offer a better picture of the skin lesions, allowing more complex classification. The three-stage fusion approach is essential to properly combining the several properties: Using DWT, the first stage combines features from the first layer of every CNN, so lowering dimensionality while maintaining time–frequency information. The second fusion stage generates an extensive feature set for every CNN by concatenating these combined features with those from the second layer of every CNN. The last fusion stage aggregates the features of all three CNNs to generate a very useful feature vector including the strengths of every network and layer. This sequential fusion approach guarantees the effective integration of complementary information and controls the high dimensionality of the merged feature space. DCT enhancement, multi-CNN architecture, and multi-layer feature fusion taken together strengthen the proposed hybrid model to the natural variability in dermoscopic images. This variability, which can be attributed to variations in imaging conditions, equipment, or lesion presentations, is a prevalent difficulty in the classification of skin lesions.
On the other hand, several of the methods being examined depend on individual CNN structures or only the original dermoscopic photographs, which restricts their capacity to capture intricate patterns and variations in skin lesions. The robust strategy of the proposed hybrid model effectively tackles these limitations, leading to a substantial improvement in performance. The results emphasise the possibility of integrating colour correction, multiple deep feature fusion strategies, and various CNN designs to improve the accuracy of the skin cancer diagnosis.
6.2. Limitations and Future Work
It is imperative to examine the constraints of the proposed hybrid model for skin cancer classification. An important concern arises from the potential impact of an imbalanced split between skin cancer categories in the HAM10000 dataset. The data imbalance may lead to an insufficient amount of training data for specific subclasses of skin cancer, potentially compromising the efficacy of the procedure for classification. Furthermore, further investigation is necessary to ascertain the degree to which the suggested hybrid model might be exploited for a broader spectrum of skin-related problems. Further research can particularly evaluate the effectiveness of the model in accurately identifying and diagnosing other skin diseases and abnormalities. Additionally, additional research is required to investigate the efficacy of the model in properly recognising patients with unique attributes. One other limitation of this study is the huge feature dimensionality obtained in the third fusion stage of the proposed model. Additionally, this study did not employ explainable artificial intelligence (XAI) techniques to interpret how predictions are accomplished.
To enhance the reliability and appropriateness of the proposed model in a clinical setting for a wider population, it is crucial to engage with experts and perform external verification. Subsequent studies will explore sampling methodologies to tackle the problem of class imbalance. In addition, future work will consider using feature selection and reduction techniques to lower feature dimensionality. There are intentions to gather data from a more extensive cohort of patients from various scan sites to improve the applicability and effectiveness of this study. The following investigations will assess the effectiveness of the hybrid model on a wider spectrum of skin disorders and abnormalities, in addition to on individuals who have distinctive characteristics. Ultimately, the proposed model will undergo assessment by expert dermatologists in a controlled clinical setting. Qualified physicians will evaluate the proposed model in clinical environments. Upcoming work will take into consideration using XAI approaches to help dermatologists understand how deep learning models make decisions.
The applicability of the presented model’s effectiveness to alternative skin cancer datasets is a critical factor to evaluate. Although the highest achieved accuracy (96.40%) by the proposed model on the HAM10000 dataset is outstanding, it is crucial to be aware that the efficacy of deep learning models may fluctuate considerably across diverse datasets owing to differences in image quality, tumour forms, and dataset attributes. The ISIC dataset may pose distinct challenges regarding image diversity, image quality, and distribution of classes in comparison to HAM10000. Consequently, it is expected to see some kind of performance variability when implementing this model on the ISIC dataset or other skin cancer image repositories.
Nevertheless, various elements of the proposed methodology indicate possible resilience across datasets. The application of DCT for colour correction and enhancement may effectively alleviate the impact of diverse photo acquisition conditions, a prevalent challenge in various skin lesion datasets. Moreover, the multi-CNN construction offers an extensive variety of features, improving the model’s capacity to identify complex structures in skin cancer photos. Moreover, the integration of attributes from various layers of the CNNs enables the model to utilise both local and global information, thereby enhancing its classification quality. Furthermore, the trio-deep feature fusion phases may yield a more thorough and generalisable description of features, thereby matching more effectively to the characteristics of various datasets. To comprehensively evaluate the generalisability of this methodology, it is recommended to carry out comprehensive experiments across various datasets, including the ISIC skin cancer datasets, and possibly refine the model parameters to enhance performance for each distinct dataset. These assessments would yield significant insights into the model’s suitability across various skin cancer imaging scenarios and its promise as a widely applicable technique in dermatological investigations. In future studies, additional experiments on the ISIC skin cancer dataset will be conducted to confirm the generalizability of the proposed model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}