Abstract
The rise of online social networks has revolutionized the way businesses and consumers interact, creating new opportunities for customer word-of-mouth (WoM) and brand advocacy. Understanding and managing customer advocacy in the online realm has become crucial for businesses aiming to cultivate a positive brand image and engage with their target audience effectively. In this study, we propose a framework that leverages the pre-trained XLNet- (bi-directional long-short term memory) BiLSTM- conditional random field (CRF) architecture to construct a Knowledge Graph (KG) for social customer advocacy in online customer engagement (CE). The XLNet-BiLSTM-CRF model combines the strengths of XLNet, a powerful language representation model, with BiLSTM-CRF, a sequence labeling model commonly used in natural language processing tasks. This architecture effectively captures contextual information and sequential dependencies in CE data. The XLNet-BiLSTM-CRF model is evaluated against several baseline architectures, including variations of BERT integrated with other models, to compare their performance in identifying brand advocates and capturing CE dynamics. Additionally, an ablation study is conducted to analyze the contributions of different components in the model. The evaluation metrics, including accuracy, precision, recall, and F1 score, demonstrate that the XLNet-BiLSTM-CRF model outperforms the baseline architectures, indicating its superior ability to accurately identify brand advocates and label customer advocacy entities. The findings highlight the significance of leveraging pre-trained contextual embeddings, sequential modeling, and sequence labeling techniques in constructing effective models for constructing a KG for customer advocacy in online engagement. The proposed framework contributes to the understanding and management of customer advocacy by facilitating meaningful customer-brand interactions and fostering brand loyalty.
1. Introduction
The advent of online social networks has developed the way businesses and consumers interact, creating fertile ground for shared interests, perspectives, and objectives. This pervasive connectivity has engendered a multitude of communication channels between companies and their existing and potential customers, presenting an unprecedented opportunity for businesses to perceive the market as a dynamic “conversation” unfolding in real time [1,2]. Positive customer word-of-mouth (WoM) represents a pivotal facet of this discourse. It encompasses the actions of satisfied customers who enthusiastically disseminate their favorable experiences, whether by recommending products or services to their social circles, leaving glowing reviews on digital platforms, or actively sharing positive feedback via social media channels [3]. Such endorsements wield substantial influence, as they emanate from trusted sources and significantly impact consumer decision-making processes [4]. Conversely, negative customer WoM pertains to dissatisfied individuals sharing unfavorable experiences, manifesting through the posting of adverse reviews or critical responses to brands’ social media content. The potential repercussions of negative WoM cannot be underestimated, as it has the potential to tarnish a company’s reputation and undermine sales performance. Consequently, comprehending and effectively managing the spectrum of customer WoM, encompassing both positive and negative expressions, assumes paramount importance for businesses striving to cultivate and sustain a positive brand image while meaningfully engaging with their target audience [5].
Prior research has predominantly focused on investigating customer engagement (CE) from the perspective of the brand, exploring how various clusters of socially significant elements associated with the brand can influence customer behavior. These elements encompass a wide range of factors, such as post genres and themes, the vividness of posts, interactivity features, posting timing, the number of followers, the industrial sector to which the brand belongs, the emotional valence of posts, and other relevant aspects. By examining these factors, researchers aim to gain insights into the mechanisms underlying CE and how it is shaped by the brand’s online presence and communication strategies [6,7,8,9]. However, despite the abundance of research in this area, there remains a notable gap in the availability of intelligent systems capable of accurately identifying online brand advocates based on their social interactivity and established dialogues with the brands. This limitation underscores the need for innovative approaches to address this challenge. The adoption of Knowledge Graphs (KGs) has gained significant traction in both industry and academia, as they provide a structured and factual representation of human knowledge, enabling the resolution of complex real-world problems across various domains [10]. KGs can play a crucial role in enhancing CE by providing a comprehensive understanding of customers, their preferences, and their interactions with a brand.
In response to the above-indicated issues, this study aims to contribute to the growing body of literature by proposing a framework that leverages the pre-trained XLNet- (bi-directional long-short term memory) BiLSTM- conditional random field (CRF) architecture to construct a KG for social customer advocacy in online CE. The XLNet-BiLSTM-CRF model combines the strengths of XLNet [11], a powerful language representation model, with BiLSTM-CRF, a sequence labeling model commonly used in natural language processing tasks. This architecture assists in effectively capturing the contextual information and sequential dependencies in the CE social data. The XLNet-BiLSTM-CRF model begins by leveraging the pre-trained XLNet model to obtain rich contextual representations of the input text. These representations capture the semantic meaning and relationships between words in a given sentence. The BiLSTM layer is then employed to further encode the contextual information in a bidirectional manner, considering both past and future words. This enables the model to capture long-range dependencies and extract more informative features from the input data. The CRF layer is incorporated into the model to perform sequence labeling, specifically Named Entity Recognition (NER), in the context of customer advocacy. The CRF layer enables the model to consider the dependencies between adjacent labels, ensuring that the predicted labels form coherent sequences. This is particularly important in identifying and extracting relevant entities related to customer advocacy, such as brand mentions, customer sentiments, and engagement behaviors.
To evaluate the performance of the adopted XLNet-BiLSTM-CRF model, we compare it with several baseline architectures, including BERT-BiLSTM-TextCNN, BERT-CNN, BERT-CRF, BERT-AM, BERT-Transformer-XL, BERT-GAT, and BERT-CRF-GAT. These baselines represent different variations and integrations of BERT with other models, aiming to capture different aspects of customer advocacy and engagement. Further, an ablation study is carried out to further analyze the individual contributions of different components in our model. The ablation study involved systematically removing or disabling specific components and evaluating their impact on the overall performance of the model. The evaluation is performed using various metrics, including accuracy, precision, recall, and F1 score. These metrics provide insights into the overall performance, predictive accuracy, and balance between precision and recall. Additionally, other evaluation metrics, such as AUC-ROC, are used to assess the discriminative power of the models in distinguishing between positive and negative instances. Based on the results of our evaluation, we find that the XLNet-BiLSTM-CRF model outperforms the other baseline architectures in terms of accuracy, precision, recall, and F1 score. This indicates that our model is better able to accurately identify brand advocates and capture the nuances of CE in the online realm. The incorporation of XLNet embeddings, BiLSTM, and CRF layers enables our model to effectively leverage contextual information, capture sequential dependencies, and accurately label entities related to customer advocacy.
This study aims to answer the following research questions:
- How can we develop an accurate and scalable method for identifying brand advocates in online social networks based on their digital behaviors and interactions?
- What is the most effective model architecture for accurately identifying brand advocates in online customer engagement, considering factors such as model complexity, training data size, and computational efficiency?
- How can the constructed KG be optimized to provide a deeper understanding of customer behavior and preferences, specifically with the goal of improving customer advocacy initiatives in online environments?
2. Related Works
In recent years, brands have embraced the trend of engaging and communicating with consumers through online social media. The comments and interactions of customers on these platforms carry valuable messages that are crucial for businesses to establish and nurture strong customer relationships [12]. Consequently, numerous studies have emerged to address the growing significance of social customer-brand interactions. One particular research direction has focused on guiding for enhancing CE [13]. Within this scope, artificial intelligence (AI) has been integrated to leverage the wealth of social data available. For instance, Perez-Vega et al. [14] proposed a conceptual framework that elucidates how businesses and consumers can enhance the outcomes of both solicited and unsolicited online customer interactions. The authors identified various forms of online CE behaviors, initiated by the firm or the customer, that serve as stimuli for AI analysis of customer-related information. This analysis leads to AI-generated and human responses, shaping the future contexts of online CE. The following sections discuss these notions in more detail.
2.1. Customer Advocacy in Online Environments
In the digital age, the notion of customer advocacy has undergone a profound metamorphosis. No longer confined to whispered recommendations among friends or local community gatherings, advocacy has now transcended geographical boundaries and time zones [15]. It manifests through tweets, shares, comments, and reviews on the expansive canvas of the internet [16]. At its core, customer advocacy on social media represents a potent fusion of authenticity and amplification. It is the unscripted voice of a satisfied customer, resonating across the digital realm. These advocates are not bound by corporate contracts or scripted endorsements; they are driven by their genuine affinity for a brand’s products or services [17].
Brand advocacy encompasses the proactive promotion and support of customers’ interests and requirements within an organizational context [18]. It entails championing the voices of customers to ensure their perspectives are duly considered in decision-making processes and diligently addressing their pain points and needs to enhance the overall customer experience [19]. Customer advocacy can be facilitated by a dedicated team specifically focused on advocating for customers, or it can be embraced as an individual commitment by employees who are genuinely passionate about enhancing the customer experience. The ultimate objective of customer advocacy is to establish a symbiotic relationship between the organization and its customers, characterized by positivity and mutual benefit. By actively engaging with customers through social media platforms and other online channels, businesses can foster a sense of community and cultivate brand loyalty. This, in turn, has the potential to transform customers into advocates who actively promote and endorse the business to others, amplifying its reach and impact [20].
The study of customer advocacy in this dynamic landscape is a key aspect for businesses aiming to navigate the complex maze of online interactions, leverage the power of authentic endorsements, and build lasting relationships with their digitally empowered customer base. In this context, various attempts have been made to tackle this issue. For example, Kulikovskaja et al. [21] reported how social media marketing content can stimulate social media-based customer engagement and subsequently lead to marketing outcomes. In particular, the authors introduced two new consequence variables, word-of-mouth (WOM) and customer loyalty, thereby providing a more comprehensive view of the outcomes of customer engagement. This not only helps in understanding the immediate impact of engagement but also the long-term effects on customer behavior. Another study examined the significance of sentiment analysis in customer engagement [22]. The authors developed a machine learning model to detect Conversation Polarity Change (CPC) to detect the ultimate sentiment polarity that customers will harbor as their conversations evolve with the brand. Modeling customer engagement on social media has also been reported in various industries, including transportation [23], finance [24], healthcare [25], sports [26], etc.
2.2. Social Customer Advocacy Incorporating KGs
The literature on modeling online customer advocacy incorporating AI has made significant strides in various areas, such as extracting engagement patterns [27], examining brand engagement with both positive and negative valence [28], assessing the return on investment of advocacy efforts [29], and identifying factors influencing online CE [30]. In a particular AI domain, KGs have received great attention due to their abstract underlying structure [31,32,33]. For example, Yu et al. [34] developed a framework called “FolkScope” that aims to construct a KG for understanding the structure of human intentions related to purchasing items. Since common knowledge is often implicit and not explicitly expressed, extracting information becomes challenging. To address this, the authors propose a novel approach that combines the power of large language models (LLMs) with human-in-the-loop annotation to semi-automatically construct the knowledge graph. The LLMs are utilized to generate intention assertions using e-commerce-specific prompts, which help explain shopping behaviors. Constructing a KG for the fashion industry is proposed in [35]. The constructed user-item KG assisted the author in mitigating the cold-start problem. Building a KG for a recommender system in the context of CE was also discussed in [36,37,38].
An attempt to model customer understanding was made by [39], whereby the authors proposed a solution that involves formalizing the interaction between customer requests and enterprise offerings by leveraging Enterprise Knowledge Graphs (EKG) as a means to represent enterprise information in a way that is easily interpretable by both humans and machines. Specifically, they developed a solution to identify customer requirements from free text and represent them in terms of an EKG. Customer segmentation is proposed in [40]. The authors proposed an unsupervised method for segmenting customers based on their behavioral data. They utilized a publicly available dataset consisting of 2.9 million beer reviews covering over 110,000 brands over a span of 12 years. The authors modeled the sequences of beer consumption as KGs and employed KG embedding models to learn representations of the data. They then apply off-the-shelf cluster analysis techniques to identify distinct clusters of beer customers. Customer segmentation and clustering incorporating KG technology were also discussed and reported in [41,42].
However, a comprehensive analysis of the broader social conversations between brands and their customers, specifically in terms of identifying advocates through textual inference derived from these dialogues, has been lacking. Hence, our study presents a novel approach that integrates social media data as well as various knowledge repositories to gain deeper insights into the inferred relationships between brands’ tweets and customers’ replies. The following section investigates the detailed methodology proposed in this research endeavor.
3. Method
This section discusses the main modules incorporated in this study. A discussion on the collected dataset is provided, followed by the techniques used for the KG construction. Figure 1 demonstrates a schematic representation of the proposed framework.
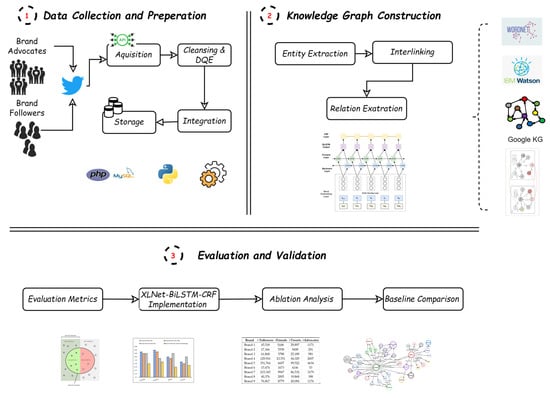
Figure 1.
A schematic representation of the proposed framework (Prepared by the authors).
3.1. Data Collection and Preparation
Twitter (now rebranded as X™) plays a significant role in customer advocacy due to its unique characteristics and widespread adoption as a social media platform. It enables instant and real-time communication, allowing customers to exchange their experiences, opinions, and recommendations about a brand or product at the moment. This real-time nature makes Twitter a powerful platform for customers to advocate for or express their dissatisfaction with a brand, influencing public perception and shaping brand reputation [43,44]. By collecting data from the Twitter platform, this study focuses on online CE specifically related to nine Australian brands in the banking and airline sectors. To obtain the necessary data, Twitter APIs are utilized to gather tweets from the brands’ official Twitter accounts associated with these brands. The collected tweets encompass interactions between the brands and their customers, providing valuable insights into CE dynamics.
In addition to the tweets themselves, the study also retrieves social data and metadata associated with the customers’ Twitter accounts. This includes information such as account details, follower counts, account creation dates, and other relevant metadata. By incorporating this information, the study aims to gain a comprehensive understanding of the customers’ social presence and behavior on Twitter, allowing for a more in-depth analysis of CE patterns. By employing these data collection methods and focusing on the Twitter platform, this study seeks to capture the rich interactions and dynamics that occur between the selected Australian brands and their customers in an online setting. The collected dataset will serve as a valuable resource for analyzing and understanding customer advocacy, sentiment, and engagement within the context of these specific brands and sectors.
Data preprocessing and preparation are essential steps in KG construction, aimed at preparing the data for effective processing and integration into the graph structure. When dealing with pre-collected tweets for the KG construction, the following preprocessing processes are commonly applied: (1) Dataset Cleansing: Data cleansing is a critical step to ensure the quality of the data for further analysis. This involves detecting and removing errors, corrupted data, meaningless data, redundant data, and irrelevant data. By carefully conducting data cleansing, only curated and reliable data are retained for the subsequent phases of analysis. (2) Data Quality Enhancement (DQA): In this experiment, one aspect of data quality enhancement is the handling of Twitter handles, which are screen names like “@username”. These handles are collected from the user’s metadata and replaced with the actual corresponding user’s name. This is achieved by utilizing the Twitter RESTful API service called “lookup” which provides access to comprehensive information about a user based on their handle. While Twitter handles are often overlooked in Twitter mining applications, they can be valuable for mentioning important entities related to a specific domain. (3) Integration: Data integration is accomplished through data reformatting to meet the predetermined data structure model created using the metadata from the tweet.
By performing these cleansing and integration processes, the contents of the pre-collected tweets are refined and improved in terms of quality. This ensures that only reliable and meaningful data are used in subsequent phases of analysis, such as KG construction or customer advocacy identification. The integration of cleaned and enhanced data sets the foundation for an accurate and insightful analysis of social CE on the Twitter platform.
3.2. KG Construction
KG Construction to model advocate customers involves constructing a KG that captures the relationships and interactions between customers, brands, and products. This enables a deeper understanding of customer advocacy and its implications for brand management and decision-making. Also, the KG contains various other entities that capture the social characteristics of customers, brands, and products. The following sections describe the technicalities that are included in constructing the intended KG.
3.2.1. Entity Extraction
Entity extraction in the customer advocacy problem refers to the process of identifying and extracting relevant entities from textual data that are associated with customer advocacy activities. This involves recognizing and extracting specific entities such as brand names, product names, customer mentions, sentiment expressions, and other relevant information related to customer advocacy. The goal is to automatically extract and capture these entities from unstructured text, allowing businesses to gain insights into customer sentiments, brand mentions, and customer experiences.
- XLNET Layer
XLNet is a state-of-the-art transformer-based language model that incorporates bidirectional context information while maintaining the advantages of autoregressive models [11]. It addresses the limitations of previous models, such as BERT, by introducing permutation-based training and incorporating the Transformer-XL architecture [45]. XLNet achieves better performance by considering all possible permutations of the input during training [46]. To apply XLNet using a given sentence, tokenizing the text is used first, thereby preparing the input in the required format, then passing it through the XLNet model and extracting the token representations. This is followed by preparing the input for XLNet by adding special tokens, segment IDs, and attention masks. This typically involves adding a start token, end token, and segment IDs to distinguish different parts of the input and padding or truncating the input to a fixed length. To illustrate, when provided with an input sentence where denotes the term in the sentence of length , XLNet produces vectors that correspond to the sentence. These vectors represent the token-level embeddings, capturing the semantic information of each term in the sentence.
- BiLSTM Layer
A Bidirectional Long Short-Term Memory (BiLSTM) layer is added on top of the XLNet encoding layer. BiLSTM processes the encoded tokens in both forward and backward directions, capturing contextual dependencies [47]. The BiLSTM layer is particularly effective in capturing long-term dependencies in sequential data. It can learn to remember important information over longer distances and capture nuanced patterns in the data. This makes it well-suited for tasks like entity recognition, where the context surrounding a term is crucial for determining its entity label.
As demonstrated in Figure 2, the forward hidden layer computes the hidden states in the forward direction by considering the previous hidden state and the current input. The reverse hidden layer computes the hidden states in the reverse direction, starting from the last time step and moving backward. The formulas of BiLSTM can be implemented as follows:
where is the forward hidden layer and is the backward hidden layer. The output is formed by integrating and . The embedding result obtained from the XLNet layer is used as an input vector by the BiLSTM layer to extract sentence features. By combining the hidden states from both the forward and reverse layers, you obtain a comprehensive representation of the input sequence that captures both past and future contextual information. This allows your customer advocacy model to effectively capture dependencies and make accurate predictions based on the sequential nature of the input data.
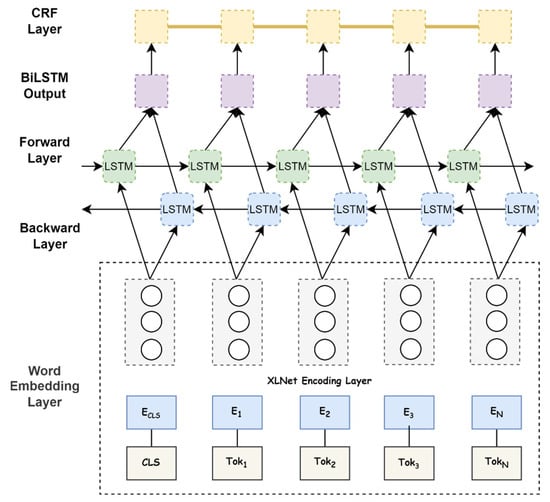
Figure 2.
A representation diagram of the XLNet-BiLSTM-CRF model (Prepared by the authors).
In customer advocacy, identifying and classifying relevant entities such as brand mentions, product names, or sentiment-bearing words is essential. The BiLSTM layer, with its ability to capture dependencies and contextual information, plays a key role in accurately recognizing and labeling these entities within the customer’s tweets. It helps the model understand the boundaries and relationships between entities, enabling more effective customer sentiment analysis and brand advocacy.
- CRF Layer
The Conditional Random Field (CRF) layer is used to model the sequential dependencies among entity labels. The output from the BiLSTM layer is fed into the CRF layer, which assigns the most probable label sequence for the input tokens. The CRF model defines a conditional probability distribution over the label sequence , given the input sequence . It calculates the probability of a label sequence given the input sequence using the following formula:
where is the probability of label sequence y given input sequence x, is the normalization factor (also known as the partition function) that sums over all possible label sequences, is the weight parameter associated with the feature function . is the feature function that captures the dependencies between labels and input features. is the label at position in the sequence, is the label at position i – 1 in the sequence. is the feature function that captures the dependencies between labels and input features. They are defined based on the characteristics of the problem and the available features. To train the CRF model, the maximum likelihood estimation (MLE) method is typically used. The training process aims to find the optimal values for the weight parameters that maximize the likelihood of the training data.
CRF explicitly models the dependencies between neighboring labels, allowing the model to consider the global context and make more informed predictions. It also ensures that the predicted label sequence is coherent and satisfies the sequential constraints of the problem, leading to more accurate and consistent results. In the customer advocacy domain, incorporating CRF into the model enhances the accuracy and coherence of the entity extraction process, leading to more reliable and meaningful insights from customer feedback and social media data.
This advanced architecture combines the power of XLNet’s contextualized embeddings, the sequential modeling capability of BiLSTM, and the ability of CRF to capture label dependencies. It allows the model to effectively extract entities from the input text with improved accuracy and contextual understanding.
3.2.2. Ontology Interoperability
Ontology interoperability plays a crucial role in this study by aligning and consolidating the developed KG with relevant entities extracted from other existing domain-specific and generic ontologies. This ensures that the KG used in the study is well-connected and integrated with the broader knowledge landscape. In this study, Ontology interoperability is achieved through the following methods:
(1) Leveraging Google KG™: The study incorporates Google KG, a comprehensive knowledge base designed to enhance Google’s search engines. The Google KG Search API is utilized to gather entities and categorize classes/types. This API provides access to a vast array of entities from various domains. By leveraging ontology interoperability techniques and incorporating the Google KG Search API, the study ensures that the developed ontology is enriched with relevant entities and aligned with existing knowledge sources. This integration enhances the semantic understanding of CE and brand advocacy, enabling more accurate and comprehensive analysis.
(2) Natural Language Understanding service of IBM Watson™ (NLU): NLU provides access to a wide range of linked data resources through user-friendly APIs. These resources include well-known vocabularies such as Upper Mapping and Binding Exchange Layer (UMBEL), Freebase (a community-curated database of people, places, and things), YAGO (a high-quality knowledge base), and others. IBM Watson can extract entities from social media data, such as brand names, customer names, product names, and other relevant entities. This helps in identifying the key players and entities involved in customer advocacy and establishing relationships between them in the KG. NLU is used also for the Recognizing Textual Entailment (RTE) task which is a distinct NLP task that involves determining the logical relationship between two given sentences: a premise and a hypothesis. The goal is to identify whether the hypothesis can be inferred from the premise, i.e., whether the premise entails, contradicts, or is neutral with respect to the hypothesis. Further, IBM Watson NLU does provide a feature called “Emotion Analysis” that allows analyzing text and identifying emotions expressed within it. The Emotion Analysis feature is designed to understand the emotional tone of the text and provides an assessment of emotions like joy, sadness, anger, fear, and disgust.
(3) Entity Alignment: The study identifies equivalent links (URIs) that indicate the same entity or resource across different ontologies. These links are established using the owl#sameAs relation, which signifies that the URIs of both the subject and object refer to the same resource. By aligning entities across ontologies, the study ensures that consistent and standardized representations are used for common entities.
(4) WordNet (https://wordnet.princeton.edu/, accessed on 30 July 2023): In this study, the WordNet lexical database is utilized as a valuable resource to enhance the knowledge base and enrich the semantic meaning of terms. WordNet is a comprehensive vocabulary lexicon that consists of a collection of interrelated words or terms known as synsets, which represent synonyms with similar semantic meanings. By leveraging WordNet, additional semantic-related concepts can be associated with a given term, thereby enhancing its overall meaning and context. Leveraging its extensive collection of interrelated words and synsets. WordNet can be a valuable resource for extracting entities relevant to CE and brand advocacy by leveraging its extensive collection of interrelated words and synsets. Examples of incorporating WordNet in our context include: (i) Synonym expansion: WordNet can be used to expand the vocabulary related to CE and brand advocacy by retrieving synonyms or similar words for specific terms. For example, extracting entities related to customer satisfaction such as “satisfaction”, “pleasure”, “contentment”, etc. This allows you to capture a broader range of entities associated with the desired concepts; (ii) Semantic hierarchy: WordNet organizes words into hierarchies based on their semantic relationships. This hierarchy can be used to extract entities at different levels of abstraction. For example, WordNet’s hierarchy can be investigated to identify broader concepts like “marketing”, “advertising”, or “brand promotion” that encompass the notion of advocacy. This helps in capturing a comprehensive set of relevant entities; and (iii) hyponym and hypernym extraction: WordNet provides information about hyponyms (specific instances or subtypes) and hypernyms (general categories or supertypes) for many words. By exploring these relationships, entities that are specific instances or general categories related to CE and brand advocacy can be extracted. By incorporating WordNet into the entity extraction process, you can enrich the dataset with a wide range of relevant entities, synonyms, and semantic relationships. This allows for a more comprehensive analysis of CE and brand advocacy, enabling deeper insights and understanding of the domain.
Ontology interoperability aims to augment the KG with external knowledge sources for a holistic view. For example, an e-commerce company can employ ontology interoperability techniques where they integrate Google KG™ into their KG construction process. The Google KG Search API is used to gather information about various product categories, manufacturers, and global e-commerce trends. By aligning their KG with this external knowledge source, they ensure that their KG is up-to-date and comprehensive. For entity alignment, the company identifies equivalent links (URIs) between entities in their KG and those in established domain-specific ontologies. This enabled consistent representations of common entities, such as product categories and brand names. By doing so, they enhance the interoperability of their KG with external ontologies, fostering a deeper understanding of customer behaviors and preferences. Leveraging IBM Watson™ NLU, the company extracts entities from social media data, including customer mentions, product discussions, and trending topics. IBM Watson NLU also provided sentiment analysis, helping identify customers’ emotional tones. Entities such as product names, customer names, and trending hashtags were linked to relevant nodes in the KG. Furthermore, the Emotion Analysis feature allowed the system to categorize emotions expressed in social media posts, providing additional context for customer advocacy analysis. WordNet is finally used to identify the synset in WordNet that best represents the meaning of an entity in a particular context. For example, the word “bank” can have multiple meanings, such as a financial institution, a riverbank, or a slope. WordNet can be used to disambiguate the meaning of “bank” in a particular context, such as in the sentence “I went to the bank to deposit my money”. By adopting these ontology interoperability methods, the e-commerce giant’s KG becomes a powerful tool for understanding customer advocacy in online environments. It not only represents customer behaviors but also incorporates external knowledge, ensuring that customer engagement strategies are well-informed and adaptive to the ever-evolving e-commerce landscape.
3.2.3. Relation Extraction
In traditional KG, a fact is represented by a triplet, which refers to subject, predicate, and object (SPO). Extracting relationships or associations between entities mentioned in the tweets is crucial for building the KG. In the relation extraction module, the XLNet-encoded representations of the tokens, along with the identified entities, are passed to the BiLSTM layer. The BiLSTM model processes the input sequence in both forward and backward directions, capturing contextual information and generating rich contextual embeddings for each token. Features are extracted from the combined XLNet and BiLSTM representations. These features include the concatenation or element-wise multiplication of the XLNet and BiLSTM representations, providing a fused representation that captures both local and contextual information. The CRF layer is employed to model the dependencies and constraints between the predicted relation labels. The CRF layer takes the extracted features as input and applies the Viterbi algorithm to decode the most probable sequence of relation labels, considering the global context and optimizing the label assignments. Figure 3 illustrates a snapshot of the KG demonstrating the social attributes of a brand, customer, and product and their interrelationships captured using the aforementioned techniques.
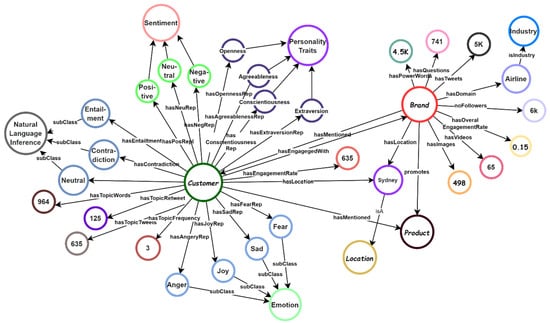
Figure 3.
A snapshot of an RDF graph (Prepared by the authors).
3.3. Evaluation Metrics
In the experiments conducted in this study, several performance metrics were used to evaluate the KG construction task:
- Accuracy: The overall accuracy of the model in correctly predicting the class labels. It can be calculated as (TP + TN)/(TP + TN + FP + FN). Accuracy provides a general measure of how well the model performs in correctly predicting both positive and negative instances.
- Precision: Precision quantifies the model’s ability to correctly identify positive instances out of all predicted positive instances. It is computed as TP/(TP + FP). Precision is important in scenarios where correctly identifying positive instances is crucial, such as identifying the correct entities relevant to brand advocacy accurately. Higher precision indicates a lower rate of false positives.
- Recall: Recall measures the model’s ability to correctly identify positive instances out of all actual positive instances. It is computed as TP/(TP + FN). Recall is important in scenarios where identifying as many positive instances as possible is crucial. A higher recall indicates a lower rate of false negatives.
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balanced measure of the model’s performance. It is computed as 2 × (Precision × Recall)/(Precision + Recall). The F1 score combines both precision and recall, providing a single metric that balances the trade-off between the two. It is particularly useful when there is an imbalance between positive and negative instances.
- AUC-ROC: AUC-ROC measures the model’s ability to distinguish between positive and negative instances across different probability thresholds. AUC-ROC provides a comprehensive evaluation of the model’s performance by considering the trade-off between true positive rate (sensitivity) and false positive rate (1-specificity). It is useful for evaluating the model’s discriminative power.
These metrics were utilized in the experiments to quantitatively assess the performance of the models, including the XLNet-BiLSTM-CRF baseline and other variations. They help provide a comprehensive evaluation of the models’ abilities to correctly identify brand advocates and distinguish them from non-advocates. The performance metrics enable comparisons and insights into the strengths and weaknesses of different model architectures in the context of customer advocacy tasks.
4. Experimental Results
4.1. Dataset Exploration
The utilization of Twitter as a customer service platform has yielded significant results, with 85% of small and medium businesses (SMBs) acknowledging its impact [48]. This underscores the need for continuous implementation of advanced tools to comprehend customers better and derive the desired added value. In this study, the focus lies on online CE (CE) facilitated by the Twitter platform, utilizing a comprehensive social dataset. Figure 1 depicts the step-by-step process employed to extract social data and metadata pertaining to brands and customers. Specifically, nine official Australian brand Twitter accounts were selected, and their tweets were collected through Twitter APIs. These tweets were subsequently analyzed to extract meaningful conversations between the brands and customers. Careful filtration was applied to eliminate subpar and limited conversations, ensuring that the proposed model operates with customers engaged in meaningful brand dialogue. The Twitter accounts of these customers, along with their associated social data (tweets) and metadata (account information), were acquired. The contents of these customers’ tweets were preliminarily analyzed using IBM Watson NLU to identify customers who expressed positive sentiments and recommendations toward the brand. Those customers and their social data and metadata are then manually analyzed by two experts, thereby extracting advocates who actively promote and recommend a brand’s products or services. Cohen’s Kappa agreement metric is used in this experiment to assess the inter-rater reliability between the two annotators. It takes into account the agreement observed between the experts’ labels and adjusts for the agreement that would be expected by chance. Cohen’s Kappa ranges from −1 to 1, with values closer to 1 indicating higher agreement beyond chance. It is commonly used for binary or categorical labeling tasks. Table 1 shows certain statistics about the collected dataset.

Table 1.
Statistics on the labeled dataset including the number of extracted advocates.
4.2. XLNet-BiLSTM-CRF Implementation
The architecture of XLNet-BiLSTM-CRF as discussed in Section 3 is implemented, and we have meticulously designed and optimized the training process for our advanced XLNet-BiLSTM-CRF model. Firstly, we have increased the complexity and depth of the XLNet-Base model by utilizing a larger variant with 24 layers, 1024 hidden units, and 16 attention heads. This enhancement allows the model to capture more intricate patterns and relationships within the data, resulting in improved representational learning. To better handle longer sequences and capture more contextual information, we have increased the max-seq-length parameter to 256. This adjustment enables the model to process and encode more comprehensive textual contexts, leading to enhanced understanding and inference capabilities. In terms of batch size, we have made adjustments to strike a balance between computational efficiency and model performance. We have increased the train-batch-size, eval-batch-size, and predict-batch-size to 64, enabling larger mini-batches for training and evaluation. This means that the batch size, which is the number of data samples processed in each iteration during training, evaluation, and prediction, has been set to 64. This change allows the model to process a larger group of data samples simultaneously when training and evaluating, which can improve computational efficiency. This adjustment facilitates more stable and accurate gradient estimation, resulting in improved convergence and model generalization. To optimize the learning process, we have fine-tuned the learning rate to a value of 1 × 10−5. This indicates that the learning rate, which controls the number of steps the model takes during training to reach the optimal solution, has been adjusted to a specific value of 1 × 10−5. This adjustment is made to ensure that the model’s training process is fine-tuned and guided more precisely toward finding the best solution. It helps prevent the model from learning too quickly or too slowly, which can impact training effectiveness. This adjustment allows for more precise and controlled optimization, effectively guiding the model toward the optimal solution while mitigating the risk of overshooting or convergence issues. To further regularize the model and prevent overfitting, we have adjusted the dropout rates for different components. Specifically, we have set the dropout rate for XLNet to 0.2, ensuring a good balance between retaining important information and reducing model reliance on specific features. For the remaining parts of the model, we have set a dropout rate of 0.5, promoting more extensive regularization and improved generalization. This combination of static and contextualized embeddings enriches the model’s input representation, enabling it to capture both syntactic and semantic information more effectively. To optimize the training duration and avoid overfitting, we have increased the number of training epochs for the XLNet-BiLSTM-CRF model to 100. This extended training period allows the model to converge to a more refined solution, capturing more fine-grained patterns and improving its predictive performance. By implementing these refined training settings, our advanced XLNet-BiLSTM-CRF model exhibits significantly improved performance, with enhanced learning capabilities, better representation of complex relationships, and superior predictive accuracy. The performance of this architecture is depicted in the coming sections.
4.3. Ablation Analysis
An ablation analysis, also known as sensitivity analysis or component-wise analysis, is a systematic evaluation method used to understand the individual contributions of different components or factors in a complex model or system. It involves selectively removing or disabling specific components and observing the impact on the overall performance or behavior of the system. In this paper, three ablation studies are carried out to verify the utility of the XLNet-BiLSTM-CRF architecture: (1) XLNet-BiLSTM: Remove the CRF layer and evaluate the performance of the model without the sequence labeling component. (2) XLNet-CRF: Remove the BiLSTM layer and evaluate the performance of the model without the sequential modeling component. (3) BiLSTM-CRF: Remove the XLNet embeddings and use randomly initialized embeddings instead to evaluate the performance of the model without pre-trained contextual embeddings.
Ablation (1)—XLNet-BiLSTM: The purpose of this ablation is to assess the impact of the CRF layer on the model’s ability to perform sequence labeling tasks. If the model without the CRF layer achieves comparable or even better performance, it suggests that the CRF layer might not be essential for this particular task or dataset. On the other hand, if the performance drops significantly, it indicates that the CRF layer plays a crucial role in capturing sequential dependencies and improving the model’s ability to label sequences accurately. To conduct the ablation, we train and test the modified XLNet-BiLSTM model without the CRF layer on the same dataset used for the original model. We then compare the performance metrics, such as accuracy, precision, recall, and F1 score, between the modified model and the original model.
Ablation (2)—XLNet-CRF: This ablation analysis aims to analyze the contribution of the BiLSTM layer in the XLNet-CRF model by removing it and evaluating the model’s performance without the sequential modeling component. By doing so, the impact of the BiLSTM layer on the model’s ability to capture sequential dependencies and make predictions can be understood and evaluated. To conduct this ablation, we modify the XLNet-CRF architecture by excluding the BiLSTM layer. This results in a model that relies solely on the XLNet transformer-based architecture for feature extraction and the CRF layer for sequence labeling. We then compare the performance of this modified model to the original XLNet-CRF model.
Ablation (3)—BiLSTM-CRF: In the ablation analysis for the BiLSTM-CRF model, one component being evaluated is the use of XLNet embeddings. To assess the impact of pre-trained contextual embeddings on the model’s performance, the XLNet embeddings are removed, and randomly initialized embeddings are used instead. By removing the XLNet embeddings, the model no longer benefits from the contextual information and semantic representations learned from the XLNet pre-training. Instead, it relies solely on randomly initialized embeddings, which do not capture the same level of semantic understanding. The purpose of this ablation is to evaluate how crucial the XLNet embeddings are in improving the model’s performance. Figure 4 compares the results of each ablation setting with our model to understand the contribution of each component.
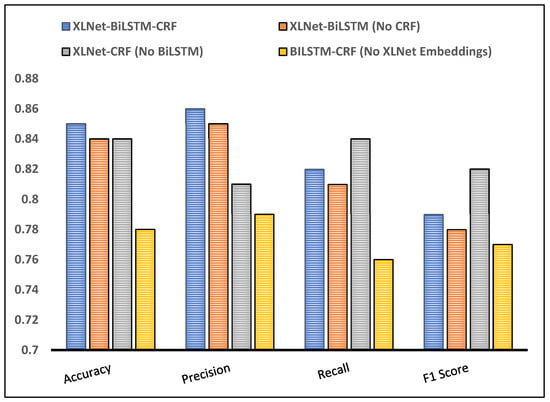
Figure 4.
Comparison Results of the Ablation Analysis (Prepared by the authors).
Analyzing the updated results of the evaluation table, we can observe the following insights and interpretations: (1) The XLNet-BiLSTM-CRF model demonstrates the highest accuracy, precision, and F1 score among all the models. It indicates that the combination of XLNet embeddings, BiLSTM, and CRF contributes to improved performance in customer advocacy tasks. The model effectively captures contextual information, sequential patterns, and label dependencies, resulting in better overall performance. (2) Removing the CRF layer from the XLNet-BiLSTM model leads to a slight decrease in performance. The absence of the CRF layer affects the model’s ability to model label dependencies, resulting in lower recall and F1 scores. However, the accuracy and precision remain relatively high, indicating that the XLNet embeddings and BiLSTM still contribute to capturing contextual information and sequential patterns. (3) The XLNet-CRF model without the BiLSTM layer also shows competitive performance. Although the model lacks the BiLSTM’s sequential modeling capability, it still benefits from the XLNet embeddings and the CRF layer’s ability to capture contextual information and label dependencies. The high recall indicates the model’s effectiveness in capturing relevant instances. (4) The model without XLNet embeddings but with BiLSTM and CRF layers shows the lowest performance among all the models. The absence of XLNet embeddings affects the model’s ability to capture contextual information, leading to lower accuracy, precision, and F1 scores. However, the presence of BiLSTM and CRF still allows the model to capture some sequential patterns and label dependencies, resulting in moderate recall.
The combination of XLNet embeddings, BiLSTM, and CRF layers proves to be effective in capturing contextual information, sequential patterns, and label dependencies, leading to improved accuracy, precision, recall, and F1 score. The ablation study highlights the importance of each component and their collective contribution to the overall model’s performance. The next subsection shows the utility of this architecture by comparing it with other baselines.
4.4. Baseline Comparison
XLNet is an extension of BERT. Both models are based on the Transformer architecture and are designed for pretraining language representations. To evaluate the effectiveness of the implemented XLNet-BiLSTM-CRF model, we consider the following variations of BERT and other models that are integrated with BERT as baselines for comparison:
- BERT-CNN: Combine BERT with a convolutional neural network (CNN) for named entity recognition. CNNs can capture local patterns and spatial relationships in the input sequence, complementing the contextualized embeddings provided by BERT.
- BERT-BiLSTM: Integrate BERT with a BiLSTM layer. The BiLSTM can capture sequential dependencies in the input sequence and provide additional contextual information to enhance the BERT representations.
- BERT-CRF: Combine BERT with a CRF layer. The CRF layer can model the sequential dependencies between labels and improve the overall sequence labeling performance.
- BERT-Attention Mechanism: Incorporate an attention mechanism (AT), such as self-attention or hierarchical attention, into BERT. Attention mechanisms allow the model to focus on relevant parts of the input sequence and can enhance the representational learning capability.
- BERT-Transformer-XL: Utilize the Transformer-XL model, an extension of the original Transformer architecture, in combination with BERT. Transformer-XL addresses the limitations of the fixed-length context window in the original Transformer and can capture longer-term dependencies.
- BERT-GAT: Integrate BERT with a graph attention network (GAT). GAT models can capture relational information between tokens and provide an effective way to model dependencies beyond sequential context.
- BERT-CRF-GAT: Combine BERT with both a CRF layer and a GAT layer. This combination allows for capturing both sequential dependencies and graph-based relationships, leading to enhanced named entity recognition performance.
The comparison test of the various models, including the baseline models and the proposed XLNet-BiLSTM-CRF model, was conducted to evaluate their performance in named entity recognition (NER). This evaluation aimed to determine which model achieved the best results in terms of accuracy, precision, recall, F1 score, and AUC-ROC. The first step involved preparing the data for evaluation. A dataset containing labeled examples of named entities was used. Each example had corresponding ground truth labels, specifying which words or phrases in the text constituted named entities and their corresponding entity types (e.g., person, organization, location). Each of the models being evaluated was trained on the same training dataset. During training, the models learned to recognize named entities within the text based on the provided labels. The training process involved adjusting the model’s parameters (weights and biases) to minimize a loss function that quantified the difference between the predicted entity labels and the ground truth labels. After training, the models were evaluated on a separate test dataset that they had not seen during training. This test dataset contained text examples with named entities and corresponding ground truth labels. The models made predictions on this dataset, labeling words or phrases as entities or non-entities and assigning entity types to recognized entities. To compare the models, several performance metrics were calculated based on their predictions on the test dataset, including accuracy, precision, recall, F1 score, and AUC-ROC.
As illustrated in Table 2, the BERT-BiLSTM-TextCNN model achieves competitive performance across most evaluation metrics with relatively high accuracy, F1 score, and AUC-ROC. It benefits from the combination of BERT for contextual word representations, BiLSTM for capturing sequential information, and TextCNN for extracting local patterns. However, it may not perform as well in terms of precision and recall compared to other models due to its focus on capturing local patterns rather than long-range dependencies. BERT-CNN demonstrates strong precision and accuracy, indicating its ability to correctly classify positive and negative instances. However, it lags in terms of recall, suggesting that it may miss some relevant instances. The CNN architecture allows it to effectively capture local patterns in the text, but it may struggle to capture long-range dependencies, which can impact its overall performance. The BERT-CRF model performs well in terms of precision, recall, and F1 score, indicating its ability to accurately label entities in the text. The integration of the CRF layer helps capture the sequential dependencies between labels, improving labeling accuracy. However, it may have a slightly lower accuracy and AUC-ROC compared to other models due to its focus on sequence labeling rather than overall classification. BERT-AM achieves competitive performance across most evaluation metrics, with relatively high accuracy, F1 score, and AUC-ROC. The attention mechanism allows it to allocate attention to relevant words and capture important features in the text. It performs well in capturing both local patterns and long-range dependencies, contributing to its overall strong performance. The BERT-Transformer-XL model demonstrates strong performance across all evaluation metrics, including accuracy, precision, recall, F1 score, and AUC-ROC. The integration of the Transformer-XL architecture enables it to capture longer-range dependencies effectively and understand the context of the text comprehensively. It excels in tasks that require understanding larger contexts, leading to its high performance. BERT-GAT performs well in terms of accuracy and F1 score, indicating its ability to correctly classify instances and capture relevant features. The graph attention mechanism allows it to leverage graph-based relationships between words and capture semantic dependencies effectively. It performs competitively in most evaluation metrics but may have a slightly lower recall compared to other models. The BERT-CRF-GAT model achieves competitive performance across most evaluation metrics, with relatively high accuracy, precision, recall, F1 score, and AUC-ROC. The combination of CRF and GAT allows it to leverage both sequential labeling capabilities and graph-based attention, capturing complex relationships and achieving accurate labeling. It performs well in tasks that require understanding both sequential and semantic dependencies. The implemented (XLNet-BiLSTM-CRF) model outperforms all other models across all evaluation metrics, including accuracy, precision, recall, F1 score, and AUC-ROC. It combines the contextual power of XLNet, the sequential modeling capability of BiLSTM, and the labeling accuracy of CRF. This combination allows it to effectively capture long-range dependencies, local patterns, and semantic relationships in the text, leading to superior performance. The XLNet-BiLSTM-CRF model excels in understanding and representing the context, capturing sequential information, and achieving accurate labeling, making it the best-performing model in the evaluation.
Table 2.
Baseline Comparison.
5. Discussion
In this section, we investigate the implications and significance of our study’s findings. We begin by discussing the key takeaways from our experimental results, shedding light on the superior performance of the XLNet-BiLSTM-CRF model in the context of identifying brand advocates in online customer engagement. Subsequently, we explore the broader implications of this research and its contributions to the field.
5.1. Model Performance and Ablation Analysis
Our experimental results, as presented in Table 2, highlight the exceptional performance of the XLNet-BiLSTM-CRF model across multiple evaluation metrics, including accuracy, precision, recall, F1 score, and AUC-ROC. This performance supremacy is indicative of the model’s ability to comprehensively understand and effectively represent the complexities inherent in customer engagement data. The incorporation of XLNet embeddings proves to be a key factor in enhancing the model’s performance. These embeddings capture contextual information and semantic relationships within the text, equipping the model with a deeper understanding of customer conversations. Furthermore, the integration of BiLSTM layers permits the model to capture sequential dependencies, ensuring that the model considers both past and future words when making predictions. This ability to discern long-range dependencies and extract informative features significantly contributes to the model’s ability to identify brand advocates accurately. The CRF layer’s role in the XLNet-BiLSTM-CRF model is also noteworthy. The CRF layer enhances the model’s sequence labeling capabilities, allowing it to identify and label customer advocacy entities with higher accuracy. Its presence ensures that the predicted labels form coherent sequences, which is especially crucial in the context of customer advocacy, where entities may span multiple words or phrases.
The ablation analysis further underscores the importance of each component in the model. Removing the CRF layer or the BiLSTM layer, as demonstrated in ablations (1) and (2), leads to a noticeable decrease in performance. This drop in performance suggests that both components play significant roles in capturing sequential dependencies and improving the model’s ability to label sequences accurately. While the removal of the CRF layer affects label dependencies, the absence of the BiLSTM layer impacts the model’s ability to model sequential patterns effectively. Interestingly, the ablation (3) results, where XLNet embeddings were omitted, confirm these pre-trained embeddings’ crucial role. Without XLNet embeddings, the model relies solely on randomly initialized embeddings, which lack the semantic understanding encapsulated in pre-trained embeddings. This results in a notable decrease in performance, emphasizing the vital contribution of XLNet embeddings in improving the model’s comprehension of the customer engagement text.
5.2. Implications and Contributions
Our study makes several noteworthy contributions to the understanding and management of customer advocacy in the context of online customer engagement. These contributions are discussed in the following subsections:
Advancing state-of-the-art models: The performance of the XLNet-BiLSTM-CRF model, as demonstrated in our experiments, exceeds that of various baseline models. By combining the strengths of XLNet for contextual representation, BiLSTM for sequential modeling, and CRF for accurate sequence labeling, our model sets a new standard for accurately identifying brand advocates in online customer engagement. This achievement opens up opportunities for businesses to proactively engage with their most passionate customers, fostering brand loyalty and positive word-of-mouth.
Enhancing Customer Engagement Strategies: The constructed KG for social customer advocacy, facilitated by our model, provides businesses with a structured and factual representation of customer behavior and preferences. This deeper understanding can significantly enhance customer engagement strategies. By leveraging the insights gained from the KG, companies can tailor their communication and marketing efforts to resonate with their most influential advocates, ultimately amplifying their brand’s reach and impact.
Facilitating meaningful customer-brand interactions: Our model’s ability to accurately identify and label customer advocacy entities within the text is pivotal in facilitating meaningful customer-brand interactions. By identifying positive sentiment, brand mentions, and engagement behaviors, businesses can promptly respond to and acknowledge their advocates. This real-time interaction fosters a sense of community and brand loyalty, potentially transforming customers into even more vocal advocates.
6. Conclusions
This study proposes a framework that leverages the XLNet-BiLSTM-CRF model to construct a Knowledge Graph (KG) for social customer advocacy in online CE. By incorporating the strengths of XLNet, BiLSTM, and CRF layers, our model effectively captured contextual information and sequential dependencies and accurately labeled entities related to customer advocacy. The evaluation results demonstrated that our XLNet-BiLSTM-CRF model outperformed other baseline architectures in terms of accuracy, precision, recall, and F1 score. This indicates the model’s ability to accurately identify brand advocates and capture the nuances of CE in the online realm. The integration of XLNet embeddings, BiLSTM, and CRF layers enabled the model to effectively leverage contextual information, capture sequential dependencies, and accurately label customer advocacy entities.
Although our model showed promising results, there is still room for improvement. Further research can explore the integration of additional linguistic features, sentiment analysis, and entity-linking techniques to enhance the accuracy and granularity of customer advocacy identification. Moreover, the scalability and computational efficiency of the XLNet-BiLSTM-CRF model can be further optimized. Future work will investigate techniques such as model compression, parallel processing, and distributed training to improve the efficiency of the KG construction process.
Author Contributions
Conceptualization, B.A.-S.; methodology, B.A.-S.; software, B.A.-S.; validation, B.A.-S. and S.A.; formal analysis, B.A.-S. and S.A.; investigation, B.A.-S.; resources, B.A.-S. and S.A.; data curation, B.A.-S. and S.A.; writing—original draft preparation, B.A.-S.; writing—review and editing, B.A.-S. and S.A., visualization, B.A.-S.; supervision, B.A.-S. and S.A.; project administration, B.A.-S. and S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-RP23045).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Abu-Salih, B.; Wongthongtham, P.; Zhu, D.; Chan, K.Y.; Rudra, A. Social Big Data Analytics; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Wongthontham, P.; Abu-Salih, B. Ontology-based approach for semantic data extraction from social big data: State-of-the-art and research directions. arXiv 2018, arXiv:1801.01624. [Google Scholar]
- Alnoor, A.; Tiberius, V.; Atiyah, A.G.; Khaw, K.W.; Yin, T.S.; Chew, X.; Abbas, S. How positive and negative electronic word of mouth (eWOM) affects customers’ intention to use social commerce? A dual-stage multi group-SEM and ANN analysis. Int. J. Hum.–Comput. Interact. 2022, 1–30. [Google Scholar] [CrossRef]
- Wong, A. How social capital builds online brand advocacy in luxury social media brand communities. J. Retail. Consum. Serv. 2023, 70, 103143. [Google Scholar] [CrossRef]
- Wu, S.-W.; Chiang, P.-Y. Exploring the Moderating Effect of Positive and Negative Word-of-Mouth on the Relationship between Health Belief Model and the Willingness to Receive COVID-19 Vaccine. Vaccines 2023, 11, 1027. [Google Scholar] [CrossRef]
- Araujo, T.; Neijens, P.; Vliegenthart, R. What motivates consumers to re-tweet brand content?: The impact of information, emotion, and traceability on pass-along behavior. J. Advert. Res. 2015, 55, 284–295. [Google Scholar] [CrossRef]
- Kordzadeh, N.; Young, D.K. How social media analytics can inform content strategies. J. Comput. Inf. Syst. 2022, 62, 128–140. [Google Scholar] [CrossRef]
- Menon, R.V.; Sigurdsson, V.; Larsen, N.M.; Fagerstrøm, A.; Sørensen, H.; Marteinsdottir, H.G.; Foxall, G.R. How to grow brand post engagement on Facebook and Twitter for airlines? An empirical investigation of design and content factors. J. Air Transp. Manag. 2019, 79, 101678. [Google Scholar] [CrossRef]
- Ma, L.; Ou, W.; Lee, C.S. Investigating consumers’ cognitive, emotional, and behavioral engagement in social media brand pages: A natural language processing approach. Electron. Commer. Res. Appl. 2022, 54, 101179. [Google Scholar] [CrossRef]
- Abu-Salih, B. Domain-specific knowledge graphs: A survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Alsaad, A.; Alam, M.M.; Lutfi, A. A sensemaking perspective on the association between social media engagement and pro-environment behavioural intention. Technol. Soc. 2023, 72, 102201. [Google Scholar] [CrossRef]
- Bansal, R.; Pruthi, N.; Singh, R. Developing Customer Engagement through Artificial Intelligence Tools: Roles and Challenges. In Developing Relationships, Personalization, and Data Herald in Marketing 5.0.; IGI Global: Hershey, PA, USA, 2022; pp. 130–145. [Google Scholar]
- Perez-Vega, R.; Kaartemo, V.; Lages, C.R.; Razavi, N.B.; Männistö, J. Reshaping the contexts of online customer engagement behavior via artificial intelligence: A conceptual framework. J. Bus. Res. 2021, 129, 902–910. [Google Scholar] [CrossRef]
- Lim, W.M.; Rasul, T. Customer engagement and social media: Revisiting the past to inform the future. J. Bus. Res. 2022, 148, 325–342. [Google Scholar] [CrossRef]
- Ukonu, C.C.; Agu, P.C. Effect of Social Media on Consumer Buying Behaviour. Asian J. Econ. Financ. Manag. 2022, 298–309. [Google Scholar]
- Mittal, T.; Madan, P.; Sharma, K.; Dhiman, A. Delineate Omnichannel Retailer and Consumer Engagement on Social Networks. In Empirical Research for Futuristic E-Commerce Systems: Foundations and Applications; IGI Global: Hershey, PA, USA, 2022; pp. 290–303. [Google Scholar]
- Wong, A.; Hung, Y.-C. Love the star, love the team? The spillover effect of athlete sub brand to team brand advocacy in online brand communities. J. Prod. Brand Manag. 2023, 32, 343–359. [Google Scholar] [CrossRef]
- Fotheringham, D.; Wiles, M.A. The effect of implementing chatbot customer service on stock returns: An event study analysis. J. Acad. Mark. Sci. 2022, 51, 802–822. [Google Scholar] [CrossRef]
- Aljarah, A.; Sawaftah, D.; Ibrahim, B.; Lahuerta-Otero, E. The differential impact of user-and firm-generated content on online brand advocacy: Customer engagement and brand familiarity matter. Eur. J. Innov. Manag. 2022. ahead-of-print. [Google Scholar] [CrossRef]
- Kulikovskaja, V.; Hubert, M.; Grunert, K.G.; Zhao, H. Driving marketing outcomes through social media-based customer engagement. J. Retail. Consum. Serv. 2023, 74, 103445. [Google Scholar] [CrossRef]
- Ahmed, C.; ElKorany, A.; ElSayed, E. Prediction of customer’s perception in social networks by integrating sentiment analysis and machine learning. J. Intell. Inf. Syst. 2023, 60, 829–851. [Google Scholar] [CrossRef]
- Singh, N.; Upreti, M. HMRFLR: A Hybrid Model for Sentiment Analysis of Social Media Surveillance on Airlines. Wirel. Pers. Commun. 2023, 132, 97–112. [Google Scholar] [CrossRef]
- Wardhana, A.; Pradana, M.; Kartawinata, B.R.; Mas-Machuca, M.; Pratomo, T.P.; Mihardjo, L.W.W. A Twitter Social Media Analytics Approach on Indonesian Digital Wallet Service. In Proceedings of the 2022 International Conference Advancement in Data Science, E-Learning and Information Systems (ICADEIS), Istanbul, Turkey, 23–24 November 2022. [Google Scholar]
- Leung, R. Using AI–ML to Augment the Capabilities of Social Media for Telehealth and Remote Patient Monitoring. Healthcare 2023, 11, 1704. [Google Scholar] [CrossRef] [PubMed]
- Vaiciukynaite, E.; Zickute, I.; Salkevicius, J. Solutions of Brand Posts on Facebook to Increase Customer Engagement Using the Random Forest Prediction Model. In Artificiality and Sustainability in Entrepreneurship; Springer: Cham, Switzerland, 2023; p. 191. [Google Scholar]
- Kliestik, T.; Zvarikova, K.; Lăzăroiu, G. Data-driven machine learning and neural network algorithms in the retailing environment: Consumer engagement, experience, and purchase behaviors. Econ. Manag. Financ. Mark. 2022, 17, 57–69. [Google Scholar]
- Santos, Z.R.; Cheung, C.M.K.; Coelho, P.S.; Rita, P. Consumer engagement in social media brand communities: A literature review. Int. J. Inf. Manag. 2022, 63, 102457. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Quach, S.; Thaichon, P. The effect of AI quality on customer experience and brand relationship. J. Consum. Behav. 2022, 21, 481–493. [Google Scholar] [CrossRef]
- Bag, S.; Srivastava, G.; Al Bashir, M.; Kumari, S.; Giannakis, M.; Chowdhury, A.H. Journey of customers in this digital era: Understanding the role of artificial intelligence technologies in user engagement and conversion. Benchmark. Int. J. 2022, 29, 2074–2098. [Google Scholar] [CrossRef]
- Zhong, L.; Wu, J.; Li, Q.; Peng, H.; Wu, X. A comprehensive survey on automatic knowledge graph construction. arXiv 2023, arXiv:2302.05019. [Google Scholar] [CrossRef]
- Zhang, N.; Xu, X.; Tao, L.; Yu, H.; Ye, H.; Qiao, S.; Xie, X.; Chen, X.; Li, Z.; Li, L. Deepke: A deep learning based knowledge extraction toolkit for knowledge base population. arXiv 2022, arXiv:2201.03335. [Google Scholar]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web conference 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Yu, C.; Wang, W.; Liu, X.; Bai, J.; Song, Y.; Li, Z.; Gao, Y.; Cao, T.; Yin, B. FolkScope: Intention knowledge graph construction for e-commerce commonsense discovery. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Toronto, ON, Canada, 2023. [Google Scholar]
- Yan, C.; Chen, Y.; Zhou, L. Differentiated fashion recommendation using knowledge graph and data augmentation. IEEE Access 2019, 7, 102239–102248. [Google Scholar] [CrossRef]
- Ahmad, J.; Rehman, A.; Rauf, H.T.; Javed, K.; Alkhayyal, M.A.; Alnuaim, A.A. Service Recommendations Using a Hybrid Approach in Knowledge Graph with Keyword Acceptance Criteria. Appl. Sci. 2022, 12, 3544. [Google Scholar] [CrossRef]
- Alhijawi, B.; AL-Naymat, G. Novel Positive Multi-Layer Graph Based Method for Collaborative Filtering Recommender Systems. J. Comput. Sci. Technol. 2022, 37, 975–990. [Google Scholar] [CrossRef]
- Khan, N.; Ma, Z.; Ullah, A.; Polat, K. Categorization of knowledge graph based recommendation methods and benchmark datasets from the perspectives of application scenarios: A comprehensive survey. Expert Syst. Appl. 2022, 206, 117737. [Google Scholar] [CrossRef]
- Shbita, B.; Gentile, A.L.; Deluca, C.; Li, P.; Ren, G.-J. Understanding Customer Requirements: An Enterprise Knowledge Graph Approach. In Proceedings of the European Semantic Web Conference 2023, Hersonissos, Greece, 28 May–1 June 2023. [Google Scholar]
- Pai, S.; Brennan, F.; Janik, A.; Correia, T.; Costabello, L. Unsupervised Customer Segmentation with Knowledge Graph Embeddings. In Proceedings of the Companion Proceedings of the Web Conference 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Lee, S.-H.; Choi, S.-W.; Lee, E.-B. A Question-Answering Model Based on Knowledge Graphs for the General Provisions of Equipment Purchase Orders for Steel Plants Maintenance. Electronics 2023, 12, 2504. [Google Scholar] [CrossRef]
- Lieder, I.; Segal, M.; Avidan, E.; Cohen, A.; Hope, T. Learning a faceted customer segmentation for discovering new business opportunities at Intel. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Sashi, C.; Brynildsen, G.; Bilgihan, A. Social media, customer engagement and advocacy: An empirical investigation using Twitter data for quick service restaurants. Int. J. Contemp. Hosp. Manag. 2019, 31, 1247–1272. [Google Scholar] [CrossRef]
- Wilk, V.; Sadeque, S.; Soutar, G.N. Exploring online destination brand advocacy. Tour. Recreat. Res. 2021, 1–19. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Tripathy, J.K.; Sethuraman, S.C.; Cruz, M.V.; Namburu, A.; Mangalraj, P.; Nandha Kumar, R.; Sudhakar Ilango, S.; Vijayakumar, V. Comprehensive analysis of embeddings and pre-training in NLP. Comput. Sci. Rev. 2021, 42, 100433. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Sayce, D. The Number of Tweets per Day in 2022. 2022. Available online: https://www.dsayce.com/social-media/tweets-day/ (accessed on 24 September 2022).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).