
Self-Supervised Human Activity Representation for Embodied Cognition Assessment


Abstract
:1. Introduction
2. Related Works
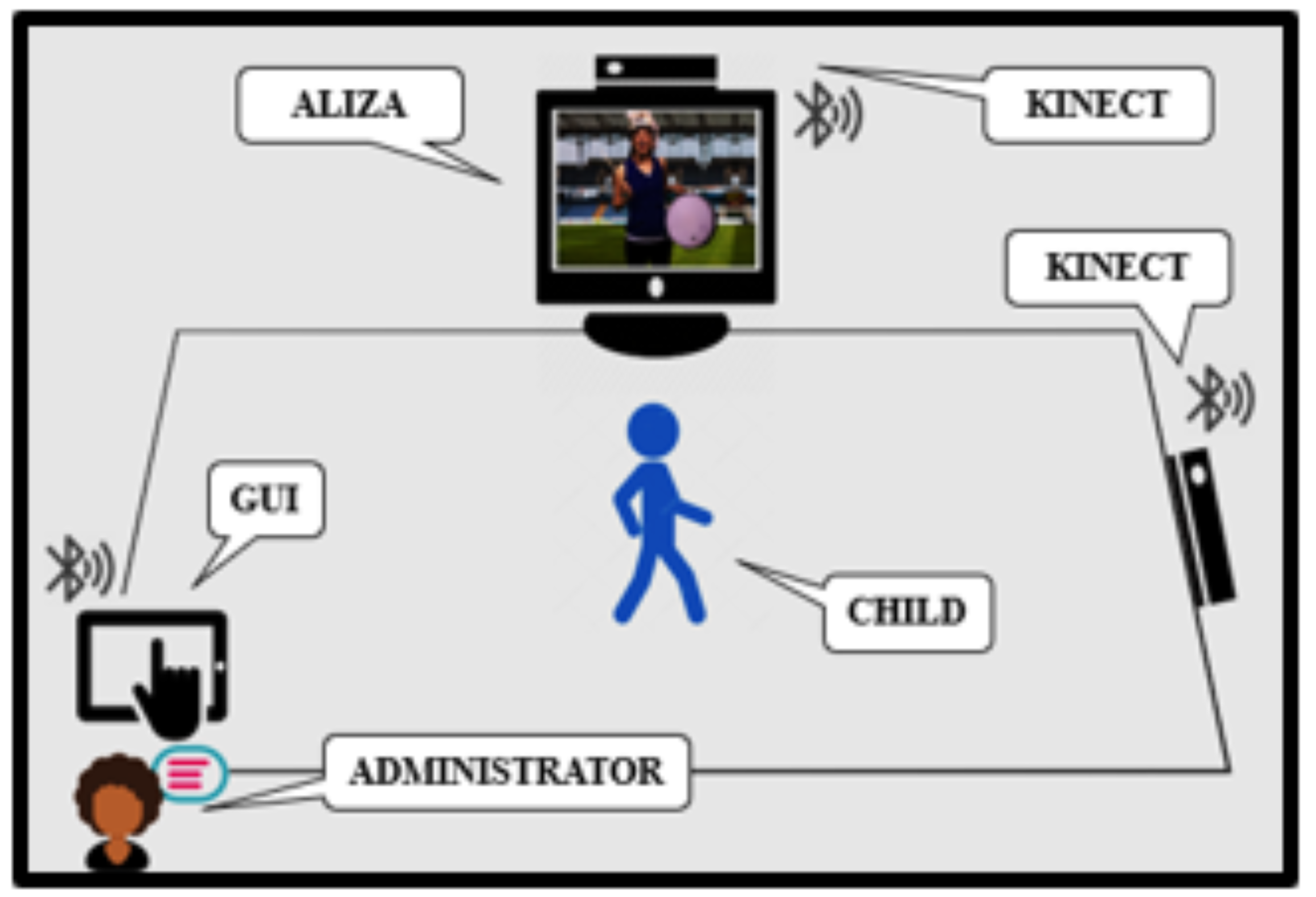
3. ATEC Dataset
3.1. Ball Drop to the Beat
3.2. Tandem Gait Forward
3.3. Stand on One Foot
4. Methodology and Results
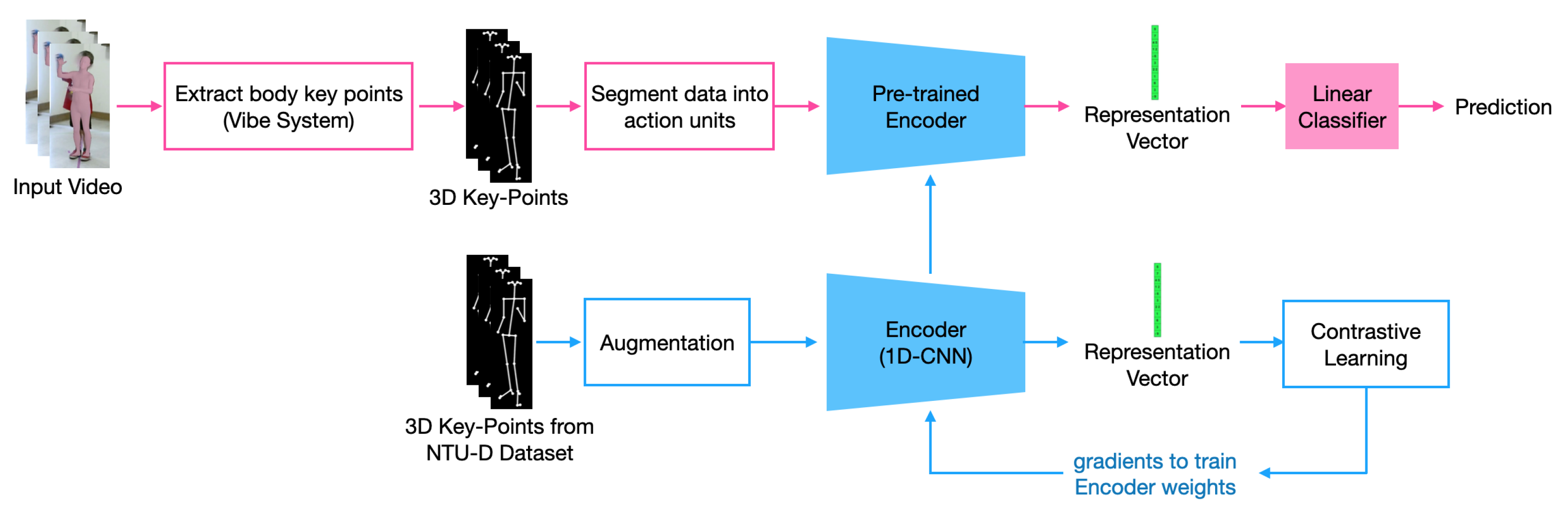
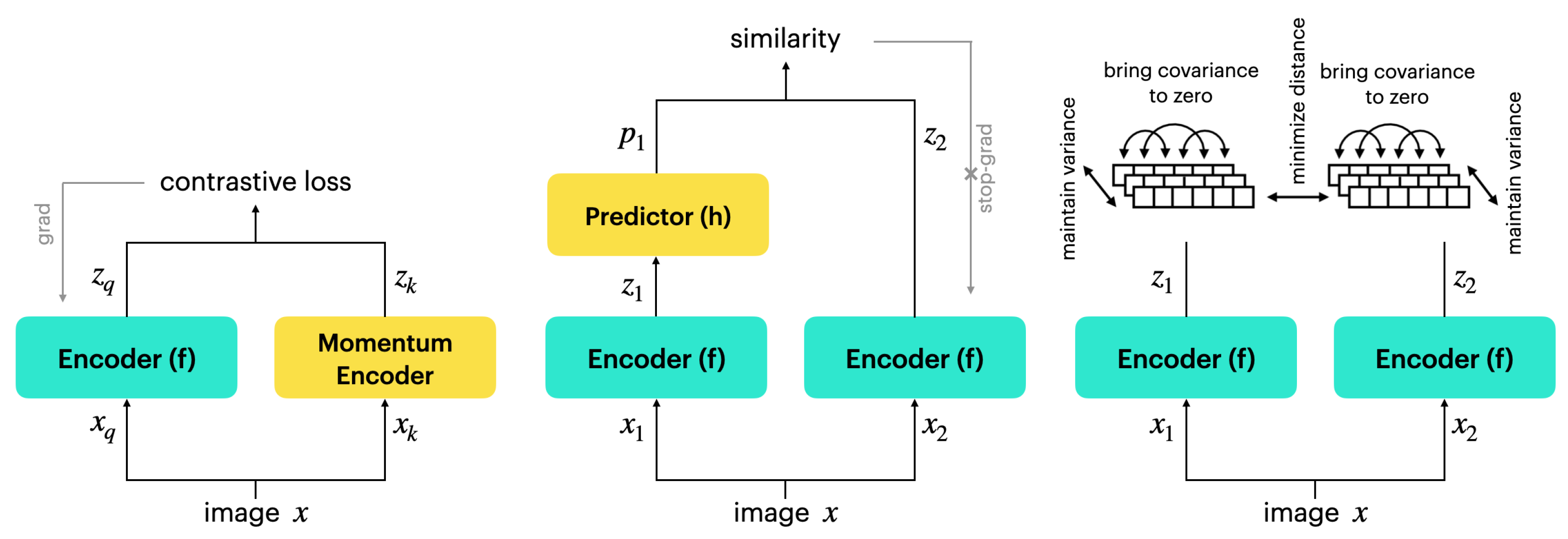
4.1. Self-Supervised Learning
4.2. Proposed System
4.3. Results and Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leitner, Y.; Barak, R.; Giladi, N.; Peretz, C.; Eshel, R.; Gruendlinger, L.; Hausdorff, J.M. Gait in attention deficit hyperactivity disorder. J. Neurol. 2007, 254, 1330–1338. [Google Scholar] [CrossRef] [PubMed]
- Buderath, P.; Gärtner, K.; Frings, M.; Christiansen, H.; Schoch, B.; Konczak, J.; Gizewski, E.R.; Hebebrand, J.; Timmann, D. Postural and gait performance in children with attention deficit/hyperactivity disorder. Gait Posture 2009, 29, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Bell, M.D.; Weinstein, A.J.; Pittman, B.; Gorman, R.M.; Abujelala, M. The Activate Test of Embodied Cognition (ATEC): Reliability, concurrent validity and discriminant validity in a community sample of children using cognitively demanding physical tasks related to executive functioning. Child Neuropsychol. 2021, 27, 973–983. [Google Scholar] [CrossRef] [PubMed]
- Jaiswal, A.; Ramesh Babu, A.; Zadeh, M.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Wang, Z.; Mian, L.; Zhang, J.; Tang, J. Self-Supervised Learning: Generative or Contrastive. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Bardes, A.; Ponce, J.; LeCun, Y. VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. arXiv 2021, arXiv:2105.04906. [Google Scholar]
- Dillhoff, A.; Tsiakas, K.; Babu, A.R.; Zakizadehghariehali, M.; Buchanan, B.; Bell, M.; Athitsos, V.; Makedon, F. An automated assessment system for embodied cognition in children: From motion data to executive functioning. In Proceedings of the 6th International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 16–17 September 2019; pp. 1–6. [Google Scholar]
- Babu, A.R.; Zakizadeh, M.; Brady, J.R.; Calderon, D.; Makedon, F. An Intelligent Action Recognition System to assess Cognitive Behavior for Executive Function Disorder. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 164–169. [Google Scholar]
- Kocabas, M.; Athanasiou, N.; Black, M.J. VIBE: Video Inference for Human Body Pose and Shape Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Atkins, M.S.; Pelham, W.E.; Licht, M.H. A comparison of objective classroom measures and teacher ratings of attention deficit disorder. J. Abnorm. Child Psychol. 1985, 13, 155–167. [Google Scholar] [CrossRef]
- Donnelly, J.E.; Lambourne, K. Classroom-based physical activity, cognition, and academic achievement. Prev. Med. 2011, 52, 36–42. [Google Scholar] [CrossRef]
- Malina, R.M.; Cumming, S.P.; Silva, M.J.C. Physical Activity and Inactivity Among Children and Adolescents: Assessment, Trends, and Correlates. In Biological Measures of Human Experience across the Lifespan; Springer: Berlin/Heidelberg, Germany, 2016; pp. 67–101. [Google Scholar]
- Dusen, D.P.V.; Kelder, S.H.; Ranjit, N.; Perry, C.L. Associations of physical fitness and academic performance among schoolchildren. J. Sch. Health 2011, 81, 733–740. [Google Scholar] [CrossRef] [PubMed]
- Davis, C.; Cooper, S. Fitness, fatness, cognition, behavior, and academic achievement among overweight children: Do cross-sectional associations correspond to exercise trial outcomes? Prev. Med. 2011, 52 (Suppl. 1), S65–S69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hopkins, M.E.; Davis, F.C.; VanTieghem, M.R.; Whalen, P.J.; Bucci, D.J. Differential effects of acute and regular physical exercise on cognition and affect. Neuroscience 2012, 215, 59–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mannini, A.; Trojaniello, D.; Cereatti, A.; Sabatini, A. A Machine Learning Framework for Gait Classification Using Inertial Sensors: Application to Elderly, Post-Stroke and Huntington’s Disease Patients. Sensors 2016, 16, 134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, A.; Madden, J.; Snyder, K. Framework Utilizing Machine Learning to Facilitate Gait Analysis as an Indicator of Vascular Dementia. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar] [CrossRef]
- Karvekar, S. Smartphone-Based Human Fatigue Detection in an Industrial Environment Using Gait Analysis. Ergonomics 2019, 64, 1–28. [Google Scholar]
- Li, C.; Zhang, X.; Liao, L.; Jin, L.; Yang, W. Skeleton-Based Gesture Recognition Using Several Fully Connected Layers with Path Signature Features and Temporal Transformer Module. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Ali, A.; Taylor, G.W. Real-Time End-to-End Action Detection with Two-Stream Networks. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 31–38. [Google Scholar]
- Zhang, J.; Li, W.; Ogunbona, P.O.; Wang, P.; Tang, C. RGB-D-Based Action Recognition Datasets: A Survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef] [Green Version]
- Piergiovanni, A.; Ryoo, M.S. Fine-grained Activity Recognition in Baseball Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Rezaei, M.; Farahanipad, F.; Dillhoff, A.; Elmasri, R.; Athitsos, V. Weakly-Supervised Hand Part Segmentation from Depth Images. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference (PETRA 2021), Corfu, Greece, 29 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 218–225. [Google Scholar] [CrossRef]
- Farahanipad, F.; Rezaei, M.; Dillhoff, A.; Kamangar, F.; Athitsos, V. A Pipeline for Hand 2-D Keypoint Localization Using Unpaired Image to Image Translation. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference (PETRA 2021), Corfu, Greece, 29 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 226–233. [Google Scholar] [CrossRef]
- Ramesh Babu, A.; Zadeh, M.; Jaiswal, A.; Lueckenhoff, A.; Kyrarini, M.; Makedon, F. A Multi-Modal System to Assess Cognition in Children from Their Physical Movements; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Zaki Zadeh, M.; Ramesh Babu, A.; Jaiswal, A.; Kyrarini, M.; Makedon, F. Self-Supervised Human Activity Recognition by Augmenting Generative Adversarial Networks. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference (PETRA 2021), Corfu, Greece, 29 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 171–176. [Google Scholar] [CrossRef]
- Zaki Zadeh, M.; Ramesh Babu, A.; Jaiswal, A.; Kyrarini, M.; Bell, M.; Makedon, F. Automated System to Measure Tandem Gait to Assess Executive Functions in Children. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference (PETRA 2021), Corfu, Greece, 29 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 167–170. [Google Scholar] [CrossRef]
- Brigato, L.; Iocchi, L. A Close Look at Deep Learning with Small Data. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021. [Google Scholar]
- Olson, M.; Wyner, A.; Berk, R. Modern Neural Networks Generalize on Small Data Sets. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; 2018; Volume 31, Available online: https://www.semanticscholar.org/paper/Modern-Neural-Networks-Generalize-on-Small-Data-Olson-Wyner/a25bb56506fd1772e17d5b57a75ec838dafb6757 (accessed on 10 February 2022).
- Arora, S.; Du, S.S.; Li, Z.; Salakhutdinov, R.; Wang, R.; Yu, D. Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks. arXiv 2019, arXiv:1910.01663. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Liu, L.; Muelly, M.; Deng, J.; Pfister, T.; Li, L.J. Generative Modeling for Small-Data Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Barz, B.; Denzler, J. Deep Learning on Small Datasets without Pre-Training Using Cosine Loss. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Achenbach, T.; Ruffle, T.M. The Child Behavior Checklist and related forms for assessing behavioral/emotional problems and competencies. Pediatr. Rev. 2000, 21, 265–271. [Google Scholar] [CrossRef]
- Zelazo, P.; Anderson, J.; Richler, J.; Wallner-Allen, K.; Beaumont, J.; Weintraub, S. NIH toolbox cognition battery (CB): Measuring executive function and attention. Monogr. Soc. Res. Child Dev. 2013, 78, 16–33. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. arXiv 2018, arXiv:1806.11230. [Google Scholar]
- Castelló, J.S. A Comprehensive Survey on Deep Future Frame Video Prediction. Master’s Thesis, Universitat de Barcelona, Barcelona, Spain, 2018. [Google Scholar]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-Supervised GANs via Auxiliary Rotation Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Silver Spring, MD, USA, 14–19 June 2020. [Google Scholar]
- Trinh, T.H.; Luong, M.T.; Le, Q.V. Selfie: Self-supervised Pretraining for Image Embedding. arXiv 2019, arXiv:1906.02940. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-Contrastive Estimation: A New Estimation Principle for Unnormalized Statistical Models. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Bromley, J.; Bentz, J.; Bottou, L.; Guyon, I.; Lecun, Y.; Moore, C.; Sackinger, E.; Shah, R. Signature Verification using a “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Available online: http://proceedings.mlr.press/v139/zbontar21a/zbontar21a.pdf (accessed on 10 February 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Huckvale, K.; Venkatesh, S.; Christensen, H. Toward clinical digital phenotyping: A timely opportunity to consider purpose, quality, and safety. Npj Digit. Med. 2019, 2, 1–11. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Test |
|---|---|
| Gross Motor, Gait and Balance | Natural Walk, Gait on Toes, Tandem Gait, Stand Arms Outstretched, Stand on One Foot |
| Synchronous Movements | March Slow, March Fast |
| Bilateral Coordination and Response Inhibition | Bi-Manual Ball Pass with Green, Red, and Yellow Light |
| Visual Response Inhibition | Sailor Step Slow, Sailor Step Fast |
| Cross Body Game | Cross your Body (Ears, Shoulders, Hips, Knees) |
| Finger-Nose Coordination | Hand Eye Coordination |
| Rapid Sequential Movements | Foot Tap, Foot-Heel, Toe Tap, Hand Pat, Finger Tap, Oppose Finger Succession |
| Approach | Ball Drop to the Beat | Tandem Gait | Stand on One Foot | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 50% | 25% | 10% | 50% | 25% | 10% | 50% | 25% | 10% | |
| Supervised | 77.61 | 61.98 | 54.79 | 74.81 | 60.21 | 51.72 | 88.98 | 79.36 | 76.93 |
| Multimodal | 75.29 | 52.77 | 48.13 | 69.52 | 55.46 | 51.11 | 87.82 | 75.55 | 71.96 |
| MoCo | 74.70 | 71.87 | 70.63 | 75.52 | 73.70 | 72.36 | 89.63 | 88.07 | 85.59 |
| SimSiam | 75.44 | 74.08 | 71.91 | 75.81 | 74.42 | 73.46 | 89.76 | 88.05 | 87.24 |
| VICReg | 77.11 | 74.65 | 72.59 | 75.96 | 74.45 | 73.51 | 90.54 | 89.86 | 89.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaki Zadeh, M.; Ramesh Babu, A.; Jaiswal, A.; Makedon, F. Self-Supervised Human Activity Representation for Embodied Cognition Assessment. Technologies 2022, 10, 33. https://doi.org/10.3390/technologies10010033
Zaki Zadeh M, Ramesh Babu A, Jaiswal A, Makedon F. Self-Supervised Human Activity Representation for Embodied Cognition Assessment. Technologies. 2022; 10(1):33. https://doi.org/10.3390/technologies10010033
Chicago/Turabian StyleZaki Zadeh, Mohammad, Ashwin Ramesh Babu, Ashish Jaiswal, and Fillia Makedon. 2022. "Self-Supervised Human Activity Representation for Embodied Cognition Assessment" Technologies 10, no. 1: 33. https://doi.org/10.3390/technologies10010033
APA StyleZaki Zadeh, M., Ramesh Babu, A., Jaiswal, A., & Makedon, F. (2022). Self-Supervised Human Activity Representation for Embodied Cognition Assessment. Technologies, 10(1), 33. https://doi.org/10.3390/technologies10010033