Abstract
In this paper, we propose a semi-Markov chain to model the salary levels of participants in a pension scheme. The aim of the models is to understand the evolution in time of the salary of active workers in order to implement it in the construction of the actuarial technical balance sheet. It is worth mentioning that the level of the contributions in a pension scheme is directly proportional to the incomes of the active workers; in almost all cases, it is a percentage of the worker’s incomes. As a consequence, an adequate modeling of the salary evolution is essential for the determination of the contributions paid to the fund and thus for the determination of the fund’s sustainability, especially currently, when all jobs and salaries are subject to changes due to digitalization, ICT, innovation, etc. The model is applied to a large dataset of a real compulsory Italian pension scheme of the first pillar. The semi-Markovian hypothesis is tested, and the advantages with respect to Markov chain models are assessed.
MSC:
60J20; 60K20
1. Introduction
Currently, pension funds are acquiring even more importance in the management of pension contributions of participants in a pension scheme. Fund managers need to assure safety of the fund, establishing equilibrium conditions on in-flows and out-flows of the fund. To achieve this result, it is necessary to use a realistic model of the salary levels of participants in the pension scheme, which in turn allows a correct representation of contributions that are proportional to the incomes. Salary levels change over time due to the innovation of society, especially if we consider those jobs that are subject to digitalization, ICT, big data application, etc.
One of the main approaches in risk management of pension funds is to consider different grades of working conditions for members, and according to these grades, different payments are conveyed to the pension fund; see, e.g., D’Amico et al. (2013) and the bibliography therein. Accurate modeling of the pension scheme is very important, and too simplistic frameworks may represent a real risk for the pension fund (see, e.g., Slipsager 2018) as well as incorrect investment strategies (see, e.g., Wang et al. 2018).
In this paper, we do not consider the different grades of work as the main determinant of the salary because this choice is viable only when it is applied to specific funds that admit a rigid and fixed organizational structure over time. To overcome this limitation, we propose to model directly the income of the participants in the fund independently of the adoption of a specific working structure. The key point is then the appropriate modeling of participants’ incomes. To this end, we consider a model based on semi-Markov processes of income dynamics. This choice is motivated by the fact that semi-Markov processes admit transition probabilities that are duration dependent; see, e.g., D’Amico et al. (2012). This means that the time the system is in a state influences the transition probabilities for the exit from this state. In our case, if two people have the same income level, but they started to have it from two different dates, they can have different chances to experience transitions outside the current state of income and moving towards different income. The semi-Markov hypothesis of income dynamics is tested on real data through the application of a test proposed by Stenberg et al. (2006) involving the geometric distribution of the sojourn time distributions in the different levels of income. Furthermore, the computation of cash flows related to the pension fund is executed by considering a reward semi-Markov process. Reward processes of the semi-Markovian type have found different applications, and some of them are related to the cash-flow analysis of a pension fund or different problems; see, e.g., Janssen and Manca (1997); D’Amico (2013); Stenberg et al. (2006, 2007). Reward processes may convey relevant information to the managers of the fund about the total contributions the pension fund received by some time t. The proposed methodology is applied to a real dataset of active participants in the Italian Institute of Social Security.
The paper is divided as follows. First, a description of the database is described in Section 2. Next, in Section 3, the methodology is presented by introducing semi-Markov processes as related to the income evolution, as well as the reward structure. Finally, in Section 4, the results of the application of the model to the data are presented and discussed. In the last section, some concluding remarks are given.
2. Data
The stream of salaries of the active participants in the Italian Institute of Social Security is considered in this investigation. This is one of the biggest private schemes concerning first pillar pensions for professionals in Italy. The database contains information regarding more then 27,000 active participants recorded for a time span of 30 years, starting from 1981 till 2011.
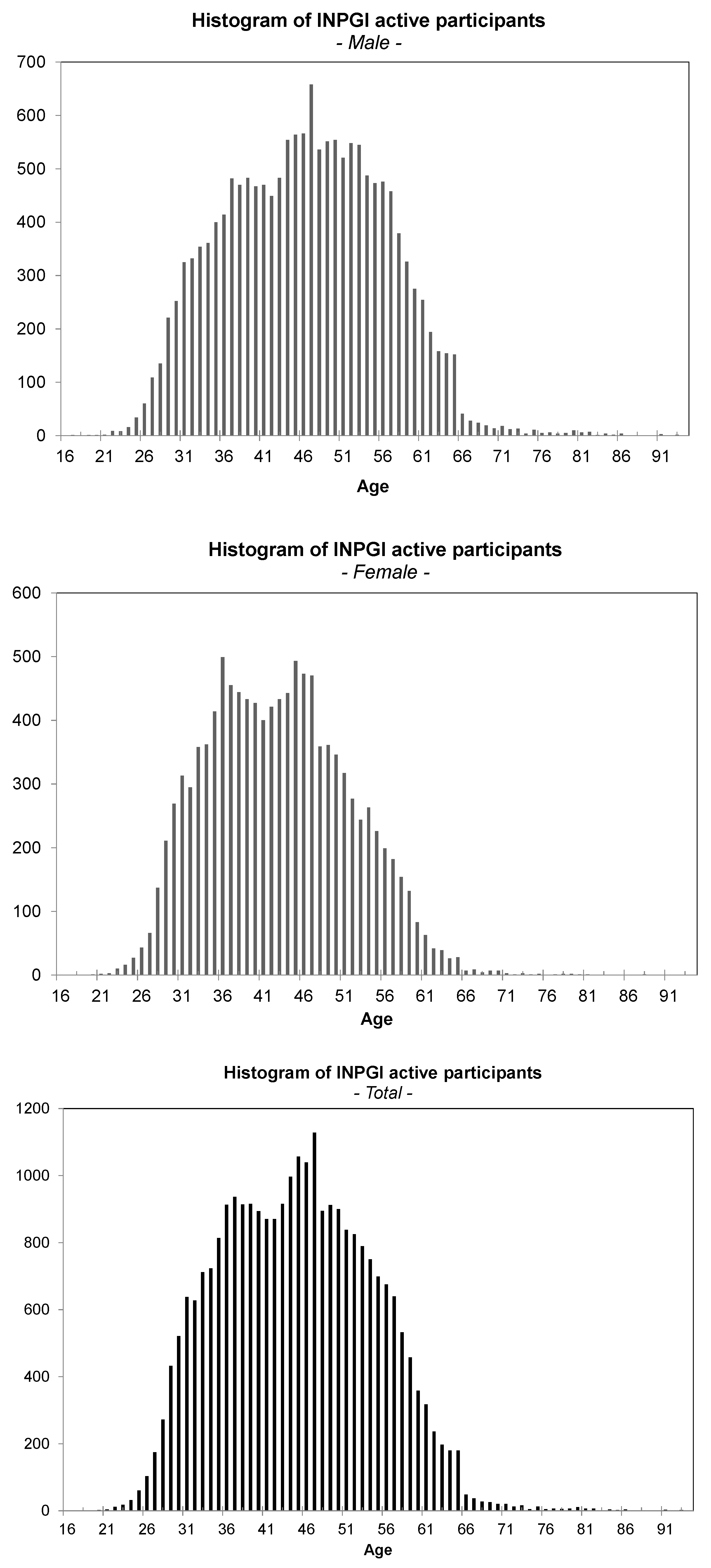
The following tables summarize some of the most relevant descriptive statistics of the dataset. In Table 1, the age distribution of the active participants is shown. The age is calculated at the end of the observation period, i.e., at end of December 2011. Furthermore, the histograms of the age distribution by gender, as well as for the total population of the active workers are shown in Figure 1. From the plots, it can be noticed that female workers are younger than males and that the distributions are far from being normal. Both distribution have a cut off at 65, the age at which the workers can retire. Only a few of the pensioners continue to work after 65. In both cases, the distributions are asymmetric, but while for males, we have a sharp right tail, for females, the behavior is the opposite.

Table 1.
Age class distribution of active participants.
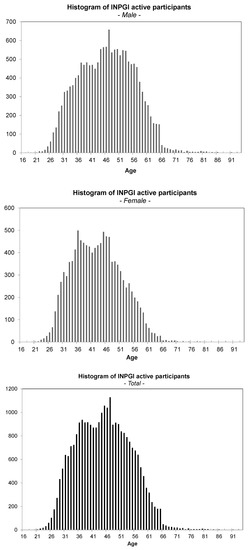
Figure 1.
Histogram of active workers by age.
Since the participants considered may have entered the pension scheme in different years, it seems relevant to calculate also the seniority of each active member of the dataset at the end of the observation period. The seniority is thus calculated considering the date of the first subscription of the member to the scheme, and the results are shown in Table 2.
Table 2.
Seniority class distribution of active participants.
Since the database consists of streams of salaries that refer to a long time span, it is important to also consider the monetary reevaluation of wages. In order to perform this, the index FOI (the Italian Consumer Price Index) calculated by ISTAT (The Italian Institute of Statistics) and obtained from www.istat.it was used. In particular, wages of active workers have been reevaluated up to the year 2011. Table 3 shows the coefficients used for the reevaluation for each year.
Table 3.
FOIindex.
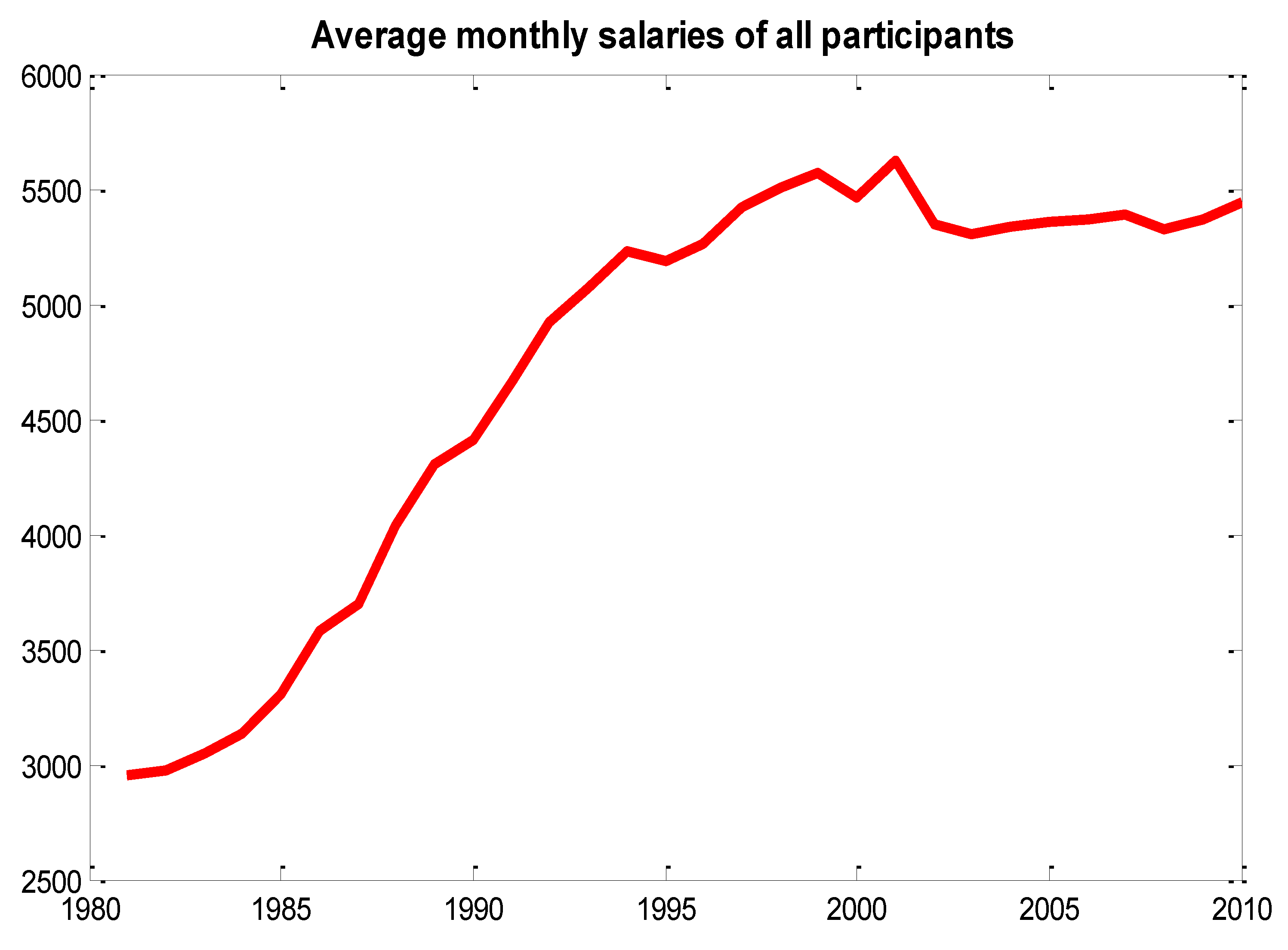
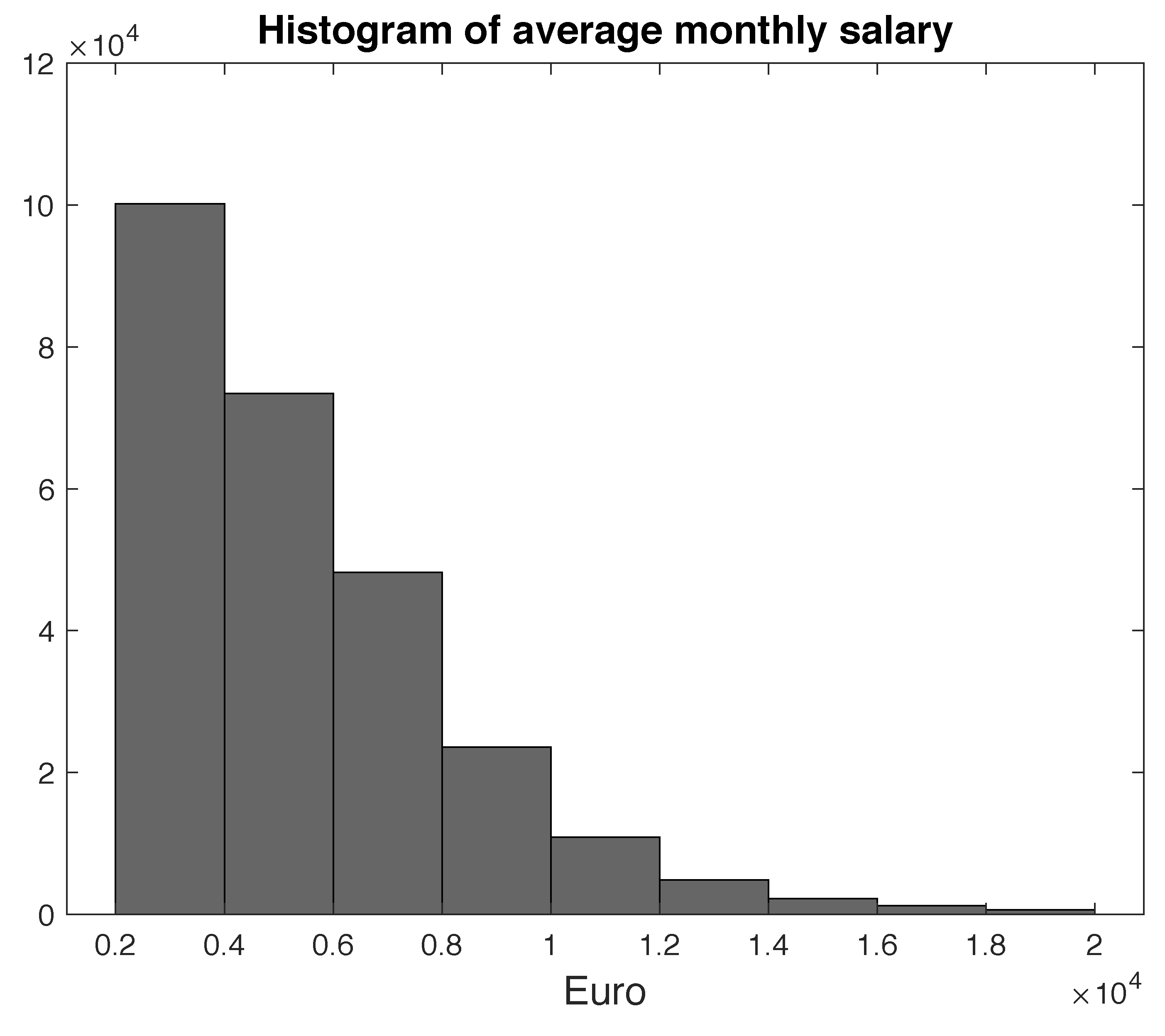
The salaries of the participants are collected by the Institute because the amount of the contribution paid by each single participant is proportionally dependent on his/her incomes. Given that the database reports only annual salaries collected by the scheme for contribution purposes, we calculated the monthly salaries by taking into account the effective months of contributions paid by each participant. Figure 2 shows the mean salary value of all participants for the time span considered, while Figure 3 shows the histogram of the average monthly salaries.
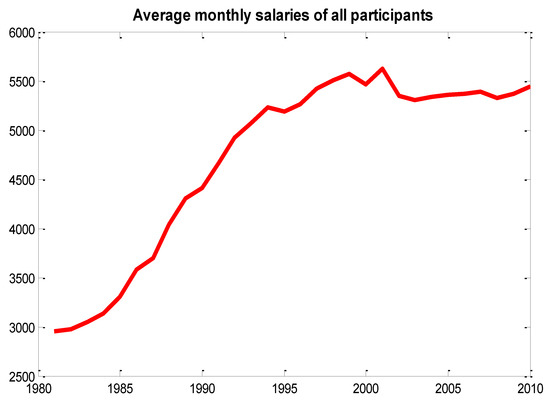
Figure 2.
Average monthly salaries of active participants.
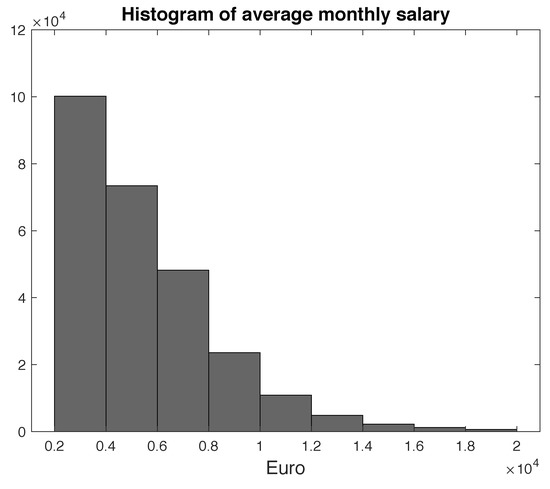
Figure 3.
Histogram of monthly salaries of active participants.
3. Methodology
In this section, we first present the semi-Markov model, and we explain it in relation to the income evolution of participants in the pension fund. Successively, we extend the mathematical model by introducing a reward structure that allows computing the financial evolution of the whole pension fund.
3.1. The Semi-Markov Model of Income Evolution
In this subsection, we introduce the semi-Markov processes as a tool for the description of the income evolution of participants in the pension fund.
Let us consider a probability space where the upcoming random variables are defined. Initially, we consider two sequences of random variables:
They denote, for a given individual in the fund, the level and the time when the level of his/her income changed, respectively. Thus, if and , the considered individual has an initial income of ; at some random time , she/he changes the level of the income that will be given by the random variable , and so on and so forth.
We assume that is a Markov renewal process on the state space with kernel . The set E denotes the state space of the model that collects the different values of the income that the participants in the fund may have during their life.
The kernel has the following probabilistic interpretation:
Relation (1) asserts that the joint distribution of the next income level and the time to reach it from the last income change depend only on the last income level i and not on the past evolution of incomes and times when the changes occurred. Note that Equation (1) does not depend either on n or on the specific value of , but only on the difference , then is said to be a time-homogeneous process.
From the kernel , we can obtain the transition probability matrix of the embedded Markov chain , as:
denotes the probability of assuming with the next change the income level j given the current level is i. These probabilities have nothing to say about the effective time of changing the state. The joint law of level income and transition time can be obtained as follows:
Equation (2) shows that instantaneous transitions, those having a sojourn time length equal to zero, are not allowed. It should also be remarked that the model may describe the case when transitions imply a real change of state of the system, and the case when a transition to the same state is possible as well. In the application considered in this paper, we will exclude the possibility of having a virtual transition, i.e., a transition from one state to itself because it is not observable in our dataset.
The distribution function that represents the unconditional waiting time distribution in a generic state i is defined as follows:
The quantity represents the probability that a participant in the fund remains at least for a time t at the level of income i. The same probability can be conditioned on the next level of income, leading to the following formula:
The function defined above denotes the waiting time distribution function (also denoted as the sojourn time distribution function) in state i given that, in the next transition, the process will be in the state j. It should be noted that in the semi-Markovian framework, the sojourn time distribution can be modeled by any type of distribution function. In cases where is geometrically or exponentially distributed, we obtain the discrete or the continuous time Markov chain, respectively.
It is possible to define the homogeneous semi-Markov chain (HSMC) as:
where . The process represents the level of income for each waiting time t.
Let us denote the transition probabilities of the HSMC by:
They satisfy the following evolution equation that can be solved using well-known algorithms deeply discussed in the literature (see, e.g., Barbu et al. 2004).
In the considered application, represents the probability that the participant in the fund does not change his/her income level in a time t. This part contributes to only if . The second part on the right-hand side of Formula (6) can be explained as follows: represents the probability a member of the fund remained at income level i up to the time and that he/she went to state k at time . After this change of state, we consider the probability the member will reach income state j following one of all the possible trajectories that go from state k to state j in the remaining time .
Once the HSMC is defined, it is necessary to introduce the discrete backward recurrence time process linked to the HSMC.
For each time , let us define the following stochastic process:
This process is called the discrete backward recurrence time process.
In our application, if the semi-Markov process indicates the income state of a member at time t, indicates the time since the last transition, i.e., the time elapsed since the last change in income level. It is well known that the joint process with values in is a Markov process; thus, it satisfies the following relation:
To save space, the event will be denoted in a more compact form by . To understand how the transition probabilities of the HSMC may change according to different values of the backward recurrence time process, we report here some of the results obtained in D’Amico et al. (2009).
We consider the following probabilities:
Formula (8) denotes the probability the member occupies income state j at time t with the entrance in this state periods before, given that at Time 0, the member was in state i, but entered in that state v time units before. Similarly, Formula (9) denotes the probability the member occupies income state j at time t given that at Time 0, the member was in state i, but entered in that state v time units before.
These probabilities are known in the literature as transition probabilities with initial and final backward () and transition probabilities with initial backward (); see, e.g., D’Amico et al. (2010).
In D’Amico et al. (2009), it was explained how it is possible to compute as a function of the semi-Markov kernel. For all states and times such that , we have that:
Notice that satisfies the following system of equations:
and if we denote by , we obtain:
3.2. Semi-Markov Reward Processes
The considered transition probabilities allow the computation of the probability of some events (state income and times) of interest that in turn generate financial payments. Nonetheless, the management of a pension fund needs the correct modeling and assessment of the cumulated amount of money along the life of its members. To this end, it is necessary to introduce the concept of a reward structure.
A reward is paid by the member to the fund at time due to the occupancy of income state having the member elapsed units of time in this state. Therefore, is a positive amount of money for the fund and a negative one for the member who is paying it.
Notice that and are random variables, and therefore, is a random variable as well. As a matter of example, if , then the reward paid/gained at current time t is equal to .
In our application, it is important to discount rewards because they represent monetary values, and finance operators assign different values to the same amount of money available to different times. For this purpose, we consider a deterministic one-period discount factor with such that:
expresses a value of zero of the permanence reward paid at time and due to the occupancy at this time of state .
The accumulated discounted reward during the time interval is the main variable in which we are interested. It is denoted by and is defined as the discounted sum of the permanence rewards (12) collected in times ; formally,
It should be noted that our model is able to consider different rewards for members that belong to the same income class (state), but that experience a different duration of permanence in this state.
Let us also denote by:
the expected discounted sum of rewards conditional on the occupancy at time zero of state i with backward time equal to v.
The function satisfies the following equation (see Stenberg et al. 2007):
More general semi-Markov reward processes were studied in Papadopoulou and Tsaklidis (2007); D’Amico et al. (2013, 2015).
The quantity represents the amount of money paid by the member to the pension fund, but assuming that the dynamics of all members can be considered independent and evolving according to the same semi-Markov kernel, it is possible to evaluate the characteristic of the total fund in terms of the total expected discounted amount of deposits. More precisely, if the fund is composed at the initial time zero of K members allocated in the income classes according to the matrix where is the number of members that at Time 0 are in income level i with the duration of occupancy of this class equal to v, then the expected deposit is given by:
It should be mentioned that according to the general theory developed for semi-Markov systems, it is also possible to evaluate open systems, as done for example in McClean (1980); Papadopoulou et al. (2012); Papadopoulou and Vassiliou (1999).
4. Results and Discussion
In this section, we will try to implement a Markov process to describe the salary evolution of the active participants of the pension scheme. In particular, we are interested in finding out whether the model described in Section 3.1, i.e., a semi-Markov model with a backward reward process, is more suitable than a simple Markov chain to model salaries.
From the analysis of the graphs shown in the above paragraph, and in particular of the histogram of the average monthly salaries, we chose to divide salaries into 11 states. The first ten states were constructed considering salaries from 0–20,000 Euros and forming groups by a step of 2000 Euros, i.e., the first state considered the interval , the second one , and so on. The last state was a residual class for salaries higher than 20,000 Euros.
The salary evolution can be modeled considering transitions from the above defined classes through a Markov process, which as mentioned before considers geometrically-distributed waiting times, or through a semi-Markov process, which permits the use of whatever type of distribution of the waiting times.
First, we estimated the transition probability matrices of a Markov chain through its maximum likelihood estimator. To this end, we observed that in our applied problem, the income evolution of the K members was over a fixed observation period of length T. If we considered the observations from each member as independent and statistically identical copies, we can estimate the transition probability matrix as follows:
where denote the number of times the process transitioned from a generic state i to another generic state j in the next time unit and the total number of times the process transitioned in the generic state i, respectively. As is possible to see from Equation (15), the transition probability matrix of the Markov chain was obtained by counting the number of transitions from every time to the successive one. The estimated matrix is:
The second step is that of modeling the salary evolution through a semi-Markovian process. In order to do so, first the transition probabilities of the embedded Markov chain have to be estimated according to:
where is the number of transitions in the member of the pension scheme. Once the embedded Markov chain has been estimated, we need to estimate the distribution of the waiting times.
Let us firstly define the probability mass function of the sojourn times as follows:
We considered a discrete time step of one year and calculated the waiting times for up to 20 years. Through an algorithm, we estimated the sojourn times on the data using the following:
where denotes the number of transitions from state i to state j held by member n in the observational period .
In order to verify the semi-Markov hypothesis, a test proposed by Stenberg et al. (2006) can be applied. Obviously, the model can be considered Markovian if the sojourn times are geometrically distributed.
Under the geometric hypothesis, the equality must hold. Then, a sufficiently strong deviation from this equality has to be interpreted as evidence in favor of the semi-Markov model.
The test-statistic is the following:
where is the empirical estimator of the probability .
The results of the test statistic are shown in Table 4. It reports the score as calculated from Equation (19) for the eleven states of the salaries.
Table 4.
Test scores for the classes of salaries.
This statistic, under the geometric hypothesis (or Markovian hypothesis), has approximately the standard normal distribution. This means that large values of the test statistic suggest the rejection of the Markovian hypothesis in favor of the more general semi-Markov one. We applied this procedure to our data to execute tests at a significance level of .
In Table 5, we show the results of the test applied to the waiting time distribution functions where R means the null hypothesis is , while A means that the null hypothesis of geometric distribution of the waiting times is .
Table 5.
Decision for the null hypothesis for classes of salaries. R, Rejected; A, Accepted.
As shown in Table 5, the geometric hypothesis was rejected for 31% of the waiting time distributions. There is, thus, evidence that we should be inclined to choose the more general model of a semi-Markov process over that of a simple Markov chain.
We also considered the case of the worker’s job qualification for the construction of the states of the salary process. The database furnished the necessary information regarding the different levels of qualification for each participant in each year of the observation period. In order to have an estimation as robust as possible, only qualifications with more then 5000 participants were considered.
The hypothesis under such modeling is that the transition from one qualification to the other, which would indirectly imply a transition in the salary level, can be described by a Markov process. The procedure applied was quite similar to the one described above. First, we estimated the transition probability matrix of the Markov chain through the same algorithm described above. The estimated matrix is:
Secondly, we supposed that a semi-Markov model could better explain the transitions between states since it gives the possibility of using whatever type of waiting time distribution.
The values of the statistic test were obtained in the same way as seen above and are reported in Table 6. We fixed a level of significance of 95%, and the results of the statistic test are given in Table 7. The null hypothesis of the geometric distribution was rejected for 25% of the waiting time distributions considered, and thus, we concluded that the semi-Markov process was more suitable to model the salary evolution of participants with states formed on the basis of the active workers’ qualification.
Table 6.
Test scores for the qualification states.
Table 7.
Decision for the null hypothesis for qualification states.
4.1. Markov versus Semi-Markov: An Alternative Test Based on Wilk’s Test
A more powerful test could be applied to test the Markov chain assumption against the semi-Markov alternative.1
To this end, we observed that if the model under the null hypothesis was a Markov chain with transition probabilities , then the following relation could be established with the corresponding semi-Markov kernel (see, e.g., Barbu and Limnios 2008):
from which it is simple to establish that:
and consequently:
Relation (20) shows that , under the null hypothesis, is independent of j, and then, the equality:
should be the same for all . The test proposed by Stenberg et al. (2006) ignored this fact and therefore can be improved by an alternative test that considers this additional property.
Informally, it would be possible to compare the log-likelihood function under the null hypothesis (Markov model) with that under the alternative hypothesis (semi-Markov model) . The specific form of this likelihood can be obtained for example in Sadek and Limnios (2002) and in Trevezas and Limnios (2011).
Once these values have been computed, a Wilk’s likelihood ratio test can be applied using the statistic:
which is approximately distributed as a chi-squared distribution with the degree of freedom equal to the difference between the number of free parameters of the semi-Markov model and those of the Markov chain model.
4.2. Results on Accumulated Rewards
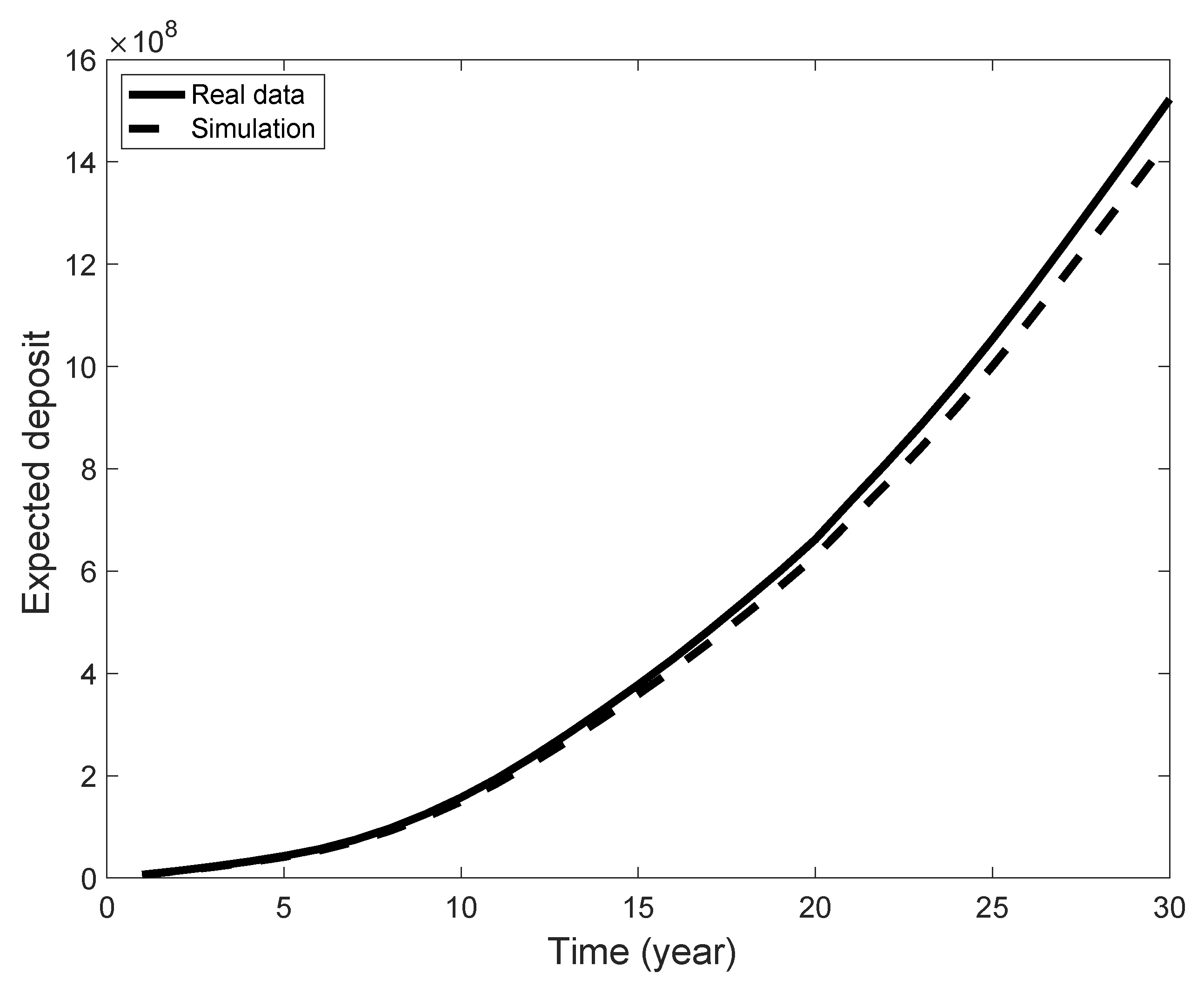
According to Equation (14), it is possible to estimate, at Time 0, the total expected discounted amount of deposits due to the payments of all members of the fund up to time t. To do so, we fixed a constant discount factor (a term structure of discount factors can also be simply used) and a the level of contribution, which is just a constant fraction of the salary, to for the whole time period t. Using the estimated probabilities, according to the previous section, we ran extensive Monte Carlo simulations and back tested the performance of the proposed model. In Figure 4, a comparison between real and simulated data is shown. We estimated the mean percentage absolute error between the two curves, obtaining a value of , showing a good agreement between the data and model.
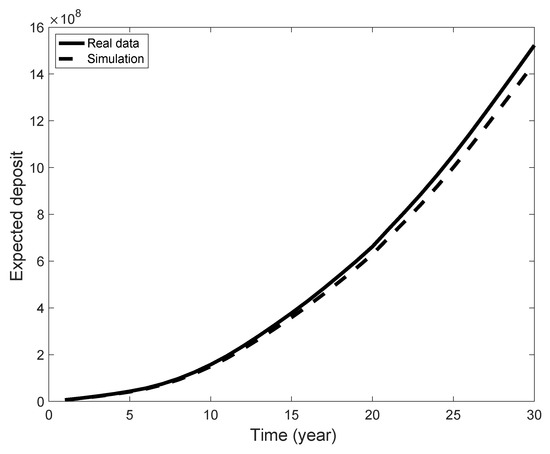
Figure 4.
Expected deposit as a function of time.
The analysis shows that the model can be useful to estimate the future reserve accumulated in the fund by giving a good prediction of the salary lines of the workers.
5. Conclusions
In this paper, we proposed a semi-Markov Chain with backward recurrence time to model salary lines. This is a more general model compared to the simple Markov chain since any type of distribution can be used for the waiting times, while the latter allows only the geometric distribution.
The model was applied to a dataset of active participants in the Italian Pension Scheme of the First Pillar. More than 27 thousand workers were observed over a period of 30 years. Salaries of participants were clustered to form the states of a stochastic process in two ways: the first one considered classes of salaries of 2000 Euros, while the second one was based on the qualification of the workers. In both cases, the transition probability matrices of the embedded Markov chain were estimated. Then, the semi-Markov hypothesis was tested by a statistical test applied in the recent literature. We fixed a significance level of 95% and performed the statistical test on the distribution of the waiting times. The null hypothesis of the geometric distribution was rejected for nearly 30% and 25% of the tests, in the two cases considered, and thus, we concluded that the semi-Markov model should be preferred to a simple Markov chain to model salary evolution of participants. The model was also used to estimate the total expected discounted amount of deposits and compared to real data, showing a good agreement.
Further extension could be the use of a non-homogeneous semi-Markov process, which can be used to take into account the variation of the mean salary due to digitalization, ICT, the employment of the big data technique, and other technological evolutions. This interesting generalization for future studies needs the development of specific procedure for testing the hypothesis of homogeneity against the more general non-homogeneity assumption. A departing point could be the application of a chi-squared-type test of homogeneity proposed by Vassiliou and Vasileiou (2013).
Author Contributions
The authors equally contributed to the present work.
Funding
This research received no external funding.
Acknowledgments
F. Petroni wishes to acknowledge financial support from the project “INTANGIBLES 4.0” of DiMa, Polytechnic University of Marche.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Barbu, Vlad, Michel Boussemart, and Nikolaos Limnios. 2004. Discrete time semi-Markov model for reliability and survival analysis. Communications in Statistics-Theory and Methods 33: 2833–68. [Google Scholar] [CrossRef]
- Barbu, Vlad Stefan, and Nikolaos Limnios. 2008. Semi-Markov Chains and Hidden Semi-Markov Models toward Applications—Their Use in Reliability and DNA Analysis. Lecture Notes in Statistics. New York: Springer, vol. 191. [Google Scholar]
- D’Amico, Guglielmo, Montserrat Guillen, and Raimondo Manca. 2009. Full backward non homogeneous semi-Markov processes for disability insurance models: A Catalunya real data application. Insurance: Mathematics and Economics 45: 173–9. [Google Scholar] [CrossRef]
- D’Amico, Guglielmo, Jacques Janssen, and Raimondo Manca. 2010. Initial and final backward and forward discrete time non homogeneous semi-Markov processes credit risk models. Methodology and Computing in Applied Probability 12: 215–25. [Google Scholar] [CrossRef]
- D’Amico, Guglielmo, Jacques Janssen, and Raimondo Manca. 2011. Duration Dependent Semi-Markov Models. Applied Mathematical Sciences 5: 2097–108. [Google Scholar]
- D’Amico, Guglielmo. 2013. A semi-Markov approach to the stock valuation problem. Annals of Finance 9: 589–610. [Google Scholar] [CrossRef]
- D’Amico, Guglielmo, Montserrat Guillen, and Raimondo Manca. 2013. Semi-Markov Disability Insurance Models. Communications in Statistics-Theory and Methods 42: 2172–88. [Google Scholar] [CrossRef]
- D’Amico, Guglielmo, Filippo Petroni, and Flavio Prattico. 2015. Performance Analysis of Second Order Semi-Markov Chains: An Application to Wind Energy Production. Methodology and Computing in Applied Probability 17: 781–94. [Google Scholar] [CrossRef]
- Janssen, Jacques, and Raimondo Manca. 1997. A realistic non-homogeneous stochastic pension funds model on scenario basis. Scandinavian Actuarial Journal 1997: 113–37. [Google Scholar] [CrossRef]
- McClean, Sally I. 1980. A Semi-Markov model for a multigrade population with poisson recruitment. Journal of Applied Probability 17: 846–52. [Google Scholar] [CrossRef]
- Papadopoulou, Aleka, and George Tsaklidis. 2007. Some Reward Paths in Semi-Markov Models with Stochastic Selection of the Transition Probabilities. Methodology and Computing in Applied Probability 9: 399–411. [Google Scholar] [CrossRef]
- Papadopoulou, Aleka A., and Panagiotis C. G. Vassiliou. 1999. Continuous Time Non Homogeneous Semi-Markov Systems. In Semi-Markov Models and Applications. Edited by Jacques Janssen and Nikolaos Limnios. Boston: Springer. [Google Scholar]
- Papadopoulou, Aleka A., George Tsaklidis, Sally McClean, and Lalit Garg. 2012. On the moments and the Distribution of the Cost of a semi-Markov Model for Healthcare Systems. Methodology and Computing in Applied Probability 14: 717–37. [Google Scholar] [CrossRef]
- Sadek, Amr, and Nikolaos Limnios. 2002. Asymptotic properties for maximum likelihood estimators for reliability and failure rates of Markov chains. Communications in Statistics Theory and Methods 31: 1837–61. [Google Scholar] [CrossRef]
- Slipsager, Søren Kærgaard. 2018. The real risk in pension forecasting. Scandinavian Actuarial Journal 2018: 250–73. [Google Scholar] [CrossRef]
- Stenberg, Fredrik, Raimondo Manca, and Dmitrii Silvestrov. 2006. Semi-Markov reward models for disability insurance. Theory of Stochastic Processes 12: 239–54. [Google Scholar]
- Stenberg, Fredrik, Raimondo Manca, and Dmitrii Silvestrov. 2007. An algorithmic approach to discrete time non-homogeneous backward semi-Markov reward processes with an application to disability insurance. Methodology and Computing in Applied Probability 9: 497–519. [Google Scholar] [CrossRef]
- Trevezas, Samis, and Nikolaos Limnios. 2011. Exact MLE and asymptotic properties for nonparametric semi-Markov models. Journal of Nonparametric Statistics 23: 719–39. [Google Scholar] [CrossRef]
- Vassiliou, Panagiotis, and Aglaia Vasileiou. 2013. Asymptotic behavior of the survival probabilities in an homogeneous semi-Markov model for the migration process in credit risk. Linear Algebra and its Applications 438: 2880–903. [Google Scholar] [CrossRef]
- Wang, Suxin, Yi Lu, and Barbara Sanders. 2018. Optimal investment strategies and intergeneretional risk sharing for target benefit pension plans. Insurance: Mathematics and Economics 80: 1–14. [Google Scholar]
| 1. | The authors acknowledge an anonymous referee for suggesting this testing strategy. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).