In this section, we first present the semi-Markov model, and we explain it in relation to the income evolution of participants in the pension fund. Successively, we extend the mathematical model by introducing a reward structure that allows computing the financial evolution of the whole pension fund.
3.1. The Semi-Markov Model of Income Evolution
In this subsection, we introduce the semi-Markov processes as a tool for the description of the income evolution of participants in the pension fund.
Let us consider a probability space
where the upcoming random variables are defined. Initially, we consider two sequences of random variables:
They denote, for a given individual in the fund, the level and the time when the level of his/her income changed, respectively. Thus, if and , the considered individual has an initial income of ; at some random time , she/he changes the level of the income that will be given by the random variable , and so on and so forth.
We assume that is a Markov renewal process on the state space with kernel . The set E denotes the state space of the model that collects the different values of the income that the participants in the fund may have during their life.
The kernel has the following probabilistic interpretation:
Relation (
1) asserts that the joint distribution of the next income level and the time to reach it from the last income change depend only on the last income level
i and not on the past evolution of incomes and times when the changes occurred. Note that Equation (
1) does not depend either on
n or on the specific value of
, but only on the difference
, then
is said to be a time-homogeneous process.
From the kernel
, we can obtain the transition probability matrix of the embedded Markov chain
,
as:
denotes the probability of assuming with the next change the income level
j given the current level is
i. These probabilities have nothing to say about the effective time of changing the state. The joint law of level income and transition time can be obtained as follows:
Equation (
2) shows that instantaneous transitions, those having a sojourn time length equal to zero, are not allowed. It should also be remarked that the model may describe the case when transitions imply a real change of state of the system, and the case when a transition to the same state is possible as well. In the application considered in this paper, we will exclude the possibility of having a virtual transition, i.e., a transition from one state to itself because it is not observable in our dataset.
The distribution function that represents the unconditional waiting time distribution in a generic state
i is defined as follows:
The quantity
represents the probability that a participant in the fund remains at least for a time
t at the level of income
i. The same probability can be conditioned on the next level of income, leading to the following formula:
The function defined above denotes the waiting time distribution function (also denoted as the sojourn time distribution function) in state i given that, in the next transition, the process will be in the state j. It should be noted that in the semi-Markovian framework, the sojourn time distribution can be modeled by any type of distribution function. In cases where is geometrically or exponentially distributed, we obtain the discrete or the continuous time Markov chain, respectively.
It is possible to define the homogeneous semi-Markov chain (HSMC)
as:
where
. The process
represents the level of income for each waiting time
t.
Let us denote the transition probabilities of the HSMC by:
They satisfy the following evolution equation that can be solved using well-known algorithms deeply discussed in the literature (see, e.g.,
Barbu et al. 2004).
In the considered application,
represents the probability that the participant in the fund does not change his/her income level in a time
t. This part contributes to
only if
. The second part on the right-hand side of Formula (
6) can be explained as follows:
represents the probability a member of the fund remained at income level
i up to the time
and that he/she went to state
k at time
. After this change of state, we consider the probability the member will reach income state
j following one of all the possible trajectories that go from state
k to state
j in the remaining time
.
Once the HSMC is defined, it is necessary to introduce the discrete backward recurrence time process linked to the HSMC.
For each time
, let us define the following stochastic process:
This process is called the discrete backward recurrence time process.
In our application, if the semi-Markov process
indicates the income state of a member at time
t,
indicates the time since the last transition, i.e., the time elapsed since the last change in income level. It is well known that the joint process
with values in
is a Markov process; thus, it satisfies the following relation:
To save space, the event
will be denoted in a more compact form by
. To understand how the transition probabilities of the HSMC may change according to different values of the backward recurrence time process, we report here some of the results obtained in
D’Amico et al. (
2009).
We consider the following probabilities:
Formula (
8) denotes the probability the member occupies income state
j at time
t with the entrance in this state
periods before, given that at Time 0, the member was in state
i, but entered in that state
v time units before. Similarly, Formula (
9) denotes the probability the member occupies income state
j at time
t given that at Time 0, the member was in state
i, but entered in that state
v time units before.
These probabilities are known in the literature as transition probabilities with initial and final backward (
) and transition probabilities with initial backward (
); see, e.g.,
D’Amico et al. (
2010).
In
D’Amico et al. (
2009), it was explained how it is possible to compute
as a function of the semi-Markov kernel. For all states
and times
such that
, we have that:
Notice that
satisfies the following system of equations:
and if we denote by
, we obtain:
3.2. Semi-Markov Reward Processes
The considered transition probabilities allow the computation of the probability of some events (state income and times) of interest that in turn generate financial payments. Nonetheless, the management of a pension fund needs the correct modeling and assessment of the cumulated amount of money along the life of its members. To this end, it is necessary to introduce the concept of a reward structure.
A reward is paid by the member to the fund at time due to the occupancy of income state having the member elapsed units of time in this state. Therefore, is a positive amount of money for the fund and a negative one for the member who is paying it.
Notice that and are random variables, and therefore, is a random variable as well. As a matter of example, if , then the reward paid/gained at current time t is equal to .
In our application, it is important to discount rewards because they represent monetary values, and finance operators assign different values to the same amount of money available to different times. For this purpose, we consider a deterministic one-period discount factor
with
such that:
expresses a value of zero of the permanence reward paid at time
and due to the occupancy at this time of state
.
The accumulated discounted reward during the time interval
is the main variable in which we are interested. It is denoted by
and is defined as the discounted sum of the permanence rewards (
12) collected in times
; formally,
It should be noted that our model is able to consider different rewards for members that belong to the same income class (state), but that experience a different duration of permanence in this state.
Let us also denote by:
the expected discounted sum of rewards conditional on the occupancy at time zero of state
i with backward time equal to
v.
The quantity
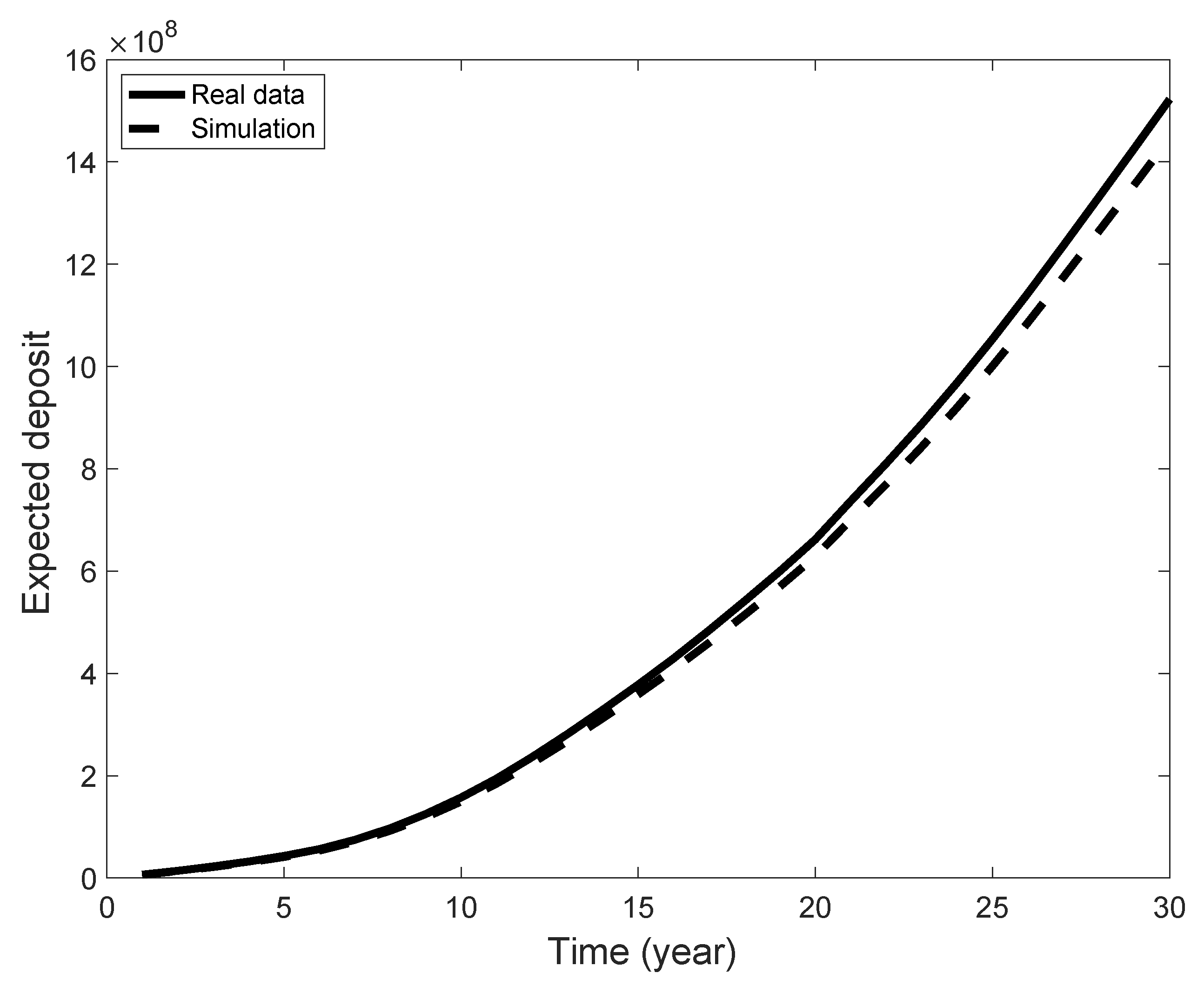
represents the amount of money paid by the member to the pension fund, but assuming that the dynamics of all members can be considered independent and evolving according to the same semi-Markov kernel, it is possible to evaluate the characteristic of the total fund in terms of the total expected discounted amount of deposits. More precisely, if the fund is composed at the initial time zero of
K members allocated in the income classes according to the matrix
where
is the number of members that at Time 0 are in income level
i with the duration of occupancy of this class equal to
v, then the expected deposit is given by:





{kind=link}
{kind=link}
{kind=link}
{kind=link}