The hidden Markov model has been widely used in the financial mathematics area to predict economic regimes or predict stock prices. In this paper, we explore a new approach of HMM in predicting stock prices and trading stocks. In this section, we discuss how to use the Akaike information criterion (AIC)
Akaike (
1974), the Bayesian information criterion (BIC)
Schwarz (
1978), the Hannan– Quinn information criterion (HQC)
Hannan and Quinn (
1979), and the Bozdogan Consistent Akaike Information Criterion (CAIC)
Bozdogan (
1987) to test the HMM’s performances with different numbers of states. We will then present how to use HMM to predict stock prices. Finally, we will use the predicted results to trade the stocks.
3.1. Model Selection
Choosing a number of hidden states for the HMM is a critical task. In the section, we use four common criteria: the AIC, the BIC, the HQC, and the CAIC to evaluate the performances of HMM with different numbers of states. These criteria are suitable for HMM because, in the model training algorithm, the Baum–Welch
Algorithm A.3, the EM method was used to maximize the log-likelihood of the model. We limit numbers of states from two to six to keep the model simple and feasible to stock prediction. These criteria are calculated using the following formulas, respectively:
where
L is the likelihood function for the model,
M is the number of observation points, and
k is the number of estimated parameters in the model. In this paper, we assume that the distribution corresponding with each hidden state is a Gaussian distribution; therefore, the number of parameters,
k, is formulated as
, where
N is numbers of states used in the HMM.
To train HMM’s parameters, we use a historical observed data of a fixed length
T,
where
with
or 4 represents the open, low, high or closing price of a stock, respectively. For the HMM with a single observation sequence, we use only closing price data,
where
is the stock closing price at time
t. We use S&P 500 monthly data to train the HMM and calculate these AIC, BIC, HQC, and CAIC. Each time, we use a block of length
(ten year period) of S&P 500 prices,
O = (open, low, high, close), to calibrate HMM’s parameters and calculate the AIC and BIC numbers. The first block of data is the S&P 500 monthly prices from December 1996 to November 2006. We use the set of data to calibrate HMM’s parameters using the Baum–Welch
Algorithm A.3. Then we use the parameters to calculate the probability of the observations, which is the likelihood
L of the model, using the forward
algorithm A.1. Finally, we use the likelihood to calculate the criteria using formulas (1)–(4). We choose initial parameters for the first calibration as follows:
where
and
is the standard normal distribution.
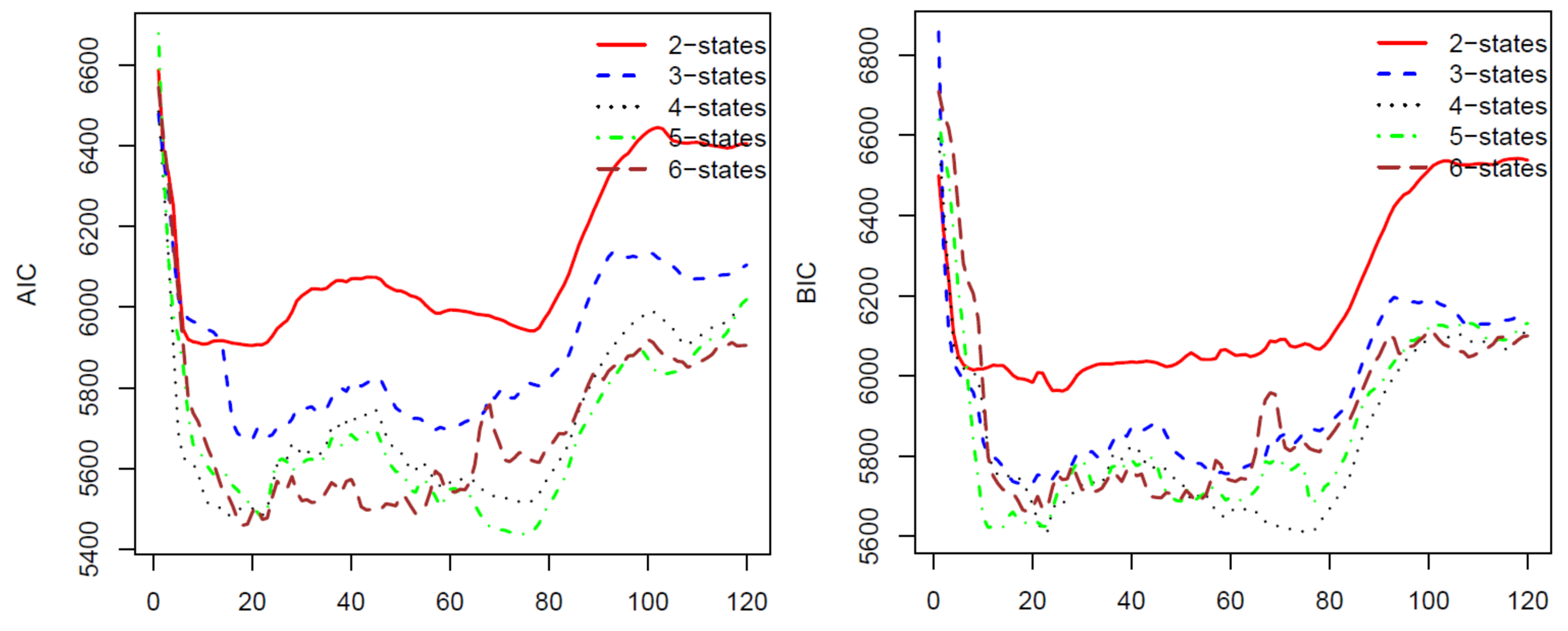
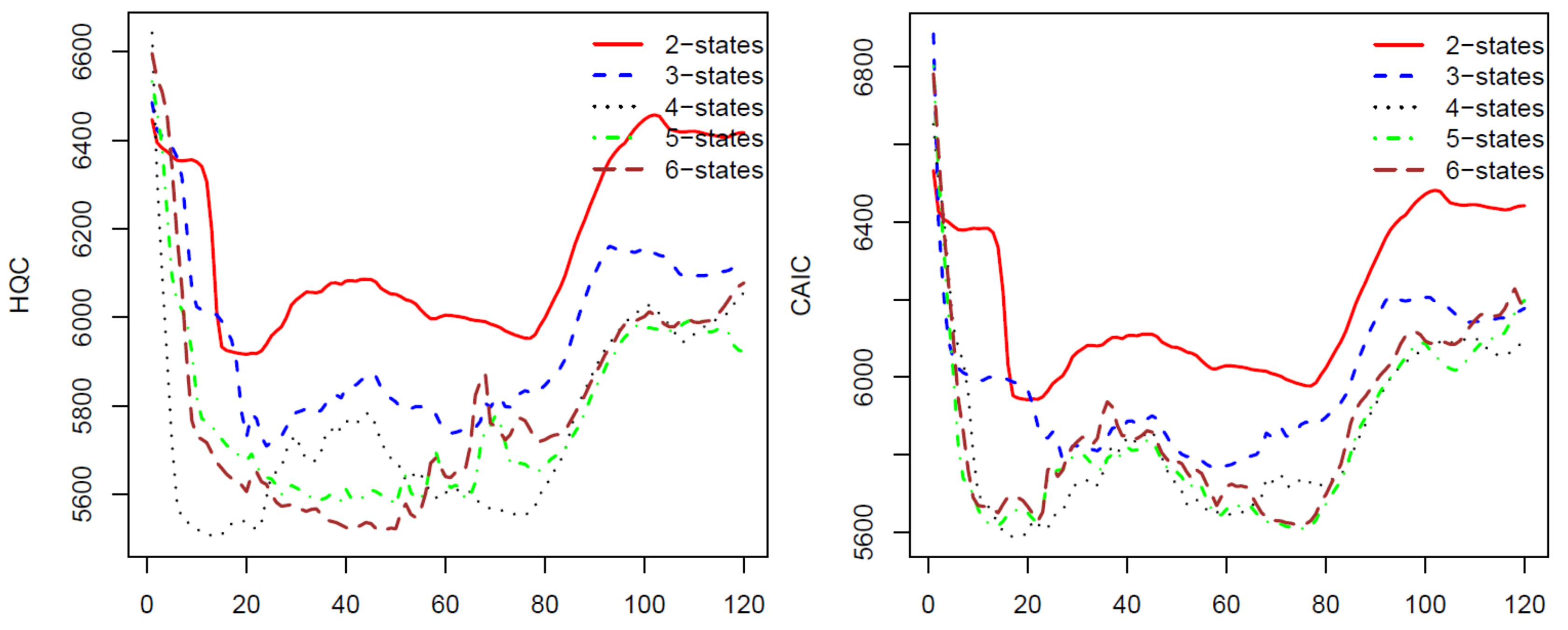
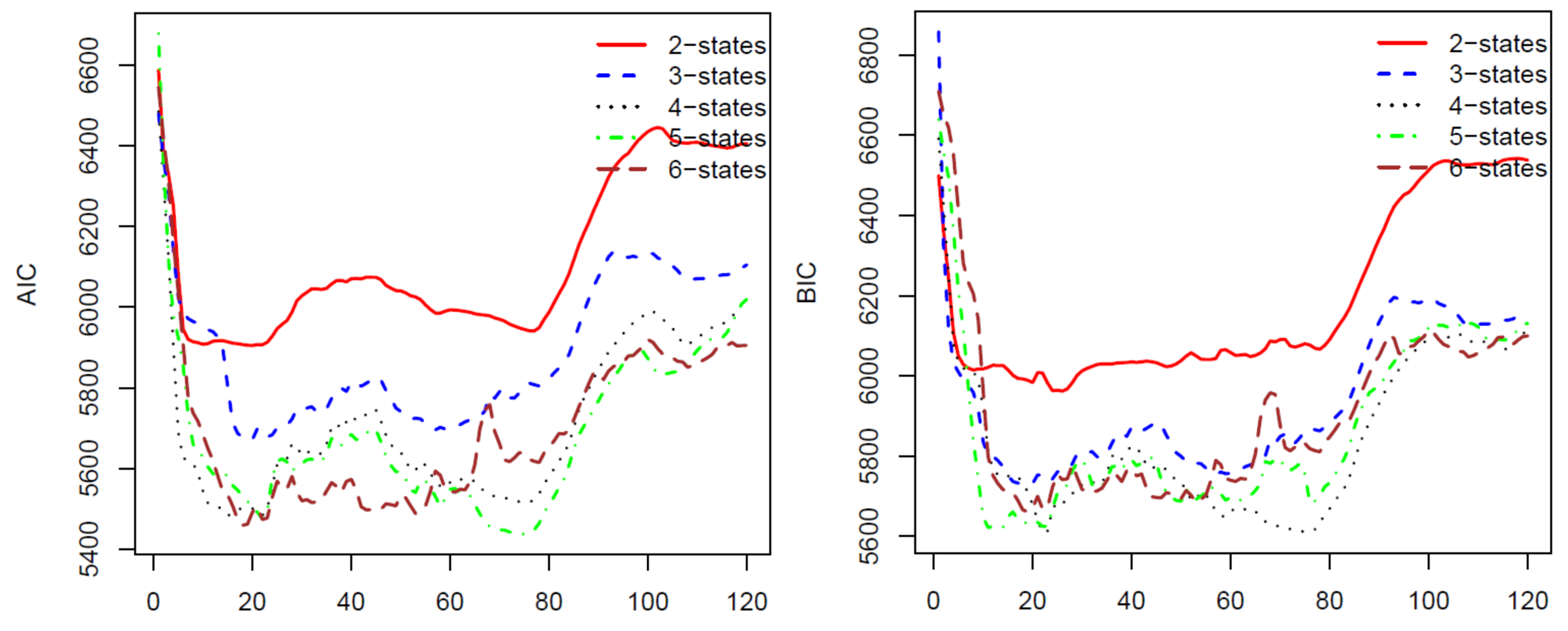
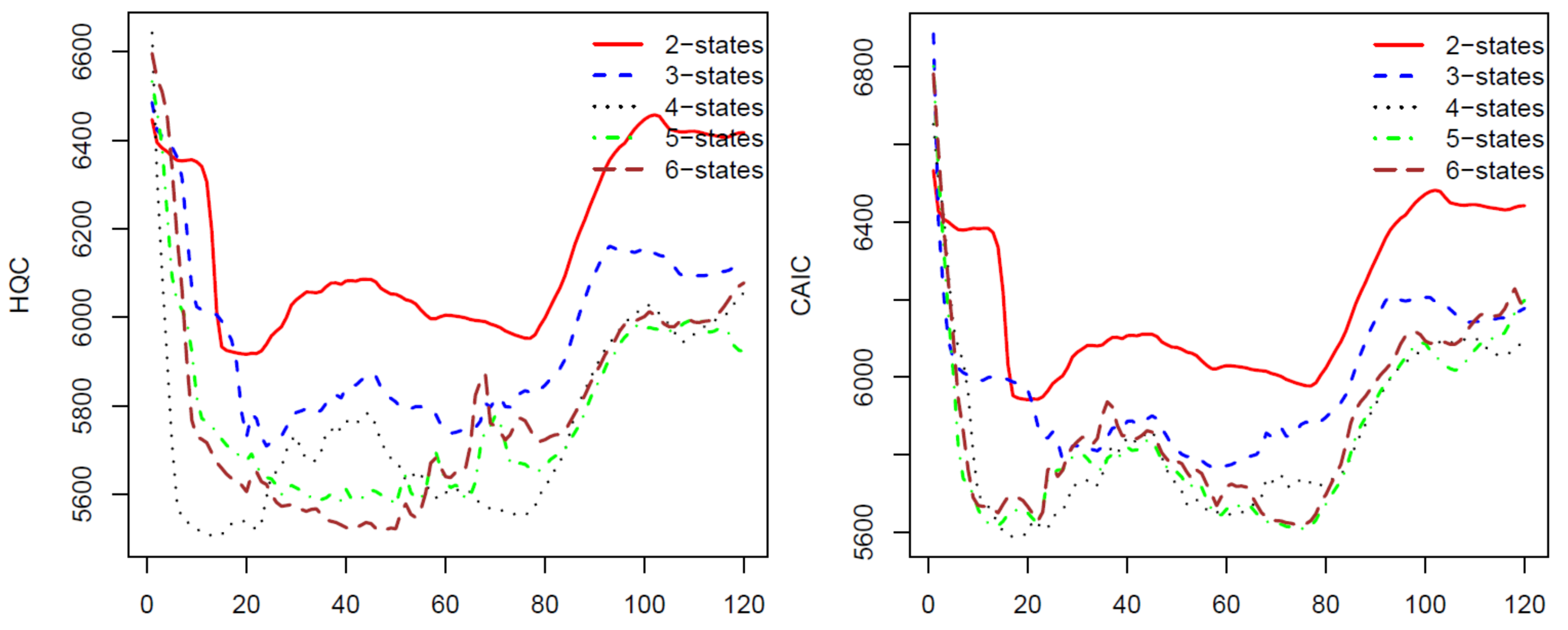
For the second calibration, we move the ten-year data upward one month, we have a new data set from January 1997 to December 2006 and use the calibrated parameters from the first calibration as initial parameters. We repeat the process 120 times for 120 blocks of data by moving the block of data forward. The last block of data is the monthly prices from November 2006 to November 2016. The AIC, BIC, HQC, and CAIC of the 120 calibrations are presented in
Figure 1 and
Figure 2. In all of these four criteria, a model with a lower criterion value is better. Thus, the results from
Figure 1 and
Figure 2 show that the four-state HMM is the best model among the two to six state HMMs. Therefore, we will use HMM with four states in stock price predicting and trading. We want to note that, for a different stock using these criteria, we may have another optimal number of states for the HMM. Therefore, we suggest that, before applying the HMM to predict prices for a stock, researchers should use some of the criteria to choose a number of states of the HMM that works the best for the stock.
3.2. Out-of-Sample Stock Price Prediction
In this section, we will use the HMM to predict stock prices and compare the predictions with the real stock prices, and with the results of using the historical average return method. We use S&P 500 monthly prices from January 1950 to November 2016.
We first introduce how to predict stock prices using HMM. The prediction process can be divided into three steps. First, HMM’s parameters are calibrated using training data and the probability is calculated (or likelihood) of the observation of the data set. Then, we will find a “similar data” set in the past that has a similar likelihood to that of the training data. Finally, we will use the difference of stock prices in the last month of the founded sequence with the price of the consecutive month to predict future stock prices. This prediction approach is based on the work of
Hassan and Nath (
2005). However, the authors predicted daily prices of four airline stocks while we predict monthly prices of the U.S. benchmark market, the S&P 500. Suppose that we want to predict closing price at time
of the S&P 500. In the first step, we will choose a fixed time length
D of the training data (we call
D is the training window) and then use the training data from time
to
T to calibrate HMM’s parameters,
. We assume that the observation probability
, defined in
Section 1, is Gaussian distribution, so the matrix
B, in the parameter
, is a two by
N matrix of means,
, and variances,
, of the
N normal distributions, where
N is the number of states. The initial HMM’s parameters for the calibration were calculated by using formula (5). The training data is the four sequences: open, low, high, and closing price:
We then calculate the probability of observation,
. In the second step, we move the block of data backward by one month to have new observation data
and calculate
. We keep moving blocks of data backward month by month until we find a data set
, (
), such that
. In the final step, we estimate the stock’s closing price for time
,
, by using the following formula:
Similarly, to predict stock price at time , we will use new training data O: to predict stock price for the time . The calibrated HMM’s parameters in the first prediction were used as the initial parameters for the second prediction. We repeat the three-step-prediction process for the second prediction and so on. For convenience, we use the training window D equal to the out-of-sample forecast period. In practice, we can choose an out-of-sample of any length, but, for the training window D, due to the efficiency of model simulations, we should determine a proper length based on the characteristics of chosen data.
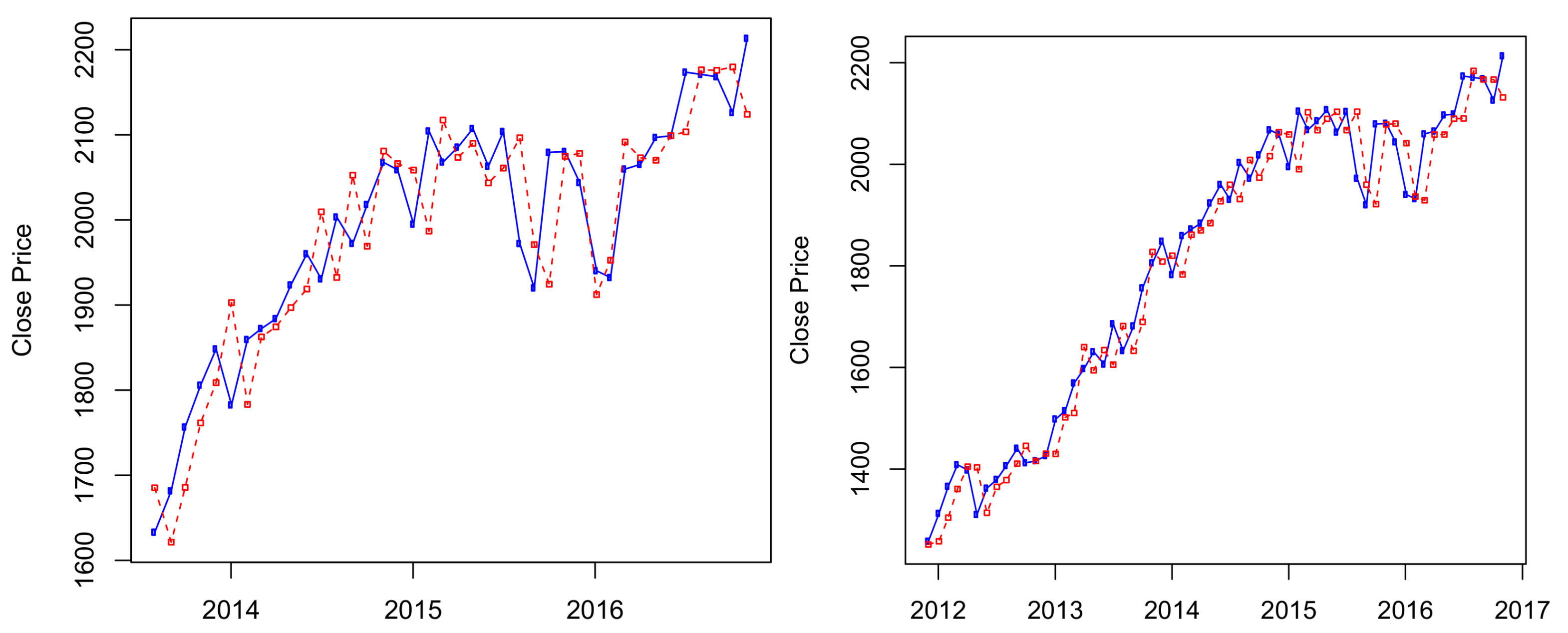
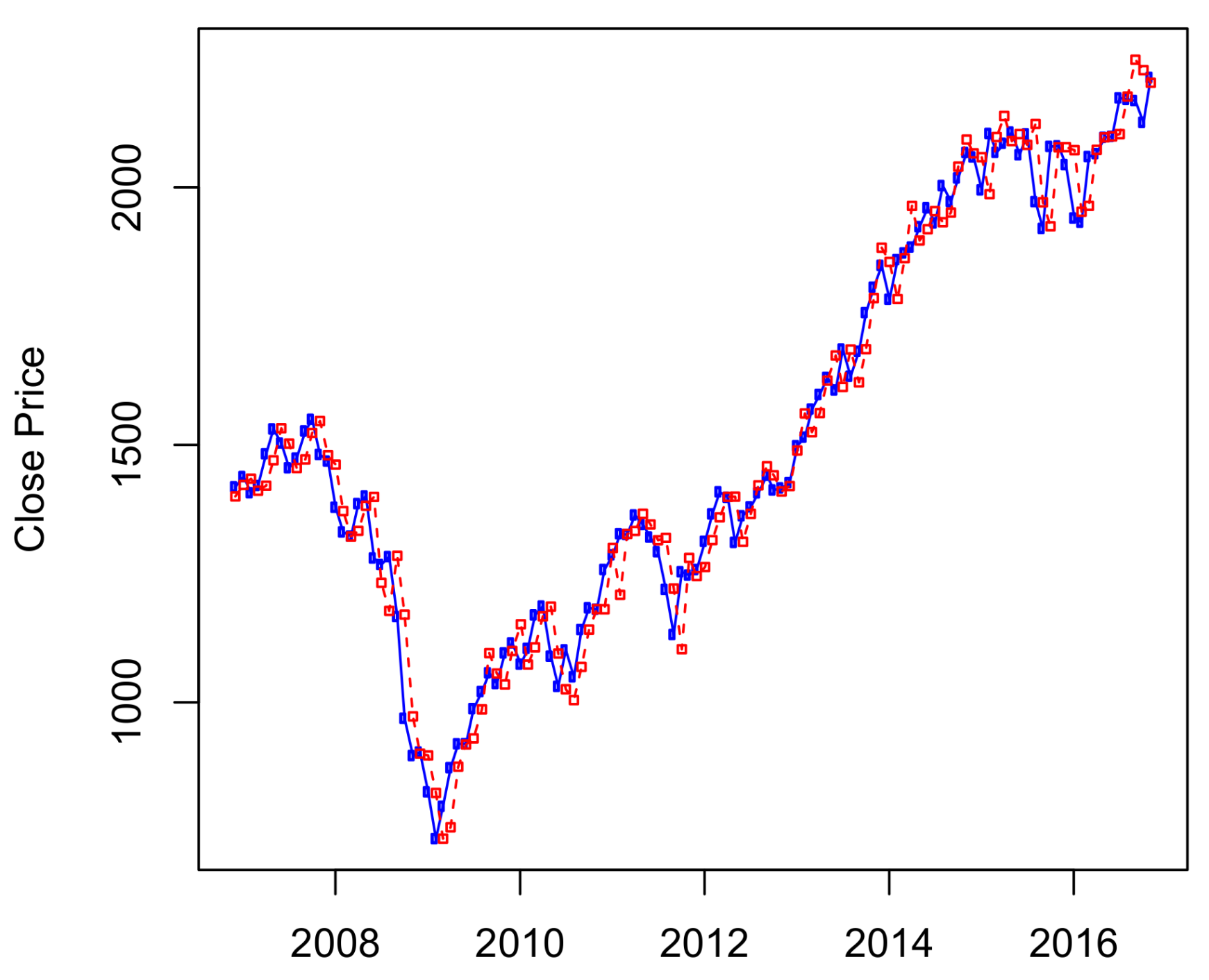
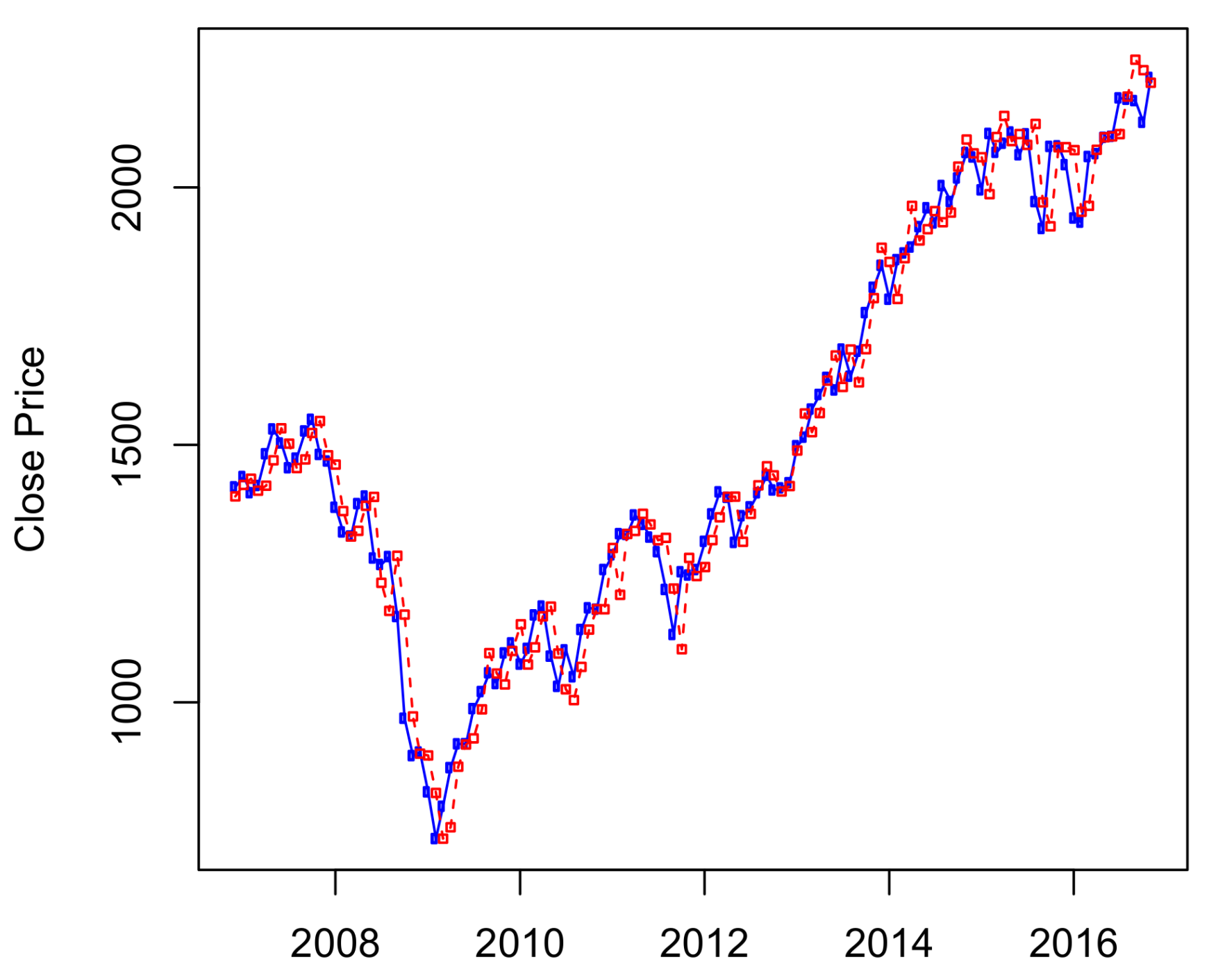
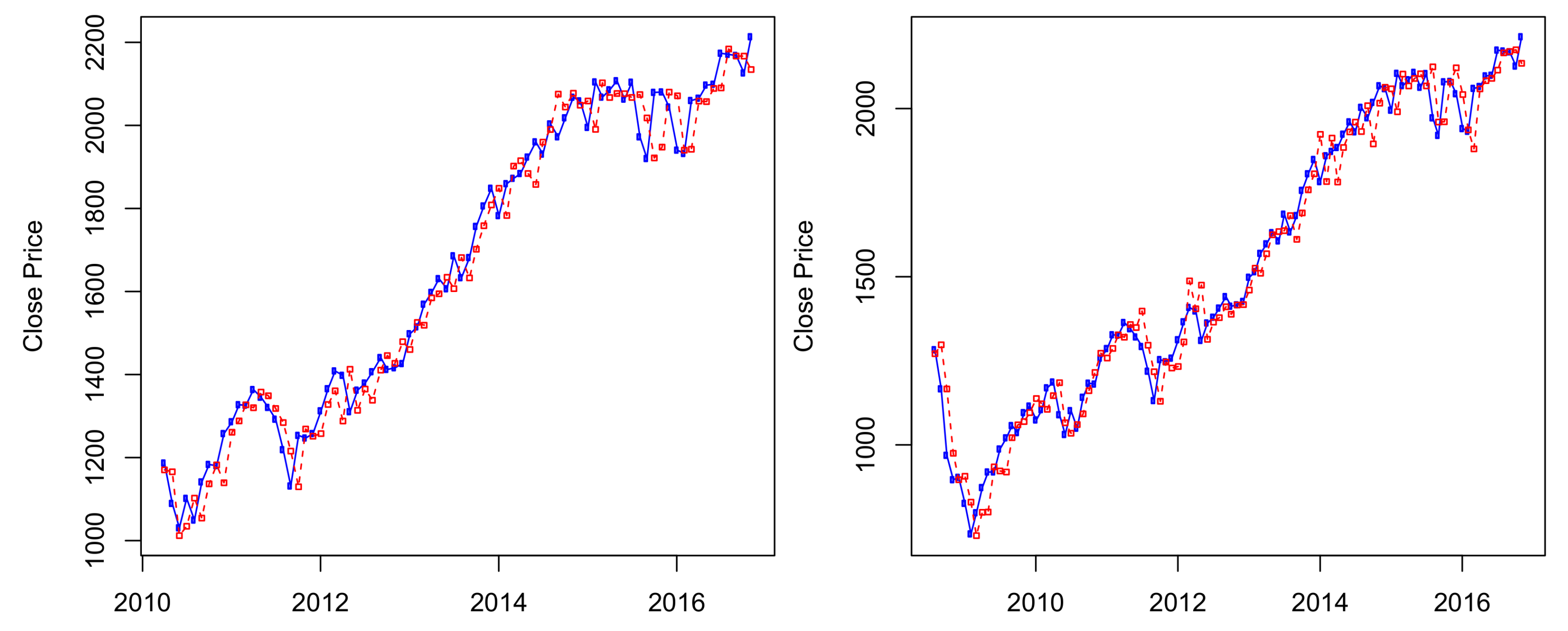
The results of ten-years out-of-sample data (
) are presented in
Figure 3, in which the S&P 500 historical data from January 1950 to October 2006 was used to predict its stock prices from November 2006 to November 2016. We can see from
Figure 3 that the HMM captures well the price changes around the economic crisis time from 2008–2009. Results of predictions for other time periods are presented in
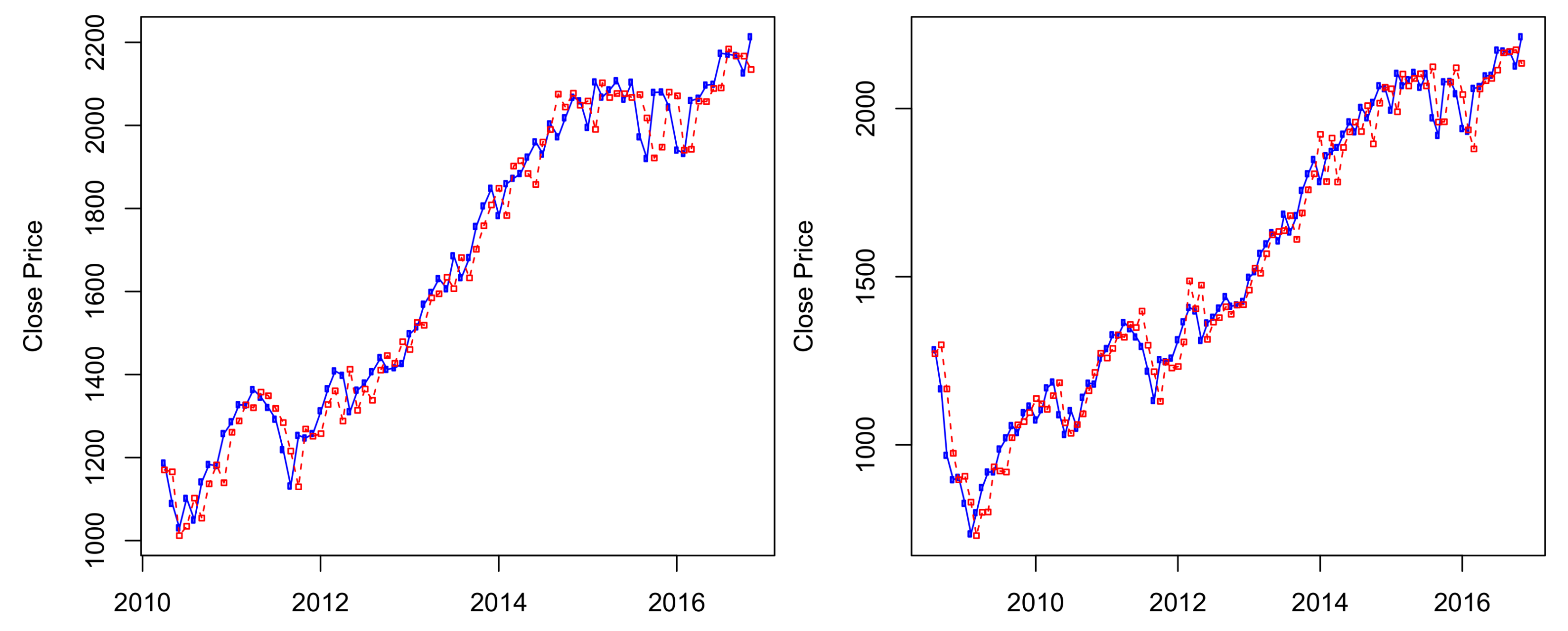
Figure A1 and
Figure A2 of
Appendix A.
3.3. Model Validation
To test our predictions, we used the out-of-sample
statistics,
, introduced by
Campbell and Thompson (
2008). Many researchers have employed the statistic measure to evaluate their forecasting models.
Campbell and Thompson (
2008) used the out-of-sample
to compare the performances of the stock return prediction model inspired by
Welch and Goyal (
2008) and that of the historical average return model. The authors used monthly total returns (including dividend) of S&P 500.
Rapach et al. (
2010) use the out-of-sample
to test the efficiency of their combination approach to the out-of-sample equity premium forecasting against the historical average return method.
Zhu and Zhu (
2013) also used the out-of-sample
to show their regime-switching combination forecasts of excess returns gain relative to the historical average model. All of these above approaches were based on a regression model for multi-economic variables to predict stock returns.
The out-of-sample
is calculated as follows. First, a time series of returns is divided into two sets: the first
m points were called the in-of-sample data set, and the last
q points were called the out-of-sample data set. Then, the out-of-sample
for forecasted returns is defined as:
where
is the real return at time
,
is the forecasted return from the desired model, and
is the forecasted return from the competing model. We can see from the Equation (7) that the
evaluates the reduction in the mean squared predictive error (MSPE) of two models. Therefore, if the out-of-sample
is positive, then the desired model performed better than the competing model. The historical average return method is used as a benchmark competing model, for which the forecasted return for the next time step is calculated as the average of historical returns up to the time,
In this study, we use the HMM model to predict stock prices based only on historical prices. However, we can calculate stock prices based on its predicted returns and reverse. Therefore, we will calculate the out-of-sample by using two approaches: out-of-sample for stock returns and out-of-sample for stock prices based on predicted returns (without dividends). Numerical results present in this section are for an out-of-sample and the training periods of the length .
The out-of-sample
for relative return (without dividends), namely
, is determined by
where
is the real relative stock return price at time
,
is the forecasted relative return from the HMM,
and
is the forecasted price from the historical average model,
. The out-of-sample
for stock price based on predicted returns, namely
, is given by
where
is the real stock price at time
,
is the forecasted price of the HMM, and
is the forecasted price based on the predicted return of the historical average return model,
A positive
indicates that the HMM outperforms the historical average model. Therefore, we will use the MSPE-adjusted hypothesized statistics test introduced by
Clark and West (
2007) to test the null hypothesized
versus the alternating hypothesized
. In the MSPE-adjusted test, we first define
We then test for
(or equal MSPE) by regressing
on a constant and using
p-value for a zero coefficient. Our
p-value for testing
and
, which are presented in
Table 3, are bigger than the efficient level
, indicating that we accept the null hypothesis that the coefficient of each test equals zero. Furthermore, the
p-values of constants for both tests are significant at
level, which imply that we reject the null hypothesized that the
and accept the alternating hypothesized that
. The out-of-sample
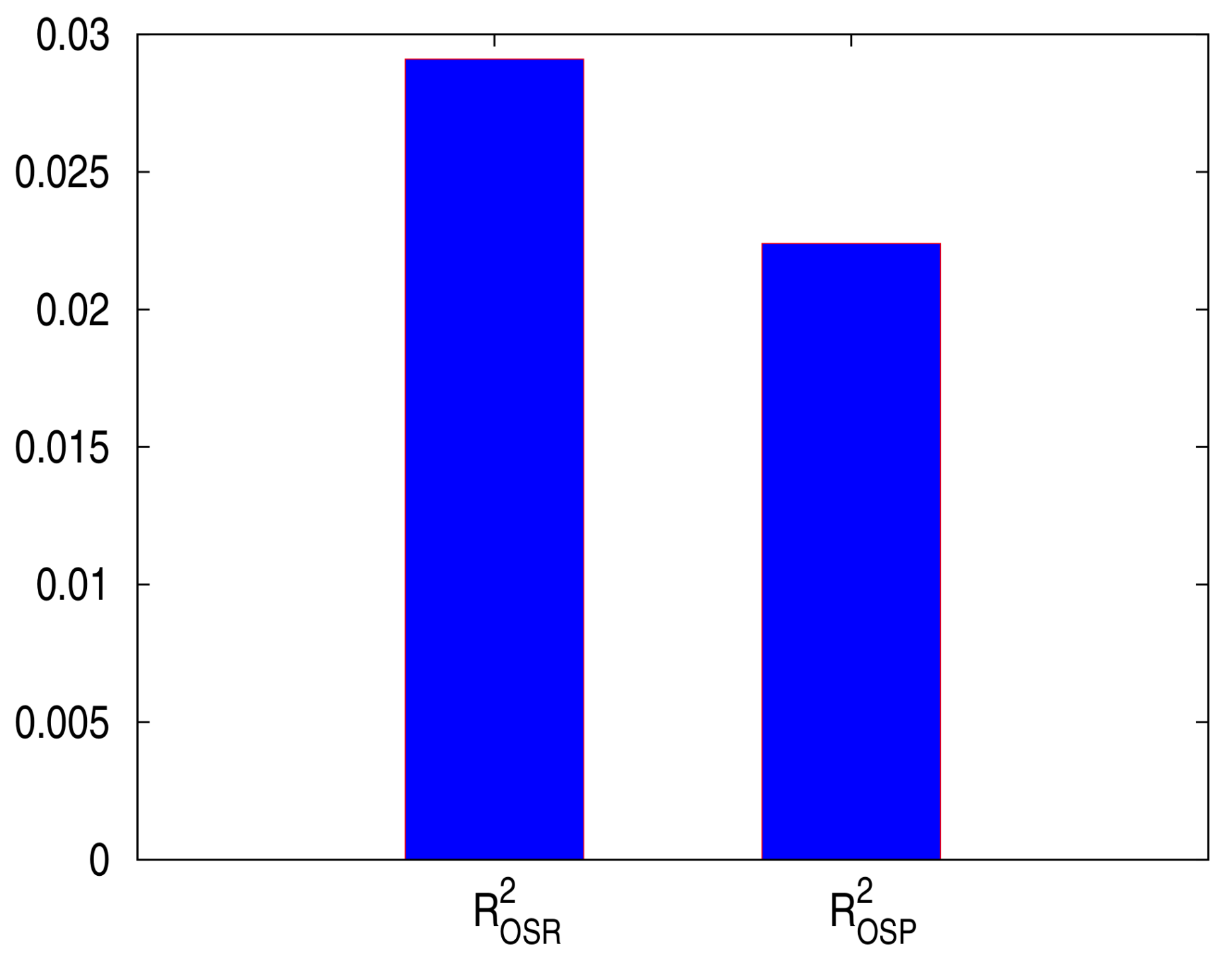
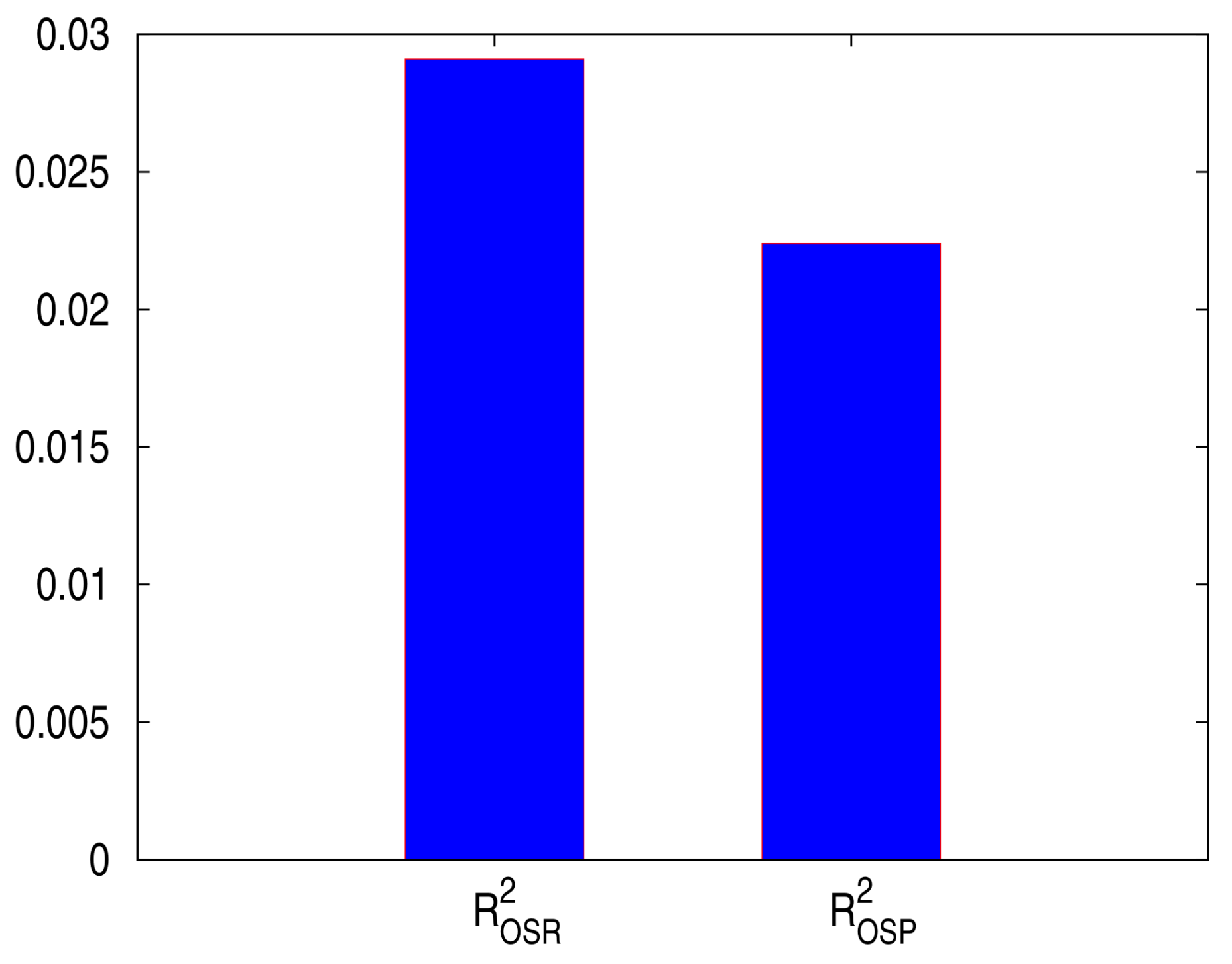
for predicted prices and predicted returns are presented in
Figure 4, showing that both out-of-sample
are positive, i.e., the HMM outperforms the historical average in predicting stock returns and stock prices.
Although the
compares the performances of two models on the whole out-of-sample forecasting period, it does not show the efficiency of the two competing models for each point estimation. Therefore, we use the cumulative squared predictive errors (CSPEs), which was presented by
Zhu and Zhu (
2013), to show the relative performances of the two models after each prediction. The CSPE statistic at time
, denoted by CSPE
, is calculated as:
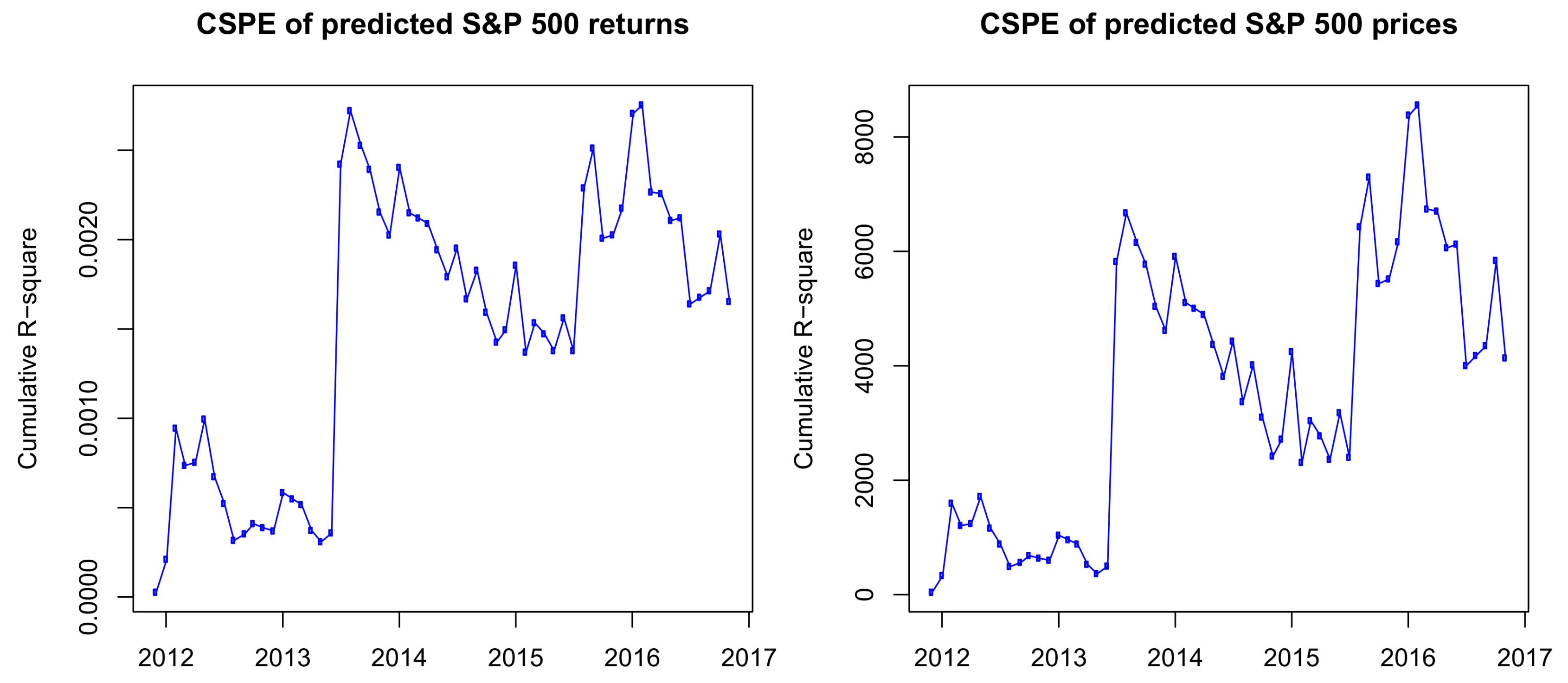
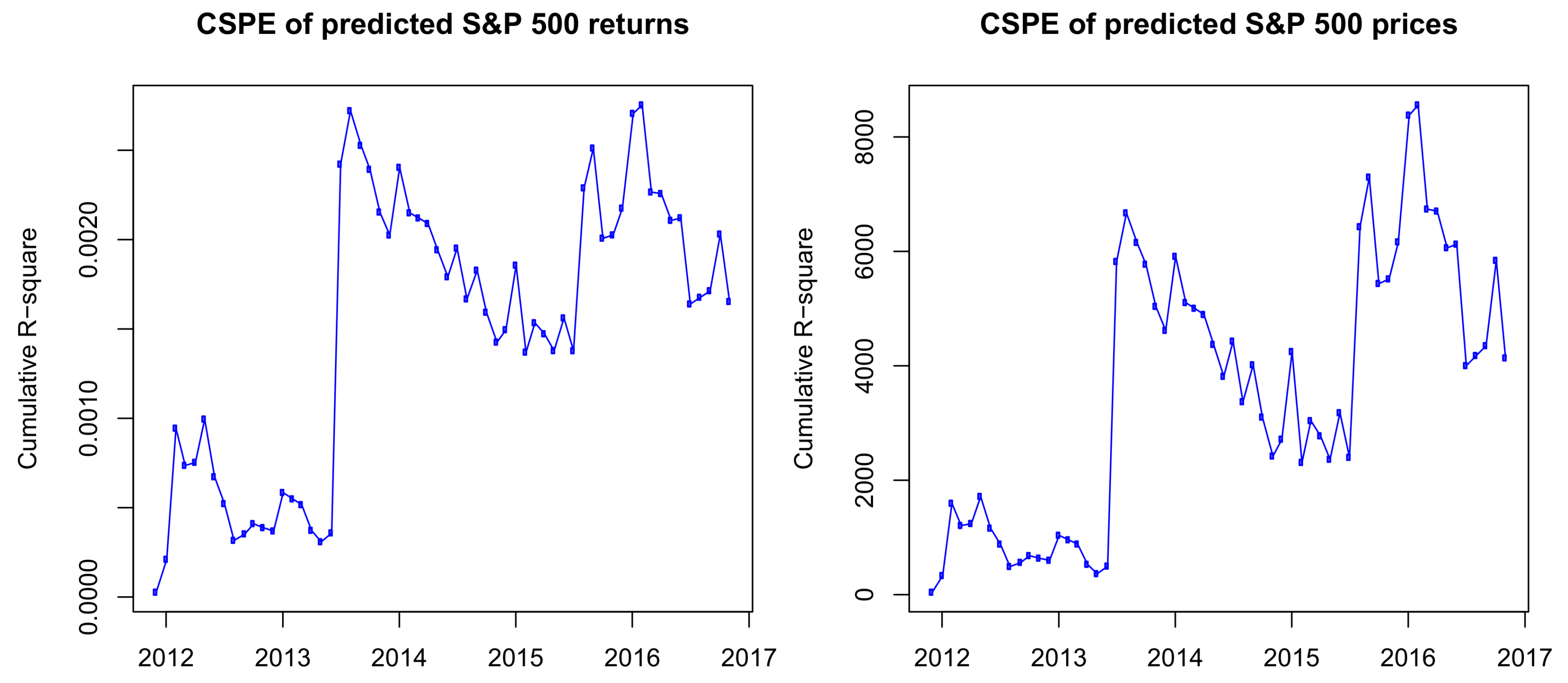
From the definition of the cumulative squared predictive errors, we can see that, if the function is increasing, the HMM outperforms the historical average model. In contrast, if the function is decreasing, the historical average model outweighs the HMM on the time interval. If we replace the return prices in Label (12) by the predicted prices, we will have the CSPE for prices. The CSPE of predicted returns and prices is presented in
Figure 5.
The results in
Figure 5 show that, although in some periods the HAR outperforms the HMM, the CSPEs are positive and follow an uptrend on the whole out-of-sample period. Therefore, we have a conclusion that, in out-of-sample predictions, the HMM outperforms the HAR model.
We also compare the performances of HMM with the historical average model by using the four standard error estimators: the absolute percentage error (APE), the average absolute error (AAE), the average relative percentage error (ARPE) and the root-mean-square error (RMSE). These error estimators are calculated using the following expressions:
where
N is a number of simulated points,
is the real stock price (or stock return),
is the estimated price (or return), and
is the mean of the sample. We use the error estimators to calculate the errors of predictions of the HMM and HAR models for predicted returns (Equation (8)) and predicted prices (Equation (10)). Adopting the
statistics, we define the efficiency measure to compare the HMM with the HAR model as:
Errors of the two models and the efficiency of the HMM over the HAR are calculated using Equations (13)–(17). A positive efficiency (Eff) indicates that the HMM surpasses the HAR model. Results are presented in
Table 4.
Table 4 presents errors and efficiency of HMM over the HAR model. We can see from the table that the HAR model beats the HMM based on the absolute percentage error estimator, APE, for stock returns. However, in all the remaining cases, we have the positive efficiency, which strongly indicates that the HMM outperforms the HAR.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}