Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam

Abstract
:1. Introduction
2. Literature Review
2.1. Definition of Financial Bubbles
2.2. Literature Review on Detecting Financial Bubbles
2.3. Literature Review on Machine Learning Applied to Economic Forecasting
3. Data
4. Methodology
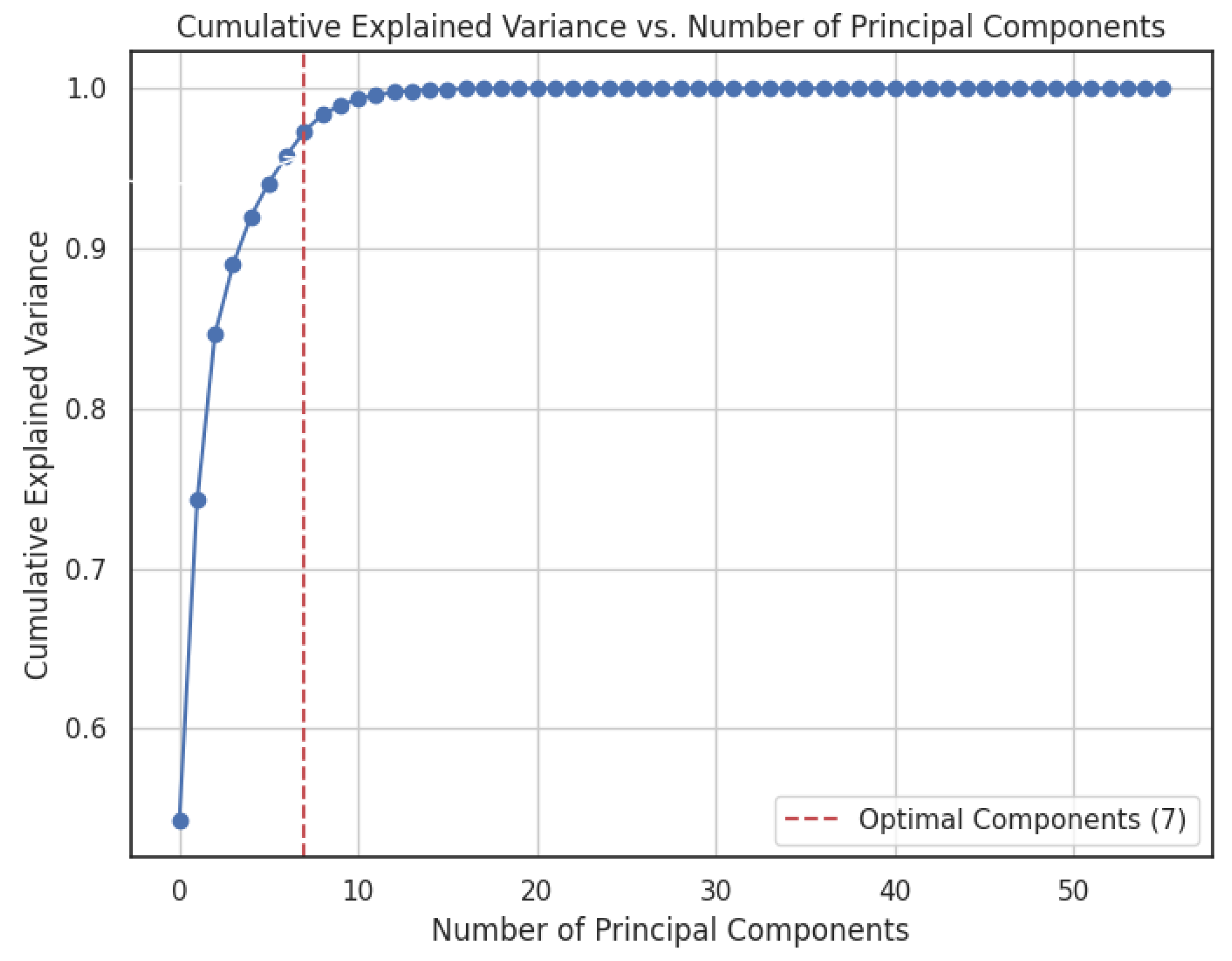
4.1. Research Design and Data Preprocessing
4.2. PSY Method for Bubbles Detection
4.3. Machine Learning Methods to Predict Financial Bubbles
4.3.1. Logistic Regression
4.3.2. Support Vector Machine
4.3.3. Decision Tree
4.3.4. Random Forest
4.3.5. Gradient Boosting (GB)
4.3.6. Artificial Neural Network
4.4. Evaluation of the Model Performance
5. Results and Discussion
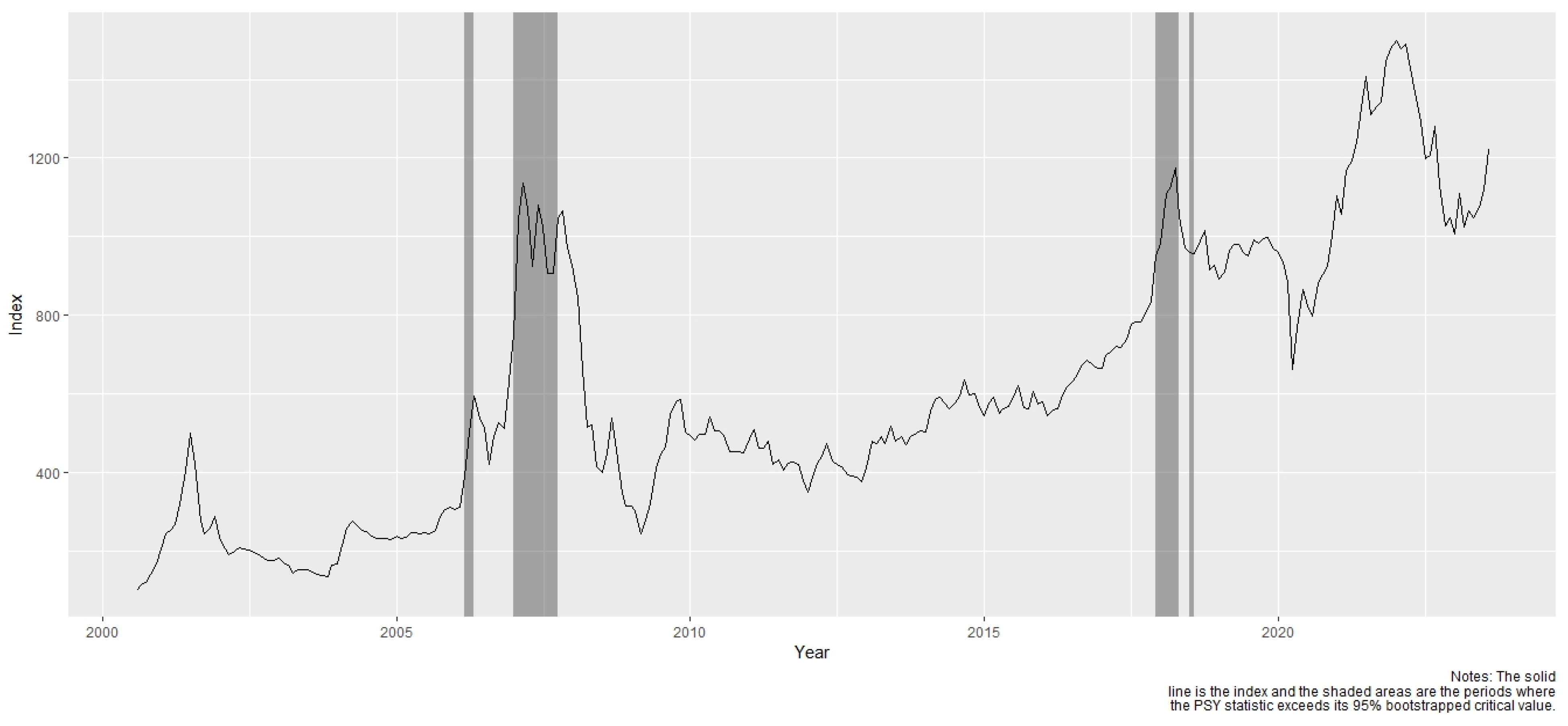
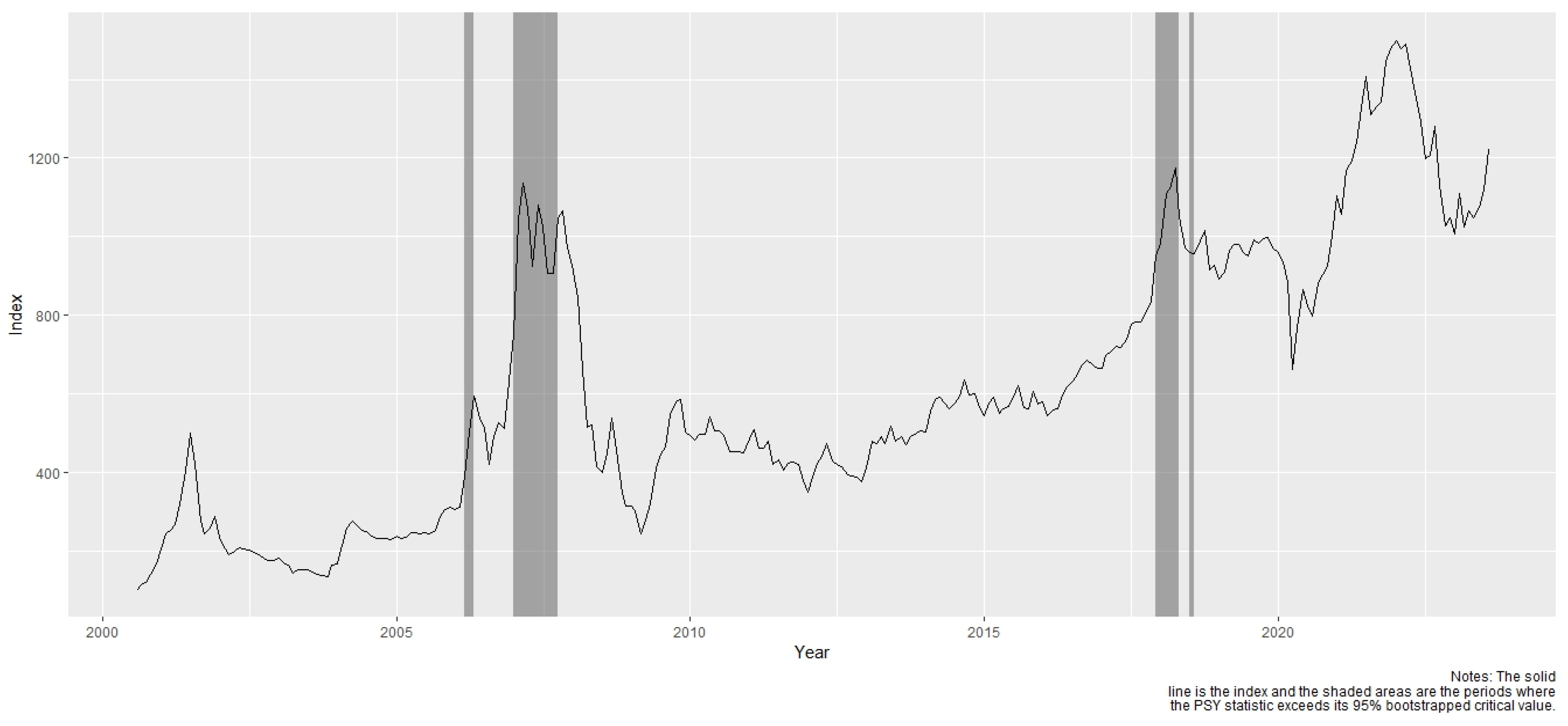
5.1. Results of the Financial Bubble Detection
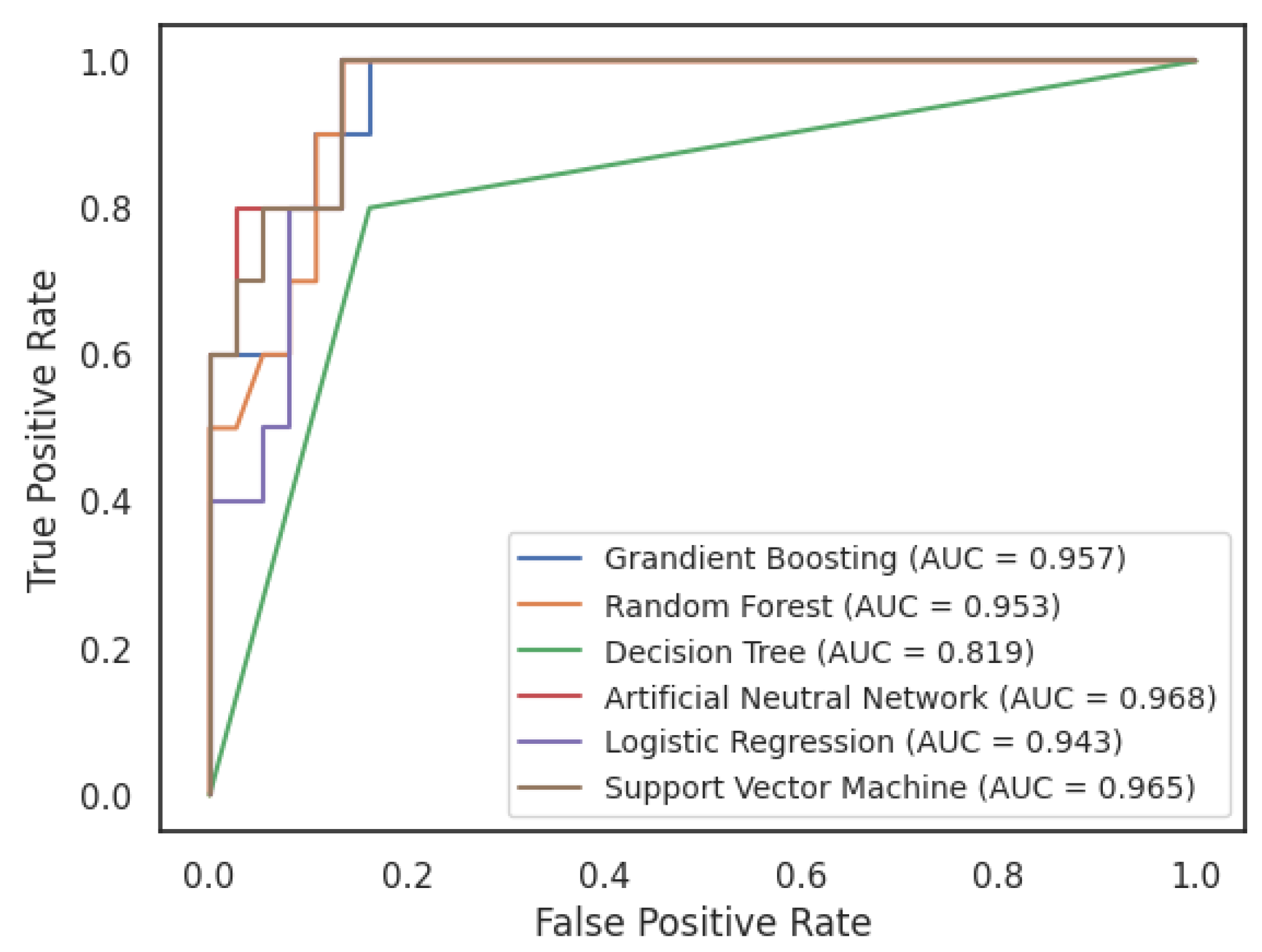
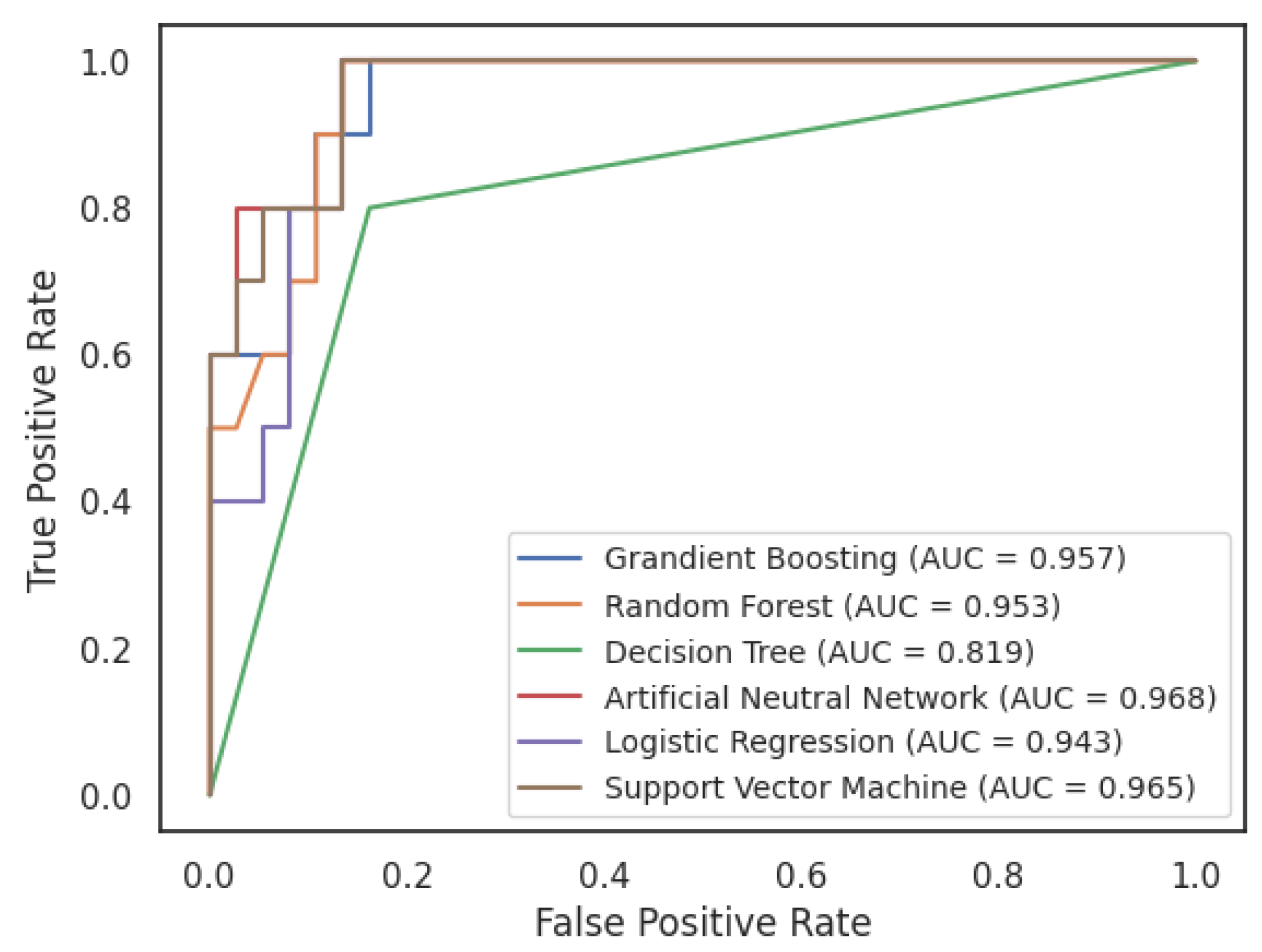
5.2. Results of Forecasting Financial Bubbles Using Machine Learning Algorithms
5.3. Robustness Test
5.4. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alessi, Lucia, and Carsten Detken. 2018. Identifying excessive credit growth and leverage. Journal of Financial Stability 35: 215–25. [Google Scholar] [CrossRef]
- Barboza, Flavio, Herbert Kimura, and Edward Altman. 2017. Machine learning models and bankruptcy prediction. Expert Systems with Applications 83: 405–17. [Google Scholar] [CrossRef]
- Başoğlu Kabran, Fatma, and Kamil Demirberk Ünlü. 2021. A two-step machine learning approach to predict S&P 500 bubbles. Journal of Applied Statistics 48: 2776–94. [Google Scholar] [PubMed]
- Beutel, Johannes, Sophia List, and Gregor von Schweinitz. 2019. Does machine learning help us predict banking crises? Journal of Financial Stability 45: 100693. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine learning 45: 5–32. [Google Scholar] [CrossRef]
- Cakici, Nusret, Christian Fieberg, Daniel Metko, and Adam Zaremba. 2023. Do Anomalies Really Predict Market Returns? New Data and New Evidence. Review of Finance. Forthcoming. [Google Scholar] [CrossRef]
- Case, Karl E., and Robert J. Shiller. 2003. Is there a bubble in the housing market? Brookings Papers on Economic Activity 2003: 299–362. [Google Scholar] [CrossRef]
- Chatzis, Sotirios P., Vassilis Siakoulis, Anastasios Petropoulos, Evangelos Stavroulakis, and Nikos Vlachogiannakis. 2018. Forecasting stock market crisis events using deep and statistical machine learning techniques. Expert Systems with Applications 112: 353–71. [Google Scholar] [CrossRef]
- Dong, Xi, Yan Li, David E. Rapach, and Guofu Zhou. 2022. Anomalies and the expected market return. The Journal of Finance 77: 639–81. [Google Scholar] [CrossRef]
- Fama, Eugene F. 2014. Two pillars of asset pricing. American Economic Review 104: 1467–85. [Google Scholar] [CrossRef]
- Fuster, Andreas, Paul Goldsmith-Pinkham, Tarun Ramadorai, and Ansgar Walther. 2022. Predictably unequal. The Effects of Machine Learning on Credit Markets. Journal of Finance 77: 1–808. [Google Scholar] [CrossRef]
- Galbraith, James K., Sara Hsu, and Wenjie Zhang. 2009. Beijing bubble, Beijing bust: Inequality, trade, and capital inflow into China. Journal of Current Chinese Affairs 38: 3–26. [Google Scholar] [CrossRef]
- Geng, Ruibin, Indranil Bose, and Xi Chen. 2015. Prediction of financial distress: An empirical study of listed Chinese companies using data mining. European Journal of Operational Research 241: 236–47. [Google Scholar] [CrossRef]
- Gu, Shihao, Bryan Kelly, and Dacheng Xiu. 2020. Empirical asset pricing via machine learning. The Review of Financial Studies 33: 2223–73. [Google Scholar] [CrossRef]
- Harris, Charles R., K. Jarrod Millman, Stéfan J. Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, and Nathaniel J. Smith. 2020. Array programming with NumPy. Nature 585: 357–62. [Google Scholar] [CrossRef]
- Homm, Ulrich, and Jörg Breitung. 2012. Testing for speculative bubbles in stock markets: A comparison of alternative methods. Journal of Financial Econometrics 10: 198–231. [Google Scholar] [CrossRef]
- Kindleberger, Charles Poor, Robert Z. Aliber, and Robert M. Solow. 2005. Manias, Panics, and Crashes: A History of Financial Crises. London: Palgrave Macmillan London, vol. 7. [Google Scholar]
- McKinney, Wes. 2010. Data structures for statistical computing in python. Paper presented at the 9th Python in Science Conference, Austin, TX, USA, June 28–July 3. [Google Scholar]
- Ouyang, Zi-sheng, and Yongzeng Lai. 2021. Systemic financial risk early warning of financial market in China using Attention-LSTM model. The North American Journal of Economics and Finance 56: 101383. [Google Scholar] [CrossRef]
- Pedregosa, Fabian, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, and Vincent Dubourg. 2011. Scikit-learn: Machine learning in Python. The Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Phillips, Peter C. B., Shuping Shi, and Jun Yu. 2015a. Testing for multiple bubbles: Limit theory of real-time detectors. International Economic Review 56: 1079–134. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., Shuping Shi, and Jun Yu. 2015b. Testing for multiple bubbles: Historical episodes of exuberance and collapse in the S&P 500. International Economic Review 56: 1043–78. [Google Scholar]
- Phillips, Peter C. B., Shuping Shi, Itamar Caspi, and Maintainer Itamar Caspi. 1984. Package ‘psymonitor’. Biometrika 71: 599–607. [Google Scholar]
- Phillips, Peter C. B., Yangru Wu, and Jun Yu. 2011. Explosive behavior in the 1990s Nasdaq: When did exuberance escalate asset values? International Economic Review 52: 201–26. [Google Scholar] [CrossRef]
- Shiller, Robert J. 1981. Do stock prices move too much to be justified by subsequent changes in dividends? The American Economic Review 71: 421–436. [Google Scholar]
- Shiller, Robert J. 2002. Bubbles, human judgment, and expert opinion. Financial Analysts Journal 58: 18–26. [Google Scholar] [CrossRef]
- Shiller, Robert J. 2015. Irrational Exuberance. Princeton: Princeton University Press. [Google Scholar]
- Shin, Kyung-Shik, Taik Soo Lee, and Hyun-jung Kim. 2005. An application of support vector machines in bankruptcy prediction model. Expert Systems with Applications 28: 127–35. [Google Scholar] [CrossRef]
- Stiglitz, Joseph E. 1990. Symposium on bubbles. Journal of Economic Perspectives 4: 13–18. [Google Scholar] [CrossRef]
- Tirole, Jean. 2008. Liquidity shortages: Theoretical underpinnings. Financial Stability Review 11: 53–63. [Google Scholar]
- Tran, Kim Long, Hoang Anh Le, Thanh Hien Nguyen, and Duc Trung Nguyen. 2022. Explainable machine learning for financial distress prediction: Evidence from Vietnam. Data 7: 160. [Google Scholar] [CrossRef]
- Waskom, Michael, Olga Botvinnik, Drew O’Kane, Paul Hobson, Saulius Lukauskas, David C. Gemperline, Tom Augspurger, Yaroslav Halchenko, John B. Cole, and Jordi Warmenhoven. 2017. Mwaskom/Seaborn: V0. 8.1 (September 2017). Zenodo. Available online: https://github.com/mwaskom/seaborn/tree/v0.8.1 (accessed on 24 September 2023).
- West, Kenneth D. 1987. A specification test for speculative bubbles. The Quarterly Journal of Economics 102: 553–80. [Google Scholar] [CrossRef]
- Zhao, Zongyuan, Shuxiang Xu, Byeong Ho Kang, Mir Md Jahangir Kabir, Yunling Liu, and Rainer Wasinger. 2015. Investigation and improvement of multi-layer perceptron neural networks for credit scoring. Expert Systems with Applications 42: 3508–16. [Google Scholar] [CrossRef]
- Zhou, Xianzheng, Hui Zhou, and Huaigang Long. 2023. Forecasting the equity premium: Do deep neural network models work? Modern Finance 1: 1–11. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Start Date | End Date | |
|---|---|---|
| 1 | 28 February 2006 | 28 April 2006 |
| 2 | 30 June 2006 | 30 June 2006 |
| 3 | December 2006 | 28 September 2007 |
| 4 | November 2017 | 27 April 2018 |
| 5 | 29 June 2018 | 31 July 2018 |
| Bubble Months | Non-Bubble Months | Overall | |
|---|---|---|---|
| count | 33 | 218 | 251 |
| mean | 896.70 | 524.54 | 573.47 |
| std | 220.47 | 286.81 | 305.78 |
| min | 401.90 | 135.78 | 135.78 |
| 25% | 842.71 | 291.25 | 320.92 |
| 50% | 975.94 | 489.06 | 514.92 |
| 75% | 1049.32 | 631.40 | 782.85 |
| max | 1196.61 | 1478.44 | 1478.44 |
| Algorithms | Hyperparameter | AUC | F1 Score | Accuracy | Precision | Sensitivity |
|---|---|---|---|---|---|---|
| Neural Networks | hidden_layer_sizes = 100, max_iter = 300, activation = “relu”, solver = ‘adam’, alpha = 0.0001 | 0.968 | 0.750 | 0.915 | 0.600 | 1.000 |
| Random Forest | max_depth = 5, n_estimators = 50 | 0.953 | 0.800 | 0.894 | 1.000 | 0.667 |
| Gradient Boosting | max_depth = 3, learning_rate = 0.1, n_estimators = 100 | 0.957 | 0.727 | 0.872 | 0.800 | 0.667 |
| Logistic Regression | C = 1 | 0.943 | 0.700 | 0.872 | 0.700 | 0.700 |
| Support Vector Machine | C = 1, kernel = ‘rbf’, class_weight = ‘balanced’ | 0.965 | 0.696 | 0.851 | 0.800 | 0.615 |
| Decision Trees | max_depth = 5 | 0.819 | 0.667 | 0.830 | 0.800 | 0.571 |
| Neural Network | Random Forest | |||||||
|---|---|---|---|---|---|---|---|---|
| September 2001–February 2007 | March 2007–August 2012 | June 2014–December 2019 | Average | September 2001–February 2007 | March 2007–August 2012 | June 2014–December 2019 | Average | |
| Accuracy | 0.950 | 0.950 | 0.905 | 0.935 | 0.950 | 0.950 | 0.952 | 0.951 |
| AUC | 0.875 | 0.900 | 0.750 | 0.842 | 0.875 | 0.900 | 0.875 | 0.883 |
| Sensitivity | 0.750 | 0.800 | 0.500 | 0.683 | 0.750 | 0.800 | 0.750 | 0.767 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, K.L.; Le, H.A.; Lieu, C.P.; Nguyen, D.T. Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam. Int. J. Financial Stud. 2023, 11, 133. https://doi.org/10.3390/ijfs11040133
Tran KL, Le HA, Lieu CP, Nguyen DT. Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam. International Journal of Financial Studies. 2023; 11(4):133. https://doi.org/10.3390/ijfs11040133
Chicago/Turabian StyleTran, Kim Long, Hoang Anh Le, Cap Phu Lieu, and Duc Trung Nguyen. 2023. "Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam" International Journal of Financial Studies 11, no. 4: 133. https://doi.org/10.3390/ijfs11040133
APA StyleTran, K. L., Le, H. A., Lieu, C. P., & Nguyen, D. T. (2023). Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam. International Journal of Financial Studies, 11(4), 133. https://doi.org/10.3390/ijfs11040133