

Opening a New Era with Machine Learning in Financial Services? Forecasting Corporate Credit Ratings Based on Annual Financial Statements


Abstract
1. Introduction
2. Theoretical Foundations
2.1. Corporate Credit Ratings
2.2. Regulatory Principles for the Use of ML in the Finance Industry
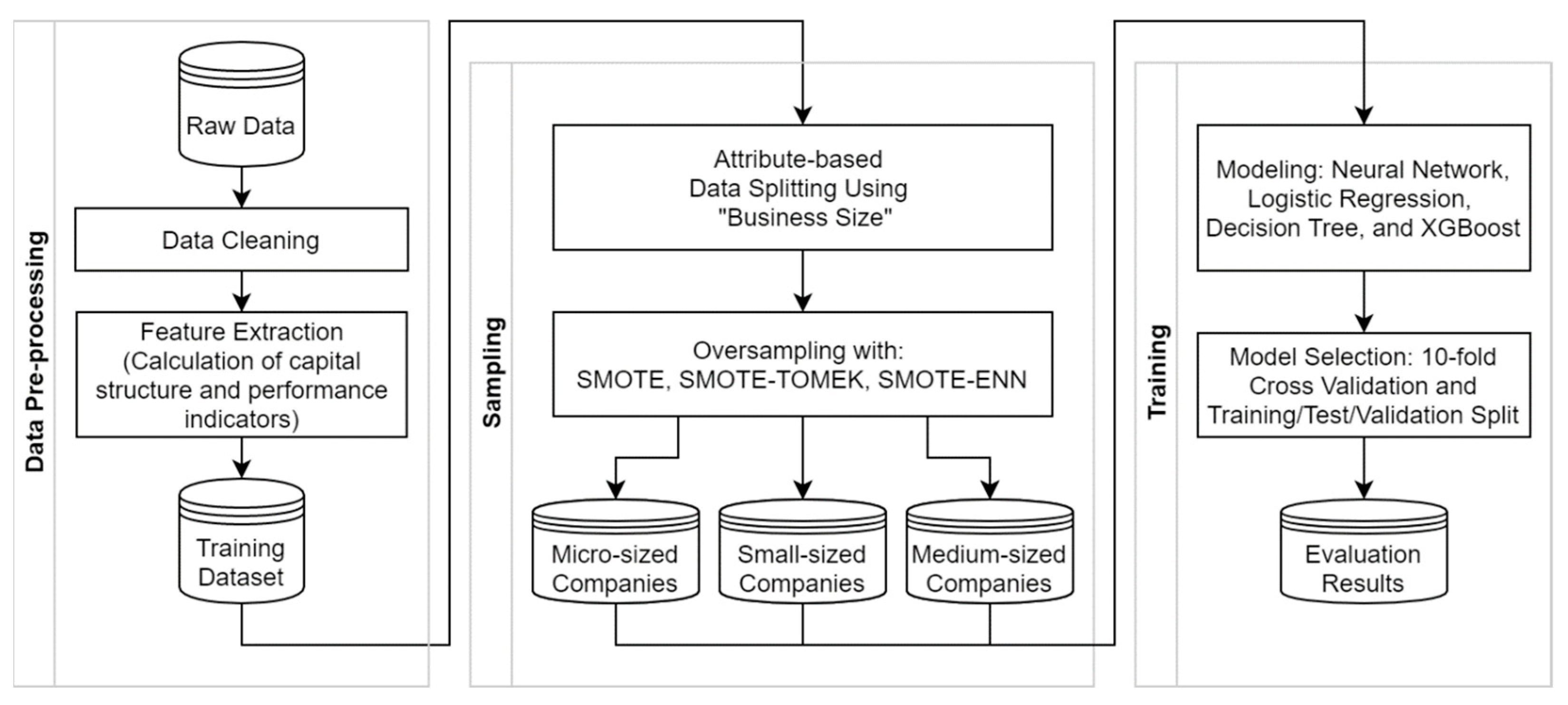
3. Research Approach for Forecasting Credit Ratings
3.1. Dataset of Annual Financial Statements
3.2. Data Analysis and Pre-Processing of Annual Financial Statements
3.3. Oversampling Structure
3.4. Modeling
3.5. Evaluation of the ML-Approach for Forecasting Credit Ratings
4. Discussion and Implications for ML-Based Forecasting Credit Ratings
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Financial Ratio Quartiles for the Exploratory Data Analysis and Variable Selection


Appendix B. Sampling Results




References
- Abad, Pilar, and M. Dolores Robles. 2014. Credit rating agencies and idiosyncratic risk: Is there a linkage? Evidence from the Spanish Market. International Review of Economics & Finance 33: 152–71. [Google Scholar] [CrossRef]
- Ala’raj, Maher, and Maysam F. Abbod. 2016. A new hybrid ensemble credit scoring model based on classifiers consensus system approach. Expert Systems with Applications 64: 36–55. [Google Scholar] [CrossRef]
- Altman, Edward I., and Anthony Saunders. 1997. Credit risk measurement: Developments over the last 20 years. Journal of Banking & Finance 21: 1721–42. [Google Scholar] [CrossRef]
- Andersson, Andreas, and Paolo Vanini. 2008. Credit Migration Risk Modelling. SSRN Electronic Journal 6: 3–30. [Google Scholar] [CrossRef]
- Andreeva, Galina, Raffaella Calabrese, and Silvia Angela Osmetti. 2016. A comparative analysis of the UK and Italian small businesses using Generalised Extreme Value models. European Journal of Operational Research 249: 506–16. [Google Scholar] [CrossRef]
- Andriosopoulos, Dimitris, Michalis Doumpos, Panos M. Pardalos, and Constantin Zopounidis. 2019. Computational approaches and data analytics in financial services: A literature review. Journal of the Operational Research Society 70: 1581–99. [Google Scholar] [CrossRef]
- Arrieta, Alejandro Barredo, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, and et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Information Fusion 58: 82–115. [Google Scholar] [CrossRef]
- Arya, Vijay, Rachel K. E. Bellamy, Pin-Yu Chen, Amit Dhurandhar, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Q. Vera Liao, Ronny Luss, Aleksandra Mojsilović, and et al. 2019. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques. arXiv arXiv:1909.03012. [Google Scholar] [CrossRef]
- BaFin. 2021. Big Data and Artificial Intelligence: Principles for the Use of Algorithms in Decision-Making Processes. BaFin. Available online: https://www.bafin.de/SharedDocs/Downloads/EN/Aufsichtsrecht/dl_Prinzipienpapier_BDAI_en.html (accessed on 15 June 2022).
- Bathaee, Yavar. 2018. The Artificial Intelligence Black Box and the Failure of Intent and Causation. Harvard Journal of Law & Technology 31. Available online: https://jolt.law.harvard.edu/assets/articlePDFs/v31/The-Artificial-Intelligence-Black-Box-and-the-Failure-of-Intent-and-Causation-Yavar-Bathaee.pdf (accessed on 1 April 2023).
- Batista, Gustavo E. A. P. A., Ronaldo C. Prati, and Maria Carolina Monard. 2004. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explorations Newsletter 6: 20–29. [Google Scholar] [CrossRef]
- Bauer, Julian, and Vineet Agarwal. 2014. Are hazard models superior to traditional bankruptcy prediction approaches? A comprehensive test. Journal of Banking & Finance 40: 432–42. [Google Scholar] [CrossRef]
- Bauer, Kevin, Oliver Hinz, and Patrick Weber. 2021. KI in der Finanzbranche: Im Spannungsfeld zwischen technologischer Innovation und regulatorischer Anforderung. SAFE White Paper 80. Frankfurt am Main: Leibniz Institute for Financial Research SAFE. Available online: https://www.econstor.eu/handle/10419/230672 (accessed on 15 March 2023).
- Beckman, Judy, Christina Brandes, and Brigitte Eierle. 2007. German Reporting Practices: An Analysis of Reconciliations from German Commercial Code to IFRS or US GAAP. Advances in International Accounting 20: 253–94. [Google Scholar] [CrossRef]
- Benbya, Hind, Thomas H. Davenport, and Stella Pachidi. 2020. Artificial Intelligence in Organizations: Current State and Future Opportunities. MIS Quarterly Executive 19: 4. [Google Scholar] [CrossRef]
- Benlala, Mejd Aures. 2023. Perspectives on Fractional Reserve Banking and Money Creation/Production through the Lenses of Legal and Religious Moral Precepts and Ethics. Perspectives of Law and Public Administration 12: 5–30. Available online: https://ideas.repec.org/a/sja/journl/v12y2023i1p5-30.html (accessed on 15 April 2023).
- Bergstra, James, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems. Edited by J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira and K. Q. Weinberger. Red Hook: Curran Associates, Inc. [Google Scholar]
- BIS, ed. 2000. Principles for the Management of Credit Risk. Basel: Bank for International Settlements. [Google Scholar]
- BIS. 2005. International Convergence of Capital Measurement and Capital Standards. A Revised Framework, 2005th ed. Basel: BIZ. [Google Scholar]
- BIS. 2011. Basel III: A Global Regulatory Framework for More Resilient Banks and Banking Systems. Basel: Bank for International Settlements. [Google Scholar]
- Cao, Longbing. 2020. AI in Finance: A Review. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Chawla, N. V., K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research 16: 321–57. [Google Scholar] [CrossRef]
- Chen, Yuh-Jen, and Yuh-Min Chen. 2022. Forecasting corporate credit ratings using big data from social media. Expert Systems with Applications 207: 118042. [Google Scholar] [CrossRef]
- Ciampi, Francesco. 2015. Corporate governance characteristics and default prediction modeling for small enterprises. An empirical analysis of Italian firms. Journal of Business Research 68: 1012–25. [Google Scholar] [CrossRef]
- Daniel, Avram Costin, Avram Marioara, and Dragomir Isabela. 2017. Annual Financial Statements as a Financial Communication Support. Ovidius University Annals, Economic Sciences Series 17: 403. Available online: https://ideas.repec.org/a/ovi/oviste/vxviiy2017i1p403-406.html (accessed on 15 January 2023).
- de Andrés, Javier, Manuel Landajo, and Pedro Lorca. 2012. Bankruptcy prediction models based on multinorm analysis: An alternative to accounting ratios. Knowledge-Based Systems 30: 67–77. [Google Scholar] [CrossRef]
- Deutsche Bundesbank. 2020. Policy Discussion Paper: The Use of Artificial Intelligence and Machine Learning in the Financial Sector. Available online: https://www.bundesbank.de/resource/blob/598256/5e89d5d7b7cd236ad93ed7581800cea3/mL/2020-11-policy-dp-aiml-data.pdf (accessed on 11 September 2022).
- Deutsche Bundesbank, and BaFin. 2021. Consultation Paper: Machine Learning in Risk Models—Characteristics and Supervisory Priorities. Available online: https://www.bundesbank.de/resource/blob/793670/61532e24c3298d8b24d4d15a34f503a8/mL/2021-07-15-ml-konsultationspapier-data.pdf (accessed on 11 September 2022).
- Dimler, Nick, Joachim Peter, and Boris Karcher. 2018. Unternehmensfinanzierung im Mittelstand. Wiesbaden: Springer Fachmedien Wiesbaden. [Google Scholar]
- Dittrich, Fabian. 2007. The Credit Rating Industry: Competition and Regulation. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Doerr, Sebastian, Leonardo Gambacorta, and Jose Maria Serena. 2021. Big Data and Machine Learning in Central Banks. Available online: https://www.bis.org/publ/work930.pdf (accessed on 11 July 2022).
- EBA. 2020. EBA Report on Big Data and Advanced Analytics. Available online: https://www.eba.europa.eu/eba-report-identifies-key-challenges-roll-out-big-data-and-advanced-analytics (accessed on 13 November 2022).
- El Kalak, Izidin, and Robert Hudson. 2016. The effect of size on the failure probabilities of SMEs: An empirical study on the US market using discrete hazard model. International Review of Financial Analysis 43: 135–45. [Google Scholar] [CrossRef]
- European Commission. 2021. Regulation of the European Parliament and of the Council. Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:52021PC0206 (accessed on 10 November 2022).
- Faraj, Samer, Stella Pachidi, and Karla Sayegh. 2018. Working and organizing in the age of the learning algorithm. Information and Organization 28: 62–70. [Google Scholar] [CrossRef]
- Fraisse, Henri, and Matthias Laporte. 2022. Return on investment on artificial intelligence: The case of bank capital requirement. Journal of Banking & Finance 138: 106401. [Google Scholar] [CrossRef]
- Fridson, Martin S., and Fernando Alvarez. 2022. Financial Statement Analysis. A Practitioner’s Guide. Hoboken: John Wiley & Sons. [Google Scholar]
- Friedrich, Lars, Andreas Hiese, Robin Dreßler, and Franziska Wolfenstetter. 2021. Künstliche Intelligenz in Banken—Status quo, Herausforderungen und Anwendungspotenziale. In Künstliche Intelligenz. Berlin and Heidelberg: Springer Gabler, pp. 49–63. [Google Scholar]
- Gavalas, Dimitris, and Theodore Syriopoulos. 2014. Bank Credit Risk Management and Rating Migration Analysis on the Business Cycle. International Journal of Financial Studies 2: 122–43. [Google Scholar] [CrossRef]
- Gordy, Michael B. 2003. A risk-factor model foundation for ratings-based bank capital rules. Journal of Financial Intermediation 12: 199–232. [Google Scholar] [CrossRef]
- Guerra, Pedro, Mauro Castelli, and Nadine Côrte-Real. 2022. Machine learning for liquidity risk modelling: A supervisory perspective. Economic Analysis and Policy 74: 175–87. [Google Scholar] [CrossRef]
- He, Haibo, and E. A. Garcia. 2009. Learning from Imbalanced Data. IEEE Transactions on Knowledge and Data Engineering 21: 1263–84. [Google Scholar] [CrossRef]
- Hirk, Rainer, Laura Vana, and Kurt Hornik. 2022. A corporate credit rating model with autoregressive errors. Journal of Empirical Finance 69: 224–40. [Google Scholar] [CrossRef]
- Huang, Jason. 2020. RMSProp—Cornell University Computational Optimization Open Textbook. Available online: https://optimization.cbe.cornell.edu/index.php?title=RMSProp (accessed on 9 July 2023).
- Huang, Guang-Bin, Hongming Zhou, Xiaojian Ding, and Rui Zhang. 2012. Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics. Part B, Cybernetics: A Publication of the IEEE Systems, Man, and Cybernetics Society 42: 513–29. [Google Scholar] [CrossRef]
- Hurley, Mikella, and Julius Adebayo. 2016. Credit Scoring in the Era of Big Data. Yale Journal of Law and Technology 18: 148. Available online: https://heinonline.org/HOL/Page?handle=hein.journals/yjolt18&id=148&div=6&collection=journals (accessed on 15 January 2023).
- Hwang, Ruey-Ching, Huimin Chung, and C. K. Chu. 2010. Predicting issuer credit ratings using a semiparametric method. Journal of Empirical Finance 17: 120–37. [Google Scholar] [CrossRef]
- Islam, Md Saiful. 2020. Predictive Capability of Financial Ratios for Forecasting of Corporate Bankruptcy. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Júdice, Pedro, and Qiji Jim Zhu. 2021. Bank balance sheet risk allocation. Journal of Banking & Finance 133: 106257. [Google Scholar] [CrossRef]
- Kao, Yu-Chun, Yu Tsou, Pei-Yu Jhang, D. N. Chen, and Chia-Yu Lai. 2020. Credit Rating Prediction Using Corporate Innovation and Financial Ratios. Paper presented at the 24th Pacific Asia Conference on Information Systems, PACIS 2020, Dubai, United Arab Emirates, June 22–24, vol.24. [Google Scholar]
- Kim, Kyoung-jae, and Hyunchul Ahn. 2012. A corporate credit rating model using multi-class support vector machines with an ordinal pairwise partitioning approach. Computers & Operations Research 39: 1800–11. [Google Scholar] [CrossRef]
- Kim, Myoung-Jong, and Dae-Ki Kang. 2012. Classifiers selection in ensembles using genetic algorithms for bankruptcy prediction. Expert Systems with Applications 39: 9308–14. [Google Scholar] [CrossRef]
- Korol, Tomasz. 2019. Dynamic Bankruptcy Prediction Models for European Enterprises. Journal of Risk and Financial Management 12: 185. [Google Scholar] [CrossRef]
- Krüger, Steffen, Daniel Rösch, and Harald Scheule. 2018. The impact of loan loss provisioning on bank capital requirements. Journal of Financial Stability 36: 114–29. [Google Scholar] [CrossRef]
- Lessmann, Stefan, Bart Baesens, Hsin-Vonn Seow, and Lyn C. Thomas. 2015. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research 247: 124–36. [Google Scholar] [CrossRef]
- Li, Weiping, and Feng Mei. 2020. Asset returns in deep learning methods: An empirical analysis on SSE 50 and CSI 300. Research in International Business and Finance 54: 101291. [Google Scholar] [CrossRef]
- Li, L., K. Jamieson, Giulia DeSalvo, A. Rostamizadeh, and A. Talwalkar. 2018. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research 18: 1–52. [Google Scholar]
- Liang, Deron, Chih-Fong Tsai, and Hsin-Ting Wu. 2015. The effect of feature selection on financial distress prediction. Knowledge-Based Systems 73: 289–97. [Google Scholar] [CrossRef]
- Lokanan, Mark Eshwar, and Kush Sharma. 2022. Fraud prediction using machine learning: The case of investment advisors in Canada. Machine Learning with Applications 8: 100269. [Google Scholar] [CrossRef]
- Marqués, A. I., V. García, and J. S. Sánchez. 2013. A literature review on the application of evolutionary computing to credit scoring. Journal of the Operational Research Society 64: 1384–99. [Google Scholar] [CrossRef]
- Matthies, Alexander B. 2013. Empirical Research on Corporate Credit-Ratings: A Literature Review. SFB 649 Discussion Paper 2013-003. Berlin: Humboldt University of Berlin, Collaborative Research Center 649—Economic Risk. Available online: https://www.econstor.eu/handle/10419/79580 (accessed on 15 January 2023).
- Montavon, Grégoire, Geneviève B. Orr, and Klaus-Robert Müller, eds. 2012. Neural Networks: Tricks of the Trade. Berlin and Heidelberg: Springer. [Google Scholar]
- Moody’s Investors Services. 2022. Rating Symbols and Definitions. Available online: https://www.moodys.com/researchdocumentcontentpage.aspx?docid=PBC_79004 (accessed on 13 June 2022).
- Obermann, Lennart, and Stephan Waack. 2016. Interpretable Multiclass Models for Corporate Credit Rating Capable of Expressing Doubt. Frontiers in Applied Mathematics and Statistics 2: 16. [Google Scholar] [CrossRef]
- OECD. 2021. Artificial Intelligence, Machine Learning and Big Data in Finance: Opportunities, Challenges, and Implications for Policy Makers. Available online: https://www.oecd.org/finance/financial-markets/Artificial-intelligence-machine-learning-big-data-in-finance.pdf (accessed on 13 November 2022).
- Olson, David L., Dursun Delen, and Yanyan Meng. 2012. Comparative analysis of data mining methods for bankruptcy prediction. Decision Support Systems 52: 464–73. [Google Scholar] [CrossRef]
- Onay, Ceylan, and Elif Öztürk. 2018. A review of credit scoring research in the age of Big Data. Journal of Financial Regulation and Compliance 26: 382–405. [Google Scholar] [CrossRef]
- Pai, Ping-Feng, Yi-Shien Tan, and Ming-Fu Hsu. 2015. Credit Rating Analysis by the Decision-Tree Support Vector Machine with Ensemble Strategies. International Journal of Fuzzy Systems 17: 521–30. [Google Scholar] [CrossRef]
- Pamuk, Mustafa, René Oliver Grendel, and Matthias Schumann. 2021. Towards ML-based Platforms in Finance Industry—An ML Approach to Generate Corporate Bankruptcy Probabilities based on Annual Financial Statements. Paper presented at ACIS 2021 Proceedings, Sydney, Australia, December 6–10, vol. 8. Available online: https://easychair.org/cfp/ACIS2021 (accessed on 13 November 2022).
- Peráček, Tomáš, and Michal Kaššaj. 2023. A Critical Analysis of the Rights and Obligations of the Manager of a Limited Liability Company: Managerial Legislative Basis. Laws 12: 56. [Google Scholar] [CrossRef]
- Prechelt, Lutz. 2012. Early Stopping—But When? In Neural Networks: Tricks of the Trade. Edited by Grégoire Montavon, Geneviève B. Orr and Klaus-Robert Müller. Berlin and Heidelberg: Springer, pp. 53–67. [Google Scholar]
- Prenio, Jermy, and Jeffery Yong. 2021. Humans Keeping AI in Check—Emerging Regulatory Expectations in the Financial Sector. Basel: Bank for International Settlements, Financial Stability Institute. [Google Scholar]
- Raschka, Sebastian. 2014. About Feature Scaling and Normalization. Available online: https://sebastianraschka.com/Articles/2014_about_feature_scaling.html (accessed on 3 June 2021).
- Rodrigues, Ana Rita D., Fernando A. F. Ferreira, Fernando J. C. S. N. Teixeira, and Constantin Zopounidis. 2022. Artificial intelligence, digital transformation and cybersecurity in the banking sector: A multi-stakeholder cognition-driven framework. Research in International Business and Finance 60: 101616. [Google Scholar] [CrossRef]
- Saunders, Anthony, and Linda Allen. 2010. Credit risk management in and out of the financial crisis. In New Approaches to Value at Risk and Other Paradigms, 3rd ed. Hoboken: Wiley. [Google Scholar]
- Shearer, Colin. 2000. The CRISP-DM Model: The New Blueprint for Data Mining. Journal of Data Warehousing 5: 13–22. [Google Scholar]
- Tache, Cristina Elena Popa. 2022. Public International Law And Fintech Challenges. Perspectives of Law and Public Administration 11: 218–25. Available online: https://ideas.repec.org/a/sja/journl/v11y2022i2p218-225.html (accessed on 15 January 2023).
- Tomak, Kerem. 2022. Machine-Learning-Anwendungen im Banking: Wie aus Daten Produkte werden. Available online: http://www.ki-note.de/einzelansicht/machine-learning-anwendungen-im-banking-wie-aus-daten-produkte-werden-1 (accessed on 9 November 2022).
- van Gestel, Tony, and Bart Baesens. 2009. Credit Risk Management. Basic Concepts: Financial Risk Components, Rating Analysis, Models, Economic and Regulatory Capital. Edited by Tony van Gestel and Bart Baesens. Oxford: Oxford University Press. [Google Scholar]
- Wall, Larry D. 2018. Some financial regulatory implications of artificial intelligence. Journal of Economics and Business 100: 55–63. [Google Scholar] [CrossRef]
- Wang, Jialan, Jeyul Yang, Benjamin Charles Iverson, and Raymond Kluender. 2020. Bankruptcy and the COVID-19 Crisis. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- White, Lawrence J. 2013. Credit Rating Agencies: An Overview. Annual Review of Financial Economics 5: 93–122. [Google Scholar] [CrossRef]
- Xia, Han. 2014. Can investor-paid credit rating agencies improve the information quality of issuer-paid rating agencies? Journal of Financial Economics 111: 450–68. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Features | |
|---|---|---|
| Capital Structure | ER | (1) Equity Ratio |
| STDR | (2) Short-term Debt Ratio | |
| WCR | (3) Working Capital Ratio * | |
| Profitability | RTA | (4) Return on Total Assets * |
| ROE | (5) Return on Equity * | |
| Liquidity | ACR | (6) Asset Coverage Ratio * |
| L2 | (7) 2nd Degree Liquidity |
| Business Size (Asset Size) | Raw Dataset | % | After Data Cleaning | % |
|---|---|---|---|---|
| Micro <350k € | 2,087,867 | 63.1 | 1,443,739 | 56.3 |
| Small 350k €–6 Mio. € | 1,077,832 | 32.6 | 1,028,480 | 40.1 |
| Medium 6 Mio. €–20 Mio. € | 97,253 | 2.9 | 93,044 | 3.6 |
| Large >20 Mio. € | 46,055 | 1.4 | - | - |
| ∑ | 3,309,007 | 2,565,263 | ||
| Business Sizes | ||||
|---|---|---|---|---|
| Micro <350k € | Small 350k–6 Mio. € | Medium 6–20 Mio. € | ||
| Sampling Strategy | SMOTE | 3,147,530 | 3,269,140 | 309,090 |
| SMOTE-Tomek | 2,813,874 | 3,079,375 | 295,014 | |
| SMOTE-ENN | 835,832 | 1,537,544 | 154,576 | |
| Neural Network | XGBoost | Logistic Regression | Decision Tree | ||||
|---|---|---|---|---|---|---|---|
| Parameter | Values | Parameter | Values | Parameter | Values | Parameter | Values |
| 1st Layer Number of Neurons | 10–100 in increments of 5 | Learning Rate | 0.1, 0.2, 0.3 | Inverse of Regularization Strength | 1, 2, 3, 4 | Max depth | 2, 3, 5 |
| Max Depth | 2, 4, 6 | Max Iteration of Optimization Algorithm | 10, 50, 100, 200 | Max Feature | Sqrt, auto, log | ||
| Learning Rate | 0.01, 0.001, 0.0001 | Number of Gradient Boosted Trees | 10, 50, 100 | Penalty (Norm) | L2 | Min Sample Leaf | 1, 10, 100, 1000 |
| Solver (Optimier) | Lbfgs, newton_cg, sag | CCP Alpha (Pruning Parameter) | 0.0, 0.05, 0.1, 0.15 | ||||
| Neural Network | XGBoost | Logistic Regression | Decision Tree | ||||
|---|---|---|---|---|---|---|---|
| Parameter | Values | Parameter | Values | Parameter | Values | Parameter | Values |
| 1st Layer Number of Neurons | 90 | Base Score | 0.5 | Inverse of Regularization Strength | 2 | CCP Alpha | 0.0 |
| 1st and 2nd Layer Activation Function | Rectified Linear Unit | Learning Rate | 0.3 | Maximum Number of Iterations | 100 | Criterion | Gini |
| 2nd Layer Number of Neurons | 20 | Max Depth | 6 | Penalty | l2 | Max Depth | 5 |
| 3rd Layer Number of Neurons | 10 | Number of Gradient Boosted Trees | 100 | Solver | newton-cg | Max Features | 7 |
| 3rd Layer Activation Function | Softmax | Tolerance | 0.0001 | Min Samples Leaf | 1 | ||
| Optimizer | RMSProp | Reg_alpha | 0 | Splitter | best | ||
| Learning Rate | 0.001 | ||||||
| NN | XGBoost | LR | DT | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Business Sizes | Mic | Sm | Med | Mic | Sm | Med | Mic | Sm | Med | Mic | Sm | Med | Metrics | |
| Sampling Strategies | SMOTE | 0.298 | 0.429 | 0.488 | 0.440 | 0.511 | 0.650 | 0.201 | 0.328 | 0.327 | 0.290 | 0.399 | 0.450 | Accuracy |
| 0.299 | 0.461 | 0.494 | 0.449 | 0.519 | 0.648 | 0.228 | 0.316 | 0.322 | 0.216 | 0.424 | 0.469 | Precision | ||
| 0.298 | 0.429 | 0.488 | 0.440 | 0.511 | 0.650 | 0.201 | 0.328 | 0.327 | 0.290 | 0.399 | 0.450 | Recall | ||
| 0.285 | 0.419 | 0.482 | 0.438 | 0.511 | 0.646 | 0.154 | 0.310 | 0.311 | 0.255 | 0.395 | 0.442 | F1 Score | ||
| SMOTE-TOMEK | 0.285 | 0.446 | 0.513 | 0.459 | 0.523 | 0.672 | 0.164 | 0.327 | 0.311 | 0.304 | 0.408 | 0.464 | Accuracy | |
| 0.262 | 0.450 | 0.527 | 0.468 | 0.531 | 0.669 | 0.163 | 0.325 | 0.323 | 0.306 | 0.433 | 0.482 | Precision | ||
| 0.285 | 0.446 | 0.513 | 0.459 | 0.523 | 0.672 | 0.164 | 0.327 | 0.311 | 0.304 | 0.408 | 0.464 | Recall | ||
| 0.244 | 0.446 | 0.511 | 0.457 | 0.524 | 0.668 | 0.119 | 0.316 | 0.292 | 0.275 | 0.400 | 0.456 | F1 Score | ||
| SMOTE-ENN | 0.513 | 0.592 | 0.644 | 0.748 | 0.708 | 0.894 | 0.343 | 0.425 | 0.419 | 0.515 | 0.516 | 0.615 | Accuracy | |
| 0.486 | 0.600 | 0.649 | 0.748 | 0.710 | 0.893 | 0.232 | 0.419 | 0.392 | 0.427 | 0.527 | 0.580 | Precision | ||
| 0.513 | 0.592 | 0.644 | 0.748 | 0.708 | 0.894 | 0.343 | 0.425 | 0.419 | 0.515 | 0.516 | 0.615 | Recall | ||
| 0.475 | 0.589 | 0.634 | 0.747 | 0.707 | 0.893 | 0.210 | 0.388 | 0.385 | 0.460 | 0.510 | 0.594 | F1 Score | ||
| SMOTE-ENN (with PR) | 0.520 | 0.574 | 0.637 | 0.739 | 0.699 | 0.897 | 0.284 | 0.424 | 0.453 | 0.498 | 0.501 | 0.589 | Accuracy | |
| 0.486 | 0.585 | 0.634 | 0.739 | 0.702 | 0.896 | 0.231 | 0.417 | 0.441 | 0.407 | 0.508 | 0.568 | Precision | ||
| 0.520 | 0.574 | 0.637 | 0.739 | 0.699 | 0.897 | 0.284 | 0.424 | 0.453 | 0.498 | 0.501 | 0.589 | Recall | ||
| 0.469 | 0.571 | 0.629 | 0.737 | 0.699 | 0.896 | 0.194 | 0.395 | 0.417 | 0.443 | 0.493 | 0.560 | F1 Score | ||
| Business Sizes | ||||
|---|---|---|---|---|
| Micro <350k € | Small 350k–6 Mio. € | Medium 6–20 Mio. € | ||
| Rating Classes | AAA | 0.762 | 0.778 | 0.897 |
| AA | 0.639 | 0.571 | 0.791 | |
| A | 0.723 | 0.529 | 0.759 | |
| BBB | 0.559 | 0.525 | 0.775 | |
| BB | 0.592 | 0.675 | 0.821 | |
| B | 0.634 | 0.681 | 0.859 | |
| CCC | 0.634 | 0.673 | 0.920 | |
| CC | 0.663 | 0.670 | 0.939 | |
| C | 0.797 | 0.730 | 0.953 | |
| D | 0.809 | 0.873 | 0.971 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pamuk, M.; Schumann, M. Opening a New Era with Machine Learning in Financial Services? Forecasting Corporate Credit Ratings Based on Annual Financial Statements. Int. J. Financial Stud. 2023, 11, 96. https://doi.org/10.3390/ijfs11030096
Pamuk M, Schumann M. Opening a New Era with Machine Learning in Financial Services? Forecasting Corporate Credit Ratings Based on Annual Financial Statements. International Journal of Financial Studies. 2023; 11(3):96. https://doi.org/10.3390/ijfs11030096
Chicago/Turabian StylePamuk, Mustafa, and Matthias Schumann. 2023. "Opening a New Era with Machine Learning in Financial Services? Forecasting Corporate Credit Ratings Based on Annual Financial Statements" International Journal of Financial Studies 11, no. 3: 96. https://doi.org/10.3390/ijfs11030096
APA StylePamuk, M., & Schumann, M. (2023). Opening a New Era with Machine Learning in Financial Services? Forecasting Corporate Credit Ratings Based on Annual Financial Statements. International Journal of Financial Studies, 11(3), 96. https://doi.org/10.3390/ijfs11030096