
Equity-Market-Neutral Strategy Portfolio Construction Using LSTM-Based Stock Prediction and Selection: An Application to S&P500 Consumer Staples Stocks


Abstract
1. Introduction
2. Literature Review
3. Data and Methodology
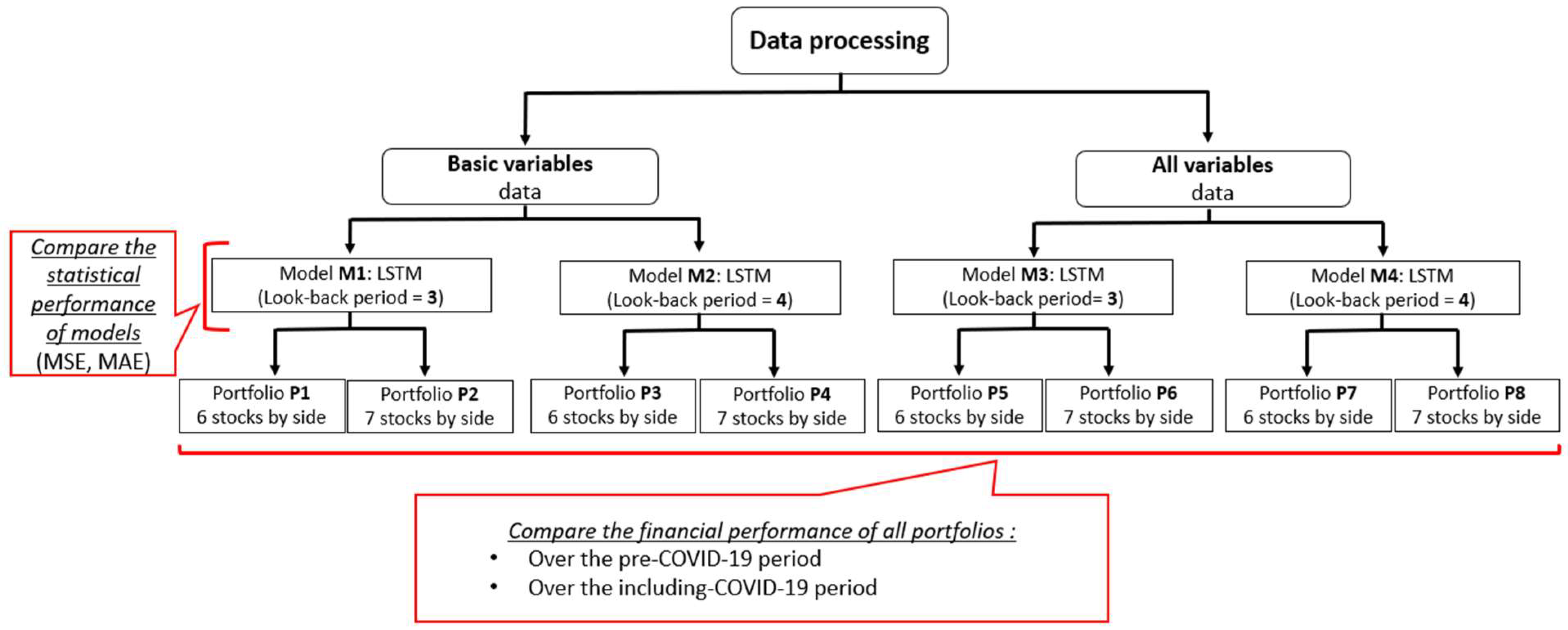
- The category of explanatory variables introduced into the model, i.e., a basket of “basic variables” versus “all variables”.
- The size of the look-back period considered in LSTM to predict future weekly returns. Two sizes are to be compared: a window of the past three observations versus a window of the past four observations.
- The number of stocks selected for the two sides of the robust portfolio, i.e., six stocks in each side versus seven stocks.
- The financial performance during the test period, namely, the pre-COVID-19 period versus the whole period including the COVID-19 crisis period.
3.1. Data Preparation
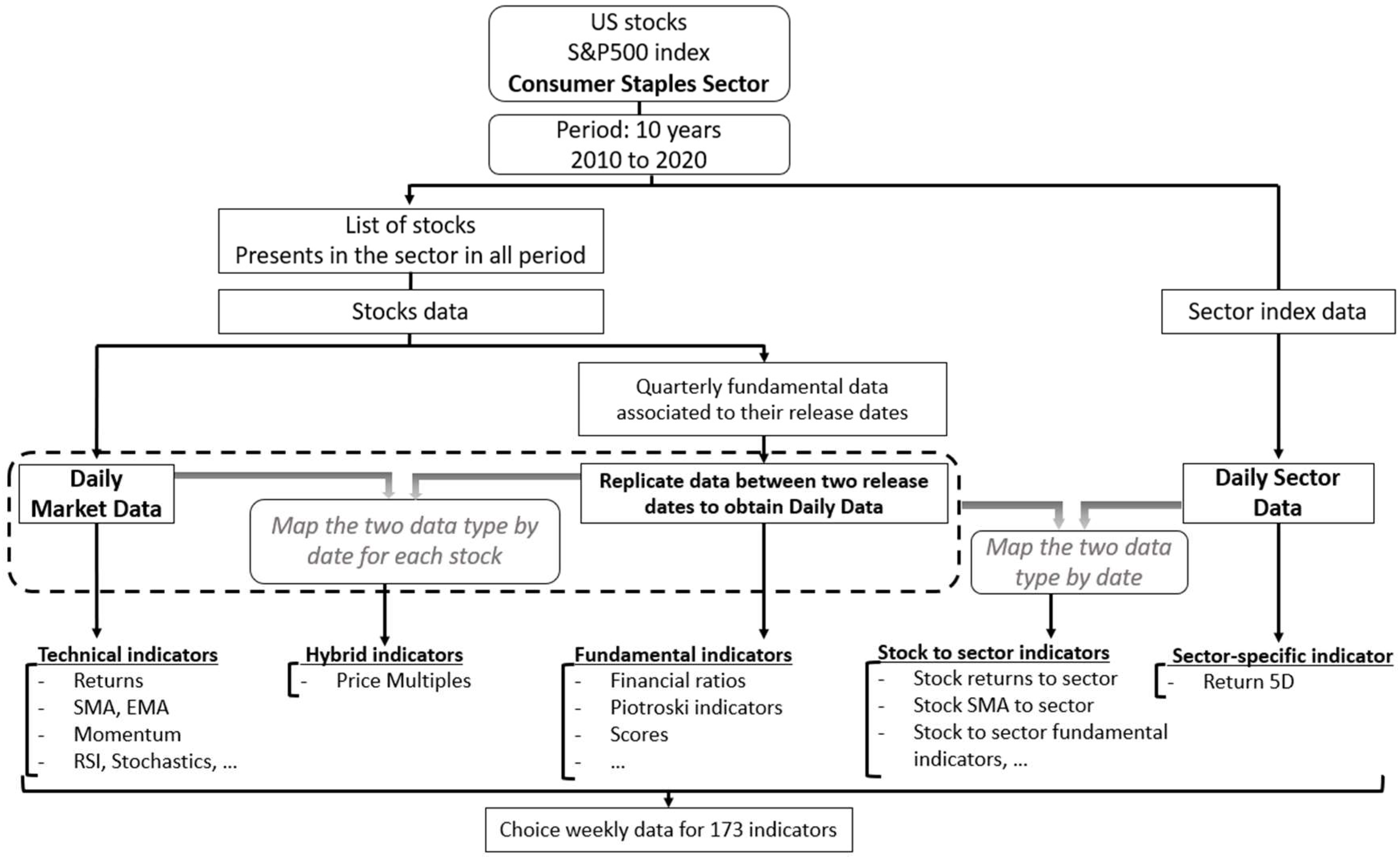
3.1.1. Data Acquisition
3.1.2. Calculating the Indicators
- Technical indicators: this category of indicators includes stock market data without transformations, OCHLV and Market Capitalization, returns, volatilities, ratio of returns to volatilities, simple moving averages (SMA), exponential moving averages (EMA), prices relative to simple and exponential moving averages, momentum, the 14-day relative strength index (RSI), the 5-day RSI moving average, 14-day stochastic oscillators (slow and fast), the Williams 14-day indicator (%R), and On Balance Volume (OBV).
- Fundamental indicators: most of the fundamental indicators used in our model are ratios between the fundamental indicators of the stocks and the same indicators calculated on the sector data (“stock to sector fundamental indicators”). Other indicators are calculated differently, such as the “Piotroski indicators” and the “Scores”. The “Piotroski” indicators are binary indicators assigned to the stock at a given time if certain fundamental indicators satisfy certain criteria (0 if the criterion is satisfied, 1 otherwise). Thus, a total Piotroski score is the sum of all the calculated indicators (Piotroski 2000).Inspired by Piotroski’s indicators, we established “Scores” that can takes the values 0, 1, or 2, which are attributed to the stock at a given time according to the value of certain financial ratios. These ratios are compared to threshold set beforehand. For instance, if the value of the ratio is less than that of the small threshold, the score will be set at 0, and if the value of the ratio is situated between the small and the big thresholds, the score will equal 1. Otherwise, the score will take the value of 2. Thus, the total score of a group of financial ratios is the sum of the constituent scores.
- Hybrid indicators: these are indicators calculated based on both technical and fundamental indicators. This category of indicators consists mainly of price multiples (price-earnings ratio, price-to-book ratio, price-to-sales ratio, etc.)
- Stock to sector indicators: most of the final variables used in the model fall into this category of indicators. A stock-to-sector indicator is a ratio of a stock indicator and a sector indicator. For instance, close to sector, open to sector, price-to-sell to sector, price-to-book to sector, stock returns to sector, volatilities relative to sector, simple moving averages relative to sector, exponential moving averages relative to sector, momentum relative to sector, or price-to-moving average ratios relative to sector.
- Sector-specific indicators: in this category, we considered only the five-day sector return, since other indicators in the sector are already included in the calculation of the other variables.
3.1.3. Cleaning and Standardization of Data
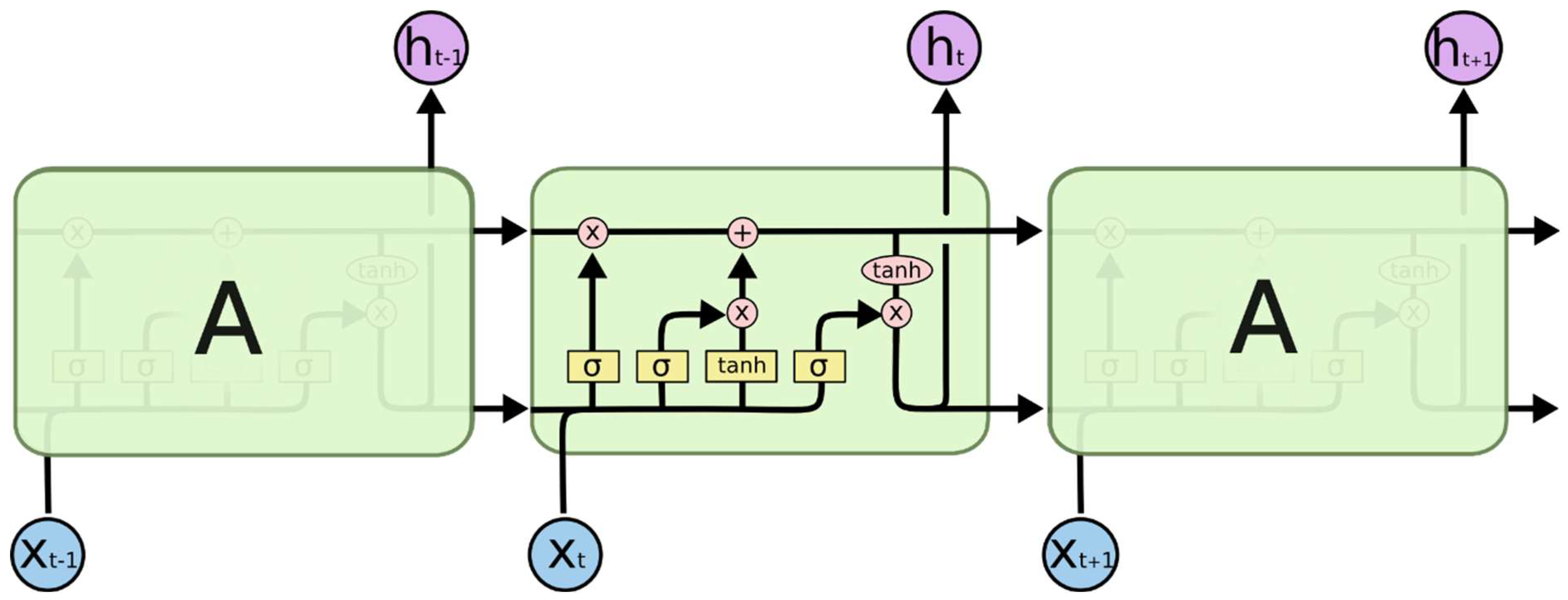
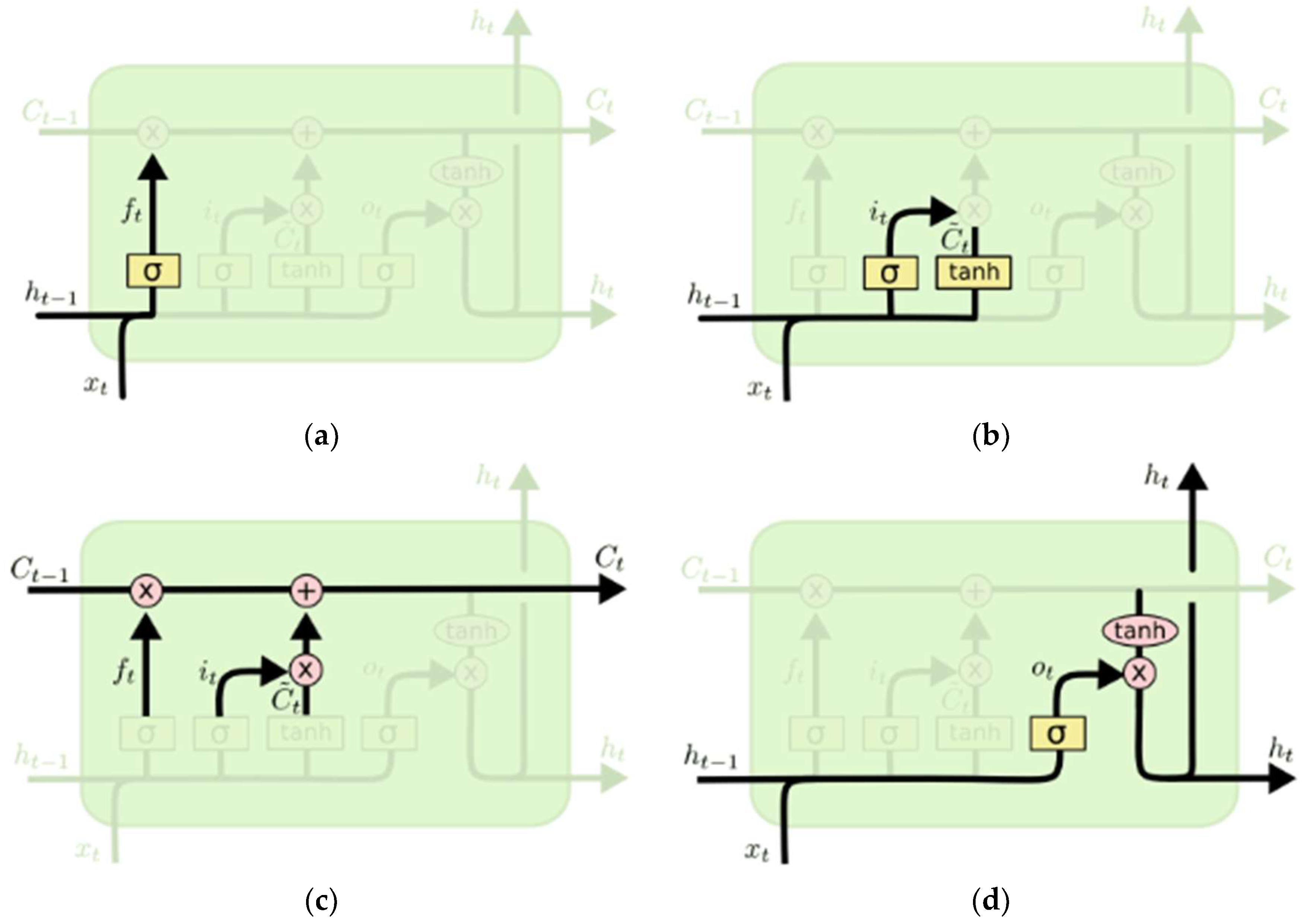
3.2. LSTM Neural Networks
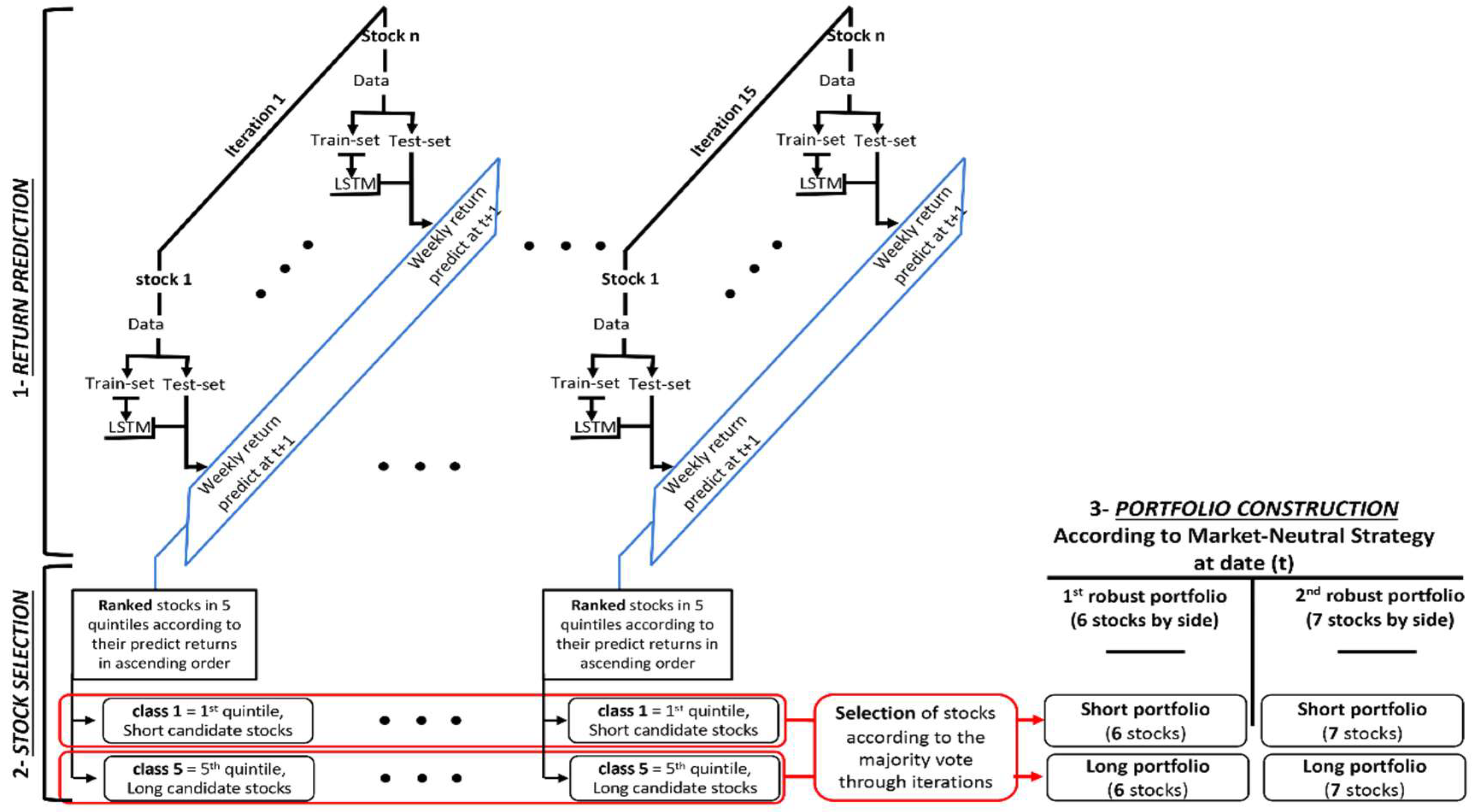
3.3. Prediction of Stock Returns
3.3.1. Training Set and Testing Set
3.3.2. LSTM Structure and Setup
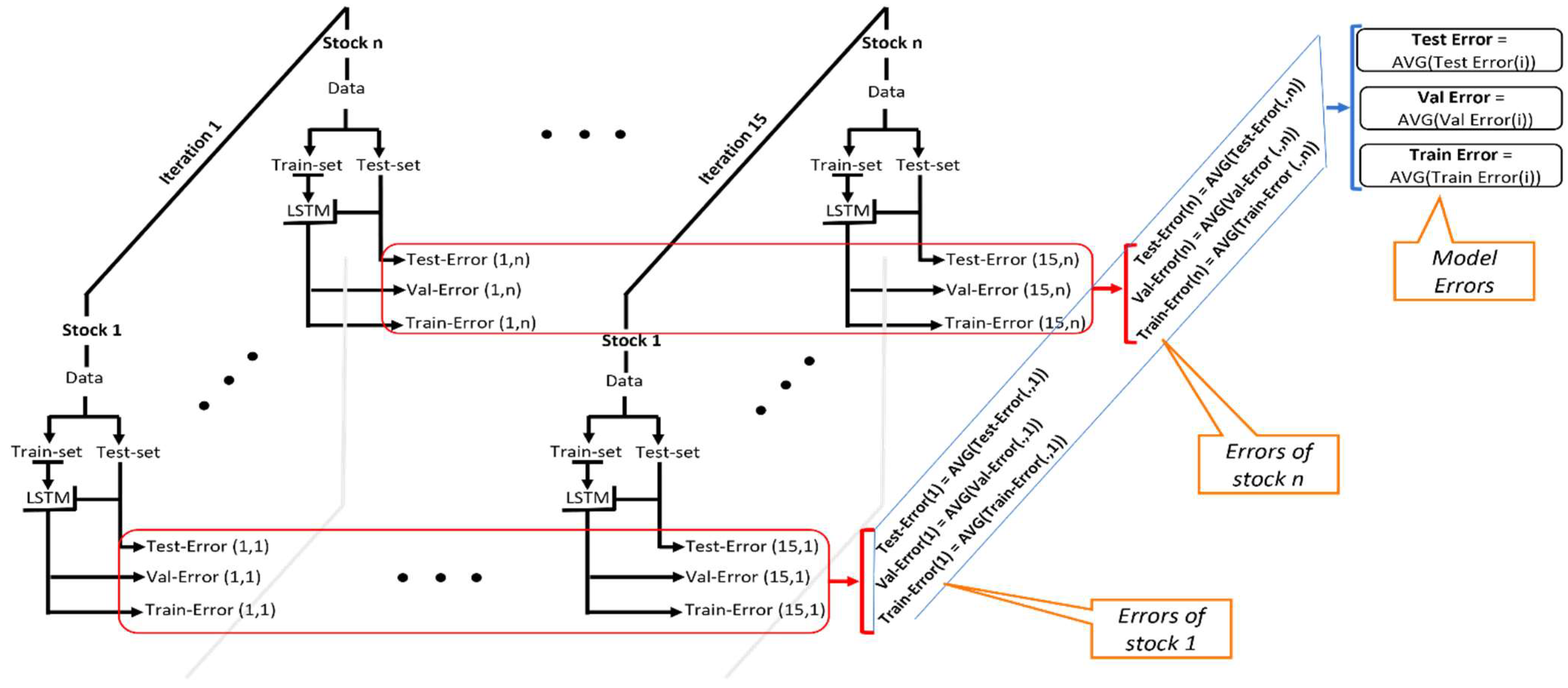
3.3.3. Statistical Evaluation of the Model
3.4. Portfolio Construction
3.5. Evaluation of Portfolio Performance
- The type of basket of explanatory variables taken in the model, including a first basket of “basic variables” with 128 variables, and a second basket of “all variables” with 173 variables.
- The size of the look-back period used by the LSTM networks, which takes the following two values: w = 3 and w = 4.
- The number of stocks taken for each side of the robust portfolio, with the following two values: n = 6 and n = 7.
3.5.1. Return
3.5.2. NAV
3.5.3. Volatility
3.5.4. Sharpe Ratio
3.5.5. Downside Volatility
3.5.6. Sortino Ratio
3.5.7. Beta
3.5.8. Alpha
3.5.9. Correlation
3.5.10. Treynor Ratio
3.5.11. Information Ratio
3.5.12. Capture Ratios
3.5.13. Omega Ratio
3.5.14. Maximum Drawdown
3.5.15. Calmar Ratio
4. Results and Discussion
4.1. Statistical Performance of the Model
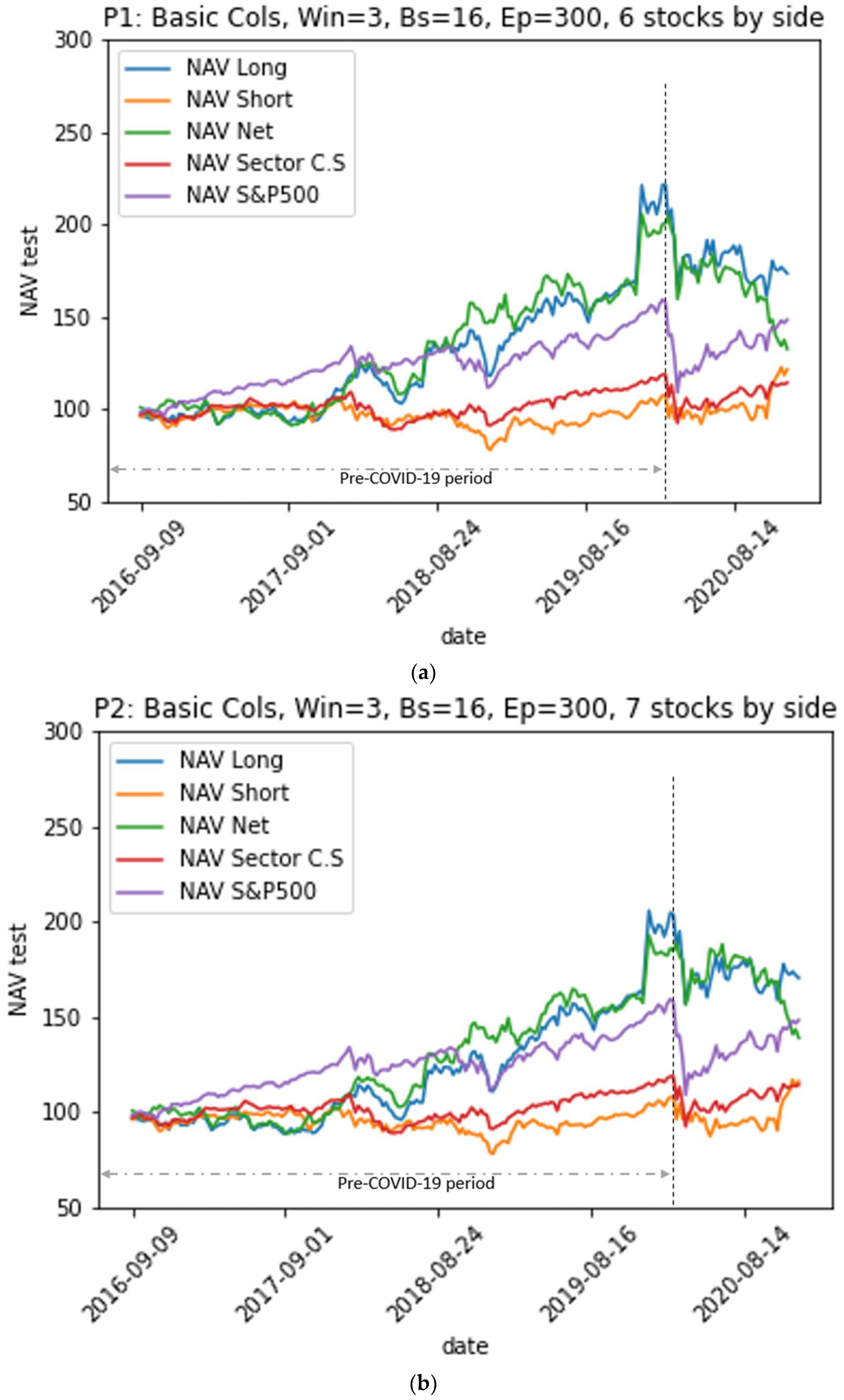
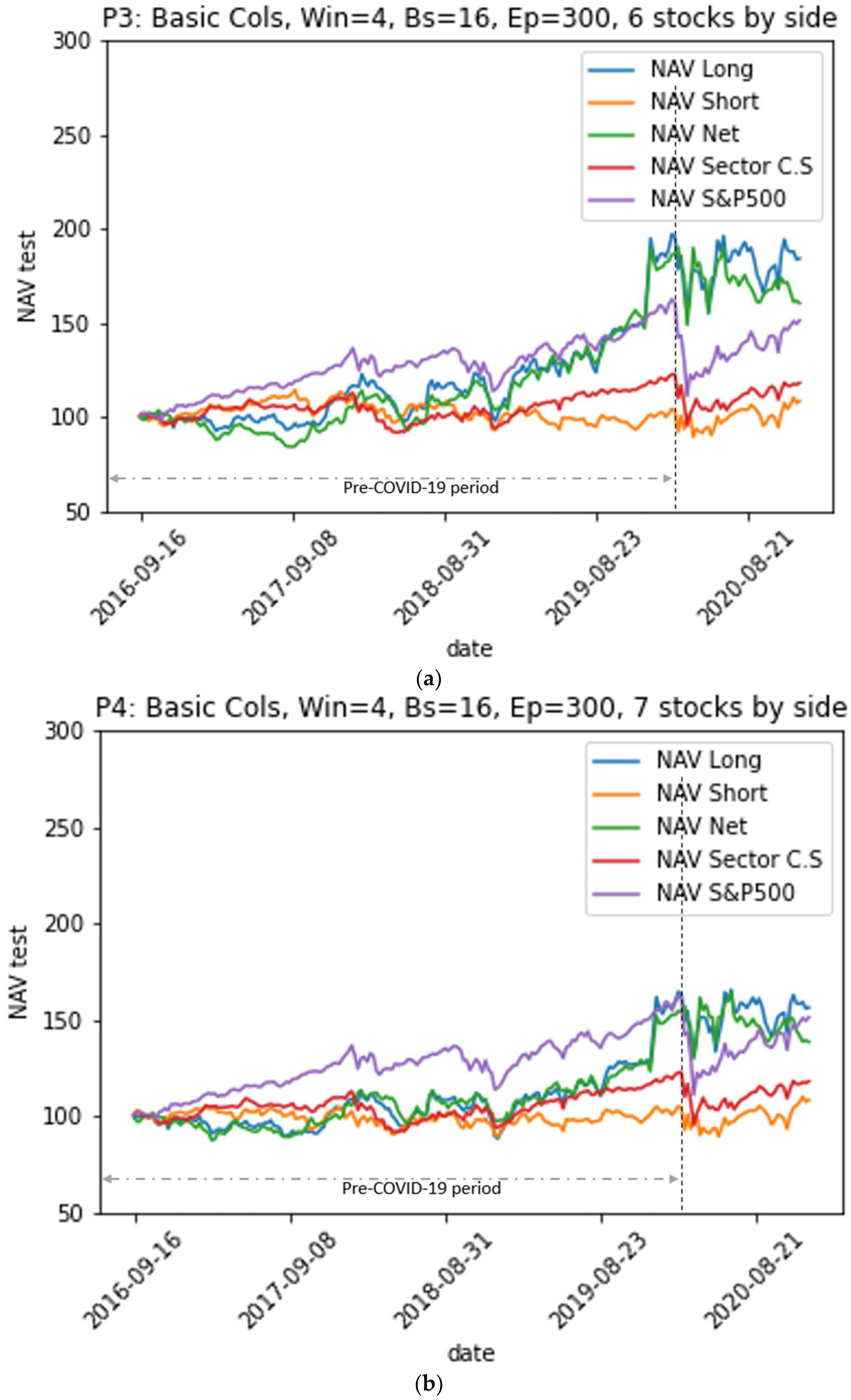
4.2. Financial Performance of the Model
- All portfolios outperformed their sector index in terms of risk-adjusted returns (Sharpe ratio, Sortino ratio, Treynor ratio, Omega ratio, Calmar ratio, and information ratio).
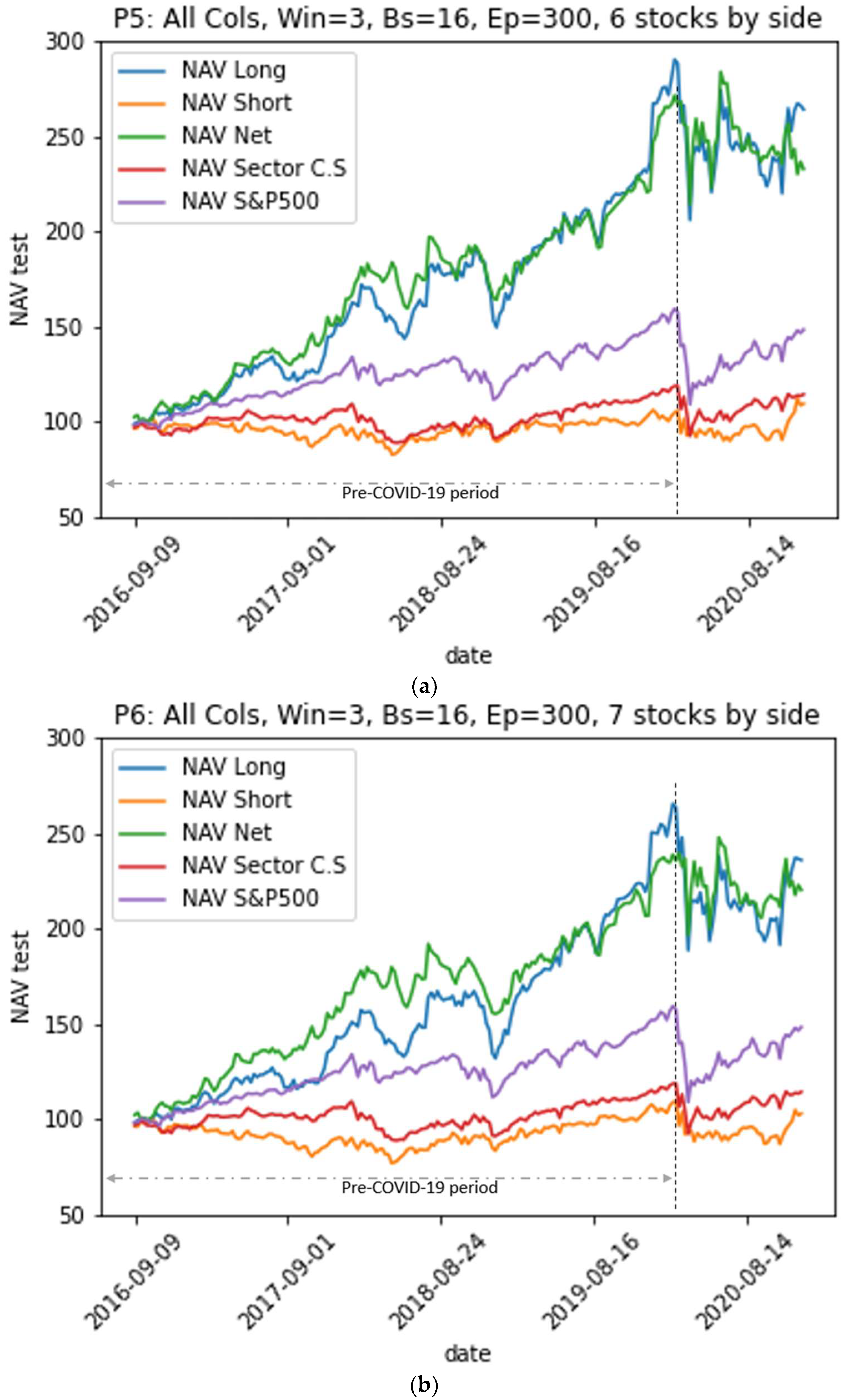
- Portfolios P5, P6, P7, and P8 from models M3 and M5, which use all of the explanatory variables, outperformed the sector index and the S&P500 index representing the market on the one hand; on the other hand, they largely outperformed portfolios P1, P2, P3, and P4 from models M1 and M2, which use “basic variables”.
- Portfolios from models where LSTM neural networks use a look-back period of size w = 4 to predict the stock’s future return outperformed the other models using w = 3 for the whole period including-COVID-19. However, portfolios from models using a look-back period with a size w = 3 outperformed the others during the pre-COVID-19 period.
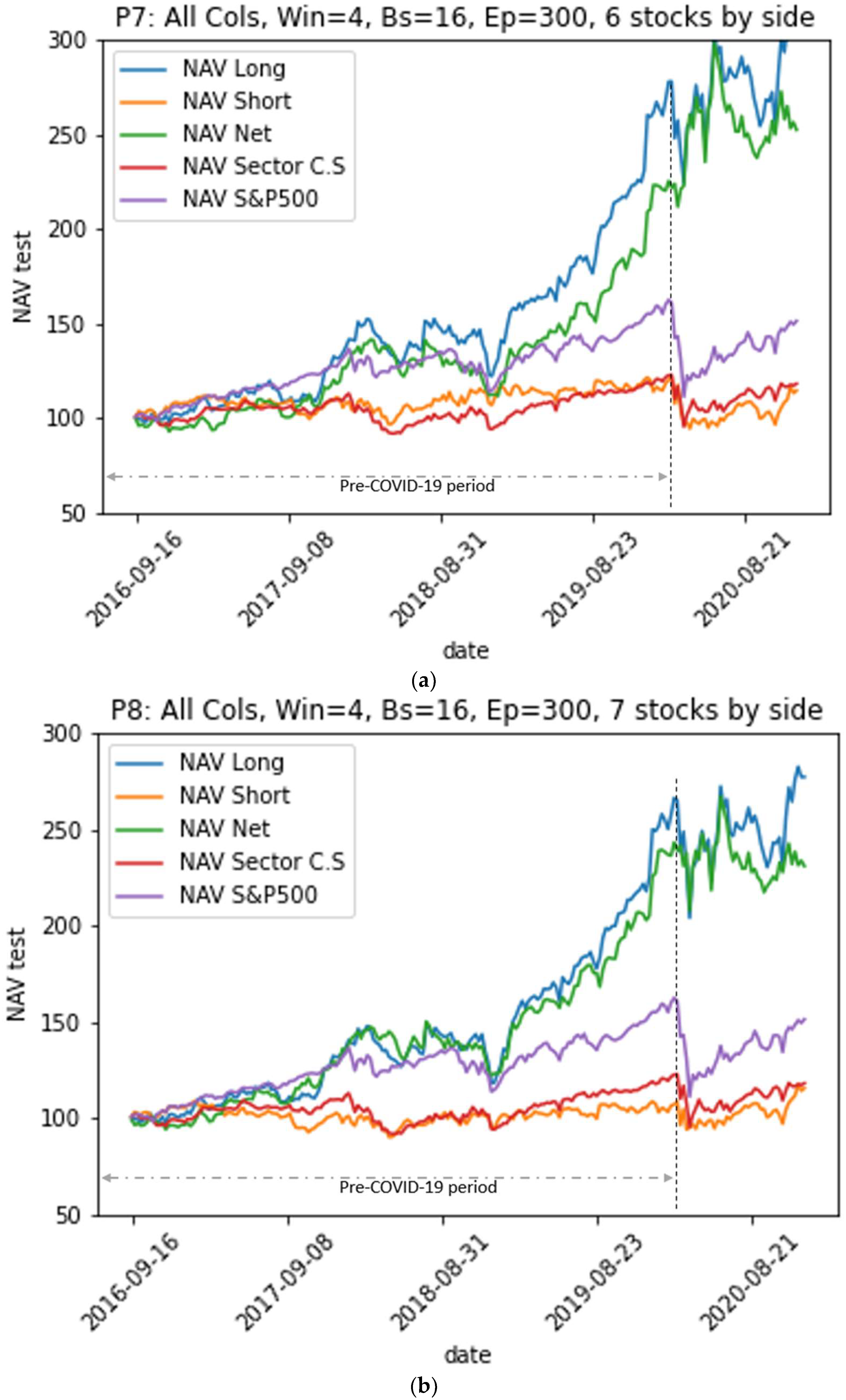
- The P7 portfolio, which consists of six stocks in each of its long and short sides and which is generated by the model M4 (w = 4, all variables), provided the best performance both in the pre-COVID-19 period and in the period including COVID-19. It achieved an annualized average return of 25% over the entire test period compared to 27% over the pre-COVID-19 period, a decrease of 2%; meanwhile, the annualized average returns of the S&P 500 index and the sector index decreased from 15% to 10% and from 5% to 3%, respectively. However, the annualized volatility of the P7 portfolio increased from 19% pre-COVID-19 to 22% over the entire period (including COVID-19): an increase of 3%. Meanwhile, the annualized volatilities of the S&P500 index and the CS sector index increased from 12% to 18% and from 12% to 16%, increases of 6% and 4%, respectively.
- Over the entire period, the P7 portfolio achieved 1.04, 1.92, and 0.93 for the Sharpe, Sortino, and Treynor ratios, respectively, indicating that it achieved an acceptable risk-adjusted excess return. Indeed, the Sortino ratio is higher than the Sharpe ratio because it only takes into account the downside volatility, which is lower than volatility. In addition, its Sharpe, Sortino, and Treynor ratios are significantly higher than those of the benchmarks: the S&P500 market index had values of 0.48, 0.62, and 0.09 and the CS sector index had values of 0.12, 0.16, and 0.03 for the three ratios.
- The P7 portfolio has an Alpha of 23%, i.e., most of its returns are not made through systematic market risk taking, but are rather due to its own strategy. Its Beta and Correlation relative to the market are 0.25 and 0.20 over the whole test period, and 0.17 and 0.11 over the pre-COVID-19 period, respectively. This means that the portfolio has a very low correlation to the market, which is the goal of the EMN strategy.
- The P7 portfolio has an information ratio of 0.56, which means that it outperformed the benchmark, given its risk. Furthermore, its positive excess returns outperformed its negative excess returns over the entire period, which is reflected in its Omega ratio of 1.51. This is higher than the benchmarks S&P500 index and the CS sector index, which had values of 1.26 and 1.09, respectively.
- The Calmar ratio of the P7 portfolio reaches 1.11, compared to 0.27 for the S&P 500 index and 0.09 for the CS sector. This ratio measures the risk-adjusted return using the maximum drawdown in the denominator, which reached a value of −21% for this portfolio on 11 January 2019. This maximum loss is lower than the maximum drawdown of the benchmarks that took place simultaneously on 20 March 2020, with values of −32% for the S&P 500 index and −22% for the CS sector index.
- As for the upside capture and downside capture ratios, the P7 portfolio scored 0.42 and 0.09 for these two ratios, respectively, indicating that the P7 portfolio underperformed while the benchmark S&P 500 index was performing well; however, the portfolio was very resilient during periods when the benchmark S&P500 index declined. In addition, the CS Sector index had an upside capture value of 0.53, meaning that it also underperformed while the benchmark S&P500 index performed well, but with a downside capture of 0.79, showing little resilience to market downturns compared to the P7 portfolio.
- The risk-adjusted performance of all portfolios in the pre-COVID-19 period was better than that in the period including the COVID-19 pandemic. When the COVID-19 pandemic period was introduced to the test data, the returns experienced a decline ranging from 6% to 16% for the M1 and M2 model portfolios (using the basic variables). The level of decline ranged from 2% to 12% for the M3 and M4 model portfolios (using all variables). The pandemic caused the volatility of all portfolios to rise. The increase in volatility ranged from 3% to 6%. Similarly, the returns for the S&P500 benchmark and the CS sector index decreased by 5% and 2% and their volatilities increased by 6% and 4%, respectively. This means that the EMN strategy portfolios were more strongly impacted by the COVID-19 pandemic than the benchmarks were. Moreover, EMN was the strategy with the lowest performance according to a study conducted by Ganchev (2022) on the performance of hedge fund strategies before and after the COVID-19 crisis.
- Transitioning from the M1 and M2 models to the M4 and M5 models by introducing the three baskets of variables (“Piotroski”, “Scores”, and “stock to sector fundamental indicators”) greatly improved the performance of the EMN strategy portfolios. Indeed, for all of the portfolios, we saw an increase in the annualized average return, from 6% to 15%, with almost the same volatility.
- Portfolios from models M1 and M3 using a look-back period of size w = 3 performed well during the pre-COVID-19 period, while those from models M3 and M4 using w = 4 outperformed over the entire period, including the COVID-19 crisis period.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Start Date | End Date | Number of Weeks | |
|---|---|---|---|---|
| 1 | ADM | 2010-01-08 | 2020-12-18 | 553 |
| 2 | AVP | 2010-01-08 | 2020-01-03 | 505 |
| 3 | BF/B | 2010-01-08 | 2020-12-18 | 553 |
| 4 | CAG | 2010-01-08 | 2020-12-18 | 553 |
| 5 | CCE | 2010-12-31 | 2018-11-02 | 396 |
| 6 | CHD | 2010-01-08 | 2020-12-18 | 553 |
| 7 | CL | 2010-01-08 | 2020-12-18 | 553 |
| 8 | CLX | 2010-01-08 | 2020-12-18 | 553 |
| 9 | COST | 2010-01-08 | 2020-12-04 | 551 |
| 10 | COTY | 2014-03-28 | 2020-12-18 | 338 |
| 11 | CPB | 2010-01-08 | 2020-12-18 | 553 |
| 12 | DPS | 2010-12-31 | 2018-07-06 | 379 |
| 13 | EL | 2010-01-08 | 2020-12-18 | 553 |
| 14 | GAPTQ | 2010-01-08 | 2012-03-09 | 111 |
| 15 | GIS | 2010-01-08 | 2020-12-18 | 553 |
| 16 | GMCR | 2010-01-08 | 2016-02-26 | 308 |
| 17 | HNZ | 2010-01-08 | 2013-06-07 | 174 |
| 18 | HRL | 2010-01-08 | 2020-12-18 | 553 |
| 19 | HSY | 2010-01-08 | 2020-12-18 | 553 |
| 20 | K | 2010-01-08 | 2020-12-18 | 553 |
| 21 | KHC | 2016-07-08 | 2020-12-18 | 228 |
| 22 | KMB | 2010-01-08 | 2020-12-18 | 553 |
| 23 | KO | 2010-01-08 | 2020-12-18 | 553 |
| 24 | KR | 2010-01-08 | 2020-12-18 | 553 |
| 25 | KRFT | 2013-07-12 | 2015-06-26 | 98 |
| 26 | LO | 2010-07-02 | 2015-06-05 | 249 |
| 27 | LW | 2017-08-25 | 2020-12-18 | 170 |
| 28 | MDLZ | 2010-01-08 | 2020-12-18 | 553 |
| 29 | MJN | 2010-03-12 | 2017-06-09 | 364 |
| 30 | MKC | 2010-01-08 | 2020-12-18 | 553 |
| 31 | MNST | 2010-01-08 | 2020-12-18 | 553 |
| 32 | MO | 2010-01-08 | 2020-12-18 | 553 |
| 33 | PEP | 2010-01-08 | 2020-12-18 | 553 |
| 34 | PG | 2010-01-08 | 2020-12-18 | 553 |
| 35 | PM | 2010-04-09 | 2020-12-18 | 541 |
| 36 | RAD | 2010-01-08 | 2020-12-18 | 553 |
| 37 | RAI | 2010-01-08 | 2017-07-21 | 379 |
| 38 | SJM | 2010-01-08 | 2020-12-18 | 553 |
| 39 | STZ | 2010-01-08 | 2020-12-18 | 553 |
| 40 | SVU | 2010-01-08 | 2018-10-19 | 443 |
| 41 | SWY | 2010-01-08 | 2015-01-23 | 255 |
| 42 | SYY | 2010-01-08 | 2020-12-18 | 553 |
| 43 | TAP | 2010-01-08 | 2020-12-18 | 553 |
| 44 | TSN | 2010-01-08 | 2020-12-18 | 553 |
| 45 | UN | 2010-01-08 | 2013-09-20 | 189 |
| 46 | WAG | 2010-12-31 | 2014-12-19 | 203 |
| 47 | WBA | 2010-01-08 | 2020-12-18 | 553 |
| 48 | WFM | 2010-01-08 | 2017-08-25 | 384 |
| 49 | WMT | 2010-01-08 | 2020-11-13 | 548 |
| Variable Name | Description | Bloomberg Field Name |
|---|---|---|
| Stock market data: BBG field (daily frequency) | ||
| curMrkCap | Current market capitalization | CUR_MKT_CAP |
| Open | Open price | OPEN |
| High | High price | HIGH |
| Low | Low price | LOW |
| Volume | Volume | PX_VOLUME |
| Close | Close price | PX_LAST |
| nbrShares | Total current number of shares outstanding | EQY_SH_OUT |
| indDivYld | Indicative dividend per share | EQY_IND_DPS_ANNUAL_GROSS |
| Fundamental data: BBG field (quarterly frequency) | ||
| _debt | Short-term and long-term debt | SHORT_AND_LONG_TERM_DEBT |
| _debtLT | Long term borrowing | BS_LT_BORROW, |
| _debtST | Short term borrowing | BS_ST_BORROW, |
| _marge1Y | Trailing 12-month gross margin | TRAIL_12M_GROSS_MARGIN |
| _cash | Cash | CASH_&_ST_INVESTMENTS |
| _cshMrkSecr | Cash and marketable securities | CASH_AND_MARKETABLE_SECURITIES |
| _Eqy | Total Equity | TOTAL_EQUITY |
| _sales1Y | Trailing 12-month sales | TRAIL_12M_NET_SALES |
| _CF1y | Trailing 12-month cash flow | TRAIL_12M_CASH_FROM_OPER |
| _FCF1y | Trailing 12-month free cash flow | TRAIL_12M_FREE_CASH_FLOW |
| _assets | Total assets | BS_TOT_ASSET |
| _divPerSh1y | Trailing 12-month dividend per share | TRAIL_12M_DVD_PER_SH |
| _Liab | Total liability | BS_TOT_LIAB2 |
| _earn1Y | Trailing 12-month earning | T12M_INC_BEF_XO_LESS_MIN_INT_PFD |
| _EPS1y | Trailing 12-month EPS | TRAIL_12M_EPS |
| _nbrShEps | Average number of shares for EPS | IS_AVG_NUM_SH_FOR_EPS |
| _nbrShDilEps | Average number of shares used for diluted Eps | IS_SH_FOR_DILUTED_EPS |
| _ROE | Return on common equity | RETURN_COM_EQY |
| _ebitda1Y | Trailing 12-month EBITDA | TRAIL_12M_EBITDA |
| _curAssets | Current assets | BS_CUR_ASSET_REPORT |
| _curLiab | Current liability | BS_CUR_LIAB |
| _inventori | Inventories | BS_INVENTORIES |
| _accReceiv | Receivable account | BS_ACCT_NOTE_RCV |
| _accPayble | Payable account | BS_ACCT_PAYABLE |
| _augCap | Trailing 12-month increase capital stock | TRAIL_12M_INCR_CAP_STOCK |
| _dimCap | Trailing 12-month decrease capital stock | TRAIL_12M_DECR_CAP_STOCK |
| Variable Name | Description | BBG Field |
|---|---|---|
| Sector data: BBG field (weekly frequency) | ||
| open_sec | Open price | OPEN |
| high_sec | High price | HIGH |
| low_sec | Low price | LOW |
| volume_sec | Volume | PX_VOLUME |
| close_sec | Close price | PX_LAST |
| curMrkCap_sec | Current market capitalization | CUR_MKT_CAP |
| rvnPerSh_sec | Revenue per share | REVENUE_PER_SH |
| divPerSh1Y_sec | Dividend per share last 12 months | DVD_SH_12M |
| Eps_sec | Trailing 12-month earnings per share | TRAIL_12M_EPS_BEF_XO_ITEM |
| assets_sec | Assets | BS_TOT_ASSET |
| EV_sec | Entreprise value | ENTERPRISE_VALUE |
| bkPerSh_sec | Book value per share | BOOK_VAL_PER_SH |
| cfPerSh_sec | Cash flow per share | CASH_FLOW_PER_SH |
| fcfPerSh_sec | Free cash flow per share | FREE_CASH_FLOW_PER_SH |
| ptMrg_sec | Trailing 12-month profit margin | TRAIL_12M_PROF_MARGIN |
| fcf2Pr_sec | Free cash flow to price | FREE_CASH_FLOW_YIELD |
| liab_sec | Total liability | BS_TOT_LIAB2 |
| ROE_sec | Return on equity | RETURN_COM_EQY |
| dbt2Eqy_sec | Debt to equity | TOT_DEBT_TO_TOT_EQY |
| salesPerSh1Y_sec | Sales per share last 12 months | TRAIL_12M_SALES_PER_SH |
| pr2CF_sec | Price to cash flow | PX_TO_CASH_FLOW |
| pr2Bk_sec | Price to book value | PX_TO_BOOK_RATIO |
| pr2Ern_sec | Price to earning | PE_RATIO |
| Variable Name | Description | Formula |
|---|---|---|
| _assetsTrnv | Asset turnover | _sales1Y/_assets |
| _debtSTminsCash | Short term debt minus cash | Max (_debtST − _cash, 0) |
| _debtMinsCash | Debt minus cash | _debtLT + _debtSTminsCash |
| _netIncome | Net income (NI) | _Eps1Y × _nbrShEps |
| Eps | Earnings per share (EPS) | earn1Y/nbShares |
| _ptMrg | Profit margin | earn1Y/sales1Y |
| _dbt2Eqy | Debt to Equity | _debt/_Eqy |
| _cfoMrg | Cash flow margin | _CF1y/_sales1Y |
| _yoyErnGr | Year to year earnings growth | _earn1Y(Q)/_earn1Y(Q-4) |
| _yoyErnGrRate | Year to year earnings growth rate | _yoyErnGr − 1 |
| yoyEpsGrRate | Year to year EPS growth rate | EPS(j)/EPS(j-252) − 1 |
| _yoyEbitdaGrRate | Year to year EBITDA growth rate | _ebitda1y(Q)/_ebitda1y(Q-4) − 1 |
| _yoySlGr | Year to year sales growth | _sales1Y(Q)/_sales1Y(Q-4) |
| _yoySlGrRate | Year to year sales growth rate | _yoySlGr − 1 |
| _netDebt | Net debt | _debt − _cshMrkSecur |
| EV | Enterprise value | curMrkCap + _debtMinsCash |
| _netDbtToEV | Net debt to EV | _netDebt/EV |
| _netDbt2Ebd | Net debt to EBITDA | _netDebt/_ebitda1Y |
| _curRatio | Current ratio | _curAssets/_curLiab |
| _ebitdaMrg | EBITDA margin | _ebitda1Y/_sales1Y |
| _inventryToSales | Inventories to sales | _inventori/_sales1y |
| _receivTurnover | Receivables turnover | _sales1y/_accReceiv |
| _operFin | Operations financing | (_accPayble − _accReceiv)/_sales1y |
| fcfPerSh | Free cash flow per share | _FCF1y/nbrShares |
| FcfDivCovRt | Free cash flow dividend coverage ratio | indDivYld/fcfPerSh |
| NiDivCovRt | Net income dividend coverage ratio | indDivYld/EPS |
| divPerShGr4Q | 4Q dividend per share growth | _divPerSh1y(Q)/_divPerSh1y(Q-4) |
| divPerShGr12Q | 12Q dividend per share growth | _divPerSh1y(Q)/_divPerSh1y(Q-12) |
| _netDebtIss | Net debt issuance | _debt(Q) − _debt(Q-4) |
| _netEqyIss | Net equity issuance | _augCap − _dimCap |
| _netFin | Net financing | _netEqyIss + _netDebtIss |
| _cfoToNiAcr | CFO to net income accrual | (_CF1y(Q) − _netIncome(Q))/assets(Q-4) |
| _ebidaToCfoAcr | EBITDA to CFO accrual | (_ebitda1Y(Q) − _CF1Y(Q))/assets(Q-4) |
| _acrEarn | Accrual earning | (_cshMrkSecr(Q) − _netEqyIss(Q)) − _cshMrkSecr(Q-4) |
| _3yAcrEarn | 3-year accrual earnings | _acrEarn(Q) + _acrEarn(Q-4) |
| _earn3Y | 3-year earnings | _earn1Y(Q) + _earn1Y(Q-4) + _earn1Y(Q-8) |
| _netAccrual | Net accrual | (_acrEarn − _earn1Y)/_Eqy |
| _3yNetAccrual | 3-year net accrual | (_3yAcrEarn(Q) − _earn3Y(Q))/_Eqy(Q-8) |
| _3yErnGrRate | 3-year earnings growth rate |
|
| _3ySlGrRate | 3-year sales growth rate |
|
| 3yEpsGrRate | 3-year EPS growth rate |
|
| _3yEbitdaGrRate | 3-year EBITDA growth rate |
|
| _pPsCurRtV | Piotroski positive current ratio variation indicator |
|
| _pNgEqyIss | Piotroski negative equity issuance indicator |
|
| _pPsGrsMrgV | Piotroski positive gross margin variation indicator |
|
| scNetDebtToEBITDA | Net debt to EBITDA score |
|
| scCurrentRatio | Current ratio score |
|
| scROE | Return on equity score |
|
| scEbidtaToSales | EBITDA to sales score |
|
| scInvtryToSales | Inventory to sales score |
|
| scReceivTurnover | Receivable turnover score |
|
| scOperFinancing | Operation financing score |
|
| scFcfDivCovRatio | FCF dividend coverage ratio score |
|
| scNiDivCovRatio | Net income dividend coverage ratio score |
|
| scDivShareGrowth4Q | 4Q dividend per share growth score |
|
| scDivShareGrowth12Q | 12Q dividend per share growth score |
|
| scNetEqyIssuance | Net equity issuance score |
|
| scNetFinancing | Net financing score |
|
| scEbitdaToCfoAccrual | EBITDA to CFO accrual score |
|
| scNetAccrual | Net accrual score |
|
| sc3yrNetAccrual | 3-year net accrual score |
|
| scYoyEbitdaGrowth | Year-on-year EBITDA growth score |
|
| sc3yrEbitdaGrowth | 3-year EBITDA growth score |
|
| Variable Name | Description | Formula |
|---|---|---|
| EV2Ass_sec | Enterprise value to total assets | EV_sec/assets_sec |
| debt_sec | Debt | bkPerSh_sec × dbt2Eqy_sec/100 |
| cfoMrg_sec | Cash flow margin | cfPerSh_sec/rvnPerSh_sec |
| yoyErnGr_sec | Year-to-year earning growth | Eps_sec/Eps_sec (j-252) |
| yoySlGr_sec | Year-to-year sales growth | rvnPerSh_sec/rvnPerSh_sec(j-252) |
| retD_sec | Daily return | (close_sec(j)/close_sec(j-1)) − 1 |
| ret5D_sec | 5-day return | (close_sec(j)/close_sec(j-5)) − 1 |
| ret9D_sec | 9-day return | (close_sec(j)/close_sec(j-9)) − 1 |
| ret22D_sec | 22-day return | (close_sec(j)/close_sec(j-22)) − 1 |
| ret50D_sec | 50-day return | (close_sec(j)/close_sec(j-50)) − 1 |
| ret130D_sec | 130-day return | (close_sec(j)/close_sec(j-130)) − 1 |
| ret200D_sec | 200-day return | (close_sec(j)/close_sec(j-200)) − 1 |
| ret252D_sec | 252-day return | (close_sec(j)/close_sec(j-252)) − 1 |
| RSI14D_sec | Sector 14-day Relative Strength Index (RSI) | 100 × SUM(UPs)/(SUM(UPs) + SUM(DOWNs)), Where, Ups = (px − px(j-1)) if px > px(j-1), DOWNs = (px(j-1) − px) if px < px(j-1) over 14 days, and px = Close_sec |
| MA5Rsi14D_sec | 5-day average 14-day RSI | AVG(RSI14D) over 5 days |
| stOscK14D_sec | 14-day Stochastic Oscillator (%k) | k = 100 × (close_sec − MIN(low_sec) over 14 days)/(MAX(high_sec) − MIN(low_sec) over 14 days) |
| fStOscK14D_sec | Fast 14-day Stochastic Oscillator | AVG(stOscK14D) over 3 days |
| sStOscK14D_sec | Slow 14-day Stochastic Oscillator | AVG(fStOscK14D) over 3 days |
| wliamR14D_sec | 14-day Williams percent range (%R) | 100 × (close_sec − MAX(high_sec) over 14 days)/(MAX(high_sec)−MIN(low_sec) over 14 days) |
| OBV_sec | On-balance-volume | OBV = SUM(sign(close_sec(j) − close_sec(j-1)) × Volume) over all historical data |
| volAn130D_sec | 130-day annualized volatility | sqrt(252) × std(retD_sec) over 130 days |
| volAn26W_sec | 26-week annualized volatility | sqrt(52) × std(ret5D) over 26 weeks |
| volAn52W_sec | 52-week annualized volatility | sqrt(52) × std(ret5D) over 52 weeks |
| volAn104W_sec | 104-week annualized volatility | sqrt(52) × std(ret5D) over 104 weeks |
| MA5D_sec | 5-day simple moving average | AVG(close_sec) over 5 days |
| MA20D_sec | 20-day simple moving average | AVG(close_sec) over 20 days |
| MA50D_sec | 50-day simple moving average | AVG(close_sec) over 50 days |
| MA130D_sec | 130-day simple moving average | AVG(close_sec) over 130 days |
| MA200D_sec | 200-day simple moving average | AVG(close_sec) over 200 days |
| MA252D_sec | 252-day simple moving average | AVG(close_sec) over 252 days |
| EMA5D_sec | 5-day exponential moving average | EMA5D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA5D_sec(j-1) Where, alpha = 2/(5 + 1) and EMA5D_sec(initial) = MA5D_sec |
| EMA20D_sec | 20-day exponential moving average | EMA20D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA20D_sec(j-1) Where, alpha = 2/(20 + 1) and EMA20D_sec(initial) = MA20D_sec |
| EMA50D_sec | 50-day exponential moving average | EMA50D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA50D_sec(j-1) Where, alpha = 2/(50 + 1) and EMA50D_sec(initial) = MA50_sec |
| EMA130D_sec | 130-day exponential moving average | EMA130D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA130D_sec(j-1) Where, alpha = 2/(130 + 1) and EMA130D_sec(initial) = MA130D_sec |
| EMA200D_sec | 200-day exponential moving average | EMA200D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA200D_sec (j-1) Where, alpha = 2/(200 + 1) and EMA200D_sec(initial) = MA200D_sec |
| EMA252D_sec | 252-day exponential moving average | EMA252D_sec(j) = alpha × close_sec(j) + (1 − alpha) × EMA252_sec (j-1) Where, alpha = 2/(252 + 1) and EMA252D_sec(initial) = MA252D_sec |
| momTCT_sec | Very short-term momentum | (close_sec/MA5D_sec) − 1 |
| momCT_sec | Short-term momentum | (MA5D_sec/MA20D_sec) − 1 |
| momMT_sec | Middle-term momentum | (MA20D_sec/MA50D_sec) − 1 |
| momLT_sec | Long-term momentum | MA50D_sec/MA200D_sec − 1 |
| momTLT_sec | Very long-term momentum | (MA200D_sec/MA252D_sec) − 1 |
| mmRt53Ex2w_sec | Momentum of weekly returns 1 year before 2 last weeks | mom53w_sec = AVG(rendW) over 52 weeks before 2 last weeks. Where, rendW is 5 days sector return weekly taken |
| pr2MA5D_sec | Price to 5-day simple moving average | close_sec/MA5D_sec |
| pr2MA20D_sec | Price to 20-day simple moving average | close_sec/MA20D_sec |
| pr2MA50D_sec | Price to 50-day simple moving average | close_sec/MA50D_sec |
| pr2MA130D_sec | Price to 130-day simple moving average | close_sec/MA130D_sec |
| pr2MA200D_sec | Price to 200-day simple moving average | close_sec/MA200D_sec |
| pr2MA252D_sec | Price to 252-day simple moving average | close_sec/MA252D_sec |
| pr2EMA5D_sec | Price to 5-day exponential moving average | close_sec/EMA5D_sec |
| pr2EMA20D_sec | Price to 20-day exponential moving average | close_sec/EMA20D_sec |
| pr2EMA50D_sec | Price to 50-day exponential moving average | close_sec/EMA50D_sec |
| pr2EMA130D_sec | Price to 130-day exponential moving average | close_sec/EMA130D_sec |
| pr2EMA200D_sec | Price to 200-day exponential moving average | close_sec/EMA200D_sec |
| pr2EMA252D_sec | Price to 252-day exponential moving average | close_sec/EMA252D_sec |
| Variable Name | Description | Formula |
|---|---|---|
| Price | ||
| Open | Open price | |
| High | High price | |
| Low | Low price | |
| volume | Volume | |
| Close | Close price | |
| curMrkCap | Current market capitalization | |
| Stock price to sector | ||
| low2Sec | Low price to sector | low/low_sec |
| close2Sec | Close price to sector | close/close_sec |
| mrktCap2Sec | Market capitalisation price to sector | curMrkCap/curMrkCap_sec |
| open2Sec | Open price to sector | open/open_sec |
| high2Sec | High price to sector | high/high_se |
| Returns | ||
| retTD | Daily stock total return | (close(j) − close(j-1) + div)/close(j-1) |
| retT5D | 5-day stock total return | (close(j) − close(j-5) + div)/close(j-5) |
| retT9D | 9-day stock total return | (close(j) − close(j-9) + div)/close(j-9) |
| retT22D | 22-day stock total return | (close(j) − close(j-22) + div)/close(j-22) |
| retT50D | 50-day stock total return | (close(j) − close(j-50) + div)/close(j-50) |
| retT130D | 130-day stock total return | (close(j) − close(j-130) + div)/close(j-130) |
| retT200D | 200-day stock total return | (close(j) − close(j-200) + div)/close(j-200) |
| retT252D | 252-day stock total return | (close(j) − close(j-252) + div)/close(j-252) |
| Stock return to sector | ||
| retD2Sec | Daily return to sector | retTD/retD_sec |
| ret5D2Sec | 5-day return to sector | retT5D/ret5D_sec |
| ret9D2Sec | 9-day return to sector | retT9D/ret9D_sec |
| ret22D2Sec | 22-day return to sector | retT22D/ret22D_sec |
| ret50D2Sec | 50-day return to sector | retT50D/ret50D_sec |
| ret130D2Sec | 130-day return to sector | retT130D/ret30D_sec |
| ret200D2Sec | 200-day return to sector | retT200D/ret200D_sec |
| ret252D2Sec | 252-day return to sector | retT252D/ret252D_sec |
| Volatility | ||
| volAn130D | 130-day stock annualized volatility | sqrt(252) × std(retTD) over 130 days |
| volAn26W | 26-week stock annualized volatility | sqrt(52) × std(retT5D) over 26 weeks |
| volAn52W | 52-week stock annualized volatility | sqrt(52) × std(retT5D) over 52 weeks |
| volAn104W | 104-week stock annualized volatility | sqrt(52) × std(retT5D) over 104 weeks |
| Stock volatility to sector | ||
| volAn130D2Sec | 130-day annualized volatility to sector | volAn130D/volAn130D_sec |
| volAn26W2Sec | 26-week annualized volatility to sector | volAn26W/volAn26W_sec |
| volAn52W2Sec | 52-week annualized volatility to sector | volAn52W/volAn52W_sec |
| volAn104W2Sec | 104-weeksannualized volatility to sector | volAn104W/volAn104W_sec |
| Return to volatility | ||
| r5DToVol52W | 5-day return to 52-week volatility | retT5D/volAn52W |
| r5DToVol26W | 5-day return to 26-week volatility | retT5D/volAn26W |
| r5DToVol104W | 5-day return to 104-week volatility | retT5D/volAn104W |
| r5DToVol130D | 5-day return to 130-day volatility | retT5D/volAn130D |
| rDToVol130D | 1-day return to 130-day volatility | retTD/volAn130D |
| Simple moving average (SMA) | ||
| MA5D | 5-day SMA of stock Close | AVG(close) over 5 days |
| MA20D | 20-day SMA of stock Close | AVG(close) over 20 days |
| MA50D | 50-day SMA of stock Close | AVG(close) over 50 days |
| MA130D | 130-day SMA of stock Close | AVG(close) over 130 days |
| MA200D | 200-day SMA of stock Close | AVG(close) over 200 days |
| MA252D | 252-day SMA of stock Close | AVG(close) over 252 days |
| Stock SMA to Sector | ||
| MA5D2Sec | 5-day SMA to sector | MA5D/MA5D_sec |
| MA20D2Sec | 20-day SMA to sector | MA20D/MA20D_sec |
| MA50D2Sec | 50-day SMA to sector | MA50D/MA50D_sec |
| MA130D2Sec | 130-day SMA to sector | MA130D/MA130D_sec |
| MA200D2Sec | 200-day SMA to sector | MA200D/MA200D_sec |
| MA252D2Sec | 252-day SMA to sector | MA252D/MA252D_sec |
| Exponential moving average (EMA) | ||
| EMA5D | 5-day EMA of stock close | EMA5D(j) = alpha × close(j) + (1 − alpha) × EMA5D(j-1) Where, alpha = 2/(5 + 1) and EMA5D(initial) = MA5D |
| EMA20D | 20-day EMA of stock close | EMA20D(j) = alpha × close(j) + (1 − alpha) × EMA20D(j-1) Where, alpha = 2/(20 + 1) and EMA20D(initial) = MA20D |
| EMA50D | 50-day EMA of stock close | EMA50D(j) = alpha × close(j) + (1 − alpha) × EMA50D(j-1) Where, alpha = 2/(50 + 1) and EMA50D(initial) = MA50 |
| EMA130D | 130-day EMA of stock close | EMA130D(j) = alpha × close(j) + (1 − alpha) × EMA130D(j-1) Where, alpha = 2/(130 + 1) and EMA130D(initial) = MA130D |
| EMA200D | 200-day EMA of stock close | EMA200D(j) = alpha × close(j) + (1 − alpha) × EMA200D (j-1) Where, alpha = 2/(200 + 1) and EMA200D(initial) = MA200D |
| EMA252D | 252-day EMA of stock close | EMA252D(j) = alpha × close(j) + (1 − alpha) × EMA252 (j-1) Where, alpha = 2/(252 + 1) and EMA252D(initial) = MA252D |
| Stock EMA to Sector | ||
| EMA5D2Sec | 5-day EMA to sector | EMA5D/EMA5D_sec |
| EMA20D2Sec | 20-day EMA to sector | EMA20D/EMA20D_sec |
| EMA50D2Sec | 50-day EMA to sector | EMA50D/EMA50D_sec |
| EMA130D2Sec | 130-day EMA to sector | EMA130D/EMA130D_sec |
| EMA200D2Sec | 200-day EMA to sector | EMA200D/EMA200D_sec |
| EMA252D2Sec | 252-day EMA to sector | EMA252D/EMA252D_sec |
| Momentum | ||
| momTCT | Very short-term momentum | (close/MA5D) − 1 |
| momCT | Short-term momentum | (MA5D/MA20D) − 1 |
| momMT | Middle-term momentum | (MA20D/MA50D) − 1 |
| momLT | Long-term momentum | MA50D/MA200D − 1 |
| momTLT | Very long-term momentum | (MA200D/MA252D) − 1 |
| mmRt53Ex2w | Momentum of 1 year’s weekly returns before 2 last weeks | mom53w_sec = AVG(rendW) over 52 weeks before 2 last weeks. Where, rendW= rendT5D weekly taken |
| Stock Momentum to sector | ||
| momTCT2Sec | Very short-term momentum to sector | momTCT/momTCT_sec |
| momCT2Sec | Short-term momentum of sector | momCT/momCT_sec |
| momMT2Sec | Middle-term momentum of sector | momMT/momMT_sec |
| momLT2Sec | Long-term momentum of sector | momLT/momLT_sec |
| momTLT2Sec | Very long-term momentum of sector | momTLT/momTLT_sec |
| mmRet53Ex2w2Sec | Momentum of 1 year’s weekly returns before 2 last weeks to sector | mmRet53Ex2w/mmRet53Ex2w_sec |
| Price to SMA | ||
| pr2MA5D | Price to 5 days SMA ratio | close/MA5D |
| pr2MA20D | price to 20 days SMA ratio | close/MA20D |
| pr2MA50D | price to 50 days SMA ratio | close/MA50D |
| pr2MA130D | price to 130 days SMA ratio | close/MA130D |
| pr2MA200D | price to 200 days SMA ratio | close/MA200D |
| pr2MA252D | price to 252 days SMA ratio | close/MA252D |
| Price to SMA ratio to sector | ||
| pr2MA5D2Sec | Price to 5-day SMA ratio to sector | pr2MA5D/pr2MA5D_sec |
| pr2MA20D2Sec | price to 20-day SMA ratio to sector | pr2MA20D/pr2MA20D_sec |
| pr2MA50D2Sec | price to 50-day SMA ratio to sector | pr2MA50D/pr2MA50D_sec |
| pr2MA130D2Sec | price to 130-day SMA ratio to sector | pr2MA130D/pr2MA130D_sec |
| pr2MA200D2Sec | price to 200-day SMA ratio to sector | pr2MA200D/pr2MA200D_sec |
| pr2MA252D2Sec | price to 252-day SMA ratio to sector | pr2MA252D/pr2MA252D_sec |
| Price to EMA | ||
| pr2EMA5D | Price to 5-day EMA ratio | close/EMA5D |
| pr2EMA20D | price to 20-day EMA ratio | close/EMA20D |
| pr2EMA50D | price to 50-day EMA ratio | close/EMA50D |
| pr2EMA130D | price to 130-day EMA ratio | close/EMA130D |
| pr2EMA200D | price to 200-day EMA ratio | close/EMA200D |
| pr2EMA252D | price to 252-day EMA ratio | close/EMA252D |
| Price to EMA ratio to sector | ||
| pr2EMA5D2Sec | Price to 5-day EMA ratio to sector | pr2EMA5D/pr2EMA5D_sec |
| pr2EMA20D2Sec | price to 20-day EMA ratio to sector | pr2EMA20D/pr2EMA20D_sec |
| pr2EMA50D2Sec | price to 50-day EMA ratio to sector | pr2EMA50D/pr2EMA50D_sec |
| pr2EMA130D2Sec | price to 130-day EMA ratio to sector | pr2EMA130D/pr2EMA130D_sec |
| pr2EMA200D2Sec | price to 200-day EMA ratio to sector | pr2EMA200D/pr2EMA200D_sec |
| pr2EMA252D2Sec | price to 252-day EMA ratio to sector | pr2EMA252D/pr2EMA252D_sec |
| Other technical indicators | ||
| RSI14D | 14-day Relative Strength Index (RSI) | 100 × SUM(UPs)/(SUM(UPs) + SUM(DOWNs)), where, Ups = (px−px(j-1)) if px > px(j-1) and DOWNs = (px(j-1)-px) if px < px(j-1) over 14 days, and px = Close |
| MA5Rsi14D | 5-day average 14-day RSI | AVG(RSI14D) over 5 days |
| stOscK14D | 14-day stochastic oscillator (%k) | k = 100 × (close − MIN(low) over 14 days)/(MAX(high) − MIN(low) over 14 days) |
| fStOscK14D | Fast 14-day stochastic oscillator | AVG(stOscK14D) over 3 days |
| sStOscK14D | Slow 14-day stochastic oscillator | AVG(fStOscK14D) over 3 days |
| wliamR14D | 14-day Williams percent range (%R) | 100 × (close − MAX(high) over 14 days)/(MAX(high) − MIN(low) over 14 days) |
| OBV | On-Balance-Volume | OBV = SUM(sign(close(j) − close(j-1)) × Volume) over all historical data |
| Other stock to sector technical indicators | ||
| RSI14D2Sec | 14-day RSI to sector | RSI14D/RSI14D_sec |
| MA5Rsi14D2Sec | 5-day average 14-day RSI | MA5RSI14D/MA5RSI14D_sec |
| stOscK14D2Sec | 14-day stochastic oscillator to sector | stOscK14D/stOscK14D_sec |
| fStOscK14D2Sec | Fast 14-day stochastic oscillator to sector | fStOscK14D/fStOscK14D_sec |
| sStOscK14D2Sec | Slow 14-day stochastic oscillator to sector | sStOscK14D/sStOscK14D_sec |
| wliamR14D2Sec | 14-day Williams percent range to sector | wliamR14D/wliamR14D_sec |
| OBVlm2Sec | On-balance-volume to sector | OBV/OBV_sec |
| Price multiples | ||
| EV | Enterprise value | curMrkCap + _debtMinsCash |
| pr2Ern | Price to earning ratio | curMrkCap/_earn1Y |
| pr2ErnDil | Price to earning diluted ratio | close/_earn1Y/_nbrShDilEps |
| pr2Bk | Price to book ratio | curMrkCap/_Eqy |
| pr2Sl | Price to sales ratio | curMrkCap/_sales1Y |
| pr2CF | Price to cash flow ratio | curMrkCap/_CF1Y |
| pr2FCF | Price to free cash flow ratio | curMrkCap/_FCF1Y |
| Ev2As | Enterprise value to total assets ratio | EV/_assets |
| Stock price multiples to sector | ||
| pr2Sl2Sec | Price to sales to sector | pr2Sl/salesPerSh1Y_sec |
| pr2CF2Sec | Price to cash flow to sector | pr2CF/pr2CF_sec |
| pr2Bk2Sec | Price to free cash flow to sector | pr2Bk/pr2Bk_sec |
| pr2Ern2Sec | Price to book to sector | pr2Ern/pr2Ern_sec |
| Stock to sector fundamental indicators | ||
| dvPerSh1y2Sec | Dividend per share for 1 year to sector | _divPerSh1y/divPerSh1y_sec |
| eps2Sec | Earning per share to sector | EPS/Eps_sec |
| sl1y2Sec | Sales 4Q to sector | sales1Y/rvnPerSh_sec |
| assets2Sec | Assets to sector | _assets /assets_sec |
| ev2Sec | Enterprise value to sector | EV/EV_sec |
| eqy2Sec | Equity to sector | _Eqy/bkPerSh_sec |
| dbt2Eqy2Sec | Debt to equity to sector | _dbt2Eqy/dbt2Eqy_sec |
| cf1y2Sec | Cash flow to sector | (_CF1y/nbrShares)/cfPerSh_sec |
| fcf2Sec | Free cash flow to sector | (_FCF1y/nbrShares)/fcfPerSh_sec |
| ptMrg2Sec | Profit margin to sector | _ptMrg/ptMrg_sec |
| fcf2Pr2Sec | Free cash flow to price to sector | (1/pr2FCF)/fcf2Pr_sec |
| liab2Sec | Liability to sector | _liab/liab_sec |
| retOnEqy2Sec | Return on equity to sector | _ROE/ROE_sec |
| debts2Sec | Debt to sector | _debts/debts_sec |
| ev2Ass2Sec | Enterprise value to assets to sector | Ev2As/EV2Ass_sec |
| CfoMrg2Sec | Cash flow margin to sector | _cfoMrg/CfoMrg_sec |
| yoyErnGr2Sec | Year-to-year earning growth to sector | _yoyErnGr/yoyErnGr_sec |
| yoySlGr2Sec | year-to-year sales growth to sector | _yoySlGr/yoySlGr_sec |
| Piotroski indicators | ||
| _piotrROA | Piotroski return on assets (ROA) | _earn1Y/assets(Q-4) |
| _piotrCFO | Piotroski cash flow (CFO) | _CF1y/assets(Q-4) |
| _pPsRoa | Piotroski positive ROA indicator | If _piotrROA > 0: _pPsRoa = 1 Else _pPsRoa = 0 |
| _pPsCfo | Piotroski positive CFO indicator | If _piotrCFO > 0: _pPsCfo = 1 Else _pPsCfo = 0 |
| _pPsRoaV | Piotroski positive ROA variation indicator | If _piotrROA > _piotrROA(Q-4): _pPsRoaV = 1 Else: _pPsRoaV = 0 |
| _pPsCfoV | Piotroski positive CFO variation indicator | If _piotrCFO > _piotrCFO(Q-4): _pPsCfoV = 1 Else: _pPsCfoV = 0 |
| _pCfoS2Roa | Piotroski CFO greater than ROA indicator | IF _piotrCFO > _piotrROA: _pCfoS2Roa = 1 Else _pCfoS2Roa = 0 |
| _pNgDbtV | Piotroski negative debt variation indicator | if _debt > _debt(Q-4): _pNgDbtV = 0 Else _pNgDbtV = 1 |
| _pPsAsTrnV | Piotroski positive asset turnover variation indicator | If _assetsTrnv > _assetsTrnv(Q-4): _pPsAsTrnV = 1 Else _pPsAsTrnV = 0 |
| _piotrSc | Piotroski score | SUM (piotroski indicators) = _pPsRoa + _pPsRoaV + _pPsCfo + _pPsCfoV + _pCfoS2Roa + _pNgDbtV + _pPsAsTrnV + _pPsCurRtV + _pNgEqyIss + _pPsGrsMrgV |
| Scores | ||
| scNetDbt2EV | Net debt to enterprise value score | If _netDbtToEV < 0.25: score = 2 If 0.25 ≤ _netDbtToEV < 0.35: score = 1 If _netDbtToEV ≥ 0.35: score = 0 |
| scEty | Equity score | If _netDebt ≥ 0 and _Eqy > 0 and _Eqy ≥ (2 × _netDebt): score = 2 If _netDebt ≥ 0 and _Eqy > 0 and _Eqy < (2 × _netDebt): score = 1 If _netDebt ≥ 0 and _Eqy ≤ 0: score = 0 If _netDebt ≤ 0 and _Eqy > 0: score = 2 If _netDebt ≤ 0 and _Eqy ≤ 0: score = 0 |
| scBlncSht | Balance sheet score | score = scNetDebtToEBITDA + scNetDbt2EV + scCurrentRatio + scEty |
| scNi2Sl | Net income to sales score | If _ptMrg > 0.15: score = 2 If 0.1 < _ptMrg ≤ 0.15: score = 1 If _ptMrg ≤ 0.1: score = 0 |
| scOpEff | Operation efficiency score | score = (3 × scROE) + (3 × scEbidtaToSales) + (4 × scNiToSales) + (1 × scInvtryToSales) + (1 × scReceivTurnover) + (1 × scOperFinancing) |
| scDivQly | Dividend quality score | score = (2 × scFcfDivCovRatio) + (2 × scNiDivCovRatio) + (1 × scDivShareGrowth4Q) + (1 × scDivShareGrowth12Q) |
| scNetDbtIss | Net debt issuance score | If _netDebtIss < 0: score = 2 If _netDebtIss ≥ 0 and f_netDebtIss < (0.15 × curMrkCap): score = 1 If _netDebtIss ≥ (0.15 × curMrkCap): score = 0 |
| scFin | Financing score | scFin = (1 × scNetDebtIssuance) + (1 × scNetEqyIssuance) + (3 × scNetFinancing) |
| scCfo2NiAc | Cash flow to net income accrual score | If _cfoToNiAcr > −0.03: score = 2 If −0.07 < _cfoToNiAcr ≤ −0.03: score = 1 If _cfoToNiAcr ≤ −0.07: score = 0 |
| scErnQly | Earning quality score | score = (1 × scEbitdaToCfoAccrual) + (1 × scCfo2NiAc) + (1 × scNetAccrual) + (3 × sc3yrNetAccrual) |
| scYoyErnGrh | Year-to-year earning growth score | If _yoyErnGrRate > 0.15: score = 2 If 0.07 < _yoyErnGrRate ≤ 0.15: score = 1 If _yoyErnGrRate ≤ 0.07: score = 0 |
| sc3yrErnGr | 3-year earning growth score | If _3yErnGrRate > 0.15: score = 2 If _3yErnGrRate > 0.07 and _3yErnGrRate <= 0.15: score = 1 If _3yErnGrRate ≤ 0.07: score = 0 |
| scYoySlGr | Year-to-year sales growth score | If _yoySlGrRate > 0.10: score = 2 If 0.05 < _yoySlGrRate ≤ 0.10: score = 1 If _yoySlGrRate <= 0.05: score = 0 |
| sc3yrSlGr | 3-year sales growth score | If _3ySlGrRate > 0.10: score = 2 If 0.05 < _3ySlGrRate ≤ 0.10: score = 1 If _3ySlGrRate ≤ 0.05: score = 0 |
| scYoyEpsGr | Year-to-year earnings per share growth score | If yoyEpsGrRate > 0.15: score = 2 If 0.07 < yoyEpsGrRate ≤ 0.15: score = 1 If yoyEpsGrRate <= 0.07: score = 0 |
| sc3yrEpsGr | 3-year EPS growth score | If 3yEpsGrRate > 0.15: score = 2 If 0.07 < 3yEpsGrRate ≤ 0.15: score = 1 If 3yEpsGrRate ≤ 0.07: score = 0 |
| scGrowth | Growth score | scGrowth = (1 × scYoyEarnGrowth) + (3 × sc3yrEarnGrowth) + (1 × scYoyEbitdaGrowth) + (3 × sc3yrEbitdaGrowth) + (1 × scYoySalesGrowth) + (3 × sc3yrSalesGrowth) + (1 × scYoyEpsGrowth) + (3 × sc3yrEpsGrowth) |
| Other indicators | ||
| ret5D_sec | 5-day return of sector | [close_sec(j)/close_sec(j-5)) − 1 |
| sp | 5-day return spread between stock and sector | retT5D − ret5D_sec |
References
- Bodson, Laurent, Pascal Grandin, Georges Hübner, and Marie Lambert. 2010. Performance de Portefeuille. Paris: Pearson. [Google Scholar]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Box, George E. P., and Gwilym M. Jenkins. 1970. Time Series Analysis, Forecasting and Control. San Francisco: Holden-Day. [Google Scholar]
- Carhart, Mark M. 1997. On Persistence in Mutual Fund Performance. The Journal of Finance 52: 57–82. [Google Scholar] [CrossRef]
- Chaweewanchon, Apichat, and Rujira Chaysiri. 2022. Markowitz Mean-Variance Portfolio Optimization with Predictive Stock Selection Using Machine Learning. International Journal of Financial Studies 10: 64. [Google Scholar] [CrossRef]
- Cipiloglu Yildiz, Zeynep, and Selim Baha Yildiz. 2022. A portfolio construction framework using LSTM-based stock markets forecasting. International Journal of Finance & Economics 27: 2356–66. [Google Scholar] [CrossRef]
- Dangeti, Pratap. 2017. Statistics for Machine Learning. Birmingham: Packt Publishing Ltd. [Google Scholar]
- Ding, Guangyu, and Liangxi Qin. 2020. Study on the prediction of stock price based on the associated network model of LSTM. International Journal of Machine Learning and Cybernetics 11: 1307–17. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica: Journal of the Econometric Society 50: 987–1007. [Google Scholar] [CrossRef]
- Fama, Eugene F. 1970. Efficient capital markets: A review of theory and empirical work. The Journal of Finance 25: 383–417. [Google Scholar] [CrossRef]
- Fama, Eugene F., and Kenneth R. French. 1993. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics 33: 3–56. [Google Scholar] [CrossRef]
- Ganchev, Alexander. 2022. The Performance of Hedge Fund Industry during the COVID-19 Crisis—Theoretical Characteristics and Empirical Aspects. Economic Studies (Ikonomicheski Izsledvania) 31: 18–37. [Google Scholar]
- Gers, Felix A., Jürgen Schmidhuber, and Fred Cummins. 2000. Learning to Forget: Continual Prediction with LSTM. Neural Computation 12: 2451–71. [Google Scholar] [CrossRef]
- Ghosh, Achyut, Soumik Bose, Giridhar Maji, Narayan Debnath, and Soumya Sen. 2019. Stock price prediction using LSTM on Indian Share Market. Paper presented at the 32nd International Conference on Computer Applicationsin Industry and Engineering, San Diego, CA, USA, September 30–October 2, vol. 63, pp. 101–10. [Google Scholar]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef]
- Hou, Xiurui, Kai Wang, Jie Zhang, and Zhi Wei. 2020. An enriched time-series forecasting framework for long-short portfolio strategy. IEEE Access 8: 31992–2002. [Google Scholar] [CrossRef]
- Hu, Zexin, Yiqi Zhao, and Matloob Khushi. 2021. A survey of forex and stock price prediction using deep learning. Applied System Innovation 4: 9. [Google Scholar] [CrossRef]
- Jacobs, Bruce I., and Kenneth N. Levy. 2005. Market Neutral Strategies, Frank J. Fabozzi Series. New York: John Wiley & Sons. [Google Scholar]
- Jensen, Michael C. 1968. The performance of mutual funds in the period 1945–1964. The Journal of Finance 23: 389–416. [Google Scholar] [CrossRef]
- Jiang, Weiwei. 2021. Applications of deep learning in stock market prediction: Recent progress. Expert Systems with Applications 184: 115537. [Google Scholar] [CrossRef]
- Keating, Con, and William F. Shadwick. 2002. An introduction to omega. AIMA Newsletter. Available online: https://scholar.google.ca/scholar?hl=fr&as_sdt=0%2C5&as_vis=1&q=%28Keating+and+Shadwick+2002%29+Keating%2C+Con%2C+and+William+F.+Shadwick.+2002.+An+introduction+to+omega.+AIMA+Newsletter.&btnG= (accessed on 20 January 2023).
- Kohavi, Ron. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. International Joint Conferences on Artificial Intelligence 14: 1137–45. [Google Scholar]
- Lanbouri, Zineb, and Said Achchab. 2019. A new approach for Trading based on Long-Short Term memory Ensemble technique. International Journal of Computer Science Issues (IJCSI) 16: 27–31. [Google Scholar] [CrossRef]
- Liu, Shuanglong, Chao Zhang, and Jinwen Ma. 2017. CNN-LSTM neural network model for quantitative strategy analysis in stock markets. In International Conference on Neural Information Processing. Cham: Springer, pp. 198–206. [Google Scholar] [CrossRef]
- Markowitz, Harry. 1952. Portfolio Selection. The Journal of Finance 7: 77–91. [Google Scholar]
- Michańków, Jakub, Paweł Sakowski, and Robert Ślepaczuk. 2022. LSTM in Algorithmic Investment Strategies on BTC and S&P500 Index. Sensors 22: 917. [Google Scholar] [CrossRef]
- Nafia, Abdellilah, Abdellah Youssefi, and Abdellah Echaoui. 2022. Modèles classiques et de datamining les plus utilisés en évaluation et en prédiction de la performance des actions. Revue des Etudes Multidisciplinaires en Sciences Economiques et Sociales 7: 231–68. [Google Scholar] [CrossRef]
- Naik, Nagaraj, and Biju R. Mohan. 2019. Study of stock return predictions using recurrent neural networks with LSTM. In International Conference on Engineering Applications of Neural Networks. Cham: Springer, pp. 453–59. [Google Scholar]
- Neyman, J. 1939. Review of A Study in Analysis of Stationary Time Series, by Herman Wold. Journal of the Royal Statistical Society 102: 295. [Google Scholar] [CrossRef]
- Olah, Christopher. 2015. Colah’s Blog: Understanding LSTM Networks. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs (accessed on 6 November 2022).
- Ozbayoglu, Ahmet Murat, Mehmet Ugur Gudelek, and Omer Berat Sezer. 2020. Deep learning for financial applications: A survey. Applied Soft Computing 93: 106384. [Google Scholar] [CrossRef]
- Patel, Jigar, Sahil Shah, Priyank Thakkar, and K Kotecha. 2015. Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques. Expert Systems with Applications 42: 259–68. [Google Scholar] [CrossRef]
- Piotroski, Joseph D. 2000. Value investing: The use of historical financial statement information to separate winners from losers. Journal of Accounting Research 38: 1–41. [Google Scholar] [CrossRef]
- Qiu, Jiayu, Bin Wang, and Changjun Zhou. 2020. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PLoS ONE 15: e0227222. [Google Scholar] [CrossRef]
- Rosenblatt, Frank. 1957. The Perceptron, a Perceiving and Recognizing Automaton. Buffalo: Cornell Aeronautical Laboratory. [Google Scholar]
- Sen, Jaydip, Sidra Mehtab, Abhishek Dutta, and Saikat Mondal. 2021. Precise Stock Price Prediction for Optimized Portfolio Design Using an LSTM Model. Paper presented at the 2021 19th OITS International Conference on Information Technology (OCIT), Bhubaneswar, India, December 16–18; pp. 210–15. [Google Scholar] [CrossRef]
- Sharpe, William F. 1994. The Sharpe Ratio. Journal of Portfolio Management 21: 49–58. [Google Scholar] [CrossRef]
- Tfaily, Fatima, and Mohamad M. Fouad. 2022. Multi-level stacking of LSTM recurrent models for predicting stock-market indices. Data Science in Finance and Economics 2: 147–62. [Google Scholar] [CrossRef]
- Touzani, Yassine, and Khadija Douzi. 2021. An LSTM and GRU based trading strategy adapted to the Moroccan market. Journal of Big Data 8: 126. [Google Scholar] [CrossRef]
- Treynor, Jack L. 1962. Toward a Theory of Market Value of Risky Assets. (SSRN Scholarly Paper Nᵒ 628187). Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=628187 (accessed on 22 March 2023). [CrossRef]
- Yao, Siyu, Linkai Luo, and Hong Peng. 2018. High-frequency stock trend forecast using lstm model. Paper presented at the 2018 13th International Conference on Computer Science & Education (ICCSE), Colombo, Sri Lanka, August 8–11; pp. 1–4. [Google Scholar]
- Yi, Kan, Jin Yang, Shuangling Wang, Zhengtong Zhang, Jing Zhang, Jinqiu Song, and Xiao Ren. 2022. IntelliPortfolio: Intelligent Portfolio for Enhanced Index Tracking Using Clustering and LSTM. Mathematical Problems in Engineering 2022: 3751452. [Google Scholar] [CrossRef]
- Yule, G. Udny. 1926. Why Do We Sometimes Get Nonsense-Correlations between Time-Series? A Study in Sampling and the Nature of Time-Series. Journal of the Royal Statistical Society 89: 1–63. [Google Scholar] [CrossRef]
- Zhang, Xiaolin, and Ying Tan. 2018. Deep stock ranker: A LSTM neural network model for stock selection. In International Conference on Data Mining and Big Data. Cham: Springer, pp. 614–23. [Google Scholar] [CrossRef]













| Autor | Method and Strategy | Performance Metrics | Variables | Conclusion |
|---|---|---|---|---|
| Chaweewanchon and Chaysiri (2022) | Hybrid model R-CNN-BiLSTM. CNN for feature extraction. BiLSTM for stock prediction, and Markowitz mean-variance model for optimal portfolio construction. | Mean return. Standard deviation. Sharpe ratio. | Close price | Their model is more accurate than benchmarks. Portfolios built with the LSTM or BiLSTM models outperform portfolios where stocks are randomly selected. |
| Sen et al. (2021) | LSTM to predict price and build: Minimum Risk Portfolios and optimal Risk Portfolios | Return. Volatility. | OCHLV | LSTM is very accurate |
| Zhang and Tan (2018) | Deep Stock Ranker using LSTM for Stock Selection (select top M stocks according to the predict stocks’ future return ranking score) | Information coefficient. Active return. Information ratio. | OCHLV | The equally weighted portfolio, based on their model and using raw data, perform well compared to benchmarks. |
| Touzani and Douzi (2021) | LSTM for short term and GRU for medium term close price prediction. Buy or sell stock depending on the prediction. | Global return. Winerate ratio. Annualized return. | Close price. | Their approach allows selecting profitable stocks and the creation of portfolio that outperform all benchmarks except IT index. |
| Liu et al. (2017) | Hybrid model: CNN for stock selection and LSTM for a timing strategy to buy, hold or sell stocks. | Annualized rate of return. Maximum retracement. | OCHLV prices and returns | Their strategy is more profitable than the benchmark |
| Hou et al. (2020) | Hybrid model: LSTM-DNN to build a portfolio with a long-short strategy (buying stocks in the top decile of the predicted returns ranking and selling those in the bottom decile) | Average monthly return. Sharpe ratio. | 18 monthly returns in LSTM and 19 fundamental variables in DNN | Their model has outperformed other comparative models (OLS and DNN) |
| Cipiloglu Yildiz and Yildiz (2022) | LSTM to predict close price for calculation of portfolio weights. | Mean annualized return. Volatility. Sharpe ratio. Maximum drawdown. cVaR. | OCHLV | LSTM outperformed the benchmarks. |
| Hyperparameters | Values |
|---|---|
| Number of units in LSTM | 128 |
| Activation function | Relu |
| Look-back period | {3, 4} |
| Number of features | {173, 128} |
| Number of units in dense layer | 1 |
| Optimizer | Adam |
| Cost function | MSE |
| Batch size | 16 |
| Number of epochs | 300 |
| Portfolios | Models | Number of Stocks by Side | Period |
|---|---|---|---|
| P1 | M1 (basic variables, w = 3) | n = 6 | pre-COVID-19 |
| including COVID-19 | |||
| P2 | M1 (basic variables, w = 3) | n = 7 | pre-COVID-19 |
| including COVID-19 | |||
| P3 | M2 (basic variables, w = 4) | n = 6 | pre-COVID-19 |
| including COVID-19 | |||
| P4 | M2 (basic variables, w = 4) | n = 7 | pre-COVID-19 |
| including COVID-19 | |||
| P5 | M3 (all variables, w = 3) | n = 6 | pre-COVID-19 |
| including COVID-19 | |||
| P6 | M3 (all variables, w = 3) | n = 7 | pre-COVID-19 |
| including COVID-19 | |||
| P7 | M4 (all variables, w = 4) | n = 6 | pre-COVID-19 |
| including COVID-19 | |||
| P8 | M4 (all variables, w = 4) | n = 7 | pre-COVID-19 |
| including COVID-19 | |||
| Sector | S&P 500 Consumer Staples | pre-COVID-19 | |
| including COVID-19 | |||
| Market | S&P 500 | pre-COVID-19 | |
| including COVID-19 | |||
| Models | M1 | M2 | M3 | M4 | ||||
|---|---|---|---|---|---|---|---|---|
| Basic Variables | Basic Variables | All Variables | All Variables | |||||
| w: 3 | w: 4 | w: 3 | w: 4 | |||||
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| Train | 0.01 | 0.06 | 0.01 | 0.07 | 0.01 | 0.07 | 0.01 | 0.07 |
| Val | 2.07 | 1.04 | 2.27 | 1.07 | 2.03 | 1.03 | 2.09 | 1.04 |
| Test | 3.65 | 1.39 | 3.73 | 1.40 | 3.75 | 1.41 | 3.74 | 1.41 |
| (a) | ||||||
| Portfolios | S&P500 | CS | P1 | P2 | P3 | P4 |
| Models | M1 | M1 | M2 | M2 | ||
| Number of stocks | 6 | 7 | 6 | 7 | ||
| Annualized return | 15% | 5% | 23% | 20% | 20% | 14% |
| Annualized volatility | 12% | 12% | 21% | 18% | 20% | 18% |
| Downside volatility | 8.8% | 8.6% | 11% | 10% | 10% | 10% |
| Alpha | 0% | −4% | 21% | 19% | 18% | 11% |
| Beta | 1 | 0.65 | 0.15 | 0.09 | 0.17 | 0.15 |
| Correlation | 1 | 0.68 | 0.09 | 0.06 | 0.10 | 0.10 |
| Sharpe ratio | 1.05 | 0.30 | 1.03 | 1.02 | 0.93 | 0.67 |
| Sortino ratio | 1.48 | 0.41 | 1.89 | 1.85 | 1.81 | 1.21 |
| Treynor ratio | 0.13 | 0.06 | 1.42 | 2.11 | 1.13 | 0.81 |
| Omega Ratio | 1.49 | 1.14 | 1.50 | 1.48 | 1.45 | 1.31 |
| Calmar Ratio | 0.78 | 0.19 | 1.49 | 1.30 | 0.99 | 0.77 |
| Information ratio | −0.99 | 0.35 | 0.25 | 0.21 | −0.08 | |
| Upside capture ratio | 1 | 0.45 | 0.44 | 0.34 | 0.44 | 0.36 |
| Downside capture ratio | 1 | 0.70 | 0.02 | −0.09 | 0.13 | 0.25 |
| Max drawdown | −17% | −19% | −14% | −14% | −19% | −16% |
| Date max drawdown | 21 December 2018 | 18 May 2018 | 25 May 2018 | 8 September 2017 | 8 September 2017 | 8 June 2018 |
| (b) | ||||||
| Portfolios | S&P500 | CS | P1 | P2 | P3 | P4 |
| Models | M1 | M1 | M2 | M2 | ||
| Number of stocks | 6 | 7 | 6 | 7 | ||
| Annualized return | 10% | 3% | 7% | 8% | 12% | 8% |
| Annualized volatility | 18% | 16% | 23% | 20% | 24% | 22% |
| Downside volatility | 14% | 12% | 16% | 13% | 15% | 13% |
| Alpha | 0% | −4% | 6% | 7% | 9% | 6% |
| Beta | 1 | 0.71 | 0.24 | 0.15 | 0.38 | 0.32 |
| Correlation | 1 | 0.81 | 0.19 | 0.13 | 0.28 | 0.26 |
| Sharpe ratio | 0.48 | 0.12 | 0.24 | 0.34 | 0.44 | 0.31 |
| Sortino ratio | 0.62 | 0.16 | 0.36 | 0.51 | 0.73 | 0.52 |
| Treynor ratio | 0.09 | 0.03 | 0.23 | 0.45 | 0.28 | 0.21 |
| Omega Ratio | 1.26 | 1.09 | 1.15 | 1.18 | 1.25 | 1.18 |
| Calmar Ratio | 0.27 | 0.09 | 0.16 | 0.24 | 0.49 | 0.39 |
| Information ratio | −0.62 | −0.11 | −0.07 | 0.06 | −0.10 | |
| Upside capture ratio | 1 | 0.53 | 0.20 | 0.15 | 0.33 | 0.29 |
| Downside capture ratio | 1 | 0.79 | 0.24 | 0.08 | 0.31 | 0.37 |
| Max drawdown | −32% | −22% | −36% | −28% | −22% | −17% |
| Date max drawdown | 20 March 2020 | 20 March 2020 | 18 December 2020 | 18 December 2020 | 20 March 2020 | 20 March 2020 |
| (a) | ||||||
| Portfolios | S&P500 | CS | P5 | P6 | P7 | P8 |
| Models | M3 | M3 | M4 | M4 | ||
| Number of stocks | 6 | 7 | 6 | 7 | ||
| Annualized return | 15% | 5% | 34% | 29% | 27% | 30% |
| Annualized volatility | 12.5% | 11.8% | 18% | 17% | 19% | 17% |
| Downside volatility | 8.8% | 8.6% | 9.1% | 8.7% | 9.7% | 8.7% |
| Alpha | 0% | −4% | 32% | 28% | 24% | 26% |
| Beta | 1 | 0.65 | 0.11 | 0.07 | 0.17 | 0.20 |
| Correlation | 1 | 0.68 | 0.07 | 0.05 | 0.11 | 0.15 |
| Sharpe ratio | 1.05 | 0.30 | 1.78 | 1.63 | 1.34 | 1.64 |
| Sortino ratio | 1.48 | 0.41 | 3.58 | 3.17 | 2.64 | 3.26 |
| Treynor ratio | 0.13 | 0.06 | 2.97 | 4.00 | 1.46 | 1.41 |
| Omega Ratio | 1.49 | 1.14 | 1.83 | 1.74 | 1.65 | 1.79 |
| Calmar Ratio | 0.78 | 0.19 | 1.94 | 1.44 | 1.21 | 1.52 |
| Information ratio | −0.99 | 0.91 | 0.71 | 0.55 | 0.74 | |
| Upside capture ratio | 1 | 0.45 | 0.51 | 0.40 | 0.48 | 0.56 |
| Downside capture ratio | 1 | 0.70 | −0.35 | −0.37 | −0.08 | −0.05 |
| Max drawdown | −16.8% | −18.7% | −16.7% | −19.2% | −21.1% | −18.7% |
| Date max drawdown | 21 December 2018 | 18 May 2018 | 28 December 2018 | 28 December 2018 | 11 January 2019 | 21 December 2018 |
| (b) | ||||||
| Portfolios | S&P500 | CS | P5 | P6 | P7 | P8 |
| Models | M3 | M3 | M4 | M4 | ||
| Number of stocks | 6 | 7 | 6 | 7 | ||
| Annualized return | 10% | 3% | 22% | 21% | 25% | 22% |
| Annualized volatility | 18% | 16% | 24% | 22% | 22% | 21% |
| Downside volatility | 13.74% | 12.23% | 14.48% | 14.1% | 12.21% | 12.47% |
| Alpha | 0% | −4% | 18% | 17% | 23% | 18% |
| Beta | 1 | 0.71 | 0.48 | 0.42 | 0.25 | 0.40 |
| Correlation | 1 | 0.81 | 0.36 | 0.34 | 0.20 | 0.34 |
| Sharpe ratio | 0.48 | 0.12 | 0.88 | 0.86 | 1.04 | 0.98 |
| Sortino ratio | 0.62 | 0.16 | 1.45 | 1.37 | 1.92 | 1.67 |
| Treynor ratio | 0.09 | 0.03 | 0.44 | 0.46 | 0.93 | 0.52 |
| Omega Ratio | 1.26 | 1.09 | 1.45 | 1.43 | 1.51 | 1.48 |
| Calmar Ratio | 0.27 | 0.09 | 0.99 | 1.01 | 1.11 | 1.11 |
| Information ratio | −0.62 | 0.51 | 0.46 | 0.56 | 0.52 | |
| Upside capture ratio | 1 | 0.53 | 0.43 | 0.38 | 0.42 | 0.47 |
| Downside capture ratio | 1 | 0.79 | 0.18 | 0.13 | 0.09 | 0.25 |
| Max drawdown | −32% | −22% | −21% | −19.2% | −21% | −18.7% |
| Date max drawdown | 20 March 2020 | 20 March 2020 | 20 March 2020 | 28 December 2018 | 11 January 2019 | 21 December 2018 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nafia, A.; Yousfi, A.; Echaoui, A. Equity-Market-Neutral Strategy Portfolio Construction Using LSTM-Based Stock Prediction and Selection: An Application to S&P500 Consumer Staples Stocks. Int. J. Financial Stud. 2023, 11, 57. https://doi.org/10.3390/ijfs11020057
Nafia A, Yousfi A, Echaoui A. Equity-Market-Neutral Strategy Portfolio Construction Using LSTM-Based Stock Prediction and Selection: An Application to S&P500 Consumer Staples Stocks. International Journal of Financial Studies. 2023; 11(2):57. https://doi.org/10.3390/ijfs11020057
Chicago/Turabian StyleNafia, Abdellilah, Abdellah Yousfi, and Abdellah Echaoui. 2023. "Equity-Market-Neutral Strategy Portfolio Construction Using LSTM-Based Stock Prediction and Selection: An Application to S&P500 Consumer Staples Stocks" International Journal of Financial Studies 11, no. 2: 57. https://doi.org/10.3390/ijfs11020057
APA StyleNafia, A., Yousfi, A., & Echaoui, A. (2023). Equity-Market-Neutral Strategy Portfolio Construction Using LSTM-Based Stock Prediction and Selection: An Application to S&P500 Consumer Staples Stocks. International Journal of Financial Studies, 11(2), 57. https://doi.org/10.3390/ijfs11020057