1. Introduction
According to theories of embodied cognition, sensorimotor experience is an important aspect of gaining, representing, and accessing conceptual knowledge (
Wilson 2002). The role of embodiment in adult language processing has been studied quite extensively (e.g.,
Fischer and Zwaan 2008), and sensory experiences are considered important to infants’ early learning and development (
Laakso 2011). However, less is known about the influence of embodied experiences in childhood and whether sensorimotor experiences can help older children learn new words and concepts (for a review see
Wellsby and Pexman 2014a). The focus of the current research is on embodied cognition in a developmental context, on how sensorimotor experiences might influence children’s developing linguistic and conceptual systems. More specifically, we investigated whether the provision of sensorimotor experience with novel objects influenced the accuracy of 5-year-old children in learning labels for these objects.
1.1. Theories of Embodied Cognition
In general, theories of embodied cognition emphasize the importance of sensorimotor experience for gaining and representing conceptual knowledge, but there is variability in the degree of embodiment proposed. That is, theories can be conceptualized along a continuum ranging from strong embodied theories to unembodied theories. Theories along the continuum differ in their assumptions about the relationship between sensorimotor and cognitive processes (
Mahon and Caramazza 2008;
Meteyard et al. 2012).
The unembodied end of the spectrum is represented by what is essentially a classical cognitive perspective in which sensorimotor experiences are not involved in cognitive processing. According to this perspective, sensorimotor experiences may be involved in infants’ early learning, but with development the role of sensorimotor experience becomes progressively less important as cognitive processing increasingly involves more abstract symbol manipulation (for more extensive treatment of this and the following perspectives see
Meteyard et al. 2012).
Moving further along the spectrum, weak embodied theories propose that sensorimotor experiences can be beneficial during concept acquisition, but are not always necessary. According to weak embodied theories, after initial learning sensorimotor information may not be required, as representations are abstracted from experience and organized to form conceptual knowledge (
Gennari 2012).
Dove (
2011) proposed that while previous sensorimotor experience may indeed contribute to representations of concrete concepts, such experience is less applicable to representations of abstract concepts. Dove proposed that abstract concepts are grounded in previous experience with language and linguistic symbols. In a similar vein,
Pulvermüller and Garagnani (
2014) suggested that different types of cognitive processing involve differing degrees of embodiment. From a developmental perspective, a weak embodied theory proposes that in some situations sensorimotor experience may be involved in conceptual development, but children can also learn new information by other means, for instance through associations to already known words and concepts (
Howell et al. 2005).
Finally, theories at the strong embodied end of the spectrum suggest that cognitive processing is based upon action and sensorimotor processing, and that conceptual representations are a direct result of sensorimotor experiences (
Glenberg and Gallese 2012). From a developmental perspective, strong embodied theories propose that action experience and sensory interactions are necessary for word learning and children’s conceptual development is entirely dependent upon sensorimotor experiences (for a review see
Pexman 2018).
While numerous theories of embodied cognition have been proposed, the majority have tended to focus on adult language processing and/or conceptual representation. Very few embodied theories have specifically addressed child development or examined the role of embodied experiences across the lifespan (
Wellsby and Pexman 2014a). Yet the idea of sensorimotor experience being essential for cognitive development is certainly not a new one. For instance, the notion that sensorimotor experience is essential to infants’ cognitive development was a central aspect of Piaget’s work (
Laakso 2011;
Piaget 1952). Within the developmental literature, the consensus is that infants are embodied learners who use sensorimotor experience to gain information about the world. Early concept formation is thought to be facilitated by experience interacting with concrete objects. With sufficient experience, the features of objects can then be activated in the absence of an actual physical stimulus (
Antonucci and Alt 2011;
Laakso 2011). This knowledge of the sensory features and functional features of objects can then help support early word learning.
Beyond infancy, there is disagreement about the extent to which sensorimotor experience is required for learning.
Piaget (
1952) proposed that embodied activities were necessary for children to learn about the world, but he also argued that higher-order forms of thought become separated from early sensorimotor experiences throughout child development, such that children move from sensorimotor processing to abstract processing. Alternatively, others have argued that sensorimotor interactions with the environment continue to be important for language processing and conceptual representations throughout the life span (
Antonucci and Alt 2011;
Ernst et al. 2007;
Gibbs 2006;
Thelen 2008).
The notion that sensorimotor experiences continue to be an integral part of cognitive processing across the life span is supported by evidence that adults use sensorimotor information gained through their experience with the world to simulate the meaning implied in words and sentences (e.g., implied motion (
Glenberg and Kaschak 2002), object orientation (
Stanfield and Zwaan 2001), object affordances (
Myung et al. 2006)). Similarly, there is evidence that children’s language processing is facilitated by previous sensorimotor experience. Like adults, children construct perceptual simulations during language comprehension (e.g., object orientation (
Engelen et al. 2011)). Children also use knowledge of how easily they can interact with a word’s referent to construct rich simulations that facilitate language processing (e.g., body-object interaction (BOI);
Inkster et al. 2016;
Siakaluk et al. 2008;
Wellsby and Pexman 2014b). These studies suggest that once children have had sufficient life experience interacting with words’ referents, they are able to access this sensorimotor information when reading words; concepts that afford easy interactions have richer representations, which in turn facilitate faster and/or more accurate word naming.
1.2. Effects of Manipulatives on Conceptual Processing
Extensive research has examined the influence of interactions with manipulative objects on a variety of learning outcomes. However, this developmental research typically does not adopt an embodied cognition framework to describe predictions or findings. Interestingly, the research examining the influence of manipulatives on learning outcomes indicates that interacting with objects is not always beneficial to learning, and that many factors can influence whether using manipulatives will improve or hinder performance.
Children’s math problem-solving performance is one area in which the effects of manipulatives have been examined. For instance, the influence of manipulatives on fourth- and sixth-grade children’s performance in a math problem-solving task was investigated using realistic looking (perceptually rich) money manipulatives, black and white (bland) money manipulatives, or no manipulatives (
McNeil et al. 2009). Contrary to what might be predicted from a strong embodied perspective, these researchers found that children in the perceptually rich money condition made the most errors. This may have been because the perceptually rich details distracted children from the intended purpose (to solve a math problem), or the children may have associated the perceptually rich money with play money (such as that used in board games), and not as a tool to represent a mathematical concept.
Other kinds of sensorimotor interactions can be beneficial to children, by facilitating the development of certain cognitive skills.
Antle (
2013) investigated how different learning interfaces, which afforded different types of interaction, influenced children’s spatial performance, as measured by accuracy solving a jigsaw puzzle. Children worked on a jigsaw puzzle using one of three interaction styles: physical, mouse-based virtual, or tangible virtual. In the physical condition, children solved the puzzle using traditional cardboard puzzle pieces. Children in the mouse-based condition completed the puzzle on a computer and used a mouse to drag and drop puzzle pieces into place. Finally, children in the tangible condition used a virtual interactive tabletop, where the puzzle pieces could be manipulated by hand and moved into place. Antle found that there was a positive correlation between actively manipulating pieces and successful puzzle completion. This study provided some preliminary evidence to demonstrate that both physical and virtual manipulation can be beneficial for children’s spatial task performance, but only when the virtual manipulation involves active, hands-on manipulation.
The use of manipulatives to support reading comprehension has also been examined, by having children interact with story relevant toys while reading sentences (
Marley et al. 2010). To determine the effect of manipulation, 7- and 8-year-old children read a story using one of three strategies: active, where they read sentences and moved toys in accordance with story events; observe, where they read sentences and watched the experimenter move the toys, and reread, where they simply read each sentence twice. Children in both the active and the observe conditions later recalled more story events than those children who simply reread the sentences (
Marley et al. 2010). A similar facilitory effect of manipulation was observed using virtual objects on a computer (
Glenberg et al. 2011). For six- and seven-year-old children, manipulating images of toys on a computer screen after reading sentences benefitted their later story comprehension as much as physical manipulation of the toys. Together, these findings indicate that both actively manipulating an object oneself (in real life or on a computer) and observing someone else manipulate an object can be beneficial to language comprehension.
1.3. The Influence of Sensorimotor Interactions on Word and Concept Learning
Young children can develop conceptual representations for objects based on only brief experience interacting with these objects. Action plays an important role in object representation, as the way in which we hold, move, and interact with an object comprises part of the representation for that object (
Smith 2005). To examine this notion, two-year-old children were shown an object and told a novel name for the object (e.g., “This is a wug”). The experimenter then took the exemplar object and moved it either horizontally or vertically. In the action condition, the child was then given the object to move in the same way as the experimenter. In the no-action condition the child simply observed the experimenter move the object back and forth, and in the no-action-no-movement condition the experimenter showed the child the exemplar and provided a label for it, but did not move the object.
Next, the children in the
Smith (
2005) study were shown two new objects (one vertically extended, and one horizontally extended) and asked to select the object that belonged to the same category as the exemplar (e.g., “Choose the wug”). Results showed that children chose the horizontally extended test object when they had moved the exemplar along a horizontal path, but chose the vertically extended test object when they had moved the exemplar along a vertical path. Additionally, this finding was only observed when the children actively moved the object themselves. The accuracy of children in the no-action conditions, who either watched the experimenter move the exemplar or saw no movement of the exemplar, did not differ from chance. These findings suggest that self-performed action plays a role in concept and category development in childhood, and that multimodal experiences are important in the development of cognitive processes.
The role of action observation has also been examined in the context of adjective learning (
O’Neill et al. 2002). Five novel adjectives were taught to 2- and 3-year-old children using toys that possessed specific qualities. Depending on whether the child was in the descriptive gesture group or point gesture group, the experimenter would either perform a gesture on the toy demonstrating the particular property (e.g., feeling the beans inside the cat between their fingers), or make a point gesture to the toy. Children were then given the toy to explore manually and visually. During this teaching phase, children in the descriptive gesture group produced their own interactions with the objects to a significantly greater extent than children in the point gesture group.
Children were then asked to choose a toy displaying a certain property. The findings indicated that children in the descriptive gesture group chose the toy with the correct target property significantly more often than children in the point gesture group. Additionally, observing a descriptive gesture had a larger impact in the learning of properties that could not be detected from vision alone, such as lumpiness and sponginess.
O’Neill et al. (
2002) also observed that for children in the descriptive gesture group, better test performance was related to the child’s own production of descriptive gestures with the target toy during the test trials. These findings demonstrate that observing actions that involve sensorimotor interactions with objects can be beneficial when learning new adjectives, especially when the property is non-visible. Children used the sensorimotor knowledge gained through observation to later perform their own actions. These self-produced actions during the recognition task may have allowed the children to more accurately access their representations of the specific property they were asked about. Thus, they were able to learn the properties through observation, but later used self-performed action to facilitate their conceptual processing.
Action-based language (ABL) is an embodied theory of language acquisition, comprehension, and production, which outlines how language gains meaning through grounding in perception, action, and emotion (
Glenberg and Gallese 2012). According to the ABL theory, the process by which infants learn the meaning of a noun is grounded in two ways. The first process involves directing attention to the object named by the noun. For example, a parent can say the word “bottle” when displaying a bottle to the infant, which results in the infant moving their eyes to locate the object. The infant then generates knowledge such as the size, shape, and colour of the bottle based on previous experience interacting with the object. The second way the meaning of a noun is grounded is that after attention has been directed to an object and information about that object has been activated, the infant then determines the possible affordances of the object, or what they could do with the object.
Eventually, after repeated exposure and experience with the object, a similar process takes place when the word is named but the object is not present, as a mental image of the object is activated, along with knowledge of the object’s properties and possible interactions. Essentially, the main premise of the ABL theory is that once children have previous bodily experience with an object or an action they can then map on a word for that experience. For both nouns and verbs, the ABL theory predicts that learning will occur only after the child has gained sufficient experience, either through interactions with objects or through goal-directed actions, such as giving objects to a parent to learn the verb “give”. Thus, the ABL theory can provide an explanation of how children learn the meaning of words through interaction. Similarly, recent work by Yu and colleagues suggests that word learning depends on children’s actions and input from caregivers (
Yu et al. 2019).
Previous research has demonstrated that sensorimotor interactions are an important aspect of lexical and conceptual acquisition, and that embodied knowledge gained through previous sensorimotor experience can influence child language processing. For instance, research with children under 2 years of age has demonstrated that children’s physical experiences, including action, spatial location, and proprioceptive states, shape their concepts (
Smith 2005,
2013;
Smith et al. 2007;
Smith and Samuelson 2010). In the same developmental period, children begin to learn labels for concepts (
Houston-Price et al. 2005). However, there has been limited research conducted to examine how sensorimotor experience can be used to teach older children new words. One exception is the research by James and colleagues, using functional magnetic resonance imaging (fMRI) to provide insight about how learning conditions shape the neural representation of verb concepts. First, in a study by
James and Swain (
2011), 5- and 6-year-old children were taught 10 novel verbs; half were learned while performing an action on a novel object, and half were learned through observation of the experimenter performing an action on a novel object. After this training session, children were placed in the fMRI scanner and passively listened to the names of the action labels they had learned. Results indicated that children only showed activation of the motor system when listening to verbs they had learned through active interaction.
In a related study, 5- to 7-year-old children were taught to perform 10 unlabeled actions on objects that each produced a sound (
James and Bose 2011). Half were learned through self-performed action and half through observation of the experimenter performing the action. After training, children watched videos of the actions being performed during fMRI. Results indicated greater activation in brain areas associated with tool use, integrating motor information, and visual processing when children watched videos of actions they had performed themselves.
Together, these fMRI findings revealed differences in brain activation for self-performed vs. observed actions. As such, the results suggest that the representations of concepts differ as a function of how those concepts are acquired, and that the same sensorimotor pathways that were activated during learning are reactivated during conceptual processing. This research also provides evidence that when children actively interact with objects, language and action become linked and motor representations are activated during language processing (
James and Swain 2011). While these fMRI results suggest that there are neural differences for verbs learned through self-generated vs. observed actions, we do not know whether differences in sensorimotor conditions during learning have behavioural consequences and whether these effects extend to nouns. This is addressed in the present study.
1.4. The Current Research
As in the studies by James and colleagues, our participants were 5-year-old children. However, while the studies by James and colleagues focused on learning verbs and actions, our focus was on learning nouns. Children at this age are still building a lexicon of object names (
McGregor et al. 2002). Children in the present study were taught labels for 10 novel objects and received varying degrees of sensorimotor experience with the objects, depending on the learning condition to which they were assigned. After learning the labels for all 10 objects the children completed a recognition task, where they were shown pairs of objects and asked to select the target object in each pair. Thus, children learned labels under conditions of fast mapping (single exposure of each label and referent,
Carey 1978). During fast mapping children begin to associate labels with the semantic features of their referents (e.g.,
Alt et al. 2004), and our goal was to determine how sensorimotor experience might influence that process.
Experiment 1
In Experiment 1, we tested predictions derived from four different theoretical perspectives: a strong embodied perspective (e.g.,
Glenberg and Gallese 2012), a weak embodied perspective (e.g.,
Howell et al. 2005), an attentional perspective (e.g.,
McNeil et al. 2009) and a depth of processing perspective (e.g.,
Craik and Lockhart 1972). In order to do so, as described in more detail below, children were taught labels for novel objects in one of six learning conditions (see
Appendix A for a description of the learning conditions and predictions associated with each theoretical position). These conditions were designed to vary in terms of the sensorimotor experience children had with the objects, and also in terms of the presence of and type of semantic information children were given for the objects. Sensorimotor experience was manipulated such that in two of the conditions (active interaction, active interaction with function) children had first-hand experience interacting with the objects, in one condition (observe interaction), children watched the experimenter interact with the objects, and in three conditions (object observation, object observation with fact, object observation with function) neither the child nor the experimenter interacted with the object. Additional (verbal) semantic information was provided in three conditions (active interaction with function, object observation with fact, object observation with function) to determine how its presence and type (function vs. fact) influenced children’s label learning. We manipulated the presence of semantic information to see if learning was enhanced by additional (but non-sensorimotor) verbal semantic information. We manipulated the type of semantic information to see if learning was enhanced by the provision of information that was more object-relevant (function) compared to information that was less object-relevant (fact). Indeed, there is evidence that children are sensitive to the importance of functional information for manipulable objects (
Kalénine and Bonthoux 2008;
McGregor et al. 2002).
Depending on the theoretical position adopted, it was possible to derive very different predictions for these learning conditions. First, a strong embodied position (e.g.,
Glenberg and Gallese 2012) would predict that the children in the active interaction and active interaction with function conditions, who have direct sensorimotor interactions with the items, should be the most accurate at learning novel object labels. When interacting with the objects, multiple sensorimotor aspects of the experience, such as what the objects look like, feel like, and how it can be manipulated, will all contribute to the construction of mental representations of the objects. The object names will then be linked to these rich mental representations (
Glenberg and Gallese 2012). Later, when viewing the objects in the recognition task, these representations will be simulated, allowing the children to access their representations of the objects and more accurately map the labels to the correct objects (
Mareschal et al. 2010). For the children who get to interact with the objects during the learning phase, a strong embodied theory would also predict that children who have relatively more extensive sensorimotor interactions with the objects will be more accurate at later recognizing the objects by name.
In addition, a strong embodied position (e.g.,
Marley et al. 2010) would predict that children who watch the experimenter interacting with the objects during the learning phase will also be relatively accurate at learning the object labels. The mirror neuron system is active for both self-performed and observed action (
Glenberg and Gallese 2012), and thus the children in the observe interaction condition could also develop rich sensorimotor representations of the objects by observing the experimenter manipulate the objects. Therefore, from a strong embodied view, children in the active interaction, active interaction with function, and observe interaction conditions should be significantly more accurate on the recognition task compared to children in the object observation, object observation with fact, and object observation with function conditions.
A different prediction for the effect of observing interaction can be derived from the findings of
James and Swain (
2011). James and Swain concluded that in the developing brain, self-generated action has different consequences than action observation. If the neural differences that James and colleagues observed for self-generated vs. observed action are also associated with behavioural differences for noun learning then one would predict a behavioural advantage for the learning through active interaction condition. As such, in the present study, the children who actively interact with the objects should be more accurate on the recognition task than the children who watch the experimenter interact with the objects.
Next, the predictions derived from a weak embodied or unembodied position are that the sensorimotor experience gained though active or observed interaction is not necessary to construct conceptual representations of the objects (
Meteyard et al. 2012). Thus, the sensorimotor knowledge gained by the children in the active interaction, active interaction with function, and observe interaction conditions should not provide any benefit to word learning, and there should be no difference in recognition accuracy between learning conditions.
It is also possible to predict that children in the active interaction and active interaction with function conditions will have
less accurate word learning compared to the other four conditions. From an attentional perspective (e.g.,
McNeil et al. 2009), children in the active interaction conditions may be distracted by the perceptually rich features of the objects (which are not directly relevant to learning the object names). For instance, children in the active interaction conditions may be focused on playing with the objects or with the functions described for the objects. Therefore, children in these two conditions could be less successful at learning the object names compared to those in the other four conditions.
A final set of predictions could be derived from a depth of processing perspective (
Capone and McGregor 2005;
Craik and Lockhart 1972). By this theory, conditions that involve more extensive encoding should result in better learning. Items that are encoded in a more elaborative way, either through sensorimotor interaction or associated semantic information, should be recognized more accurately. By this theory, the children in the active interaction with function should be the most accurate, followed by the active interaction and object observation with function conditions, and then the object observation with fact condition. The children who receive function information should demonstrate more accurate recognition because the function information provides rich concrete information about the purposes served by the object, while the fact provides a generic and more abstract piece of information about the object that does not provide any information about the sensory properties of the object. Furthermore, children in these four conditions should all demonstrate more accurate recognition than children in the observe interaction and object observation conditions. The children in the active interaction conditions will have rich sensorimotor information about the objects, while the children in the object observation with fact and object observation with function conditions will have more extensive semantic information about the objects based on the verbal semantic information provided to them. These conditions should thus enable stronger memory traces for the object labels, which will facilitate more accurate recognition performance.
2. Materials and Methods
2.1. Participants
The participants in Experiment 1 were 211 5-year-old children. Ten of these children participated in a pilot test of potential objects to help determine the experimental stimuli. The remaining 201 children were pseudo-randomly (constraints were gender balance and total number per condition) assigned to one of six learning conditions. After testing, the data for 13 children were removed because they did not follow instructions for either the learning task or recognition task (e.g., children who reached into the box and grabbed objects, children who pointed before being told the name of the target object). The data for an additional eight children were excluded due to experimenter error. The remaining 180 children provided useable data (5.00–5.99 years old, mean (
M) = 5.52 years old, standard deviation (
SD) = 0.27 years; 90 female), with 30 children (15 males and 15 females) in each condition. There were no significant differences in children’s mean age or vocabulary across the six learning conditions. The parents of the child participants were asked to provide information on their own highest level of education: 97% of their parents had some form of post-secondary education. The descriptive statistics for children in each condition are provided in
Table 1. After completing the study, children received a small toy as a gift for their participation. For this and the following experiment, the research was approved by the Institutional Research Ethics Board.
2.2. Stimuli
The stimuli used in this experiment were real objects that we expected would be unfamiliar to 5-year-old children. The objects were all artifacts or tools and were small and light so they could be held and manipulated by a child. A pilot test was conducted with ten 5-year-old children who were shown 16 potential objects and 16 familiar objects. The children were asked to indicate if they knew what each object was called. The objects for which the children were not able to provide a label were selected as the experimental objects. Examples of the objects include a turkey baster, a manual massager, and a latch-hook tool. Refer to
Appendix B for pictures of all 10 objects. The objects were given monosyllabic non-word labels (e.g.,
zake,
flass,
Appendix C), obtained from the English Lexicon Database (
Balota et al. 2007) such that the 10 nonwords all started with different letters and had between 5 and 11 orthographic neighbours. Across children each label was paired with each object with equal frequency (10 versions of object-label pairings), to avoid any effects of a particular label being well suited to an object.
2.3. Procedure
After arriving at the lab, each parent or guardian provided written consent for their child to participate and each child provided verbal assent. Children first completed the label learning task in one of six learning conditions: active interaction, active interaction with function, observe interaction, object observation, object observation with fact, or object observation with function. In all six conditions the child and experimenter were seated across from one another at a table. The experimenter told the child that they would be looking at objects and learning the names for the objects.
In all six learning conditions the experimenter stated the object’s label four times (“This is a yull. Look, it’s a yull. This is a yull. That’s a yull”). On each trial, after 15 s (which the experimenter timed using a stopwatch), the experimenter asked the child to provide verbally the name of the object (to ensure they were paying attention). The experimenter then removed the object and a new object was introduced. This procedure was repeated until the experimenter had presented the child with all 10 objects and labels. In all six conditions, the experimenter presented the objects in a random order to each child.
2.3.1. Active Interaction Condition
The experimenter gave the child each object one at a time, and told them they could touch the object. The child interacted with the object while the experimenter told them the object’s label.
2.3.2. Active Interaction with Function Condition
The experimenter gave the child each object one at a time, and told them they could touch the object. The child interacted with the object while the experimenter told them the object’s label and the object’s function (“
This is a yull. Look, it’s a yull. A yull is for giving yourself a massage. That’s a yull”). Object function was described in a child appropriate manner. For instance, one of the objects is for rolling out fondant icing but children were told that this object was used for making a design in Play-Doh. Refer to
Appendix D for a list of the 10 function statements given.
2.3.3. Observe Interaction Condition
The experimenter interacted with each object while telling the child the object’s label. The experimenter manipulated the objects to demonstrate what you could do with them or how they could be moved. The experimenter did not give the child any opportunity to interact with the objects.
2.3.4. Object Observation Condition
The experimenter presented each object one at a time inside a clear plastic rectangular box placed on the table. The experimenter told the child the object’s label while they looked at each object. During this time the experimenter rotated the box twice so that the child could see the object from all angles.
2.3.5. Object Observation with Fact Condition
This was the same procedure as in the object observation condition, with one addition: the fourth time the experimenter stated the object’s label they included a verbal statement of fact about each object (e.g., “
I bought a darb at the store” or “
Flasses are very expensive”). The fact provided the child with additional information about the object, but it did not give any functional information. There were 10 different facts, which were paired randomly with objects for each child. Refer to
Appendix E for a list of all 10 statements used.
2.3.6. Object Observation with Function Condition
As in the other object observation conditions, the experimenter presented each object one at a time inside a clear plastic box placed on the table. The experimenter told the child the object’s name and the object’s function.
After the experimenter had taught the child the labels for all 10 objects, the child completed a recognition task. The experimenter placed a tray on the table in front of the child and presented two of the previously learned objects side-by-side on the tray. The experimenter asked the child to point to a target object (“Can you please point to the darb?”). There were 10 recognition trials, with each object presented once as a target and once as a distracter. There were 10 different versions of object order in the recognition task, and in all versions the same object was never presented in consecutive trials. On five recognition trials the target object was presented on the left side of the tray and on five trials the target object was presented on the right side of the tray.
Finally, all children completed the Peabody Picture Vocabulary Test-4th Edition (PPVT-4;
Dunn and Dunn 2007), a measure of receptive vocabulary abilities. The experimenter scored the PPVT-4 during administration to determine when each participant had reached ceiling. Testing sessions were video recorded for later coding.
All videos were coded to determine accuracy scores for the recognition task. In addition, the videos from the learning task were also coded in terms of the comments that children made as they learned the object labels. Children’s utterances were coded into the following categories: object label (the child repeated the label given to the object; e.g., “bint”), sensory comment (the child commented on the sensory features of the object; e.g., “it’s smooth” or “it looks hard”), sensory resemblance (the child commented on something they thought the object resembled; e.g., “it looks like a hat” or “it looks like one of my toys”), metaphor (the child made a metaphoric statement about what they thought the object was; e.g., “it’s a gun” or “it’s a screwdriver”), manipulation statement (the child provided an action that could be performed with the object, or inquired about object use; e.g., “I can push it down” or “What does it do?”), related but non-sensory (the child made a comment about the object but it did not contain a sensory or motor attribute; e.g., “That is really pretty” or “It rhymes with mint!”), and non-relevant (the child made a general exclamation or a comment unrelated to the object; e.g., “Oooh” or “I went on vacation last week”). These categories were devised based on initially transcribing a subset of participants during the learning phase, noting the types of comments the children were making, and deriving categories that fit the utterances. An utterance was considered to consist of a complete idea (e.g., “Soft!”; “If you put some paint on here and put it on a piece of paper you could make a stamp”). On 12 trials (0.67%) children produced the object’s actual label (e.g., “That’s a cherry pitter’). When they did so, the experimenter corrected them, saying “I call it a bint”. The number of utterances was calculated for each category for each child, as well as their overall total number of utterances.
All of the videos were transcribed and coded by a research assistant blind to the purpose of the study, and then an experimenter second-coded the videos for 17% of the children. Inter-rater reliability was assessed using a two-way mixed model, absolute agreement, average measures intra-class correlation (ICC;
McGraw and Wong 1996) to determine the degree to which the two coders were consistent in their ratings for each utterance type across children. The ICCs were in the excellent range (
ICC > 0.75;
Cicchetti 1994;
Hallgren 2012) for the coding of object labels,
ICC = 1.00; sensory resemblance,
ICC = 1.00; metaphors,
ICC = 1.00; non-relevant utterances,
ICC = 0.99; object manipulations,
ICC = 0.99; related but non-sensory utterances,
ICC = 0.96, and sensory properties,
ICC = 0.94. These ICCs indicate that the coders had a high degree of agreement.
In addition, the videos for children in the active interaction condition and active interaction with function condition were coded to determine the proportion of time they spent interacting with the objects and the numbers of actions they performed on the objects. The videos were coded frame by frame using Windows Live Movie Maker. Interaction proportion was coded as the proportion of time a child held or touched the object from when it was presented to them until the experimenter took the object back (a 15 s window on each trial). The number of actions was coded such that holding the object counted as one action, and then each additional action after that was added to compute an overall number of actions. For example, a child who just looked at the object on the table and did not pick it up received a 0 for number of actions, a child who held the object in their hand and looked at it received a 1 for number of actions, and a child who held the object in their hand and looked at it, then spun it around on the table, then held it on top of their head and pretended it was a little hat received a 3 for number of actions.
3. Results
Children’s accuracy on the recognition task was coded from video and an accuracy score out of 10 was tallied for each child.
Figure 1 displays the mean recognition scores for each learning condition. For each learning condition we first conducted a one-sample
t-test to determine if children’s performance was better than chance (with chance set at a score of 5/10). These
t-tests indicated that children in all six learning conditions performed significantly better than chance on the recognition task: active interaction
t(29) = 6.64,
p < 0.001,
d = 1.21; active interaction with function
t(29) = 3.53,
p < 0.01,
d = 0.64; observe interaction
t(29) = 3.90,
p < 0.01,
d = 0.71; object observation
t(29) = 4.26,
p < 0.001,
d = 0.78; object observation with fact
t(29) = 4.97,
p < 0.001,
d = 0.91; object observation with function
t(29) = 5.34,
p < 0.001,
d = 0.97.
Next, recognition data were analyzed using a between subjects analysis of variance (ANOVA) to examine effects of learning condition (active interaction, active interaction with function, observe interaction, object observation, object observation with fact, object observation with function) and gender (male, female) on recognition performance. The ANOVA revealed no effect of learning condition on recognition task performance,
F(5, 168) < 1. There was also no effect of gender,
F(1, 168) < 1. There was, however, a significant interaction of learning condition and gender,
F(5, 168) = 3.50,
p < 0.01,
ηp2 = 0.09. Follow-up
t-tests revealed that in the object observation condition, female children (
M = 7.93,
SD = 1.53) performed significantly better than male children (
M = 5.47,
SD = 2.07),
t(28) = 3.71,
p < 0.01,
d = 1.53. There were no significant differences between males and females in the other five conditions (all
p > 0.08).
1In an additional analysis, we took a Bayesian approach and calculated the relative posterior probabilities of the null and alternative hypotheses (
Masson 2011) for the effect of learning condition. The posterior probability favouring the alternative hypothesis (
pBIC(H
1|D)) was 0.001, and the posterior probability favouring the null hypothesis (
pBIC(H
0|D)) was 0.999, which indicated that the data clearly favour the null hypothesis (no effect of learning condition) over the alternative hypothesis. This provides very strong evidence (
pBIC(H
i|D) > 0.99;
Raftery 1995) that the learning condition manipulation did not influence recognition performance.
We conducted a further analysis of the learning task for the active interaction and active interaction with function conditions to determine whether the proportions of time children spent manipulating the objects (interaction proportion) or the numbers of different actions they performed on the objects (number of actions) were related to their subsequent recognition task performance.
2 On average, children in the active interaction condition interacted with the objects 86.45% of the time (
SD = 20.33) and performed 2.07 actions on the objects (
SD = 0.53), while children in the active interaction with function condition interacted with the objects 73.18% of the time (
SD = 36.41) and performed 1.53 actions on the objects (
SD = 0.80). There were no significant correlations between children’s interaction proportions and their recognition performance (
r(58) = 0.11,
p = 0.42) or between children’s numbers of actions and their recognition performance (
r(58) = 0.07,
p = 0.62). Not surprisingly, children’s interaction proportions and their numbers of actions were correlated (
r(58) = 0.88,
p < 0.001), such that children who interacted with the objects for a greater proportion of time also performed more actions with the objects.
The average numbers of each type of utterance in each learning condition are presented in
Table 2. Before analyzing children’s comments further, we excluded non-relevant statements (31.57% of all comments). We also excluded comments in which children provided the actual label for the object (0.49% of all comments, e.g., “
That’s a cherry pitter”). Of the remaining comments, the most frequent was to repeat the object label (41.72% of object relevant comments), followed by commenting on how you could manipulate the object or questioning what the object was used for (23.72% of object relevant comments).
A series of one-way ANOVAs were conducted to determine if there were significant differences between the six learning conditions for the numbers of each type of comment children made. These analyses included only one significant effect of learning condition: for object manipulation statements, F(5, 174) = 2.78, p < 0.05, ηp2 = 0.07. Post hoc multiple comparisons using the Bonferroni procedure were conducted to examine differences in manipulation statements between the six learning conditions. These analyses revealed that children in the active interaction condition made significantly more comments about how the objects could be manipulated or what they could be used for (M = 4.80, SD = 6.24) compared to children in the object observation condition (M = 1.07, SD = 2.27), t(58) = 3.08, p < 0.05, d = 0.79. There were no significant differences between any of the other learning conditions for numbers of object manipulation statements.
4. Discussion
Contrary to the majority of predictions we derived from the four different theoretical positions considered, there was no effect of learning condition on children’s recognition performance in Experiment 1. More specifically, in contrast to predictions derived from a strong theory of embodied cognition, children in the active interaction and active interaction with function conditions did not perform better on the recognition task than children in the other learning conditions. There was also no support for predictions we derived from a depth of processing theory or an attentional perspective. Instead, consistent with the predictions derived from a weak embodied or an unembodied theory of cognition, children in all six learning conditions had similar levels of performance. According to a weak embodied or unembodied theory, the sensorimotor experience some children received was not necessary to build their conceptual representations of the objects. As a result, there was no significant difference in recognition accuracy across the six groups.
In each of the six learning conditions, children performed significantly better than chance. Therefore, it is unlikely that the recognition task was too difficult for the children. Additionally, children’s performance did not appear to be at ceiling and the standard deviations indicated that there was good variability of accuracy scores on the recognition task, so it does not appear that the task was too easy. Therefore, 10 seemed to be an appropriate number of items for 5-year-old children to learn (sufficiently challenging but not too challenging), and it seems unlikely that recognition task difficulty can be blamed for the null effects observed for learning conditions.
The analysis of children’s actions during the learning task for the active interaction condition and active interaction with function condition indicated that, contrary to predictions, there was no relationship between the proportions of time children spent interacting with the objects and their recognition performance, nor between the numbers of actions children performed on the objects and their recognition performance. This may be because there was not much variability in interaction proportions and numbers of actions. Most children interacted with the objects the entire time they were presented with them (only 2/60 children did not touch the objects and simply looked at them). Most of the children held the object and then discovered an action they could perform on the object and repeated that action.
The post-hoc analysis of children’s utterances during the learning phase was conducted to give more insight into children’s thought processes while learning the object labels, and to provide clues about the kinds of information on which children were focused. The analysis across all conditions indicated that when children made comments about the objects, they tended to be (a) repeating the label given to the object, (b) making a comment pertaining to an action one could perform with the object, or (c) inquiring about what it was used for. Thus, it appeared that the children were mainly focused on the names of the objects and the functions (or perceived functions) of the objects, even though the intended purpose of the learning phase was not to learn object function. The children’s focus on function and action may have detracted from their learning of the object labels. In particular, we observed that children in the active interaction condition made significantly more comments about object manipulations than children in the object observation condition. Therefore, children in the active interaction condition may indeed have had a richer sensorimotor experience, but their focus on object function may have distracted them from mapping the labels to the objects and counteracted any beneficial effect of interaction. It was not simply the case that children who interacted with the objects were more talkative than the other children, as there was no difference between conditions for children’s total number of utterances. Of course, children were not required to make comments during the learning phase, but their spontaneous utterances do provide some insight into what they were thinking as they encountered each object.
One possible explanation for the null effect of learning condition observed in Experiment 1 is that the children were focused on the manipulations that the objects afforded, which may have been particularly distracting for children in the active interaction condition. For Experiment 2, we tried to reduce this potential interference by modifying the stimuli to decrease the saliency of function attributes and shift focus to the sensorimotor properties of objects.
Experiment 2
We created a new set of objects to serve as the stimuli for Experiment 2. These objects had no moveable parts or obvious functions. We acknowledge that it is impossible to create objects that do not afford
any possible actions, but care was taken to make the sensory features the focus of the objects. The new set of 10 objects had multiple sensory features, including some which could not be detected from visual inspection alone (e.g., weight, internal material). This was intended to emphasize sensory information for children in the active interaction condition. Previous research has suggested that interacting with objects and gaining sensorimotor knowledge may play an important role in learning words that require knowledge of non-visual properties (
O’Neill et al. 2002). While learning the labels for the objects did not require knowledge of these nonvisual properties, the enhanced sensorimotor experience may still result in construction of richer representations and enhanced word learning.
For Experiment 2 we used only two learning conditions: active interaction and object observation. We chose these two conditions because the active interaction condition should provide the richest sensorimotor experience with the objects, especially with the unobservable sensory properties, while the object observation condition should provide the most limited sensorimotor experience. Comparing these two conditions thus provided the strongest test of effects of sensorimotor experience on word learning. In order to facilitate comparison between experiments, all other aspects of the procedure for Experiment 2 were the same as in Experiment 1.
From a strong embodied cognition position, children who interact with the objects should be more accurate at learning the labels compared to children who only observe the objects. During the learning task, the multiple sensory dimensions of the objects should be encoded by the children in the active interaction condition and should help comprise the representations these children have for the objects. When they are later asked to identify the objects in the recognition task, these sensorimotor representations should again be activated. Both a strong embodied theory and a depth of processing theory would predict that the children in the active interaction condition would receive rich sensorimotor experience on multiple dimensions from the new experimental stimuli during the learning task, which should help facilitate encoding and retrieval of the labels.
In contrast, an attentional perspective would predict that children in the object observation condition should perform better than children in the active interaction condition. The multiple sensory features of the objects are not relevant to the task at hand, as the children are not learning adjectives, property features, or object categorization. As a result, these rich sensory features could be more distracting than beneficial to the children, hindering their ability to accurately map labels to objects.
Finally, from a weak embodied or unembodied position, there should be no difference between the two learning conditions on recognition task performance. Weak embodied theories propose that conceptual representations are abstracted from experience and sensorimotor information is not necessary when accessing conceptual knowledge (
Gennari 2012); therefore, the sensorimotor information the children in the active interaction condition receive should neither help nor hinder their accuracy in the recognition task.
We also predicted that children in Experiment 2 should offer less commentary during the learning task about what the objects are used for or how they could be manipulated than did children in Experiment 1. Instead, we predicted that the children’s commentary in Experiment 2 should reflect more focus on sensory properties. This would indicate that the change we made to the experimental items was effective in focusing children’s attention on the sensory properties of the objects.
5. Method
5.1. Participants
The participants in Experiment 2 were 64 5-year-old children. The data for one child were removed because the family indicated after completing the study that the child had a learning disorder. The data for two additional children were removed for failure to follow instructions. Finally, the data for one child were excluded due to experimenter error. Thus, 60 children (5.00–5.92 years old,
M = 5.50 years old,
SD = 0.25 years, 30 female) provided usable data. The children were pseudo-randomly assigned to one of two learning conditions, with 30 children (15 males and 15 females) in each condition. There were no significant differences between the two learning conditions in children’s mean age or vocabulary. Of the 60 children, 91.67% of their parents had some form of post-secondary education. The descriptive statistics for children in each condition are provided in
Table 3. After completing the study, children received a small toy as a gift for their participation.
5.2. Stimuli
The objects used in this experiment were 10 hand-made items. Because the participants in Experiment 1 seemed to be focused on the function of the objects or ways in which the objects could be manipulated, care was taken to create objects for Experiment 2 that did not have any moveable parts or an obvious function. Instead, the stimuli were conceptualized as a set of objects that the experimenter collected and they were designed with salient sensory features. The objects were small enough to be picked up and held by the children. The objects varied in colour, exterior texture, interior material, and weight. Two objects were blue, two were purple, two were beige, two were grey/silver, and two were green. Two objects were bumpy on the outside (covered in beads or sequins), two were soft (covered in fake fur or felt), two were squishy (covered in the material from a stretchy toy), two were smooth (covered in foam or lycra), and two were rough (covered in sandpaper or burlap). Five of the objects had a sponge interior, while five of the objects had a small box interior. Finally, five of the objects had nothing inside (making them light), while five of the objects had rocks or sand inside (making them heavy). Refer to
Appendix F for pictures of all 10 objects.
The entire collection of objects was given the name
Greebles. This made-up category label has been used by other researchers when using novel objects (e.g.,
Gauthier and Tarr 1997). The object labels were the same non-words used in Experiment 1, and again there were 10 versions of the pairings of labels with objects.
5.3. Procedure
After arriving at the lab, each parent or guardian provided written consent for their child to participate and each child provided verbal assent. Each child first completed the label learning task in one of two learning conditions: active interaction or object observation. In both conditions the child and the experimenter were seated across from one another at a table. The experimenter gave the child the following information before presenting them with the objects:
“One of my favourite hobbies is to collect greebles! I know a lady that makes greebles, and each one is different. Today we’re going to look at my collection of greebles, and I will teach you the name for each one. They are very important to me because each one is homemade and special…”
Then, depending on the condition to which they were assigned, the experimenter provided the child with one additional instruction:
“But I am going to let you touch them.” or, “So we are just going to look at them.”
The rest of the label learning task followed the same procedure as in Experiment 1.
The videos from the learning task were again examined to code children’s comments, using the same seven categories: object label, sensory comment, sensory resemblance, metaphor, manipulation statement, related but non-sensory, and non-relevant. The number of utterances was calculated for each category for each child, as well as each child’s total number of utterances. Once again, a statement could be coded into two categories (15.38% of utterances). An experimenter transcribed and coded the videos, and then a research assistant blind to the purpose of the study second-coded 25% of the videos. Inter-rater reliability was assessed using a two-way mixed model, absolute agreement, average measures ICC (
McGraw and Wong 1996) to determine the degree to which the two coders were consistent in their ratings for each utterance type across children. The ICCs were in the excellent range for the coding of object labels,
ICC = 1.00; sensory properties,
ICC = 0.99; non-relevant utterances,
ICC = 0.99; metaphors,
ICC = 0.98, sensory resemblance,
ICC = 0.95; and object manipulations,
ICC = 0.95. The ICC for the coding of related but non-sensory utterances was in the good range (
ICC between 0.60 and 0.74;
Cicchetti 1994;
Hallgren 2012),
ICC = 0.74. These ICCs indicate that the coders had high agreement.
6. Results
Children’s accuracy on the recognition task was coded from the videos and each child was given an accuracy score out of 10.
Figure 2 displays children’s mean recognition accuracies for both learning conditions. For each condition a one-sample t-test was conducted to determine if children’s recognition accuracy was above chance. Children in both learning conditions performed significantly better than chance: active interaction
t(29) = 3.76,
p < 0.01,
d = 0.68; object observation
t(29) = 3.42,
p < 0.01,
d = 0.62.
Recognition task accuracy was analyzed using a between subjects ANOVA to examine the effects of learning condition (active interaction, object observation) and gender (male, female) on recognition performance. The ANOVA revealed that there was no effect of learning condition, F(1, 56) < 1. There was also no effect of gender, F(1, 56) = 1.77, p = 0.19, nor was there an interaction of learning condition and gender, F(1, 56) < 1.
We again took a Bayesian approach and calculated the relative posterior probabilities of the null and alternative hypotheses (
Masson 2011) for the effect of learning condition. The posterior probability favouring the alternative hypothesis (
pBIC(H
1|D)) was 0.115, and the posterior probability favouring the null hypothesis (
pBIC(H
0|D)) was 0.885, which indicated that the data favour the null hypothesis (no effect of learning condition) over the alternative hypothesis. This provides positive evidence (
pBIC(H
i|D) = 0.75–0.95; (
Raftery 1995) that the learning condition manipulation did not influence recognition performance.
For the analyses of children’s comments during the learning task, we excluded 14.64% of the total comments because they were considered non-relevant. Overall, the most frequent type of comment children made was to repeat the object label (38.81% of object relevant comments), followed by commenting on the sensory properties of the object (27.03% of object relevant comments). Only 3.20% of the object relevant comments pertained to manipulation of the object. A series of independent samples
t-tests was conducted to determine if there were significant differences between the two learning conditions for the numbers of each type of comment children made. These analyses indicated that children in the active interaction condition made significantly more comments about sensory properties of the objects (
M = 4.67,
SD = 6.51) than did children in the object observation condition (
M = 1.53,
SD = 2.18),
t(58) = 2.50,
p < 0.05,
d = 0.65. There was also a statistically significant difference between the two conditions on object manipulation statements, with children in the active interaction condition making more comments about performing actions on the object (
M = 0.63,
SD = 1.27) compared to children in the object observation condition (
M = 0.10,
SD = 0.31),
t(58) = 2.32,
p < 0.05,
d = 0.57. See
Table 4 for the average numbers of each type of comment for the two learning conditions.
7. Discussion
As in Experiment 1, the results of Experiment 2 showed no effect of learning condition on children’s recognition accuracy. The new stimuli were designed to present the children who interacted with the objects with multiple sensory features during the learning task and allow richer semantic information to be mapped to their representations of the object labels. However, children in the active interaction condition still did not perform better than the children in the object observation condition. This finding is inconsistent with predictions derived from both a strong theory of embodied cognition and a depth of processing theory.
From an attentional perspective, we hypothesized that children in the active interaction condition may have less accurate performance than children in the object observation condition. The focus of the experiment was not to learn object properties and, therefore, the enhanced sensory information could have distracted from the task of simply learning the labels for the objects; however, this was not the case. Instead, in line with predictions derived from a weak embodied or unembodied theory, children in both learning conditions had similar levels of recognition task accuracy.
Children in both learning conditions performed significantly better than chance on the recognition task. Therefore, it is unlikely that the task was too difficult for the children, even though the visual similarities of the objects (all approximately the same size and shape) could conceivably have made them more difficult to differentiate than the objects in Experiment 1.
The analysis of children’s utterances in the learning phase of Experiment 2 indicated that when children made comments about the objects, they tended to either repeat the label given to the object, or make a comment about the sensory properties of the object. Compared to Experiment 1, children in Experiment 2 made very few comments about how the objects could be manipulated. Thus, the new objects we constructed did seem to emphasize the objects’ sensory aspects and diminish the salience of the objects’ functions. Children in the active interaction condition made significantly more comments about the sensory properties of the objects than did children in the object observation condition. The children were not required to make any comments during the learning task, but the utterances provided by the children in the active interaction condition suggested that they noticed the rich sensory properties of the objects; however, this sensory knowledge did not lead to better performance on the recognition task. The children in the active interaction condition also made significantly more comments about how the objects could be manipulated compared to the children in the object observation condition. However, it is unlikely that the children in the active interaction condition were distracted by manipulation features of the objects (which we proposed may be the case in Experiment 1), because the average number of comments about manipulation features was small for both groups (M = 0.63 and M = 0.10).
8. General Discussion
The purpose of the present research was to investigate whether children’s word learning, more specifically, children’s object label learning, could be influenced by sensorimotor interaction experience with the objects. We conducted two experiments. During the label learning phase of each experiment we manipulated whether children interacted with the objects or not, and how much (if any) semantic information they received about the objects. We then measured children’s recognition accuracy performance for the object labels. The results indicated that there was no significant effect of learning condition in either experiment; all children had similar recognition accuracy, regardless of the learning condition to which they were assigned. These results suggest that, contrary to predictions derived from a strong embodied cognition perspective, sensorimotor experience interacting with objects did not facilitate word learning. The results from both experiments suggest that embodied effects on label learning are not observed in all contexts.
8.1. Reconceptualising Optimal Embodied Learning Paradigms
There has been an increased focus on designing embodied instructional paradigms, which incorporate the body and sensorimotor interactions with the environment (e.g.,
Marley et al. 2010). The main idea behind such embodied approaches is that when relevant sensorimotor systems are engaged, the learner can create richer conceptual representations for the material being learned (
Lindgren and Johnson-Glenberg 2013). These representations will then be easier to activate at a later point in time. In keeping with this idea, we predicted that the children in our experiments who interacted with objects while learning the object labels would create richer representations for these objects, which they would map to the labels. From a strong embodied cognition perspective, these representations should have then been more easily activated during the recognition task, leading to more accurate performance. This prediction was not borne out in the results and one potential reason may be that there was insufficient congruency between the sensorimotor experience children received and the information to be learned. Embodied experiences with objects are most beneficial to learning when there is a high degree of congruency between the action being performed or the sensorimotor knowledge being acquired and the information that is being learned (
Lindgren and Johnson-Glenberg 2013).
Congruency is a key aspect of the distinction between high-embodied and low-embodied interactions (
Lindgren and Johnson-Glenberg 2013). High-embodied interactions involve learning conditions that are highly immersive; for example, they may consist of sensorimotor interactions with the whole body. Most importantly, high-embodied interactions have a high degree of congruency between the actions being performed and the information to be learned. In contrast, low-embodied interactions involve learning conditions that are much less immersive; they can involve observing something happening or watching someone else interact with an object. Low-embodied interactions can also consist of general “hands-on” learning experiences; that is, interacting with something but not in an immersive, conceptually congruent fashion.
By this distinction, it seems likely that the children in the present active interaction conditions had low-embodied interactions with the objects in the sense that the sensorimotor experience the children gained and the actions they performed with the objects were not congruent with the material being learned. That is, the children in Experiment 1 often performed actions with the objects or manipulated them to see what they could do with them, but they were not learning the label of a verb or an action to perform on the objects. Similarly, the children in the active interaction condition in Experiment 2 also had low-embodied interactions with the objects in that they were obtaining sensory information from interacting with the objects, but they were not learning adjectives or trying to form a concept of the category ‘Greeble’. It may be impossible for children to have truly high-embodied, immersive learning when learning object labels in isolation. The embodied experience of interacting with objects may teach children the sensory features and affordances of objects, which in turn will comprise rich conceptual representations of the objects, but this experience will not have an immediate effect on noun learning. Indeed, it is notable that in the present study we tested only immediate recognition for the object labels. While there was no difference in recognition accuracy in the short term, it is possible that with a delay (e.g., one week later), children might have shown differences between learning conditions. This possibility could be addressed in future research.
3Another potential reason that we did not observe an effect of learning condition in either experiment was the between-groups nature of our design. In both of our experiments each child was assigned to just one learning condition. This was in contrast to study designs in
James and Bose (
2011) and
James and Swain (
2011), where each child learned five novel actions through self-performed action and five novel actions through observed action. We chose to use a between-groups design so that each condition would have 10 trials and thus greater likelihood of detecting variability in recognition performance. However, in a basic word-learning paradigm, children may need to have varied experience—interacting with some objects and observing other objects—in order to show effects of sensorimotor experience on word learning. Indeed, research on adult memory suggests that this may be the case (e.g.,
Engelkamp and Zimmer 1997). Within-subjects designs may enhance distinctiveness, which may produce more accurate recognition for the items learned through active interaction.
It is important to note that any effects of a within-groups design would depend on the experiment being constructed in a very specific way (
McDaniel and Bugg 2008), and as such, the practical relevance of those effects to education and word learning would be questionable. That is, if an embodied effect can only be observed in highly constrained situations, such as when children learn one set of items with interactions and another set without, this begs the question of whether these types of embodied instruction would be practical and generalizable to an educational setting.
A continuing debate within the field of embodied cognition is the extent to which embodied experiences are beneficial for learning in older children. The children in both of our experiments had high vocabulary scores as measured by the PPVT-4 and were likely skilled word learners. Embodied interactions with objects have been found to be more beneficial for learning with younger children (
Mounoud et al. 2007) or when the information to be learned is particularly difficult (
Chan and Black 2006). At this particular stage in their language development, the children in our experiments may have simply been able to fast-map the labels to objects based on visual cues, and thus the sensorimotor experience and/or verbal semantic information some children received did not provide any additional benefit.
8.2. Re-Examining the Nature of the Stimuli
The null results we obtained may also be a function of the type of linguistic information that children were learning; that is, sensorimotor experience may be beneficial (and even necessary) for learning certain types of words (e.g., verbs, adjectives), but not for the object labels (nouns) that children learned in our experiments. There is evidence that sensorimotor experiences interacting with objects and with the environment are beneficial to children’s verb acquisition and that children’s representations of verbs are comprised of knowledge from previous motor experiences (e.g.,
Maouene et al. 2008;
Maouene et al. 2011). Findings obtained using verb stimuli provide support for embodied theories of cognition and for the notion that there is a link between the body and some aspects of early language development.
Findings from research using fMRI also provide support for the notion that children’s representations of verbs are comprised of previous sensorimotor experience. For example, research has indicated that 4- and 5-year-old children show greater activation in the motor cortex when they listen to verbs compared to adjectives (
James and Maouene 2009). Similarly, research with adults has found differences in neural activation for different lexical categories. For example, processing concrete verbs is associated with greater activation in areas of the motor cortex compared to processing object-related concrete nouns (
Moseley and Pulvermüller 2014). Verbs, in particular, may be grounded in motor representations.
While the representations of concrete verbs may be grounded in the motor system, the same may not be true for representations of abstract verbs. Children aged 8 and 9 were taught different types of verbs by de Nooijer and colleagues (
de Nooijer et al. 2014) using four different instructional methods: hearing a verbal definition, observing a gesture, imitating a gesture, or generating own gesture. Observing gestures facilitated learning of locomotion verbs, and both imitating gestures and generating own gestures facilitated children’s learning of object manipulation verbs (but only for children with high vocabulary skills). However, children’s abstract verb learning performance did not differ for any of the instructional methods. These findings suggest that abstract verb learning is not facilitated by embodied experience, and contrary to predictions of a strong theory of embodied cognition, gesture and action may not be effective methods for learning words unless those words have a direct link to the motor system. These findings and the proposed rationale fit nicely with the findings from both of our experiments: in our experiments the object labels did not have a direct link to the motor system, and this may be why we did not observe an effect of learning condition on recognition accuracy. Therefore, our findings could be interpreted as evidence against a strong theory of embodied cognition. This possibility will be discussed in more detail below.
8.3. Implications for Theories of Embodied Cognition
From a strong embodied cognition perspective, we predicted that the children in both experiments who interacted with the objects while learning the object labels would form rich conceptual representations for the objects and link these representations to the object labels. When the children were asked to point to a specific object in the recognition task, hearing the label should have activated their representation of that object based on their previous sensorimotor experience (
Glenberg and Gallese 2012). These predictions were not supported; in both experiments children performed equally well on the recognition task regardless of learning condition. Therefore, our findings place some limits on a strongly embodied view of cognition.
The findings from our experiments are more consistent with both a weak embodied and an unembodied theory of cognition, as there was no effect of learning condition on recognition accuracy. The sensorimotor information acquired by children in the active interaction conditions did not facilitate (nor inhibit) their label learning. In verb learning studies the actions performed are often exact reflections of the meaning of the word (e.g., a locomotion action in
de Nooijer et al. 2014 or a novel verb manipulation in
James and Swain 2011), but in our studies any action performed on the objects did not directly relate to the meaning of the word and, therefore, the strength of the link to the motor system was likely weaker. A weak embodied theory or an unembodied theory could be used to interpret the present results by arguing that children do not need sensorimotor experience to map the labels to the objects; rather, children can simply rely on visual cues to fast-map a novel label to an object. Therefore, it may be the case that when learning concrete noun labels, the most important aspect for successful label mapping is attention to the visual features of the object, consistent with evidence from previous research (e.g.,
Yürüten et al. 2013). Additionally, weak embodied theories propose that sensorimotor experience becomes significantly less important with development as children learn more complex and abstract aspects of language that do not have a direct link to the motor system (
Meteyard et al. 2012). Concepts can be represented based on linguistic experience, augmenting sensorimotor experience (
Dove 2011).
Our findings indicate that sensorimotor experience is not always beneficial to label learning. There was no effect of sensorimotor interaction on label learning for novel objects. As such, the findings from both experiments can provide some insight to refine theories of embodied cognition by demonstrating a specific situation in which embodied experience does not influence children’s language development.
Clearly, there is much work that needs to be done to refine theories of embodied cognition (
Barsalou 2010). Even proponents of strong embodied cognition theories acknowledge that it is necessary to determine whether sensorimotor experience is necessary for all aspects of cognitive processing or if sensorimotor experience merely influences conceptual processing (
Glenberg et al. 2013). If theories of embodied cognition are to be considered a framework for understanding all aspects of cognitive processing, these theories need to be able to explain processes that have no apparent direct relationship to sensorimotor experience (
Goldinger et al. 2015). Going forward, embodied theories should strive to take a multidimensional approach and include factors like linguistic experience and emotions to be able to adequately explain how we acquire and represent concrete as well as abstract concepts and information (
Pexman 2018).
9. Conclusions
The results of the present experiments indicate that, contrary to predictions derived from a strong theory of embodied cognition, sensorimotor experience was not beneficial for novel noun learning in 5-year-old children in a laboratory task. Children performed equally well on a recognition task regardless of learning condition. Further research needs to be conducted to determine the conditions under which sensorimotor experience can (and cannot) benefit the developing conceptual and linguistic systems, in order that developmental theories can accurately model the role of sensorimotor experience in language acquisition.



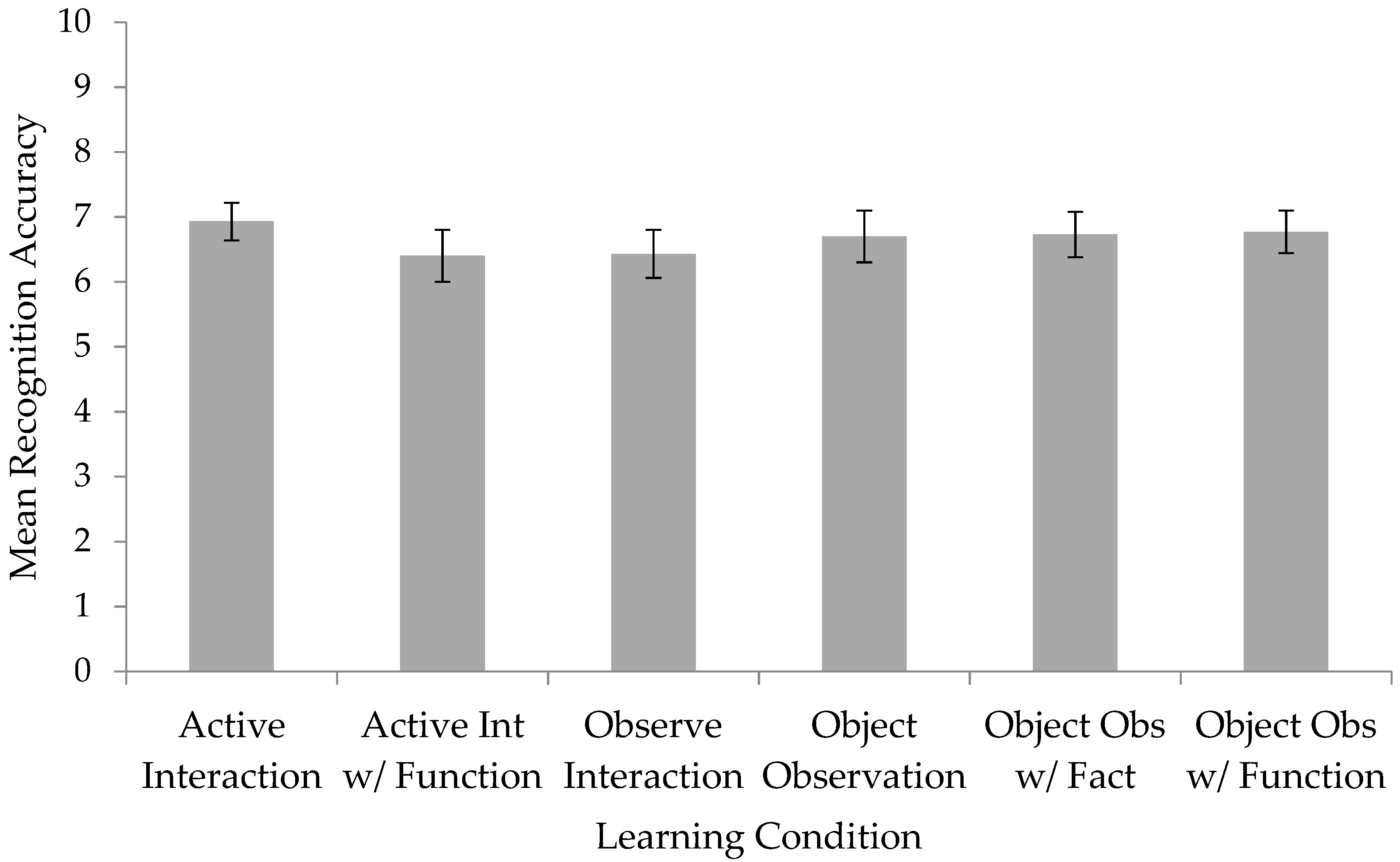{kind=link}
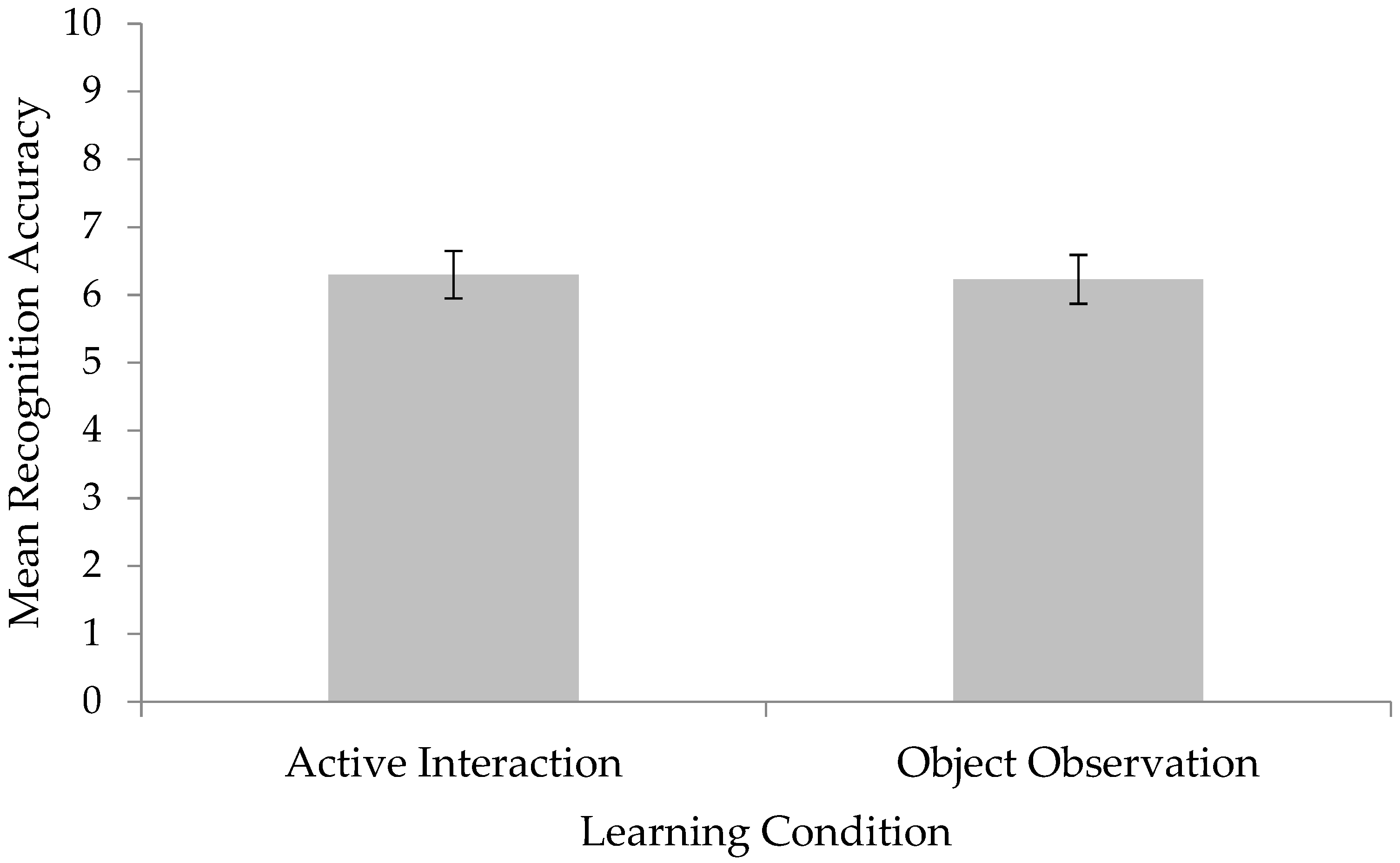{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
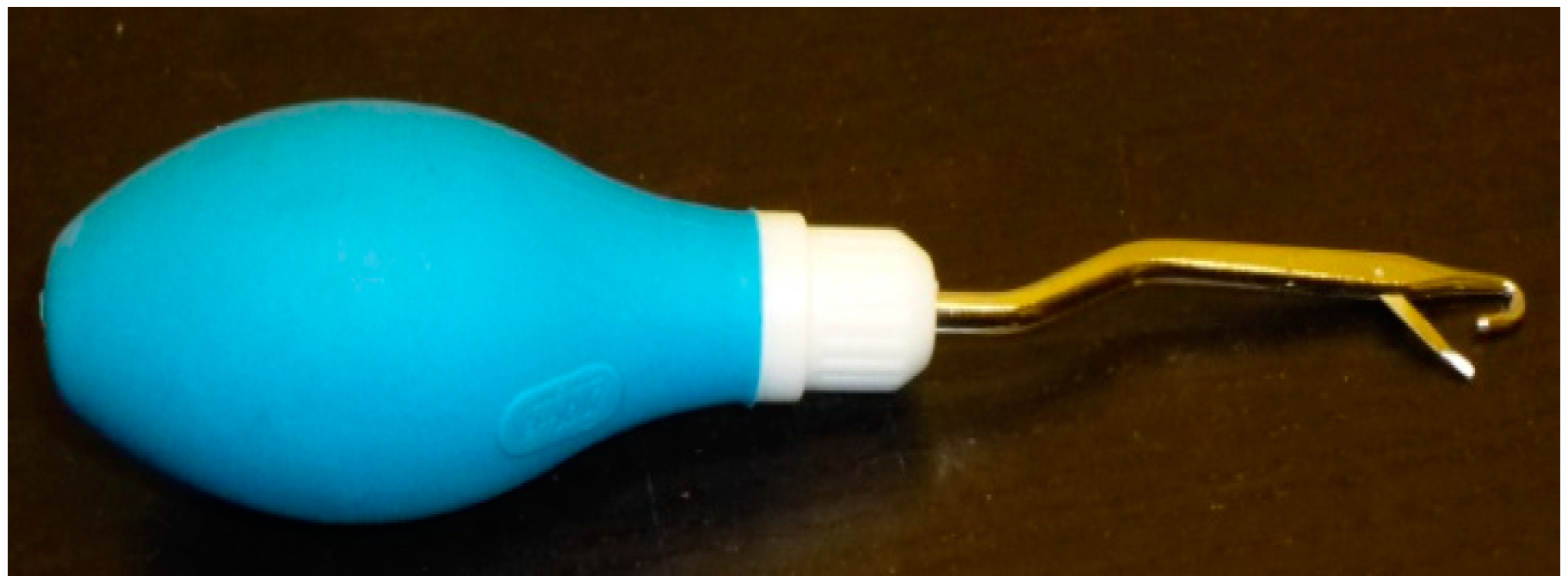{kind=link}















