Abstract
Conventional projection systems typically require a fixed spatial configuration relative to the projection surface, with strict control over distance and angle. In contrast, UAV-mounted projectors overcome these constraints, enabling dynamic, large-scale projections onto non-planar and complex environments. However, such flexible scenarios introduce a key challenge: severe geometric distortions caused by intricate surface geometry and continuous camera–projector motion. To address this, we propose a novel image registration method based on global dense matching, which estimates the real-time optical flow field between the input projection image and the target surface. The estimated flow is used to pre-warp the image, ensuring that the projected content appears geometrically consistent across arbitrary, deformable surfaces. The core idea of our method lies in reformulating the geometric distortion correction task as a global feature matching problem, effectively reducing 3D spatial deformation into a 2D dense correspondence learning process. To support learning and evaluation, we construct a hybrid dataset that covers a wide range of projection scenarios, including diverse lighting conditions, object geometries, and projection contents. Extensive simulation and real-world experiments show that our method achieves superior accuracy and robustness in correcting geometric distortions in dynamic UAV projection, significantly enhancing visual fidelity in complex environments. This approach provides a practical solution for real-time, high-quality projection in UAV-based augmented reality, outdoor display, and aerial information delivery systems.
1. Introduction
UAVs have been widely applied in areas such as localization, detection, and tracking, owing to their high mobility [1,2,3,4]. When extended to the field of computer graphics [5,6,7], UAV systems equipped with visual and optical devices offer a revolutionary approach to projection applications in dynamic, large-scale, and non-planar environments. Traditionally, projectors must be physically mounted at fixed positions, maintaining precise distance and orientation with respect to a planar or near-planar projection surface. In contrast, when UAVs serve as mobile platforms, the projection position and angle can be adjusted in real time during flight. As illustrated in Figure 1, this new type of projection system shows great potential in scenarios such as outdoor performances, augmented reality interactions, industrial visualization, emergency information broadcasting, and nighttime advertising. It enables the accurate projection of visual information onto arbitrary surfaces in wide spaces, free from the constraints of fixed projector installations and flat screens.
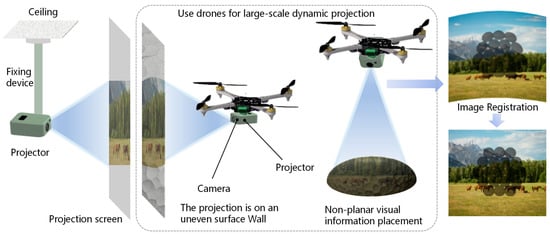
Figure 1.
The process of large-scale dynamic projection using UAVs. Following geometric correction, projected content can be projected onto non-planar surfaces while maintaining perceptual realism.
However, achieving high-quality and distortion-free dynamic projection faces a fundamental challenge: the severe geometric distortions caused by dynamic changes and complex shapes of non-planar object surfaces. When a projector, mounted on a fast-moving UAV, projects content onto various non-planar surfaces—some of which may also be in motion—the resulting images often exhibit noticeable warping and stretching. These geometric distortions significantly degrade the visual fidelity and effectiveness of the projected information, becoming a critical bottleneck that limits the practical deployment and visual quality of UAV-based large-scale dynamic projection systems. Traditional projection correction techniques, particularly pre-warping methods designed for static planar screens, struggle to handle such unstructured and dynamic 3D scenarios. These methods are generally incapable of adapting in real time to rapid changes in the relative pose between the projector and the target surface, as well as to the complex geometry of the surface itself. Therefore, there is an urgent need for an innovative approach that can robustly and efficiently correct geometric distortions in real time during dynamic projection. This challenge can be reformulated as a large-motion estimation problem in the domain of global optical flow. By leveraging optical flow algorithms, it is possible to establish dense pixel-level correspondences between the projected image and the target surface during the dynamic projection process. In doing so, complex 3D distortions on non-planar surfaces can be addressed through global matching in the 2D image space, enabling accurate correction of projection geometry in real-world UAV-based systems.
Inspired by the global matching paradigm in GMFlow [8], this paper proposes a novel projection image registration model based on a global matching architecture and constructs a hybrid dataset tailored for UAV-based dynamic large-area projection. By combining saliency guidance with statistical feature modulation, we design a Saliency–Statistics Joint Modulation (SSJM) module [9,10]. The core idea of our method is to reformulate the dynamic geometric mapping between the projected image and the non-planar target surface as a dense optical flow estimation task. By leveraging the powerful global context modeling and feature matching capabilities of Transformer and the proposed SSJM module [11], our model can accurately compute pixel-wise correspondences in real time. This enables precise characterization of the geometric deformation that the projected content should undergo in the current dynamic scene. Based on the estimated dense optical flow field, the system efficiently generates a corresponding pre-warped image. Once this pre-warped image is projected by the UAV system, it automatically compensates for geometric distortions on the dynamically changing non-planar surface, resulting in visually natural and geometrically accurate projection content. To effectively train and evaluate the proposed model under complex and variable UAV projection scenarios, we construct a hybrid dataset that covers a wide range of representative environments and target objects. This dataset simulates real-world challenges in UAV-based dynamic projection applications, including variations in background, lighting conditions, object materials, geometric shapes, and projection content. Such diversity ensures the generalization ability and robustness of the model across different deployment scenarios.
Compared to existing approaches, our method significantly improves the visual quality and geometric fidelity of the projected content in dynamic, non-planar, and challenging environments. This provides a solid technical foundation for the development of practical and high-quality UAV-based large-area dynamic projection systems. To enable accurate image registration during UAV dynamic projection, we introduce three key innovations:
- To address the significant geometric distortions caused by projecting images onto complex, non-planar surfaces during UAV flight, this paper formulates the task as a large-displacement global optical flow estimation problem. We propose an image registration model based on a Transformer architecture, which is capable of establishing high-quality pixel-wise geometric correspondences. These correspondences are then used to generate pre-compensated images, enabling automatic correction of geometric distortions in dynamic scenes. This provides both a theoretical foundation and a practical solution for achieving high-quality dynamic projection.
- A saliency-guided and statistical feature modulation mechanism is introduced through the design of the SSJM module, which enables joint perception of the projection area and background structure. This enhances the model’s ability to adapt to real-world projection disturbances such as complex textures, occlusions, and strong lighting. Ablation studies and visualization results demonstrate that this module plays a crucial role in improving projection compensation, suppressing false motion, and reinforcing structural consistency.
- To comprehensively evaluate the effectiveness and generalization ability of the proposed model, we construct a synthetic dataset that combines natural and generated images, covering various projection targets and transformation disturbances. In addition, we design a real-world projection experiment using a fixed laser projector and a high-resolution camera platform.
The remainder of this paper is organized as follows. Firstly, we introduce the related work of image registration in Section 2. In Section 3, we present the method proposed in this paper in detail, including the introduction of the dataset and network framework. Subsequently, the performance of our method is demonstrated in Section 4 by comparing it with existing methods. The simulation experiment is verified by setting up real scenarios in Section 5. Finally, we discuss and conclude the paper.
2. Related Work
This study is the first to integrate UAVs with projection systems while explicitly addressing the critical step of image registration. Registration refers to the alignment of projected images with captured images, aiming to establish precise geometric correspondences within a unified coordinate system. The primary goal of registration is to ensure that the projected image is accurately aligned with the known projection coordinates in the camera-captured image, thereby maintaining the geometric accuracy of the system. Currently, image-to-image registration methods can be broadly categorized into two approaches: traditional feature-based matching and end-to-end prediction using deep neural networks.
2.1. Traditional Registration Methods
Traditional registration methods mainly rely on projection code–decode matching or local feature matching to establish correspondences between the projected pattern and the captured image. These approaches typically utilize geometric or texture features for matching and can achieve high accuracy in static environments. Projection code–decode matching, also known as structured light encoding [12], is one of the earliest techniques used for projector–camera registration. However, due to the requirement of projecting and decoding multiple frames, these methods suffer from poor real-time performance and involve complex operations, making them unsuitable for high-dynamic projection mapping tasks.
In addition, image registration can be achieved using local feature matching, which is based on detecting and matching keypoints in natural images. The SIFT (Scale-Invariant Feature Transform) algorithm addresses challenges such as rotation [13,14], affine transformation, illumination variation, and viewpoint changes. It uses the DoG to detect extrema in scale space [15], producing candidate keypoints that are robust to scale variations. To enhance reliability, SIFT further applies contrast thresholding and keypoint refinement to eliminate unstable points. Then, the algorithm computes the local image gradient distributions to assign a dominant orientation to each keypoint, ensuring rotation invariance. Finally, local descriptors are constructed based on the magnitude and orientation information around each keypoint, and feature similarity is measured using Euclidean distance to establish correspondences between images [16]. The SURF (Speeded-Up Robust Features) algorithm is an optimized version of SIFT [17,18], employing integral image filters to accelerate computation. During keypoint detection [19], SURF uses the determinant of the Hessian matrix for blob detection [20], and applies Gaussian-weighted Haar wavelet responses to determine the keypoint orientation. For descriptor generation, SURF uses Haar wavelet responses and applies the Laplacian operator to distinguish between bright blobs and dark backgrounds, improving the stability of selected features. In the matching phase, SURF compares only keypoints with the same contrast polarity, which significantly increases matching speed. Due to its high computational efficiency and stable feature performance, SURF is well-suited for real-time applications [21]. The ORB(Oriented FAST and Rotated BRIEF) algorithm combines the strengths of the FAST keypoint detector and the BRIEF descriptor [22,23]. It offers efficient feature extraction and matching, and further improves robustness by incorporating orientation correction into the BRIEF descriptor. This allows ORB to maintain reliable matching performance even under significant rotational changes.
2.2. Deep Learning-Based Registration Methods
Traditional local feature matching methods rely on detecting and matching keypoints in images to compute correspondences between frames. However, their stability often degrades under challenging conditions such as lighting changes, dynamic environments, and non-rigid surfaces. In contrast, deep learning-based methods learn feature representations in an end-to-end manner, enabling better adaptation to complex projection scenarios.
The pioneering deep learning-based method for optical flow estimation, FlowNet [24,25,26], was proposed by Dosovitskiy et al., FlowNet introduced a fully convolutional network (FCN) to directly predict the optical flow between consecutive frames. FlowNet marked a significant advancement in monocular video flow estimation and has become a foundational benchmark in the field. However, due to its relatively simple convolutional structure, it struggles to capture long-range global context. In addition, the model tends to produce inaccurate results in the presence of large displacements, fast motion, or complex scene structures—particularly in dynamic, non-planar environments where geometric distortions may compromise the quality of flow estimation. To address these limitations, RAFT (Recurrent All-Pairs Field Transforms) was proposed by Teed et al. in 2020 as a novel deep learning framework for optical flow estimation [27]. RAFT combines convolutional feature extraction with a recurrent update operator (GRU) to iteratively refine the flow field through residual updates, progressively converging to a globally consistent solution. It constructs a 4D correlation pyramid from multi-scale features, enabling efficient all-pairs matching in a learned feature space, which captures both large and fine-grained displacements. While RAFT achieves state-of-the-art performance across diverse motion regimes, its accuracy can still degrade in occluded regions, textureless areas, or scenes with complex non-rigid motions. CRAFT (Cross-Attentional Flow Transformer), introduced by Sui et al. [28], advances the RAFT framework by addressing large displacements and multi-scale motion through a transformer-based approach. Unlike RAFT’s dot-product correlation, CRAFT leverages cross-frame attention to suppress noisy feature matches and establish more reliable motion correspondences. One limitation of CRAFT is its convolutional feature backbone, which may inadequately capture global context in a single pass, occasionally leading to local drift in repetitive textures or extreme scale variations. However, CRAFT markedly outperforms RAFT in cases of dynamic blur. GMA [29], proposed by Jiang et al., is an improved optical flow estimation algorithm based on RAFT, which addresses the optical flow estimation problem of occluded points through a global aggregation module. It introduces the global motion assumption, allowing the network to perform reasoning at a higher level, thereby improving estimation accuracy. To further enhance long-range correspondence modeling, GMFlowNet introduces a learning-based matching-optimization framework to address large displacements in optical flow estimation [30]. Unlike direct-regression methods, it first performs global matching via argmax on 4D cost volumes and then refines the flows using an optimization module. To improve matching accuracy, the proposed Patch-based Overlapping Attention extracts large-context features by attending to overlapping patches, mitigating ambiguities in textureless regions.
3. Methods
3.1. Dataset
During the process of creating a synthetic dataset, we first considered the diversity of the projected content: half is real natural photos, and the other half is AI-generated animation frames. Specifically, we selected five representative scenes—urban, rural, prairie, forest, and ocean—to ensure the dataset covers a variety of environmental types. The natural images were sourced from multiple open-access image websites, which provide a wide range of scene images that accurately reflect the visual features of different environments. The generated images were produced using the ControlNet model [31], which is guided by textual descriptions of the five aforementioned scenes to generate corresponding images. Ultimately, the synthetic images in the dataset are composed of a 1:1 ratio of natural images to generated images, ensure that the two types of samples are exactly equal in quantity and distribution. This method not only ensures the consistency and realism of the generated images in terms of visual content, but also offers greater flexibility to meet the requirements of diverse scene types. The specific data collection process is shown in Figure 2.
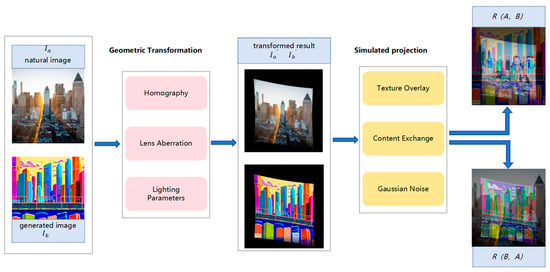
Figure 2.
The synthesis process of the dataset: The dataset generation process incorporates comprehensive image synthesis procedures, employing extensive computer graphics operations to realistically simulate projection effects.
Simulate the real projection through the “bidirectional interchange” strategy: First, map the natural image as the projection content onto the surface of the generated image, and then project the generated image onto the natural scene, allowing the two types of samples to alternate between the foreground and background roles, showcasing the fusion of virtual elements with the real world. Ultimately, we can obtain a pair of projected images and composite images, which represent the projected image and the image captured after being projected onto the object’s surface. This image pairing not only increases the scale of the dataset but also significantly enhances its diversity, allowing it to better represent complex projection scenarios. Moreover, by using natural and generated images as foreground and background, we simulated the relative relationship between the projected content and the target surface in different environments. This setup not only helps simulate projection effects on different surfaces but also effectively models various challenges encountered during real-world projections, such as lighting variations, image distortion, and surface reflections. Through this approach, the dataset more accurately reflects the application of UAV projection systems in dynamic, large-scale, and non-planar scenes, and accounts for the environmental factors that influence real-world projection processes.
During the dataset generation process, we mainly simulated the effects of dynamic UAV projection in two steps. First, geometric transformations were applied to the natural and generated images, including perspective adjustments, lens distortion corrections, and lighting parameter modifications, to simulate changes in projector angle, camera characteristics, and geometric deformations. Then, in the projection simulation stage, techniques such as texture overlay, content swapping, and Gaussian noise were used to simulate noise, distortion, and content changes in the projected images. Through these two steps, the generated image dataset effectively reflects the performance of projectors in complex dynamic environments, providing rich and diverse simulated data for the training of subsequent algorithms.
3.1.1. Geometric Transformation
To simulate the image distortions that may occur during dynamic UAV projection we introduced geometric transformation operations while constructing the synthetic dataset, thereby approximating the deformations experienced by projected imagery. These operations played a crucial role in the generated dataset, as they not only enhanced the diversity of the dataset but also effectively simulated the geometric distortions encountered by projectors when projecting onto dynamic, non-planar surfaces during flight.
Homography Transform is one of the core operations for achieving geometric distortion of projected content. During UAV projection, the projected content undergoes deformation due to changes in the angle between the camera and the target surface. By mapping the four corner points of the source image to four slightly offset positions in the target image, we simulate the slight geometric distortion caused by the relative angle change between the projector and the target surface. The mathematical expression for this operation is:
where represents the coordinates of the four corner points in the source image, represents the transformed corner points in the target image, and is the homography matrix that describes the perspective transformation from the source image to the target image. This operation allows us to simulate the geometric distortion of projected images in the dataset, enhancing the realism of the projection in dynamic environments.
Lens distortion is a common issue during projection, especially in UAV projection systems, where the distortion of the lens itself can affect the quality of the projected image. To simulate this distortion, we introduced slight barrel distortion, quadratic distortion, and other types into the image, which were corrected using the camera’s intrinsic matrix and distortion coefficients. The distortion parameters are described by the following formula:
where represents the pixel coordinates in the source image, represents the distorted pixel coordinates, is the camera’s intrinsic matrix, and represents the distortion coefficients. The introduction of these distortions makes the dataset more representative of real-world projection effects, particularly when the relative position between the lens and the target surface changes, causing more noticeable image distortion. Therefore, this step plays an important role in simulating the lens characteristics of the projector.
In actual projection, projectors typically adjust brightness and contrast according to the needs of the environment to meet projection requirements under different conditions. To simulate this process, we made slight adjustments to the brightness and contrast of the image. The formula for this step is as follows:
where is the contrast coefficient, and is the brightness adjustment value. By reducing the contrast and slightly increasing the brightness, we simulate variation in the projected image under different lighting conditions. The introduction of this step enhances the diversity of the images in terms of brightness and contrast within the dataset, thereby improving the model’s generalization ability.
3.1.2. Simulated Projection
By precisely adjusting the background brightness—dimming to reproduce the low-light projection at night and brightening to simulate the strong daylight environment—we have realistically reproduced the coupling process of “projected light and ambient light” in the real scene, thereby achieving the optimal match between the projected content and the background brightness. Particularly in UAV dynamic projection scenarios, the integration and processing of the projected image with the background directly affect the realism and visual quality of the final projection. By darkening the background, we make the projection image more prominent, ensuring that the projected content is clearly visible against a complex background. Background darkening simulates the process in real-world scenarios, where the projector adjusts brightness to achieve the optimal visual effect between the projected content and the background.
By overlaying the foreground image with the background image, we simulate the blending effect between the projection and the background. In this process, the transparency of the foreground image determines its influence on the final image. The transparent areas of the foreground image transition into the background image, achieving a smooth blending effect. In fact, it simulates the texture superposition of the projected content and the background in a real projection scene. This approach enhances the diversity of the dataset by simulating different levels of transparency and foreground–background interactions, which in turn improves the robustness of the subsequent model.
The introduction of Gaussian noise is intended to simulate noise interference that might occur in the real world. In dynamic projection scenarios, various factors such as ambient lighting, air quality, and limitations of the projector itself often affect the quality of the projected image. By adding slight Gaussian noise, we simulate this interference, making the generated image more complex and improving the adaptability of image processing models in real-world applications.
The final formula for simulated projection is as follows:
where represents the foreground image (i.e., the projected content), and represents the alpha channel of the foreground image, indicating the transparency information of the foreground. is the blending ratio of the foreground image, controlling its influence on the final image. normalizes the alpha channel value to a range of 0 to 1, representing the weight of the transparency’s impact on the foreground. This part calculates the weighted influence of the foreground image in the final image, where pixels in transparent areas are reduced, and fully opaque areas are fully displayed. represents the background image (i.e., the projection scene). is the background darkening coefficient, which controls the brightness of the background image. calculates the weighted coefficient for the background image in the final image, where the background brightness increases in transparent areas and decreases in foreground-covered areas. represents Gaussian noise with mean and variance , simulating common noise in the environment.
This series of operations not only increases the diversity of the data but also provides a realistic simulation of the interaction between projected content and the environment, offering more authentic training samples for subsequent geometric calibration algorithms.
3.2. Image Registration Method
After building the synthetic dataset, we obtained a series of projected images and captured image pairs. Subsequently, we need to know the corresponding relationship between the two to carry out the registration operation. That is, where each pixel in the projected image is located in the captured image. Traditional methods, such as feature point matching approaches, rely on the quality of feature points for registration accuracy. These methods perform poorly when features are not prominent or when there is significant noise. Convolutional Neural Networks can automatically learn powerful feature representations from data, making them suitable for complex image transformations, such as occlusion and illumination changes. However, they depend on relatively simple convolutional structures and struggle to capture long-range global context. Transformer, on the other hand, can handle long-range dependencies, allowing them to capture relationships between distant pixels, which is beneficial for processing large-scale image transformations.
3.2.1. Network Structure
Inspired by the concept of global matching optical flow in GMFlow, this paper proposes an innovative projection image registration model based on a global matching architecture. The network structure is shown in Figure 3. By employing self-attention mechanisms and modeling global context, this approach can capture large-scale motion and global transformations. For projection registration tasks, especially those involving large perspective changes and global deformations of objects, GMFlow can capture displacement information across the entire image, rather than being limited to local feature points.
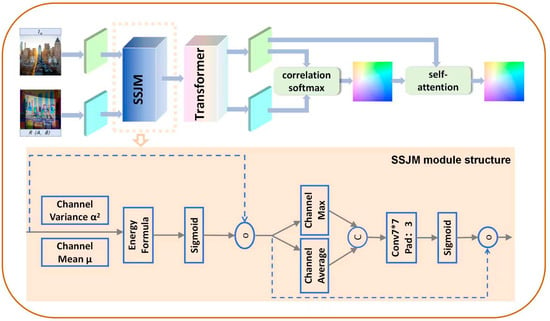
Figure 3.
The registration network structure based on global matching and the SSJM module structure. The complete data processing pipeline has been meticulously presented, illustrating the transformation from input composite images to output optical streams. Within this framework, the SSJM module emerges as the cornerstone component of our neural network architecture, demonstrating critical functionality in the geometric correction process.
In UAV dynamic projection tasks, ensuring the geometric accuracy of the projected image on complex, non-planar surfaces is a core challenge. Since the projected image encounters unstructured, dynamically changing surfaces, the feature maps often exhibit significant unevenness in terms of lighting and texture distribution, which complicates subsequent optical flow computation and global matching. To address these issues, we propose a Saliency and Statistical Spatial Joint Modulation (SSJM) module, aimed at enhancing the contrast and stability of the feature maps. This improves the quality of the input features for the subsequent optical flow estimation.
3.2.2. Saliency–Statistics Joint Modulation
Saliency Energy Branch: During the feature extraction process of the projection effect image captured by the camera, geometric edges and texture details often exhibit strong variations, while background areas may lack prominent features. In such cases, traditional feature extraction methods are often prone to interference from noise and redundant information, leading to inaccurate optical flow estimation. To address this issue, we introduce an energy branch. This module measures the “energy” of each pixel by calculating its difference from the global mean, and generates a saliency mask based on this energy distribution. The mask enhances important features in the image and suppresses background and low-contrast regions. In this way, pixels in edge and texture areas are assigned higher weights, while background and low-contrast areas are suppressed, ensuring that important features are prioritized in the subsequent processing steps.
Statistical Spatial Attention Branch: For surfaces with low texture or relatively flat regions, traditional local feature extraction methods often fail. Therefore, we introduce a statistical spatial attention mechanism. This mechanism extracts feature information at different spatial scales using two operations: max pooling and average pooling. Max pooling helps capture geometric edge information in the image, while average pooling is used to capture the statistical characteristics of global brightness or flatter areas. After these two pooling operations, we fuse the information through a convolutional operation and apply a Sigmoid function to obtain the final spatial gating mask. This mechanism allows us to adaptively adjust spatial weights across feature maps, ensuring that sufficient information is retained in low-texture regions while suppressing irrelevant background noise.
The SSJM structure is shown in Figure 3. By applying these two modules to projection image registration, the subsequent global matching based on Transformer can more accurately estimate the optical flow field. The saliency branch enhances the geometric edges and texture information in the image, ensuring that key features are preserved even under strong perspective distortions. The statistical spatial attention branch effectively handles the feature information of low-texture or flatter regions, ensuring balanced attention to features from different areas during the global matching process. Finally, the dense optical flow field obtained through computation is used to pre-correct the projection image, ensuring its geometric accuracy on dynamic, non-planar surfaces. The introduction of this module significantly enhances the stability of the projection image, especially in complex dynamic environments, providing a notable improvement in projection correction for non-planar surfaces.
Simulation The SSJM mechanism is formulated as follows:
where is the input feature map, and denote channel-wise mean and variance, respectively. The is a small constant for numerical stability, and represent channel-wise max and average pooling outputs. denotes channel-wise concatenation. is a convolutional layer with a 7 × 7 kernel and padding 3.
4. Simulation
4.1. Simulation Setup
In the experiments, we used the hybrid dataset constructed in Section 3, which covers various representative projection environments and target objects. Generated images and natural images were paired as image pairs, alternately serving as foreground and background to simulate realistic projection content and background interference under complex conditions. To better replicate a dynamic projection process, each image pair was subjected to 160 transformations selected from the Geometric Transformation and Simulated Projection sets. These transformations simulate the conditions of multi-directional and large-area projection by applying 160 different parameter configurations during synthesis. The projection image registration network was trained on our custom dataset with a learning rate of 0.0004. Based on empirical evidence from multiple experiments, we set a convergence criterion of 15,000 iterations, at which point the model was consistently observed to have reached sufficient convergence. Since this iteration count corresponds to approximately 230 training epochs under our experimental setup, the training process was terminated upon completion of the 230th epoch. The experimental settings are detailed in Table 1. Hardware models and software versions used in the experiment.

Table 1.
Hardware models and software versions used in the experiment.
4.2. Simulation Results
4.2.1. Comparison Experiment
We conducted a comprehensive comparison between our method and state-of-the-art optical flow prediction models, including GMFlow and the GMA series. The evaluation metrics include the average EPE (end-point error) and the error distribution across three deformation intervals (,, ).
Table 2 Measurement results of errors in simulation experiments of different models reports four types of error results for three groups of test image pairs. Each image pair consists of two synthetic projection image sets: , where the natural image serves as the projection subject and the generated image as background interference; and , where the roles are reversed. Each synthetic set includes 160 simulated projection variations, and each result in the table represents the average prediction error across all 160 transformations for one projection subject configuration. Based on the results shown in the table, the following conclusions can be drawn:
Table 2.
Measurement results of errors in simulation experiments of different models.
- (1)
- On the constructed high-complexity dynamic projection dataset, our method achieves outstanding overall registration accuracy, with the average endpoint error (EPE) significantly lower than all baseline methods. Across the six test sets—including three image pairs and their foreground–background reversed versions—our method consistently obtains the lowest average EPE, with a maximum of only 6.091, while other methods such as GMFlow and the GMA series typically exceed 20. These results demonstrate the strong generalization capability of our optical flow estimation framework and its robustness in handling geometric registration tasks under complex projection disturbances.
- (2)
- The method demonstrates stable performance across different levels of deformation and is well-suited for large-scale projection distortions. By analyzing the optical flow magnitude between projection image pairs, we categorize the error into three deformation levels: mild (), moderate (), and severe (). Experimental results show that our method achieves the lowest average error in all three intervals, regardless of whether the deformation is minor or highly severe. Notably, in the interval—which corresponds to large-scale non-planar distortions—our method attains an average error of only 6.436, significantly lower than that of other models under similar high-deformation conditions. This strongly confirms the stability of our approach when dealing with complex and dynamic projection distortions.
- (3)
- The method exhibits consistent adaptability under foreground–background structure reversal with the same projection configuration. By analyzing the results of each image pair with swapped foreground and background, we observe that the prediction error remains highly stable between the original synthetic image set and the reversed set . This indicates that the model can effectively extract the geometric structure of the projection subject while suppressing the influence of background interference on registration accuracy. Such insensitivity to foreground–background structure further supports the practicality and reliability of the proposed method in real UAV-based projection scenarios.
4.2.2. Ablation Experiment
In addition, to investigate the specific role of the SSJM module in projection prediction, we conducted ablation studies using the test datasets from the simulation experiments described above. As shown in Table 3. Comparative experimental results of baseline and SSJM addition, the inclusion of the SSJM module leads to a reduction of approximately 90% in the average error across all deformation intervals, indicating that SSJM significantly improves the overall accuracy of optical flow prediction under varying levels of distortion.
Table 3.
Comparative experimental results of baseline and SSJM addition.
When considering the type of projection subject in the image pairs, Figure 4 shows that the improvement brought by SSJM is consistent for both generated and natural images. This further confirms the stability and general effectiveness of SSJM in such tasks. We conclude that SSJM enhances global correspondence learning in projection deformation regions by introducing scene-aware information and joint modeling of foreground and background. As a result, the optical flow estimation becomes less dependent on local texture matching and gains the ability to perform geometric alignment across regions and structures.
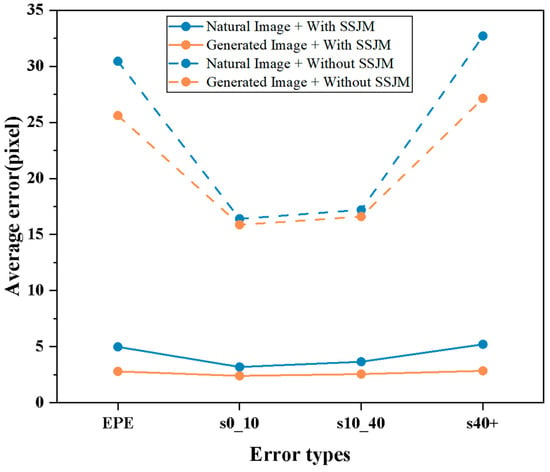
Figure 4.
Stability verification results for the SSJM module under two experimental conditions: (1) variations in projected primary image type, and (2) SSJM module activation state (enabled/disabled).
4.3. Visualization
The visualization results in Figure 5 show that our method produces optical flow outputs that closely match the ground truth (GT) in terms of color continuity and structural completeness when handling complex synthetic image pairs. The predicted flow accurately captures the pixel-level geometric transformations caused by projection distortions. In contrast, baseline methods such as GMA and GMFlow often suffer from issues like blurred edges, structural discontinuities, or false motion, especially in regions with large-scale projection deformation. These methods struggle to distinguish between foreground projection content and background interference under such conditions. These findings indicate that our method exhibits superior spatial structure understanding and non-rigid deformation modeling capabilities, enabling more accurate image registration in complex dynamic projection scenarios.

Figure 5.
Visualization Results of the Prediction of Projection Deformation Relationships by Each Model. Controlled variable comparisons of visualized optical flow results provide clear insights into the impact of subject image types, the effect of the SSJM module, and the advantages over other models.
Compared to the version without the SSJM module, the complete model demonstrates higher consistency in optical flow prediction. The results from the “Without SSJM” version often exhibit issues such as color jitter, boundary discontinuities, and structural mismatches. These problems become more pronounced when there are significant differences in material or texture between the foreground and background, indicating a lack of effective joint modeling capability. In contrast, with the SSJM module integrated, the model can better leverage alignment information from the synthetic structures and the characteristics of the projection scenario, leading to more stable and continuous optical flow estimation. The visualization results further confirm the important role of SSJM in enhancing foreground–background joint matching, suppressing noise, and reducing mismatches.
5. Experiments
Based on the results of the simulation experiments, we further conducted real-world experiments to validate the effectiveness of the proposed model. These experiments aim to evaluate the model’s performance in practical projection environments and to establish a reliable image registration foundation for UAV-based projection applications.
5.1. Experimental Setup
Conducting experiments with UAV-mounted projectors involves considerable costs related to payload capacity, flight endurance, stability, and safety. In this study, we fixed a laser projector in the air and projected images onto non-planar surfaces in multiple directions. A high-resolution camera was used to capture the projected images, aiming to verify the applicability of our method for projection prediction on non-planar structures. To ensure a constant relative position between the camera and the projector, both devices were rigidly mounted and remained unadjusted throughout the experiment. This setup provided a highly stable environment for image acquisition.
5.2. Ground Truth Calculation
To ensure the completeness and rigor of the experiment, our procedure consists of three stages, as illustrated in Figure 6. The first stage involves the computation of ground truth. Since it is challenging to obtain accurate pixel-wise correspondences across the entire image, we manually collected ground-truth correspondences for 400 selected pixels. Before conducting the real projection experiments, we first projected 11 encoded binary dot-pattern images, each containing a 20 × 20 grid, onto the object surface. These patterns were captured by the camera, and after decoding, we obtained pixel-level correspondences between the projector and camera views for the 20 × 20 grid points. This correspondence data serves as the ground-truth reference for subsequent experiments.
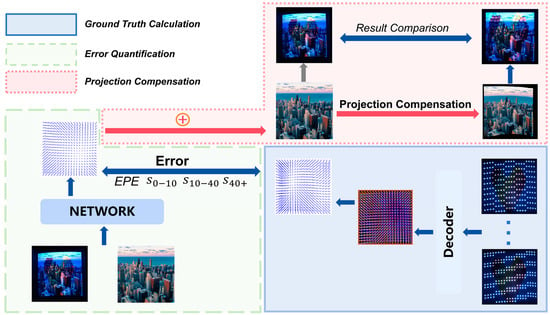
Figure 6.
The three specific steps of the experiments are as follows: GT Calculation, Error Quantification, Projection Compensation. The GT for the current scene is computed via binary encoding and decoding, and combined with the model output to quantify errors. The model output is then inversely computed to compensate for the projected image.
5.3. Error Quantification
After obtaining the ground-truth reference, we conducted real-world experiments under two distinct scenarios. In Scenario 1, the projection image was cast onto a concave object surface, with a color heart-shaped texture containing complex patterns added at the center as a source of visual interference. In Scenario 2, the image was projected onto a convex object surface, and the brightness of the central region was significantly increased to introduce contrast-related disturbance. We then applied the proposed registration model to predict the correspondence between the projector and camera views, and computed the errors by comparing the predicted results with the ground-truth data. As shown in Table 4. Error measurement results of different models in two real-world scenarios, our registration model achieved the best performance in both scenarios, validating the effectiveness of the simulation experiments.
Table 4.
Error measurement results of different models in two real-world scenarios.
In two representative real-world non-planar projection scenarios, our method consistently demonstrated high registration accuracy on the captured images. Compared to mainstream optical flow models such as GMFlow and the GMA series, our approach achieved the best results in terms of average EPE and across different levels of projection deformation regions (, , ). Even under challenging conditions involving complex texture interference and significant brightness variations, our method reliably preserved the geometric relationships of the projected content. The average EPE was significantly lower than that of other methods, indicating strong practical applicability and robustness to real-world disturbances. These findings are consistent with the conclusions drawn from our simulation experiments.
The importance of the SSJM module was further validated through real-world experiments. In both the concave surface with texture interference and the convex surface with brightness disturbance scenarios, removing the SSJM module led to a significant increase in prediction error, particularly in regions with severe geometric deformation. This was accompanied by a noticeable rise in structural mismatches. With the SSJM module included, the predicted correspondence aligned more closely with the ground-truth data collected during the experiments, demonstrating its effectiveness in enhancing joint modeling of foreground and background structures as well as maintaining global structural consistency. These results confirm that the improvements observed in simulation experiments also hold in real-world settings, further supporting the stability and reliability of the proposed method.
5.4. Projection Compensation
To further verify the accuracy of the correspondences predicted by our registration model, we applied the estimated correspondences back to the projection images to perform geometric compensation.
Figure 7 and Figure 8 presents a comparison of compensation results between our method and mainstream optical flow models such as GMFlow and GMA in real-world projection environments. It is clearly observed that our method consistently achieves higher-fidelity image restoration across all test cases. Whether using natural or generated images, the compensated results exhibit sharp structural boundaries, uniform color distributions, significantly reduced geometric distortion, and accurately reconstructed spatial relationships. In contrast, GMFlow and GMA models often suffer from noticeable geometric warping, edge misalignment, pattern discontinuities, or background drift, particularly in regions with severe deformation (e.g., Natural Image 2 in Figure 7 and Generated Image 2 in Figure 8). These findings indicate that our method not only enables precise geometric compensation on non-planar surfaces but also maintains strong image consistency and visual quality under complex and diverse projection content. This validates the strong generalization ability and practical value of the proposed approach.
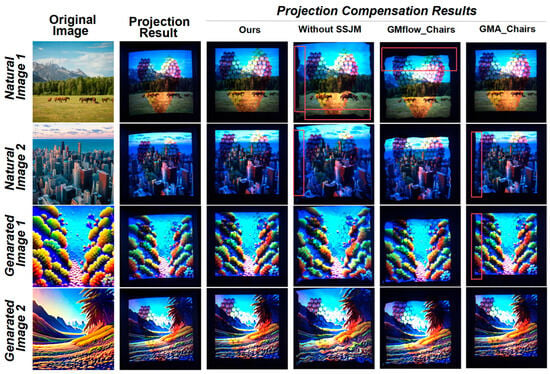
Figure 7.
Visualization of projection compensation results for each model in scene 1. The use of controlled variables can provide intuitive insights into the impact of the type of projection subject image, the effect of the SSJM module, and the advantages over other models.
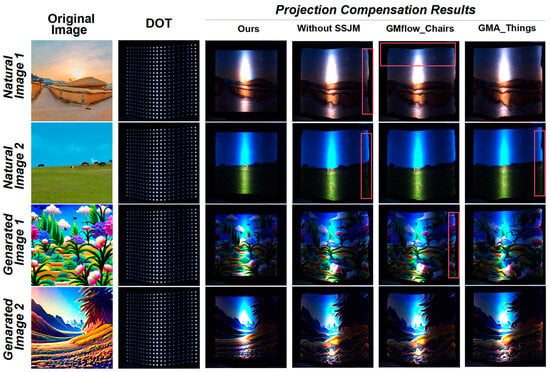
Figure 8.
Visualization of projection compensation results for each model in scene2. The use of controlled variables can provide intuitive insights into the impact of the type of projection subject image, the effect of the SSJM module, and the advantages over other models.
As shown in Figure 7 and Figure 8, removing the Saliency–Statistics Joint Modulation (SSJM) module leads to a noticeable decline in compensation quality across multiple aspects: geometric contours become blurred, content distortion intensifies, and uneven stretching appears in various regions (e.g., Natural Image 2 in Figure 7 and Natural Image 1 in Figure 8). In some cases, clear misalignment or missing information is observed. In contrast, when the SSJM module is included, our method accurately preserves content details at corresponding locations, maintains boundary alignment, and significantly alleviates distortion.
These results further demonstrate the critical role of the SSJM module in modeling complex structures and predicting joint foreground–background relationships. By incorporating both saliency cues and statistical modulation, the model becomes capable of capturing not only texture correspondences but also structural alignment, thereby enabling higher-quality projection compensation.
6. Discussion
We demonstrate that the proposed method significantly outperforms existing mainstream optical flow approaches across various representative projection environments. Real-world experiments further confirm the practical applicability of the method.
In our experiments, we identified an important influencing factor: when the synthesized projection images use generated images as the projection content and natural images as the background, the model not only achieves superior overall registration accuracy (EPE), but also performs better across all three levels of projection deformation, particularly in regions with severe distortion. Future work may further explore how the content and construction methods of synthetic datasets affect the model’s ability to predict projection-related geometric deformations, with potential extensions to the broader field of optical flow estimation.
Although the proposed method demonstrates excellent performance across multiple scenarios, the current experiments are primarily based on a fixed camera–projector setup and do not fully address the stability challenges under high-dynamic UAV flight conditions. Future work will incorporate motion compensation mechanisms to further evaluate the method’s performance in non-static flight environments, and explore integrated optimization strategies with tasks such as content-aware projection and target-guided projection.
While the proposed method demonstrates robust performance across diverse projection environments, several limitations remain. First, the approach is susceptible to highly reflective surfaces and strong occlusions, which may degrade optical flow estimation accuracy. Second, the current experiments assume a fixed camera–projector configuration and do not fully account for real-world UAV dynamics, such as rapid motion or vibration-induced instability. These factors could impact registration stability in highly dynamic airborne scenarios.
Future work will focus on improving resilience to complex environmental conditions, including the development of reflection-aware processing modules and occlusion-resistant alignment strategies. We also plan to integrate motion compensation mechanisms to enhance performance under UAV instability and explore task-aware optimization in applications such as content-adaptive projection.
7. Conclusions
This paper presents a global matching-based image registration method for correcting geometric distortions in UAV-based dynamic projection. A Saliency–Statistics Joint Modulation module is designed to enhance the modeling capability for projection deformation on non-planar surfaces. In addition, a hybrid dataset is constructed, covering diverse projection content and complex background disturbances. The proposed method is systematically evaluated in both simulated and real-world environments.
Through systematic simulation experiments, we demonstrate that the proposed method significantly outperforms existing mainstream optical flow approaches across various representative projection scenarios. It not only achieves superior overall registration accuracy (EPE), but also maintains stable performance across regions with mild, moderate, and severe projection deformations, showing strong robustness. Moreover, foreground–background reversal experiments indicate that our method is insensitive to the specific projection structure and can effectively extract the underlying geometric relationships from image pairs, reflecting strong generalization capability.
Real-world experiments further validate the practical effectiveness of the proposed method. When projection images are applied to concave and convex non-planar targets, under challenging conditions such as texture interference and brightness variation, our model still achieves high-precision geometric compensation and projection correction. Both visual results and quantitative error metrics confirm that, compared to traditional optical flow methods—which often suffer from structural mismatches, blurred contours, and residual deformations—our approach demonstrates clear advantages in preserving image structure and controlling projection distortions. Notably, ablation studies show that the SSJM module consistently improves prediction accuracy and consistency across various types of images, indicating its generality and stability. This provides a critical technical foundation for enabling large-scale, dynamic projection with UAVs.
Author Contributions
Conceptualization, H.Y.; methodology, H.Y.; software, H.Y.; validation, H.Y.; formal analysis, H.Y.; investigation, S.L.; resources, S.L.; data curation, F.Y.; writing—original draft preparation, H.Y.; writing—review and editing, S.L. and F.Y.; visualization, F.Y.; supervision, X.C. and M.X.; project administration, H.Y.; funding acquisition, X.C. and M.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Ningbo Science and Technology Innovation Yongjiang Key R&D Plan (Grant No. E52122DT) and the Top Talent Technology Project in Ningbo City (Grant No. E20939DL06).
Data Availability Statement
The experimental data have been presented within this paper. For any additional information or data inquiries, please reach out to the first author or the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zheng, Y.; Zheng, C.; Zhang, X.; Chen, F.; Chen, Z.; Zhao, S. Detection, localization, and tracking of multiple MAVs with panoramic stereo camera networks. IEEE Trans. Autom. Sci. Eng. 2022, 20, 1226–1243. [Google Scholar] [CrossRef]
- Chu, M.; Zheng, Z.; Ji, W.; Wang, T.; Chua, T.-S. Towards natural language-guided drones: GeoText-1652 benchmark with spatial relation matching. In Proceedings of the European Conference on Computer Vision, Milano, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 213–231. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, X.; Yang, X.; Liu, M.; Zeng, D.; Ye, H.; Li, S. Learning Occlusion-Robust Vision Transformers for Real-Time UAV Tracking. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 17103–17113. [Google Scholar] [CrossRef]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal contexts for aerial tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14798–14808. [Google Scholar] [CrossRef]
- Tang, J.; Gao, Y.; Yang, D.; Yan, L.; Yue, Y.; Yang, Y. Dronesplat: 3D gaussian splatting for robust 3D reconstruction from in-the-wild drone imagery. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 833–843. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, L.; Hu, Y.; Xie, K.; Fu, C.-W.; Zhang, H.; Huang, H. Learning reconstructability for drone aerial path planning. ACM Trans. Graph. (TOG) 2022, 41, 197. [Google Scholar] [CrossRef]
- Lee, J.; Jeon, B.; Song, S.H.; Choi, H.R. Stabilization of floor projection image with soft unmanned aerial vehicle projector. In Proceedings of the 2021 15th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 4–6 January 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Tao, D. GMFlow: Learning optical flow via global matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8121–8130. [Google Scholar]
- Hadizadeh, H. A saliency-modulated just-noticeable-distortion model with non-linear saliency modulation functions. Pattern Recognit. Lett. 2016, 84, 49–55. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, L.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2048–2057. Available online: https://dl.acm.org/doi/10.5555/3045118.3045336 (accessed on 25 June 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhinl, I. Attention is all you need. Advances in Neural Information Processing Systems 30. 2017. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 25 June 2025).
- Baptista, T.; Marques, M.; Raposo, C.; Ribeiro, L.; Antunes, M.; Barreto, J.P. Structured light for touchless 3D registration in video-based surgical navigation. Int. J. Comput. Assist. Radiol. Surg. 2024, 19, 1429–1437. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Cui, Z.; Sheng, V.S.; Zhao, P.; Su, D.; Gong, S. A Comparative Study of SIFT and its Variants. Meas. Sci. Rev. 2013, 13, 122–131. [Google Scholar] [CrossRef]
- Bellavia, F. SIFT matching by context exposed. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2445–2457. [Google Scholar] [CrossRef] [PubMed]
- Lv, Y.; Jiang, G.; Yu, M.; Xu, H.; Shao, F.; Liu, S. Difference of Gaussian statistical features based blind image quality assessment: A deep learning approach. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec City, QC, Canada, 27–30 September 2015; IEEE: New York, NY, USA, 2015; pp. 2344–2348. [Google Scholar]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Hussein, M.; Porikli, F.; Davis, L. Kernel integral images: A framework for fast non-uniform filtering. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: New York, NY, USA, 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Thacker, W.C. The role of the Hessian matrix in fitting models to measurements. J. Geophys. Res. Oceans 1989, 94, 6177–6196. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; IEEE: New York, NY, USA, 2004; Volume 2, pp. 506–513. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary robust independent elementary features. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar] [CrossRef]
- Han, J.; Tao, J.; Wang, C. FlowNet: A deep learning framework for clustering and selection of streamlines and stream surfaces. IEEE Trans. Vis. Comput. Graph. 2018, 26, 1732–1744. [Google Scholar] [CrossRef] [PubMed]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 402–419. [Google Scholar] [CrossRef]
- Sui, X.; Li, S.; Geng, X.; Wu, Y.; Xu, X.; Liu, Y.; Goh, R.; Zhu, H. Craft: Cross-attentional flow transformer for robust optical flow. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17602–17611. [Google Scholar] [CrossRef]
- Jiang, S.; Campbell, D.; Lu, Y.; Li, H.; Hartley, R. Learning to estimate hidden motions with global motion aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9772–9781. [Google Scholar]
- Zhao, S.; Zhao, L.; Zhang, Z.; Zhou, E.; Metaxas, D. Global matching with overlapping attention for optical flow estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17592–17601. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).