
DBO-CNN-BiLSTM: Dung Beetle Optimization Algorithm-Based Thrust Estimation for Micro-Aero Engine

Abstract
1. Introduction
- (1)
- For thrust prediction of the engine, DBO is combined with CNN-BiLSTM to construct a predictive model for the thrust of a micro-turbojet engine;
- (2)
- Based on the dung beetle optimization algorithm, the hyperparameters of CNN-BiLSTM are adjusted utilizing the optimization capability of DBO;
- (3)
- DBO-CNN-BiLSTM is validated for thrust prediction of a micro-turbojet engine, and its performance is compared with that of other models.
2. Methodology
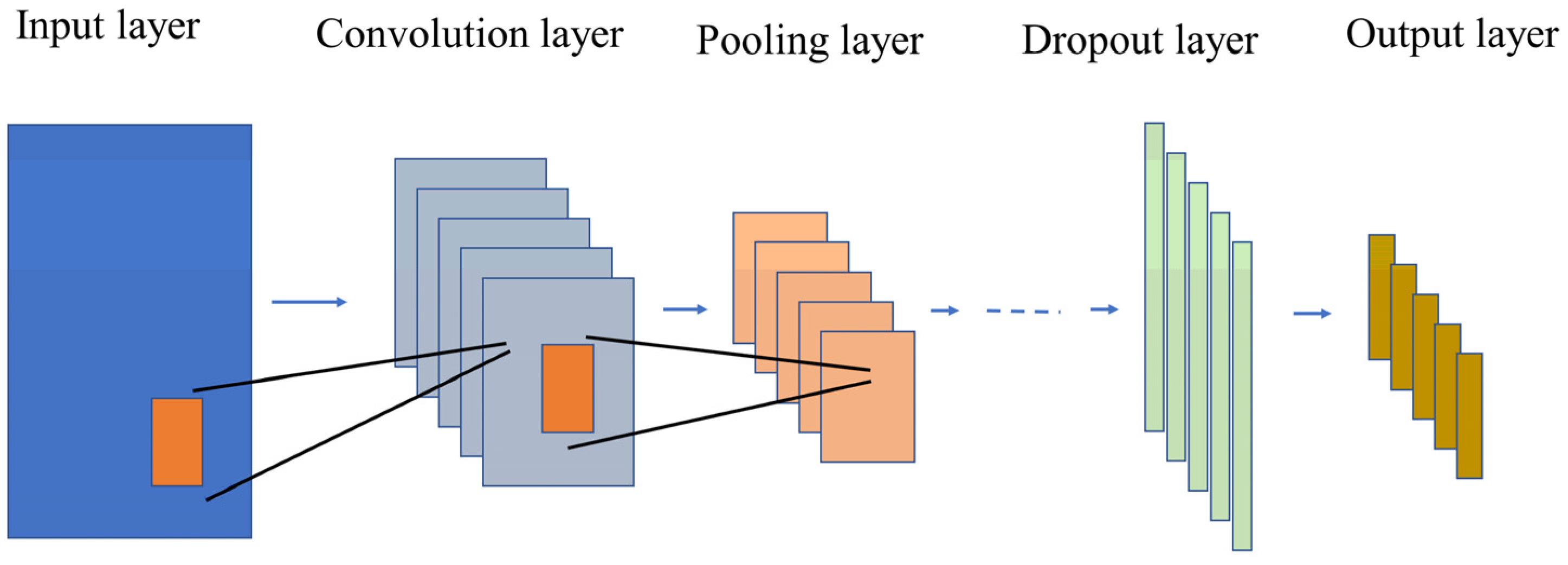
2.1. Convolutional Neural Network (CNN)
2.2. Bi-Directional Long Short-Term Memory Network (BiLSTM)
2.3. Dung Beetle Optimizer (DBO)
2.3.1. Rolling Behavior
2.3.2. Reproductive Behavior
2.3.3. Foraging Behavior
2.3.4. Stealing Behavior
3. Model and Data Processing
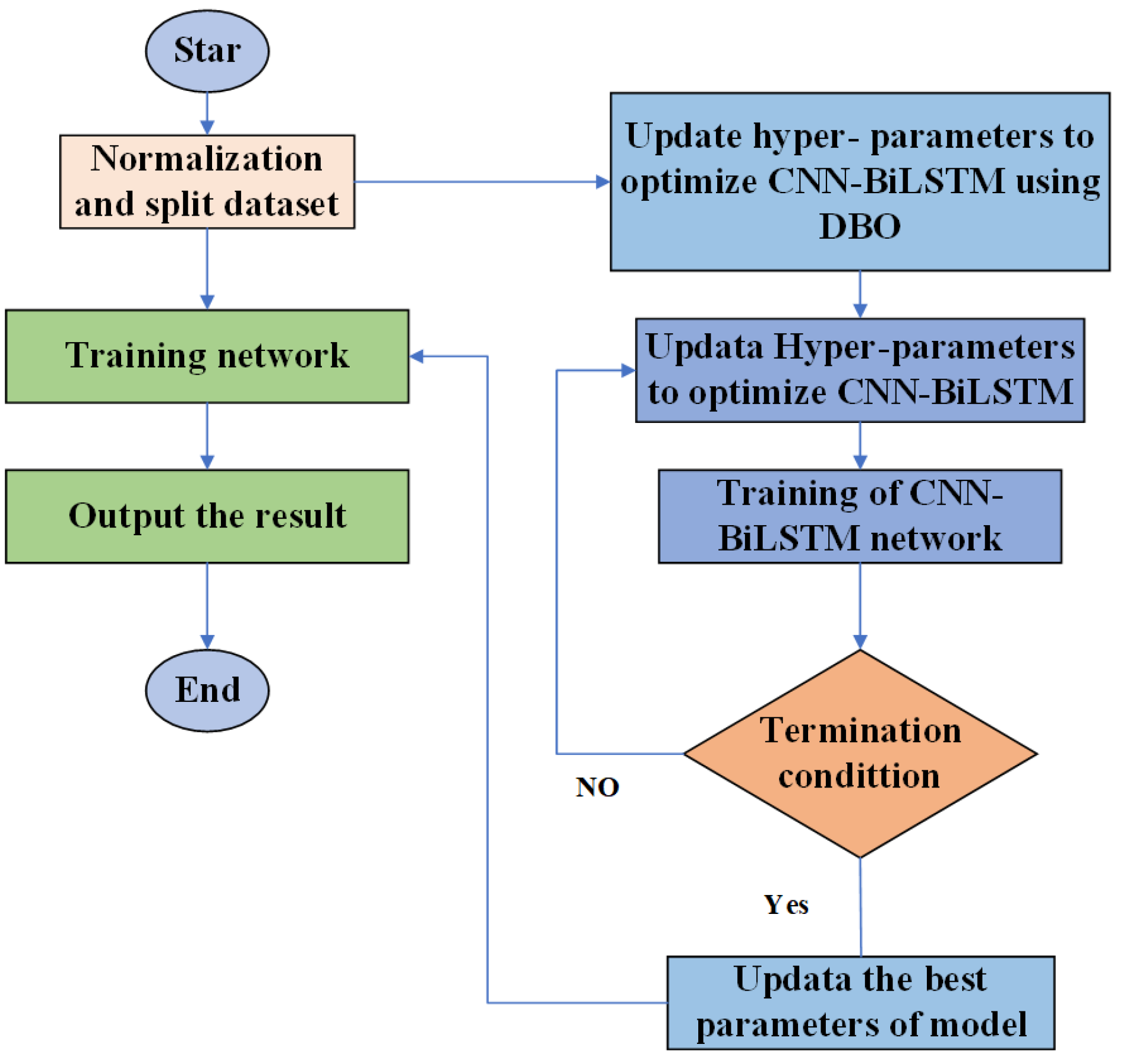
3.1. DBO-CNN-BiLSTM Prediction Model
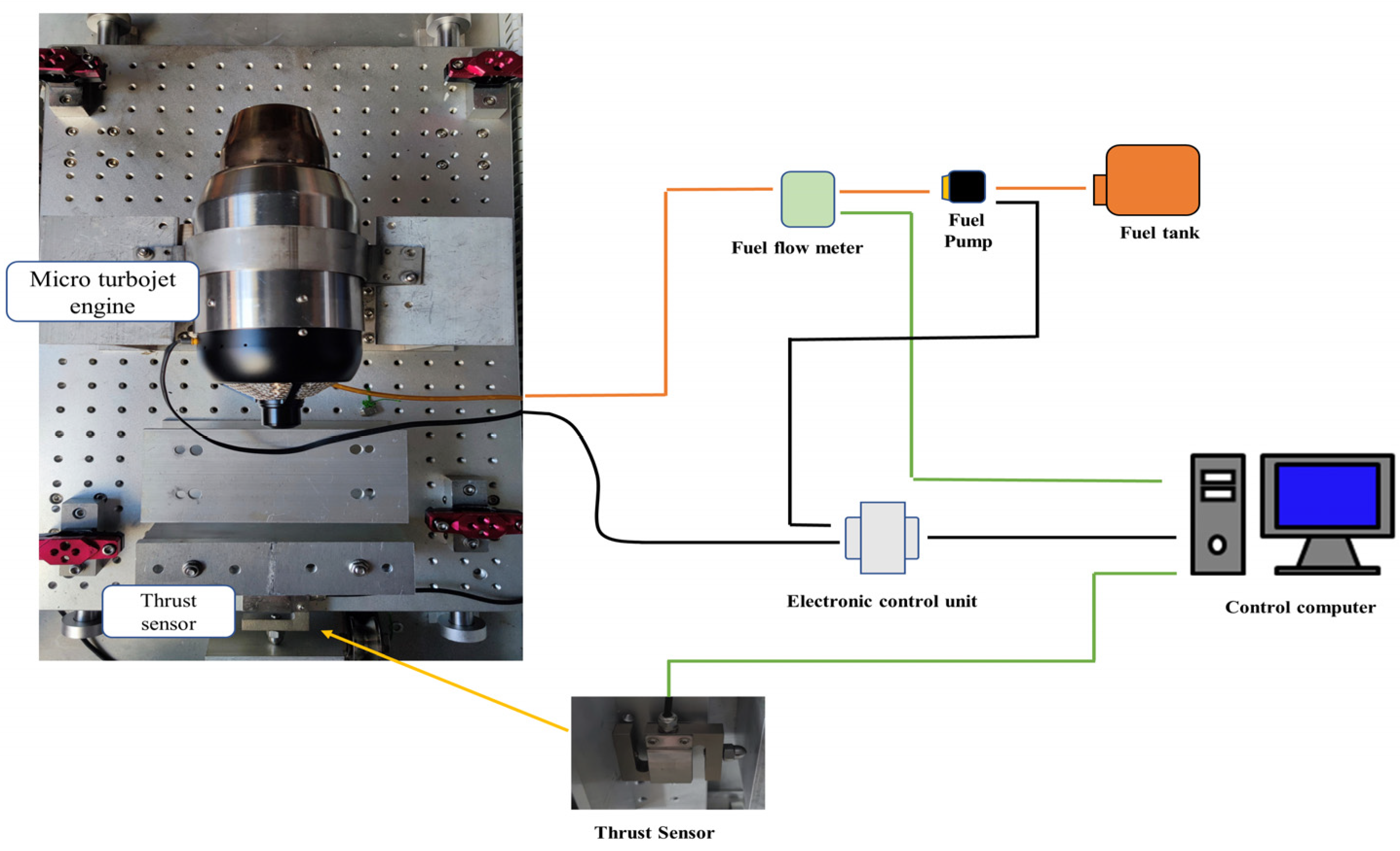
3.2. Experimental Setup
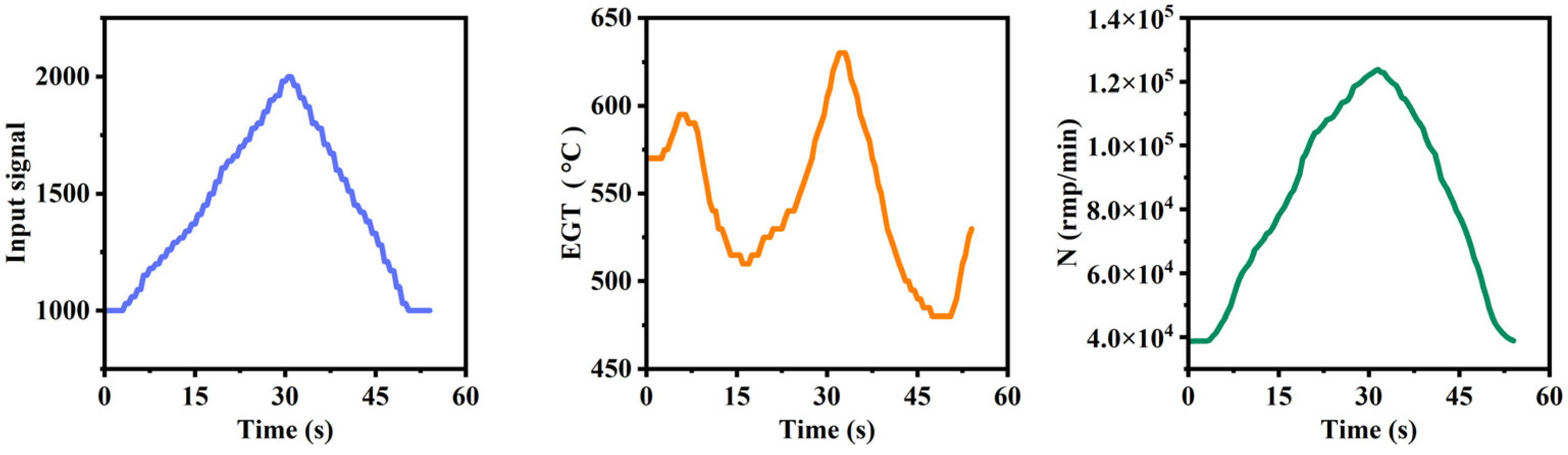
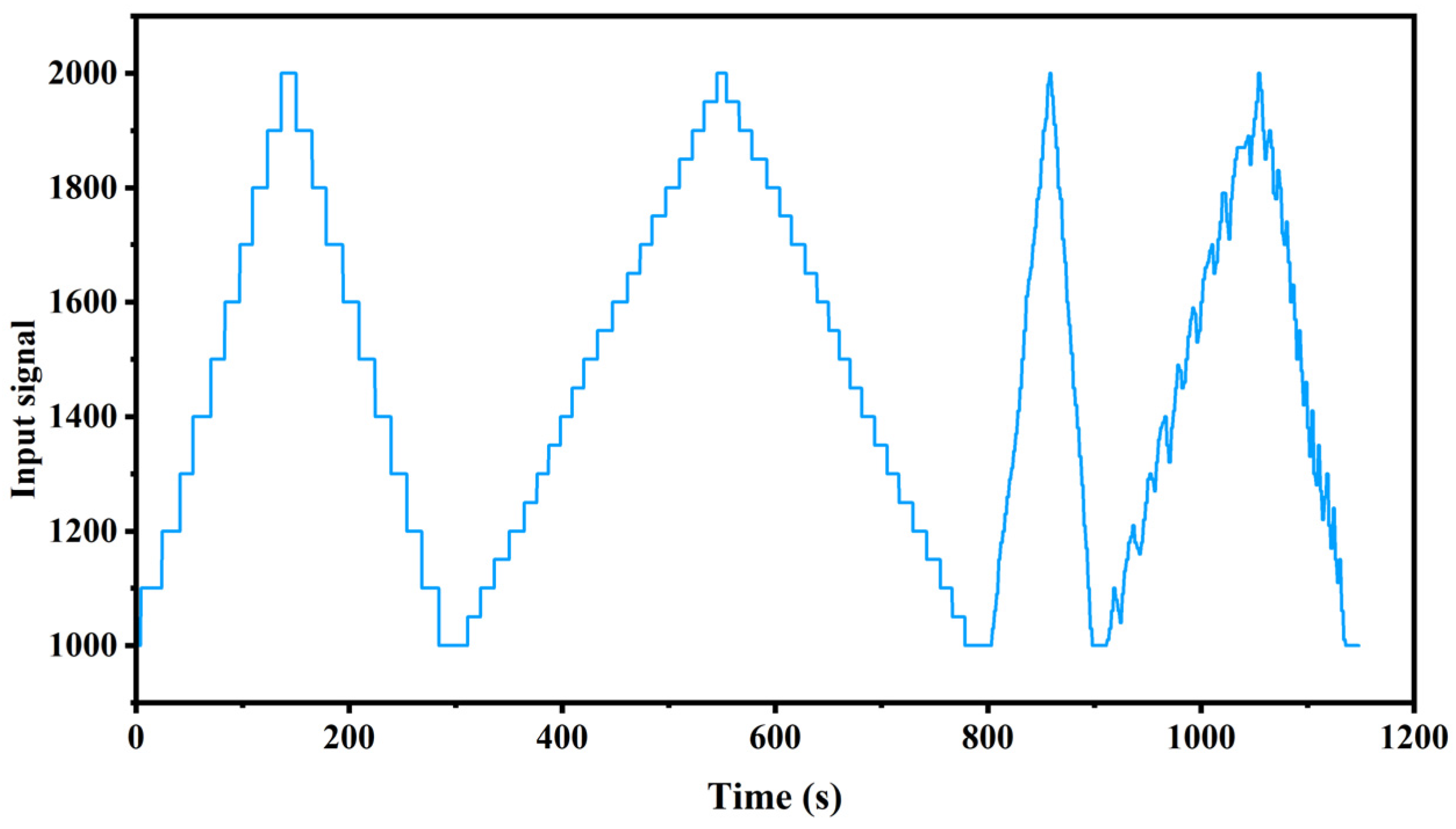
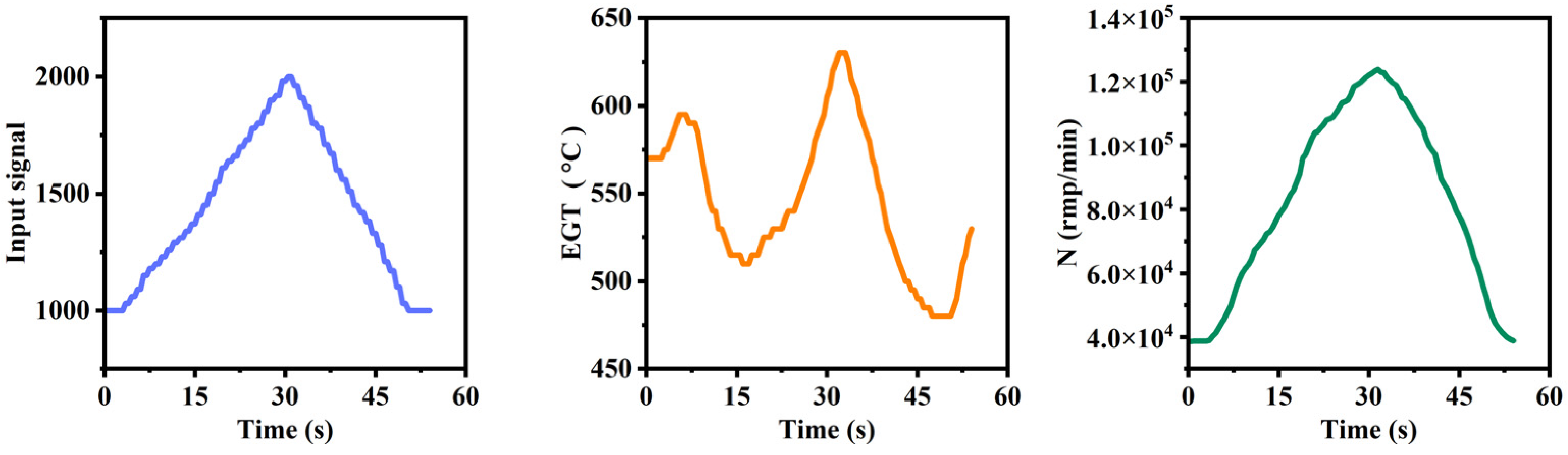
3.3. Data Collection and Processing
4. Experimental Results and Discussion
4.1. Experimental Environment Introduction
4.2. Performance Indicators
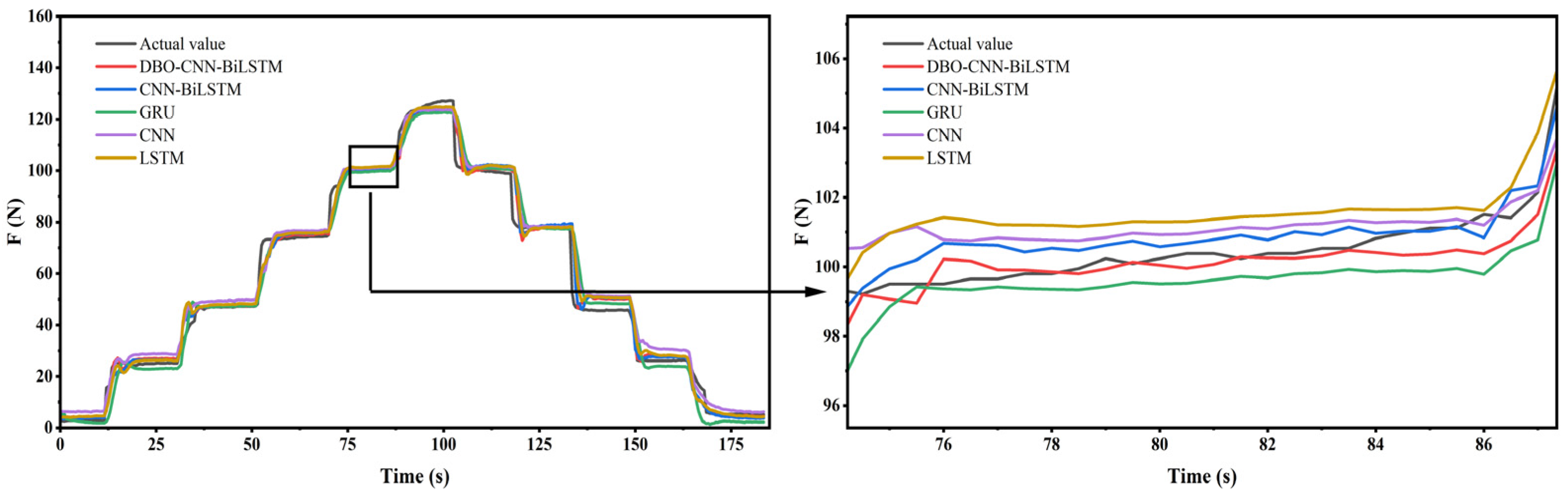
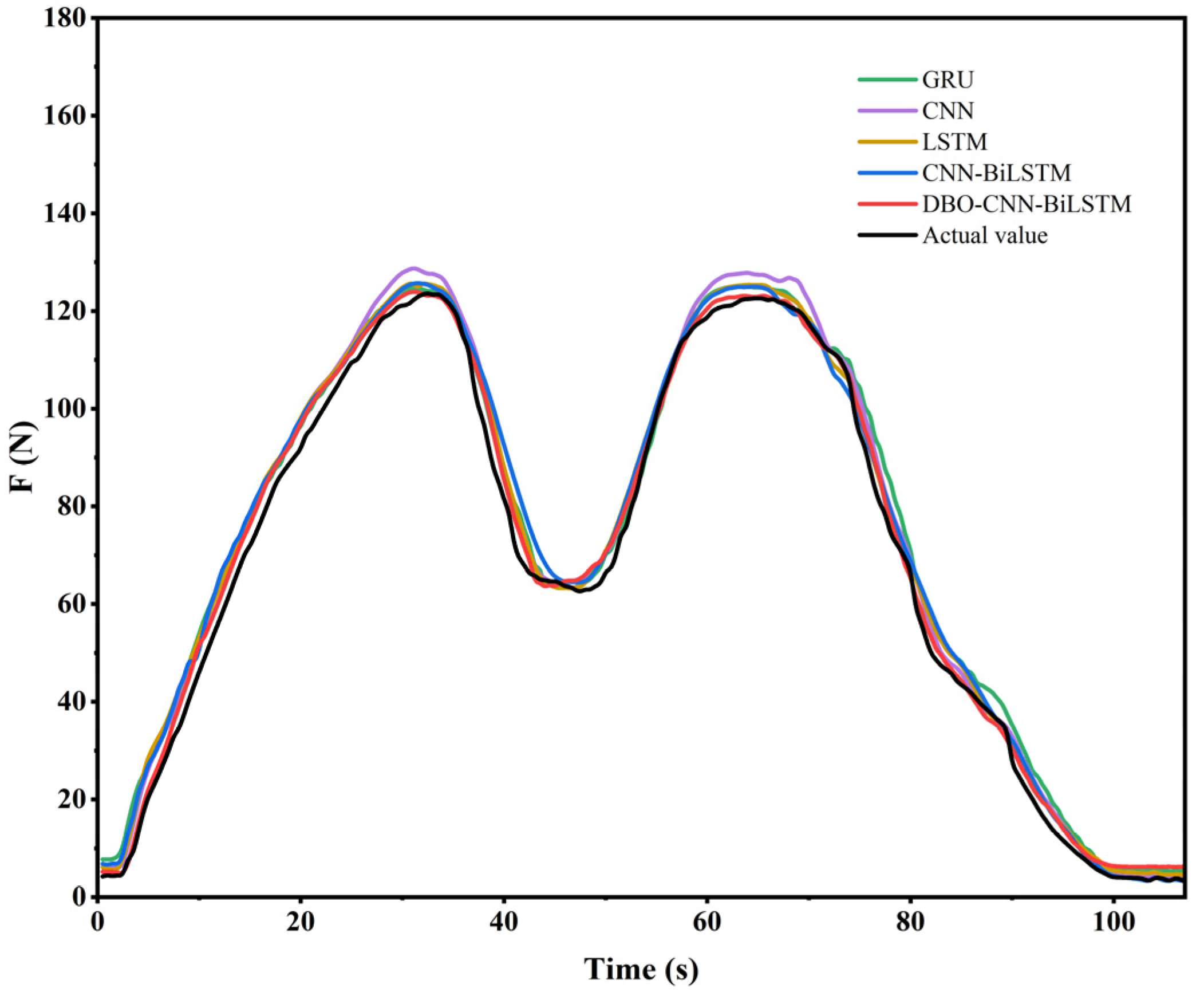
4.3. Forecast Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the Unmanned Aerial Vehicles (UAVs): A Comprehensive Review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Kikutis, R.; Stankūnas, J.; Rudinskas, D. Evaluation of UAV autonomous flight accuracy when classical navigation algorithm is used. Transport 2018, 33, 589–597. [Google Scholar] [CrossRef]
- Large, J.; Pesyridis, A. Investigation of Micro Gas Turbine Systems for High Speed Long Loiter Tactical Unmanned Air Systems. Aerospace 2019, 6, 55. [Google Scholar] [CrossRef]
- Oppong, F.; Van Der Spuy, S.J.; Diaby, A.L. An overview on the performance investigation and improvement of micro gas turbine engine. R D J. S. Afr. Inst. Mech. Eng. 2015, 31, 35–41. [Google Scholar]
- Turan, O. Exergetic effects of some design parameters on the small turbojet engine for unmanned air vehicle applications. Energy 2012, 46, 51–61. [Google Scholar] [CrossRef]
- Nava, G.; Fiorio, L.; Traversaro, S.; Pucci, D. Position and Attitude Control of an Underactuated Flying Humanoid Robot. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–9. [Google Scholar]
- Mohamed, H.A.O.; Nava, G.; L’Erario, G.; Traversaro, S.; Bergonti, F.; Fiorio, L.; Vanteddu, P.R.; Braghin, F.; Pucci, D. Momentum-Based Extended Kalman Filter for Thrust Estimation on Flying Multibody Robots. IEEE Robot. Autom. Lett. 2022, 7, 526–533. [Google Scholar] [CrossRef]
- Fu, M.; Guo, Q.; Cheng, Z. Structural Design and Finite Element Analysis of a Vortex Jet Power Vehicle. In Proceedings of the 2019 International Conference on Robotics, Intelligent Control and Artificial Intelligence (RICAI 2019), Shanghai, China, 20–22 September 2019; pp. 706–711. [Google Scholar]
- Jie, M.S.; Mo, E.J.; Hong, G.Y.; Lee, K.W. Fuzzy logic controller for turbojet engine of unmanned aircraft. In Knowledge-Based Intelligent Information and Engineering Systems; Part 1, Proceedings; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4251, pp. 29–36. [Google Scholar]
- Amirante, R.; Catalano, L.A.; Tamburrano, P. Thrust Control of Small Turbojet Engines Using Fuzzy Logic: Design and Experimental Validation. J. Eng. Gas Turbines Power 2012, 134, 121601. [Google Scholar] [CrossRef]
- Henriksson, M.; Grönstedt, T.; Breitholtz, C. Model-based on-board turbofan thrust estimation. Control Eng. Pract. 2011, 19, 602–610. [Google Scholar] [CrossRef]
- Litt, J.S. An optimal orthogonal decomposition method for Kalman filter-based turbofan engine thrust estimation. J. Eng. Gas Turbines Power 2008, 130, 011601. [Google Scholar] [CrossRef]
- Zhu, Y.; Huang, J.; Pan, M.; Zhou, W. Direct thrust control for multivariable turbofan engine based on affine linear parameter-varying approach. Chin. J. Aeronaut. 2022, 35, 125–136. [Google Scholar] [CrossRef]
- Simon, D.L.; Borguet, S.; Leonard, O.; Zhang, X.F. Aircraft Engine Gas Path Diagnostic Methods: Public Benchmarking Results. J. Eng. Gas Turbines Power 2014, 136, 041201. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Quarta, M. Hybrid Multigene Genetic Programming—Artificial neural networks approach for dynamic performance prediction of an aeroengine. Aerosp. Sci. Technol. 2020, 103, 105902. [Google Scholar] [CrossRef]
- KrishnaKumar, K.; Yachisako, Y.; Huang, Y. Jet engine performance estimation using intelligent system technologies. In Proceedings of the 39th Aerospace Sciences Meeting and Exhibit, Reno, NV, USA, 8–11 January 2001; p. 1122. [Google Scholar]
- Liu, Y.N.; Zhang, S.X.; Zhang, C. Aero engine thrust estimator design based on kernel method. J. Propuls. Technol. 2013, 34, 829–835. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Song, H.Q.; Li, B.W.; Zhang, Y.; Jiang, K.Y. Aero-engine thrust estimator design based on clustering and particle swarm optimization extreme learning machine. Tuijin Jishu/J. Propuls. Technol. 2017, 38, 1379–1385. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 1942–1948. [Google Scholar]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Cai, Z.; Xi, P.; Pan, Y.; Huang, G.; Zhang, T. A proposed self-organizing radial basis function network for aero-engine thrust estimation. Aerosp. Sci. Technol. 2019, 87, 167–177. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, Y.; Li, Z. A proposed algorithm based on long short-term memory network and gradient boosting for aeroengine thrust estimation on transition state. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2021, 235, 2182–2192. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA; pp. 3285–3292. [Google Scholar]
- Momin, A.J.A.; Nava, G.; L’Erario, G.; Mohamed, H.A.O.; Bergonti, F.; Vanteddu, P.R.; Braghin, F.; Pucci, D. Nonlinear Model Identification and Observer Design for Thrust Estimation of Small-scale Turbojet Engines. In Proceedings of the 2022 IEEE International Conference On Robotics and Automation (ICRA 2022), Philadelphia, PA, USA, 23–27 May 2022; pp. 5879–5885. [Google Scholar]
- Tang, W.; Wang, L.; Gu, J.; Gu, Y. Single Neural Adaptive PID Control for Small UAV Micro-Turbojet Engine. Sensors 2020, 20, 345. [Google Scholar] [CrossRef] [PubMed]
- Shehata, A.M.; Khalil, M.K.; Ashry, M.M. Adaptive Fuzzy PID Controller applied to micro turbojet engine. J. Phys. Conf. Ser. 2021, 2128, 012030. [Google Scholar] [CrossRef]
- Altarazi, Y.S.M.; Abu Talib, A.R.; Gires, E.; Yu, J.; Lucas, J.; Yusaf, T. Performance and exhaust emissions rate of small-scale turbojet engine running on dual biodiesel blends using Gasturb. Energy 2021, 232, 120971. [Google Scholar] [CrossRef]
- Balli, O.; Kale, U.; Rohács, D.; Karakoc, T.H. Exergoenvironmental, environmental impact and damage cost analyses of a micro turbojet engine (m-TJE). Energy Rep. 2022, 8, 9828–9845. [Google Scholar] [CrossRef]
- Xu, Y.; Gao, L.; Cao, R.; Yan, C.; Piao, Y. Power Balance Strategies in Steady-State Simulation of the Micro Gas Turbine Engine by Component-Coupled 3D CFD Method. Aerospace 2023, 10, 782. [Google Scholar] [CrossRef]
- Cican, G.; Frigioescu, T.; Crunteanu, D.; Cristea, L. Micro Turbojet Engine Nozzle Ejector Impact on the Acoustic Emission, Thrust Force and Fuel Consumption Analysis. Aerospace 2023, 10, 162. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Lu, W.; Li, J.; Wang, J.; Qin, L. A CNN-BiLSTM-AM method for stock price prediction. Neural Comput. Appl. 2021, 33, 4741–4753. [Google Scholar] [CrossRef]
- Antonius, F.; Sekhar, J.C.; Sreenivasa Rao, V.; Pradhan, R.; Narendran, S.; Fernando Cosio Borda, R.; Silvera-Arcos, S. Unleashing the power of Bat optimized CNN-BiLSTM model for advanced network anomaly detection: Enhancing security and performance in IoT environments. Alex. Eng. J. 2023, 84, 333–342. [Google Scholar] [CrossRef]
- Ramshankar, N.; Joe Prathap, P.M. Automated sentimental analysis using heuristic-based CNN-BiLSTM for E-commerce dataset. Data Knowl. Eng. 2023, 146, 102194. [Google Scholar] [CrossRef]
- Muhammad, K.; Mustaqeem; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; de Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated CNN features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Aslan, M.F.; Unlersen, M.F.; Sabanci, K.; Durdu, A. CNN-based transfer learning—BiLSTM network: A novel approach for COVID-19 infection detection. Appl. Soft Comput. 2021, 98, 106912. [Google Scholar] [CrossRef] [PubMed]
- Mellit, A.; Pavan, A.M.; Lughi, V. Deep learning neural networks for short-term photovoltaic power forecasting. Renew. Energ. 2021, 172, 276–288. [Google Scholar] [CrossRef]
- Guo, X.; Bi, Z.; Wang, J.; Qin, S.; Liu, S.; Qi, L. Reinforcement learning for disassembly system optimization problems: A survey. Int. J. Netw. Dyn. Intell. 2023, 2, 1–14. [Google Scholar] [CrossRef]
- Kim, T.; Cho, S. Optimizing CNN-LSTM neural networks with PSO for anomalous query access control. Neurocomputing 2021, 456, 666–677. [Google Scholar] [CrossRef]
- Sekhar, C.; Dahiya, R. Robust framework based on hybrid deep learning approach for short term load forecasting of building electricity demand. Energy 2023, 268, 126660. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 2022, 79, 7305–7336. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, Y. Predicting the Mechanical Properties of Heat-Treated Woods Using Optimization-Algorithm-Based BPNN. Forests 2023, 14, 935. [Google Scholar] [CrossRef]
- Yoo, Y.; Baek, J. A Novel Image Feature for the Remaining Useful Lifetime Prediction of Bearings Based on Continuous Wavelet Transform and Convolutional Neural Network. Appl. Sci. 2018, 8, 1102. [Google Scholar] [CrossRef]
- Ilesanmi, A.E.; Ilesanmi, T.O. Methods for image denoising using convolutional neural network: A review. Complex Intell. Syst. 2021, 7, 2179–2198. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Swapna, G.; Kp, S.; Vinayakumar, R. Automated detection of diabetes using CNN and CNN-LSTM network and heart rate signals. Procedia Comput. Sci. 2018, 132, 1253–1262. [Google Scholar]
- Kamalov, F. Forecasting significant stock price changes using neural networks. Neural Comput. Appl. 2020, 32, 17655–17667. [Google Scholar] [CrossRef]
- Zhang, G.; Bai, X.; Wang, Y. Short-time multi-energy load forecasting method based on CNN-Seq2Seq model with attention mechanism. Mach. Learn. Appl. 2021, 5, 100064. [Google Scholar] [CrossRef]
- Kim, T.; Cho, S. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Cheng, H.; Ding, X.; Zhou, W.; Ding, R. A hybrid electricity price forecasting model with Bayesian optimization for German energy exchange. Int. J. Electr. Power 2019, 110, 653–666. [Google Scholar] [CrossRef]
- Wu, K.; Wu, J.; Feng, L.; Yang, B.; Liang, R.; Yang, S.; Zhao, R. An attention-based CNN-LSTM-BiLSTM model for short-term electric load forecasting in integrated energy system. Int. Trans. Electr. Energy Syst. 2021, 31, e12637. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S. Improved artificial bee colony algorithm for global optimization. Inf. Process Lett. 2011, 111, 871–882. [Google Scholar] [CrossRef]
- Sun, R. Optimization for Deep Learning: An Overview. J. Oper. Res. Soc. China 2020, 8, 249–294. [Google Scholar] [CrossRef]
- Abou Houran, M.; Salman Bukhari, S.M.; Zafar, M.H.; Mansoor, M.; Chen, W. COA-CNN-LSTM: Coati optimization algorithm-based hybrid deep learning model for PV/wind power forecasting in smart grid applications. Appl. Energ. 2023, 349, 121638. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation; Cornell University Library: Ithaca, NY, USA, 2014; Available online: https://arxiv.org/abs/1406.1078 (accessed on 18 April 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Value |
|---|---|
| DBO-CNN-BiLSTM | optimal hyper-parameter combination is obtained by DBO. activation function (RELU). pooling layer activation function (RELU) |
| CNN-BiLSTM | batch size (128) learning rate (0.001) hidden nodes (100) activation function (RELU) pooling layer activation function (RELU) |
| CNN | batch size (128) learning rate (0.001) activation function (RELU) pooling layer activation function (RELU) |
| LSTM | batch size (128) hidden nodes (100) learning rate (0.001) activation function (RELU) |
| GRU | batch size (128) hidden nodes (100) learning rate (0.001) activation function (RELU) |
| Evaluation Metrics | DBO-CNN-BiLSTM | GRU | LSTM | CNN | CNN-BiLSTM |
|---|---|---|---|---|---|
| RSME | 0.0502 | 0.0647 | 0.0587 | 0.0636 | 0.0625 |
| MAE | 0.0391 | 0.0486 | 0.0429 | 0.0492 | 0.0508 |
| R2 | 0.9924 | 0.9834 | 0.9901 | 0.9885 | 0.9884 |
| Evaluation Metrics | DBO-CNN-BiLSTM | GRU | LSTM | CNN | CNN-BiLSTM |
|---|---|---|---|---|---|
| MAE | 0.0406 | 0.0509 | 0.0454 | 0.0544 | 0.0437 |
| RSME | 0.0651 | 0.0840 | 0.0717 | 0.0762 | 0.0662 |
| Mean Error | 2.01% | 2.52% | 2.21% | 2.69% | 2.16% |
| Maximum Error | 8.71% | 11.79% | 10.58% | 11.50% | 9.76% |
| Evaluation Metrics | DBO-CNN-BiLSTM | GRU | LSTM | CNN | CNN-BiLSTM |
|---|---|---|---|---|---|
| MAE | 0.0410 | 0.0476 | 0.0455 | 0.0469 | 0.0453 |
| RSME | 0.0484 | 0.0587 | 0.0549 | 0.0548 | 0.0554 |
| Mean Error | 2.03% | 2.35% | 2.25% | 2.32% | 2.24% |
| Max Error | 8.05% | 9.49% | 10.14% | 10.67% | 8.91% |
| Evaluation Metrics | DBO-CNN-BiLSTM | GRU | LSTM | CNN | CNN-BiLSTM |
|---|---|---|---|---|---|
| MAE | 0.0478 | 0.0632 | 0.0569 | 0.0627 | 0.0521 |
| RSME | 0.0608 | 0.0759 | 0.0679 | 0.1048 | 0.0669 |
| Mean Error | 2.10% | 3.13% | 2.81% | 3.10% | 2.57% |
| Max Error | 8.24% | 9.67% | 9.31% | 10.07% | 9.08% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, B.; Huang, H.; Chen, G.; Liang, J.; Long, H. DBO-CNN-BiLSTM: Dung Beetle Optimization Algorithm-Based Thrust Estimation for Micro-Aero Engine. Aerospace 2024, 11, 344. https://doi.org/10.3390/aerospace11050344
Lei B, Huang H, Chen G, Liang J, Long H. DBO-CNN-BiLSTM: Dung Beetle Optimization Algorithm-Based Thrust Estimation for Micro-Aero Engine. Aerospace. 2024; 11(5):344. https://doi.org/10.3390/aerospace11050344
Chicago/Turabian StyleLei, Baijun, Haozhong Huang, Guixin Chen, Jianguo Liang, and Huigui Long. 2024. "DBO-CNN-BiLSTM: Dung Beetle Optimization Algorithm-Based Thrust Estimation for Micro-Aero Engine" Aerospace 11, no. 5: 344. https://doi.org/10.3390/aerospace11050344
APA StyleLei, B., Huang, H., Chen, G., Liang, J., & Long, H. (2024). DBO-CNN-BiLSTM: Dung Beetle Optimization Algorithm-Based Thrust Estimation for Micro-Aero Engine. Aerospace, 11(5), 344. https://doi.org/10.3390/aerospace11050344