
Autonomous Decision-Making for Air Gaming Based on Position Weight-Based Particle Swarm Optimization Algorithm


Abstract
1. Introduction
2. Related Works
3. A Model of the Air Gaming Decision Problem
3.1. Description of the Problem
3.2. AHP-Based Constraint Establishment
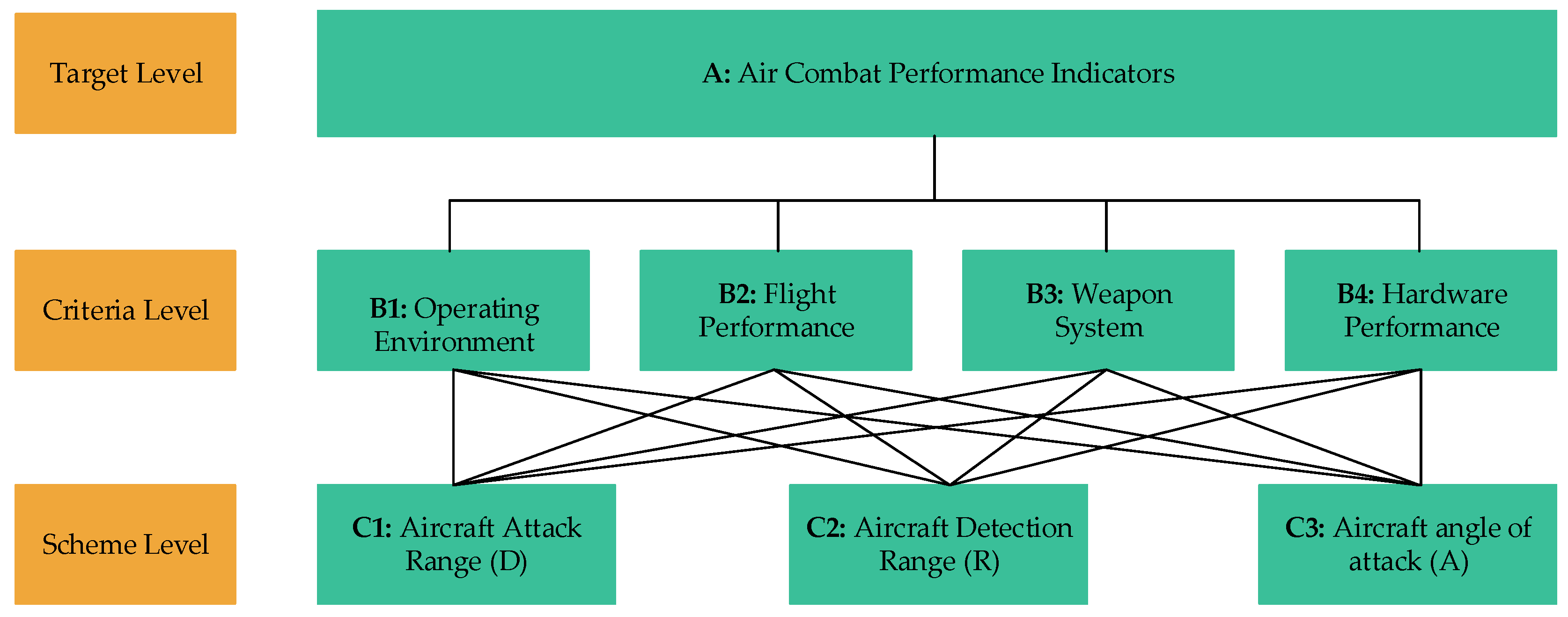
3.2.1. Hierarchical Modeling
3.2.2. Judgment Matrix Construction
3.2.3. Calculation of Relative Weights of Elements
3.2.4. Consistency Test
3.3. Objective Function
4. Particle Swarm Algorithm Based on Position Weight Velocity Update Strategy
4.1. Particle Swarm Algorithm (PSO)
4.2. Speed Update Strategy Based on Positional Weights (PW-PSO)
| Algorithm 1: PW-PSO-based air gaming decision-making |
| Begin |
| for each particle i do: |
| Randomly initialize the position ; |
| Randomly initialize the velocity ; |
| Calculate fitness value EFFECT(); |
| Set individual optimal position ; |
| Set the global optimal position as the position of the particle with the best fitness value among all ; |
| while eval ≤ MaxEval do |
| if r < 0.6 then |
| for each particle i do |
| Update the velocity according Equation (16); |
| Update position according to Equation (15); |
| Calculate the fitness value; |
| eval++; |
| end for |
| else |
| for each particle i do |
| Update the velocity according Equation (14); |
| Update position according to Equation (15); |
| Calculate the fitness value; |
| eval++; |
| end for |
| end if |
| Update the and in the population; |
| end while |
| End |
5. Simulation Analysis
5.1. Randomized Parameter Setting
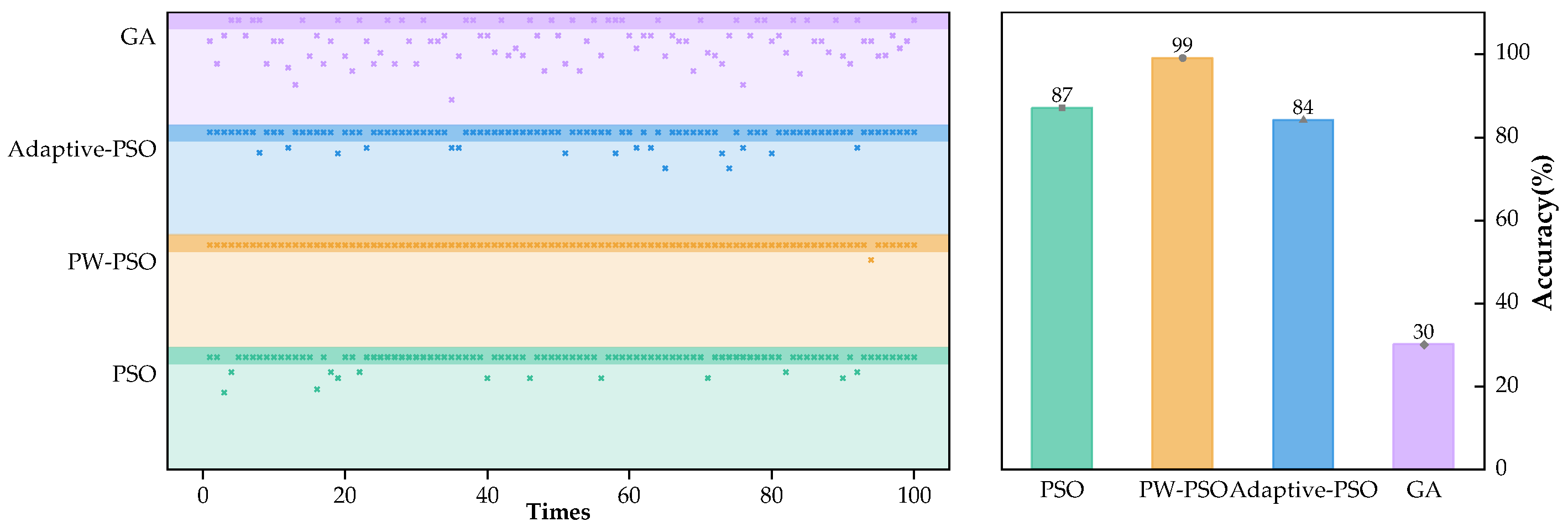
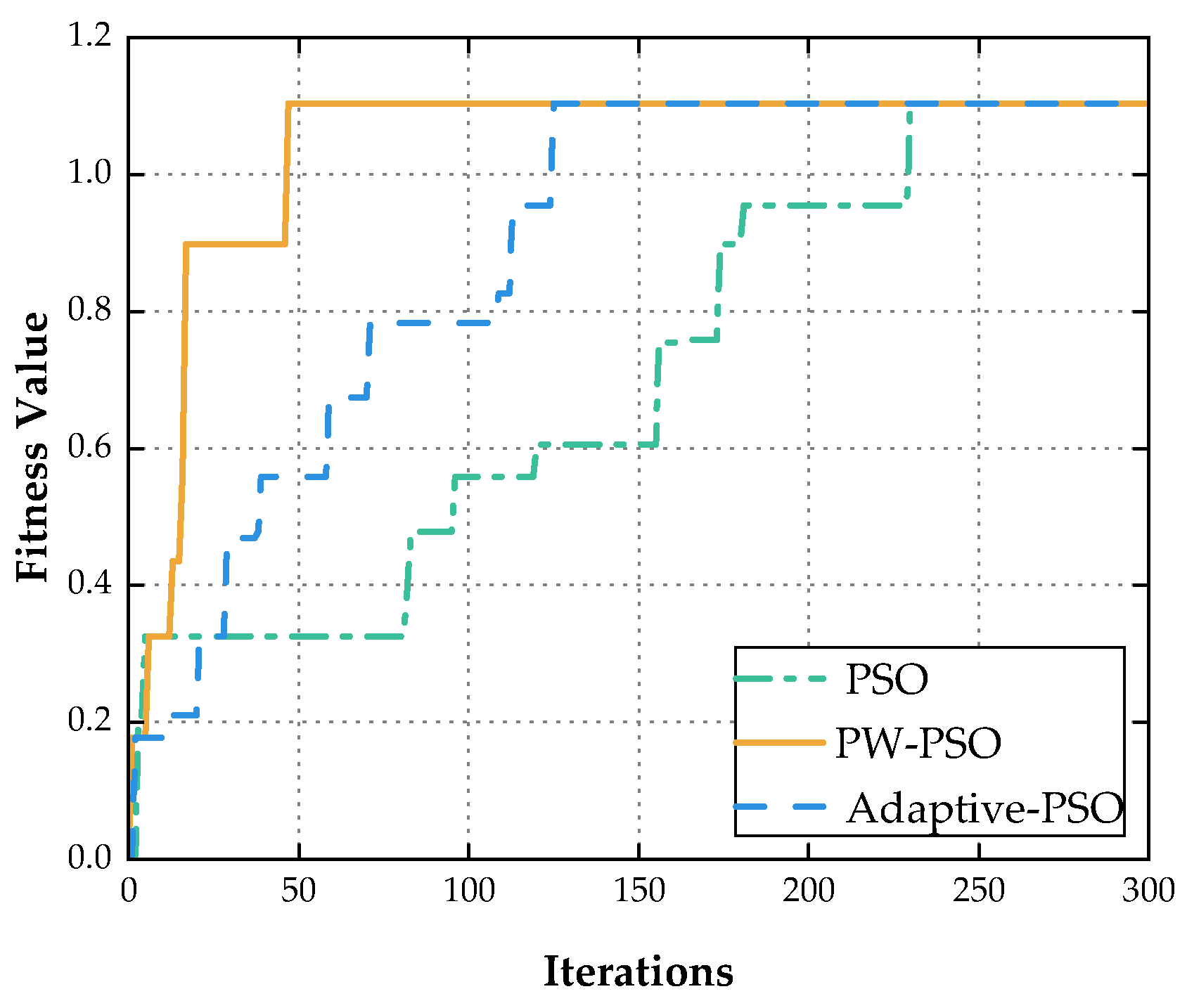
5.2. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R.I. | 0 | 0 | 0.52 | 0.89 | 1.12 | 1.26 | 1.36 | 1.41 | 1.46 | 1.49 | 1.52 | 1.54 | 1.56 | 1.58 |
| A | B1 | B2 | B3 | B4 | |||||
| B1 | 1 | 1/2 | 1/3 | 1/4 | 0.452 | 0.097 | 4.104 | ||
| B2 | 2 | 1 | 1/2 | 1/3 | 0.759 | 0.164 | 4.078 | ||
| B3 | 3 | 2 | 1 | 2 | 1.861 | 0.401 | 4.226 | ||
| B4 | 4 | 3 | 1/2 | 1 | 1.565 | 0.338 | 4.205 | ||
| B1 | C1 | C2 | C3 | ||||||
| C1 | 1 | 1/3 | 2 | 0.874 | 0.230 | 3.002 | |||
| C2 | 3 | 1 | 5 | 2.466 | 0.648 | 3.004 | |||
| C3 | 1/2 | 1/5 | 1 | 0.464 | 0.122 | 3.005 | |||
| B2 | C1 | C2 | C3 | ||||||
| C1 | 1 | 1/3 | 1/5 | 0.406 | 0.105 | 3.036 | |||
| C2 | 3 | 1 | 1/3 | 1.000 | 0.258 | 3.040 | |||
| C3 | 5 | 3 | 1 | 2.466 | 0.637 | 3.040 | |||
| B3 | C1 | C2 | C3 | ||||||
| C1 | 1 | 7 | 3 | 2.759 | 0.682 | 3.003 | |||
| C2 | 1/7 | 1 | 1/2 | 0.415 | 0.103 | 3.003 | |||
| C3 | 1/3 | 2 | 1 | 0.874 | 0.215 | 3.002 | |||
| B4 | C1 | C2 | C3 | ||||||
| C1 | 1 | 3 | 2 | 1.817 | 0.540 | 3.009 | |||
| C2 | 1/3 | 1 | 1/2 | 0.550 | 0.163 | 3.010 | |||
| C3 | 1/2 | 2 | 1 | 1.000 | 0.297 | 3.008 | |||
References
- Xue, S.; Wang, Z.; Bai, H.; Yu, C.; Deng, T.; Sun, R. An Intelligent Bait Delivery Control Method for Flight Vehicle Evasion Based on Reinforcement Learning. Aerospace 2024, 11, 653. [Google Scholar] [CrossRef]
- Karali, H.; Inalhan, G.; Tsourdos, A. Advanced UAV Design Optimization Through Deep Learning-Based Surrogate Models. Aerospace 2024, 11, 669. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Zhou, Y.; Jia, Y.; Shi, H.; Yang, F.; Zhang, C. Multi-UAV Cooperative Air Combat Decision-Making Based on Multi-Agent Double-Soft Actor-Critic. Aerospace 2023, 10, 574. [Google Scholar] [CrossRef]
- Tian, C.; Song, M.; Tian, J.; Xue, R. Evaluation of Air Combat Control Ability Based on Eye Movement Indicators and Combination Weighting GRA-TOPSIS. Aerospace 2023, 10, 437. [Google Scholar] [CrossRef]
- Wang, L.; Wang, J.; Liu, H.; Yue, T. Decision-Making Strategies for Close-Range Air Combat Based on Reinforcement Learning with Variable-Scale Actions. Aerospace 2023, 10, 401. [Google Scholar] [CrossRef]
- Dong, P.; Chen, W.; Wang, K.; Zhou, K.; Wang, W. Research on Combat Mission Configuration of Unmanned Aerial Vehicle Maritime Reconnaissance Based on Particle Swarm Optimization Algorithm. Complexity 2024, 2024, 1–12. [Google Scholar] [CrossRef]
- Khelifi, M.; Butun, I. Swarm Unmanned Aerial Vehicles (SUAVs): A Comprehensive Analysis of Localization, Recent Aspects, and Future Trends. J. Sens. 2022, 2022, 8600674. [Google Scholar] [CrossRef]
- Mcgrew, J.S.; How, J.P.; Williams, B.; Roy, N. Air-Combat Strategy Using Approximate Dynamic Programming. J. Guid. Control Dyn. 2010, 33, 1641–1654. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, Y.; Sun, M.; Chen, Z. Air Combat Maneuver Decision Based on Deep Reinforcement Learning with Auxiliary Reward. Neural Comput. Appl. 2024, 36, 13341–13356. [Google Scholar] [CrossRef]
- Xing, D.; Zhen, Z.; Gong, H. Offense-Defense Confrontation Decision Making for Dynamic UAV Swarm versus UAV Swarm. Proc. Inst. Mech. Eng. 2019, 233, 5689–5702. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Q.; Shi, G.; Yi, L.; Yong, W. UAV Cooperative Air Combat Maneuver Decision Based on Multi-Agent Reinforcement Learning. J. Syst. Eng. Electron. 2021, 32, 18. [Google Scholar]
- You, H. Mission-Driven Autonomous Perception and Fusion Based on UAV Swarm. Chin. J. Aeronaut. 2020, 33, 2831–2834. [Google Scholar]
- Guo, J.; Hu, G.; Guo, Z.; Zhou, M. Evaluation Model, Intelligent Assignment, and Cooperative Interception in Multimissile and Multitarget Engagement. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3104–3115. [Google Scholar] [CrossRef]
- Li, W. Autonomous Maneuver Decision of Air Combat Based on Simulated Operation Command and FRV-DDPG Algorithm. Aerospace 2022, 9, 658. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Sun, C.; Ru, C. Intelligent Maneuver Decision Method of UAV Based on Reinforcement Learning and Neural Network. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8544–8549. [Google Scholar]
- Jia, L.; Cai, C.; Wang, X.; Ding, Z.; Xu, J.; Wu, K.; Liu, J. Multi-Intent Autonomous Decision-Making for Air Combat with Deep Reinforcement Learning. Appl. Intell. 2023, 53, 29076–29093. [Google Scholar] [CrossRef]
- Dou, X.; Tang, G.; Zheng, A.; Wang, H.; Liang, X. Research on Autonomous Decision-Making in Manned/Unmanned Coordinated Air Combat. In Proceedings of the 2023 9th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 21 April 2023; pp. 170–178. [Google Scholar]
- Nantogma, S.; Xu, Y.; Ran, W.Z. A Coordinated Air Defense Learning System Based on Immunized Classifier Systems. Symmetry 2021, 13, 271. [Google Scholar] [CrossRef]
- Liu, S.; Huang, F.; Yan, B.; Zhang, T.; Liu, R.; Liu, W. Optimal Design of Multimissile Formation Based on an Adaptive SA-PSO Algorithm. Aerospace 2022, 9, 21. [Google Scholar] [CrossRef]
- Liang, Z.; Li, Q.; Fu, G. Multi-UAV Collaborative Search and Attack Mission Decision-Making in Unknown Environments. Sensors 2023, 23, 7398. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Chen, M.; Wang, Y.; Wu, Q. Air Combat Decision-Making of Multiple UCAVs Based on Constraint Strategy Games—ScienceDirect. Def. Technol. 2022, 18, 16. [Google Scholar]
- Yin, H.; Li, D.; Li, Y.W. Adaptive Dynamic Occupancy Guidance for Air Combat of UAV. Unmanned Syst. 2024, 12, 29–46. [Google Scholar] [CrossRef]
- Ren, Z.; Zhang, D.; Tang, S.; Xiong, W.; Yang, S.H. Cooperative Maneuver Decision Making for Multi-UAV Air Combat Based on Incomplete Information Dynamic Game. Def. Technol. 2023, 27, 308–317. [Google Scholar] [CrossRef]
- Fang, C.; Kou, Y.; Xu, A.; Deng, S.; Peng, M. A VIKOR Method for Threat Assessment in Air Combat Based on AHP-CRITIC Combination Weighting. Electron. Opt. Control 2021, 28, 24–28. [Google Scholar]
- Zhang, Y.; Yang, G.; Meng, H.; Wang, R.; Qi, B. Threat measurement and sequencing of air raid targets based on entropy method fused with AHP. J. Telem. Track. Command. 2020, 41, 57–64. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the Icnn95-international Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Sun, B.; Zeng, Y.; Zhu, D. Dynamic Task Allocation in Multi Autonomous Underwater Vehicle Confrontational Games with Multi-Objective Evaluation Model and Particle Swarm Optimization Algorithm. Appl. Soft Comput. 2024, 153, 111295. [Google Scholar] [CrossRef]
- Ding, Y.; Liu, C.; Lu, Q.; Zhu, M. Effectiveness Evaluation of UUV Cooperative Combat Based on GAPSO-BP Neural Network. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 4620–4625. [Google Scholar]
- Cheng, Z.; Fan, L.; Zhang, Y. Multi-agent decision support system for missile defense based on improved PSO algorithm. J. Syst. Eng. Electron. 2017, 28, 514–525. [Google Scholar]
- Wu, P.; Li, T.; Song, G. UCAV Path Planning Based on Improved Chaotic Particle Swarm Optimization. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 1069–1073. [Google Scholar]
- Zhao, R.; Wang, Y.; Xiao, G.; Liu, C.; Hu, P.; Li, H. A Method of Path Planning for Unmanned Aerial Vehicle Based on the Hybrid of Selfish Herd Optimizer and Particle Swarm Optimizer. Appl. Intell. Int. J. Artif. Intell. Neural Netw. Complex. Probl.-Solving Technol. 2022, 52, 16775–16798. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Zhang, J.; Li, Y.; Chung, H.S.-H. Adaptive Particle Swarm Optimization. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 1362–1381. [Google Scholar] [CrossRef] [PubMed]



| B1 | B2 | B3 | B4 | W | |
|---|---|---|---|---|---|
| 0.097 | 0.164 | 0.401 | 0.338 | ||
| C1 | 0.230 | 0.105 | 0.682 | 0.540 | 0.496 |
| C2 | 0.648 | 0.258 | 0.103 | 0.163 | 0.202 |
| C3 | 0.122 | 0.637 | 0.215 | 0.297 | 0.302 |
| x | 930.85 | 416.03 | 842.14 | 852.24 | 375.65 | 821.45 | 787.02 | 326.78 | 810.63 | 374.63 | 183.52 | 68.71 |
| y | 655.17 | 771.38 | 45.47 | 976.99 | 566.90 | 527.89 | 52.94 | 646.00 | 743.36 | 442.05 | 862.94 | 902.56 |
| A | 20.53 | 35.95 | 58.41 | 216.17 | 129.67 | 265.52 | 54.24 | 165.82 | 211.89 | 77.61 | 141.74 | 171.79 |
| Number of Experiments | Success Rate (%) | Optimal Convergence Value | Average Convergence Value | Average Convergent Algebra | Convergence Value Variance | |
|---|---|---|---|---|---|---|
| PSO | 100 | 87 | 1.10301 | 1.07665 | 142 | 0.00519 |
| PW-PSO | 100 | 99 | 1.10301 | 1.10152 | 62 | 0.00022 |
| Adpative-PSO | 100 | 84 | 1.10301 | 1.07195 | 124 | 0.00578 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, A.; Li, H.; Hong, Y.; Liu, G. Autonomous Decision-Making for Air Gaming Based on Position Weight-Based Particle Swarm Optimization Algorithm. Aerospace 2024, 11, 1030. https://doi.org/10.3390/aerospace11121030
Xu A, Li H, Hong Y, Liu G. Autonomous Decision-Making for Air Gaming Based on Position Weight-Based Particle Swarm Optimization Algorithm. Aerospace. 2024; 11(12):1030. https://doi.org/10.3390/aerospace11121030
Chicago/Turabian StyleXu, Anqi, Hui Li, Yun Hong, and Guoji Liu. 2024. "Autonomous Decision-Making for Air Gaming Based on Position Weight-Based Particle Swarm Optimization Algorithm" Aerospace 11, no. 12: 1030. https://doi.org/10.3390/aerospace11121030
APA StyleXu, A., Li, H., Hong, Y., & Liu, G. (2024). Autonomous Decision-Making for Air Gaming Based on Position Weight-Based Particle Swarm Optimization Algorithm. Aerospace, 11(12), 1030. https://doi.org/10.3390/aerospace11121030