1. Introduction
To improve aeroengine efficiency and reach aircraft performance requirements, the environment for engine parts, particularly engine blades, has become increasingly strenuous. Safety and reliability in operation have long been a concern in industry and academia. However, in the aeroengine turbine blades casting process, internal defects such as slag inclusion, remainder, broken core, gas cavity, crack and cold shut are apt to occur inevitably [
1,
2]. In addition, turbine blades usually work under strenuous conditions of high pressure, high temperature and high speed for a long time. If internal defects go undetected, they are likely to produce stress concentrations and cause fracture failure, leading to flight accidents [
3,
4]. To avoid such problems, quality management for turbine blades is essential before they leave the factory.
Nondestructive testing is an inevitable part of the investment casting turbine blade quality management. Conventional nondestructive testing methods include eddy current testing, magnetic particle testing, radiographic testing, ultrasonic testing, isotopic photography, penetrant testing, infrared thermography, and noise testing [
5,
6,
7]. These methods use auxiliary tools to detect defects and rely on human subjective judgment. They are a semiautomatic detection means. For example, the recognition and classification of defects depend on visual observation of X-ray images obtained from radiographic testing, which always tends to be error-prone and time-consuming. However, with the rapid development of the aviation industry and increasing production demands, conventional nondestructive testing faces tremendous pressure and challenges.
Many scholars devote themselves to the automation and intellectualization of defect detection. Most of these methods are based on computer vision technology for defect detection [
8]. In recent years, deep learning has performed well in defect detection [
9,
10,
11,
12] and segmentation [
13,
14,
15,
16] in many industrial fields. These defect recognition and classification methods based on deep learning learn and extract defect features from a large number of defect samples, and their detection performance has greatly outperformed traditional manual feature extraction methods [
17,
18,
19]. Applying computer vision technology to X-ray images is an effective method for realizing the intellectualization of radiographic testing. Mery et al. [
20] are devoted to a variety of computer vision methods based on a self-built X-ray image dataset called GDXray. They compared and studied 24 computer vision techniques, including deep learning, local descriptors, sparse representations and texture features, among others, by using GDXray datasets of cropped X-ray images in automotive components [
21]. Ferguson et al. [
22,
23] adopted transfer learning to train different backbones and object detection models, including VGG16 [
24], residual network (ResNet-101) [
25], Faster R-CNN [
26] and single-shot multibox detector (SSD) [
27], based on GDX-ray datasets [
20], and evaluated and compared their performance for defect detection of X-ray images in industrial castings. Fuchs et al. [
28,
29] trained and tested different deep learning models [
30,
31] based on simulated data in cast aluminum parts. Du et al. [
32,
33] used a feature pyramid network (FPN) [
34] to extract features from X-ray images of automotive aluminum casting parts and further improved the performance of the defect detection and recognition system by utilizing the RoIAlign algorithm [
35]. Wu et al. [
36] adopted feature engineering and machine learning methods to study computed aided detection of casting defects in X-ray images. The above research focuses on automatic radiographic testing using state-of-the-art computer vision technology. In addition to applying deep learning to the detection of X-ray images, the deep learning method is also applied to aircraft engine borescope inspection [
37,
38,
39]. However, there are few reports on the application of deep learning to defect detection for X-ray images of aeroengine turbine blades. In this paper, deep learning is applied to the radiographic testing of aeroengine turbine blades. We aim to utilize a considerable number of X-ray images with defects to learn defect characteristics and realize the automatic recognition and location of defects (automation and intelligence of radiographic detection). The main contributions of this study are summarized as follows:
- (1)
We propose a novel dual backbone detection framework based on a one-stage object detection algorithm for aeroengine turbine blade X-ray images by employing two DCNNs to extract hierarchical defect features.
- (2)
We design a novel concatenation form containing all feature maps to build a PAN (path aggregation network). The PAN we build, as the neck of the defect detection model, fuses different scale feature maps, enhances valid feature propagation, and ensures defect detection performance.
- (3)
We adopt nine cropping cycles for one defect and employ image preprocessing and data augmentation techniques such as rotation, flipping, and brightness increasing and decreasing, which greatly expands the training dataset and significantly improves the defect detection model accuracy.
The remainder of this paper is outlined as follows: In
Section 2, we introduce one-stage and two-stage object detection algorithms based on deep learning in detail by taking classical object detection algorithms (Faster R-CNN and YOLOv3) as examples in computer vision. In
Section 3, we illustrate the framework and details of our method.
Section 4 describes the relevant parameter settings and details of the experiments (model training and testing). The results are demonstrated and discussed in
Section 5. Finally,
Section 6 presents the conclusions and further work.
2. The Object Detection Algorithm on Deep Learning
The object detection algorithm is a basic algorithm generally used in the computer vision field. It combines region selection and image classification. The purpose of object detection is to classify objects in images or videos and give their location information. Therefore, the main task includes two parts: object classification and object location.
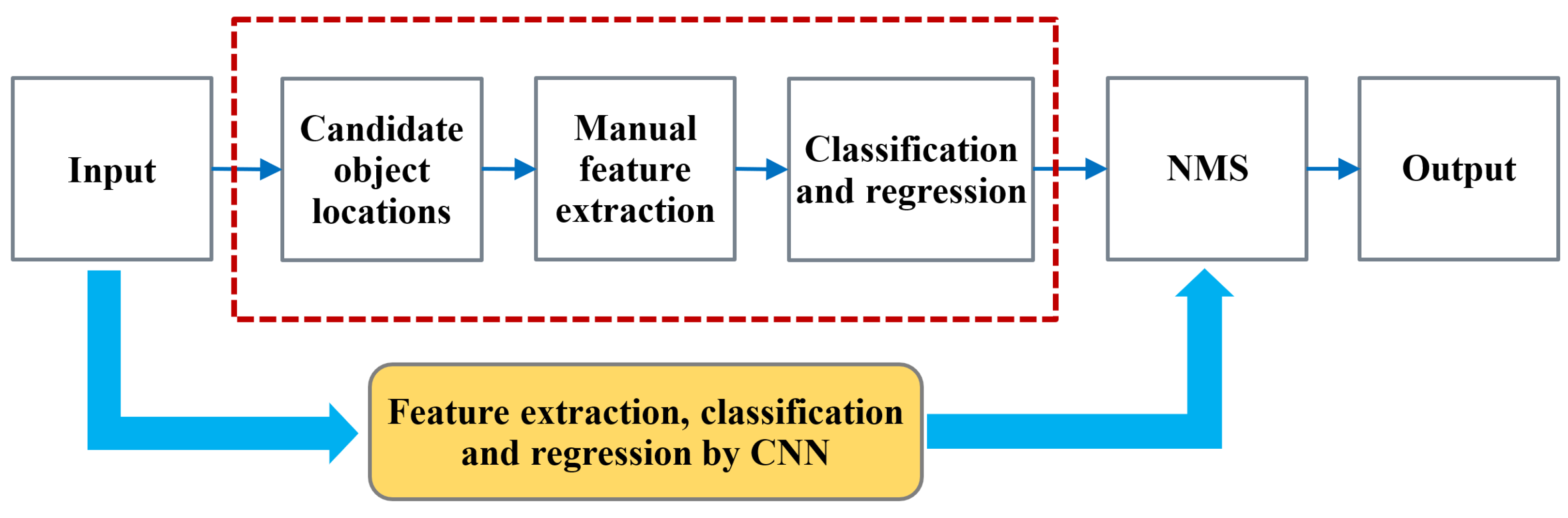
Figure 1 shows the object detection implementation process. In the traditional object detection algorithm, a sliding window is utilized to obtain candidate regions, feature extraction is performed manually, and traditional classifiers are used for classification. The accuracy and its real-time performance are relatively low. As shown in
Figure 1, the red dashed box represents the traditional image processing, and the yellow filled box below represents the image processing by CNNs. The success of CNNs in classification as in AlexNet has led to their adoption in object detection. Because of learning features by deep neural networks, image feature extraction is more effective, which brings higher accuracy, real-time performance of object detection and increasingly wide utilization in all fields. Object detection algorithms based on deep learning are divided into two-stage algorithms and one-stage algorithms according to the differences in the structure and process.
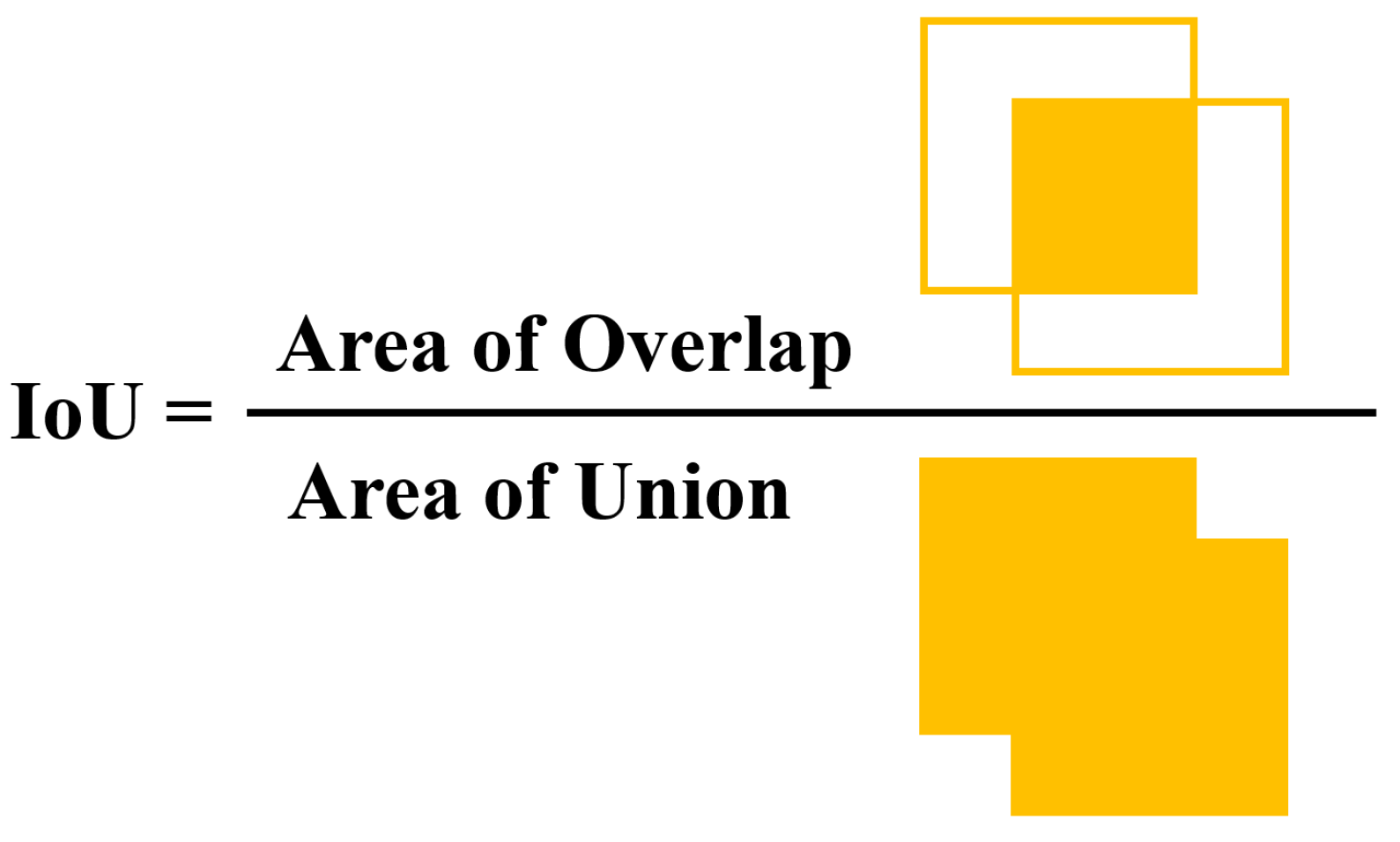
The process of object detection with a two-stage algorithm goes through two steps. First, rough classification and location of objects are carried out based on the main features extracted by the backbone. In this process, a large number of region proposals containing foreground (object) and background are obtained. The second step is to select some images with high confidence scores in these region proposals for final thorough object classification and location. The intersection over union (IoU) is a typical indicator for judging goals or background in region proposals, which is the overlap ratio between the ground-truth box and the region of proposal, as shown in
Figure 2.
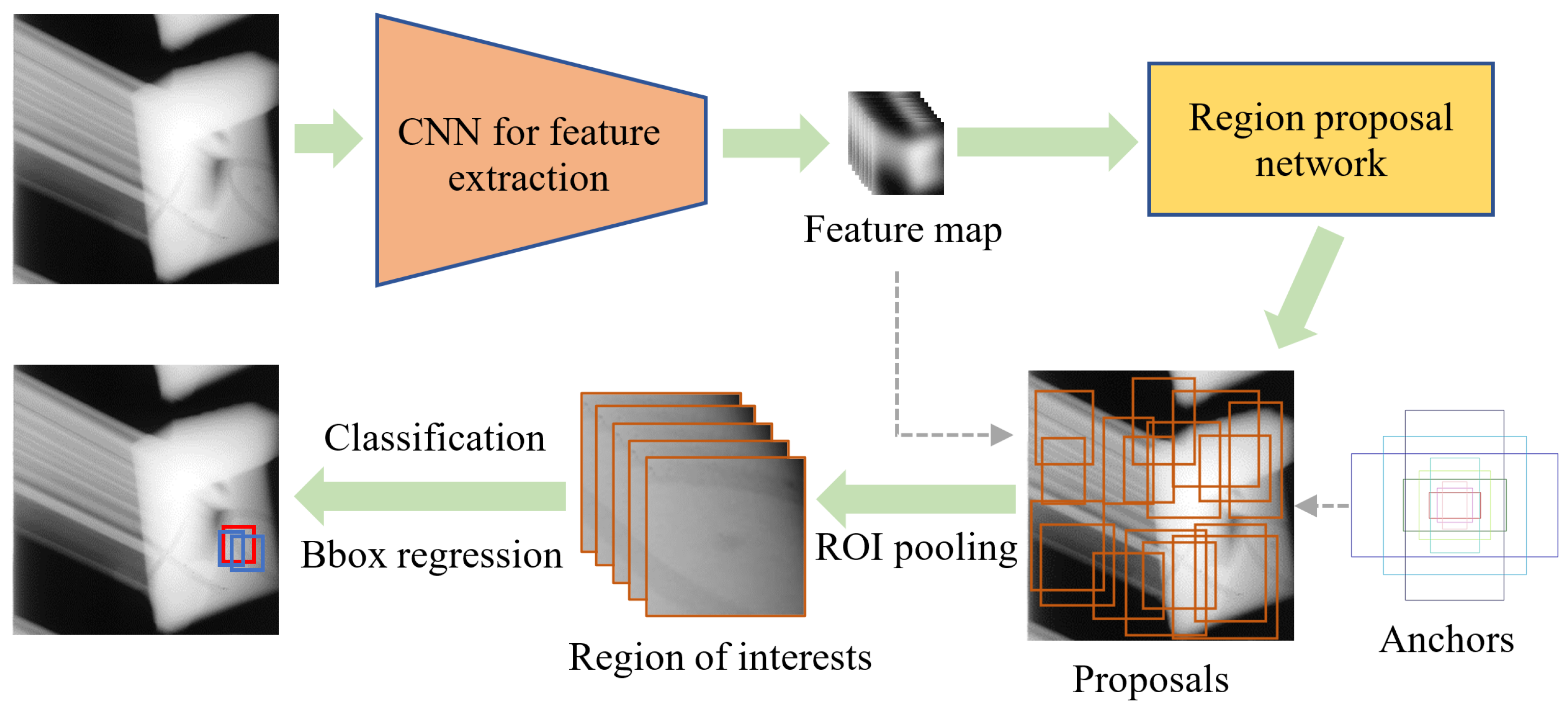
The typical two-stage algorithm for object detection is Faster R-CNN, which includes four contents as follows [
26]: 1. Main feature extraction. 2. Proposals acquisition by RPN (region proposal network). 3. ROI pooling for cropping proposal feature maps. 4. Image classification and bounding box regression for output. The implementation process is shown in
Figure 3.
Compared with the two-stage object detection algorithm, the one-stage object detection algorithm directly predicts the object category and location. The framework of the algorithm is relatively simple. This end-to-end detection method makes it more advantageous in detection speed. There are several typical algorithms within one stage, such as SSD (single-shot multibox detector) [
27] and YOLO (you only look once) series [
40].
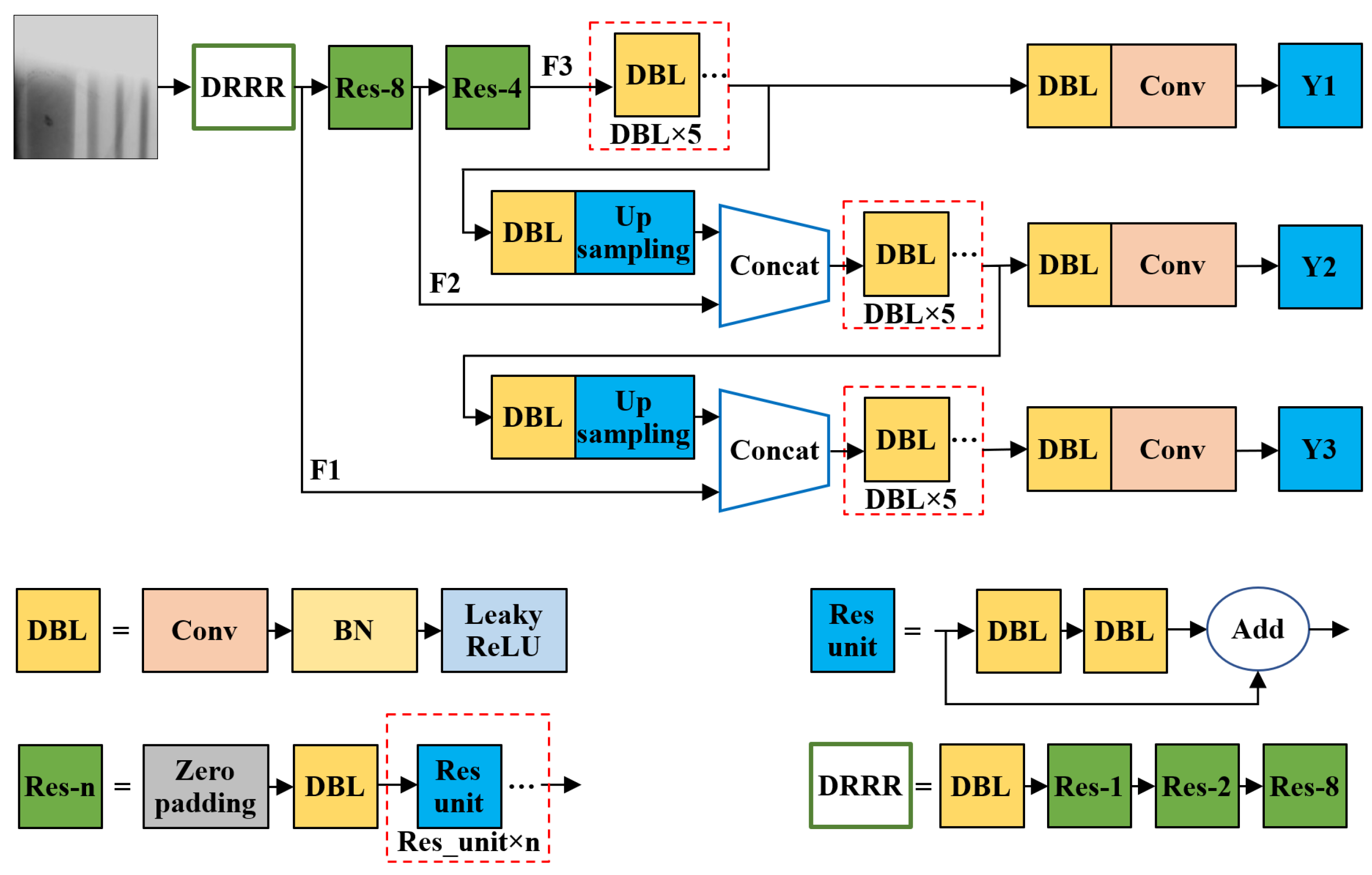
Figure 4 shows the network structure of the YOLOv3 algorithm. The DBL (represented as DarknetConv2d_BN_Leaky in the code) in the figure is the basic component of YOLOv3, and its structure is composed of convolution (Conv), batch normalization (BN), and the leaky ReLU activation function. The Res_unit in the figure is a residual unit composed of two DBL connected. Res-n represents a residual connection block, which is successively connected by zero-padding, DBL and N Res_unit residual units and has the function of downsampling the input image. DRRR is the main feature extraction network used by YOLOv3, which consists of a DBL followed by three residual connection blocks. YOLOv3 is one of the most popular object detection algorithms. The concrete realization of YOLOv3 algorithm can refer to [
40].
3. The Deep Learning Method of Defect Localization and Recognition for Turbine Blades
In this study, the implementation process of the detection method we proposed can be described by four parts. First, X-ray images of defective turbine blades are accessed and preprocessed for the building training set, validation set, and testing set. Next, a defect detection model for turbine blades is built, which adopts dual backbone networks for feature extraction, a feature pyramid network (FPN) and a path aggregation network (PAN) for feature fusion and is based on one-stage object detection. Moreover, the objective function (also called the loss function) and weight optimization algorithm are determined for model training. Then, the model training process is performed by utilizing the training set and validation set based on the gradient descent method. Finally, the defect detection model is tested on the testing set. The details of implementation for each section are given below.
3.1. X-ray Image Acquisition and Preprocessing
3.1.1. Defect Samples and Labels
Deep learning for image recognition is generally pure data-driven, and the training data have a great impact on the prediction accuracy of the model. However, high detection accuracy not only requires that the number and coverage of training data be large enough but also requires that the corresponding label data be accurate. With the help of an aviation manufactory, we collected 600 X-ray films containing defective turbine blades with a size of 0.5 m × 0.5 m. There were 50 turbine blade images on each film, in which scattered defective blades are hidden. To obtain high-resolution X-ray digital images of aeroengine turbine blades, the original films were scanned with an industrial film digital scanner using optimal resolution scanning parameters. The size of each X-ray image scanned from the original film was 7960 × 9700.
Figure 5 shows the process to obtain X-ray film digital images with an industrial film digital scanner. The industrial film digital scanner was connected to a computer. After automatic scanning, these images were corrected, marked, and saved manually as X-ray film digital images.
Figure 6 shows an X-ray film digital image and a defective turbine blade sample with a locally enlarged region of defects. We cropped defective turbine blade images with the identical pixel size (770 × 1700) from the X-ray film digital image. Finally, 2137 X-ray images of turbine blades with defects were obtained as the defect sample dataset of this study.
In the process of model training based on deep learning, the information of defect category and location on each training sample should be given in advance by manual evaluation as a training objective. Based on edge smoothness, end sharpness, trend change rate, relative position, symmetry, included angle, length to short axis ratio, and gray relative change rate, the main characteristics of six kinds of defects were analyzed and evaluated by fuzzy reasoning. The six kinds of defects were slag inclusion, remainder, broken core, gas cavity, crack and cold shut, which are all internal defects. Slag inclusion, remainder, and broken core are all inclusion defects. It looks like there are slag inside of metal castings. Slag inclusion is low-density inclusion, and remainder and broken core are high-density inclusion. Gas cavity is a kind of cavities defect. Gases are entrapped by solidifying metal on the inside of the casting, which results in a rounded or oval blowhole as a cavity. The crack of castings can divided into hot crack and cold crack, which are caused by a variety of factors [
41]. Some cracks are very obvious and can be easily seen with the naked eye. Other cracks are very difficult to see without magnification in radiographic testing. Cold shut is also called cold lap. It is a crack with round edges. Cold shut is because of a low melting temperature or a poor gating system.
Figure 7 presents these different kinds of defects. These defect X-ray images were categorized and labeled by certified and experienced NDT engineers. We found that approximately 12% of the pseudo defects in X-ray images were caused by the film itself and the film digitization process, and these pseudo defects were considered as non-defects. For each defective turbine blade picture, label data, including the defect category and the vertex coordinates of defect rectangular area (
,
,
,
), were determined by labeling software. To date, training and label datasets containing 2137 samples with six kinds of defects were obtained for model training.
Table 1 shows the statistical results of the defect samples.
3.1.2. Image Preprocessing and Data Augmentation
The pixel size of most defects is smaller than
, which is extremely small compared with the pixel size of the turbine blade. This large scale difference makes it almost impossible to directly input the turbine blade image for defect detection. In our detection method, each turbine blade image was cut to a fixed size first. Then, these local images of the turbine blade were detected in turn. Finally, the mosaic of the complete turbine blade from these local images was output for visualization. Based on experience, we cropped the defect image with a size of
from each defective turbine blade image. Each defective turbine blade image was cropped nine times in the defect region such that the defect falls evenly on the cropped image of fixed size, as shown in
Figure 8. The corresponding label data were revised simultaneously. This process expanded the number of original defect samples to nine.
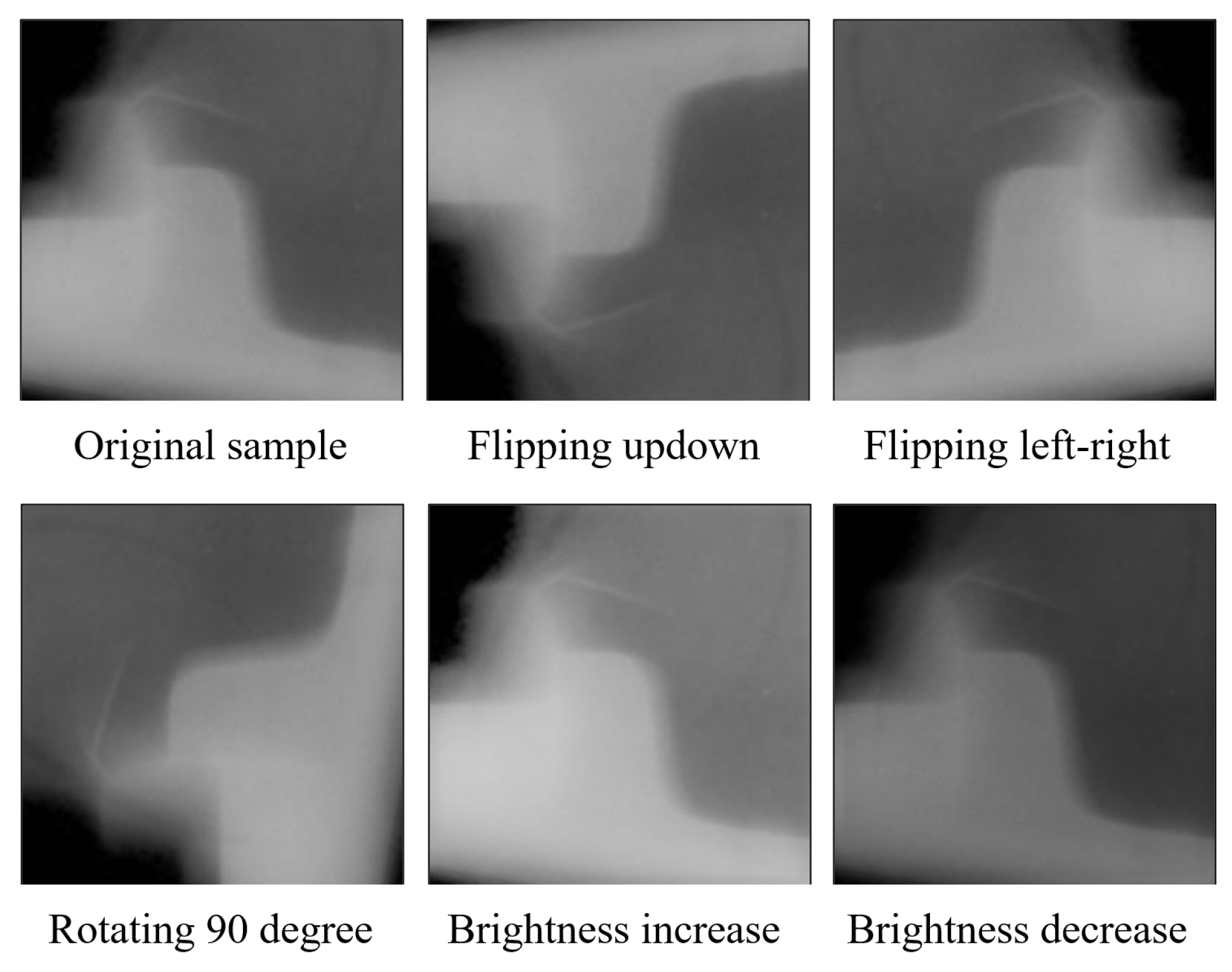
Data augmentation is an effective means to improve the prediction accuracy of deep learning models. Images can be either flipped or rotated for data augmentation. In this study, each cropped picture was flipped or rotated counterclockwise by 90 degrees with a 50% probability, and the brightness was randomly increased or decreased by 20%. All data augmentation methods were applied to the training datasets, and testing images were kept in their original states all the time.
Figure 9 depicts our data augmentation examples.
3.2. Network Structure of the Defect Detection Model Based on Deep Learning
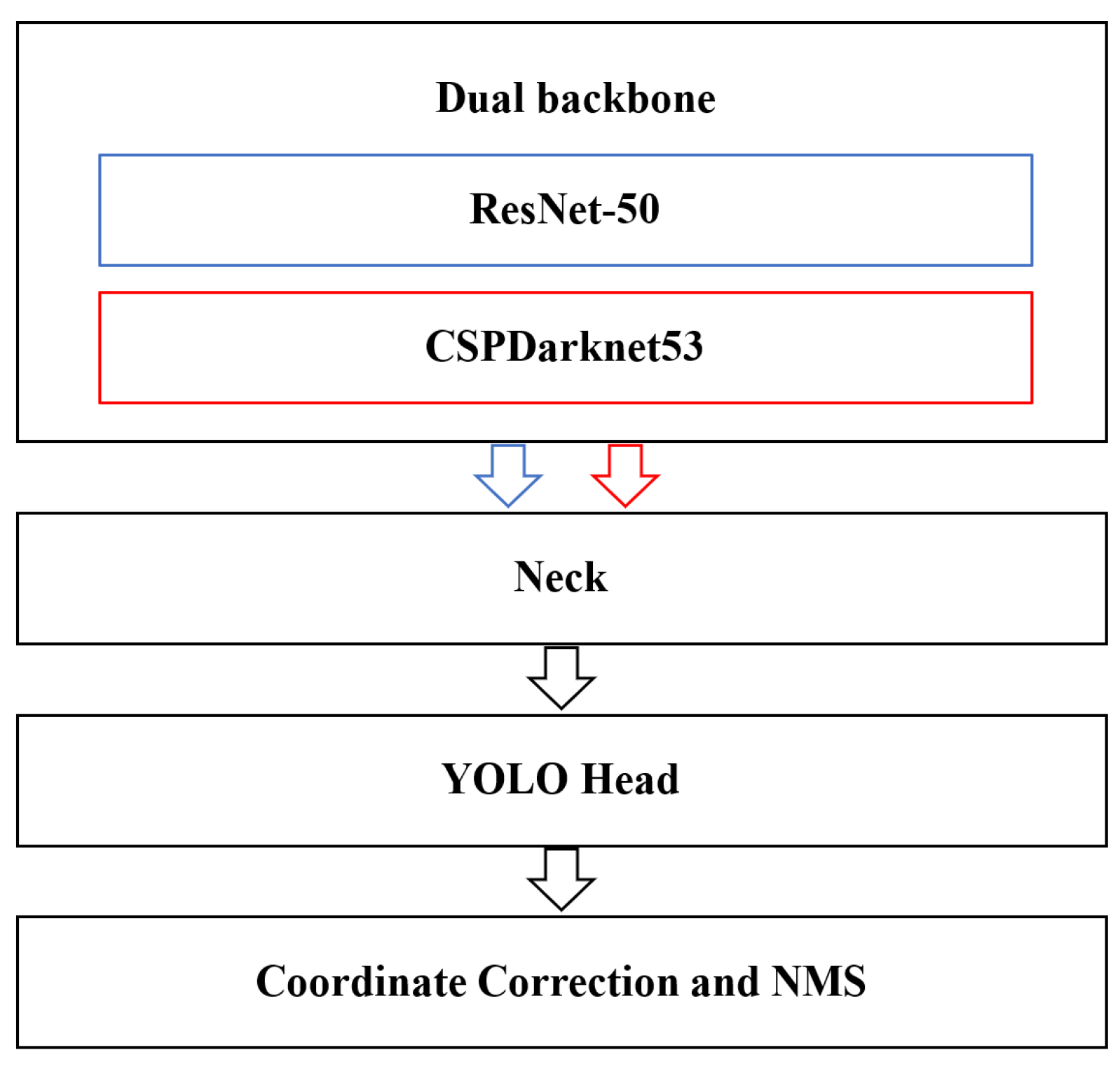
In addition to the training and label data, network structure is a crucial factor in determining the performance of the deep learning model. Our defect detection model made of a deep neural network, called DBFF-YOLOv4 (dual backbone feature fusion YOLOv4), is composed of four modules (as shown in
Figure 10). The first module is the dual backbone feature extraction networks named ResNet-50 and CSPDarknet-53, which are responsible for generating feature maps with different scales. The second module, called the neck, is composed of a feature pyramid network (FPN) and a path aggregation network (PAN), which adopt a novel concatenation form between different scales and different backbone feature maps for feature fusion. The third module is the head, which is identical to that of YOLOv3 (as shown in
Figure 4). The last module is coordinate correction and NMS for final detection results. The entire system is a single, unified network for defect detection of turbine blades. Using a dual backbone and a concatenation structure, sufficient defect semantic information and location information are captured. In the first part of this section, we introduce the dual backbone feature extraction networks with their different scale feature maps. In the second part, we present the details of PAN with a novel concatenation form. In the third part, we demonstrate defect prediction in the model head and the final outputs of the detection results.
3.2.1. Dual Backbone Networks for Feature Extraction
We adopt ResNet-50 and CSPDarknet53 as the dual backbone networks of our model. In ResNet-50, the last three layers (pooling, full connection and softmax) are removed.
Table 2 shows the framework of ResNet-50 without the last three layers, where the square brackets represent the bottleneck blocks.
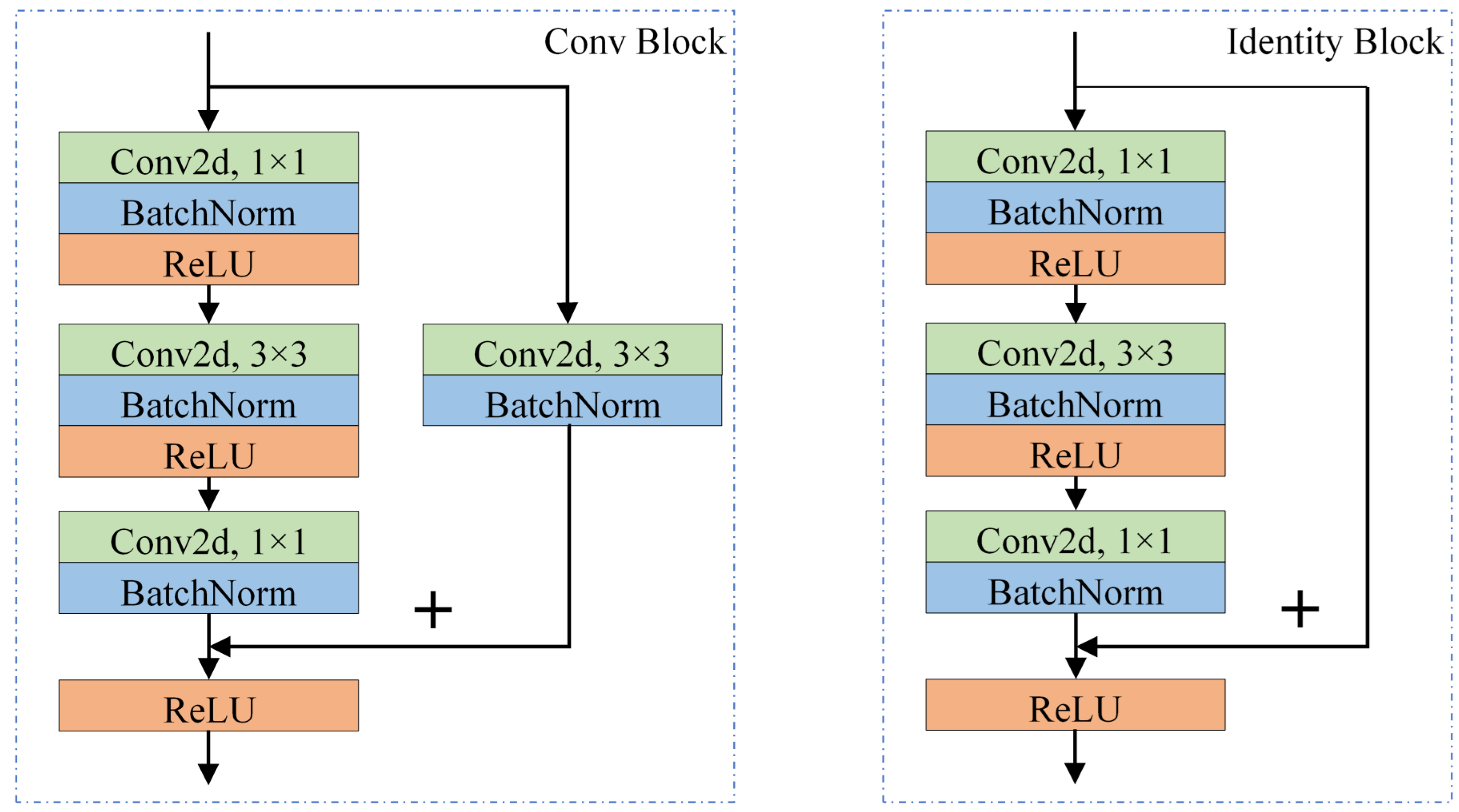
Figure 11 shows two kinds of bottleneck frameworks composed of three convolutional layers named Conv Block and Identity Block. In both blocks, the shortcut connections simply perform one conv or identity mapping, and their outputs are added to the outputs of the stacked layers. Conv mapping with a stride size of 2 halved the size of the input feature map. Therefore, in many stacked blocks, downsampling is performed by the Conv Block first. The stacked layers are composed of three convolutional layers with filter sizes of
,
and
. The
layers are responsible for reducing and then increasing dimensions, leaving the
layer with smaller input/output dimensions. Batch normalization and linear rectification activation functions (ReLUs) are used in the bottleneck block. Three feature maps are output after Conv3_4, Conv4_6, and Conv5_3, called F1, F2, and F3.
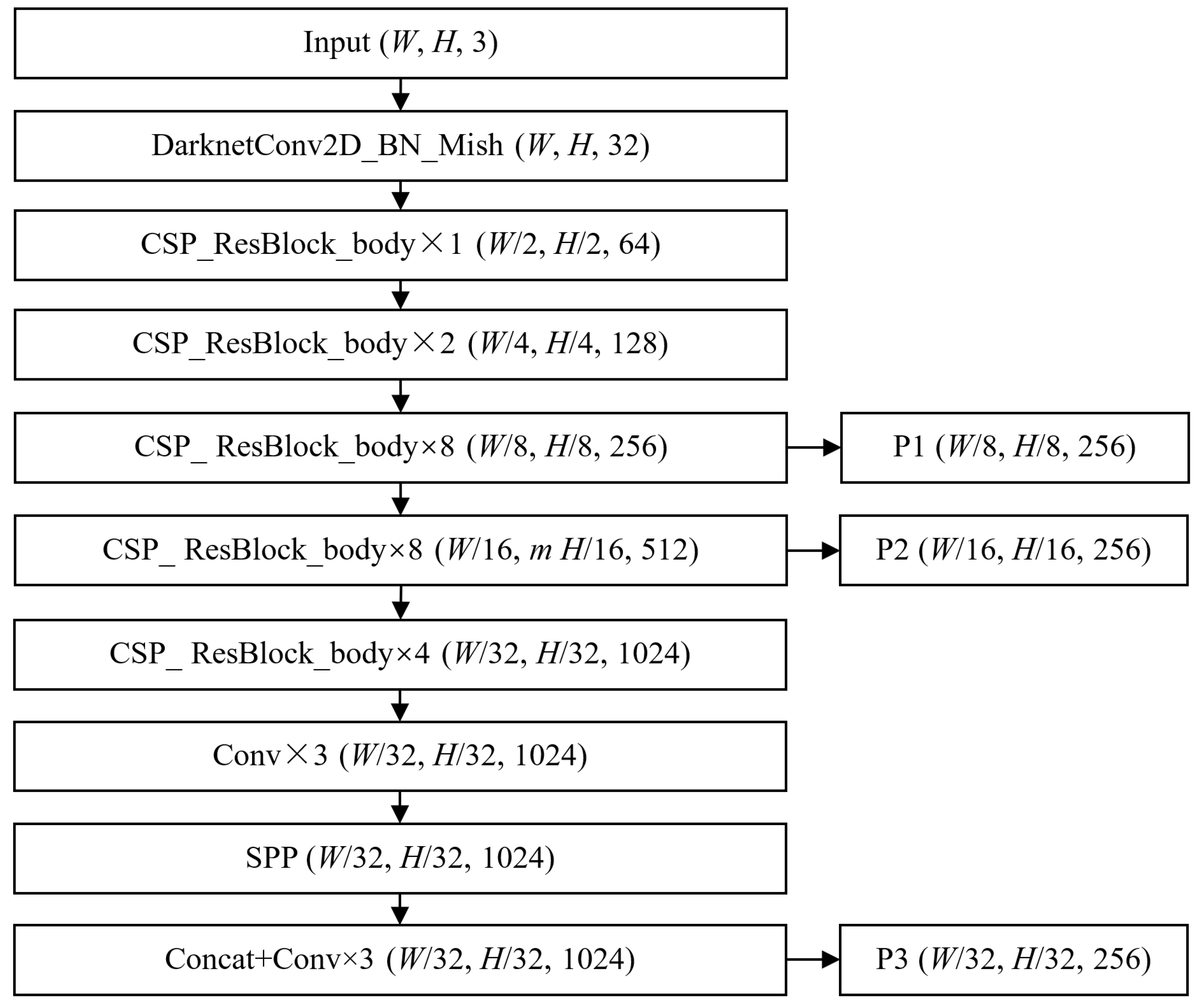
CSPDarknet53 is the backbone of YOLOv4, which employs a CSPNet strategy to partition the feature map of the base layer into two parts and then merge them through a cross-stage hierarchy. In CSPDarknet53, the first stacked layers are composed of convolution, batch normalization, and Mish activation functions (as shown in Equation (
1)). Downsampling is performed after each stacked block is composed of several ResBlock bodies with the CSPNet strategy. After that, the SPP-block is used to enhance the receptive field. The whole CSPDarknet53 outputs three feature maps with different scales, called P1, P2, and P3.
Figure 12 shows the structure of CSPDarknet53 and its output feature maps.
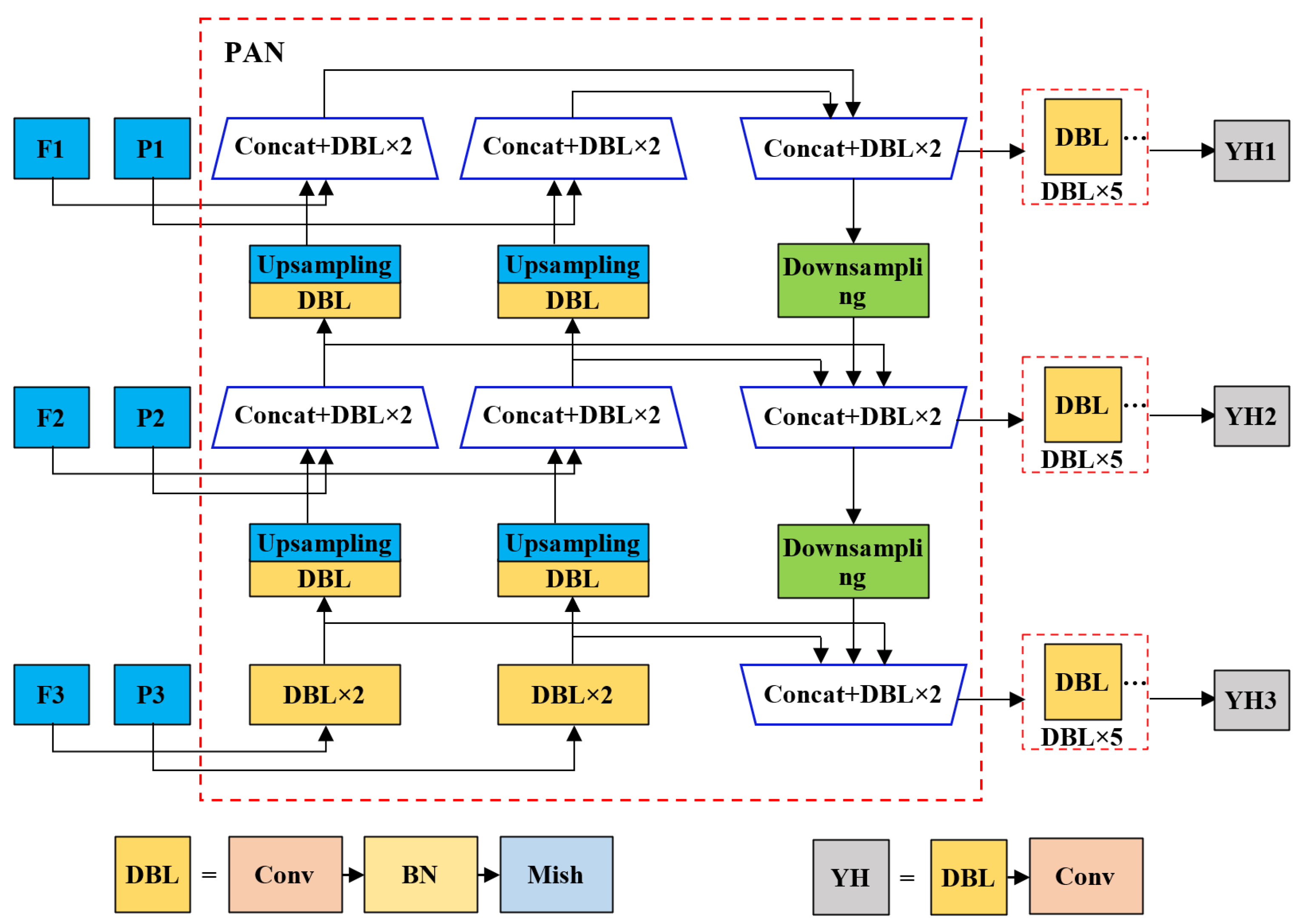
3.2.2. PAN with a Novel Concatenation Form for Feature Fusion and Propagation
For six feature maps output from two backbones, a novel concatenation form containing all feature maps is proposed to construct a PAN. Our PAN, as the neck of the defect detection model, is conducted to fuse different scale feature maps to improve performance.
Figure 13 demonstrates the structure of our PAN. The inputs are six feature maps that are divided into three hierarchies. F1 and P1 are the largest feature maps from the shallow layer output of ResNet-50 and CSPDarknet53, respectively. Similarly, F2 and P2 are feature maps from the middle layer output of ResNet-50 and CSPDarknet53, and F3 and P3 are the smallest feature maps from the last layer output of the above two backbone networks. F3 and P3 containing semantic information of the larger receptive field are concatenated with P2 and F2 after performing upsampling, respectively. Then, identical upsampling and concatenation are performed on medium feature maps obtained in the previous concatenation and the largest feature maps. It is worth noting that the bottom-up process is a dual path since there are two sets of backbone feature maps. In the bottom-up process, the top-level mapping is obtained by concatenating the last outputs of the two previous bottom-up paths. At this point, one bottom-up path is performed to fuse features from different features and hierarchies. After the bottom-up process, PAN outputs fusion feature maps of three scales. Here, each fusion feature map is used to predict defects of different sizes.
3.2.3. Defect Prediction and Final Outputs
After PAN, five DBL layers (convolution followed by batch normalization and the mish activation function) are performed, as shown in
Figure 13. In the head module, the structure is identical to that of YOLOv3. The output of the head is three arrays with dimensions of
, which can be regarded as three feature maps with
W width,
H height, and
C number of channels. Here, the subscript
i refers to three hierarchies of defect detection,
, and
. In addition, 3 refers to the number of predicted bounding boxes, 4 contains the location information of defects, 1 is the confidence score of defects, and 6 presents the type of defects. The regression of defect location coordinates is similar to YOLOv3. First, the revised values of the coordinates relative to the anchor are output, and then the predicted coordinates of the defect are obtained based on the anchor we designed in advance. We designed nine anchors by utilizing the K-means algorithm. Three large anchors
are used for YH1, three medium-sized anchors
are used for YH2, and the last three small anchors
are applied to YH3. Therefore, each output contains
prediction boxes. The model outputs
predicted bounding boxes in total. Finally, NMS is applied to obtain the final prediction results.
3.3. Objective Function
The object function (also called the loss function) of our defect detection model is identical to that of YOLOv3, which is composed of three parts: the coordinate prediction error, the intersection over union (IoU) error, and the classification error. In coordinate error, it is worth noting that the goal of location regression is the expected revised value relative to the anchor rather than the real coordinate. The total loss is defined as follows:
where
indicates that the target is detected by the
jth bounding box of grid
i. In a predicted output hierarchy,
indicates the number of grids, and
B is the number of anchors per grid. If a real box is closest to the
jth bounding box of grid
i, and
is equal to 1 at this point; otherwise, it is 0. The meaning of
is the opposite of
. The first two terms of the expression above are coordinate errors, in which
,
,
, and
are four revised values of the predicted box relative to the anchor corresponding to grid
i, and
,
,
, and
are four real revised values. Terms 3 and 4 indicate the IoU error, in which
and
are the predicted confidence score and real confidence score (
) in grid
i, respectively. The last term represents classification error, in which
refers to the predicted value of the probability of the object in grid
i belonging to class
c, and
is the real value. Except for coordinate error, which adopts the mean square error, the others adopt the binary cross-entropy loss
, which is defined as follows:
3.4. Weight Optimization Algorithm
The weight optimization algorithm of deep learning is a gradient descent method based on backpropagation. The weight updated in the next step can be obtained by subtracting the product of the gradient and the learning rate from the current weight. Equation (
4) gives the expression for optimizing the network weight by the gradient descent method:
where
refers to the network weights, and
is the learning rate. Since more than one image (a batch) is input to the network each time, to comprehensively consider the loss of each batch, the batch gradient descent algorithm is generally used; that is, the average gradient is calculated by using the whole training set of each batch. Adaptive moment estimation (Adam) [
42] for stochastic optimization proposed by Diederik et al. is widely utilized in the field of image recognition, which can adjust the learning rate adaptively and can consider the cumulative effect of the gradient by introducing first and second gradient moments. Hence, we also use Adam for the optimization of our defect detection model.
5. Results and Discussion
In this section, we adopt the commonly used indicators mAP, recall, and precision to evaluate the defect detection model we proposed in this study. In addition to training and testing our model, we also built and trained YOLOv4 [
43] by utilizing our defective blade images with the raw input size,
. We used 427 defect samples for testing.
Table 4 gives the details of the testing sets. The comparison results of the proposed DBFF-YOLOv4 and YOLOv4 with the raw input size are presented in
Table 5. The results show that the DBFF-YOLOv4 we built in this study has obvious advantages for defect detection of aeroengine blades; its mAP is up to 99.58%, and the average recall within the score threshold of 0.5 is up to 91.87%. The performance of DBFF-YOLOv4 in mAP, precision, and recall significantly improved compared with YOLOv4.
To evaluate the performance of the DBFF-YOLOv4 framework on defect feature extraction, the YOLOv4 framework with different backbones was built and trained for comparison by applying our defect cropping method and data augmentation. The image input size remains
in all models. All models were tested with the same testing set. We evaluated five models, in which four models for comparative research were built based on the YOLOv4 framework with the backbones of VGG16, ResNet-50, ResNet-101 and CSPDarknet-53. The results are exhibited in
Table 6,
Table 7 and
Table 8. The comparison results of AP, mAP, and FPS in
Table 6 show that our defect detection framework DBFF-YOLOv4 has the optimal performance, with a 1.54% improvement in mAP compared with the YOLOv4 framework with the backbone of CSPDarknet-53 (AP for remainder improved 0.174%, broken core improved by 0.03% and cold shut improved by 9.09%). The AP of our framework in the broken core, gas cavity, crack, and cold shut was up to 100%. Although the detection time consumption increased (37.32 ms vs. 25.86 ms), the improvement of accuracy is desirable for the quality management of aeroengine blades. These results demonstrate that our defect detection framework DBFF-YOLOv4 outperformed the others. In four models based on the YOLOv4 framework, the model with the backbone of ResNet-101 has the most layers and the lowest performance. The possible reason is that too many layers lead to overfitting.
The comparison results of recall and precision in
Table 7 and
Table 8 show that our DBFF-YOLOv4 model outperformed the other models in average recall and precision. Compared with the YOLOv4 framework using the backbone of CSPDarknet-53, our model gained 1.46% and 0.7% improvement in recall of slag inclusion and remainder when the score threshold was 0.5, and the precision on slag inclusion and remainder improved by 0.06% and 1.54%. It is worth noting that the precision of our model on the remainder, broken core, gas cavity crack, and cold shut was up to 100% when the score threshold is 0.5, and the average precision for all defects was 99.9%.
We further studied the effectiveness of our cropping method and data augmentation on the detection performance of our DBFF-YOLOv4 model.
Table 9 shows the mAP, average precision, and recall of DBFF-YOLOv4 using our cropping method and data augmentation. The results show that the mAP, average precision, and recall of DBFF-YOLOv4 significantly improved by using our cropping (nine cropping times) and data augmentation. This is especially true for nine cropping times, which expanded the number of the dataset to 9 times, and with 59.19%, 27.01% and 62.49% improvement in mAP, average precision and average recall, respectively. Our data augmentation (rotation, flipping, brightness increasing and decreasing) is also effective at improving the prediction accuracy of model detection and classification. The results show that the mAP of our model using only nine cropping times was 97.05%, and it reached 99.58% if using data augmentation based on this, with an improvement of 2.53%.
Although our model DBFF-YOLOv4 reached satisfactory performance for defect detection of aeroengine blades, missed and incorrect detection still exists.
Figure 15 presents an example of the visual test results. The first two lines in
Figure 15 exhibit the results of correct detection, in which ‘S’ refers to slag inclusion, ‘DX’ refers to broken core, ‘DYW’ refers to remainder, ‘A’ refers to gas cavity, ‘C’ refers to crack, and ‘CI’ refers to cold shut. The last two lines show the results of missed detection. The result demonstrates that our model fails to detect defects with extremely small sizes and excessively fuzzy outlines. The characteristics of these defects are extremely weak, containing little feature information, and the defects are similar to the background, which is the main reason for the failure of detection.
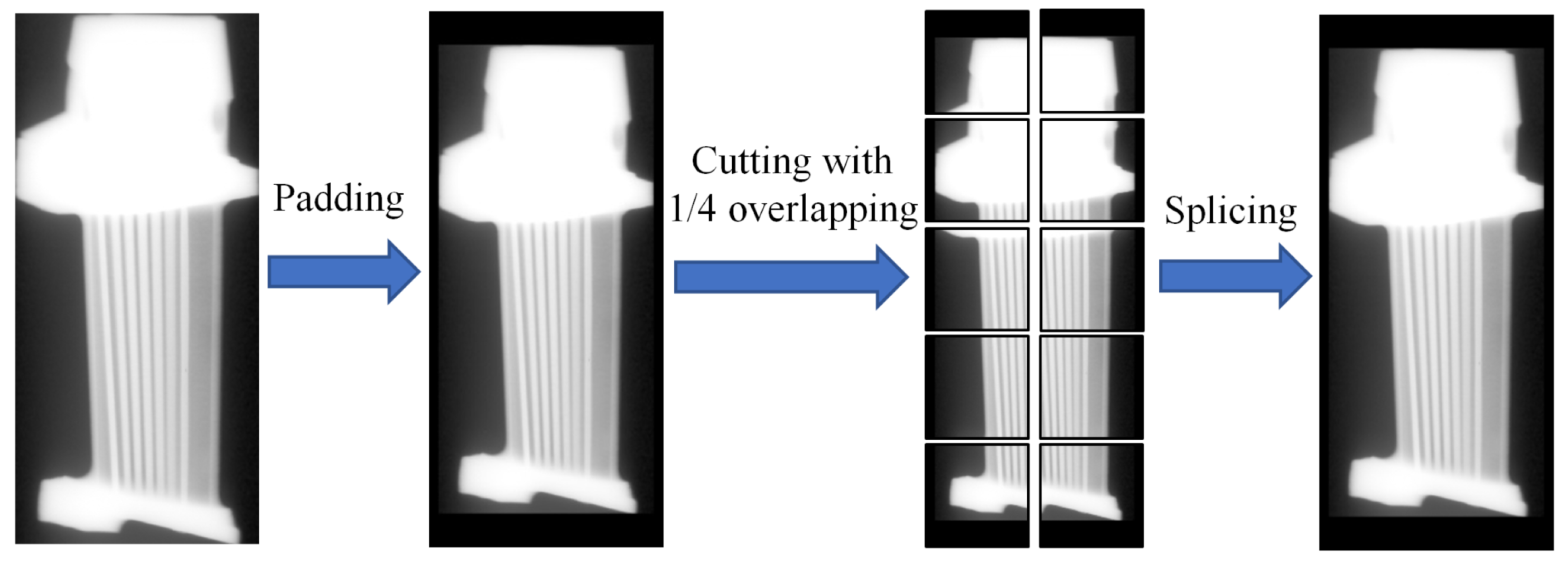
The input of DBFF-YOLOv4 is 256 × 256 cutting images. However, it is necessary to detect a single complete blade image in real quality management of turbine blades. For this reason, an image cutting module and splicing module were added before and after DBFF-YOLOv4, respectively. A quarter size overlapping strategy of adjacent cutting pictures was used for cutting and splicing module. Finally, a defect detection and recognition system was established for testing and output of complete turbine blade X-ray images. An example of blade image cutting and splicing is shown in
Figure 16. The testing process with defect detection system is as follows. First, the size of turbine blade X-ray images was calculated, and original images were padding and cutting with the size of 256×256 in cutting module. Next, the cutting pictures were input to DBFF-YOLOv4 in sequence for testing, and the results containing defect type, confidence and prediction box of each cutting picture were output visually. Finally, these cutting pictures with visual testing results were pieced into a complete turbine blade image in splicing module.
We chose 527 complete X-ray images of turbine blades for the system testing, in which 427 images are defective and 100 are nondefective. The results show that the average recall of defect detection system is 91.87% within the score threshold of 0.5, which is consistent with that of the DBFF-YOLOv4 model, while its average precision is reduced from 99.9% to 96.7%. For 100 nondefective blades, the defect detection and recognition system has a false rate of 7%. An example of visual testing results for complete turbine blades is shown in
Figure 17. Because the defect detection system detects the complete X-ray images of turbine blades, a large number of nondefective cutting pictures are detected additionally compared with the previous testing only using a DBFF-YOLOv4 model. Some cutting pictures of pseudo defects and similar defects may be the main reason for the high false rate of the detection system.
6. Conclusions and Future Work
Radiographic testing is a general approach for quality management of aeroengine turbine blades. In this study, a new defect detection method was given by combining radiographic testing with computer vision. A dual backbone detection framework DBFF-YOLOv4 based on a one-stage object detection algorithm was developed for X-ray images of aeroengine turbine blades by employing two DCNNs to extract hierarchical defect features. In the present DBFF-YOLOv4 framework, PAN (path aggregation network) with a novel concatenation form containing all feature maps was introduced. It plays an important role in the defect detection framework for fusing different scale feature maps, enhancing valid feature propagation. The results show that the present defect detection model can obtain 99.58% mAP (with 99.9% average precision and 91.87% average recall within the score threshold of 0.5), outperforming others built by using the common object detection algorithm YOLOv4 directly. Cropping nine times and data augmentation methods greatly increased the number of samples and proved to be extremely helpful in improving the accuracy of the defect detection model, which obtained 59.19%, 27.01% and 62.49% improvements in mAP, average precision and recall, respectively. In addition, the defect detection and recognition system established for testing and visual output of complete turbine blade X-ray images can obtain a recall rate of 91.87%, a precision rate of 96.7%, and a false detection rate of 7% within the score threshold of 0.5. The present defect detection system can be applied as an auxiliary tool for manual film evaluation to improve the detection efficiency in traditional radiographic testing of aeroengine turbine blades.
The current defect detection system still exhibits missed and incorrect detection, especially for detecting defects with small sizes and fuzzy outlines. In real engineering applications, most X-ray images are non-defect. These non-defect big data were not well utilized in our model training and testing. Further work will focus on small target detection and weak feature information extraction technology, and the research of defect detection algorithm based on unsupervised deep learning for real engineering applications. In addition, generative adversarial networks (GANs) [
44,
45] will be studied for further data augmentation of defect samples.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}