1. Introduction
Sequential Monte Carlo (SMC) algorithm is a simulation-based procedure used in Bayesian frameworks for drawing distributions. Its core idea relies on an iterated application of the importance sampling technique to a sequence of distributions converging to the distribution of interest
1. For many years, on-line inference was the most relevant applications of SMC algorithms. Indeed, one powerful advantage of sequential filtering consists in being able to update the distributions of the model parameters in light of new coming data (hence the term on-line) allowing for an important time saving compared to off-line methods such as the popular Markov-Chain Monte-Carlo (MCMC) procedure that requires a new estimation based on all the data at each new observation entering in the system. Other SMC features making it very promising are an intuitive implementation based on the importance sampling technique ([
1,
2,
3]) and a direct computation of the marginal likelihood (
i.e., the normalizing constant of the targeted distribution, see, e.g., [
4]).
Recently, the SMC algorithms have been applied to infer static parameters, field in which the MCMC algorithm excels. Neal [
5] provides a relevant improvement in this direction by building a SMC algorithm, named annealed importance sampling (AIS), that sequentially evolves from the prior distribution to the posterior distribution using a tempered function, which basically consists in gradually introducing the likelihood information into the sequence of distributions by means of an increasing function. To preclude particles degeneracies, he uses an MCMC kernel at each SMC iteration. Few years later, [
6] proposes an Iterated Batch Importance Sampling (IBIS) SMC algorithm, a special case of the Re-sample Move (RM) algorithm of [
7], which sequentially evolves over time and adapts the posterior distribution using the previous approximate distribution. Again, an MCMC move (and a re-sampling step) is used for diversifying the particles. The SMC sampler (see [
8]) unifies, among others, these SMC algorithms in a theoretical framework. It is shown that the methods of [
5,
7] arise as special cases with a specific choice of the ’backward kernel function’ introduced in their paper. These researches have been followed by empirical works (see [
9,
10,
11]) where it is demonstrated that the SMC mixing properties often dominate the MCMC approach based on a single Markov-chain. Nowadays papers are devoted to build self-adapting SMC samplers by automatically tuning the MCMC kernel (e.g., [
12]), by marginalizing the state vector (in a state space specification) using the particle MCMC framework (e.g., [
13,
14]), to construct efficient SMC samplers for parallel computations (see [
15]) or to simulate from complex multi-modal posterior distributions (e.g., [
16]).
In this paper, we document a generic SMC inference for change-point models that can additionally be updated through time. For example, in a model comparison context the standard methodology consists in repeating estimations of the parameters given an evolving number of observations. In circumstances where the Bayesian estimation is highly demanding as it is usually the case for complex models and where the number of available observations is huge, this iterative methodology can be too intensive. Change-point (CP) Generalized Autoregressive Conditional Heteroskedastic (GARCH) processes may require several hours for one inference (e.g., [
17]). A recursive forecast exercise on many observations is therefore out of reach. Our first contribution is a new SMC algorithm, called tempered and time (TNT), which exhibits the AIS, the IBIS and the RM samplers as special cases. It innovates by switching over tempered and time domains for estimating posterior distributions. For instance, it firstly iterates from the prior to the posterior distributions by means of a sequence of tempered posterior distributions. It then updates in the time dimension the slightly different posterior distributions by sequentially adding new observations, each SMC step providing all the forecast summary statistics relevant for comparing models. The TNT algorithm combines the tempered approach of [
5] with the IBIS algorithm of [
6] if the model parameters are static or with the RM method of [
7] if their support evolves with the SMC updates. Since all these methods are built on the same SMC steps (re-weighting, re-sampling and re-juvenating) and the same SMC theory, the combination is achieved without efforts.
The proposed methodology exhibits several advantages over SMC algorithms that directly iterate on the time domain ([
6,
7]). In fact, these algorithms may experience high particle discrepancies. Although the problem is more acute for models where the parameter space evolves through time, it remains an issue for models with static parameters at the very first SMC steps. To quote [
6] (p. 546) :
Note that the particle system may degenerate strongly in the very early stages, when the evolving target distribution changes the most[...].
The combination of tempered and time SMC algorithms allows to limit this particle discrepancy observed at the early stage since the first posterior distribution of interest is estimated by taking into account more than a few observations. One advantage of using a sequence of tempered distributions to converge to the posterior distribution consists in the number of SMC steps that can be used. Compared to the SMC algorithms that directly iterate on time domain where the sequence of distributions is obviously defined by the number of data, the tempered approach allows for choosing this sequence of distribution and for targeting the posterior distribution of interest by using as many bridging distributions as needed.
Many SMC algorithms rely on MCMC kernels to rejuvenate the particles. The TNT sampler is no exception. We contribute by proposing several new generic MCMC kernels based on the heuristic optimization literature. These kernels are well appropriated in the SMC context as they build their updates on the particles interactions. We start by emphasizing that the DiffeRential Evolution Adaptive Metropolis (DREAM, see [
18]), the walk move (see [
19]) and the stretch one (see [
20]) separately introduced in the statistic literature as generic Metropolis-Hastings proposals are in fact standard mutation rules of the Differential Evolution (DE) optimization. From this observation, we propose seven new MCMC updates based on the heuristic literature and emphasize that many other extensions are possible. The proposed MCMC kernel is adapted for continuous parameters. Consequently, discrete parameters such as the break parameters of change-point models cannot directly be inferred from our algorithm. To solve this issue, we transform the break parameters into continuous ones which make them identifiable up to a discrete value. To illustrate the potential of the TNT sampler, we compare several CP-GARCH models differing by their number of regimes on the S&P 500 daily percentage returns.
The paper is organized as follows.
Section 2 presents the SMC algorithm as well as its theoretical derivation.
Section 3 introduces the different Metropolis-Hastings proposals which compose what we call the Evolutionary MCMC. We then detail a simulation exercise on the CP-GARCH process in
Section 4. Eventually we study the CP-GARCH performance on the S&P 500 daily percentage returns in
Section 5.
Section 6 concludes.
2. Off-line and On-Line Inferences
We first theoretically and practically introduce the tempered and time (TNT) framework. To ease the discussion, let us consider a standard state space model:
where
is a random variable driven by a Markov chain and the functions f(-) and g(-) are deterministic given their arguments. The observation
belongs to the set
with
T denoting the sample size and is assumed to be independent conditional to the state
and
θ with distribution
. The innovations
and
are mutually independent and stand for the noise of the observation/state equations. The model parameters included in
θ do not evolve over time (
i.e., they are static). Let us denote the set of parameters at time
t by
defined on the measurable space
.
We are interested in estimating many posterior distributions starting from
, where
, until
T. The SMC algorithm approximates these posterior distributions with a large (dependent) collection of
M weighted random samples
where
such that as
, the empirical distribution converges to the posterior distribution of interest, meaning that for any
-integrable function g :
:
The TNT method combines an enhanced Annealed Importance sampling
2 (AIS, see [
5]) with the Re-sample Move (RM) SMC inference of [
7]
3. To build the TNT algorithm, we rely on the theoretical paper of [
8] that unifies the two SMC methods into one SMC framework called “SMC sampler”. The TNT algorithm first estimates an initial posterior distribution, namely
, by an enhanced AIS (E-AIS) algorithm and then switches from the tempered domain to the time domain and sequentially updates the approximated distributions from
to
by adding one by one the new observations. We now begin by mathematically deriving the validity of the SMC algorithms under the two different domains and by showing that they are particular cases of the SMC sampler. The practical algorithm steps are given afterward (see
Subsection 2.3).
2.1. E-AIS : The Tempered Domain
The first phase, carried out by an E-AIS, creates a sequence of probability measures that are defined on the measurable spaces , where , is a counter and does not refer to ’real time’, p denotes the number of posterior distribution estimations and coincides with the first posterior distribution of interest . The sequence distribution, used as bridge distributions, is defined as where denotes the normalizing constant, and respectively are the likelihood function and the prior density of the model. Through an increasing function respecting the bound conditions and , the E-AIS artificially builds a sequence of distributions that converges to the posterior distribution of interest.
Remark 1: The random variables exhibit the same support E which is also shared by . Furthermore, the random variable coincides with since .
The E-AIS is merely a sequential importance sampling technique where the draws of a proposal distribution
combined with an MCMC kernel are used to approximate the next posterior distribution
, the difficulty lying in specifying the sequential proposal distribution. Del Moral, Doucet, and Jasra [
8] theoretically develop a coherent framework for choosing a generic sequence of proposal distributions.
In the SMC sampler framework, we augment the support of the posterior distribution ensuring that the targeted posterior distribution marginally arises :
where
,
is the normalizing constant, and
is a backward MCMC kernel such that
.
By defining a sequence of proposal distributions as
where
is an MCMC kernel with stationary distribution
such that it verifies
, we derive a recursive equation of the importance weight:
For a smooth increasing tempered function
, we can argue that
will be close to
. W therefore define the backward kernel by detailed balance argument as
It gives the following weights :
The normalizing constant
is approximated as
where
,
i.e., the normalized weight.
The E-AIS requires to tune many parameters : an increasing function
, the MCMC kernels with the invariant distributions
, a number of particles
M, of iterations
p, of MCMC steps
J. Adjusting these parameters can be difficult. Some guidance are given in [
16] for DSGE models. For example, they propose a quadratic tempered function
. It slowly increases for small values of
n and the step becomes larger and larger as
n tends to
p. In this paper, the TNT algorithm generically adapts the different user-defined parameters and belongs to the class of adaptive SMC algorithms. It automatically adjusts the tempered function with respect to an efficiency measure as it was proposed by [
10]. By doing so, we preclude the difficult choice of the function
and the number of iteration
p. The number of MCMC steps
J will be controlled by the acceptance rate exhibited by the MCMC kernels. The choice of MCMC kernels and the number of particles are discussed later (see
Section 3).
2.2. The Re-Sample Move Algorithm : The Time Domain
Once we have a set of particles that approximates the first posterior distribution of interest
, a second phase takes place. Firstly, let us assume that the support of
does not evolve over time (
i.e.,
). In this context, the SMC sampler framework shortly reviewed here for the tempered domain still applies. Let us define the following distributions:
Then the weight equation of the SMC sampler is equal to
which is exactly the weight equation of the IBIS algorithm (see [
6], step 1, p. 543).
Let now consider the more difficult case where a subset of the support of
evolves with
t such as
(see the state space model Equations (1) and (2)) meaning that
and
. The previous method cannot directly be applied (due to the backward kernel) but with another choice of the kernel functions, the SMC sampler also operates. Let us define the following distribution :
To deal with the time-varying dimension of , we augment the support of the artificial sequence of distributions by several new random variables (see in Equation (7)) while ensuring that the posterior distribution of interest marginally arises. Sampling from the proposal distribution is achieved by drawing from the prior distribution and then by sequentially sampling from the distributions , which are composed by a user-defined distribution and an MCMC kernel exhibiting as the invariant distribution.
Under this framework, the weight equation of the SMC sampler becomes
By setting the distributions
, where
denotes the probability measure concentrated at
i, and
, we recover the weight equation of [
7] (see Equation (20), p. 135)
Like in [
7], only the distribution
has to be specified. For example, it can be set either to the prior distribution or the full conditional posterior distribution (if the latter exhibits a closed form).
Remark 2: The division appearing in the weight Equations ((5) and (13)) can be reduced to which highly limits the computational cost of the weights.
2.3. The TNT Algorithm
The algorithm initializes the
M particles using the prior distributions, sets each initial weight
to
and then iterates from
as follows
Correction step: , Re-weight each particle with respect to the
nth posterior distribution
- –
If in tempered domain (
) :
- –
If in time domain (
) and the parameter space does not evolve over time (
i.e.,
) :
- –
If in time domain ( ) and the parameter space increases (i.e., ) :
Set
with
.
Compute the unnormalized weights : .
Normalize the weights :
Re-sampling step: Compute the Effective Sample Size (ESS) as
If where κ is a user-defined threshold then re-sample the particles and reset the weight uniformly.
Mutation step: , run J steps of an MCMC kernel with an invariant distribution for and for .
Remark 3: According to the algorithm derivation, note that the mutation step is not required at each SMC iteration.
When the parameter space does not change over time (
i.e., tempered or time domains with
), the algorithm reduces to the SMC sampler with a specific choice of the backward kernel (see Equation (
3), more discussions in [
8]) that implies that
must be close to
for non-degenerating estimations. The backward kernel is introduced for avoiding the choice of an importance distribution at each iteration of the SMC sampler. This specific choice of the backward kernel does not work for model where the parameter space increases with the sequence of posterior distributions (hence the use of a second weighting scheme when
, see Equation (
12)) but the algorithm also reduces to a SMC sampler with another backward kernel choice (see Equation (10)). In the empirical applications, we first estimate an off-line posterior distribution with fixed parameters and then by just switching the weight equation, we sequentially update the posterior distributions by adding new observations. This two phases preclude the particle degeneration that may occur at the early stage of the SMC algorithms that directly iterate on time such as the IBIS and the RM algorithms. The tempered function
allows for converging to the first targeted posterior distribution as slowly as we want. Indeed, as we are not constraint by the time domain, we can sequentially iterate as much as needed to get rid of the degeneracy problem. The choice of the tempered function
is therefore relevant. In the spirit of a black-box algorithm as the IBIS one is, the
Section 2.4 shows how the TNT algorithm automatically adapts the tempered function at each SMC iteration.
During the second phase (
i.e., updating the posterior distribution through time), one may observe high particle discrepancies especially when the space of the parameters evolves over time
4. In that case, one can run an entire E-AIS on the data
when a degeneracy issue is detected (
i.e., the ESS falls below a user-defined value
). The adaptation of the tempered function (discussed in the next section) makes the E-AIS faster than usual since it reduces the number of iteration
p at its minimum given the ESS threshold
κ. Controlling for the degeneracy issue is therefore automated and a minimal number of effective sample size is ensured at each SMC iteration.
2.4. Adaptation of the Tempered Function
Previous works on the SMC sampler usually provide a tempered function
obtained by several empirical trials
5, making these functions model-dependent. Jasra
et al. [
10] innovate by proposing a generic choice of
that only requires a few more codes. The E-AIS correction step (see Equation (
14)) of iteration
n is modified as follows
Roughly speaking, we find the value that makes the ESS criterion close to the previous one in order to keep the artificial sequence of distributions very similar as required by the choice of the backward kernel (3).
Because the tempered function is adapted on the fly using the SMC history, the usual SMC asymptotic results do not apply. Del Moral
et al. [
21] and Beskos
et al. [
22] provide asymptotic results by assuming that the adapted tempered function converges to the optimal one (if it exists).
3. Choice of MCMC Kernels
The MCMC kernel is the most computational demanding step of the algorithm and it determines the posterior support exploration, making its choice very relevant. Chopin [
6] emphasizes that the IBIS algorithm is designed to be a true “black box” (
i.e., whose the sequential steps are not model-dependent), reducing the task of the practitioner to only supply the likelihood function and the prior densities. For this purpose, a natural choice of the MCMC kernel is the Metropolis-Hastings with an independent proposal distribution whose summary statistics are derived from the particles of the previous SMC step and from the weight of the current step. The IBIS algorithm uses an independent Normal proposal. It is worth noting that this “black box” structure is still applicable in this framework that combines SMC iterations on tempered and time domains.
Nevertheless the independent Metropolis-Hastings kernel may perform poorly at the early stage of the algorithm if the posterior distribution is well behaved and at any time otherwise. We rather suggest using a new adaptative Metropolis algorithm of random walk (RW) type that is generic, fully automated, suited for multi-modal distributions and that dominates most of the other RW alternatives in terms of sampling efficiencies. The algorithm is inspired from the heuristic Differential Evolution (DE) optimization literature (for a review, see [
23]).
The DE algorithms have been designed to solve optimization problems without requiring derivatives of the objective function. The algorithms are initiated by randomly generating a set of parameter values. Afterward, relying on a mutation rule and a cross-over (CR) probability, these parameters are updated in order to explore the space and to converge to the global optimum. The mutation equation is usually linear with respect to the parameters and the CR probability determines the number of parameters that changes at each iteration. The first DE algorithm dates back to [
24]. Nowadays, numerous alternatives based on this principle have been designed and many of them display a different mutation rule. Considering a set of parameters
lying in
, the standard algorithm operates by sequentially updating each parameter given the other ones. For a specific parameter
, the mutation equation to obtain a new value
are typically chosen among the following ones
where
,
;
and
stand for random integers uniformly distributed on the support
and it is required that
when
,
F is a fixed parameter and
denotes the parameter related to the highest objective function in the swamp. Then, for each element of the new vector
, the CR step consists in replacing its value with the one of
according to a fixed probability.
The DE algorithm is appealing in an MCMC context as it has been built up to explore and find the global optimum of complex objective functions. However, the DE method has to be adapted if one wants to draw realizations from a complex distribution. To employ the mutation Equations (17)–(19) into an MCMC algorithm, we need to insure that the detailed balance is preserved, that the Markov-chain is ergodic with a unique stationary distribution and that this distribution is the targeted one. To do so, we slightly modify the mutation equations as follows
in which
;
,
is a fixed parameter,
and
are random variables driven by two different distributions defined below.
These three update rules (20)–(22) are valid in an MCMC context and have been separately proposed in the literature. The first Equation (20) refers to the DiffeRential Evolution Adaptive Metropolis (DREAM) proposal distribution of [
18] and is the MCMC analog of the DE mutation (17). In their paper, it is shown that the proposal distribution is symmetric and so that the acceptance ratio is independent of the proposal density. Also, they fix
to a very small value (such as 1e-4) and
to
because it constitutes the asymptotic optimal choice for a multivariate Normal posterior distribution as demonstrated in [
25].
6 Since the posterior distribution is rarely a Normal one, we prefer adapting
from one SMC iteration to another so that the scale parameter is fixed during the entire MCMC moves of each SMC step. The adapting procedure is detailed below. Importantly, [
18] provide empirical evidence that the DREAM equation dominates most of the other RW alternatives (including the optimal scaling and the adaptive ones) in terms of sampling efficiencies.
The second Equation (21) is an adapted version of the walk move of [
19] and can be thought as the MCMC equivalence of the mutation (18).
7 When the density
of
verifies
, it can be shown that the proposal parameter
is accepted with a probability given by
As in their paper, we set the density to
if
(with
) and zero otherwise. The cumulative density function, its inverse and the first two moments of the distributions are given by
In the seminal paper of the walk move, the parameter
is set to 2. However, we rather suggest solving the equation
in order to obtain the optimal value of
. Note that Equation (21) is slightly different from the standard walk move of [
19] in the sense that the random parameter
δ can be greater than one and also because only one realization from
is generated in order to update an entire new vector
. The latter modification is motivated by the success of the novel MCMC algorithm based on deterministic proposals (see the Transformation-based MCMC of [
26]) and by the DREAM update which also exhibits one (fixed) parameter
to propose the entire new vector.
Lastly, the third Equation (22) corresponds to the stretch move proposed in [
19] and improved by [
20]. The probability of accepting the proposal
is
when the density
of
verifies
. We adopt the same density function as in their paper which is given by
for
,
and zero otherwise. The corresponding cumulative density function, its inverse, the expectation and the variance are analytically tractable and are given by
In the standard stretch move, the parameter
is set to 2.5. Like the DREAM algorithm, the stretch move has been proven to be a powerful generic MCMC approach to generate complex posterior distributions. The method is becoming very popular in astrophysics (see references in [
20]).
Once it is recognized that all these updates are also involved in the DE optimization problems, incorporating many other techniques from the latter becomes straightforward. To highlight the potential, we extend the DREAM, the walk and the stretch moves by proposing new update equations that are derived from the trigonometric move, the standard DE mutation and the firefly optimization.
In the DE literature, [
27] suggest using a trigonometric mutation equation based on three random parameters
and their corresponding posterior density values
with
. From these quantities, the new parameter is given by
in which
for
are probabilities such that
. Similarly, we can extend the DREAM, the walk and the stretch moves using the trigonometric parameter as follows
where
with probability
and -1 otherwise. Note that due to the random variable
, the DREAM proposal (25) is still symmetric and therefore the acceptance ratio remains identical to the standard RW one.
The last two extensions are adaptations only for the stretch and the walk moves (as for the DREAM one, it does not change the initial proposal distribution). The next proposal comes from another heuristic optimization technique. The firefly (FF) algorithm, initially introduced in [
28], updates the parameters by combining the attractiveness and the distance of the particles. For our purpose, we define the FF update as
where
is a chosen constant and
,
are taken without replacement in the
remaining particles. The two new moves based on the FF equation are given by
We set of the walk move to and the constant of the stretch move is fixed to .
Regarding the last new updates, one can notice that the standard Differential Evolution mutation can also be used to improve the proposal distribution of the stretch and the walk moves. In particular, we consider the move of the DE optimization given by
in which
is a fixed constant and
,
,
are taken without replacement in the
remaining particles. Inserting this update into the stretch and the walk moves delivers new proposal distributions as follows
Similarly to the Firefly proposal, we fix of the walk move to and the constant of the stretch move is set to .
The standard DREAM, the walk and the stretch moves are typically used in an MCMC context. However, when the parameter dimension
d is large, many parallel chains must be run because, as all these updates are based on linear transformations, they can only generate subspaces spanned by their current positions. To remedy this issue in the MCMC scheme, [
18] have introduced the CR probability. Once the proposal parameter has been generated, each element is randomly kept or set back to the previous value according to some fixed probability
. Eventually, the standard MH acceptance step takes place. In contrast, these multiple chains arise naturally in SMC frameworks since the rejuvenate step consists in updating all the particles by some MCMC iterations. However, the CR probability has the additional advantage of generating many other moves of the parameters. For this reason, we also include the CR step into our MCMC kernel.
In order to test all the new move strategies,
Table 1 documents the average autocorrelation times over the multivariate random realizations (computed by batch means, see [
29]), obtained from each update rule. The dimension of each distribution from which the realizations are sampled is set to 5 and we consider Normal distributions with low and high correlations as well as a student distribution with a degree of freedom equal to 5. From this short analysis, the DREAM update is the most efficient in terms of mixing. We also observe that the additional moves perform better than the standard ones for the walk and the stretch moves.
As the posterior distribution can take many different shapes, a specific MCMC kernel which may work in bags of situations can fail for some ill posterior distributions (see for example the anisotropic density in [
20] or the twisted gaussian distribution in [
18]). An appealing automatic approach is to use several kernels which can behave differently depending on the posterior distribution. To do so, we suggest to incorporate all the generic moves in combination with a fixed CR probability into the MCMC rejuvenation step of the SMC algorithm. In practice, at each MCMC iteration, the proposal distribution is chosen among the different update Equations ((20)–(22), (25)–(31)) according to a multinomial probability
. Then, some of the new elements of the updated vector are set back to their current MCMC value according to the CR probability. The proposal is then accepted with probability that is defined either by the standard RW Metropolis ratio, by (23) or by (24) depending on the selected mutation rule.
8 By assessing the efficiency of each update equation with the Mahalanobis distance, one can monitor which proposal leads to the best exploration of the support and can appropriately and automatically adjust the probability
at the end of the rejuvenation step. More precisely, once a proposed parameter is accepted, we add the Mahalanobis distance between the previous and the accepted parameters to the distance already achieved by the selected move. At the end of each rejuvenation step, the probabilities
are reset proportionally to the distance performances of all the moves.
Two relevant issues should be discussed. First, the MCMC kernel makes interacting the particles, which rules out the desirable parallel property of the SMC. To keep this advantage, we apply the kernel on subsets of particles instead of on all the particles and we perform paralelization between the subsets. Secondly and more importantly, the SMC theory derived in
Section 2 does not allow for particle interactions. Proposition 1 ensures that the TNT sampler also works under a DREAM-type MCMC kernel.
Proposition 1. Consider a SMC sampler with a given number of particles
M and the MCMC kernels given by the proposal distribution (20) or (25). Then, it yields a standard SMC sampler with particle weights given by the Equation (
4).
Adapting the proof for the walk and the stretch moves is straightforward as the stationary distribution of the Markov-chain also factorizes into a product of the targeted distribution.
Adaptation of the Scale Parameters and
Since the chosen backward MCMC kernel in the algorithm derivation implies that the consecutive distributions approximated by the TNT sampler are very similar, we can analyze the mixing properties of the previous MCMC kernel to adapt the scale parameters
and
. Atchadé and Rosenthal [
31] present a simple recursive algorithm in order to achieve a specified acceptance rate in an MCMC framework. Considering one scale parameter (either
or
) generically denoted by
, at the end of the
SMC step, we adapt the parameter as follows :
where the function
is such that
if
and
if
, the parameter
stands for the acceptance rate of the MCMC kernel of the
SMC step and
is a user-defined acceptance rate. The function
prevents from negative values of the recursive equation and if the optimal scale parameter lies in the compact set
, the equation will converge to it (in an MCMC context). In the empirical exercise, we fix the variable
to 1e-8 for the DREAM-type move and to 1.01 for the other updates. The rate
is set to
implying that every three MCMC iterations, all the particles have been approximately rejuvenated. It is worth emphasizing that the denominator
has been chosen as proposed in [
31] but its value, which ensures the ergodicity property in an MCMC context, is not relevant in our SMC framework since at each rejuvenation step, the scale parameter
is fixed for the entire MCMC step. The validity of this adaptation can be theoretically justified by [
22].
When the parameter space evolves over time, the MCMC kernel can become model dependent since sampling the state vector using a filtering method is often the most efficient technique in terms of mixing. In special cases where the forward-backward algorithm ([
32]) or the Kalman filter ([
33]) operate, the state variables can be filtered out. By doing so, we come back to the framework with static parameter space. For non linear state space model, recent works of [
13,
14] rely on the particle MCMC framework of [
34] for integrating out the state vector. We believe that switching from the tempered domain to the time one as well as employing the evolutionary MCMC kernel presented above could even more increase the efficiency of these sophisticated SMC samplers. For example, the particle discrepancies of the early stage inherent to the IBIS algorithm is present in all the empirical simulations of [
13] whereas with the TNT sampler, we can ensure a minimum ESS value during the entire procedure.
4. Simulations
We first illustrate the TNT algorithm through a simulation exercise before presenting results on the empirical data. As the TNT algorithm is now completely defined, we start by spelling out the values set for the different parameters to be tuned. The threshold
κ is recommended to be high as the evolutionary MCMC updates crucially depend on the diversification of the particles. For that reason we set it to 0.75 M. The second threshold
that triggers a new run of the simulated annealing algorithm is chosen as 0.1 M and the number of particles is set to
. We fix the acceptance rate of the MCMC move to 1/3 and the number of MCMC iterations is set to
. This number should insure that each particle has moved away from its current position as it approximately implies 30 accepted draws. For all the simulations of the paper,
Table 2 summaries these choices.
Our benchmark model for testing the algorithm is a change-point Generalized Autoregressive Conditional Heteroskedastick (CP-GARCH) process that is defined as follows
where
,
and
with
denotes the observation when the break
i occurs. The number
K of break points are fixed before the estimation and occur sequentially (
i.e.,
). Stationarity conditions are imposed within each regime by assuming
. The
Table 3 documents the prior distributions of the model parameters.
We innovate by assuming that the regime durations
and
are continuous and are driven by exponential distributions. The duration parameters are therefore identifiable up to a discrete value since they indicate at which observation the process switches from one set of parameters to another. However it brings an obvious advantage as it makes possible to use the Metropolis update developed in
Section 3 for the duration parameters too. Consequently, we are able to update in one block all the model parameters. The TNT algorithm of the CP-GARCH models is available on the author’s website.
In this section, we test our algorithm on a simulated series and a financial time series. In addition to that, we found relevant to compare our results with the algorithm of [
35] which allows for an online detection of the breaks in the GARCH parameters. A proper comparison of the two approaches is detailed in
Appendix C.
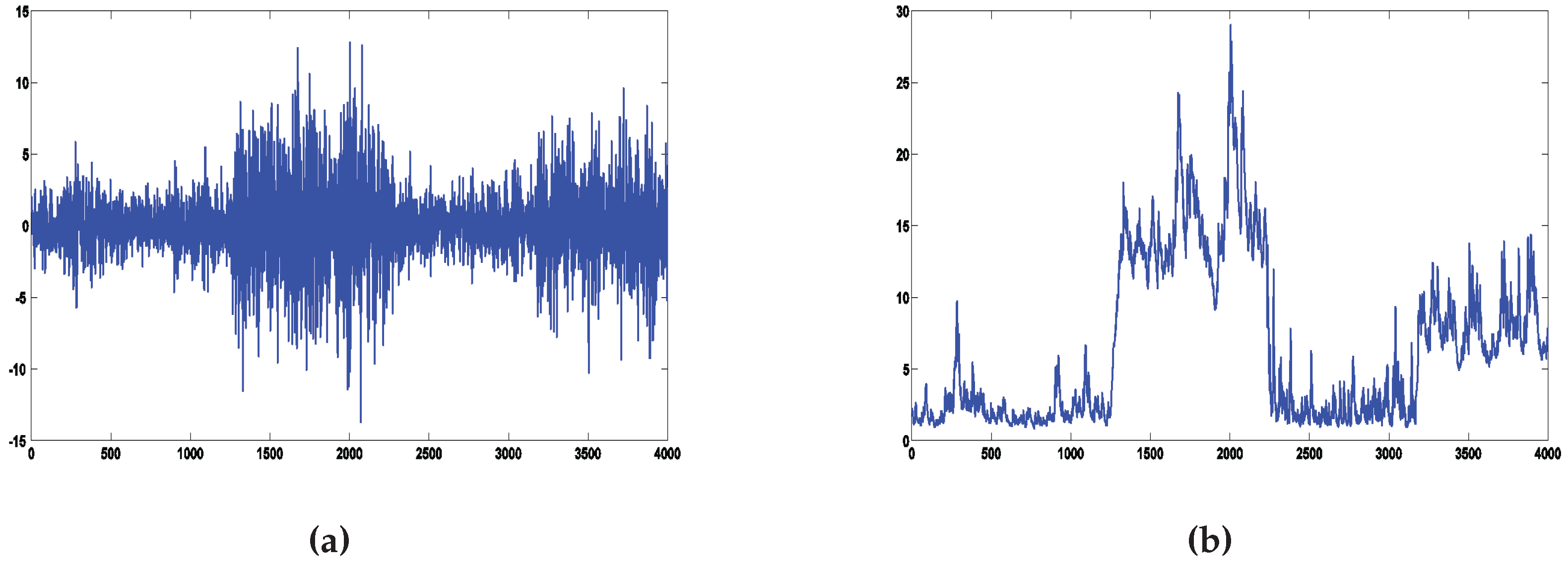
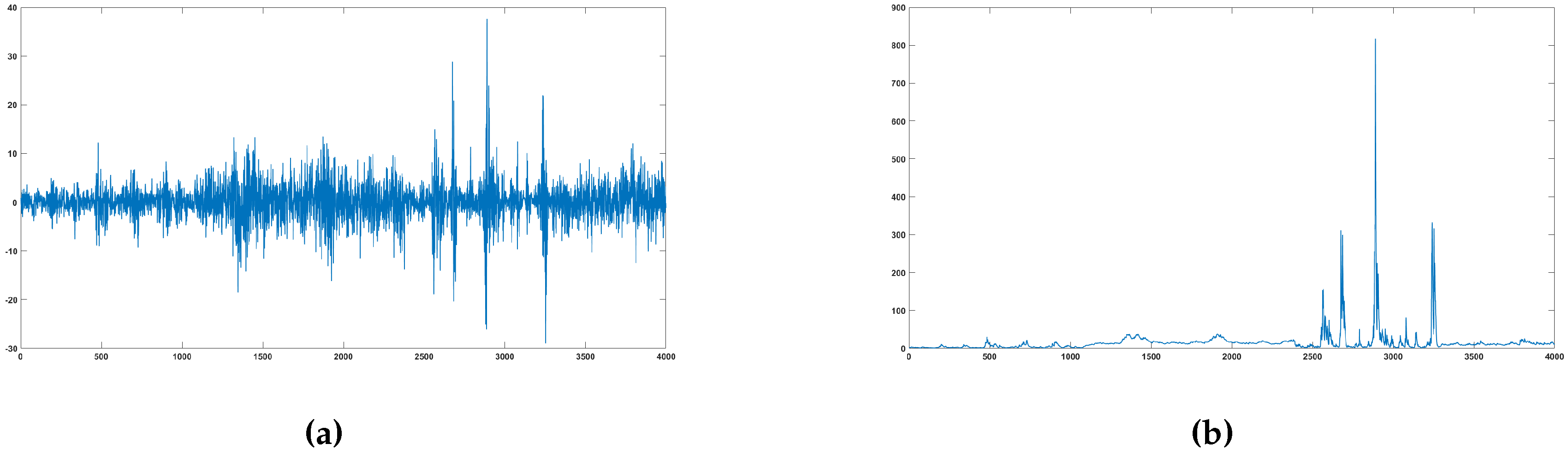
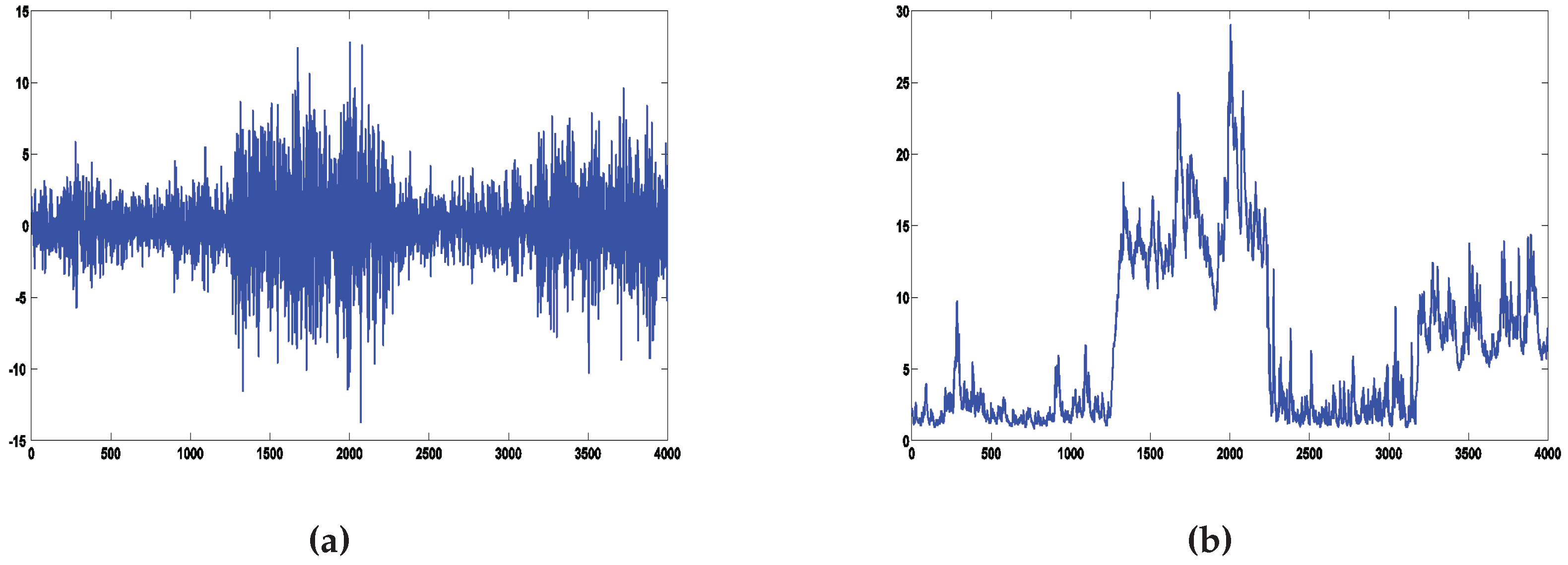
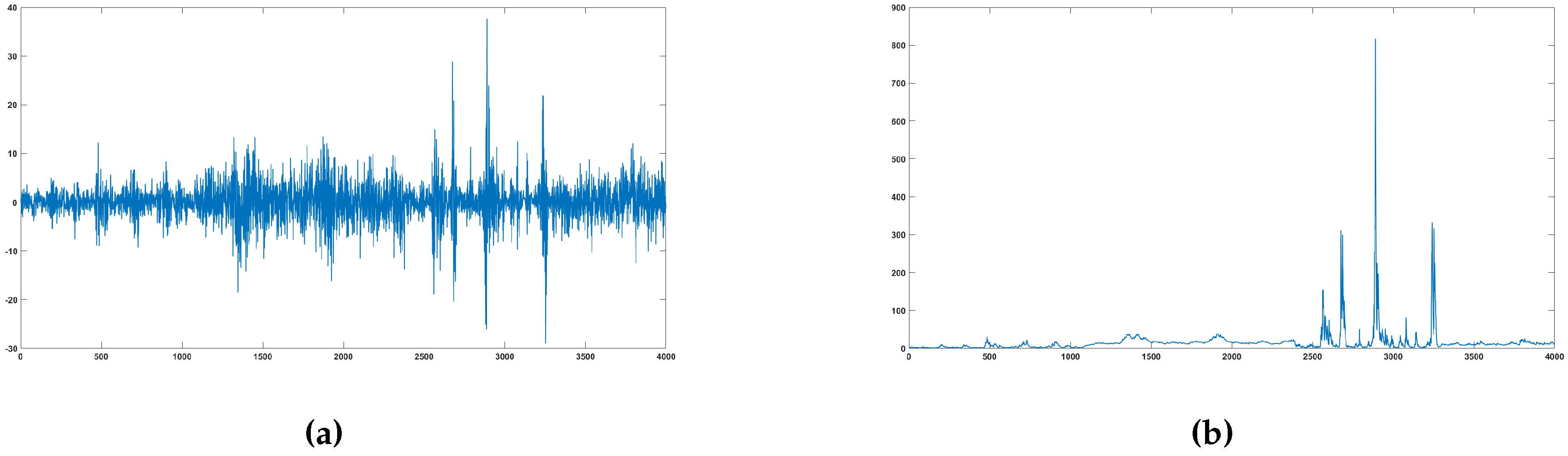
We generate 4000 observations from the data generating process (DGP) of
Table 4. The DGP exhibits four breaks in the volatility dynamic and tries to mimic the turbulent and quiet periods observed in a financial index.
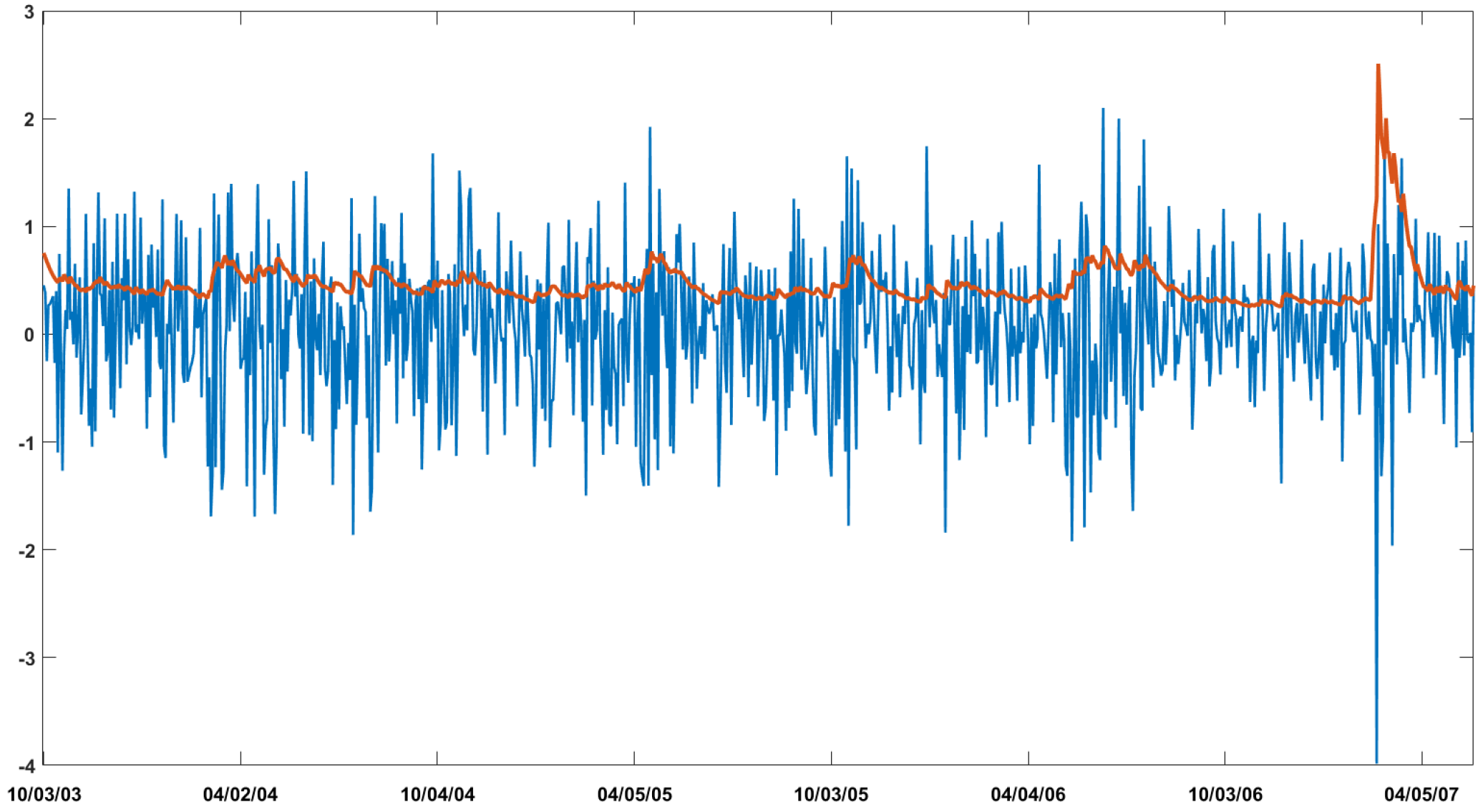
Figure 1 shows a simulated series and the corresponding volatility over time.
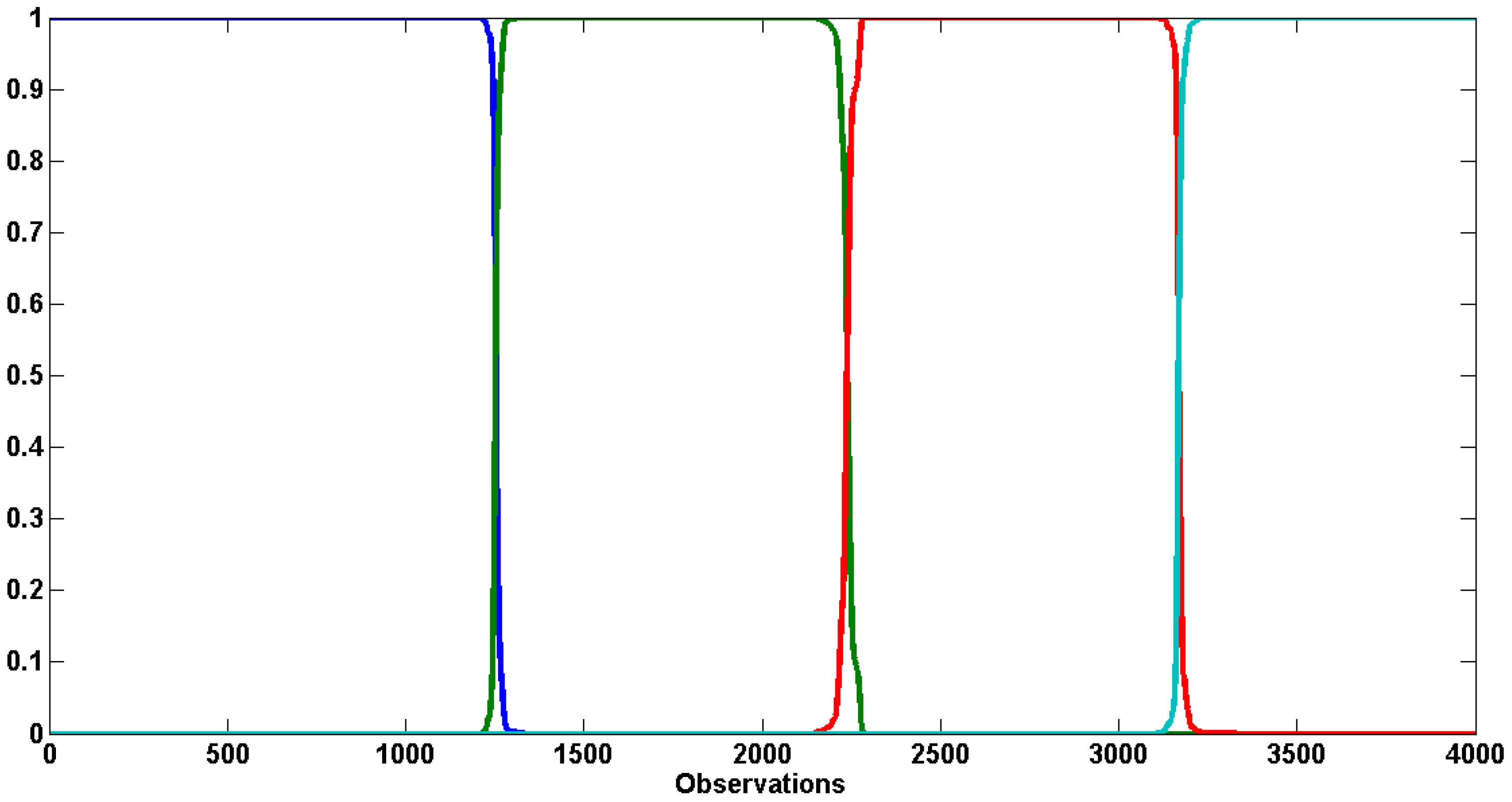
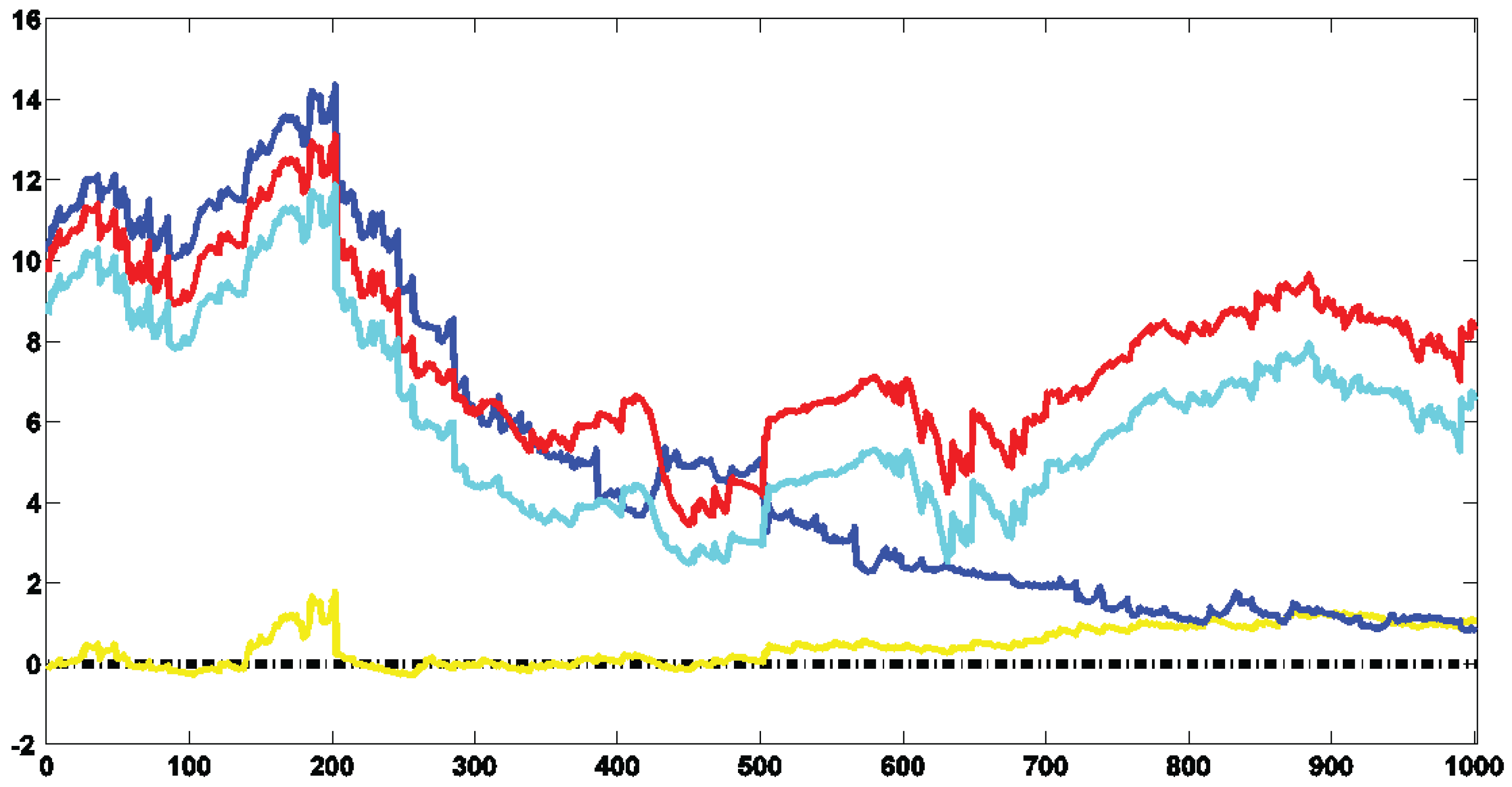
We use the marginal log-likelihood (MLL) for selecting the number of regimes by estimating several CP-GARCH models differing by their number of regimes (see [
36]). As the TNT algorithm is both an off-line and an on-line method, we start by estimating the posterior distribution with 3000 observations (
i.e.,
) and then we add one by one the remaining observations. For each model, we obtain 1001 estimated posterior distributions (from
to
) and their respective 1001 MLLs. By so doing, the evolution of the best model over time can be observed. A sharp decrease in the MLL value means that the model cannot easily capture the new observation. According to the DGP
Table 4, the model exhibiting three regimes should at least dominate over the first 170 observations and then the model with four regimes should gradually take the lead.
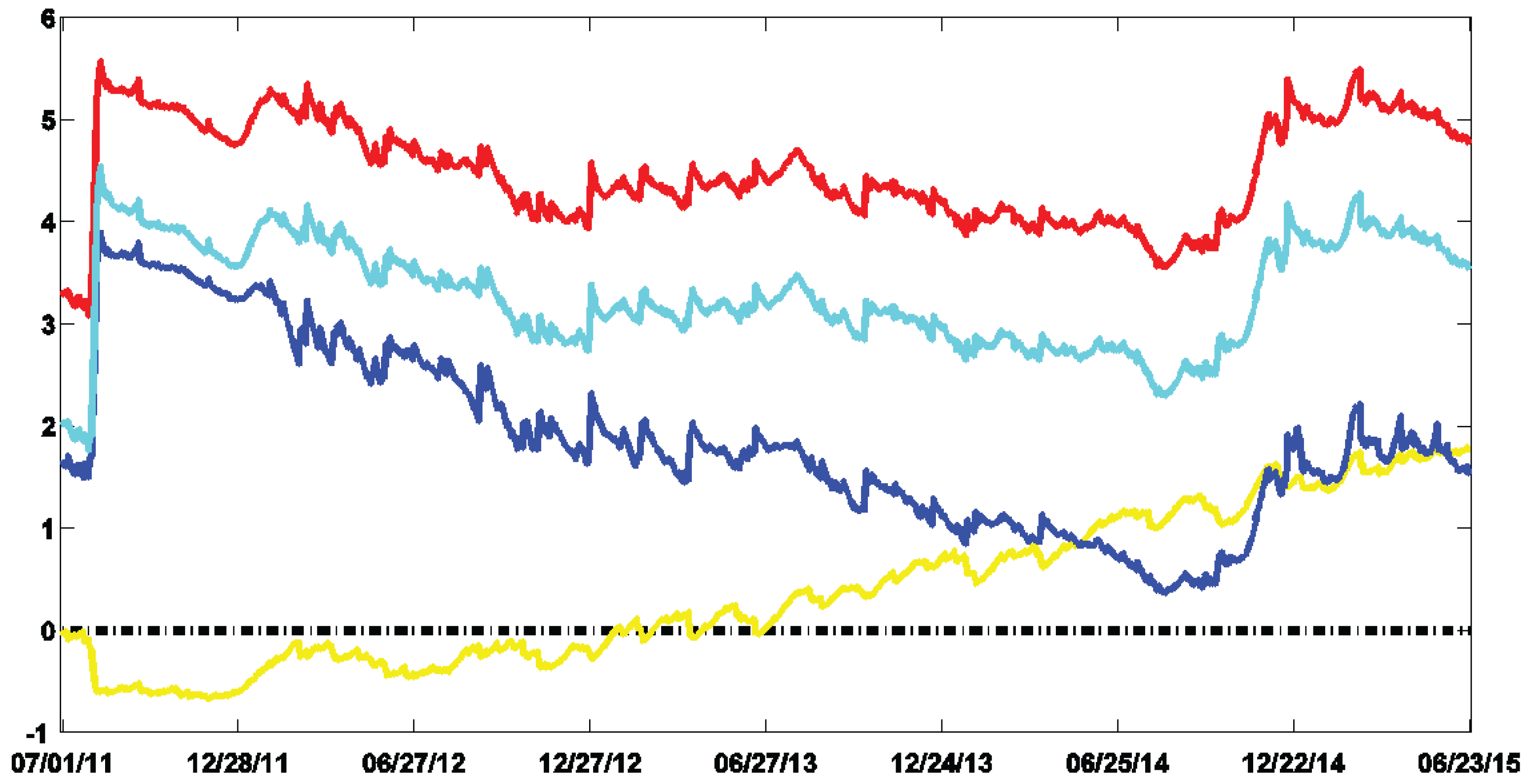
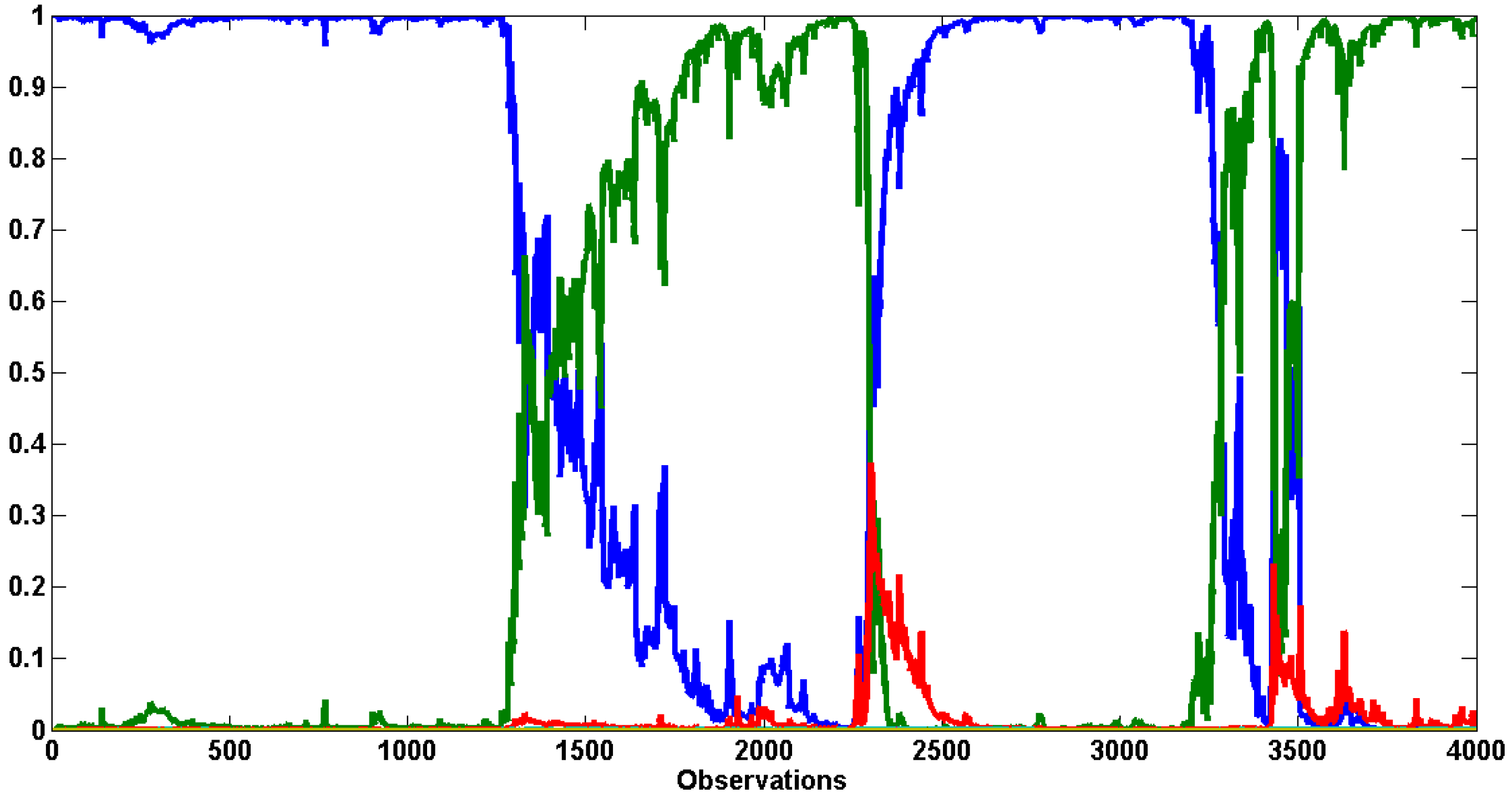
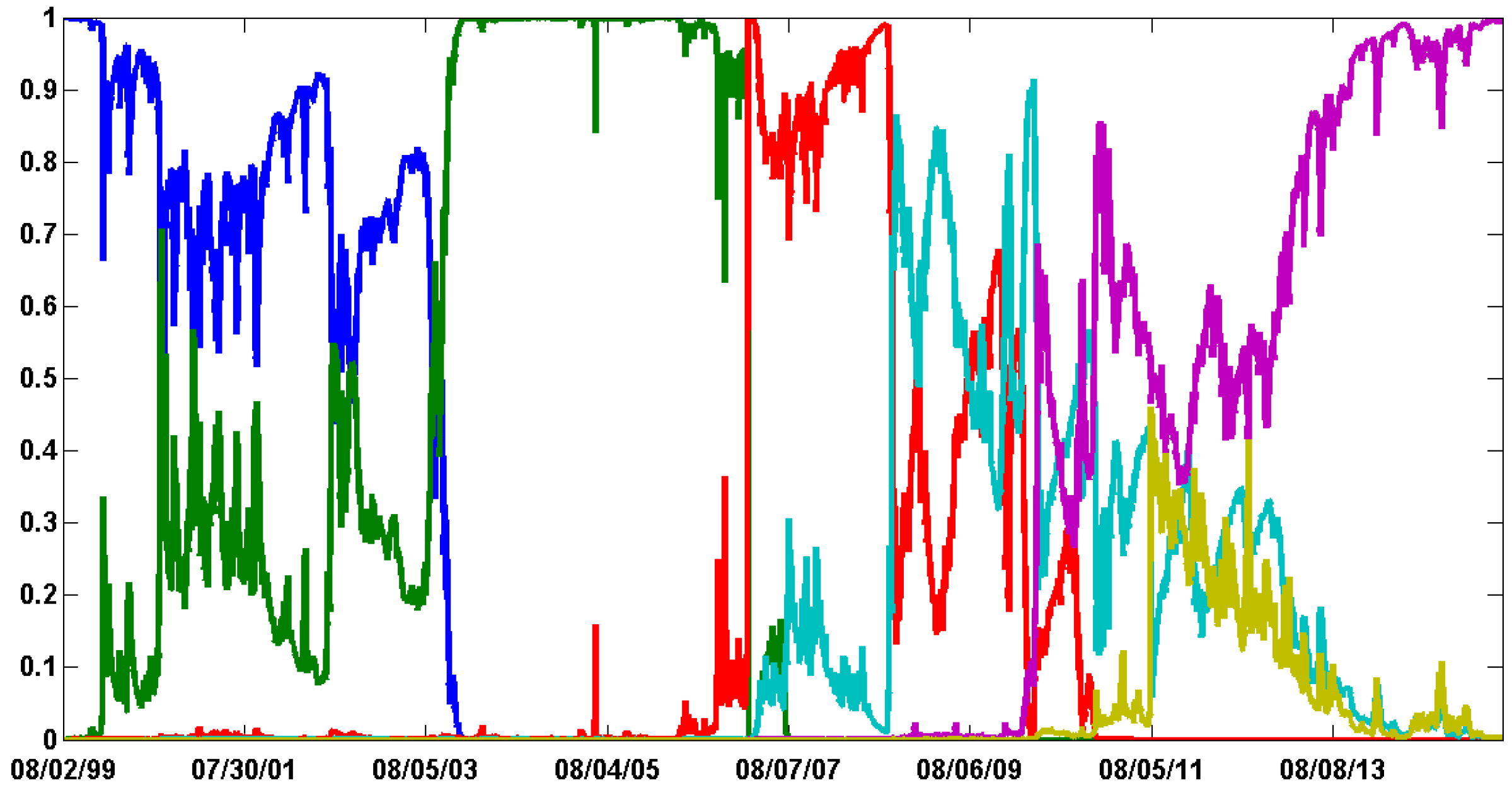
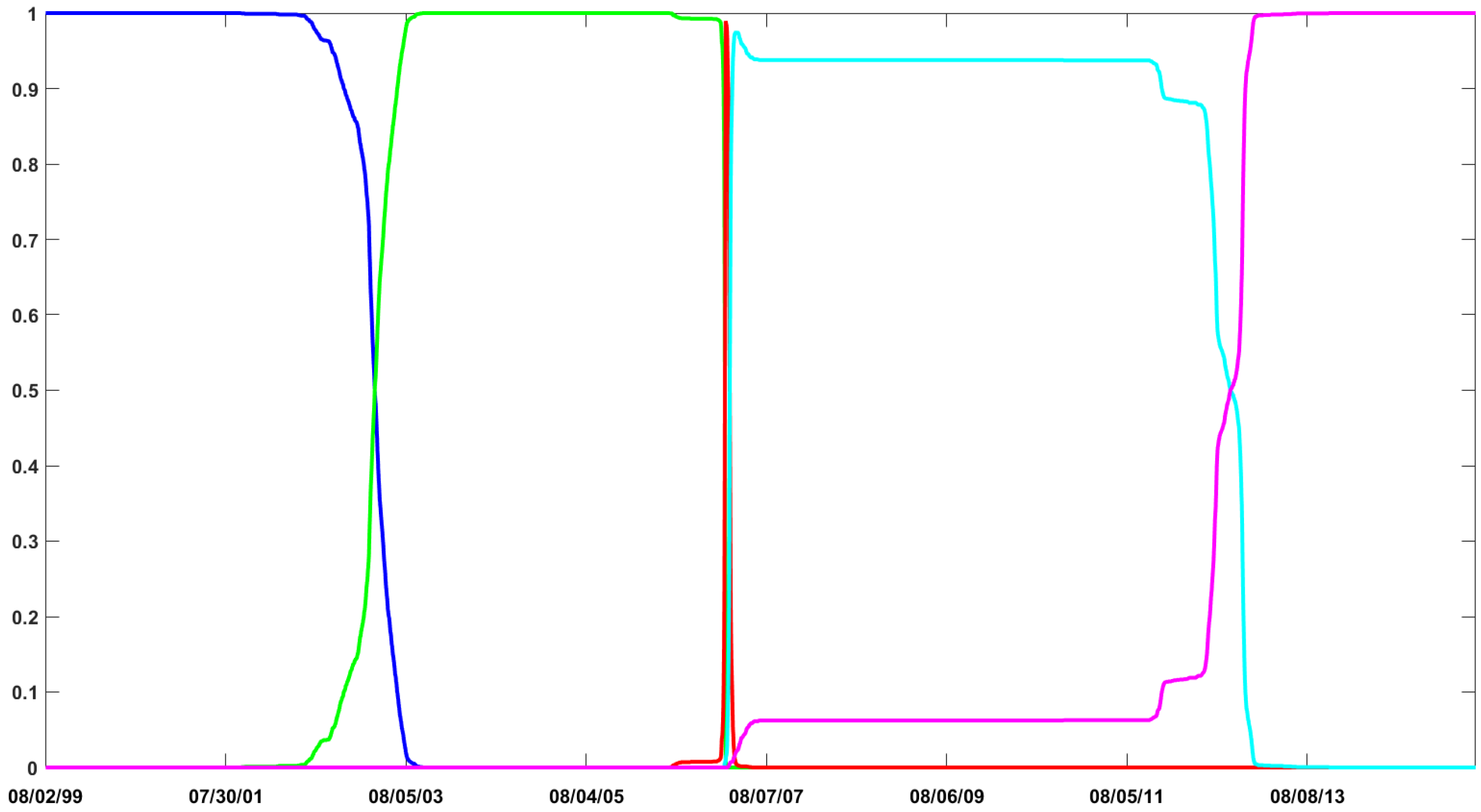
Figure 2 shows the log-Bayes factors (log-BFs) of CP-GARCH models with respect to the standard GARCH process (
i.e.,
).
9 The best model over give or take the first 300 observations is the one exhibiting three regimes. Afterward, it is gradually dominated by the process with four regimes (in red). The on-line algorithm has been able to detect the coming break and according to the MLLs, around 150 observations are needed to identify it.
Table 5 documents the posterior means of the parameters of the model exhibiting the highest MLL at the end of the simulation (
i.e., with a number of regimes equal to 4) as well as their standard deviations. We observe that the values are close to the true ones which indicates an accurate estimation of the model. The breaks are also precisely inferred. At least for this particular DGP, the TNT algorithm is able to draw the posterior distribution of the CP-GARCH models and correctly updates the distribution in the light of new observations.
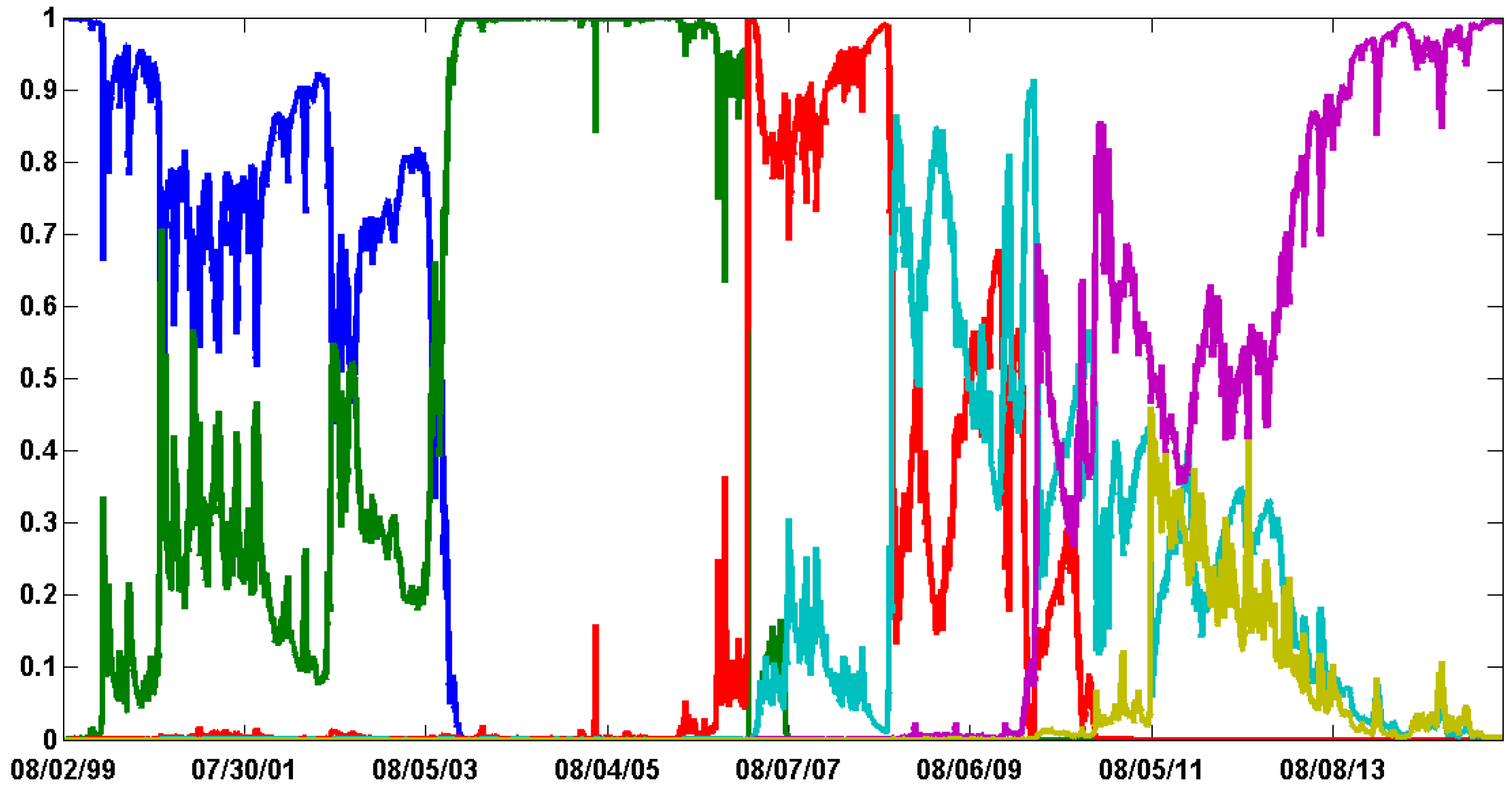
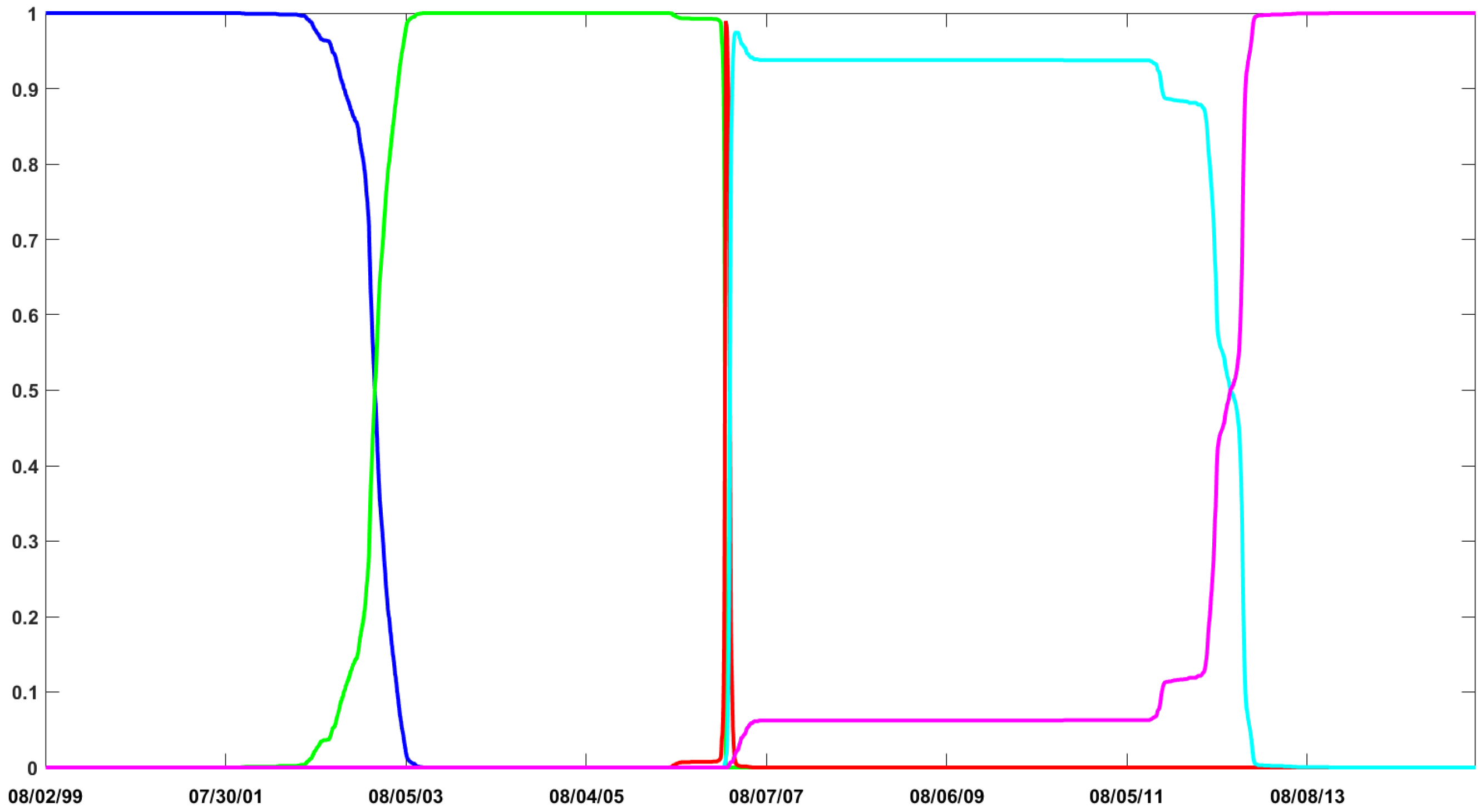
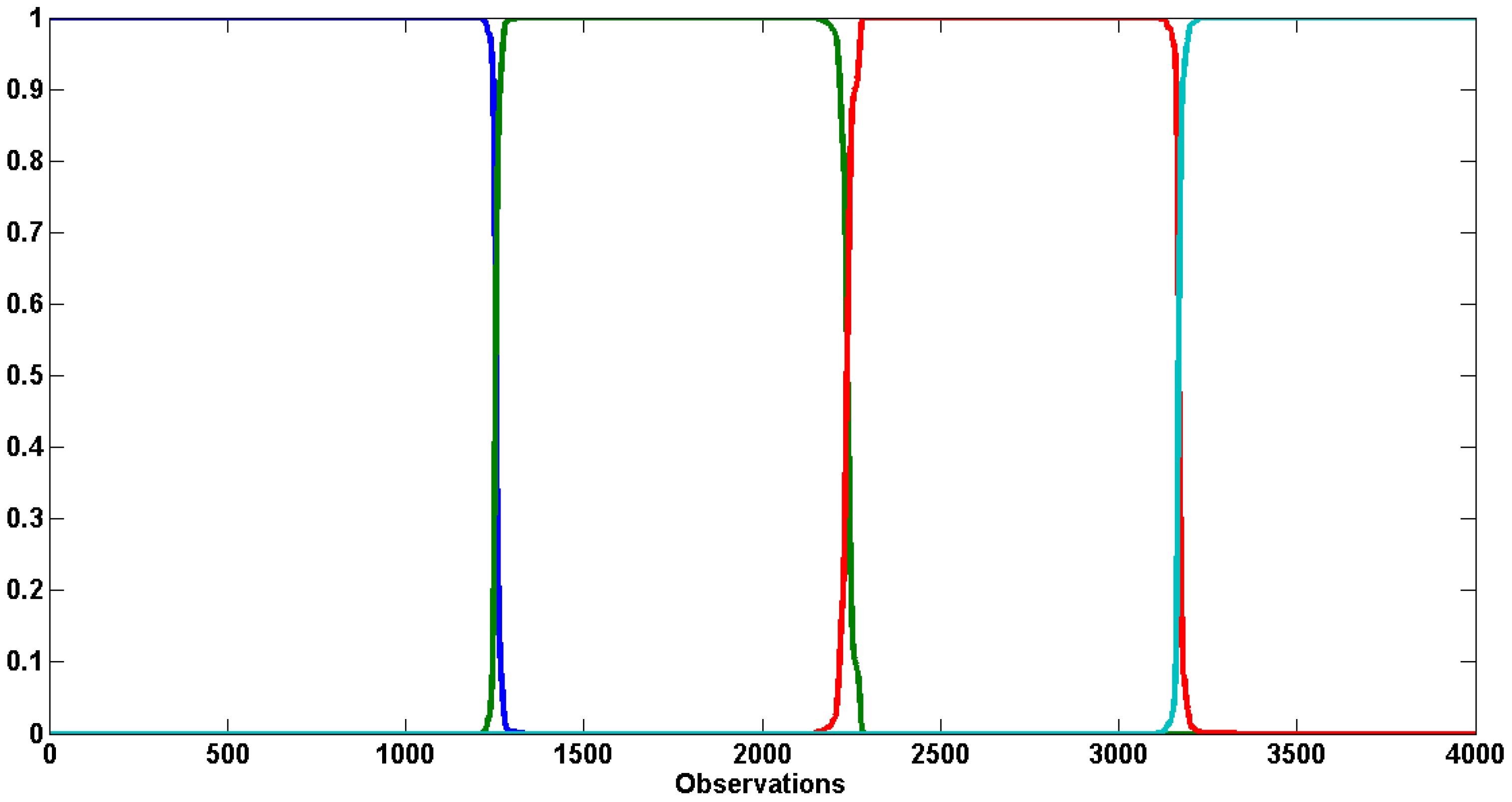
Eventually, one can have a look to the varying probabilities associated with each evolutionary update function. These probabilities are computed at each SMC iteration and are proportional to the Mahalanobis distances of the accepted draws.
Table 6 documents the values for several SMC iterations. We observe that the probabilities highly vary over the SMC iterations. Moreover, the stretch move and the DREAM algorithm slightly dominate the walk update.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}