1. Introduction
The assumption of bivariate normal and homoskedastic disturbances is a prerequisite for the consistency of the maximum likelihood estimator of the Heckman sample selection model. Moreover, some studies focus on the prediction of counterfactuals based on the Heckman sample selection model taking into account both changes in participation and outcome, which is often only feasible under the assumption of bivariate normality.
1 Lastly, under the assumption of bivariate normality one can the estimate the Heckman sample selection model by maximum likelihood methods that are less sensitive to weak exclusion restrictions.
Before employing alternative semiparametric estimators that do not need the normality assumption (see e.g., Newey, 2009 [
3]), it seems useful to test the underlying normality assumption of sample selection models. So far, the literature offers several approaches to test this hypothesis.
2 Bera
et. al., (1984) [
6] develop an LM test for normality of the disturbances in the general Pearson framework, which implies testing the moments up to order four. Lee (1984) [
7] proposes Lagrangian multiplier tests within the bivariate Edgeworth series of distributions. Van der Klaauw and Koning (1993) [
8] derive LR tests in a similar setting, while Montes-Rojas (2011) [
9] proposes LM and
tests that are likewise based on bivariate Edgeworth series expansions, but robust to local misspecification in nuisance distributional parameters. In general, these approaches tend to lead to complicated test statistics that are sometimes difficult to implement in standard econometric software. More importantly, some of these tests for bivariate normality seem to exhibit unsatisfactory performance in Monte Carlo simulations and are rejected too often in small to medium samples sizes, especially if the parameter of the Mills’ ratio is high in absolute value (see e.g., Montes-Rojas, 2011 [
9],
Table 1). This motivates Montes-Rojas (2011) [
9] to focus on the assumptions of the two-step estimator that requires less restrictive assumptions, namely a normal marginal distribution of the disturbances of the selection equation and a linear conditional expectation of the disturbances of the outcome equation. He proposes to test for marginal normality and linearity of the conditional expectation of outcome model separately and shows that the corresponding locally size-robust test statistics based on the two-step estimator perform well in terms size and power .
In a possibly neglected, but very valuable paper, Meijer and Wansbeek (2007) [
10] embed the two-step estimator of the Heckman sample selection model in a GMM-framework. In addition, they argue that within this framework it is easily possible to add moment conditions for designing Wald tests in order to check the assumption of bivariate normality and homoskedasticity of the disturbances. Their approach does not attempt to develop a most powerful test, rather they intended to design a relatively simple test for normality that can be used as an alternative to the existing tests. The test can be interpreted as a conditional moment test and checks whether the third and fourth moments of the disturbances of the outcome equation of the Heckman model conform to those implied by the truncated normal distribution. For
to hold, the test in addition requires normally distributed disturbances of the selection equation and the absence of heteroskedasticity in both the outcome and the selection equation.
Meijer and Wansbeek (2007) [
10] do not explicitly derive the corresponding test statistic nor do they provide Monte Carlo simulations on its performances in finite samples. The present contribution takes up their approach arguing that a GMM based pseudo-score LM test is well suited to test the hypothesis of bivariate normality and is easy to calculate. The derived LM test is similar to the widely used Jarque and Bera LM test (1980) [
11], and in the absence of sample selection reverts to their LM test statistic. Monte Carlo simulations show good performance of the proposed test for samples of sizes of 1000 or larger, especially if a powerful exclusion restriction is available.
2. The GMM Based Pseudo-Score LM Test for Normality
In a cross-section of
n units the Heckman (1979) [
12] sample selection model is given as
where
and
denote latent random variables. The outcome variable,
is observed if the latent variable
or, equivalently, if
.
is a
vector containing the exogenous variables of the selection equation and
is the
vector of the exogenous variables of the outcome equation.
may include the variables in
but also additional ones so that an exclusion restriction holds.
γ and
β denote the corresponding parameter vectors. Under
the disturbances are assumed to be distributed as bivariate normal,
i.e.,
It is easy to show that under these assumptions
where
denotes the inverse Mills’ ratio. Under the normal assumption one can specify
so that
.
is independent of
as
. Since
, it holds that
. Therefore, the two-step Heckman sample selection model includes the estimated inverse Mills’ ratio in the outcome equation as an additional regressor. For the observed outcome at
the model can be written as
where
and
Meijer and Wansbeek (2007) [
10] embed the two-step Heckman sample selection estimator in a GMM framework and demonstrate that the estimation can be based on
where
and
Note, there are as many parameters as moment conditions and the model is just-identified.
The first set of moment equations is based on and refers to the score of the Probit model. Since these moment conditions do not include the parameters entering and (i.e., ) and are exactly identified, estimation can proceed in steps: In the first step, one can solve and in the second step one solves the sample moment condition using the estimated derived in the first stage. This leads to the two-step Heckman estimator, which first estimates a Probit model, inserts the estimated Mills’ ratio as additional regressor in the outcome equation and applies OLS. Lastly, from one can obtain an estimator of
As Meijer and Wansbeek (2007) [
10] remark, a rough and simple test for normality can be based on two additional moment conditions that allow comparing the third and fourth moments of the estimated residuals of the outcome equation,
, with their theoretical counterparts based on the truncated normal distribution. These moment conditions use
Thereby,
denotes additional parameters that are zero under normality. More importantly, under
the expectations
can be derived recursively from the moments of the truncated normal distribution as shown in the Appendix (see alsoMeijer and Wansbeek, 2007, pp. 45–46) [
10]. In general, these moments depend on the parameters
and, especially, on the inverse Mills’ ratio
and the parameter
τ.
To detect violations of the normality assumption, one can test
and
vs.
and/or
Although this hypothesis checks the third and fourth moments of the disturbances of the two-step outcome Equation (1), it can only be true if
and
are the correct expected values. Therefore, the test additionally requires the moment conditions
and
to hold so that the parameters of both the selection equation and the outcome equation are consistently estimated. The present hypothesis is somewhat more restrictive than that tested, e.g., in Montes-Rojas (2011) [
9], who emphasizes that the Heckman two-step estimator is robust to distributional misspecification if (i) the marginal distribution of
is normal and (ii)
,
i.e., the conditional expectation is linear.
3In addition,
also requires the absence of heteroskedasticity ( see Meijer and Wansbeek, 2007, p. 46 ) [
10]. To give an example, assume that
and
are bivariate normal, but the variances of
differ across
i and are given as
(see also the DGP6 in the Monte Carlo set-up below and the excess kurtosis of DGP6 in
Table 1 below). Then, it follows that
where
and
(see the Appendix). In this case, we have
and
, while the corresponding uneven moments are zero. Hence, under heteroskedasticity
differs from that obtained under
which assumes
and
and the population moment condition
is violated. Hence, a test based on these moments should also be able to detect heteroskedasticity, although not in the most efficient way.
Applying a pseudo-score LM test (Newey and West, 1987 [
13]; Hall, 2005 [
14]), in this GMM-framework leads to a
-test statistic that can be calculated easily. In order to derive the LM test statistic, define
and
, where
. It is assumed that
=
exists, is positive definite and invertible. Under standard assumptions, it holds that
where the subscript 0 indicates that
is assumed. Thereby,
and
is the probability limit of
. Note,
is invertible as the model is just-identified.
Under
the moment conditions
referring to the third and fourth moments of the outcome equation are zero at
and
and the separability result in Ahn and Schmidt (1995,
Section 4) [
15] can be applied. Denoting the restricted estimates under
by a tilde, using the invertibility of
and the partitioned inverse of
, the pseudo-score LM test statistic can be derived as (see the Appendix for details):
Thereby,
and we use
where
, as well as the partitioned inverse (see the Appendix)
where
and
.
is obtained from Σ by deleting all rows and columns referring to
, and similarly
can be consistently estimated by plugging in
. In addition, Meijer and Wansbeek (2007) [
10] show that one can substitute
for
so that only information on the observed units is necessary. Note however, the summation runs over all observations (zero and ones in
).
Under standard assumptions it follows that under
we have
(see Newey and West, 1987, pp. 781–782 [
13] and Theorems 5.6 and 5.7 in Hall, 2005 [
14]) . In the absence of sample selection (
) it holds that
, while
and
and the LM test statistic reverts to that of Jarque and Bera (1980) [
11].
3. Monte Carlo Simulation
Monte Carlo simulations may shed light on the performance of the proposed LM test in finite samples. It is based on a design that has been used previously by van der Klaauw and Koning (1993) [
8] and Montes-Rojas (2011) [
9], but includes a few modifications. The simulated model is specified as
where for
and
The explanatory variables
, and
are generated as
and
respectively. With respect to the disturbances,
, and
the following data generating processes are considered. Note DGP1-DGP3 imply
and
In contrast, van der Klaauw and Koning (1993) [
8] and Montes-Rojas (2011) [
9] consider the case with
and thus receive less precise estimates of the slope parameters of the outcome equation.
DGP1:
DGP2:
and being independent.
The degrees of freedom are set to 10 to guarantee that the moments up to order 4 exists.
DGP3:
DGP4:
and are independent.
DGP5:
and are independent.
DGP6:
and being independent.
DGP7:
and being independent.
DGP1 serves as a reference to assess the size of the pseudo-score LM test. The second DGP deviates from the bivariate normal in terms of a higher kurtosis, while DGP3 exhibits both higher skewness and kurtosis than the normal. DGP4 allows for deviation from normality in the outcome equation, while keeping the normality assumption in the selection equation. DGP5 reverses this pattern. The disturbances of the outcome equation are normal and those of the selection equation are not. DGP6 and DGP7 introduce heteroskedasticity in either the outcome or the selection equation, respectively. In case of the latter two, the variances of and is normalized to an average of 1 and , respectively. Note, the explanatory variables are held fixed in repeated samples.
Overall, for these DGPs four experiments are considered. In the baseline Experiment 1 (first row of the figures of graphs) of the data remain unobserved and in the absence of sample selection the implied amounts to = using and . Experiment 2 (second row of the figures of graphs) analyzed the performance of the Heckman two-step estimator under a weaker exclusion restriction, assuming so that : Experiment 3 (third row of the figures of graphs) sets the constant of the outcome equation to zero so that instead of units are unobserved. Lastly, Experiments 4 (fourth row of the figures of graphs) considers a weaker fit in the outcome equation setting so that in the absence of sample selection we have
Table 1 summarizes the average variance, skewness and kurtosis of the generated disturbances
and
under Experiment 1. In DGP2-DGP7, depending on
ρ, the average kurtosis of
varies between
and
, while the kurtosis of
lies between
and
in DGP5. In the other ones the kurtosis of
is held constant taking values
(DGPs 1,4 and 6),
(DGP2),
(DGP3) and
(DGP7), respectively. The skewness coefficient of the generated disturbances is zero for all DGPs except for DGP3 with corresponding values of 0.63 (
) and
to 0.43 (
) and DGP5 where the skewness of
varies between
and
.
Table 1.
Variance, Skewness and Kurtosis of the simulated disturbances.
Table 1.
Variance, Skewness and Kurtosis of the simulated disturbances.
| DGP | ρ | | | |
|---|
| Variance | Skewness | Kurtosis | Variance | Skewness | Kurtosis |
|---|
| 1 | all | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 2.99 |
| 2 | −0.8 | 1.00 | 0.00 | 3.97 | 0.25 | 0.00 | 3.52 |
| 2 | −0.4 | 1.00 | 0.00 | 3.97 | 0.25 | 0.00 | 3.70 |
| 2 | 0.0 | 1.00 | 0.00 | 3.97 | 0.25 | 0.00 | 3.96 |
| 2 | 0.4 | 1.00 | 0.00 | 3.97 | 0.25 | 0.00 | 3.70 |
| 2 | 0.8 | 1.00 | 0.00 | 3.97 | 0.25 | 0.00 | 3.52 |
| 3 | −0.8 | 1.00 | 0.63 | 3.58 | 0.25 | −0.21 | 3.29 |
| 3 | −0.4 | 1.00 | 0.63 | 3.58 | 0.25 | 0.35 | 3.28 |
| 3 | 0.0 | 1.00 | 0.63 | 3.58 | 0.25 | 0.51 | 3.38 |
| 3 | 0.4 | 1.00 | 0.63 | 3.58 | 0.25 | 0.43 | 3.28 |
| 3 | 0.8 | 1.00 | 0.63 | 3.58 | 0.25 | 0.43 | 3.29 |
| 4 | −0.8 | 1.00 | 0.00 | 2.99 | 0.25 | 0.11 | 3.05 |
| 4 | −0.4 | 1.00 | 0.00 | 2.99 | 0.25 | 0.39 | 3.27 |
| 4 | 0.0 | 1.00 | 0.00 | 2.99 | 0.25 | 0.51 | 3.38 |
| 4 | 0.4 | 1.00 | 0.00 | 2.99 | 0.25 | 0.39 | 3.27 |
| 4 | 0.8 | 1.00 | 0.00 | 2.99 | 0.25 | 0.11 | 3.04 |
| 5 | −0.8 | 1.00 | 0.63 | 3.58 | 0.25 | 0.00 | 2.99 |
| 5 | −0.4 | 1.00 | 0.63 | 3.58 | 0.25 | 0.00 | 2.99 |
| 5 | 0.0 | 1.00 | 0.63 | 3.58 | 0.25 | 0.00 | 2.99 |
| 5 | 0.4 | 1.00 | 0.63 | 3.58 | 0.25 | 0.00 | 2.99 |
| 5 | 0.8 | 1.00 | 0.63 | 3.58 | 0.25 | 0.00 | 2.99 |
| 6 | −0.8 | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 3.34 |
| 6 | −0.4 | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 4.89 |
| 6 | 0.0 | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 5.68 |
| 6 | 0.4 | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 4.89 |
| 6 | 0.8 | 1.00 | 0.00 | 2.99 | 0.25 | 0.00 | 3.35 |
| 7 | −0.8 | 0.99 | 0.00 | 5.71 | 0.25 | 0.00 | 4.11 |
| 7 | −0.4 | 0.99 | 0.00 | 5.71 | 0.25 | 0.00 | 3.06 |
| 7 | 0.0 | 0.99 | 0.00 | 5.71 | 0.25 | 0.00 | 2.99 |
| 7 | 0.4 | 0.99 | 0.00 | 5.71 | 0.25 | 0.00 | 3.06 |
| 7 | 0.8 | 0.99 | 0.00 | 5.71 | 0.25 | 0.00 | 4.11 |
Following Davidson and MacKinnon (1998) [
16] the size and power is analyzed in terms of size-discrepancy and power-size curves. The former is based on the empirical cumulative distribution function of the
p-values,
, defined as
, where
R is the number of Monte Carlo replications. The size-discrepancy curves are defined as plots of
against
q under the assumption that
holds and DGP1 is the correct one. In addition, one can use a Kolmogorov and Smirnov test to see whether
differs significantly from 0 (see Davidson and MacKinnon 1998, p. 11) [
16]. The size-power curves plot power against size,
i.e.,
against
In both plots
and step size is
An important feature of this procedure is that it avoids size adjustments of the power curves if the tests reject too often under
.
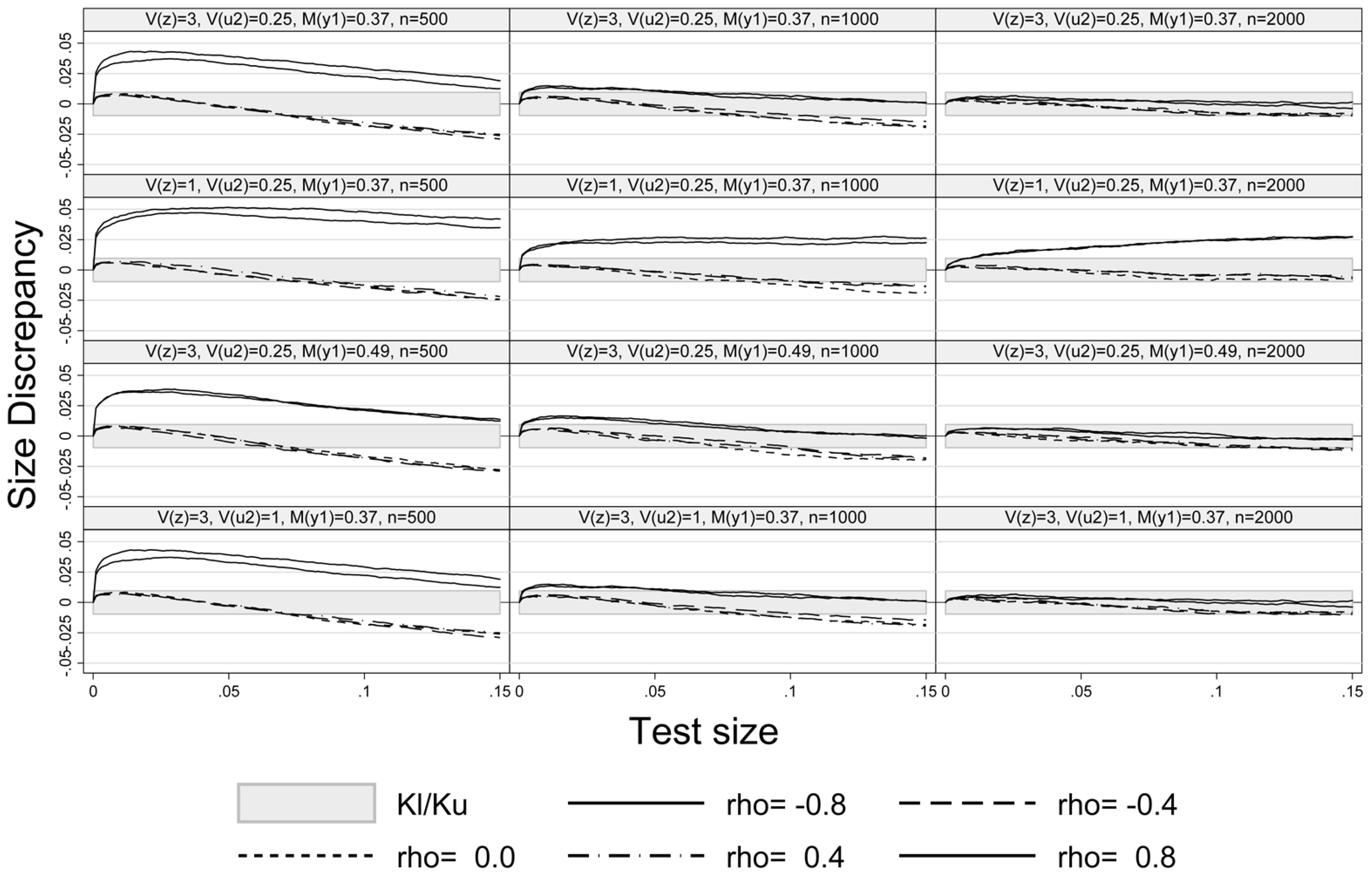
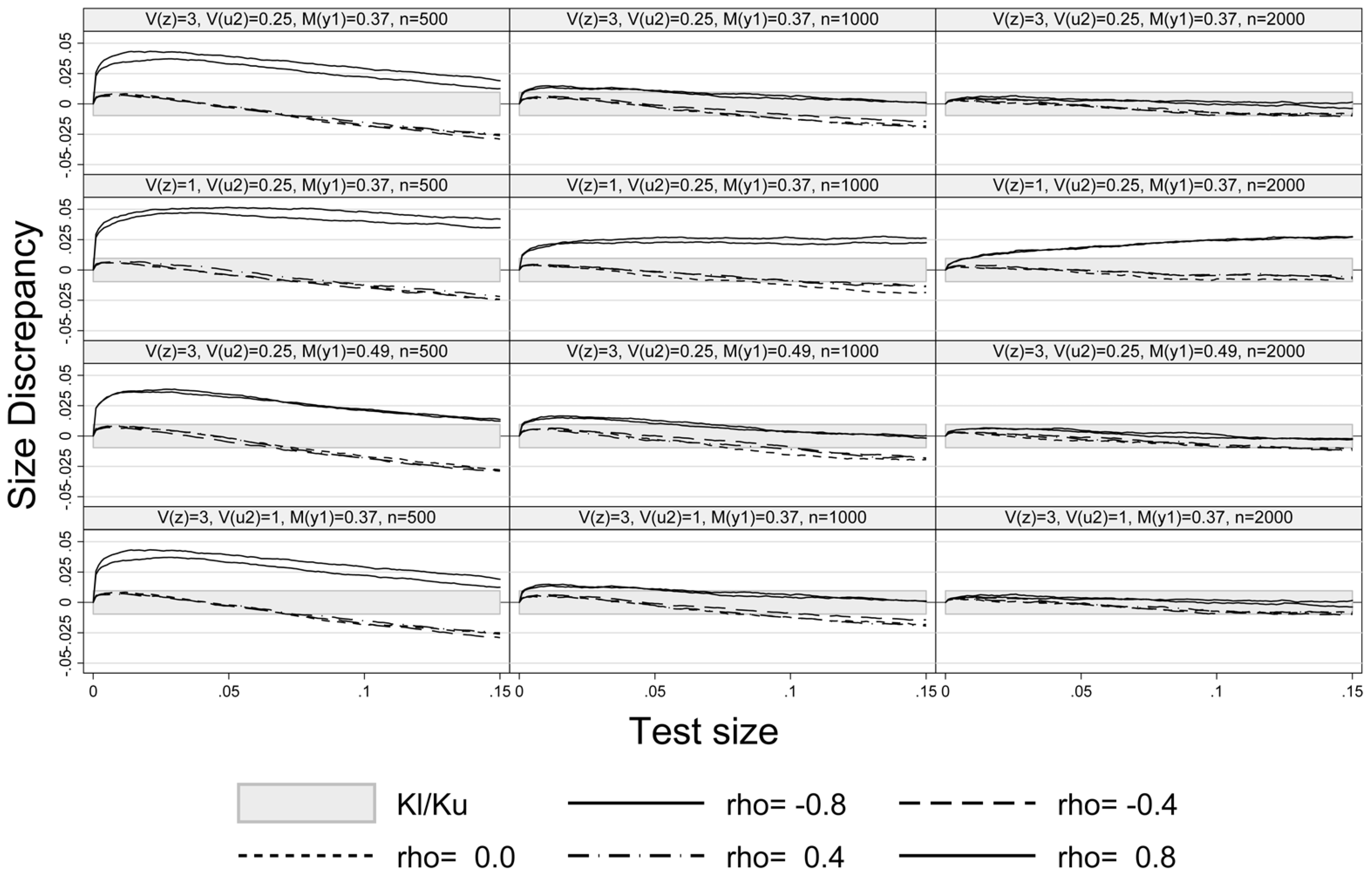
Figure 1 exhibits the size-discrepancy plots for Experiments 1–4 and sample sizes
,
. The plots show that the pseudo-score LM test is properly sized for
and
in all experiments, while it slightly over-rejects at
and
, especially at a small sample size (
). For example, at a nominal test size of
and a sample size of 1000 the size of LM test is too high by
percentage points at
. For
and
the size-discrepancy is within the Kolmogorov and Smirnov
confidence of bound
p ±
for
p-values smaller than
. A similar result has also been mentioned in Montes-Rojas (2011) [
9] in case of robust LM and
tests. A weaker exclusion restriction, setting
in Experiment 2, increases the size-discrepancy at high absolute values of
ρ (Experiment 2, row 2 of
Figure 1), but hardly affects the size of the test at
. The size-discrepancy remains in the confidence bounds at medium values of
ρ. Increasing the share of unobserved values to 0.49 (Experiment 3, row 3 of
Figure 1) hardly affects the size-discrepancy. Lastly, Experiment 4 (last row of
Figure 1) shows that a weaker fit (
) does not result in a larger size distortion as compared to the baseline in the first row of
Figure 1. As one would expect, a larger number of observations generally enhances the performance of the LM test (see the last column in
Figure 1). However, the large sample approximation improves relatively slowly with sample size under a weak exclusion restriction at high absolute values of
ρ (confer the second row of graphs in
Figure 1).
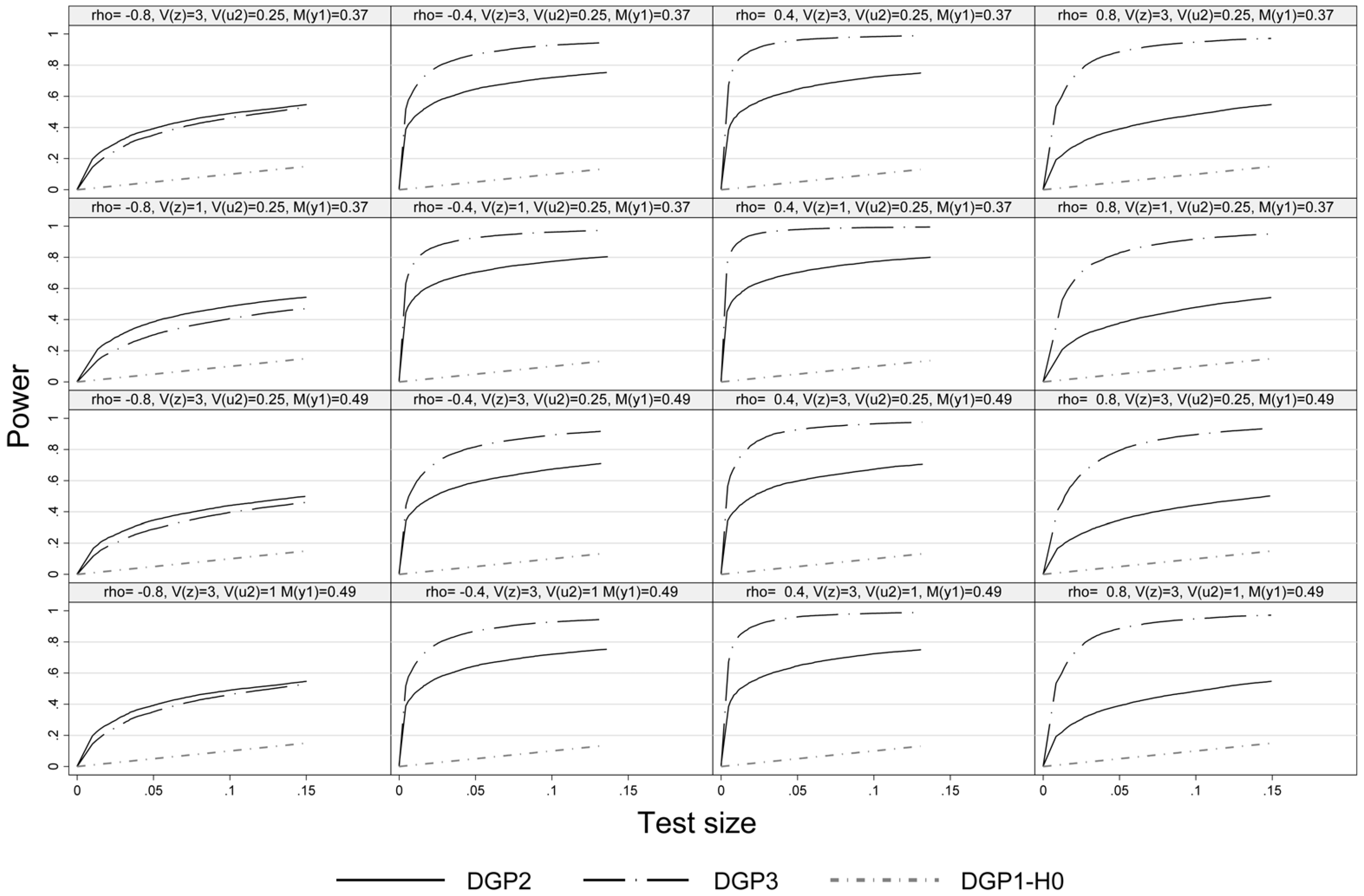
Figure 2,
Figure 3 and
Figure 4 present the power-size plots of the pseudo-score LM test for the DGPs 2–3, 4–5 and 6–7, respectively. In general and in line with the literature, for all DGPs referring to the alternative hypothesis we observe lower power of the pseudo-score LM test at high absolute values of
ρ, but especially so at
. If the distribution of the disturbances of the outcome equation exhibits both skewness and excess kurtosis (DGP3) the simulated power of the pseudo-score LM test is higher than that of a symmetric distribution with fatter tails than the normal distribution except for (
). Furthermore, for DGP3 the power is generally lower at
as compared to large positive values (
, which reflects differences in the skewness of the distribution of
with respect to
ρ (confer
Table 1).
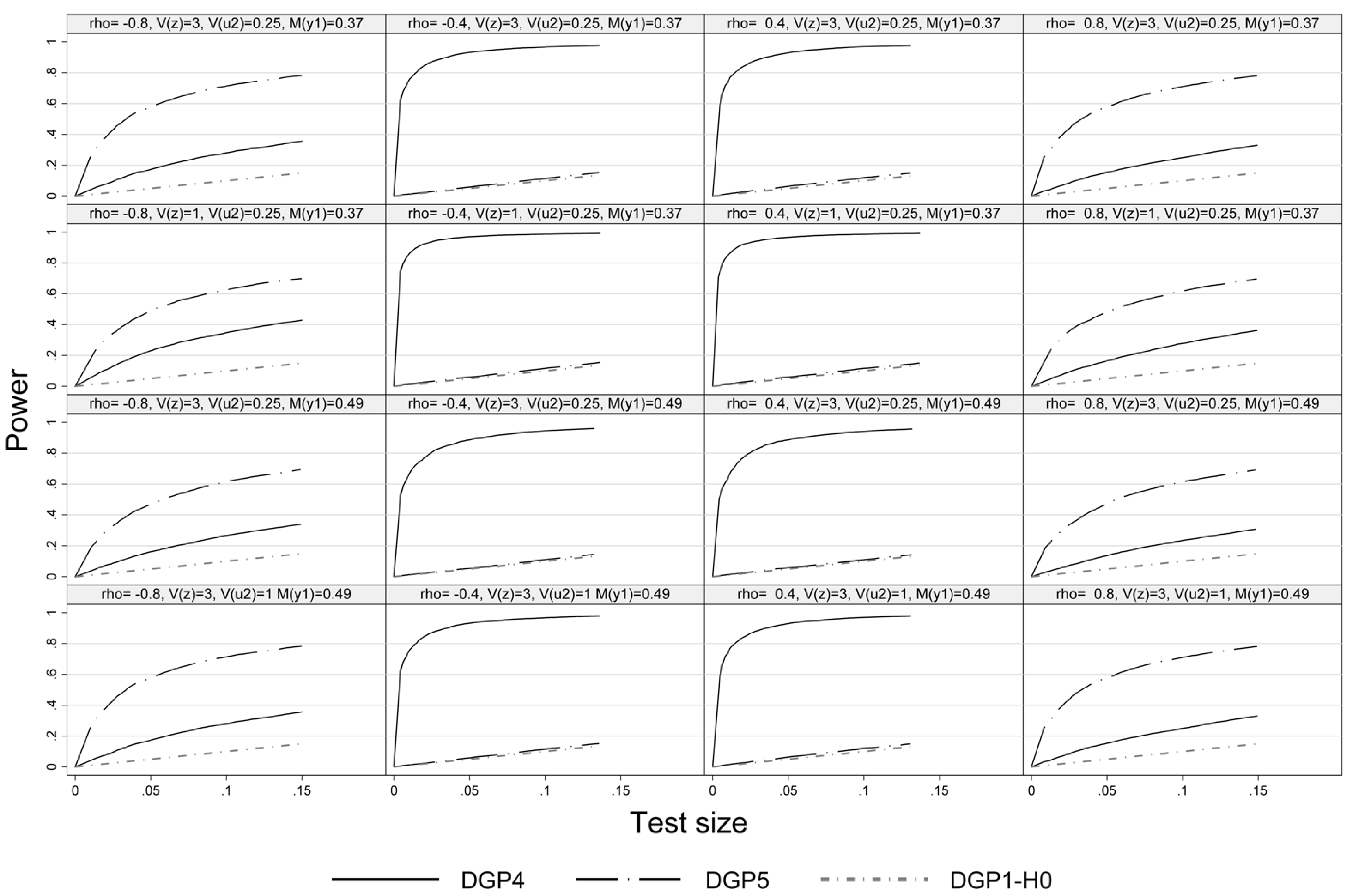
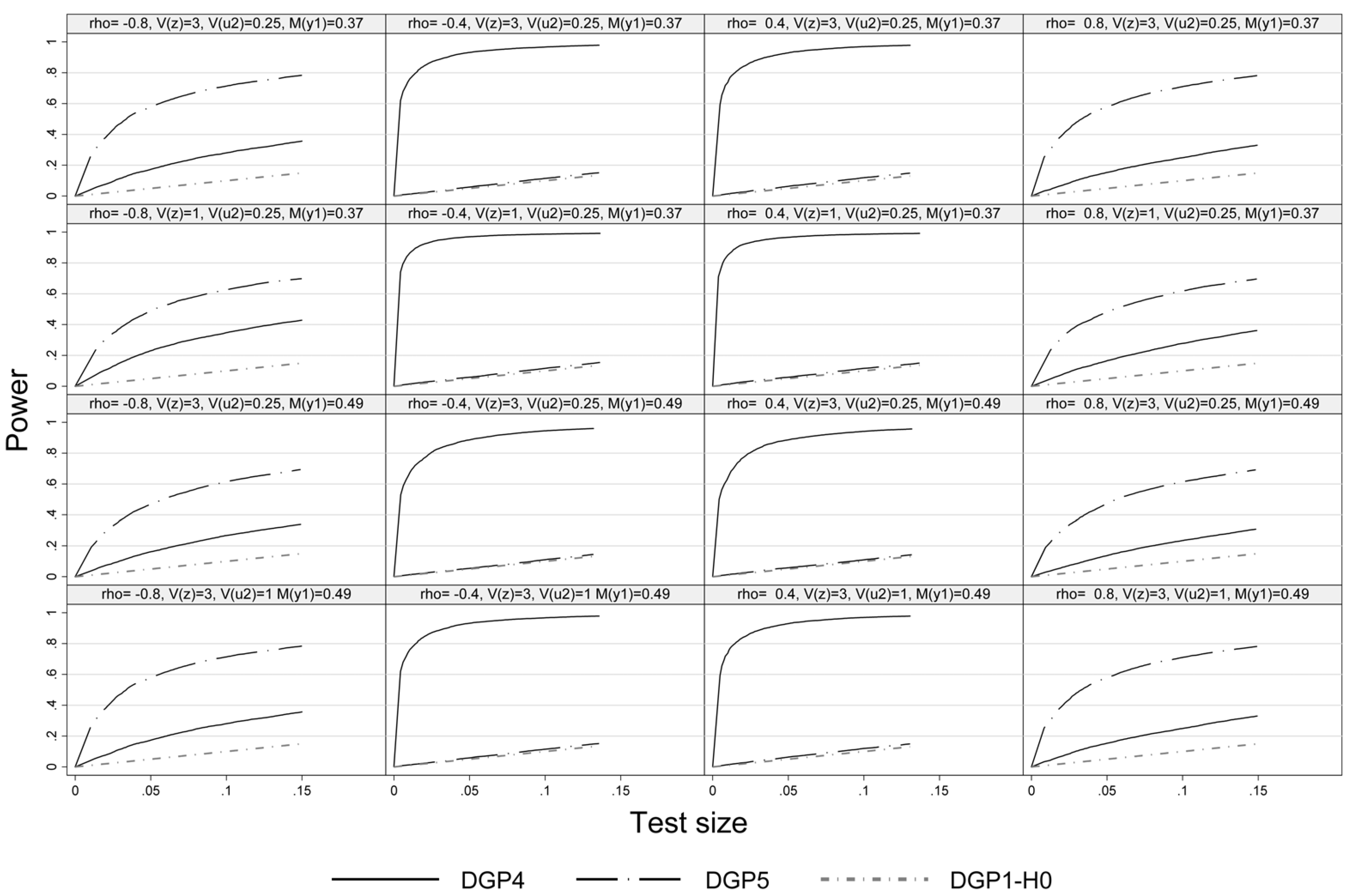
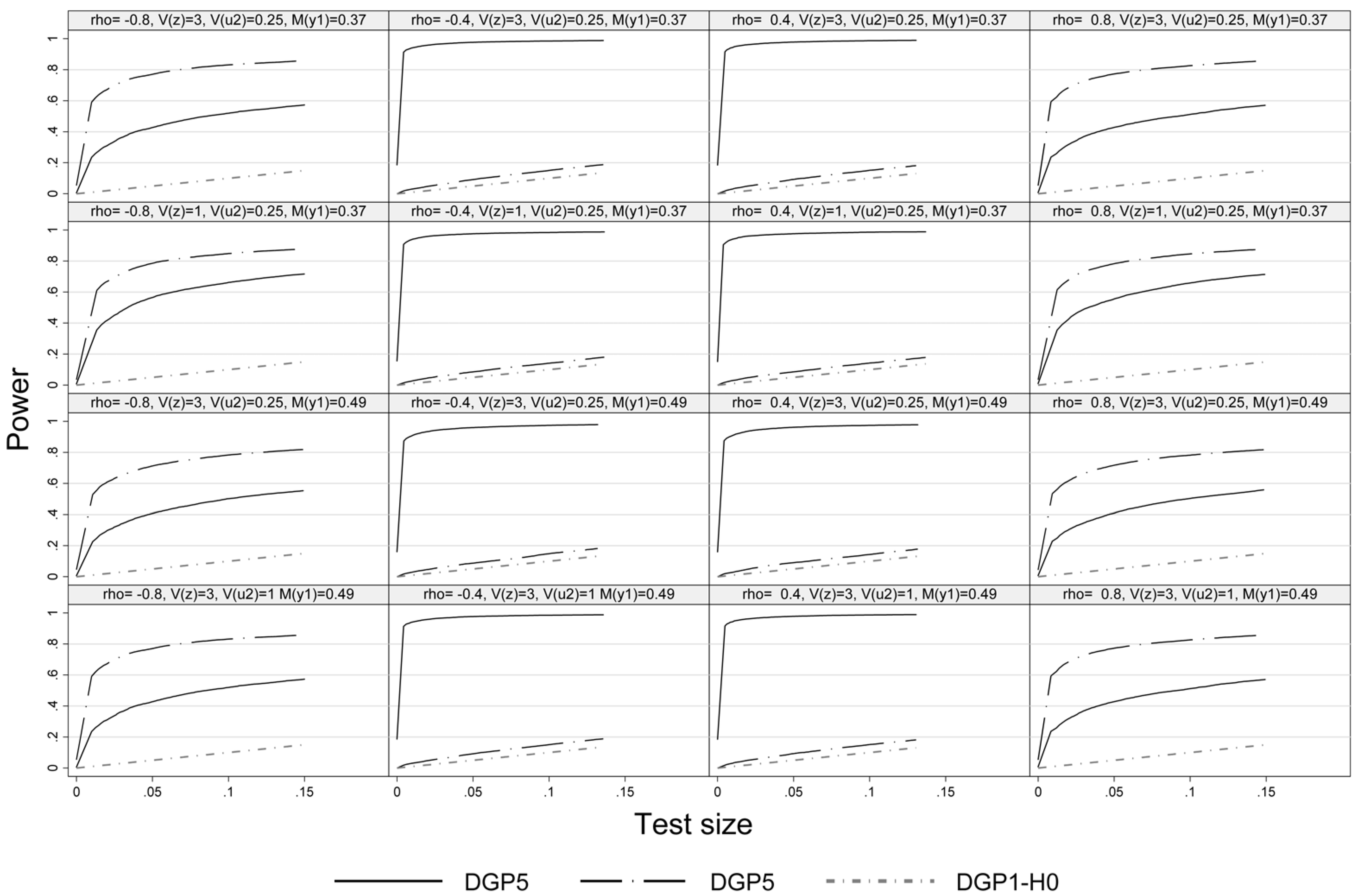
Figure 3 illustrates the power of the pseudo-score LM test under non-normality in either the outcome (DGP4) or the selection equation (DGP5) but not in both. Under DGP4 the pseudo-score LM test exhibits high power at intermediate absolute values of
ρ, while at high absolute values of
ρ the power tends to be lower as the weight of
(that is assumed to be normal) is higher in the disturbances of the outcome equation. In case of DGP5 we see the reversed pattern. Deviations from normality are only detected in case of high absolute values of
ρ. Actually, under DGP5 the test has no power at all at
, since in this case there is no effect of the truncation of
and disturbances of the outcome equation are normal. This results can be found in all four considered Experiments.
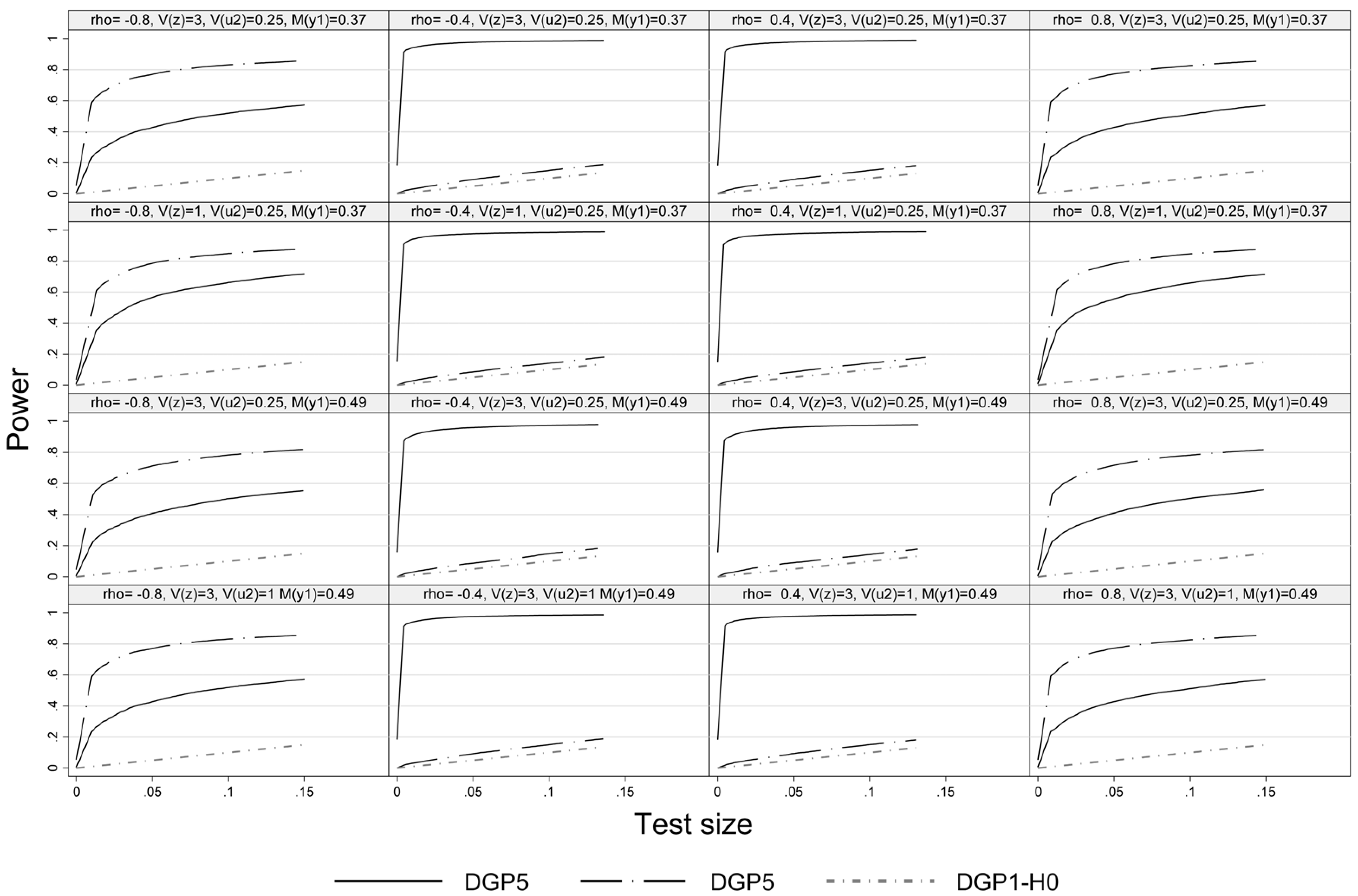
Figure 4 presents the size-power plot of DGP6 and DGP7 and refers to heteroskedasticity. DGP6 allows for heteroskedasticity in the outcome equation and DGP7 in the selection equation. The power-size curves indicate that the pseudo-score LM test is also able to detect this type of deviation from the model assumptions as heteroskedasticity translates into pronounced excess kurtosis of the disturbances of the outcome equation. For DGP6 this is the case at medium to low values of
. DGP7 introduces heteroskedasticity in Probit selection model. In this case, the LM test exhibits power at high absolute vales of
ρ, but has virtual no power at
and
. The reason is that the nominal kurtosis of
is hardly affected (amounting to 3.06, see
Table 1) and the bias of the Mills’ ratio and the estimated coefficients of the outcome equation, especially that of the Mills’ ratio turn out small in comparison.
Figure 1.
Size-discrepancy plot.
Figure 1.
Size-discrepancy plot.
Figure 2.
Size power plot, DGP1-DGP3, n = 1000.
Figure 2.
Size power plot, DGP1-DGP3, n = 1000.
Figure 3.
Size power plot, DGP1, DGP4 and DGP 5, n = 1000.
Figure 3.
Size power plot, DGP1, DGP4 and DGP 5, n = 1000.
Figure 4.
Size power plot, DGP1, DGP6 and DGP7, n = 1000.
Figure 4.
Size power plot, DGP1, DGP6 and DGP7, n = 1000.
Comparing the first and second row of graphs in
Figure 2,
Figure 3 and
Figure 4 indicates that there is not much power lost with the weaker exclusion restriction. A higher share of unobserved units tends to slightly reduce the power of the LM test as one would expect (see the graphs in row 3
vs. 1 in
Figure 2,
Figure 3 and
Figure 4). Comparing the first and the last row in
Figure 2,
Figure 3 and
Figure 4 indicates that a weaker fit (
i.e.,
is increased from 0.25 to 1) does not result in a significant loss of power. Lastly, as expected a larger sample size improves the power of the pseudo-score LM test across the board.
4

{kind=link}
{kind=link}
{kind=link}
{kind=link}