
Generative Artificial Intelligence and the Evolving Challenge of Deepfake Detection: A Systematic Analysis


Abstract
1. Introduction
1.1. Review Objectives
1.2. Methodology for Literature Collection
2. Deepfake Technology Overview
2.1. History of Deepfake Technology
2.2. Evolution of Deepfake Generation Techniques
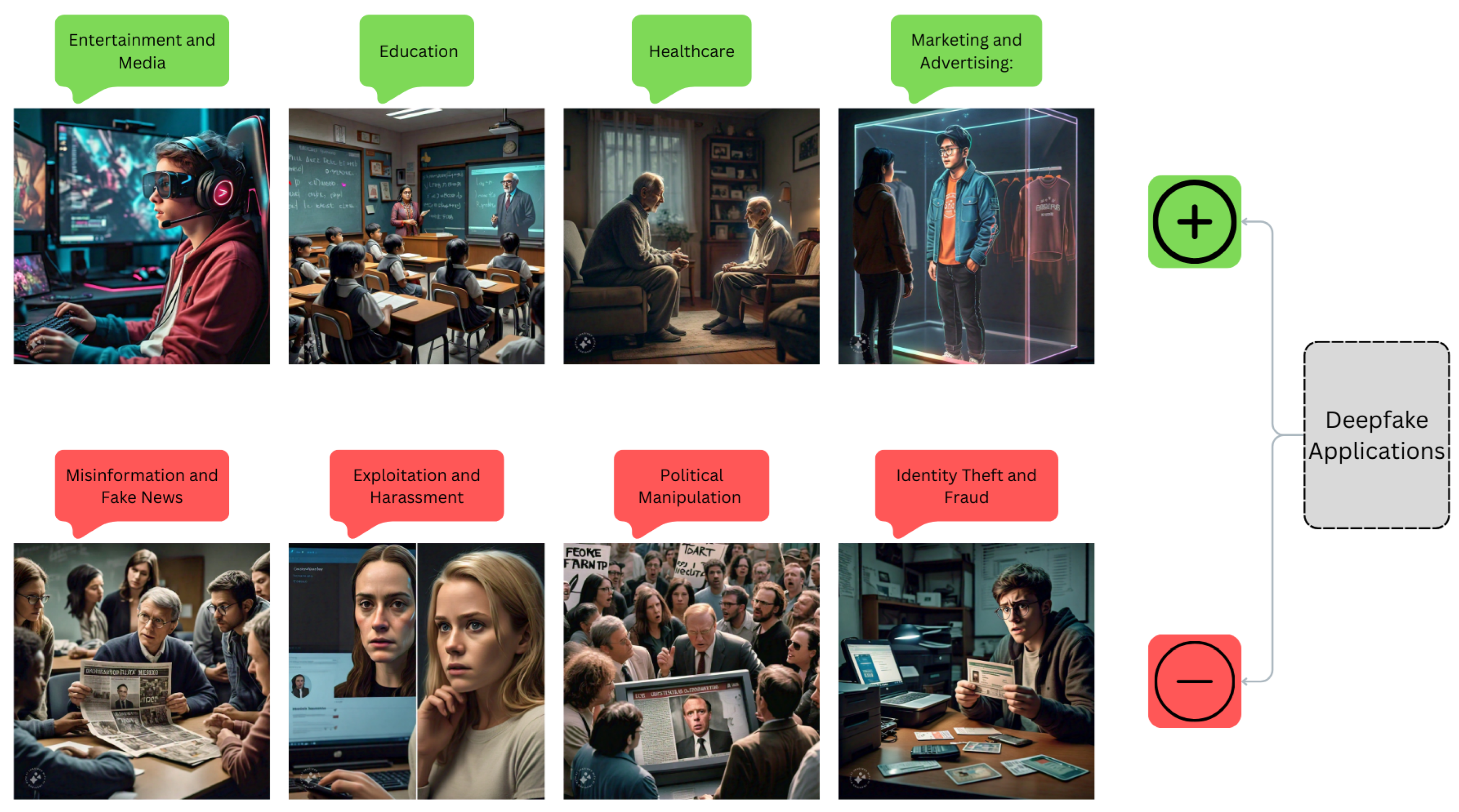
2.3. Applications of Deepfake Technology
2.4. Implications with Deepfake Technology
3. Deepfake Detection Approaches, Countermeasures, and Evaluations
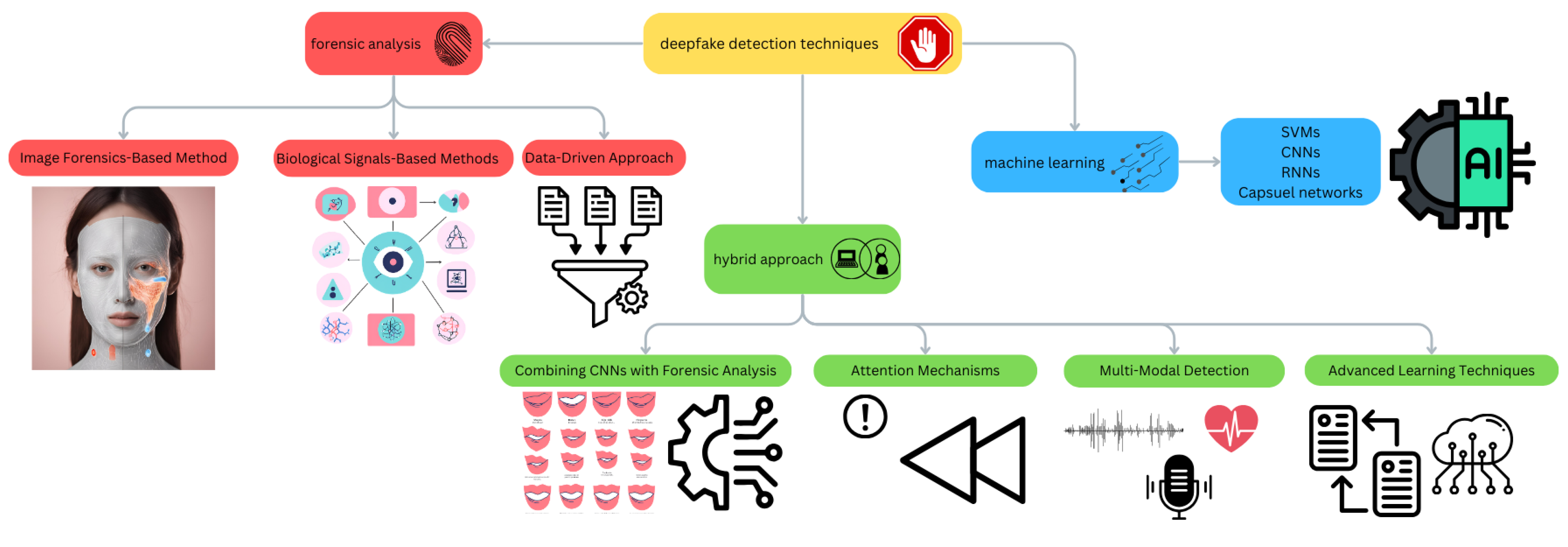
3.1. Deepfake Detection Methods and Countermeasures
3.1.1. Forensic-Based Approaches
3.1.2. Machine-Learning-Based Approaches
3.1.3. Hybrid Approaches
3.2. Deepfake Detection Evaluations and Key Datasets
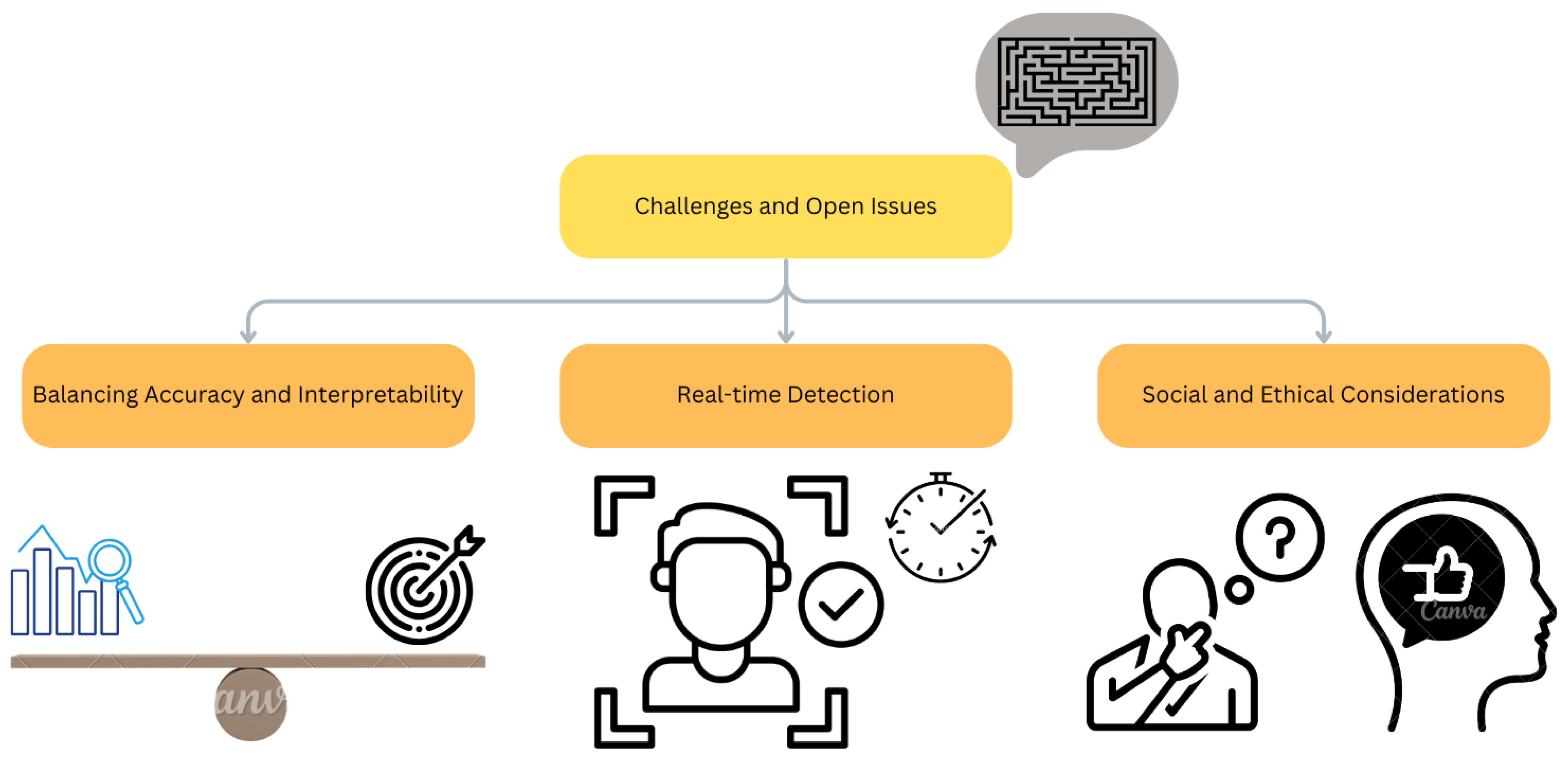
4. Discussion
4.1. Computational Resource Requirements
4.2. Real-Time Detection Versus Post-Analysis
4.3. Interpretability in Deep Fake Detection
4.4. The Impact of Generative AI on Deepfake Technology
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef]
- Xi, Z.; Huang, W.; Wei, K.; Luo, W.; Zheng, P. Ai-generated image detection using a cross-attention enhanced dual-stream network. In Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Taipei, Taiwan, 31 October–3 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1463–1470. [Google Scholar]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Kane, T.B. Artificial intelligence in politics: Establishing ethics. IEEE Technol. Soc. Mag. 2019, 38, 72–80. [Google Scholar] [CrossRef]
- Maras, M.H.; Alexandrou, A. Determining authenticity of video evidence in the age of artificial intelligence and in the wake of Deepfake videos. Int. J. Evid. Proof 2019, 23, 255–262. [Google Scholar] [CrossRef]
- Öhman, C. Introducing the pervert’s dilemma: A contribution to the critique of Deepfake Pornography. Ethics Inf. Technol. 2020, 22, 133–140. [Google Scholar] [CrossRef]
- Kang, J.; Ji, S.K.; Lee, S.; Jang, D.; Hou, J.U. Detection enhancement for various deepfake types based on residual noise and manipulation traces. IEEE Access 2022, 10, 69031–69040. [Google Scholar] [CrossRef]
- Firc, A.; Malinka, K.; Hanáček, P. Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors. Heliyon 2023, 9, e15090. [Google Scholar] [CrossRef]
- Nah, F.-H.; Zheng, R.; Cai, J.; Siau, K.; Chen, L. Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration. J. Inf. Technol. Case Appl. Res. 2023, 25, 277–304. [Google Scholar]
- Malik, A.; Kuribayashi, M.; Abdullahi, S.M.; Khan, A.N. DeepFake detection for human face images and videos: A survey. IEEE Access 2022, 10, 18757–18775. [Google Scholar] [CrossRef]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2023, 53, 3974–4026. [Google Scholar] [CrossRef]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph. (ToG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Khalid, H.; Woo, S.S. Oc-fakedect: Classifying deepfakes using one-class variational autoencoder. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 656–657. [Google Scholar]
- Juefei-Xu, F.; Wang, R.; Huang, Y.; Guo, Q.; Ma, L.; Liu, Y. Countering malicious deepfakes: Survey, battleground, and horizon. Int. J. Comput. Vis. 2022, 130, 1678–1734. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, Q.V.H.; Nguyen, D.T.; Nguyen, D.T.; Huynh-The, T.; Nahavandi, S.; Nguyen, T.T.; Pham, Q.V.; Nguyen, C.M. Deep learning for deepfakes creation and detection: A survey. Comput. Vis. Image Underst. 2022, 223, 103525. [Google Scholar] [CrossRef]
- Passos, L.A.; Jodas, D.; Costa, K.A.; Souza Júnior, L.A.; Rodrigues, D.; Del Ser, J.; Camacho, D.; Papa, J.P. A review of deep learning-based approaches for deepfake content detection. Expert Syst. 2024, 41, e13570. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Jacobsen, B.N.; Simpson, J. The tensions of deepfakes. Inf. Commun. Soc. 2024, 27, 1095–1109. [Google Scholar] [CrossRef]
- Zheng, Y.; Bao, J.; Chen, D.; Zeng, M.; Wen, F. Exploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15044–15054. [Google Scholar]
- Khormali, A.; Yuan, J.S. DFDT: An end-to-end deepfake detection framework using vision transformer. Appl. Sci. 2022, 12, 2953. [Google Scholar] [CrossRef]
- Cao, X.; Gong, N.Z. Understanding the security of deepfake detection. In Proceedings of the International Conference on Digital Forensics and Cyber Crime, Virtual, 6–9 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 360–378. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Horvitz, E. On the horizon: Interactive and compositional deepfakes. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru (Bangalore), India, 7–11 November 2022; pp. 653–661. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Chintha, A.; Rao, A.; Sohrawardi, S.; Bhatt, K.; Wright, M.; Ptucha, R. Leveraging edges and optical flow on faces for deepfake detection. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–10. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Qi, H.; Guo, Q.; Juefei-Xu, F.; Xie, X.; Ma, L.; Feng, W.; Liu, Y.; Zhao, J. Deeprhythm: Exposing deepfakes with attentional visual heartbeat rhythms. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4318–4327. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Pei, G.; Zhang, J.; Hu, M.; Zhai, G.; Wang, C.; Zhang, Z.; Yang, J.; Shen, C.; Tao, D. Deepfake generation and detection: A benchmark and survey. arXiv 2024, arXiv:2403.17881. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.; Nayar, S.K. Face swapping: Automatically replacing faces in photographs. ACM Trans. Graph. (TOG) 2008, 27, 1–8. [Google Scholar] [CrossRef]
- Lin, Y.; Lin, Q.; Tang, F.; Wang, S. Face replacement with large-pose differences. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1249–1250. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. X2face: A network for controlling face generation using images, audio, and pose codes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–686. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Nirkin, Y.; Masi, I.; Tuan, A.T.; Hassner, T.; Medioni, G. On face segmentation, face swapping, and face perception. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 98–105. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. Rsgan: Face swapping and editing using face and hair representation in latent spaces. arXiv 2018, arXiv:1804.03447. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. Fsnet: An identity-aware generative model for image-based face swapping. In Computer Vision—ACCV 2018, Proceedings of the 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part VI 14; Springer: Berlin/Heidelberg, Germany, 2019; pp. 117–132. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Siarohin, A.; Lathuilière, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First order motion model for image animation. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Wang, Y.; Bilinski, P.; Bremond, F.; Dantcheva, A. Imaginator: Conditional spatio-temporal gan for video generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1160–1169. [Google Scholar]
- Ha, S.; Kersner, M.; Kim, B.; Seo, S.; Kim, D. Marionette: Few-shot face reenactment preserving identity of unseen targets. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, New York, USA, 7–12 February 2020; Volume 34, pp. 10893–10900. [Google Scholar]
- Lahiri, A.; Kwatra, V.; Frueh, C.; Lewis, J.; Bregler, C. Lipsync3d: Data-efficient learning of personalized 3d talking faces from video using pose and lighting normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2755–2764. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Lu, Y.; Chai, J.; Cao, X. Live speech portraits: Real-time photorealistic talking-head animation. ACM Trans. Graph. (ToG) 2021, 40, 1–17. [Google Scholar] [CrossRef]
- Bregler, C.; Covell, M.; Slaney, M. Video rewrite: Driving visual speech with audio. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; Association for Computing Machinery: New York, NY, USA, 2023; pp. 715–722. [Google Scholar]
- Vivekananthan, S. Comparative analysis of generative models: Enhancing image synthesis with vaes, gans, and stable diffusion. arXiv 2024, arXiv:2408.08751. [Google Scholar]
- Deshmukh, P.; Ambulkar, P.; Sarjoshi, P.; Dabhade, H.; Shah, S.A. Advancements in Generative Modeling: A Comprehensive Survey of GANs and Diffusion Models for Text-to-Image Synthesis and Manipulation. In Proceedings of the 2024 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 24–25 February 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Lee, Y.; Sun, A.; Hosmer, B.; Acun, B.; Balioglu, C.; Wang, C.; Hernandez, C.D.; Puhrsch, C.; Haziza, D.; Guessous, D.; et al. Characterizing and Efficiently Accelerating Multimodal Generation Model Inference. arXiv 2024, arXiv:2410.00215. [Google Scholar]
- Bode, L.; Lees, D.; Golding, D. The digital face and deepfakes on screen. Convergence 2021, 27, 849–854. [Google Scholar] [CrossRef]
- Altuncu, E.; Franqueira, V.N.; Li, S. Deepfake: Definitions, performance metrics and standards, datasets and benchmarks, and a meta-review. arXiv 2022, arXiv:2208.10913. [Google Scholar] [CrossRef]
- Mukta, M.S.H.; Ahmad, J.; Raiaan, M.A.K.; Islam, S.; Azam, S.; Ali, M.E.; Jonkman, M. An investigation of the effectiveness of deepfake models and tools. J. Sens. Actuator Netw. 2023, 12, 61. [Google Scholar] [CrossRef]
- Kaur, A.; Noori Hoshyar, A.; Saikrishna, V.; Firmin, S.; Xia, F. Deepfake video detection: Challenges and opportunities. Artif. Intell. Rev. 2024, 57, 1–47. [Google Scholar] [CrossRef]
- Sun, F.; Zhang, N.; Xu, P.; Song, Z. Deepfake Detection Method Based on Cross-Domain Fusion. Secur. Commun. Netw. 2021, 2021, 2482942. [Google Scholar] [CrossRef]
- Kingra, S.; Aggarwal, N.; Kaur, N. SiamNet: Exploiting source camera noise discrepancies using Siamese network for Deepfake detection. Inf. Sci. 2023, 645, 119341. [Google Scholar] [CrossRef]
- Haq, I.U.; Malik, K.M.; Muhammad, K. Multimodal neurosymbolic approach for explainable deepfake detection. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 20, 1–16. [Google Scholar] [CrossRef]
- Monkam, G.; Yan, J. Digital image forensic analyzer to detect AI-generated fake images. In Proceedings of the 2023 8th International Conference on Automation, Control and Robotics Engineering (CACRE), Guangzhou, China, 13–15 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 366–373. [Google Scholar]
- Shree, M.S.; Arya, R.; Roy, S.K. Investigating the Evolving Landscape of Deepfake Technology: Generative AI’s Role in it’s Generation and Detection. Int. Res. J. Adv. Eng. Hub (IRJAEH) 2024, 2, 1489–1511. [Google Scholar] [CrossRef]
- Kingsley, M.S.; Adithya, S.; Babu, B. AI Simulated Media Detection for Social Media. Int. Res. J. Adv. Eng. Hub (IRJAEH) 2024, 2, 938–943. [Google Scholar] [CrossRef]
- Sawant, P. Neural Fake Det Net-Detection and Classification of AI Generated Fake News. In Proceedings of the CS & IT Conference Proceedings, CS & IT Conference Proceedings, Turku, Finland, 7–12 July 2023; Volume 13. [Google Scholar]
- Zobaed, S.; Rabby, F.; Hossain, I.; Hossain, E.; Hasan, S.; Karim, A.; Md Hasib, K. Deepfakes: Detecting forged and synthetic media content using machine learning. In Artificial Intelligence in Cyber Security: Impact and Implications: Security Challenges, Technical and Ethical Issues, Forensic Investigative Challenges; Springer: Berlin/Heidelberg, Germany, 2021; pp. 177–201. [Google Scholar]
- Vaccari, C.; Chadwick, A. Deepfakes and disinformation: Exploring the impact of synthetic political video on deception, uncertainty, and trust in news. Soc. Media+ Soc. 2020, 6, 2056305120903408. [Google Scholar] [CrossRef]
- Eberl, A.; Kühn, J.; Wolbring, T. Using deepfakes for experiments in the social sciences-A pilot study. Front. Sociol. 2022, 7, 907199. [Google Scholar] [CrossRef] [PubMed]
- Akhtar, Z.; Pendyala, T.L.; Athmakuri, V.S. Video and Audio Deepfake Datasets and Open Issues in Deepfake Technology: Being Ahead of the Curve. Forensic Sci. 2024, 4, 289–377. [Google Scholar] [CrossRef]
- Maniyal, V.; Kumar, V. Unveiling the Deepfake Dilemma: Framework, Classification, and Future Trajectories. IT Prof. 2024, 26, 32–38. [Google Scholar] [CrossRef]
- Narayan, K.; Agarwal, H.; Thakral, K.; Mittal, S.; Vatsa, M.; Singh, R. Deephy: On deepfake phylogeny. In Proceedings of the 2022 IEEE International Joint Conference on Biometrics (IJCB), Abu Dhabi, United Arab Emirates, 10–13 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–10. [Google Scholar]
- Naitali, A.; Ridouani, M.; Salahdine, F.; Kaabouch, N. Deepfake attacks: Generation, detection, datasets, challenges, and research directions. Computers 2023, 12, 216. [Google Scholar] [CrossRef]
- Shahzad, H.F.; Rustam, F.; Flores, E.S.; Luis Vidal Mazon, J.; de la Torre Diez, I.; Ashraf, I. A review of image processing techniques for deepfakes. Sensors 2022, 22, 4556. [Google Scholar] [CrossRef]
- Baraheem, S.S.; Nguyen, T.V. AI vs. AI: Can AI Detect AI-Generated Images? J. Imaging 2023, 9, 199. [Google Scholar] [CrossRef]
- Li, H.; Chen, H.; Li, B.; Tan, S. Can forensic detectors identify gan generated images? In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 722–727. [Google Scholar]
- Liang, Z.; Wang, R.; Liu, W.; Zhang, Y.; Yang, W.; Wang, L.; Wang, X. Let Real Images be as a Judger, Spotting Fake Images Synthesized with Generative Models. arXiv 2024, arXiv:2403.16513. [Google Scholar]
- Nanabala, C.; Mohan, C.K.; Zafarani, R. Unmasking AI-Generated Fake News Across Multiple Domains. Preprints 2024. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Battiato, S. Deepfake detection by analyzing convolutional traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2307–2311. [Google Scholar]
- Ji, L.; Lin, Y.; Huang, Z.; Han, Y.; Xu, X.; Wu, J.; Wang, C.; Liu, Z. Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features. arXiv 2024, arXiv:2405.15343. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5039–5049. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- Xia, F.; Akoglu, L.; Aggarwal, C.; Liu, H. Deep Anomaly Analytics: Advancing the Frontier of Anomaly Detection. IEEE Intell. Syst. 2023, 38, 32–35. [Google Scholar] [CrossRef]
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Nastasi, C.; Battiato, S. Preliminary forensics analysis of deepfake images. In Proceedings of the 2020 AEIT International Annual Conference (AEIT), Catania, Italy, 23–25 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Agarwal, S.; Farid, H. Detecting deep-fake videos from aural and oral dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 981–989. [Google Scholar]
- Roy, M.; Raval, M.S. Unmasking DeepFake Visual Content with Generative AI. In Proceedings of the 2023 IEEE 11th Region 10 Humanitarian Technology Conference (R10-HTC), Rajkot, India, 15 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 169–176. [Google Scholar]
- Fernandes, S.; Raj, S.; Ortiz, E.; Vintila, I.; Salter, M.; Urosevic, G.; Jha, S. Predicting heart rate variations of deepfake videos using neural ode. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Hernandez-Ortega, J.; Tolosana, R.; Fierrez, J.; Morales, A. Deepfakeson-phys: Deepfakes detection based on heart rate estimation. arXiv 2020, arXiv:2010.00400. [Google Scholar]
- Çiftçi, U.A.; Demir, İ.; Yin, L. Deepfake source detection in a heart beat. Vis. Comput. 2024, 40, 2733–2750. [Google Scholar] [CrossRef]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020. early access. [Google Scholar] [CrossRef]
- Rana, M.S.; Nobi, M.N.; Murali, B.; Sung, A.H. Deepfake detection: A systematic literature review. IEEE Access 2022, 10, 25494–25513. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a capsule network to detect fake images and videos. arXiv 2019, arXiv:1910.12467. [Google Scholar]
- Chen, Z.; Yang, H. Manipulated face detector: Joint spatial and frequency domain attention network. arXiv 2020, arXiv:2005.02958. [Google Scholar]
- Zhu, X.; Wang, H.; Fei, H.; Lei, Z.; Li, S.Z. Face forgery detection by 3d decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2929–2939. [Google Scholar]
- Wang, T.; Cheng, H.; Chow, K.P.; Nie, L. Deep convolutional pooling transformer for deepfake detection. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–20. [Google Scholar] [CrossRef]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 667–684. [Google Scholar]
- Das, S.; Seferbekov, S.; Datta, A.; Islam, M.S.; Amin, M.R. Towards solving the deepfake problem: An analysis on improving deepfake detection using dynamic face augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3776–3785. [Google Scholar]
- Yu, X.; Wang, Y.; Chen, Y.; Tao, Z.; Xi, D.; Song, S.; Niu, S. Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities. arXiv 2024, arXiv:2405.00711. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Yu, P.; Fei, J.; Xia, Z.; Zhou, Z.; Weng, J. Improving generalization by commonality learning in face forgery detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 547–558. [Google Scholar] [CrossRef]
- Wang, Y.; Hao, Y.; Cong, A.X. Harnessing machine learning for discerning ai-generated synthetic images. arXiv 2024, arXiv:2401.07358. [Google Scholar]
- Hussain, S.; Neekhara, P.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial deepfakes: Evaluating vulnerability of deepfake detectors to adversarial examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 10–17 October 2021; pp. 3348–3357. [Google Scholar]
- De Lima, O.; Franklin, S.; Basu, S.; Karwoski, B.; George, A. Deepfake detection using spatiotemporal convolutional networks. arXiv 2020, arXiv:2006.14749. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Gallagher, J.; Pugsley, W. Development of a Dual-Input Neural Model for Detecting AI-Generated Imagery. arXiv 2024, arXiv:2406.13688. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2823–2832. [Google Scholar]
- Oorloff, T.; Koppisetti, S.; Bonettini, N.; Solanki, D.; Colman, B.; Yacoob, Y.; Shahriyari, A.; Bharaj, G. AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 27102–27112. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16317–16326. [Google Scholar]
- Sandotra, N.; Arora, B. A comprehensive evaluation of feature-based AI techniques for deepfake detection. Neural Comput. Appl. 2024, 36, 3859–3887. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 83–92. [Google Scholar]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting deep-fake videos from phoneme-viseme mismatches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 660–661. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 86–103. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Kowloon, Hong Kong, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision And Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. Deepfake detection based on the discrepancy between the face and its context. arXiv 2020, arXiv:2008.12262. [Google Scholar]
- Ismail, A.; Elpeltagy, M.; S. Zaki, M.; Eldahshan, K. A new deep learning-based methodology for video deepfake detection using XGBoost. Sensors 2021, 21, 5413. [Google Scholar] [CrossRef]
- Cozzolino, D.; Rössler, A.; Thies, J.; Nießner, M.; Verdoliva, L. Id-reveal: Identity-aware deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15108–15117. [Google Scholar]
- Alnaim, N.M.; Almutairi, Z.M.; Alsuwat, M.S.; Alalawi, H.H.; Alshobaili, A.; Alenezi, F.S. DFFMD: A deepfake face mask dataset for infectious disease era with deepfake detection algorithms. IEEE Access 2023, 11, 16711–16722. [Google Scholar] [CrossRef]
- Nadimpalli, A.V.; Rattani, A. ProActive deepfake detection using gan-based visible watermarking. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 20, 1–27. [Google Scholar] [CrossRef]
- Tang, L.; Ye, Q.; Hu, H.; Xue, Q.; Xiao, Y.; Li, J. DeepMark: A Scalable and Robust Framework for DeepFake Video Detection. ACM Trans. Priv. Secur. 2024, 27, 1–26. [Google Scholar] [CrossRef]
- Jiang, Z.; Guo, M.; Hu, Y.; Gong, N.Z. Watermark-based Detection and Attribution of AI-Generated Content. arXiv 2024, arXiv:2404.04254. [Google Scholar]
- Combs, K.; Bihl, T.J.; Ganapathy, S. Utilization of generative AI for the characterization and identification of visual unknowns. Nat. Lang. Process. J. 2024, 7, 100064. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, K.Y.; Yao, T.; Ding, S.; Yang, X.; Ma, C. Towards Unified Defense for Face Forgery and Spoofing Attacks via Dual Space Reconstruction Learning. Int. J. Comput. Vis. 2024, 132, 5862–5887. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Z.; Papatheodorou, T. Staying vigilant in the Age of AI: From content generation to content authentication. arXiv 2024, arXiv:2407.00922. [Google Scholar]
- Chakraborty, U.; Gheewala, J.; Degadwala, S.; Vyas, D.; Soni, M. Safeguarding Authenticity in Text with BERT-Powered Detection of AI-Generated Content. In Proceedings of the 2024 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 24–26 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 34–37. [Google Scholar]
- Bai, J.; Lin, M.; Cao, G. AI-Generated Video Detection via Spatio-Temporal Anomaly Learning. arXiv 2024, arXiv:2403.16638. [Google Scholar]
- Sun, K.; Chen, S.; Yao, T.; Liu, H.; Sun, X.; Ding, S.; Ji, R. DiffusionFake: Enhancing Generalization in Deepfake Detection via Guided Stable Diffusion. arXiv 2024, arXiv:2410.04372. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Wang, R.; Juefei-Xu, F.; Ma, L.; Xie, X.; Huang, Y.; Wang, J.; Liu, Y. Fakespotter: A simple yet robust baseline for spotting ai-synthesized fake faces. arXiv 2019, arXiv:1909.06122. [Google Scholar]
- Rafique, R.; Nawaz, M.; Kibriya, H.; Masood, M. Deepfake detection using error level analysis and deep learning. In Proceedings of the 2021 4th International Conference on Computing & Information Sciences (ICCIS), Karachi, Pakistan, 29–30 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Zhou, T.; Wang, W.; Liang, Z.; Shen, J. Face forensics in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5778–5788. [Google Scholar]
- Khalil, S.S.; Youssef, S.M.; Saleh, S.N. iCaps-Dfake: An integrated capsule-based model for deepfake image and video detection. Future Internet 2021, 13, 93. [Google Scholar] [CrossRef]
- Groh, M.; Epstein, Z.; Firestone, C.; Picard, R. Deepfake detection by human crowds, machines, and machine-informed crowds. Proc. Natl. Acad. Sci. USA 2022, 119, e2110013119. [Google Scholar] [CrossRef] [PubMed]
- Guan, L.; Liu, F.; Zhang, R.; Liu, J.; Tang, Y. MCW: A Generalizable Deepfake Detection Method for Few-Shot Learning. Sensors 2023, 23, 8763. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Wang, S. Content-Insensitive Dynamic Lip Feature Extraction for Visual Speaker Authentication Against Deepfake Attacks. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Vora, V.; Savla, J.; Mehta, D.; Gawade, A. A Multimodal Approach for Detecting AI Generated Content using BERT and CNN. Int. J. Recent Innov. Trends Comput. Commun. 2023, 11, 691–701. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, Z.; Zhang, Y.; Zhou, X.; Wang, S. RU-AI: A Large Multimodal Dataset for Machine Generated Content Detection. arXiv 2024, arXiv:2406.04906. [Google Scholar]
- Mone, G. Outsmarting Deepfake Video. Commun. ACM 2023, 66, 18–19. [Google Scholar]
- Khaleel, Y.L.; Habeeb, M.A.; Alnabulsi, H. Adversarial Attacks in Machine Learning: Key Insights and Defense Approaches. Appl. Data Sci. Anal. 2024, 2024, 121–147. [Google Scholar]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial attacks and defenses in deep learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Zhang, T. Deepfake generation and detection, a survey. Multimed. Tools Appl. 2022, 81, 6259–6276. [Google Scholar] [CrossRef]
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. Deepsec: A uniform platform for security analysis of deep learning model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 673–690. [Google Scholar]
- Carlini, N.; Farid, H. Evading deepfake-image detectors with white-and black-box attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 658–659. [Google Scholar]
- Aneja, S.; Markhasin, L.; Nießner, M. TAFIM: Targeted adversarial attacks against facial image manipulations. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 58–75. [Google Scholar]
- Panariello, M.; Ge, W.; Tak, H.; Todisco, M.; Evans, N. Malafide: A novel adversarial convolutive noise attack against deepfake and spoofing detection systems. arXiv 2023, arXiv:2306.07655. [Google Scholar]
- Zhong, H.; Chang, J.; Yang, Z.; Wu, T.; Mahawaga Arachchige, P.C.; Pathmabandu, C.; Xue, M. Copyright protection and accountability of generative ai: Attack, watermarking and attribution. In Proceedings of the Companion Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 94–98. [Google Scholar]
- Gong, L.Y.; Li, X.J. A contemporary survey on deepfake detection: Datasets, algorithms, and challenges. Electronics 2024, 13, 585. [Google Scholar] [CrossRef]
- Firc, A.; Malinka, K.; Hanáček, P. Diffuse or Confuse: A Diffusion Deepfake Speech Dataset. In Proceedings of the 2024 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 25–27 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8261–8265. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5781–5790. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting World Leaders Against Deep Fakes. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 15–20 June 2019; Volume 1, p. 38. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. Wilddeepfake: A challenging real-world dataset for deepfake detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. Forgerynet: A versatile benchmark for comprehensive forgery analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, Nashville, TN, USA, 20–25 June 2021; pp. 4360–4369. [Google Scholar]
- Khalid, H.; Tariq, S.; Kim, M.; Woo, S.S. FakeAVCeleb: A novel audio-video multimodal deepfake dataset. arXiv 2021, arXiv:2108.05080. [Google Scholar]
- Barrington, S.; Bohacek, M.; Farid, H. DeepSpeak Dataset v1. 0. arXiv 2024, arXiv:2408.05366. [Google Scholar]
- Neves, J.C.; Tolosana, R.; Vera-Rodriguez, R.; Lopes, V.; Proença, H.; Fierrez, J. Ganprintr: Improved fakes and evaluation of the state of the art in face manipulation detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Peng, B.; Fan, H.; Wang, W.; Dong, J.; Li, Y.; Lyu, S.; Li, Q.; Sun, Z.; Chen, H.; Chen, B.; et al. Dfgc 2021: A deepfake game competition. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Deepfake Detection Challenge. 2019. Available online: https://www.kaggle.com/c/deepfake-detection-challenge (accessed on 25 January 2025).
- DeepForensics Challenge. 2020. Available online: https://competitions.codalab.org/competitions/25228 (accessed on 25 January 2025).
- Deepfake Game Competition. 2021. Available online: https://competitions.codalab.org/competitions/29583 (accessed on 25 January 2025).
- Face Forgery Analysis Challenge. 2021. Available online: https://competitions.codalab.org/competitions/33386 (accessed on 25 January 2025).
- Shim, K.; Sung, W. A comparison of transformer, convolutional, and recurrent neural networks on phoneme recognition. arXiv 2022, arXiv:2210.00367. [Google Scholar]
- Lu, Z.; Wang, F.; Xu, Z.; Yang, F.; Li, T. On the performance and memory footprint of distributed training: An empirical study on transformers. arXiv 2024, arXiv:2407.02081. [Google Scholar]
- Panopoulos, I.; Nikolaidis, S.; Venieris, S.I.; Venieris, I.S. Exploring the Performance and Efficiency of Transformer Models for NLP on Mobile Devices. In Proceedings of the 2023 IEEE Symposium on Computers and Communications (ISCC), Tunis, Tunisia, 9–12 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–4. [Google Scholar]
- Heidari, A.; Jafari Navimipour, N.; Dag, H.; Unal, M. Deepfake detection using deep learning methods: A systematic and comprehensive review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2024, 14, e1520. [Google Scholar] [CrossRef]
- Akhtar, Z. Deepfakes generation and detection: A short survey. J. Imaging 2023, 9, 18. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Lee, C.; Farhat, K.; Qiu, L.; Geluso, S.; Kim, A.; Etzioni, O. The Tug-of-War Between Deepfake Generation and Detection. arXiv 2024, arXiv:2407.06174. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Approach | Performance | Dataset | Limitations |
|---|---|---|---|---|---|
| Face Swap | |||||
| Bitouk et al. [35] | 2008 | Seamless integration of faces across varying poses, lighting conditions, and skin tones without requiring 3D models | Validated by a user study where 58% of replaced face images were misidentified as real | 33,000 faces collected from public sources, filtered for quality and pose alignment | Dependency on the accuracy of face detection, potential mismatches in gender and age, and challenges in handling occlusions and extreme poses |
| Lin et al. [36] | 2012 | 3D head model from a single frontal image | Subjective evaluations, outperformed or matched a commercial software solution in 80% of cases | Specific datasets were not detailed | Requirement for a single frontal image, the subjective nature of performance evaluation, the need for offline labeling of target face masks, and potential variability in color and illumination adjustments |
| Korshunova et al. [2] | 2017 | Style transfer via CNN, face alignment, multi-image style loss, integration of lighting conditions | Qualitative evaluation, focusing on visual fidelity and the preservation of key facial features | Nicolas Cage Images, CelebA | Lower performance with profile views compared to frontal views |
| Suwajanakorn et al. [14] | 2017 | RNN to synthesize photorealistic lip-sync video from audio | Phoneme overlaps averaged across the four targets were 99.9% (diphones), 82.9% (triphones), 35.7% (tetraphones), 12.1% (pentaphones), and 4.9% for five consecutive phonemes | 17 h of Pres. Obama’s weekly address videos | Requiring teeth proxy selection step as a manual process for each target video |
| Zhu et al. [37] | 2017 | Leveraging cycle consistency to learn mappings between two domains without the need for paired training examples | Per-pixel accuracy of 0.52, compared to 0.40 for CoGAN and 0.71 for the fully supervised pix2pix method | Cityscapes dataset, Imagenet, Flickr, WikiArt | High perceptual realism, but limited in new domains |
| Wiles et al. [38] | 2018 | Using various modalities, such as images, audio, and pose codes, without requiring explicit facial representations or annotations | Generating realistic facial expressions and poses while maintaining the identity of the source face | VoxCeleb dataset | Potential for lower generation quality compared to methods specifically designed for face transformation, dealing with unseen identities or significant variations in pose and expression |
| Wang et al. [39] | 2018 | Conditional GANs, new adversarial loss and multi-scale generator and discriminator architectures | Generating images at a resolution of 2048 × 1024, high pixel accuracy and mean intersection-over-union scores on the Cityscapes dataset | Cityscapes, NYU Indoor RGBD, ADE20K, and Helen Face | Reliance on high-quality training data, generating diverse outputs while maintaining realism |
| Nirking et al. [40] | 2018 | Standard fully convolutional network (FCN) for fast and accurate face segmentation | Evaluated on the Labeled Faces in the Wild (LFW) benchmark, demonstrating that intra-subject face swapping maintains high recognition accuracy while inter-subject swapping results in decreased recognizability | The IARPA Janus CS2 dataset | Reliance on accurate facial landmark localization |
| Choi et al. [41] | 2018 | Simultaneously train across multiple datasets, flexible domain translation, and mask vector introduction | Classification error of 2.12% with facial expression synthesis on the RaFD dataset | CelebA, RaFD Dataset | Performance limited by domain size |
| Natsume et al. [42] | 2018 | Variationally learning separate latent spaces for face and hair regions | Multi-scale structural similarity index (MS-SSIM) score of 0.760, | CelebA | Max. resolution of 128x128 pixels |
| He et al. [3] | 2019 | Attribute classification constraint, reconstruction learning, and adversarial learning | Average of 90.89% accuracy per attribute on CelebA testing set | CelebA, LFW (Labeled Faces in the Wild) | Attribute-Independent Constraint, Complex Attribute Changes |
| Nirkin et al. [34] | 2019 | Subject Agnostic Methodology, RNN for pose and expression adjustments, face completion network | SSIM of 0.51 | IJB-C, VGGFace2, CelebA, FF++, LFW Parts Labels Dataset, | May struggle with large angular differences in facial poses |
| Natsume et al. [43] | 2019 | Deep generative model that disentangles face appearance as a latent variable, independent of face geometry and non-face regions | Achieving high scores in identity preservation and image quality metrics during evaluation on the CelebA dataset | CelebA | Handling occluded faces and the potential for inaccuracies in face region segmentation |
| Karras et al. [26] | 2020 | Redesign of generator normalization, path length regularization, progressive growing revisited | Improving the Fréchet Inception Distance (FID) score from 4.40 for the baseline StyleGAN to 2.84 for StyleGAN2 | FFHQ (Flickr-Faces-HQ), LSUN (Large-Scale Scene Understanding) | Reliance on the perceptual path length (PPL) metric for assessing image quality |
| Face Reenactment | |||||
| Thies et al. [44] | 2016 | Real-time facial reenactment using only monocular RGB video input | Live facial reenactment at an average frame rate of approximately 28.4 Hz | Monocular video sequences sourced from YouTube | Limited to specific reenactment applications |
| Siarohin et al. [45] | 2019 | Animate objects in still images based on driving videos using self-supervised learning, employing learned keypoints and local affine transformations | Better video reconstruction and user preference ratings | The Tai-Chi-HD, VoxCeleb, UvA-Nemo, and BAIR datasets | Assumption of similar poses between source and driving objects and reliance on large datasets for training |
| Thies et al. [28] | 2019 | Integration of traditional graphics rendering techniques with learnable components | MSE of 0.38 at a resolution of 2048 × 2048 | Custom real and synthetic sequences, facial reenactment | Dependent on quality of 3D reconstructions |
| Wang et al. [46] | 2020 | Decomposing appearance and motion through a spatiotemporal fusion mechanism and a transposed (1+2)D convolution | Better quantitative and qualitative results compared to methods like VGAN and MoCoGAN | MUG, UvA-NEMO, NATOPS, and Weizmann | Reliance on high-quality input images and the challenge of generating videos with complex motions, or actions that were not well represented in the training datasets |
| Ha et al. [47] | 2020 | Addressing the identity preservation problem in face reenactment through components such as an image attention block, target feature alignment, and a landmark transformer | High scores in metrics like cosine similarity (CSIM) and masked peak signal-to-noise ratio (M-PSNR) across various experiments | VoxCeleb1 and CelebV datasets | Difficulty in properly disentangling identity and expression, especially for large pose variations and in one-shot settings |
| Lahiri et al. [48] | 2021 | Animating personalized 3D talking faces from audio, utilizing pose and lighting normalization | Achieving high realism, lip-sync accuracy, and visual quality, as evidenced by human ratings and objective metrics | GRID, CREMA-D, and TCD-TIMIT | Inability to explicitly handle facial expressions and potential issues with strong movements in target videos, the processing speed is slightly slower than real time |
| Zhou et al. [49] | 2021 | Lip synchronization and free pose control without relying on structural intermediate information | Excelling in lip-sync accuracy and robustness under extreme conditions | VoxCeleb2 and LRW datasets | Reliance on high-quality input data for effective pose control and challenges in scenarios with significant head pose variations or low-light conditions |
| Lu et al. [50] | 2021 | Generating personalized, photorealistic talking-head animations in real time, driven solely by audio input, achieving over 30 frames per second | User studies, preserving individual talking styles and generating high-fidelity facial details | Various video sequences of different subjects, totaling approximately 3 to 5 min each, with a focus on Mandarin Chinese audio | Challenges in accurately capturing plosive and nasal consonants, potential issues with fast speech, and dependency on the quality of the training corpus |
| From Scratch | |||||
| Rombach et al. [32] | 2022 | Latent space utilization, separation of learning phases, cross-attention mechanism | FID score of 5.11, outperforming StyleGAN, which scored 4.16 on the CelebA-HQ dataset | CelebA-HQ, FFHQ, LSUN-Churches and LSUN-Bedrooms, MS-COCO | Slow computation compared to GANs |
| Bregler et al. [51] | 2023 | Automatically generate new video footage of a person mouthing words that were not originally spoken | Mean spatial registration error of just 1.0 pixels | Dataset comprising approximately 8 min of video containing 109 sentences, historic footage of John F. Kennedy | Accurately modeling large head rotations and the potential for lip fluttering due to mismatched triphone sequences |
| Study | Year | Performance | Dataset | Approach | Limitations |
|---|---|---|---|---|---|
| Forensic Techniques | |||||
| Matern et al. [113] | 2019 | AUC of up to 0.866 in classifying manipulated videos | CelebA, Deepfakes, Face2Face | Handcrafted features for classification | Varies across different datasets |
| Fernandes et al. [89] | 2019 | Neural-ODE model achieving average training losses of 0.010927 (original) and 0.010041 (donor) | COHFACE, DeepfakeTIMI, VidTIMIT | Heart rate extraction based on facial color variation | Requires precise video quality for accurate results |
| Agarwal et al. [114] | 2020 | Accuracies of 99.4% and 99.6% on original dataset; 83.7% and 71.1% on T2V-L dataset | Audio-to-Video (A2V), Text-to-Video (T2V), In-the-wild deep fakes | Phoneme–viseme mismatch analysis | Performance varies across datasets |
| Hernandez et al. [90] | 2020 | 98.7% accuracy on Celeb-DF v2; 94.4% accuracy on DFDC Preview | Celeb-DF (v2), DFDC Preview | Heart rate estimation through rPPG | Dependence on video quality, susceptible to motion artifacts |
| Ciftci et al. [92] | 2020 | 99.39% accuracy on Face Forensics; 91.07% on Deep Fakes Dataset | Face Forensics (FF), FF++, Celeb-DF, Deep Fakes | Leveraging biological signals as implicit descriptors of authenticity | Generalization and biological signal variability |
| Li et al. [102] | 2020 | AUC of 99.17 on unseen manipulations; 95.40 on FF dataset | FF++, DFD. DFDC, Celeb-DF | Face X-ray framework revealing the blending boundaries | Susceptible to low-resolution images and deepfakes created from scratch |
| Guarnera et al. [86] | 2020 | Up to 95% accuracy on image detection; 97% on video-based detection | Celen-A, Oxford-102, Cross-Age Celebrity Dataset (CACD), HOHA | Frequency analysis post Fourier transform | Robust to JPEG compression, blurring, and scaling |
| Luo et al. [111] | 2021 | The model trained on FF++ (HQ) achieved an AUC of 0.919 on DFD, 0.797 on DFDC, 0.794 on CelebDF, and 0.738 on DF1.0 | FF++, DFD, CelebDF, DFDC, DF1.0 | High-frequency noise features extraction | Lower accuracy than the F3Net [115] on FF++ dataset |
| Qian et al. [115] | 2020 | Accuracy of 90.43% and an AUC of 0.933 on LQ settings of FF++ with Xception backbone | FF++ | Introducing two novel frequency-aware components: Frequency-Aware Decomposition (FAD) and Local Frequency Statistics (LFS) | Evaluations limited to FF++ dataset |
| Machine Learning Techniques | |||||
| Afchar et al. [116] | 2018 | Exceeds 98% detection for Deepfake, 95% for Face2Face | Deepfake, Face2Face | CNN-based network, Meso-4 and MesoInception-4 | Performance affected by compression at low rates |
| Guera et al. [107] | 2018 | Classification accuracies of 99.5% on 20 frames | 300 deepfake videos from multiple video-hosting websites + HOHA dataset [117] | Temporal-aware pipeline (CNN + RNN) | Limited to 2 s of video data |
| Li et al. [81] | 2018 | Achieving AUC scores of 97.4% for ResNet50 on the UADFV dataset and 99.9% on the low-quality set of DeepfakeTIMIT | UADFV, DeepfakeTIMIT | Targeting affine face warping artifacts | Varies by model; specific metrics provided |
| Nguyen et al. [29] | 2019 | 93.63% accuracy with 7.20% EER for Deeper-FT; 92.77% accuracy with 8.18% EER for Proposed-New | FF and FF++ | CNN with Y-shaped autoencoder | FT methods recorded lower accuracy and higher EER |
| Nguyen et al. [95] | 2019 | Accuracies of 89.57% for Real, 92.17% for Deepfakes, 90.00% for Face2Face, 92.79% for FaceSwap | FF++, CGI, and PI Dataset, Idiap’s Replay-Attack Database | Capsule network for detecting deepfake videos | Applying capsule networks directly to time-series data (video) rather than just aggregating frames |
| De et al. [106] | 2020 | Significantly outperformed classical methods (66.8% accuracy) on Celeb-DF dataset with 98.26% accuracy | Kinetics dataset, Celeb-DF (v2) | Spatiotemporal convolution | Evaluated only on the Celeb-DF dataset |
| Guarnera et al. [78] | 2020 | Accuracies of 88.40% against GDWCT, 99.81% against STYLEGAN2 on CELEBA | CELEBA | Expectation Maximization for forensic trace detection | Adaptation to “wild” situations without prior knowledge of the image generation process |
| Nirkin et al. [118] | 2020 | 99.7 and 66.0 AUC scores on FF-Deepfakes subset and Celeb-DF (v2), respectively | FF++, Celeb-DF (v2), DFDC | Analyzing discrepancies between the manipulated face and its surrounding context | Complexity of the contextual features around the face |
| Masi et al. [99] | 2020 | Video-level AUC of 76.65% on Celeb-DF; recall of 0.943 on DFDC preview set | FF++, Celeb-DF, DFDC preview | Two-Branch Recurrent Network with multi-scale LoG | Low performance on very low false alarm rates for practical, web-scale applications |
| Khalid et al. [15] | 2020 | 95.30% accuracy on NeuralTextures; 98.00% accuracy on DFD | FF++, Deepfake Detection (DFD) | One-class classification using VAE | Relying on the RMSE function to compute the reconstruction score of images |
| Ismail et al. [119] | 2021 | 90.73% accuracy, 90.62% AUC on CelebDF-FF++ | CelebDF-FF++ (c23) | YOLO for face detection, InceptionResNetV2 for feature extraction, XGBoost for classification | Imbalance dataset, real-time applications |
| Zhu et al. [97] | 2021 | AUC of 98.73% with two-stream structure with halfway fusion on FF++; AUC of 66.09% when using the two-stream structure with halfway fusion on DFDC | FF++, DFD, DFDC | Two-stream network with 3D decomposition and supervised attention | The model’s interpretability |
| Zheng et al. [21] | 2021 | AUC of 89.6% across four unseen datasets; video-level AUC of 99.7% on FF++ dataset | FaceShifter (FSh), FF++, DeeperForensics (DFo), DFDC, Celeb-DF (V2) | Fully Temporal Convolution Network (FTCN) | Low performance scores on Celeb-DF (V2) and DFDC datasets |
| Zhao et al. [83] | 2021 | 97.60% accuracy on FF++ HQ; 67.44 AUC(%) cross-dataset evaluation on Celeb-DF by training on FF++ | Celeb-DF, FF++ | Multi-attentional framework for texture features | Sensitive to high compression rate |
| Czzolino et al. [120] | 2021 | 80.4% accuracy and 0.91 AUC on high-quality videos DFDCp | VoxCeleb2, FF++, DFD, DFDCp | Low-dimensional 3D morphable model (3DMM) | Reliance on the availability of pristine reference videos of the target person |
| Das et al. [100] | 2021 | LogLoss of 0.178 and an AUC of 98.77% on FF++ with EfficientNet-B4 backbone | DFDC, FF++, Celeb-DF | Dynamic cutting of image regions based on landmarks | Lower performance benchmarks on Celeb-DF compared to Random Erase on EfficientNet-B4 backbone |
| Khormali et al. [22] | 2022 | Accuracies of 99.41% (FF), 99.31% (Celeb-DF V2), 81.35% (WildDeepfake) | FF, Celeb-DF (V2), WildDeepfake | End-to-end deepfake detection using transformers | Focused on facial area |
| Yu et al. [103] | 2022 | Outperformed SFFExtractors in cross-dataset evaluations | FF++, DFDC, Celeb-DF | Leveraging commonality learning to enhance generalization across various forgery methods | Assumption of common traces |
| Baraheem et al. [74] | 2023 | 100% accuracy on Real or Synthetic Images (RSI) dataset | RSI, ADE20K, Sketchy, CUB-200-2011 Dataset | CNNs with EfficientNetB4 for GAN image detection | The model struggles with image classification errors, particularly with blurry, vintage, low-quality images, and those containing motion |
| Alnaim et al. [121] | 2023 | 99.81% accuracy detecting face-mask deepfakes on Inception-ResNet-v2 model | Deepfake Face Mask Dataset (DFFMD) | Inception-ResNet-v2 architecture | The lack of video resources of humans wearing masks |
| Kingra et al. [60] | 2023 | 99.7% accuracy on frame-levl FF++; 96.08% on DFD | FF++, DFD, Celeb-DF, DeeperForensics | Two-stream Siamese-like network | Degraded performance on lip-sync deepfakes |
| Xi et al. [4] | 2023 | 93.1% accuracy on DALL-E2; 97.8% on DreamStudio | DALL-E2, DreamStudio | Text-to-image (T2I) detection | Limited to two T2I dataset benchmarks |
| Sawant et al. [65] | 2023 | Good sensitivity in distinguishing machine-generated content | Fake News Net, Machine Generated Fake News Dataset | Linear classifiers with TFIDF vectorization | Tracing the source of machine-generated fake news |
| Nadimpalli et al. [122] | 2023 | Enhances detection by human observers and state-of-the-art detectors | FF++, CelebA, Celeb-DF, RaDF | GAN-based visible watermarking | Vulnerability to cropping operations for watermark removal |
| Tang et al. [123] | 2024 | AUC of 1.0 for face replacement and 0.9999 for lip reenactment when the video quality was high (CRF = 23) | FF++, Celeb-DF | Embedding essential visual features into the DeepMark Meta (DMM) structure | Security relies on the robustness of the watermarking technology, inability to detect manipulations of features not explicitly protected |
| Jiang et al. [124] | 2024 | Near-perfect true detection rates (TDR) and attribution rates (TAR) above 0.94 for unprocessed images | Midjourney, DALLE 2 | Watermark-based detection and attribution | Vulnerable to adversarial post-processing |
| Combs et al. [125] | 2024 | 65% cosine similarity with true labels; 22.5% average classification accuracy | Caltech-256 | Generative AI version of IRTARA | Dependence on pre-trained models, term frequency list limitations |
| Nanabala et al. [77] | 2024 | Over 95% accuracy in “GeneratedBy” classifier; 99.82% for Politics | Various domains, dividing into human or AI generated | Fake news detection | Difficulties in ethically creating fake news articles while adhering to ethical guidelines |
| Cao et al. [126] | 2024 | 97.53% accuracy with 16.43% ACER (EfNet-b4) | FF-DFDC, FF-Celeb-DF | Dual space reconstruction learning framework | UniAttack benchmark’s reliance on the existing datasets; susceptible to novel forgery types |
| Li et al. [127] | 2024 | Over 80 correct judgments on Kaggle true–false news dataset | Kaggle dataset | GPT-4 with web plugins for content authenticity assessment | The potential for biases and inaccuracies in the LLM assessments |
| Chakraborty et al. [128] | 2024 | High accuracy in real-time text analysis | Various datasets | Fine-tuned BERT model with preprocessing steps | Lack of detailed evaluations and comparison with other methods |
| Liang et al. [76] | 2024 | 78.4% accuracy on Midjourney images | Midjourney, Self-Built Dataset | Natural Trace Forensics for fake image detection | Complexity of implementation |
| Wang et al. [104] | 2024 | DenseNet 97.74%, VGGNet 95.99%, ResNet 94.95% | CIFAKE | Machine learning to differentiate AI-generated from genuine images | Transfer learning dependence |
| Ji et al. [80] | 2024 | 96.77% accuracy on GenVidDet dataset | GenVidDet | Dual-Branch 3D Transformer for motion and visual data | Motion modeling challenges, computational costs |
| Monkam et al. [62] | 2024 | 94.14% accuracy on CelebA images | FFHQ, CelebA, and FF++ | GAN for generating realistic images and identifying manipulated ones | Susceptible to adversarial attacks, incomplete comparison to state-of-the-art methods |
| Gallagher et al. [108] | 2024 | 94% accuracy on CIFAKE dataset | CIFAKE | Dual-branch neural network using color images and DFT | Falling short in all metrics compared to VGGNet and DenseNet |
| Bai et al. [129] | 2024 | 95.1% accuracy on Moonvalley; 91.1% on various datasets | Moonvalley generator, Large-scale generated video dataset (GVD), YouTube vos2 dataset | Two-branch spatiotemporal CNN | Dependence on quality of generated videos |
| Sun et al. [130] | 2024 | Boosting the AUC score on the unseen Celeb-DF dataset by 11% when integrated with the EfficientNet-B4 | FF++, DeepFake Detection, DFDC Preview, WildDeepfake | Integrating a frozen pre-trained Stable Diffusion model to guide the forgery detector | Reliance on paired source and target images for training, which may limit the real-world applicability |
| Hybrid Techniques | |||||
| Li et al. [75] | 2018 | Accuracy of over 90% for DCGANs (10,000 samples); over 94% for WGANs (nearing 99% with 100,000 pairs) | CelebA | Combines intrusive and non-intrusive approaches | Accuracy drops by 10% with mismatched datasets |
| Li et al. [131] | 2018 | AUC of 0.99, surpassing CNN’s 0.98 and EAR’s 0.79 | CEW dataset, Eye Blinking Video (EBV) dataset | Long-Term Recurrent CNN (LRCN) | Sophisticated forgers can generate realistic blinking effects |
| Wang et al. [132] | 2019 | Over 90% average detection accuracy on four types of fake faces; AUC score of 66.8 on Celeb-DF (v2) | DFDC, FF++, Flicker-Faces-HQ (FFHQ), Celeb-DF (v2) | Neuron behavior monitoring with MNC criterion | Deteriorated performance on the DFDC deepfakes |
| Qi et al. [30] | 2020 | Top accuracies: 0.987 on DFD, 1.0 on DF, 0.995 on F2F | FF++, DFDC-Preview | Heartbeat rhythm analysis | Susceptible against specific adversarial attacks, worse performance than MesoNet on the DFDC dataset |
| Mittal et al. [109] | 2020 | Per-video AUC score of 96.6% on the DF-TIMIT dataset and 84.4% on the DFDC dataset | DFDC, DF-TIMIT | Audio-visual modality analysis | Misclassification due to different expressed perceived emotions, limited handling of multiple subjects in a video |
| Chintha et al. [27] | 2020 | 100% accuracy on FF++; new benchmarks on DFDC-mini | FF++, DFDC-mini | Integration of edge and dense optical flow maps | Risk of adversarial attacks |
| Chen et al. [96] | 2020 | 99.94% accuracy on Whole Face Forgery; 99.93% on FF | Whole Face Forgery, FF++ | Joint spatial and frequency domain features | Limited region focus, model complexity |
| Rafique et al. [133] | 2021 | 89.5% accuracy using ResNet18 feature vector and SVM classifier | Custom dataset compiled by Yonsei University’s Computational Intelligence and Photography Lab | Integrated Error Level Analysis (ELA) with CNNs | Limited evaluation dataset |
| Sun et al. [59] | 2021 | 90.50% accuracy on Meso-4Deepfake Database dataset; AUCs of 0.97 on DP23, 0.84 on F2F23 | Meso4, DP23, F2F23 | Edge geometric features and high-level semantic features | Performs less effectively on other datasets that require attention to subtle features like lips, eyes, and nose |
| Zhou et al. [134] | 2021 | 69.4% accuracy on FFIW10K; AUC of 70.9%; and AUC of 99.3% on FF++ | FFIW10K, FF++, Celeb-DF, DFDC | Multi-temporal-scale instance feature aggregation | Trained solely with video-level labels |
| Haliassos et al. [82] | 2021 | AUC of 95.1 on FaceSwap; outperforming existing methods on FaceShifter | DeeperForensics, FaceShifter, Celeb-DF (v2), DFDC | Spatiotemporal network pre-trained on lipreading | Lower scores on DFDC due to domain shifts |
| Khalil et al. [135] | 2021 | Frame-level AUC of 76.8 on DFDC-P; 91.70% video-level accuracy on Celeb-DF dataset | DFDC-P, Celeb-DF | Local Binary Patterns (LBP) and HRNet integration | Focus on visual manipulations |
| Kang et al. [9] | 2022 | Accuracies of 95.51% (face swap), 94.32% (puppet-master), 95.64% (attribute change), and 94.96% overall | DFDC, Celeb-DF, MegaFace, FF, ICFace, Glow, CelebA-HQ | SRNet for noise capture, landmark patch extraction | Prediction failures in cases of rapid facial movements or image overlaps during scene changes in video frames |
| Groh et al. [136] | 2022 | 65% accuracy on 4000 videos; human participants outperformed model on political leaders | DFDC, Custom dataset | Evaluating deepfake detection through human–machine collaboration | Struggles with inverted videos |
| Wang et al. [98] | 2023 | 65.76%, 63.27%, and 62.46% accuracy on DFDC, Celeb-DF, DF-1.0, respectively | DFDC, Celeb-DF, DF-1.0 | Deep convolutional transformer | Likely to be fooled if the opponents intentionally raise the authenticity of the deepfake upon the keyframes |
| Haq et al. [61] | 2023 | 87.5% accuracy on Presidential Deepfakes Dataset (PDD); 75.34% on WLD | PDD, World Leaders Dataset (WLD) | Emotional reasoning integration | Complexity of emotion recognition |
| Guan et al. [137] | 2023 | ACC of 0.644 and an AUC of 0.703 on the FF++-DFDC dataset | FF-DFDC, FF-Celeb-DF, Google DFD | Multi-feature channel domain-weighted framework | Fine-tuning results vary by dataset |
| Guo et al. [138] | 2023 | HTERs: 1.33 (HTERfs), 0.84 (HTERfg), 2.62 (HTERls), 4.66 (HTERlg) | GRID dataset | Lip-based visual speaker authentication | Evaluations are limited to the GRID dataset |
| Vismay et al. [139] | 2023 | 89.99% accuracy on ML Olympiad dataset; 93.55% on CIFAKE | ML Olympiad, CIFAKE | Multi-modal method using text and image techniques | The model exhibited a slightly higher number of false positives and false negatives |
| Cciftcci et al. [91] | 2024 | 97.29% deepfake detection accuracy; 93.39% source detection accuracy on FF++ | FF++, Celeb-DF, FakeAVCeleb Dataset | Interpreted generative residuals through biological signals | Dependency on biological signals, demographic variability |
| Huang et al. [140] | 2024 | 75.04% (text), 94.74% (image), 100.00% (voice) | COCO (Common Objects in Context), Flickr8K, Places205 | Unified classification model with multi-modal embeddings | Challenges in cross-modality detection |
| Study | Year | Performance | Dataset | Approach | Limitations |
|---|---|---|---|---|---|
| Ling et al. [145] | 2019 | Average 42.4% transferability rate of all attacks on the three models on CIFAR-10 | MNIST, CIFAR-10 | DEEPSEC incorporates 16 state-of-the-art attacks with 10 attack utility metrics and 13 state-of-the-art defenses with 5 defensive utility metrics | Employing one setting for each individual attack and defense, mainly focusing on non-adaptive and white-box attacks |
| Carlini et al. [146] | 2020 | Classifier performance drops significantly to AUC of 0.22 under the black-box attack | ProGAN images, real images | Vulnerability analysis under adversarial attacks | Harder to execute than real-world attacks |
| Hussain et al. [105] | 2021 | XceptionNet: 97.49%, MesoNet: 89.55% on FF++ | FF++ | Iterative gradient sign approach and Expectation over Transforms | Only focusing on deep neural networks |
| Cao et al. [23] | 2021 | Face classifiers’ accuracies drop to nearly random guessing (i.e., 0.5) in cross-method settings | Six public datasets | Investigating vulnerabilities in detection systems | Only considered deepfake detection for a static face image |
| Aneja et al. [147] | 2022 | Takes only 77.89 ± 2.71 ms and 117.0 MB memory to compute the perturbation for a single image | CelebHQ, VGGFace2HQ | A novel attention-based fusion of manipulation-specific perturbations, only needing a single forward pass | Limited performance when evaluated with different compression qualities, while trained on a fixed quality |
| Panariello et al. [148] | 2023 | Increases EER significantly; highest EER 22.0 for RawNet2 CM | AASIST, RawNet2, and SSL countermeasures | Adversarial attack on ASV spoofing countermeasures | The performance of the integrated system that uses self-supervised learning countermeasures is reasonably robust against this attack |
| Zhong et al. [149] | 2023 | Underscoring the need for robust approaches to safeguard training sets and ensure provenance tracing | Various datasets | Evaluation framework for copyright protection measures | Solely focusing on GANs as generative models |
| Dataset | Real Videos | Fake Videos | Year | Description |
|---|---|---|---|---|
| UADFV [152] | 49 | 49 | 2018 | Focus on head pose |
| EBV [131] | - | 49 | 2018 | Focus on eye blinking |
| Deepfake-TIMIT [153] | 320 | 640 | 2018 | GAN-based methods |
| DFFD [154] | 1000 | 3000 | 2019 | Multiple SOTA methods |
| DeepfakeDetection | 363 | 3068 | 2019 | Collected from actors with publicly available generation methods |
| Celeb-DF (v2) [31] | 590 | 5639 | 2019 | High quality |
| DFDC [19] | 23,564 | 104,500 | 2019 | DFDC competition on Kaggle |
| FF++ [155] | 1000 | 5000 | 2019 | Five different generation methods |
| FFIW-10K [134] | 10,000 | 10,000 | 2019 | Multiple faces in one frame |
| WLDR [156] | - | - | 2019 | Person of interest video from YouTube |
| DeeperForensics-1.0 [157] | 50,000 | 10,000 | 2020 | Add real-world perturbations |
| Wild-Deepfake [158] | 3805 | 3509 | 2021 | Collected from the Internet |
| ForgeryNet [159] | 99,630 | 121,617 | 2021 | 8 video-level generation methods, added perturbations |
| FakeAVCeleb [160] | 500 | 19,500 | 2021 | Audio-visual multi-modal dataset |
| DeepSpeak [161] | 6226 | 5958 | 2024 | Lip-sync and face-swap deepfakes with audio manipulation |
| Dataset | Real Images | Fake Images | Year | Description |
|---|---|---|---|---|
| DFFD [154] | 58,703 | 240,336 | 2019 | Multiple SOTA methods |
| iFakeFaceDB [162] | - | 87,000 (StyleGAN) | 2020 | Generated by StyleGAN |
| 100k Faces Website (accessed on 25 January 2025) https://generated.photos/datasets | - | 100,000 (StyleGAN) | 2021 | Generated by StyleGAN |
| DFGC [163] | 1000 | N × 1000 | 2021 | DFGC 2021 competition, fake images generated by users |
| ForgeryNet [159] | 1,438,201 | 1,457,861 | 2021 | 7 image-level generation methods, added perturbations |
| Name | Reference | Year | Description |
|---|---|---|---|
| Deepfake Detection Challenge | [164] | 2019 | 1. Video-level detection. 2. The first worldwide competition. 3. More than 2000 teams participated. |
| DeepForensics Challenge | [165] | 2020 | 1. Video-level detection. 2. Use DeeperForensics-1.0 datasets. 3. Simulates real-world scenarios. |
| Deepfake Game Competition | [166] | 2021 | 1. Both image-level generation and video-level detection track. 2. Use Celeb-DF (v2) datasets. |
| Face Forgery Analysis Challenge | [167] | 2021 | 1. Both image-level and video-level detection track. 2. Additional temporal localization track. 3. Use ForgeryNet dataset. |
| Category | Main Findings | Open Research Questions |
|---|---|---|
| Deepfake Evolution | Generative AI models like GANs, transformers, and diffusion models have advanced deepfake realism and cross-modal capabilities. | How can detection systems keep pace with the rapid advancements in generative AI technologies? |
| Detection Methods | Detection approaches include forensic, machine learning, and hybrid techniques, leveraging artifacts, physiological signals, and multi-modal analysis. | What new techniques can enhance the adaptability and generalization of detection models for unseen deepfake types? |
| Challenges | Deepfake quality outpaces detection systems; adversarial attacks and limited generalization remain key issues. | How can detection algorithms remain robust to adversarial attacks and highly realistic deepfakes? |
| Applications | Positive uses include education, healthcare, and marketing; negative uses include misinformation, political sabotage, and privacy violations. | How can the benefits of deepfake technologies be promoted while minimizing harm in real-world applications? |
| Ethical and Regulatory | Strong ethical guidelines, public awareness, and robust policies are essential for balancing innovation and risk mitigation. | What are the most effective ways to implement global regulations and ethical frameworks for deepfake creation and detection? |
| Future Directions | Focus areas include real-time and cross-modal detection systems, adversarial robustness, standardized benchmarks, and interdisciplinary collaboration. | How can standardized datasets and evaluation benchmarks be designed to improve the reliability and scalability of detection algorithms across various applications? |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Babaei, R.; Cheng, S.; Duan, R.; Zhao, S. Generative Artificial Intelligence and the Evolving Challenge of Deepfake Detection: A Systematic Analysis. J. Sens. Actuator Netw. 2025, 14, 17. https://doi.org/10.3390/jsan14010017
Babaei R, Cheng S, Duan R, Zhao S. Generative Artificial Intelligence and the Evolving Challenge of Deepfake Detection: A Systematic Analysis. Journal of Sensor and Actuator Networks. 2025; 14(1):17. https://doi.org/10.3390/jsan14010017
Chicago/Turabian StyleBabaei, Reza, Samuel Cheng, Rui Duan, and Shangqing Zhao. 2025. "Generative Artificial Intelligence and the Evolving Challenge of Deepfake Detection: A Systematic Analysis" Journal of Sensor and Actuator Networks 14, no. 1: 17. https://doi.org/10.3390/jsan14010017
APA StyleBabaei, R., Cheng, S., Duan, R., & Zhao, S. (2025). Generative Artificial Intelligence and the Evolving Challenge of Deepfake Detection: A Systematic Analysis. Journal of Sensor and Actuator Networks, 14(1), 17. https://doi.org/10.3390/jsan14010017