
Use of Machine Learning for Early Detection of Knee Osteoarthritis and Quantifying Effectiveness of Treatment Using Force Platform

 , , , and
, , , and 
Abstract
:1. Introduction
2. Methodology
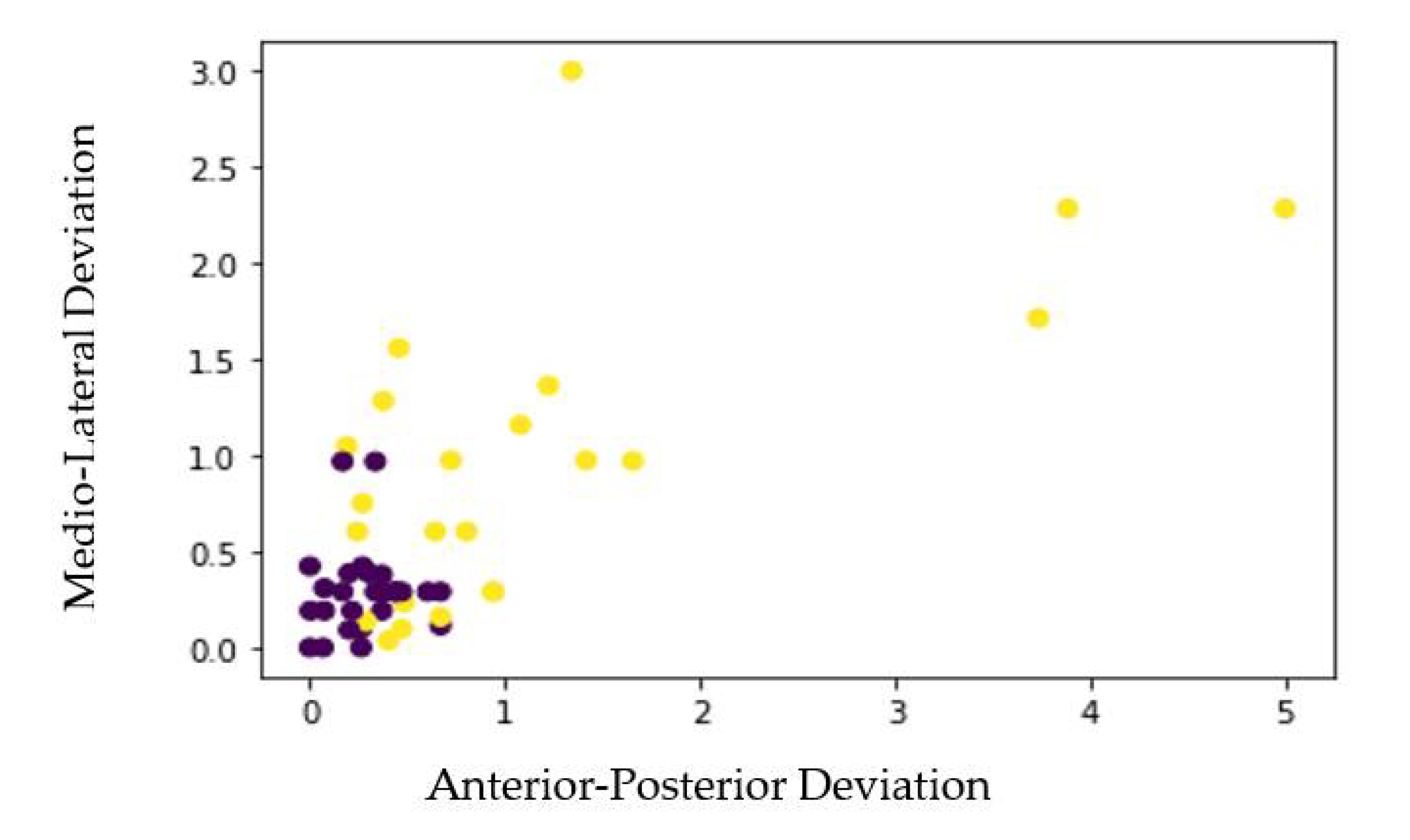
2.1. Postural Balance Measurement
- Age ≥20 and <45 years.
- Satisfying four out of six clinical symptoms criteria (Recurrent pain, Pain following a duration of rest, Discomfort at rest, Swelling, Instability, Reduced range of motion).
- Subject with clinically and radiologically (Kellgren Lawrence grade 1 or 2) confirmed diagnosis of EOA by an Orthopaedist or a Rheumatologist.
- If patient demonstrates any neurological, neuromuscular or musculoskeletal condition other than EOA, RA or other inflammatory arthritis.
- Obesity (BMI > 30 kg/m2).
- Subjects with a history of vertigo (vestibular dysfunction).
- Patients with hypertension.
- K and L grade 3 and above.
- Recent surgeries and significant injuries of a lower limb.
2.2. Pre-Processing
3. Results
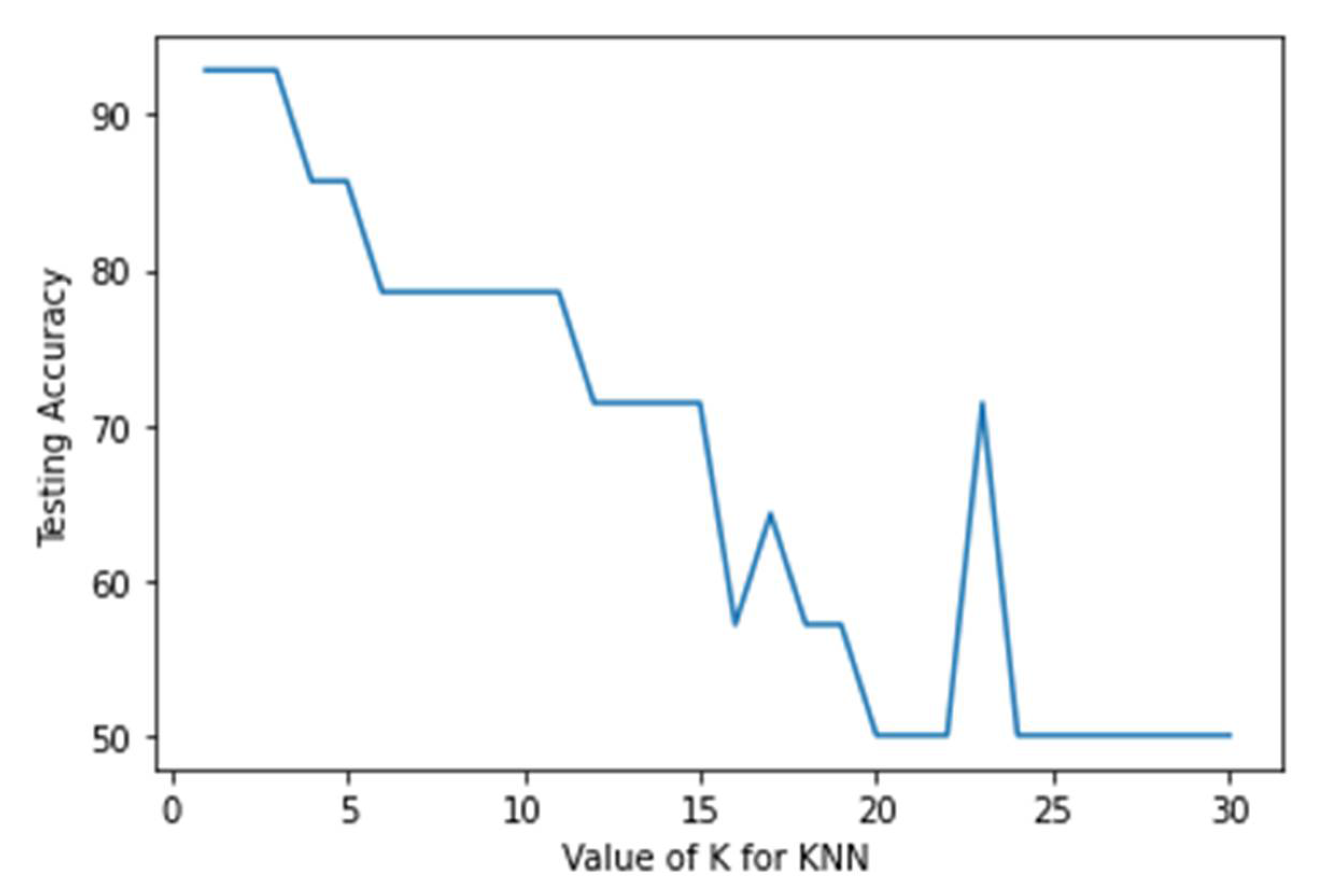
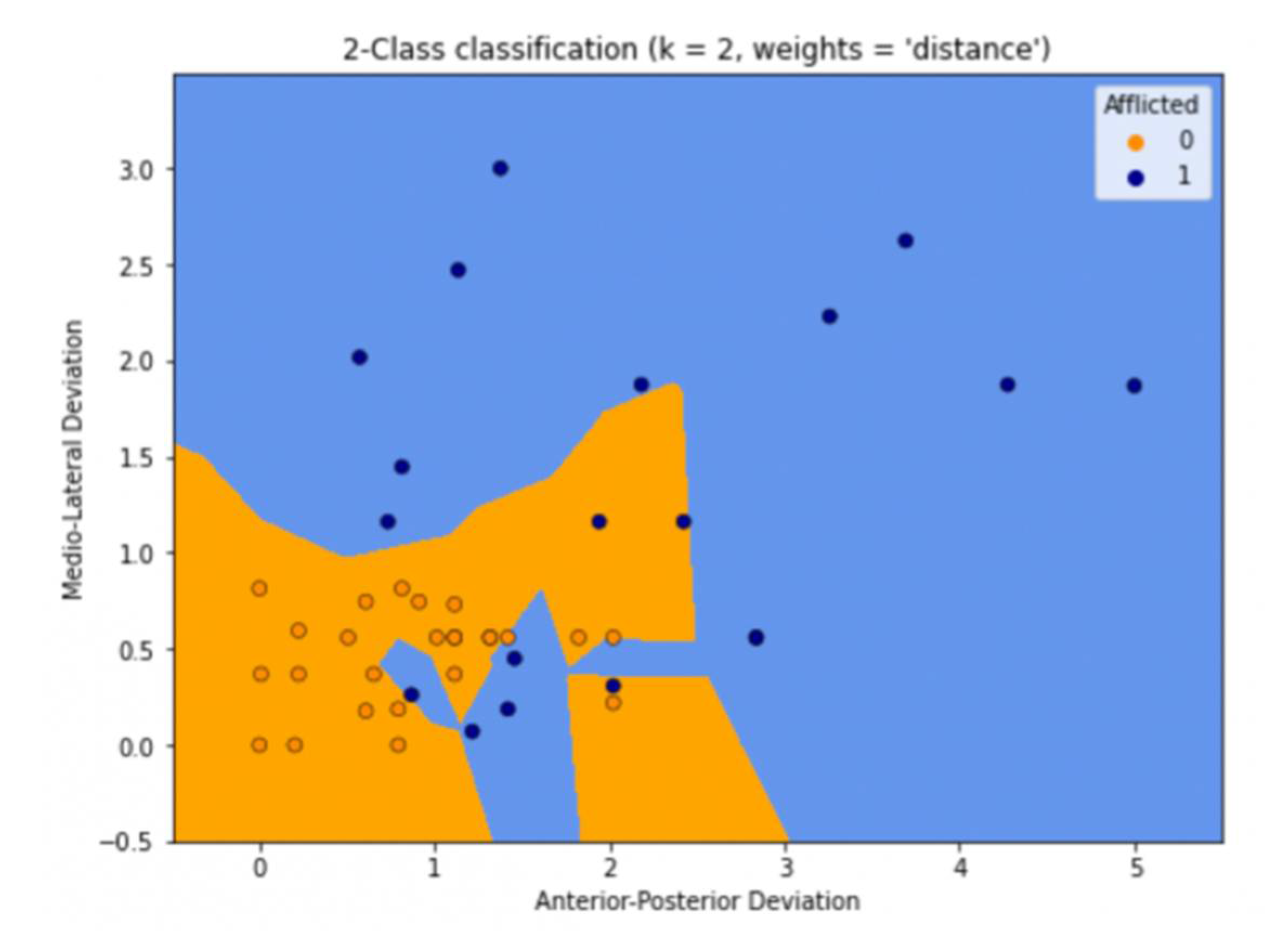
3.1. K-Nearest Neighbours (KNN)
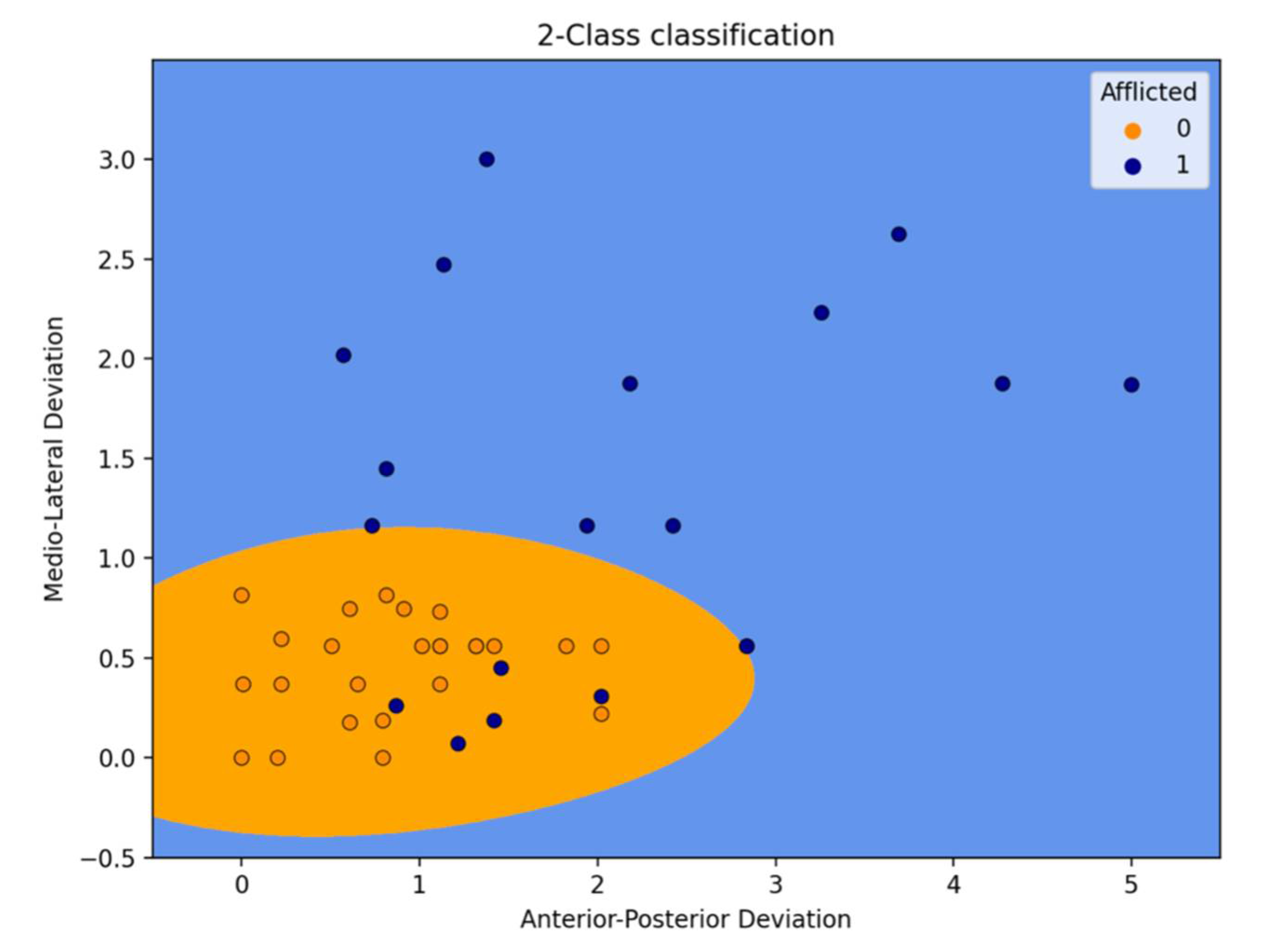
3.2. Logistic Regression
3.3. Gaussian Naive Bayes
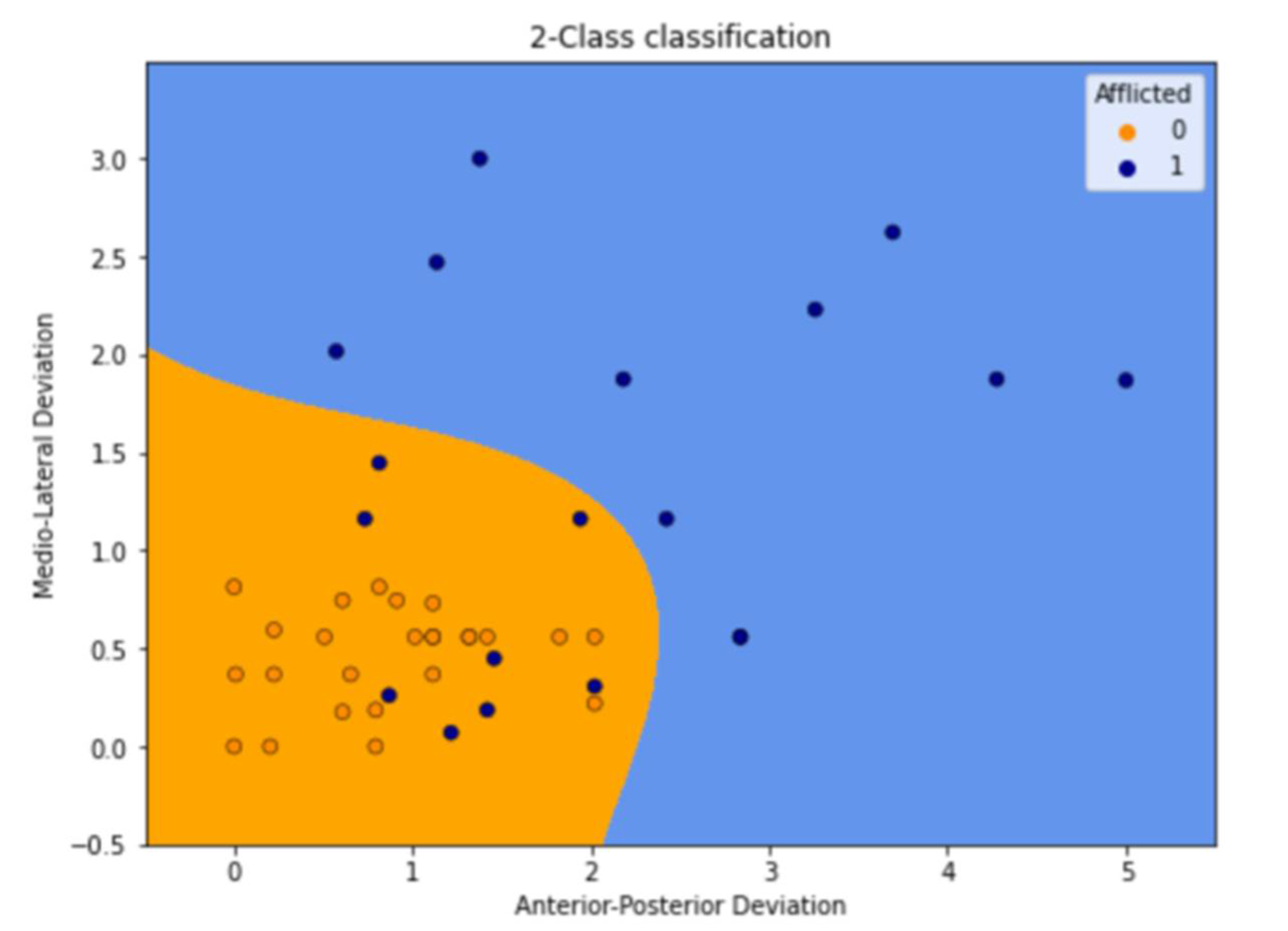
3.4. Support Vector Machine (SVM)
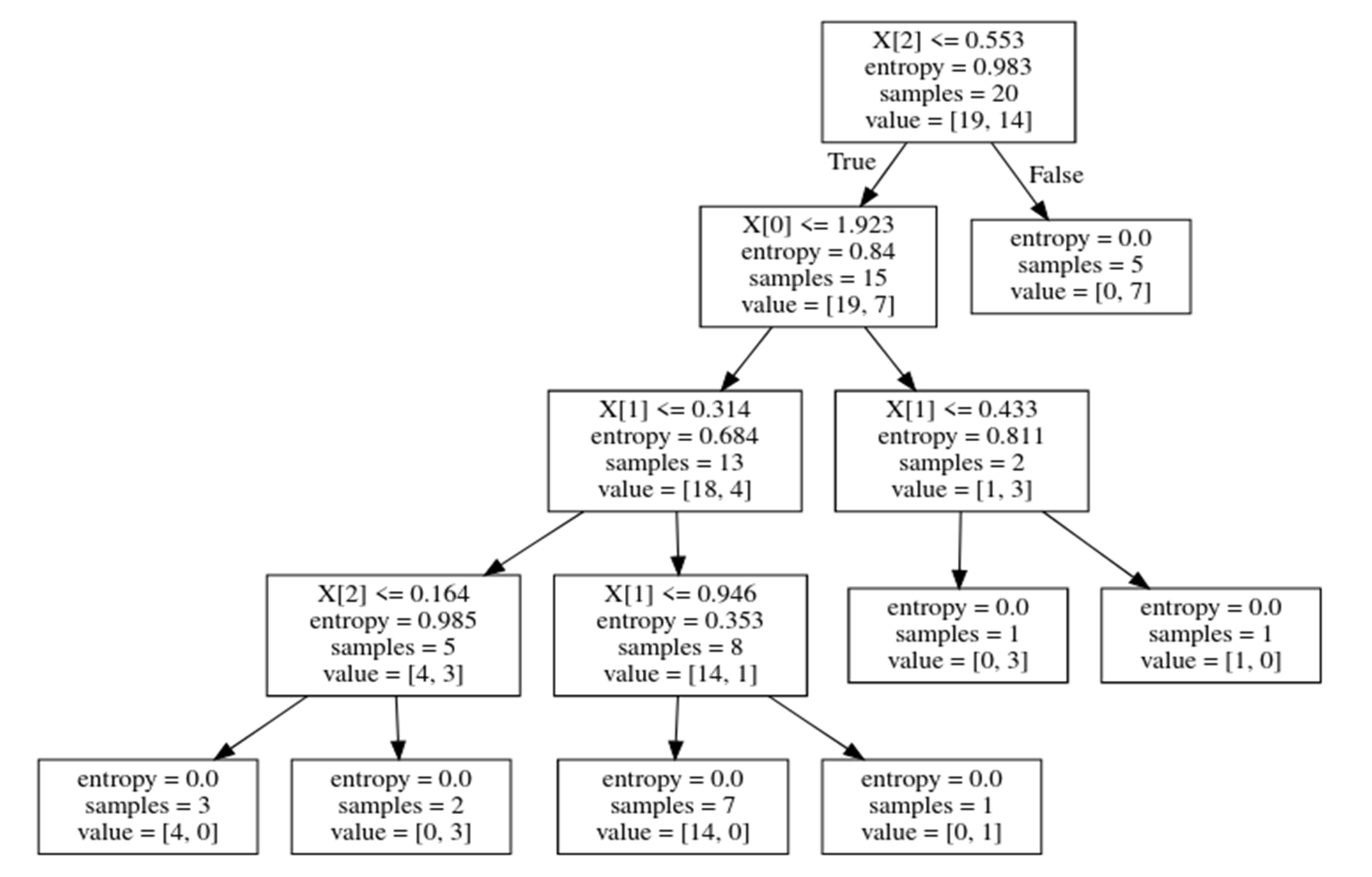
3.5. Decision Tree Classifier (DT)
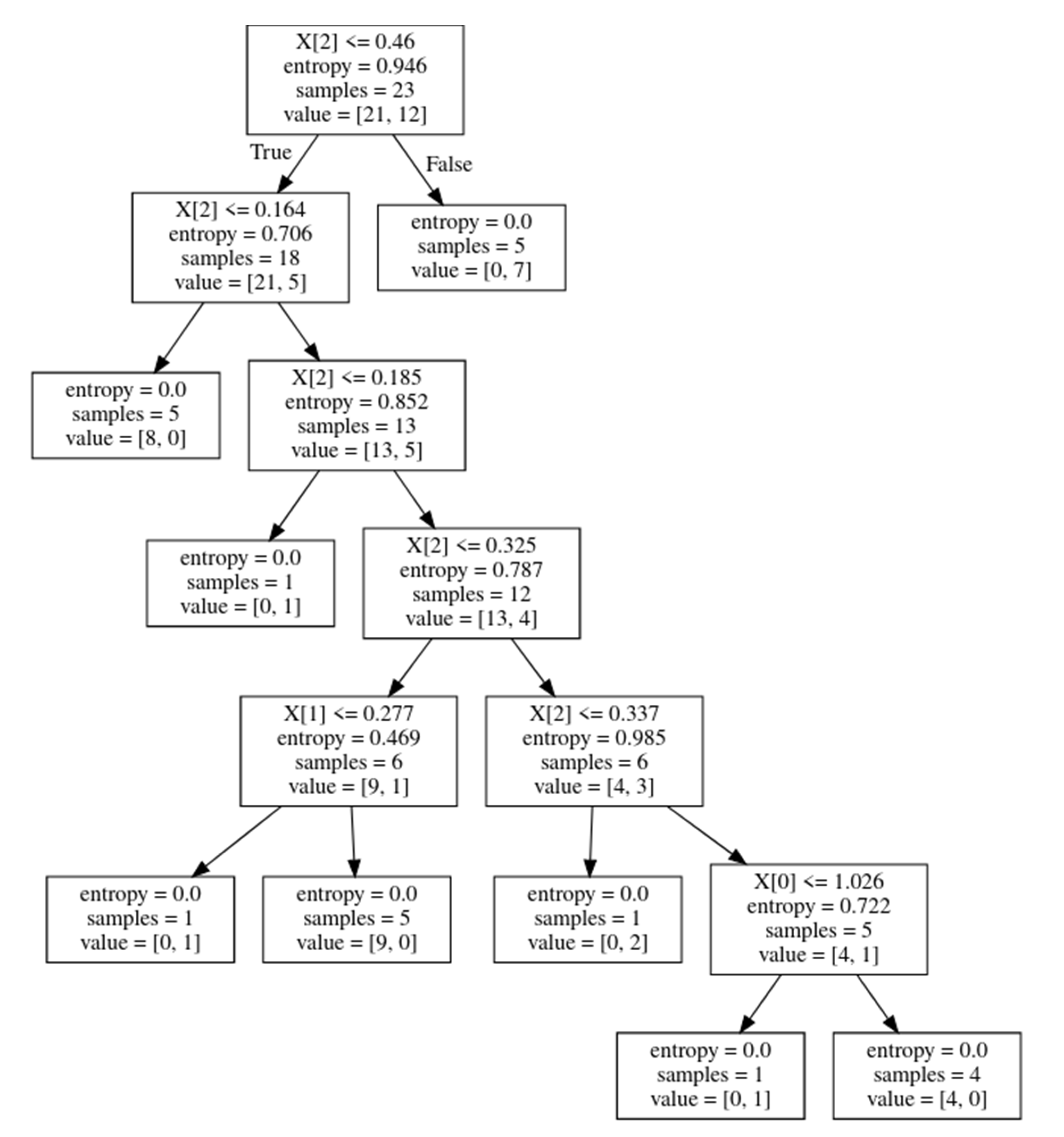
3.6. Random Forest Classifier
3.7. Accuracy Summary
4. Discussion
Importance of Force Plate
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviation
| OA | Osteoarthritis |
| ML | Medio-lateral |
| AP | Anterior-posterior |
| COP | Centre of pressure |
| KNN | K-Nearest Neighbours |
| LR | Logistic Regression |
| SVM | Support Vector Machine |
| GNB | Gaussian Naive Bayes |
| DT | Decision Tree Classifier |
| TP | True positive |
| FP | False positive |
| TN | True negative |
| FN | False negative |
Appendix A
References
- Lawson, T.; Morrison, A.; Blaxland, S.; Wenman, M.; Schmidt, C.G.; Hunt, M.A. Laboratory-based measurement of standing balance in individuals with knee osteoarthritis: A systematic review. Clin. Biomech. 2015, 30, 330–342. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, G.L.; Morrison, A.; Wenman, M.; Hammond, C.A.; Hunt, M.A. Clinical Tests of Standing Balance in the Knee Osteoarthritis Population: Systematic Review and Meta-analysis. Phys. Ther. 2016, 96, 324–337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, C.; Wan, Q.; Zhou, W.; Feng, X.; Shang, S. Factors associated with balance function in patients with knee osteoarthritis: An integrative review. Int. J. Nurs. Sci. 2017, 4, 402–409. [Google Scholar] [CrossRef] [PubMed]
- Whittle, M. Gait Analysis: An Introduction, 4th ed.; Butterworth-Heinemann: Oxford, UK, 2007; p. 160. [Google Scholar]
- Paillard, T.; Noé, F. Techniques and Methods for Testing the Postural Function in Healthy and Pathological Subjects. BioMed Res. Int. 2015, 2015, 891390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taglietti, M.; Bela, L.F.D.; Dias, J.M.; Pelegrinelli, A.R.M.; Nogueira, J.F.; Júnior, J.P.B.; da Sivla Carvalho, R.G.; McVeigh, J.G.; Facci, L.M.; Moura, F.A.; et al. Postural Sway, Balance Confidence, and Fear of Falling in Women with Knee Osteoarthritis in Comparison to Matched Controls. PM R J. Inj. Funct. Rehabil. 2017, 9, 774–780. [Google Scholar] [CrossRef] [PubMed]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; Grimm, L.G., Yarnold, P.R., Eds.; American Psychological Association: Washington, DC, USA, 1995; pp. 217–244. [Google Scholar]
- Rish, I.; An empirical study of the naive bayes classifier. In IJCAI, Workshop on Empirical Methods in Artificial Intelligence; 2001; Volume 3, pp. 41–46. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.330.2788 (accessed on 23 June 2022).
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2007, 26, 217–222. [Google Scholar] [CrossRef]
- Prajwala, T.R. A Comparative Study on Decision Tree and Random Forest Using R Tool. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 196–199. [Google Scholar] [CrossRef]
- Lamkin-Kennard, K.A.; Popovic, M.B. 4-Sensors: Natural and Synthetic Sensors in Biomechanics, 1st ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 81–107. [Google Scholar] [CrossRef]
- Duffell, L.D.; Southgate, D.F.L.; Gulati, V.; McGregor, A.H. Balance and gait adaptations in patients with early knee osteoarthritis. Gait Posture 2014, 39, 1057–1061. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.86 | 1.00 | 0.92 |
| 1 | 1.00 | 0.80 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 1.00 | 1.00 | 0.92 |
| 1 | 1.00 | 0.80 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.86 | 1.00 | 0.92 |
| 1 | 1.00 | 0.80 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.79 | 1.00 | 0.88 |
| 1 | 1.00 | 0.64 | 0.78 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.86 | 1.00 | 0.92 |
| 1 | 1.00 | 0.80 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.83 | 1.00 | 0.90 |
| 1 | 1.00 | 0.71 | 0.83 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.75 | 1.00 | 0.86 |
| 1 | 1.00 | 0.60 | 0.75 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.76 | 1.00 | 0.86 |
| 1 | 1.00 | 0.57 | 0.73 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 1.00 | 0.83 | 0.91 |
| 1 | 0.83 | 1.00 | 0.91 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 |
| 1 | 1.00 | 1.00 | 1.00 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 0.86 | 1.00 | 0.92 |
| 1 | 1.00 | 0.80 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 |
| 1 | 1.00 | 1.00 | 1.00 |
| Classifier | KNN | Logistic Regression | Gaussian Naive Bayes | Support Vector Machine | Decision Tree | Random Forest Classifier |
|---|---|---|---|---|---|---|
| Accuracy | 91% | 91% | 91% | 82% | 91% | 91% |
| Classifier | KNN | Logistic Regression | Gaussian Naive Bayes | Support Vector Machine | Decision Tree | Random Forest Classifier |
|---|---|---|---|---|---|---|
| Accuracy | 100% | 85% | 88% | 82% | 100% | 100% |
| Classifier | KNN | Logistic Regression | Gaussian Naive Bayes | Support Vector Machine | Decision Tree | Random Forest Classifier |
|---|---|---|---|---|---|---|
| Recall(0) | 1 | 1 | 1 | 1 | 0.83 | 1 |
| Recall(1) | 0.8 | 0.8 | 0.8 | 0.6 | 1 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prabhakar, A.J.; Prabhu, S.; Agrawal, A.; Banerjee, S.; Joshua, A.M.; Kamat, Y.D.; Nath, G.; Sengupta, S. Use of Machine Learning for Early Detection of Knee Osteoarthritis and Quantifying Effectiveness of Treatment Using Force Platform. J. Sens. Actuator Netw. 2022, 11, 48. https://doi.org/10.3390/jsan11030048
Prabhakar AJ, Prabhu S, Agrawal A, Banerjee S, Joshua AM, Kamat YD, Nath G, Sengupta S. Use of Machine Learning for Early Detection of Knee Osteoarthritis and Quantifying Effectiveness of Treatment Using Force Platform. Journal of Sensor and Actuator Networks. 2022; 11(3):48. https://doi.org/10.3390/jsan11030048
Chicago/Turabian StylePrabhakar, Ashish John, Srikanth Prabhu, Aayush Agrawal, Siddhisa Banerjee, Abraham M. Joshua, Yogeesh Dattakumar Kamat, Gopal Nath, and Saptarshi Sengupta. 2022. "Use of Machine Learning for Early Detection of Knee Osteoarthritis and Quantifying Effectiveness of Treatment Using Force Platform" Journal of Sensor and Actuator Networks 11, no. 3: 48. https://doi.org/10.3390/jsan11030048
APA StylePrabhakar, A. J., Prabhu, S., Agrawal, A., Banerjee, S., Joshua, A. M., Kamat, Y. D., Nath, G., & Sengupta, S. (2022). Use of Machine Learning for Early Detection of Knee Osteoarthritis and Quantifying Effectiveness of Treatment Using Force Platform. Journal of Sensor and Actuator Networks, 11(3), 48. https://doi.org/10.3390/jsan11030048