1. Introduction
Wireless sensor networks (WSNs) consist of a large number of cooperative sensor nodes that are randomly distributed and spatially correlated in specific areas. The sensor nodes are tiny electronic devices with low power and low cost, and they are equipped with sensors to sense physical conditions in the surrounding area. Further, they have the ability to communicate with each other via wireless channels.
The WSNs have two-tiered architecture: the sensor nodes and the base station (BS). The sensor nodes independently sense or predict particular objects such as temperature and sound and then perform some processing tasks and periodically send their sensed data to the BS. Hence, the BS is a powerful device that is responsible for collecting and processing data from all the nodes to make the proper decisions.
Recently, the emergence of IoT applications in different fields such as the automotive industry [
1], health care systems [
2], and intrusion detection [
3] has accelerated the research and improved the functionality of a WSN as the core component in any IoT application. As the idea in IoT is to embed devices in everyday objects, and since these devices are low cost and highly accessible, WSNs take credit for spreading IoT applications [
4]. In general, WSN applications can be classified into three objectives: monitoring or detection applications, where the sensor nodes send reports to the BS once an expected event occurs; data collection applications in which the sensor nodes handle readings from surrounding environment at a regular time; and object tracking applications that are used for tracking the movement of an object.
However, the limitations of the node’s battery power and the nature of random deployment of sensor nodes make the recharging of the battery difficult or even impossible. Such a problem opens the door for researchers to propose algorithms to suit the sensor nodes’ capabilities to prolong network lifetime. Generally, the sensor nodes consume most of the energy when transmitting and receiving data [
5]. As long as the required energy for data transmission is a function of the distance between the communicating parties, reducing the distance between the sensor nodes themselves and between the sensors nodes and the sink plays a major role in reducing the required energy for data transmission. Several approaches were proposed to properly utilize the available energy resources. One approach is to use multihopping, where the nodes cooperate with the intermediate nodes to forward their data to the BS [
6,
7]. This technique increases the lifetime of the sensor nodes that are located far from the sink, but the sensor nodes that are near the sink (relay nodes) will die quickly due to the depletion of their energy when receiving and forwarding the data that is coming from the previous hop(s).
Clustering algorithms were proposed to reduce the communication distance and to balance the energy consumption between all sensor nodes. The whole area of the WSN is divided into clusters, and each cluster has a local sensor node called the cluster head (CH). The role of the CH is to receive and aggregate the data from the cluster members and then forward them to the BS. The CHs relieve the other nodes from the burden of transmitting directly to the BS, which saves their energy. However, this results in depleting the energy of the CHs quickly. To overcome such problem, each node is selected as a CH for some period of time and then other nodes take over. One well-known clustering protocol is the LEACH protocol [
8].
Recently, the mobility of sensor nodes has received significant attention as a valuable solution for increasing the network’s lifetime by decreasing the transmission distance using a mobile sink (MS) [
9]. A sink node in WSNs is a capable machine that has relatively higher resources such as power, buffer size, and computational capability. Commonly, the sensor sink communication is done via direct or multihop modes. The nodes near the sink will deplete their energy early and isolate the sink from other nodes. Additionally, the non-uniform energy consumption between the senor nodes will degrade network performance. Employing mobile sinks for data collection not only increases the network’s lifetime, but it also enhances the efficiency of the network by decreasing the time delay for collecting the data in specific applications. Furthermore, sink mobility has been proposed as a sufficient way to avoid network isolation and to balance the energy consumption among the sensor nodes [
10]. Sink mobility can be classified into three categories according to the MS travel trajectory:
Random movement: the MS moves and changes its direction and speed in an arbitrary way. However, the performance of the WSN could be affected negatively because there is no guarantee that the MS will serve all stationary nodes in regular time intervals. Increasing the time delay for data gathering will lead to buffer overflow and increased power consumption due to no sleeping mode utilization.
Controlled movement: the MS does not move completely randomly in the environment. The direction and speed of the next destination for the MS will be determined according to the network conditions, such as giving priority to the regions where the sensor nodes have urgent information.
Predefined movement: the MS moves according to a known path. The target path can be generated as a function of network parameters such as the sensor nodes’ locations or the energy of the sensor nodes, resulting in an enhancement of performance and the efficient exploitation of the sleeping mode since each sensor node can predict the time of arrival of the MS.
As for the methods that can be used by the MS to collect the data from the sensor nodes, two methods can be used:
Direct data collection: the sensor nodes deliver the data directly to the MS using one hop. However, it may increase the time delay of data collection. Depending on the network size and communication range, the MS may need an algorithm to generate sufficient travel trajectories to serve all sensor nodes and minimize the time delay.
Multihop data collection: the sensor nodes deliver their data using the multihop to subset nodes called rendezvous points (RPs), which are selected by a suitable algorithm based on the network conditions. The RPs are considered stop stations for the MS to collect the data and are proposed as a tradeoff between time delay and energy consumption.
In this work, principal component analysis (PCA) [
11] is used to generate a predefined path for the MS, and two data collection modes are exploited: direct and multihop. The rest of this paper is organized as follows:
Section 2 discusses the related work.
Section 3 discusses the proposed approach.
Section 4 presents the experimental results. Then, the paper is concluded in
Section 5.
2. Related Work
Recently, a considerable effort has been directed to exploit the mobility characteristics in improving network functionality, such as the network lifetime, enhancing the efficiency and decreasing the time delay for collecting data in specific applications. In this section, we highlight the work that addresses the predefined MS path for data collection in WSNs.
A novel cluster-based scheme to achieve efficient and fair coverage of data gathering was proposed by H. Nakayama et al. in [
12]. The authors combined the set packing algorithm (SPA) and the traveling salesman problem (TSP). The energy consumption was decreased by using the SPA, which reduces the clusters in a network by eliminating those clusters with sensor nodes that are members of more than one cluster. However, the SPA does not guarantee that all nodes will be members of a cluster. Thus, new clusters may be added to accommodate them. The aggregated data will be collected by the MS moving to every single cluster head. The MS will use the TSP algorithm to visit each cluster with the least time trip.
The authors in [
13] proposed two algorithms called reduced k-means (RkM) and delay bound reduced k-means (DBRkM) for RP-based path construction for the MS. Initially, a set of potential positions using k-means clustering over the set of SNs is selected. Then, the selected positions are optimized using the RkM or DBRkM algorithms to obtain the minimum number of RPs.
The work in [
14] divides the network into a set of clusters. The MS moves among the CHs for data reporting within a limited time (
tdr). If
tdr is large, the MS can visit all CHs; thus, the CH consumes minimum energy for data reporting. However, in fact, that is not applicable due to the limitation of the buffer capacity in CHs. The author proposed using mixed-integer linear programming to find the path for the MS that can collect the data from the CHs within
tdr with minimum energy consumed by the CHs, provided that
tdr is not long enough to cause data dropping from the CHs. However, the authors assumed that CHs can change their transmission range in order to maximize network lifetime. This assumption will add extra overhead onto the sensor nodes as they have to adjust their transmission range frequently.
In [
15], the authors proposed a mobile-sink-based energy-efficient clustering algorithm (MECA). In this approach, the MS moves around the sensing field in a predetermined velocity and direction (counterclockwise or clockwise) on a circle or rectangle. The MS needs to broadcast its current location
Po one time at the beginning of its movement. Given
Po and the velocity, where velocity is the changing angle
θ within an interval time Δ
t, the sensor nodes can determine the new location
PΔt for MS at
t.
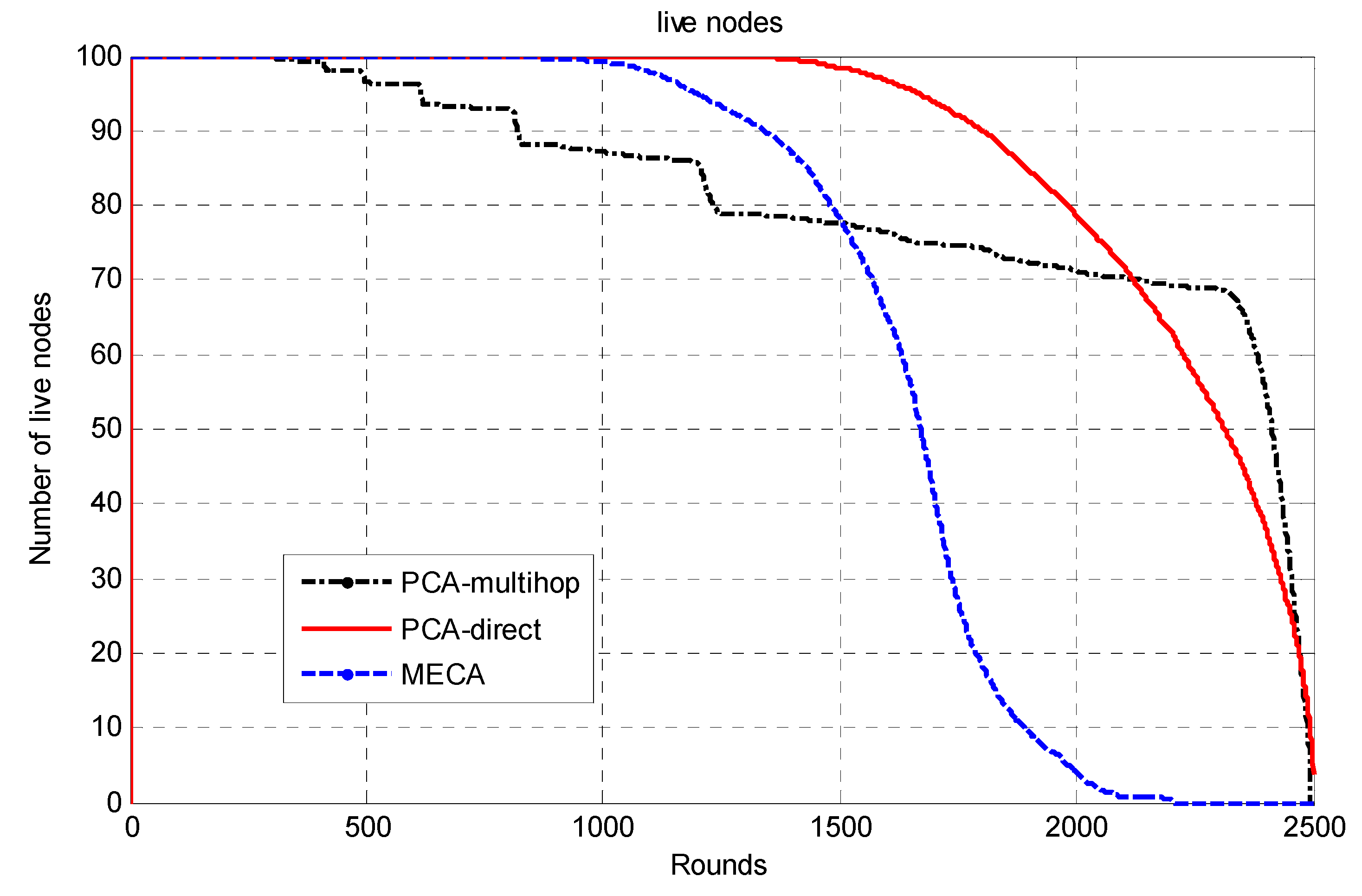
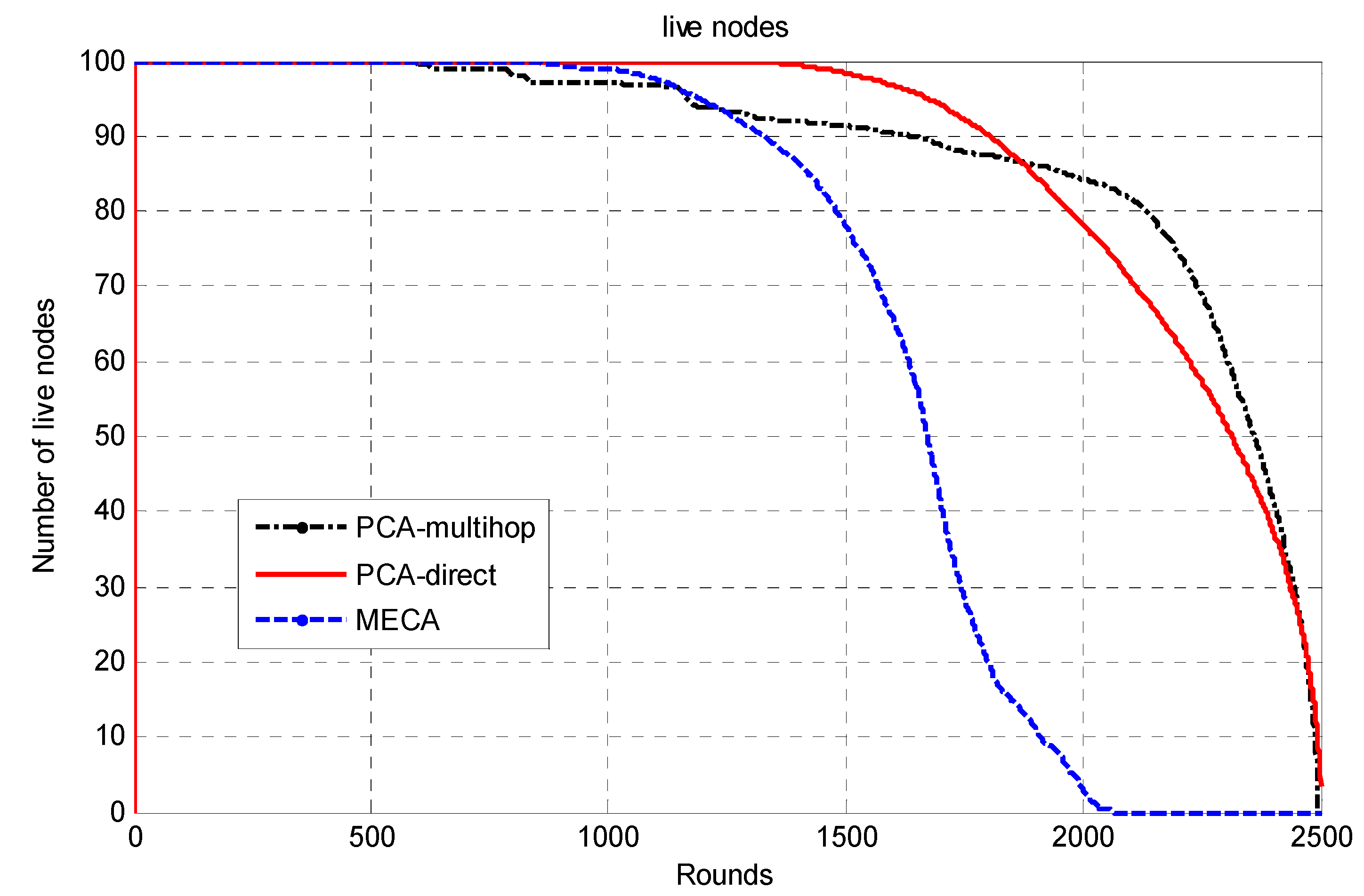
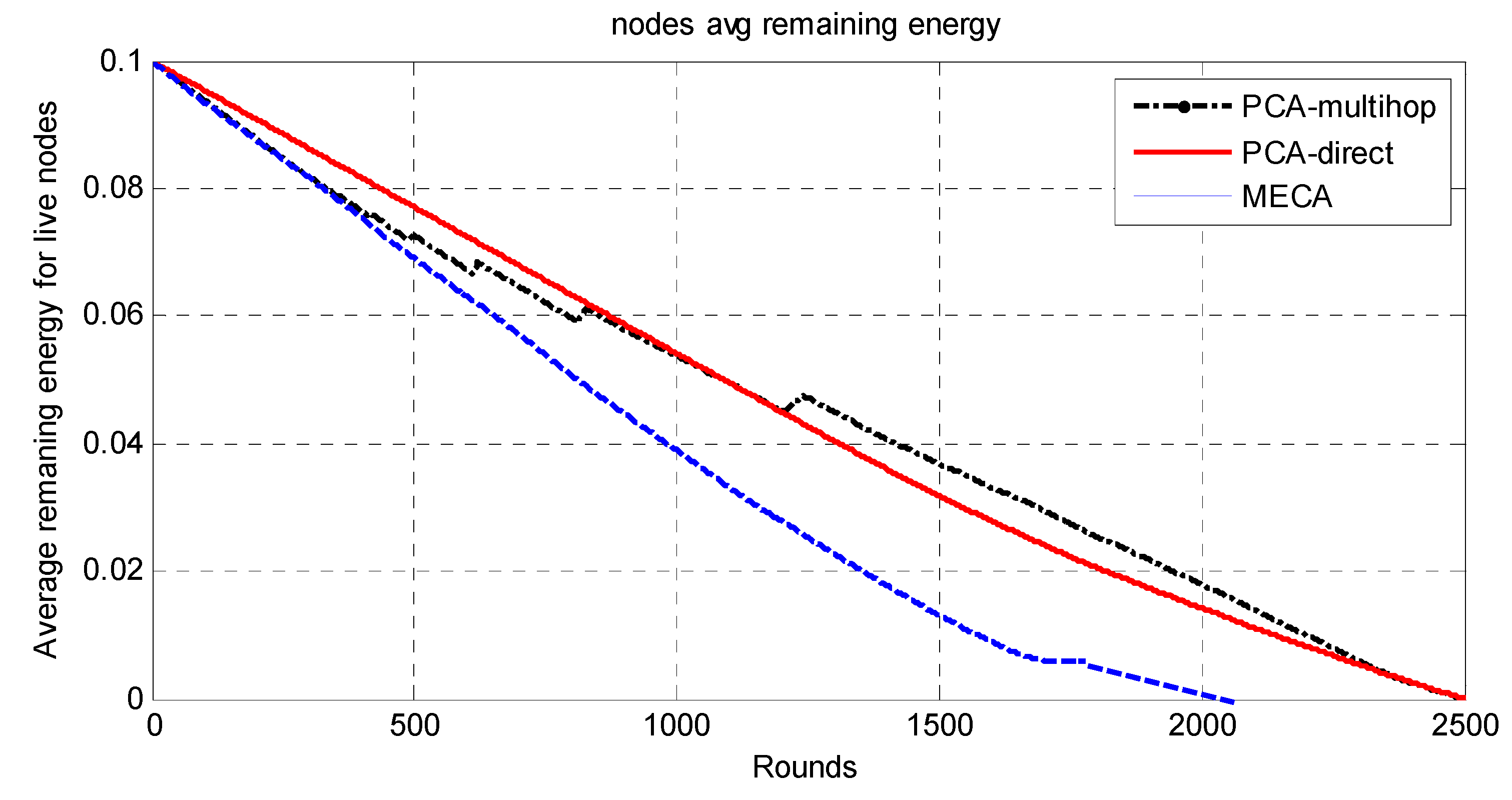
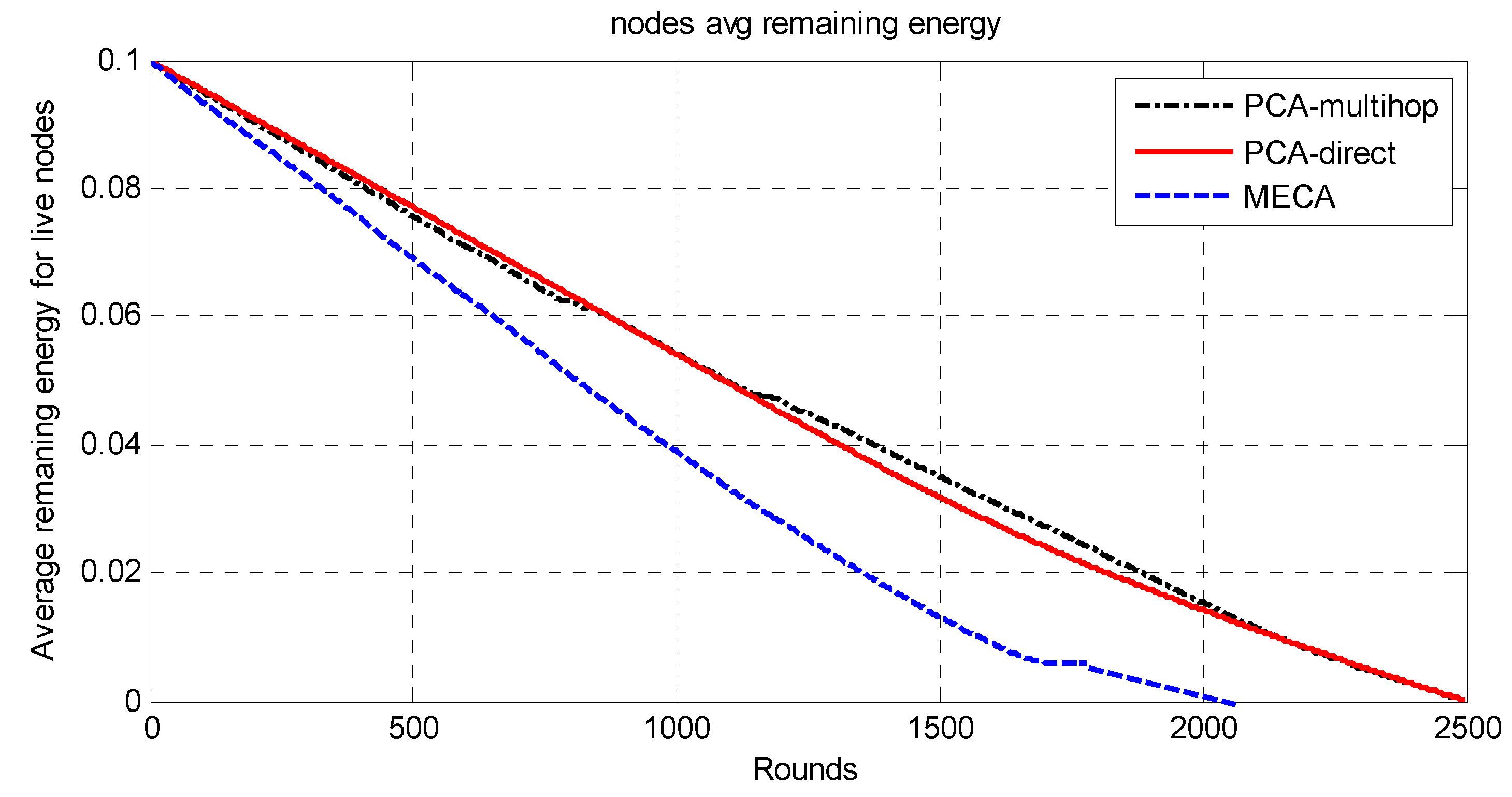
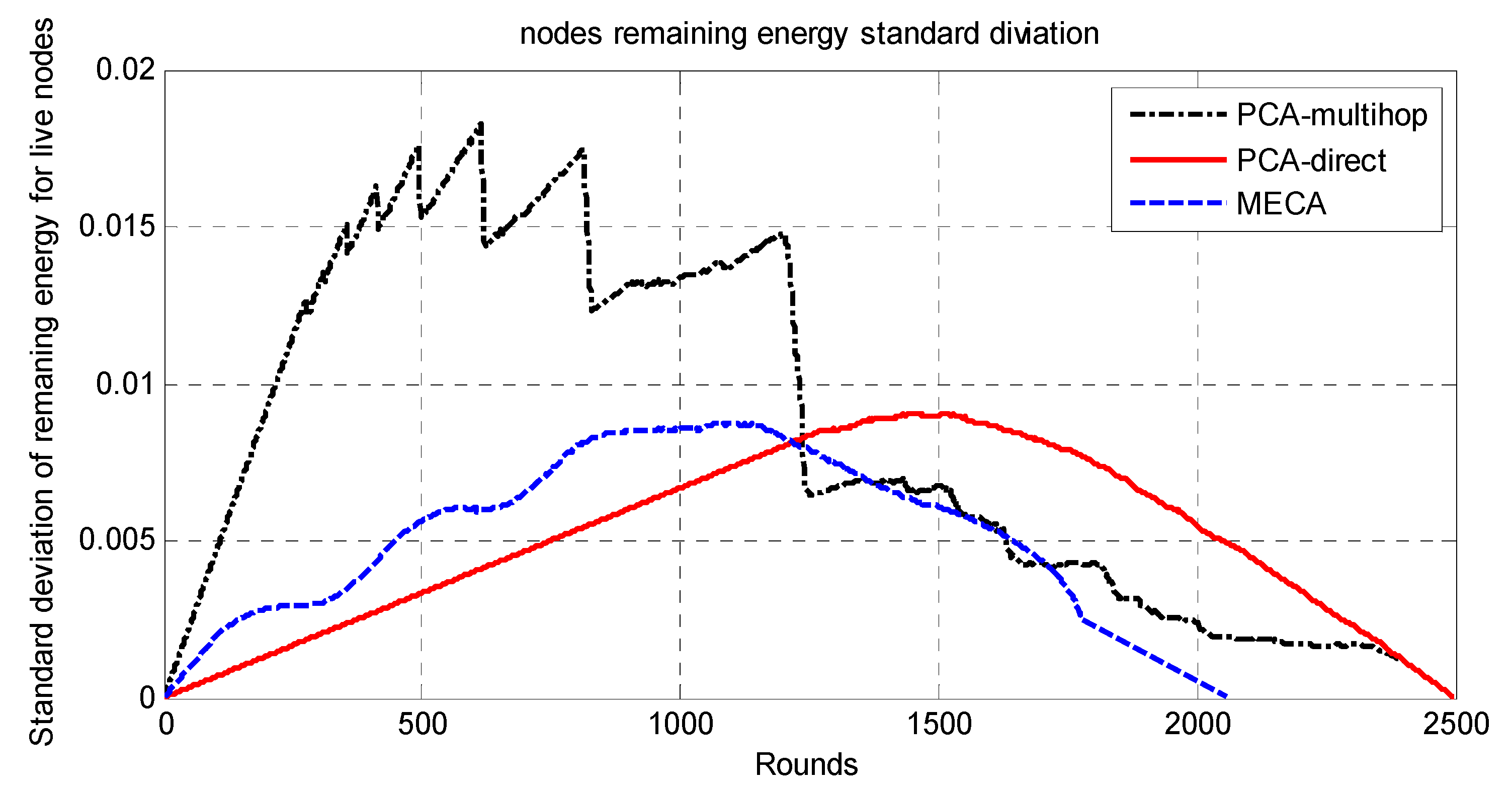
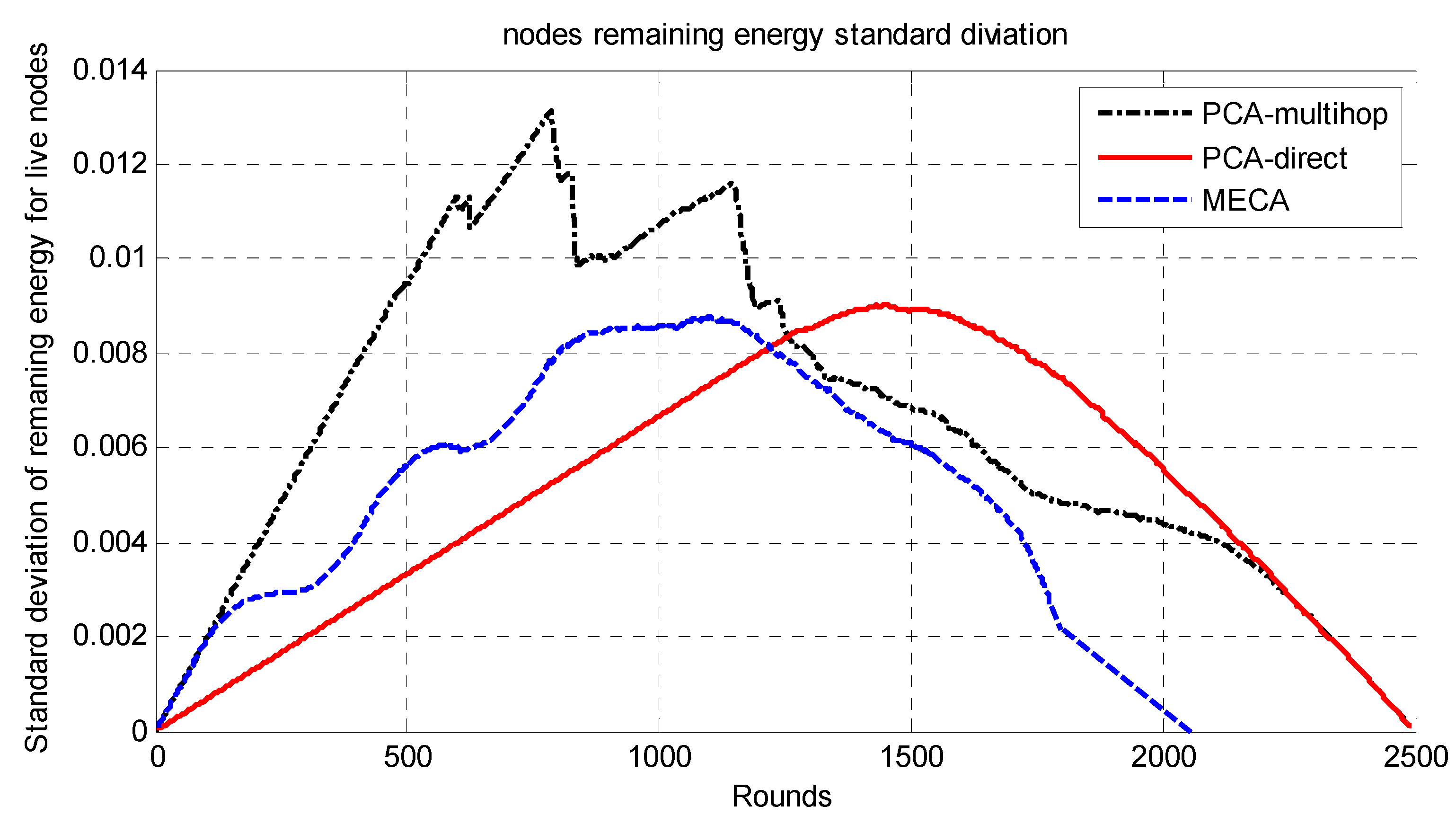
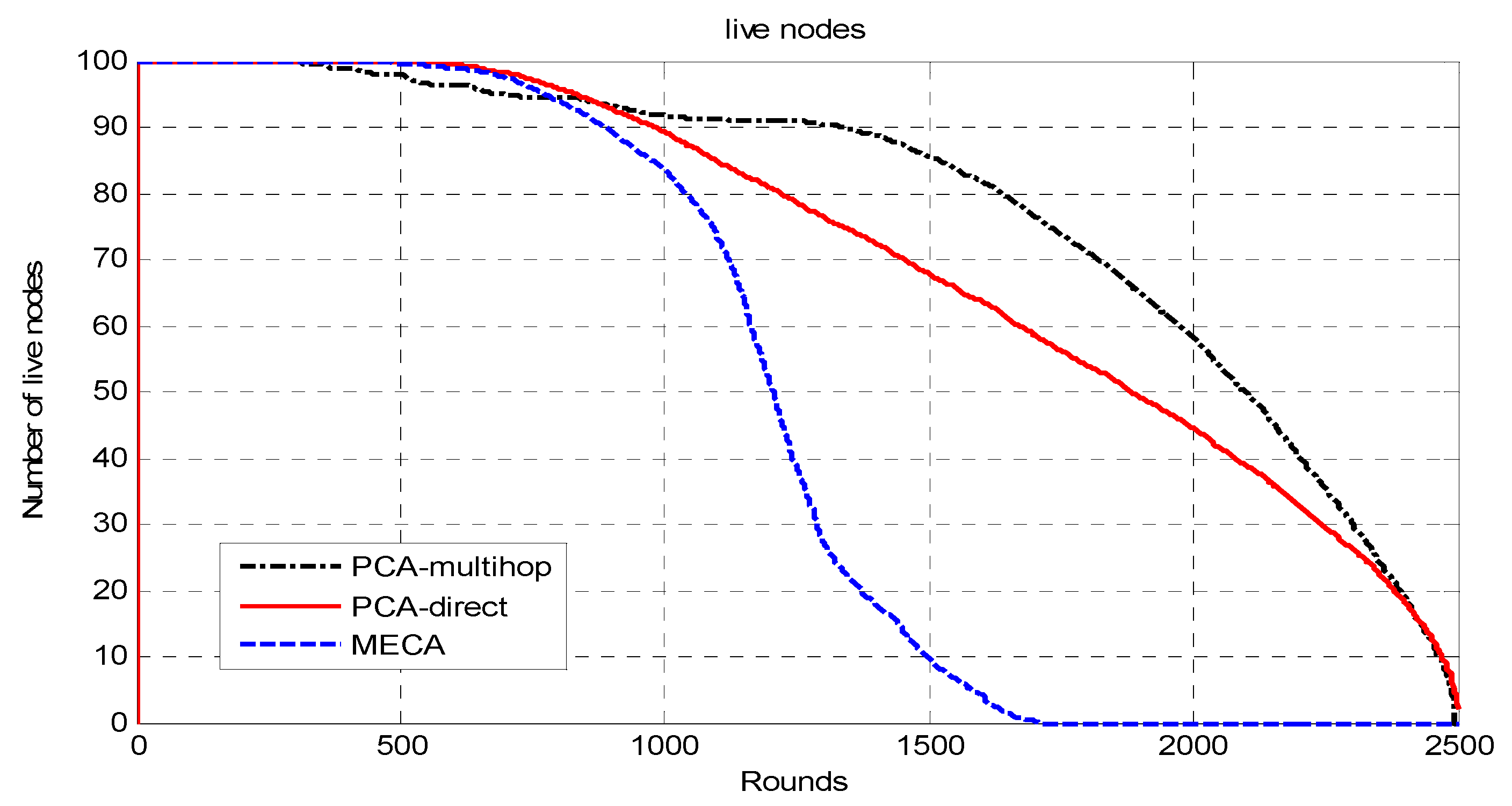
The whole network is divided into symmetric clusters; the nodes that have the highest remaining energy would be the CHs. Since the MS moves around the sensing field, for a sensor node to consume less energy, it would choose from three options. First, if the MS is close to the sensor node, it will send the data to it directly; second, if the cluster head is near the sensor, it will send the data to the cluster head and then to the MS; finally, if neither, it may choose a relay node and send data to it. The sensor node decision for the destination node is determined by the minimum of (E1(Si,CHi), E2(Si,Sj,Chi), E3(Si,MS)), where E1 is the required energy to send data from sensor node i to Chi; E2 is the required energy to send data from sensor i to CHi via sensor node j; E3 is the required energy to send data from sensor i to MS directly. The main drawback of this approach is that the path length will be long in wide-area networks as the MS has to travel around the sensing field to collect the data, which makes the period of data collection long.
In [
16], the Euclidian distance is used to calculate the distance between the CHs and the MS, while the TSP algorithm is used to find the optimum path with a short round trip time. However, the authors did not show any performance analysis of their proposed work. In [
17], the network is divided into small and large clusters, the large clusters are located far from the MS path, while the small clusters are located near the MS path, and the small (near) clusters use high energy nodes—rendezvous nodes (RNs)—to buffer and transfer data to the MS. The large (far) clusters forward their data to the RNs of the small clusters via the CHs.
The use of multihop for data collection was proposed in [
18]. It was aimed at generating a path for the MS in which the maximum tour length (
L) is given by (L =
Vm D), where
Vm is the average MS velocity and
D is the data collection deadline. However, the generated path could be a straight line or may take any shape. However, calculating the difference between the length of the TSP tour and the maximum length of the BS tour (L) could result in extra overhead time for constructing the path.
In [
19], the MS moves in a fixed path and stops on a set of stop points to collect data from the sensor nodes via multihop. The authors used the heuristic algorithm-based Tabu search algorithm to select the optimal number of set stop points in which the minimal hop count from sensor nodes and the MS is achieved. However, the path length in wide-area networks might become long because it is bent into the interior of the target area.
In [
20], the MS moves around a fixed route during a fixed time. The MS can predict the sensory data according to spatial and temporal correlations. Hence, while moving, it will broadcast a beacon message to inform the sensors that come within communication range and send sensory data prediction. Only sensors whose data exceed the threshold will send their data.
In [
21], the network is considered as fragmentations due to the obstacles or node failure. The author proposed using the dynamic programming approach to find the MS movement trajectory into each fragment that minimizes the energy consumption. In addition, integer linear programming is used to generate the shortest tour in terms of the time for the MS to visit all fragmentations.
A data collection approach for detecting phenomena in an IoT environment was proposed in [
22]. In the proposed approach, the sensor nodes and the sink are mobile. The mobile sensors organize themselves into groups and elect a sensor node per group called the GH. The GH in each group collects data from sensors in its group to detect possible local phenomena. Then, the mobile sink passes by the GHs’ locations to collect the group’s data and discover the global phenomena. However, the main draw of this approach is that extra overhead time is required in calculating a new path in every net window.
An algorithm for data gathering in WSNs with obstacles (DGOB) was proposed in [
23]. The problem is addressed in two phases. In the first phase, the nodes are grouped in clusters, where the authors exploit hierarchical agglomerative clustering and ant colony optimization to construct high-quality clusters in the presence of obstacles. In the second phase, the MS is used for data gathering from the cluster heads, and a tour construction method is introduced based on the GA and multi-agent reinforcement learning.
It is noteworthy to mention that the initial results of this work were presented in [
24]. However, in this paper, we show the efficiency of the proposed approach by using PCA to construct the MS path for data collection using the two modes: direct and multihop. Furthermore, in this paper, we compare our results with another reference that uses an approach that is close to the method used to collect the data in our proposed approach.
Table 1 compares the related works discussed in this paper with the proposed approach in terms of number of mobile sinks, path construction or type, data collection latency, and data collection mode.
3. Proposed Approach
In this section, we present our proposed approach. We start by introducing principle component analysis. Then, we discuss the pseudocode of the proposed approach. Then, we discuss the data gathering modes that were used to collect the data from the sensor nodes, where we consider the requirements of each mode in terms of the buffer size of the MS, the velocity of the MS, and the data collection rate.
3.1. Principle Component Analysis Overview
PCA is an applied linear algebra technique that is widely used in data analysis, face recognition, image compression, and finding the pattern of data because it is a simple and nonparametric tool that extracts relevant information from confusing data sets [
11]. In the real world, each data sample has
m number of measurements, which means that each data sample is a vector of
m dimension. PCA is a method for expressing the data in such a way as to highlight their similarities and differences. Generally, PCA re-expresses the original data as a linear combination of its original basis. PCA uses a vector space transform (eigenvectors) to reduce the dimensionality of large data sets. Using mathematical projection, PCA will reduce the dimension of features for the original data set from
m to
q, where
m >
q [
11]. Hence, PCA attempts to find a low-dimensional subspace passing close to a given data set that minimizes the sum of the squared distances from the data set to their projections in the subspace.
Assume that we start with a data set that is represented in terms of an X
n×m matrix, where the
n columns are the samples and the
m rows are the variables. Assume the objective is to linearly represent this matrix into another matrix, Y
n×m, which are called projections points, using eigenvectors V
m×mNow, what is the eigenvector of
V that provides the best representation for X? Generally, PCA finds the directions of which the variance between the projections is maximized and then uses these directions to define the new basis for the original data. In other words, the minimum sum of the square distance between the original data and the new data set (projection points) is achieved. The variance is the measurement of data spread and is identical to standard deviation. Now, to find V that maximizes the variance of projections, we can solve the following optimization problem:
where σ
2 is the variance of projections
Since V has arbitrary length, we can safely constraint it to have the norm of 1.
The Lagrangian function corresponding to the problem is
where
is the eigenvalue. In order to solve the optimization problem, we take the derivative and set it equal to 0.
The result is the famous eigenvalue problem
The eigenvalue problem can be solved by the eigenvalue decomposition of a data matrix or singular value decomposition (SVD) of a data matrix. We adopt the singular value decomposition to find the matrix of the eigenvectors from V for matrix
. SVD is a linear algebra theory that considers each rectangular matrix as a combination of the product of three matrices
where U is the eigenvectors of AA
T,
V is the eigenvectors of A
TA, and S is a diagonal matrix containing the square roots of eigenvalues from V.
Note that V contains m eigenvectors. In a 2-dimension data set, PCA will produce two eigenvectors: V1 and V2. The V1
m×1 defines the direction of the new data set (data projections) that has a longer variance between the projections, which is called the first principle component. In other words, while V1 maximizes the variance, the square distance would be minimized. The second principle component V2
m×1 would be orthogonal to
. Now, V1 is known, and the projection points would be found by the following equation:
From Equation (10), we note that the results are the projection points in 1-dimension. Since, in our work, the data points (sensor node positions) are real values in two dimensions and are not centered, the projection points that have been found in principle components space should be reconstructed to produce the projection points in actual original data points space and kept on the variance between the projection points using the following equation:
3.2. Pseudocode of the Proposed Approach
Given a WSN where N sensor nodes are deployed randomly over that network, our objective is to generate a path for the MS in order to collect the data from the nodes in the sensing field. The following assumptions are made in our approach:
The MS has unlimited energy;
Sensor nodes are homogeneous and fixed;
Each sensor node is capable of determining its location;
Each sensor node takes readings at a fixed rate;
The generated path by the MS is fixed during the lifetime of the WSN;
All sensor nodes are within the communication range of the MS.
The pseudocode of the proposed algorithm is shown in Algorithm 1. After deploying the nodes over the sensing field, the MS starts collecting the locations of the sensor nodes. Then, the PCA algorithm is run by the MS in order to generate the path. Once the path that will be used by the MS is generated, the MS then builds the transmission time schedule (TTS) for each sensor node in the network in order to inform that node about the time to send its data. Finally, each node will start sending its sensed data to the MS at the beginning of the time that was scheduled by the MS.
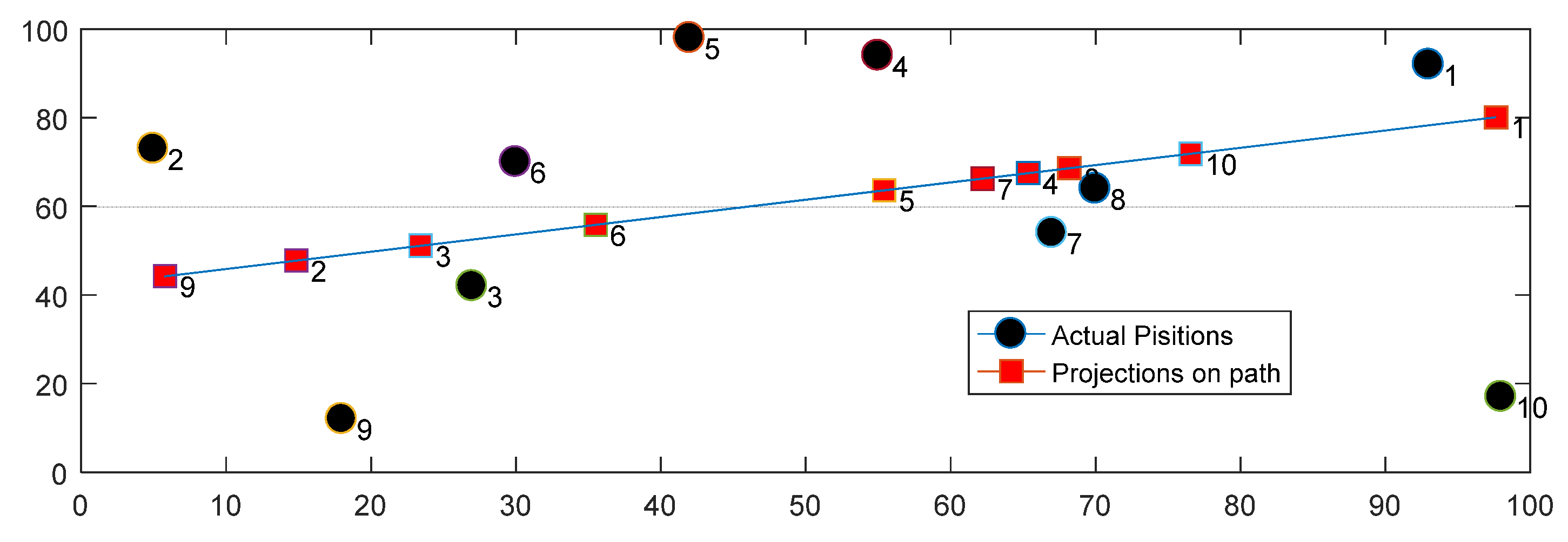
In order to illustrate how the path is generated by the MS after it collects the lactations of the sensor nodes, consider
Figure 1, which shows a WSN of size (100 × 100), where ten sensor nodes are deployed randomly in the network.
Table 2 shows the (x, y) location of each sensor node.
| Algorithm 1: Pseudocode of the proposed approach |
| 1. | Deploy n sensor nodes randomly |
| | // PCA algorithm |
| 2. | Xn×2 ← Sensor node locations // MS collects the location of sensor nodes |
| 3. | MS applies PCA on Xn×2 |
| 4. | Find the projection points |
| | // End of PCA algorithm |
| 5. | MS builds transmission time schedule (TTS) for sensor nodes in the case of |
| | direct transmission mode or for rendezvous nodes in case of multihop mode. |
| 6. | For i = 1 to m // m = number of sensor nodes if direct mode is used |
| 7. | if t = Ti then // m = number of rendezvous nodes if multihop
mode is used |
| 8. | MS starts receiving messages from sensor i |
| 9. | EndFor |
The following steps explain how the PCA algorithm is performed by the MS to generate the path:
The locations of the sensor nodes are organized in the following matrix:
The mean of the
matrix is computed column-wise, as follows:
The X matrix is adjusted by subtracting the mean value from each data point. The adjusted X matrix becomes as follows:
The principle components’ coefficients (eigenvectors) are calculated using Equation (8):
We have two eigenvectors, V1 = [], and V2 = [].
Then, the projection points for
are computed using Equation (10)
The projection points are reconstructed using Equation (11) to get their approximate locations on the line.
A fixed path for the MS that passes through the reconstructed projection points is generated, as shown in
Figure 2.
The projection points for nodes 9 and 1 are assigned as the start and end points for the MS path, respectively.
3.3. Data Gathering Modes
In our approach, two modes are proposed to gather the data from the sensor nodes after generating the path. These modes are: PCA-direct and PCA-multihop. In the PCA-direct mode, the sensor nodes send their data directly to the MS, while in the PCA-multihop mode, the MS collects the data from certain nodes called rendezvous points. In this section, we discuss the requirements of the two modes in terms of the MS buffer size, the velocity of the MS, and the data rate. Assume the length of the generated path is L, where L is calculated as:
where
is the location of the starting point, and
is the location of the end point over the generated path. Moreover, assume
i is the distance between the projection point for sensor node
i and the start point of the MS path. Then,
i is calculated as:
Additionally, assume
i is the distance between the projection point for sensor node
i and the end point of the MS path. Then,
i is given as:
Let V be the MS velocity, and R in bit/second is the rate of taking readings from the environment.
3.3.1. PCA-Direct
In this mode, the MS collects the data directly from each sensor node while it moves back and forth over the generated path. The distance between the projection point for each sensor node and the actual location of that node represents the minimum distance between the sensor node and the MS when it moves over the generated path. Based on that, the MS builds a transmission time schedule (TTS) to inform all sensor nodes about the times in which they should transmit their data.
We assume that the TTS is built such that some sensor nodes are scheduled to transmit their data when the MS moves from the start point to the end point, and the other sensor nodes send their data to the MS while it moves from the end point to the start point. This two-way movement of the MS composes one round. Therefore, the distance that is covered by each round is:
and the time required for each round is:
Therefore, the TTS for each sensor node in the first round can be calculated as follows. For sensor node
i, the starting time for sending its data, when the MS moves from the start point to the projection point of sensor node
I, is given as follows:
where (
) is the projection point for sensor node
i. If sensor node
i is scheduled to send its data when the MS moves from the end point to the start point, then the starting time for sensor node
i to send its data to the MS in the first round is given as:
For the other rounds, the starting time for sensor node
i to send its data in round
j,, is given as:
To avoid the buffer overflow that may occur at sensor nodes or the MS, the sensor nodes and the MS will be provided with enough buffer size. The size of the required buffer for each sensor node
i is:
while the size of the required buffer for the MS is:
3.3.2. PCA-Multihop
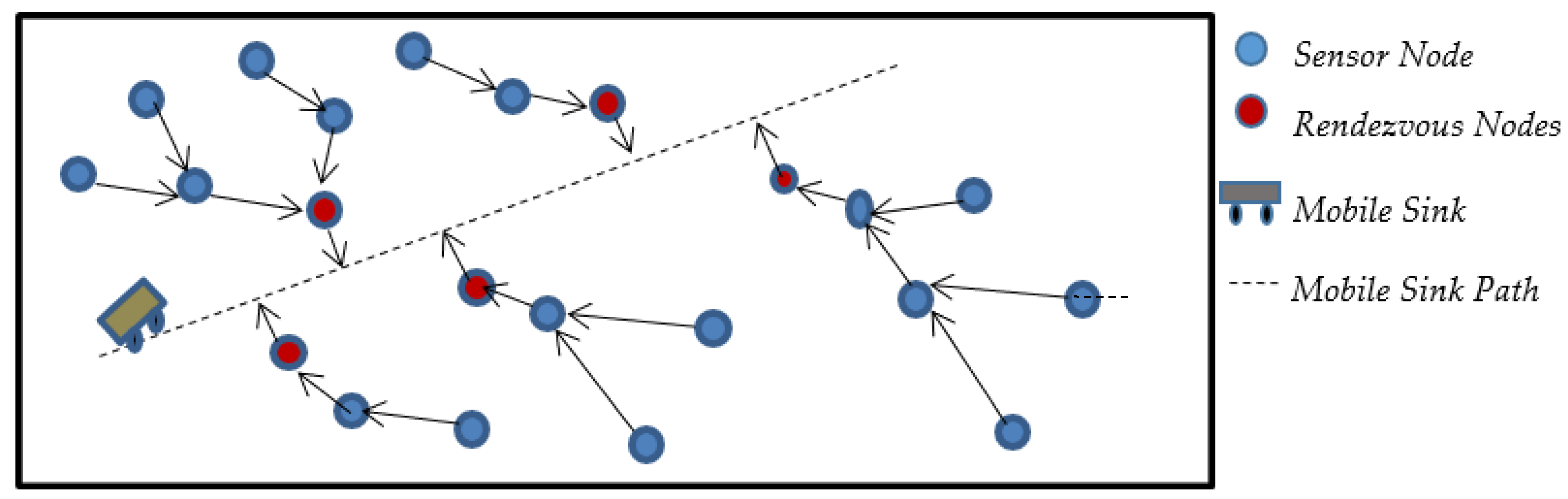
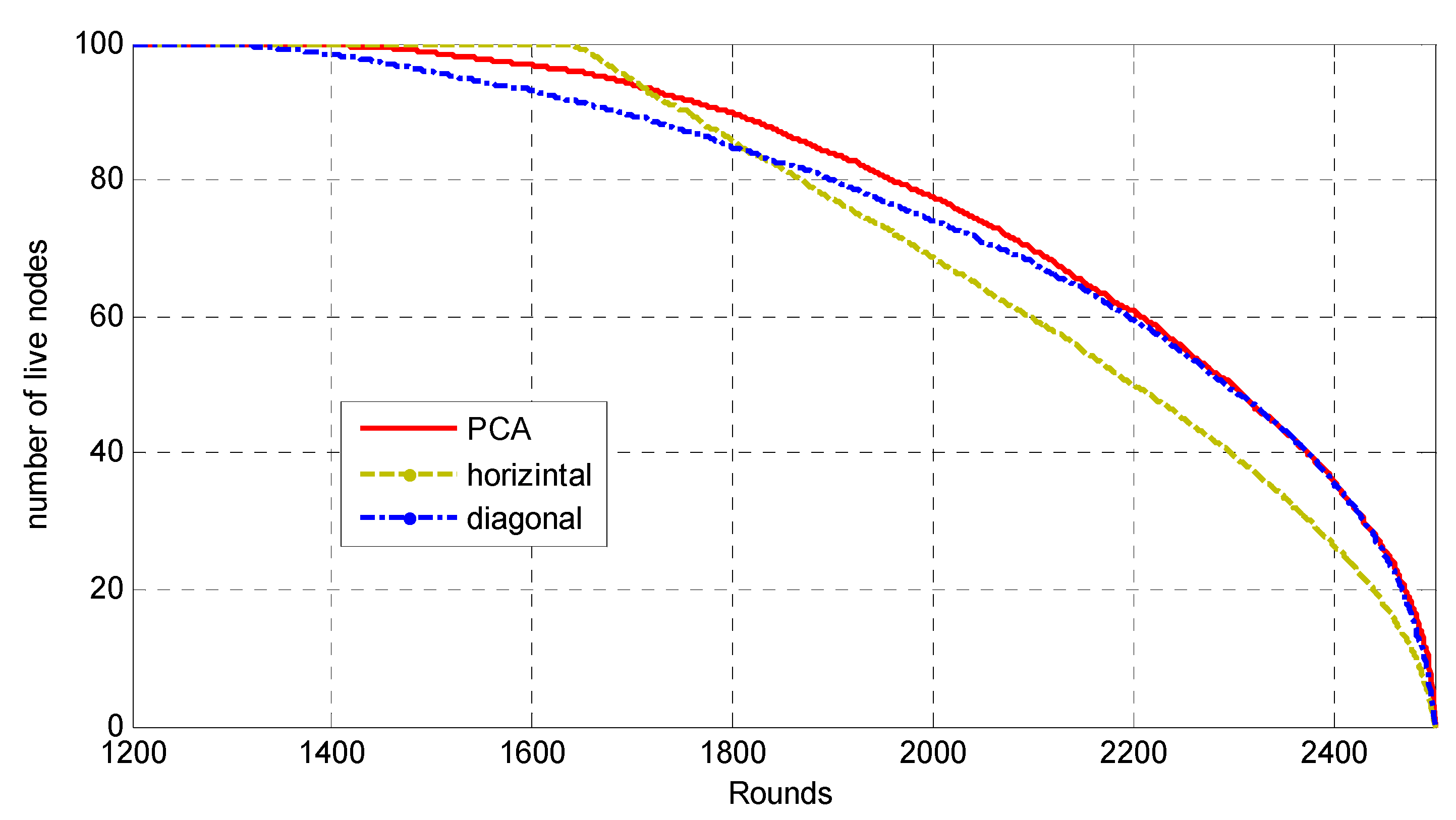
Unfortunately, in the PCA-direct data-gathering mode, the energy of the sensor nodes that are located far from the MS path will be depleted faster than the energy of the sensors nodes that are close to the MS path. Thus, the network’s lifetime would be affected negatively. The multihop mode has been proposed for saving the energy of the far sensor nodes as much as possible, in which it can adjust their transmission range. In PCA-multihop mode, the data of the far sensor nodes will be aggregated at rendezvous points (RPs) via intermediate sensor nodes.
The rendezvous points are subsets of sensor nodes that are located near the MS path and are selected by the MS to be the agents for data delivery. While the MS moves over its generated path, it only contacts these rendezvous points. Other normal sensor nodes can deliver their data to the rendezvous points using the multihop technique, and then the rendezvous points forward those data to the MS directly. Thus, many trees will be constructed in the network, such that the root of each tree will be a rendezvous point and the leaves of these trees will be the farthest nodes from the path, as shown in
Figure 3.
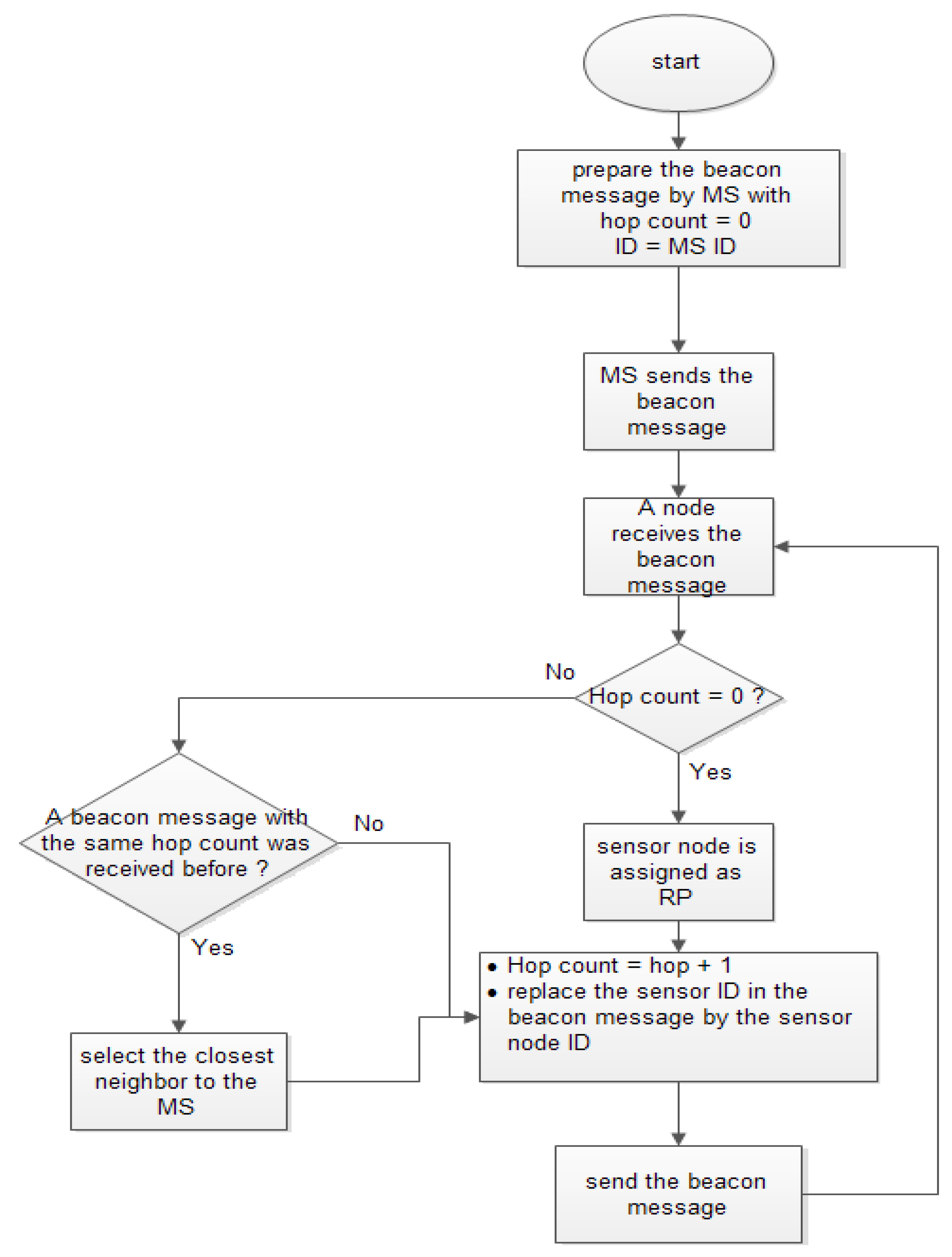
To construct the delivery tree in the multihop mod, the MS moves along the generated path and broadcasts a beacon message within a limited range. The beacon message consists of three parameters: the ID of the node that sends the beacon message, the hop counter, and the distance between the node that sends the beacon message and its projection point.
Each sensor node that receives the beacon message will replace the sender ID with its own ID and increment the hop count by 1 as well as its distance from its projection points before forwarding it to its neighbors and so on. If the sensor node receives the beacon message directly from the MS, it will reply to the MS to declare itself as an RP. Each sensor node that cannot receive the beacon message directly from the MS will select one that has the lowest hop count from its neighbors. If there is more than one neighbor with the same number of hop count, it will select the closest neighbor to the MS path to be its destination. The flowchart shown in
Figure 4 summarizes the tree construction.
To avoid the buffer overflow that may occur at rendezvous points or any nodes, the sensor nodes will be provided with enough buffer size. Assume a set of sensor nodes form a tree that is rooted at an RP sensor node. Assume the
level is the tree depth. The buffer capacity for the node RP that is required to collect the data from the sensor nodes in the tree as well as its own data is:
where level = hop count + 1.
Since the sensor nodes are homogenous, the sensor nodes in the same tree will be provided with a buffer queue (see the results in Equation (26)). Furthermore, the maximum buffer size that is required for one of RPs will be taken as a suitable buffer size for all sensor nodes. After the tree construction, the MS will generate the TTS for the rendezvous points, as explained in
Section 4.2.2. To ensure that the data have been collected at each RP before the MS arrives, each RP will generate its own TTS to its children sensor nodes; additionally, each child node will generate a TTS and send that to its children sensor nodes and so on.




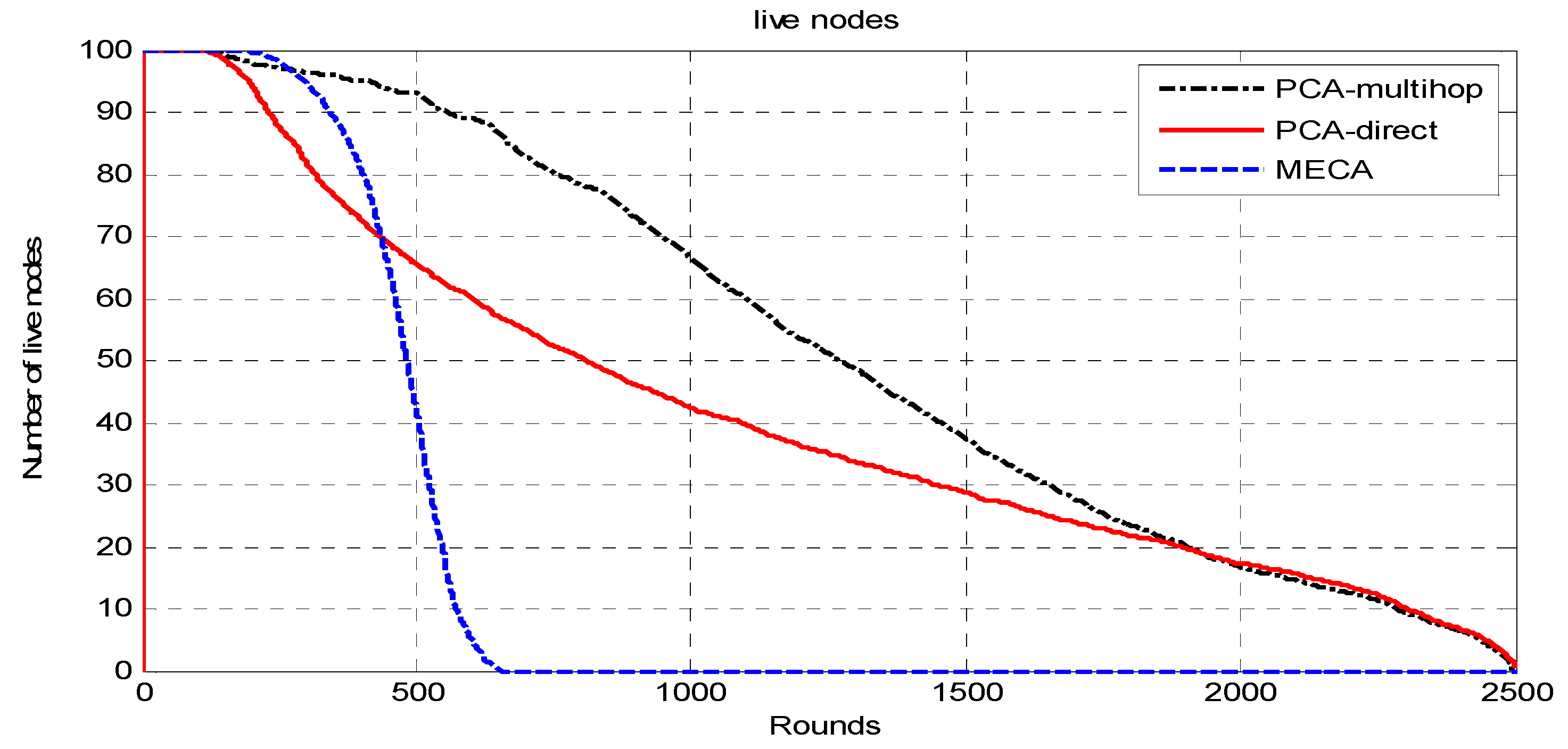
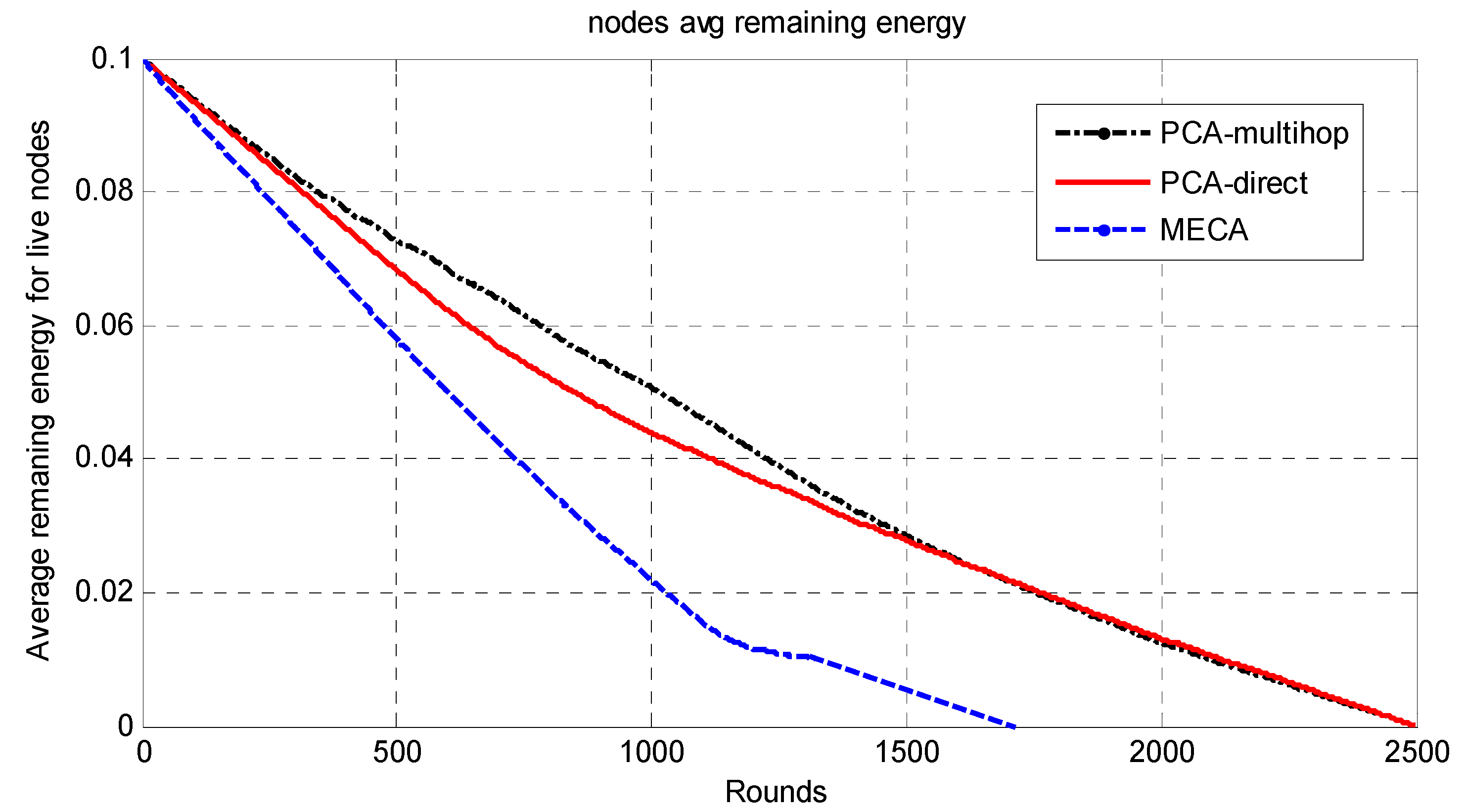
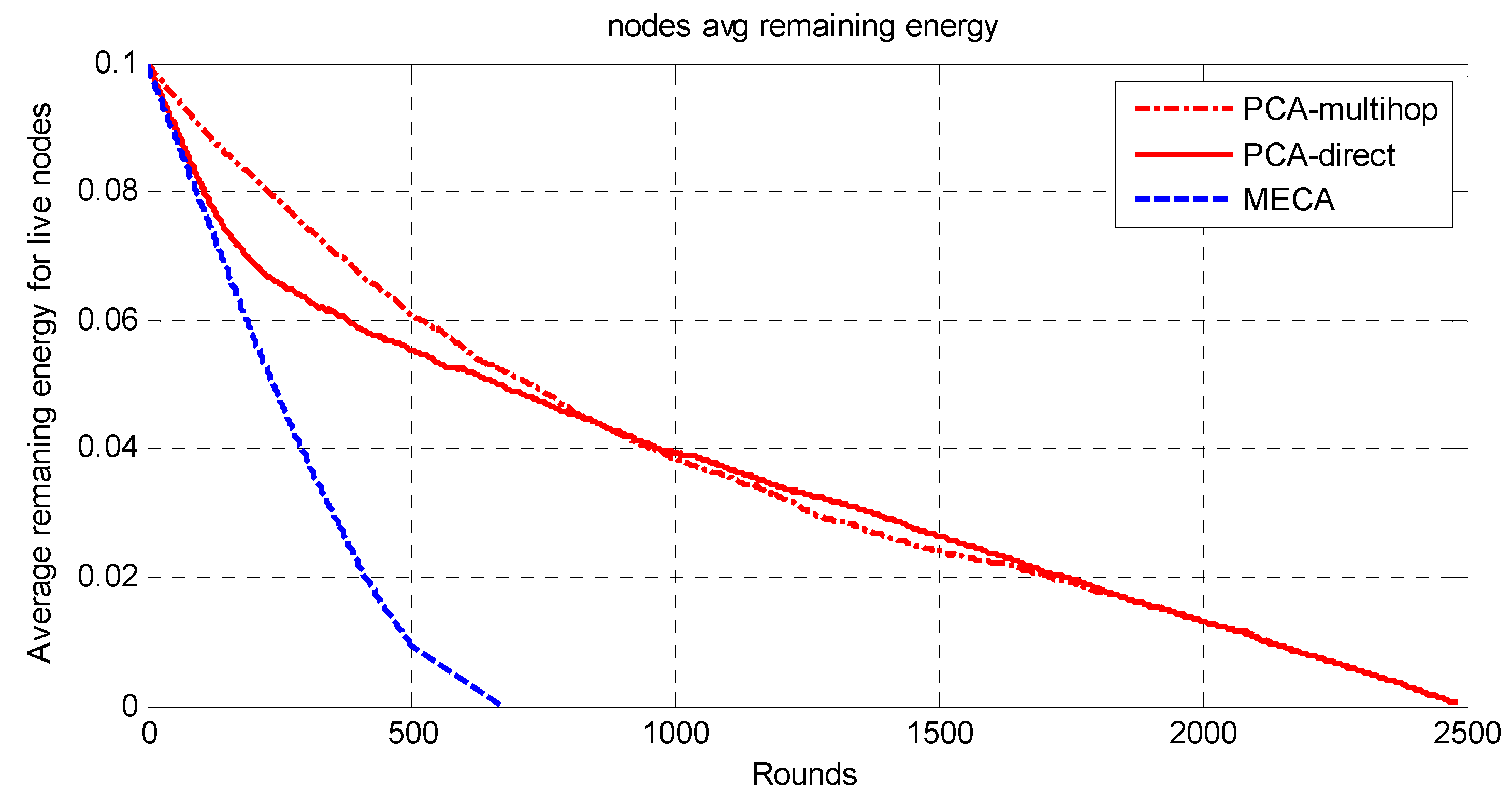

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}