1. Introduction
Brazil is the fourth largest producer of banana (
Musa spp.) in the world, and ranks fifth in harvested area [
1]. The main banana subgroups in Brazil are “Prata” (AAB), that dominates in the north and the northeast, and “Cavendish” (AAA), dominant in the south and the southeast. In 2018, the Brazilian production was 6.75 × 10
6 Mg on 449 × 10
3 ha, averaging 15.0 Mg ha
−1 yr
−1. In comparison, the average banana yield of the top ten banana producing countries reached 44.8 to 65.5 Mg ha
−1 yr
−1. While the productivity of banana orchards nearly doubled globally over the past 50 years from 11.7 to 20.2 Mg ha
−1 yr
−1, that of the Brazilian orchards stagnated around 15.0 Mg ha
−1 yr
−1. The frequent low productivity of Brazilian orchards is attributed to inadequate nutrient and water management [
2] and insufficient soil and tissue testing [
3]. Brazil is a large country which experiences highly variable rainfall regimes. In north-eastern Brazil, fertigation systems have been installed to automate water and nutrient management at the plot scale [
4,
5,
6]. Fertilization and irrigation represent 16–22% and 14–27% of production costs, respectively [
7].
Because genetic, environmental and managerial factors impact on plant elemental composition [
8,
9], and plants can explore the soil beyond the soil sampling layer, tissue tests are generally more closely related to crop yield than soil tests [
10]. Common tissue nutrient diagnostic methods for banana crops are the “Diagnosis and Recommendation Integrated System” (DRIS) and the “Compositional Nutrient Diagnosis” (CND). Regional DRIS and CND tissue diagnostic standards have been elaborated for rainfed “Cavendish” in East Africa [
11,
12], irrigated “Cavendish” in Ecuador [
13] and Brazil [
14], and irrigated “Prata” in Brazil [
15,
16], using yield thresholds or boundary lines as yield separators. The latter approaches are unable to separate true negative (high yielding, nutritionally balanced) from false positive (high yielding, nutritionally imbalanced, due to luxury consumption or contamination) specimens.
Different numerical methods, cultivars and environments affect the accuracy of nutrient diagnostic standards for banana. Nevertheless, regional diagnoses are based on the assumption that all factors except those being addressed are at equal or optimum levels [
17]. Regional diagnosis differs from the intuitive growers’ approach that compares unhealthy to nearby healthy specimens grown under otherwise similar conditions at a local scale. There is a need to develop a methodology to customize nutrient diagnoses of fertigated banana under similar conditions at a plot scale, where most growth-impacting factors can be assumed to be uniform.
Local scale nutrient diagnoses require collecting large amounts of high-quality data and using efficient data-processing procedures to make defective and successful compositions comparable at factor-specific levels [
18]. Paradoxically, more than two hundred years ago, Alexander von Humboldt elaborated the principles of biogeography by assembling measurements, observations and local knowledge to describe complex natural systems as coherent entities including human groups [
19]. It was not until recently that machine learning (ML) methods could process massive datasets to unravel complex ecosystem patterns [
19,
20]. ML models can predict agronomic yields from genetic, environmental and managerial features and soil and tissue tests [
21,
22,
23].
On the other hand, Compositional Data Analysis (CoDa) methods can provide nutrient ranking in the order of their limiting effect upon yields, and report on the perturbation of soil and tissue nutrient status by fertilization. Soil and tissue nutrient concentrations are compositional data that are intrinsically multivariate and strictly positive. Such data are constrained to measurement units or scaled to the sum of fractions [
24]. The CoDa methods developed to solve the closure problem in compositional data [
24] confer Euclidean geometries upon soil and tissue nutrient test results, making it possible to compare compositional entities rather than separately analyzed parts. Nutritionally imbalanced compositions can thus be compared with neighboring, successful, equal-length compositions at a local scale where other yield-impacting factors are similar [
18,
25]. Thereafter, nutrients can be ranked in the order of their limitation to guide fertilization decisions at a plot scale, where fertigation systems can be regulated.
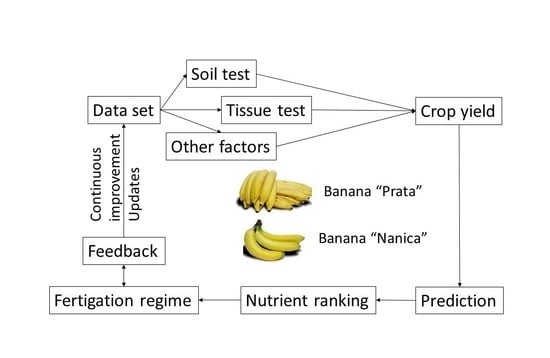
The ML and CoDa tools can be combined to solve nutrient problems at the plot scale in banana orchards. We hypothesized that (1) ML models could accurately predict yield from soil tests, tissue tests and local factors, and (2) local diagnoses at the plot scale, where factors interact in a unique manner, differ from regional diagnoses, where nutrient standards are averaged across factors. Our objective was to customize banana nutrition to guide fertigation decisions. Concepts of ML and CoDa are first defined to facilitate interpretation of the results at regional and local scales.
3. Material and Methods
3.1. Experimental
Observational data were collected from 2010 to 2017 in 6- to 19-year-old banana stands at Missão Velha, Ceará state, Brazil (7°35′ S and 39°21′ W, 442 m in altitude). The banana dataset comprised 811 observations on cv. ‘Prata’, AAB “Prata” subgroup, and 129 observations on cv. ‘Nanica’, AAA “Cavendish” subgroup. The dataset used by Deus et al. [
2] for regional scale nutrient diagnosis was augmented by adding one more year of “Prata” observations (
n = 108 new “Prata” observations) and 129 “Cavendish” observations (2010–2017).
Soils were sandy and classified as Neossolo Quartzarênico or Quartzipsamment [
51]. The regional climate is semiarid/tropical (Aw in the Köppen-Geiger classification) with dry winters and rainfall concentrated in summer. The warmest months in the area extend from September to December [
59]. Maximum and minimum temperatures ranged between 31–35 °C and 19–21 °C, respectively, compared to optimal mean temperatures for banana production, i.e., 22 °C for floral initiation, 31 °C for leaf growth and development, and 28 °C (range: 15–35 °C) for high commercial yields [
60]. Total rainfall averaged 1006 mm, below the 1200–1800 mm required for high fruit production.
“Prata” was planted at a density averaging 1275 plants ha
−1 (2.8 m × 2.8 m). “Cavendish” was planted at a density averaging 1479 plants ha
−1 (2.6 m × 2.6 m). Fertigation equipment was set to supply plant demand for water and nutrients down to plot units [
7] that averaged 3.26 ha in size. Integrated pest management was carried out as recommended in [
61]. Yield data were reported for both dry (July–December) and rainy (January–June) seasons. Fruit yield was reported as the sum of harvests per plot unit through the months of January to June (rainy season), and the months of July to December (dry season), respectively, and then converted to kg ha
−1 semester
−1.
3.2. Soil and Tissue Analysis
Soils and leaf tissues were analyzed as composite samples in each plot unit [
62,
63]. In the first and second semester every year, the third most fully expanded leaf of banana plants was collected at the blooming stage [
64]. Pieces with 10-cm width were cut at the midpoint on both sides of the midrib. Four samples made of ten subsamples each were composited, then oven-dried at 72 °C and ground to less than 1 mm. The N was quantified by micro-Kjeldahl. After sample digestion in a mixture of nitric and perchloric acids [
65], Ca, Mg, Fe Zn, Cu, Al and Mn were quantified by atomic absorption spectrophotometry, P and B by colorimetry, S by turbidimetry, and K and Na by emission flame photometry [
66,
67]. Soil samples were collected in the 0–0.20 m layer. Twenty subsamples were composited per plot into 250-cm
3 samples, air-dried, ground and sieved to <2 mm for chemical analysis [
66]. The pH was measured in 1:2.5 soil-to-water volumetric ratio. P and K were extracted using the Mehlich-1 method. Ca, Mg and Al were extracted with 1 N KCl. Elements were quantified by inductively coupled plasma (ICP-OES). Exchangeable acidity (H + Al) was extracted using calcium acetate 0.5 M at pH 7.0. Cation exchange capacity was computed as the sum of exchangeable cations (K, Ca, Mg) and exchangeable acidity. Total carbon was determined by dichromate oxidation (Walkley–Black) and multiplied by 1.724 to obtain organic matter content [
68].
3.3. Statistical Analysis
The clr biplot was drawn using command Graphs-clr biplot in the Codapack 2.02.21 freeware. The ML classification models were run using the Orange vs. 3.23 freeware. The following machine learning (ML) models were compared in a cross-validation following classification mode: Random Forest (RF), Neural Network (NN), Naive Bayes, support vector machine (SVM), k-nearest neighbors (KNN), Adaboost and stochastic gradient decent (SGD). Model features were cultivar, year and semester of data acquisition, and tissue composition (N, P, K, Mg, Ca, S, Cu, Zn, Mn, Fe, B, Na, Al). Soil features (pH, organic matter content, available P, K, Ca, Mg, and exchangeable acidity) were used to determine the closest successful neighbors in terms of soil properties. Closeness of the successful compositional neighbors was measured as Euclidean distance. The target (dependent) variable was either fruit yield (regression mode) or fruit yield class about yield cut-off (classification mode).
Yield cut-offs between high- and low-yielders were set at 17,500 kg ha
−1 semester
−1 for “Prata”, and 25,000 kg ha
−1 semester
−1 for “Cavendish”. The confusion matrix partitioned data into true-negative (TN), false-negative (FN), true-positive (TP) and false-positive (FP) quadrants [
36]. The significance of the partition was assessed by a chi-square test against equal distribution. The TN specimens were the reference subpopulation (high yield of nutritionally balanced specimens). The FN specimens presented yield limitations due to factors other than mineral nutrition. The TP specimens showed nutrient imbalance, leading to low yield. The FP specimens represented high yielders subject to luxury nutrient consumption or contamination.
Model performance was measured as area under curve (AUC) and classification accuracy (CA). The model is informative if AUC lies between 0.7 and 0.9 [
69]. Classification accuracy (CA) computed as (TN + TP)/(TN + FN + TP + FP) was compared to the CA of other crops [
70]. Nutrient ranges were assessed as the quartile concentration values of TN specimens. Quartiles concentration ranges of merged TN and FN specimens were reported as “compatibility intervals”, [
71] indicating compatibility between the composition of the diagnosed specimen and that of the statistically reconstituted, well-balanced specimens at a regional scale [
43]. The predictive model returned the probability that a diagnosed specimen would belong to the low- or the high-yielding subpopulation.
6. Conclusions
Agroecosystems are described by specific combinations of environmental and managerial features. Compositional systems are defined explicitly by soil and tissue tests that may be arranged into balances to facilitate interpretations of the results in terms of a physiological system or for management purposes. The ML models accurately related yield to cultivar, soil and tissue tests, and other local features. The NN model, applied at a local scale, can be increasingly informed by adding more yield-impacting features, and may return nutrient diagnoses which are different than current regional diagnoses averaged across features. The NN model reached an AUC of 0.827 using cultivar, tissue and soil nutrient composition, field and well numbers, and time of harvest as features. Tissue tests that integrate all factors contributing to plant nutrition provided the most effective features to diagnose nutrient problems. This paper showed that the use of categorial features such as well or plot numbers, year and semester did not suffice to fully understand orchard performance. In particular, the state of soil and well water quality may limit the performance of fertigated banana orchards and lead to overfertilization and nutrient imbalance where yield potential is lower than average, hence reducing fertilizer-use efficiency. Fertilization dosage should thus be documented in the dataset whenever possible. Managers of banana orchards can evaluate whether regional or local diagnoses are most suitable to guide fertigation, and whether additional features must be added to improve the accuracy of predictive and recommendation models.
Using median tissue nutrient concentrations, we showed that local diagnoses at a plot scale, where factors interact, differed from regional diagnoses, where nutrient standards are elaborated across factors. While regional diagnosis provided a comparison with regional centroids weighted by their respective standard deviations for nutrient management at a regional scale, local diagnosis compared nutrient compositions as unique combinations of leaf nutrients in response to local factors. The ML-CoDa predictive models provided realistically attainable high yields at a local scale, as documented in the dataset. The site-specific probability of successfully reaching high yields can reduce uncertainty when assessing expected yield and the risk of taking erroneous fertigation decisions.
Crop managers should take part in the knowledge building process by documenting features and updating the banana dataset with observational data. Researchers can contribute to the dataset with experimental data to solve specific problems in cropping systems. Indeed, all stakeholders should collect and share data to better understand the myriad of factor interactions involved in banana production systems, and to facilitate taking informed fertilization decisions at the appropriate scale of nutrient management.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}