1. Introduction
With the continuous growth of the global population and the impact of climate change, agricultural production is facing increasingly severe challenges [
1,
2,
3]. In the northern regions of China, climate change has exacerbated the frequency of crop diseases, posing significant threats to agricultural productivity [
4]. Leafy vegetables, as one of the essential categories of vegetables in China, are particularly susceptible to diseases due to their complex growing environments and diverse types of pathogens, which significantly affect both yield and quality [
5,
6,
7]. The accurate and timely detection and prevention of diseases are crucial for ensuring agricultural productivity, enhancing crop yields, and maintaining food safety [
8]. Traditionally, disease detection has relied on manual inspection and diagnosis [
9]. However, such methods are labor-intensive, require significant technical expertise, and are influenced by subjective factors, making it challenging to detect potential diseases promptly, thereby missing the optimal time for intervention [
10].
With the modernization of agricultural practices, the limitations of traditional disease detection methods have become increasingly apparent, especially in large-scale agricultural production systems where manual inspection is no longer sufficient to meet the demands [
11]. Therefore, an automated and accurate disease detection approach is urgently needed to improve efficiency and ensure precision. In recent years, deep learning technologies have achieved remarkable breakthroughs in computer vision and demonstrated significant potential in agricultural disease detection [
12]. By training deep neural networks, computers can automatically extract features from images and identify and classify different types of diseases, offering unparalleled advantages over traditional methods [
13]. Consequently, the application of deep learning-based methods for disease detection and segmentation in agriculture has become a prominent research focus in both academic and industrial fields [
14].
With the advancements in computer vision technologies, image-processing-based disease detection methods have emerged [
15]. These methods primarily rely on extracting image features such as color, texture, and shape to identify diseased areas [
16]. Common image processing techniques include threshold segmentation, edge detection, and texture analysis [
17]. Although these methods can achieve satisfactory results in simple scenarios, they depend heavily on manually defined features and rules, making them inadequate for complex and dynamic agricultural environments. Particularly in situations where diseases are diverse and environmental conditions fluctuate significantly, traditional image processing methods often fail to effectively differentiate between diseased and healthy plants, resulting in low detection accuracy [
18]. Additionally, traditional methods exhibit poor adaptability in scenarios involving multiple diseases or diverse planting conditions. In cases of limited data or imbalanced disease types, the robustness and generalization capabilities of these models are weak [
19]. These limitations present substantial challenges for practical applications, necessitating the development of novel technological solutions.
The early detection and rapid control of leafy vegetable diseases are critical for enhancing agricultural productivity [
20]. Timely and accurate disease detection can not only prevent the spread of diseases but also reduce pesticide usage, minimize environmental pollution, and ensure the healthy growth of crops, thereby improving the quality and yield of agricultural products [
21]. Early detection provides farmers with scientific decision-making support, preventing disease outbreaks and reducing economic losses. Currently, disease control for leafy vegetables primarily relies on manual inspection and chemical treatment [
22]. While technologies such as remote sensing, drones, and ground-based sensors are being used to assist in monitoring, these methods remain in the preliminary stages of application and face challenges such as incomplete data collection, low accuracy, and operational complexity [
23]. In many rural areas, agricultural infrastructure is underdeveloped, and the application of information technology is not widespread. Therefore, efficient and intelligent methods for detecting leafy vegetable diseases hold significant application value.
In recent years, the successful application of deep learning techniques, particularly convolutional neural networks (CNNs), in computer vision has provided new solutions for intelligent agricultural scenarios [
24,
25]. Compared to traditional image processing methods, deep learning can automatically learn effective feature representations from large datasets, reducing the need for manual feature design. Specifically, deep learning models have demonstrated exceptional performance in tasks such as image classification, object detection, and semantic segmentation. Abdu et al. proposed a plant disease identification method that optimally extracts global and local feature descriptors representing lesions, reducing feature redundancy and vector length to improve performance and thus achieving high precision and a recall rate exceeding 99% [
26]. Rahman et al. introduced an image-processing-based technique for the automatic detection and treatment of tomato leaf diseases, calculating 13 statistical features from tomato leaves and using a support vector machine (SVM) to classify diseases, achieving an accuracy exceeding 85% [
27]. Li et al. developed an improved vegetable disease detection algorithm based on YOLOv5s, modifying the CSP, FPN, and NMS modules within YOLOv5s to mitigate the impact of environmental factors, enhance multi-scale feature extraction capabilities, and improve detection performance, achieving a mean average precision (mAP) of 93.1% for vegetable disease detection [
28]. Tiwari et al. proposed a potato disease detection model utilizing transfer learning to extract relevant features from datasets, achieving an accuracy of 97.8% [
29]. Wang et al. presented a two-stage model for cucumber leaf disease severity classification under complex backgrounds, combining DeepLabV3+ and U-Net. The leaf segmentation accuracy reached 93.27%, the lesion segmentation’s Dice coefficient was 0.6914, and the average accuracy for disease severity classification was 92.85% [
30]. Jiang et al. used a CNN to extract features from rice leaf disease images and applied an SVM for the classification and prediction of specific diseases, achieving an average accuracy of 96.8% [
31].
While these deep learning-based models demonstrate strong performance, they typically require large-scale labeled datasets and are not designed to handle new disease classes with minimal data. Few-shot learning approaches in agriculture have attempted to address this issue by introducing meta-learning frameworks that learn from limited samples. However, the existing FSL-based methods often struggle with distinguishing visually similar diseases or segmenting diseased regions precisely due to feature extraction limitations. To address the limitations of the traditional disease detection methods and the challenges of deep learning in practical applications, this study proposes a disease detection and segmentation model based on few-shot learning. The proposed method is particularly suited for monitoring diseases in leafy vegetables, enabling accurate detection and segmentation with limited disease samples. The primary innovations of this study are as follows:
Few-shot learning framework: To address the scarcity of agricultural disease data samples, a few-shot learning (FSL) network architecture is introduced. By incorporating a prototype extraction module and prototype attention mechanism, the rapid and accurate identification and segmentation of diseased areas are achieved under limited data conditions.
Dual-task network design: A dual-task network structure is designed to combine object detection and semantic segmentation tasks, simultaneously performing disease localization and fine-grained segmentation, thereby enhancing detection accuracy and segmentation performance.
Integration of prototype extraction and attention mechanism: A prototype-based attention mechanism is proposed to guide the model in focusing on the key features of diseased areas, effectively improving learning capabilities under low-sample conditions.
Practical applicability: Considering the practical application requirements, the model’s precision, computational efficiency, and deployment are optimized. The proposed method enables real-time disease detection and control in vegetable-growing regions, aiding farmers in efficient disease management.
Through these innovations, the proposed disease detection and segmentation model is applicable to various regions, enabling the efficient and precise automated detection and control of leafy vegetable diseases, with significant theoretical and practical implications.
3. Results and Discussion
3.1. Disease Detection Results
The objective of this experiment was to compare the performance of mainstream detection and segmentation models and validate the effectiveness of the proposed model in the tasks of leafy vegetable disease detection and segmentation. The evaluation metrics included precision, recall, accuracy, mAP@50, and mAP@75, providing a comprehensive assessment of the models’ accuracy and robustness for the object detection and segmentation tasks. The experimental results are summarized in
Table 1 and
Table 2, which highlight the performance of different models in disease detection and segmentation. As shown in the tables, models with strong multi-scale feature modeling capabilities, such as YOLOv10 and TinySegformer, outperformed their predecessors, while the proposed method surpassed all the existing models across all metrics, demonstrating significant advantages in complex backgrounds and few-shot scenarios.
Specifically, in the object detection task, YOLOv10 achieved mAP@50 and mAP@75 scores of 0.87 and 0.86, respectively, showing notable improvement over DETR and YOLOv9. This improvement can be attributed to YOLOv10’s optimized detection head and multi-scale feature fusion module, which enhanced its capability to detect small objects. However, the proposed method achieved mAP@50 and mAP@75 scores of 0.91 and 0.90, respectively, significantly outperforming YOLOv10. This highlights the effectiveness of the proposed prototype extraction module and prototype attention mechanism in optimizing few-shot feature representation and focusing on critical regions. In the segmentation task, TinySegformer, leveraging its Transformer architecture, exhibited strong global feature modeling capabilities, with mAP@50 and mAP@75 scores of 0.91 and 0.90, respectively. Nonetheless, the proposed method further improved these metrics to 0.92 and achieved precision and recall scores of 0.95 and 0.92, respectively, demonstrating its comprehensive superiority in accuracy and robustness. From a mathematical perspective, DETR’s self-attention mechanism facilitates global correlations among features, but its high computational complexity and limited small-object detection capability led to relatively weaker performance in recall. In contrast, YOLO models achieved significant reductions in computational overhead through structural optimization and lightweight design, while enhancing robustness via multi-scale feature pyramids. TinySegformer leveraged a lightweight Transformer architecture to improve the capture of contextual information, although its feature extraction was still constrained by the resolution capacity of multi-head attention. The proposed method combined the prototype extraction module and prototype attention mechanism to significantly enhance intra-class compactness and inter-class separability in the feature space. Furthermore, the prototype-based loss function explicitly constrained the distance relationships between the samples and the prototypes during optimization, thereby improving class discrimination and suppressing background noise in both the detection and segmentation tasks. These mathematical characteristics ensured the superior performance of the proposed method in challenging agricultural scenarios with limited samples, enabling it to achieve leading experimental results in both object detection and semantic segmentation tasks.
3.2. Discussion of Challenging Cases
The objective of this experiment was to analyze the performance of the proposed model in detecting different types of diseases, especially under complex backgrounds or with confusing features, and to evaluate the model’s ability to handle challenging cases. By comparing the detection results of various diseases such as downy mildew, gray mold, black rot, sclerotinia, and brown spot, the experiment aimed to reveal the strengths and weaknesses of the model in the fine-grained discrimination and few-shot disease categories. The detection results for each disease type are shown in
Table 3.
It can be seen that the proposed model performs well across all the disease types, with downy mildew achieving a precision of 0.96 and mAP@50 of 0.94, indicating high accuracy in detecting diseases with clear features. However, for disease types with complex backgrounds or similar features, such as brown spot and sclerotinia, although the model still outperforms existing methods, the mAP@75 slightly decreases, highlighting the challenge these types of diseases pose to the model’s discriminative ability. From the experimental results, the high performance of the model on diseases like downy mildew can be attributed to the distinctive features of these diseases, such as the white powdery spots of downy mildew and the decaying areas of gray mold. These features exhibit strong separability in the feature space. The model captures these features through the prototype extraction module.
3.3. Ablation Study on Different Attention Mechanisms
The objective of this experiment was to analyze the impact of different attention mechanisms on model performance, particularly in the tasks of leafy vegetable disease detection and segmentation. The following three different attention mechanisms were evaluated in the experiment: standard self-attention, the convolutional block attention module (CBAM), and the proposed prototype attention mechanism. By comparing the performances of these models in terms of precision, recall, accuracy, mAP@50, and mAP@75, the aim was to reveal how the different attention mechanisms contribute to enhancing feature expression, improving the robustness of the model, and increasing detection accuracy. The experimental results are shown in
Table 4, where significant differences in performance across the three methods are observed.
From the experimental results, it can be observed that the standard self-attention mechanism shows relatively low performance across precision, recall, accuracy, mAP@50, and mAP@75, with values of 0.73, 0.70, 0.72, 0.72, and 0.71, respectively. This is primarily because while self-attention can capture global features, it has limitations when processing complex backgrounds and fine-grained distinctions. Self-attention calculates the relationships between all the positions to obtain global information, but it fails to effectively suppress noise and irrelevant backgrounds, leading to weaker discriminative power in detailed and complex scenarios. On the other hand, the CBAM, which introduces both spatial and channel-wise attention mechanisms based on standard self-attention, improves the model’s performance in complex backgrounds by focusing on important spatial regions and feature channels. CBAM demonstrates a significant improvement in all the evaluation metrics, with precision at 0.85, recall at 0.81, accuracy at 0.83, mAP@50 at 0.84, and mAP@75 at 0.83. This indicates CBAM’s advantage in capturing important features, particularly when dealing with various backgrounds and interfering diseases, and it effectively enhances detection accuracy and robustness. However, the proposed prototype attention mechanism outperforms all the other models in every evaluation metric, achieving precision of 0.95, recall of 0.92, accuracy of 0.93, mAP@50 of 0.92, and mAP@75 of 0.92. The prototype attention mechanism combines the advantages of prototype extraction and adaptive attention weighting, significantly enhancing the model’s discriminative power and focusing ability. Through the prototype extraction module, the model effectively generates global prototype vectors for each disease category. These prototype vectors further guide the weighting of the feature map through the attention mechanism thus strengthening the response of disease regions and suppressing background interference. This approach exhibits superior performance in solving the challenges of FSL and complex backgrounds, and it can effectively improve both the precision and robustness of the model. From a mathematical perspective, the prototype attention mechanism calculates the correlation between each position and the class prototype, generating a weight matrix that achieves adaptive focusing on the categories in the feature space. This prototype-based optimization not only enhances class separability but also increases the model’s sensitivity to details. Therefore, this method achieves high detection and segmentation accuracy for all disease types, making it a highly effective approach for the detection and segmentation of leafy vegetable diseases in complex real-world scenarios.
3.4. Ablation Study on Different Loss Functions
This experiment aims to compare the impact of different loss functions on model performance, particularly in the tasks of leafy vegetable disease detection and segmentation, through an ablation study. The following three commonly used loss functions are evaluated: Cross-entropy loss, focal loss, and the proposed prototype loss. By comparing the performance of these loss functions in terms of precision, recall, accuracy, mAP@50, and mAP@75, the experiment seeks to reveal how different loss functions affect the model’s training stability, accuracy, and robustness. The experimental results, as shown in
Table 5, clearly demonstrate that the prototype loss outperforms both cross-entropy loss and focal loss across all the evaluation metrics.
From the experimental results, it can be observed that the model using cross-entropy loss performs poorly across all the metrics, with precision at 0.67, recall at 0.64, accuracy at 0.65, mAP@50 at 0.66, and mAP@75 at 0.65. This is because while cross-entropy loss is simple and widely applied, it struggles to effectively differentiate between the fine-grained categories, especially in the case of imbalanced or few-shot classes, leading to weak performance in recognizing rare categories. In contrast, the model using focal loss shows significant improvements in precision and recall, with precision at 0.84, recall at 0.80, accuracy at 0.82, mAP@50 at 0.81, and mAP@75 at 0.81. This improvement is due to focal loss placing a greater emphasis on hard-to-classify examples, enhancing the model’s ability to learn difficult categories, especially when handling imbalanced datasets. However, the prototype loss function proposed in this study performs the best, with precision at 0.95, recall at 0.92, accuracy at 0.93, mAP@50 at 0.92, and mAP@75 at 0.92. Prototype loss optimizes the distance relationship between sample embeddings and class prototypes, significantly improving the model’s ability to discriminate few-shot classes while suppressing background interference, thereby enhancing both classification and segmentation accuracy.
3.5. Mobile Application Deployment
To address the limited computational resources of mobile devices, a lightweight disease detection and segmentation model is designed and implemented for deployment on mobile platforms. The lightweight deployment process involves model compression, optimization, and efficient inference on mobile devices. By incorporating knowledge distillation techniques, the model’s computational complexity and memory usage are significantly reduced while maintaining superior detection accuracy. The teacher model is the complete FSL-based disease detection and segmentation model, while the student model is derived by compressing the backbone network and scaling down the feature extraction module. The distillation process comprises the following steps: First, the teacher and student models generate the corresponding feature representations from the input images. Let the teacher model’s output features be
and the student model’s output features be
, where
are the feature dimensions of the teacher model, and
are the feature dimensions of the student model, typically satisfying
. To transfer the knowledge from the teacher model to the student model, a feature alignment-based distillation loss function is employed. The teacher features are first mapped to the same dimensions as the student features using a dimensionality reduction mapping function
, as follows:
The mapped teacher features
and the student features
are then used to compute the distillation loss, defined as the Euclidean distance (L2 Loss), as in the following equation:
By minimizing
, the student model progressively learns feature representations similar to those of the teacher model. Additionally, the student model is optimized with standard task-specific loss functions, including classification loss for object detection
, bounding box regression loss
, and mask loss for segmentation
. The total optimization objective is expressed as follows:
where
are weighting hyperparameters that balance the contributions of each loss term. The proposed lightweight model demonstrated significant improvements in the deployment efficiency for the leafy vegetable disease detection tasks. On mobile devices, the inference speed increased by approximately fivefold, while the model size reduced to only 20% of the teacher model’s size. Despite this compression, detection accuracy remained above 92%. This deployment solution provides crucial technological support for intelligent agricultural applications, showcasing its broad potential for practical use.
3.6. Future Work
In future work, we plan to validate our proposed model in real-world agricultural environments to further assess its robustness and applicability. Specifically, we will conduct field experiments at the experimental farmland of the Meteorological Bureau in Wuyuan County, Bayannur, Inner Mongolia, where the agricultural conditions are representative of real-world crop cultivation. This region experiences diverse climatic variations, making it an ideal location to evaluate the model’s performance under varying environmental conditions. We will employ UAVs and multispectral cameras to collect real-time images of leafy vegetable diseases and compare the model’s predictions with expert-annotated ground truth data. Additionally, we will refine the few-shot learning strategy to enhance the model’s adaptability to newly emerging diseases with limited labeled data. Moreover, we aim to integrate our approach into an agricultural disease early warning system, incorporating meteorological data and disease detection results to provide farmers with real-time disease monitoring and prevention recommendations. By bridging the gap between research and practical applications, we seek to further improve the model’s reliability and contribute to intelligent agricultural disease management.
4. Materials and Methods
4.1. Dataset Collection
Dataset collection is a critical step in machine learning research to ensure the effectiveness of model training and the reliability of its final application. In this study, an image database was constructed for leafy vegetable disease detection and segmentation, encompassing various vegetables and their associated diseases. The data were sourced from two main channels—the Science Park of the Western Campus of China Agricultural University in Haidian District, Beijing, and publicly available online resources. First, on-site image acquisition was conducted at the Science Park of China Agricultural University. The leafy vegetables collected included spinach, lettuce, Chinese cabbage, cabbage, and romaine lettuce. These varieties were selected due to their widespread cultivation in China and their susceptibility to multiple diseases. Images were specifically collected for the following diseases: downy mildew, white rust, anthracnose, viral disease, gray mold, soft rot, black rot, black spot, sclerotinia, and powdery mildew. The number of images for each disease ranged from 1000 to 2000, ensuring the diversity and sufficiency of the data. Although healthy leaf samples were not explicitly labeled as a separate category, the dataset inherently contained a substantial number of healthy leaf regions. Since disease symptoms typically appear as localized lesions, large portions of many collected images contained healthy, unaffected leaf areas. These regions were naturally included within the background of the disease images and served as negative samples during model training.
Table 6 presents the detailed distribution of images for each disease.
During data collection, high-resolution digital cameras were used to ensure image clarity and detail preservation. The equipment included DSLR cameras from Nikon and Canon. Image acquisition was primarily conducted in the morning and afternoon to avoid any overexposure caused by strong midday sunlight. Each disease was systematically documented, covering the different stages of infection—from early onset to severe infection—to capture the progression of each disease comprehensively. Additionally, online images were collected to supplement and enhance the dataset. The selection criteria for the online images included high resolution, clear disease features, and reliable sources, as shown in
Figure 1.
All images collected underwent rigorous screening and quality control to exclude unclear or mislabeled samples. Each image was accompanied by detailed metadata, including collection date, location, camera model, shooting parameters (such as aperture, shutter speed, ISO), and disease type. These details are crucial for subsequent data processing and model training, as they help researchers understand how background and shooting conditions may influence disease recognition. Regarding disease characteristics, detailed records were maintained for each type of disease manifestation on leaves. Downy mildew often appears as white powdery spots on leaves, significantly impairing photosynthesis and thriving under humid conditions. White rust causes white or pale yellow powdery spots on the underside of leaves, leading to leaf brittleness and wilting. Anthracnose forms dark brown to black lesions, often circular or irregular, which can cause leaf wilting when severe. Viral diseases result in stunted growth, deformation, or mosaic patterns on leaves, seriously affecting crop yield and quality. Gray mold manifests as gray, rotting patches on leaves, usually spreading from the edges inward. Soft rot causes water-soaked, mushy decay in plant tissues and thrives in warm and humid conditions. Black rot primarily affects leaf veins, causing blackening and necrosis that spreads along the veins. Black spot leads to circular or irregular black lesions on leaves, often surrounded by yellow halos. Sclerotinia survives in plant tissues as sclerotia, creating lesions and hardening infected parts. Brown spot appears as brown lesions, typically darker in the center and lighter at the edges, affecting the overall appearance of the plant. Powdery mildew forms a white powdery fungal layer on leaf surfaces, not only affecting the plant’s appearance but also weakening its growth.
4.2. Data Augmentation
In deep learning tasks, particularly when datasets are limited, data augmentation techniques play a crucial role in improving model performance. Data augmentation generates additional training samples by applying various transformations to the original data, thereby enhancing model generalization and reducing the risk of overfitting. Traditional augmentation methods, such as rotation, scaling, cropping, and flipping, have been widely adopted. However, with the advancement of deep learning, innovative augmentation methods like Cutout, Mixup, and CutMix have gained significant attention. These methods employ distinct transformation strategies to further diversify datasets, achieving remarkable performance improvements across various tasks.
4.2.1. Cutout
Cutout is a simple yet effective image augmentation method. Its core idea involves randomly selecting a rectangular region in the input image and setting the pixel values within that region to zero. This technique simulates occlusion scenarios, compelling the network to learn more robust features instead of overly relying on specific regions of the image. A key advantage of Cutout is its computational efficiency, requiring only local masking during training. The operation of Cutout can be expressed as follows:
where
I denotes the original image,
represents the augmented image, and
M is a binary mask of the same size as the input image. The mask
M generates a rectangular region at a random position, with a value of 1 indicating retained pixels and 0 indicating masked pixels. By introducing occluded regions, Cutout enhances the network’s ability to learn features across various areas, particularly under conditions involving partial occlusion or noise.
4.2.2. Mixup
Mixup is a mixing-based augmentation method that creates new training samples by blending two images in a specific ratio. This is achieved through a linear interpolation of the image pixels and the weighted averaging of their corresponding labels. The primary advantage of Mixup is its ability to improve the model’s robustness to boundary ambiguities, mislabeled samples, and small datasets. The operation of Mixup can be described as follows:
where
and
are two input images,
and
are their corresponding labels, and
is a value sampled from a uniform distribution
, representing the blending ratio of the two images. By interpolating both the data and the labels, Mixup enhances the model’s robustness to ambiguous sample boundaries and mitigates overfitting.
4.2.3. CutMix
CutMix is another innovative image augmentation method that generates new images by cutting and pasting regions between two images. Specifically, a rectangular region is randomly selected from image
A, cut out, and pasted onto a random position in image
B. The labels are adjusted using a weighted average approach. By incorporating different local regions into the image, CutMix enhances the model’s robustness and improves its ability to learn local image features. The operation of CutMix can be formulated as follows:
where
and
are two input images,
and
are their respective labels,
M is a binary mask representing the rectangular region cut from image
A, and
is the augmented label. The value
, sampled from a uniform distribution
, determines the proportion of the cut region. CutMix enhances the model’s understanding of local image regions and improves its ability to recognize combinations of diverse object features.
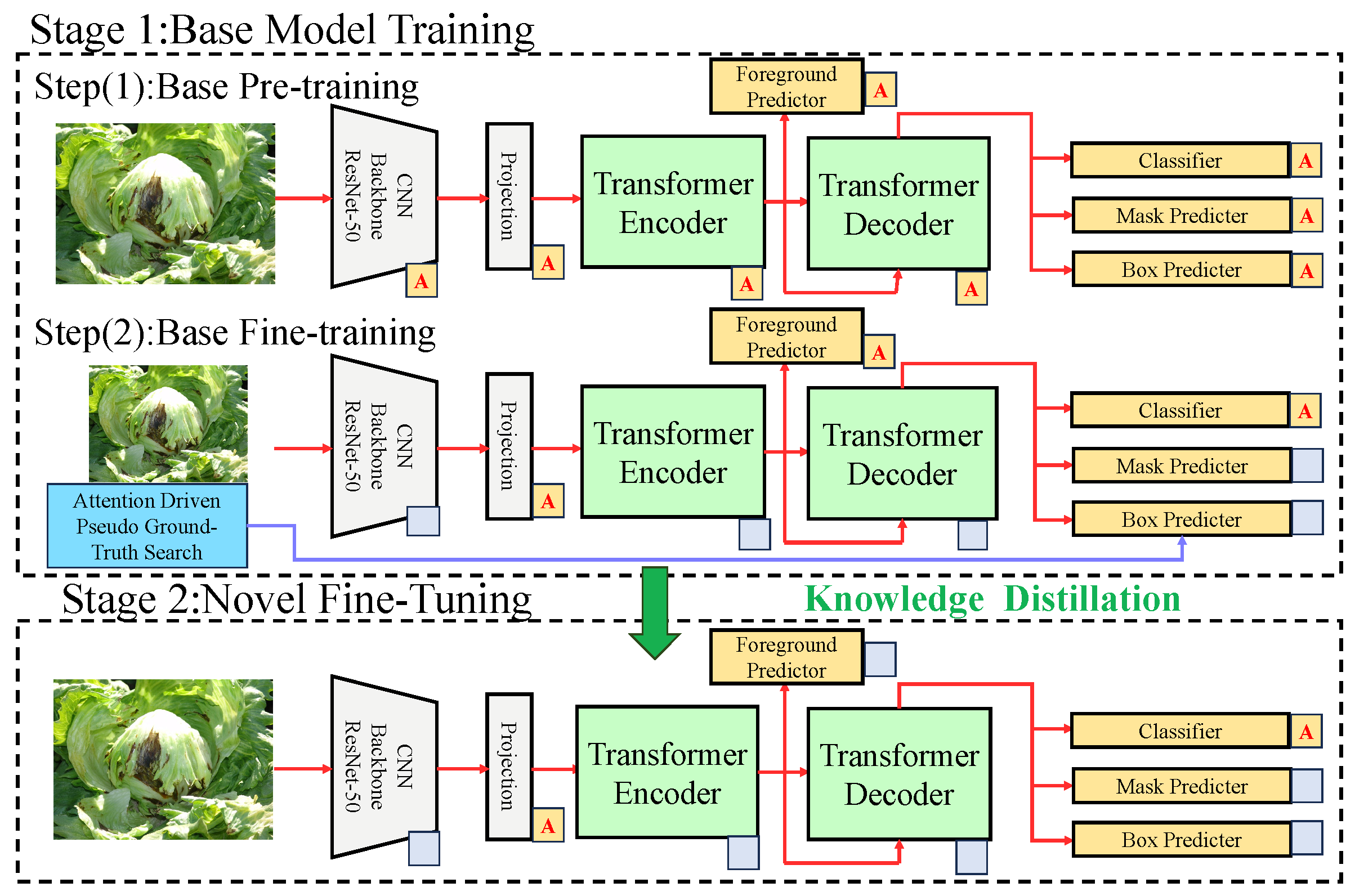
4.3. Proposed Method
The proposed few-shot learning model for leafy vegetable disease detection and segmentation consists of multiple modules, as illustrated in
Figure 2.
The overall process begins with the extraction of features from the input data, followed by task-specific processing, attention enhancement, and loss optimization. The preprocessed data are first passed through the backbone feature extraction module, which is built on the ResNet-50 CNN structure. Through multiple convolutional and pooling operations, the multi-scale features are extracted from the input images. The extracted features are then fed into the Transformer encoder, where global semantic representations are generated using the self-attention mechanism. The encoded features are subsequently decoded by the Transformer decoder, which connects to the dual-task modules for object detection and semantic segmentation. In the object detection branch, the decoder’s features are used to generate candidate bounding boxes and predict object categories. Accurate object locations are produced using regression formulas. In parallel, the segmentation branch employs a mask predictor to produce fine-grained segmentation masks for diseased regions, with mask generation relying on the activation of disease-relevant pixels via the attention mechanism. The attention-driven prototype module, denoted by the ‘A’ labels, refines feature representation by dynamically reweighting extracted feature maps, ensuring improved disease segmentation and classification. Additionally, the gray projection layers provide a transition between the convolutional feature maps and the attention-based Transformer pipeline.
To further enhance detection and segmentation performance, a prototype extraction module is utilized to extract prototype vectors for each disease class from the feature space. These prototype vectors are then incorporated into a prototype attention mechanism, which uses them to reweight the model’s feature maps, amplifying the feature responses for diseased regions. While the dataset contains 1000 to 2000 images per disease, our approach simulates few-shot learning by restricting the number of samples available to the model during training episodes. Specifically, the model is designed to generalize from only a handful of samples per class at a time, aligning with the meta-learning principles commonly employed in few-shot learning paradigms. Finally, the model is optimized using a multi-task loss function comprising detection loss, segmentation loss, and prototype loss. This approach allows the model to handle new disease variations with minimal labeled data, making it particularly useful for real-world agricultural applications where annotated disease images may be scarce or imbalanced. This comprehensive process ensures an efficient end-to-end pipeline, enabling the precise detection and segmentation of leafy vegetable diseases even under limited supervision conditions.
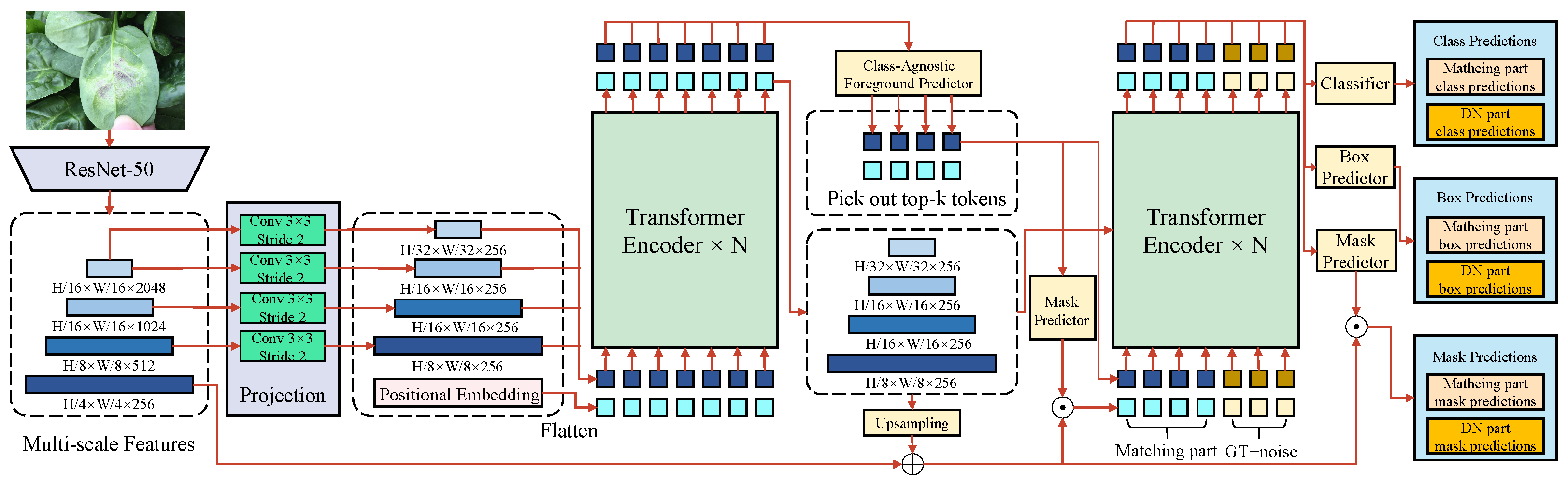
4.3.1. Few-Shot Network Based on Detection and Segmentation
An FSL-based network for object detection and segmentation is designed, as illustrated in
Figure 3, to address the issue of data scarcity in leafy vegetable disease detection and segmentation. The architecture integrates multi-scale feature extraction, a Transformer-based encoder–decoder mechanism, and prototype learning to enhance performance under low-shot conditions.
The backbone of the network employs ResNet-50, which progressively reduces the input image resolution to
through multiple convolution operations, such as
convolution kernels with a stride of 2. Positional embeddings are added to the extracted feature maps at each layer to preserve spatial information. Multi-scale feature extraction then generates feature maps of varying resolutions to accommodate the diversity and complexity of leafy vegetable diseases. The feature dimensions are defined as
,
,
, and
, providing rich contextual information for the subsequent detection and segmentation tasks. The Transformer encoder models these multi-scale features globally, processing the input features using a self-attention mechanism. The attention mechanism computes query (
Q), key (
K), and value (
V) matrices, as in the following formula:
where
denotes the scaling factor for feature dimensions to stabilize training. After
N layers of the Transformer encoder, globally aware features are outputted and passed to the decoder for the detection and segmentation tasks. The decoder comprises a class-agnostic foreground predictor and a box predictor. The most salient
k tokens are selected from the global features, representing the potential disease regions. These tokens are passed through a classifier to predict disease categories and a box predictor to regress bounding box coordinates. The classification and bounding box regression losses are defined as follows:
where
and
are the ground truth labels and predicted probabilities, respectively, while
and
are the ground truth and predicted coordinates of bounding boxes. To enhance the fine-grained segmentation performance, the mask predictor generates pixel-level segmentation masks from multi-scale features. The masks are upsampled to the original resolution using an upsampling module. The mask loss is defined as a binary cross-entropy loss, as follows:
where
and
denote the ground truth and predicted pixel masks, respectively. Additionally, a prototype learning mechanism is incorporated, where the mean embeddings of each class are computed to generate class prototypes. These prototypes are used to construct an attention matrix, enhancing the model’s response to disease-relevant features. The prototype loss function is designed as follows:
where
represents the embedding of sample
,
is the prototype vector of the ground truth class
, and
represents the prototype vectors of other classes. This mechanism ensures strong generalization and robustness under low-shot conditions. This design addresses several challenges in leafy vegetable disease detection. First, multi-scale feature extraction captures the morphological diversity of diseases. Second, the Transformer’s global modeling capability mitigates interference from complex backgrounds. Finally, the prototype learning mechanism improves feature representation with limited samples, enhancing detection and segmentation performance. Thus, this network provides an efficient and reliable solution for low-shot scenarios in agricultural disease control.
4.3.2. Prototype Extraction Module and Prototype Attention
The prototype extraction module and prototype attention mechanism, as illustrated in
Figure 4, are designed to generate class-specific prototype representations through few-shot feature learning. These prototypes are used to guide the model’s focus on critical disease regions, thereby enhancing the accuracy and robustness of disease detection and segmentation.
The prototype extraction module retrieves high-dimensional embeddings from the feature maps extracted by the backbone network. The dimensions of the input features are , where H and W represent the height and width of the feature map, and C represents the number of channels. For this study, the output feature maps from the backbone network include two levels— and . These features undergo dimensionality reduction and clustering operations to generate class-specific prototype vectors.
The prototypes are derived by averaging the embeddings of samples belonging to the same class, ensuring that the prototypes capture the global feature distribution of each class. Once the prototype vectors are generated, they are passed to the prototype attention mechanism to reweight the feature maps. The core of the attention mechanism lies in calculating the correlation between the feature map
and the prototype vectors
to generate attention weights, as follows:
where
represents the embedding at position
i of the feature map,
represents the prototype vector of class
j, and
is the attention weight between position
i and class
j. This mechanism assigns higher weights to regions of the feature map that are relevant to the target class, thereby enhancing the model’s focus on disease-specific regions. The attention weights are then used to reweight the original feature map, as expressed by the following equation:
where ⊙ denotes element-wise multiplication, and
represents the attention-weighted feature map. The reweighted feature map is subsequently fed into the object detection and segmentation modules for further processing. This design offers several mathematical advantages. By computing the prototypes as the mean of sample embeddings, the inter-class distributional variance is significantly reduced, improving the representation capability for few-shot classes. The attention mechanism further aligns the feature map’s distribution with the target class, enabling the model to concentrate on relevant regions while suppressing background noise.
From a computational perspective, assuming the feature map contains N positions, each with a feature dimension of D, and the prototype vectors are represented as , where K is the number of classes, the computational complexity of the prototype attention mechanism is . This complexity is lower than that of the standard self-attention mechanisms, making it well suited for large-scale feature maps. In the context of leafy vegetable disease detection, this module effectively addresses several challenges. First, the prototype extraction module reduces reliance on large-scale annotated data by efficiently clustering features from limited samples. Second, the prototype attention mechanism strengthens the model’s response to disease-specific regions, particularly in complex backgrounds. Third, by combining global feature representations with attention mechanisms, the model demonstrates improved robustness in handling FSL scenarios and class imbalance. These attributes make the proposed approach an efficient solution for disease detection and segmentation in data-scarce agricultural environments.
4.3.3. Prototype Loss Function
A prototype loss function is designed to address the challenges of data scarcity and class confusion in FSL scenarios. This loss function incorporates the prototype extraction module and prototype attention mechanism to enforce prototype matching constraints, enhancing the class distinctiveness and robustness in the feature space. Compared to the traditional cross-entropy and regression loss functions, the prototype loss function provides stronger discriminative power and adaptability. The core idea of the prototype loss function is to optimize the distance relationships between sample embeddings and their corresponding class prototypes, ensuring that samples are closer to their true class prototypes while being farther from the prototypes of other classes.
In the loss computation, the first term, , minimizes the distance between the sample and its corresponding class prototype, while the second term, , maximizes the distance between the sample and other class prototypes. By optimizing this loss function, the model learns a feature space with higher inter-class separability and intra-class compactness. Compared to traditional cross-entropy and regression losses, the prototype loss function offers several notable advantages, including the following:
Structural constraints in feature space: Traditional cross-entropy loss optimizes classification probability distributions but does not directly optimize sample distributions in the feature space. The prototype loss function explicitly guides feature distribution through distance-based optimization.
Adaptability to FSL: Traditional loss functions rely heavily on large-scale labeled data, whereas the prototype loss function compresses sample feature information via prototype representation, making it more effective in few-shot scenarios.
Enhanced robustness: In cases of inter-class data confusion or label imbalance, the prototype loss function directly optimizes feature space distributions, mitigating the impact of class confusion.
The prototype loss function operates in conjunction with the prototype extraction module and prototype attention mechanism, forming a comprehensive optimization pipeline for FSL. The prototype vector is not only used to guide feature reweighting in the prototype attention mechanism but also to calculate the distance in the prototype loss function.
In this process, the optimization of the prototype loss function synergizes with the attention mechanism to ensure the separability of feature distributions and the relevance of class relationships. Assuming the feature space satisfies a manifold hypothesis, where each class’s data distribution forms a connected sub-manifold in the feature space, the prototype vector can be regarded as the center of the class manifold. By optimizing the prototype loss function, the embedding of each sample is gradually pulled towards the center of its corresponding manifold while being pushed away from the other manifolds. This optimization process improves intra-class compactness and inter-class separability in the feature space, significantly reducing classification confusion. In the context of leafy vegetable disease detection, the class feature distributions are often highly confused due to background interference and data scarcity. The prototype loss function effectively addresses these challenges. First, the optimization of prototype vectors establishes clear class boundaries in the feature space. Second, by integrating the prototype extraction module and prototype attention mechanism, the model demonstrates enhanced feature representation capabilities under few-shot conditions. Third, the loss function’s construction ensures robustness against class confusion, thereby improving the model’s detection and segmentation performance. These characteristics make the prototype loss function highly valuable, both theoretically and practically, in the task of agricultural disease detection.
4.4. Experimental Configuration
4.4.1. Hardware and Software Platforms
The experiment was conducted on a high-performance computing platform equipped with a GPU-accelerated deep learning environment. Specifically, an NVIDIA RTX 3090 GPU (Santa Clara, CA, USA) was utilized to enable the efficient training and inference of deep neural networks. The system was built on PyTorch 2.4.1, leveraging its GPU acceleration capabilities through CUDA and cuDNN to enhance computational efficiency. For software and environment management, Anaconda was used to maintain consistency across dependencies, ensuring experiment reproducibility. Python 3.13.2 served as the primary programming language, with libraries such as NumPy, Pandas, and OpenCV employed for data processing and visualization. TensorBoard was used to monitor training progress and performance metrics. The entire setup was designed to ensure scalability and reproducibility, allowing experiments to be efficiently replicated in different environments.
4.4.2. Hyperparameter Settings and Training Conditions
For the FSL task in agricultural disease detection, a series of suitable hyperparameter settings were adopted to ensure optimal performance on limited training data. The learning rate was identified as a critical hyperparameter, determining the step size for parameter updates during training. A high learning rate may cause oscillations around the optimal solution, while a low learning rate can result in slow convergence or getting trapped in local optima. In this study, the learning rate was set to , which has demonstrated effective convergence in most neural network training scenarios. A learning rate decay strategy was implemented, reducing the learning rate by a factor of every 10 epochs to improve stability and guide the model toward a global optimum.
The batch size was set to 16, meaning that 16 images were used for gradient updates in each training iteration. A smaller batch size reduces memory overhead and improves gradient estimation accuracy, particularly with smaller training datasets, helping to mitigate overfitting. During data preprocessing, all images were resized to to meet the input requirements of CNNs. The dataset was divided into training data, validation data, and test data. The training set was used to train the model, the validation set for hyperparameter tuning and model selection, and the test set for evaluating the model’s performance in practical applications.
To further enhance the model’s generalization capability and address potential instability caused by uneven data splits, 5-fold cross-validation was employed. The entire dataset was divided into 5 subsets, with 4 subsets used for training and the remaining subset for validation in each iteration, repeated across 5 cycles. The final model performance was calculated as the average of the 5 experimental results, reducing the influence of randomness and improving stability and reliability. To prevent overfitting, regularization techniques such as L2 regularization (weight decay) and Dropout were applied. The coefficient for L2 regularization was set to , and the Dropout rate was set to , meaning of the neurons were randomly dropped during training to improve model robustness.
The number of training epochs was set to 50. Cross-entropy loss was selected as the loss function, effectively measuring the difference between the predicted results and the ground truth in classification tasks. The Adam optimizer was used for optimization, as it provides adaptive learning rates and fast convergence. The hyperparameters for the Adam optimizer were configured as , , and , which have been proven effective across various tasks.
4.5. Baseline Models
Several state-of-the-art object detection and semantic segmentation models were selected as baselines for comparison, including YOLOv9 [
56], YOLOv10 [
57], DETR (Detection Transformer) [
58], SegNet [
46], TinySegformer [
55], and MaskRCNN [
59]. These models represent the diverse directions and advancements in object detection and semantic segmentation.
For object detection, the YOLO series (specifically YOLOv9 and YOLOv10) was chosen for its efficiency and real-time detection capabilities. YOLO uses a single CNN to simultaneously perform object classification and localization. YOLOv9 improves detection accuracy with deeper network architectures and optimized training strategies, while YOLOv10 further enhances inference speed and accuracy, particularly in small object detection. DETR employs a novel Transformer-based architecture, replacing traditional convolutional designs with self-attention mechanisms to capture relationships between positions in the image. By incorporating query mechanisms and precise bounding box localization, DETR improves recognition in complex scenes.
For semantic segmentation, SegNet, TinySegformer, and MaskRCNN were included as benchmarks. SegNet is a classic encoder–decoder-based network that compresses and reconstructs input images to perform pixel-level classification. Its lightweight design and low computational cost make it suitable for resource-constrained scenarios. TinySegformer, a lightweight Transformer-based model, leverages self-attention mechanisms to achieve pixel-level classification. Unlike the traditional CNNs, TinySegformer captures long-range dependencies, demonstrating superior performance in segmentation tasks with complex backgrounds. MaskRCNN, a widely-used method for instance segmentation, extends Faster R-CNN with an additional branch for generating segmentation masks for each detected object. MaskRCNN excels in precise object detection and pixel-level segmentation, making it ideal for complex instance segmentation tasks.
4.6. Evaluation Metrics
In this study, accuracy, precision, recall, and mAP were selected as the evaluation metrics. Accuracy is one of the most straightforward evaluation indicators, representing the proportion of correctly predicted samples among all samples. In classification tasks, accuracy is used to measure the proportion of correct predictions among the total number of predictions. Precision is another important metric that reflects the proportion of true positive samples among all samples predicted as positive by the model. Recall focuses on the model’s ability to capture positive samples, indicating the proportion of true positive samples correctly identified by the model out of all actual positive samples. Recall emphasizes “finding all positive samples”, aiming to predict as many positive samples as possible.
mAP combines precision and recall to comprehensively evaluate the model’s performance across different categories and detection thresholds. The calculation of mAP requires first plotting the precision–recall (PR) curve for the predictions of each category and then computing the area under the curve to obtain the average precision (AP) for each category. Finally, mAP is calculated as the mean of the AP values across all categories. The formulas for these metrics are as follows:
In these equations, represents the number of true positives, represents the number of true negatives, N denotes the total number of samples, represents the number of false positives, and represents the number of false negatives. is the precision corresponding to recall r, and N denotes the number of categories.






{kind=link}
{kind=link}
{kind=link}
{kind=link}