1. Introduction
Maize, one of the world’s top three crops, has significantly influenced global food security, environmental sustainability, and smallholder economies over the past two decades [
1]. The specialized stomatal complex found in the epidermal tissue of maize leaves, comprising guard cells and accessory cells, serves as a crucial gateway for regulating gas exchange and photosynthesis between the maize plant and its surroundings [
2]. Maize can adjust its gas exchange capacity by either reducing stomatal size or increasing stomatal density to enhance its response to drought conditions [
3,
4]. Therefore, the precise identification of stomata in maize leaves holds substantial theoretical and practical importance for investigating the regulatory mechanisms governing maize stomatal development, physiological reactions to drought stress, and genetic enhancement of crop yield.
Recent years have witnessed a surge in the application of cutting-edge deep learning and computer vision techniques, particularly advancements in algorithms like convolutional neural networks and target detection, to the realm of plant stomatal phenotype detection. Xie et al. [
5] successfully employed optical topography in conjunction with Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect epidermal cells and characterize stomata on maize leaves. This approach unveiled the genetic associations between stomatal traits and pinpointed Quantitative Trait Loci (QTLs). Aono et al. [
6] utilized a Deep Convolutional Neural Network (DCNN) with a sliding-window mechanism to efficiently classify and identify maize stomata, achieving a classifier accuracy of nearly 97.1% in identifying stomatal regions, offering an automated solution for stomatal research. Jayakody et al. [
7] introduced an enhanced Mask R-CNN method incorporating a Feature Pyramid Network (FPN) and statistical filter to achieve the precise instance segmentation of stomata. By mitigating color bias through preprocessing, this method attained an accuracy of 95.10% across 16 datasets, representing a 7% improvement in Intersection over Union (IoU) over conventional techniques. Liang et al. [
8] developed the StomataScorer system, integrating deep learning and enhanced computer vision (CV) models to automatically identify and accurately score stomatal features. The system demonstrated a mean absolute percentage error (MAPE) ranging from 0.02% to 6.34%, significantly enhancing detection efficiency and accuracy. Gibbs et al. [
9] conducted a comprehensive review of deep learning applications in stomatal analysis, highlighting the training of models such as YOLO and Mask R-CNN on labeled image data using CNN structures for effective stomatal detection, segmentation, and feature extraction. Zhang et al. [
10] proposed enhancements to the U-Net architecture by integrating dual symmetric decoding paths, hybrid dilation convolution, and an attention mechanism, substantially boosting multi-scale feature extraction capabilities and enabling the precise segmentation of stomatal regions. The improved U-Net network achieved IoU, PA, and MPA metrics of 83.73%, 98.71%, and 92.16%, respectively, optimizing both accuracy and efficiency.
Despite the progress made by existing methods in stomatal detection, challenges persist in detecting microscopic stomatal datasets due to their small size and the high computational complexity of deploying high-precision models on lightweight devices. The primary difficulty in Small Object Detection in a micro-scale cell dataset lies in the small target size, hindering effective information extraction by the model. To address the bottleneck of Small Object Detection, researchers have proposed innovative solutions in recent years. Wang et al. [
11] achieved accurate segmentation by introducing a deep learning process based on UNet++ and entropy-based-masking indicator kriging (IK-EBM), utilizing the UNet++ model for boundary and small target segmentation through multi-scale feature integration and optimized jump connection. Li et al. [
12] introduced the YOLOSR-IST method, which incorporates super-resolution preprocessing into the enhanced YOLOv5 architecture, enhancing performance in infrared remote sensing Small Object Detection by reducing leakage rate through the coordinate attention mechanism and high-resolution feature map optimization. P. Liu et al. [
13] proposed the YoLoWaternet (YWnet) method, integrating a convolutional block attention module (CBAM), skip residual C3 (SRC3), and Channel Relation Feature Pyramid Network (CR-FPN) modules within the YOLOv5 framework. By combining decoupling head and EIoU loss, this method significantly enhances underwater image detection accuracy and generalization performance. To improve Small Object Feature Extraction, the auxiliary training method in Multi-Task Learning can be utilized to support Small Object Detection training by associating it with larger objectives, which has proven effective. Recent research has shown significant progress in Multi-Task Learning. Wang et al. [
14] introduced the cross-task feature enhancement (CTFE) strategy, which reconstructs detection features, aligning them with segmentation features through the feature harmonization module (FHM), and optimizes boundary segmentation by combining it with the asymmetrical feature-sharing and fusing module (AFSFM). This strategy enhances multi-task robust sensing for pepper detection, segmentation, and stem segmentation, notably improving model performance in unstructured environments. Li et al. [
15] proposed a multi-tasking weed detection framework based on YOLOv5, comparing the performance of YOLO-High-Resolution Net (HRNet) and YOLO-Pose in weed and jointed stem detection and achieving efficient identification in grassy environments through parameter-sharing. Zhang et al. [
16] introduced the YOLO multi-scale (YOLOMS) model, optimizing the YOLOv5s backbone network with the re-parameterized Visual Geometry Group (RepVGG), utilizing the Focal-EIoU loss function, integrating mango detection and fruit stalk segmentation multitasking, and enhancing detection efficiency through feature-sharing. B. Liu et al. [
17] proposed a Multi-Task Learning Framework for the Multi-Task Co-Optimization of Tomato Disease Classification and Severity Prediction to enhance model performance through knowledge deconstruction, mutual learning, and knowledge integration strategies.
High-precision models excel in various tasks but are limited in terms of their deployment on mobile devices due to their large parameter scales. Knowledge distillation, an effective method for compressing models, has emerged as a crucial research direction for lightweighting models. This approach involves training lightweight student models to learn soft labels or intermediate features from a teacher model, thereby reducing model complexity while preserving performance. Liu et al. [
18] highlighted that knowledge distillation facilitates model compression by transferring knowledge between teacher–student networks, enabling lightweight networks to maintain their detection performance on UAV edge devices for precision agriculture applications. Kang et al. [
19] introduced a lightweight single-stage detection model based on the attention mechanism, which maintains accuracy through multi-scale feature fusion and knowledge distillation techniques to enhance the efficiency of rice pest detection. Hu et al. [
20] enhanced YOLOv5s to develop a lightweight disease detection model, leveraging Faster-C3 and CoordConv for optimized feature extraction and incorporating channel knowledge distillation to enhance maize leaf disease detection accuracy while reducing parameter count. Gong et al. [
21] enhanced YOLOv5s with a MobileNetV3 backbone network, integrated CBAM and Distance–IoU (DloU) for non-maximum suppression (NMS) optimization, and applied knowledge distillation for efficient and accurate maize seedling navigation line detection. Liang et al. [
22] proposed the citrus picking-point localization (CPPL) algorithm based on an improved YOLOv8 for efficient and accurate citrus picking-point localization, utilizing knowledge distillation and model pruning techniques with YOLOv8l guiding the training of YOLOv8n.
Building upon the aforementioned analysis, we advocate for an optimized model that leverages the YOLOv11 object detection model, the most recent iteration in the YOLO series, as its primary framework [
23]. This model incorporates techniques such as Small Object Detection, Multi-Task Learning, and knowledge distillation to enhance the accuracy of maize stomata detection. The primary contributions of this study are as follows:
In this study, a dataset specifically designed for detecting epidermal stomata in maize was developed.
This study introduces a target detection model that integrates Small Object Detection, Multi-Task Learning, and knowledge distillation techniques, offering both high accuracy and a lightweight design that is suitable for implementation on a microscope to observe maize epidermal stomata.
In this study, we introduced a novel assisted training detection approach utilizing Multi-Task Learning to facilitate the localization and identification of small stomata objects. This method involves establishing a structural hierarchy of maize epidermal tissues and leverages prominent features of large-scale epidermal cells.
2. Materials and Methods
2.1. Datasets
2.1.1. Dataset Collection
The maize stomatal microscopy data utilized in this research were sourced from the Maize Research Institute at Sichuan Agricultural University. Researchers selected mature leaves from healthy maize plants and prepared samples using the epidermal peeling technique. Intact stomatal structures were obtained by gently pressing the lower leaf epidermis with transparent adhesive tape. Subsequently, the samples underwent glutaraldehyde fixation, ethanol gradient dehydration, and critical point drying, followed by spray-coating with a gold film to enhance imaging quality. Imaging was conducted using a field emission scanning electron microscope (FE-SEM) at 5 kV acceleration voltage and a working distance of 8–10 mm to achieve nanoscale resolution, enabling the clear visualization of stomatal guard cell surface ultrastructure, including cuticle ornamentation and microfibril arrangement. All images were captured in greyscale mode at 6.3× magnification, 10 μm scale, and a pixel resolution of 1360 × 1024. They were saved in 16-bit TIFF format to preserve the full dynamic range. A total of 491 electron microscopy images of maize stomatal cells were obtained for analysis.
2.1.2. Data Processing
The maize stomatal dataset analyzed in this study predominantly comprises single-cell samples with a homogeneous background, potentially constraining the applicability of neural network models trained on such data. To improve the models’ generalization capacity and practical utility, we employed image stitching to amalgamate samples. We generated and annotated maize stomatal cell images at various microscope magnifications (depicted in
Figure 1; “Original/4” denotes a simulated scenario with a 4:1 scale reduction from the original configuration) to more accurately replicate the diverse conditions encountered in real-world detection settings.
To improve dataset diversity and model generalization, we implemented data augmentation techniques including random rotation, brightness adjustments, image combination, splicing, and noise addition. This process yielded over 1500 images for the experimental dataset, with a subset exemplified in
Figure 2. The dataset was partitioned using a 7:2:1 ratio for model training and performance evaluation.
2.2. Methodology
2.2.1. The Network Architecture of StomaYOLO
The StomaYOLO model closely follows the algorithmic framework of YOLOv11 from the YOLO algorithm series. Notably, we integrated the dynamic convolution module in place of the standard convolution in YOLOv11, incorporated the Small Object Detection layer P2 in the network architecture, and leveraged auxiliary task training in Multi-Task Learning, along with knowledge distillation during training. These modifications significantly enhanced the network’s feature extraction capabilities and improved the alignment of detection boxes with the maize stomatal aperture edge. The specific network structure of StomaYOLO is illustrated in
Figure 3 [
24,
25].
2.2.2. Multi-Task Learning
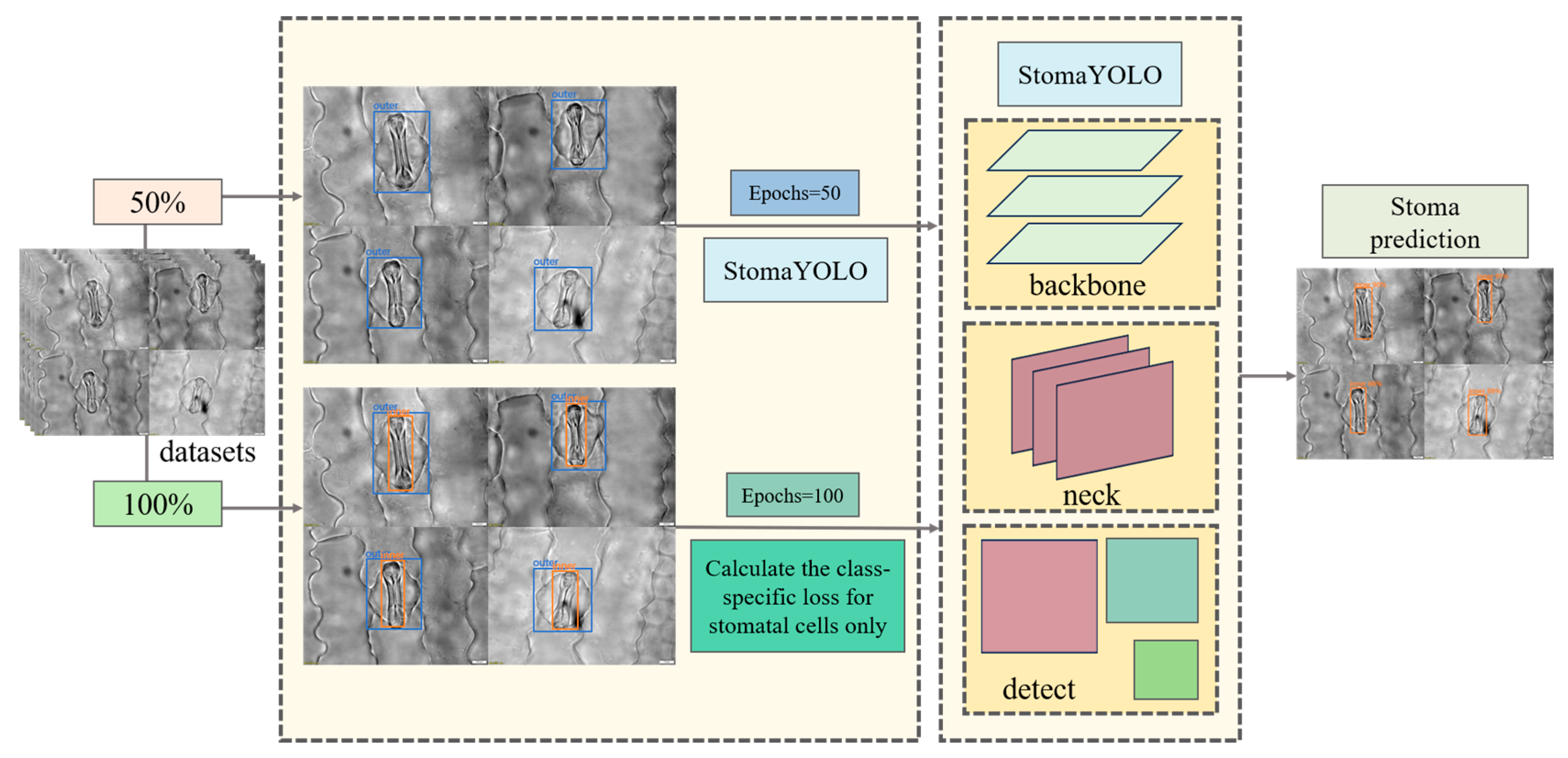
When detecting stomatal cells, the target cell’s outer layer is surrounded by a larger layer of cells, posing a challenge due to the small size of stomatal cells, which hinders effective feature extraction by the model. To address this issue, we employed auxiliary task training within a Multi-Task Learning framework to enhance model performance. Initially, we conducted 50 rounds of pre-training by randomly selecting 50% of samples from the training and validation sets to create a pre-training dataset comprising solely the labeled information of the outer cells. This pre-training phase aims to enable the model to accurately localize the stomatal cell region during forward propagation, thereby facilitating subsequent feature extraction from stomatal cells. Subsequently, formal training was carried out using the complete training and validation sets, where input images are annotated for both outer-layer cells and stomatal cells. This approach allows the model to acquire a more comprehensive understanding of the field of view. However, during backpropagation, only the stomatal cell loss is computed to ensure that model optimization focuses solely on precise stomatal cell detection. The detailed training process is illustrated in
Figure 4.
The initial loss function optimizes the prediction errors for both epidermal and stomatal cells without discrimination, leading to partial gradient updates being allocated to enhance epidermal cell detection accuracy during backpropagation. To prioritize the recognition performance of stomatal cells, we suggest a mask-driven optimization approach. This method involves creating a binary mask based on the original hard labels, represented mathematically as Equation (1):
Let M denote the mask matrix, represent the class, and (i, j) indicate the horizontal and vertical coordinates within the matrix.
Next, we compute the initial binary cross-entropy (BCE) loss for all positions using Equation (2):
where
represents the model’s predicted probability at position (
i,
j),
represents the ground truth label at position (
i,
j), and N denotes the total number of pixels.
We train the model by utilizing the specific loss function tailored for stomatal cells, denoted as Equation (3).
In our ablation analysis, we extensively examined the impact of the Multi-Task Learning (MTL) framework on model performance. Our experimental findings indicate that the MTL-based model outperforms the traditional single-task baseline model (YOLOv11) significantly. This improvement is mainly attributed to its enhanced feature extraction capabilities, with our suggested large-target-guided feature learning mechanism notably boosting the quality of feature representation for small targets. Quantitative assessments demonstrate a 2.2% increase in mean average precision (mAP) on the test dataset, providing definitive evidence of the effectiveness of the Multi-Task Learning approach.
2.2.3. Small Object Detection Layer
In high-magnification microscopy images, stomatal cells often present as small objects with limited feature information, posing challenges for detection. To address this issue, we propose the integration of a specialized Small Object Detection layer P2, within the network architecture. Positioned at a shallower depth in the network, the Small Object Detection layer P2 operates at a higher feature map resolution, enabling the preservation of intricate spatial details. Leveraging the refined features extracted from the Small Object Detection layer P2 enhances the model’s capacity to discern the morphological characteristics of small-scale targets, thereby facilitating the more precise capture of details pertaining to small objects. This enhancement equips the network with an improved ability to delineate features relevant to stomatal cells in microscopic imagery. The architecture of the enhanced network is delineated in
Figure 3.
In the subsequent ablation analysis, we thoroughly examined the impact of integrating a Small Object Detection layer on model performance. Our experimental findings indicate that the model augmented with this supplementary layer exhibits a notable performance enhancement compared to the baseline YOLOv11. This improvement primarily arises from the reinforced multi-scale feature-fusion capability, where our proposed Small Object Detection layer P2 adeptly captures intricate features from shallower feature maps, thereby significantly enhancing the model’s capacity to detect small-scale objects. Quantitative assessments demonstrate a 2.9% increase in mean average precision (mAP) on the test dataset, decisively affirming the effectiveness of this architectural refinement.
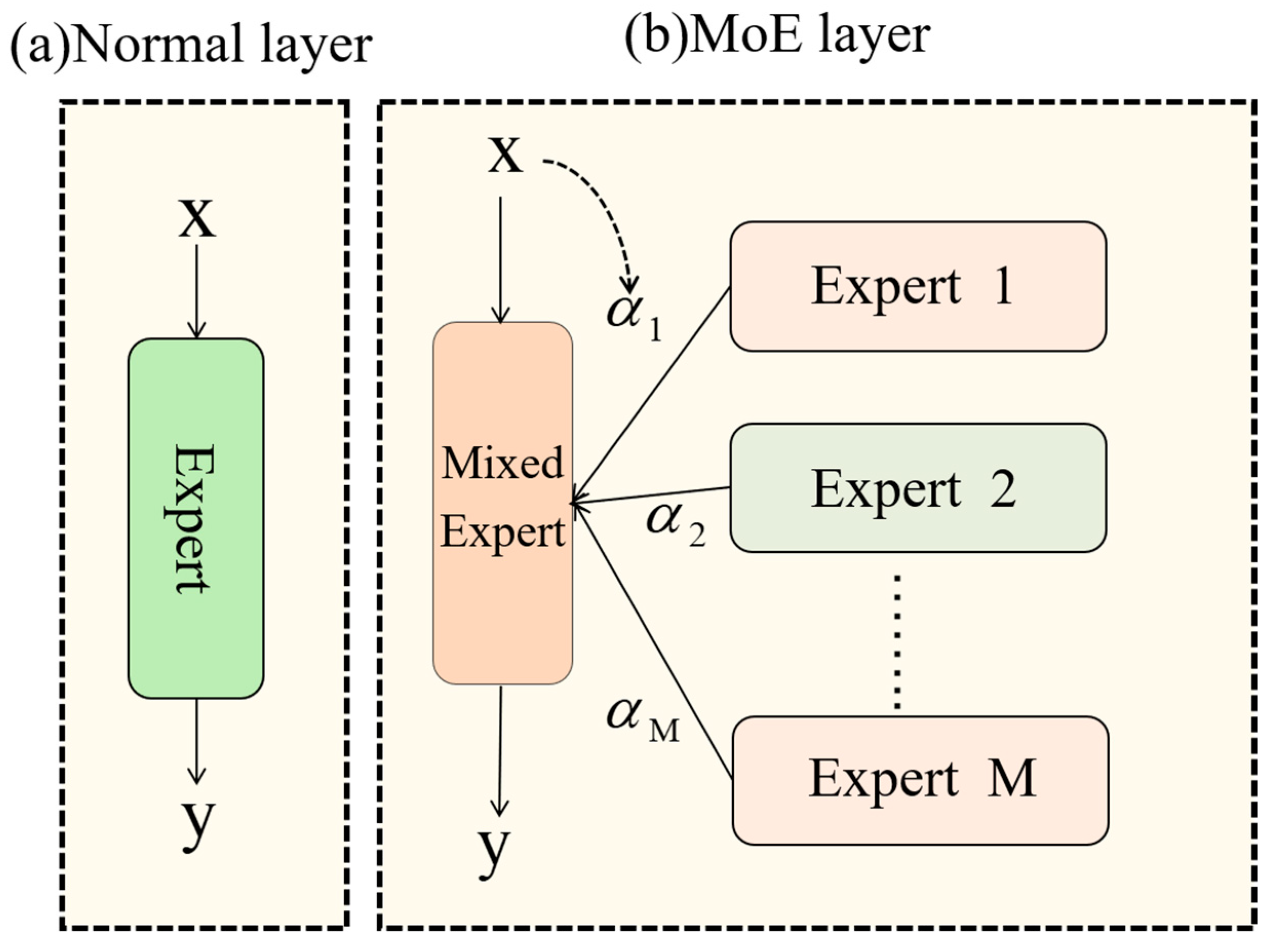
2.2.4. DynamicConv
The primary application scenario for this model involves detecting stomatal cells in maize leaf microscopic images within a laboratory setting, necessitating high inference efficiency. To address this, we incorporate the DynamicConv mechanism. Dynamic convolution operates by dynamically selecting or combining various convolution kernels for each input sample, enabling the network to adjust its parameters based on input features.
In traditional neural networks, a typical convolutional layer operates on input features, denoted as
X, by applying a weight tensor W, as shown in Equation (4):
In this context, Y signifies the output, * denotes the convolution operation, and for simplicity, we exclude the bias term. It is important to recognize that a fully connected layer can be conceptualized as a specific instance of a convolutional operation using 1 × 1 kernels.
The design philosophy of DynamicConv aims to enable the implementation of intricate network structures without incurring significant computational costs. This objective is realized by employing a parameter augmentation mechanism that increases the model’s capability (see Equation (5)):
The function f must meet two essential criteria: (1) computational efficiency and (2) a substantial improvement in model capacity through the incorporation of more trainable parameters. DynamicConv operationalizes Equation (6) as follows:
where
denotes the i-th convolutional weight tensor and
represents its corresponding dynamic coefficient. These coefficients are sample-specific and generated through an input-dependent multilayer perceptron (MLP). The generation process first applies global average pooling to input
X, producing a compact representation vector, which is then processed by a two-layer MLP with softmax activation Equation (7):
DynamicConv, functioning as a proficient dynamic convolution operator (shown as the MoE layer in
Figure 5), enables a substantial parameter capacity increase while minimizing computational expenses via kernel-sharing and dynamic combination. This feature renders it well-suited for implementing intricate network structures with limited computational resources. Thus, DynamicConv exhibits robust adaptability to the practical application scenarios examined in this investigation.
In our ablation analysis, we systematically assess the influence of DynamicConv on model performance. Our experimental findings indicate that integrating DynamicConv leads to notable enhancements in both accuracy and computational efficiency compared to the baseline YOLOv11. This improvement is attributed to DynamicConv’s adaptive kernel mechanism, which dynamically adjusts convolutional weights to optimize feature extraction by selectively enhancing discriminative features and suppressing redundant ones. As a result, the model achieves higher precision while reducing computational costs. Quantitative evaluation reveals that this approach enhances the model’s mean average precision (mAP) by 0.2% on the test dataset while decreasing Giga Floating-point Operations Per Second (GFLOPS) by 1.6. Comparative assessments with other lightweight models further demonstrate that the finalized model incorporating DynamicConv outperforms these models in terms of computational efficiency, thereby affirming the efficacy of integrating DynamicConv.
2.2.5. Knowledge Distillation
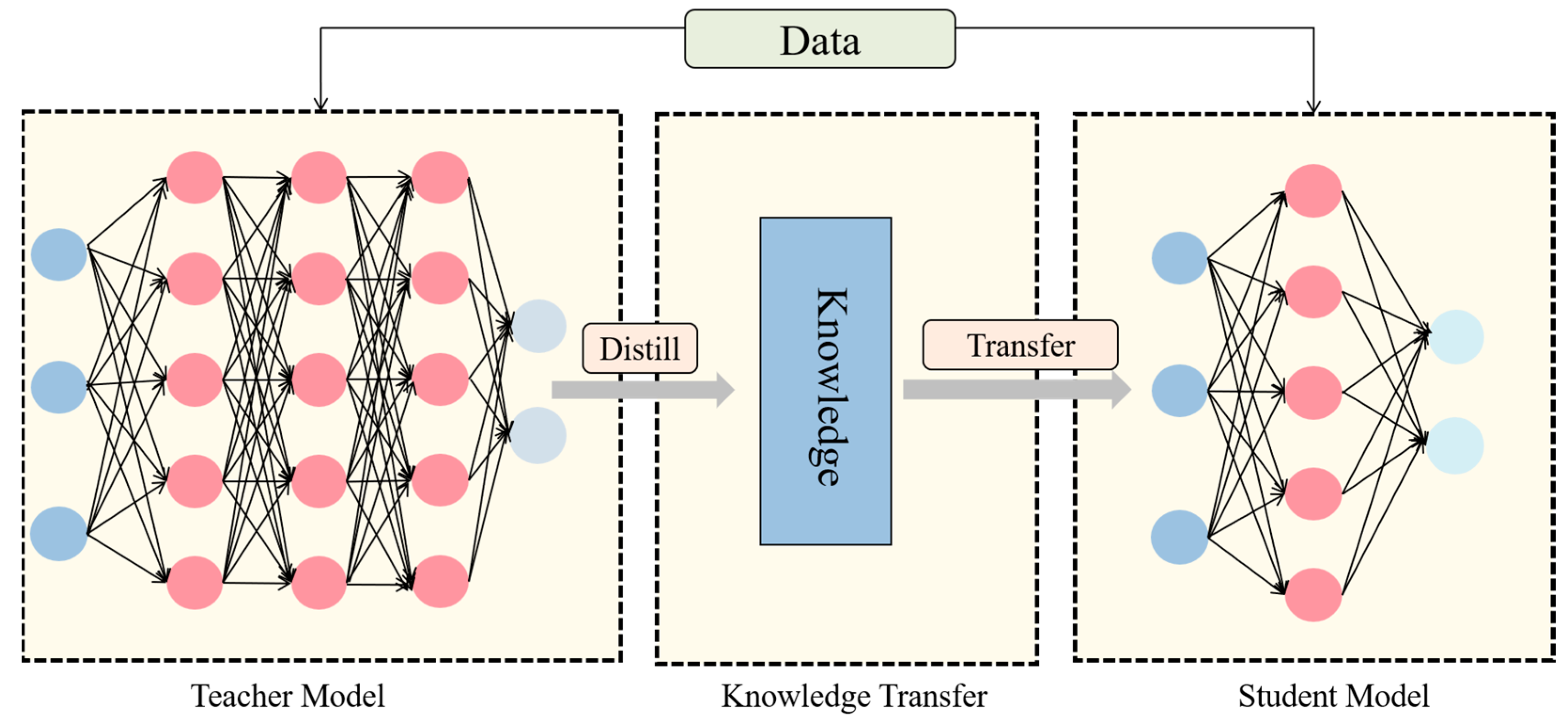
This model is primarily utilized for identifying stomatal cells in maize leaves through electron microscopy in a laboratory setting, with a focus on enhancing detection accuracy and deployment efficiency. Traditional approaches often enhance detection performance by escalating model intricacy, which in turn escalates computational demands and poses challenges regarding efficient deployment on constrained devices like electron microscopes. To address this issue, we propose integrating a knowledge distillation technique during model training to enhance detection accuracy without augmenting model complexity. Knowledge distillation facilitates the student model in refining decision boundaries by transferring the insights from the high-capacity teacher model to the lightweight student model through soft labels generated by the teacher model [
26].
Figure 6 delineates the fundamental stages of knowledge distillation.
During the training of our model, we utilize Masked Generative Distillation Loss (MGDLoss) for knowledge distillation. In contrast to traditional methods that focus on the direct replication of the teacher model’s feature responses by the student model, our approach based on MGDLoss reframes feature imitation as a feature generation challenge. This novel strategy mandates that the student model recreates the teacher model’s higher-order features within its constrained representation capability, which proves to be highly advantageous in situations characterized by restricted sample diversity [
27].
Given that images exhibit local similarity and neighboring pixels share information, the MGDLoss leverages pixels to reconstruct the entire feature map. Denoting the l-th feature map of the teacher and student as T and S, respectively, a random mask is initially applied to cover the student’s l-th feature, as shown in Equation (8):
where
is a random number in (0,1),
i and
j are the horizontal coordinates of the feature maps, respectively,
is a hyperparameter that represents the ratio of the masks, and the
l-th feature map is covered by the
l-th random mask. The MGDLoss method utilizes this mask to conceal the student’s feature map. The masked student features are then fed into the generative network to produce reconstructed teacher features. Subsequently, the disparity between the generated features and the actual teacher features is assessed to derive the loss value for backpropagation. This process can be mathematically represented by Equations (9) and (10):
where
G denotes the projection layer, including two convolutional layers,
and
, and one activation layer, ReLU. Based on the above method, the MGDLoss demonstrated in Equation (11) is obtained:
Here, L represents the total number of distillation layers, while C, H, and W refer to the dimensions of the feature maps. S and T represent the features of the students and teachers, respectively.
For the final loss, MGDLoss trains all models using the following total loss (Equation (12)):
where
is the original loss of the model in all tasks and
is a hyperparameter to balance the loss.
In essence, the precise protocol for employing MGDLoss in knowledge distillation entails the following steps: initially, the student model processes inputs to derive its feature representation and predicted outputs, while the teacher model processes the same inputs to obtain their feature representations. Subsequently, the loss of the student model for the original task and the distillation loss are computed, and a weighted combination of these components yields the total loss. This total loss is then utilized for back-propagation to update the parameters of the student model, resulting in the optimized student model.
In our comparative experiments assessing knowledge distillation, we thoroughly examined the impact of the MGDLoss-based distillation technique on model performance. Our results indicate a significant enhancement in performance when employing the MGDLoss method compared to both the baseline model and models trained using alternative distillation loss functions. This improvement is primarily attributed to MGDLoss’s capacity to augment the model’s learning capabilities through label-softening. Specifically, the teacher model refines supervision signals by softening the probability distribution, enabling the student model to capture inter-class correlation features and thereby enhancing its representation-learning proficiency. Quantitative analysis validates the efficacy of the MGDLoss-based distillation framework, demonstrating a 1.1% increase in test-set mAP without escalating model complexity.
2.3. Experimental Environment
The experimental setup utilizes an Ubuntu (64-bit) operating system(developed by Canonical Ltd., London, United Kingdom) running on a 12-core Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz processor (Intel Corporation, Santa Clara, CA, USA), with an RTX 3080 GPU. The PyTorch(version 1.8.1) open-source deep learning framework serves as the development environment, with Python 3.8, a CUDA version of 11.1, and 43 GB of computer memory(Corsair, Fremont CA, USA).
2.4. Evaluation Indicators
This study assessed the maize stomatal detection model’s performance using seven metrics: precision, mAP, recall, FPS, parameters, GFLOPS, and weight. The definitions of these parameters used in the formulas for calculating the evaluation indicators are presented in
Table 1.
TP represents the number of samples correctly predicted as positive by the model, FP refers to the number of samples incorrectly predicted as positive by the model, FN is the number of samples incorrectly predicted as negative by the model, and TN indicates the number of samples correctly predicted as negative by the model.
Precision indicates the probability that a sample predicted to be positive is actually positive. The specific calculation formula is shown in Equation (13).
AP denotes the integral from P-index to R-index. mAP refers to the average of AP values for all categories. The specific calculation formula is shown in Equations (14) and (15).
Recall denotes the proportion of individuals correctly judged by the model to be in the positive category out of all individuals that are actually in the positive category. The specific calculation formula is shown in Equation (16).
FPS (Frames Per Second) is a key performance metric used to quantify the number of image frames processed per second by a model or system, which directly reflects the inference efficiency of the model. A higher FPS value indicates that the model can process more image frames per unit time and that its computational performance is stronger. The specific formula for this metric is shown in Equation (17), where Inference_Time_per_Frame represents the time (in seconds) required by the model to complete inference on a single image frame.
GFLOPS, short for Giga Floating-point Operations Per Second, serves as a fundamental metric for assessing a model’s computational efficiency by quantifying the billions of floating-point operations executed per second during its reasoning process, directly mirroring the model’s computational complexity. Conversely, model weights denote the storage capacity of its parameters, typically quantified in MB or GB. Reduced GFLOPS and weights values signify lower computational and storage demands, yielding a more streamlined model structure. In contrast, higher GFLOPS and weights values indicate increased computational and storage overhead, resulting in a more intricate model architecture.
Parameters are crucial indicators of model complexity, reflecting the aggregate count of all trainable parameters within the model. While a higher number of parameters can enhance the theoretical representation of the model, it can also escalate computational expenses and the likelihood of overfitting. Assessing the parameter count is a common method for gauging model magnitude, and by fine-tuning this count, a harmonious equilibrium between model efficacy and computational effectiveness can be attained.
4. Discussion
In the context of advancing precision agriculture and plant phenomics, the forefront of agricultural information technology has shifted towards plant microstructure detection technology. Among the various target detection algorithms, the YOLO series models have emerged as prominent due to their superior real-time performance, optimal accuracy–speed balance, and robust scene adaptability. Nonetheless, a critical examination of prior studies reveals potential enhancements are warranted in terms of their accuracy, lightweight design, and detection speed.
This paper introduces StomaYOLO, a novel target detection network designed for identifying epidermal stomatal cells in maize leaves. StomaYOLO surpasses conventional YOLO models by integrating a Small Object Detection Layer (P2) and DynamicConv mechanisms to enhance the fusion of deep and shallow features, thereby improving computational efficiency for real-time, high-precision detection. The P2 layer enhances small object detection by extracting detailed features from shallow maps, while DynamicConv optimizes feature extraction efficiency through adaptive convolutional kernel-sharing and dynamic combination. This approach prioritizes relevant features, leading to a notable 3.4% increase in mean average precision (mAP) compared to the YOLOv11 baseline model, with minimal additional computational cost. During training, we employed auxiliary task training in Multi-Task Learning and knowledge distillation, utilizing a cascade detection method based on multi-scale correlated features to establish the structural hierarchy of maize epidermal tissues. By leveraging the salient features of large-scale epidermal cells, the model accurately localizes and identifies stomata in Small Object Detection. Through knowledge distillation, we enhanced model accuracy without increasing parameters or computations. The experimental results on a self-generated maize epidermal stomatal cell dataset demonstrate that StomaYOLO outperforms other models by 9–10% in mAP with only 8.4 GFLOPS of computation. Unlike traditional machine learning methods requiring manual feature extraction design, this model automates feature extraction through deep learning algorithms, enhancing generalization capabilities without the constraints of manual engineering. With ample training data, this model can be effectively fine-tuned for various plant cell types and applications.
Throughout our investigation, we faced notable challenges and identified key limitations in our study. First, our dataset lacks diversity, particularly in simulating maize epidermal stomatal cells across different magnification levels using image-stitching techniques. While effective to a certain extent, this method still presents noticeable disparities compared to the intricate structures of actual stomatal cells. Second, our dataset predominantly comprises images of healthy cells in the closed state, with few samples depicting alternative stomatal morphologies. This limitation inherently hinders the model’s ability to generalize comprehensively.




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}