
Harnessing Artificial Intelligence and Machine Learning for Identifying Quantitative Trait Loci (QTL) Associated with Seed Quality Traits in Crops


Abstract
1. Introduction
1.1. Traditional QTL Mapping and Its Limitations
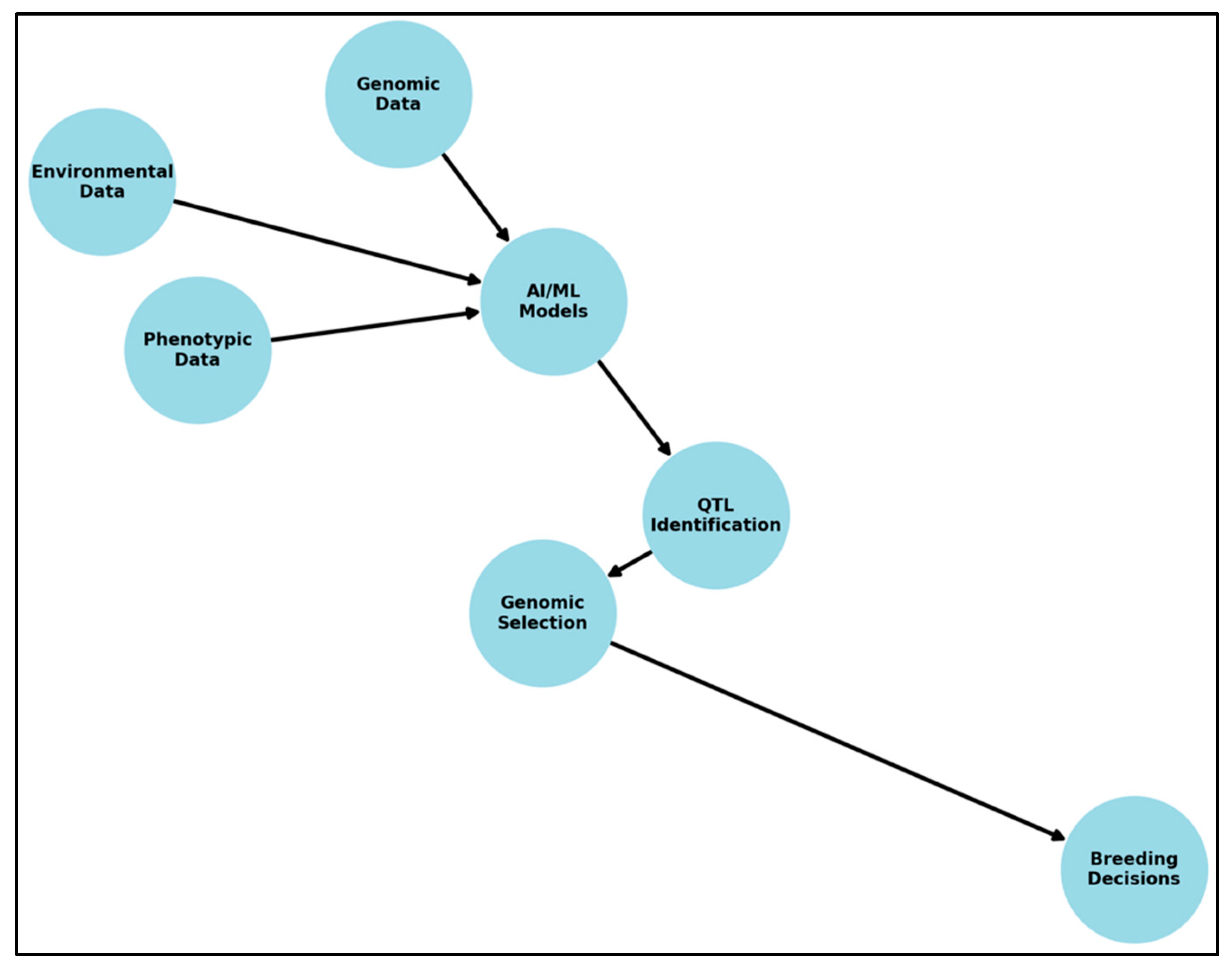
1.2. The Role of AI and ML in QTL Mapping
2. Seed Quality Traits and Their Genetic Basis
- Physical Traits: Seed size, shape, weight, and texture, which affect germination and processing quality [11].
- Biochemical Traits: Oil, protein, sugars, isoflavones, fatty acids, fiber contents, etc., which influence nutritional quality and industrial applications [12].
- Physiological Traits: Germination rate, seed vigor, dormancy, and longevity, which are critical for seed storage and crop establishment [13].
3. AI and ML Techniques for QTL Mapping
3.1. Overview of AI and ML in Genomics
3.2. Suitability of ML Methods for QTL Mapping Tasks
3.2.1. Feature Selection and Marker Prioritization
3.2.2. Trait Prediction and Genomic Selection
3.2.3. Multi-Omics and Network-Based Integration
3.3. Practical Considerations for Model Selection
- Dataset size: Tree-based and regularized linear models perform well on smaller datasets, while deep learning requires larger datasets.
- Computational resources: DL and ensemble models are computationally intensive and may require GPU infrastructure.
- Interpretability: Linear models and Random Forest offer more transparency, while deep models may require SHAP or LIME methods for explanation.
3.4. Hybrid and Ensemble Approaches for QTL Discovery
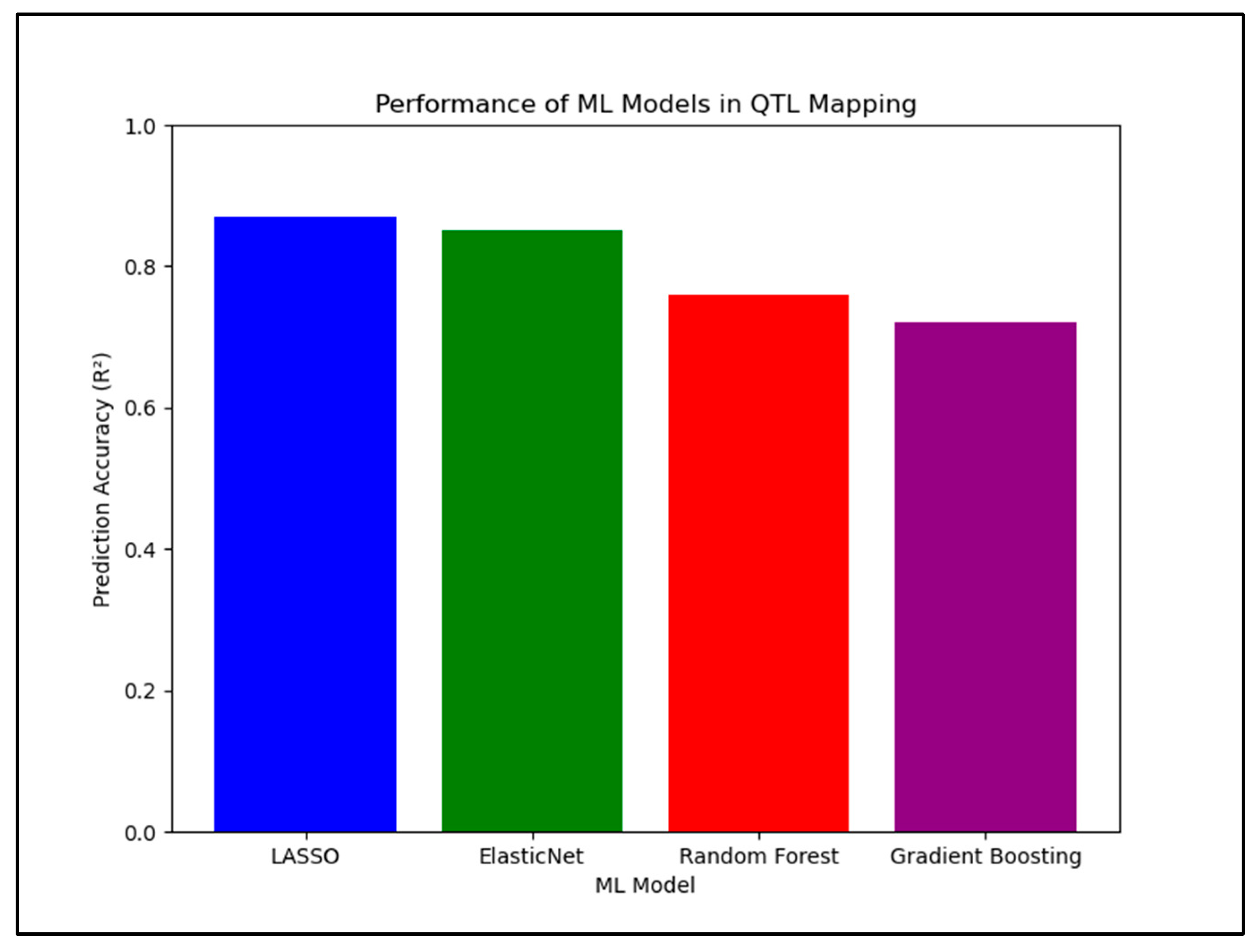
3.5. Benchmarking AI Models in Trait Mapping
4. Integrating Multi-Omics Data Using AI/ML for QTL Discovery
4.1. AI-Based Approaches for Multi-Omics Integration
4.1.1. Multi-View Learning
4.1.2. Graph Neural Networks (GNNs)
4.1.3. Deep Neural Networks (DNNs) and Autoencoders
4.1.4. Bayesian and Probabilistic Models
4.1.5. Case Studies: Multi-Omics Integration in QTL Discovery
4.2. Challenges and Future Directions
- Data harmonization: Omics data may differ in scale, noise, or missing values.
- Model interpretability: Deep learning models require explainable AI add-ons.
- Experimental validation: Findings from integrated models must be functionally confirmed.
4.3. Integration of Environmental and Epigenetic Layers
4.4. Open-Source Platforms for Multi-Omics QTL Analysis
5. Case Studies on AI-Driven QTL Discovery
5.1. ML-Based QTL Mapping for Seed Mineral Nutrients in Soybean
5.2. ML Applications in Other Seed Quality Traits
5.2.1. Seed Morphology and Weight Prediction
5.2.2. Oil and Protein Content
5.2.3. Yield Prediction Across Crops
5.2.4. Image-Based High-Throughput Phenotyping
5.2.5. Secondary Metabolites and Nutraceutical Traits
5.3. Comparative Summary of AI vs. Traditional Methods in Seed Trait QTL Studies
6. Challenges and Limitations of AI/ML in QTL Mapping
6.1. Data Quality, Quantity, and Availability
6.2. Model Interpretability and Biological Validation
6.3. Computational Complexity and Infrastructure Needs
6.4. Ethical, Regulatory, and Equity Considerations
6.5. Lack of Domain-Specific ML Expertise
7. Future Directions and Opportunities
7.1. Integration with Emerging Computational Technologies
- Quantum computing could dramatically accelerate the analysis of large-scale multi-omics datasets by solving high-dimensional optimization problems in genotype–phenotype modeling [14];
- Edge computing can enable real-time genomic prediction and image-based phenotyping in the field using portable devices and sensors—especially relevant for low-resource or remote agricultural settings;
- Federated learning offers a privacy-preserving framework where institutions can train shared AI models without exchanging raw data, thus fostering cross-institutional collaboration.
7.2. Development of AI-Assisted Breeding Pipelines
- Genomic selection and trait prioritization;
- Marker-assisted selection (MAS);
- Trait-environment optimization under climate change.
7.3. Explainable and Interpretable AI Models
- Integrate explainable AI (XAI) techniques such as SHAP values, feature attribution, and attention-based neural networks;
- Visualize gene-gene and marker-trait interactions using intuitive interfaces;
- Combine prior biological knowledge (e.g., gene ontologies, metabolic pathways) into model training.
7.4. Open-Source Platforms and Equitable Access
8. Conclusions
Funding
Conflicts of Interest
References
- Ronald, P. Plant Genetics, Sustainable Agriculture and Global Food Security. Genetics 2011, 188, 11–20. [Google Scholar] [CrossRef] [PubMed]
- Wimalasekera, R. Role of Seed Quality in Improving Crop Yields. In Crop Production and Global Environmental Issues; Hakeem, K., Ed.; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Qaim, M. Role of New Plant Breeding Technologies for Food Security and Sustainable Agricultural Development. Appl. Econ. Perspect. Policy 2020, 42, 129–150. [Google Scholar] [CrossRef]
- Varshney, R.K.; Bohra, A.; Yu, J.; Garner, A.; Zhang, Q.; Sorrells, M.E. Designing Future Crops: Genomics-Assisted Breeding Comes of Age. Trends Plant Sci. 2021, 26, 631–649. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Gore, M.; Buckler, E.S.; Yu, J. Status and prospects of association mapping in Plants. Plant Genome 2008, 1, 5–20. [Google Scholar] [CrossRef]
- Korte, A.; Farlow, A. The advantages and limitations of trait analysis with GWAS: A review. Plant Methods 2013, 9, 29. [Google Scholar] [CrossRef]
- Ma, W.; Qiu, Z.; Song, J.; Li, J.; Cheng, Q.; Zhai, J.; Ma, C. A deep convolutional neural network approach for predicting phenotypes from genotypes. Planta 2018, 248, 1307–1318. [Google Scholar] [CrossRef]
- Montesinos-Lopez, O.A.; Montesinos-Lopez, A.; Pérez-Rodríguez, P.; Barrón-López, J.A.; Martini, J.W.R.; Fajardo-Flores, S.B.; Gaytan-Lugo, L.S.; Santana-Mancilla, P.C.; Crossa, J. A review of deep learning applications for genomic selection. BMC Genom. 2021, 22, 19. [Google Scholar] [CrossRef] [PubMed]
- Desta, Z.A.; Ortiz, R. Genomic selection: Genome-wide prediction in plant improvement. Trends Plant Sci. 2014, 19, 592–601. [Google Scholar] [CrossRef]
- Crossa, J.; Perez-Rodriguez, P.; Cuevas, J.; Montesinos-López, O.; Jarquín, D.; de los Campos, G.; Burgueño, J.; Camacho-González, J.M.; Pérez-Elizalde, S.; Beyene, Y.; et al. Genomic Selection in Plant Breeding: Methods, Models, and Perspectives. Heredity 2017, 22, 961–975. [Google Scholar] [CrossRef]
- Lurstwut, B.; Pornpanomchai, C. Image analysis based on color, shape and texture for rice seed (Oryza sativa L.) germination evaluation. Agric. Nat. Resour. 2017, 51, 383–389. [Google Scholar] [CrossRef]
- Kassem, M.A. Soybean Seed Composition: Protein, Oil, Fatty Acids, Amino Acids, Sugars, Mineral Nutrients, Tocopherols, and Isoflavones; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Reed, R.C.; Bradford, K.J.; Khanday, I. Seed germination and vigor: Ensuring crop sustainability in a changing climate. Heredity 2022, 128, 450–459. [Google Scholar] [CrossRef] [PubMed]
- Montesinos-Lopez, O.A.; Chavira-Flores, M.; Kismiantini Crespo-Herrera, L.; Saint-Piere, C.; Li, H.; Fritsche-Neto, R.; Al-Nowibet, K.; Montesinos-Lopez, A.; Crossa, J. A review of multimodal deep learning methods for genomic-enabled prediction in plant breeding. Genetics 2024, 228, iyae161. [Google Scholar] [CrossRef]
- Singh, N.; Rai, V.; Singh, N.K. Multi-omics strategies and prospects to enhance seed quality and nutritional traits in pigeonpea. Nucleus 2020, 63, 249–256. [Google Scholar] [CrossRef]
- Nguyen, N.D.; Wang, D. Multiview learning for understanding functional multi-omics. PLoS Comp. Biol. 2020, 16, e1007677. [Google Scholar] [CrossRef]
- Kassem, M.A. QTL and Candidate Genes for Seed Mineral Nutrients and Application of Machine Learning Models to Predict Seed Composition Traits in Soybean. In Proceedings of the International Plant and Animal Genome Conference (PAG 32), San Diego, CA, USA, 10–15 January 2025. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf (accessed on 23 April 2025).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L.; Archontoulis, S.V. A CNN-RNN Framework for Crop Yield Prediction. Front. Plant Sci. 2020, 10, 1750. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [PubMed]
- Cuevas, J.; Montesinos-Lopez, O.; Juliana, P.; Guzman, C.; Perez-Rodriguez, P.; Gonzalez-Bucio, J.; Burgueno, J.; Montesinos-Lopez, A.; Cross, J. Deep kernel for genomic and near infrared predictions in multi-environment breeding trials. G3 Genes|Genomes|Genet. 2020, 10, 2247–2264. [Google Scholar] [CrossRef]
- Mahmood, U.; Li, X.; Fan, Y.; Chang, W.; Niu, Y.; Li, J.; Qu, C.; Lu, K. Multi-omics revolution to promote plant breeding efficiency. Front. Plant Sci. 2022, 13, 1062952. [Google Scholar] [CrossRef]
- Hasibi, R.; Michoel, T.; Oyarzun, D.A. Integration of graph neural networks and genome-scale metabolic models for predicting gene essentiality. npj Syst. Biol. Appl. 2024, 10, 24. [Google Scholar] [CrossRef]
- Zhou, J.; Troyanskaya, O.G. Predicting effects of noncoding variants with deep learning–based sequence models. Nat. Methods 2015, 12, 931–934. [Google Scholar] [CrossRef]
- Wang, X.; Zeng, H.; Lin, L.; Huang, Y.; Lin, H.; Que, Y. Deep learning-empowered crop breeding: Intelligent, efficient and promising. Front. Plant Sci. 2023, 14, 1260089. [Google Scholar] [CrossRef] [PubMed]
- Fisch, K.M.; Meibner, T.; Gioia, L.; Duck, J.C.; Carland, T.M.; Loguercio, S.; Su, A.I. Omics Pipe: A community-based framework for reproducible multi-omics data analysis. Bioinformatics 2015, 31, 1724–1728. [Google Scholar] [CrossRef] [PubMed]
- Argelaguet, R.; Velten, B.; Arnol, D.; Bredikhin, D.; Delors, Y.; Velten, B.; Marioni, J.C.; Steel, O. MOFA+: A statistical framework for comprehensive integration of multi-modal single-cell data. Genome Biol. 2020, 21, 111. [Google Scholar] [CrossRef]
- Althubaiti, S.; Kulmanov, M.; Liu, Y.; Gkoutos, G.V.; Schofield, P.; Hoehndorf, R. DeepMOCCA: A pan-cancer prognostic model identifies personalized prognostic markers through graph attention and multi-omics data integration. bioRxiv 2021, 1–25. [Google Scholar] [CrossRef]
- Bellaloui, N.; Knizia, D.; Yuan, J.; Vuong, T.D.; Usovsky, M.; Song, Q.; Betts, F.; Register, T.; Williams, E.; Lakhssassi, N.; et al. Genetic Mapping for QTL Associated with Seed Nickel and Molybdenum Accumulation in the Soybean ‘Forrest’ by ‘Williams 82’ RIL Population. Plants 2023, 12, 3709. [Google Scholar] [CrossRef] [PubMed]
- Bellaloui, N.; Knizia, D.; Yuan, J.; Song, Q.; Betts, F.; Register, T.; Williams, E.; Lakhssassi, N.; Mazouz, H.; Nguyen, H.T.; et al. Genomic regions and candidate genes for seed iron and seed zinc accumulation identified in the soybean ‘Forrest’ by ‘Williams 82’ RIL population. Int. J. Plant Biol. 2024, 15, 452–467. [Google Scholar] [CrossRef]
- Seki, K.; Toda, Y. QTL mapping for seed morphology using the instance segmentation neural network in Lactuca spp. Front. Plant Sci. 2022, 13, 949470. [Google Scholar] [CrossRef]
- Miranda, M.C.C.; Aono, A.H.; Pinheiro, J.B. A novel image-based approach for soybean seed phenotyping using machine learning techniques. Crop Sci. 2023, 63, 2665–2684. [Google Scholar] [CrossRef]
- Duc, N.T.; Ramlal, A.; Rajendran, A.; Raju, D.; Lal, S.K.; Kumar, S.; Sahoo, R.N.; Chinnusamy, V. Image-based phenotyping of seed architectural traits and prediction of seed weight using machine learning models in soybean. Front. Plant Sci. 2023, 14, 1206357. [Google Scholar] [CrossRef]
- Yoosefzadeh-Najafabadi, M.; Torabi, S.; Tulpan, D.; Rajcan, I.; Eskandari, M. Application of SVR-Mediated GWAS for Identification of Durable Genetic Regions Associated with Soybean Seed Quality Traits. Plants 2023, 12, 2659. [Google Scholar] [CrossRef] [PubMed]
- Abdipour, M.; Ramazani, S.H.R.; Younessi-Hmazekhanlu, M.; Niazian, M. Modeling Oil Content of Sesame (Sesamum indicum L.) Using Artificial Neural Network and Multiple Linear Regression Approaches. J. Am. Oil Chem. Soc. 2018, 95, 283–297. [Google Scholar] [CrossRef]
- Parsaeian, M.; Shahabi, M.; Hassanpour, H. Estimating Oil and Protein Content of Sesame Seeds Using Image Processing and Artificial Neural Network. J. Am. Oil Chem. Soc. 2020, 97, 691–702. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Parsaeian, M.; Baradaran, M. Seed yield prediction of sesame using artificial neural network. Eur. J. Agron. 2015, 68, 89–96. [Google Scholar] [CrossRef]
- Niedbala, G. Application of artificial neural networks for multi-criteria yield prediction of winter rapeseed. Sustainability 2019, 11, 533. [Google Scholar] [CrossRef]
- Niedbala, G.; Kozłowski, R.J. Application of Artificial Neural Networks for Multi-Criteria Yield Prediction of Winter Wheat. J. Agric. Sci. Technol. 2019, 21, 51–61. [Google Scholar]
- Niedbala, G.; Kurasiak-Popowska, D.; Stuper-Szablewska, K.; Nawracała, J. Application of Artificial Neural Networks to Analyze the Concentration of Ferulic Acid, Deoxynivalenol, and Nivalenol in Winter Wheat Grain. Agriculture 2020, 10, 127. [Google Scholar] [CrossRef]
- Haider, S.A.; Naqvi, S.R.; Akram, T.; Umar, G.A.; Shahzad, A.; Sial, M.R.; Khaliq, S.; Kamran, M. LSTM Neural Network Based Forecasting Model for Wheat Production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef]
- Lee, S.; Jeong, Y.; Son, S.; Lee, B. A Self-Predictable Crop Yield Platform (SCYP) Based on Crop Diseases Using Deep Learning. Sustainability 2019, 11, 3637. [Google Scholar] [CrossRef]
- Tang, H.; Kong, W.; Nabukalu, P.; Lomas, J.S.; Moser, M.; Zhang, J.; Jiang, M.; Zhang, X.; Paterson, A.H.; Yim, W.C. GRABSEEDS: Extraction of plant organ traits through image analysis. Plant Methods 2024, 20, 140. [Google Scholar] [CrossRef]
- Sadeghi-Tehran, P.; Virlet, N.; Ampe, E.M.; Reyns, P.; Hawkesford, M.J. DeepCount: In-Field Automatic Quantification of Wheat Spikes Using Simple Linear Iterative Clustering and Deep Convolutional Neural Networks. Front. Plant Sci. 2019, 10, 1176. [Google Scholar] [CrossRef] [PubMed]
- Ray, A.; Halder, T.; Jena, S.; Sahoo, A.; Ghosh, B.; Mohanty, S.; Mahapatra, N.; Nayak, S. Application of artificial neural network (ANN) model for prediction and optimization of coronarin D content in Hedychium coronarium. Ind. Crops Prod. 2020, 146, 112186. [Google Scholar] [CrossRef]
- Niazian, M.; Sadat-Noori, S.A.; Abdipour, M. Artificial neural network and multiple regression analysis models to predict essential oil content of ajowan (Carum copticum L.). J. Appl. Res. Med. Aromat. Plants 2018, 9, 124–131. [Google Scholar] [CrossRef]
- Zhao, T.; Wu, H.; Wang, X.; Zhao, Y.; Wang, L.; Pan, J.; Mei, H.; Han, J.; Wang, S.; Lu, K.; et al. Integration of eQTL and machine learning to dissect causal genes with pleiotropic effects in genetic regulation networks of seed cotton yield. Cell Rep. 2023, 42, 113111. [Google Scholar] [CrossRef]
- Geng, Z.; Lu, Y.; Duan, L.; Chen, H.; Wang, Z.; Zhang, J.; Liu, Z.; Wang, X.; Zhai, R.; Ouyang, Y.; et al. High-throughput phenotyping and deep learning to analyze dynamic panicle growth and dissect the genetic architecture of yield formation. Crop Environ. 2024, 3, 1–11. [Google Scholar] [CrossRef]
- Lin, F.; Lazarus, E.Z.; Rhee, S.Y. A Generalized Machine-Learning Algorithm for Prioritizing QTL Causal Genes in Plants. G3 Genes|Genomes|Genet. 2020, 10, 2411–2421. [Google Scholar] [CrossRef]
- Toda, Y.; Okura, F.; Ito, J.; Okada, S.; Kinoshita, T.; Tsuji, H.; Saisho, D. Training instance segmentation neural network with synthetic datasets for crop seed phenotyping. Commun. Biol. 2020, 3, 173. [Google Scholar] [CrossRef]
- Pessoa, H.P.; Copati, M.G.F.; Azevedo, A.M.; Dariva, F.D.; de Almeida, G.Q.; Gomes, C.N. Combining deep learning and X-ray imaging technology to assess tomato seed quality. Sci. Agric. 2023, 80, e20220121. [Google Scholar] [CrossRef]
- Shahsavari, M.; Mohammadi, V.; Alizadeh, B.; Alizadeh, H. Application of machine learning algorithms and feature selection in rapeseed (Brassica napus L.) breeding for seed yield. Plant Methods 2023, 19, 57. [Google Scholar] [CrossRef]
- Tu, K.; Wu, W.; Cheng, Y.; Zhang, H.; Xu, Y.; Dong, X.; Wang, M.; Sun, Q. AIseed: An automated image analysis software for high-throughput phenotyping and quality non-destructive testing of individual plant seeds. Comput. Electron. Agric. 2023, 207, 107740. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| ML Model | Main Use | Strengths | Limitations |
|---|---|---|---|
| LASSO Regression | Feature selection, SNP prioritization | Simple, interpretable; reduces overfitting | Assumes linear relationships |
| ElasticNet | Handling correlated features | Balances LASSO and Ridge regression benefits | Requires careful tuning |
| Random Forest (RF) | Classification, regression, SNP ranking | Nonlinear modeling, robust to noise | Prone to overfitting, less interpretable |
| Gradient Boosting (GB) | Trait prediction | High predictive accuracy | Sensitive to hyperparameters |
| Support Vector Machines (SVM) | Binary classification, regression | Good in high-dimensional spaces | Limited interpretability; slower training |
| Convolutional Neural Networks (CNNs) | Image-based phenotyping, seed shape | Learns hierarchical features | Requires large, labeled datasets |
| Deep Neural Networks (DNNs) | Multi-omics integration, trait prediction | Learns complex nonlinearities | Acts as a “black box”; high computational cost |
| Graph Neural Networks (GNNs) | Gene-gene or multi-omics network analysis | Captures topological interactions | Still emerging in plant sciences |
| Crop | Integrated Omics | AI Technique | Key Outcome |
|---|---|---|---|
| Soybean | Genomics, Metabolomics | LASSO, DNNs | Improved detection of QTLs for oil and protein content |
| Rice | Genomics, Transcriptomics, Metabolomics | Deep Neural Networks | Accurate predictions of starch composition and amylose content |
| Wheat | Transcriptomics, Genomics | ML-Based Classification | Identified regulatory genes for dormancy and germination |
| Pigeonpea | Genomics, Proteomics, Metabolomics | Multi-layer ML pipeline | Discovered multi-trait QTLs for seed size, protein, and resistance |
| Trait | Crop | Traditional Method | AI/ML Method | Reported Improvement | Reference |
|---|---|---|---|---|---|
| Mineral accumulation | Soybean | IM, CIM | LASSO, ElasticNet | ↑ R2 (0.72 vs. ~0.4), ↓ RMSE | [17,30,31] |
| Oil/protein content | Soybean | FarmCPU-GWAS | SVR-GWAS | More QTLs detected; nonlinear relationships captured | [35] |
| Seed shape | Lettuce | Manual QTL mapping | CNN | 11 QTLs linked to domestication; image-based accuracy improved | [32] |
| Seed yield | Cotton | eQTL only | XGBoost + eQTL | Identified pleiotropic yield genes (e.g., NF-YB3, GRDP1) | [48] |
| Seed weight (HSW) | Soybean | Multiple Linear Regression | Random Forest, MLR | R2: 0.98 (RF), 0.94 (MLR); higher than traditional MLR | [34] |
| Panicle traits | Rice | Manual phenotyping | Deep Learning | Real-time analysis of growth and yield-related traits | [49] |
| Protein and nutrient traits | Pigeonpea | Single-omics analysis | Multi-omics + ML | Multi-trait QTL detection; deeper functional insights | [15] |
| QTL gene discovery | Multi-crop | Statistical QTL mapping (e.g., GWAS, CIM) | ML-Based QTL Discovery | Machine learning improved QTL gene identification | [50] |
| Image-based HSW | Soybean | Manual image analysis | CNN + Image Processing | CNNs achieved 98% segmentation accuracy | [33] |
| Seed phenotyping | Barley | Manual annotation, classical morphometry | CNN + Synthetic Data | Synthetic data improved neural network training, high accuracy | [51] |
| Seed quality classification | Tomato | Visual inspection, lab germination tests | CNN + X-Ray Imaging | Mask R-CNN accurately classified seed viability and quality | [52] |
| Seed yield prediction | Rapeseed | Linear regression, ANOVA | Nu-SVR, MLPNN | Nu-SVR predicted seed yield with R2 = 0.86 | [53] |
| Yield forecasting | Wheat | Time series regression models | LSTM Neural Network | Higher prediction accuracy than traditional forecasting methods | [42] |
| Image segmentation | Multi-crop | Thresholding, edge detection, manual masks | CNNs + Instance Segmentation | CNN-based methods highlighted as effective for plant phenotyping | [44] |
| High-throughput phenotyping | Multi-crop | Manual measurement, lab-based QC methods | AIseed Software + ML | Automated seed phenotyping and quality testing | [54] |
| Seed yield | Sesame | Linear regression models | Artificial Neural Network (ANN) | Higher accurate seed yield predictions across varied environments | [38] |
| Oil content | Sesame | Multiple Linear Regression | Artificial Neural Network (ANN) | ANN achieved higher prediction accuracy and lower error than MLR | [36] |
| Yield under disease stress | Multi-crop | Statistical yield forecasting | Deep Learning (SCYP) | Improved yield prediction by incorporating crop disease factors using deep learning | [43] |
| Essential oil prediction | Ajowan | Multiple Regression | ANN | ANN outperformed regression in modeling oil content | [47] |
| Coronarin D optimization | Garland flower | Manual lab-based optimization | ANN | Efficient prediction and optimization of metabolite content | [46] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kassem, M.A. Harnessing Artificial Intelligence and Machine Learning for Identifying Quantitative Trait Loci (QTL) Associated with Seed Quality Traits in Crops. Plants 2025, 14, 1727. https://doi.org/10.3390/plants14111727
Kassem MA. Harnessing Artificial Intelligence and Machine Learning for Identifying Quantitative Trait Loci (QTL) Associated with Seed Quality Traits in Crops. Plants. 2025; 14(11):1727. https://doi.org/10.3390/plants14111727
Chicago/Turabian StyleKassem, My Abdelmajid. 2025. "Harnessing Artificial Intelligence and Machine Learning for Identifying Quantitative Trait Loci (QTL) Associated with Seed Quality Traits in Crops" Plants 14, no. 11: 1727. https://doi.org/10.3390/plants14111727
APA StyleKassem, M. A. (2025). Harnessing Artificial Intelligence and Machine Learning for Identifying Quantitative Trait Loci (QTL) Associated with Seed Quality Traits in Crops. Plants, 14(11), 1727. https://doi.org/10.3390/plants14111727