Application of Reinforcement Learning to a Robotic Drinking Assistant



Abstract
:1. Introduction
1.1. Benefits of Proposed Solution
- (a)
- Easier modification of the system—when the system model needs to be updated, a traditional force control program would require extensive code refactoring. However, using the presented RL-based approach, wherein the model of the system and the controller are decoupled, only the model needs to be updated. An emulator trains the algorithm with the updated model in a matter of seconds, whereas the control program executing on the robot remains completely unchanged. This provides a huge advantage in terms of software development and testing cycles.
- (b)
- Deep reinforcement learning—this technique allows for even further flexibility since it can potentially handle models with a very large number of states. The level of abstraction provided in formulating the model of the environment enables this, and the usage of novel software training techniques means that newer versions can be rapidly developed. This becomes invaluable for the next planned stages, where more redundant safety sensors will be included, extending the state space exponentially. Using a simple “if–else” based programmatic state machine becomes too complex to handle thereafter.
2. Related Work and Motivation
2.1. State-Of-The-Art
2.2. Motivation and Unique Contribution
- Human in the (open) loop force control—a robotic assistant with direct HRI, where the human and robot influence each other, will be presented. It provides a more intuitive and natural feeling drinking experience to the user, akin to traditionally drinking from a cup, while keeping the cost low. The user has a greater degree of control over the robot, and moves the cup as preferred, which is an improvement over fixed trajectories or straws which are seen in the current literature. The previous related works as presented above do not have the human in the control loop and instead use human input as triggers to only start/stop preprogrammed robot movements that the user cannot influence (i.e., indirect HRI).
- User customization—‘force profiles’ of each user are tweaked until satisfactory and then manually stored for future use, based on trial and error to find the best fit, which allows for the personalization of the MAR.
- RL in meal assistance robots—this work is the first to apply RL to a MAR, allowing for greater flexibility in rapid prototyping and further developments, as outlined in the previous chapter.
- Direct comparison of RL algorithms—this system proved to be a good testbed for comparing the training of the five different algorithms (not performance), which provides valuable insights (shown in Section 5.1).
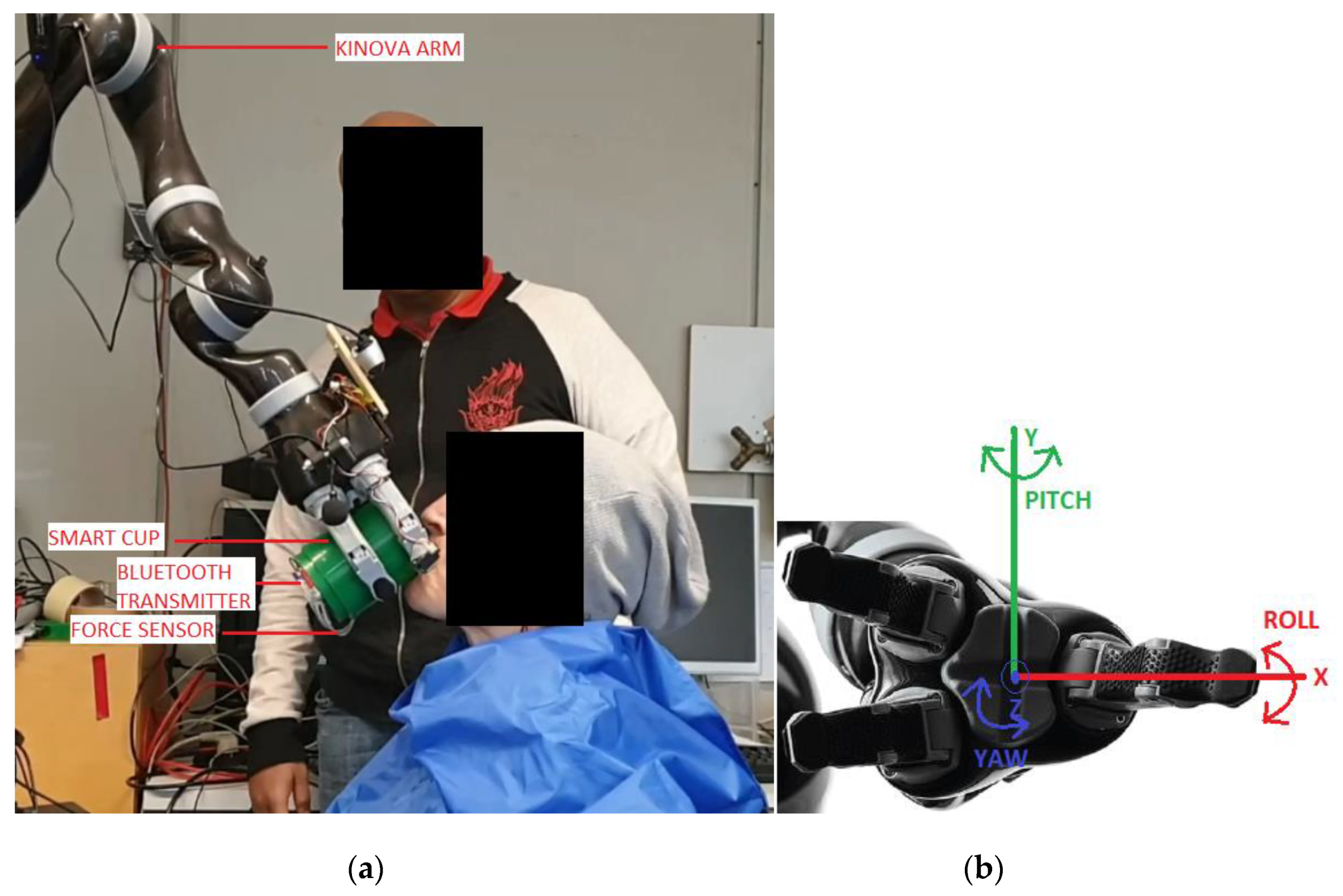
3. Robotic Drinking Assistant
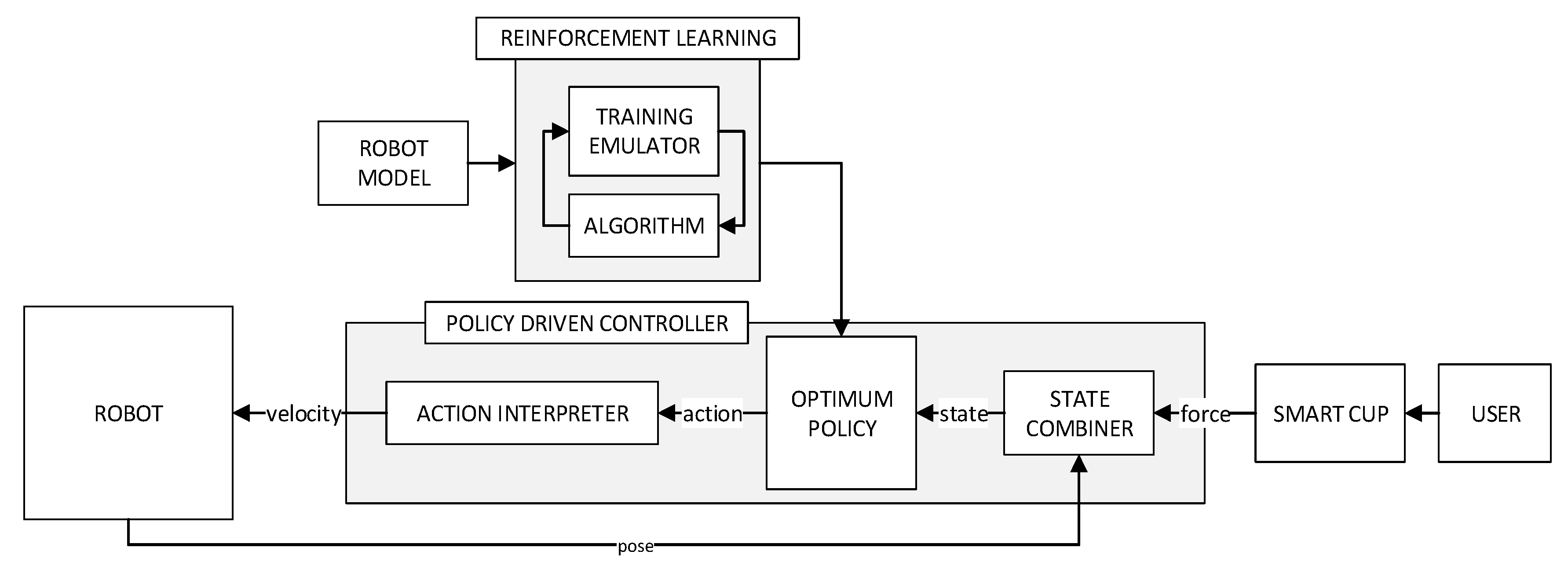
4. Reinforcement Learning Solution for Robotic Drinking Assistance
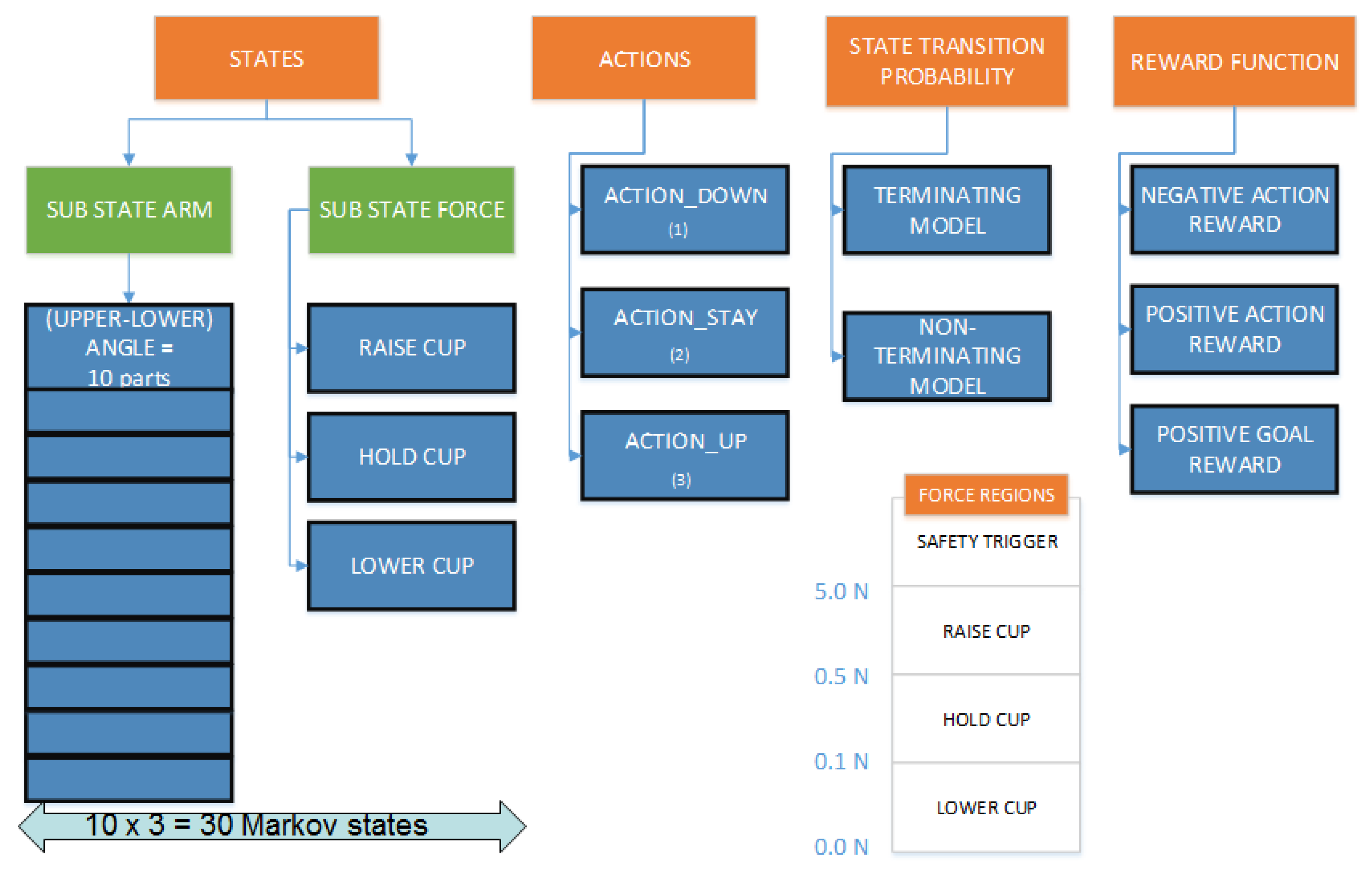
4.1. Markov Decision Process of Reinforcement Learning
4.2. Training Setup
4.3. Reinforcement Learning Algorithms
- Value iteration (VI) and policy Iteration (PI) [24]. The approach of VI is to optimize a so-called value function over many iterations until convergence, and extracting the optimum policy based on it. PI functions in a similar manner by computing the value function but optimizes the policy directly. Since they are both offline, the training emulator was not used, and the training process is drastically simpler and faster compared to the other algorithms. The resulting optimum policy obtained served as not only a benchmark for further algorithms but also a reference for the rapid prototyping of the PDC for live testing. The value function is iteratively calculated in both cases, and convergence is said to occur when it drops to 0.00001. Convergence was achieved consistently after five episodes for non-terminating and six episodes for terminating models respectively for PI, and two episodes for both models for VI.
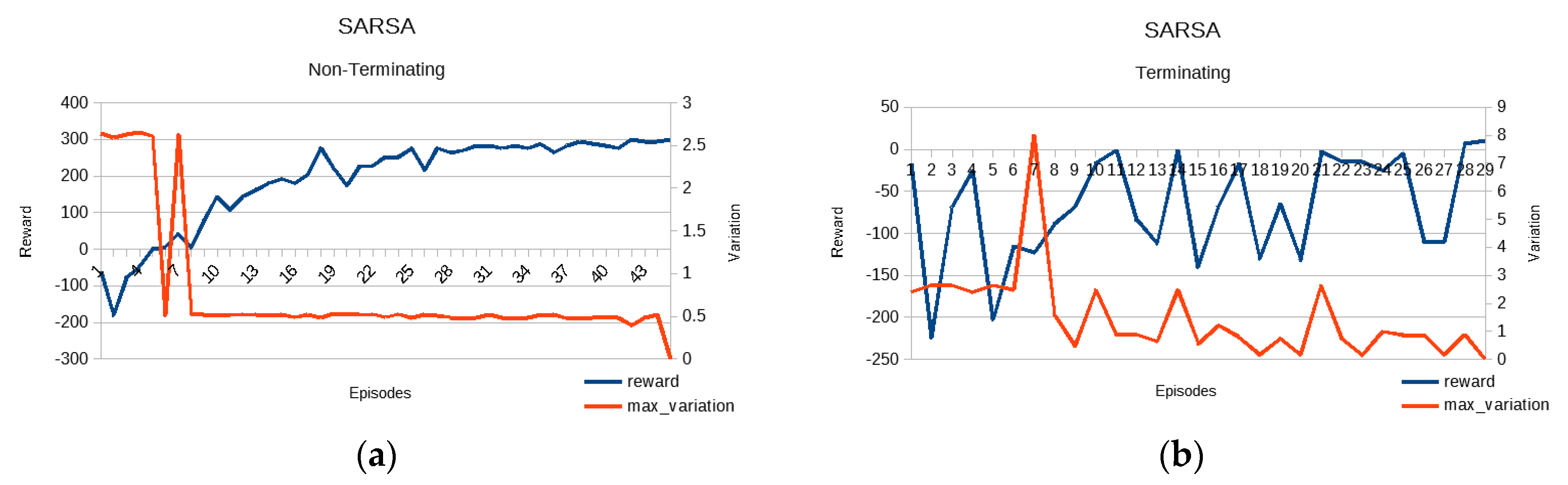
- Q learning and state–action–reward–state–action (SARSA) [25,26]. These two algorithms are similar since they both compute and optimize the Q table as the convergence factor. The difference is that the SARSA algorithm takes into account one more state action pair than Q learning (QL). These two are of greater interest since they are online and avoid the need for a full model, while at the same time being simple/fast enough to compute solutions efficiently. Being model-free also helps with rapid prototyping and development whenever the environment is modified. The learning rate was selected to be 0.8, the epsilon greedy approach to exploration vs. exploitation was used with a decay rate of 0.1 and the convergence threshold was set to 0.001.
- Deep Q network (DQN) [27,28,29]. This final deep reinforcement learning class of algorithms combines the advantages of deep learning as well as RL. Whereas the Q table is still computed, it is used to train a neural network instead of saving as a lookup table. This allows for even more number of states to be modeled (which could be useful to capture data from the environment at a greater resolution), at a reduced cost of training time. The learning rate and epsilon factor were the same as before. The neural network used had four fully connected regular layers of 24 neurons with relu activation. There were 30 inputs (states) and 3 outputs (actions). Loss function was mean square error which serves as the convergence factor, the threshold of which was 0.0001.
5. Training, Experiment Study and Results
5.1. Training the Algorithms
5.2. Experiment
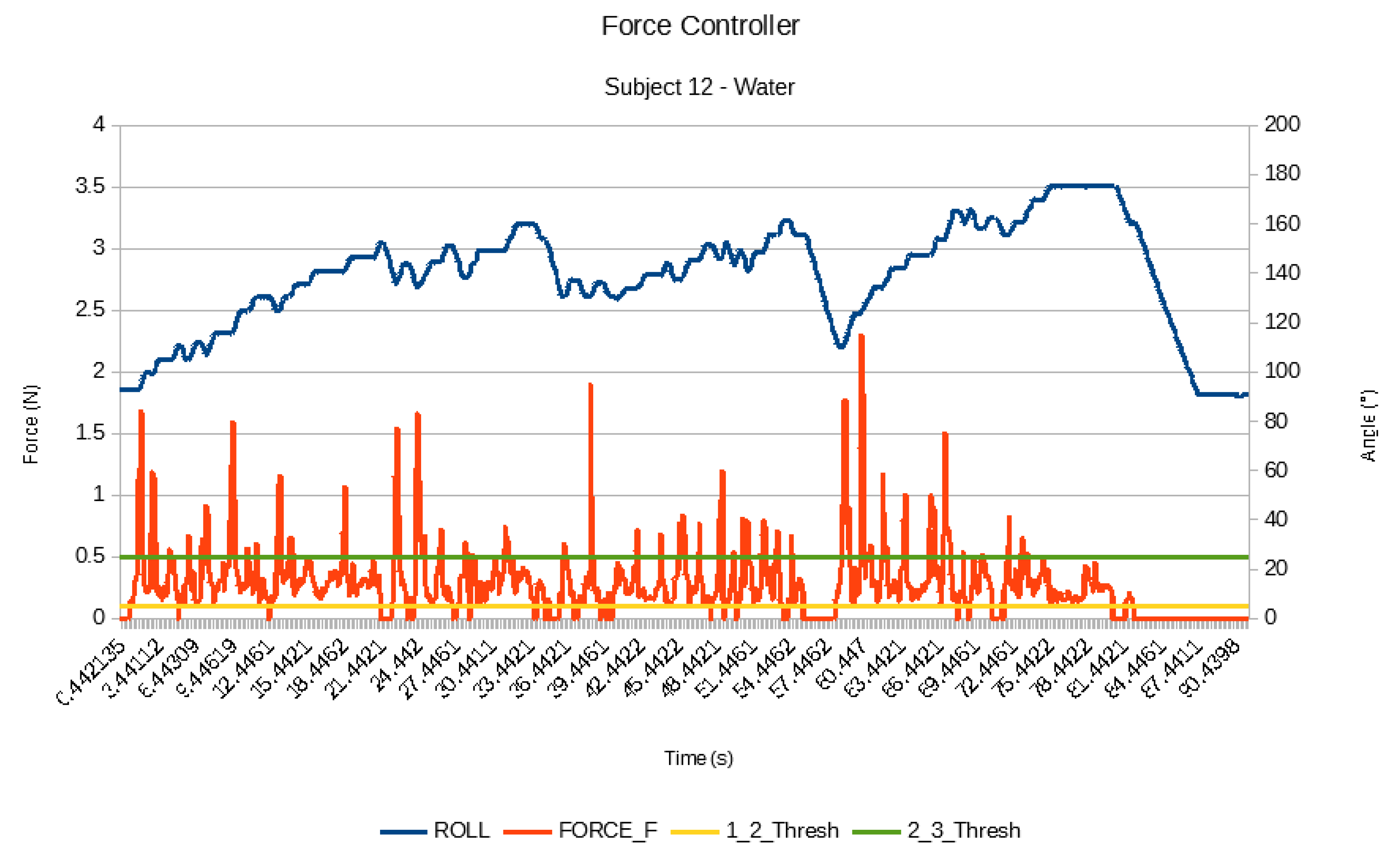
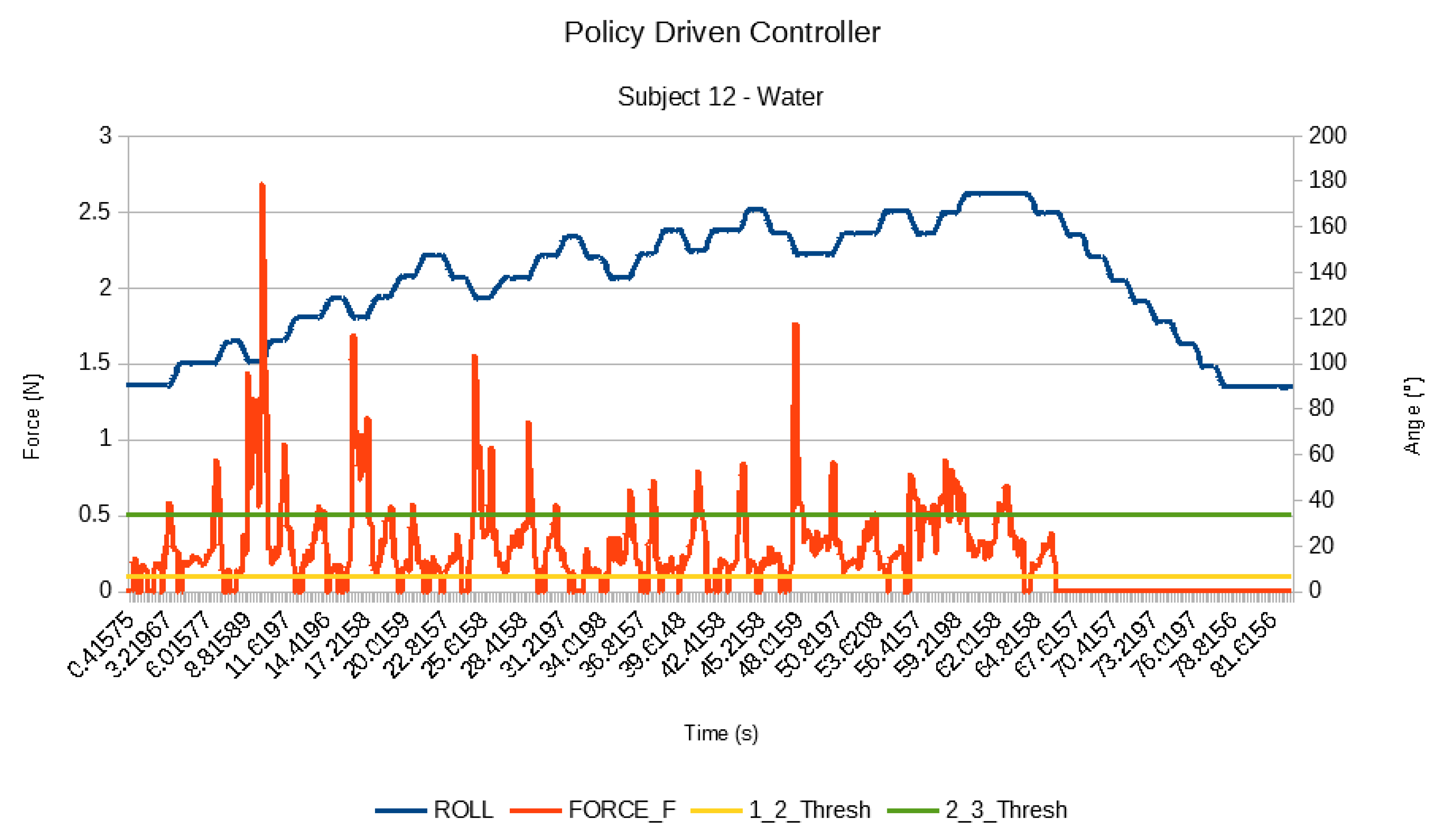
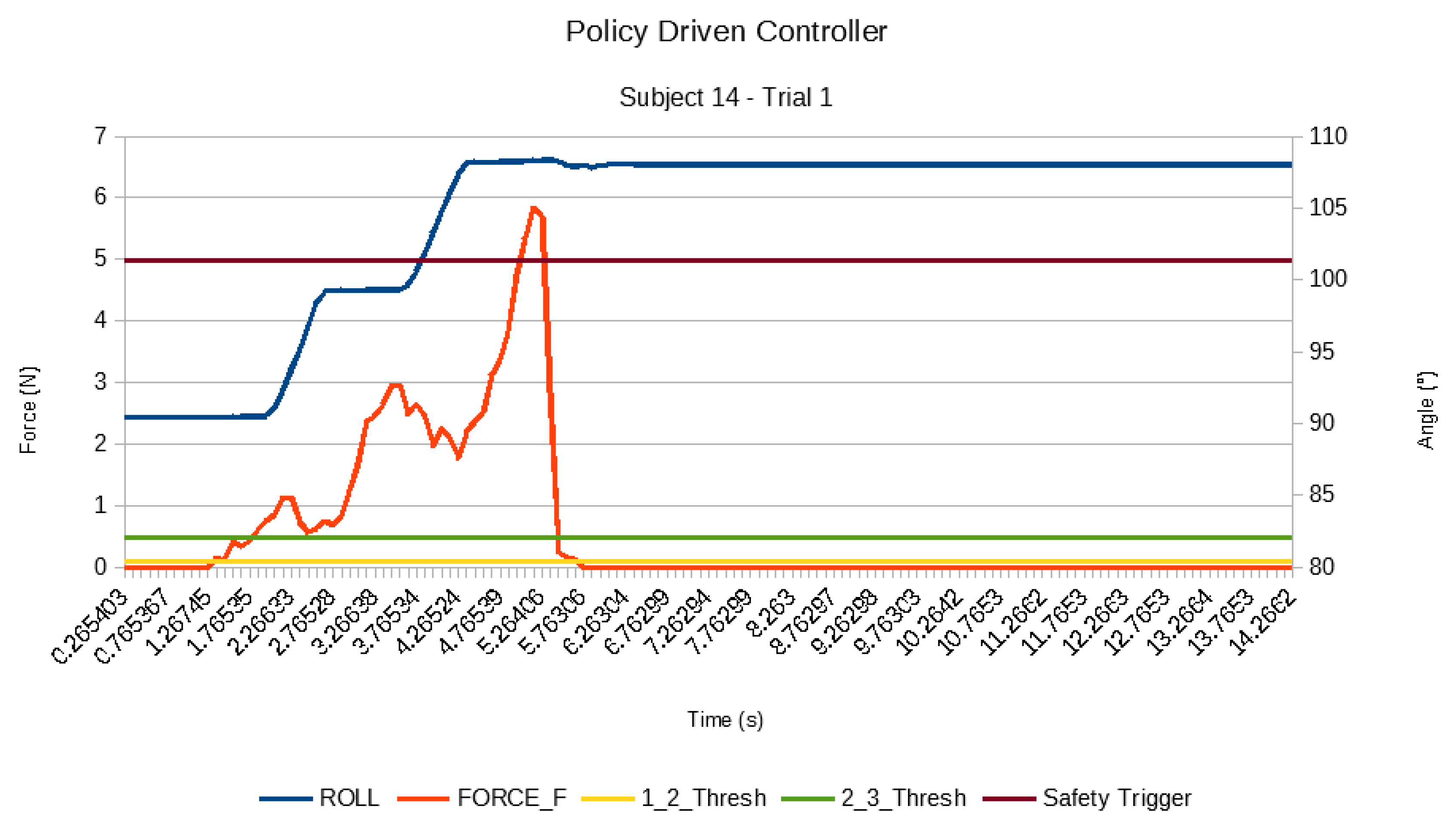
5.3. Results
5.4. Discussion
5.5. Feedback from the User with Tetraplegia
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ritschel, H.; Seiderer, A.; Janowksi, K.; Wagner, S.; Andre, E. Adaptive linguistic style for an assistive robotic health companion based on explicit human feedback. In Proceedings of the 12th ACM International Conference on Pervasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; pp. 247–255. [Google Scholar]
- Ritschel, H. Socially-aware reinforcement learning for personalized human-robot interaction. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, Stockholm, Sweden, 10–15 July 2018; pp. 1775–1777. [Google Scholar]
- Tsiakas, K.; Dagioglou, M.; Karkaletsis, V.; Makedon, F. Adaptive robot assisted therapy using interactive reinforcement learning. In Proceedings of the International Conference on Social Robotics, Kansas City, MO, USA, 1–3 November 2016; pp. 11–21. [Google Scholar]
- Naotunna, I.; Perera, C.J.; Sandaruwan, C.; Gopura, R.A.R.C.; Lalitharatne, T.D. Meal assistance robots: A review on current status, challenges and future directions. In Proceedings of the 2015 IEEE/SICE International Symposium on System Integration (SII), Nagoya, Japan, 12–13 December 2015; pp. 211–216. [Google Scholar]
- Hall, A.K.; Backonja, U.; Painter, I.; Cakmak, M.; Sung, M.; Lau, T.; Thompson, H.J.; Demiris, G. Acceptance and perceived usefulness of robots to assist with activities of daily living and healthcare tasks. Assist. Technol. 2019, 31, 133–140. [Google Scholar] [CrossRef] [PubMed]
- Chung, C.S.; Wang, H.; Cooper, R.A. Functional assessment and performance evaluation for assistive robotic manipulators: Literature review. J. Spinal Cord Med. 2013, 36, 273–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neater Solutions Ltd. 2017 Brochure. Available online: http://www.neater.co.uk/neater-eater/ (accessed on 8 March 2019).
- Zhang, X.; Wang, X.; Wang, B.; Sugi, T. Real-time control strategy for EMG-drive meal assistance robot—My Spoon. In Proceedings of the 2008 International Conference on Control, Automation and Systems, Seoul, Korea, 14–17 April 2008; pp. 800–803. [Google Scholar]
- Ohshima, Y.; Kobayashi, Y.; Kaneko, T. Meal support system with spoon using laser range finder and manipulator. In Proceedings of the 2013 IEEE Workshop on Robot Vision (WORV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 82–87. [Google Scholar]
- Topping, M.J.; Smith, J.K. The development of handy 1. A robotic system to assist the severely disabled. Technol. Disabil. 1999, 10, 95–105. [Google Scholar] [CrossRef] [Green Version]
- Bühler, C.; Heck, H.; Topping, M.; Smith, J. Practical experiences using the ‘Handy 1’assistive robot far various ADL tasks. In Proceedings of the 5th European Conference for the Advancement of Assistive Technology AAATE 99, Düsseldorf, Germany, 1–4 November 1999. [Google Scholar]
- Yamamoto, M.; Sakai, Y.; Funakoshi, Y.; Ishimatsu, T. Assistive robot hand for the disabled. In Proceedings of the International Conference on Systems, Man, and Cybernetics (Cat. No. 99CH37028), Tokyo, Japan, 12–15 October 1999; Volume 1, pp. 131–134. [Google Scholar]
- Lopes, P.; Lavoie, R.; Faldu, R.; Aquino, N.; Barron, J.; Kante, M.; Magfory, B. Icraft-Eye-Controlled Robotic Feeding Arm Technology. Available online: https://ece.northeastern.edu/personal/meleis/icraft.pdf (accessed on 1 September 2018).
- Mealtime Partner Inc. Hands-Free eating and Drinking Products for Individuals with Disabilities. Available online: http://www.mealtimepartners.com/ (accessed on 8 March 2019).
- Schröer, S.; Killmann, I.; Frank, B.; Voelker, M.; Fiederer, L.; Ball, T.; Burgard, W. An autonomous robotic assistant for drinking. In Proceedings of the International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015; pp. 6482–6487. [Google Scholar]
- Bien, Z.; Chung, M.J.; Chang, P.H.; Kwon, D.S.; Kim, D.J.; Han, J.S.; Kim, J.H.; Kim, D.H.; Park, H.S.; Kang, S.H.; et al. Integration of a rehabilitation robotic system (KARES II) with human-friendly man-machine interaction units. Auton. Robot. 2004, 16, 165–191. [Google Scholar] [CrossRef] [Green Version]
- Goldau, F.F.; Shastha, T.K.; Kyrarini, M.; Gräser, A. Autonomous multi-sensory robotic assistant for a drinking task. In Proceedings of the 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 210–216. [Google Scholar]
- Kinova. Jaco User Guide. Available online: https://www.robotshop.com/media/files/PDF/jaco-arm-user-guide-jaco-academique.pdf (accessed on 25 February 2019).
- Tekscan, Flexiforce Datasheet. Available online: https://www.tekscan.com/products-solutions/electronics/flexiforce-quickstart-board (accessed on 1 September 2018).
- Koller, T.L.; Kyrarini, M.; Gräser, A. Towards robotic drinking assistance: Low cost multi-sensor system to limit forces in human-robot-interaction. In Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; pp. 243–246. [Google Scholar]
- National Cancer Institute, Anatomical Terminology. Available online: https://training.seer.cancer.gov/anatomy/body/terminology.html (accessed on 26 February 2019).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Bertsekas, D.P. Dynamic Programming and Optimal Control, 3rd ed.; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Keras Documentation, Layers, Core Layers. Available online: https://keras.io/layers/core/ (accessed on 3 March 2019).
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal. Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Brooke, J. System Usability Scale (SUS). Available online: https://www.usability.gov/how-to-and-tools/methods/system-usability-scale.html (accessed on 15 November 2019).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Definition | Name |
|---|---|---|
| 1 | The cup shall rotate up | ACTION_DOWN |
| 2 | Do nothing | ACTION_STAY |
| 3 | The cup shall rotate down | ACTION_UP |
| Name of RLA | Convergence Factor | Convergence Threshold | Average No. of Episodes to Convergence (Non-Terminating Model) | Average No. of Episodes to Convergence (Terminating Model) |
|---|---|---|---|---|
| PI | Value function | 0.00001 | 5 | 6 |
| VI | Value function | 0.00001 | 2 | 2 |
| QL | Q Table | 0.001 | 12.8 | 40.2 |
| SARSA | Q Table | 0.001 | 49.2 | 31.1 |
| DQN | Loss function | 0.0001 | 49.7 | 31 |
| No. | Category | Questions | Average Response | Standard Deviation |
|---|---|---|---|---|
| 1 | Introduction | I could understand the instructions clearly | 4.75 | 0.56 |
| 2 | I felt comfortable during the experiments | 4.69 | 0.46 | |
| 3 | I felt safe during the experiments | 4.81 | 0.53 | |
| 4 | Force Control | The overall schema was intuitive | 4.63 | 0.6 |
| 5 | The thresholds for force regions were convenient | 4.19 | 0.81 | |
| 6 | The robot behaved as I expected (No surprises) | 4.44 | 0.86 | |
| 7 | The speed of operation was appropriate | 4.56 | 0.7 | |
| 8 | I could comfortably drink water | 4.31 | 0.98 | |
| 9 | Policy Driven Control | The overall schema was intuitive | 4.69 | 0.58 |
| 10 | The thresholds for force regions were convenient | 4.5 | 0.71 | |
| 11 | The robot behaved as I expected (No surprises) | 4.56 | 0.61 | |
| 12 | The speed of the cup per step was appropriate | 4.44 | 0.61 | |
| 13 | The number of steps to completely drink water was appropriate | 4.5 | 0.79 | |
| 14 | I could comfortably drink water | 4.44 | 0.79 | |
| 15 | General Control Strategy | The path taken by the cup from start to finish was comfortable | 4.69 | 0.46 |
| 16 | The movement of the robot was aggressive/disturbing | 1.5 | 1.06 | |
| 17 | I would use this system if I had need of it | 4.19 | 1.13 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar Shastha, T.; Kyrarini, M.; Gräser, A. Application of Reinforcement Learning to a Robotic Drinking Assistant. Robotics 2020, 9, 1. https://doi.org/10.3390/robotics9010001
Kumar Shastha T, Kyrarini M, Gräser A. Application of Reinforcement Learning to a Robotic Drinking Assistant. Robotics. 2020; 9(1):1. https://doi.org/10.3390/robotics9010001
Chicago/Turabian StyleKumar Shastha, Tejas, Maria Kyrarini, and Axel Gräser. 2020. "Application of Reinforcement Learning to a Robotic Drinking Assistant" Robotics 9, no. 1: 1. https://doi.org/10.3390/robotics9010001
APA StyleKumar Shastha, T., Kyrarini, M., & Gräser, A. (2020). Application of Reinforcement Learning to a Robotic Drinking Assistant. Robotics, 9(1), 1. https://doi.org/10.3390/robotics9010001