1. Introduction
Adaptive tracking control algorithms employ challenging and complex control architectures under prescribed constraints about the dynamical system parameters, initial tracking errors, and stability conditions [
1,
2]. These schemes may include cascade linear stages or over-parameterize the state feedback control laws to solve the tracking problems [
3,
4]. Among the challenges associated with this class of control algorithms, is the need to have full or partial knowledge of the dynamics of the underlying systems, which can degrade their operation in the presence of uncertainties [
5,
6]. Some approaches employ tracking error-based control laws and cannot guarantee overall optimized dynamical performance. This motivated the introduction of flexible innovative machine learning tools to tackle some of the above limitations. In this work, online value iteration processes are employed to solve optimal tracking control problems. The associated temporal difference equations are arranged to optimize the tracking efforts as well as the overall dynamical performance. Linear quadratic utility functions, which are used to evaluate the above optimization objectives, result in two model-free linear feedback control laws which are adapted simultaneously in real time. The first feedback control law is flexible to the tracking error combinations (i.e., possible higher-order tracking error control structures compared to the traditional continuous-time Proportional-Derivative (PD) or Proportional-Integral-Derivative (PID) control mechanisms), while the second is a state feedback control law that is designed to obtain an optimized overall dynamical performance, while affecting the closed-loop characteristics of the system under consideration. This learning approach does not over-parameterize the state feedback control law and it is applicable to uncertain dynamical learning environments. The resulting state feedback control laws are flexible and adaptable to observe a subset of the dynamical variables or states, which is really convenient in cases where it is either hard or expensive to have all dynamical variables measured. Due to the straightforward adaptation laws, the tracking scheme can be employed in systems with coupled dynamical structures. Finally, the proposed method can be applied to nonlinear systems, with no requirement of output feedback linearization.
To showcase the concept in hand and to highlight its effectiveness under different modes of operation, a trajectory-tracking system is simulated using the proposed machine learning mechanism for a flexible wing aircraft. Flexible wing systems are described as two-mass systems interacting through kinematic constraints at the connection point between the wing system and the pilot/fuselage system (i.e., the hang-strap point) [
7,
8,
9,
10]. The modeling approaches of the flexible wing aircraft typically rely on finding the equations of motion using perturbation techniques [
11]. The resulting model decouples the aerodynamics according to the directions of motion into the longitudinal and lateral frames [
12]. Modeling this type of aircraft is particularly challenging due to the time-dependent deformations of the wing structure even in steady flight conditions [
13,
14,
15,
16]. Consequently, model-based control schemes typically degrade the operation under uncertain dynamical environments. The flexible wing aircraft employs weight shift mechanism to control the orientations of the wing with respect to the pilot/fuselage system. Thus, the aircraft pitch/roll orientations are controlled by adjusting the relative centers of gravities of these highly coupled and interacting systems [
7,
8].
Optimal control problems are formulated and solved using optimization theories and machine learning platforms. Optimization theories provide rigorous frameworks to solve control problems by finding the optimal control strategies and the underlying Bellman optimality equations or the Hamilton–Jacobi–Bellman (HJB) equations [
17,
18,
19,
20,
21]. These solution processes guarantee optimal cost-to-go evaluations. Tracking control mechanism that uses time-varying sliding surfaces is adopted for a two-link manipulator with variable payloads in [
22]. It is shown that a reasonable tracking precision can be obtained using approximate continuous control laws, without experiencing undesired high frequency signals. An output tracking mechanism for nonminimum phase flat systems is developed to control the vertical takeoff and landing of an aircraft [
23]. The underlying state-tracker works well for slightly as well as strongly nonminimum phase systems, unlike the traditional state-based approximate-linearized control schemes. A state feedback mechanism based on a backstepping control approach is developed for a two-degrees-of-freedom mobile robot. This technique introduced restrictions about the initial tracking errors and the desired velocity of the robot [
1]. Observer-based fuzzy controller is employed to solve the tracking control problem of a two-link robotic system [
2]. This controller used a convex optimization approach to solve the underlying linear matrix inequality problem to obtain bounded tracking errors [
2]. A state feedback tracking mechanism for underactuated ships is developed in [
3]. The nonlinear stabilization problem is transformed into equivalent cascaded linear control systems. The tracking error dynamics are shown to be globally
- exponentially stable provided that the reference velocity does not decay to zero. An adaptive neural network scheme is employed to design a cooperative tracking control mechanism where the agents are interacting via a directed communication graph, and they are tracking the dynamics of a high-order non-autonomous nonlinear system [
24]. The graph is assumed to be strongly connected and the cooperative control solution is implemented in a distributed fashion. Adaptive backstepping tracking control technique is adopted to control a class of nonlinear systems with arbitrary switching forms in [
4]. It includes an adaptive mechanism to overcome the over-parameterization of the underlying state feedback control laws. A tracking control strategy is developed for a class of Multi-Input-Multi-Output (MIMO) high-order systems to compensate for the unstructured dynamics in [
25]. Lyapunov proof with weak assumptions emphasized semi-global asymptotic tracking characteristics of the controller. Fuzzy adaptive state feedback and observer-based output feedback tracking control architecture is developed for Single-Input-Single-Output (SISO) nonlinear systems in [
26]. This structure employed backstepping approach to design the tracking control law for uncertain non-strict feedback systems.
Machine learning platforms present implementation kits of the derived optimal control mathematical solution frameworks. These use artificial intelligence tools such as Reinforcement Learning (RL) and Neural Networks to solve the Approximate Dynamic Programming problems (ADP) [
27,
28,
29,
30,
31,
32,
33]. The optimization frameworks provide various optimal solution structures which enable solutions of different categories of the approximate dynamic programming problems such as Heuristic Dynamic Programming (HDP), Dual Heuristic Dynamic Programming (DHP), Action Dependent Heuristic Dynamic Programming (ADHDP), and Action-Dependent Dual Heuristic Dynamic Programming (ADDHP) [
34,
35]. These forms in turn are solved using different two-step temporal difference solution structures. ADP approaches provide means to solve the curse of dimensionality in the states and action spaces of the dynamic programming problems. Reinforcement learning frameworks suggest processes that can implement solutions for the different approximate dynamic programming structures. These are concerned with solving the Hamilton–Jacobi–Bellman equations or Bellman optimality equations of the underlying dynamical structures [
36,
37,
38]. Reinforcement learning approaches employ dynamic learning environment to decide the best actions associated with the state-combinations to minimize the overall cumulative cost. The designs of the cost or reward functions reflect the optimization objectives of the problem and play crucial role to find suitable temporal difference solutions [
39,
40,
41]. This is done using two-step processes, where one solves the temporal difference equation and the other solves for the associated optimal control strategies. Value and policy iteration methods are among the various approaches that are used to implement these steps. The main differences between the two approaches are related to the sequence of how the solving value functions are evaluated, and the associated control strategies are updated.
Recently, innovative robust policy and value iteration techniques have been developed for single and multi-agent systems, where the associated computational complexities are alleviated by the adoption of model-free features [
42]. A completely distributed model-free policy iteration approach is proposed to solve the graphical games in [
21]. Online policy iteration control solutions are developed for flexible wing aircraft, where approximate dynamic programming forms with gradient structures are used [
43,
44]. Deep reinforcement learning approaches enable agents to drive optimal policies for high-dimensional environments [
45]. Furthermore, they promote multi-agent collaboration to achieve structured and complex tasks. The augmented Algebraic Riccati Equation (ARE) for the linear quadratic tracking problem is solved using Q-learning approach in [
46]. The reference trajectory is generated using a linear generator command system. A neural network scheme based on a reinforcement learning approach is developed for a class of affine (MIMO) nonlinear systems in [
47]. This approach customized the number of updated parameters irrespective of the complexity of the underlying systems. Integral reinforcement learning scheme is employed to solve the Linear-Quadratic-Regulator (LQR) problem for optimized assistive Human Robot Interaction (HRI) applications in [
48]. The LQR scheme optimizes the closed-loop features for a given task to minimize the human efforts without acquiring information about their dynamical models. A solution framework based on a combined model predictive control and reinforcement learning scheme is developed for robotic applications in [
6]. This mechanism uses a guided policy search technique and the model predictive controller generates the training data using the underlying dynamical environment with full state observations. Adaptive control approach based on a model-based structure is adopted to solve the optimal tracking infinite horizon problem for affine systems in [
5]. In order to effectively explore the dynamical environment, a concurrent system identification learning scheme is adopted to approximate the underlying Bellman approximation errors. A reinforcement learning approach based on deep neural networks is used to develop a time-varying control scheme for a formation of unmanned aerial vehicles in [
49]. The complexity of the multi-agent structure is tackled by training an individual vehicle and then generalizing the learning outcome of that agent to the formation scheme. Deep Q-Networks are used to develop generic multi-objective reinforcement learning scheme in [
50]. This approach employed single-policy as well as multi-policy structures and it is shown to converge effectively to optimal Pareto solutions. Reinforcement Learning approaches based on deterministic policy gradient, proximal policy optimization, and trust region policy optimization approaches are proposed to overcome the PID control limitations of the inner attitude control loop of the unmanned aerial vehicles in [
51]. The cooperative multi-agent learning systems use the interactions among the agents to accomplish joint tasks in [
52]. The complexity of these problems depends on the scalability of the underlying system of agents along with their behavioral objectives. Action coordination mechanism based on a distributed constraint optimization approach is developed for multi-agent systems in [
53]. It uses an interaction index to trade-off between the beneficial coordination among the agents and the communication cost. This approach enables non-sequenced coupled adaptations of the coordination set and the policy learning processes for the agents. The mapping of single-agent deep reinforcement learning to multi-agent schemes is complicated due to the underlying scaling dilemma [
54]. The experience replay memory associated with deep Q-learning problems is tackled using a multi-agent sampling mechanism which is based on a variant of importance mechanism in [
54].
The adaptive critics approaches are employed to advise various neural network solutions for optimal control problems. They implement two-step reinforcement learning processes using separate neural network approximation schemes. The solution for Bellman optimality equation or the Hamilton–Jacobi–Bellman equation is implemented using a feedforward neural structure described by the critic structure. On the other hand, the optimal control strategy is approximated using an additional feedforward neural network structure called the actor structure. The update processes of the actor and critic weights are interactive and coupled in the sense that the actor weights are tuned when the critic weights are updated following reward/punish assessments of the dynamic learning environment [
28,
30,
33,
37,
40]. The sequences of the actor and critic weights-updates follow those advised by the respective value or policy iteration algorithms [
28,
37]. Reinforcement learning solutions are implemented in continuous-time platforms as well as discrete-time platforms, where integral forms of Bellman equations are used [
55,
56]. These structures are applied to multi-agent systems as well as single-agent systems, where each agent has its own actor-critic structure [
34,
35]. The adaptive critics are employed to provide neural network solutions for the dual heuristic dynamic programming problems for multi-agent systems [
19,
20]. These structures solve the underlying graphical games in a distributed fashion where the neighbor information is used. Actor-critic solution implementation for an optimal control problem with nonlinear cost function is introduced in [
55]. The adaptive critics implementations for feedback control systems are highlighted in [
57]. A PD scheme is combined with a reinforcement learning mechanism to control the tip-deflection and trajectory-tracking operation of a two-link flexible manipulator in [
58]. The adopted actor-critic learning structure compensates for the variations in the payload. An adaptive trajectory-tracking control approach based on actor-critic neural networks is developed for a fully autonomous underwater vehicle in [
59]. The nonlinearities in the control input signals are compensated for during the adaptive control process.
This work contributions are four-fold:
An online control mechanism is developed to solve the tracking problem in uncertain dynamical environment without acquiring any knowledge about the dynamical models of the underlying systems.
An innovative temporal difference solution is developed using a reformulation of Bellman optimality equation. This form does not require existence of admissible initial policies and it is computationally simple and easy to apply.
The developed learning approach solves the tracking problem for each dynamical process using separate interactive linear feedback control laws. These optimize the tracking as well as the overall dynamical behavior.
The outcomes of the proposed architecture can be generalized smoothly for structured dynamical problems. Since, the learning approach is suitable for discrete-time control environments and it is applicable for complex coupled dynamical problems.
The paper is structured as follows:
Section 2 is dedicated to the formulation of the optimal tracking control problem along with the model-free temporal difference solution forms. Model-free adaptive learning processes are developed in
Section 3, and their real-time adaptive critics or neural network implementations are presented in
Section 4. Digital simulation outcomes for an autonomous controller of a flexible wing aircraft are analyzed in
Section 5. The implications of the developed machine learning processes in practical applications and some future research directions are highlighted in
Section 6. Finally, concluding remarks about the adaptive learning mechanisms are presented in
Section 7.
2. Formulation of the Optimal Tracking Control Problem
Optimal tracking control theory is used to lay out the mathematical foundation of various adaptive learning solution frameworks. Thus, many adaptive mechanisms employ complicated control strategies which are difficult to implement in discrete-time solution environments. In addition, many tracking control schemes are model-dependent, which raises concerns about their performances in unstructured dynamical environments [
17]. This section tackles these challenges by mapping the optimization objectives of underlying tracking problem using machine learning solution tools.
2.1. Combined Optimization Mechanism
The optimal tracking control problem, in terms of the operation, can be divided broadly into two main objectives [
17]. The first is concerned with asymptotically stabilizing the tracking error dynamics of the system, and the second optimizes the overall energy during the tracking process. Herein, the outcomes of the online adaptive learning processes are two linear feedback control laws. The adaptive approach uses simple linear quadratic utility or cost functions to evaluate the real-time optimal control strategies. The proposed approach tackles many challenges associated with the traditional tracking problems [
17]. First, it allows an online model-free mechanism to solve the tracking control problem. Second, it allows several flexible tracking control configurations which are adaptable with the complexity of the dynamical systems. Finally, it allows interactive adaptations for both the tracker and optimizer feedback control laws.
The learning approach does not employ any information about the dynamics of the underlying system. The selected online measurements can be represented symbolically using the following form
where
is a vector of selected measurements (i.e., the sufficient or observable online measurements),
is a vector of control signals,
k is a discrete-time index, and
F represents the model that generates the online measurements of the dynamical system which could retain linear or nonlinear representations.
The tracking segment of the overall tracking control scheme generates the optimal tracking control signal using a linear feedback control law that depends on the sequence of tracking errors where each error signal is associated with the state or measured variable of vector (i.e., ). The error is defined by where is the reference signal of the state or measured variable . On one side, the number of online tracking control loops is determined by the number of reference variables or states. Each reference signal has a tracking evaluation loop. In this development, a feedback control law that uses combination of three errors (i.e., ) is considered in order to mimic the mechanism of a Proportional-Integral-Derivative (PID) controller in discrete-time where the tracking gains are adapted in real time in an online fashion. On the other side, the form of each scalar tracking control law can be formulated for any combinations of error samples (i.e., ). Thus, the proposed tracking structure enables higher-order difference schemes which can be realized smoothly in discrete-time environments. In order to simplify the tracking notations, and are used to refer to the tracking error signal and tracking control signal for each individual tracking loop respectively. Herein, each scalar actuating tracking control signal simultaneously adjusts all relevant or applicable actuation control signals .
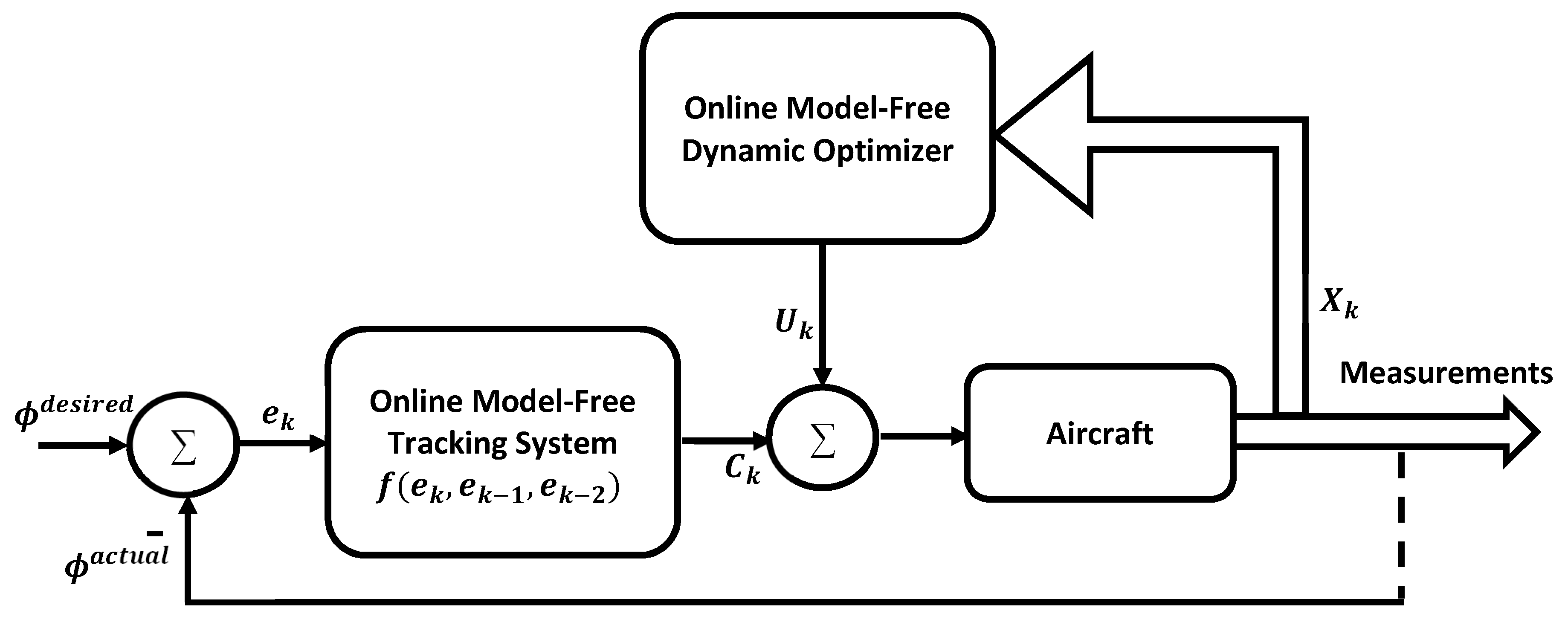
The overall layout of the control mechanism (i.e., considering the optimizing and tracking features) is sketched in
Figure 1, where
denotes a desired reference signal (i.e., each
) and
refers to the actual measured signal (i.e., each
) for each individual tracking loop.
The goals of the optimization problem are to find the optimal linear feedback control laws or the optimal control signals and using model-free machine learning schemes. The underlying objective utility functions are mapped into different temporal difference solution forms. As indicated above, since linear feedback control laws are used, then linear quadratic utility functions are employed to evaluate the optimality conditions in real time. The objectives of the optimization problem are detailed as follows:
(1) A measure index of the overall dynamical performance is minimized to calculate the optimal control signal
such that
with linear quadratic objective cost function
where
and
are symmetric positive definite matrices.
Therefore, the underlying performance index
J is given by
(2) A tracking error index is optimized to evaluate the optimal tracking control signal
such that
with an objective cost function
where
is a symmetric positive definite matrix, and
. The choice of the tracking error vector
E is flexible to the number of the memorized tracking error signals
such that
.
Therefore, the underlying performance index
P is given by
Herein, the choice of the optimized policy structure to be a function of the states is not meant to achieve asymptotic stability in a standalone operation (i.e., all the states go to zero). Instead, it is incorporated into the overall control architecture where it can select the minimum energy path during the tracking process. Hence, it creates an asymptotically stable performance around the desired reference trajectory. Later, the performance of the standalone tracker is contrasted against that of the combined tracking control scheme to highlight this energy exchange minimization outcome.
2.2. Optimal Control Formulation
Various optimal control formulations of the tracking problem promote multiple temporal difference solution frameworks [
17,
18]. These use Bellman equations or Hamilton–Jacobi–Bellman structures or even gradient forms of Bellman optimality equations [
19,
20,
35]. The manner at which the cost or objective function is selected plays a crucial role in forming the underlying temporal difference solution and hence its associated optimal control strategy form. This work provides a generalizable machine learning solution framework, where the optimal control solutions are found by solving the underlying Bellman optimality equations of the dynamical systems. These can be implemented using policy iteration approaches with model-based schemes. However, these processes necessitate having initial admissible policies, which is essential to ensure admissibility of the future policies. This is further faced by computational limitations, for example, the reliance of the solutions on least square approaches with possible singularities-related calculation risks. This urged for flexible developments such as online value iteration processes where they do not encounter these problems.
Value iteration processes based on two temporal difference solution forms are developed to solve the tracking control problem. These are equivalent to solving the underlying Hamilton–Jacobi–Bellman equation of the optimal tracking control problem [
17,
46]. Regarding the problem under consideration, it is required to have two temporal difference equations: One solves for the optimal control strategies to minimize the tracking efforts, and the other selects the supporting control signals to minimize the energy exchanges during the tracking process. In order to do that, two solving value functions related to the main objectives, are proposed such that
where
is a solving value function that approximates the overall minimized dynamical performance and it is defined by
Similarly, the solving value function that approximates the optimal tracking performance is given by
where
These performance indices yield the following Bellman or temporal difference equations
and
where the optimal control strategies associated with both Bellman equations are calculated as follows
Therefore, the optimal policy for the overall optimized performance is given by
In a similar fashion, the optimal tracking control strategy is calculated using
Therefore, the optimal policy for the optimized tracking performance is given by
Using the optimal policies (
4) and (
5) into Bellman Equations (
2) and (
3) respectively yields the following Bellman optimality equations or temporal difference equations
and
where
and
are the optimal solutions for the above Bellman optimality equations
Solving Bellman optimality Equations (
6) or (
7) is equivalent to solving the underlying Hamilton–Jacobi–Bellman equations of the optimal tracking control problem.
Remark 1. Model-free value iteration processes employ temporal difference solution forms that arise directly from Bellman optimality Equations (6) or (7), in order to solve the proposed optimal tracking control problem. This learning platform shows how to enable Action-Dependent Heuristic Dynamic Programming (ADHDP) solution, a class of approximate dynamic programming that employs a solving value function that is dependent on a state-action structure, in order to solve the optimal tracking problem in an online fashion [37,60]. 5. Autonomous Flexible Wing Aircraft Controller
The proposed online adaptive learning approaches are employed to design an autonomous trajectory-tracking controller for a flexible wing aircraft. The flexible wing aircraft functions as a two-body system (i.e., the pilot/fuselage and wing systems) [
10,
13,
14,
15,
16]. Unlike fixed wing systems, the flexible wing aircraft do not have exact aerodynamic models, due to the deformations in the wings which are continuously occurring [
13,
64,
65]. Aerodynamic modeling attempts rely on semi-experimental results with no exact models, which complicated the autonomous control task and made it very challenging [
13]. Recently, these aircraft have captured increasing attention to join the unmanned aerial vehicles family due to their low-cost operation features, uncomplicated design, and simple fabrication process [
44]. The maneuvers are achieved by changing the relative centers of gravity between the pilot and wing systems. In order to change the orientation of the wing with respect to the pilot/fuselage system, the control bar of the aircraft takes different pitch-roll commands to achieve the desired trajectory. The pitch/roll maneuvers are achieved by applying directional forces on the control bar of the flexible wing system in order to create or alter the desired orientation of the wing with respect to the pilot/fuselage system [
65,
66].
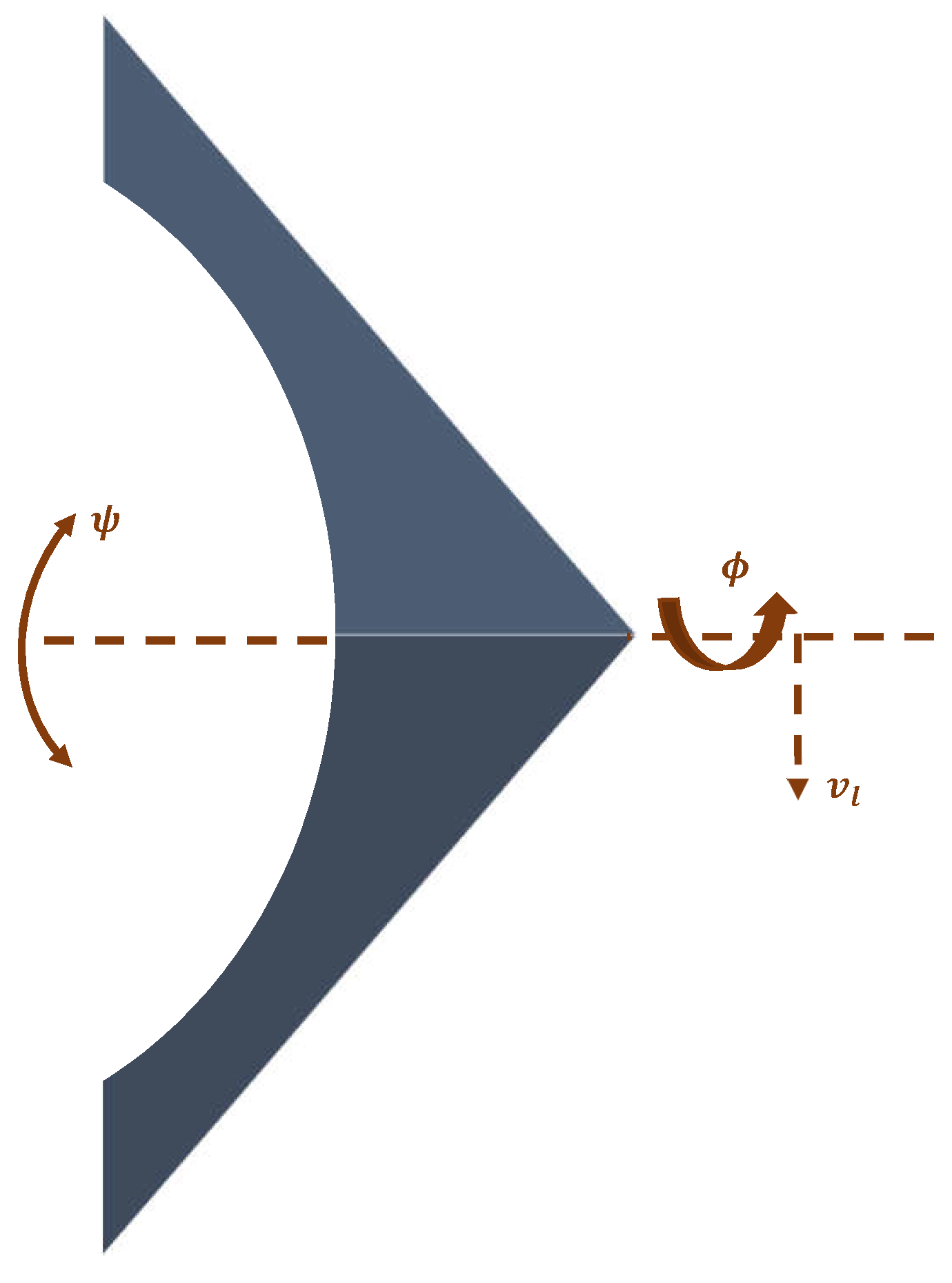
The objective of the autonomous aircraft controller design is to use the proposed online adaptive learning structures in order to achieve the roll-trajectory-tracking objectives, and to minimize energy paths (the dynamics of the aircraft) during the tracking process. The energy minimization is crucial for the economics of flying systems that share the same optimization objectives. The motions of the flexible wing aircraft are decoupled into longitudinal and lateral frames [
13,
64]. The lateral motion frame is hard to control compared to the inherited stability in the pitch motion frame. A lateral motion frame of a flexible wing aircraft is shown in
Figure 3.
5.1. Assessment Criteria for the Adaptive Learning Algorithms
The effectiveness of the proposed online model-free adaptive learning mechanisms is assessed based on the following criteria:
The convergence of the online adaptation processes (i.e., tuning of the actor and critic weights achieved using Algorithms 1 and 2). Consequently, the resulting trajectory-tracking error characteristics.
The performance of the standalone tracking system versus the overall or combined tracking control scheme.
The stability results of the online combined tracking control scheme (i.e., the aircraft is required to achieve the trajectory-tracking objective in addition to minimizing the energy exchanges during the tracking process).
The benefits of the attempted adaptive learning approaches on improving the closed-loop time-characteristics of the aircraft during the navigation process.
Additionally, the simulation cases are designed to show how broadly Algorithm 2 (i.e., the newly modified Bellman temporal difference framework) will perform against Algorithm 1.
5.2. Generation of the Online Measurements
To apply the proposed adaptive approaches on the lateral motion frame, a simulation environment is needed to generate the online measurements. The different control methodologies do not use all the available measurements to control the aircraft [
13,
65]. Thus, the proposed approach is flexible to the selection of the key measurements. Hence, a lateral aerodynamic model at a trim speed, based on a semi-experimental study, is employed to generate the measurements as follows [
13]
where the lateral state vector of the wing system is given by
and
is the lateral control signal applied to the control bar.
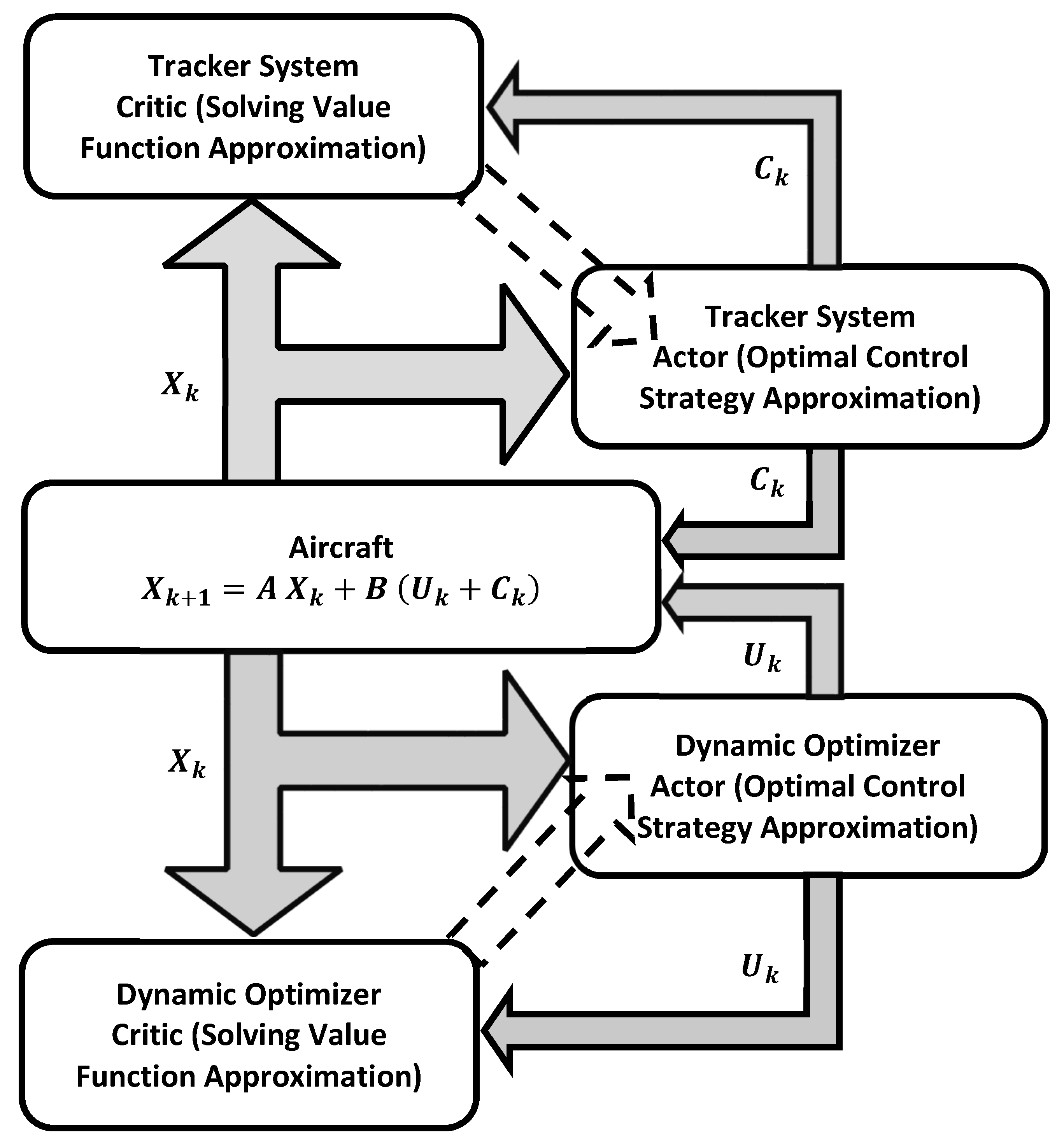
The control signal is the overall combined control strategy decided by the tracker system and the optimizer system (i.e., ). In this example, the banking control signal aggregates dynamically the scalar signals and in real time in order to get an equivalent control signal that is applied to the control bar in order to optimize the motion following a trajectory-tracking command. The optimizer will decide the state feedback control policy using the measurements , where the linear state feedback optimizer control gains are decided by the proposed adaptive learning algorithms. Similarly, the tracking system will decide the linear tracking feedback control policy based on the error signals , where . The linear feedback tracking control gains are adapted in real time using the online reinforcement learning algorithms.
Noticeably, the proposed online learning solutions do not employ any information about the dynamics (i.e., drift dynamics A and control input matrix B), where they function like black-box mechanisms. Moreover, the control objectives are implemented in an online fashion, where only real-time measurements are considered. In other words, the control mechanism for the roll maneuver generates the real-time control strategy for the roll motion frame regardless what is occurring in the pitch direction and vice versa.
5.3. Simulation Environment
As described earlier, a state space model captured at a trim flight condition is used to generate online measurements [
13]. A sampling time of
, creates the discrete-time state space matrices
The learning parameters for the adaptive learning algorithms are given by . The learning parameters are selected to be comparable to the sampling time to have smooth adjustments for the adapted weights. Later, random learning rates are superimposed at each evaluation step.
The initial conditions are set to
The weighting matrices of the cost functions and are selected in such a way as to normalize the effects of the different variables in order to increase the sensitivity of the proposed approach against the variations in the measured variables. These are given by , , ,
The desired roll-tracking trajectory consists of two smooth opposite turns represented by a sinusoidal reference signal such that (i.e., right and left turns with max amplitudes of ).
5.4. Simulation Outcomes
The simulation scenarios tackle the performance of the standalone tracker, then the characteristics of the overall or combined adaptive control approach. Finally, a third scenario is considered to discuss the performance of the adaptive learning algorithms under unstructured dynamical environment and uncertain learning parameters. These simulation cases can be detailed out as follows
Standalone tracker: The adaptive learning algorithms are tested to achieve only the trajectory-tracking objective (i.e., no overall dynamical optimization is included, and they are denoted by STA1 and STA2 for Algorithms 1 and 2 respectively). In the standalone tracking operation mode, Bellman equations concerning the optimized overall performance and hence the associated optimal control strategies are omitted form the overall adaptive learning structure.
Combined control scheme: This case combines the adaptive tracking control and optimizer schemes (i.e., the tracking control objective is considered along with the overall dynamical optimization using Algorithms 1 and 2 which are referred to as OTA1 and OTA2 respectively).
Operation under uncertain dynamical and learning environments: The proposed online reinforcement learning approaches are validated using challenging dynamical environment, where the dynamics of the aircraft (i.e., matrices A and B) are allowed to variate at each evaluation step by around their nominal values at a normal trim condition. The aircraft is allowed to follow a complicated trajectory to highlight the capabilities of the adaptive learning processes using this maneuver. Additionally, the actor-critic learning rates are allowed to variate at each iteration index or solution step.
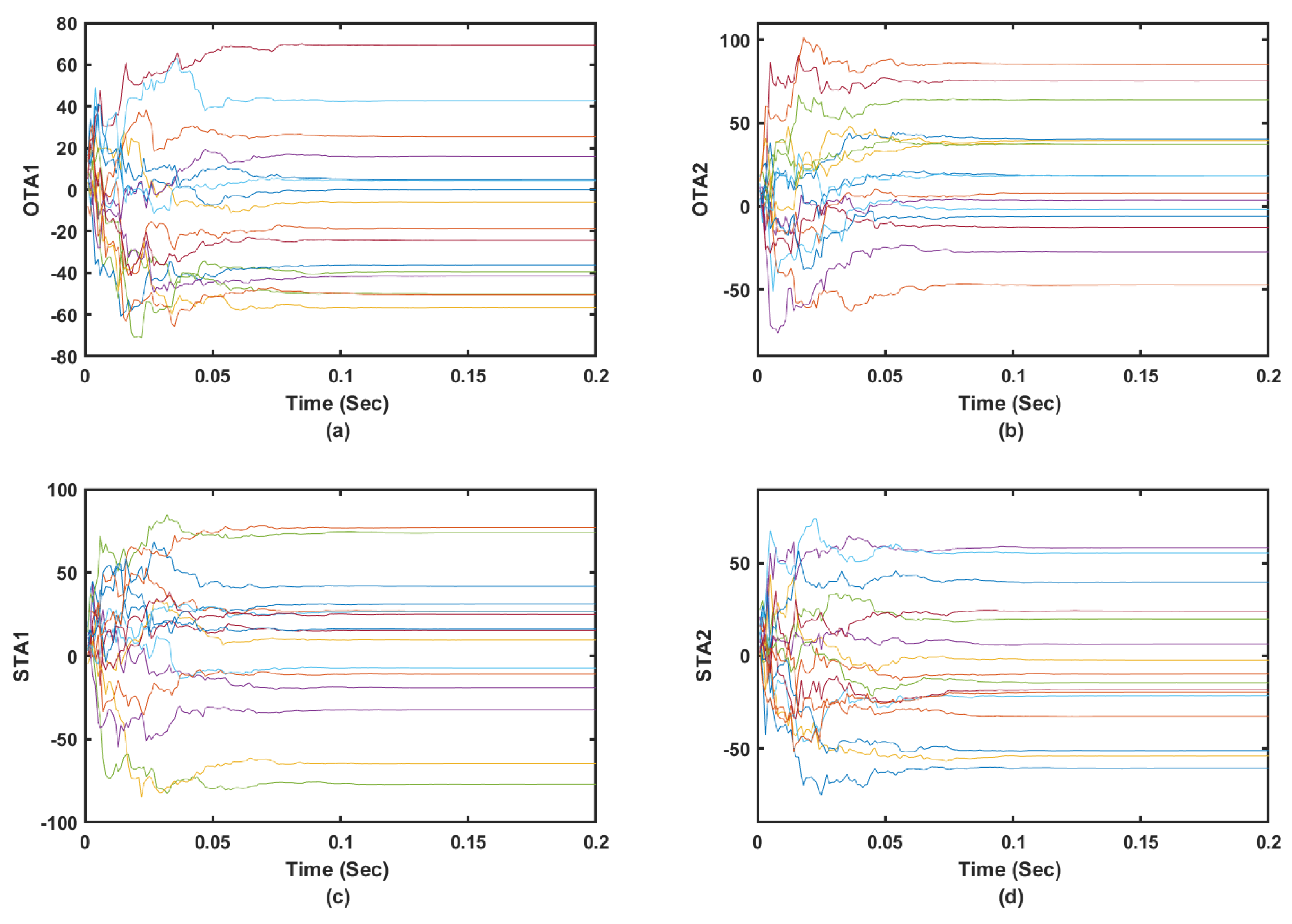
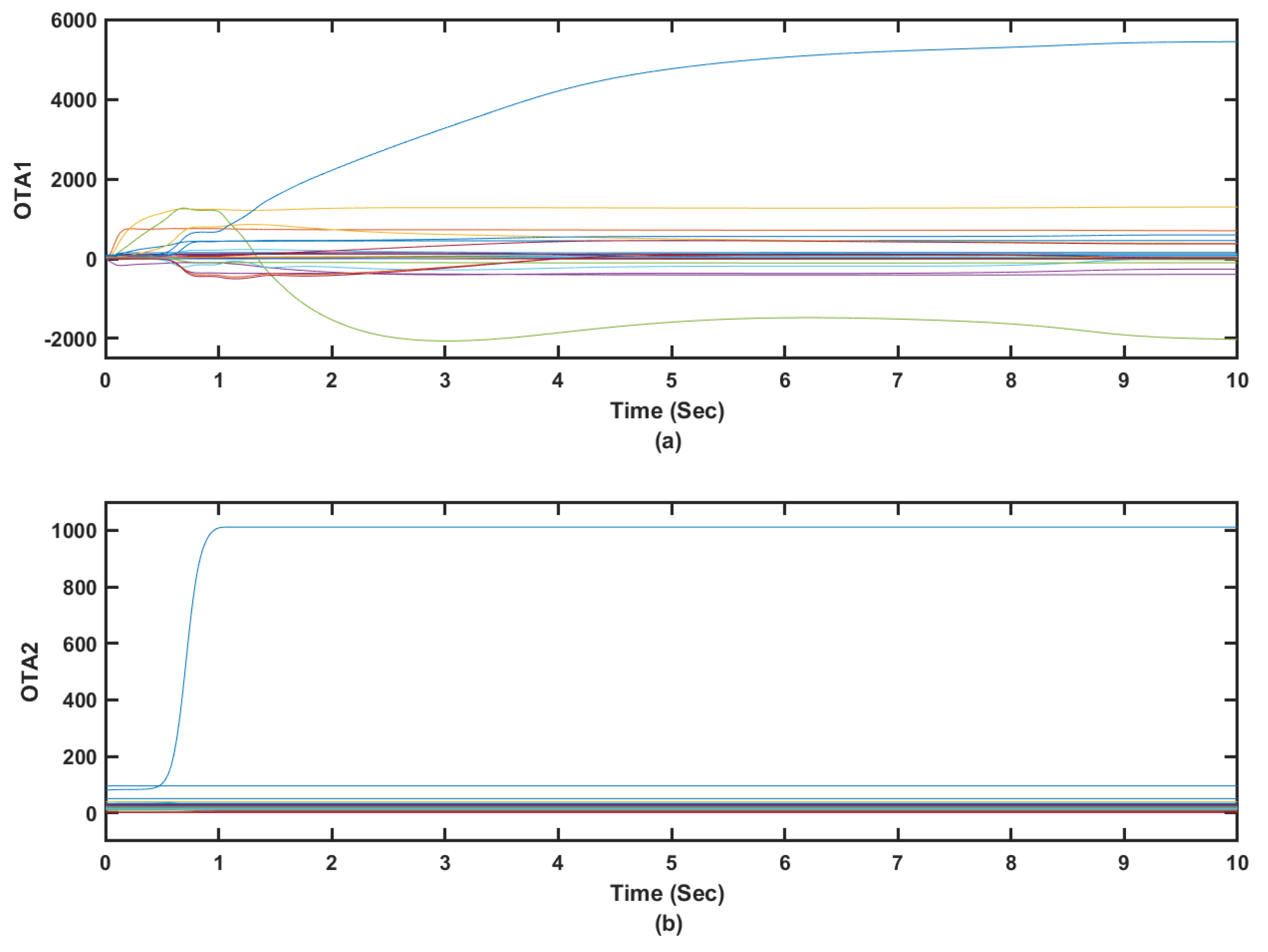
5.4.1. Adaptation of the Actor-Critic Weights
The tuning processes of the actor and critic weights are shown to converge when they follow solution Algorithms 1 and 2 as shown in
Figure 4,
Figure 5 and
Figure 6. This is noticed when the tracker is used in a standalone situation or when it is operated within the combined or overall dynamical optimizer. It is shown that the actor and critic weights for the tracking component of the optimization process converge in less than
s as shown in
Figure 4 and
Figure 5. The tuning of the critic weights in the case of optimized tracker took longer time due to the number of involved states and the objective of the overall dynamical optimization problem as shown in
Figure 6. It is worth noting that the tracker part of the controller uses the tracking error signals as inputs which facilitates the tracking optimization process. These results highlight the capability of the adaptive learning algorithms to converge in real time.
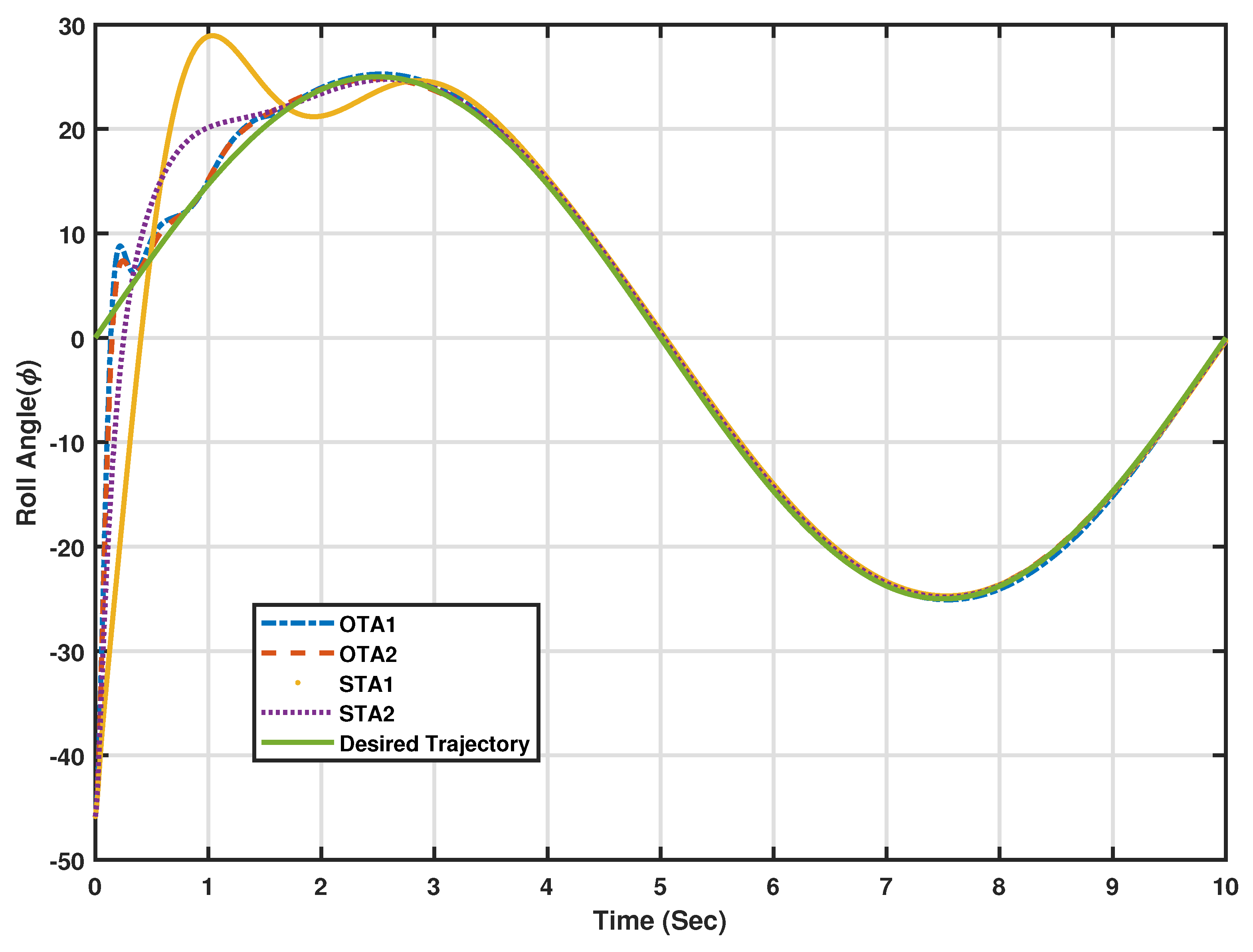
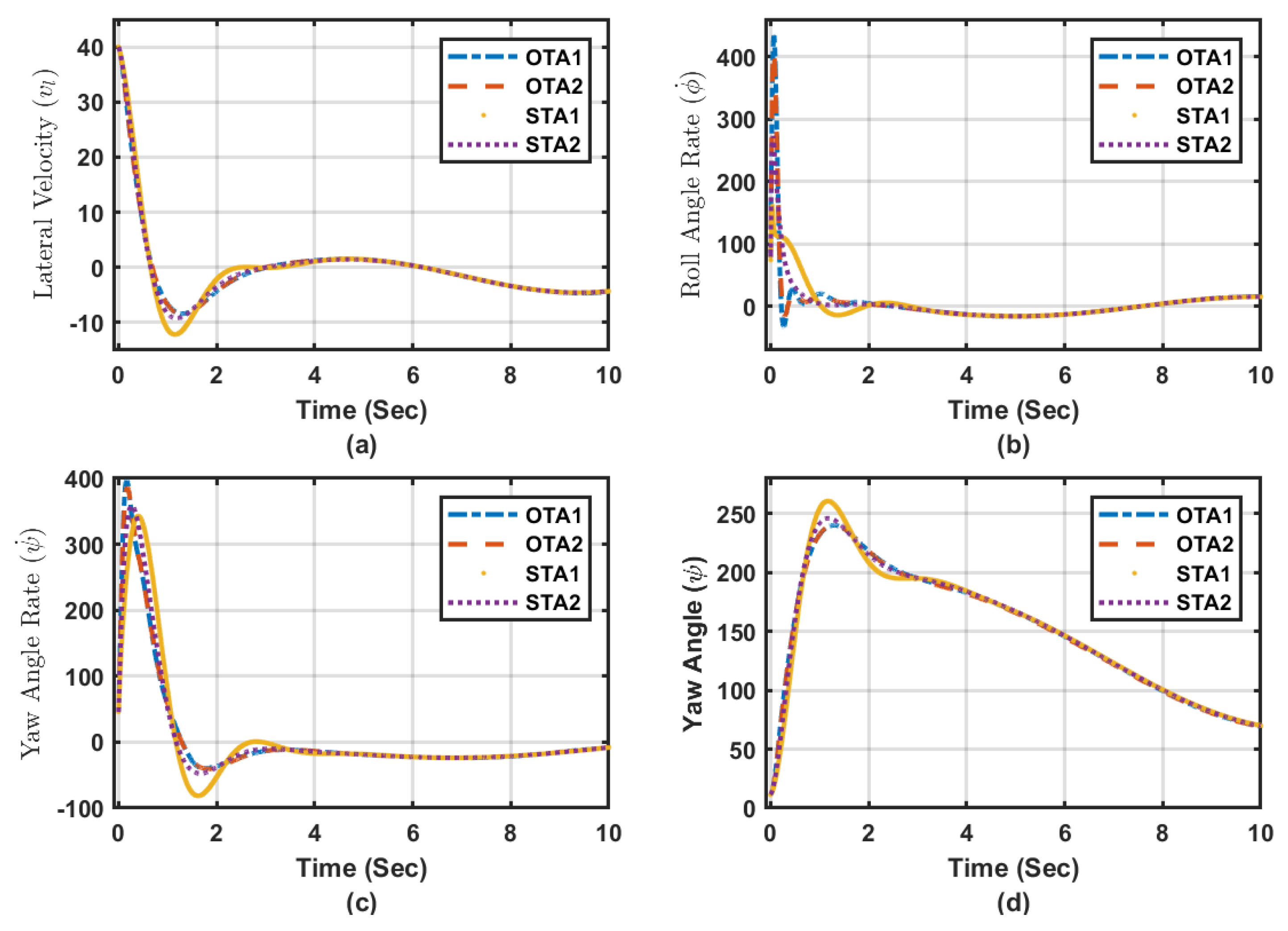
5.4.2. Stability and Tracking Error Measures
The adaptive learning algorithms under different scenarios or modes of operation, stabilize the flexible wing system along the desired trajectory as shown in
Figure 7 and
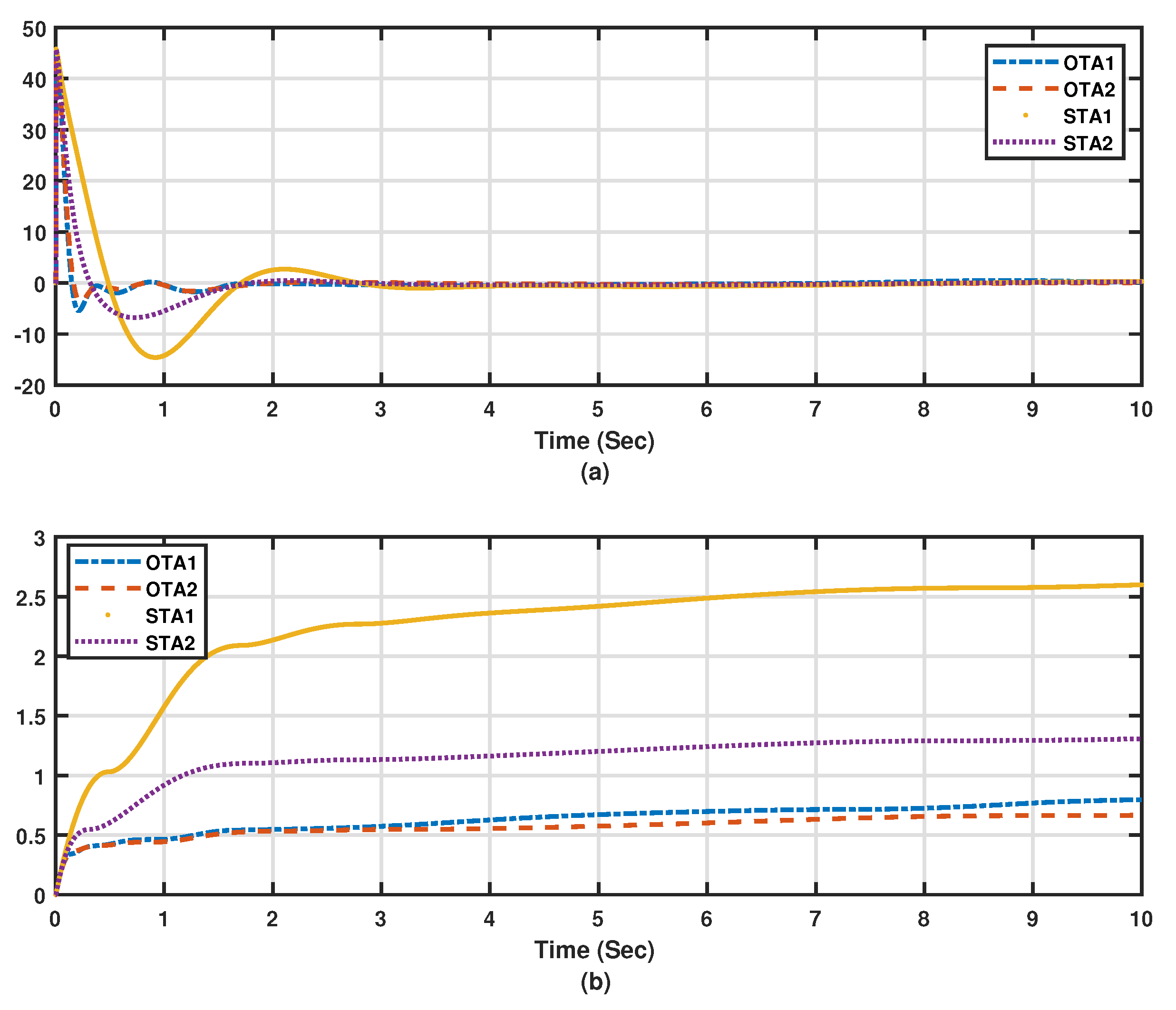
Figure 8. The lateral motion dynamics eventually follow the desired trajectory. In this case, the lateral variables are not supposed to decay to zero, since the aircraft is following a desired trajectory. The tracking scheme leads this process side by side with the overall energy optimization process, which actually improves the closed-loop characteristics of the aircraft towards minimal energy behavior. It is noticed that Algorithm 2 outperforms Algorithm 1 under standalone tracking mode or the overall optimized tracking mode. In order to quantify these effects numerically and graphically, the average accumulated tracking errors obtained using the proposed adaptive learning algorithms are shown in
Figure 9a,b respectively. These indicate that the optimized tracker modes of operation (i.e., OTA1 and OTA2) give lower errors compared to those achieved during the standalone modes of operations (i.e., STA1 and STA2), emphasizing the importance of adding the overall optimization scheme to the tracking system. Adaptive learning Algorithm 2, using the optimized tracking mode, achieves the lowest average of accumulated errors as shown in
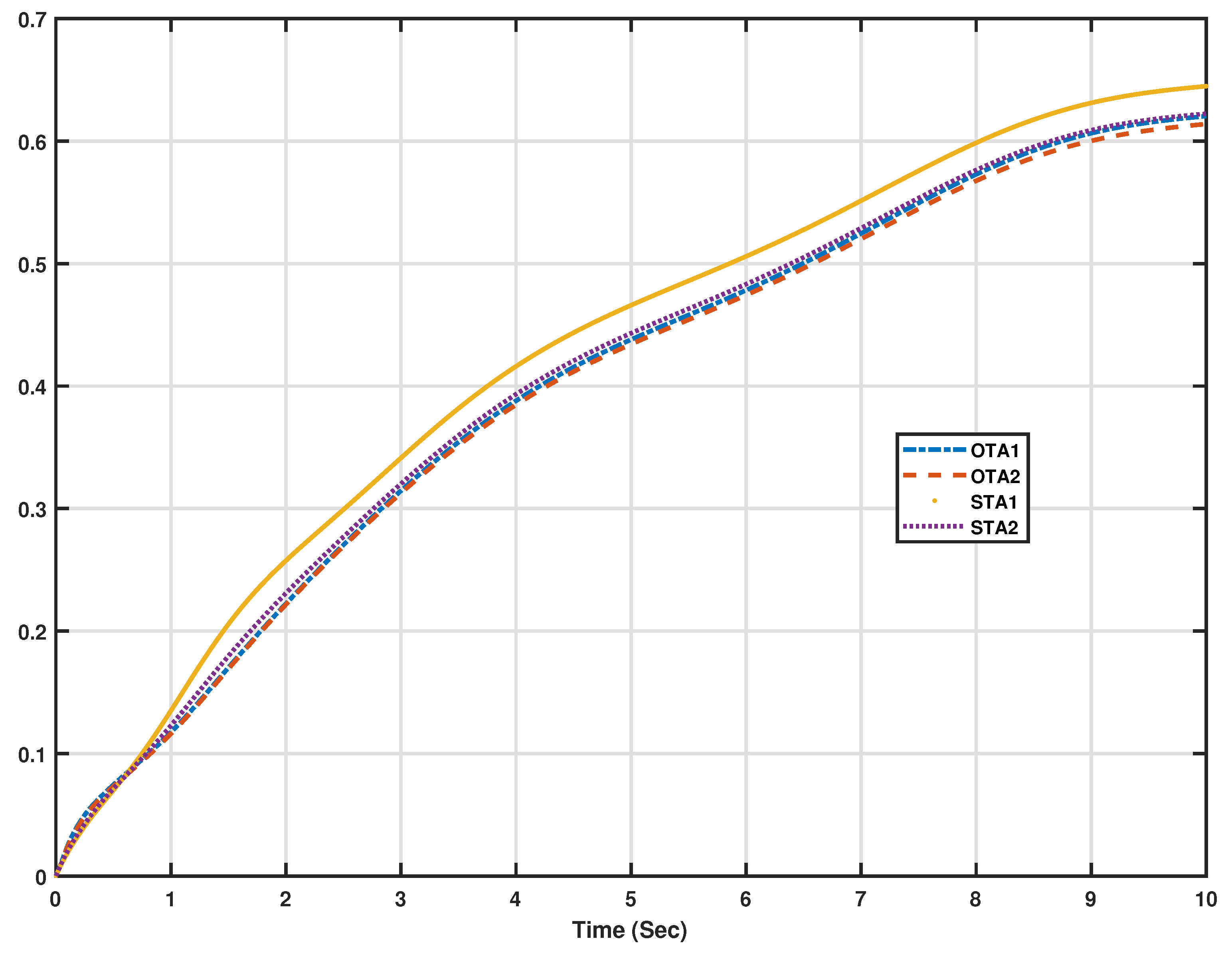
Figure 9b. An additional measure index is used, where the overall normalized dynamical effects are evaluated using the following Normalized Accumulated Cost Index (NACI)
where
and
(i.e., the number of iterations during 10 s) is the total number of samples.
The normalization values are the square of the maximum measured values of
and
. The adaptive algorithm (OTA2) achieves the lowest overall dynamical cost or effort as shown by
Figure 10. The final control laws achieved by using the different algorithms under the above modes of operation (i.e., STA1, STA2, OTA1, and OTA2) are listed in
Table 1.
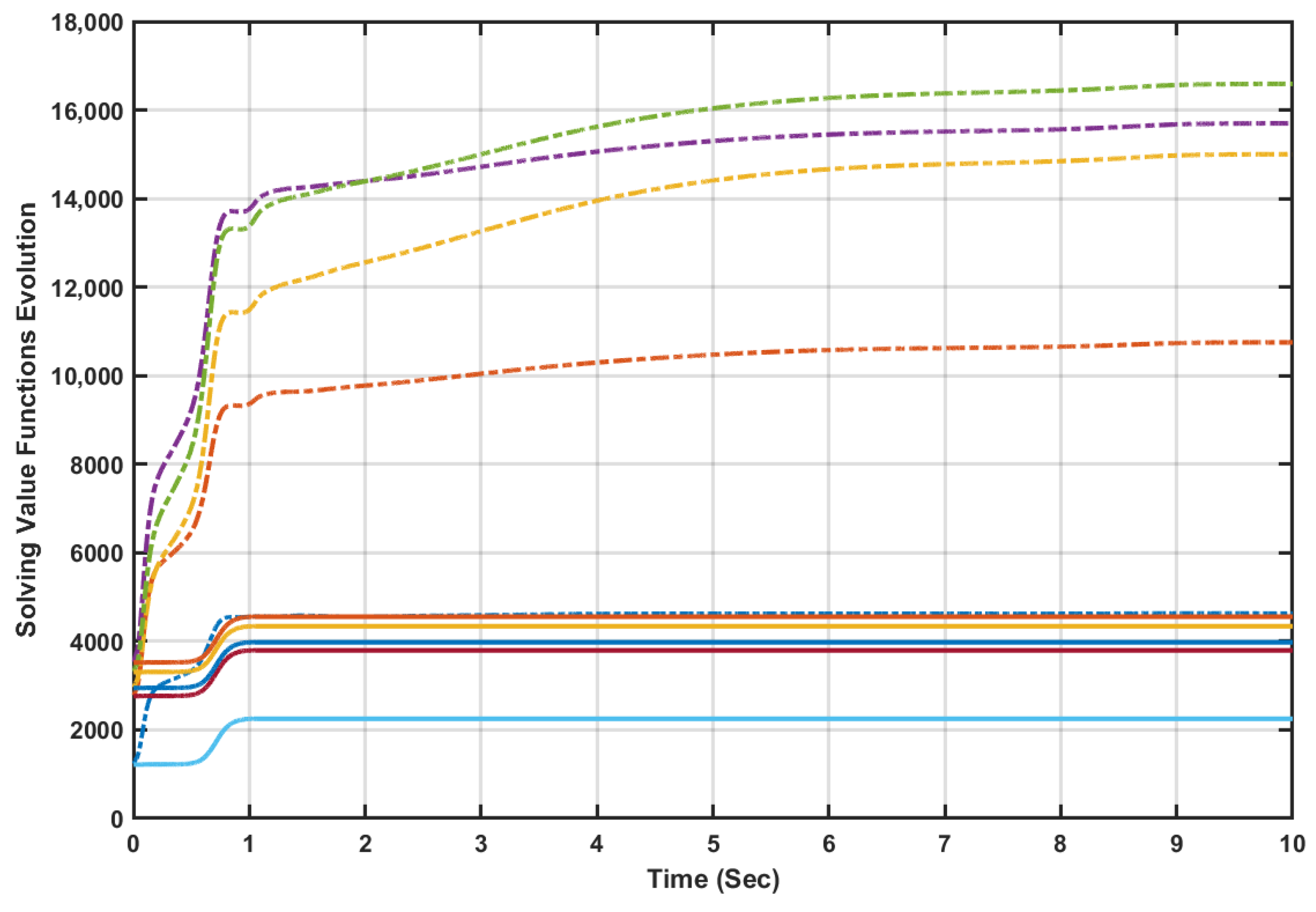
The online value iteration processes result in increasing bounded sequences of the solving value functions
and
, which is aligned with the convergence properties of typical value iteration mechanisms. The online learning outcomes of the value iteration processes
(i.e., using Algorithms 1 and 2) are applied and used for five random initial conditions as shown by
Figure 11. The initial solving value functions evaluated by Algorithms 1 and 2 start from the same positions using the same vector of initial conditions. It is observed that Algorithm 2 (solid lines) outperforms Algorithm 1 (dashed lines) in terms of the updated solving value function obtained using the attempted random initial conditions. Despite both algorithms show general increasing and converging evolution pattern of the solving value functions, value iteration Algorithm 2 exhibits rapid increment and quicker settlement to lower values compared to Algorithm 1.
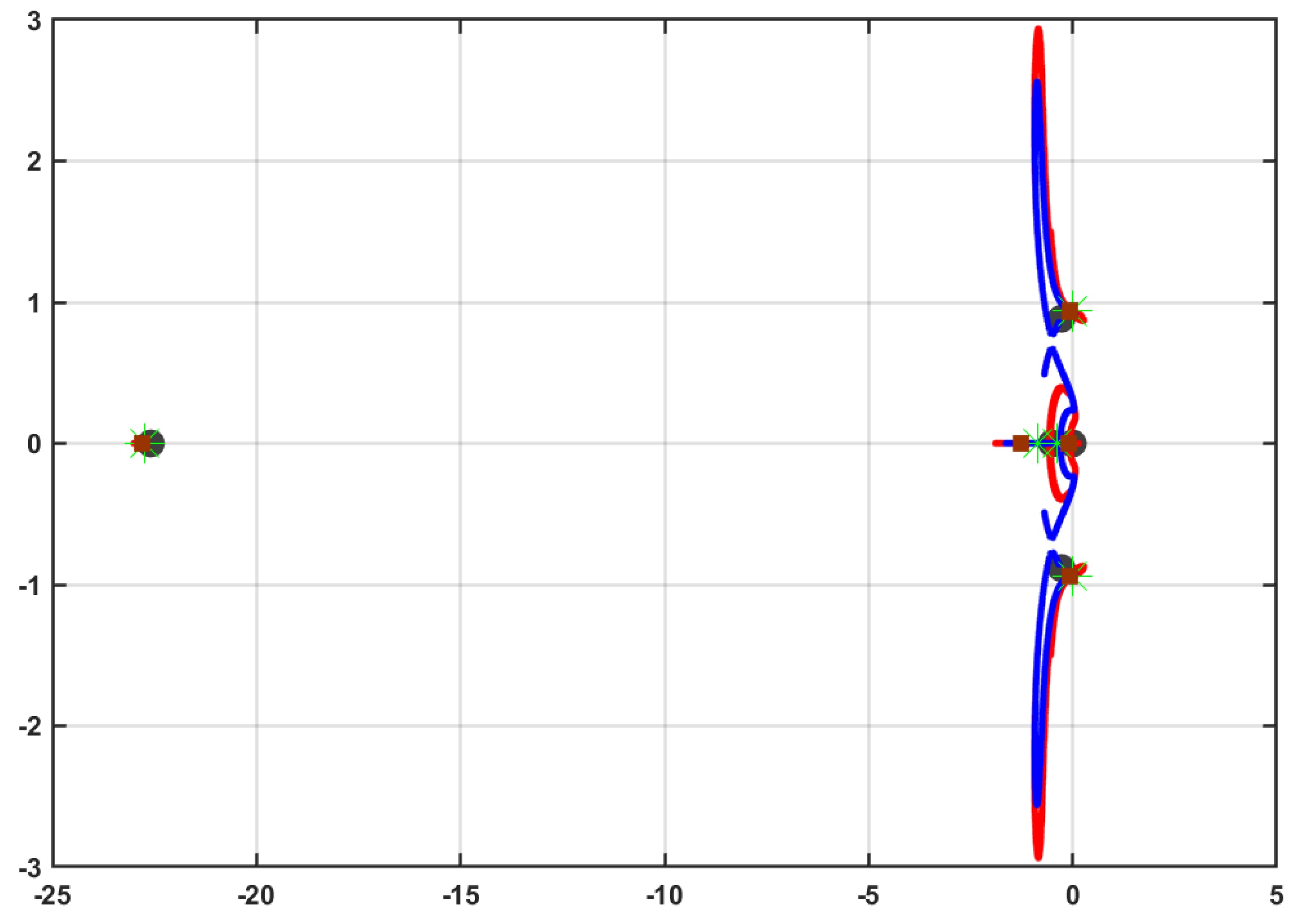
5.4.3. Closed-Loop Characteristics
To examine the time-characteristics of the adaptive learning algorithms, the closed-loop performances of the adaptive learning algorithms under the optimized tracking operation mode (i.e., OTA1 and OTA2) are plotted in
Figure 12. Apart from the tracking feedback control laws, the optimizer state feedback control laws directly affect the closed-loop system. The forthcoming analysis is to show how (1) the aircraft system initially starts (i.e., open-loop system); (2) the evolution of the closed-loop poles during the learning process; and (3) the final closed-loop characteristics when the actor weights finally converge. The trace of the closed-loop poles achieved using OTA2 (i.e., the
● marks) shows concise and faster stable behavior than that obtained using OTA1 (i.e., the
● indicators), and definitely faster than the open-loop characteristics. The dominant open-loop pole is moved further into the stability region, when the overall dynamical optimizer is included, as listed in
Table 2. These results emphasize the stability and superior time-response characteristics achieved using the adaptive learning approaches, especially Algorithm 2.
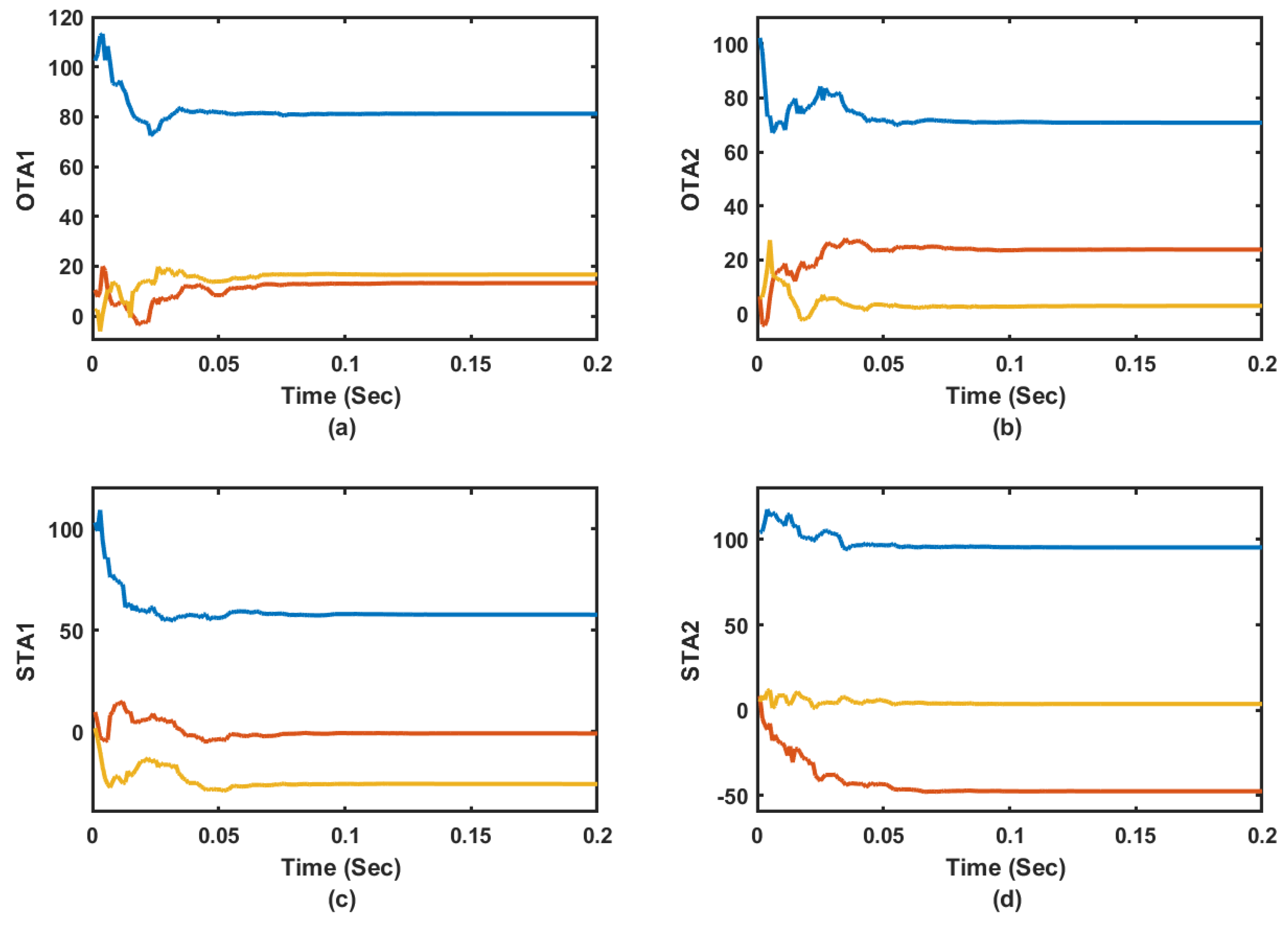
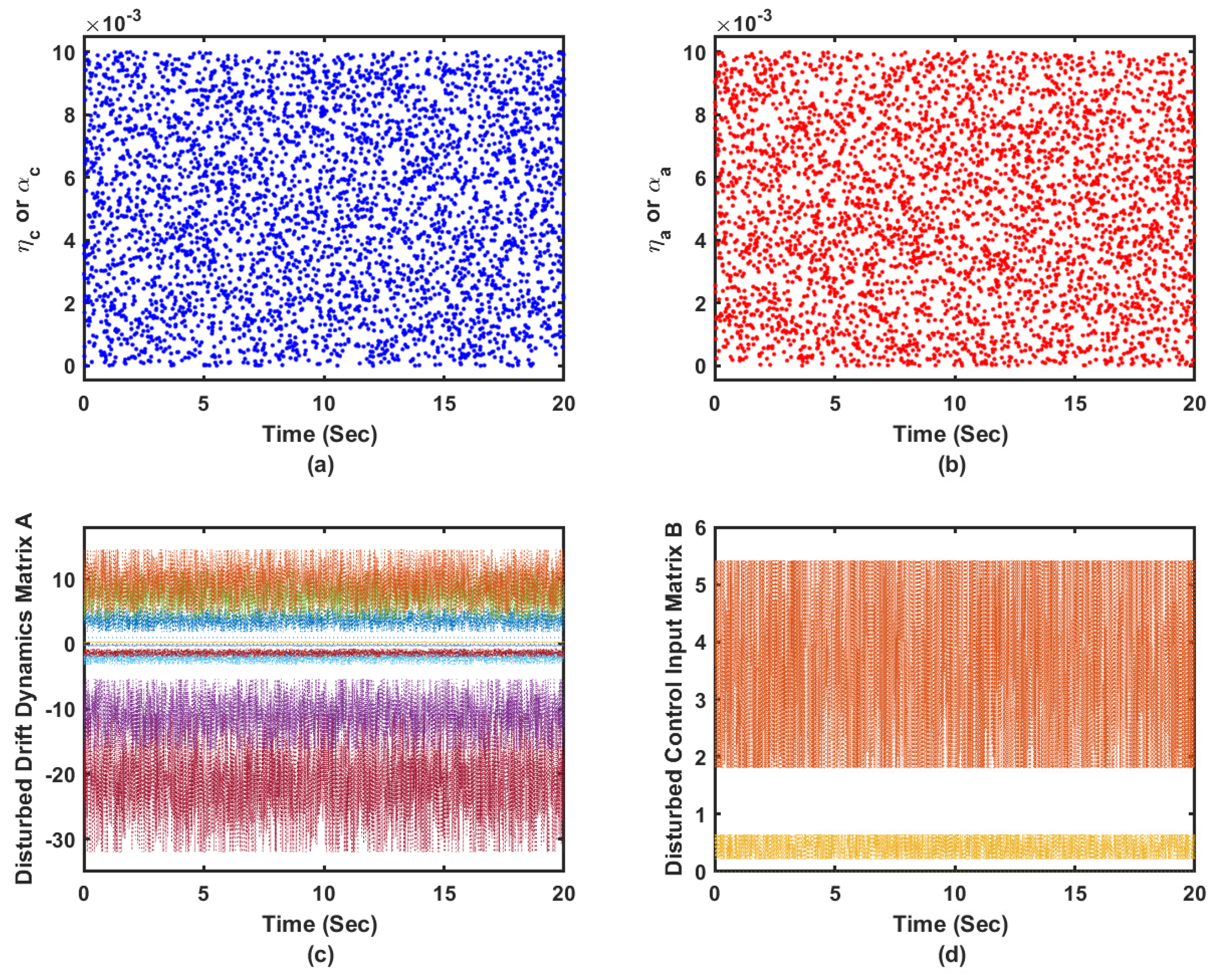
5.4.4. Performance in Uncertain Dynamical Environment
This simulation scenario challenges the performance of the online adaptive controller in uncertain dynamical environment. The continuous-time aircraft aerodynamic model (i.e., the aircraft state space model with the drift dynamics matrix
A and control input matrix
B) is forced to involve unstructured dynamics [
13]. These disturbances are of amplitudes
around the nominal values at the trim condition and they are generated from a normal Gaussian distribution as shown in
Figure 13c,d. Additionally, the sampling time is set to
s and the actor-critic learning rates are allowed to vary at each evaluation step as shown by
Figure 13a,b to test a band of learning parameters. Finally, a challenging desired trajectory is proposed such that
. These coexisting factors challenge the effectiveness of the controller. The randomness which appears in the proposed coexisting dynamical learning situations provides rich exploration environment for the adaptive learning processes. These dynamic variations occur at each evaluation step which guarantees some sort of generalization for the dynamical processes under consideration.
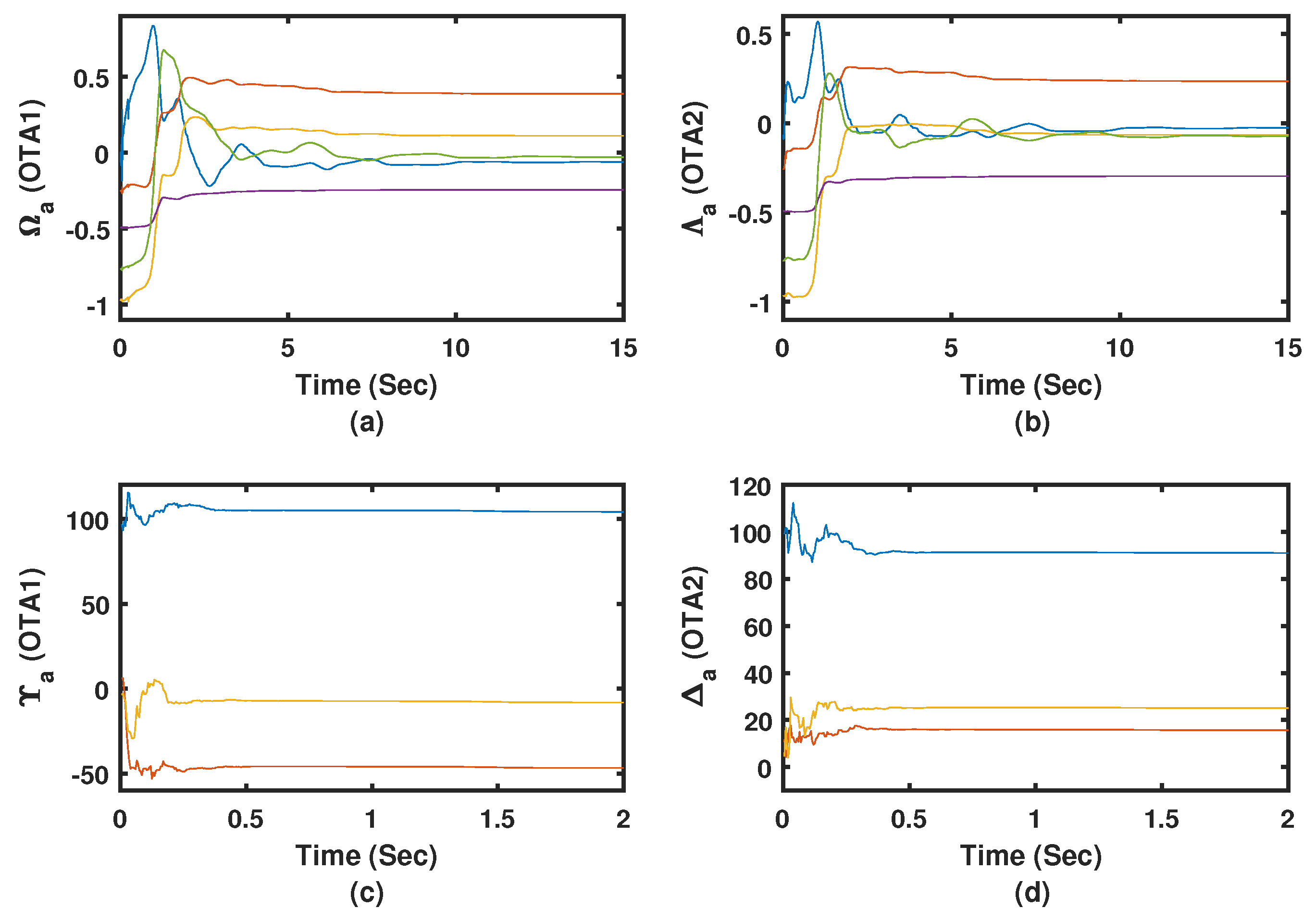
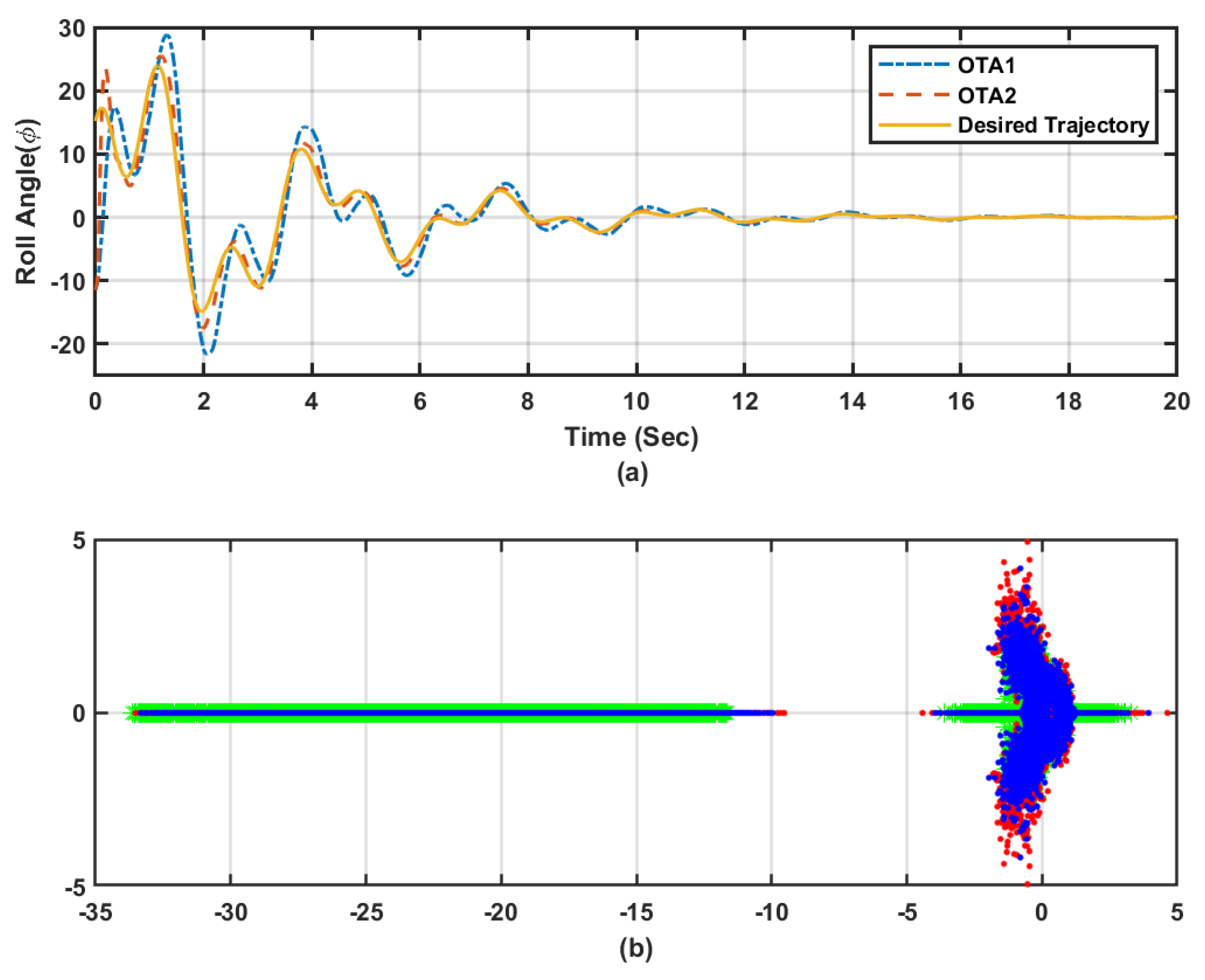
Figure 14a–d emphasize that the adaptive learning Algorithms 1 and 2 (i.e., OTA1 and OTA2) are able to achieve the trajectory-tracking objectives. The actor weights are shown to successfully converge despite the co-occurring uncertainties. The adaptation processes are effectively responding to the acting disturbances, where relatively longer time is needed to converge to the proper control gains. The tracking feedback control gains took shorter time to converge as shown by
Figure 14c,d, where the tracking feedback control law depends only on the state
, and implicitly its derivative. Algorithm 2 exhibited better trajectory-tracking features compared to those obtained using Algorithm 1 as shown by
Figure 15a.
Figure 15b, when compared to
Figure 12, shows how the open-loop poles, represented by
❋ marks (recorded disturbances at each iteration
k), spread all over the S-plane. The adaptive learning Algorithms 1 and 2, exhibited similar stable behavior as observed in the earlier scenarios. However, longer time was needed to reach asymptotic stability around the desired reference trajectory. This can be observed by examining the spread of the closed-loop poles obtained using OTA1 (
● notations) and OTA2 (
● symbols). These results highlight the insensitivity of the proposed adaptive learning approaches against different uncertainties in the dynamic learning environments.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}