1. Introduction
Recent technology solutions in intelligent systems and robotics have made possible innovative intervention and treatment for individuals affected by Autism Spectrum Disorder (ASD), which is a pervasive neurodevelopmental disorder in which deficits in social interaction and communication can make ordinary life challenging from childhood through adulthood [
1]. Children with ASD often experience anxiety when interacting with other people due to the complexity and unpredictability of human behaviors. The controllable autonomy of robots has been exploited to provide acceptable social partners for these children [
2] in the treatment of this disorder. Indeed, several studies have shown that some individuals with ASD prefer robots to humans and that robots generate a high degree of motivation and engagement, including children who are unlikely or unwilling to interact socially with human therapists (see [
3] for a review).
Epidemiological data show that ASD can often comorbid with some level of Intellectual Disability (ID) [
4], in fact, it has been reported that 54% of children with ASD have an IQ below 85, which makes therapeutic interventions more difficult due to the limited capabilities of the subjects, who often need hospitalization. The treatment of these children is more likely to benefit from the introduction of technological aids. Regarding therapeutic training of imitation presented in this article for instance, the standard approach is to employ two clinical personnel: one must be close to constantly support the child while another performs the tasks to imitate. Intelligent semi-autonomous systems like robots could provide assistance by performing the imitation tasks in this case, and, therefore, require only one therapist to support the child while controlling the system.
The work presented in this paper is part of the EU H2020 MSCA-IF CARER-AID project, which aims to improve robot-assisted therapy interventions for children with ASD and ID via an automatic personalization of the robot behavior that should meet the patient’s condition. The aim is to fully integrate the robot within a standard treatment, the TEACCH [
5] (Treatment and Education of Autistic and related Communication Handicapped Children) approach, which is commonly used for the treatment of ASD.
One of the most common characteristics of ASD is the impairment in using eye gaze to establish attention in social interaction and it is one of the most important of the traits that are assessed for diagnosis and one of the main areas of intervention for therapy [
6].
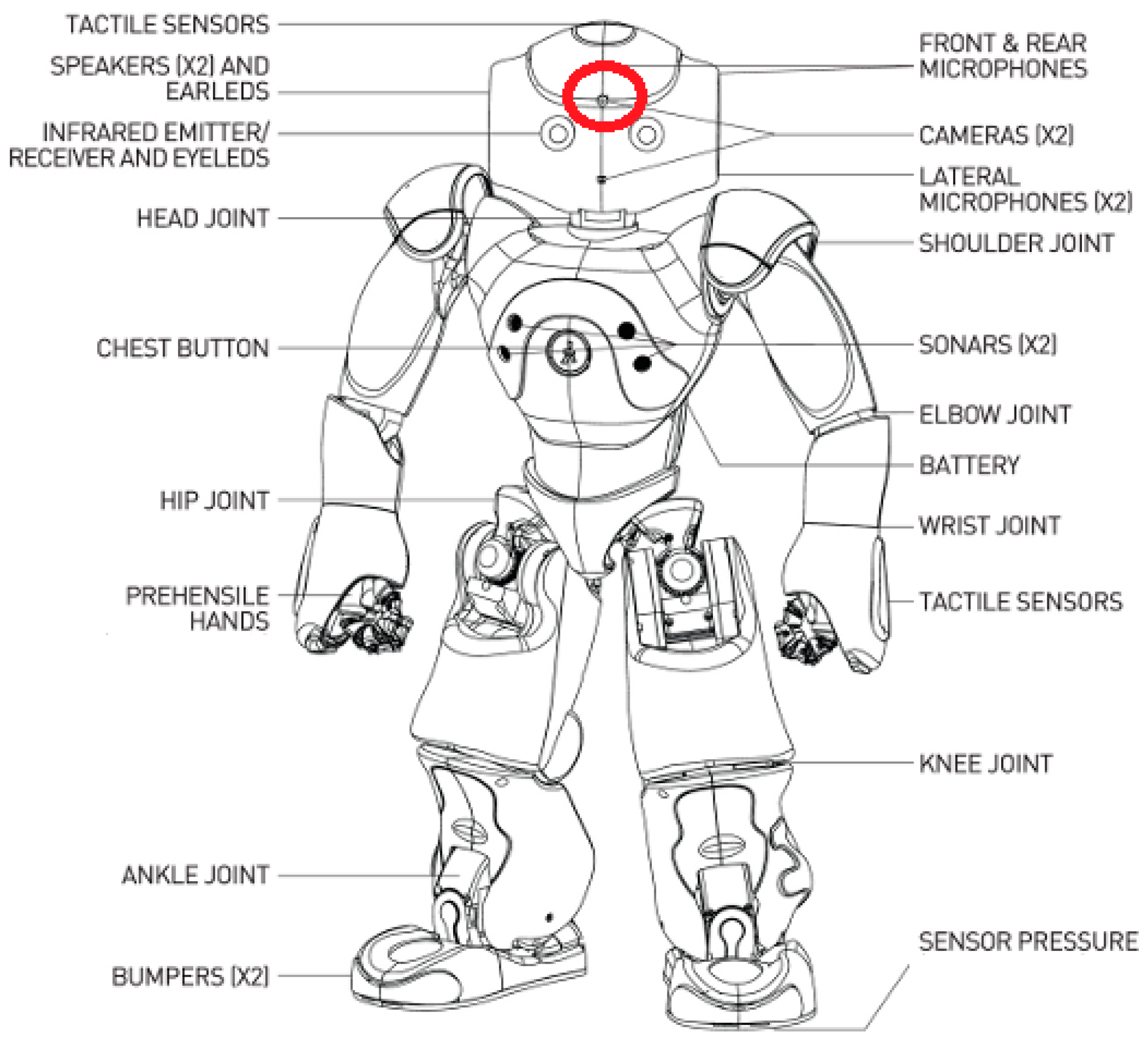
Small robotic platforms that are being used for robot-assisted therapy have usually limited sensors on-board and the use of external devices is very common in Human–Robot Interaction (HRI) for computing the human behavior in this context. Therefore, the challenge is to estimate the child’s visual attention directly from the robot cameras, possibly without the need of external devices, such as high-resolution cameras and/or Microsoft Kinects (or equivalent), which can definitely increase the performance, but at the same time limit the portability of the system and make more difficult its actual integration within the standard therapeutic environment.
Moreover, especially in the case of ID, children are unlikely to adhere to any imposed constraint like those typically required to maximize algorithm performance. Therefore, flexibility and adaptability are essential pre-requisites for the inclusion of any technology in the actual therapy [
7]. Conversely, in the case of robot-assisted therapy, preliminary experiments suggest that deriving attentional focus from a single camera would not be accurate enough [
8]. Quite the reverse, more recent experiments found acceptable levels of agreement between the robot observations and manual annotations [
9].
To investigate this issue, the authors considered training attention classifiers based on state-of-the-art algorithms of the popular deep-learning neural networks family [
10,
11]. These artificial neural network architectures achieved exceptional results in computer vision [
12] and the authors hypothesize that these technological improvements could empower the robots and allow them to perform reliably for vision tasks like estimating the engagement via the attention focus, and use this information to personalize the interaction.
The results of the evaluation of two architectures to estimate the child’s attention to the robot from low-resolution video recordings taken from the robot camera while interacting with the children are presented here. The approach was tested on videos collected during up to 14 sessions of robot-assisted therapy in an unconstrained real setting with six hospitalized children with ASD and ID. The clinical results of the field experiment presented in this article are analyzed and discussed in [
13,
14].
The rest of the paper is organized as follows:
Section 2 reviews and the scientific literature that constitutes the background for this work;
Section 3 introduces our approach for classifying the child attention status during the robot-assisted therapy, describes the procedure to collect the video recordings and produce the dataset for the experimentation, and present the algorithms that constitutes our system;
Section 4 analyses the numerical results, finally
Section 5 gives our discussion and conclusion.
4. Computational Experiments and Results
4.1. Database Creation
The authors built the training set for the classifier by extracting 4794 frames from the videos recorded during the preliminary encounters. These examples of child–robot interaction were then used both to build ad-hoc detectors using the R-CNN architecture and to train the attention classifier (K–NN) to discriminate between attention and distraction from landmarks or HOGs features.
The authors extracted 31726 frames (i.e., 2 frames per second) from 204 videos recorded by the robot during the therapy sessions for the test set. Video length varied according to the number of tasks to be performed, which was dynamically adapted to the child’s condition for each session. The duration ranges from 52 to 126 s, with an average of 77.75 s.
Following the methodology described in
Section 3.1.4, two researchers separately labeled the frames with the inter-coder agreement score which was 0.94, producing a reliability (measured by Cohen’s kappa) of 0.85. The final labels were agreed upon by both researchers after discussion.
Table 2 reports the total average time each child was demonstrating focusing the visual attention on the robot during the therapy sessions.
The robot-assisted therapy had a different impact on the children, who also have different types of ASD and level of ID. Indeed, the children cover a wide range, with C1 who was the least interested in the robot with as little as 5.7% of attention, while C5 showed high attention consistently during all the sessions. Details of the performance of the automatic attention estimation for each child are in
Appendix A.
4.2. Classification Results
The following tables present the performance metrics for the approaches considered; metrics were calculated for each of the 204 recorded videos. The descriptive statistics reported are the Average (avg), Median (median), Maximum (max), Minimum (min) and the standard deviation (
SD). The detailed results for each child are reported in
Appendix A.
The first analysis in
Table 3 focus on the Viola–Jones algorithm, which has been tested with both a Naïve classification, i.e., “attention” if a face is detected, “distraction” if no face is detected. The performance metrics of this classic approach show a good result despite its simplicity.
Despite the HOGs extraction and K–NN classification,
Table 4 shows very little improvement in the performance of the VJ approach. Indeed, there is a small increase in accuracy and a decrease in sensitivity, i.e., a reduction in true attention classifications. This means that the better performance has been caused by the K-NN classification of the HOGs that underestimates attention producing false detections of distraction.
Quite the opposite, the Naïve classification of R–CNN detections shows a better sensitivity, i.e., true classification of attention, but achieves the worst overall performance as it overestimates attention by detecting partial faces. Results for the Naïve R–CNN are in
Table 5.
Table 6 reports a significant improvement by applying the K–NN classification to the HOGs extracted from the R–CNN detections. This can be explained by the fact that the R–CNN detects more faces (true positives) than the VJ algorithm thanks to the ad-hoc training. Meanwhile, the K–NN classification stage reduces the false positive detections and therefore improves the overall performance.
The performance behavior of the MTCNN is reported in
Table 7 and
Table 8 and it is similar to the R–CNN. The version with the landmarks has the best sensitivity and reliability in the prediction of the negative statuses, i.e., distraction. However, this is achieved practically by overestimating attention which results in many false positives and the worst specificity (
Table 7). This performance is too low, and it cannot be considered reliable enough for a real application.
Finally, in
Table 8 one can see the best overall result in term of all the performance metrics considered.
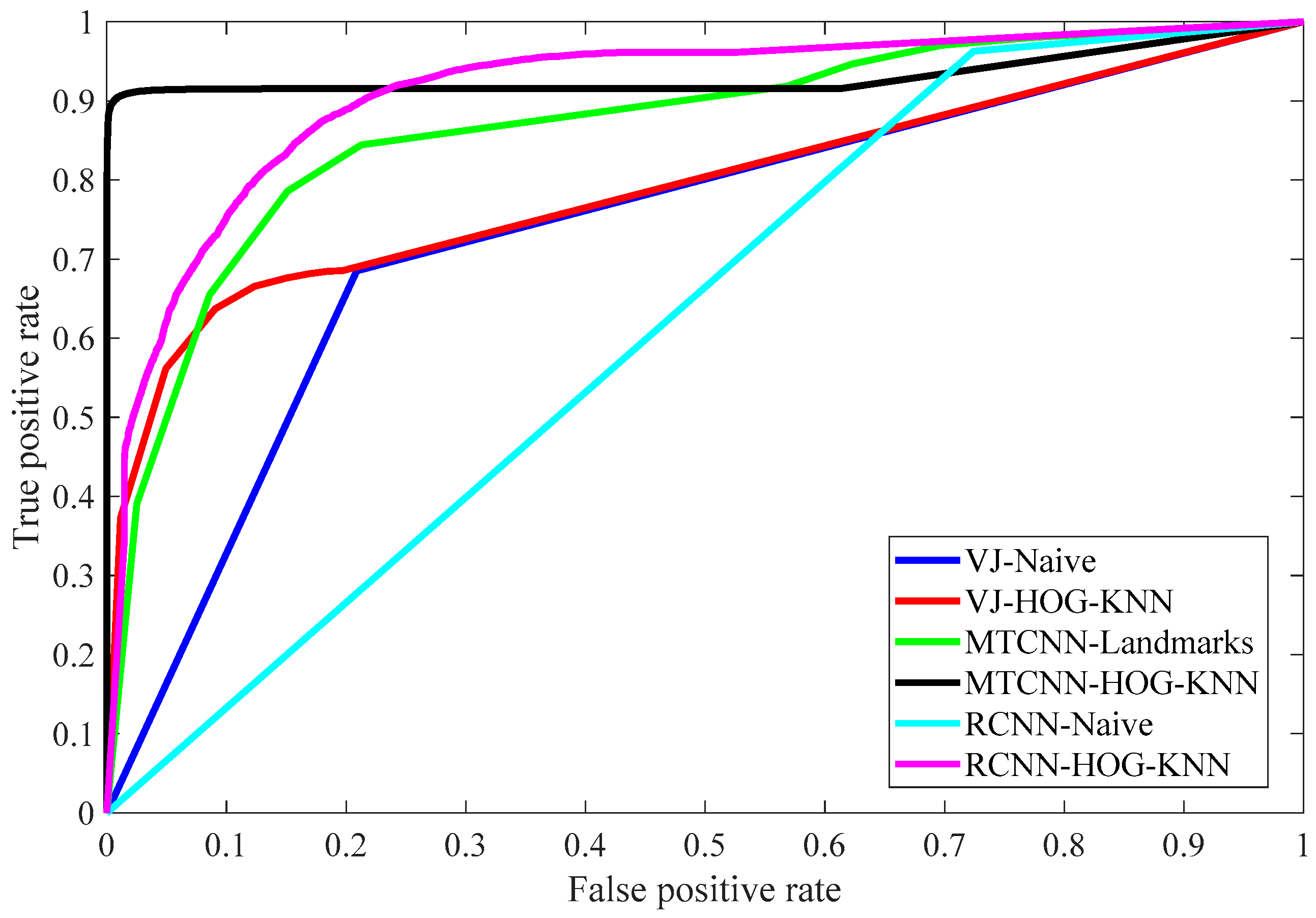
To summarize the results and show a direct comparison,
Figure 5 presents the ROC curves for all the approaches considered.
The AUCs are: VJ-Naïve 0.7382; VJ-HOG-K–NN 0.7926; MTCNN-Landmarks-K–NN 0.8681; MTCNN-HOG-K–NN 0.9314; RCNN-Naïve 0.6192; RCNN-HOG-K–NN 0.9128. The AUC values are consistent with the other metrics as they confirm that the classification of HOGs with the K–NN is best approach and that the MTCNN is the most efficient algorithm for detecting the faces. However, AUC values give a biased ranking as this measure is based on the true and false positives, i.e., the algorithms that achieve a better result in the sensitivity are in advantage over the others, while the authors remark that in this field of application true negatives (i.e., “Distraction”) are also important.
4.3. Computational Execution
The authors also considered the computational execution of the approaches considered in the numerical comparisons for further evaluation.
Table 9 presents the performance evaluation of the methods. Experiments were done on a Workstation equipped with Intel Xeon CPU E5-2683 v4 at 2.10 GHz and NVIDIA Tesla K40. If the images can be transferred to the Workstation quickly enough, the Viola–Jones is confirmed to be quickest to process the frames from the robot in a reasonable time, while the R–CNN and MTCNN can achieve decent performance only if accelerated with a GPU.
Note that, for the purpose of this application, even the lowest rate of 2 frames per second can be enough to estimate the behavior of the children, which changes in the span of seconds.
5. Discussion and Conclusions
Robot-assisted therapy is a promising field of application for intelligent social robots. However, most of the studies in the literature focus on ASD individuals without ID or neglected to analyze comorbidity. Indeed, very little has been done in this area and it could be considered as one of the current gaps between the scientific research and the clinical application [
7,
64]. Regarding the clinical context of ASD with ID, the aim is to use social assistive robots to provide assistance to the therapist and, consequently, reduce the workload by allowing the robot to take over some parts of the intervention. This includes monitoring and recording the child’s activities, proactively engaging the child when he/she is distracted, and adapting the robot behaviors according to the levels of intervention for every child on an individual basis [
18].
To this end, computational intelligence techniques should be utilized to increase the robot capabilities to favor greater adaptability and flexibility that can allow the robot to be integrated into any therapeutic setting according to the specific needs of the therapist and the individual child.
This article describes a step forward in this direction, indeed the authors tackled the problem of estimating the child’s visual focus of attention from the robot camera’s low-resolution video recordings. To investigate the applicability in a clinical setting, the authors created a database of annotated video recordings from a clinical experiment and compared some computer vision approaches, including popular deep neural network architectures for face detection combined with HOG feature extraction and a K–NN classifier.
The results show that the approaches based on CNN can significantly overcome the benchmark algorithm only if the detection is corrected using HOG features and a classifier to adjust the attention status estimation. Overall, the approach that achieves the best result is the one that makes use of the MTCNN to identify faces. The MTCNN achieved the highest accuracy on the test set, 88.2%, which is very good, and it could be used to adapt the robot behavior to the child’s current attention status, even though the computational requirements of CNN demand a proper workstation to be attached and to control the robot. However, thanks to the introduction of ultralow-power processors as accelerators for these architectures [
65], the authors hypothesize that these could empower the robots and allow them to perform reliably and in real-time vision tasks like estimating the attention focus and use this information to personalize the interaction. Despite the good result, a deeper analysis of the result with each child shows some cases in which the performance was poor, and this suggests the need to always perform a careful review by experts if the automated attention estimation is used for diagnosis. It should be noted that the researchers that analyzed the videos did not initially give the same label to some frames, and they had to discuss to come to an agreement for creating the final benchmark. These reasons, along with the low-resolution, might explain the not so remarkably high performance of some computational intelligence approaches.
However, it should be noted that the visual focus of attention is only one of the components of the social attention and the human labels were influenced also by other factors, whether the child’s posture, behavior, and actions were coherent with the task, the robot, and the environment for example. Moreover, this study is considering an estimation of the social attention from only one of its components—focusing the visual attention on the interaction partner.
Future work should focus on refining algorithms and, moreover, increase the hardware support for them. Other cues, such as the adherence of the child’s behavior to the robot’s prompt in the case of social attention evaluation should be evaluated and considered to refine the classification.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}