On the Development of Learning Control for Robotic Manipulators


Abstract
1. Introduction
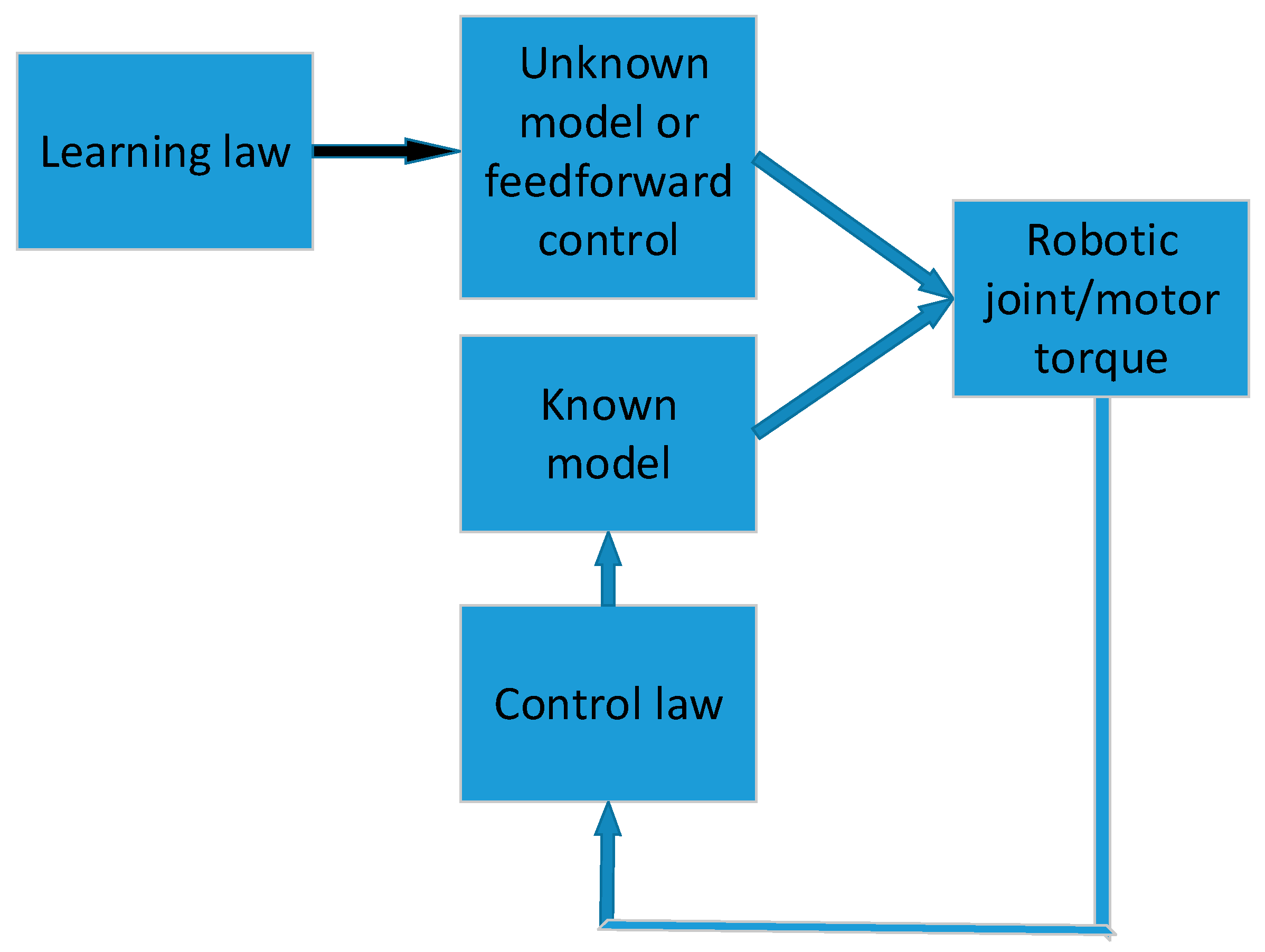
2. Learning Control
3. Learning Control in Robotic Manipulators
3.1. Iterative Learning Control and Its Variants
3.2. Repetitive Learning Control and Its Variants
3.3. Reinforcement Learning Control
4. Conclusions
Acknowledgments
Conflicts of Interest
References
- Longman, R. Iterative learning control and repetitive control for engineering practice. Int. J. Control 2000, 73, 930–954. [Google Scholar] [CrossRef]
- Bristow, D.A.; Singler, J.R. Analysis of transient growth in iterative learning control using Pseudospectra. In Proceedings of the Symposium on Learning Control at IEEE CDC 2009, Shanghai, China, 14–15 December 2009; pp. 1–6. [Google Scholar]
- Craig, J.J. Adaptive Control of Mechanical Manipulators; Addison-Wesley: Boston, MA, USA, 1988. [Google Scholar]
- Uchiyama, M. Formation of High-Speed Motion Pattern of a Mechanical Arm by Trial. Trans. Soc. Instrum. Control Eng. 1978, 14, 706–712. [Google Scholar] [CrossRef]
- Craig, J.J. Adaptive control of manipulators through repeated trials. In Proceedings of the American Control Conference, San Diego, CA, USA, 6–8 June 1984; pp. 1566–1573. [Google Scholar]
- Arimoto, S. Mathematical theory of learning with applications to robot control. In Adaptive and Learning Systems-Theory and Applications; Narendra, K.S., Ed.; Springer: Berlin, Germany, 1986; pp. 379–388. [Google Scholar]
- Arimoto, S.; Kawamura, S.; Miyazaki, F.; Tamaki, S. Learning control theory for dynamical systems. In Proceedings of the 24th IEEE Conference on Decision and Control, Fort Lauderdale, FL, USA, 11–13 December 1985; pp. 1375–1380. [Google Scholar]
- Arimoto, S.; Kawamura, S.; Miyazaki, F. Bettering operation of dynamic systems by learning: A new control theory for servomechanism or mechatronics systems. In Proceedings of the 23rd IEEE Conference on Decision and Control, Las Vegas, NV, USA, 12–14 December 1984; pp. 1064–1069. [Google Scholar]
- Arimoto, S.; Kawamura, S.; Miyazaki, F. Bettering operation of Robots by learning. J. Field Robot. 1984, 1, 123–140. [Google Scholar] [CrossRef]
- Mita, T.; Kato, E. Iterative control and its application to motion control of robot arm—A direct approach to servo-problems. In Proceedings of the 24th IEEE Conference on Decision and Control, Fort Launderdale, FL, USA, 11–13 December 1985; pp. 1393–1398. [Google Scholar]
- Arimoto, S. Robustness of learning control for robot manipulators. In Proceedings of the IEEE International Conference on Robotics and Automation, Cincinnati, OH, USA, 13–18 May 1990; pp. 1528–1533. [Google Scholar]
- Jiang, Y.; Clements, D.; Hesketh, T.; Park, J. Adaptive learning control of robot manipulators in task space. In Proceedings of the American Control Conference, Baltimore, MD, USA, 29 June–1 July 1994; pp. 207–211. [Google Scholar]
- Ngo, T.Q.; Nguyen, M.; Wang, Y.; Ge, J. An adaptive iterative learning control for robot manipulator in task space. Int. J. Comput. Commun. Control 2012, 7, 518–529. [Google Scholar] [CrossRef]
- Bouakrif, F.; Boukhetala, D.; Boudjema, F. Velocity observer-based iterative learning control for robot manipulators. Int. J. Syst. Sci. 2013, 44, 214–222. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Y.; Tomizuka, M. Nonparametric statistical learning control of robot manipulators for trajectory or contour tracking. Robot. Comput.-Integr. Manuf. 2015, 35, 96–103. [Google Scholar] [CrossRef]
- Bukkems, B.; Kostic, D.; Jager, B.; Steinbuch, M. Learning-Based Identification and Iterative Learning Control of Direct-Drive Robots. IEEE Trans. Control Syst. Technol. 2005, 13, 537–549. [Google Scholar] [CrossRef]
- Armin, S.; Goele, P.; Jan, S. Optimization-based iterative learning control for robotic manipulators. In Proceedings of the Benelux Meeting on Systems and Control, Soesterberg, The Netherlands, 22–24 March 2016. [Google Scholar]
- Norrlöf, M. An adaptive iterative learning control algorithm with experiments on an industrial robot. IEEE Trans. Robot. Autom. 2002, 18, 245–251. [Google Scholar] [CrossRef]
- Verrelli, C.M. Adaptive learning control design for robotic manipulators driven by permanent magnet synchronous motors. Int. J. Control 2011, 22, 1024–1030. [Google Scholar] [CrossRef]
- Tomei, P.; Verrelli, C.M. Learning control for induction motor servo drives with uncertain rotor resistance. Int. J. Control 2010, 83, 1515–1528. [Google Scholar] [CrossRef]
- Marino, R.; Tomei, P.; Verrelli, C.M. Robust adaptive learning control for nonlinear systems with extended matching unstructured uncertainties. Int. J. Robust Nonlinear Control 2012, 22, 645–675. [Google Scholar] [CrossRef]
- Liuzzo, S.; Tomei, P. Global adaptive learning control of robotic manipulators by output error feedback. Int. J. Adapt. Control Signal Process. 2009, 23, 97–109. [Google Scholar] [CrossRef]
- Choi, J.Y.; Lee, J.S. Adaptive iterative learning control of uncertain robotic systems. IEE Proc. Control Theory Appl. 2000, 147, 217–223. [Google Scholar] [CrossRef]
- Islam, S.; Liu, P.X. Adaptive iterative learning control for robot manipulators without using velocity signals. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Montréal, QC, Canada, 6–9 July 2010; pp. 1293–1298. [Google Scholar]
- Ichijo, Y.; Murao, T.; Fujita, H.K.M. Passivity-based iterative learning control for 2DOF robot manipulators with antagonistic bi-articular muscles. In Proceedings of the 2014 IEEE Conference on Control Applications (CCA), Antibes, France, 8–10 October 2014; pp. 234–240. [Google Scholar]
- Arimoto, S.; Naniwa, T. Learnability and Adaptability from the Viewpoint of Passivity Analysis. Intell. Autom. Soft Comput. 2002, 8, 71–94. [Google Scholar] [CrossRef]
- Sakagami, N.; Inoue, M.; Kawamura, S. Theoretical and experimental studies on iterative learning control for underwater robots. Int. J. Offshore Polar Eng. 2003, 13, 1–8. [Google Scholar] [CrossRef]
- Jia, B.; Liu, S.; Liu, Y. Visual trajectory tracking of industrial manipulator with iterative learning control. Ind. Robot Int. J. 2015, 42, 54–63. [Google Scholar] [CrossRef]
- Chen, H.; Xing, G.; Sun, H.; Wang, H. Indirect iterative learning control for robot manipulator with non-Gaussian disturbances. IET Control Theory Appl. 2013, 7, 2090–2102. [Google Scholar] [CrossRef]
- Hakvoort, W.; Aarts, R.; Dijk, J.; Jonker, J. Model-based iterative learning control applied to an industrial robot with elasticity. In Proceedings of the 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, 12–14 December 2007; pp. 4185–4190. [Google Scholar]
- Mahamood, R.; Pedro, J. Hybrid PD-PID with iterative learning control for two-link flexible manipulator. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 19–21 October 2011; Volume II, pp. 1–6. [Google Scholar]
- Wang, Y.; Chien, C.; Chuang, C. Adaptive iterative learning control of robotic systems using back-stepping design. Trans. Can. Soc. Mech. Eng. 2013, 37, 597–601. [Google Scholar]
- Zain, M.Z.; Tokhi, M.; Mohamed, Z. Hybrid learning control schemes with input shaping of a flexible manipulator system. Mechatronics 2006, 16, 209–219. [Google Scholar] [CrossRef]
- Mute, D. Adaptive Iterative Learning Control of a Single-Link Flexible Manipulator Based on an Identified Adaptive NARX Model. Master’s Thesis, National Institute of Technology Rourkela, Rourkela, India, 2013. [Google Scholar]
- Zhang, J.H.; Wang, H. Iterative learning-based minimum tracking error entropy controller for robotic manipulators with random communication time delays. IET Control Theory Appl. 2008, 2, 682–692. [Google Scholar] [CrossRef]
- Gopinath, S.; Kar, I.; Bhatt, R. Wavelet series based iterative learning controller design for industrial robot manipulators. Int. J. Comput. Appl. Technol. 2009, 35, 61–72. [Google Scholar] [CrossRef]
- Tayebi, A. Adaptive iterative learning control for robot manipulators. Automatica 2004, 40, 1195–1203. [Google Scholar] [CrossRef]
- Tayebi, A.; Islam, S. Adaptive iterative learning control for robot manipulators: Experimental results. Control Eng. Pract. 2006, 14, 843–851. [Google Scholar] [CrossRef]
- Bouakrif, F. Iterative learning control with forgetting factor for robot manipulators with strictly unknown model. Int. J. Robot. Autom. 2011, 26, 3407–3417. [Google Scholar] [CrossRef]
- Hamamoto, K.; Sugie, T. Iterative learning control for robot manipulators using the finite dimensional input subspace. IEEE Trans. Robot. Autom. 2002, 18, 632–635. [Google Scholar] [CrossRef]
- Delchev, K. Iterative learning control for robotic manipulators: A bounded-error algorithm. Int. J. Adapt. Control Signal Process. 2014, 28, 1454–1473. [Google Scholar] [CrossRef]
- Ernesto, H.; Pedro, J. Iterative learning control with desired gravity compensation under saturation for a robotic machining manipulator. Math. Probl. Eng. 2015, 2015, 1–13. [Google Scholar] [CrossRef]
- Chien, C.J.; Tayebi, A. Further results on adaptive iterative learning control of robot manipulators. Automatica 2008, 44, 830–837. [Google Scholar] [CrossRef]
- Delchev, K.; Boiadjiev, G.; Kawasaki, H.; Mouri, T. Iterative learning control with sampled-data feedback for robot manipulators. Int. J. Arch. Control Sci. 2014, 24, 299–319. [Google Scholar] [CrossRef]
- Ahn, H.; Moore, K.L.; Chen, Y. Iterative Learning Control—Robustness and Monotonic Convergence for Interval Systems; Springer: London, UK, 2007. [Google Scholar]
- Hara, S.; Omata, T.; Nakano, M. Synthesis of repetitive control systems and its application. In Proceedings of the 24th IEEE Conference on Decision and Control, Fort Launderdale, FL, USA, 11–13 December 1985; pp. 1387–1392. [Google Scholar]
- Kawamura, S.; Miyazaki, F.; Arimoto, S. Applications of learning method for dynamic control of robot manipulators. In Proceedings of the 24th IEEE Conference on Decision and Control, Fort Launderdale, FL, USA, 11–13 December 1985; pp. 1381–1386. [Google Scholar]
- Togai, M.; Yamano, O. Analysis and design of an optimal learning control scheme for industrial robots: A discrete system approach. In Proceedings of the 24th IEEE Conference on Decision and Control, Fort Launderdale, FL, USA, 11–13 December 1985; pp. 1399–1404. [Google Scholar]
- Atkeson, C.G.; McIntyre, J. Robot trajectory learning through practice. In Proceedings of the IEEE Conference on Robotics and Automation, San Francisco, CA, USA, 7–10 April 1986; pp. 1737–1742. [Google Scholar]
- Messner, W.; Kao, R.H.W.; Boals, M. A new adaptive learning rule. IEEE Trans. Autom. Control 1991, 36, 188–197. [Google Scholar] [CrossRef]
- Atkeson, C.G. Memory-Based Techniques for Task-Level Learning in Robots and Smart Machines. In Proceedings of the American Control Conference, San Diego, CA, USA, 23–25 May 1990; pp. 2815–2820. [Google Scholar]
- Horowitz, R.; Messner, W.; Moore, J. Exponential convergence of a learning controller for robot manipulators. IEEE Trans. Autom. Control 1991, 36, 890–894. [Google Scholar] [CrossRef]
- Cheah, C.; Wang, D. Learning impedance control for robotic manipulators. IEEE Trans. Robot. Autom. 1998, 14, 452–465. [Google Scholar] [CrossRef]
- Wang, D.; Cheah, C. An iterative learning-control scheme for impedance control of robotic manipulators. Int. J. Robot. Res. 1998, 17, 1091–1104. [Google Scholar] [CrossRef]
- Yan, R.; Tee, K.; Li, H. Nonlinear control of a robot manipulator with time-varying uncertainties. In Social Robotics, Proceedings of the Second International Conference on Social Robotics (ICSR), Singapore, 23–24 November 2010; Lecture Notes in Computer Science; Ge, S.S., Li, H., Cabibihan, J.J., Tan, Y.K., Eds.; Springer: Heidelberg, Germany, 2010; Volume 6414, pp. 202–211. [Google Scholar]
- Luca, A.; Paesano, G.; Ulivi, G. A frequency-domain approach to learning control: Implementation for a robot manipulator. IEEE Trans. Ind. Electron. 1992, 39, 1–10. [Google Scholar] [CrossRef]
- Xu, J.; Viswanathan, B.; Qu, Z. Robust learning control for robotic manipulators with an extension to a class of non-linear systems. Int. J. Control 2000, 76, 858–870. [Google Scholar] [CrossRef]
- Tatlicioglu, E. Learning control of robot manipulators in the presence of additive disturbances. Turkish J. Electr. Eng. Comput. Sci. 2011, 19, 705–714. [Google Scholar]
- Xian, B.; Dawson, D.; Queiroz, M.; Chen, J. A continuous asymptotic tracking control strategy for uncertain nonlinear systems. IEEE Trans. Autom. Control 2004, 49, 1206–1211. [Google Scholar] [CrossRef]
- Verrelli, C.; Pirozzi, S.; Tomei, P.; Natale, C. Linear Repetitive learning controls for robotic manipulators by Padé approximants. IEEE Trans. Control Syst. Technol. 2015, 23, 2063–2070. [Google Scholar] [CrossRef]
- Ouyang, P.R.; Zhang, W.J. Adaptive switching iterative learning control of robot manipulator. In Adaptive Control for Robotic Manipulators; Taylor & Francis Group: Boca Raton, FL, USA, 2016; pp. 337–373. [Google Scholar]
- Queen, M.P.; Kuma, M.; Aurtherson, P. Repetitive Learning Controller for Six Degree of Freedom Robot Manipulator. Int. Rev. Autom. Control 2013, 6, 286–293. [Google Scholar]
- Dixon, W.E.; Zergeroglu, E.; Dawson, D.M.; Costic, B.T. Repetitive Learning Control: A Lyapunov-Based Approach. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2002, 32, 538–545. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Chow, T.; Ho, J.; Tan, H. Repetitive learning control of nonlinear continuous-time systems using quasi-sliding mode. IEEE Trans. Control Syst. Technol. 2007, 15, 369–374. [Google Scholar] [CrossRef]
- Nakada, S.; Naniwa, T. A hybrid controller of adaptive and learning control for robot manipulators. Trans. Soc. Instrum. Control Eng. 2006, 42, 275–280. [Google Scholar] [CrossRef]
- Dawson, D.; Genet, R.; Lewis, L.F. A hybrid adaptive/learning controller for a robot manipulator. Symp. Adapt. Learn. Control ASME Winter Meet. 1991, 21, 51–54. [Google Scholar]
- Munadi, M.; Naniwa, T. Experimental verification of adaptive dominant type hybrid adaptive and learning controller for trajectory tracking of robot manipulators. J. Robot. Mechatron. 2013, 25, 737–747. [Google Scholar] [CrossRef]
- Liuzzo, S.; Tomei, P. A global adaptive learning control for robotic manipulators. In Proceedings of the 44th IEEE Conference on Decision and Control and European Control Conference, Seville, Spain, 12–15 December 2005; pp. 3596–3601. [Google Scholar]
- Ouyang, P.R.; Zhang, W.J.; Gupta, M.M. Adaptive nonlinear PD learning control for robot manipulators. In Proceedings of the ASME 2004 Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Salt Lake City, UT, USA, 28 September–2 October 2004; pp. 1–9. [Google Scholar]
- Sun, M.; Ge, S.; Mareels, I. Adaptive repetitive learning control of robotic manipulators without the requirement for initial repositioning. IEEE Trans. Robot. 2006, 22, 563–568. [Google Scholar]
- Horowitz, R. Learning Control of Robot Manipulators. J. Dyn. Syst. Meas. Control 1993, 115, 402–411. [Google Scholar] [CrossRef]
- Busoniu, L.; Schutter, B.; Babuska, R. Decentralized reinforcement learning control of a robotic manipulator. In Proceedings of the 9th International Conference on Control, Automation, Robotics and Vision, Singapore, 5–8 December 2006; pp. 1347–1352. [Google Scholar]
- Peters, J.; Schaal, S. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 1–6. [Google Scholar]
- Shah, H.; Gopal, M. Reinforcement learning control of robot manipulators in uncertain environments. In Proceedings of the IEEE International Conference on Industrial Technology, Churchill, Victoria, Australia, 10–13 February 2009; pp. 1–6. [Google Scholar]
- Ahn, H. Reinforcement learning and iterative learning control: Similarity and difference. In Proceedings of the International Conference on Mechatronics and Information Technology, Gwangju, Korea, 3–5 December 2009; pp. 422–424. [Google Scholar]
- Pipeleers, G.; Moore, K.L. Unified analysis of iterative learning and repetitive controllers in trial domain. IEEE Trans. Autom. Control 2014, 59, 953–965. [Google Scholar] [CrossRef]


{kind=link}
| Advantages | Drawbacks | Application in Robotics and Its Characteristics | |
|---|---|---|---|
| Reinforcement learning control | More flexible in terms of repetition | Usually requires strict exploration mechanisms | Learning by trial & error. Involve function approximation, and it has curse of dimensionality. |
| Repetitive Learning Control | Simple implementation and little performance dependency on system parameters | Usually needs repetitive process | Relying on the internal model. |
| Iterative Learning Control | Be able to compensate for exogenous signals | Usually needs repetitive reference trajectory | Starting from the same initial conditions at every iteration. |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Wei, B. On the Development of Learning Control for Robotic Manipulators. Robotics 2017, 6, 23. https://doi.org/10.3390/robotics6040023
Zhang D, Wei B. On the Development of Learning Control for Robotic Manipulators. Robotics. 2017; 6(4):23. https://doi.org/10.3390/robotics6040023
Chicago/Turabian StyleZhang, Dan, and Bin Wei. 2017. "On the Development of Learning Control for Robotic Manipulators" Robotics 6, no. 4: 23. https://doi.org/10.3390/robotics6040023
APA StyleZhang, D., & Wei, B. (2017). On the Development of Learning Control for Robotic Manipulators. Robotics, 6(4), 23. https://doi.org/10.3390/robotics6040023