The proposed methodology is structured around a dual-stream architecture designed to integrate object detection, pose estimation, and action recognition for effective human–object interaction analysis. The first network focuses on detecting and tracking relevant features from an RGB image using the YOLOv8 [
7] model, which performs object detection and segmentation to identify key elements such as the human body, hands, and objects. The first stream directly processes the input human body using a whole-body human pose estimation network [
15] to extract direct 3D body pose. This information is fed into an action recognition network to classify interaction states.
Meanwhile, in the second stream, the segmented hand and object regions are analyzed for spatial intersection in 2D and 3D using depth information (i.e., intersection over union and depth proximity are checked). Suppose an object is detected within the hand region. The cropped hand–object region is processed through a unified hand–object pose estimation network, which regresses hand Model with Articulated and Non-rigid defOrmations (MANO) [
41] hand parameters and object keypoints. These parameters are then refined to generate a 3D hand model using the MANO framework, while the object’s 6D pose is estimated through the Perspective-n-Point (PnP) algorithm [
29]. The detected objects from YOLOv8 [
7] are tracked using the DeepSORT [
42] algorithm to maintain object identity across frames. The overall process is structured as in
Figure 1. Additionally, we provide a flowchart of the complete model to clearly illustrate each step of the process, as shown in
Figure 2. We have color coded each section in the flow chart so that it is easier to follow.
3.1. Object Detection, Segmentation, and Tracking
YOLOv8 [
7] is a state-of-the-art object detection and segmentation model that builds upon previous YOLO [
5] architectures while incorporating several key advancements to improve accuracy, speed, and efficiency. It features an improved backbone network with a CSPDarknet-based structure, enhancing feature extraction through optimized convolutional layers and a more effective spatial pyramid pooling mechanism. The model utilizes an anchor-free detection approach, reducing computational overhead while maintaining high detection precision. YOLOv8’s detection framework directly predicts object bounding boxes and class probabilities from the feature maps, improving real-time performance. YOLOv8 extends its detection head with additional mask prediction layers for segmentation tasks, enabling instance segmentation by generating fine-grained object masks alongside bounding boxes. The model can carry out object localization and pixel-level segmentation, which gives it a remarkable ability to perform tasks where fine-grained scene understanding is necessary. The performance of YOLOv8 is studied in diverse domains, such as autonomous driving, robotic perception, and medical image analysis (real-world scenarios), demonstrating the strong generalization capability of YOLOv8 compared to previous YOLO structures. Its efficiency and ability to handle complex scenes make it a robust choice for real-time vision-based applications.
Due to the advantages of YOLOv8, we employ it for object, human, and hand detection and segmentation using a transfer learning approach. By leveraging a pre-trained YOLOv8 model, we fine-tune it on a custom dataset containing annotated images of hands, objects, and humans. Transfer learning allows the model to retain the robust feature representations learned from large-scale datasets while adapting to detecting and segmenting relevant elements in human–robot interaction scenarios. We further refine the detection accuracy during training using data augmentation, an adaptive learning rate setting, and fine-grained annotations joined from predictions that help parse occlusions and adapt to hand–object interactions. Sending multiple synchronized images from active perception provides complete information about the objects of interest in the scene, avoiding misses due to inter-frame motion and allowing accurate depth perception.
DeepSORT (Deep Simple Online and Real-time Tracker) [
42] is an advanced object-tracking algorithm that enhances the original SORT (Simple Online and Real-time Tracker) by integrating deep-learning-based appearance descriptors. Unlike SORT, which relies solely on the Kalman filter and motion information for tracking, DeepSORT introduces a deep appearance feature extractor based on a Convolutional Neural Network (CNN). This addition improves object association across frames, reducing identity switches and improving robustness in challenging scenarios such as occlusions and rapid motion. The tracker utilizes Mahalanobis distance and cosine similarity between deep feature embeddings to effectively associate detections with existing tracks.
The efficient tracking of moving objects and the continuity of tracking an object require information from previous detections; we use DeepSORT with YOLOv8 detections of humans, hands, and objects (using tracker descriptors from previous detections). DeepSORT helps with this process, assigning IDs to detected objects so that the previously identified objects have consistent IDs in subsequent frames. The synergy of these sensor types allows for tracking hands and objects with spatial precision in human–robot interactions, which is conducive to a wide range of downstream tasks, like action recognition and handover state estimation.
3.2. 3D Whole-Body Pose Tracking
To track the whole human body pose in our framework, we utilize an existing 3D whole-body pose estimation method, namely OSX [
15]. This method reconstructs a detailed 3D representation of the human body, including body, hands, and face, in a unified manner. The network follows a one-stage pipeline, directly regressing a parametric human body model from an input image. Unlike multi-stage approaches that separately estimate body and hand poses, this model employs a component-aware transformer to capture fine-grained interactions between different body parts. The architecture integrates the SMPL-X model, which represents the whole human body using shape and pose parameters, allowing seamless recovery of body components in a single pass.
The framework comprises a feature extraction backbone, a transformer-based attention module, and a regression head. The input image is passed through a CNN, which helps the model learn about spatial features. Then, we pass these features to a component-aware transformer, which learns long-range dependencies and intercomponent relationships between the body, hands, and face. Transformers have been applied to the coordinate-based representation in our model to invest an additional layer of attention in the head generation process, allowing more focused modeling. The predicted output consists of the SMPL-X [
26] parameters, which define the global body pose
, shape
, hand articulation, and facial expression coefficients.
During inference, the model takes an RGB image as input and directly outputs the 3D human mesh along with articulated hand and face poses. A component-aware transformer processes the input efficiently to refine predictions, making the method robust to occlusions and changing body poses. We stick to the existing pose estimation approach, but our implementation in the person detection module is the key difference. The original framework uses YOLOv5 [
43] to detect the human region of interest before estimating the pose. In contrast, we integrate YOLOv8 [
7], which provides superior accuracy and faster inference speeds. YOLOv8 has an improved backbone with more profound and efficient convolutional layers, enabling better feature extraction and detection performance.
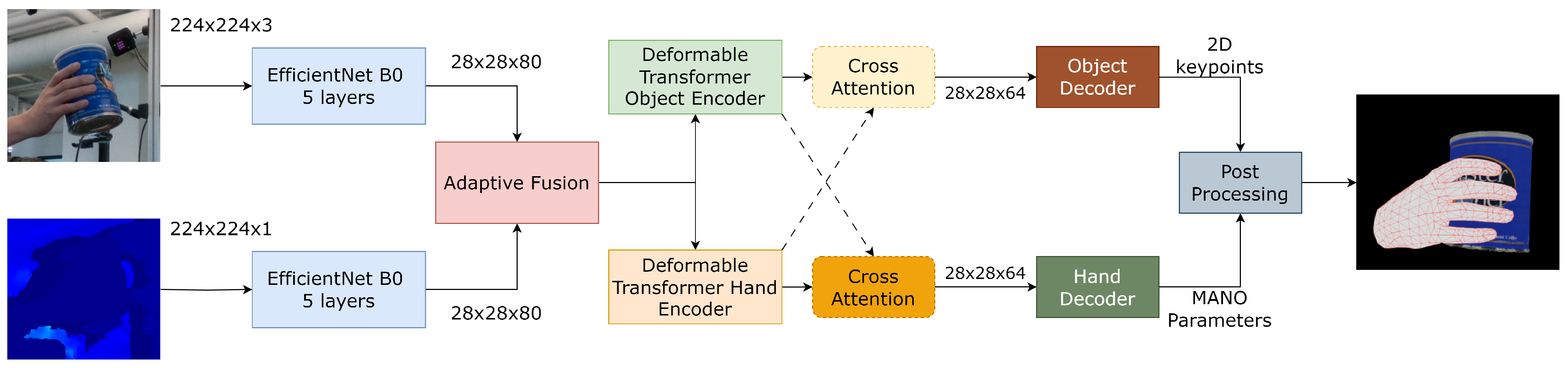
3.3. Unified Hand–Object Pose Estimation
We first detect the hand-held object using the YOLOv8 [
7] architecture for estimating the pose of the hand–object. After detecting the hand and the object, we crop the respective regions from both the RGB and aligned depth images of size
and
, respectively. These cropped regions, which include the hand and object, are then processed using two distinct streams for feature extraction. In the first stream, we pass the RGB image through the EfficientNet-B0 [
44] architecture to extract hand–object features, while in the second stream, the aligned depth image is processed to extract hand–object features. Both streams operate independently to capture unique information from each modality. The output features from both the RGB and depth streams are then forwarded to an adaptive attention fusion model. This model performs feature fusion to combine the features extracted from both streams, producing a unified representation.
Then, the adaptive attention fusion output is fed to two independent deformable transformer encoders. These encoders improve feature maps by encoding spatial relationships and pose details. We utilize a cross-attention mechanism to model the interaction behavior between hand and object. This motivates cross-attention to enable a feature set to attend to another feature set, which further encodes hand–object dependencies. Finally, focused features are fed into respective decoders. The decoder for the hand regresses the MANO [
41] hand parameters, while the decoder for the object regresses the object keypoints, enabling accurate pose estimation for both the hand and the object. The overall process is illustrated in
Figure 3.
3.3.1. EfficientNet-B0 Architecture
EfficientNet-B0 [
44] is a highly efficient Convolutional Neural Network (CNN) model that balances the trade-off between accuracy and computational efficiency. It is part of the EfficientNet family, which uses a compound scaling method to improve model performance without excessive computational cost. EfficientNet-B0 is designed to be lightweight while achieving state-of-the-art performance on various image classification tasks. The input RGB image of size
is passed through the network, and after six stages of convolutional and pooling layers the output feature map has a size of
. Each stage in the architecture consists of a series of operations, including convolution, batch normalization, activation functions, and pooling layers. Using depth-wise separable convolutions helps reduce the number of parameters and computational costs compared to traditional convolutions. The layer information is mentioned in
Table 1. We follow a procedure similar to that for depth image processing for the RGB image. The input depth image of size
is forwarded through the EfficientNet-B0 network to extract meaningful features. This process is performed independently from the RGB stream, allowing the depth information to be used to understand the scene comprehensively. The sample feature output from the EfficientNet for the RGB stream and the depth stream is illustrated in
Figure 4. From this, we can clearly understand that features extracted from these two images are different but highly related to the hand–object region. The feature map size is
for visualization purpose in the figure; we resized this to
. This process leverages the depth image to enhance spatial understanding, contributing to more accurate hand–object pose estimations by providing additional context from depth information.
Table 1 summarizes the key layers and their properties with parameters in EfficientNet-B0:
Conv1: The initial convolutional layer takes the input image of size and reduces the spatial dimensions by a factor of 2, resulting in an output size of . This layer uses a kernel.
MBConv Layers: These are the depthwise separable convolutions (MBConv), which help reduce the number of parameters and computations. Each MBConv block consists of a depthwise convolution followed by a pointwise convolution. The sizes of the output feature maps progressively decrease, with the last MBConv layer outputting a feature map of size .
3.3.2. Adaptive Attention Fusion Mechanism
From
Figure 4, we observe that the extracted features from the two different input streams are distinct and relative. These features can be fused in various ways. A straightforward approach is to combine both the RGB and depth feature maps directly. However, this method may result in information loss or the addition of redundant information. To address this, we learn an adaptive attention parameter that allows the network to adjust dynamically, capturing both features effectively based on this parameter. The output feature maps from the two EfficientNet-B0 [
44] streams, each of size
(one for the RGB input and one for the depth input), are forwarded to the Adaptive Attention Fusion (AAF) mechanism. The main task of AAF is to fuse the features of both streams in a meaningful way, for which attention-based methods are used to select and combine the features while preserving spatial information that carries relevant information about modality correlation. The proposed adaptive fusion mechanism aims to learn the correlation between RGB and depth modalities, which allows for assigning different attention weights to RGB and depth inputs, leading to better performance. This enables the system to prioritize the more informative parts of each feature map, resulting in a more refined and complementary representation of the scene.
Given the feature maps
and
from the two streams, the fusion process can be mathematically formulated as:
where:
and are the feature maps from the RGB and depth streams, respectively.
and represent the attention maps for the RGB and depth feature maps, which are learned during the fusion process.
is the final fused feature map, which combines the information from both modalities.
The attention maps and are generated by applying a lightweight attention mechanism to the respective feature maps. The attention maps focus on the spatial locations and channels that contain the most essential information for downstream tasks. We use a simple, yet effective attention mechanism based on channel and spatial attention to generate the attention maps. Spatial attention learns to focus on critical spatial regions in the feature maps, while channel attention captures the most informative channels. Both attention mechanisms are combined to produce a final attention map for each stream.
The channel attention map
is obtained by performing a global average pooling operation on the feature map and passing it through a lightweight, fully connected layer. This allows the model to assign higher weights to more informative channels.
where:
denotes the feature map at spatial location ,
is the weight matrix for the fully connected layer,
is the sigmoid activation function,
H and W are the height and width of the feature map.
The spatial attention map
is computed by applying convolutional operations over the entire feature map. This allows the model to focus on important spatial regions.
where Conv refers to a convolutional operation applied to the feature map
.
The final attention map for each modality is the product of the spatial and channel attention maps:
where ⊙ denotes the element-wise multiplication.
Once the attention maps
and
are computed, the fusion process blends the features from both streams according to their importance, as defined by the attention weights. The final fused feature map
is then used as the input for subsequent tasks, such as hand–object pose estimation or action recognition.
This results in a feature map incorporating the most relevant information from the RGB and depth streams, enabling better performance in downstream tasks.
3.3.3. Deformable Transformer Encoder Network (DTEN)
After six layers, the output feature map from EfficientNet-B0 [
44] has a spatial resolution of
, with 80 channels. This feature map is forwarded to a
DTEN, where the deformable transformer encoder idea is considered from ref. [
45] to enhance spatial adaptability and focus on relevant regions with learnable sampling offsets.
Before passing the feature map to the DTEN, the following steps are applied:
The DTEN consists of multiple layers, each performing Deformable Multi-Head Attention (DMHA) [
45], followed by a Feedforward Network (FFN).
3.3.4. Deformable Multi-Head Attention (DMHA)
Instead of attending to all pixels globally (as in a standard transformer), DMHA selectively samples relevant key locations using learned offsets.
For a given query position
, attention is computed as:
where
M = number of attention heads,
K = number of sampled key points per head,
= learnable offsets for adaptive spatial sampling, and
= learned attention weights. This mechanism ensures that the network focuses only on important spatial regions without computational overhead from full self-attention. After deformable attention, a position-wise feedforward network is applied to enhance feature extraction:
where
and
are learnable weight matrices. After multiple layers of deformable attention and feedforward transformations, the final output has the same spatial resolution but a different feature dimension (e.g.,
).
Table 2 summarizes the integration of EfficientNet-B0 with the deformable transformer.
We improve spatial adaptability by integrating DETN with
EfficientNet-B0 [
44] and ensure efficient feature extraction. The learned sampling offsets allow the model to focus on significant regions, making it highly effective for
human–object interaction tasks.
3.3.5. Cross Attention Mechanism for Hand–Object Interaction
After obtaining the refined hand and object features from their respective DTENs, we apply a cross-attention mechanism [
46] to learn dependencies and interactions between the hand and the object features. This step is crucial for accurately capturing the spatial and semantic relationships that define human–object interactions. To establish interdependencies between hand and object features, we compute the cross-attention mechanism, which involves projecting both feature sets into query (
), key (
), and value (
) representations. The overall process of cross attention is illustrated in
Figure 5. The cross-attention score between the hand (
H) and object (
O) features is computed using a scaled dot-product attention mechanism:
The final attended feature maps are computed as follows:
where
is the refined hand feature after attending to object features and
is the refined object feature after attending to hand features. The residual connections preserve the original features while enhancing them with contextual information from the cross-attention mechanism.
3.3.6. Hand Decoder
The output from the cross-attention module of size
is forwarded to the hand decoder to estimate 2D heatmaps of finger joints and subsequently refine them using a mesh regression network similar to [
35]. The complete pipeline consists of two networks: a lightweight Hourglass Network [
20] to predict 2D heatmaps of finger joints and a Mesh Regression Network that refines hand pose and shape parameters using the MANO [
41] model.
The Hourglass Network is a symmetric encoder–decoder architecture designed for keypoint detection. Given an input feature map
, the network produces a set of 2D heatmaps
, where each channel represents a specific joint.
Table 3 describes the layers in the Hourglass Network:
After obtaining the 2D heatmaps from the Hourglass Network, the intermediate feature representations from the network are concatenated with the predicted heatmaps and forwarded to the Mesh Regression Network. The combined feature representation is processed through a series of fully connected layers to regress the hand pose and shape parameters. Specifically, the network predicts the pose parameters
, which define the joint rotations, and the shape parameters
, which capture the overall hand shape variations. Once the pose and shape parameters are estimated, they are used as inputs to the MANO model, a differentiable parametric hand model. The MANO model maps these parameters to a set of 3D hand mesh vertices
and corresponding 3D joint locations
, where
. This transformation is formally represented as:
where
denotes the differentiable function of the MANO model. By leveraging both learned deep features and a parametric hand model, the proposed architecture ensures robust and accurate estimation of hand structure in 3D space.
3.3.7. Object Decoder
To estimate the 6D object pose, we employ a decoding architecture similar to the method proposed in [
35]. The object decoder takes as input the attended feature representation of size
obtained after cross-attention and forwards it through a six-layered convolution to regress the object keypoints and confidence scores. These features are then forwarded to the PnP [
29] algorithm to obtain a 6D object pose.
3.3.8. Overall Loss Function
The total loss function, denoted as
, is formulated as the sum of the hand pose estimation loss
and the object pose estimation loss
:
The hand loss function
is defined as:
where
represents the L2 loss applied to the predicted 2D hand joint locations.
corresponds to the L2 loss imposed on the estimated 3D joint positions
J and hand mesh vertices
V.
denotes the L2 loss on the MANO [
41] model parameters, specifically the shape parameter
and pose parameter
.
,
, and
are weighting coefficients that regulate the contribution of each loss term.
Similarly, the object loss function
is given by:
where
is the L1 loss applied to the predicted 2D cuboid keypoints.
represents the confidence loss imposed on the cuboid predictions.
and
are coefficients balancing the impact of the respective loss terms. These loss functions collectively ensure that the network learns both hand and object pose estimations while maintaining consistency between 2D and 3D representations.
Figure 6 illustrates the outputs via a flow chart from the hand decoder and the object decoder.
3.4. Skeleton-Based Action Recognition
Building on the previous subsections, where we extracted 3D whole-body poses and unified hand–object pose estimation, we now utilize this comprehensive information to recognize actions essential for human–robot interaction, such as object handover. In our earlier research [
18], we developed a method for action recognition using skeletal data, a key component for seamless human–robot interaction. That study introduced a self-attention mechanism to enhance action recognition models, moving beyond traditional Recurrent Neural Networks (RNNs) to improve feature extraction and sequence modeling, resulting in more accurate and efficient predictions. Expanding on this initial work, we now refine our approach by incorporating hand and object pose information, leading to more precise action recognition for interactive robotic applications.
The whole-body pose estimation provides a continuous stream of data. In contrast, hand–object pose estimation is intermittent, activated only when an object is in proximity to or being held by the hand. We employ a two-stream action recognition framework with late-stage fusion to handle this variability in data availability. This approach allows us to integrate the continuous body pose data from the first stream with the intermittent hand–object pose data from the second stream, combining them at a later stage to enhance action recognition accuracy while accommodating the varying availability of the input streams. In this two-stream action recognition framework, we utilize two types of data, as given below; the motivation is to achieve higher accuracy in action recognition. The first stream is always available and contains full-body human skeleton data of the person, giving an overview of a person moving from one position to another. The second stream incorporates hand–object pose data, which, while valuable for recognizing more complex interactions, may sometimes be missing or unavailable. The challenge is that specific actions, such as waving or crossing hands, can be effectively recognized using only the whole-body skeleton data from Stream 1. However, more complex actions, like handovers or placing objects, require the additional context provided by the hand–object pose data in Stream 2. This interaction is a dynamic dependency between the data streams, where one could be complete while the other may or may not be as evident.
We add Kalman filter tracking once the hand–object interaction is detected to enhance the hand–object pose estimation further. The Kalman filter is used to predict and smooth the estimated 6D pose of the hand object, improving the robustness and stability of the tracking over time. Once the hand–object pose is initially detected, the Kalman filter helps by continuously estimating the object’s position and orientation, even in the presence of noise or missing data. It considers previous pose estimates and new hand–object pose detection module measurements. Enabling real-time tracking from this means the system should be resilient against these intermittent occlusions or variations in the pose data.
In this action recognition framework, we define two sets of actions based on the availability of the data streams. Stream 1 provides continuous whole-body human skeleton data, including hand poses, which is always available. Stream 2 offers hand–object pose data but is not always available, as it is only activated when an object is in hand or proximity. Based on this, we can classify actions into two categories. If Stream 2 (hand–object pose data) is unavailable, the system defaults to recognizing actions from the first table, which relies only on the human skeleton data. These actions include basic gestures and body movements, such as waving, walking towards the robot, and pointing at an object.
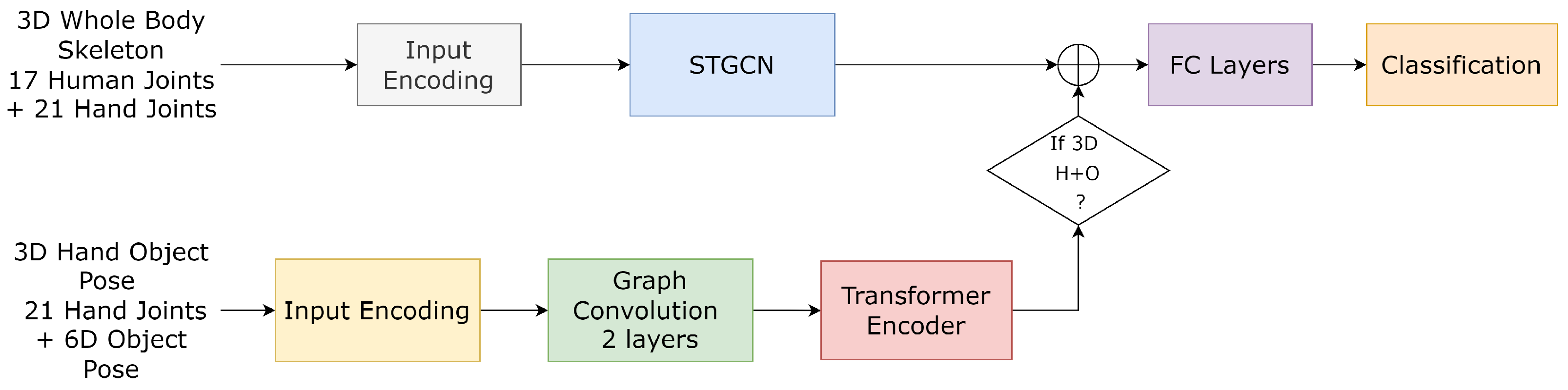
To address this challenge, we propose a two-stream network for action recognition. The first stream processes the 3D whole-body human skeleton data, including hand joints, using the well-known ST-GCN (Spatio-Temporal Graph Convolutional Network) [
47] architecture to extract spatial and temporal features. The second stream encodes the 3D hand pose and 6D object pose using two graph convolutional layers, which capture the spatial relationships between hand joints and the object. The encoded features from this second stream are then passed through a Transformer Encoder, as presented in our previous work [
18], to model the temporal dependencies and refine the action representations. The block illustrated is presented in
Figure 7.
Suppose the 3D hand and object pose data are available. In that case, we fuse the outputs from both streams and forward the combined feature representation to a series of three fully connected layers, interspersed with normalization and activation functions, to recognize the action. In cases where the 3D hand–object pose estimation is missing, we inject zero vectors into the second stream’s output and pass the modified features from the first stream through the fully connected layers to detect the action, ensuring robust performance even when some input data are absent. To train the network, we use the cross-entropy loss given by:
where
N is the number of classes,
is the true label (one-hot encoded vector),
is the predicted probability for class
i, and
is the total loss. This loss function measures the difference between the predicted class probabilities (
) and the true class labels (
y), and it is minimized during training to improve the model’s performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}