1. Introduction
Sensori-Motor Contingencies (SMCs) are the relations between the actions we perform and the perceptual consequences we experience. They enable us to adjust and refine our behaviors based on the sensory feedback we receive from our actions on the environment. For example, when we grasp an object, we use visual feedback to evaluate the success or failure of our motor action [
1]. By perceiving and understanding these contingencies, we develop a sense of agency and the ability to predict and control our environment.
SMCs are essential for the development of motor skills [
2], for the coordination of movements [
3], and for the formation of our perceptual experiences [
4], by providing a fundamental framework for our interactions with the world around us.
The paradigm of SMCs has also been applied in robotics, to build robots that can interact with real environments without explicit programming but relying on autonomous emerging behaviors. In [
5], the authors use SMCs to create a computational Markov model of visual perception that incorporates actions as an integral part of the perceptual process. This approach is extended in [
6] to loco-manipulation tasks, showing a link between prediction and evaluation of future events through SMCs. The main idea is to record the temporal order of SMC activations and to maintain it in a network of linked SMCs. This results in a two-layer structure with sequences of action-observation pairs forming SMCs and sequences of SMCs forming a network that can be used for predictions. The same Markov model is applied in [
7] to guide the development of walking algorithms, where robots rely on the predicted sensory consequences of their motor commands to adapt their gait and terrain. Moreover, SMCs can also inform the design of interaction algorithms, enabling robots to interact with humans and the environment in a more natural and intuitive way [
8]. When robot control is based on SMCs, the robot’s adaptation to its environment is mainly driven by its own experiences.
The SMCs concept can be related to the notion of affordances, introduced by Gibson in 1979 [
9], which highlights humans’ capacity to perceive the environment without the need for internal representation [
10]. In robotics, affordances connect recognizing a target object with identifying feasible actions and assessing effects for task replicability [
11]. Recent approaches, like [
12,
13], view affordances as using symbolic representations from sensory-motor experiences. Affordances play a crucial role as intermediaries organizing diverse perceptions into manageable representations that facilitate reasoning processes, ultimately enhancing task generalization [
14]. Challenges in robotics affordances include ambiguity, lack of datasets, absence of standardized metrics, and unclear applicability across contexts, with persistent ambiguities in generalizing relationships adding complexity to the field [
15].
While affordances in robotics provide a framework for understanding how robots perceive and interact with their environment, identifying actionable opportunities, the challenge of considering temporal causality in sensorimotor interactions remains: actions are not simultaneous neither to their sensory consequences nor to their sensory causes. To manage this asynchronicity, one must develop strategies that enable robots to manage these delays [
16]. This necessitates creating models that, either explicitly or implicitly, anticipate the future states of the environment based on current actions and perceptions, allowing robots to adjust their behavior proactively rather than reactively. Such models could involve learning from past experiences to forecast immediate sensory outcomes, thereby compensating for the temporal gap between action execution and sensory feedback with experience.
Another family of approaches aiming to enable an agent to learn a behavior through interactions with the environment is that of optimization and reinforcement learning (RL). Such approaches demonstrated proficiency in complex tasks such as that of manipulating elastic rods [
17] by leveraging parameterized regression features for shape representation and an auto-tuning algorithm for real-time control adjustments. Additionally, more recent approaches, such as [
18], leverage visual foundation models to augment robot manipulation and motion planning capabilities. Among those works, several reinforcement learning approaches leverage the SMC theory [
19]. The goal of RL is to build agents that develop a strategy (or policy) to take sequential decisions in order to maximize a cumulative reward signal. This can resemble the trial-and-error learning process demonstrated by humans and animals, where agents interact with an environment, receive sensory inputs, and take actions. In sensorimotor control, reinforcement learning (RL) involves an agent interacting with its environment, perceiving sensory information, and selecting actions to maximize cumulative rewards [
20,
21]. The goal is for the agent to learn a policy that maps sensory observations to actions, enhancing its performance over time. High-dimensional continuous ssensors and action spaces, as encountered in real-world scenarios, pose significant challenges for conventional RL algorithms [
22]. Focusing computations on relevant sensory elements, similar to biological attention mechanisms [
23], can address this issue.
Learning From Demonstration (LfD) is another approach that complements sensorimotor control, affordances and RL. LfD enhances robot capabilities by capturing human demonstrations, extracting relevant features and behavior information to establish a connection between object features and the affordance relation, and subsequently replicating it in the robot [
24,
25]. LfD enables agents to learn from experts, leveraging their insights into desired behaviors and actions. This integration of LfD into RL accelerates learning, benefiting from expert guidance for more efficient skill acquisition. In specific application domains [
26,
27,
28], Learning from Demonstration (LfD) has successfully taught robots a variety of tasks. These tasks include manipulating deformable planar objects [
29], complex actions like pushing, grasping, and stacking [
30,
31], autonomous ground and aerial navigation [
32,
33,
34], and locomotion for both bipedal and quadrupedal robots [
35]. It is important to note that these works assume the human operator to be an expert in the field. LfD seeks to enable robots to learn from end-user demonstrations, mirroring human learning abilities [
36]. This connection potentially links LfD back to Sensorimotor Control (SMC).
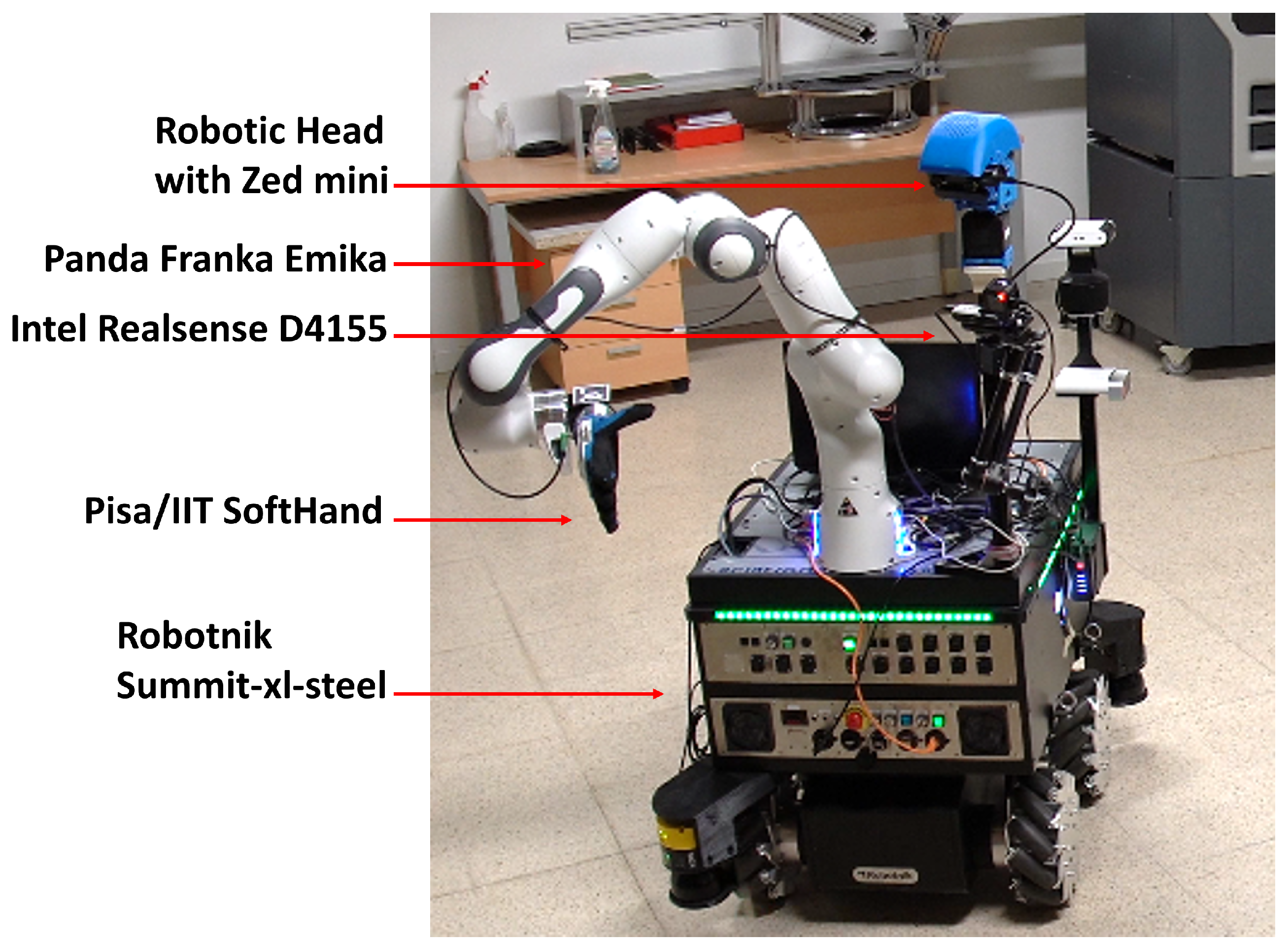
This paper aims to establish a unified framework for programming a robot through learning multiple Sensory-Motor Contingencies from human demonstrations. We adapt the concept of identifying relevant perceptions in a given context from SMC literature [
37], and propose the detection of salient phases in the Sensory-Motor Trace (SMT) to create a sensor space metric. This metric allows the agent to evaluate the robot and environment to recognize contingent SMTs from its memory. Subsequently, we utilize Learning from Demonstration techniques to abstract and generalize memorized action patterns to adapt to new environmental conditions. This process enables the extraction of SMCs, representing the relationships between actions and sensory changes in a sequential map—or tree—based on past observations and actions. The introduction of saliency, a sensor space metric, and of the tree allows us to manage the delay between action and perception that occurs in the recording of SMTs. This enables the robot to anticipate and adapt to delays by recognizing and reacting to patterns in the SMTs, facilitating a more timely and adaptive response to dynamic environmental changes. The framework’s versatility is demonstrated through experimental tests on various robotic systems and real tasks, including a 7-dof collaborative robot with a gripper and a mobile manipulator with an anthropomorphic end effector.
The main contributions of this work are outlined as follows:
We devise an algorithm to extract the contingent space-time relations intercuring within intertwined streams of actions and perceptions in the form of a tree of sensorimotor contingencies (SMC).
The algorithm is based on the introduction of an attention mechanism that helps in identifying salient features within Sensori-Motor Traces (SMTs). This mechanism aids in segmenting continuous streams of sensory and motor data into meaningful fragments, thereby enhancing learning and decision-making processes.
Moreover, the algorithm leverages the introduction of suitable metrics to assess the relationship between different SMTs and between an SMT and the current context. These metrics are crucial for understanding how actions relate to sensory feedback and how these relationships adapt to new contexts.
The underlying implicit representation is encoded in a tree structure, which organizes the SMCs in a manner that reflects their contingent relationships. This structured representation enables robots to navigate through the tree, identifying the most relevant SMTs based on the current context, thereby facilitating decision-making across diverse scenarios.
The versatility and adaptability of the framework are demonstrated through its integration into various robotic platforms, including a 7-degree-of-freedom collaborative robotic arm and a mobile manipulator. This adaptability underscores the potential for applying the proposed methods across a wide spectrum of robotic applications.
2. Problem Statement
A robot
, with sensors
, operates in a dynamic environment
. The state of the robot and the environment at time
t are fully described by vectors
and
, respectively. These states evolve according to:
where
is the control input for robot
, and
models any exogenous action on environment
. The sensors measure perception signals
that depend on both states.
Assume an autonomous agent can control robot
to successfully execute
m tasks in the environment
. This agent behaves consistently with the SMC-hypothesis [
38], meaning it performs tasks by connecting contingent actions and perceptions. This behavior is typical in humans [
2] and is assumed to extend to humans tele-operating a robot. Suppose now to register
n SMTs corresponding to
tasks executed by the robot. We define each Sensori-Motor Trace (SMT) as
where
and
are the SMT starting and finishing time, respectively,
is the stream of actions commanded to the robot, and
is the stream of perceptions recorded by the sensors.
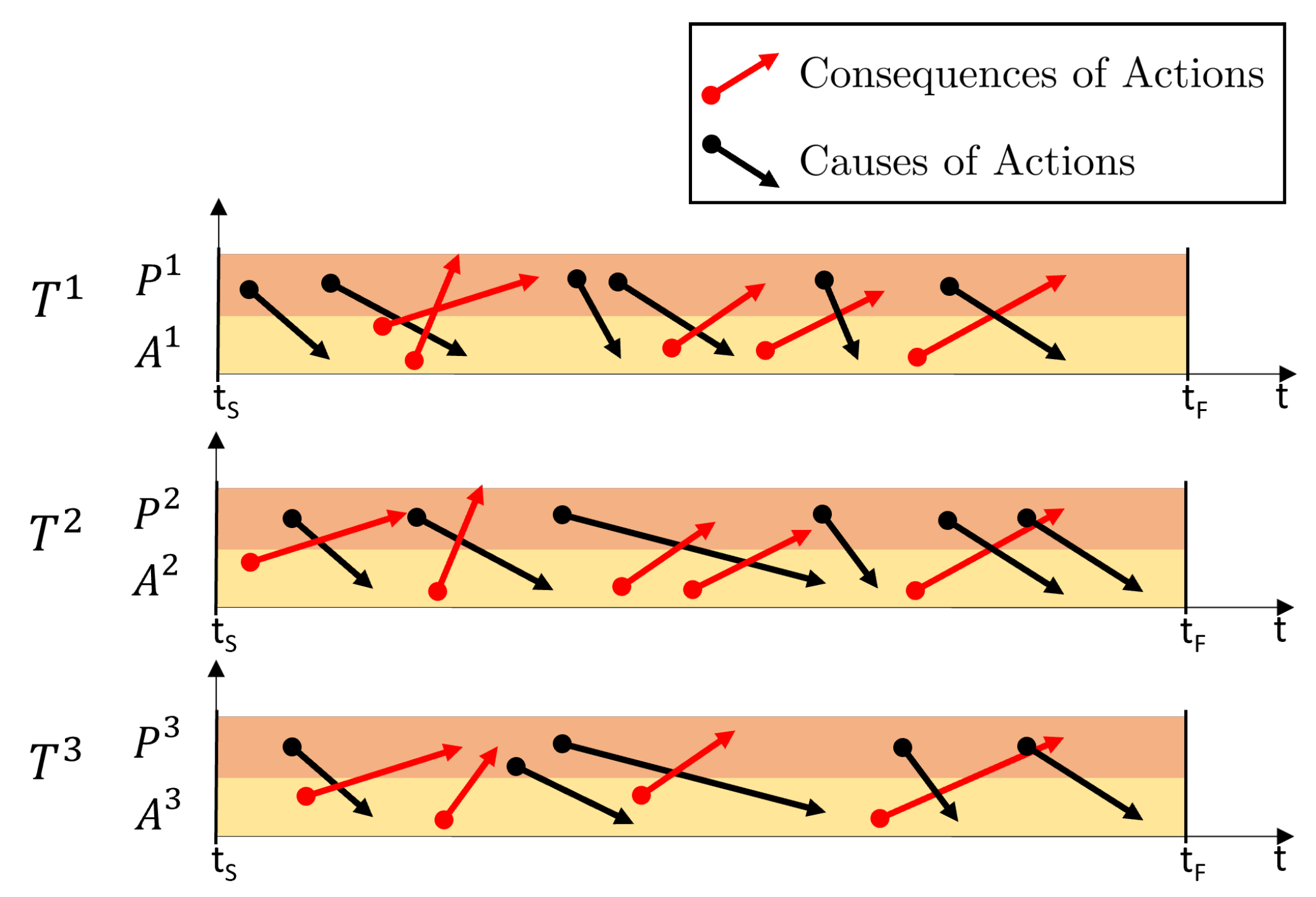
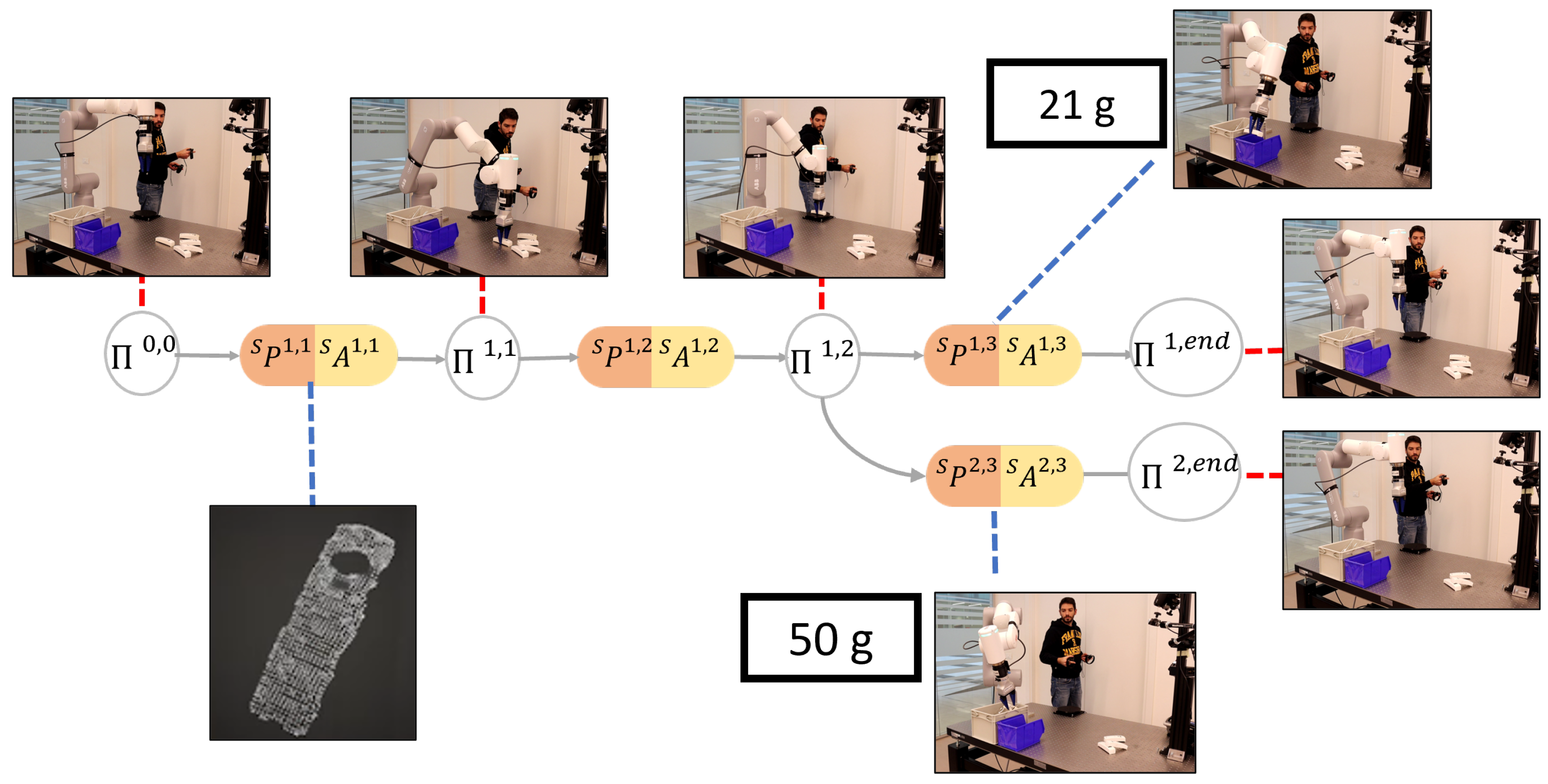
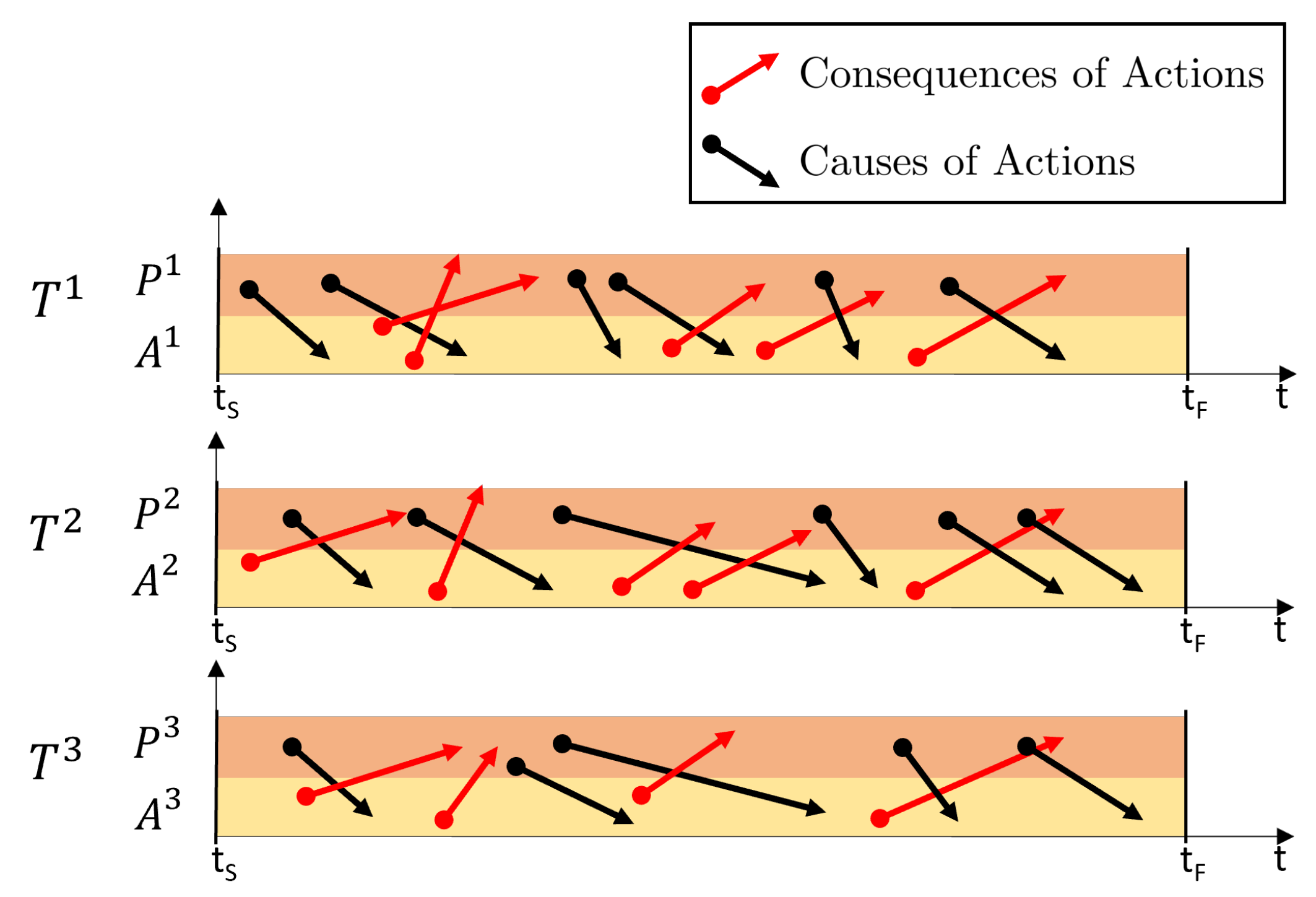
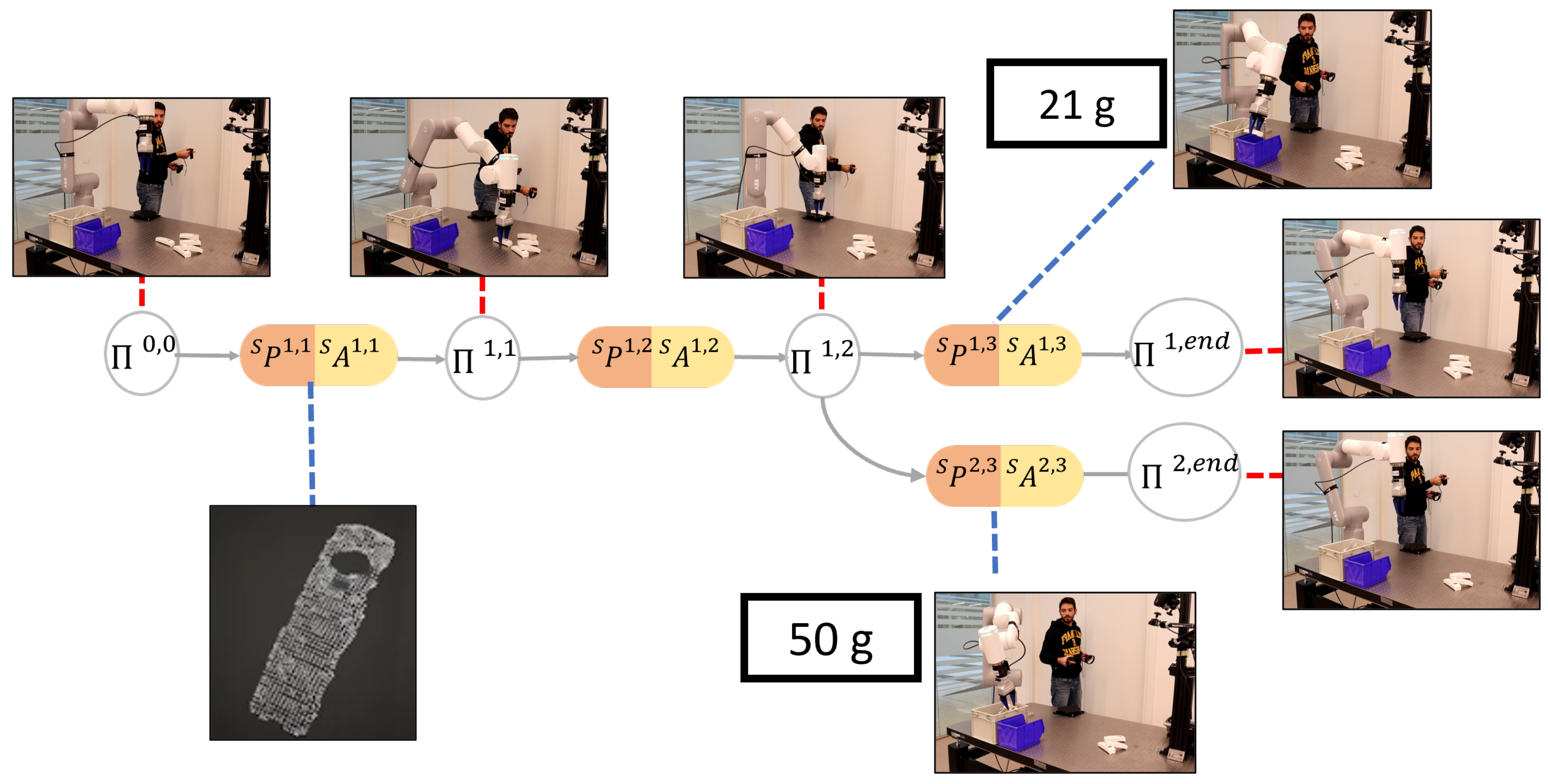
It is important to state that a core aspect of the problem is that of modeling and managing the temporal causality relations that regulate sensorimotor interactions (see
Figure 1). However, based on our previous assumptions, we claim that the specifications of the
m tasks are fully encoded in the
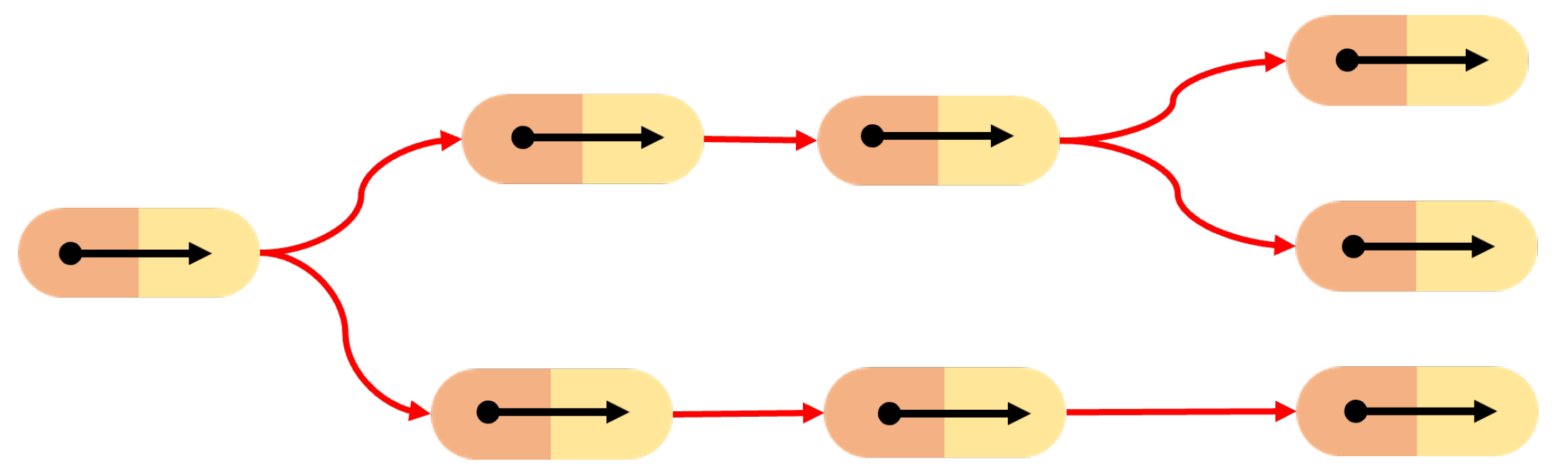
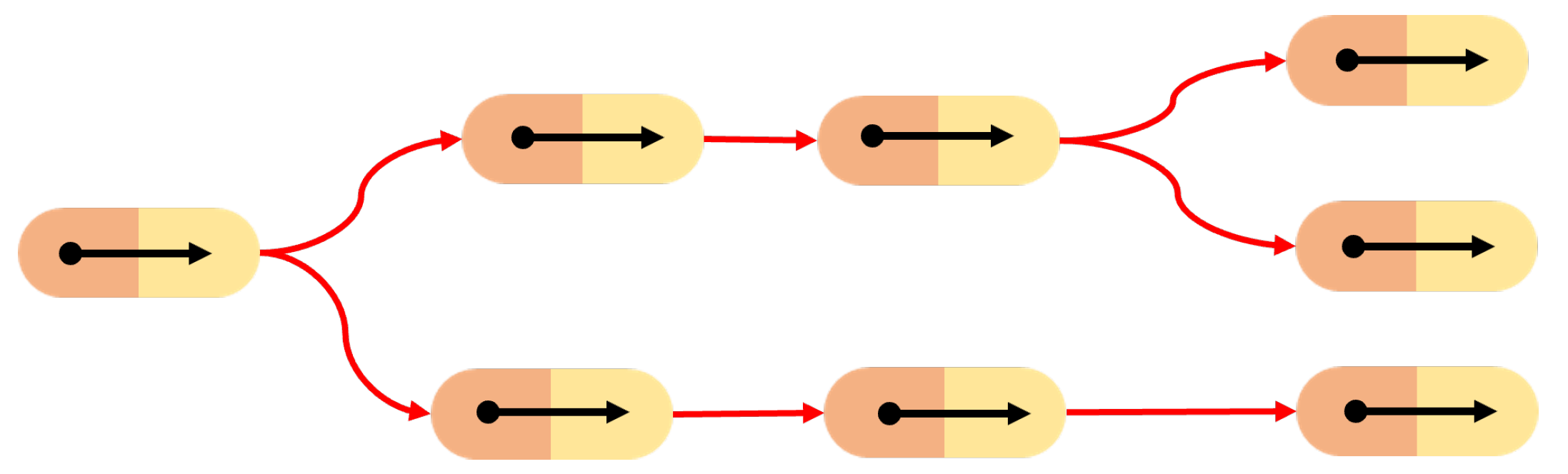
n SMTs; therefore, our aim is to devise an algorithm to abstract the SMCs underlying the recorded SMTs, i.e., to devise a representation that models (i) which perceptions cause a given action (and its modality), and (ii) what are the consequences that can be expected when a given action is undertaken, i.e., that models the contingency relations between perceptions and actions. This SMC-based representation (see
Figure 2) allows the robot to anticipate the future states based on current actions and perceptions in order to autonomously operate in novel, yet similar, contexts replicating the
m tasks.
This problem is inherently complex for several reasons. Firstly, SMTs involve numerous continuous signals, necessitating the creation of a robust strategy to effectively handle the wealth of information associated with these signals while efficiently managing memory resources. Additionally, new contexts are unlikely to be exact duplicates of memorized SMTs. Consequently, the robot must possess the capability to assess the dissimilarities between different contexts and generalize the action component of the contingent sensorimotor trace to accommodate variations in the task arising from differences in the context itself. Merely reproducing memorized actions would be insufficient and impractical. Our objective requires that the robot (i) perceives the context in which it operates, (ii) identifies the matching SMC for that context, and (iii) acts accordingly within the current context based on the identified SMC.
3. Proposed Solution
When looking for SMCs, we aim to identify consistent causal relations between actions, perceptions, and given contexts. Therefore, to formulate a definition of SMC, it is necessary to formally define what is a context.
Building on Maye and Engel’s discrete history-based approach [
5], we define the context of the robot–environment interaction at a given time
as the historical record of all robot perceptions and actions starting from an initial time,
, expressed as:
It is important to note that while Equations (
5) and (
2) may seem similar, they differ significantly. Equation (
2) represents a fixed set of actions and perceptions recorded within a specific past interval, while Equation (
5) is dynamic, depending on the current time,
, and evolving over time.
Our method comprises several objectives, including (i) matching the present context with a memorized SMT, (ii) reproduce the behavior of the matched SMT, by (iii) adapting its actions to the current context, all based on (iv) a comparison between perceptions.
To accomplish this, our approach requires the introduction of the following components:
A metric to measure the distance between perceptions and actions ;
Contingency relations between SMTs, denoted as and between a context and a SMT, denoted as ;
An operation to adapt an action to a different context.
.
It is important to note that defining and evaluating metrics such as
,
,
,
, and the operation
M, can be a complex task, as they operate on functions of time defined over continuous intervals in multi-dimensional spaces. Our solution simplifies this challenge by identifying a discrete and finite set of instants, denoted as
(for an
i-th SMT and a
j-th instant), within each interval in both the perception and action spaces. This mechanism, which we refer to as
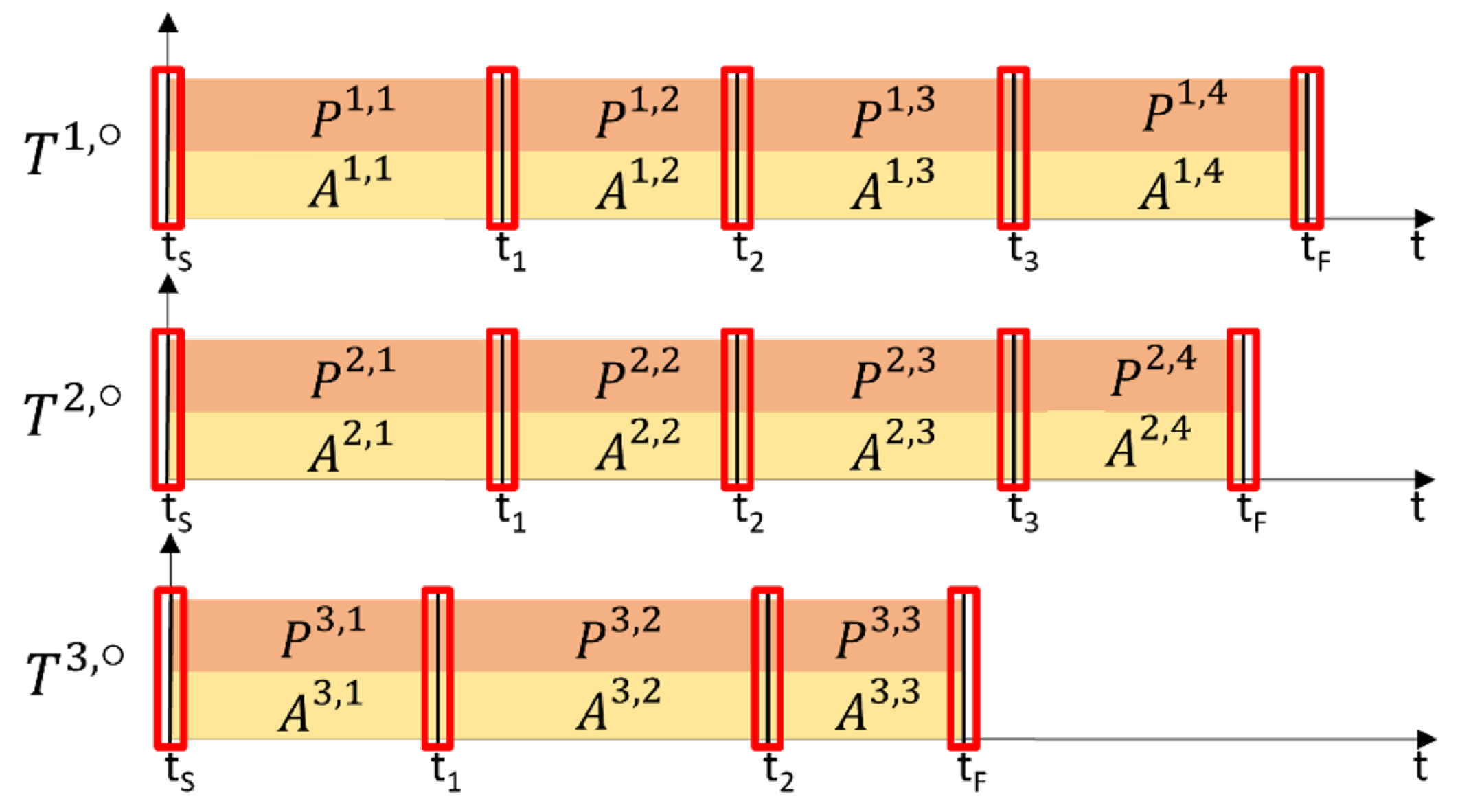
saliency, allows each SMT to be segmented into a sequence of
SMT fragments, defined as:
where most of the contingency relations between action and perception are concentrated, as illustrated in
Figure 3.
Given a spatial distance in the task space
, a distance between perceptions
, and a distance between actions
, the definition of a saliency let us introduce a
contingency relation between SMTs
, and a contingency relation between a context and an SMT
. Moreover, leveraging the tools of Dynamic Movement Primitives (DMPs) [
39], we defined a suitable
contingency map such that
. With these distances and mapping operations established in an accessible form, the notion of saliency facilitates the creation of a discrete tree structure that models causal relations by using a discrete history-based approach, similar to that in [
5]. In this tree, each directed edge corresponds to an SMC extracted from an SMT fragment, along with its saliency characterization, and nodes represent decision points. Given this SMC-tree, the system gains the ability to operate autonomously in new contexts by (i) comparing the current context with its memory using saliency, within the tree nodes to identify the best-matching SMC, and (ii) adapting the identified SMC to the present context. As we will see in the following sections, the introduction and definition of these metrics, essential for extracting salience and establishing contingency relationships, enable the system to handle various types of tasks effectively.
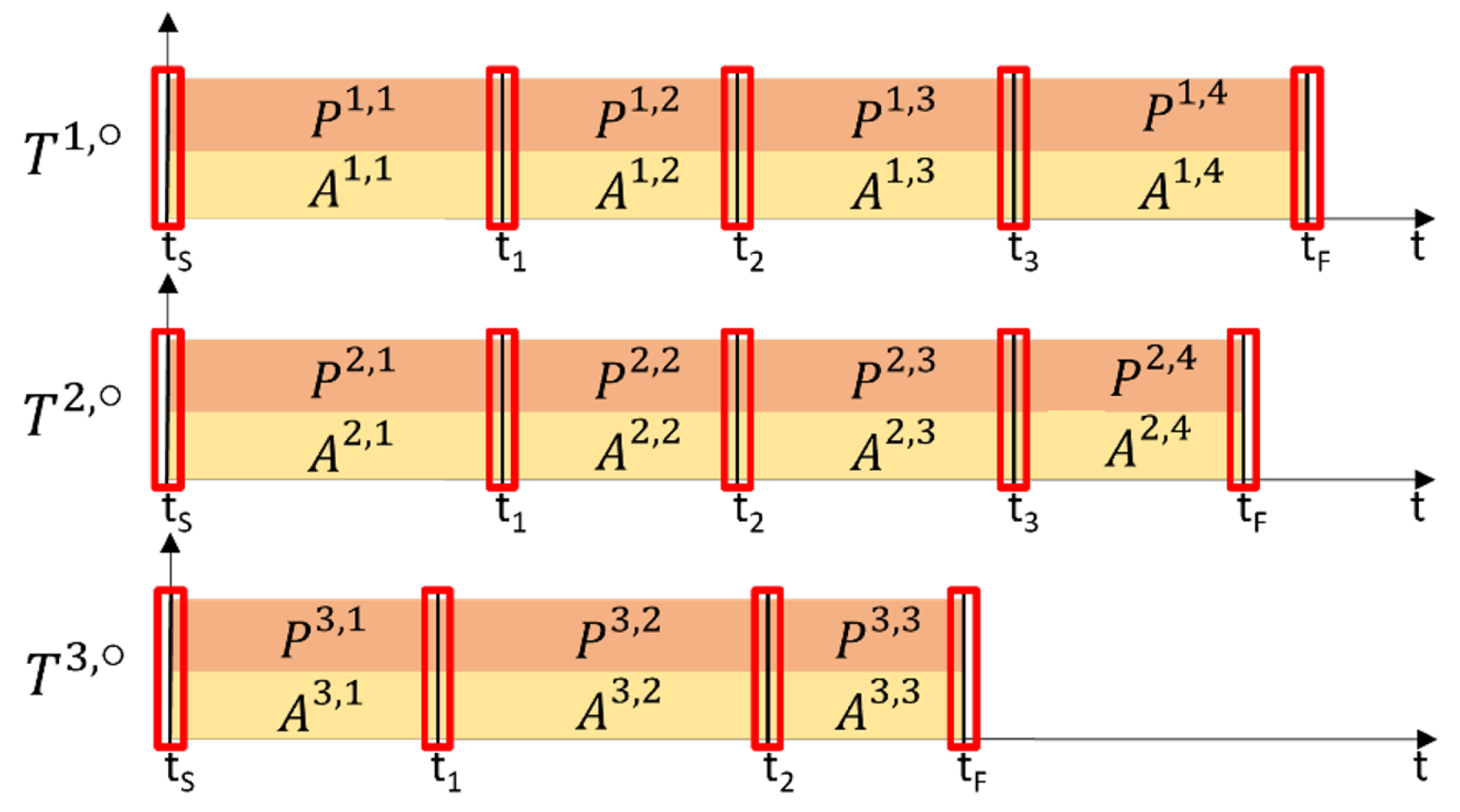
3.1. Temporal Saliency
In the work [
23], the authors propose incorporating an attention mechanism to expand upon their previously introduced discrete approach for handling continuous signals. This attention mechanism is what we refer to as a form of
temporal salience. It could be argued that temporal salience is inherent to SMTs themselves. The literature has offered various tools to enable artificial agents to extract temporal saliency from data. These techniques include Unsupervised Clustering [
40], which groups similar actions into clusters based on features like joint angles, end effector positions, and tool usage; Hidden Markov Models [
41], which identify distinct tasks in a sequence by modeling transitions between actions and estimating the probability of each task occurring; and Gaussian Mixture Models [
42], which are probabilistic models that recognize different tasks by estimating Gaussian distribution parameters for each task.
Alternatively, temporal saliency can be explicitly communicated by the operator, either through verbal or visual cues or by manual activation of a trigger. In our experiments, as described in the following sections, we combine both automatic and explicit processes for extracting temporal salience.
This approach results in the division of each SMT
into a collection of atomic SMT fragments, defined as:
where each
is simply the restriction of the SMT to the interval
.
By analogy, we refer to the perception and action components of each sub-task as and , respectively.
3.2. Spatial Saliency
To extract salient information for both perceptions and actions, we must identify the robot’s state during the recording of a SMT. This is achieved by considering a , which represents a point of interest for the robot. For instance, in the case of a robot’s end-effector, is a typical choice. For a mobile robot, its state is represented as .
The temporal evolution of is an integral part of the action stream recorded in the SMT.
As we will see in the following sections, particularly in the context of perceptions,
plays a pivotal role in narrowing the focus to perceptions in close proximity to the robot, as detailed in
Section 3.3.
On the other hand, when it comes to actions, this variable serves a dual purpose. Not only does it assist in extracting the saliency of actions, but it also facilitates their adaptation to new contexts, as explained in
Section 3.4.
3.3. Perception Saliency and Inter-Perception Distance
To provide a comprehensive introduction to the concept of perception saliency, it is essential to begin by categorizing perceptions. In the field of robotics, many types of sensors find common uses, including optical sensors like cameras, LiDAR, and depth sensors, as well as force sensors such as load cells, torque sensors, and tactile sensors. Additionally, distance sensors like ultrasonic, infrared, and LIDAR, as well as temperature and proximity sensors, play vital roles. Each of these sensors generates distinct types of raw data, ranging from images to scalar values and point clouds, and each offers a unique perspective on either the environment or the robot itself. This diversity necessitates a structured approach to organize and enhance the saliency process.
Within the realm of sensory perception, two fundamental categories emerge: intrinsic and extrinsic perceptions. Intrinsic perception entails using a sensor to gain insights into the properties of the sensor itself, while extrinsic perception involves employing the sensor to understand the properties of the surrounding environment.
A simple intrinsic (SI) perceptual signal
is a perceptual signal that admit a (sensorial perception) distance function
Note that here and in the following, the right superscript does not indicate a power, it is an index. Examples of simple intrinsic perceptual signal are, e.g., an environmental temperature sensor that measures the temperature in Kelvin degrees, for which
and
or the joint torques vector of a robot
, which can use the distance defined, e.g., by the
-norm:
A simple extrinsic or localized (SL) perceptual signal
, instead, is defined as a pair of an intrinsic perception and a location
Since simple localized perceptions contain intrinsic perception, they must admit a sensorial perception distance function too
and, due to the location, a spatial distance function
Examples of localized signals are the triangulated echo of an object sensed through a sonar sensor, or a segmented point-cloud extracted from the image of a depth camera. This type of perception (SL) can also be multiple, ML, when it does not assume a unique value but a set of values simultaneously. We define a multiple localized perceptual signal as a finite set of variable size of localized perceptual signal, that is
which admit a sensorial perception distance
where
in Equation (
15) represents the intrinsic perceptions part of
.
After outlining the various types of perceptions, we employ this classification to define a distinct salient sub-set for each sub-task
This is achieved by applying the following rules for extracting perception saliency:
- (a)
Given a simple intrinsic perception
or a set of intrinsic perceptions
, all the intrinsic perceptions are considered candidate
- (b)
Given a simple localized perception
where
is an appropriate threshold value for a specific sensor.
- (c)
Given a set of simple localized perceptions
where
- (d)
Given a multiple localized perception
where
- (e)
Given a set of multiple localized perception
where
r denotes the elements number of , that could be different for each multiple perception.
In general, the perceptions within each SMT fragment, denoted as , encompass a mix of different perceptions falling into three distinct categories (SI, SL, and ML). Consequently, the previously mentioned rules are applied to the relevant type of perception under consideration.
The outcome of the perception saliency process is the generation of a sequential set of salient perceptions , for each SMT fragment .
Lastly, the computation of the inter-perception distance
, between two sets of sub-task perceptions,
and
, which must contain the same number and types of perceptions, is facilitated through their salient perceptions. This is expressed as:
where the symbol ⊕ represents the summation of various distances, taking into account the different categories (e.g., between intrinsic and localized perceptions) and includes appropriate normalization. It is important to note, in conclusion, that the saliency of localized perceptions is also influenced by the variable
, as discussed in
Section 3.2.
3.4. Action Saliency and Inter-Action Distance
The action associated with the
j-th fragment of the
i-th SMT is encoded using a parametric function that represents its salient features:
This encoding is employed for adapting the action to a different context during autonomous execution. Here are the key components of the action encoding:
is a parameterization of the salient action.
where
is a function that encodes the action
in the time interval
. In this work, we use the DMP method to encode the robot’s movement.
is an empty variable which will be replaced by in the starting configuration during the autonomous execution, e.g., the end-effector pose or the state x, before executing the learned action.
stands for the final value that
will assume at the end of sub-task. This value depends on the type of perceptions involved. If only salient intrinsic perceptions are at play, then
, with
denoting the final value assumed by
at the end of the
j-th subtask during the SMT registration. Conversely, if at least one localized perception is involved,
becomes parameterized with the perception’s location, as explained in the Contingent Action Mapping section (
Section 3.6).
Similar to the inter-perception distance, we define the inter-action distance
between two distinct sub-task actions
,
based on their saliency actions
:
where
is the euclidian distance function applied to the action parametrization, drawing inspiration from [
43]. In particular, regarding Equation (
29), when given two parameterizations
and
of two actions, their inter-action distance is equal to zero if and only if the two parametrizations are the same:
3.5. Contingency Relation
Now that we have established the categories of perceptions and the essential attributes needed to characterize a Sensory-Motor Trace (SMT), we can delve into defining two types of contingency relations: between two SMTs and between a context and an SMT.
Starting with two distinct SMTs, denoted as
, each characterized by temporal saliency
, perception saliency
, and action saliency
, we establish their contingency based on the contingency relation between their constituent fragments. Therefore, two fragments,
, are considered contingent if the following contingency fragment relation
holds true:
where
,
are the thresholds, respectively, for the distance between actions and perceptions.
To determine the contingency between two SMTs,
and
, we declare
as True if and only if all pairs of fragments
satisfy the contingency condition:
Now, to establish contingency between an SMT and a context, we must first extract saliency from the context. Given a context
, the process of temporal saliency extraction results in a collection of context fragments denoted as:
where each
represents a fragment:
This process is analogous to the task segmentation described earlier, with the notable distinction that the number of context fragments increases over time, and the most recent fragment is always associated with the current time . Each sub-context’s perception and action components are identified as and , respectively. Saliency is then extracted from these components as for perceptions and for actions, following the methodology previously outlined.
To evaluate the contingency between a context
and an SMT
, we consider that through the extraction of temporal saliency, the context aligns with an SMT for all instances prior to the current one (i.e.,
). The key difference lies in evaluating the present instance,
. Therefore, for a context to exhibit contingency with an SMT, the contingency relationship between SMT fragments should hold for the past history, as follows:
Moreover, the contingency condition in the current instance, denoted as
, must be met, taking into account the saliency of perceptions only:
Thus, for a new context and an SMT to be considered contingent,
, they must exhibit contingency both in the past and in the current instance:
It is important to note that when the current instance aligns with the initial starting time (in discrete time, ), the contingency relation between a context and an SMT simplifies to solely the present contingency condition .
In conclusion, it is worth emphasizing that we exclusively take into account the salient perceptions to assess contingency at the current instant. This choice aligns with our goal of identifying and retrieving the action component from the stored SMTs, which, in turn, enables us to adapt the action to the current context, as explained in the following section.
3.6. Contingent Action Mapping
Given a context denoted as
and a contingent SMT fragment represented by
, we introduce a contingent mapping function
to determine a new action
to be executed at the current time
. This new action is derived from the adaptation of the salient action
to the context
, with the aim of minimizing the distance
, provided that (
37) is satisfied.
Moreover, the design of this new action
is such that, when applied, it ensures that the resulting updated context
continues to be contingent in the past to the corresponding SMT, as described in Equation (
35). This definition allows us to state that upon the successful autonomous execution and adaptation within the current context of an SMT
stored in the tree, the resultant SMT
is contingent upon
, meaning that
evaluates to True.
Mathematically, this new action
can be expressed as:
where the value of
depends on the type of perceptions involved in
and
. It is important to note that these perceptions must be of the same type and number to be compared. If they only contain intrinsic perceptions, then
is equal to the final value assumed by
at the end of
,
. However, if they involve a localized perception,
assumes the value
associated with the location of the localized perception pair (
) in
, having the minimum distance from the salient localized perception
:
where
s represent the localised perception cardinality.
3.7. Sensory-Motor Contingency
As previously discussed, after formally defining the contingency relationships between two SMTs and an SMT with the context through the extraction of perceptual and action salience, we can now introduce the concept of an SMC (Sensory-Motor Contingency). An SMC is defined as the pair of salient perceptions and actions for an SMT fragment obtained through temporal saliency extraction.
For a given sensory-motor trace
and its corresponding fragments
, we define a sensorimotor contingency SMC as:
and
is the set of SMCs associated with
.
It is important to note that since all the metrics and relationships introduced earlier rely on the salience of SMT, they naturally pertain to the SMC. This definition enables us to represent the connections between actions and changes in perceptions as a discrete tree structure, where each edge represents an SMC, and each node represents a decision point. These decision points, denoted as , are intances where temporal salience was extracted. During autonomous execution, an assessment of the tree is required to evaluate the execution of future actions by identifying the most context-contingent SMC among all the SMCs in the tree.
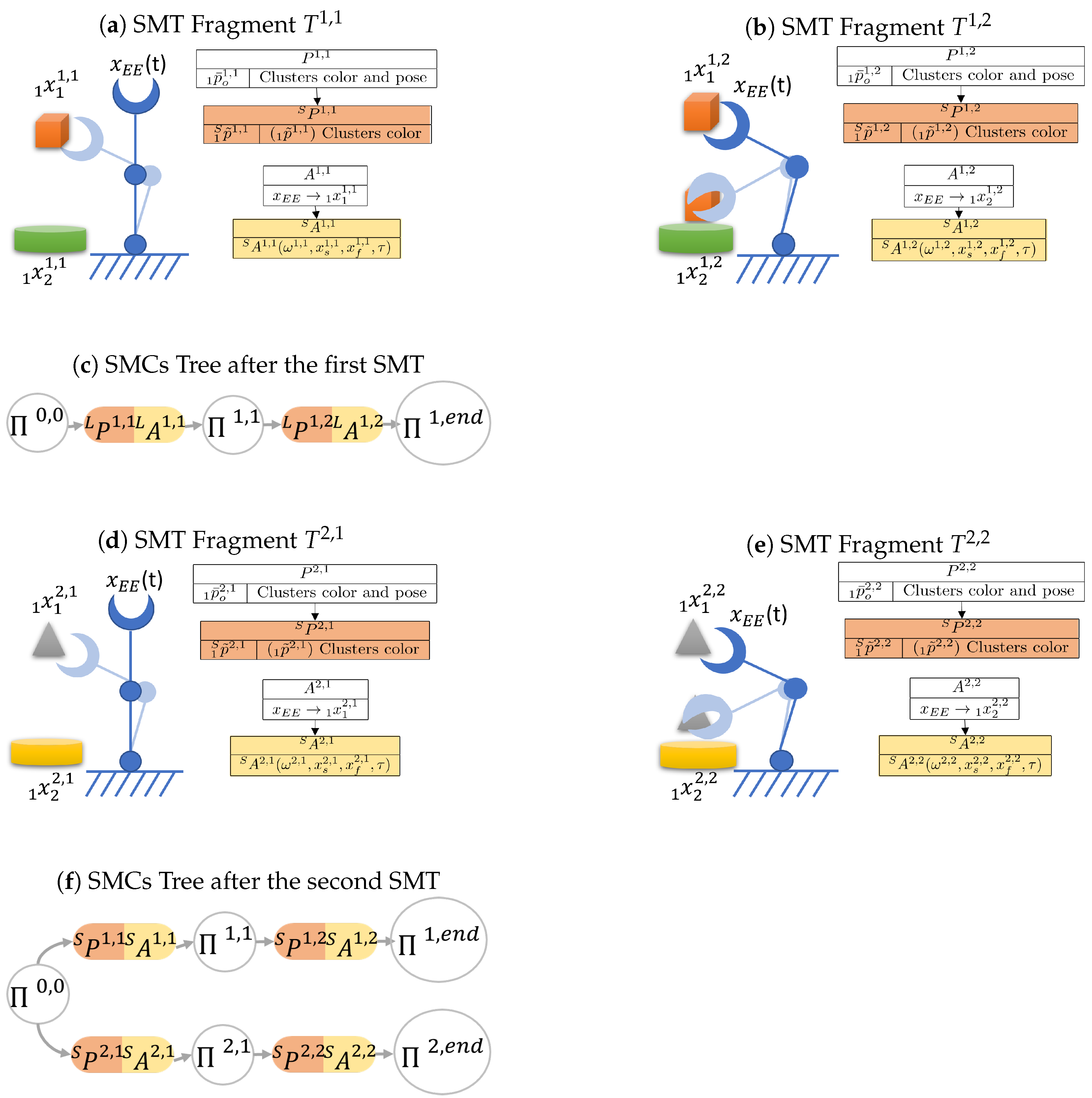
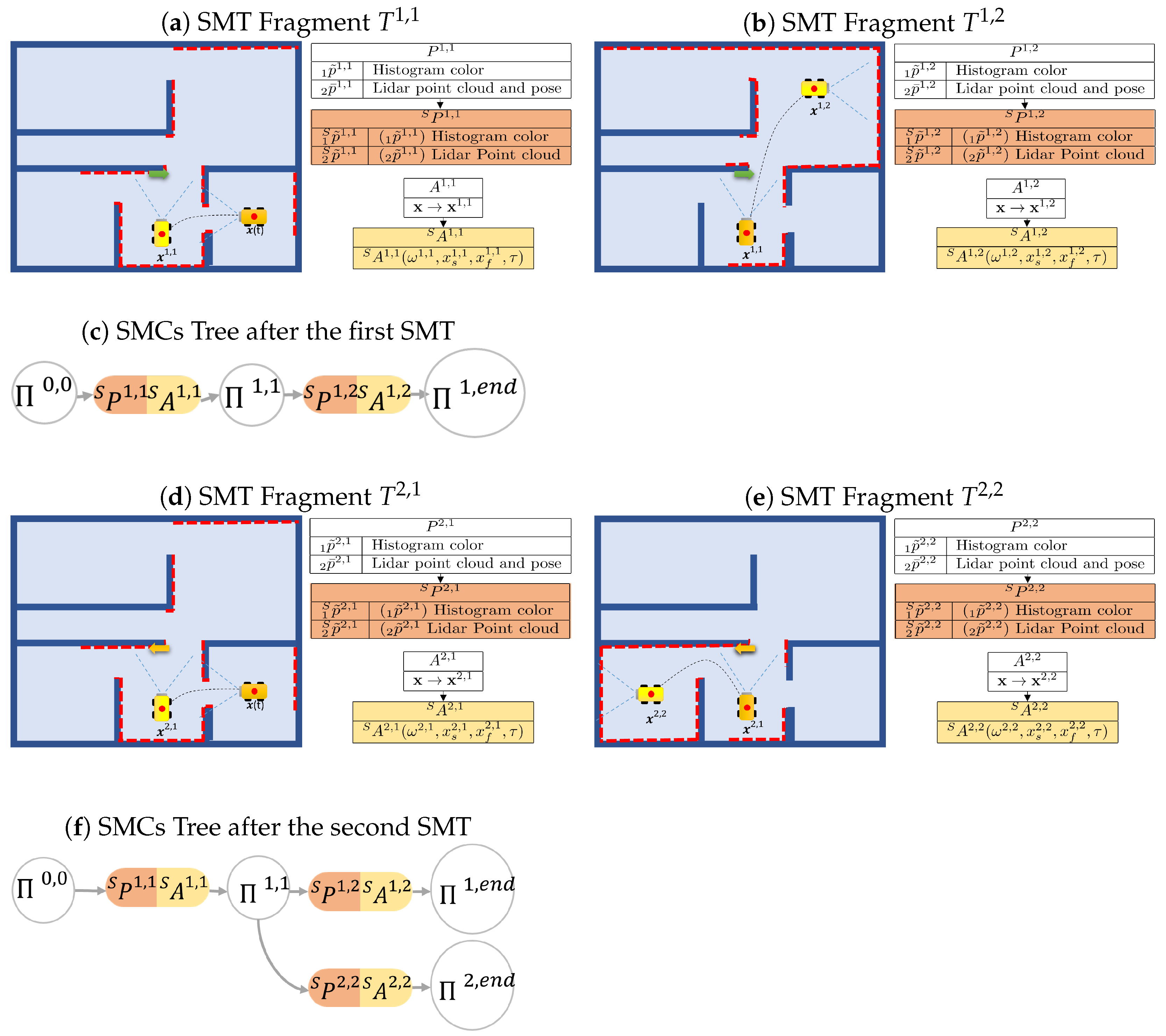
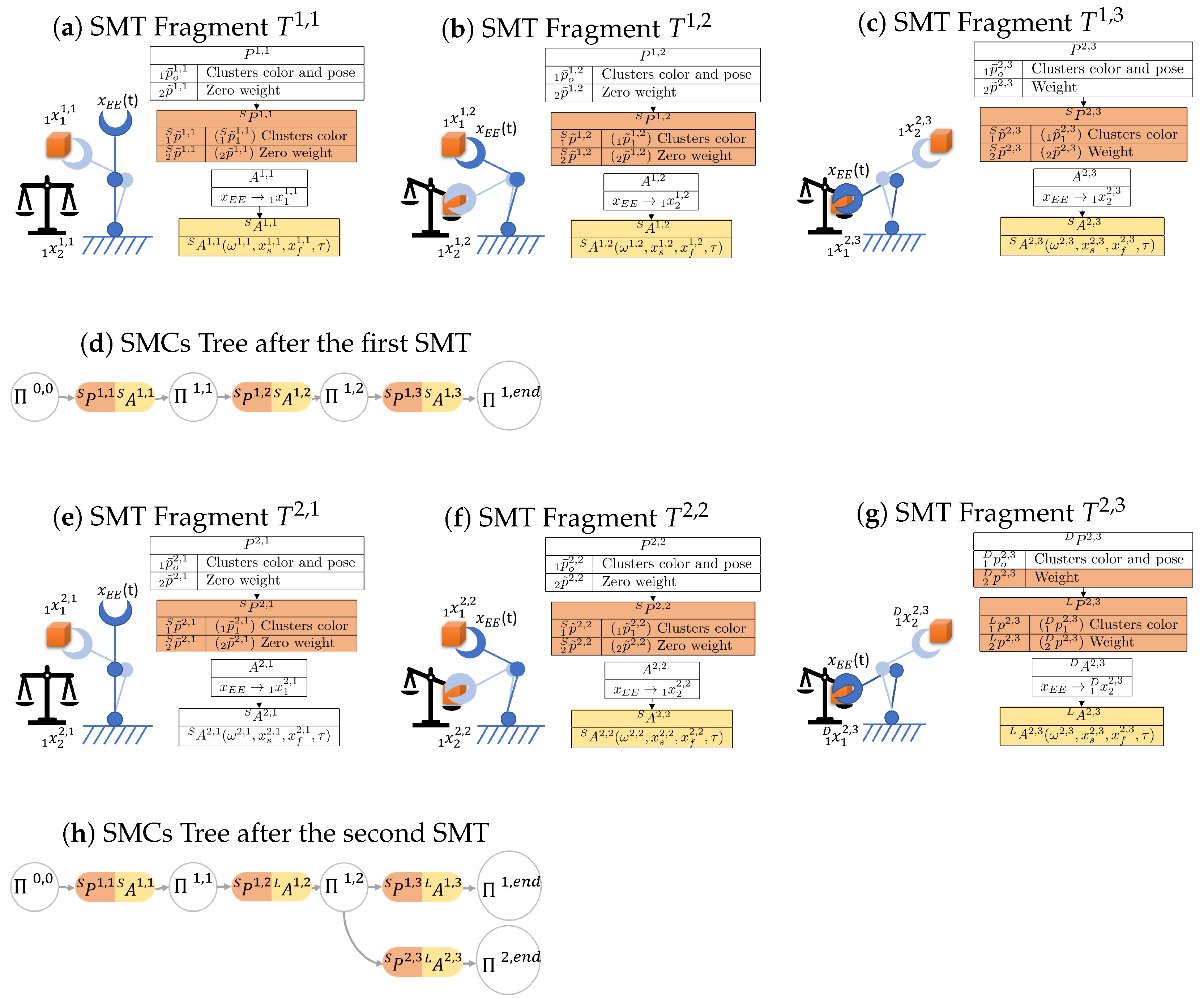
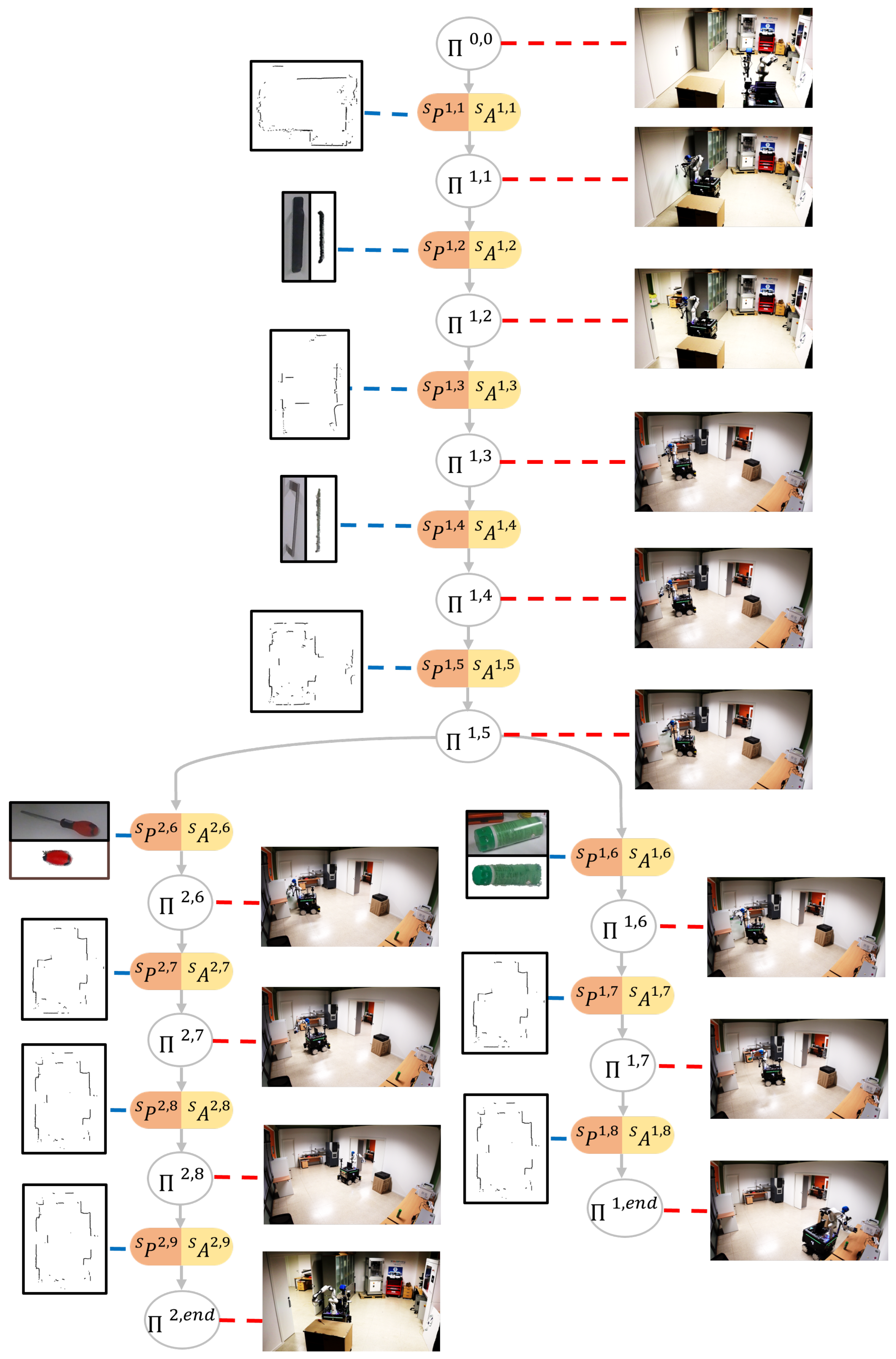
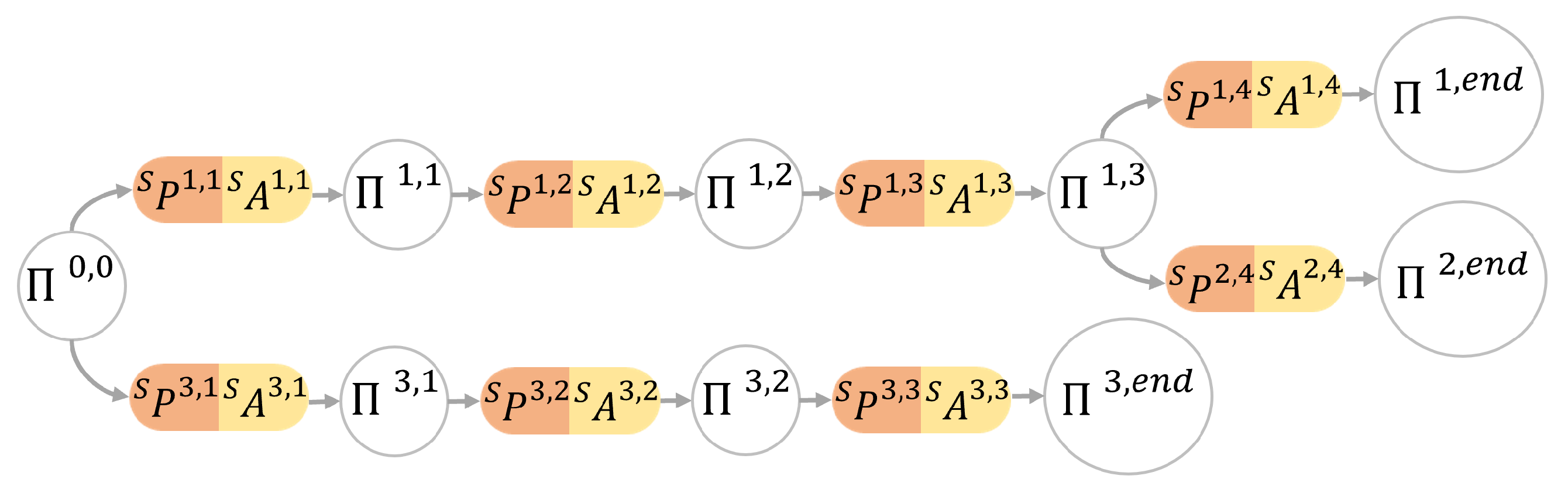
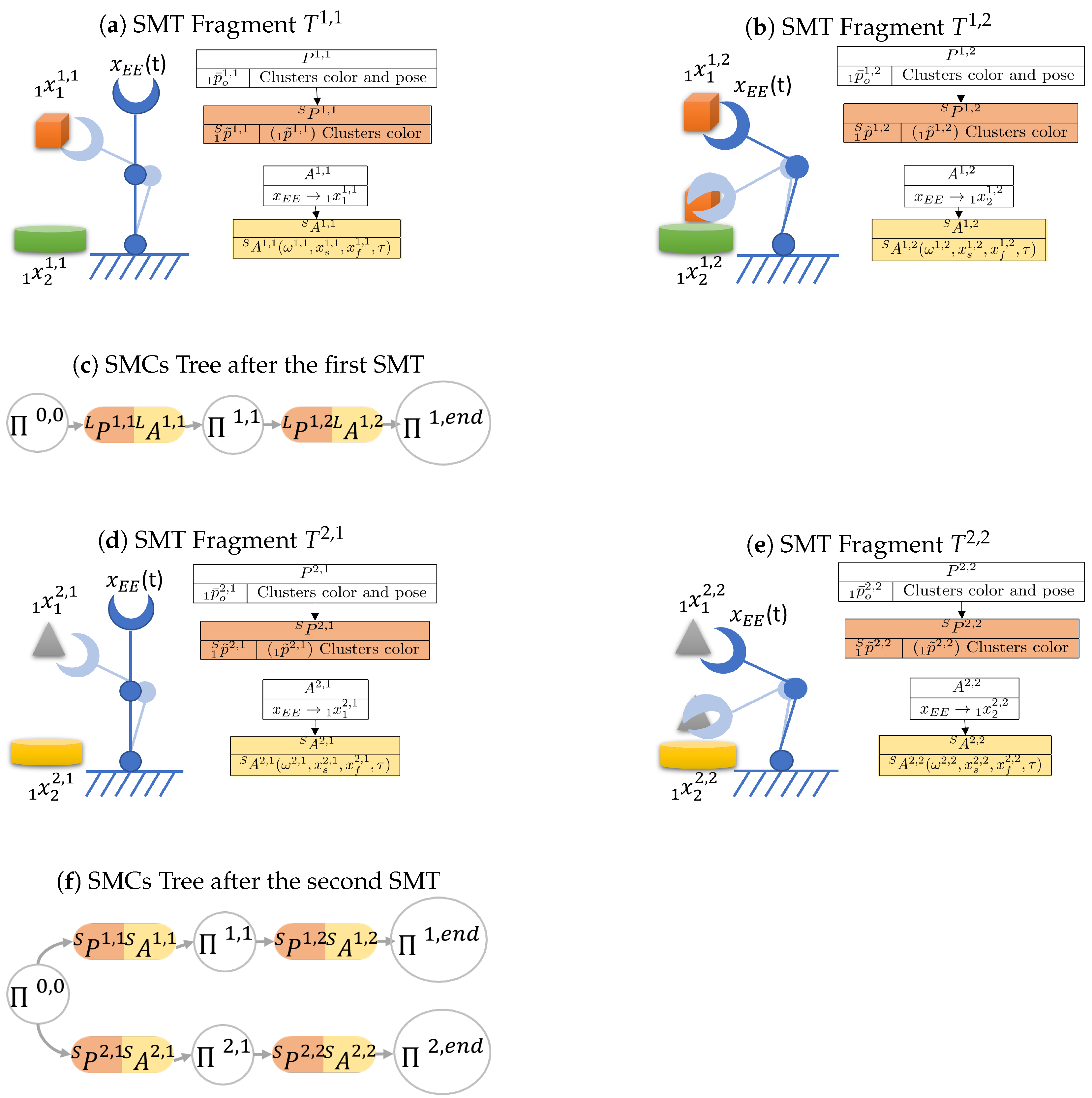
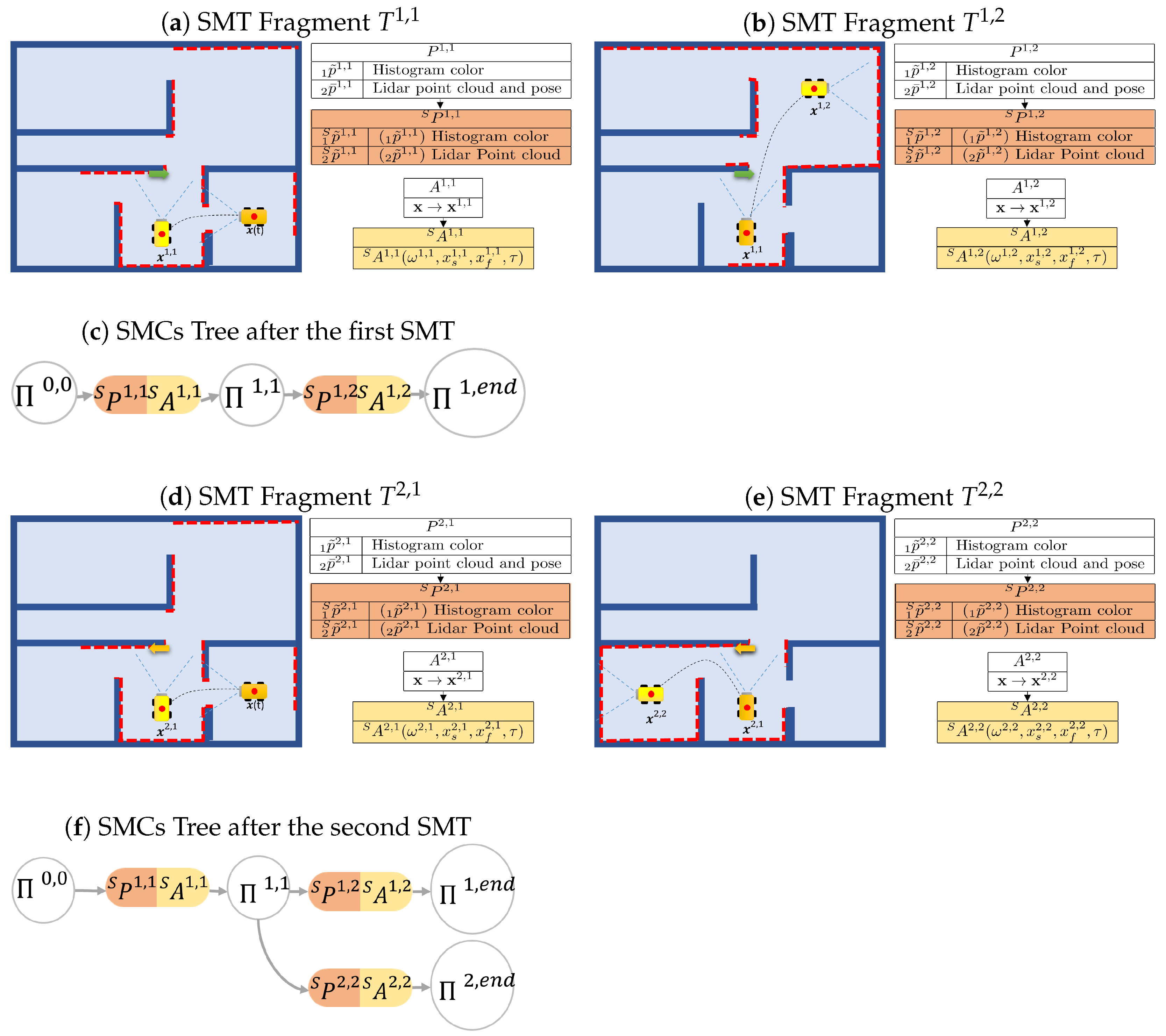
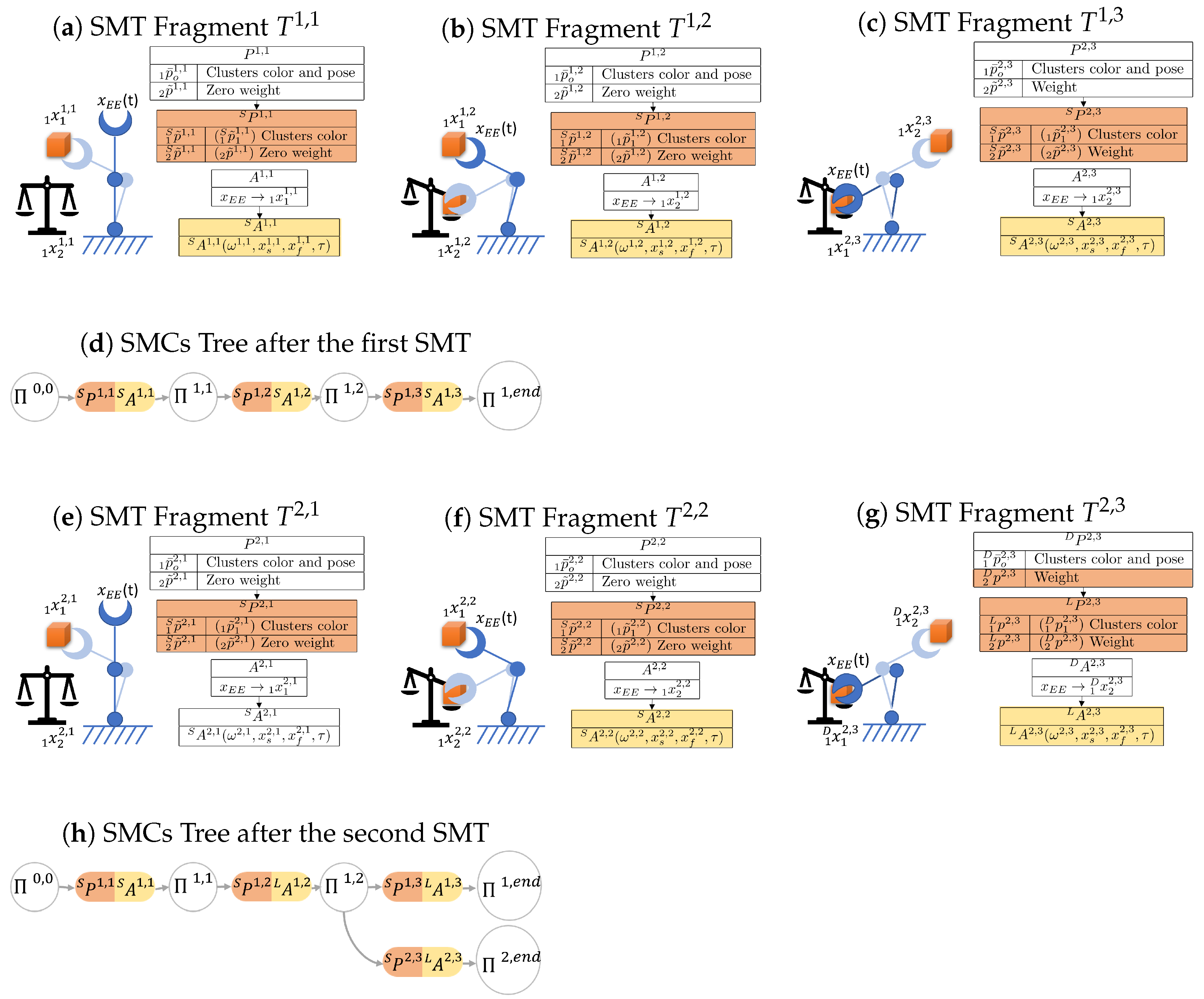
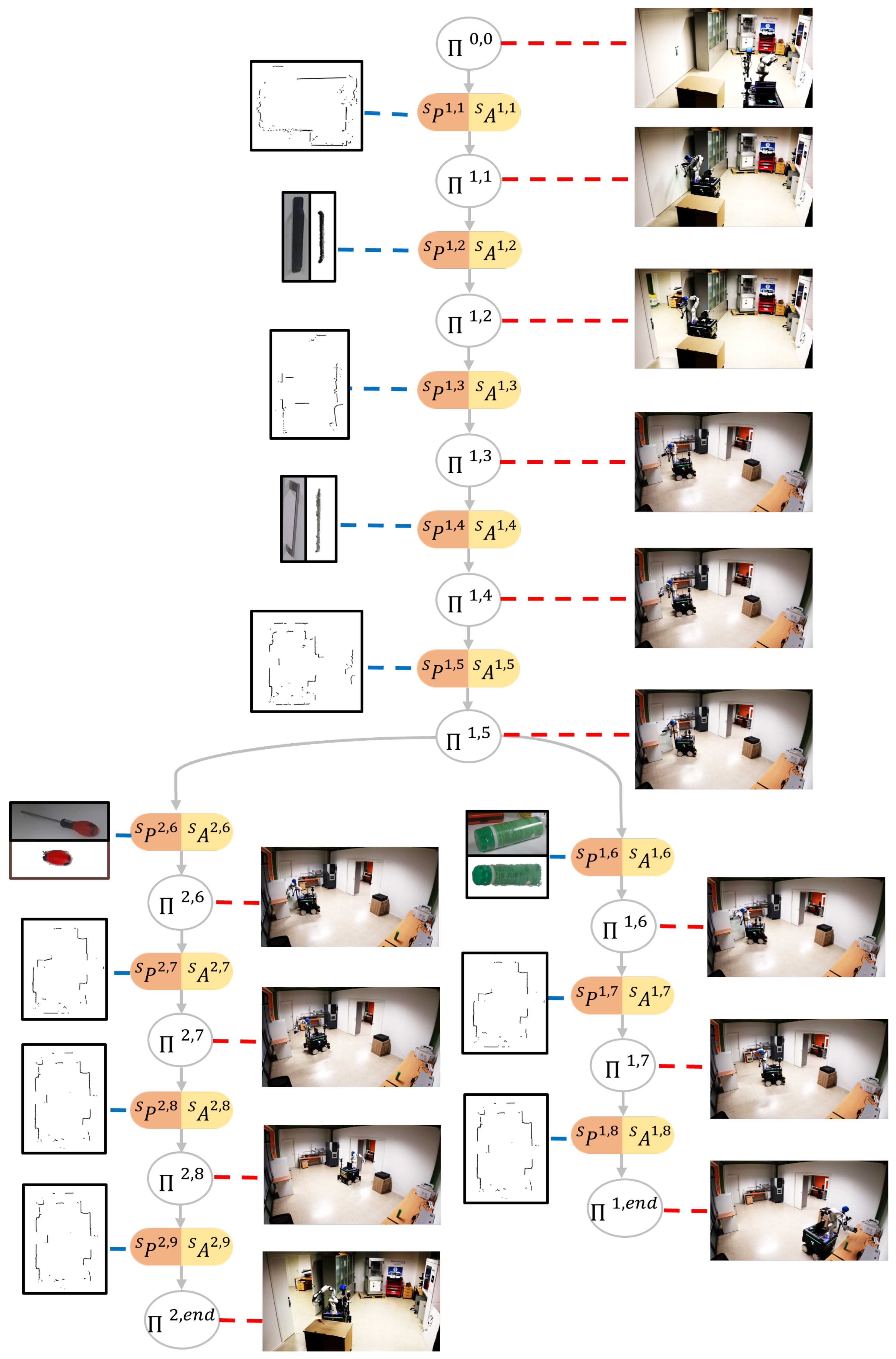
3.8. Sensory-Motor Contingencies Tree
The method for constructing the SMCs tree follows the algorithm presented in Algorithm 1. To build this tree, each SMT is processed by extracting its saliency following the procedure in
Section 3.3 and
Section 3.4. If the tree is initially empty, the first SMT is automatically stored, and the first branch is added to the tree. Otherwise, a process is executed to efficiently incorporate a new SMT into the existing tree. This procedure enables the integration of initial SMC candidates from a novel SMT with specific branches of previously stored SMTs. In essence, when elements of a new task exhibit similarities to those already stored, the system selectively archives only the distinct portions of the task. These distinct portions are then inserted into decision points associated with pre-existing SMTs.
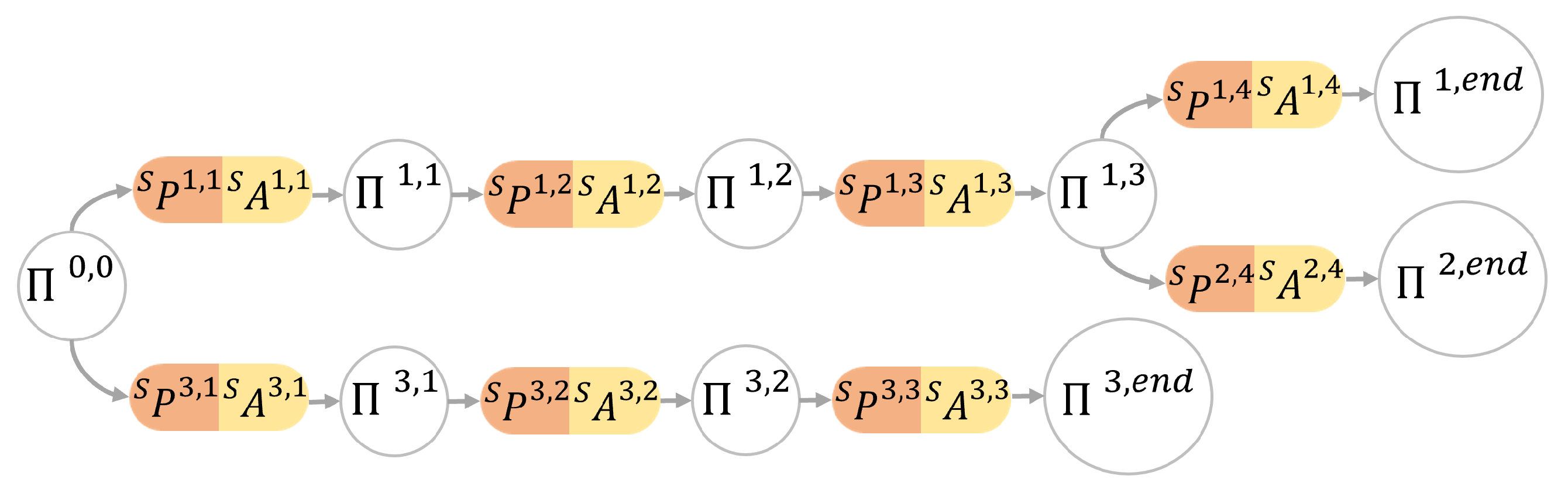
Suppose the tree is composed of
m branches, with each branch originating from the root node (as depicted in
Figure 4). After extracting the SMC candidates for a new SMT denoted as
, a new branch is created, consisting of
N SMCs to be included in the existing SMC tree:
where ∗ denotes the new branch.
At each step, the process evaluates the contingency SMT fragment relationship between
and the SMCs
present in the tree, which are admitted by the node
. This process begins with the initial step where
and
. The equation for this contingency check is as follows:
Here, represents a set of all the SMCs indexes i admitted by the node .
If is found to be contingent with , then is added to the set , which contains all -contingent SMCs. Otherwise, the contingency check continues with the next SMC connected to .
After all SMCs to be compared have been examined, if
remains empty, the new SMCs
are connected to the node
, and the check concludes. Otherwise, if
is not empty, the process proceeds to assess the salient perceptions in
to identify the most contingent SMC: the one with the least inter-perception distance. To identify it, the process computes the index that minimizes this distance:
After this, the process merges the SMCs
and
, and the check continues on the branch identified by the index
. The process concludes once all the SMCs of the new branch have been processed. The merging between two SMCs can be performed in several ways, such as choosing one of them or applying other sensor fusion and trajectory optimization methods. The merging process can also be viewed as an opportunity for the robot to enhance its understanding of the same SMC. In cases where a particular task is repeated multiple times, during the merging process, the system can systematically merge all the Sensory-Motor Contingencies by consistently integrating the parameters of the older SMCs with the new ones. This iterative refinement allows the system to progressively improve its comprehension of the task, leveraging past experiences to enhance its performance.
| Algorithm 1 SMCs Tree |
- 1:
function = () - 2:
= - 3:
= - 4:
if is empty then - 5:
else - 6:
- 7:
- 8:
- 9:
for all in do - 10:
for all admitted by do - 11:
if then ▹( 43) - 12:
- 13:
end if - 14:
end for - 15:
if is not empty then - 16:
- 17:
() - 18:
else - 19:
- 20:
Return - 21:
end if - 22:
- 23:
- 24:
end for - 25:
end if - 26:
end function
|
3.9. SMCs-Aware Control
During autonomous execution, the robot can operate in new contexts that are akin to those stored in the SMCs tree, and this is facilitated by Algorithm 2. The process begins at the initial decision point and proceeds along the identified branch of the tree, given that compatible perceptions are encountered along the way.
At each step within each decision point, the SMC control takes a new context denoted as
, extracts the context’s saliency (as detailed in (
33)), and seeks the most contingent SMC fragment within the SMC tree. The objective of this control is to generate a new action that ensures the past contingency of the subsequent context
with the identified branch of SMCs from the tree. Thus, during each step, the system evaluates only the current contingency between the context and the SMCs,
, to determine the most contingent SMC. This assessment entails identifying the index
as follows:
whereas,
represents a set of all the SMCs indexes
i admitted by the node
.
Once, the most contingent SMC is found, the index
is employed in the contingent action mapping to compute
:
Finally, if, during the execution, the system fails to establish any correspondence with the SMC-tree (
), it has the option to resume the recording process and initiate the recording of a new SMT, starting from the ongoing execution.
| Algorithm 2 Autonomous Execution |
- 1:
- 2:
- 3:
- 4:
for all
do - 5:
- 6:
= - 7:
= - 8:
▹ ( 45) - 9:
- 10:
- 11:
- 12:
- 13:
end for
|
6. Discussion
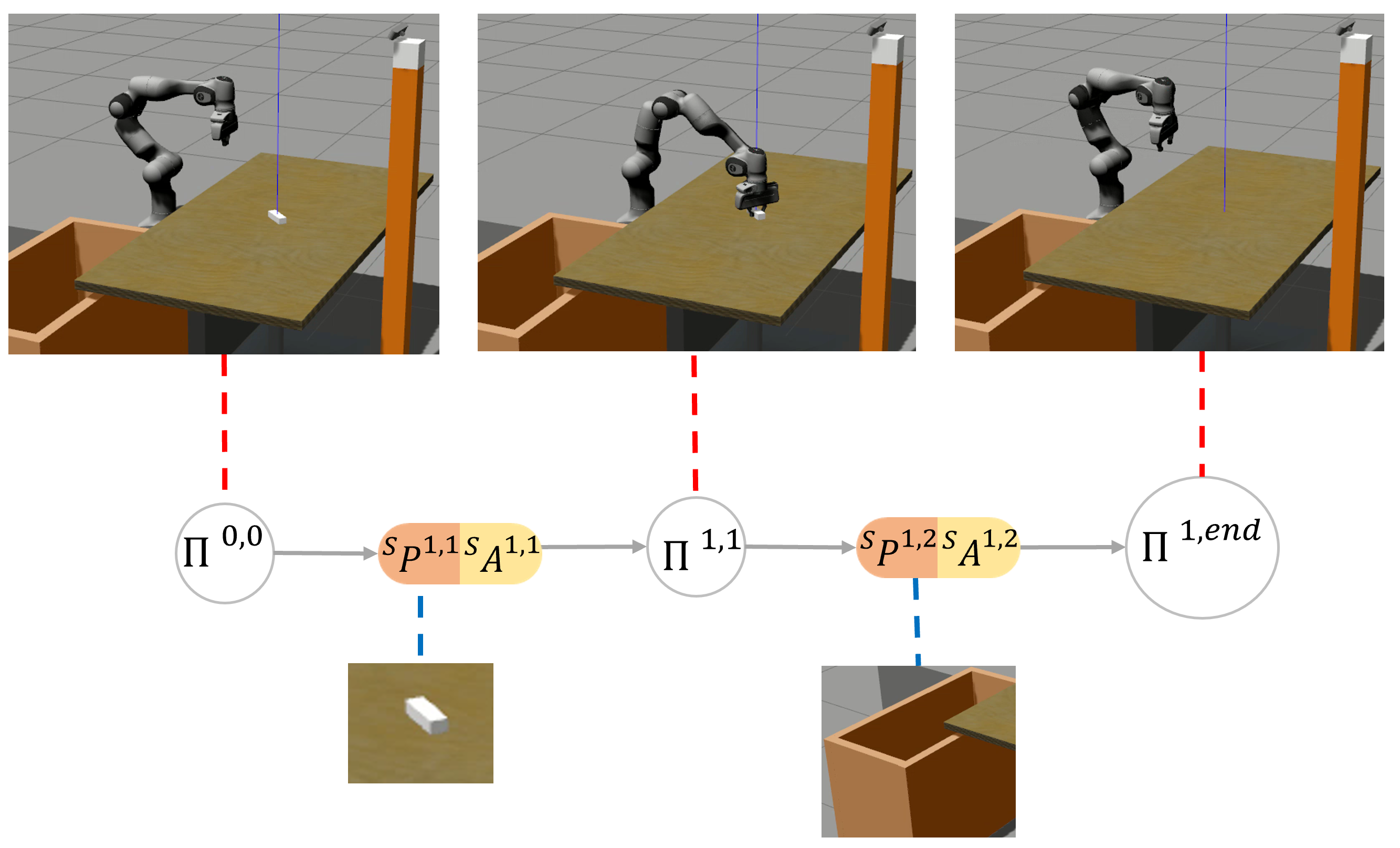
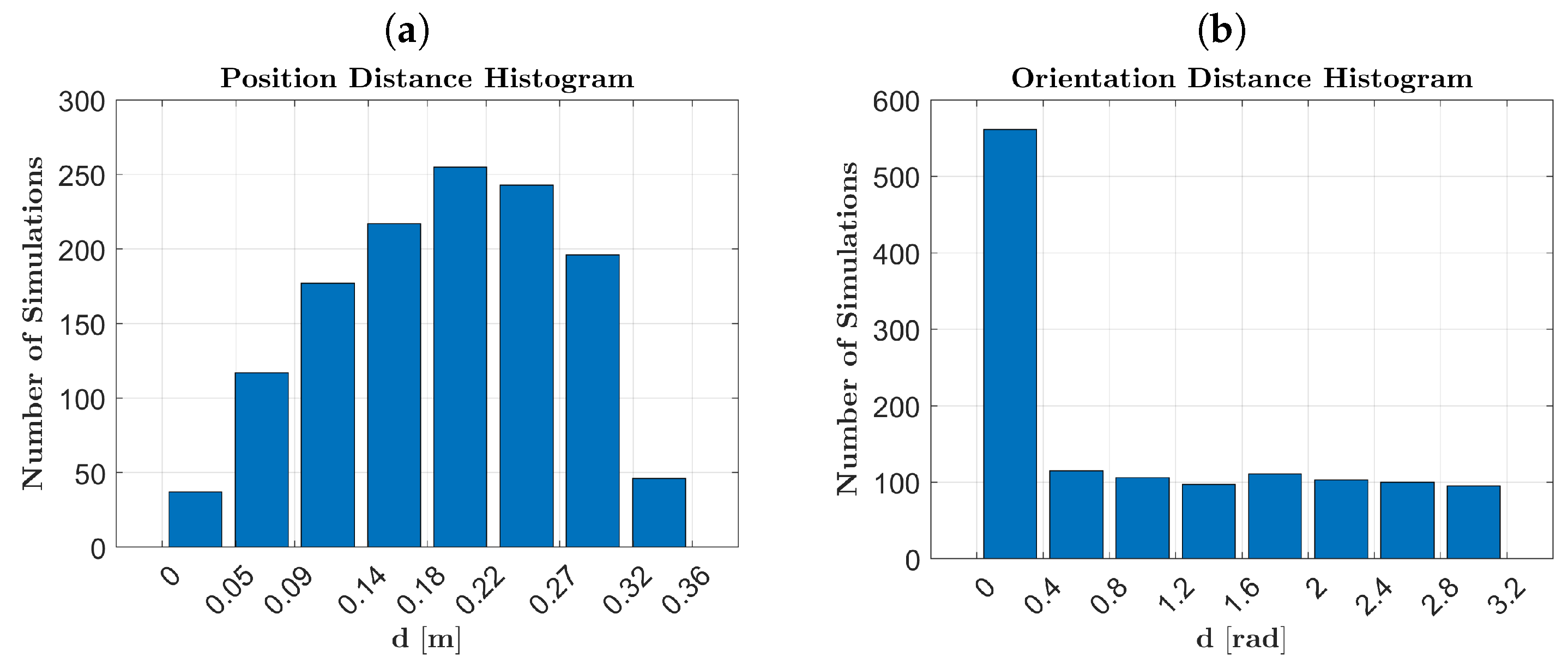
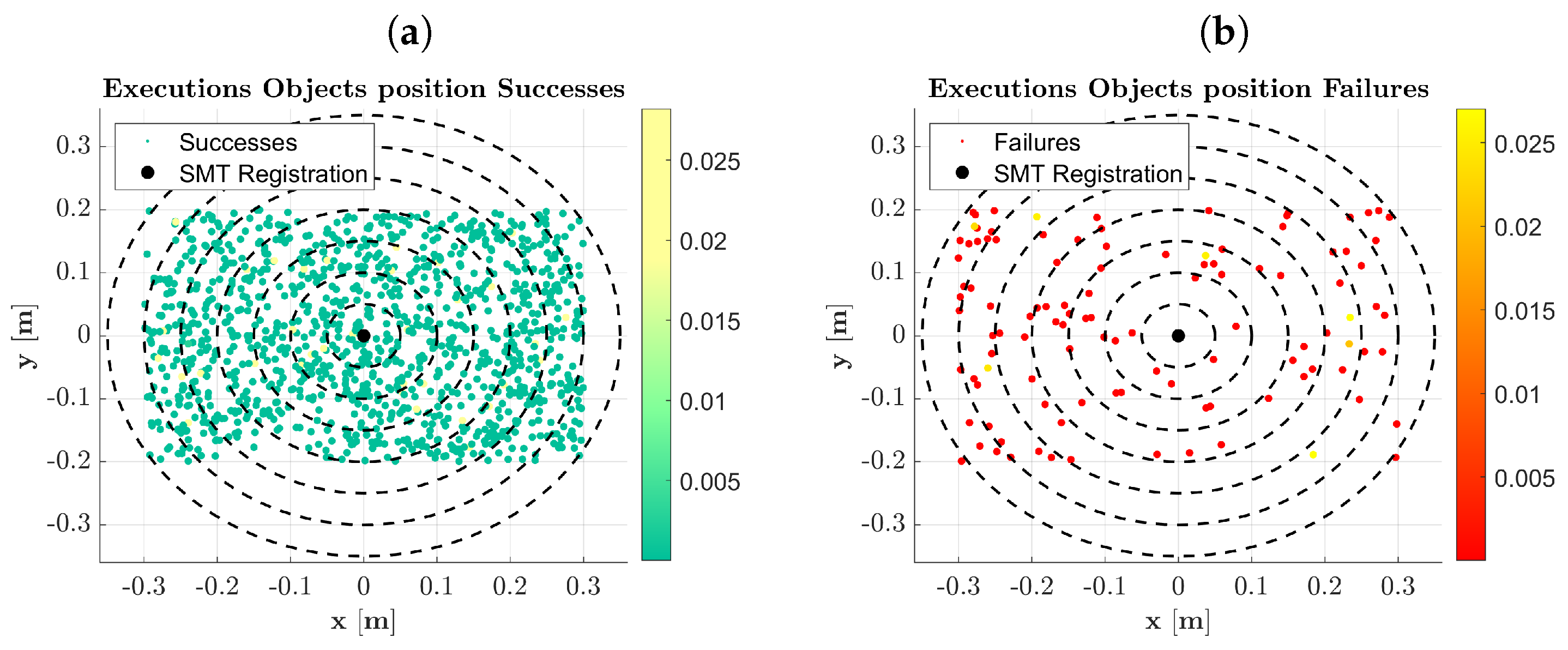
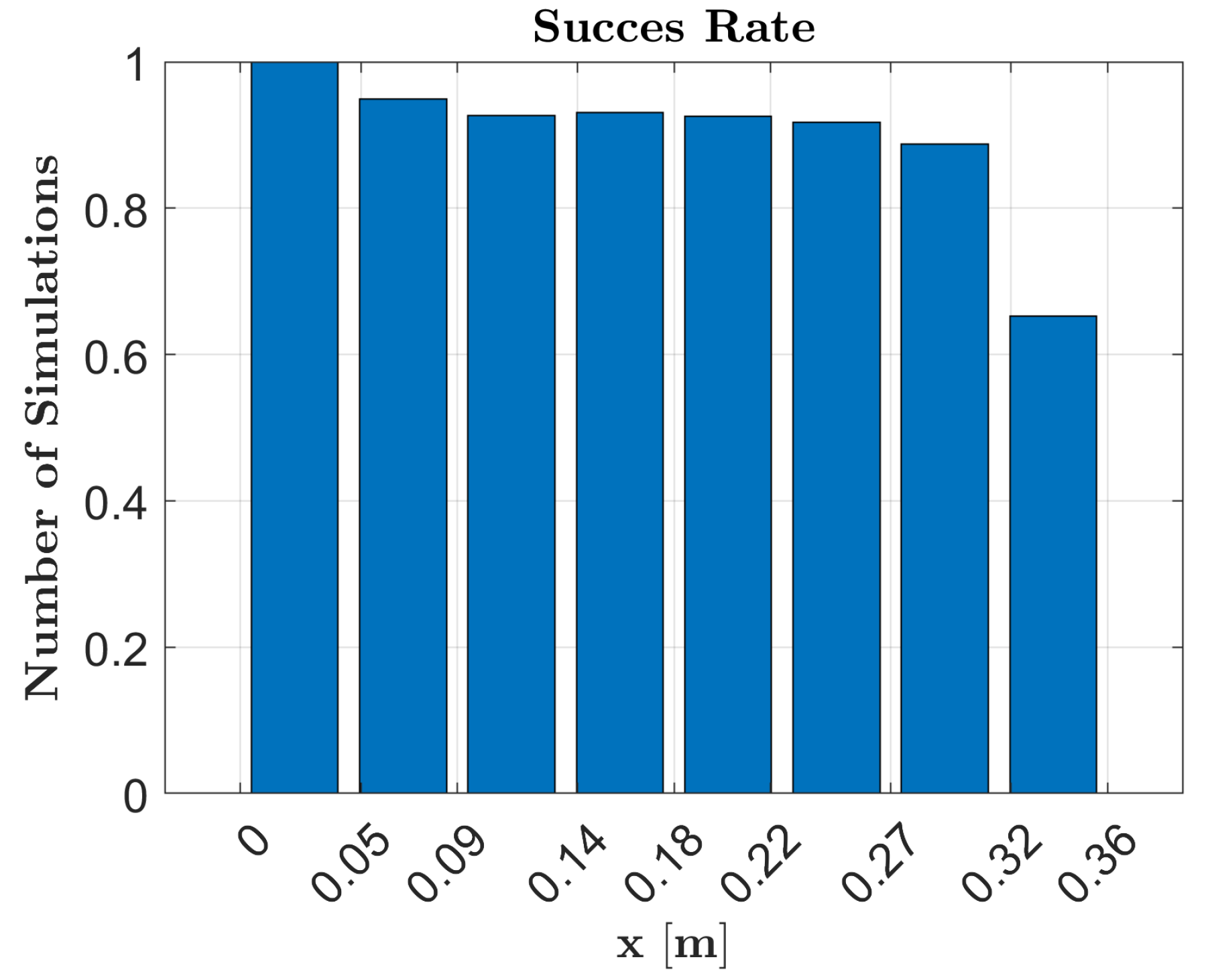
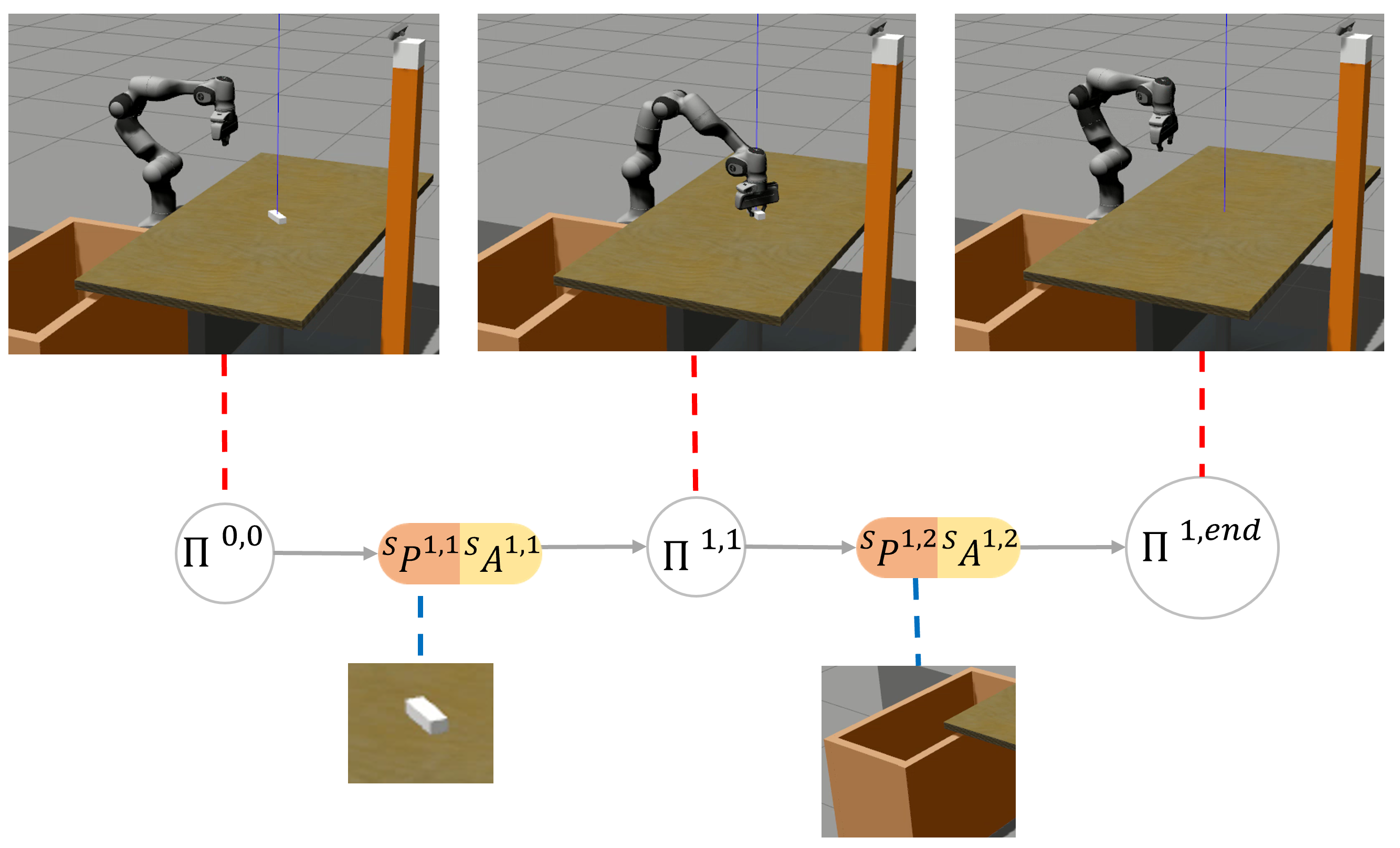
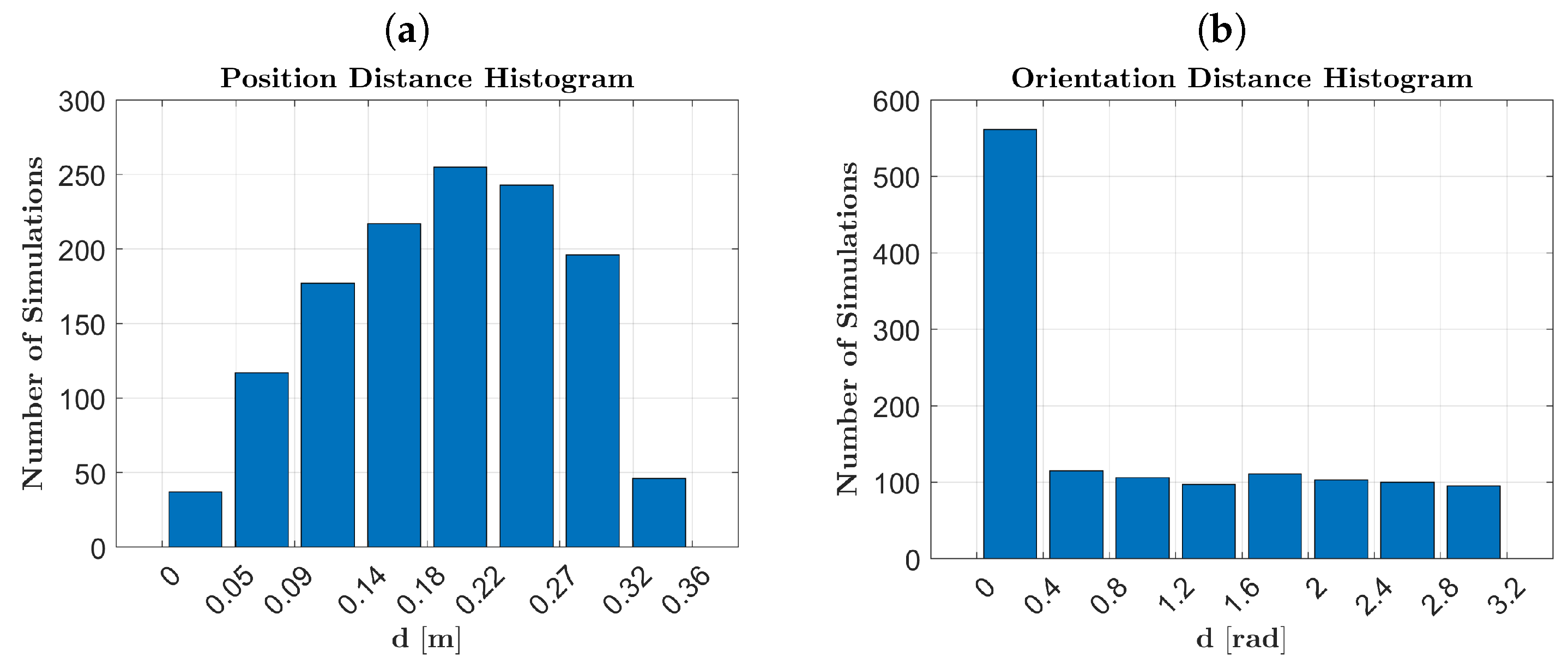
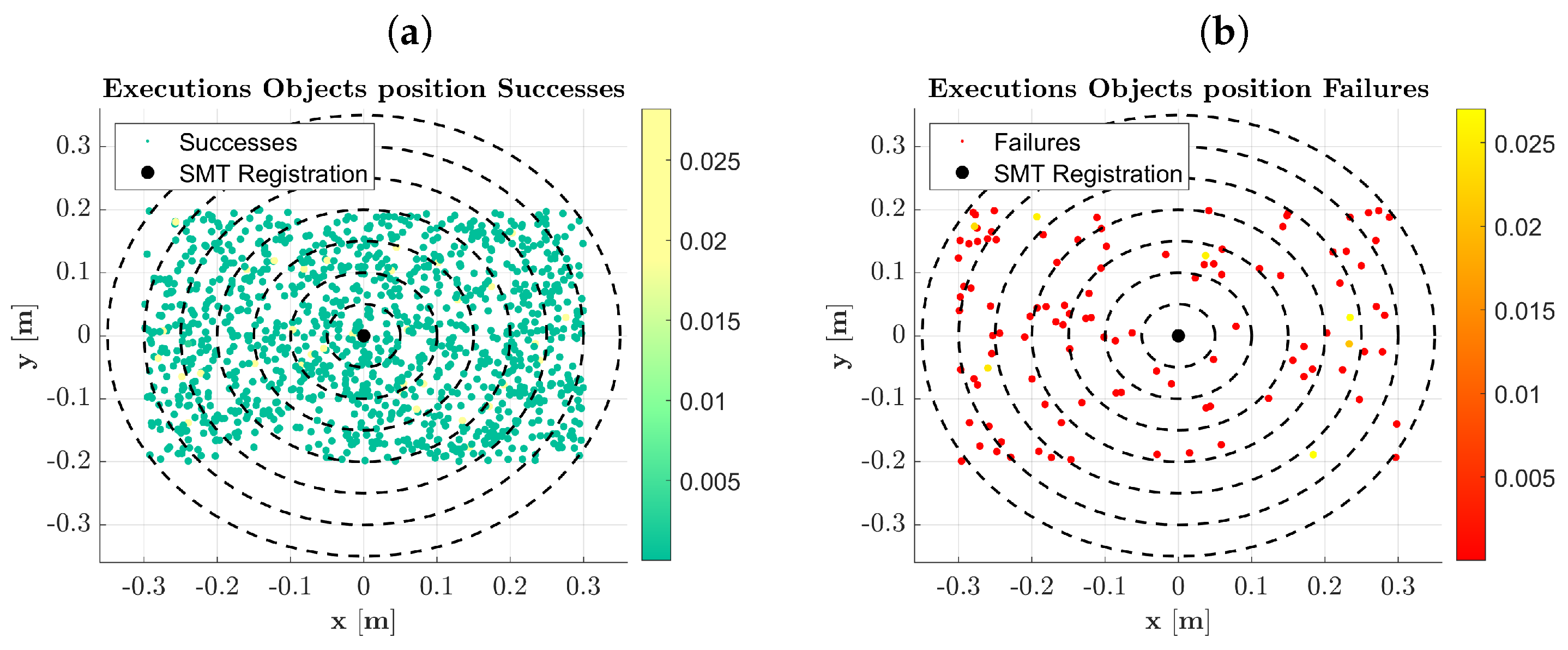
The validation in a pick-and-place simulation scenario demonstrated the robustness and repeatability of the framework, achieving a success rate of over 90%. Examining
Figure 11, we observe a decreasing success rate as the object’s location moves further away from the SMT registration point. This decrease is attributed to the increased pose error estimation as objects are positioned near the camera’s field of view boundary. Additionally, from
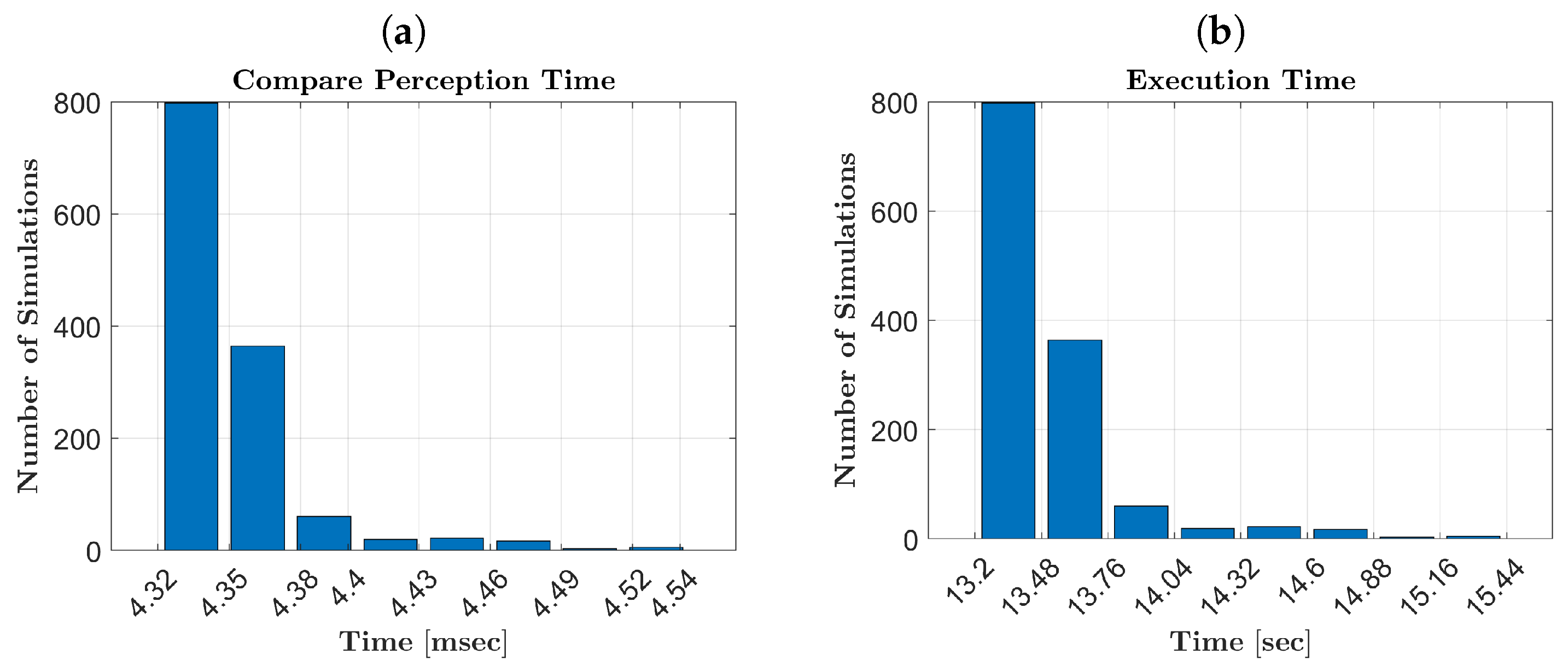
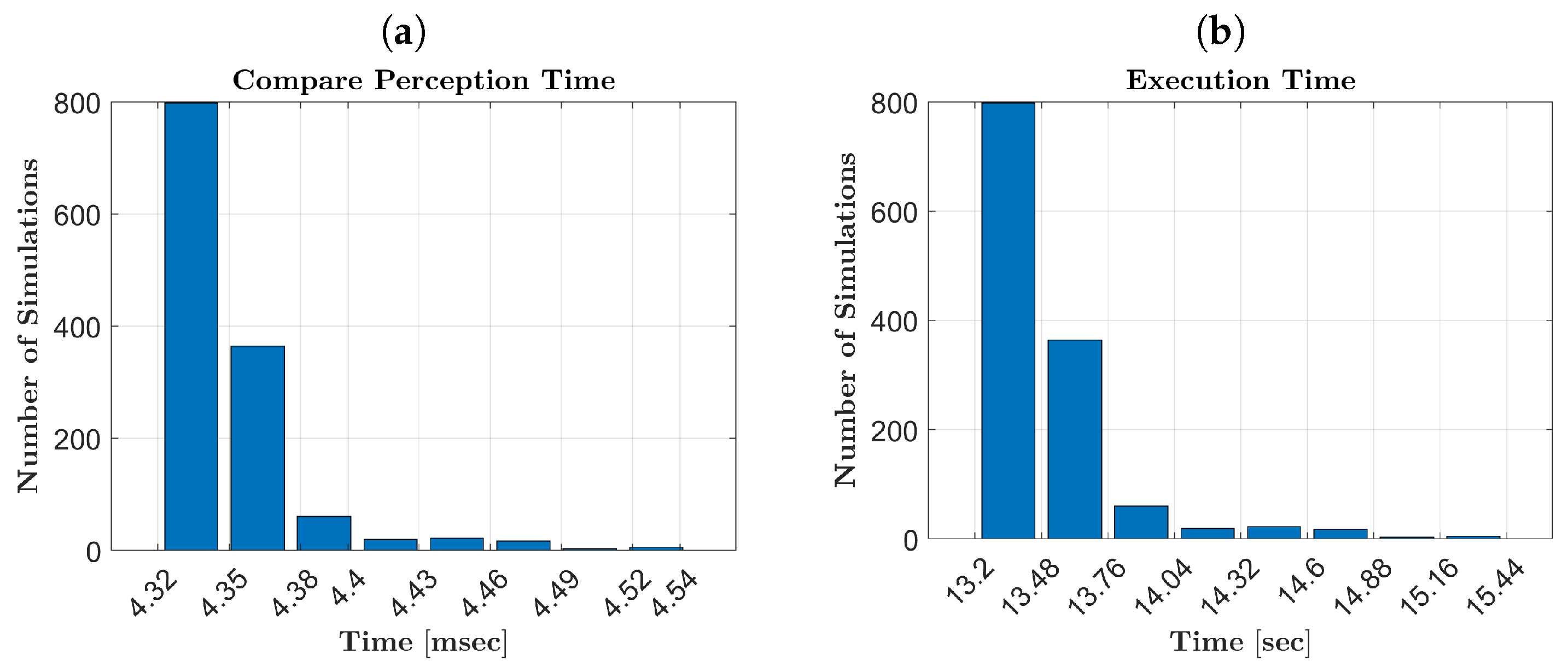
Figure 12a, we notice an increase in time for the vision system to recognize objects located farther away.
Figure 12a,b reveal that the average execution times are lower than the SMT registration time (15 s). This efficiency is achieved by the framework’s design, which eliminates waiting time when the user initiates or concludes SMT fragments. The variance in execution times is primarily due to the vision system’s need to compare incoming perceptions with stored ones to identify objects for grasping.
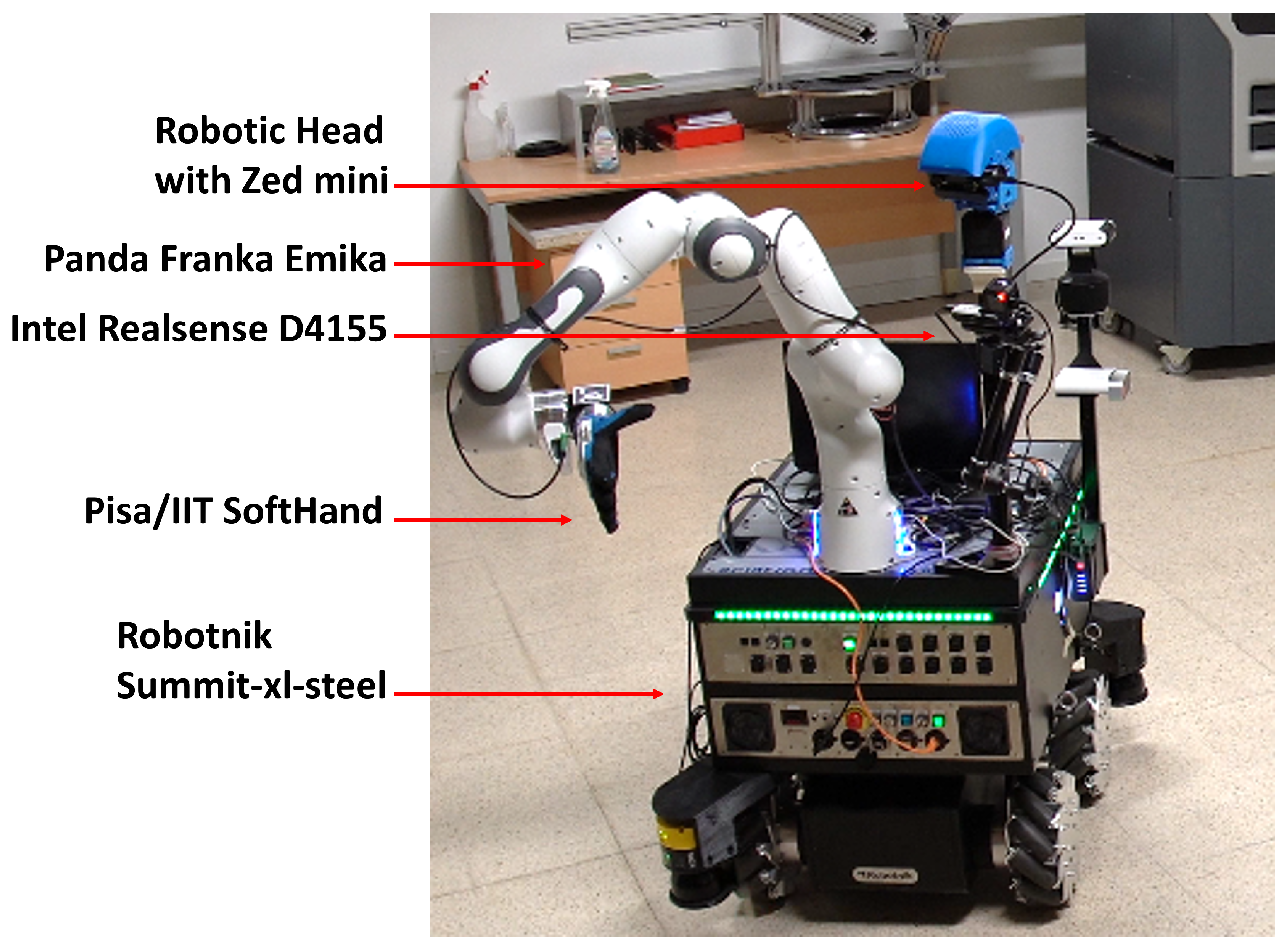
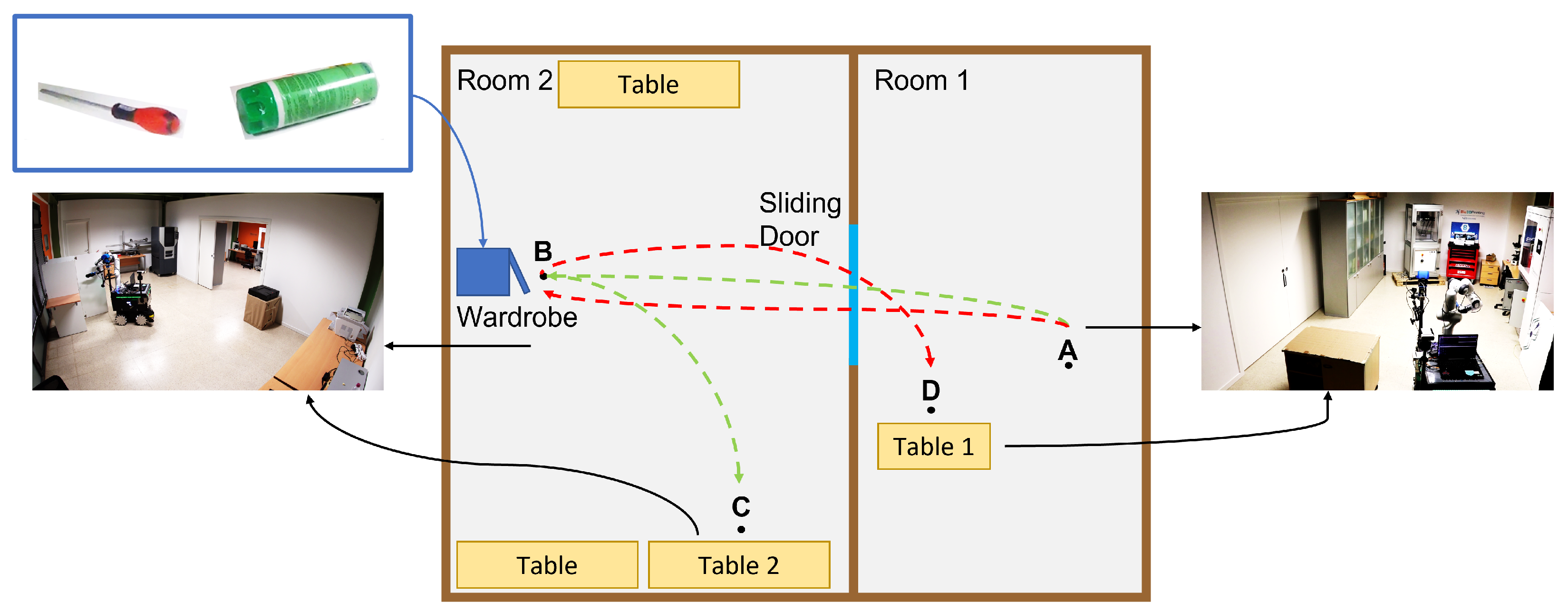
In our real experiments, we assessed the framework’s capabilities in managing and integrating diverse robotic systems and sensors. In the first real experiment, the system successfully extracted salient SMC perceptions from the camera and weight sensor, as well as merged the initial SMCs from each SMT. Thanks to the SMCs tree, the robot autonomously and efficiently sorted objects on the table. Employing identical parameters from the simulation, real-world manipulation achieved a 100% success rate in sorting the five objects. However, due to the limited number of tested objects, it is impossible to conclude on the statistical significance of that specific experiment. Nonetheless, the reported results and the experiment video contained in the multimedia file demonstrate the exemplary performance of the simulation-developed system in real-world applications.
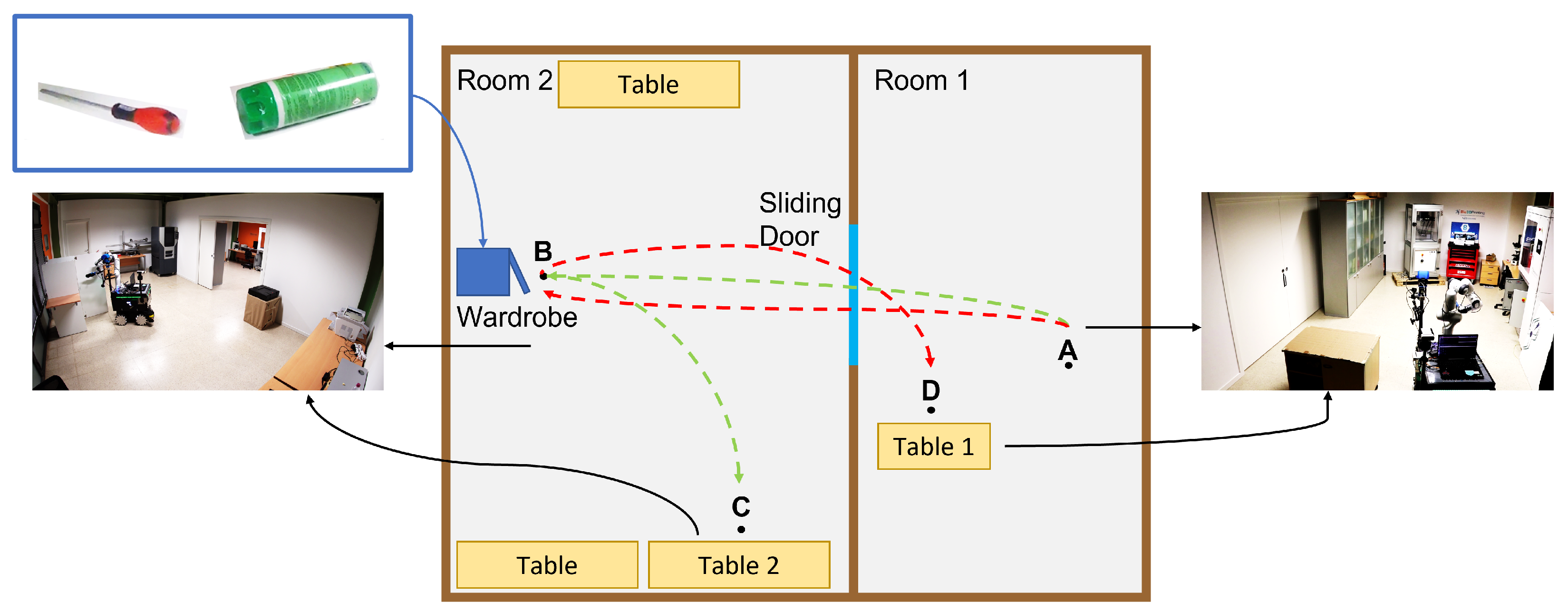
The framework’s architecture was thoughtfully designed to seamlessly transition between manipulation tasks and loco-manipulation ones, allowing us to evaluate the framework in combined tasks. The loco-manipulation experiment illustrated the framework’s proficiency in learning and managing combined SMTs, particularly in scenarios necessitating synchronization between manipulation and navigation—an accomplishment that traditional planners often struggle with. From the multimedia material depicting the autonomous executions, it becomes evident that the robot adeptly handled real-time changes in the wardrobe’s pose during execution. It demonstrated a remarkable ability to seamlessly adapt to the dynamic adjustments of the furniture, ensuring precise task execution even in the face of unexpected movements.
Affordances in SMCs-Tree
Building an SMC-Tree as described in
Section 3.8 can provide the robot with an implicit representation of the affordances that exist in a given environment. Indeed, the different branches sprouting from similar scenarios (e.g., the vision of a bottle) could lead to the execution of actions linked to different affordances (e.g., fill-in the bottle, open the bottle-cap, pour the bottle content in a glass, etc.…). However, although we can link affordances to the branches that sprout from a given node, there is not a one-to-one correspondence between affordances and branches, as there could be more than one branch associated with the same affordance, and there could be affordances that are not explored by the tree at all.
Moreover, it is important that our SMC-based framework relies on the hypothesis that there exists some perception P of the environment that can be used to tell which is the right SMC branch to follow along the tree. Therefore, although one could imagine using variations of our approach to build a tree representing all the possible affordances of a given object by combining many SMTs (one for each affordance to learn), some affordances may manifest in Sensory-Motor Traces (SMTs) as a consequence of unobservable variables that exist solely in the operator’s intentions. When two identical situations differ only in their unmanifested intentions, it becomes challenging to capture and represent the information solely through SMTs. Consequently, one would need to explicitly express these intentions, perhaps through an additional operator command signal, to effectively account for the subtle distinctions in the tree and explore all possible affordances of a scenario.
7. Conclusions
In this work, we have presented a comprehensive framework for robot programming, centered around the acquisition of multiple Sensory-Motor Contingencies (SMCs) derived from human demonstrations. Our framework extends the fundamental concept of identifying pertinent perceptions within a given context, allowing us to detect salient phases within Sensory-Motor Traces (SMTs) and establish a sensor space metric. This metric empowers the agent to assess the robot’s interactions with the environment and recognize stored contingent SMTs in its memory. Moreover, we leveraged Learning from Demonstration techniques to abstract and generalize learned action patterns, thereby enhancing the adaptability of our system to diverse environmental conditions. Consequently, we extracted a comprehensive collection of SMCs, effectively encapsulating the intricate relationships between actions and sensory changes, organized in a tree structure based on historical observations and actions.
To validate our framework, we conducted an extensive set of numerical validation experiments, involving over a thousand pick-and-place tasks in both simulated and real-world settings. In the simulated validation, we achieved a success rate of 91.382%, demonstrating the efficacy of our framework in virtual environments. Conversely, in both real-world experiments, we attained a remarkable 100% success rate, underscoring the robustness and reliability of our system across physical applications. These experiments utilized both a manipulator and a mobile manipulator platform, showcasing the versatility and robustness of our system.
In future endeavors, we aim to further test our framework in various operating conditions and explore opportunities for integrating collaborative tasks across multiple robotic systems. Moreover, we plan to explore the representation of affordances within the framework of SMC trees, since we believe that this could enable agents to perceive and respond to a wider range of action possibilities presented by their environment.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}