1. Introduction
Unmanned ground vehicles (UGVs) have seen an increase in popularity amongst operations researchers in recent years. Spanning over several applications such as autonomous cleaning [
1,
2], lawn mowing [
3], surveillance [
4], tillage [
5], and street-sweeping [
6], UGVs can be applied seamlessly to many coverage path planning (CPP) problems. Additionally, UGVs can be used individually or in fleets. When using UGVs in fleets, the efficiency can increase, and overall operation time can decrease at the expense of complicated fleet management strategies [
7,
8]. In this paper, fleet management technology and global path planning for UGV street-sweeping will be the focus.
Compared to other UGV applications, street-sweeping operations are more complex because of the increased number of constraints. Specifically, street-sweepers disperse water (to make sweeping small particles easier), accumulate debris, and drain the battery via normal operation. Typically, a depot serves as the facility where the battery can be charged, the water can be refilled, and the debris can be disposed of. During operation, the status of all the respective constraints should be carefully monitored, and depot trips can be conducted as necessary. The problem becomes increasingly more complex when fleets of UGV street-sweepers are to be managed. Complications arise when street sweepers become inactive during operation due to an unexpected breakdown. In these cases, the remainder of the path allocated to the out-of-service vehicle is left untouched. Ideally, the remainder of the unvisited path for the out-of-service vehicle should be covered by the remaining vehicles in an efficient manner.
The CPP problem relates to the problem where an entity (robot, vehicle, etc.) is assigned the task of traveling over an area. The area may be large, small, complicated, simple, and have obstacles, but the task remains the same. The CPP can be formulated as a variant of the traveling salesman problem (TSP) called the covering salesman problem (CSP) [
9]. In the TSP, the optimal traversal sequence for all nodes should be found, whereas the optimal traversal sequence of a subset of nodes should be found in the CSP [
10]. In the CSP, the vehicle width must be considered, so an edge with a predetermined offset (modeling the vehicle width) may cover some of the required nodes without directly visiting them; hence, only a subset of nodes can be visited.
It is common to see the CPP problem be applied to large and complicated areas. In these cases, the problem can be divided into several smaller feasible areas by using cellular decomposition methods. Then, a local path planner can be used to find the coverage path in each cell (typically an exhaustive sweep of the cell), and a global path planner can be used to find the optimal traversal sequence of the cells. Several methods have been explored in the literature to perform such decomposition, such as boustrophedon cell decomposition [
11], morse cell decomposition [
12], and trapezoidal decomposition [
13]. Each method has its own application, which is dependent on the problem requirements and environmental complexity.
Within the targeted area (or sub-area in the case of cell decomposition), the optimal path to the CPP problem should be found. In the literature, the CPP algorithms can be divided into two classes: classical and heuristic-based algorithms [
14]. Several algorithms exist within the classical type algorithms, such as random walk (RW) and chaotic coverage. The chaotic coverage algorithms can be characterized by topological transitivity and sensitive dependence on initial conditions for a mobile robot [
15]. Typically, to perform such chaotic movements, the controller for the mobile robot is built with a combination of chaotic dynamic variables and kinematic equations that predict the trajectory of the robot [
15]. Some examples of chaotic systems include the Arnold system [
15,
16] and the Lorenz system [
17]. For the RW, a robot moves within the target environment until a collision with an obstacle is detected. In the linear case, the robot will continuously travel linearly until a collision with an obstacle is detected. When this occurs, the next trajectory will be randomly selected within the bounds of the target area [
18,
19]. Additionally, a spiral motion can also be used [
20]. The classical methods are typically continuous and do not guarantee total area coverage [
21], so additional methods were developed to overcome these limitations.
Contrary to the classical methods, additional methods operate using a discrete model of the environment. This can be thought of as a grid-like structure where each cell has a connection to all adjacent cells, also known as a graph. In these cases, greedy search or graph search algorithms can be applied to solve the coverage path. The well-studied Dijkstra’s algorithm has been used to solve the CPP [
22]. However, due to its greedy nature, the global optimal cannot be guaranteed [
23]. Additional methods can be used instead, such as the depth-first search (DFS) and breadth-first search (BFS). DFS has been used for CPP in [
24] for cleaning applications, and BFS has been used in [
25] for aerial remote sensing. Some issues regarding DFS and BFS have been noted in the literature. Specifically, DFS fails to yield optimal paths in infinite-depth spaces, and BFS consumes large amounts of memory due to the branching technique applied [
26].
Additionally, heuristic-based approaches can be used to solve the CPP. The heuristic-based approaches include two categories of algorithms: evolutionary algorithms and human-inspired algorithms. In evolutionary algorithms, a population of search agents is used to model the CPP, and over several iterations (the exploration stage), the search agents can exploit the global optimal solution. In the human-inspired techniques, models mimic the way the human brain works by learning what ideal solutions look like (reinforced learning). Upon completion of the training stage, the model can predict the optimal path for a CPP problem.
As previously stated, the CPP can be modeled as the TSP or CSP. This problem model makes implementing the genetic algorithm (GA) very easy. In the genetic algorithm, the sequence of nodes to be visited is optimized via selection, crossover, and mutation over several iterations [
27]. The objective for this case is simply to find the minimum cost path that visits all the required nodes in the TSP or the minimum cost path that covers all the required nodes in the CSP. The fitness function in the GA is easy to change, thus making it very flexible for different categories of the CPP problem. The GA has been used in several studies in the CPP domain with success [
3,
11,
28], thus making it a great starting point for the CPP problem.
With regard to dividing the workload amongst several homogeneous vehicles, some researchers have referred to this problem as the vehicle path planning and scheduling problem (VPPSP) [
29]. By using an effective scheduling strategy, the overall operation time can be greatly reduced with a fleet of vehicles in comparison to one [
30]. In the VPPSP, a set of autonomous vehicles should visit a set of targets, and each vehicle’s path should begin and end at the depot. In [
29], a modified version of the GA was proposed to solve the VPPSP. In a separate study, the CPP for a fleet of unmanned aerial vehicles (UAV) was solved using the integer programming (IP) formulation [
31]. Their work provided solutions that operate within the constraints of the UAVs. Another study uses a cellular decomposition method to divide a large area into several smaller ones; then, the areas are continuously assigned to UAVs until the constraints are violated [
32]. In each of the sub-areas, a zig-zag pattern is used to cover the area.
Additional studies have focused on the path planning of robotic fleets as a single unit. A large portion of these studies focus on formation control schemes where robots are instructed to maintain a desired formation while following a global path. In one study, a leader-follower control scheme was developed to solve the translational maneuvering problem for robotic fleets [
33]. Their control law consists of individual tracking errors and coordination tracking errors for leader-follower pairs. Another study uses a similar approach but in more complex environments with obstacles [
34]. In this study, two separate control algorithms based on the model predictive control (MCP) scheme were proposed, namely the linear and non-linear MPC. Their methods show improvements over other methods for maintaining formation while simultaneously avoiding static obstacles. Another study focuses on the control scheme for dynamic formations [
35]. In this study, the formation-control problem was modeled as a synchronization control problem specific to the formation requirements. Then, a synchronous controller was used by each robot to ensure that the position and errors were minimized. Simulations and experimental studies validate the effectiveness of the proposed approach. In the mentioned studies, a common goal for the robot fleet is to achieve the desired formation such that the fleet moves as a single unit. However, these studies do not focus on separating the fleet to achieve a goal. Additionally, there is a large focus on the path tracking, and the path planning has not been discussed.
Some studies have considered the failure of mobile robots in fleets. Due to the difference in the expected workload in the event of a vehicle failure, the planned routes will need to be modified to ensure a proper workload balance [
36]. When a vehicle failure occurs, several different approaches may be used to redistribute the remaining paths of the out-of-service robot to the remaining ones. In one paper, a simple approach is proposed called the First-Responder (FR). In the FR, any robot that finishes its route can cover the remaining routes from broken vehicles [
37]. Since this approach does not use any optimization techniques, it was improved by the authors in a later study. In this study, the authors propose an optimization technique to redistribute the paths amongst the remaining robots called Cooperative Autonomy for Resilience and Efficiency (CARE) [
38]. In CARE, the authors were able to improve their FR approach by using a distributed discrete event supervisor to trigger games amongst the remaining robots in the fleet. The games consist of the no-idling game and the resilience game, which are triggered when a robot completes its route and when a robot fails, respectively. The CARE approach shows complete coverage under failures and reduced coverage time.
In the mentioned literature, existing studies discuss area partitioning using decomposition methods, local path planning methods within the sub-areas, and techniques to manage fleet operations for the CPP. From the mentioned literature, not all these techniques have been applied to the autonomous street-sweeping fleet CPP problem. Additionally, a portion of fleet robotic research aims to maintain the formation of a fleet of mobile robots while following a planned path. This research fails to separate the fleet to achieve a goal and instead focuses on moving the fleet as a whole while following a path. This may be beneficial for applications such as highway street-sweeping, where a fleet can cover several lanes simultaneously with a relatively consistent path defined by the road. These approaches work under the assumption that an optimal path has already been planned, and the fleet is now being instructed to follow it using tracking control strategies. However, there is a lack of research involved in the optimization of the planned path for robotic fleets, which is the focus of this study. It means that the research presented in this study aims to separate the fleet and generate the optimal path for each individual vehicle. Additionally, robotic formations cause problems in complex areas such as walking paths since the formation cannot fit within the bounds of the targeted areas, thus requiring individual paths for each vehicle.
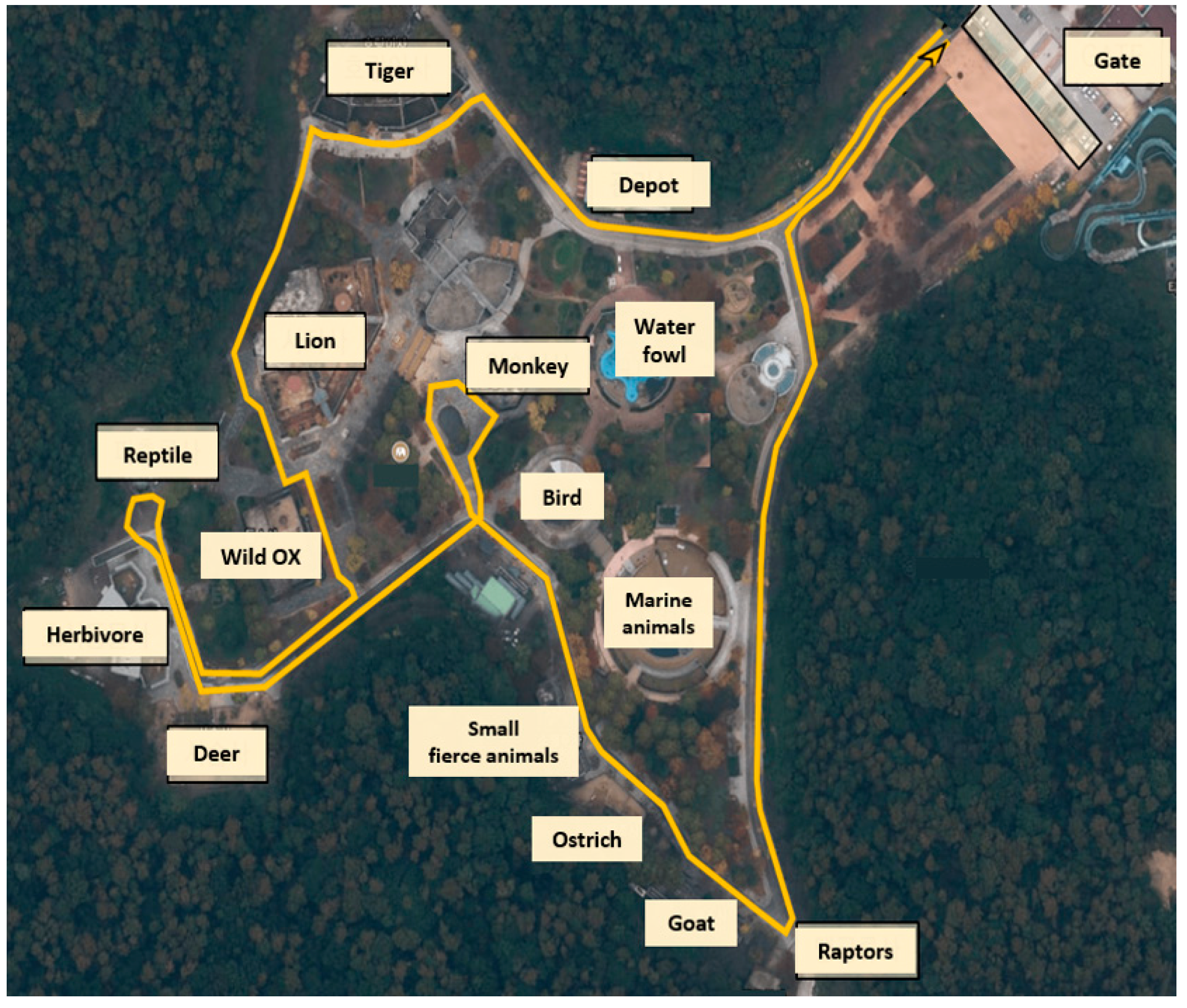
Few studies have examined the breakdown scenario in which a vehicle becomes unavailable during operation for a fleet of autonomous street-sweepers. In the above literature, breakdown scenarios have been considered, but the complex constraints of street sweeping require additional consideration. For example, it may be better for a vehicle with more room in the debris hopper to service the remaining route of one vehicle. Or it may be better for a vehicle nearing the debris capacity to cover the remaining paths near the depot so a short distance can be traveled to dispose of the debris. Such complex constraints have not been considered in the existing literature and require additional methods for proper implementation and consideration. So, the following research aims to fill this gap by applying a lower-level path generation method to calculate the coverage path in each sub-area and a higher-level path generation method to divide the sub-areas amongst the autonomous street-sweepers while selecting the optimal start location for each sub-area. The proposed route optimization techniques can consider several real-world constraints that are specific to street-sweeping (debris, water, battery, and vehicle breakdown conditions) while also providing near-optimal results for the NP-hard problem. Additionally, the proposed methods can be applied in breakdown scenarios to redistribute the un-serviced path (from the broken vehicle) to the remaining vehicles. A case study for Uchi Park Zoo will be presented to show the effectiveness of the developed algorithm.
The remainder of the article is organized as follows:
Section 2 discusses the methods used to solve the lower and higher-level path planning problems,
Section 3 discusses the problem-specific parameters for the case study in Uchi Park Zoo and the graph generation methods for the lower and higher-level optimization,
Section 4 presents results for two operational conditions (two normal vehicles, and one normal vehicle with a vehicle that breaks down) in Uchi Park Zoo, and
Section 5 concludes the following research.
2. Route Generation Methodology
Previous research has discussed several approaches for solving the CPP. However, existing methods have not considered complex operational constraints related to autonomous street-sweeping when generating routes, which makes them difficult to apply to this specific set of CPPs. Additionally, previous methods have explored the occurrence of failures in fleet robotic operations but similarly lack the ability to handle the complex constraints of autonomous street-sweeping.
Lower-level and higher-level path planning algorithms were developed to overcome such limitations. The lower-level path generation creates the optimal coverage path within each sub-area, while the higher-level path generation creates the total path for each vehicle while considering the respective constraints. The lower-level path generation is composed of a novel route optimization algorithm named the Smart Selective Navigator (SSN), and the higher-level path generation makes use of a modified version of the GA. Higher-level path generation is also responsible for generating complete routes that include depot trips as necessary (when the water or debris capacity is met). Both path-generation methods will be explained in detail in this section.
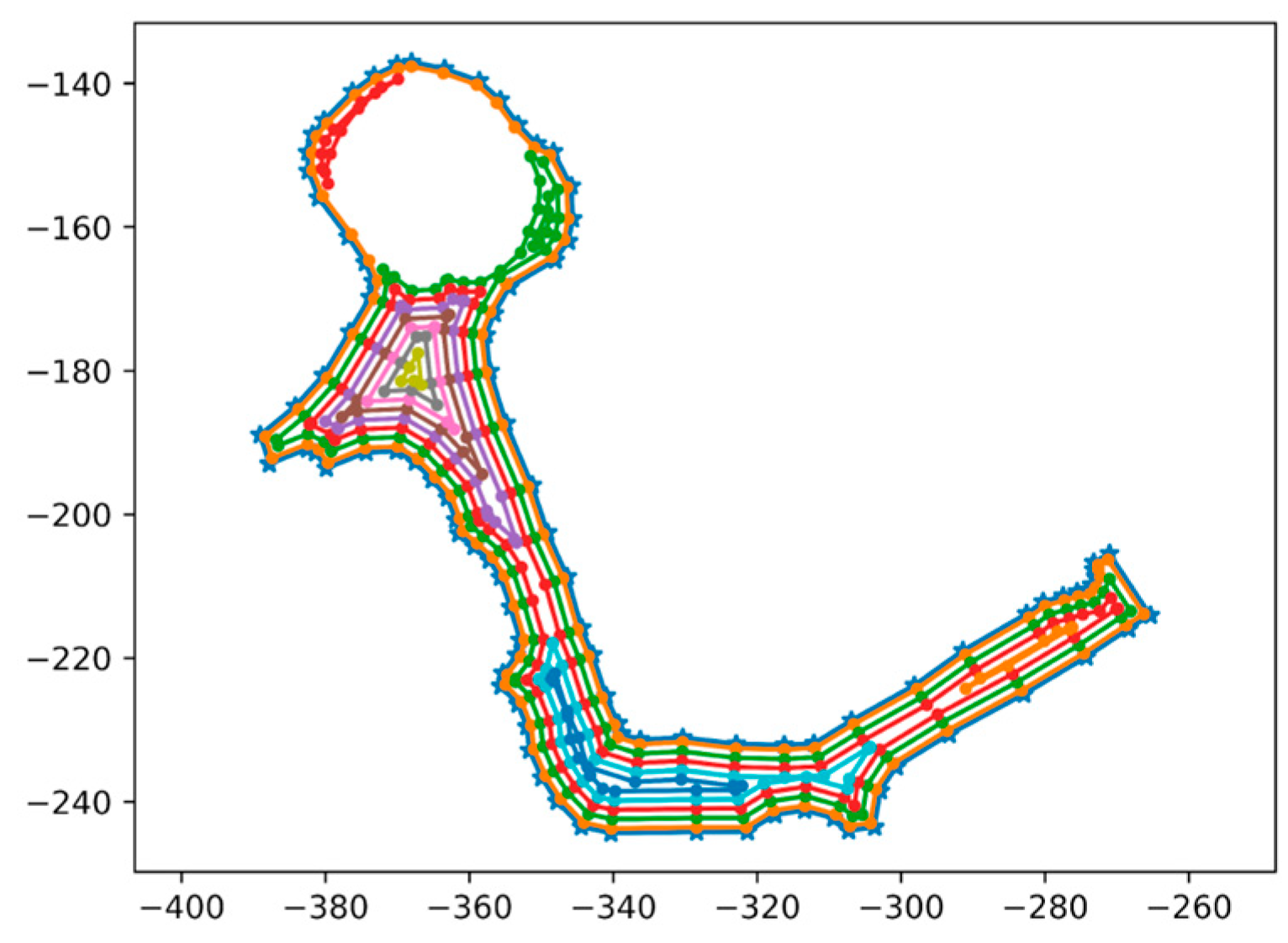
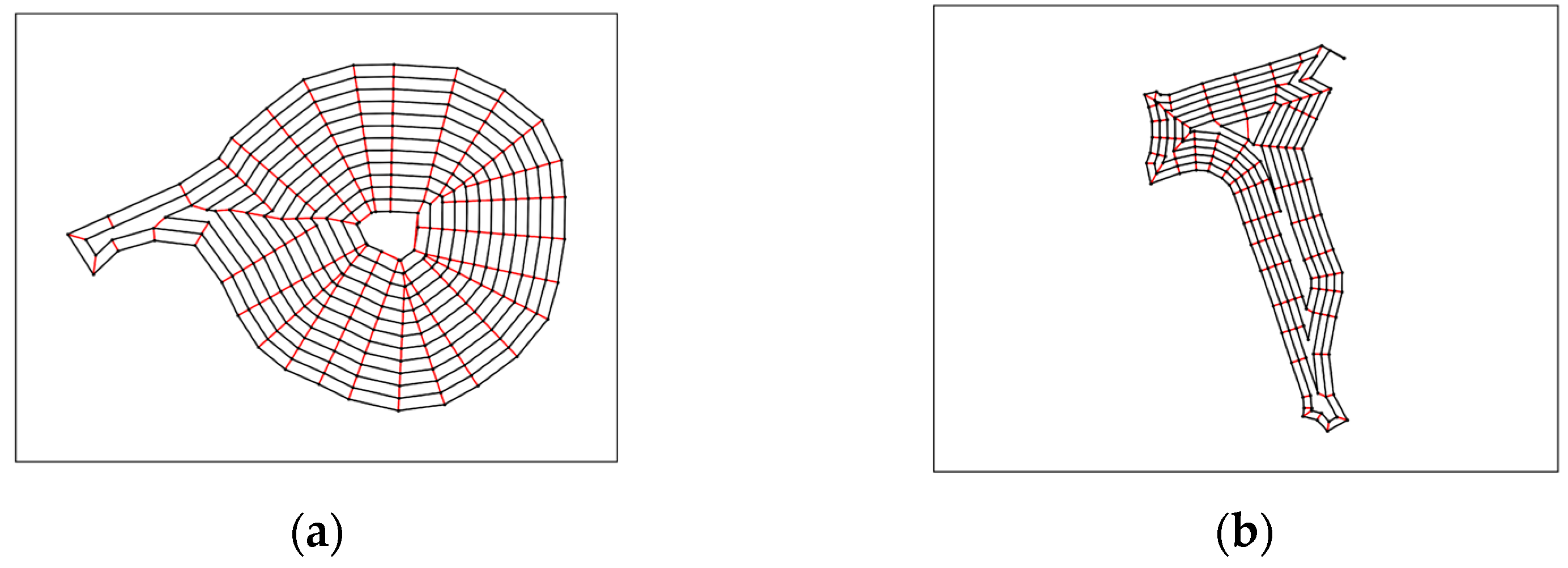
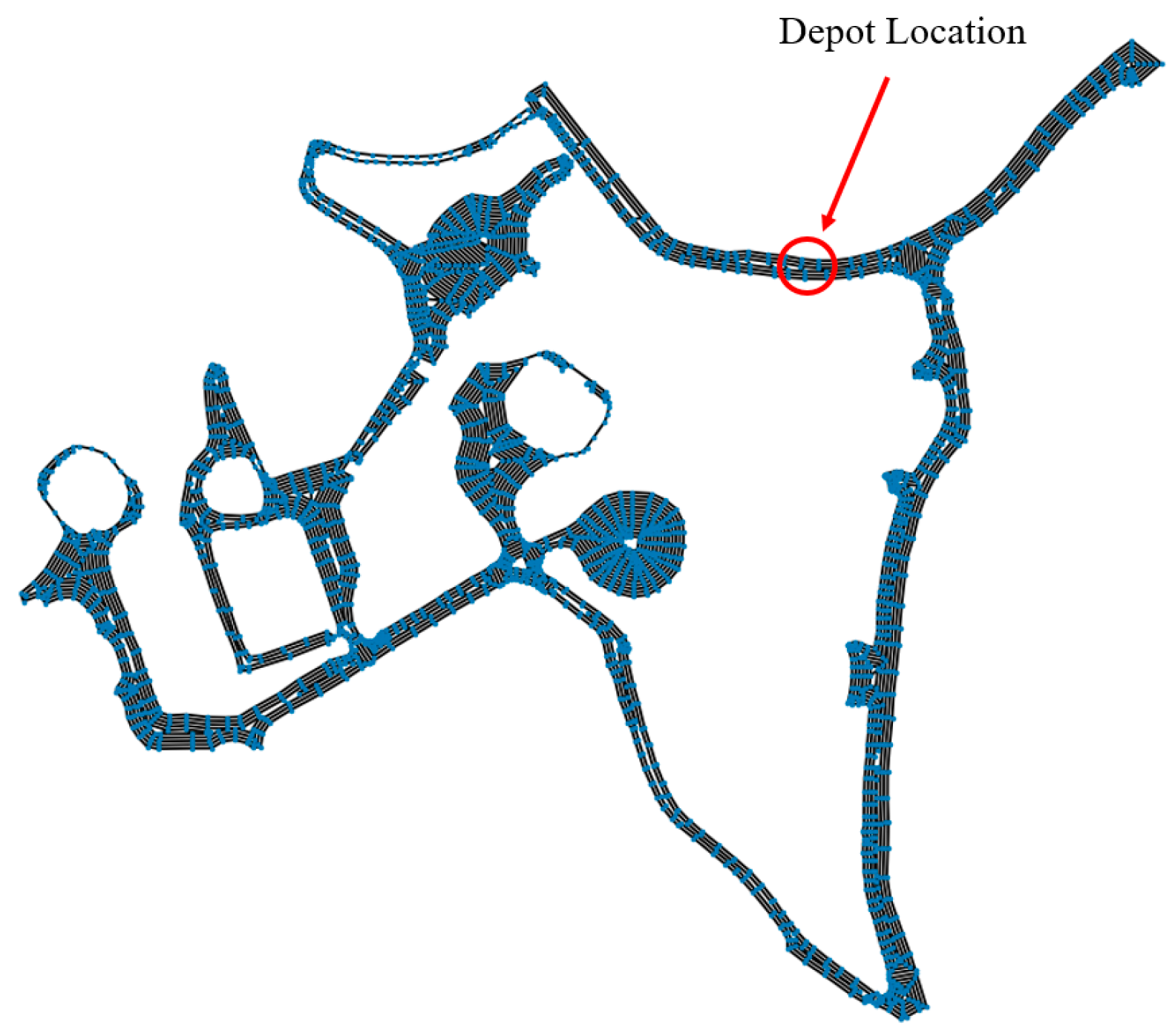
For the proposed methods to work, it is assumed that a target area has been converted into a graph structure and that the total graph is divided into several sub-areas that are to be serviced. Each sub-area may have serviceable and non-serviceable edges. The sub-area division can be performed automatically (as seen in literature as the decomposition method) or manually for logistical purposes, and each sub-area can have several candidates starting locations with predetermined endpoints.
2.1. Lower-Level Path Generation
A novel algorithm named the Smart Selective Navigator (SSN) was used to generate the lower-level paths. However, any other route optimization methods can be used in this stage. The purpose of the lower-path generation is to pre-process several candidate paths for each sub-area such that the optimal one is selected by the higher-level path generation algorithm (which will be discussed in the next section). The SNN is a non-backtracking heuristic method created for logistics problems. SSN is a turn-based approach that assigns jobs (serviceable edges) to idle vehicles at each Time Interval (TI). This method can handle multiple vehicles at the same time and incorporate many different constraints such as fuel restriction, turn restriction, etc. Instead, the vehicle constraints are handled in the higher-level path generation (which will be discussed in the next section). However, it is assumed that only a single vehicle is used, and it is equipped with enough resources to service the entire area. In the SSN, the vehicle should have a predefined starting point, and the vehicle will continue to service the graph until one of the following conditions are met:
The second condition is defined to prevent vehicles from getting stuck in loops. The quality of the routes created using the SSN can be calculated using Equation (1).
In Equation (1), the
is the number of edges that were supposed to be serviced but were not due to the second stop condition. In the ideal case, the
will be 0, but this is not the case for the initial solutions produced using SSN. Additionally, a
is applied to the paths created using SSN, which can be formulated in Equation (2). The time penalty is applied to penalize sharp turns that are difficult for vehicles to perform. In Equation (2), it is assumed that a 180° turn (u-turn) takes 10 s to perform, so any other turn is a fraction of this. This was considered because the turn radius was not directly integrated into the lower-level graphs.
As previously stated, SSN operates using a turn-based approach to assign jobs to the vehicle at each TI. At each TI, the vehicle’s current position is acquired (
), then the score of all neighboring nodes (
) is calculated. The edge created (
)) by the neighboring node with the best score will be assigned to the vehicle. The score for neighboring nodes can be calculated using Equation (3) where
−
are coefficients that need to be optimized (using a GA), and each sub-score in Equation (3) can be calculated using Equations (4)–(8).
In Equation (5), corresponds to the layer that is located on. The layer numbers are defined during the lower-level graph generation stage, where they increase inwards. In Equation (6), the set corresponds to the turn type to reach node from , where 1 is straight, 2 is right and left, and 3 is a u-turn. This is used to provide a preference for fewer turns in the generated path. The in Equation (7) is used as a predictive method to observe the score of the three edges following . For this, only the first 3 scores (: , : , : ) are used. Then, the average can be taken, hence the division by 9. Finally, the in Equation (8) is used to prevent redundant travel and to avoid endless loops. The corresponds to the number of times that has been visited. Then, 1 is also added to the denominator since unvisited nodes would have a equal to 0.
The output of the lower-level path generation is a service path that begins at the desired starting node for the corresponding lower-level graph. Due to the complexity of the problem (NP-hard), it is assumed that the solution found is a local optimum near the global one. Since a GA is used to find an acceptable set of coefficients ( − ) used by the SSN, the complexity for a single solution can be estimated as , where is the number of generations, is the population size, and is the size of the individuals. To ensure that a good solution is found, a sufficient population size and number of generations should be used, but this directly affects the computation time.
2.2. Higher-Level Path Generation
The purpose of the higher-level path generation is to assign the vehicles to each area, add depot trips (in the event of constraint violations), and create the total path that begins at the depot, services all required areas, and returns to the depot. To do so, a modified GA is proposed that can manage the fleet scheduling problem while considering all constraints. A similar approach was proposed by Sun et al. to assign robots to areas; however, their approach lacked the inclusion of depot trips since constraints were not considered in their problem [
39].
The GA was developed for solving complex discrete (combinatorial) optimization problems [
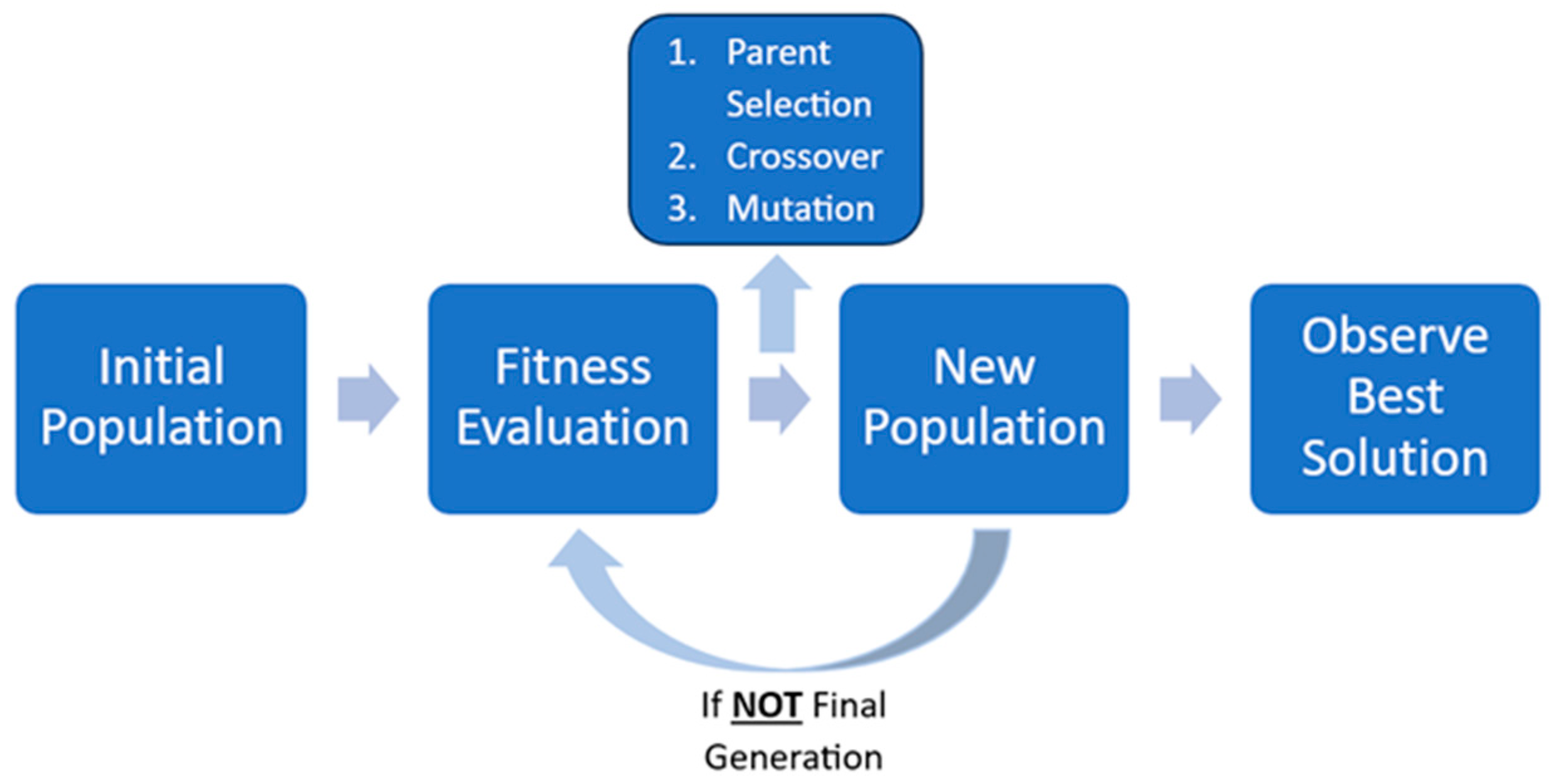
40], but it can also be encoded to solve continuous optimization problems. It does so by mimicking the evolutionary process proposed by Darwin, which consists of crossover, mutation, and survival of the fittest. After several generations, the solutions will have converged at an optimal solution. The GA process can be visualized in
Figure 1.
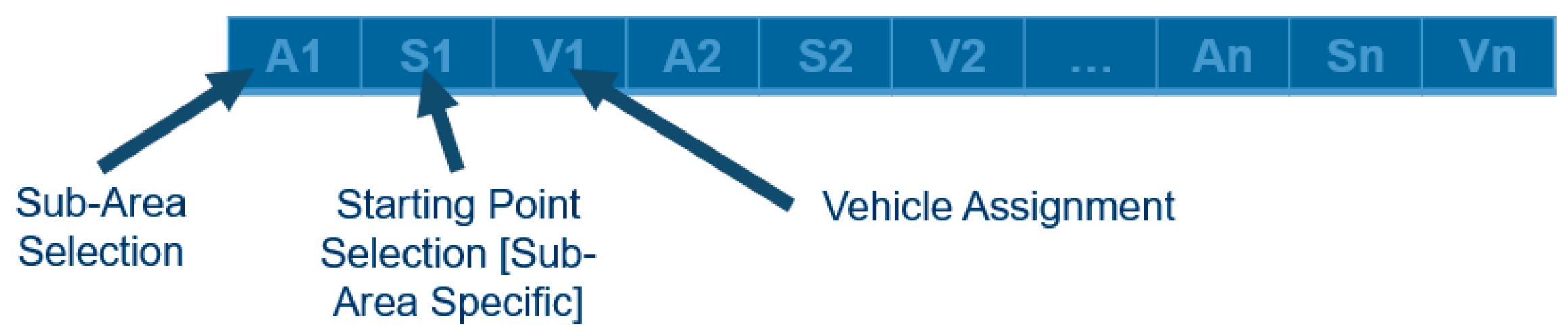
To use the GA, the problem parameters should be encoded into a structure referred to as a “chromosome,” which can be thought of as a list. In the chromosome, there are several values called “genes” that will be used to calculate how ideal the chromosome is. This is also called “fitness”; where the lower the fitness is, the better the solution is. Since the GA is a population-based metaheuristic, it consists of a population of solutions that will be continuously evolving over several generations.
As shown in
Figure 1, the GA process begins with an initial population. The population can be initialized by randomly assigning values to each gene within the problem constraints. Since the initial population is randomly generated, the average fitness is usually not good. To improve the solutions, the selection, crossover, and mutation operations are used over several generations.
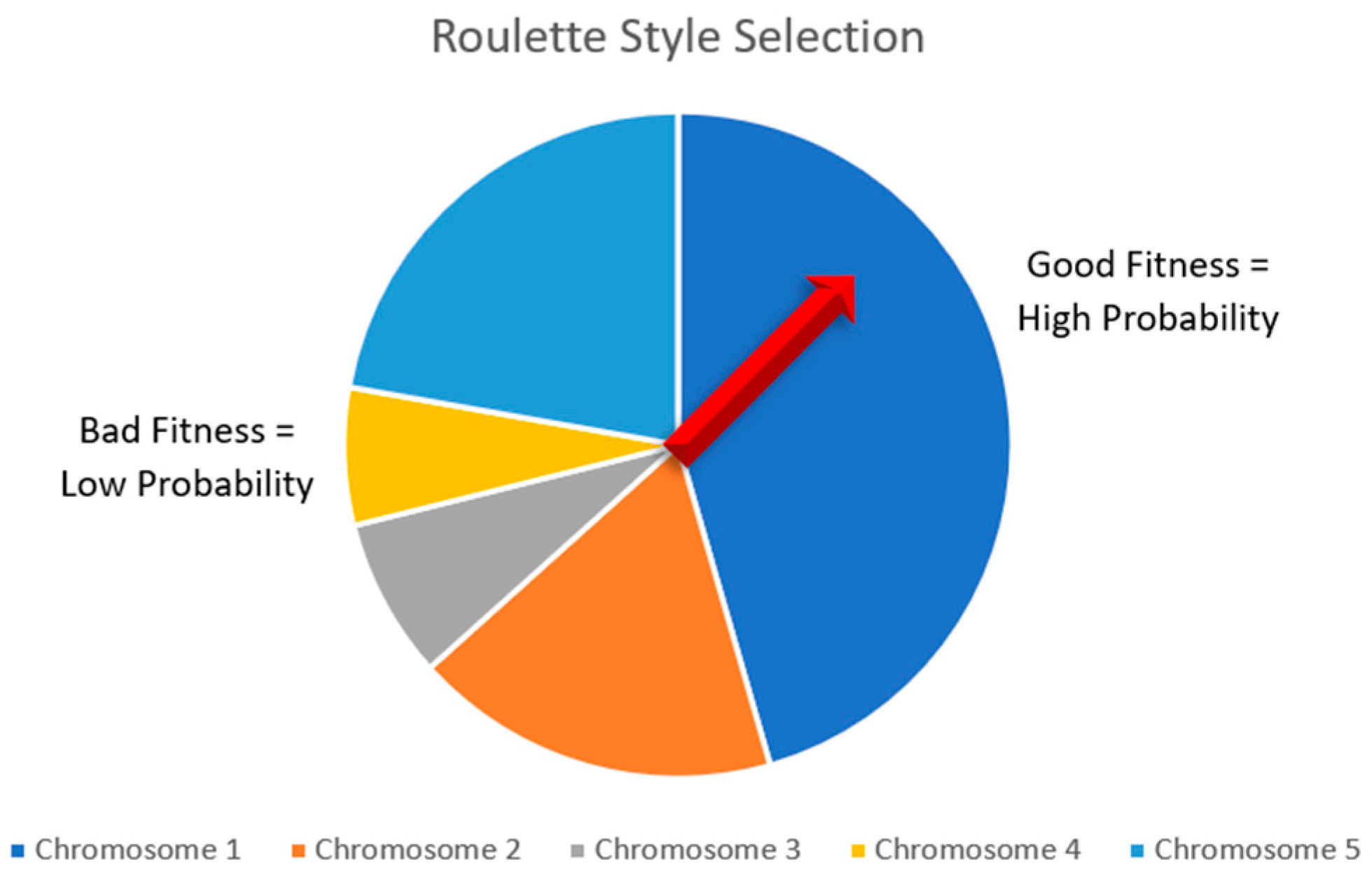
A roulette-style selection is commonly used to select parents. The purpose of selection is to pick two members of the population to create children with. The hypothesis is that when two good chromosomes are selected, the children of the parents will be even better. By using a roulette-style parent selection, solutions with better fitness have a higher probability of being selected. Additionally, the parents should both be unique such that a new pair of children is created. An example of the roulette-style selection can be visualized in
Figure 2.
The parents selected using the roulette selection will undergo crossover and mutation to create two unique children. The selection and reproduction stage repeats until the new population is the same size as the old one. Additionally, the best two solutions from the previous generation will be carried over into the next population to preserve them.
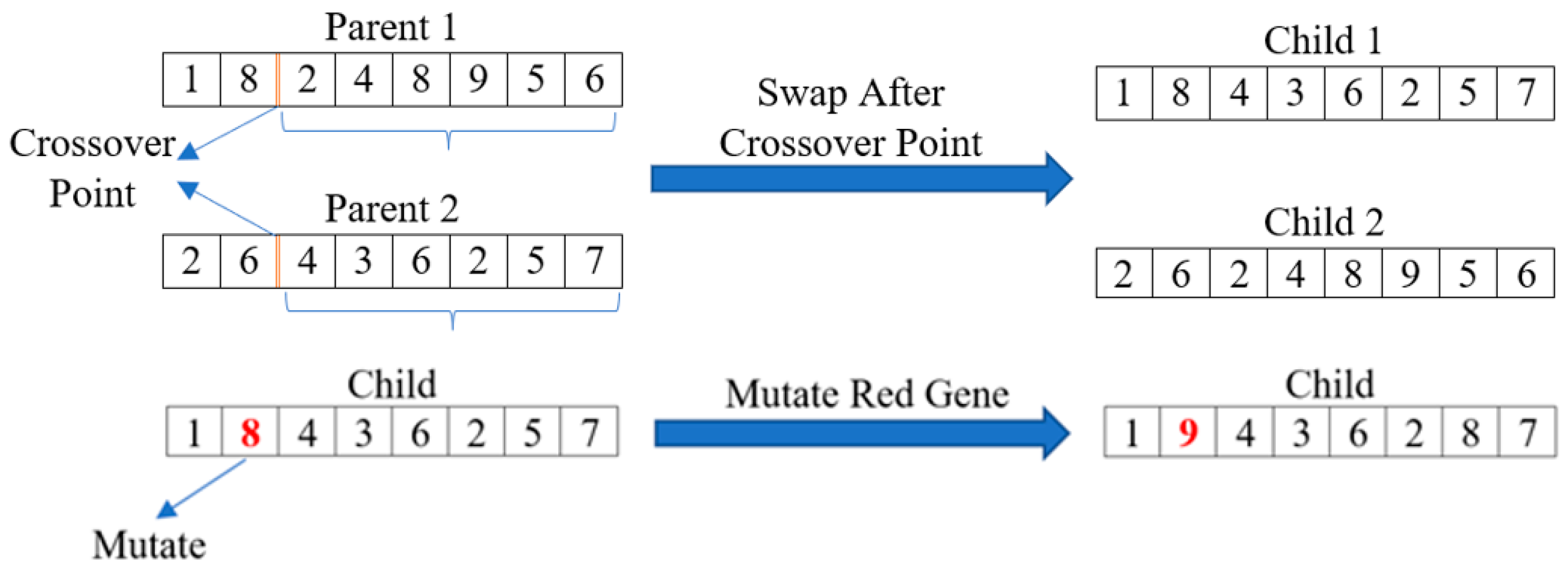
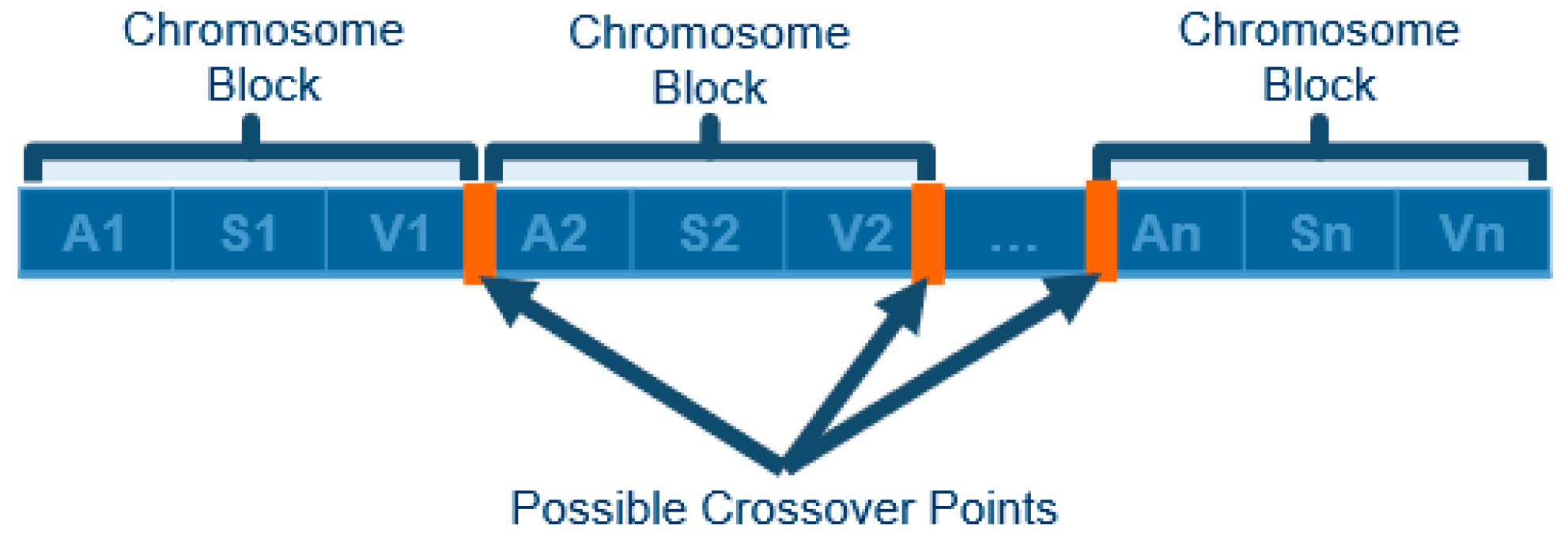
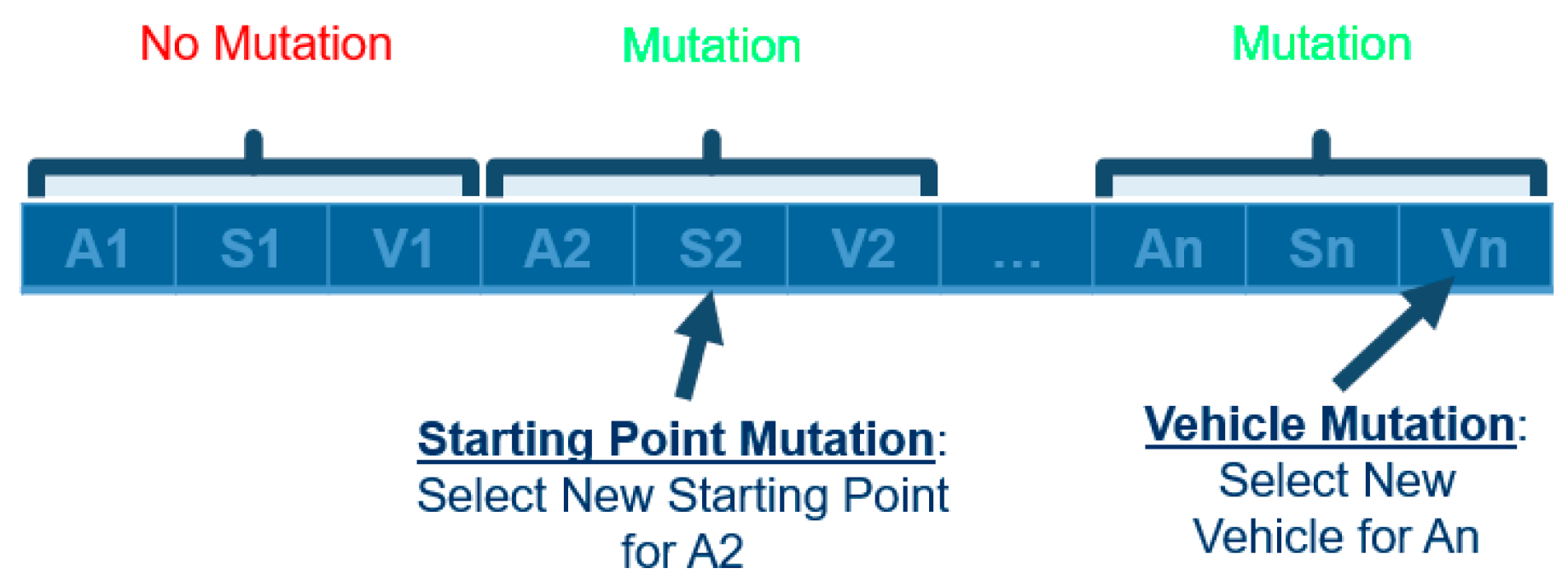
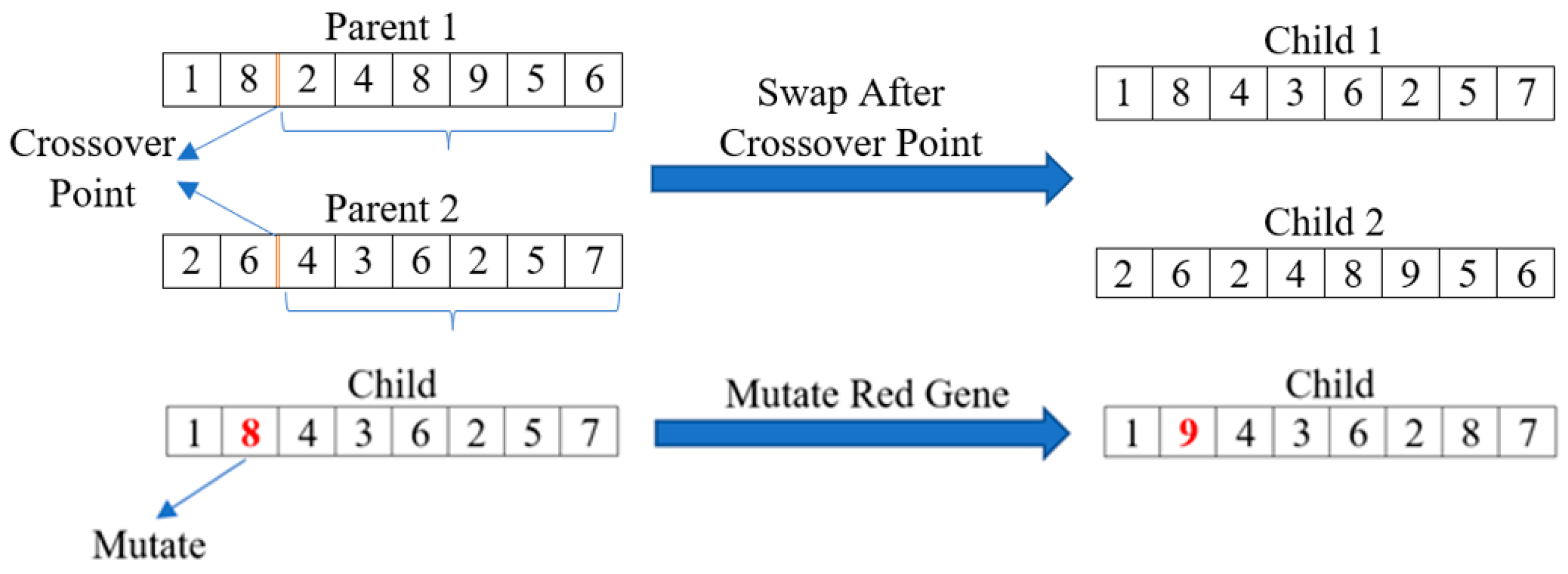
To perform crossover, a random crossover point (index) is selected, and the genes from each parent can be spliced together to create a pair of unique children. Crossover only occurs if a randomly generated number (between 0 and 1) is less than the predefined crossover rate. If crossover should not occur, the children are simply the same as the parents. Then, mutation can be applied to each of the children produced. The mutation operation randomly changes one (or more) gene in each child with respect to the problem constraints. This is performed by iterating over the genes of the children and generating a random number between 0 and 1. If this number is less than the predefined mutation rate, the gene will be mutated. In the literature, the crossover probability is much higher than the mutation probability. This is because the large crossover probability allows for greater exploration of the solution space, while the lower mutation probability allows the solutions to explore the neighboring solutions space more effectively. The crossover and mutation processes can be visualized in
Figure 3.
The GA was selected for this research as a means of assigning vehicles to sub-areas and selecting the optimal start point within each sub-area. The objective of the GA was to find the optimal solution that yields the lowest overall traveling time. The overall traveling time can be defined as the longest traveling time out of all operating vehicles. This can be formulated in Equations (9) and (10). In Equation (9),
is the objective function, which is to minimize the overall operation time (maximum operation of all operational vehicles), and
is the operation time of vehicle
. The vehicle operation time (
) can be formulated in Equation (10), where
is the distance from the last area assigned to vehicle
to the depot,
is the deadhead speed,
is the servicing speed,
is the distance from the vehicle to the starting point of the next service area
,
is the distance of the servicing path in sub-area
, and
is the distance from the point where a constraint is violated to the depot.
is multiplied by 2 since the vehicle needs to go to the depot and back when a constraint (water or debris capacity) is violated. When
,
is the distance from the depot to the starting point of the first sub-area. All distances were calculated using the A* shortest path algorithm [
41].
The objective function can be modified to improve the workload balance, minimize distance, or any other quantifiable metric. However, it was found from experimentation that the overall servicing time minimization yielded the best results.
2.3. Real-Time Scheduling
When the higher-level path generation algorithm is executed, the paths for each vehicle are planned based on the initial conditions. Typically, each vehicle begins at the depot with a full water tank, empty debris tank, and full battery. However, the algorithm can provide optimal solutions based on the input conditions if they differ from the expected ones. For example, the vehicles’ starting locations may differ from the depot, which will result in different paths.
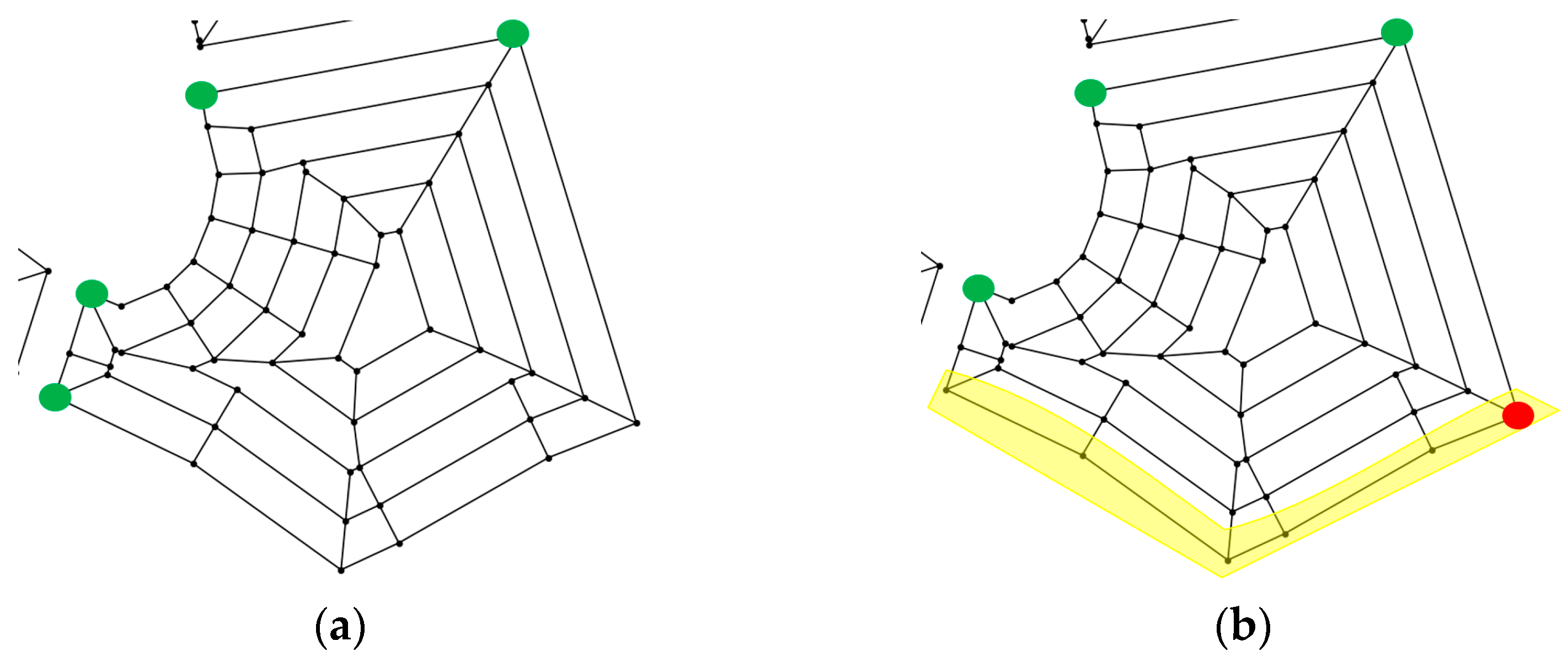
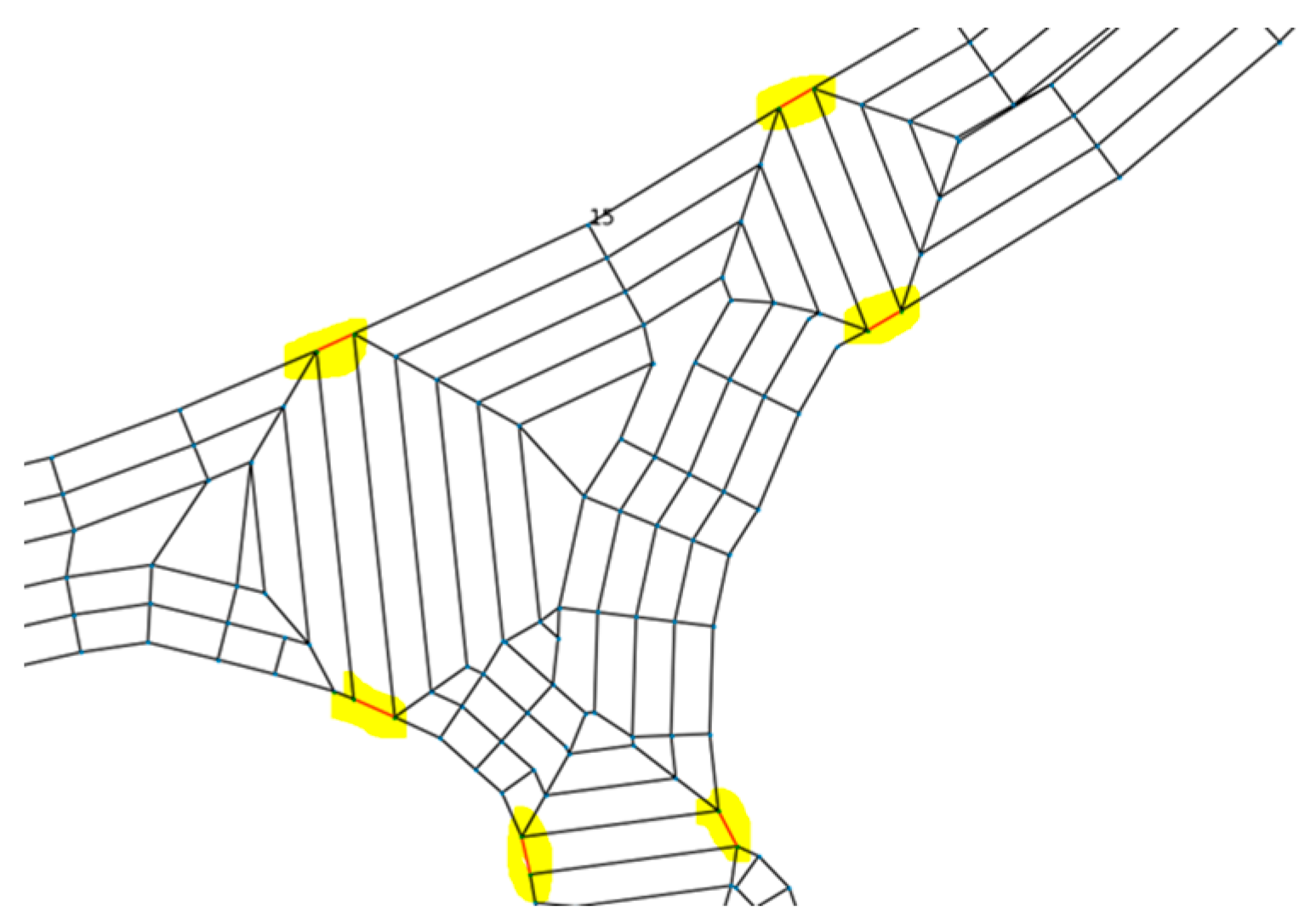
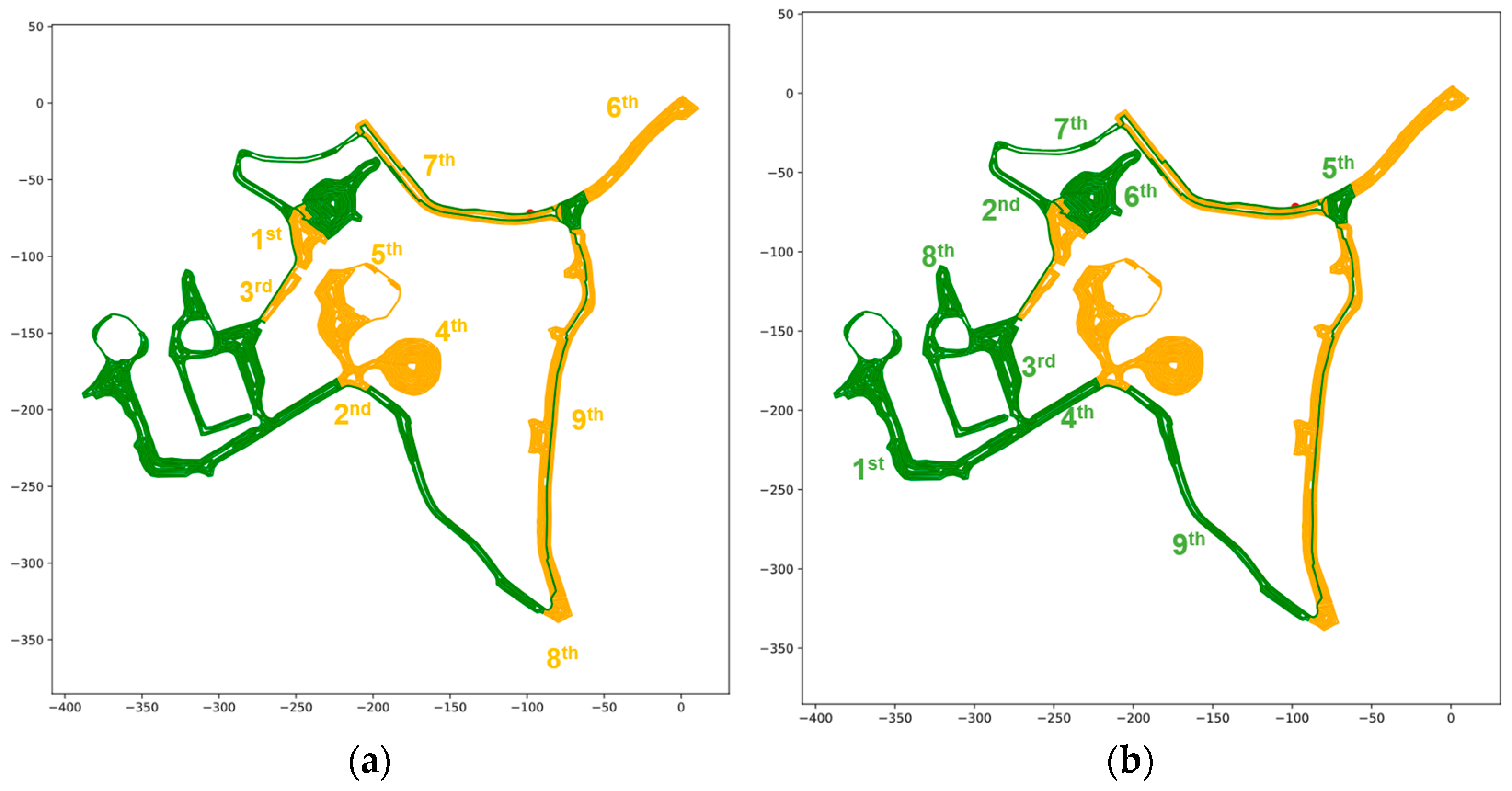
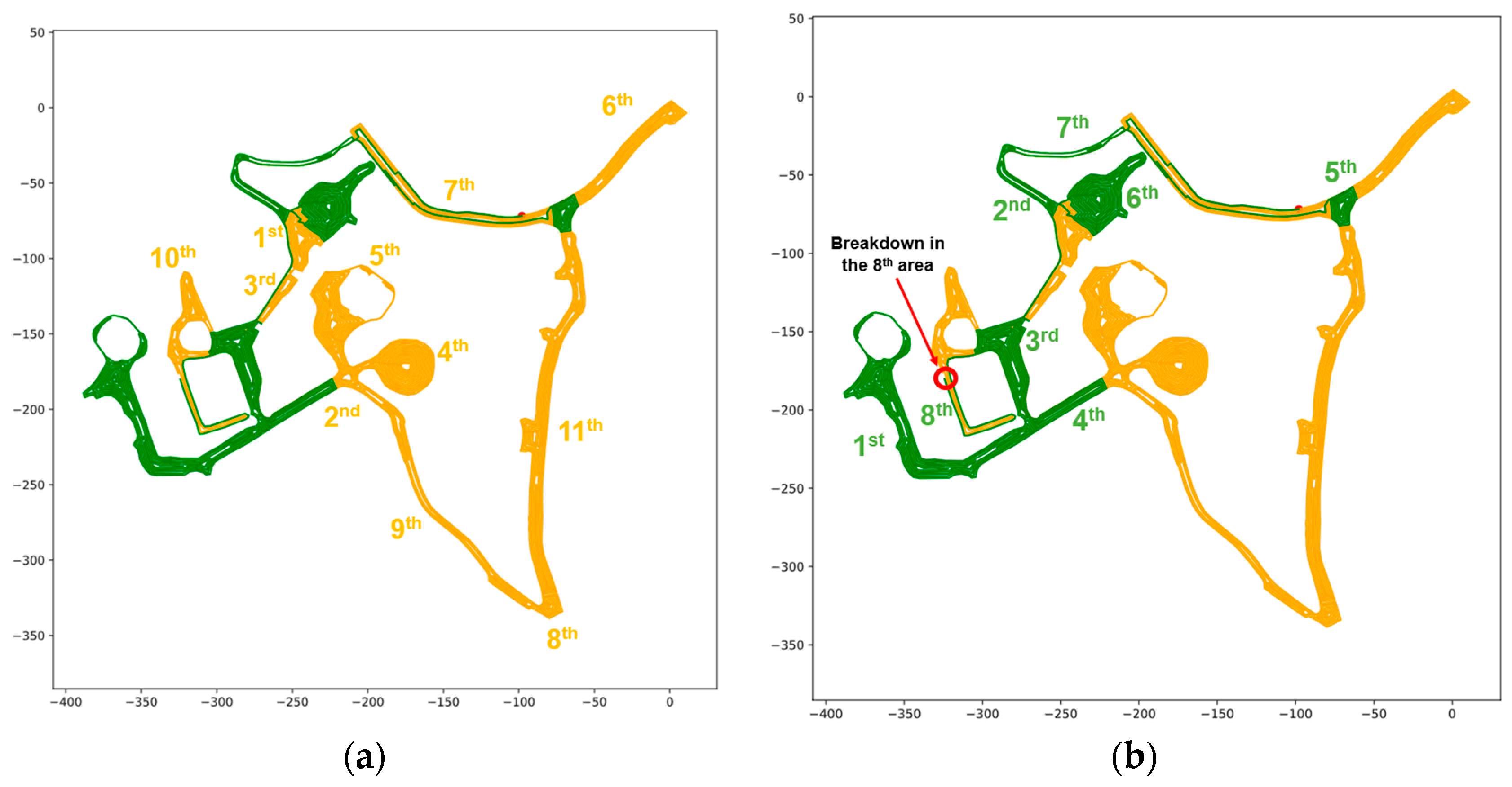
This concept can be extended to the real-time scheduling aspect of this study. Specifically, when a vehicle becomes out of service (due to an unexpected breakdown), the portion of the path that has already been serviced does not need to be serviced again by the remaining vehicles. So, each vehicle should be keeping a record of the originally planned path and the portion of that path that has been serviced already. When a breakdown occurs for one of the vehicles, the higher-level path generation algorithm can be executed again with the portion of the graph that has not yet been serviced. To do this, the edges that have been serviced in each sub-area can be removed from the higher-level graph, and the lower-level paths can be updated with new starting point(s) that are dependent on how much of the sub-area has been serviced before the breakdown. A graphical example of this can be found in
Figure 4, where the same concept can be extended to all sub-areas in the higher-level graph.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}