



Integrating the Generative Adversarial Network for Decision Making in Reinforcement Learning for Industrial Robot Agents



Abstract
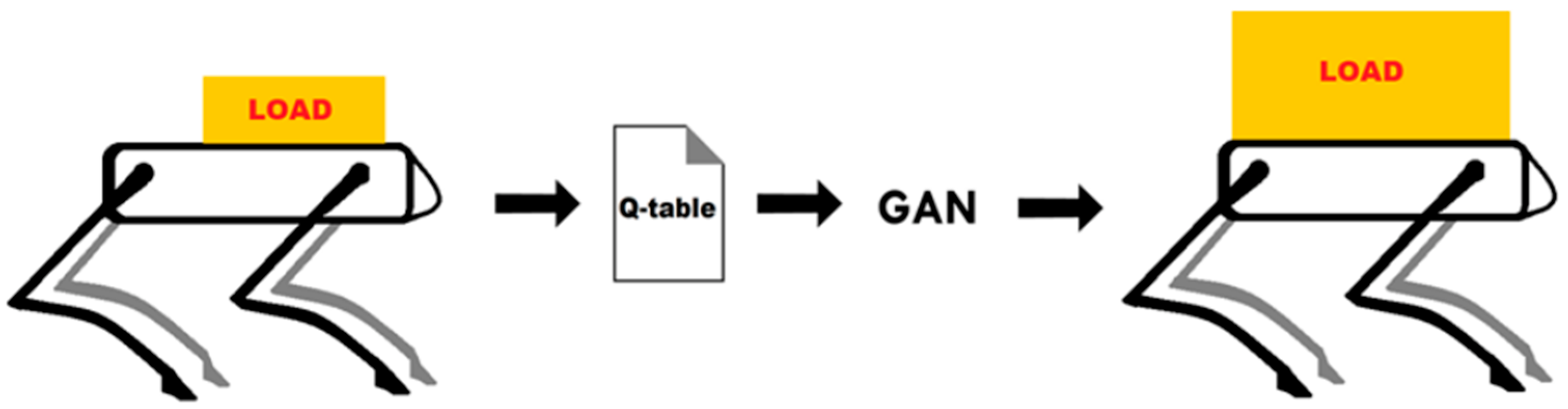
:1. Introduction
- (a)
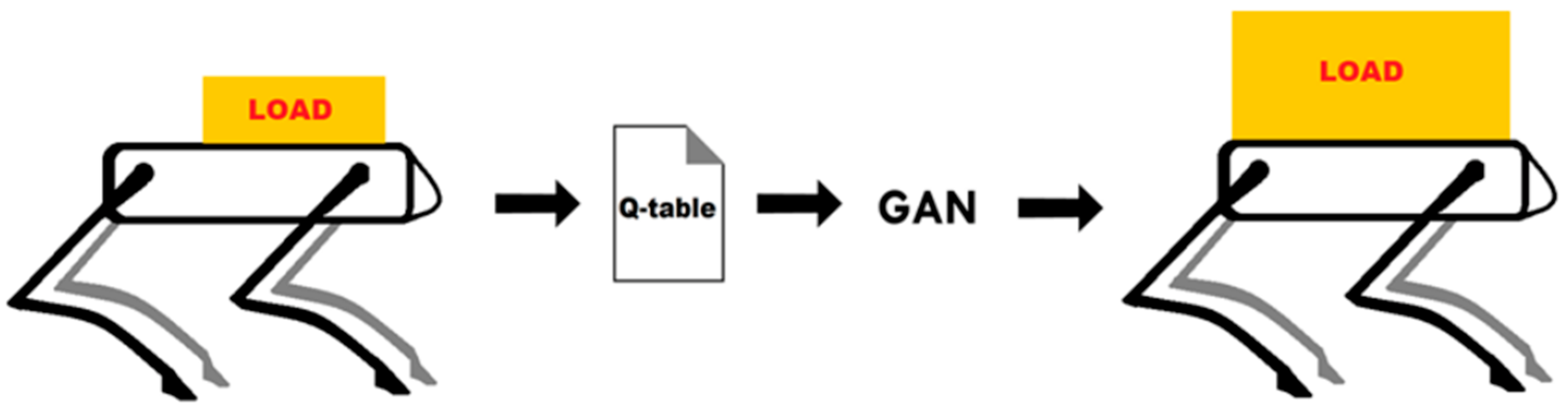
- Development and demonstration of an approach to make the robot agent adaptable to the increased payload via the use of GANs.
- (b)
- Proposed an approach for mitigating the need for agent re-training with changing payload leading to saving of time and resources.
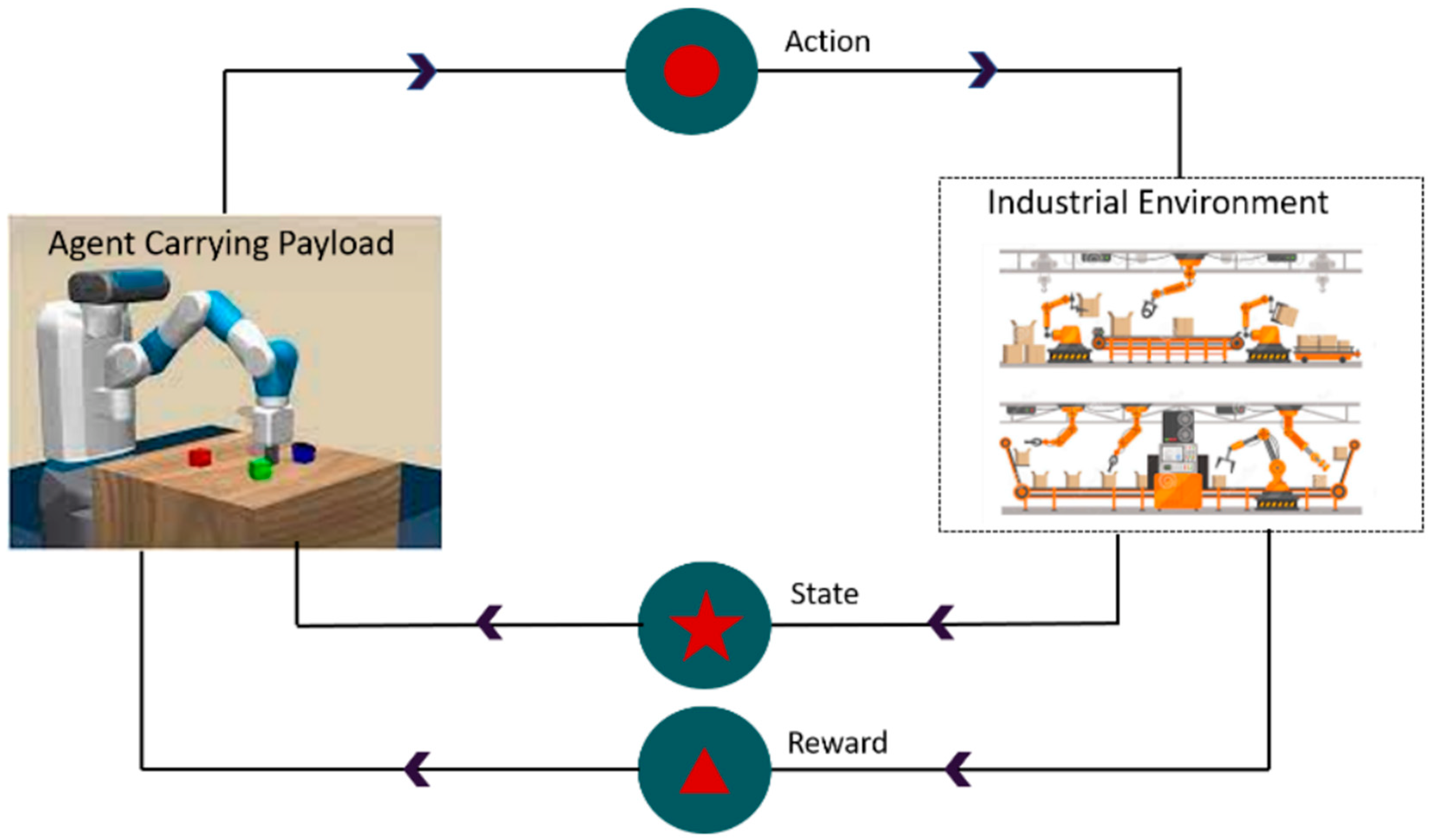
2. Problem Formulation and Assumptions
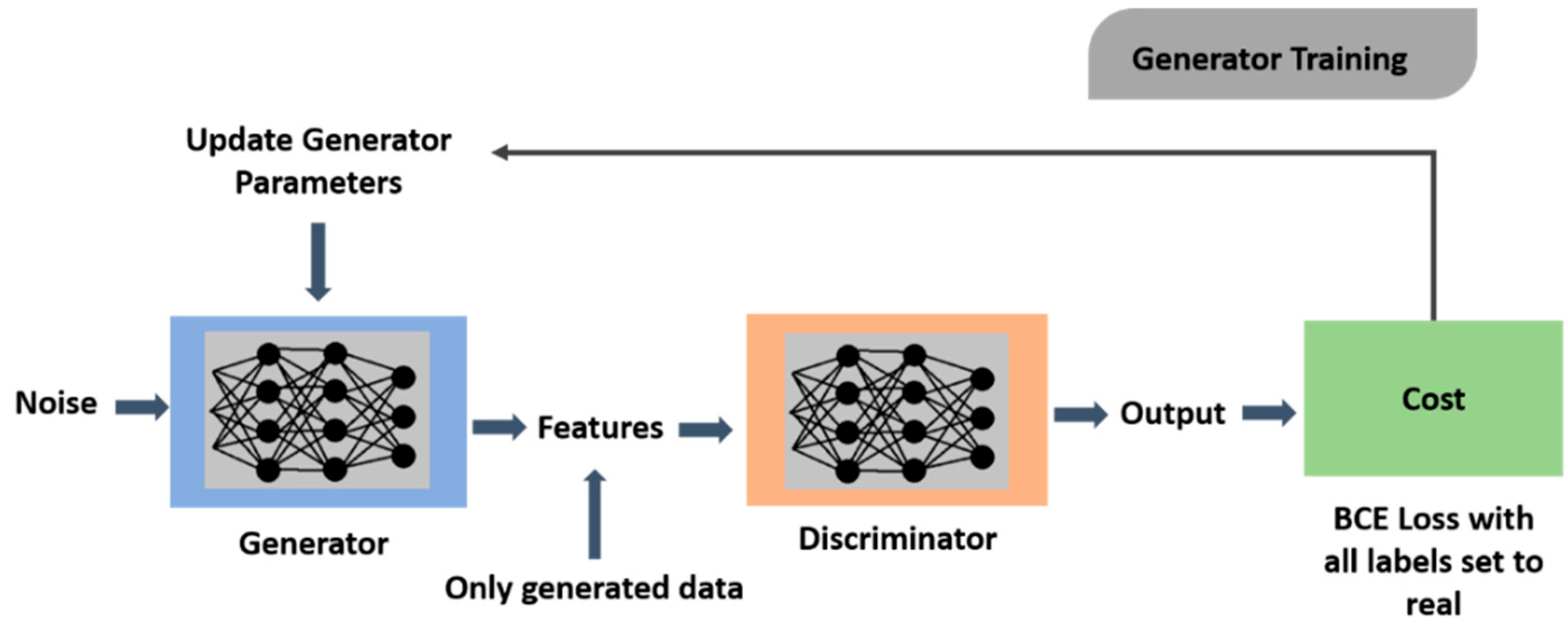
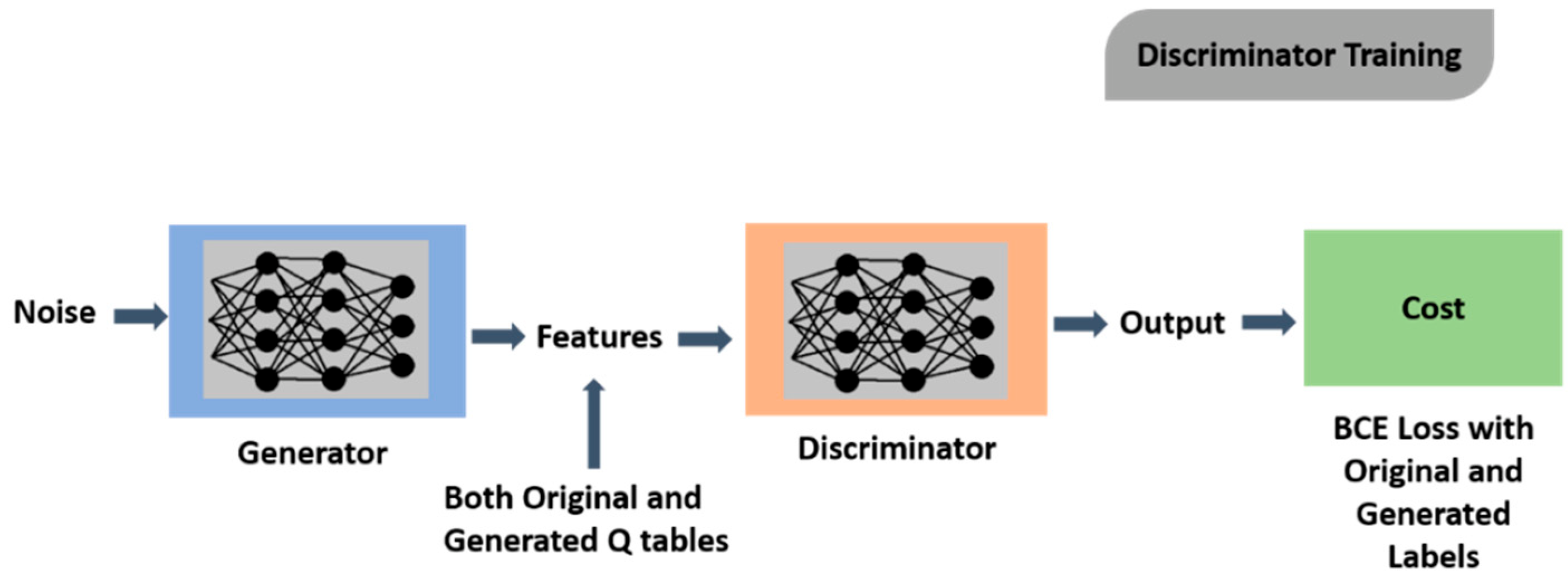
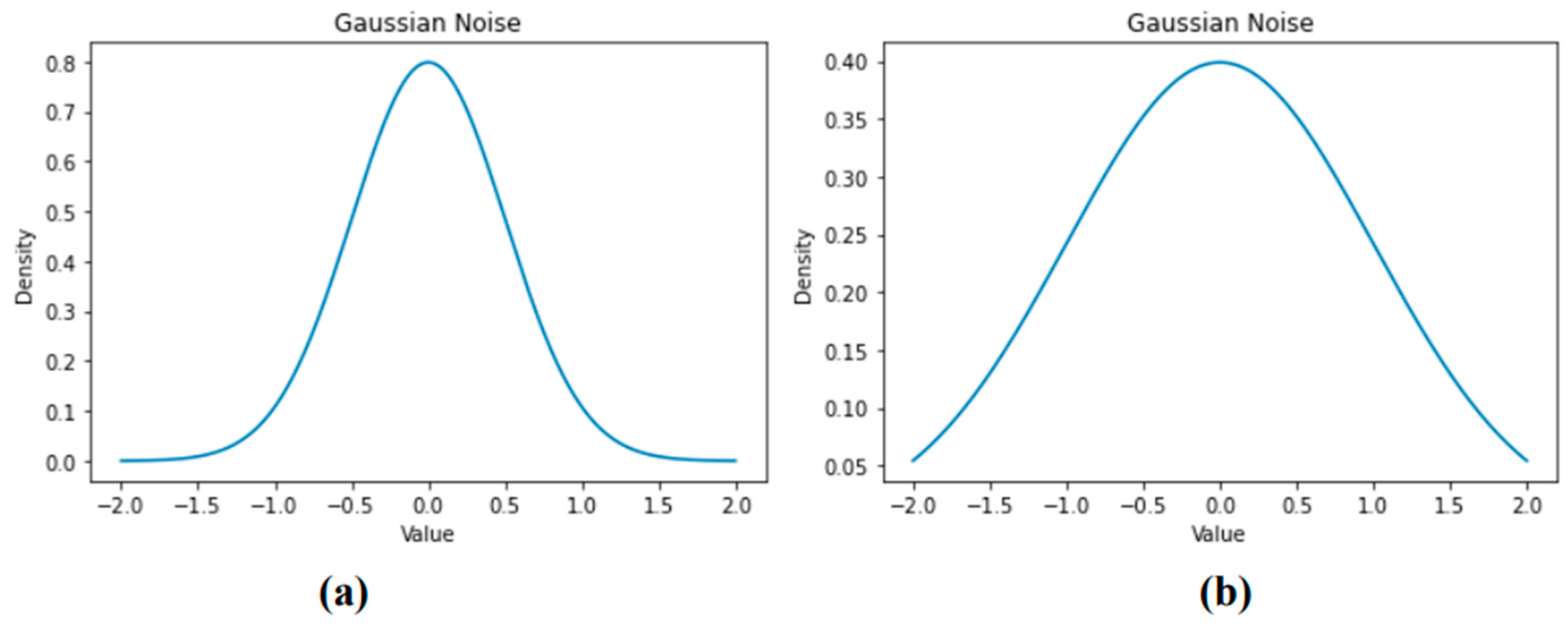
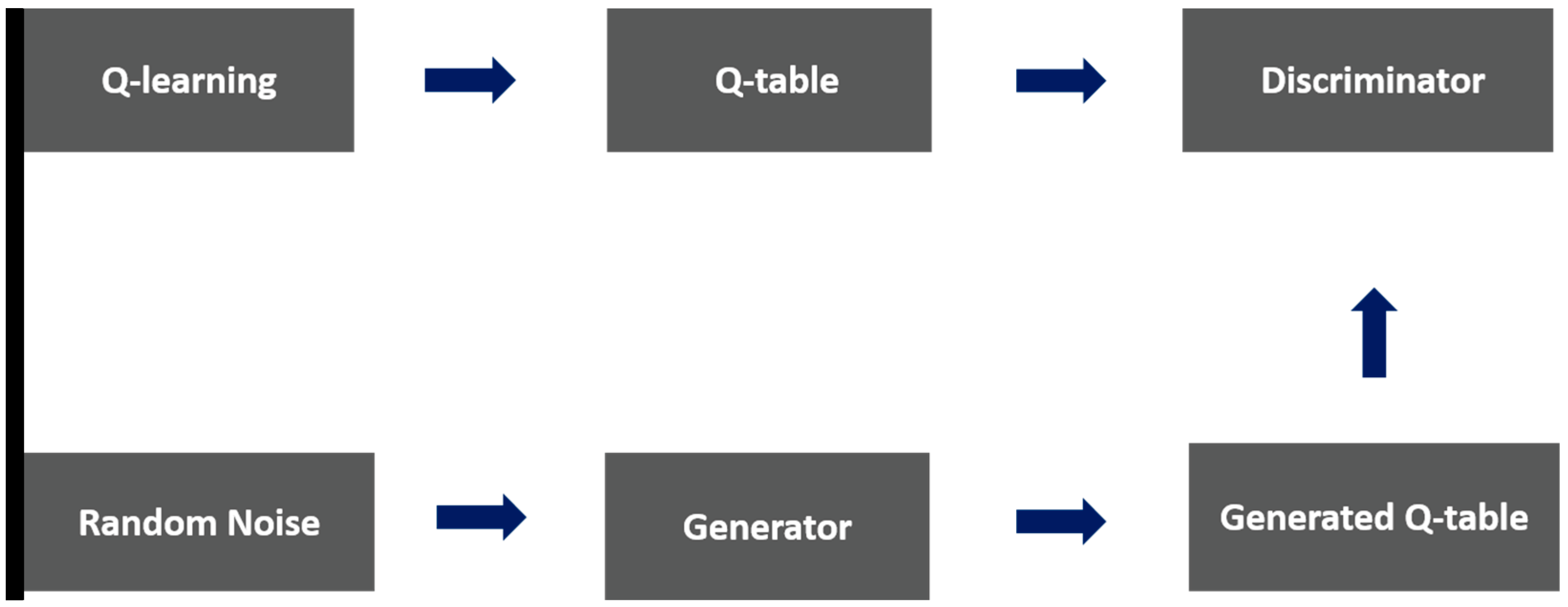
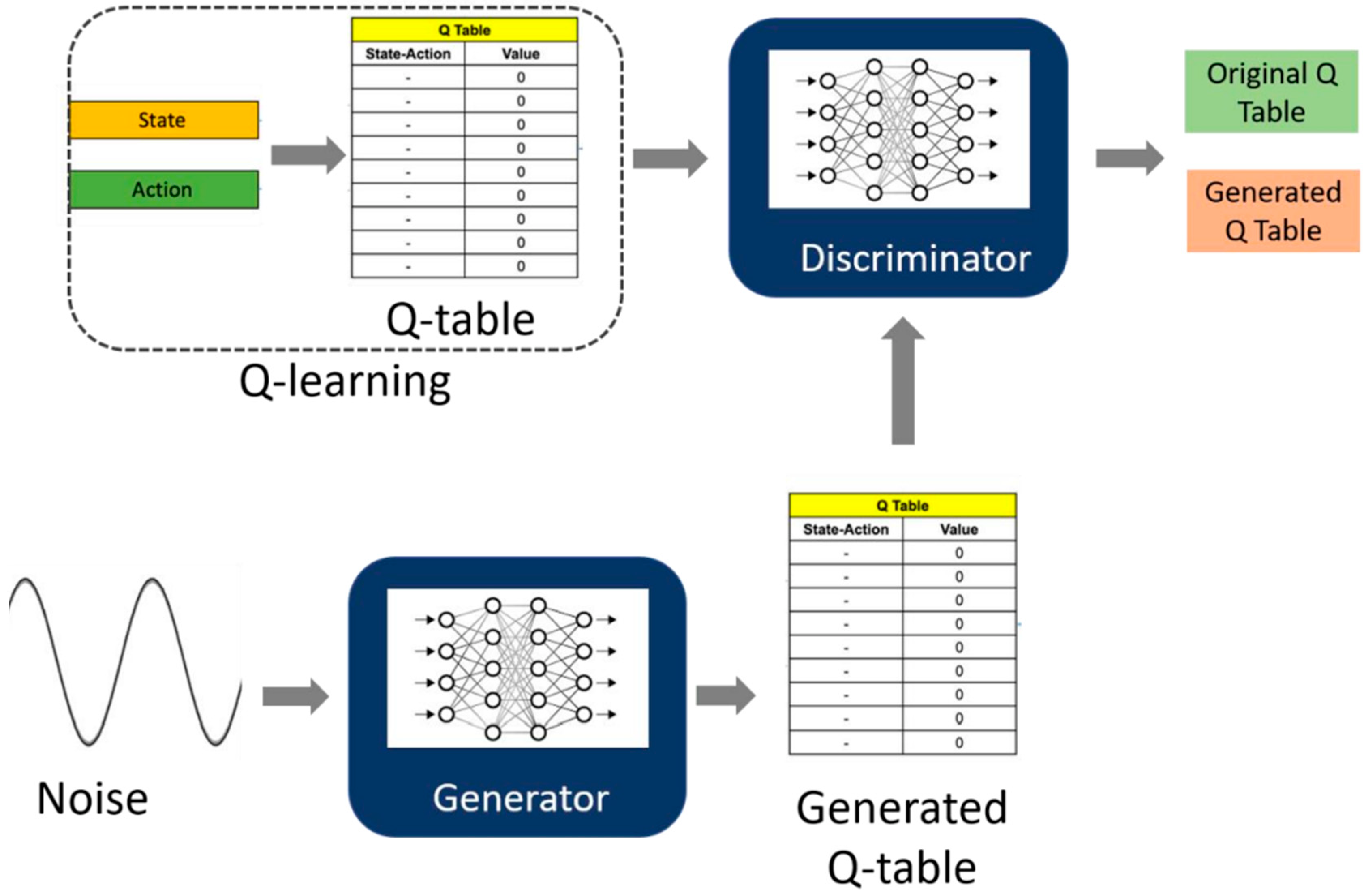
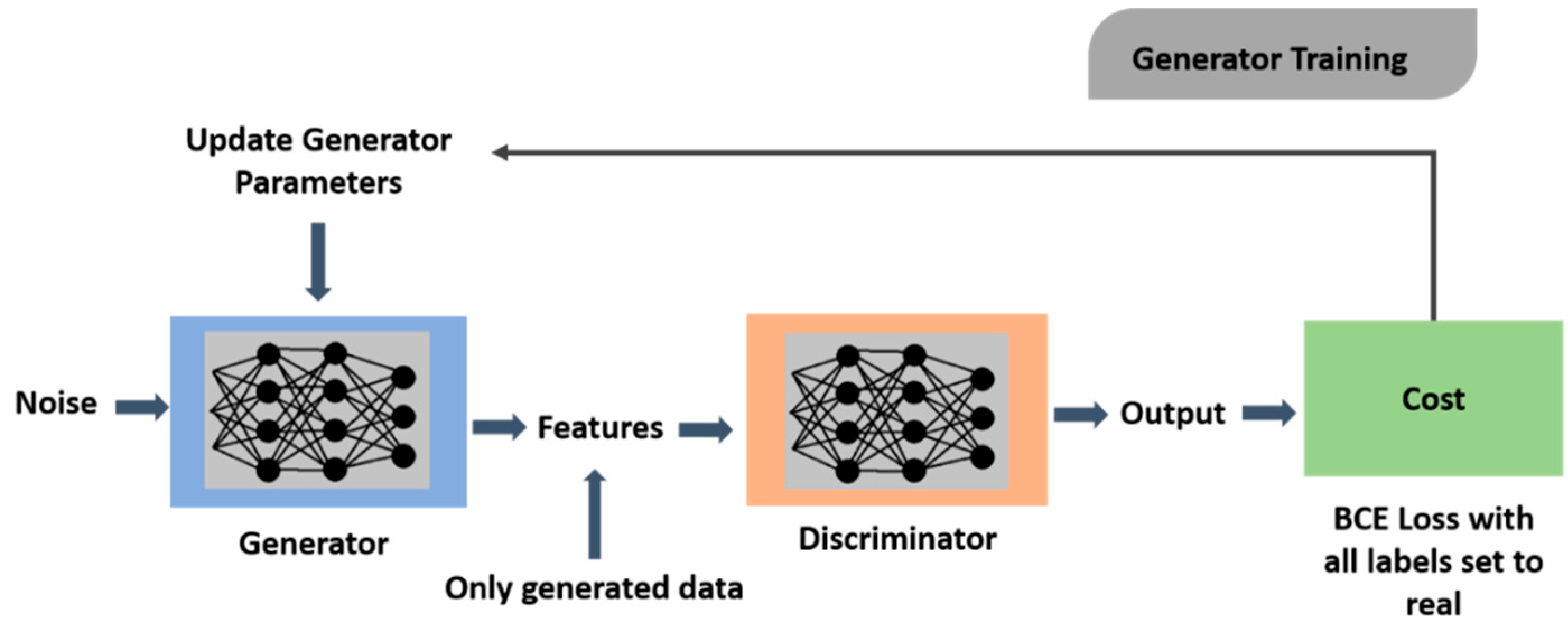
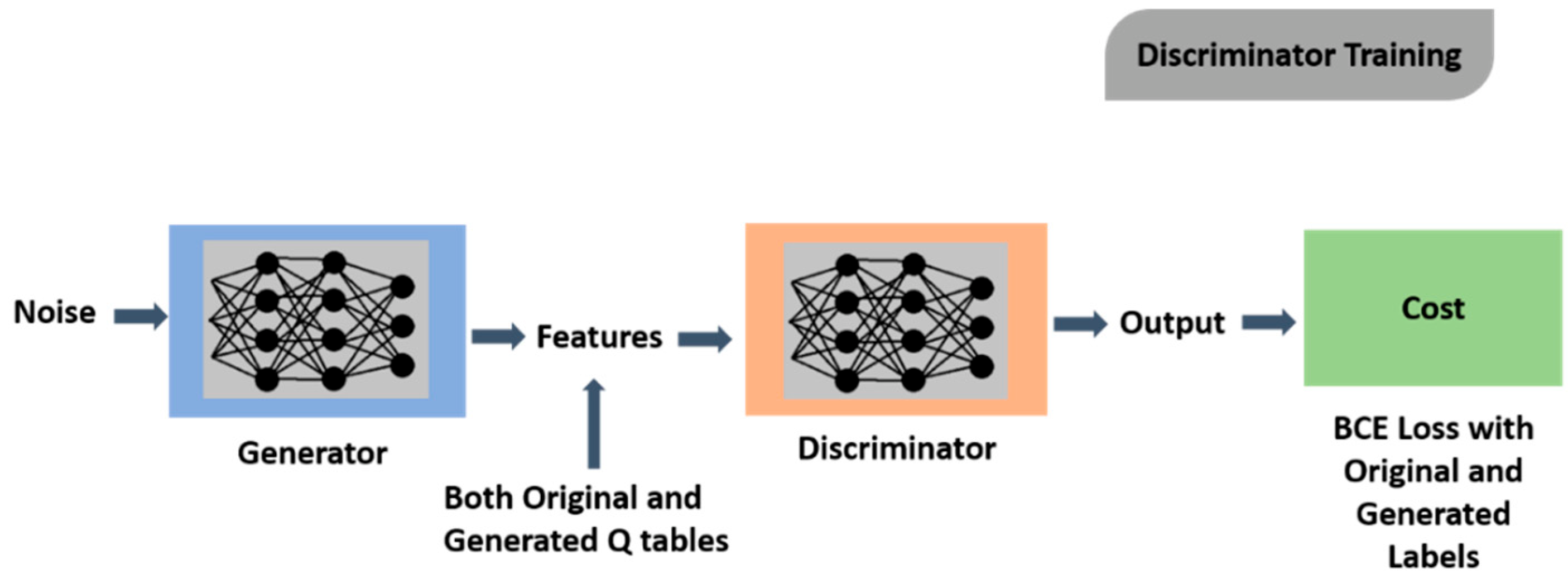
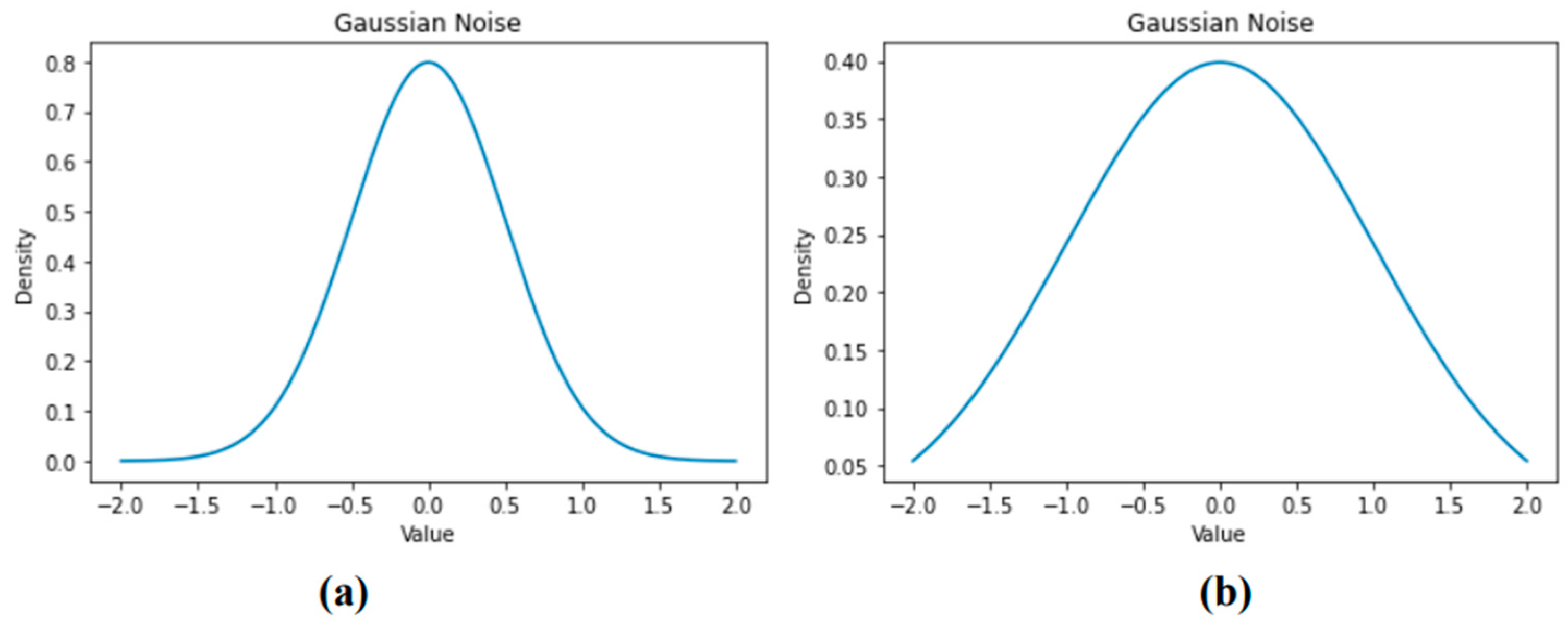
3. Methodology
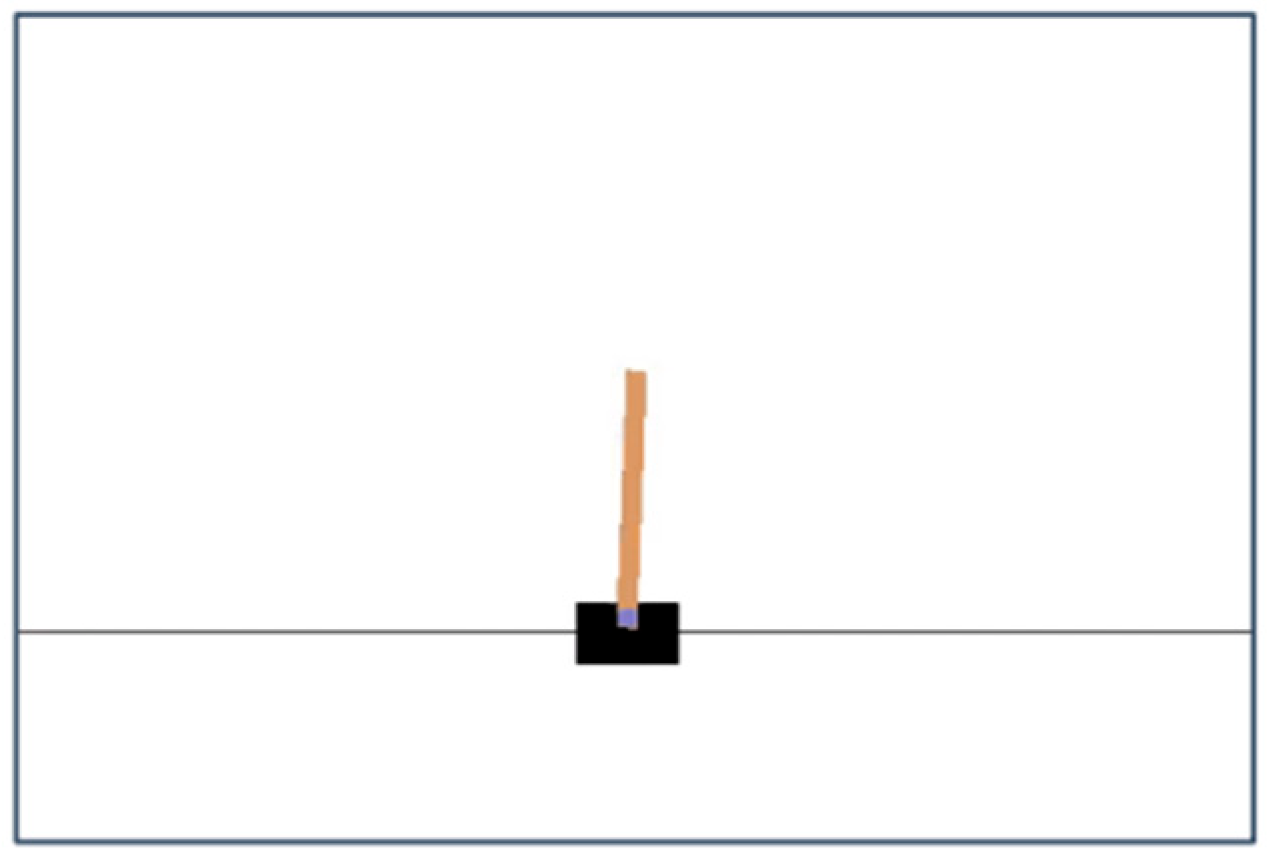
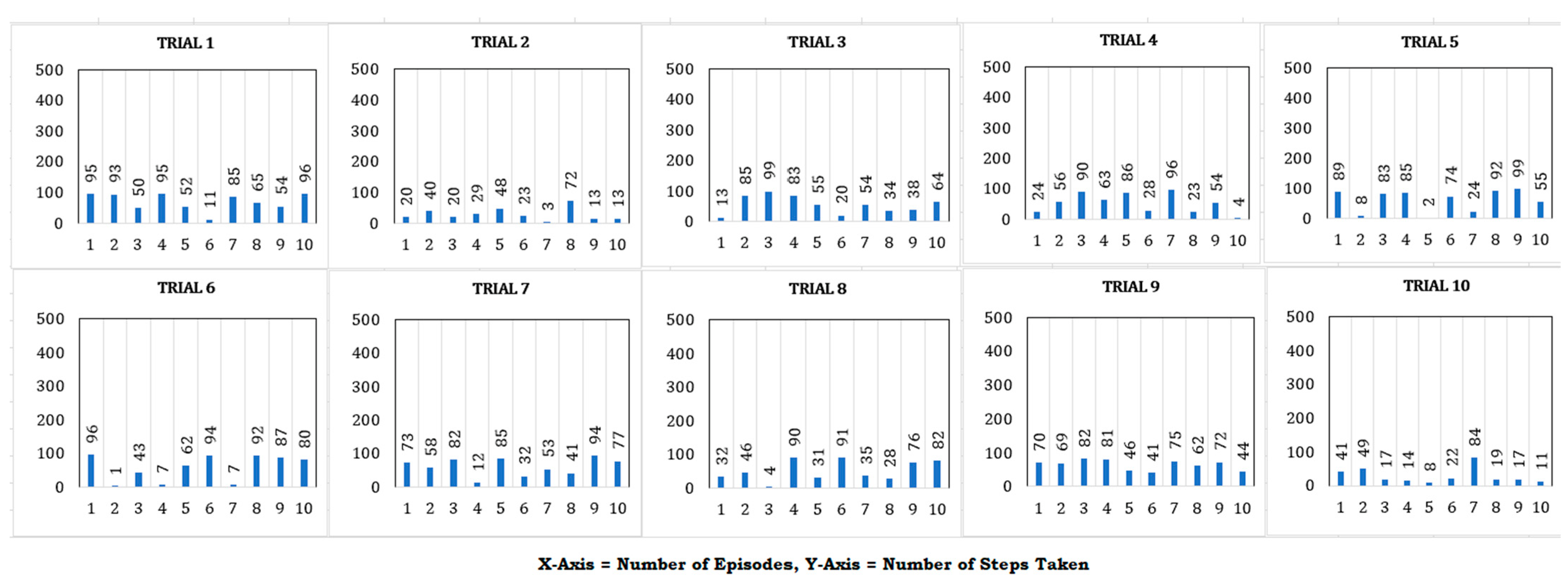
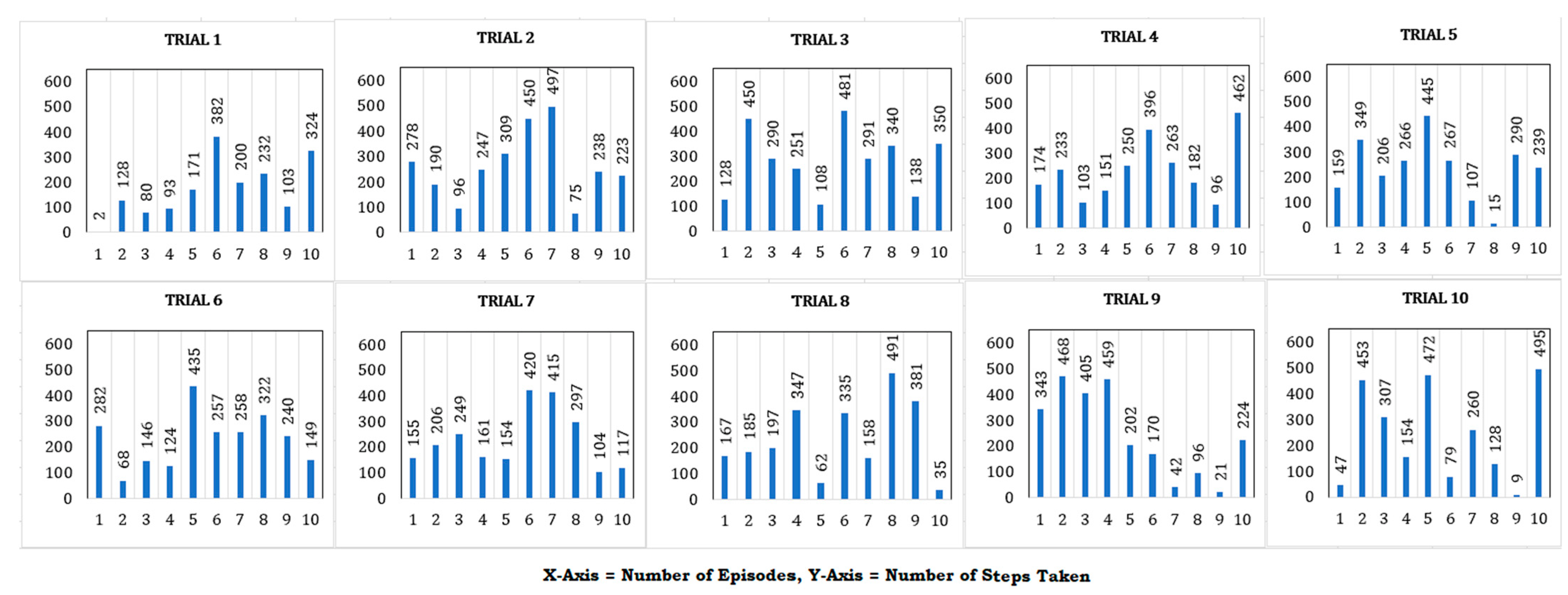
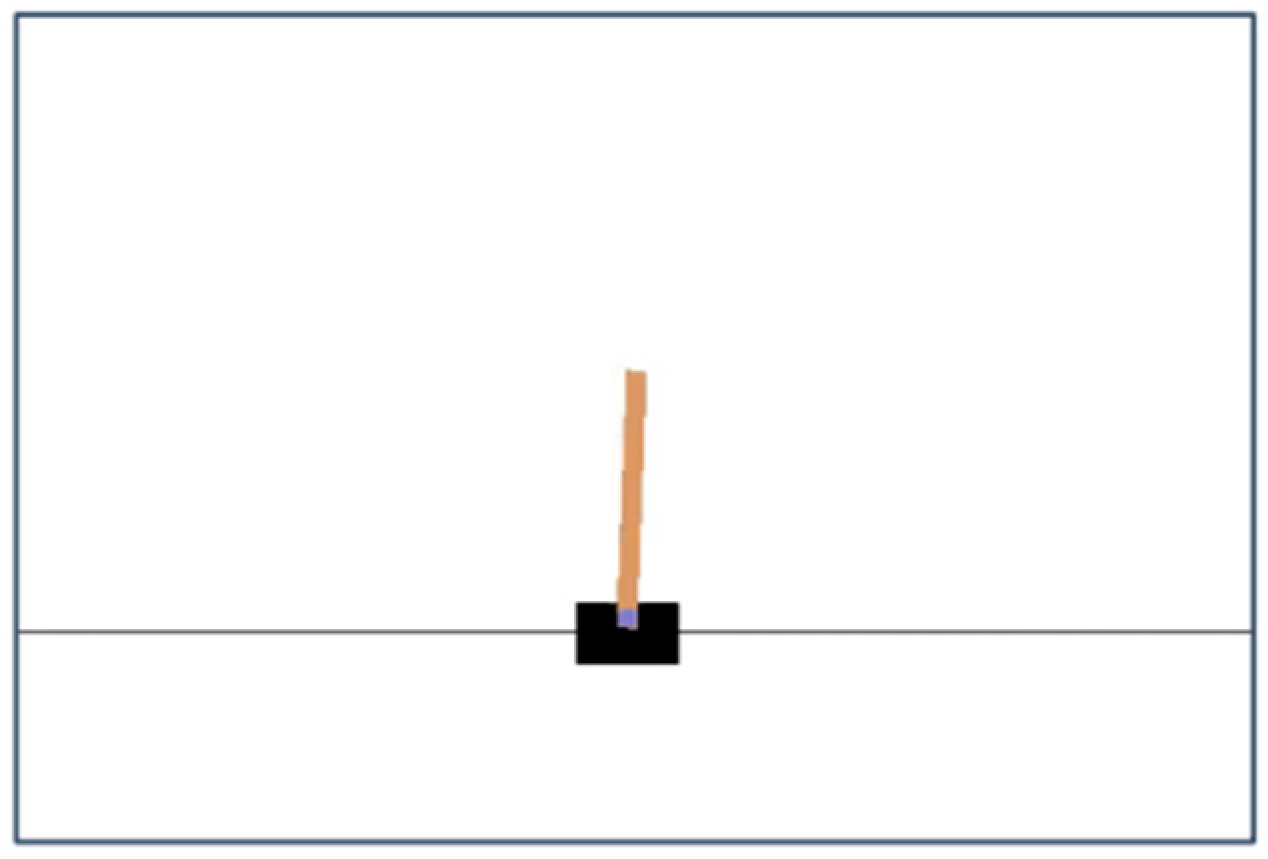
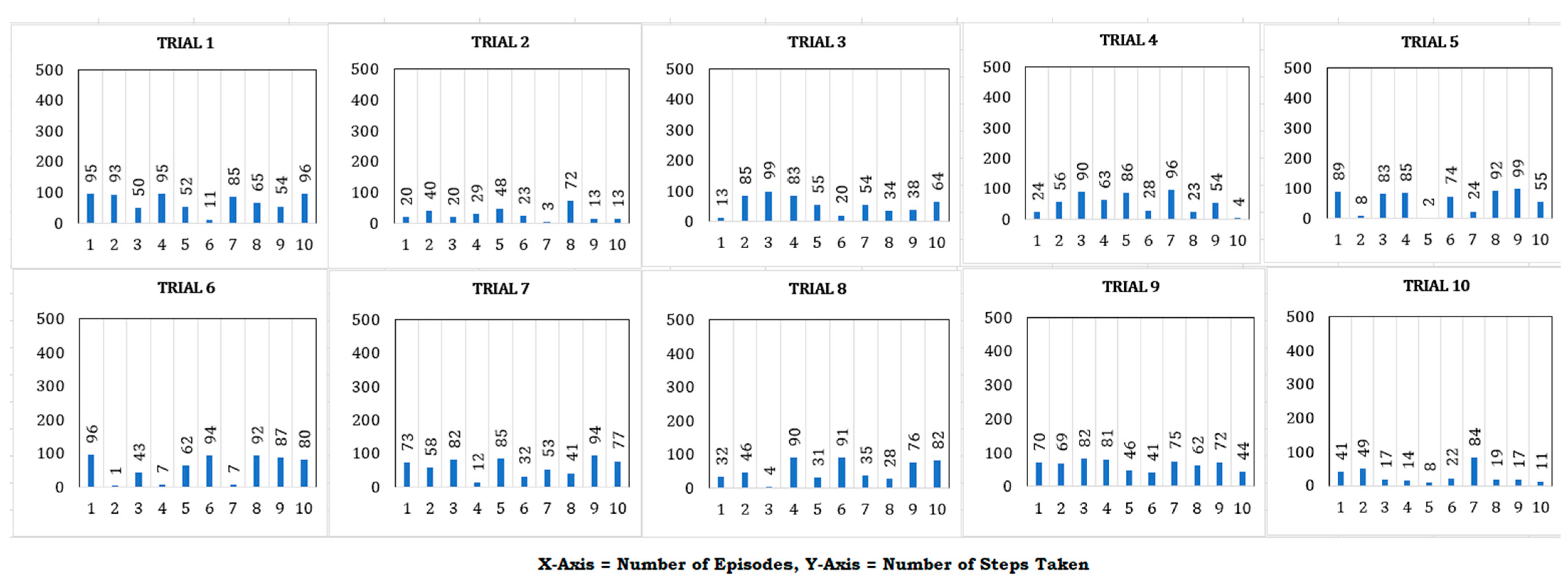
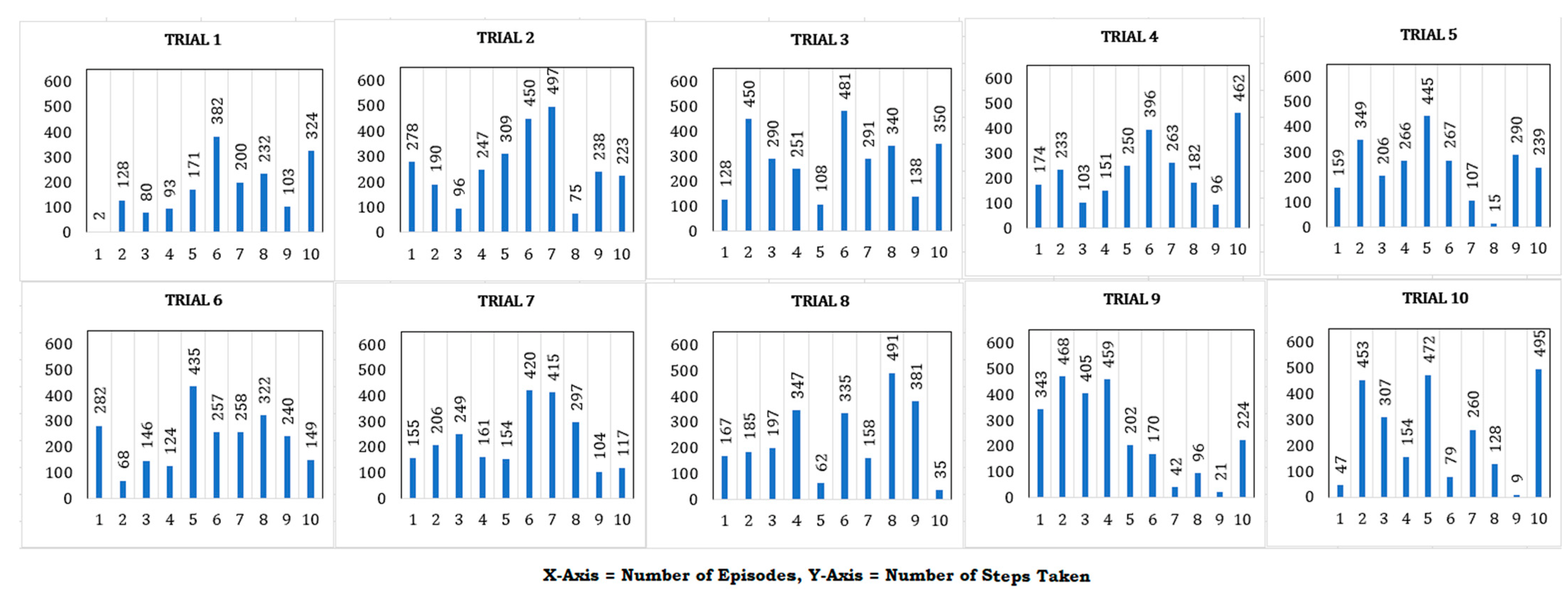
4. Results
5. Discussion
6. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bogue, R. Growth in e-commerce boosts innovation in the warehouse robot market. Ind. Robot. Int. J. 2016, 43, 583–587. [Google Scholar] [CrossRef]
- Schultz, D.E.; Block, M.P. U.S. online shopping: Facts, fiction, hopes and dreams. J. Retail. Consum. Serv. 2015, 23, 99–106. [Google Scholar] [CrossRef]
- Amazon Prime and “Free” Shipping. Available online: https://escholarship.org/uc/item/0681j9rr (accessed on 5 November 2021).
- Laber, J.; Thamma, R.; Kirby, E.D. The Impact of Warehouse Automation in Amazon’s Success. IJISET-Int. J. Innov. Sci. Eng. Technol. 2020, 7, 63–70. [Google Scholar]
- Bouman, A.; Ginting, M.F.; Alatur, N.; Palieri, M.; Fan, D.D.; Touma, T.; Pailevanian, T.; Kim, S.K.; Otsu, K.; Burdick, J.; et al. Autonomous spot: Long-range autonomous exploration of extreme environments with legged locomotion. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 2518–2525. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Wiering, M.A. Reinforcement Learning in Continuous Action. In Proceedings of the 2007 IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning, Honolulu, HI, USA, 1–5 April 2007; pp. 272–279. Available online: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=4220844 (accessed on 17 June 2022).
- Mahmood, A.R.; Korenkevych, D.; Vasan, G.; Ma, W.; Bergstra, J. Benchmarking Reinforcement Learning Algorithms on Real-World Robots. In Proceedings of the 2nd Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018; pp. 561–591. Available online: https://proceedings.mlr.press/v87/mahmood18a.html (accessed on 6 December 2022).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Q.; Huang, Z.; Li, W.; Dai, D.; Yang, M.; Wang, J.; Fink, O.; Zürich, E.; Europe, N. Off-Policy Reinforcement Learning for Efficient and Effective GAN Architecture Search (Supplementary Material). In Proceedings of the 16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Sarmad, M.; Korea, S.; Lee, H.J.; Kim, Y.M. RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5898–5907. [Google Scholar]
- Xu, D.; Zhu, F.; Liu, Q.; Zhao, P. Improving exploration efficiency of deep reinforcement learning through samples produced by generative model. Expert Syst. Appl. 2021, 185, 115680. [Google Scholar] [CrossRef]
- Rao, K.; Harris, C.; Irpan, A.; Levine, S.; Ibarz, J.; Khansari, M. RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kasgari, A.T.Z.; Saad, W.; Mozaffari, M.; Poor, H.V. Experienced Deep Reinforcement Learning with Generative Adversarial Networks (GANs) for Model-Free Ultra Reliable Low Latency Communication. IEEE Trans. Commun. 2021, 69, 884–899. [Google Scholar] [CrossRef]
- Zhan, H.; Tao, F.; Cao, Y. Human-guided Robot Behavior Learning: A GAN-assisted Preference-based Reinforcement Learning Approach. IEEE Robot. Autom. Lett. 2020, 6, 3545–3552. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-Learning; Kluwer Academic Publisher: Boston, MA, USA, 1992; Volume 8. [Google Scholar]
- Image Synthesis—Noise Generation. Available online: https://homepages.inf.ed.ac.uk/rbf/HIPR2/noise.htm (accessed on 31 October 2021).
- Miljković, Z.; Mitić, M.; Lazarević, M.; Babić, B. Neural network Reinforcement Learning for visual control of robot manipulators. Expert Syst. Appl. 2013, 40, 1721–1736. [Google Scholar] [CrossRef]
- Duguleana, M.; Mogan, G. Neural networks based reinforcement learning for mobile robots obstacle avoidance. Expert Syst. Appl. 2016, 62, 104–115. [Google Scholar] [CrossRef]
- Hu, X.; Liao, X.; Liu, Z.; Liu, S.; Ding, X.; Helaoui, M.; Wang, W.; Ghannouchi, F.M. Multi-Agent Deep Reinforcement Learning-Based Flexible Satellite Payload for Mobile Terminals. IEEE Trans. Veh. Technol. 2020, 69, 9849–9865. [Google Scholar] [CrossRef]
- Kim, P. Convolutional Neural Network. In MATLAB Deep Learning; Springer: Singapore, 2017; pp. 121–147. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Bjorck, J.; Gomes, C.; Selman, B.; Weinberger, K.Q. Understanding Batch Normalization. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7694–7705. [Google Scholar]
- Fred Agarap, A.M. Deep Learning using Rectified Linear Units (ReLU). Available online: https://github.com/AFAgarap/relu-classifier (accessed on 19 July 2021).
- Dubey, A.K.; Jain, V. Comparative Study of Convolution Neural Network’s Relu and Leaky-Relu Activation Functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2019; Volume 553, pp. 873–880. [Google Scholar] [CrossRef]
- Statistical Analysis Based on a Certain Multivariate Complex Gaussian Distribution (An Introduction) on JSTOR. Available online: https://www.jstor.org/stable/2991290?seq=1 (accessed on 30 May 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameters | Testing Parameters | Before GAN | After GAN | |
|---|---|---|---|---|
| Gravity | 9.8 | 9.8 | Figure 10 | Figure 11 |
| Mass of Cart | 1.0 | 30.0 | ||
| Mass of Pole | 0.1 | 2.1 | ||
| Length | 0.5 | 0.5 | ||
| Force Applied | 10 | 10 | ||
| Tau | 0.02 | 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paul, N.; Tasgaonkar, V.; Walambe, R.; Kotecha, K. Integrating the Generative Adversarial Network for Decision Making in Reinforcement Learning for Industrial Robot Agents. Robotics 2022, 11, 150. https://doi.org/10.3390/robotics11060150
Paul N, Tasgaonkar V, Walambe R, Kotecha K. Integrating the Generative Adversarial Network for Decision Making in Reinforcement Learning for Industrial Robot Agents. Robotics. 2022; 11(6):150. https://doi.org/10.3390/robotics11060150
Chicago/Turabian StylePaul, Neelabh, Vaibhav Tasgaonkar, Rahee Walambe, and Ketan Kotecha. 2022. "Integrating the Generative Adversarial Network for Decision Making in Reinforcement Learning for Industrial Robot Agents" Robotics 11, no. 6: 150. https://doi.org/10.3390/robotics11060150
APA StylePaul, N., Tasgaonkar, V., Walambe, R., & Kotecha, K. (2022). Integrating the Generative Adversarial Network for Decision Making in Reinforcement Learning for Industrial Robot Agents. Robotics, 11(6), 150. https://doi.org/10.3390/robotics11060150