

Preliminary Experimental Results of Context-Aware Teams of Multiple Autonomous Agents Operating under Constrained Communications

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
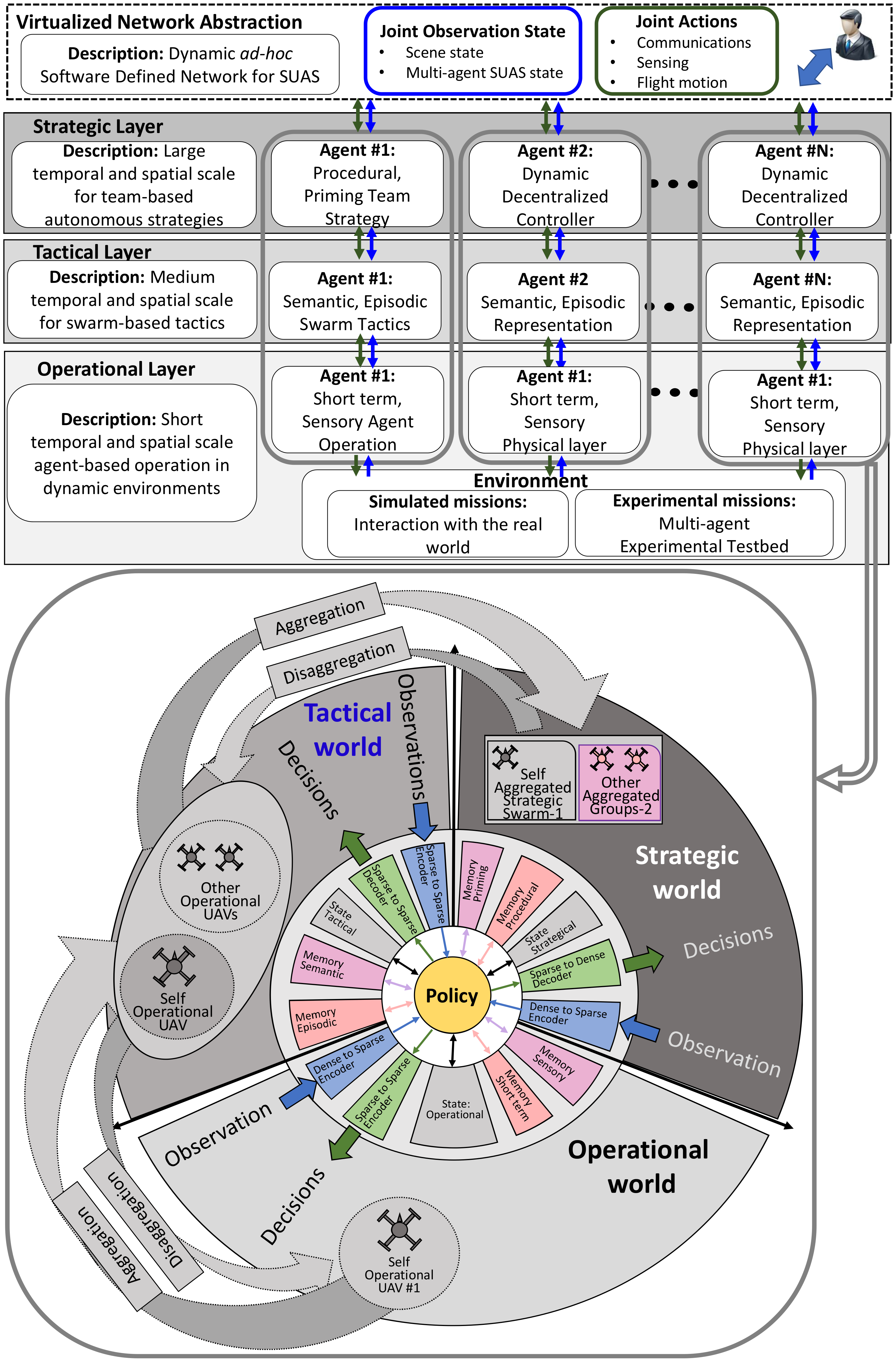
2. System Architecture
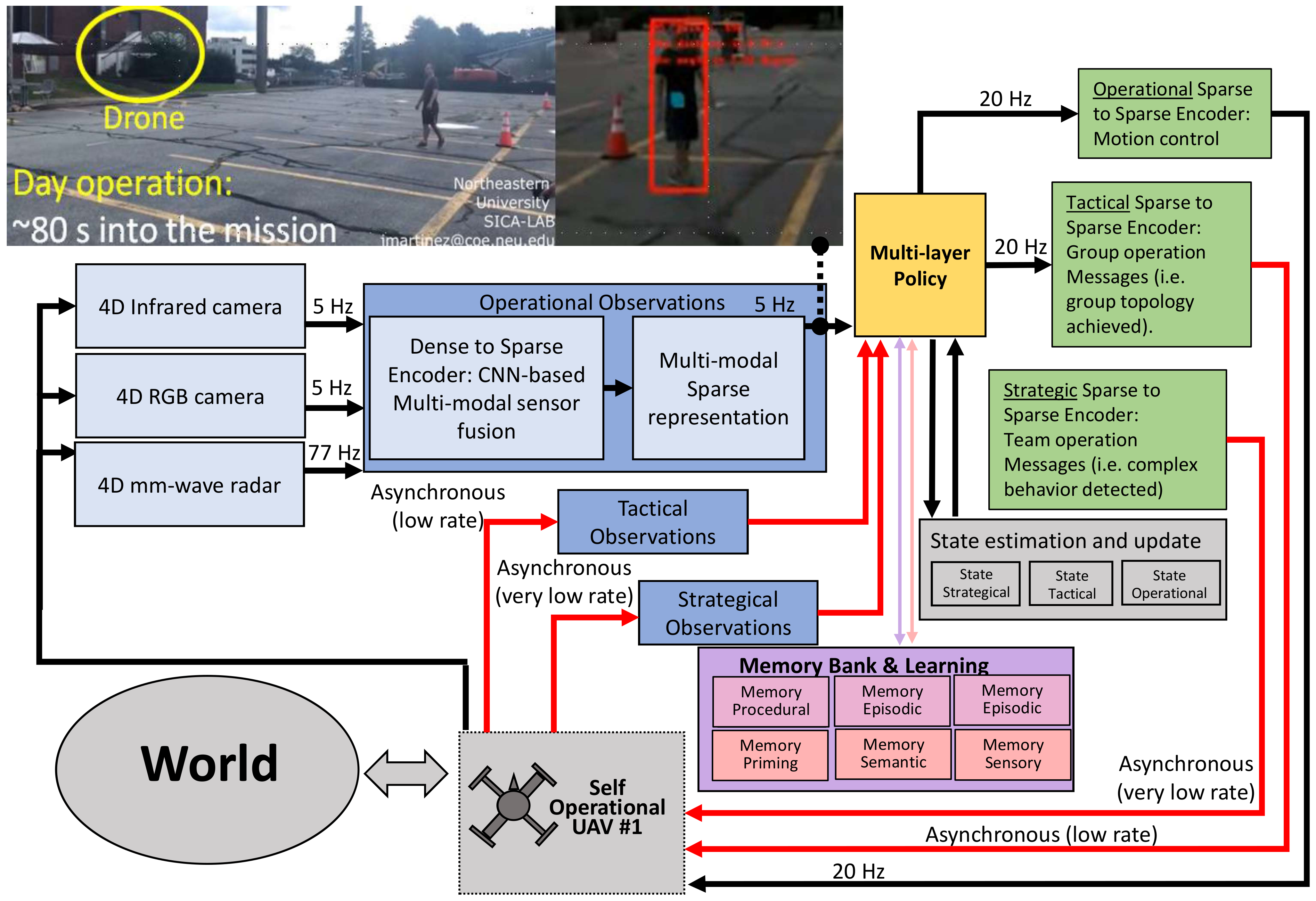
3. Multi-Layer Perception
4. Multi-Layer Policy
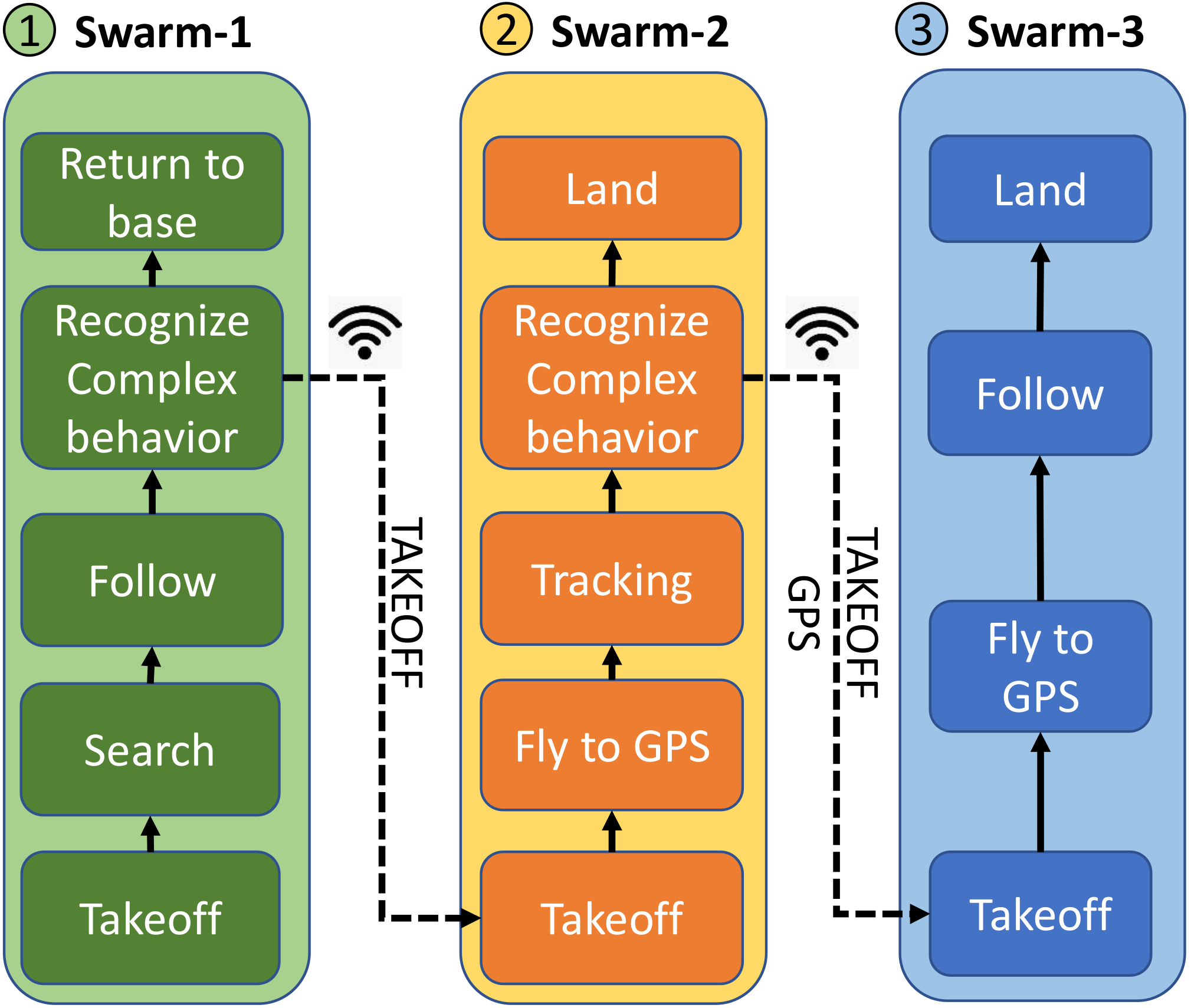
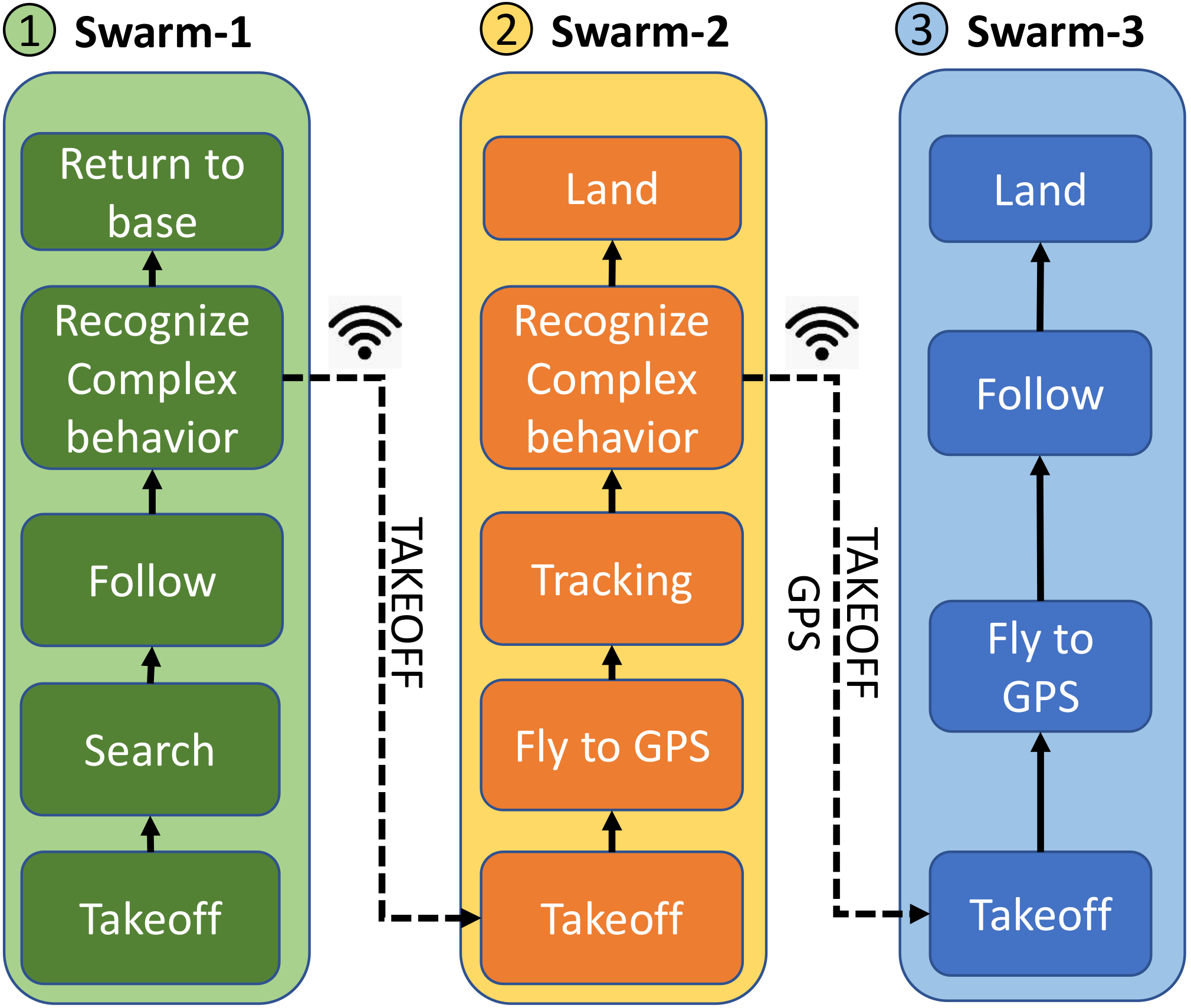
5. Multi-Layer Decisions
6. Results
Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CS | Compressive Sensing |
| GPS | Global Positioning System |
| MOT | Multiple Object Tracking |
| RGB | Red Green Blue |
| SNR | Signal-to-Noise Ratio |
| SUAS | Small Unmanned Aerial Systems |
| SUAV | Small Unmanned Aerial Vehicles |
References
- Aydemir, A.; Göbelbecker, M.; Pronobis, A.; Sjöö, K.; Jensfelt, P. Plan-based Object Search and Exploration Using Semantic Spatial Knowledge in the Real World. In Proceedings of the 5th European Conference on Mobile Robots (ECMR), Örebro, Sweden, 7–9 September 2011. [Google Scholar]
- Aydemir, A.; Sjöö, K.; Folkesson, J.; Pronobis, A.; Jensfelt, P. Search in the real world: Active visual object search based on spatial relations. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 2818–2824. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 2758–2766. [Google Scholar]
- Fu, J.; Levine, S.; Abbeel, P. One-shot learning of manipulation skills with online dynamics adaptation and neural network priors. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4019–4026. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Zhu, Y.; Wang, Z.; Merel, J.; Rusu, A.; Erez, T.; Cabi, S.; Tunyasuvunakool, S.; Kramár, J.; Hadsell, R.; de Freitas, N.; et al. Reinforcement and imitation learning for diverse visuomotor skills. arXiv 2018, arXiv:1802.09564. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th international Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Yang, X.; Ramesh, P.; Chitta, R.; Madhvanath, S.; Bernal, E.A.; Luo, J. Deep multimodal representation learning from temporal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5447–5455. [Google Scholar]
- Srivastava, N.; Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2222–2230. [Google Scholar]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-real transfer of robotic control with dynamics randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Diankov, R.; Kuffner, J. OpenRAVE: A Planning Architecture for Autonomous Robotics; Technical Report; Carnegie Mellon University: Pittsburgh, PA, USA, 2008. [Google Scholar]
- Sjö, K.; Lopez, D.G.; Paul, C.; Jensfelt, P.; Kragic, D. Object Search and Localization for an Indoor Mobile Robot. J. Comput. Inf. Technol. 2009, 17, 67–80. [Google Scholar] [CrossRef]
- De Bruin, T.; Kober, J.; Tuyls, K.; Babuška, R. Integrating state representation learning into deep reinforcement learning. IEEE Robot. Autom. Lett. 2018, 3, 1394–1401. [Google Scholar] [CrossRef]
- Cifuentes, C.G.; Issac, J.; Wüthrich, M.; Schaal, S.; Bohg, J. Probabilistic articulated real-time tracking for robot manipulation. IEEE Robot. Autom. Lett. 2016, 2, 577–584. [Google Scholar] [CrossRef]
- Zhang, W.; Heredia-Juesas, J.; Diddiy, M.; Tirado, L.; Singhy, H.; Martinez-Lorenzo, J.A. Experimental Imaging Results of a UAV-mounted Downward-Looking mm-wave Radar. In Proceedings of the IEEE International Symposium on Antennas and Propagation & USNC/URSI National Radio Science Meeting, Atlanta, GA, USA, 7–12 July 2019. [Google Scholar]
- Tirado, L.E.; Zhang, W.; Bisulco, A.; Gomez-Sousa, H.; Martinez-Lorenzo, J.A. Towards three-dimensional millimeter-wave radar imaging of on-the-move targets. In Proceedings of the 2018 IEEE International Symposium on Antennas and Propagation & USNC/URSI National Radio Science Meeting, Boston, MA, USA, 8–13 July 2018; pp. 1959–1960. [Google Scholar]
- Zhang, W.; Martinez-Lorenzo, J.A. Single-frequency material characterization using a microwave adaptive reflect-array. In Proceedings of the 2018 IEEE International Symposium on Antennas and Propagation & USNC/URSI National Radio Science Meeting, Boston, MA, USA, 8–13 July 2018; pp. 1063–1064. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Wang, W.; Schuppe, G.F.; Tumova, J. Decentralized Multi-agent Coordination under MITL Tasks and Communication Constraints. In Proceedings of the 2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), Milano, Italy, 4–6 May 2016; pp. 320–321. [Google Scholar]
- Nikou, A.; Tumova, J.; Dimarogonas, D.V. Cooperative task planning of multi-agent systems under timed temporal specifications. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 7104–7109. [Google Scholar]
- Wang, Q.; Gao, H.; Alsaadi, F.; Hayat, T. An overview of consensus problems in constrained multi-agent coordination. Syst. Sci. Control Eng. Open Access J. 2014, 2, 275–284. [Google Scholar] [CrossRef]
- Yu, P.; Dimarogonas, D.V. Distributed motion coordination for multirobot systems under LTL specifications. IEEE Trans. Robot. 2021, 38, 1047–1062. [Google Scholar] [CrossRef]
- Finn, C.; Levine, S. Deep visual foresight for planning robot motion. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2786–2793. [Google Scholar]
- Sinapov, J.; Schenck, C.; Stoytchev, A. Learning relational object categories using behavioral exploration and multimodal perception. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5691–5698. [Google Scholar]
- Kensler, J.A.; Agah, A. Neural networks-based adaptive bidding with the contract net protocol in multi-robot systems. Appl. Intell. 2009, 31, 347. [Google Scholar] [CrossRef]
- Liekna, A.; Lavendelis, E.; Grabovskis, A. Experimental analysis of contract net protocol in multi-robot task allocation. Appl. Comput. Syst. 2012, 13, 6–14. [Google Scholar] [CrossRef]
- Shehory, O.; Kraus, S. Task allocation via coalition formation among autonomous agents. IJCAI 1995, 1, 655–661. [Google Scholar]
- Li, C.; Sycara, K. A stable and efficient scheme for task allocation via agent coalition formation. In Theory and Algorithms for Cooperative Systems; World Scientific: Singapore, 2004; pp. 193–212. [Google Scholar]
- Shehory, O.; Kraus, S. Formation of overlapping coalitions for precedence-ordered task-execution among autonomous agents. In Proceedings of the ICMAS-96, Kyoto, Japan, 10–13 December 1996; pp. 330–337. [Google Scholar]
- Katt, S.; Oliehoek, F.A.; Amato, C. Learning in POMDPs with Monte Carlo tree search. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1819–1827. [Google Scholar]
- Ross, S.; Pineau, J.; Chaib-draa, B.; Kreitmann, P. A Bayesian Approach for Learning and Planning in Partially Observable Markov Decision Processes. J. Mach. Learn. Res. 2011, 12, 1729–1770. [Google Scholar]
- Li, J.K.; Hsu, D.; Lee, W.S. Act to See and See to Act: POMDP planning for objects search in clutter. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 5701–5707. [Google Scholar]
- Ross, S.; Pineau, J.; Paquet, S.; Chaib-draa, B. Online Planning Algorithms for POMDPs. J. Artif. Int. Res. 2008, 32, 663–704. [Google Scholar] [CrossRef]
- Silver, D.; Veness, J. Monte-Carlo Planning in Large POMDPs. In Advances in Neural Information Processing Systems 23; Curran Associates, Inc.: Red Hook, NY, USA, 2010; pp. 2164–2172. [Google Scholar]
- Campion, M.; Ranganathan, P.; Faruque, S. UAV swarm communication and control architectures: A review. J. Unmanned Veh. Syst. 2018, 7, 93–106. [Google Scholar] [CrossRef]
- Bekmezci, I.; Sahingoz, O.K.; Temel, Ş. Flying ad-hoc networks (FANETs): A survey. Ad Hoc Netw. 2013, 11, 1254–1270. [Google Scholar] [CrossRef]
- Pal, A.; Tiwari, R.; Shukla, A. Communication constraints multi-agent territory exploration task. Appl. Intell. 2013, 38, 357–383. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, H.; Yu, C. Global leader-following consensus of discrete-time linear multiagent systems subject to actuator saturation. In Proceedings of the 2013 Australian Control Conference, Fremantle, Australia, 4–5 November 2013; pp. 360–363. [Google Scholar]
- Lee, M.A.; Zhu, Y.; Srinivasan, K.; Shah, P.; Savarese, S.; Fei-Fei, L.; Garg, A.; Bohg, J. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. arXiv 2018, arXiv:1810.10191. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE international conference on image processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Yoon, K.; Gwak, J.; Song, Y.M.; Yoon, Y.C.; Jeon, M.G. Oneshotda: Online multi-object tracker with one-shot-learning-based data association. IEEE Access 2020, 8, 38060–38072. [Google Scholar] [CrossRef]
- Yehoshua, R.; Heredia-Juesas, J.; Wu, Y.; Amato, C.; Martinez-Lorenzo, J. Decentralized Reinforcement Learning for Multi-Target Search and Detection by a Team of Drones. arXiv 2021, arXiv:2103.09520. [Google Scholar]
- Loquercio, A.; Kaufmann, E.; Ranftl, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Learning high-speed flight in the wild. Sci. Robot. 2021, 6, eabg5810. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.Y.; Huang, X.Q.; Luo, H.Y.; Soo, V.W.; Lee, Y.L. Auction-Based Consensus of Autonomous Vehicles for Multi-Target Dynamic Task Allocation and Path Planning in an Unknown Obstacle Environment. Appl. Sci. 2021, 11, 5057. [Google Scholar] [CrossRef]
- Amanatiadis, A.A.; Chatzichristofis, S.A.; Charalampous, K.; Doitsidis, L.; Kosmatopoulos, E.B.; Tsalides, P.; Gasteratos, A.; Roumeliotis, S.I. A multi-objective exploration strategy for mobile robots under operational constraints. IEEE Access 2013, 1, 691–702. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Lorenzo, J.; Hudack, J.; Jing, Y.; Shaham, M.; Liang, Z.; Al Bashit, A.; Wu, Y.; Zhang, W.; Skopin, M.; Heredia-Juesas, J.; et al. Preliminary Experimental Results of Context-Aware Teams of Multiple Autonomous Agents Operating under Constrained Communications. Robotics 2022, 11, 94. https://doi.org/10.3390/robotics11050094
Martinez-Lorenzo J, Hudack J, Jing Y, Shaham M, Liang Z, Al Bashit A, Wu Y, Zhang W, Skopin M, Heredia-Juesas J, et al. Preliminary Experimental Results of Context-Aware Teams of Multiple Autonomous Agents Operating under Constrained Communications. Robotics. 2022; 11(5):94. https://doi.org/10.3390/robotics11050094
Chicago/Turabian StyleMartinez-Lorenzo, Jose, Jeff Hudack, Yutao Jing, Michael Shaham, Zixuan Liang, Abdullah Al Bashit, Yushu Wu, Weite Zhang, Matthew Skopin, Juan Heredia-Juesas, and et al. 2022. "Preliminary Experimental Results of Context-Aware Teams of Multiple Autonomous Agents Operating under Constrained Communications" Robotics 11, no. 5: 94. https://doi.org/10.3390/robotics11050094
APA StyleMartinez-Lorenzo, J., Hudack, J., Jing, Y., Shaham, M., Liang, Z., Al Bashit, A., Wu, Y., Zhang, W., Skopin, M., Heredia-Juesas, J., Ma, Y., Sweeney, T., Ares, N., & Fox, A. (2022). Preliminary Experimental Results of Context-Aware Teams of Multiple Autonomous Agents Operating under Constrained Communications. Robotics, 11(5), 94. https://doi.org/10.3390/robotics11050094