Faster than Real-Time Surface Pose Estimation with Application to Autonomous Robotic Grasping



Abstract
:1. Introduction
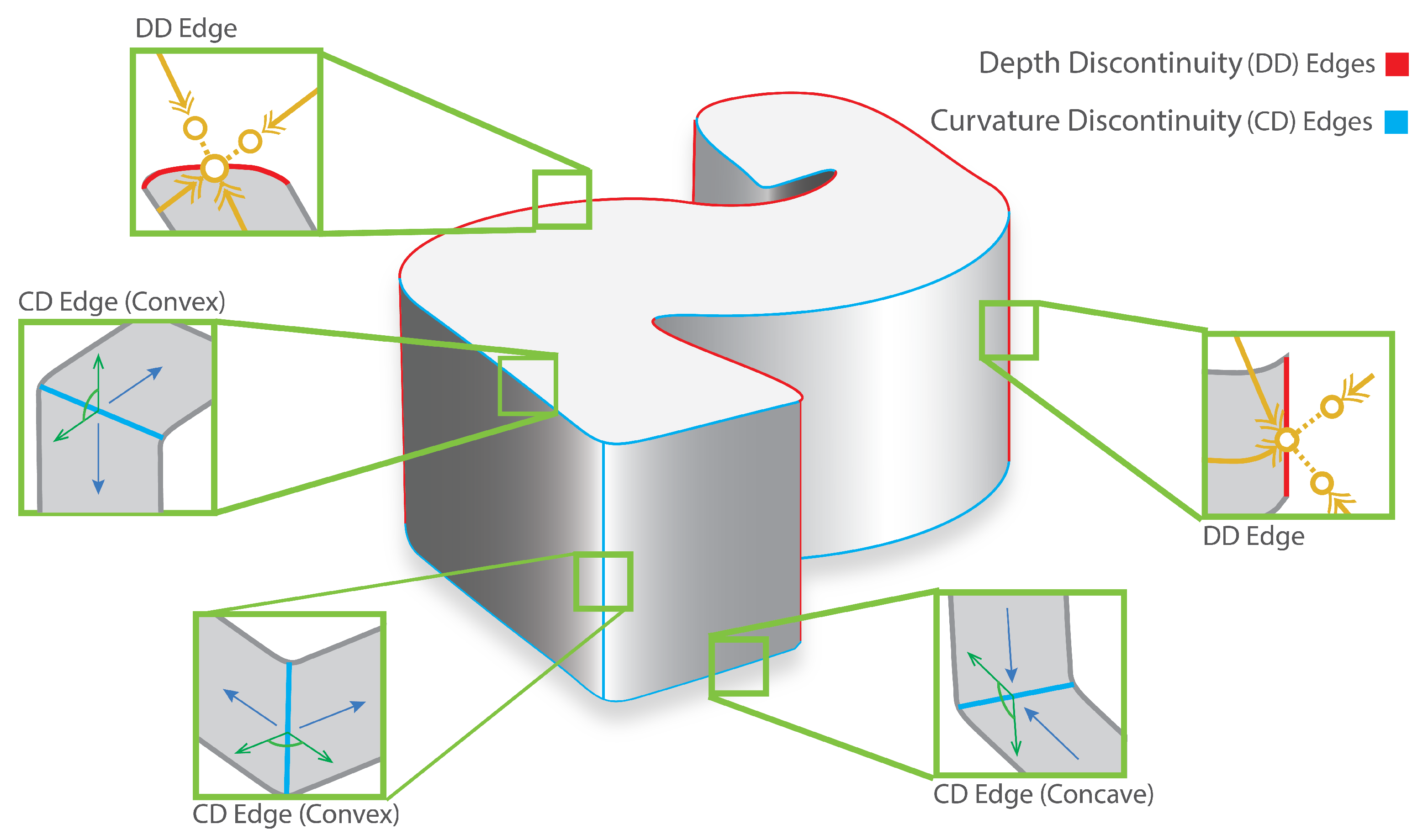
2. Problem Definition
3. Approach
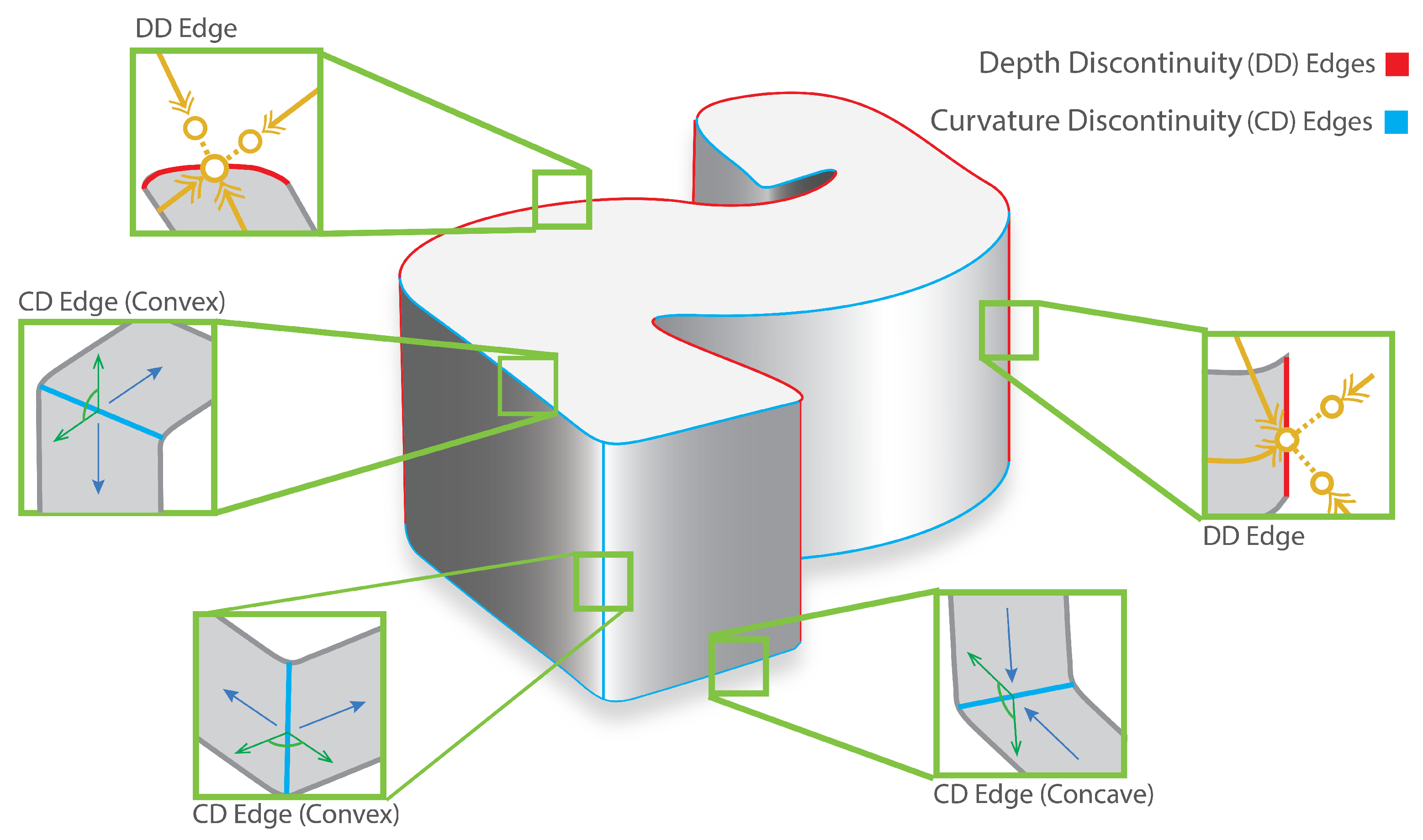
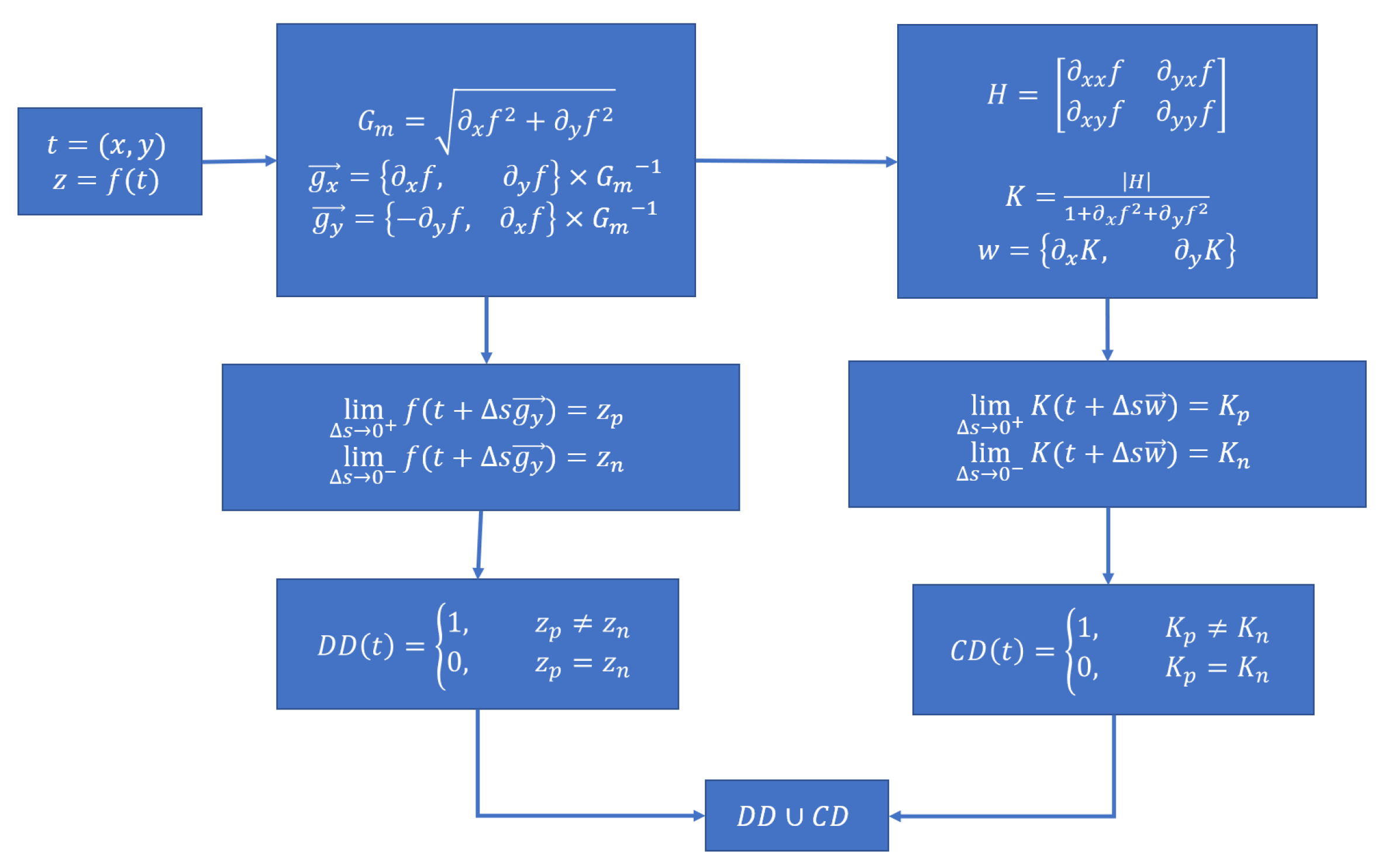
3.1. Isolating Depth Discontinuity Edges
3.2. Isolating Curvature Discontinuity Edges
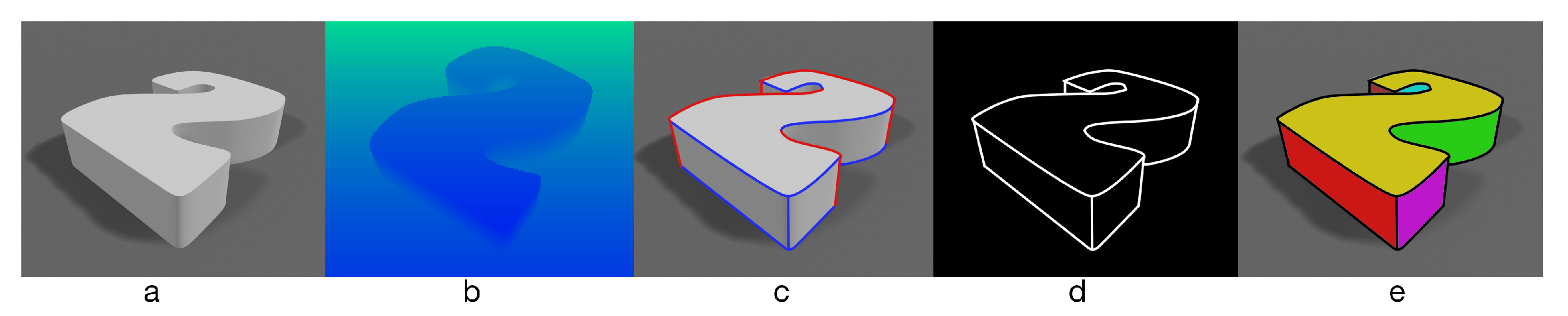
3.3. Generating Closed Contours
3.4. Robustification of Approach
3.4.1. Depth Frame Noise Filtering
3.4.2. Temporal Depth Jitter
3.4.3. Non-Depth-Return Pixel (NDP) Filling
| Algorithm 1: The NDP filling process. Each NDP pixel on a valid–invalid boundary is assigned a the mean of its neighborhood. |
 |
4. Implementation
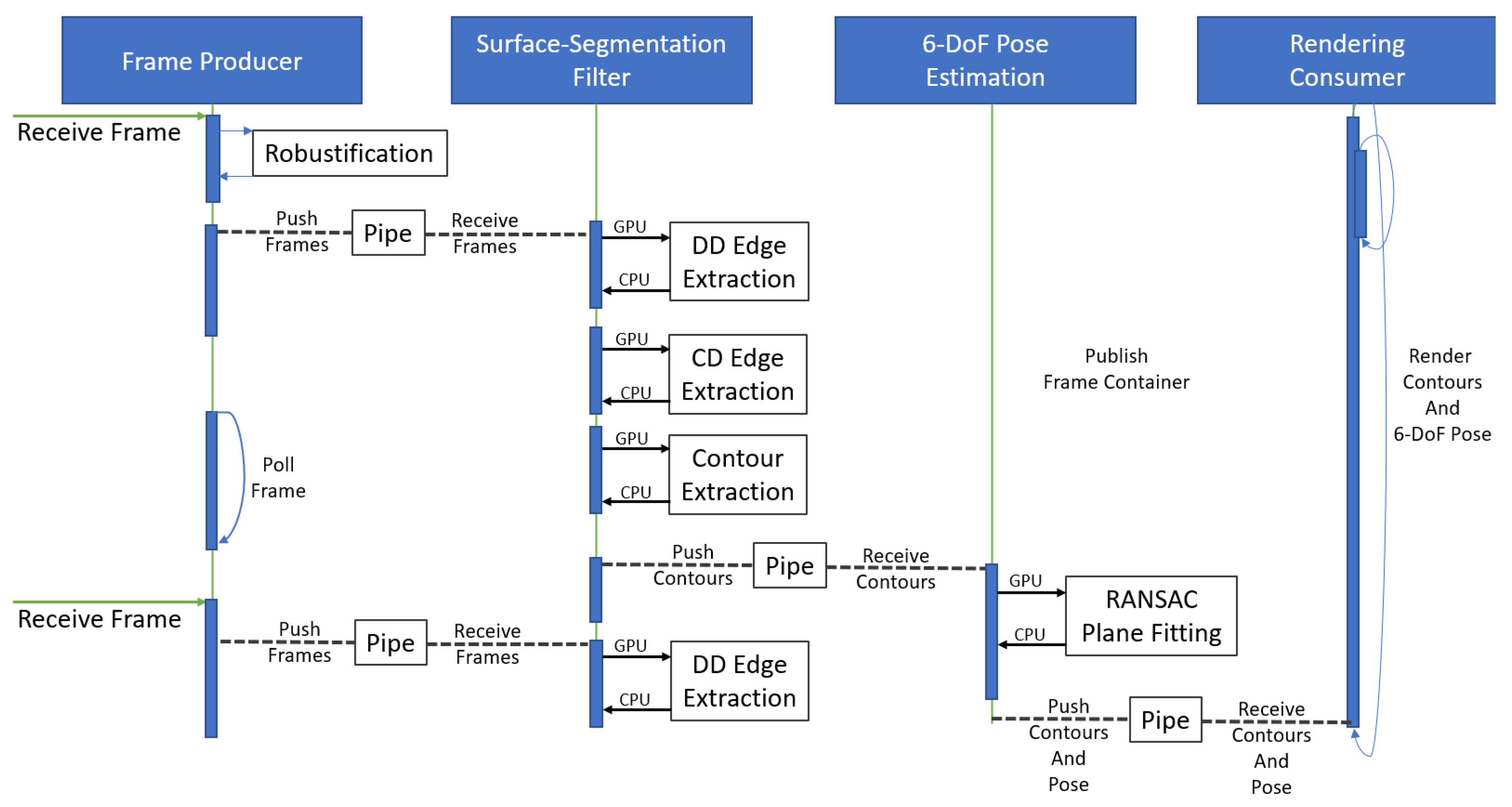
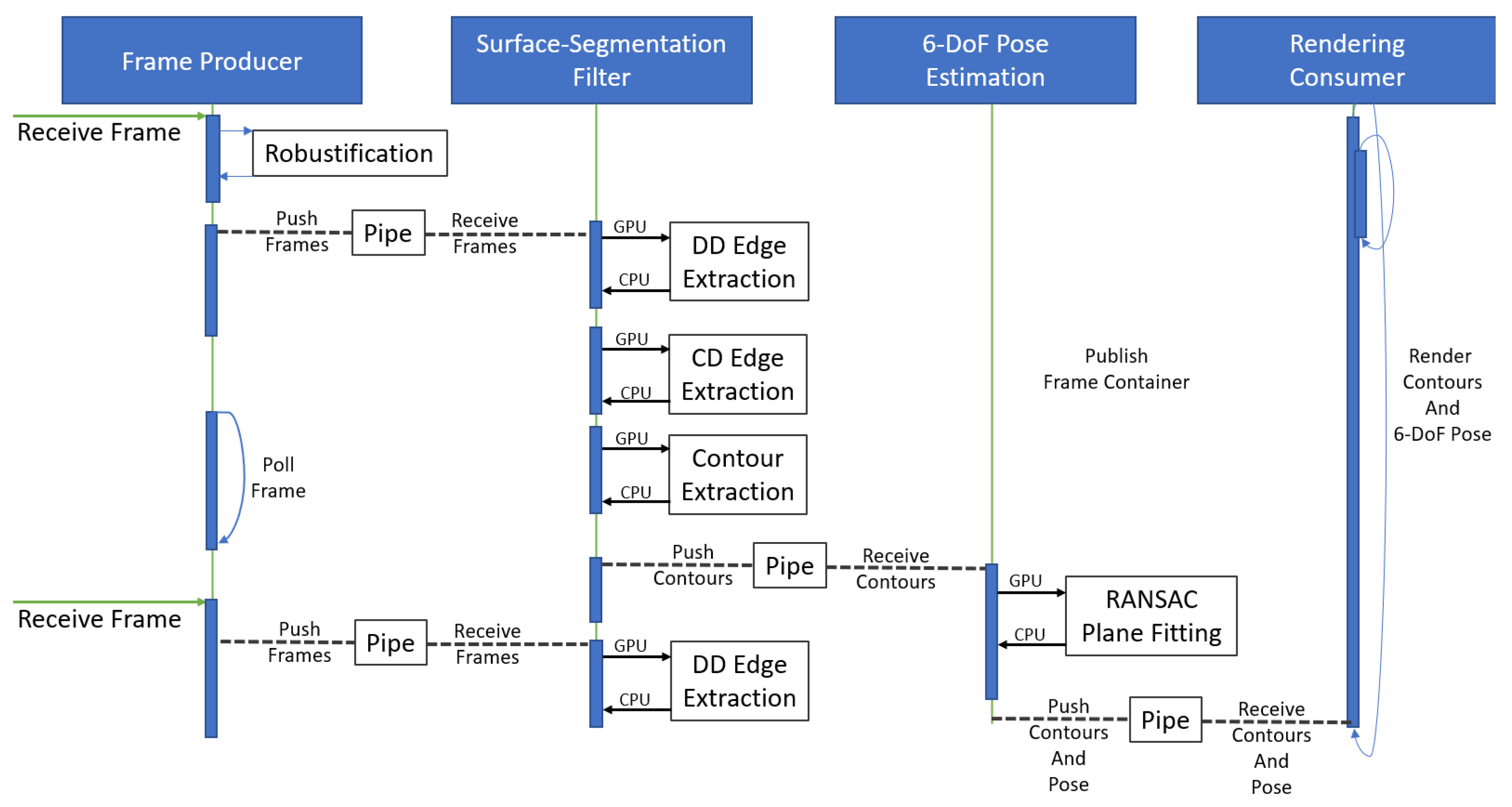
4.1. Software Design Architecture
4.1.1. Software and Hardware
4.1.2. System Architecture
4.2. Software Implementation
4.2.1. Segmentation Procedure
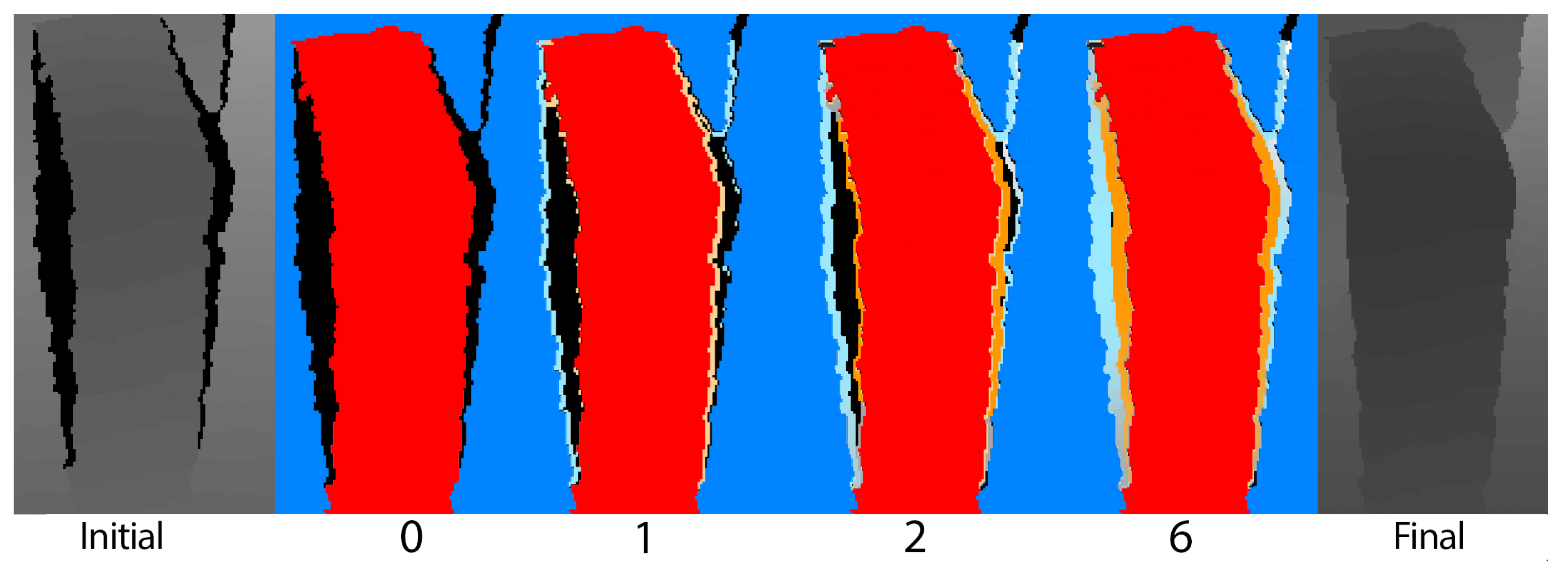
4.2.2. Contour Smoothing
- Step 1.
- A morphological opening operation is employed to obtain the background image, , from the binarized contours, . The structuring element used in the opening operation, , is designed to be larger than the high-frequency features that are desired filtered. The concatenated operator is:where ∘ represents a morphological opening operation encompassing an erosion operation ⊖ and expansion expansion operation, ⊕. This operation expands the bounds width of the contour edges while maintaining the overall form. High-frequency features and noisy elements that are smaller than the structuring elements are thereby excluded.
- Step 2.
- The morphological opening operation is employed to obtain the image, , from the binarized test image, . The structuring element used in the opening operation is , which is similar to the measured feature in shape, but slightly smaller in size. The concatenated operator is:In this case, the measured feature and the noise, whose size is smaller than the structuring elements, are excluded.
- Step 3.
- The results of morphology band-pass filtering applied to the contour, , is obtained via image differential operations, and . The operator is:The resulting binary image removes high-frequency and low-frequency features, such as kinks and sharp corners, within the contour and presents a smooth set of lines to be used for segmenting.
4.2.3. Contour Separation
- Step 1.
- Raster search for pixels satisfying inner, or outer border conditions, and store value of previous visited border as current value.
- Step 2.
- Given a border pixel, assign a numerical index and parent index to the bordering pixel and all pixels along this currently identified border.
- Step 3.
- Upon completion, increment and continue raster search from previously identified border pixel; step (1)
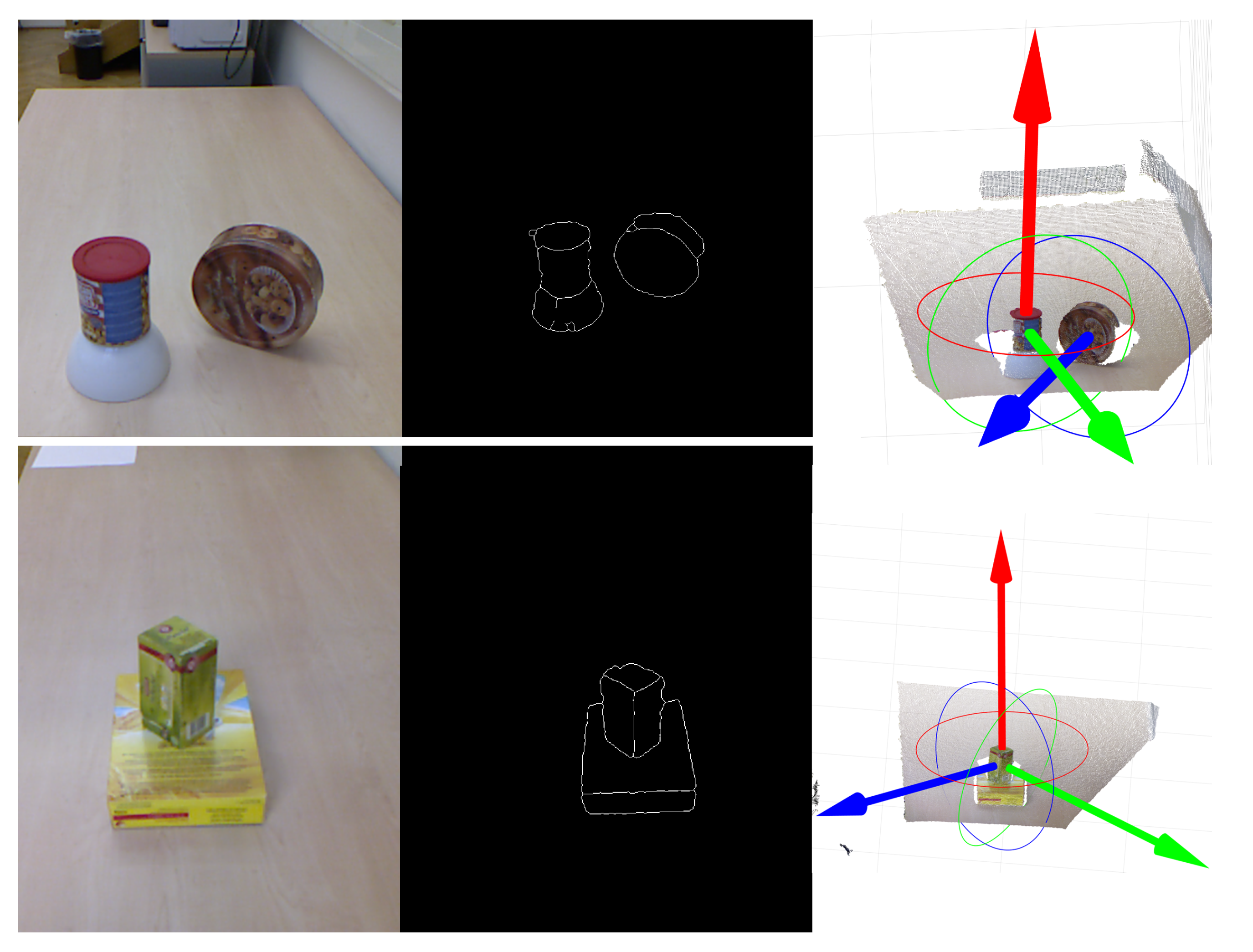
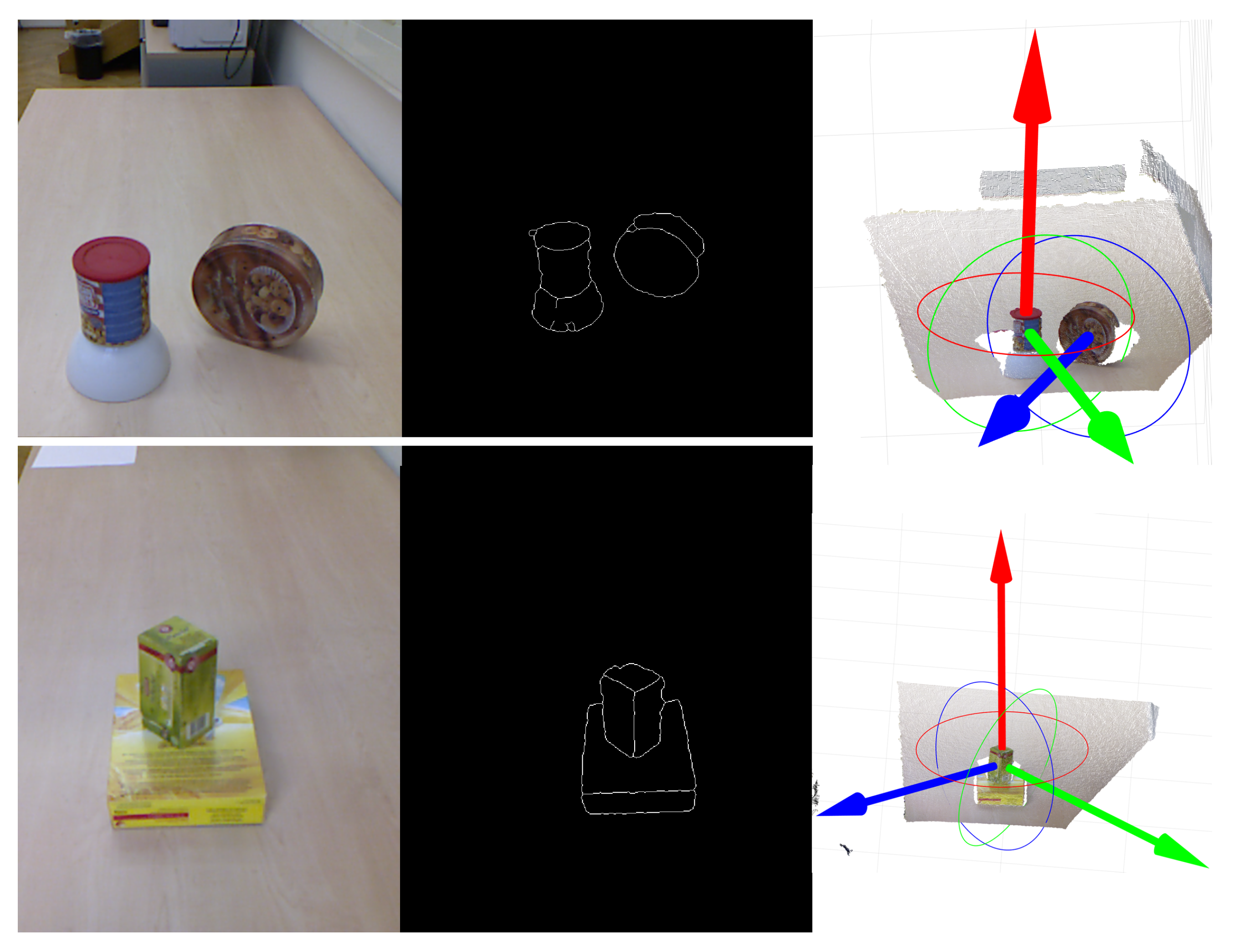
4.2.4. Identifying 6-DOF Surface Pose
5. Results
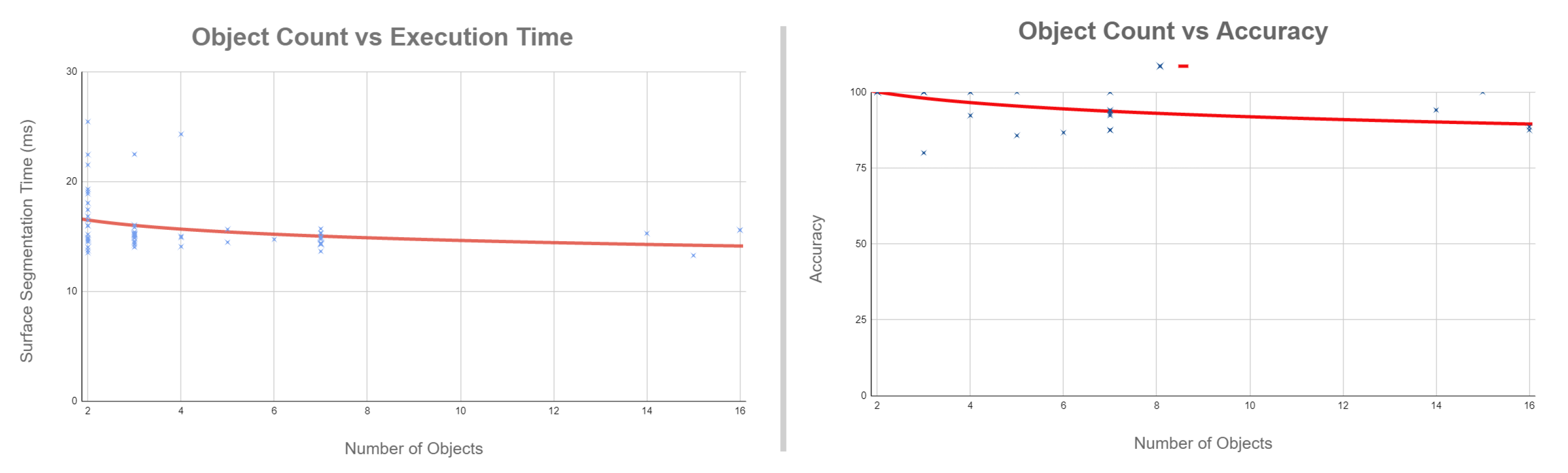
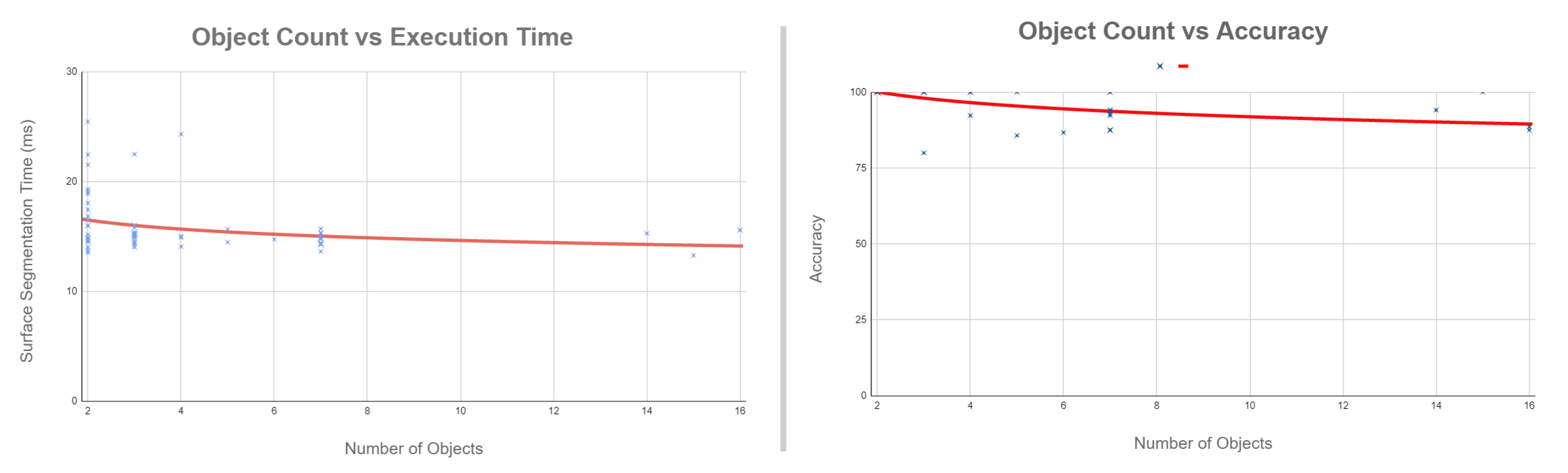
5.1. Performance Comparison
5.2. OSD Dataset Performance
5.3. Qualitative Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sahbani, S.; El-Khoury, P.B. An overview of 3D object grasp synthesis algorithms. Robot. Auton. Syst. 2012, 60, 326–336. [Google Scholar] [CrossRef] [Green Version]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-Driven Grasp Synthesis—A Survey. IEEE Trans. Robot. 2014, 30, 289–309. [Google Scholar] [CrossRef] [Green Version]
- Miller, A.; Knoop, S.; Christensen, H.; Allen, P. Automatic Grasp Planning Using Shape Primitives. In Proceedings of the Robotics and Automation, 2003. Proceedings. ICRA’03, IEEE International Conference, Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1824–1829. [Google Scholar]
- Huebner, K.; Kragic, D. Selection of robot pre-grasps using box-based shape approximation. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 1765–1770. [Google Scholar]
- Przybylski, M.; Asfour, T.; Dillmann, R. Planning grasps for robotic hands using a novel object representation based on the medial axis transform. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1781–1788. [Google Scholar]
- Detry, R.; Ek, C.H.; Madry, M.; Kragic, D. Learning a dictionary of prototypical grasp-predicting parts from grasping experience. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 601–608. [Google Scholar] [CrossRef]
- Kroemer, O.; Ugur, E.; Oztop, E.; Peters, J. A kernel-based approach to direct action perception. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MI, USA, 14–18 May 2012; pp. 2605–2610. [Google Scholar] [CrossRef]
- Kopicki, M.; Detry, R.; Schmidt, F.; Borst, C.; Stolkin, R.; Wyatt, J.L. Learning dexterous grasps that generalise to novel objects by combining hand and contact models. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5358–5365. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Driemeyer, J.; Ng, A.Y. Robotic grasping of novel objects using vision. Int. J. Robot. Res. 2008, 27, 157–173. [Google Scholar] [CrossRef] [Green Version]
- Morrison, D.; Corke, P.; Leitner, J. Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–28 June 2018. [Google Scholar]
- Liang, H.; Ma, X.; Li, S.; Gorner, M.; Tang, S.; Fang, B.; Sun, F.; Zhang, J. PointNetGPD: Detecting grasp configurations from point sets. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. In Proceedings of the Robotics: Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar]
- Kappler, D.; Bohg, J.; Schaal, S. Leveraging big data for grasp planning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4304–4311. [Google Scholar]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Schmidt, P.; Vahrenkamp, N.; Wachter, M.; Asfour, T. Grasping of unknown objects using deep convolutional neural networks based on depth images. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6831–6838. [Google Scholar]
- Veres, M.; Moussa, M.; Taylor, G.W. Modeling grasp motor imagery through deep conditional generative models. IEEE Robot. Autom. Lett. 2017, 2, 757–764. [Google Scholar] [CrossRef] [Green Version]
- Mahler, J.; Matl, M.; Satish, V.; Danielczuk, M.; DeRose, B.; McKinley, S.; Goldberg, K. Learning ambidextrous robot grasping policies. Sci. Robot. 2019, 4, 26. [Google Scholar] [CrossRef] [PubMed]
- Montaño, A.; Suárez, R. Dexterous Manipulation of Unknown Objects Using Virtual Contact Points. Robotics 2019, 8, 86. [Google Scholar] [CrossRef] [Green Version]
- Jabalameli, A.; Behal, A. From Single 2D Depth Image to Gripper 6D Pose Estimation: A Fast and Robust Algorithm for Grabbing Objects in Cluttered Scenes. Robotics 2019, 8, 63. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V. Constructing force-closure grasps. In Proceedings of the 1986 IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 7–10 April 1986; Volume 3, pp. 1368–1373. [Google Scholar]
- Roberts, Y.; Jabalameli, A.; Behal, A. Surface Segmentation Video Demonstration. 2020. Available online: https://youtu.be/2KkEk_INvTM (accessed on 12 September 2021).
- Suzuki, S.; Be, K. Topological structural analysis of digitized binary images by border following. Comput. Vision Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Sweeney, C.; Izatt, G.; Tedrake, R. A Supervised Approach to Predicting Noise in Depth Images. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 796–802. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Jang, B.K.; Chin, R. Analysis of thinning algorithms using mathematical morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 541–551. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| >0 | =0 | <0 | ||
|---|---|---|---|---|
| >0 | Concave | Concave | Saddle | |
| =0 | Concave | Plane | Convex | |
| <0 | Saddle | Convex | Convex |
| Scene | GT. Object | Proposed | [19] | GT. Surface | Proposed | [19] | GT. Edge | Proposed | [19] | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Boxes | 3 | 3 | 3 | 6 | 6 | 6 | 17 | 17 | 14 |
| 2 | Boxes | 3 | 3 | 3 | 8 | 8 | 8 | 20 | 20 | 17 |
| 3 | Cylinders | 3 | 3 | 3 | 6 | 6 | 5 | 12 | 12 | 10 |
| 4 | Cylinders | 5 | 5 | 5 | 10 | 10 | 9 | 20 | 20 | 19 |
| 5 | Mixed - LC | 6 | 6 | 6 | 13 | 13 | 9 | 28 | 28 | 21 |
| 6 | Mixed - LC | 7 | 7 | 7 | 13 | 13 | 9 | 28 | 28 | 22 |
| 7 | Mixed - HC | 11 | 11 | 11 | 24 | 24 | 17 | 55 | 53 | 42 |
| 8 | Mixed - HC | 14 | 14 | 10 | 22 | 22 | 16 | 49 | 47 | 33 |
| 100.00% | 92.31% | 100.00% | 77.45% | 98.25% | 77.73% |
| NDP Fill | DD Opr | Wiener | Sobel | CD Opr | Canny | Morphology | Validation | Total Time |
|---|---|---|---|---|---|---|---|---|
| 0.66 ± 0.0 | 0.21 ± 0.0 | 2.10 ± 0.3 | 0.84 ± 0.0 | 0.36 ± 0.3 | 0.34 ± 0.3 | 4.80 ± 0.5 | 1.87 ± 0.2 | 15.9 ± 2.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roberts, Y.; Jabalameli, A.; Behal, A. Faster than Real-Time Surface Pose Estimation with Application to Autonomous Robotic Grasping. Robotics 2022, 11, 7. https://doi.org/10.3390/robotics11010007
Roberts Y, Jabalameli A, Behal A. Faster than Real-Time Surface Pose Estimation with Application to Autonomous Robotic Grasping. Robotics. 2022; 11(1):7. https://doi.org/10.3390/robotics11010007
Chicago/Turabian StyleRoberts, Yannick, Amirhossein Jabalameli, and Aman Behal. 2022. "Faster than Real-Time Surface Pose Estimation with Application to Autonomous Robotic Grasping" Robotics 11, no. 1: 7. https://doi.org/10.3390/robotics11010007
APA StyleRoberts, Y., Jabalameli, A., & Behal, A. (2022). Faster than Real-Time Surface Pose Estimation with Application to Autonomous Robotic Grasping. Robotics, 11(1), 7. https://doi.org/10.3390/robotics11010007