1. Introduction
The canonical tensor model (CTM) is a tensor model for quantum gravity which is constructed in the canonical formalism in order to introduce time into a tensor model [
1] with, as its fundamental variables, the canonically conjugate pair of real symmetric tensors of degree three,
and
. Interestingly, under certain algebraic assumptions, this model has been found to be unique [
2]. Furthermore, several remarkable connections have been found between the CTM and general relativity [
3,
4,
5] which, combined with the fact that defining the quantised model is mathematically very simple and straightforward [
6], makes this a very attractive model to study in the context of quantum gravity.
Recent developments in the study of the canonical tensor model sparked interest in the tensor rank decomposition from the perspective of quantum gravity. The tensor rank decomposition is a decomposition of tensors into a sum of rank-1 tensors [
7], also called simple tensors, and it might be seen as a generalisation of the singular value decomposition of matrices to tensors.
1 This is a tool frequently used in a broad range of sciences as it is often a very effective way to extract information from a tensor [
8].
In Ref. [
9], tensor rank decomposition was used to extract topological and geometric information from tensors used in the CTM. Here, every term in the decomposition corresponds to a (fuzzy) point, collectively forming a space that models a universe. However, finding the exact tensor rank decomposition of a tensor is, in general, next to impossible [
10]. This means that for a given tensor
, which is in the CTM the fundamental variable that is supposed to represent a spatial slice of spacetime, it may potentially be approximated by several different decompositions, possibly corresponding to different universes. This leads to two questions related to the stability of this approach:
How many tensor rank decompositions are close to a given tensor ?
Do different decompositions describe the same space (and if not, how much do they differ)?
In this work, we focus on the former of these questions. To understand this question, we introduce the configuration space of tensor rank decompositions for rank
R, denoted by
, and introduce the quantity to describe the volume of the configuration space close to a tensor
Q:
2
where
denotes a tensor rank decomposition in the space of tensor rank decompositions that is integrated over,
is the Heaviside step function, and
is a parameter to define the maximum square distance between
Q and
. Better understanding this quantity will lead to a better understanding of the tensor rank decomposition configuration space, and what to expect when aiming to approximate a tensor using tensor rank decomposition. In this work, we study a related quantity
, which we arrive at by integrating (
1) over normalised tensors
. Analysing this quantity will give us information about the average amount of different decompositions, potentially representing different spaces, close to tensors, and analysing its divergent properties will lead to insights in the expected size, in terms of the amount of fuzzy points, of spaces in the CTM.
Another motivation coming from the CTM to study the configuration space of tensor rank decompositions comes from the quantum CTM. A noteworthy fact about the CTM is that it has several known exact solutions for the quantum constraint equations [
11]. One of these has recently been extensively analysed due to the emergence of Lie group symmetries in this wave function, which potentially hints towards the emergence of macroscopic spacetimes [
12,
13,
14,
15,
16,
17]. This wave function, in the
Q-representation, is closely related to a statistical model [
17] that is mathematically equivalent to
where
only depends on the weights of the components of the decomposition, which will be more precisely defined below. This shows that for a full understanding of this statistical model, understanding the underlying configuration space and the behaviour of volumes therein is important.
Besides research in the CTM, this work might be more generally applicable. Similar questions might arise in other areas of science and, mathematically, there are many open questions about the nature of tensor rank decomposition. Understanding the configuration space constructed here might lead to significant insights elsewhere. For these reasons, the content of the paper is kept rather general. Our main research interests are real symmetric tensors of degree three, but we will consider both symmetric and generic (non-symmetric) tensors of general degree.
This work is structured as follows. We define the configuration space of tensor rank decompositions in
Section 2. Here, we also give a proper definition of
and introduce the main quantity we will analyse,
, which is the average of
over normalised tensors.
Section 3 contains the main result of our work. There, we derive a closed formula for
, which is guaranteed to exist under the condition that a certain quantity
, which is independent of
, exists and is finite. Another interesting connection to the CTM is found at this point, since this quantity
is a generalisation of the partition function of the matrix model studied in [
14,
15,
16]. In
Section 4, the existence of
is proven for
, and numerical analysis is conducted for
for a specific choice of volume form
to arrive at a conjecture for the maximal allowed value of
R, called
. In
Section 5, we present direct numerical computations of
to further verify the analytical derivation and conclude that the closed form indeed seems to be correct. Surprisingly, up to a divergent factor, the
-behaviour still appears to hold for
. We finalise this work with some conclusions and discussions in
Section 6.
2. Volume in the Space of Tensor Rank Decompositions
In this section, we introduce the configuration space of tensor rank decompositions and define the volume quantities we will analyse. We consider two types of tensor spaces, namely the real symmetric tensors of degree
K,
, and the space of generic (non-symmetric) real tensors,
. This could be generalised even further in a relatively straightforward way, but for readability, only these two cases will be discussed. First, the symmetric case will be discussed, and afterwards, the differences to the generic case will be pointed out. For more information about the tensor rank decomposition, see
Appendix A and references therein.
Consider an arbitrary symmetric tensor of (symmetric) rank
3 R given by its tensor rank decomposition:
where we choose
to lie on the upper-hemisphere of the
-dimensional sphere, which we denote by
, and
. This is mainly to remove redundancies, for later convenience and to make the generalisation easier.
The configuration space can now be defined as all of these possible configurations for a given rank
R:
Note that while (
3) links a given tensor rank decomposition in the space
to a tensor in the tensor space
, our objects of interest are the tensor rank decompositions themselves.
We define an inner product on the tensor space by, for
,
which induces a norm
. We also use
for brevity. On the configuration space
, we introduce a measure by the infinitesimal volume element
where
is the usual line element of the real numbers, and
is the usual volume element on the
-dimensional unit sphere.
w (with
) is introduced for generality.
will turn out to be less singular, while
corresponds to treating
as hyperspherical coordinates of
.
In summary, for a given rank
R, we constructed a configuration space
in (
4) with the infinitesimal volume element (
6), taking inner product (
5) on the tensor space. If
, then
, and thus we have an increasing sequence of spaces, which limits to the whole symmetric tensor space of tensors of degree
K:
where
counts the degrees of freedom of the tensor space.
A question one might ask is “Given a tensor
Q, how many tensor rank decompositions of rank
R approximate that tensor?”. For this, we define the following quantity
where
is the maximum square distance of a tensor rank decomposition
to tensor
, and
is a (small) positive parameter. The exponential function is needed to regularise the integral, since even though
is bounded, the individual terms
might not be. This quantity gives an indication of how hard it will be to approximate a tensor
Q by a rank-
R tensor rank decomposition; a large value means there are many decompositions that approximate the tensor, while a small value might indicate that a larger rank is necessary.
While (
7) might contain all the information one would want, it is hard to compute. Instead, we will introduce a quantity to make general statements about the configuration space by averaging this quantity over all normalised tensors
(such that
):
Since the configuration space of
Q is isometric to
, it is possible to move to hyperspherical variables.
is then given by the angular part of
Q. Furthermore, we have defined
. For now, we assume the existence of the
limit of this quantity such that
This limit does not necessarily exist, and it diverges if
R is taken too large, as we will show in
Section 4. In Proposition 2 in the next section, we will obtain an explicit formula for
found in (
22) under the condition that the following quantity exists:
Note that since
is a monotonically decreasing positive function of
, the
limit either diverges or is finite if it is bounded from above.
This condition presents a peculiar connection to the canonical tensor model. Let us first rewrite
where we introduced the usual inner product on
inherited from the tensor space inner product. In Refs. [
14,
15,
16], a matrix model was analysed that corresponds to a simplified wave function of the canonical tensor model. The matrix model under consideration had a partition function given by
where
with the usual Euclidean inner product on
. Let us now go to hyperspherical coordinates
for every
N-dimensional subspace for every
i, but instead of taking the usual convention where
and
, we let
and
. Then
where we have substituted
and
is an irrelevant numerical factor. Comparing (
12) with (
11), we see that the matrix model studied in the context of the canonical tensor model is a special case of
, where
,
and
.
Let us now turn to the case of generic (non-symmetric) tensors. We will point out the differences in the treatment and the result, though the derivation in
Section 3 will be identical. We will still focus on tensors of degree
K that act on a multiple of Euclidean vector spaces
, though generalisations of this could also be considered in a very similar way. A generic rank
R tensor is given by
where we again choose
and
. Note that the main difference here is that the vectors
are independent and, thus, the generic configuration space will be bigger:
where we now define the measure by the volume element
Note that the degrees of freedom of the tensor space are now
. Under these changes, we can again define analogues of (
7), (
9), and (
10). With these re-definitions, the general result (
22) will actually be the same but now for
and
R being the generic tensor rank (instead of the symmetric rank).
3. Derivation of the Average Volume Formula
In this section, we will derive the result as presented in (
22). The main steps of the derivation are performed in this section, but for some mathematical subtleties, we will refer to
Appendix B, and for some general formulae to
Appendix C. The general strategy for arriving at (
22) is to take the Laplace transform, extract the dependence on the variables, and take the inverse Laplace transform.
Let us take the Laplace transform of (
9) with (
7) and (
8) (see
Appendix C.2):
where we have taken the limit out of the
integration. It will be shown below when this is allowed. Let us multiply this quantity by
This will be undone again at a later stage. For later use, we will also define the quantity depending on
without taking the limit:
As an aside, recall that for the Laplace transform, multiplication by
corresponds to taking the derivative in
-space. This means that we now effectively have a definition of the Laplace transform of the distributive quantity
where
is the delta distribution, assuming that (
15) is well defined (which will be shown below for the aforementioned assumption).
We will now present the first main result that will be necessary.
Proposition 1. Given that (10) is finite, (15) is finite and given by Proof. Let us prove this proposition in the following two steps.
Step one: is finite if is finite.
First let us remark that the integrand in (
16) is positive and, thus, for
to be finite, we should show that
. Furthermore, because of the reverse triangle inequality, we have the inequality
and from
for
and
, we have the inequality
Putting this together, we find that
This means that as long as is finite, is finite, since we have a finite upper bound. Moreover, it converges since it monotonically increases with and is bounded.
Step two: Find the closed form.
Let us introduce the quantity
Note that in this quantity, Q is defined over the whole tensor space , so not only the normalised tensors. In the appendix, Lemma A1 shows that this quantity is finite under the same assumption that is finite.
We can rewrite (
18) in terms of
as follows
where
. We can also relate (
18) to
by using polar coordinates for
:
Here, in the first step, we rescaled
, in the second step we introduced a new integration variable
, and in the final step we took the limit inside the integral as is proven to be allowed in the appendix Lemma A2. Note the appearance of
as defined in (
16).
By equating (
19) and (
20), we now arrive at the relation
The crucial observation now is that the left-hand side is the Laplace transform of the function
. Hence, by taking the inverse Laplace transform of the right-hand side and using (
A19) in the appendix, we find
□
Having obtained the result above, we undo the operation performed in (
15):
The main remaining task to find the central result of this paper, an expression for , is to take the inverse Laplace transform of this function. This is performed in the proposition below.
Proposition 2. Given that in (10) is finite, , as defined in (9), is given by Proof. If (
10) is finite and, thus, (
21) exists and is finite, we need to perform the inverse Laplace transform of (
21) in order to prove (
22). This may be achieved as follows. First, we write (
21) in terms of one of the Whittaker functions
where we used Kummer’s transformation (
A13), and
is one of the Whittaker functions which may be found in (
A14) in the appendix. Let us rewrite
such that we can now use the formula from the convolution theorem which can be found in (
A17) in the appendix. Let us first find the inverse Laplace transform of
, which may be found using Formula (
A18) from the appendix
The inverse Laplace transform of
may be found using Formula (
A20) from the appendix
where
is the beta-function defined in (
A9). Combining these results with the convolution product formula (
A17) in the appendix yields
where
. Let us focus on the
case first. Using (
A8), we find
For
, we find
where we changed integration variables in the first step to
. This result is in accord with (
22). □
This concludes the proof of (
22). As mentioned before, the derivation is exactly identical for generic tensors. The main difference now is that the number of degrees of freedom
is different for this tensor space. What is left to determine are the range of
R for which
is finite and the value of
. This will be carried out in
Section 4.
Before we finish this section, let us demonstrate some properties of this function. First, let us note that the parameters
R and
w always come together, even though they seemingly are unrelated when inspecting (
7). This can be understood by the fact that every term in the tensor rank decomposition comes with a weight given by
. However, in the measure, we count every unit of
with a power of
w, so we have
R terms that each scale with a factor of
w, explaining why
R and
w always come together.
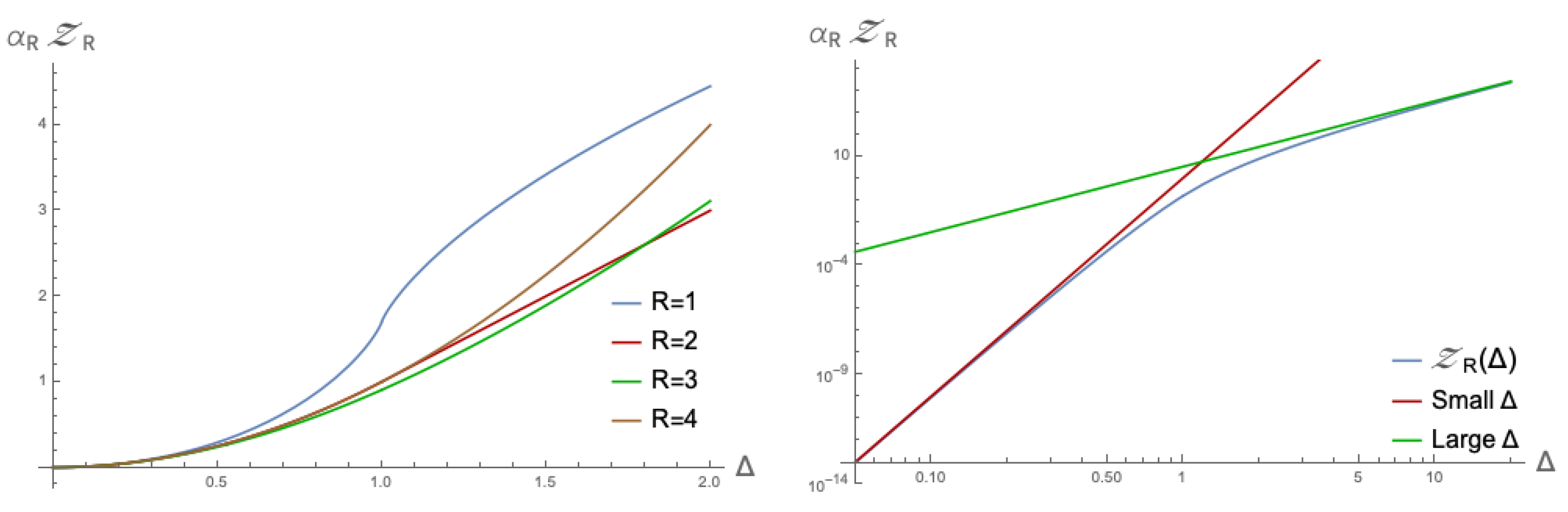
Now, we take a look at some special values of the function. Starting with the case where
, we have the situation that for
, the hypergeometric part of the function will be constant because the first argument is zero. For
, we see that the function will be of the form
. Hence, the full function will simplify to
making the function linear for larger
. Let us try another simple case, namely for
. In this case, the hypergeometric part becomes a constant everywhere, and we get
Examples of the special values above, and others, are plotted in
Figure 1.
Furthermore, let us focus on some of the limiting behaviour of the function. For
, the hypergeometric part is approximately a constant, and we see
Similarly, for
, the hypergeometric part is constant and the function tends to
In some sense, the hypergeometric part of the function interpolates between these two extremes. This is also shown in
Figure 1.
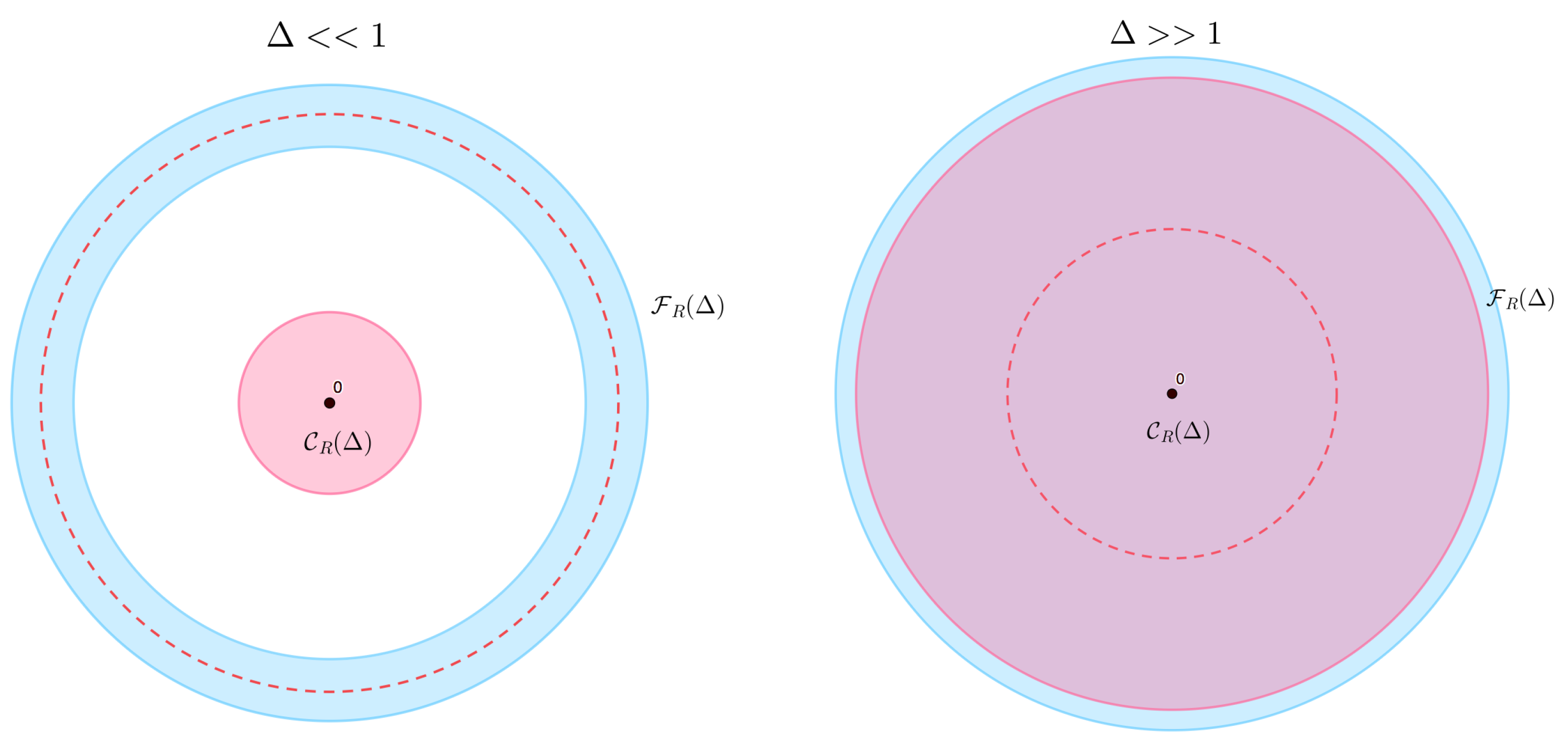
It is instructive to compare
to another quantity,
For the derivation of this quantity, we would like to refer to
Appendix D. This quantity measures the amount of tensor rank decompositions of size smaller than
, giving us a measure for the scaling of volume in the space of tensor rank decompositions.
Figure 2 sketches the difference between
and
. It can be seen that in the
limit,
.
Dividing
by this quantity yields a quantity comparing the amount of tensor rank decompositions with a distance less than
from a tensor of size 1 to the amount of decompositions of size less than
:
This quantity is useful to predict the difficulty of finding a tensor rank decomposition close to a certain tensor in the tensor space. Notice here that the dependence drops out. This implies that this quantity might be well defined, even in the case that itself is not.
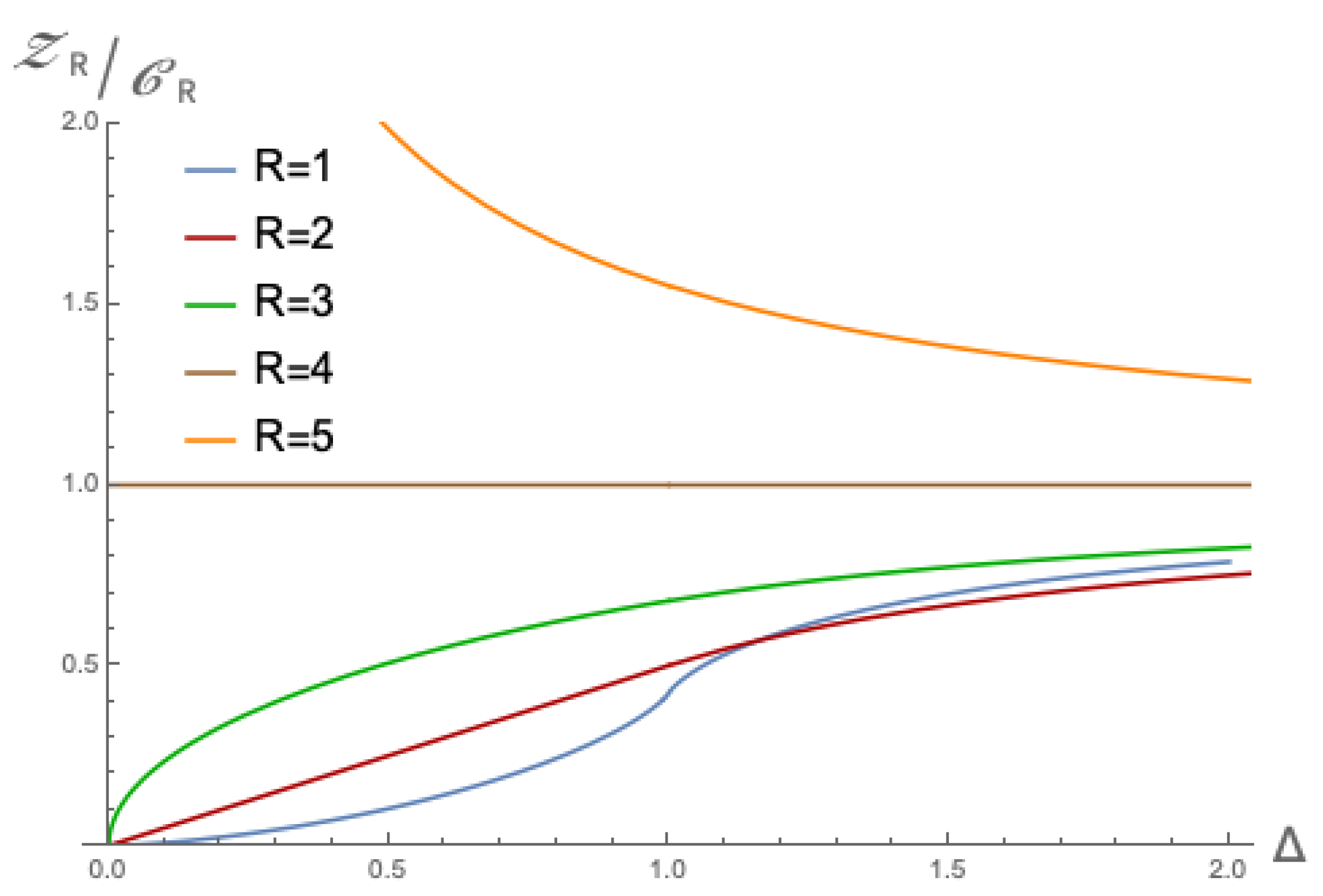
Upon inspecting
Figure 3, it can be seen that (
26) has some interesting
R-dependence. Firstly, while the limiting behaviour for
to 1 is already clear from (
24) and the overlap in the regions as sketched in
Figure 2, the quantity will limit to 1 from below for
, while for
, it will limit towards 1 from above. The reason for this is that for large
R, even with small
, there will be many tensor rank decompositions that approximate an arbitrary tensor with error allowance less than
, while for small
, the volume counted by
will be small. This shows that for small
, the regions in
Figure 2 scale in different ways. Secondly, what is interesting is that the
curve overtakes the
curve around
, and for larger
R the behaviour for small
changes from accelerating to decelerating.
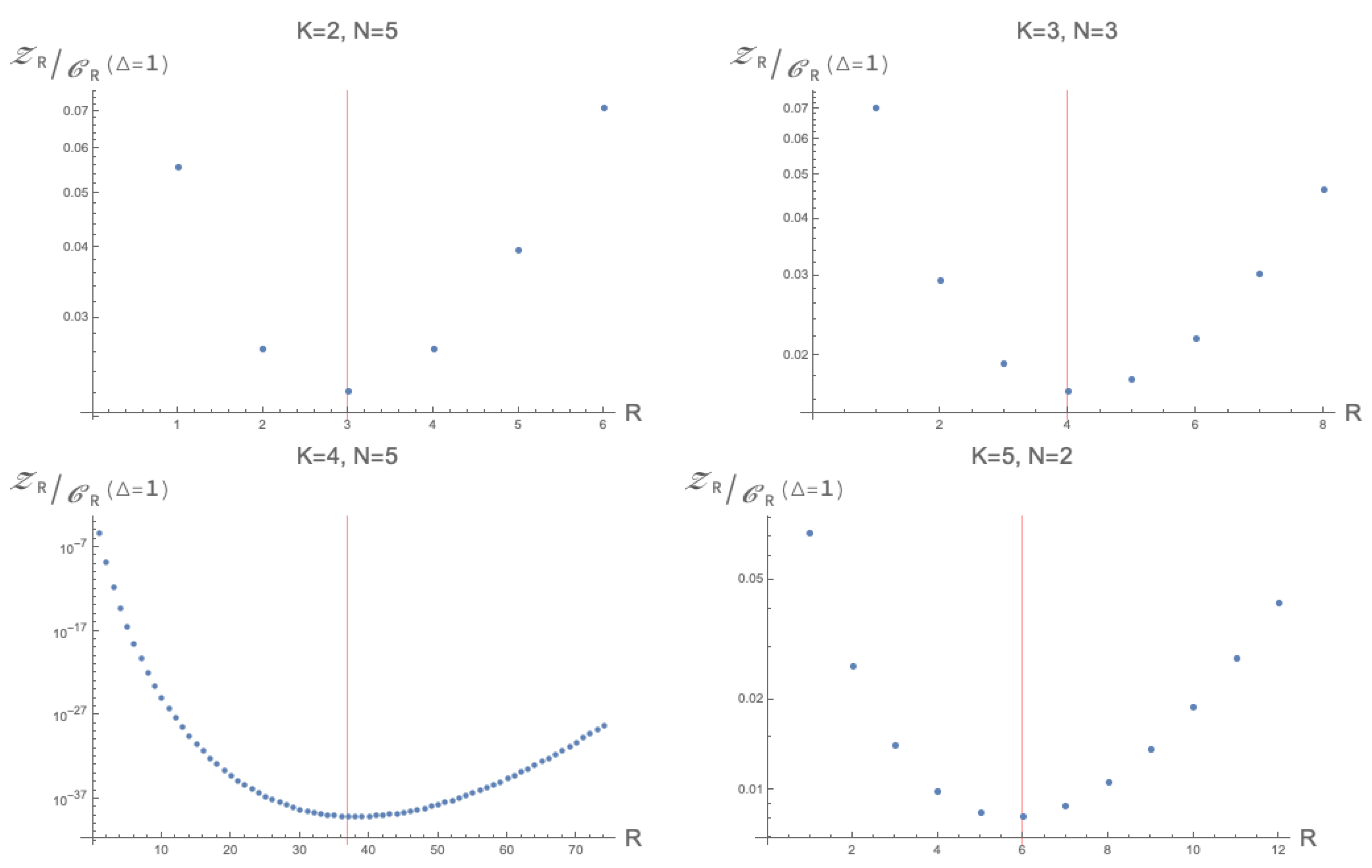
This motivates us to look at a specific case of the quantity (
26), namely for
. As is clear from the structure of the function,
appears to be a special value which we can analyse further. Fixing
gives us the opportunity to look at the
R and
w-dependence a bit closer. Up until now, we have kept the value of
w arbitrary; it is however interesting to see what happens for specific values of
w. It turns out that, peculiarly, when taking
for generic tensors, the function
, as a function of
R, appears to be minimised at (or very close to) the expected generic rank of the tensor space.
4 Some examples of this may be found in
Figure 4 This means that until the expected rank, the relative amount of decompositions that approximate tensors is decreasing, while from the expected rank, the amount of decompositions that approximate a tensor of unit norm increase. The reason for the form of (
27) is currently unknown, and it would be interesting to find a theoretical explanation for this.
4. Convergence and Existence of the Volume Formula
The derivation of the closed form of
depends on the existence of
, defined in (
10). We will analyse the existence in the current section. Except for the case where
, which is shown below, we will focus on numerical results since a rigid analytic understanding is not present at this point.
First, let us briefly focus on the case of general
and
w, but specifically for
. This case is the only known case for general
and
w that can be solved exactly. In this case the quantity simplifies to
Clearly, in this case, the
exists, so there exist at least one
R for which the quantity exists. The main question now is for up to what value of
R,
, the quantity exists.
Contrary to the
case above, one might expect (
10) does not always converge. The matrix model analysed in [
14,
15,
16], corresponding to a choice of parameters of
and
, did not converge in general. It had a critical value around
, above which the
limit did not appear to converge anymore. In the current section, we will add numerical analysis for general
K and
and discuss the apparent leading order behaviour. The main result of this section is that for
, the critical value seems to be
. Hereafter, in this section, we will always assume
.
The numerical analysis was conducted by first integrating out the
variables and subsequently using Monte Carlo sampling on the compact manifold that remains. The derivation below is for the symmetric case, but can be conducted for the generic case in a similar manner. The
can be integrated out in a relatively straightforward way since the measure in the
case is very simple. Let us rewrite (
10) in a somewhat more suggestive form
It can now be seen that, for
, this is a simple Gaussian matrix integral over the real numbers
, with the matrix
. The result of this integral is
which is a compact, finite (for
) integral. The corresponding expression for generic tensors is
We wrote a C++ program evaluating the integrals above using Monte Carlo sampling. The general method applied is the following:
Construct R, N-dimensional random normalised vectors using Gaussian sampling.
Generate the matrix by taking inner products (and adding to the diagonal elements).
Calculate the determinant of and evaluate the integrand.
Repeat this process M times.
The main difference between the above method, and the method for generic tensors, is that we generate
random vectors, and the matrix is now given by
. To generate random numbers, we used C++’s Mersenne Twister implementation mt19937, and for the calculation of the determinant of
we used the C++ Eigen package [
18].
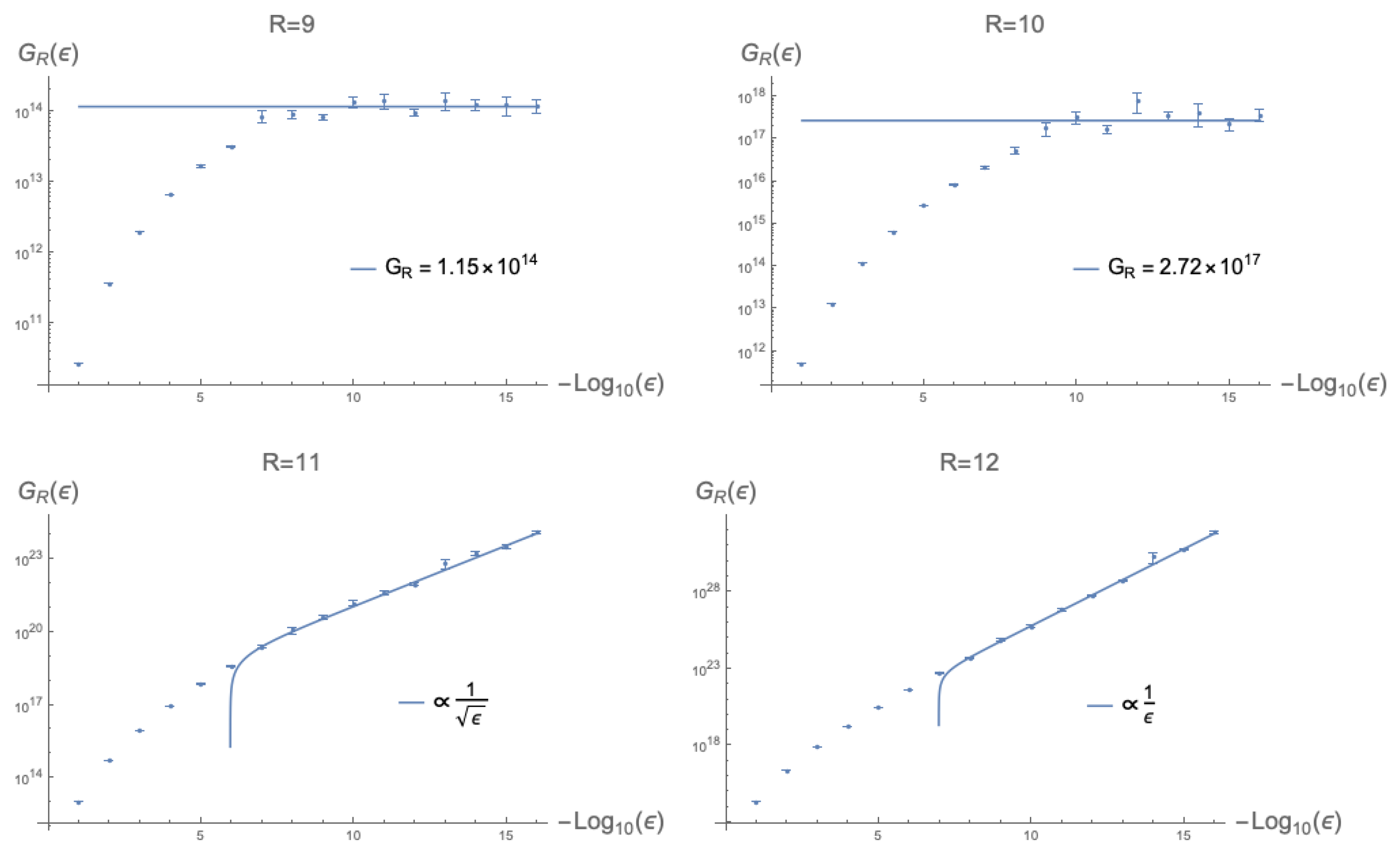
We have conducted simulations using this method for both symmetric and generic tensors. After the initial results, it became clear that the critical value for R seems to lie on , so to verify this, we calculated the integral for , and , and checked if indeed starts to diverge at .
What divergent behaviour to expect can be explained as follows. Let us take the limit of
. It is clear that this integral diverges whenever the matrix is degenerate. Assume now that
has rank
r, meaning that the matrix
in diagonalised form has
zero-entries. Thus, adding a small but positive
to the diagonal entries results in the following expansion
leading to leading order for the integrand
Thus, if there is a set with measure nonzero in the integration region with
, the final
-dependence for small epsilon is expected to be
where the constant factor
C is the measure of the divergent set, and the other factor is due to non-leading order nonzero measure integration regions. Note that now we should take
, as by definition of
, this will yield the leading order contribution for the integral. An example of this approach for finding
for symmetric tensors with
and
is given in
Figure 5. By the definition of
, for
,
should converge to a constant value.
This procedure has been carried out for both symmetric and generic tensors and for various choices of the parameters
K and
N. The results of this can be found in
Table 1. This procedure lets us also determine the value of
numerically, as is also shown in the examples of
Figure 5.
Generally, the result was quite clear: There is a transition point at . This is true for all examples we tried, except for the cases for symmetric tensors, for which the critical value is .
Let us explain why an upper bound for the value of
is given by
. The matrix may be written as
Thus, if we consider only the right part of the expression above (i.e., one of the rows of the matrix), it can be seen as the linear map
A basic result from linear algebra is that a linear map from a vector space
V to
W, with
, has a kernel of at least dimension
Thus, for
, this kernel always has a finite dimension, and since
is simply the square of this linear transformation,
. Thus, we may conclude
The reason why the critical rank actually attains this maximal value for all cases is, at present, not clear. However, it is good to note that for random matrices, the set of singular matrices has measure zero and, hence, for , the construction of the matrix appears to be random.
The current result of
, together with the previous result for
and
of
mentioned before, suggest a general formula that holds for most cases
This formula seems very simple, but there is no analytic understanding for this formula yet. At present, it should be treated merely as a conjecture.
5. Numerical Evaluation and Comparison
The main goal of this section is to numerically confirm the derived formula for
in (
22). Therefore, we will mainly focus on values of
found in
Section 4 that allow for the existence of
defined in (
10), since in those cases, the derivation is expected to hold. We will briefly comment on cases where
at the end of the section. In short, we will find that the relation found in (
22) indeed holds for all cases that could be reliably calculated. In this section, we will always take
such that the integration measure on
is given by
Since the integration region has a rapidly increasing dimension, we used Monte Carlo sampling to evaluate the integral. To do this, we alter the configuration space to a compact manifold by introducing a cutoff
and similarly for the generic tensor case:
With the integration region now being compact, there is no need for the extra regularisation parameter anymore, and we can let play that role instead.
In order to look at a more complicated example than matrices, but still keep the discussion and calculations manageable, we will only consider tensors of degree 3 (i.e.,
). Since the difficulty of the direct evaluation of
rapidly increases due to the high dimension of the integration region, we will only focus on low values of
N. To illustrate: noting that we also have to integrate over the normalised tensorspace, the integration region for generic tensors with
for
is already 40-dimensional. Considering the derivation in
Section 3 and the evidence for the existence of
presented in
Section 4, we will only show results for low values of
N, as sufficient evidence for (
22) is already at hand.
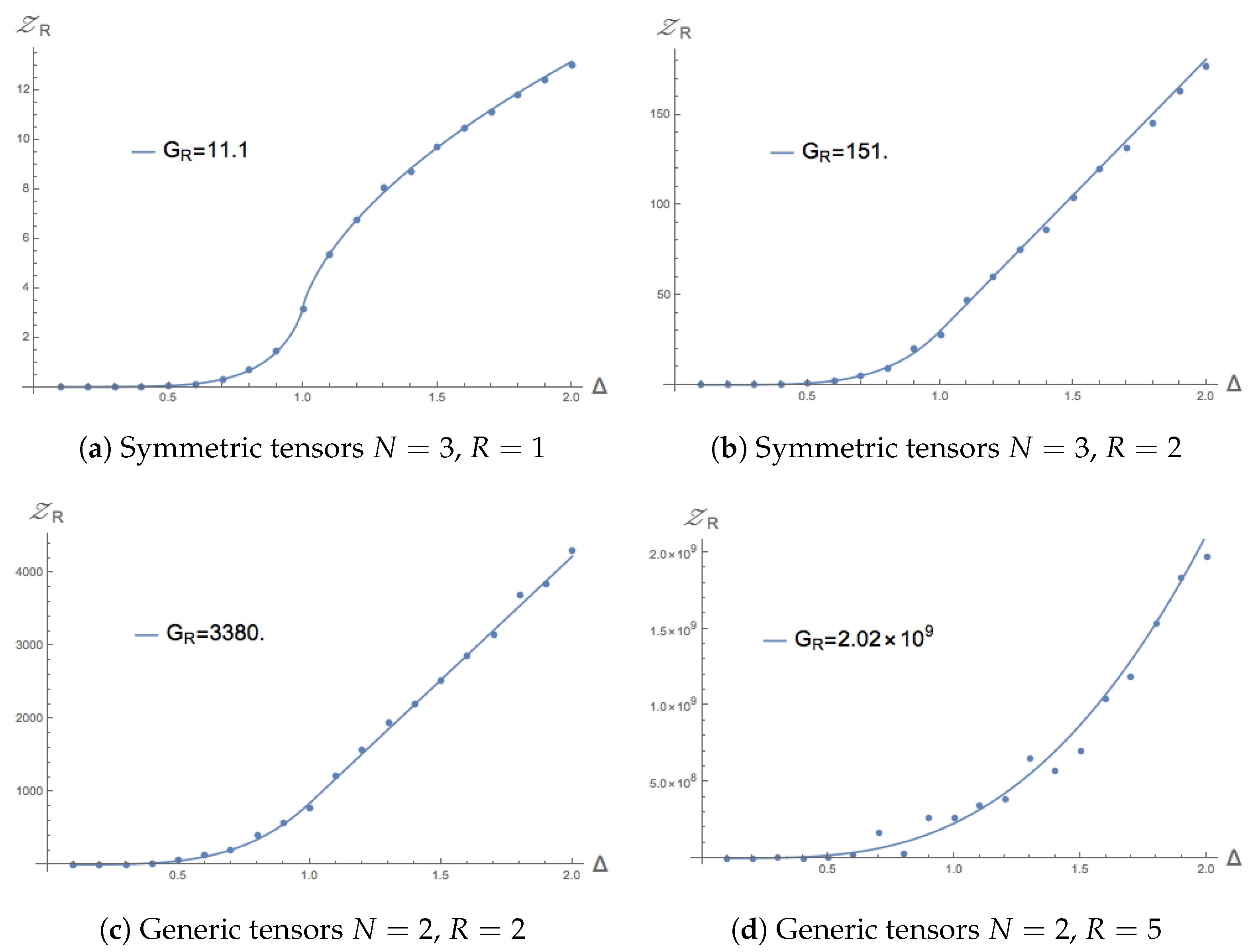
In the symmetric case, the
case is only well defined for
, since
, as can be found in
Table 1. This means that only evaluating
would yield only limited insight and, hence, we also evaluated cases for
. We evaluated all cases up to
and found that results always agree with (
22) up to numerical errors. Two examples may be found in
Figure 6. For the generic case, the situation is slightly different. For
, the critical value
, so we can already actually expect interesting behaviour in this case. Hence, we solely focus on the
case and evaluate the integral up to
. Two examples of this may be found in
Figure 6.
We may conclude that for both the symmetric and generic cases, the numerical results agree perfectly well with the derived Equation (
22) and, moreover, match the values of
determined independently in the numerical manner explained in
Section 4.
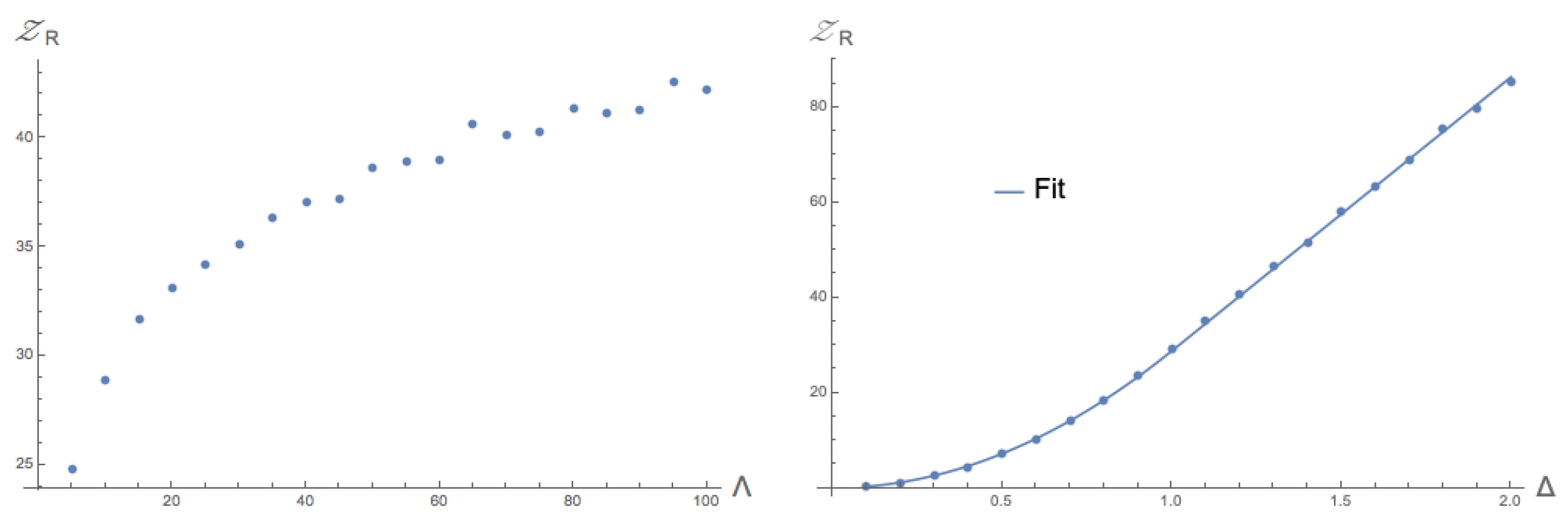
We finalise this section with a remark on the case of
. In this case,
diverges, and the correctness of formula (
22) is not guaranteed anymore. This leads to a question: Does
also diverge for
, or is the divergence of
only problematic for the derivation of its closed form? We investigated the simplest case for this: symmetric tensors with dimension
and rank
. We found that
still diverges by setting
and investigating the dependence on
, which can be seen in
Figure 7. One peculiar fact we discovered is that the functional form of
for fixed and finite
still follows the functional dependence on
of (
22), also shown in
Figure 7.
This last fact suggests the possibility that the quantity defined in (
26) might actually be finite even for
, since the diverging parts will cancel out when taking the
limit (or
as in this section). To support this a bit further, let us consider the differential equation solved by the hypergeometric function (
A7), which is a homogeneous ordinary differential equation. If we rewrite our result from (
22)
5
and plug this into the hypergeometric differential equation, we notice that the resulting equation, which is the equation that
solves and, necessarily, is still a homogeneous ordinary differential equation. If we assume that the actual physically relevant properties are described by this differential equation, an overall factor should not matter. Hence, if we extract this overall factor (which might become infinite in the limit
), we should be left with the physically relevant behaviour.
6. Conclusions and Discussions
Motivated by recent progress in the study of the canonical tensor model, in this work we turned our attention to the space of tensor rank decompositions. Because of the analogy between the terms of a tensor rank decomposition and points in a discrete space discussed in [
9], we call this the configuration space of tensor rank decompositions. This space has the topology of a product of
R times the real line and
R times an
-dimensional unit hemisphere. We equip this space with a measure generated by an infinitesimal volume element, depending on the parameter
w. In the definition, we are rather general, taking into account both symmetric and non-symmetric tensors.
The central result of this work is the derivation of a closed formula for the average volume around a tensor of unit norm,
, in terms of a hypergeometric function in (
22). This formula depends on the degrees of freedom of the tensor space, the parameter
w of the measure, and the rank of the tensor rank decompositions we are considering. The existence of such a closed form formula is far from obvious, and the derivation crucially depends on the existence of a quantity
. We have investigated the existence of this quantity numerically for the case where
. In this case, the maximum value of
R for the existence appears to agree with the degrees of freedom of the tensor space
, with the exception of the case for symmetric tensors where
. Together with earlier results in [
14,
15,
16] we conjecture a more general Formula (
30). Finally, we conducted some direct numerical checks for
and found general agreement with the derived formula.
From a general point of view, we have several interesting future research directions. For one, the conjectured Formula (
30) for the maximum
is based on the analysis of two values of
w. It might be worth extending this analysis to more values, which might lead to a more proper analytical explanation for this formula that is currently missing. Secondly, we introduced a quantity
, describing the amount of decompositions of size less than
. Dividing
by
, we expect that this leads to a meaningful quantity that is finite, even for
. Understanding this quantity and its convergence (or divergence) better would be worth investigating. Finally, a peculiar connection between
w and the expected rank was found for some examples, where tuning
w as in (
27) lead to
to be minimised for the expected rank of the tensor space. Whether this is just coincidence, or has some deeper meaning, would be interesting to take a closer look at.
Let us discuss what the results mean for the canonical tensor model of quantum gravity. The present work provides the first insight into the question how many tensor rank decompositions are close to a given tensor
. In the CTM, the rank
R considered corresponds to the amount of fuzzy points in a spatial slice of spacetime. The most natural choice for parameter
w is
because this treats the points in the fuzzy space as elements of
[
9]. The conjectured formula (
30) then implies that the expected spacetime degrees of freedom in the CTM are bounded by
which is one of the reasons why the further study of the quantity
and an analytic understanding of the critical value
is highly interesting from the point of view of the CTM.
Going back to the original question of how many discrete spaces of a given size (i.e., amount of points
R) are close to a tensor, we note that, here, we are mainly interested in the case for small
. As is shown in (
23), the function
becomes a power function proportional to
in this limit. Therefore, the
R-dependence in this regime is only present in the constant pre-factor, particularly
. This means that in future studies, to fully answer this question, only the quantity
has to be considered, dramatically simplifying our problem. Another interesting future research area would be to find a way to practically compute
for a given tensor
Q, as our main results here are estimates, since we take the average of tensors of size one.
To conclude, we would like to point out that the Formula (
22) could prove to be important in the understanding of the wave function of the canonical tensor model studied in [
12,
13,
14,
15,
16,
17]. In [
17], the phase of the wave function was analysed in the
Q-representation; the amplitude of the wave function is, however, not known. From [
12,
13], we expect that there is a peak structure, where the peaks are located at
that are symmetric under Lie group symmetries. In the present paper, we have determined a formula for the mean amplitude
6, which we can use to compare to the local wave function values in future works.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}